
Abstract
The application of content-based image retrieval method aims at retrieving similar fabric images and obtaining the existing process parameters to guide production. The process of sample analysis, trial weaving, and proofing can be eliminated in sample imitation production to give full play to the advantages of historical production experience and improve the core competitiveness of enterprises. By investigating and analyzing the applications of content-based image retrieval method technology in fabric retrieval, this article provides a detailed classification and summary of the existing fabric retrieval methods using content-based image retrieval method from six aspects: image preprocessing, feature extraction, similarity measurement, retrieval strategy, dataset construction, and evaluation metrics in the common framework of content-based image retrieval method. The advantages and disadvantages of different methods are analyzed and compared. Finally, the urgent problems and future research directions of fabric image retrieval are discussed, providing ideas for scholars to further study the retrieval methods. Taking fabric as the medium, this article combs the industrial application research and development process of content-based image retrieval method technology, which is helpful to understand the application examples of computer technology and provide research ideas for the application of different computer technologies in the textile industry.
Keywords
Increasing consumption levels make fabric styles change rapidly nowadays, leading to textile industries gradually converting from mass production to small batch production of many varieties. Traditional sample analysis 1 and repeated proofing based on manual work are difficult to manage in the manufacturing mode with a tight delivery period. The real sample retrieval (RSR) and text-based image retrieval (TBIR) methods 2 can search for similar fabrics to guide fabric production. However, RSR relies on manual comparison of similarity between fabric samples, being time-consuming and subjective. TBIR improves retrieval efficiency to a certain extent by manually tagging the fabric image and searching for similar images by keyword combination, but tagged content varies from person to person and is also highly subjective. The content-based image retrieval (CBIR) method 3 involves searching images by similarities between fabric image features to improve retrieval precision and efficiency, and is the main retrieval technology of fabric images. Investigating and summarizing the technology of fabric CBIR can help us to understand its development process and provide ideas for follow-up research to attract more researchers to invest in fabric image retrieval.
To meet the individual demands of consumers, the existing fabrics have various styles and varieties. As shown in the fabric samples exhibited in Figure 1, there are overlaps among different categories due to the lack of unified classification standards in the textile industry, like woolen goods and crepe belonging to solid-colored fabric, and horizontal stripe and vertical stripe belonging to stripe fabric. Moreover, there are both intra-class and inter-class variances in fabrics, leading to the problem that the general CBIR method cannot be directly applied. Different researchers have improved and innovated on the basis of the CBIR method and derived many image retrieval methods in specific application scenarios.

Examples of different categories of fabric images.
The studies on fabric retrieval using CBIR began in 2015. Different researchers have carried out many studies on image pre-processing, feature extraction, similarity measurement, and retrieval strategy according to the common CBIR framework shown in Figure 2. The proposed methods have definite breadth and depth. Image preprocessing is mainly adopted to reduce the influence of irrelevant factors in fabric images, improving the ability of feature recognition and the speed of feature extraction. Feature extraction analyzes and transforms fabric images to form features that can distinguish different images, which can be divided into low-level features extracted by manual feature extraction methods and deep features extracted by the convolutional neural network (CNN). Similarity measurement is used to judge the similarities of fabric images based on the feature similarities, mainly including exact nearest neighbor (ENN) search and approximate nearest neighbor (ANN) search methods. Retrieval strategy is commonly performed to improve the retrieval precision and efficiency based on the characteristics of fabric images. The existing studies not only designed the retrieval methods for different types of fabrics such as printed, color spinning, jacquard, and lace, but also proposed the retrieval methods with universality for different types of fabrics. Researchers built different fabric image datasets according to the specific research objectives and selected different evaluation metrics to verify the effectiveness of the proposed methods.
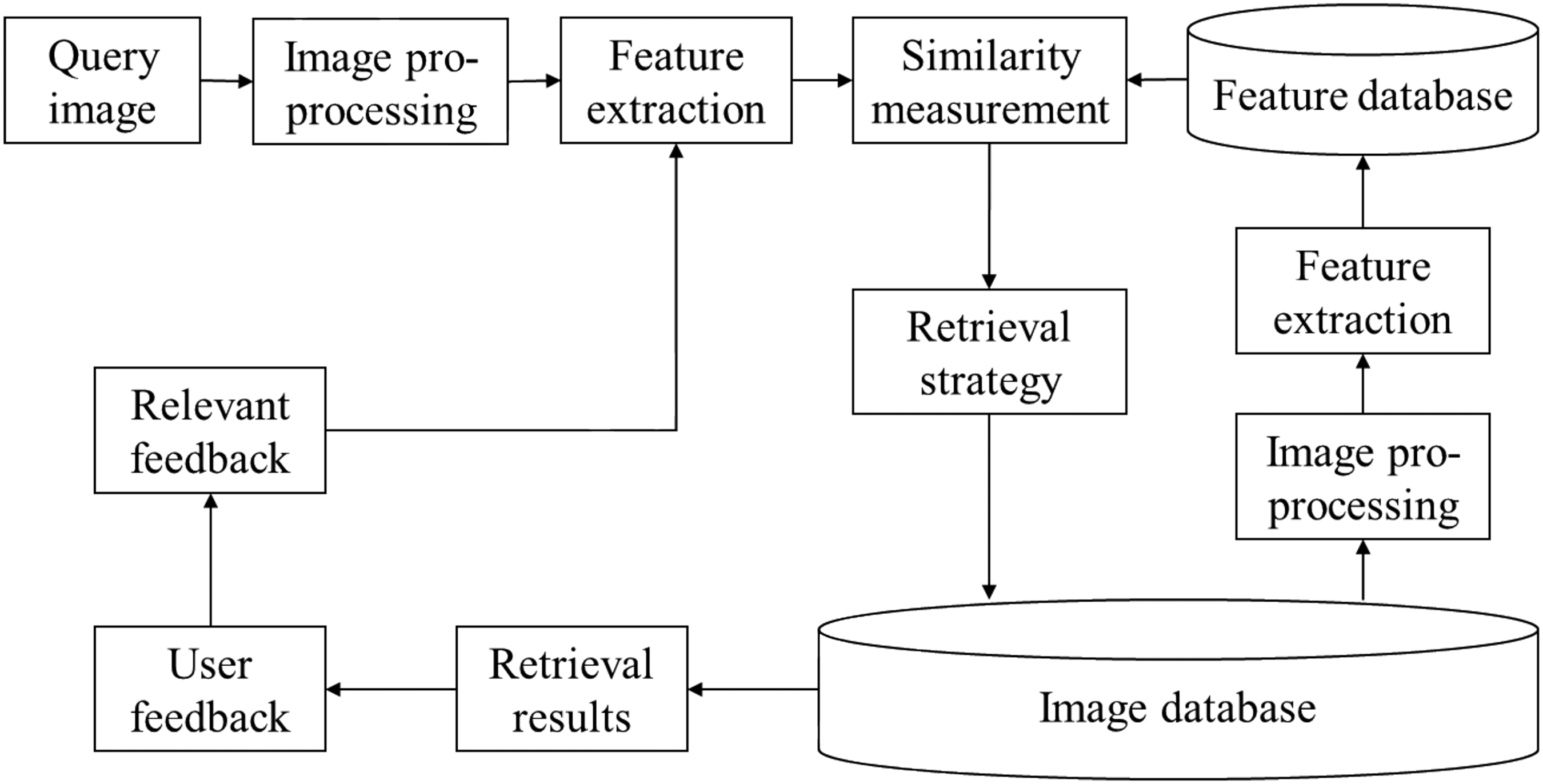
Common framework of content-based image retrieval (CBIR).
At present, there are a number of reviews of the CBIR technology from different perspectives, such as relevance feedback, 4 low-level feature extraction method, 5 deep learning, 6 and so on. These studies focus on the technology development in common using CBIR for nature images. Differently, the reviews of CBIR in different application fields are conducted to survey the application and improvement of technologies based on the characteristics of the images in each field, like the medical image 7 and the remote sensing image. 8 In the textile field, Tena et al. 9 surveyed CBIR technologies from the perspective of feature extraction methods and grouped them into traditional methods and CNN-based methods, but ignored other technologies like similarity measurement and retrieval strategy. Furthermore, the review involved the fabric and clothing image retrieval methods which are quite different. Fabric image retrieval methods aim at providing references for sample production, and the image contains fine-grained textures such as fabric weave, density, and yarn count. Clothing image retrieval methods are commonly intended to provide references for online shopping, and the image contains macroscopic features like clothing type, style, and outline. Thus, reviewing the research progress of fabric CBIR technology in detail is quite necessary to benefit researchers, engineers, and beginners.
In this review article, the key technologies of fabric image retrieval using CBIR technology are reviewed to systematically and scientifically summarize the existing methods from six aspects, including image preprocessing, feature extraction, similarity measurement, retrieval strategy, dataset construction, and evaluation metrics. Each component was comprehensively surveyed based on the characteristics of fabric images to analyze the application and improvement of computer version technology in the textile industry. The related studies are compared and discussed to show the applicability of different technologies. Based on the analysis, the challenges faced by the existing fabric image retrieval methods and future research directions are given to provide ideas for follow-up studies.
Fabric image pre-processing
At present, image pre-processing methods used in fabric image retrieval are different because of different image resolutions and fabric types. There are three commonly adopted fabric image pre-processing methods, including noise removal, repeat unit extraction, and feature enhancement methods.
Noise removal method
In the production of patterned fabrics, the designed patterns are usually covered on the base fabrics, like the printed fabric and embroidered fabric. Thus, this kind of fabric is mainly based on the pattern or appearance design, and existing fabrics can be directly selected as base fabrics. In fabric image retrieval, the noise removal method considers that the base weave of the fabric image will produce noise in the image capture process. Removing such noise can avoid affecting the following feature extraction. As shown in Figure 3, the base weaves of printed fabrics are twill and plain weaves, respectively.

Printed fabrics with different underlying weaves. (a) The underlying weave is twill and (b) the underlying weave is plain.
Zhang et al. 10 and Xiang et al. 11 adopted the median filter to smooth the fabric image, removing the base weave and avoiding the image blur caused by the linear filter simultaneously. Kang et al. 12 and Yao and Ke 13 used the relative total variation method to remove the base weave in the fabric image while preserving the pattern structure. The relative total variation method 14 can effectively decompose the structure information and texture in the image, and this can be adopted to remove the base texture. This kind of texture removal method will change the original pattern color in the fabric image, and is not suitable for fabric image retrieval with the similarity requirement for pattern color.
Repeat unit extraction method
Some fabric patterns have multiple arrangements with the repeat unit which commonly contains the key elements of the fabric image, including color, texture, and shape information. Fabric image retrieval using the repeat unit can obtain the same results as the whole image and improve retrieval efficiency. Thus, researchers proposed different repeat unit extraction methods for fabric patterns.
Li et al. 15 manually cropped the repeat unit of lace fabric image to reduce the image size after gray-scale processing. This method requires human participation and is at a low level of automation. Jiang 16 used the auto-correlation function (ACF) to extract the repeat unit of fabric patterns after grayscale and regularization processing. This method based on the auto-correlation curve is easily affected by other factors like image skew, resulting in unstable extraction results. Kuo et al. 17 used edge detection and morphological processing to obtain the fabric pattern template. Then, an extraction method of the repeat unit was proposed based on template matching to build a fabric image retrieval database. The extraction example of the fabric pattern template is shown in Figure 4. He 18 used the edge density and image size to automatically extract a template from the original fabric image. Then, an extraction method of the repeat unit of printed fabric was proposed based on adaptive template matching and boundary minimum information loss. In contrast, the template matching method can automatically extract the template and avoid template selection.

The extraction example of the fabric pattern template in literature. 17
Feature enhancement method
The feature enhancement methods adopted in fabric image retrieval can be divided into image enhancement and image transformation. Image enhancement is performed to enhance the texture information in fabric images and improve the characterization ability of features. Image conversion is adopted to convert the fabric image into an image that is easier to extract features than the original image, reducing the complexity of feature extraction.
In image enhancement, Jing et al., 19 Li, 20 Zhang et al., 21 and Xiang et al. 22 transformed the fabric image from red, green, blue (RGB) color space to hue, saturation, value (HSV) space and performed histogram equalization on the V component. The image was then transformed back to RGB color space to enhance the image brightness. Figure 5 shows an example of image and histogram comparison before and after fabric image enhancement in the literature. 22 As shown in Figure 5, the visual boundary and contour of the fabric image with dim appearance and fuzzy texture become clear after image enhancement, making the extracted features more distinguishable than those of the original image. In image transformation, Li et al. 23 performed parameter recognition methods of yarn-dyed fabric to obtain the color, yarn arrangement, and weave, and generate the fabric pattern by simulation software. The pattern obtained by this image conversion method contains the basic information of the fabric image and reduces the complexity of feature extraction. However, there are many parameters of yarn-dyed fabrics, and recognizing these parameters has high time complexity and is easily affected by the recognition results.
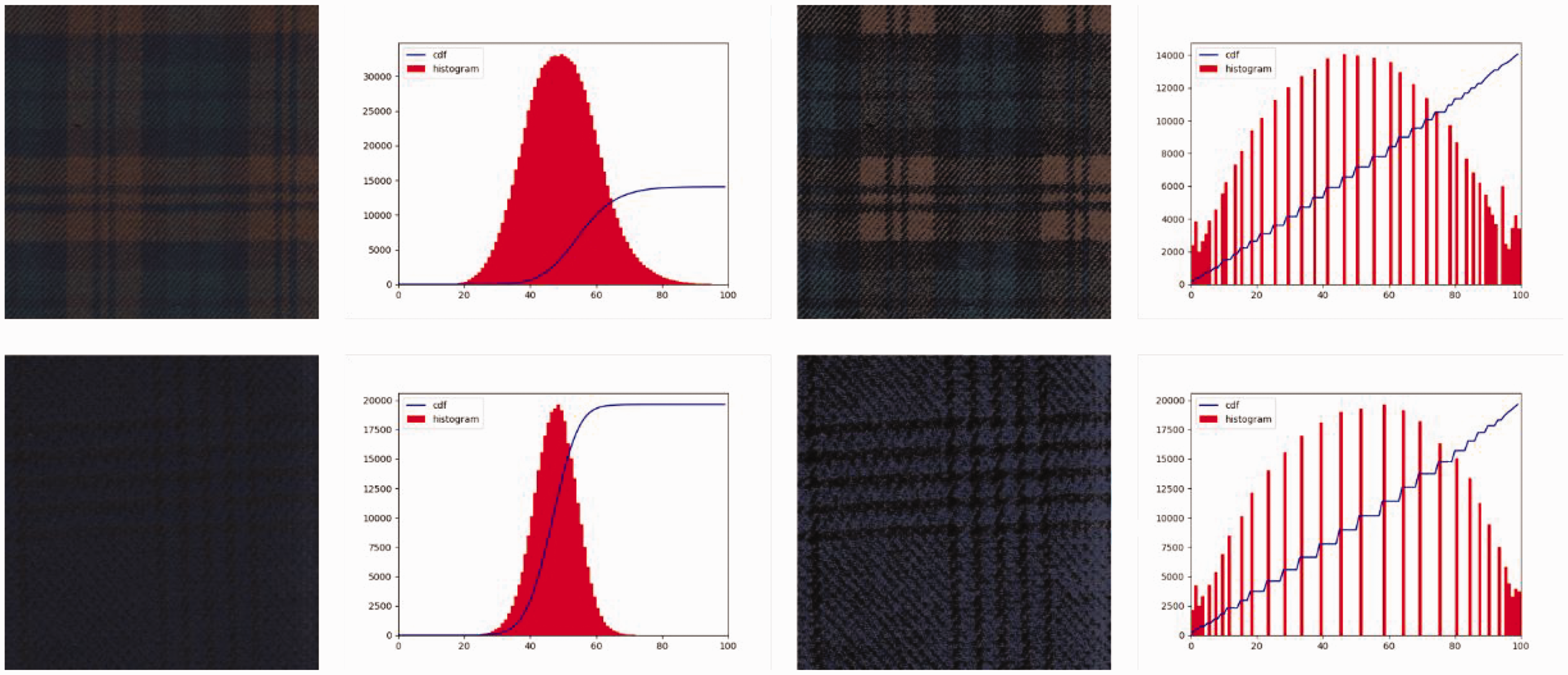
The image enhancement method of fabric adopted in literature. 22
In general, image pre-processing methods enhance the representability and identification ability of key information. The redundant information in the fabric image can be removed to provide convenience for subsequent feature extraction. Under the condition of balancing retrieval precision and efficiency, image pre-processing methods can be designed and selected according to the characteristics of fabric images.
Feature extraction of fabric image
The existing features adopted in fabric image retrieval can be roughly divided into two categories: low-level features and deep features. This section will summarize the application of these two feature extraction methods in fabric image representation.
Low-level feature extraction method
Low-level features usually rely on prior knowledge for manual design. From the perspective of visual perception, they can be divided into three categories: texture, color, and shape. The texture feature uses the gray distribution of image pixels to reflect the texture changes of the image, having noise-robust ability. The commonly adopted texture features can be extracted by statistical, frequency, model, and structure methods. The statistical method mainly describes the texture features by analyzing the gray distribution in the image, such as scale-invariant feature transform (SIFT), speeded-up robust features (SURF) and oriented FAST and rotated BRIEF (ORB), 24 where FAST refers to Features from Accelerated Segments Test and BRIEF refers to Binary Robust Independent Elementary Features. The frequency method transforms the gray distribution into the frequency distribution to describe the texture features, like the Fourier transform and wavelet transform. 25 The model method uses a small number of parameters to establish a mathematical model to describe texture features, like the fractal model. 26 The structure method assumes that the texture pattern is composed of a fixed, regular, and repeated primitive and quantitatively analyzes the distribution characteristics 27 or arrangement rules 28 to represent the texture features. However, texture feature is easily affected by factors such as scale and illumination.
Color features describe the color information of an image, such as color distribution, brightness, contrast, and so on. There are mainly four kinds of color feature extraction methods, including global, local, spatial, and emotional methods. The global method generally studies the global color index technology, and has the limited ability to recognize spatial color information. The commonly adopted global method mainly includes dominant color 29 and color moment. 30 The spatial method combines the spatial correlation and global distribution characteristics of color regions, which usually requires more computation than the global method, like color correlogram 31 and color coherence vector. 32 The local method divides the image into several specific regions to calculate and combine the global color features of different regions, integrating the local position information. Commonly used image partition methods are based on fixed size, image segmentation, 33 and saliency map. 34 The emotional method involves users' emotional understanding of the image to make the features conform to human preference, like the emotional color scheme. 35 Color features are robust to scale, rotation, and deformation, but lack the ability to represent the texture and shape in space.
Shape features describe the contour and shape information of the object in the image, and the features are commonly extracted by skeletal and zonal methods. The skeletal method uses the pixel set at the boundary of the region area to describe the target contour, such as curvature scale space descriptor and Fourier descriptor. 36 The zonal method uses the pixel set in global or local regions to describe the shape information, like Hu's invariant moment. 37 Shape features have spatial expression ability and are not sensitive to brightness and color changes. However, most methods only describe local information and have insufficient ability to represent global features due to the computational complexity of global representation. Different methods can be selected based on the fabric characteristics.
The overview of low-level features used in existing fabric image retrieval is shown in Table 1. Except for the structure method in texture features, researchers have tried different types of low-level feature extraction methods. In the early studies for fabric image retrieval, only using one of the low-level features, it is difficult to characterize the fabric image comprehensively. To integrate the advantages of different features, recent studies combine texture, color, or shape features based on the characteristics of fabric images to jointly characterize the fabric image. Different features are fused to form complementary advantages, improving the performance of fabric image representation.
The overview of low-level features of fabric images

ACF: auto-correlation function; SIFT: scale-invariant feature transform; SURF: speeded-up robust features.
Different from the image retrieval of patterned fabric, Zhang et al. 21 found that fabric weave and appearance are of the same importance in fabric production by analyzing the retrieval demands of wool fabric factories. Taking the two striped fabrics shown in Figure 6 as an example, the two images have similar stripe arrangements, but they are not similar in microstructure due to different underlying fabric weaves. The textures composed of fine-grained units such as the underlying fabric weave, density, yarn count, and so on are called the fine-grained texture, while the visually significant textures such as stripes, prints, lattices, and so on are called the macroscopic texture. To distinguish this fine-grained texture, Zhang et al. 21 partitioned the Fourier spectrum annularly and counted the frequency difference in different partitions as the Fourier feature to characterize the fine-grained and macroscopic textures in the fabric image. The LBP feature was extracted and combined with the Fourier feature to improve the characterization performance. However, the performance is still to be improved due to the characterization ability of low-level features.

Striped fabrics with different underlying weaves. (a) The underlying weave is twill and (b) the underlying weave is plain.
In general, such low-level features are interpretable and require few computing resources, but the parameters are commonly not universal. Moreover, low-level features rely heavily on manual design and it is difficult to represent the deep semantics contained in fabric images.
Deep feature extraction method
With the development of deep learning, CNN automatically extracts features at different levels of images by end-to-end model training and forms deep features to represent high-level semantics after combination and transformation. The commonly used models include AlexNet, VGG16, Inception-v3, ResNet-50, and so on. Researchers have applied CNN models to fabric image retrieval, 53 and constructed relevant characterization models according to the characteristics of fabrics. In this article, deep feature extraction methods are divided into three categories, namely training CNN models from scratch, the fine-tuned method, and the feature extractor based on pre-trained CNN.
For the first category of deep feature extraction method, the complete CNN model is trained from scratch on the fabric image dataset to characterize the fabric image. Deng et al. 54 used the AlexNet model as the basic network and constructed the CNN model by involving depth ranking similarity for fabric image characterization in complex image capture scenes. The model is guided to learn fabric image features from the perspective of similarity. To characterize the fine-grained texture of the fabric image, Xiang et al. 55 proposed a multi-task learning model based on ResNet-50 as shown in Figure 7. Fabric images were annotated from four common dimensions of people’s cognition of fabrics, and the CNN model was established to extract image features from different perspectives. Different fabric textures can be represented by the end-to-end model training. Subsequently, Xiang et al. 56 added the L0 linear layer on the basis of the previous layers of the VGG-16 model to extract fine-grained features of yarn-dyed fabrics from different perspectives. A pairwise quantified similarity was involved to compute based on the semantic labels. Yin et al. 57 introduced global and local losses into the ResNet-50 model to extract global and local features, respectively. The pooling operation was performed to aggregate depth activation maps to obtain global features. The attention module was adopted to predict discriminatory local regions and extract local features to comprehensively characterize printed fabric images.
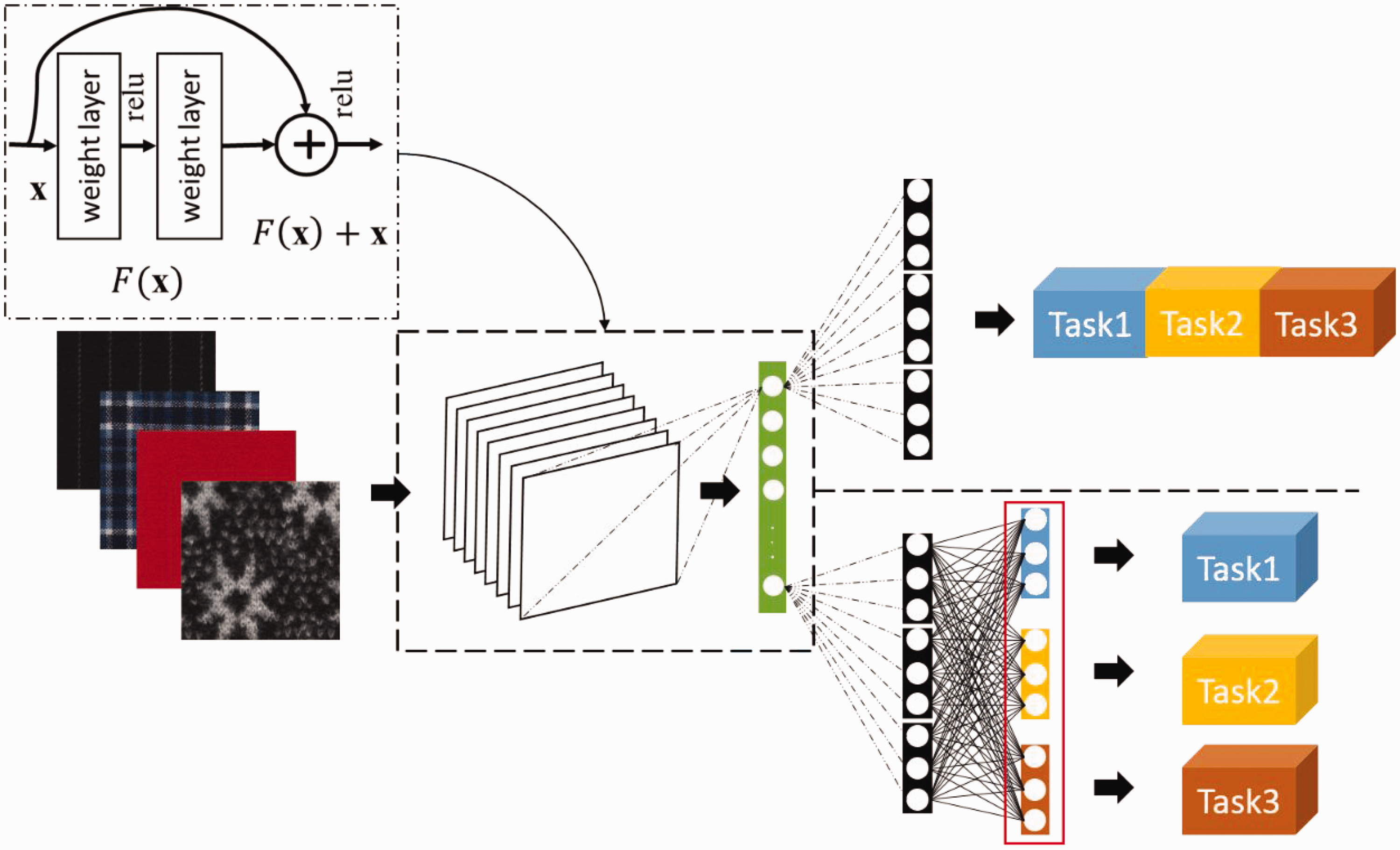
The multi-task learning model proposed in the literature. 55
The aforementioned methods have achieved excellent performances when fabric image datasets are sufficient. However, the training of the CNN model requires a large number of labeled samples and sufficient computing resources. It is difficult to obtain satisfactory results under the condition of insufficient samples. Fabric images with large differences are difficult to collect, and there is a data imbalance between different categories of fabric images. Training CNN models from scratch is difficult with limited training samples, resulting in the model being easy to result in over-fitting and having poor generalization performance.
The CNN model commonly extracts low-level features such as corners and lines in the first several layers of the image. The receptive field gradually becomes larger with the increase of network layers. The low-level features are aggregated into middle-level features such as edges and contours and are further aggregated into high-level semantic features related to the specific task. This hierarchical characterization mechanism of CNN makes the features extracted from the lower and middle layers universal and they can be migrated to other target domains. Thus, most studies on fabric image retrieval adopted pre-trained CNN models on large datasets, like the ImageNet dataset. This kind of deep feature extraction method is called the fine-tuned method. Based on the idea of transfer learning, 58 features are extracted by the fine-tuned method22,59,60 to represent fabric images. The fine-tuned method usually fixes the parameters of the first several layers of the pre-trained model unchanged and retrains the parameters of the latter several layers to make the model adapt to the data distribution of the target domain. This method can effectively reduce the requirements for training samples and computing resources, but it still needs model training, and it is difficult to avoid the inherent problems faced by model training.
Fabric images generally contain low and middle-level features such as lines, edges, and contours, such as the lines of striped fabrics and the contours of printed fabrics. These general features can usually be extracted from the first few layers of the CNN model. Zhang et al. 61 used the VGG-16 model pre-trained on ImageNet as the feature extractor to characterize different kinds of fabric images. Salience maps of fabric images were extracted by aggregating the feature maps of convolution and pooling layers to obtain deep aggregation features. Figure 8 gives the activated regions and salience maps of fabric images. As shown in Figure 8, the low-level and middle-level features are activated in fabric images, proving that the hierarchical characterization mechanism of CNN can represent fabric images. This method can not only achieve identical performance but also avoids the inherent problems of model training.

Activation regions and saliency maps of sampled feature maps extracted by the pre-trained model in literature. 61
For intuitive comparison, Table 2 summarizes different deep feature extraction methods in fabric image retrieval. Comparatively speaking, training CNN models from scratch requires a large number of labeled samples and sufficient computing resources, and the resulting model has strong generalization performance. Based on the pre-trained CNN model, using the fine-tuned method to train parts of layers can reduce the requirements of sample capacity. However, the fine-tuned method cannot obtain satisfactory results when the target domain is quite different from the source domain. Treating the pre-trained CNN model as the feature extractor can omit the model training process and avoid the problems of limited samples and insufficient computing resources, but the extraction method still needs to be designed like hand-crafted features.
Different deep feature extraction methods in fabric image retrieval

CNN: convolutional neural network.
Similarity measurement of fabric image feature
The similarity measurement method is adopted to measure the similarity between different image features and output the retrieval results according to the similarity. The commonly used methods of similarity measurement are shown in Figure 9. This section will summarize the similarity measurement methods from the two categories: ENN and ANN search algorithms.
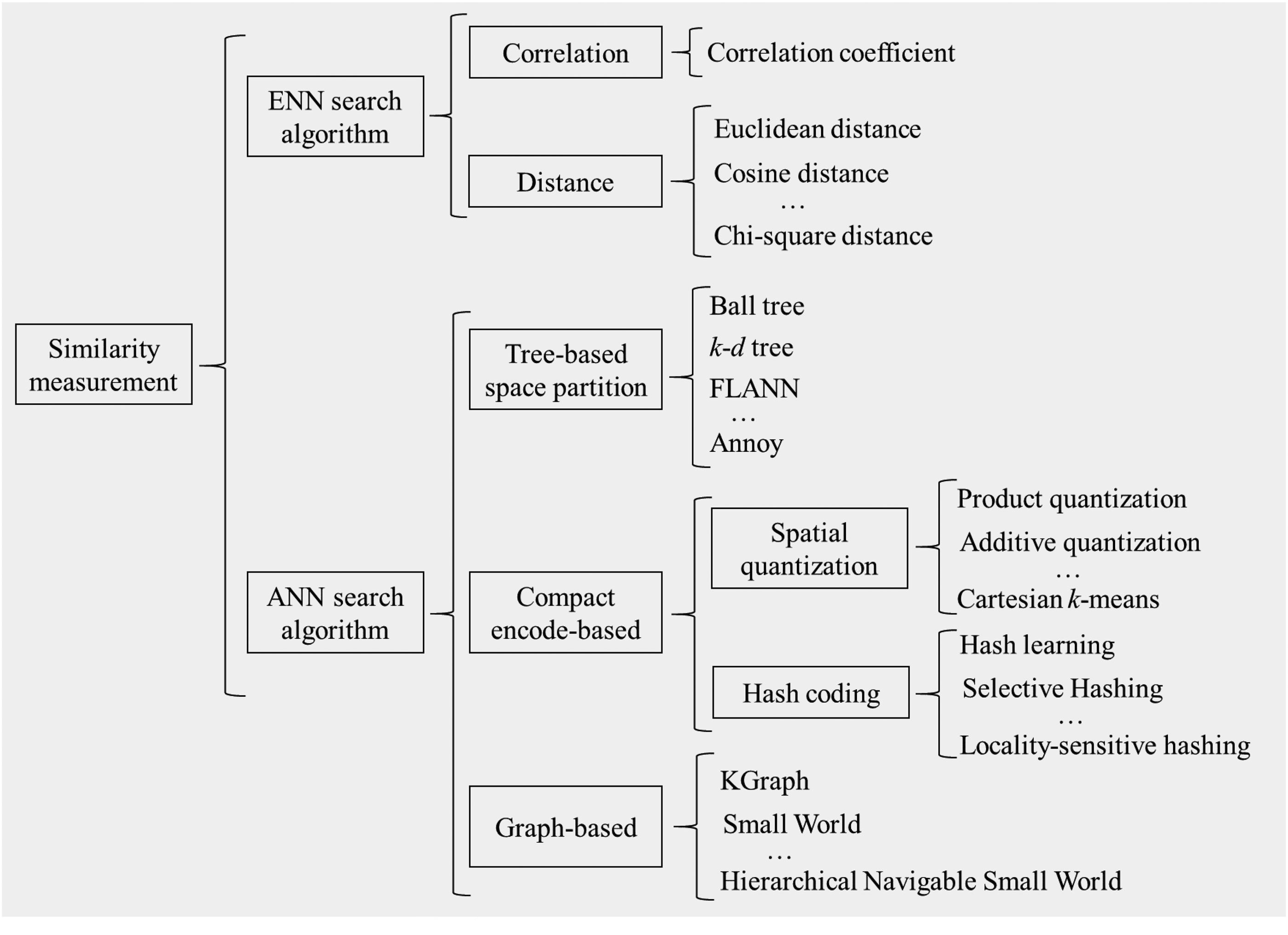
The commonly used methods of similarity measurement. ANN: approximate nearest neighbor; ENN: exact nearest neighbor; FLANN: Fast Library For Approximate Nearest Neighbors.
ENN search algorithm
The ENN search algorithm adopts the exhaustive search to measure the similarity between the feature of the query image and all image features in the database. The measurement methods mainly include correlation coefficient and distance function. A larger correlation coefficient between the two feature vectors means a larger similarity of the corresponding two images. On the contrary, a smaller distance between the two feature vectors means a larger similarity of the corresponding two images.
The correlation coefficient was seldom used in feature similarity measurement of fabric images. Zhang et al. 10 used the correlation coefficient to compare the correlation of two feature vectors to measure the feature similarity of different fabric images. The distance function is the commonly used measurement method in fabric image retrieval. At present, many distance functions have been adopted in fabric image retrieval, including Euclidean distance,12,15,19,21,47 cosine distance, 38 quadratic-like dissimilarity measure, 47 Chi-square distance, 50 and so on. For different feature vectors, the appropriate similarity measurement method can be selected based on the structure of feature vectors.
The ENN search algorithm needs to compare the similarity between the features of the query image and all features in the image feature database, being only applicable to the case of small database and low feature dimension. For massive high-dimensional data, the elapsed time increases dramatically for each query image, which is easy to cause the problem of the “curse of dimensionality.” 62 Thus, the ENN search algorithm is difficult to use and meet the timeliness requirements of industrial applications.
ANN search algorithm
The ANN search algorithm divides the original search space into different sub-spaces and encodes the image features to build the indexes. In the retrieval stage, sufficiently nearby objects of the query sample are returned as the final results. The retrieval efficiency can be improved to meet the demands of industrial applications under the condition of losing precision within the acceptable range. The commonly used ANN search algorithms are divided into three categories in this article: tree-based space partition or inverted index structure, compact encode-based, and graph-based methods.
The methods of tree-based space partition and inverted index structure divide the original search space into several regular or irregular spatial domains layer by layer and speed up the retrieval process by shrinking the search space. The commonly used methods include ball tree, vantage-point tree, 63 the Fast Library for Approximate Nearest Neighbors (FLANN), Approximate Nearest Neighbors Oh Yeah (ANNOY), and so on. 64 In the image retrieval of wool fabric, Zhang et al. 39 adopted the ball tree to build the index of the ORB low-level feature which was encoded by Vector of Locally Aggregated Descriptors (VLAD). The feature dimension was reduced to improve the efficiency of fabric image retrieval. Subsequently, Zhang et al. 61 used the ANNOY algorithm to process the deep aggregated features extracted by the CNN model, which can improve the retrieval efficiency and reduce the loss of retrieval precision. Figure 10 shows the process of constructing a feature index based on the ANNOY algorithm adopted in literature. 61 As shown in Figure 10, the ANNOY algorithm recursively builds the feature index by gradually dividing the search space until there are enough data points related to a node. In the search process, the nearest neighbors of the query sample are retrieved by traversing the nodes to judge which side of the partition hyperplane the query sample is on, so as to shrink the search space step by step.
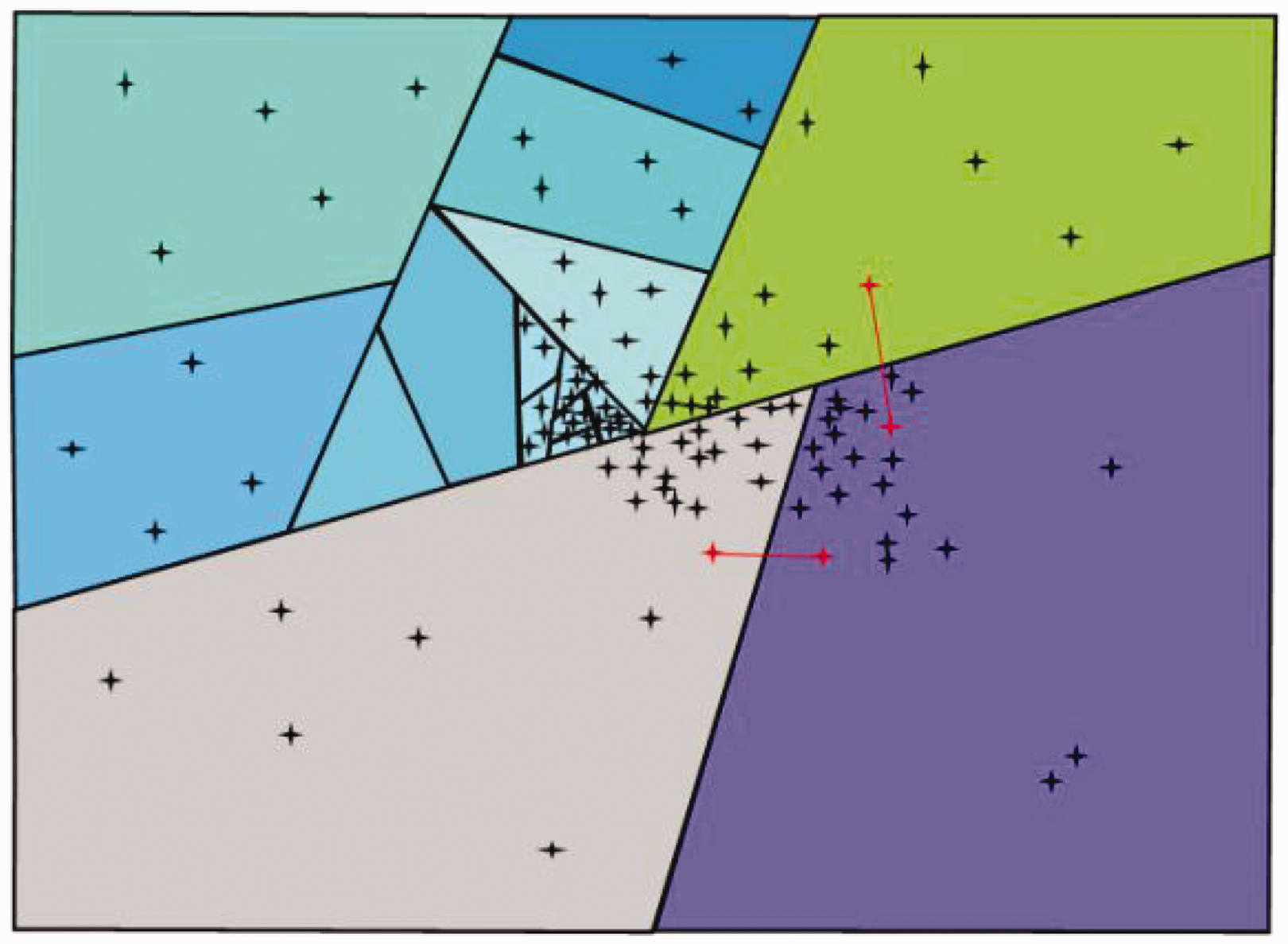
Construction process of a feature index of Approximate Nearest Neighbors Oh Yeah (ANNOY) algorithm used in the literature. 61
The compact encode-based methods encode the data points in the original search space and accelerate the search process by judging the similarity between compact codes while reducing the storage space. This method can be further divided into two categories: spatial quantization and hash coding. The spatial quantization method performed the dictionary reconstruction learning to divide the original search space into a certain number of subspaces. The clustering algorithm is adopted to train the subspace codebooks to compress high-dimensional features. The commonly used methods include product quantization, additive quantization, Cartesian k-means, and so on. 65 The hash coding method maps the high-dimensional features into binary hash compact codes 66 by the hash function and measures the similarity between hash compact codes by Hamming distance function. In fabric image retrieval, Xiang et al., 22 He, 59 and Wang et al. 60 added the hash learning layer to process the high-dimensional features which were output by the CNN model, and the feature similarities of fabric images were measured by the Hamming distance. Zhang et al. 41 extracted fabric image features by SIFT and obtained the visual words by k-means clustering algorithm. Then, the locality-sensitive hashing was adopted to build the index of each image and realize image retrieval.
The graph-based method performs the clustering algorithm to keep the neighborhood information of each data point in the graph structure to other data points or a group of pivot points for indexing. The greedy algorithm is used to locate and search the neighborhood graph of the query image. The commonly adopted methods are KGraph, Small World (SW), Hierarchical Navigable Small World (HNSW), and so on. 67 At present, there is no relevant research on fabric image retrieval using the graph-based method.
In comparison, the ENN search algorithm is superior to the ANN search algorithm in terms of retrieval precision, but its timeliness in large-scale data sets and high-dimensional features is difficult for meeting the requirements of industrial applications. ENN and ANN search algorithms have their advantages and disadvantages. In practical industrial applications, the appropriate similarity measurement method can be selected according to the characteristic of the specific image dataset.
Retrieval strategy of fabric image
Retrieval strategy 68 refers to the methods to achieve the retrieval objectives, including the selection of retrieval ways, the formulation of retrieval methods, the discrimination of retrieval results, and the adjustment method. The application of the retrieval strategy can improve retrieval precision and reduce the elapsed time. As previously mentioned, on the one hand, macroscopic texture and fine-grained texture of fabric images are not on the same scale, and, on the other hand, there are both intra-class and inter-class variances in fabric images. These two factors increase the application difficulty of traditional image retrieval methods, and the level of retrieval precision needs to be improved. The fabric retrieval strategy is commonly used to improve retrieval precision, and the related researches mainly focus on the pre-screening of the retrieval results.
At present, there are few studies on the retrieval strategy of fabric images. To improve the precision of fabric image retrieval, Xiang et al., 22 He, 59 and Wang et al. 60 proposed to use the output of the hash coding layer for rough retrieval to obtain the pre-selected results and build the candidate pools. Then, the output of the fully connected layer was used to retrieve images in candidate pools and the results were obtained as the final retrieval results. Figure 11 shows the overview of the fabric image retrieval strategy proposed in the literature. 60 Coarse retrieval obtained the pre-screening results by hash coding to establish the candidate pools to shrink the search space. The similarity of the image features without coding in the candidate pools was measured to accurately match similar fabric images.
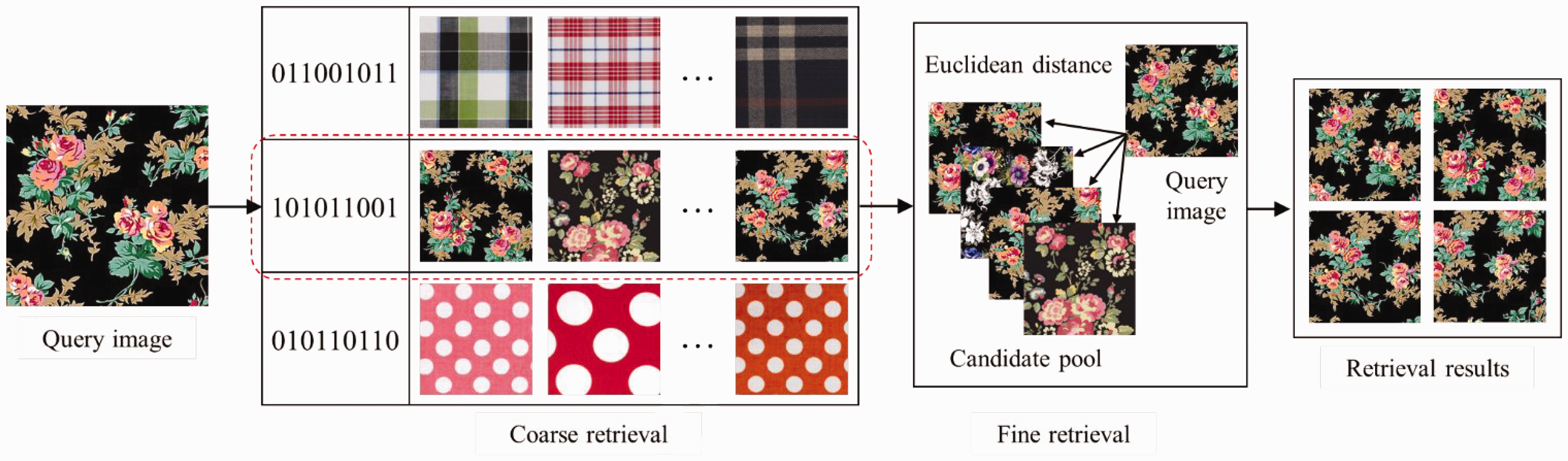
Overview of the fabric image retrieval strategy proposed in the literature. 60
Zhang et al. 39 performed the pre-trained Inception-V3 model to classify fabric images in the database into different candidate pools, and then retrieve fabric images in the candidate pools based on the ORB features. However, image classification models inevitably have misclassification problems. To avoid image misclassification affecting the subsequent retrieval results, the category output probability of the classification model was used to formulate the retrieval strategy and judge whether to search across the candidate pools. The retrieval precision was improved while ensuring the retrieval speed. Yin et al. 57 adopted global features for image retrieval of the printed fabric in the first stage and used local features to reorder the retrieval results in the second stage to further screen similar images as the final retrieval results to improve the retrieval precision.
Compared with the traditional CBIR framework, the re-screen operation in the fabric image retrieval strategy can improve retrieval precision. Although the pre-screen operation shrinks the search space, the re-screen operation increases the elapsed time. When faced with large-scale image datasets, the timeliness of these retrieval strategies will be greatly affected, and cannot meet the timeliness requirements in industrial applications.
Dataset of fabric image retrieval
The existing fabric image retrieval research studies lack a standard and unified public dataset as the verification basis. Researchers usually construct fabric datasets for image retrieval according to specific research objects. Table 3 summarizes the datasets constructed by the existing studies of fabric image retrieval, and the symbol/indicates that no relevant information is given in the literature.
The overview of image retrieval datasets of fabrics
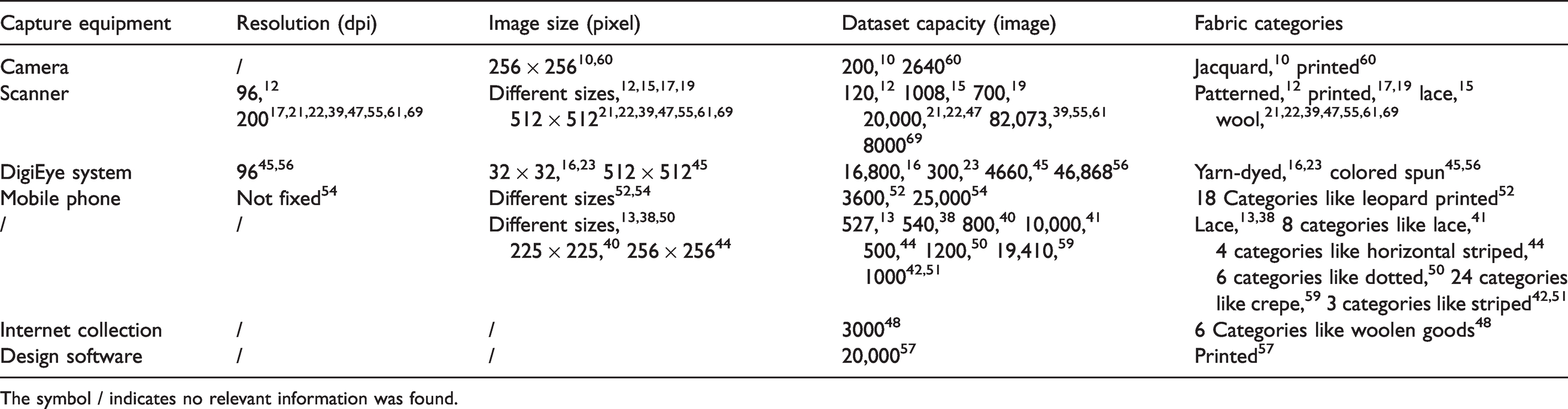
The symbol / indicates no relevant information was found.
As shown in Table 3, the scanner has become the main equipment for fabric image capture with the advantages of a stable capture environment and easy operation. The scanner is widely used in research facing the retrieval demands of textile enterprises. The Digieye system 70 equipped with a Nikon camera and stable light source also has a stable capture environment, which is usually adopted for color measurement. However, the Digieye system is not suitable for use in industrial retrieval applications due to its high price. Industrial cameras are easily affected by the external environment, and the construction equipment is complex, increasing the influence of irrelevant factors for fabric image retrieval. Although the mobile phone is flexible, easy to carry, and simple to operate, the images taken by the mobile phone have great differences in illumination and scale, increasing the difficulty of fabric image retrieval. Therefore, industrial cameras and mobile phones are rarely adopted in existing studies.
To reduce the complexity of the algorithm and improve the effectiveness of the industrial retrieval system of fabric images, some studies used fixed resolution and image size when building the dataset. The retrieval methods based on this kind of dataset are difficult to deal with in considering fabric images of other resolutions and scales, and the applicability and robustness of the method are low. To avoid this problem, some studies build datasets with variable resolution and image size, which can deal with fabric images under different capture conditions. However, such datasets have certain challenges, and the retrieval precision still needs to be improved.
At present, the sizes of fabric image datasets vary in different studies. The effectiveness and variety adaptability of the method are difficult to verify in a smaller data set, while a larger dataset can contain different kinds of fabric images to effectively verify the method. There are various historical products in fabric manufacturing enterprises. Establishing a large-scale dataset to study fabric image retrieval methods is the main way to improve the performance of retrieval algorithms and solve the retrieval demands of enterprises.
The existing studies are not unified in the category of fabrics. For example, the category range of wool fabrics is large, including printed, striped, dotted, and other fabrics, while leopard fabrics while leopard fabrics belong to a small category of printed fabrics belong to a small category of printed fabrics. The retrieval methods proposed for a small range of fabric categories can be designed according to the fabric characteristics to improve the retrieval precision, but their versatility and expansibility are weak, and their application ranges are narrow. In contrast, although the retrieval methods proposed for a wide range of fabric categories will lose some precision, the methods can be applied to a wider range and have certain expansibility. For some fabrics with large differences, the methods can be designed separately according to the fabric characteristics.
In general, the existing fabric image retrieval methods are difficult to verify and compare because the existing datasets for fabric image retrieval have differences in the capture equipment, resolution, image size, dataset size, and applied fabric categories, hindering the industrialization of fabric image retrieval. The primary task of future research is to establish a large-scale public dataset by formulating a unified fabric classification standard and image capture conditions to attract researchers to invest in the research of fabric image retrieval.
Evaluation metrics
To evaluate the performance of image retrieval methods, different evaluation metrics were adopted in previous studies. The commonly adopted evaluation metrics in CBIR include precision, recall, precision-recall (P-R) curve, mean average precision (mAP), F1 score, and so on. 71
Precision is the ratio of relevant retrieved images to total retrieved images and measures the ability of the retrieval system to push away any irrelevant images in the database. Recall refers to the ratio of the retrieved relevant images to the total relevant images and measures the ability of the retrieval system to find all similar images in the database. Precision P and recall R can be defined by equations (1) and (2).


Precision and recall are both expected to be as great as possible, but they generally affect each other. Commonly, the precision decreases with the increase of recall and vice versa. Establishing which one will be large can be determined according to the specific application. The results are different when the selected threshold is different. In most cases, the output of the retrieval system is a sorted list of images, rather than an unordered set. The precision and recall at rank K (Precision@K and Recall@K, P@K, and R@K) can also be used to evaluate the retrieval system. P@K represents the ratio of retrieved similar images are rank K to value K. R@K refers to the ratio of similar images at rank K to all similar images in the database. P@K and R@K are easy to calculate and implement and are commonly used in ranking retrieval. However, the ranks of the top K image are not considered again, and the selection of K has a direct impact on the evaluation.
The P-R curve can be obtained by counting the precision and recall under a group of thresholds to visually compare the retrieval performance, but cannot quantitatively evaluate the overall performance. By contrast, mAP sorts images in descending order of relevance for per query image and calculates the average precision of individual queries. The value of mAP is more intuitive than the P-R curve. Assuming that Q is a total number of queries, mAP is defined by equation (3).
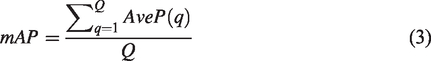
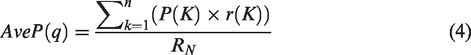
When the requirements for precision and recall are both large, the F1 score is another evaluation metric. The F1 score, also known as the balanced F score, is defined as the harmonic average of precision and recall. The maximum value of F1 = 1 and the minimum value = 0.

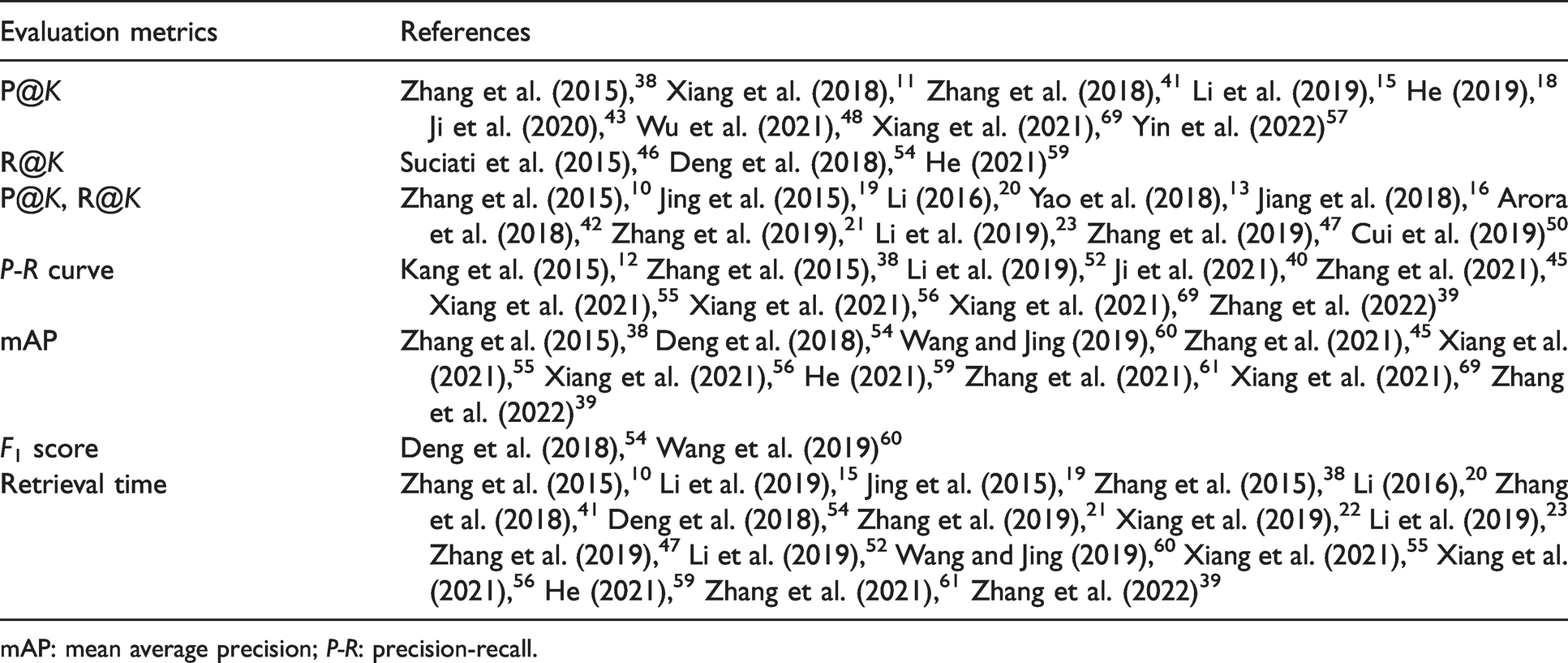
The adopted evaluation metrics in fabric image retrieval are summarized in Table 4. Since fabric image retrieval focuses on the similarities of the ranking toped images, P@K and R@K were commonly used in existing studies except for the P-R curve and mAP, while the F1 score was seldom adopted. As a typical industrial application, retrieval time is also an important factor to meet the demand for fast reaction. Thus, most studies adopted the retrieval time to evaluate the speeds of different methods. In addition to the aforementioned commonly used evaluation metrics, other metrics were also adopted in fabric image retrieval. Xiang et al. 22 used the error rate to evaluate the ranking of top K images. The error rate refers to the ratio of retrieved dissimilar images are rank K to value K. Zhang et al. 41 designed the subjective evaluation metric by considering different fabric elements, including the pattern shape, color, fabric type, and spatial distribution. The designed evaluation metric was divided into five scales: selfsame, quite similarities, similarities, difference, and quite difference to be in line with human visual characteristics. Xiang et al. 56 proposed the performance of fabric image retrieval by the false positive rate at 95% (FPR@95), which represents the false retrieval rate when the recall reaches 95%. A smaller FPR@95 means fewer false positives and better performance of the retrieval method.
The adopted evaluation metrics in fabric image retrieval
mAP: mean average precision; P-R: precision-recall.
As shown in Table 4, different metrics were combined to synthetically evaluate the performance of fabric image retrieval from different views. These studies using combined evaluation metrics make it easier to perform comparative experiments for future studies. Because of the specific retrieval requirements, few studies only adopted P@K or R@K as the evaluation metric. These studies are difficult to be verified and extended to other related fields. As previously mentioned, the existing fabric datasets for image retrieval lack the standards, resulting in comparison of different performances of the existing methods by the evaluation metrics becoming meaningless due to the differences in the capture equipment, resolution, image size, dataset size, and applied fabric categories. Building standard datasets and providing the baseline as the benchmark will become an urgent problem for research in fabric image retrieval to be solved in the future.
Conclusions and future work
This article combs and analyzes the application cases of CBIR technology for fabric retrieval in the textile industry. The existing CBIR methods for fabrics are summarized and compared from the six aspects of fabric image preprocessing, feature extraction, similarity measurement, retrieval strategy, dataset construction, and evaluation metrics. By discussing the research progress of fabric image retrieval methods, although the precision and efficiency of existing methods have been improved, there are still many challenges and problems to be solved in the construction of standard datasets, fabric retrieval with the three-dimensional effect, unbalanced data distribution, relevance feedback technology, and so on. Therefore, the future research direction of fabric image retrieval can be conducted from the following aspects.
Standard dataset construction
The researchers usually built the datasets by themselves in the existing studies of fabric image retrieval. There are many differences in image capture equipment, conditions, and dataset capacity. The lack of standard and unified public datasets results in difficulties in verifying the feasibility and effectiveness of the existing retrieval methods. Meanwhile, the fabric image retrieval method in a complex environment is the future research trend to meet fabric retrieval in different scenes. Therefore, efforts should be made to construct and make public large-scale fabric image retrieval datasets under different conditions in the future.
2. Image retrieval of the fabric with the three-dimensional effect
Some fabrics have three-dimensional bulge or hollow effects, such as embroidered fabrics and dotted fabrics. The images captured in the existing studies are difficult to represent with this three-dimensional effect, and it is easy to confuse the fabric images with similar appearance and this affects the retrieval results. Wang et al.
72
and Zhou et al.
73
used two-dimensional images to realize the retrieval of three-dimensional models based on the visual domain adaptation approach with manifold embedded distribution alignment and dual-level embedding alignment network, respectively. These two methods provide ideas for image retrieval of fabrics with three-dimensional effects. In the future, the retrieval methods of fabrics with three-dimensional effects can be explored based on two-dimensional images, and the algorithms can be designed according to the characteristics of fabrics to achieve accurate retrieval of fabrics with three-dimensional effects.
3. Unbalanced data distribution
Most of the existing studies on fabric image retrieval obtain fabric samples from enterprises for image capture. The fabrics produced by enterprises are usually determined by the orders, resulting in unbalanced fabric sample distribution of different categories. These unbalanced fabric samples will reduce the generalization performance of the model, resulting in satisfactory performance in the training set but unsatisfactory performance in the test set. Therefore, future efforts should be made in the design of model structure
74
and adaptive parameter adjustment
75
of fabric image retrieval to solve the problem of unbalanced data distribution.
4. Relevance feedback technology
Most fabric image retrieval methods have satisfactory test results, but there will inevitably be some problems in the actual application of fabric manufacturing enterprises, and the results of the retrieval system cannot be changed. Relevance feedback technology can make timely adjustments according to the user feedback to improve the applicability of the algorithm and the retrieval performance. However, there are few studies on the relevance feedback technology for fabric image retrieval. The relevance feedback method proposed by Xiang et al.69 is only applicable to fabrics with patterns, and the variety applicability of the algorithm still needs to be improved. Thus, combining the relevance feedback technology
76
to propose robust retrieval methods is a major research direction in the future.
5. Multi-modal fusion and cross-modal retrieval of fabrics
With the development of multimedia technology, different types of data have been produced in the process of fabric design and production, such as image, text, video, and sound. The text information commonly contains the technical parameters, weaving parameters, and fabric descriptions. The video information generally contains images and sounds of sequential frames, which can be transformed into rich features to help the retrieval process. However, the existing studies do not involve multi-source heterogeneous data of fabrics. By fusing multi-source data for multi-modal fusion retrieval,
77
the user's retrieval intention can be more comprehensively described and the retrieval results can be more in line with the user's demands than the retrieval methods only using images. In addition, flexible queries between multi-source heterogeneous data of fabrics can be realized to meet different retrieval demands by cross-modal retrieval.
78
Therefore, multi-modal fusion retrieval and cross-modal retrieval of fabrics will be the focus of future research.
6. Fabric image retrieval based on the sketch
When the user cannot provide the query image and describe the fabric image by text, CBIR and cross-modal retrieval methods are difficult to use to retrieve the fabric images effectively. Sketch retrieval allows users to draw the outline of the fabric sample to retrieve real images, having high retrieval flexibility. There are many studies on general sketch retrieval technology,79,80 which can provide the theoretical basis and research ideas for fabric sketch retrieval. In the future, the sketch retrieval dataset can be built to study the retrieval of real fabric images through sketches to meet the demands of different users and improve retrieval flexibility.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study received support from the National Natural Science Foundation of China under Grant (61976105) and Textile Vision Basic Research Program (J202006).