
Abstract
This article summarizes a conceptual framework and simple mathematical methods of estimating the probability that one event was a necessary cause of another, as interpreted by lawmakers. We show that the fusion of observational and experimental data can yield informative bounds that, under certain circumstances, meet legal criteria of causation. We further investigate the circumstances under which such bounds can emerge, and the philosophical dilemma associated with determining individual cases from statistical data.
Introduction
I am grateful to the editors for inviting me to comment on the article by Dawid, Fienberg, and Faigman (2014; henceforth DFF), in which they justifiably emphasize the fundamental distinction between “Effect of Causes” (EoC) and “Causes of Effect” (CoE).
My aim in this comment is to share with readers a progress report on what has been accomplished on the question of CoEs, how far we have come in using population data to decide individual cases and how well we can answer questions that lawmakers ask about individual’s liability. I hope this account convinces readers that the analysis of CoEs has not lagged behind that of EoC. Both modes of reasoning enjoy a solid mathematical basis, endowed with powerful tools of analysis, and researchers on both fronts now possess solid understanding of applications, identification conditions, and estimation techniques.
The Logic of Counterfactuals
A good place to start is the mathematization of counterfactuals, a development that is responsible, at least partially, for legitimizing counterfactuals in scientific discourse, 1 and which has reduced the quest for CoEs to an exercise in logic (Pearl 2011).
At the center of this logic lies a model, M, consisting of a set of equations similar to those used by physicists, geneticists (Wright 1921), economists (Haavelmo 1943), and social scientists (Duncan 1975) to articulate scientific knowledge in their respective domains. M consists of two sets of variables, U and V, and a set F of equations that determine how values are assigned to each variable
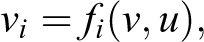
describes a physical process by which nature examines the current values, v and u, of all variables in V and U and, accordingly, assigns variable Vi the value vi = fi (v, u). The variables in U are considered “exogenous,” namely, background conditions for which no explanatory mechanism is encoded in model M. Every instantiation U = u of the exogenous variables corresponds to defining a “unit,” or a “situation” in the model, and uniquely determines the values of all variables in V. Therefore, if we assign a probability P(u) to U, it defines a probability function P(v) on V. The probabilities on U and V can best be interpreted as the proportion of the population with a particular combination of values on U and/or V.
The basic counterfactual entity in structural models is the sentence: “Y would be y had X been x in situation U = u,” denoted Yx (u) = y, where Y and X are any variables in V. The key to interpreting counterfactuals is to treat the subjunctive phrase “had X been x ” as an instruction to make a minimal modification in the current model, so as to ensure the antecedent condition X = x. Such a minimal modification amounts to replacing the equation for X by a constant x, which may be thought of as an external intervention do(X = x), not necessarily by a human experimenter that imposes the condition X = x. This replacement permits the constant x to differ from the actual value of X, namely, fx (v, u), without rendering the system of equations inconsistent, thus allowing all variables, exogenous as well as endogenous, to serve as antecedents.
Letting Mx stand for a modified version of M, with the equation/equations of X replaced by X = x, the formal definition of the counterfactual Yx (u) reads (Balke and Pearl 1994a,1994b):

In words, the counterfactual Yx (u) in model M is defined as the solution for Y in the “surgically modified” submodel Mx . Galles and Pearl (1998) and Halpern (1998) have given a complete axiomatization of structural counterfactuals, embracing both recursive and nonrecursive models (see also Pearl 2009:chap. 7). They showed that the axioms governing recursive structural counterfactuals are identical to those used in the potential outcomes framework, hence the two systems are logically identical—a theorem in one is a theorem in the other. This means that relying on structural models as a basis for counterfactuals does not impose additional assumptions beyond those routinely invoked by potential outcome practitioners. Consequently, going from effects to causes does not require extra mathematical machinery beyond that used in going from causes to effects.
Since our model M consists of a set of structural equations, it is possible to calculate probabilities that might at first appear nonsensical. As noted earlier, the probability distribution on U, P(u) induces a well-defined probability distribution on V, P(v). As such, it not only defines the probability of any single counterfactual, Yx = y, but also the joint distribution of all conceivable counterfactuals. As also noted earlier, these probabilities refer to the proportion of individuals in the population with specific counterfactual values that may or may not be observed. Thus, the probability of the Boolean combination, “Yx = y AND Zx′ = z” for variables Y and Z in V and two different values of X, x, and x′, is well defined even though it is impossible for both outcomes to be simultaneously observed as X = x and X = x′ cannot be concurrently true.
To answer CoE-type questions, such as “if X were x 1 would Y be y 1 for individuals for whom in fact X is Y x 1 and Y is y 0,” we need to compute the conditional probability P(Y x 1 = y 1 | Y = y 0, X = x 0); (Balke and Pearl 1994a, 1994b). This probability, that is, the proportion of the population with this combination of counterfactual values, is well defined once the structural equations and the distribution of exogenous variables, U, is known.
In general, the probability of the counterfactual sentence P(Y
x
= y | e), where e is any information about an individual, can be computed by the three-step process:
Step 1 (abduction): Update the probability P(u) to obtain P(u | e).
Step 2 (action): Replace the equations corresponding to variables in set X by the equation X = x.
Step 3 (prediction): Use the modified model to compute the probability of Y = y.
In temporal metaphors, step 1 explains the past (U) in light of the current evidence e; step 2 bends the course of history (minimally) to comply with the hypothetical antecedent X = x; finally, step 3 predicts the future (Y) based on our new understanding of the past and our newly established condition, X = x.
Pearl (2009:296-99, 2012) gives several examples illustrating the simplicity of this computation and how CoE-type questions can be answered when the model M is known. If M is not known, but is assumed to take a parametric form, one can use population data to estimate the parameters and, subsequently, all counterfactual queries can be answered, including those that pertain to causes of individual cases (Pearl 2009:389-91; 2012). Thus, the challenge of reasoning from group data to individual cases has been met.
When the model M is not known, we can prove that, in general, probabilities of causes are not identifiable from experimental or observational data. However, using group data with observations about an individual, tight bounds can be derived, which can be quite informative. We will illustrate these bounds as an example taken from judicial context similar to the one considered by DFF.
Legal Liability from Experimental and Nonexperimental Data
A lawsuit is filed against the manufacturer of drug x, charging that the drug is likely to have caused the death of Mr. A, who took the drug to relieve back pains. The manufacturer claims that experimental data on patients with back pains show conclusively that drug x may have only minor effect on death rates. However, the plaintiff argues that the experimental study is of little relevance to this case because it represents average effects on all patients in the study, not on patients like Mr. A who did not participate in the study. In particular, argues the plaintiff, Mr. A is unique in that he used the drug on his own volition, unlike subjects in the experimental study who took the drug to comply with experimental protocols. To support this argument, the plaintiff furnishes nonexperimental data on patients who, like Mr. A, chose drug x to relieve back pains, but were not part of any experiment. The court must now decide, based on both the experimental and the nonexperimental studies, whether it is “more probable than not” that drug x was in fact the cause of Mr. A’s death.
This example falls under the category of CoEs because it concerns situation in which we observe both the effect, Y = y, and the putative cause X = x and we are asked to assess, counterfactually, whether the former would have occurred absent the latter.
Assuming binary events, with X = x and Y = y representing treatment and outcome, respectively, and X = x′, Y = y′ their negations, our target quantity can be formulated directly from the English sentence: Find the probability that if X had been x′, Y would be y′, given that, in reality, X is x and Y is y.
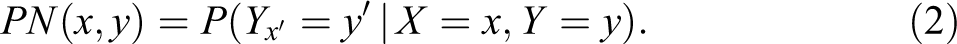
This counterfactual quantity, which Robins and Greenland (1989) named “probability of causation” (PC) and Pearl (2000a:296) named “probability of necessity” (PN), to be distinguished from two other nuances of “causation,” captures the “but for” criterion according to which judgment in favor of a plaintiff should be made if and only if it is “more probable than not” that the damage would not have occurred but for the defendant’s action (Robertson 1997). In contrast, the PC measure proposed by Dawid, Fienberg, and Faigman:
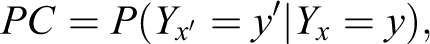
represents the probability that a person who took the drug under experimental conditions and died, Yx = y, would be alive had he not been assigned the drug, Yx ′ = y′. It thus represents the probability that the drug was the cause of death of a subject who died in the experimental setup. Very few court cases deal with deaths under experimental circumstances; most deal with deaths, damage, or injuries that took place under natural, every day conditions, for which the DFF’s measure is inapplicable.
Having written a formal expression for PN, equation (2), we can move on to the identification phase and ask what assumptions would permit us to identify PN from empirical studies, be they observational, experimental, or a combination thereof.
This problem is analyzed in Pearl (2000a:chap. 9) and yields the following results:
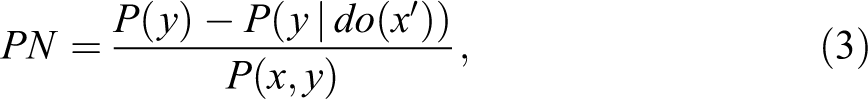
or, 2
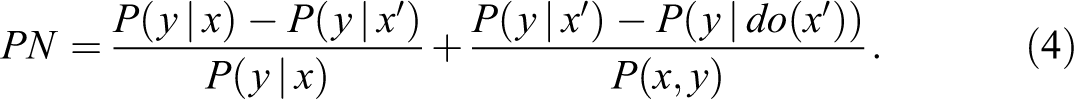
The first term on the right-hand side of equation (4) is the familiar excess risk ratio (ERR) that epidemiologists have been using as a surrogate for PN in court cases (Cole 1997; Greenland 1999; Robins and Greenland 1989). The second term represents a correction needed to account for confounding bias, that is,
Equation (4) thus provides a more refined measure of causation, which can be used for monotonic Yx
(u) whenever the causal effect
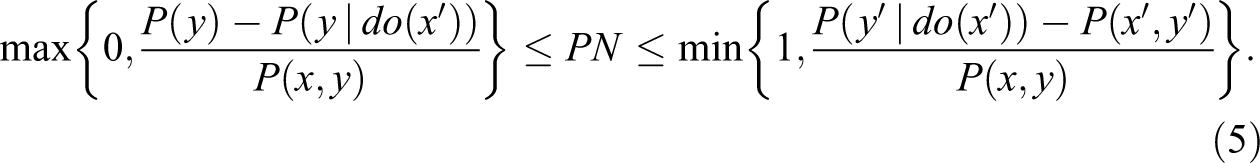
In drug-related litigation, it is not uncommon to obtain data from both experimental and observational studies. The former is usually available at the manufacturer or the agency that approved the drug for distribution (e.g., Food and Drug Administration ), while the latter is easy to obtain by random surveys of the population. If it is the case that the experimental and survey data have been drawn at random from the same population, then the experimental data can be used to estimate the counterfactuals of interest, for example, P(Yx
= y) for the observational and experimental sampled populations. In such cases, the standard lower bound used by epidemiologists to establish legal responsibility, the ERR, can be improved substantially using the corrective term of equation (4). Likewise, the upper bound of equation (5) can be used to exonerate drugmakers from legal responsibility. Remarkably, regardless of confounding the gap between the upper and the lower bounds is constant and is given by one observable parameter,
Numerical Example
To illustrate the usefulness of the bounds in equation (5), consider the (hypothetical) data associated with the two studies shown in Table 1. (In the subsequent analyses, we ignore sampling variability, that is, we assume that our population is of infinite size.)
Experimental and Nonexperimental Data used to illustrate the estimation of PN, the probability that drug x was responsible for a person's death (y).
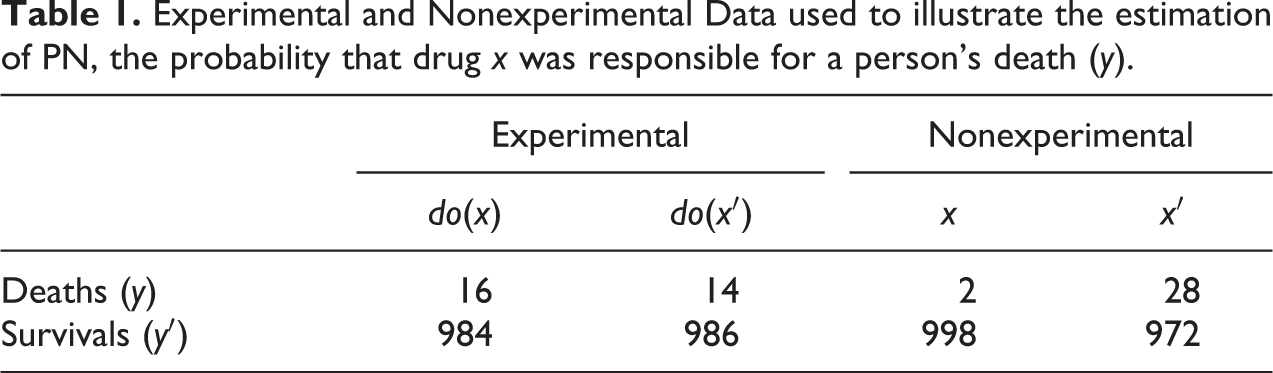
The experimental data provide the estimates
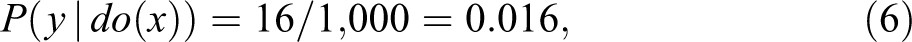
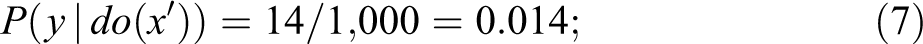
while the nonexperimental data provide the estimates
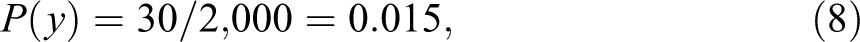

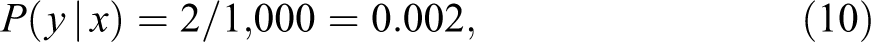

Assuming that drug x can only cause (but never prevent) death, monotonicity holds and Theorem 1 (equation 4) yields
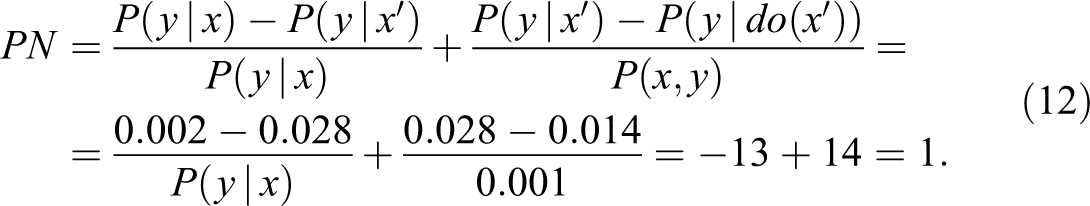
We see that while the observational ERR is negative (−13), giving the impression that the drug is actually preventing deaths, the bias correction term (+14) rectifies this impression and sets the PN to unity. Moreover, since the lower bound of equation (5) becomes 1, we conclude that PN = 1.00 even without assuming monotonicity. Thus, the plaintiff was correct; barring sampling errors, these data provide us with 100 percent assurance that drug x was in fact responsible for the death of Mr. A. Note that DFF’s proposal of using the experimental ERR 1 − 1/RR would yield a much lower result:
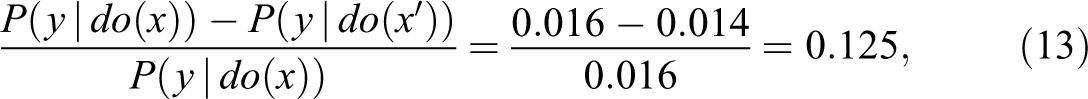
which does not meet the “more probable than not” requirement. 3
What the experimental study does not reveal is that, given a choice, terminal patients tend to avoid drug x, that is, the 14 patients in the experimental study who did not take the drug and died anyway would have avoided the drug if they were in the nonexperimental study. In fact, as our earlier analysis shows, there are no terminal patients who would choose x (given the choice). If there were terminal patients that would choose x, given the choice, then by randomization some of these patients (50 percent in our example) would be in the control group in the experimental data. As a result, the proportion of deaths in the control group in the experimental data, P(yx ′), would be higher than the proportion of terminal patients in the nonexperimental data, P(y, x′). However, examining the data in our hypothetical example, we observe that P(y | do(x′)) = P(y, x′) = .0014, implying that there are no terminal patients in the nonexperimental data who chose the treatment condition. As such, any individual in the nonexperimental data who chose the treatment and died must have died because of the treatment as they were not terminal.
The numbers in Table 1 were obviously contrived to represent an extreme case and so facilitate a qualitative explanation of the validity of equation (12). Nevertheless, it illustrates decisively that a combination of experimental and nonexperimental studies may unravel what experimental studies alone will not reveal and, in addition, that such combination may provide a necessary test for the adequacy of the experimental procedures. For example, if the frequencies in Table 1 were slightly different, they could easily yield a PN value greater than unity in equation (12), thus violating consistency,
This last point may warrant a word of explanation, lest the reader wonder why two data sets—taken from two separate groups under different experimental conditions—should constrain one another. The explanation is that certain quantities in the two subpopulations are expected to remain invariant to all these differences, provided that the two subpopulations were sampled randomly from the population at large. These invariant quantities are simply the causal effects probabilities,
The example of Table 1 shows that combining data from experimental and observational studies which, taken separately, may indicate no causal relations between X and Y, can nevertheless bring the lower bound of equation (5) to unity, thus implying causation with probability approaching one.
Such extreme results demonstrate that a counterfactual quantity PN which at first glance appears to be hypothetical, ill-defined, untestable and, hence, unworthy of scientific analysis is nevertheless definable, testable and, in certain cases, for example, when monotonicity holds, even identifiable. Moreover, the fact that, under certain combinations of data and making no assumptions whatsoever, an important legal claim such as “the plaintiff would be alive had he not taken the drug” can be ascertained with probability approaching one, is a remarkable tribute to formal analysis. 4
How Informative Are the PN Bounds?
To see how informative the bounds are, and how sensitive they are to variations in the experimental and observational data, consider the following example. Assume that the population of patients contains a fraction r of individuals who suffer from a certain death-causing syndrome Z, which simultaneously makes it uncomfortable for them to take the drug. Referring to Figure 1, let Z = z
1 and Z = z
0 represent, respectively, the presence and absence of the syndrome, Y = y
1 and Y = y
0 represent death and survival, respectively, and X = x
1 and X = x
0 represent taking and not taking the drug, respectively. Assume that patients carrying the syndrome, Z = z
1, are terminal cases, for whom death occurs with probability 1, regardless of whether they take the drug. Patients not carrying the syndrome, on the other hand, incur death with probability p
2 if they take the drug and with probability p
2 if they don’t take. We will further assume p
2 > p
1 so that the drug appears to be a risk factor for ordinary patients and that patients having the syndrome are more likely to avoid the drug; that is, q
2 < q
1 where
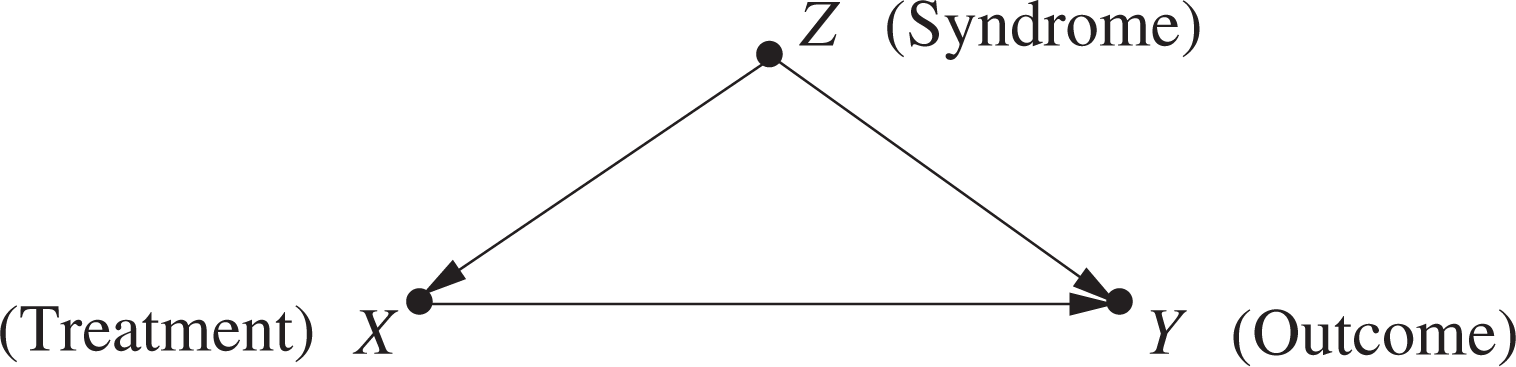
Model generating the experimental and observational data of equations (16 and 17). Z represents an unobserved confounder affecting both treatment (X) and outcome (Y).
Based on this model, we can compute the causal effect of the drug on death using:

and the joint distribution P(x, y) using:

Substituting the model’s parameters and assuming r = 1/2 gives:
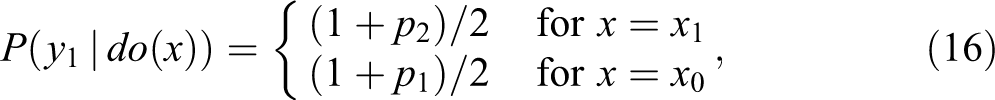
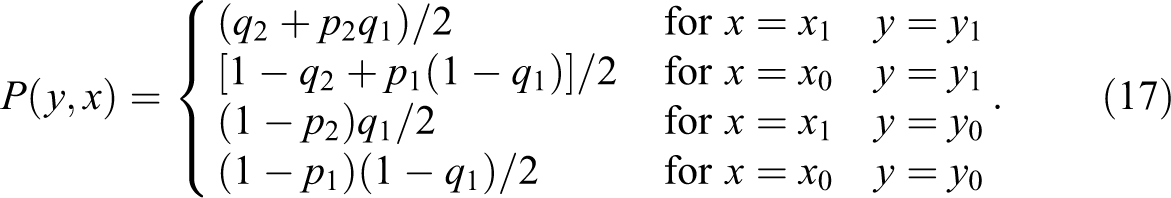
Accordingly, the bounds of equation (5) become:

Equating the upper and lower bounds in equation (18) reveals that PN is identified if and only if q 1(1 − p 2) = 0, namely, if patients carrying the syndrome either do not take the drug or do not survive if they do. For intermediate value of p 2 and q 1, PN is constrained to an interval that depends on all four parameters.
Figure 2 displays the lower bound (red curve) as a function of the parameter
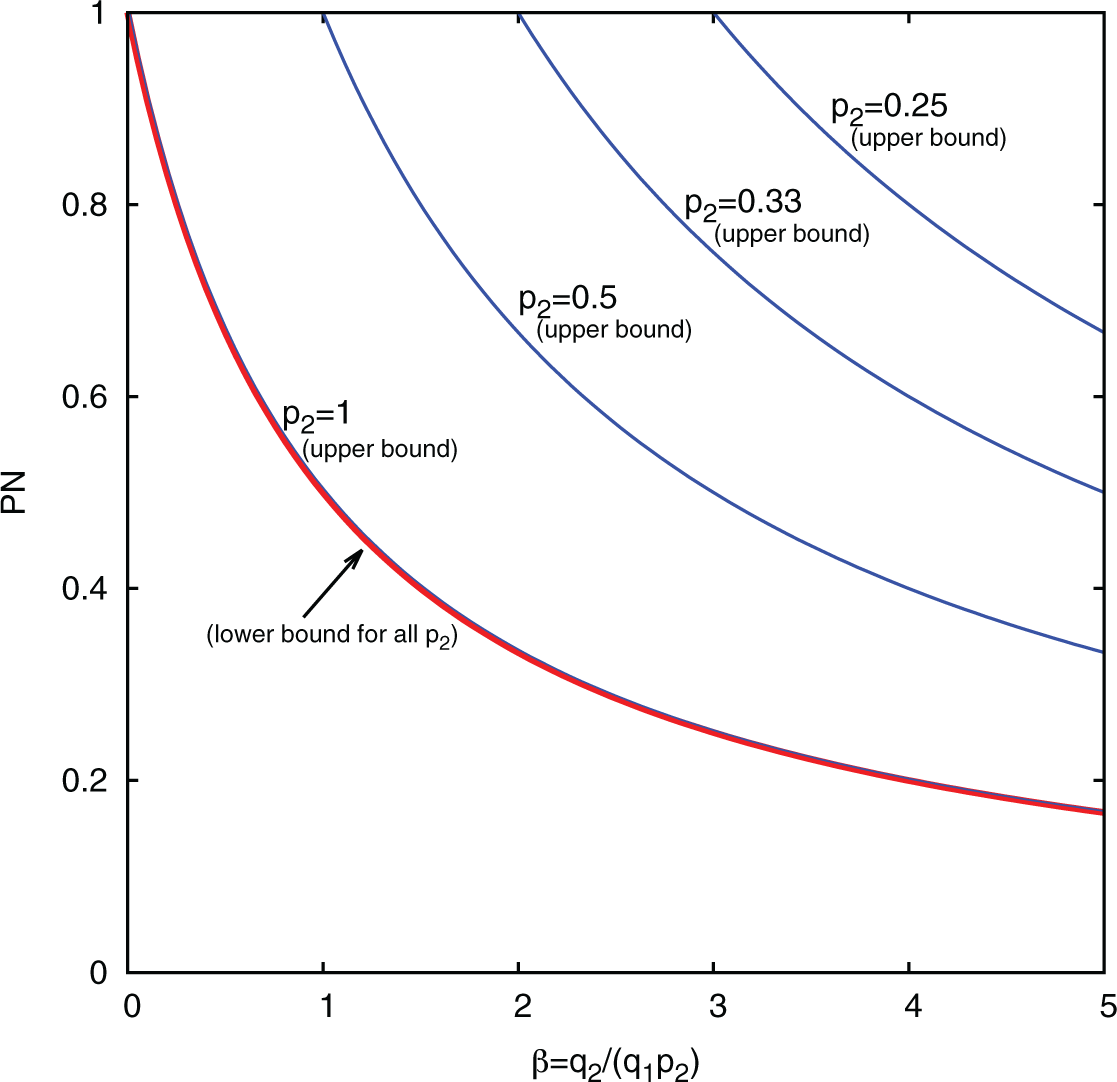
Showing the lower bound of probability of necessity (PN) for p 1 = 0 (red curve) and several upper bounds (blue curves).
Is “Guilty With Probability One” Ever Possible?
People tend to disbelieve this possibility for two puzzling aspects of the problem: that a hypothetical, generally untestable quantity can be ascertained with probability one under certain conditions; that a property of an untested individual can be assigned a probability one based on the data taken from sampled population.
The first puzzle is not really surprising for students of science who take seriously the benefits of logic and mathematics. Once we give a quantity formal semantics, we essentially define its relation to the data, and it is not inconceivable that data obtained under certain conditions would sufficiently constrain that quantity, to a point where it can be determined exactly.
The second puzzle is the one that gives most people a shock of disbelief. For a statistician, in particular, it is a rare case to be able to say anything certain about a specific individual who was not tested directly. This emanates from two factors. First, statisticians normally deal with finite samples, the variability of which rules out certainty in any claim, not merely about an individual but also about any property of the underlying distribution. This factor, however, should not enter into our discussion, for we have been assuming infinite samples throughout. (Readers should imagine that the numbers in Table 1 stand for millions.)
The second factor emanates from the fact that, even when we know a distribution precisely, we cannot assign a definite probabilistic estimate to a property of a specific individual drawn from that distribution. The reason is, so the argument goes, that we never know, let alone measure, all the anatomical and psychological variables that determine an individual’s behavior, and, even if we knew, we would not be able to represent them in the crude categories provided by the distribution at hand. Thus, because of this inherent crudeness, the sentence “Mr. A would be dead” can never be assigned a probability one (or, in fact, any definite probability).
This argument, advanced by Freedman and Stark (1999) is incompatible with the way probability statements are used in ordinary discourse, for it implies that every probability statement about an individual must be a statement about a restricted subpopulation that shares all the individual’s characteristics. Taken to extreme, such restrictive interpretation would insist on characterizing the plaintiff to minute detail and would reduce the “but for” probability to zero or one when all relevant details are accounted for. It is inconceivable that this interpretation underlies the intent of judicial standards. By using the wording “more probable than not,” lawmakers have instructed us to ignore specific features that are either irrelevant or for which data are not likely to be available, and to base our determination on the most specific yet essential features for which data are expected to be available. In our example, two properties of Mr. A were noted: (1) that he died and (2) that he chose to use the drug; these are essential and were properly taken into account in bounding PN. In certain court cases, additional characteristics of Mr. A would be deemed essential. For example, it is quite reasonable that, in the case of Mr. A, the court may deem his medical record to be essential, in which case, the analysis should proceed by restricting the reference class to subjects with medical history similar to that of Mr. A. However, having satisfied such specific requirements, and knowing in advance that we will never be able to match all the idiosyncratic properties of Mr. A, the lawmakers’ intent must be interpreted relative to the probability bounds provided by PN.
Conclusions
I agree with DFF that the issues surrounding reasoning from EoC to CoE involve the challenge of reasoning from group data to individual cases. However, the logical gulf between the two is no longer a hindrance to systematic analysis. It has been bridged by the structural semantics of counterfactuals (Balke and Pearl 1994a, 1994b) and now yields a coherent framework of fusing experimental and observational data to decide individual cases of all kinds, CoE included.
I invite Dawid, Fienberg, and Faigman to reap the benefits and opportunities unleashed by the counterfactual theory of CoE.
Footnotes
Acknowledgment
I am grateful to Nicholas Jewell and the editor of Sociological Methods and Research for calling my attention to the DFF's paper, and for helpful comments on the first version of the manuscript. Portions of this paper are based on Pearl (2000a, 2011, 2012).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by grants from NSF #IIS1249822 and #IIS1302448, and ONR #N00014-13-1-0153 and #N00014-10-1-0933.