
Abstract
Case studies are usually considered a qualitative method. However, some aspects of case study research—notably, the selection of cases—may be viewed through a quantitative template. In this symposium, we invite authors to contemplate the ways in which case study research might be conceived, and improved, by applying lessons from large-n cross-case research.
A case study focuses intensively on a single case. Generally, the chosen case is regarded as emblematic of a larger population of cases, a case of something. So defined, elements of the case study format may be traced to antiquity and to the works of Aristotle, Herodotus, Thucydides, and others. Modern case study research arose from ethnographic studies of urban sociology (the “Chicago school”) in the early twentieth century, for example, Thomas and Znaniecki (1918), Whyte (1943), and Wirth (1928). 1 A second influential strand of case study research appeared in the postwar years in the form of comparative-historical research, for example, Lipset (1968), Moore (1966), and Skocpol (1979). 2
The case study tradition survives in all the social science disciplines as well as in adjacent fields in the natural sciences (e.g., medicine) and the humanities (e.g., history). To be sure, this tradition is more prominently on display in some fields than in others. Nonetheless, our subject intersects with history, psychology, social work, applied linguistics, medicine, cultural anthropology, sociology, the study of science (sociology of science, history of science, and philosophy of science), education, political science, comparative-historical research, law, and economics (business, management, and organizational research). 3
Case study methodology may be said to begin with J. S. Mill’s magisterial study, A System of Logic, first published in 1843. In the early twentieth century, case study research was influenced by logicians such as Cohen and Nagel (1934) and was the subject of intense discussion among sociologists such as Carl Becker (1934), Ernest Burgess (1927, 1928, 1941), Charles Cooley (1927), Leonard Cottrell (1941), Paul Foreman (1948), Katharine Jocher (1928), Robert Park (1930), Clifford Shaw (1927), and Samuel Stouffer (1931, 1941, 1950). In the 1960s and 1970s, another wave of research attempted to define, improve, and integrate case study methods into the mainstream of social science methods. Influential studies include Campbell (1966, 1975), Eckstein (1975), George (1979), Glaser and Strauss (1967), Lijphart (1971, 1975), Przeworski and Teune (1970), and Skocpol and Somers (1980). 4 Today, the literature on case study methods is so abundant and diverse that it defies description—which may be a testament to either its success or its failure, depending on your point of view. 5
Amid this diversity, one feature seems fairly constant. The topic is generally viewed through a “qualitative” lens. The assumption is that a somewhat different logic of inquiry applies to research with only one or a few cases (where cross-case n is vanishingly small) than might obtain where samples are large and statistical models may be employed. The distinctiveness of case study research seems to be validated by the use of terms such as process tracing (Beach and Pedersen 2013; George and Bennett 2005) and causal-process observations (Brady 2004). Although the increasing popularity of multimethod research serves to bring qualitative and quantitative styles of research together within the same studies (Lieberman 2005), they are still viewed as predominantly separate and independent forms of analysis. Whether, or in what respects, this is true constitutes one of the leitmotifs of this volume.
In this special issue, we are primarily concerned with case studies as tools of causal inference. We leave aside, or touch briefly, on case studies whose goal is primarily descriptive or where there is no explicit and sustained causal argument.
We are also concerned primarily with methods of case selection. Case selection is a central issue whenever an author wishes to use the case study to reflect on a larger population of cases. By contrast, it is not an issue if the author’s sole purpose is to explain the case, or cases, under study. Here, the case or cases are already chosen by virtue of their intrinsic interest.
For present purposes, we assume that the author wishes to say something about a larger population of cases. As such, she or he must attempt to identify one or several cases that represent (in whatever ways are relevant to the argument) a broader population. Case selection is thus an example of sampling—albeit not (usually) random sampling but something akin to stratified random sampling.
If the cases available for intensive study are amenable to statistical or set-theoretic models, it is a short step to employing that formal model to guide the selection of cases. And even if they are not—by virtue of the absence of suitable data or theoretically grounded models—it is still possible to conceptualize the task of case selection—its prospects and its risks—within the rubric of a formal algorithm. Gerring (2007:chap. 5) and Seawright and Gerring (2008) take a step in this direction, and many of the articles in this symposium regard this as a point of departure.
What is most distinctive about this special issue is perhaps to be found in its participants rather than its subject matter. In this venue, we bring together researchers who are known more for their work on large-n cross-case studies or medium-n qualitative comparative analysis (QCA) studies than for their work on individual case studies. Some qualitative researchers may be dubious that authors steeped in statistical or set theory can help strengthen case study research. At the very least, we hope that skeptics will see these contributions as extensions of the multimethod component of qualitative and multimethod research (Collier and Elman 2008). We also hope that the “outsider” status of many of the contributors will serve as a bridge to other researchers whose métier is not the case study, couching the methodological properties of the case study in a language that they can readily understand and, perhaps, prompting them to consider case studies as a viable resource in their own work.
Whenever one draws outsiders into an established topic, one expects to elicit a certain amount of debate. We expect this will be true in the present instance. We hope that this debate is fruitful rather than desultory. In order to ensure that arguments meet, rather than pass each other in the night, we use this introduction to help clarify the scope and aims of the studies included in this symposium.
We begin by discussing the pivotal role of case selection in case study research. Next, we outline the contributions of each article and the points of general agreement. Finally, we situate this work within the rubric of case study methodology, a methodology that is highly variegated.
The Pivotal Role of Case Selection
We have pointed out that case selection plays a pivotal role in case study research. This is implicit in the practice of describing case studies by their method of selection—typical, deviant, crucial, and so forth. By contrast, in large-n cross-case research, one would never describe a study solely by its method of sampling. Likewise, sampling occupies a specialized methodological niche within the field of statistics and is not front and center in current methodological debates. The reasons for this contrast are revealing and provide a fitting entrée to our subject.
First, in large-n cross-case research, there is relatively little variation in methods of sample construction. Most samples are randomly selected, stratified random samples whose goal is to achieve a representative sample or convenience samples employing whatever data may be available on a subject. By contrast, in case study research, there are myriad approaches to case selection and they are quite disparate.
Second, in large-n cross-case research, there is little methodological debate about the goals of sampling. Each case in the population should have the same probability of being selected into the chosen sample. By contrast, in case study research, the goal of representativeness is accompanied by a second goal, causal leverage, which usually overshadows the first goal. There is little consensus about how best to achieve leverage.
Third, in large-n cross-case research, the construction of a sample and the analysis of that sample are performed sequentially and are thus clearly delineated from each other. By contrast, in case study research, they blend into one another. Choosing a case often implies a method of analysis, and the method of analysis may drive the selection of cases.
Fourth, in large-n cross-case research, precisely because there is a large sample, findings are more reliable, that is, less susceptible to stochastic error. By contrast, in case study research, findings are prone to stochastic error (except in the rare instance of a census, as discussed).
Finally, in large-n cross-case research, claims to external validity are easy to evaluate if the sample is drawn randomly from a well-defined population. Even if the sample is not randomly selected, it is often possible for readers to evaluate the generalizability of a study. By contrast, in case study research, it is often difficult to say what a chosen case is a case of—referred to as a problem of “casing” (Ragin 1992). The same case may be an example of many different things, and hence representative of many different populations.
This Issue
The seven articles in this special issue are as follows: 1. Selecting Cases for Intensive Analysis: A Diversity of Goals and Methods—John Gerring and Lee Cojocaru.
Building on a growing body of work, Gerring and Cojocaru offer a new typology of case selection strategies. The proposed typology purports to be more explicit, more disaggregated, and more comprehensive than extant typologies, while incorporating insights garnered by other scholars. A secondary goal is to explore the prospects for case selection by algorithm, also known as ex ante, automatic, quantitative, systematic, or model-based case selection. They conclude that algorithms are a valuable tool in certain circumstances but should probably not determine the final choice of cases unless the chosen sample is medium-sized. Relatedly, the authors argue that medium-n samples occupy an unstable methodological position, lacking the advantages of efficiency promised by traditional, small-n case studies but also lacking the advantages of representativeness promised by large-n samples.
6
2. Pathway Analysis and the Search for Causal Mechanisms—Jeb Barnes and Nicholas Weller
Barnes and Weller focus on how to select cases that are useful for one specific, but crucial, purpose: learning about causal mechanisms. Their work takes it for granted that qualitative case studies potentially can be valuable for opening up the black box of correlation and uncovering the pathway(s) connecting X1 and Y that have been established using quantitative or experimental methods. For them, the question is how to realize this potential, and that is primarily a matter of developing tools for choosing the right kind of cases. The authors offer two basic criteria for choosing cases, one based on the extent to which a case is expected to feature the relationship of interest and the other based on the extent to which differences in cases can facilitate hypothesis generation. They codify these selection procedures in a series of clear steps for scholars to follow, and they also consider issues that arise when one is studying a complex causal pathway with multiple and simultaneous mechanisms. 3. A Careful Look at Modern Qualitative Case Selection Methods—Michael C. Herron and Kevin M. Quinn
Herron and Quinn propose criteria for the basic question facing case study researchers: How should a case or cases be selected for analysis? They note that the criteria appropriate for case selection will vary depending on the goals of research. The specific goal of interest is the estimation of causal effects within a counterfactual (potential outcomes) causal framework. Using simulation models, they find that “influential case selection” is the best way to select cases if the goal is to infer population-level average causal effects. Their implementation of “diverse case selection” and simple random sampling strategies also fare quite well. By contrast, they find that extreme case selection, deviant case selection, and crucial case selection generally fare poorly. In addition, the authors find that, when sampling only one or two cases, the method of simply sampling from the largest cell of a 2 × 2 table performs quite well. 4. Aligning Quantitative Case Selection Procedures With Case-Study Analytic Goals—Jason Seawright
Seawright also explores which of the several existing case selection strategies are the best alternatives for case study researchers. He assumes that case study researchers seek to use their cases to test or refine an ordinary least squares regression analysis. Given this basic overarching goal, researchers may use case studies for several more specific purposes: finding measurement error, discovering an omitted variable, exploring causal pathways, and discovering sources of causal heterogeneity. Seawright finds that the best selection strategy varies depending on the specific goal of the analyst, but that two techniques generally dominate: deviant case selection and the selection of cases with extreme values on the independent variable. He also finds that typical cases are notably counterproductive for nearly all of the purposes of case studies explored in his article. 5. Case Studies Nested in Fuzzy-Set QCA on Sufficiency: Formalizing Case Selection and Causal Inference—Ingo Rohlfing and Carsten Q. Schneider.
Schneider and Rohlfing develop a framework for selecting case studies after a QCA of sufficient terms has been carried out. Based on a counterfactual understanding of causal inference, they provide guidelines for the formal choice of “typical” and different types of “deviant” cases for this kind of research design. Schneider and Rohlfing explore how case studies can be used to determine whether individual conjuncts are causal insufficient-but-necessary parts of a condition which is itself unnecessary-but-sufficient (INUS), and how they can help with causal inference on hypothesized mechanisms. If case studies are affirming, they can increase confidence in the QCA model (typical case analysis) or lead to the inclusion of an omitted condition (deviant case analysis). If case studies are disconfirming, however, the consequence can be dropping an INUS condition from the model, discarding a potential mechanism, or modifying truth table rows. 6. Case Selection via Matching—Richard Nielsen
Nielsen focuses on the use of statistical matching methods in order to select “most similar” cases for qualitative analysis. He assumes that credible inferences can be made with qualitative studies of most similar cases because process tracing and counterfactual thought experiments allow for analytic leverage with this design. The goal of his work is to provide qualitative scholars with better tools for selecting cases that are similar to each other on background characteristics. Nielsen shows how several existing matching methods can be used to formalize implicit qualitative rules of case selection. He illustrates how these methods allow for greater assurance that the similar cases selected really are similar in analytically appropriate and productive ways. 7. Increasing Inferential Leverage in the Comparative Method: Placebo Tests in Small-n Research—Adam Glynn and Nahomi Ichino
Glynn and Ichino explore the leverage that small-n comparative researchers can gain by considering additional cases beyond the primary units of analysis. They show that additional cases can be used as “placebo tests”: that is, case comparisons with the same logic as the main comparison but where it is known that there is no effect. When a placebo test detects an effect, it casts doubt on the primary comparison. The authors show how the use of additional cases for placebo tests can add value even when the researcher does not seek to generalize beyond the initial case or cases compared. The value added includes stronger tests of hypotheses about causal effects and better specifying assumptions about the homogeneity of units.
Varieties of Case Study Methods
Taken together, the seven articles support the intuition that views of case selection are inevitably framed by the overarching goals of research and the part the case study plays: The “best” case selection strategy depends on the purpose of the analysis, and case study’s role in achieving those goals. Hence, not surprisingly, where the authors make different assumptions about the objectives and role, they reach different conclusions.
The articles by Barnes and Weller, Seawright, and Herron and Quinn focus on research in which the overarching goal is to use case studies to supplement findings from a statistical model, but where the case study plays different roles. At first blush, the articles by Seawright and by Herron and Quinn appear to reach different or even opposite conclusions about the kinds of cases that are most useful. Seawright finds that deviant cases are quite useful, whereas Herron and Quinn concludes they are not. And whereas Herron and Quinn find much to praise in random sampling, Seawright disagrees. These differences are rooted in contrasting understandings of the purpose of case studies for evaluating a statistical model. For Seawright, case studies are to be used to discover something new (e.g., measurement error, a missing variable) that can be brought back to refine and improve the regression model. In this context, a diverse case has much to offer, whereas a randomly selected case may not. For Herron and Quinn, by contrast, case studies are more about representativeness and replicating a statistical model as closely as possible. In this context, a diverse set of cases or even randomly selected cases—but not deviant cases—are useful.
Assumptions about the purpose of research also shape ideas about how to select cases for the study of causal mechanisms. Barnes and Weller’s advice to focus on cases in which there is a robust X1/Y relationship might seem at odds with Seawright’s advice to focus on deviant cases. However, Barnes and Weller are more concerned with using case studies to investigate hypotheses about posited mechanisms and to develop knowledge and/or hypotheses about the type, number, and structure of causal mechanisms, whereas Seawright is focused on using case studies to discover new causal pathways. Again, the difference turns on whether case studies are sources of data for new theory or whether they are sources of data for theory evaluation.
Like most of the other authors, Schneider and Rohlfing seek to use case studies to make causal inferences on the model defined at the cross-case level. However, the model in question is not regression based but instead centered on QCA, where causal sufficiency is assumed. As a result, well-known case study types such as typical or deviant cases are defined differently. Nevertheless, these authors agree that case selection depends vitally upon model specification and that its payoff arises primarily in the identification of causal effects and causal mechanisms. Here, we find grounds for agreement between scholars versed in statistical models and scholars steeped in the tradition of set-theoretic analysis.
In contrast to the other articles, the contribution by Glynn and Ichino focuses on selecting cases where the goal of analysis is not primarily to use the case studies to test or refine a larger-N model. Instead, they are interested in how additional cases can shed light on a (pre-selected) most-similar contrast.
All of the authors in this symposium believe that in situations where a researcher wishes to generalize from one or more chosen case(s) to a larger population, the process by which that case is selected should be structured as much as possible. Algorithmic, or quantitative, case selection should be enlisted, wherever possible, as the procedure is transparent and replicable, it limits opportunities for cherry-picking, and it enhances claims for representativeness. Authors disagree on whether algorithms should serve as a final and definitive case selection procedure or as a guide, supplemented by in-depth, qualitative knowledge of potential cases, as argued by Gerring and Cojocaru.
Table 1 summarizes some of the dimensions upon which case study methods vary. Our purpose in constructing this matrix is to clarify the focus of this symposium—what the papers collected in this special issue attempt to do as well as (equally important) what they do not. (We exclude Gerring and Cojocaru from this table since their goal is to survey the field, not to elaborate or test a particular approach.)
A Matrix of Case Study Methodologies and Their Range of Applicability.
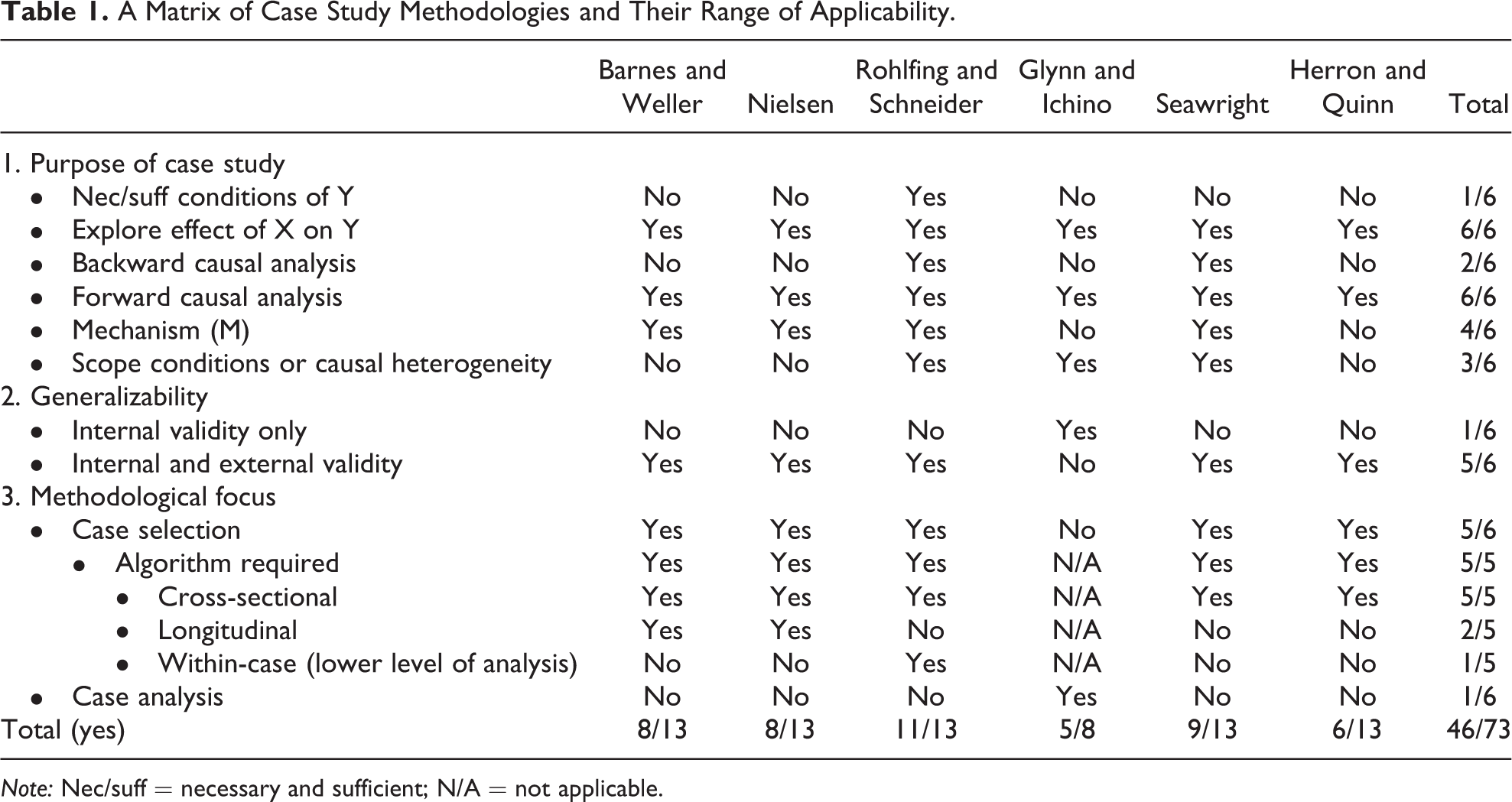
Note: Nec/suff = necessary and sufficient; N/A = not applicable.
1. To begin with, case studies serve different purposes. Sometimes, they are intended to identify causes (X 1 –n ) that are necessary and/or sufficient to produce a particular outcome (Y). Although this is a common goal of case study research, only the article by Rohlfing and Schneider assumes that researchers might use case studies in this way. By contrast, all of the articles in the symposium assume that the goal of a case study is at least in part to shed light on a particular causal effect, that is, X’s relationship to Y.
A related issue concerns whether the purpose of a case study is to work backward from an outcome to discover one or more potential causes (backward causal analysis), or whether the purpose is to start with a potential cause and work forward to its potential effect (forward causal analysis). While all of the articles assume that case study researchers engage in forward causal analysis, only Rohlfing and Schneider and Seawright consider the use of backward causal analysis with case studies.
Sometimes, the goal of a case study is to identify or test a causal mechanism (M), that is, the pathway lying between X and Y. Most of the studies in our symposium are relevant to this goal, though only one, Barnes and Weller, is focused exclusively on mechanismic understanding.
Finally, case studies are occasionally employed to identify the scope conditions of an argument (its true population) or patterns of causal heterogeneity (factors that mediate X’s relationship to Y). Because variations in X’s effect on Y may be framed either as a scope condition or as a causal heterogeneity, we treat these subjects as two sides of the same coin. The use of case studies for this purpose is discussed by Seawright and by Glynn and Ichino.
2. Occasionally, case studies are concerned with reaching causal inferences that pertain only to the case or cases under direct investigation. Internal validity is all that matters to the writer. Only two of the studies in this symposium address this genre of case studies.
By contrast, most case studies also aim to elucidate features of a population of cases extending well beyond the chosen case(s) of intensive study. As such, they are concerned with both internal and external validity. This is how most of the writers in our symposium view the case study format, that is, as addressing something broader than the case itself.
3. Case study methodologies may be concerned, finally, with case selection or with subsequent analysis of cases. As seen in Table 1, the studies in this symposium are focused mostly on the former—the notable exception being Glynn and Ichino. Among case selection strategies, all of the studies in this symposium presume the development of a mathematical model (statistical or set theoretic), which we shall refer to as an algorithm. Qualitative (informal) case selection is given short shrift. Here, it must be emphasized—as our authors are careful to note—that algorithmic case selection is only as good as the chosen model, and chosen models are in turn dependent upon accurate data for a sizable sample. These are by no means dependable commodities in the universe of case study research, which often focuses on little-studied or hard-to-study subjects. Even so, we can all perhaps agree that when relevant data are available, and when plausible models to represent that data can be constructed, researchers are well advised to make use of it when choosing cases for intensive study.
The algorithms guiding case selection may be constructed with different sorts of evidence. As shown in Table 1, the studies in this symposium rely primarily on data of a cross-sectional sort; in this respect, they follow earlier studies (e.g., Eckstein 1975; Gerring 2007; Lijphart 1971, 1975; Seawright and Gerring 2008). However, if the value added of a case study stems from the additional observations it provides, and those observations are longitudinal (through time) and/or within case (at a lower level of analysis), it is questionable whether the methods surveyed in this volume capture all the relevant dimensions that ought to inform the selection of cases intended for in-depth analysis. Barnes and Weller and to a lesser degree Nielsen and Rohlfing and Schneider are the only studies to reflect at any length on the longitudinal properties of cases.
None of the studies reflects upon the suitability of within-case observations. Arguably, these features of a case are impossible to represent in an algorithm, for they cannot usually be measured reliably across a large sample of potential cases. As a hypothetical example, consider two possible cases that might be used to investigate X’s impact on Y. In both cases, X and Y vary in tandem, while background factors appear to remain constant, suggesting that X might be a cause of Y. All measured features of the cases are identical, and thus they are regarded as identical by the algorithm. However, within case A, the intervention—electoral system change, let us say—unfolds in a sequential fashion in different regions of the country, while in case B, the intervention is adopted everywhere at once. Case A thus offers the opportunity for within-case analysis—at a lower level of analysis (regions)—while case B does not.
It goes without saying—but is perhaps worth saying anyway—that algorithms cannot adequately measure the availability of data that might be needed to reach causal inference for a chosen case, for example, the existence of detailed historical records, access to key actors, or ethnographic exposure. Likewise, algorithms measure only what is possible to measure across a large sample. Potential confounders often lurk in the shadows and are only perceptible once one gains considerable knowledge of a case. For these features of case selection, algorithms are blind, as discussed by Gerring and Cojocaru (this issue).
The obvious conclusion from Table 1 is that there are many sorts of case studies and consequently many sorts of case selection methods. Our symposium is strong on some aspects but not on others. Cells marked with a “No” in Table 1 indicate that a particular study is not applicable to that circumstance. Some case study types—those whose goal is to identify scope conditions or causal heterogeneity, those where no causal model is possible, and those where within-case evidence at a lower level of analysis forms the main evidentiary feature—are not covered by any of these methodologies. Overall, roughly half of the available cells in this matrix are marked by a negative notation. In any case, it is the combination of attributes for a given study that determines whether it properly applies to a research setting.
As for any complex subject, there is a danger of confusing the part for the whole. The matrix in Table 1 should help to alleviate confusions of this nature and to clarify the general point that the papers in this symposium hit upon some methodological issues, leaving others in abeyance. Again, it bears emphasis that case studies are not useful for all purposes (Gerring 2004). Evaluating the setting in which a case study might be useful is a delicate matter, for which large-sample analyses are often helpful but rarely determinative. It is our hope that this symposium will help researchers make better decisions on this score and better choices among possible cases.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.