
Abstract
Young and Holsteen (YH) introduce a number of tools for evaluating model uncertainty. In so doing, they are careful to differentiate their method from existing forms of model averaging. The fundamental difference lies in the way in which the underlying estimates are weighted. Whereas standard approaches to model averaging assign higher weight to better fitting models, the YH method weights all models equally. As I show, this is a nontrivial distinction, in that the two sets of procedures tend to produce radically different results. Drawing on both simulation and real-world examples, I demonstrate that in failing to distinguish between numerical variation and statistical uncertainty, the procedure proposed by YH will tend to overstate the amount of uncertainty resulting from variation across models. In standard circumstances, the quality of estimates produced using this method will tend to be objectively worse than that of conventional alternatives.
Introduction
Young and Holsteen (2017)—YH hereafter—introduce methods for dealing with the uncertainty that inevitably results from using multiple models to estimate a single parameter. In making their argument, YH go to great lengths to distinguish their approach from traditional forms of model averaging. The purpose of this comment is to further clarify the difference between these two sets of procedures, both of which provide a set of tools for depicting the distribution of estimates across multiple models. While the YH approach draws on the same basic framework as more conventional forms of model averaging, the two methods differ in how they weight the results of the underlying models. Traditional forms of model averaging typically weight models on the basis of fit, with better fitting models tending to receive more weight. This is true for both Bayesian and non-Bayesian methods. In contrast, the YH procedure treats all models the same, regardless of how well the models in question fit the data. This has substantial implications for the results, especially when it comes to the assessment of statistical uncertainty.
As I show, the weighting mechanism matters insofar as it affects the rate at which numerical variation in the observed parameter estimates is converted to statistical uncertainty. When all models are weighted equally, as is the case with the YH method, numerical variation and statistical uncertainty are one in the same. As the distribution of weights becomes increasingly concentrated, the rate at which numerical variation is converted into statistical uncertainty declines. This means that so long as some models fit better than others, the results produced using the YH method will tend to diverge from those produced using traditional forms of model averaging, with the degree of divergence depending on the extent to which one model tends to outperform all others. These patterns are evident in real-world applications, including the examples considered by YH. As expected, the estimated level of statistical uncertainty produced using the YH method is much higher than what we would get were we to use standard forms of model averaging.
On its face, the choice of whether or not to weight on the basis of fit seems like a matter of preference. This is not the case. The use of weights is integral to the process of statistical inference and is easily justified in terms of basic probability theory. Using simulation, I show that in the absence of orthogonal predictors, the YH method is generally ill-equipped to speak to the characteristics of the data generating process, as evidenced by the propensity to produce intervals that are simultaneously too wide, as well as off-center. So while the flexibility of the method is undoubtedly appealing, it comes at a steep cost. Fortunately, the majority of the procedures proposed by YH have direct analogs in the literature on model averaging.
The Mortgage Example Revisited
The difference between the YH approach and traditional forms of model averaging can be illustrated using a simple example. Here, I draw on the mortgage lending data used by YH. Following their lead, I use linear regression to examine the relationship between gender and the probability of being approved for a mortgage. For the purposes of this particular example, I consider just three controls: martial status, race, and whether or not an applicant was denied personal mortgage insurance. While there are 2,360 observations with complete data on these variables, I focus on the 2,355 observations used by YH. The results are shown in Table 1, which depicts results across the entire model space. When it comes to drawing conclusions, the standard approach is to emphasize the full model, the assumption being that the full model represents a closer approximation to the truth than the simple bivariate model from which we often begin. In most cases, uncertainty in the effect of interest is quantified solely in terms of the standard error, which is typically interpreted in terms of the uncertainty associated with random sampling. Looking at the results in Table 1, it is evident that estimates can also vary considerably across models.
Linear Regression of Loan Status on Select Covariates.

*p < .05. **p < .01. ***p < .001.
Consider, for example, the difference between the bivariate model and the full model. In the case of the former, the parameter estimate associated with gender is −0.18, suggesting that the percentage of female mortgage applicants who are approved for a loan is 0.18 percentage points lower than that of male applicants. In the case of the latter, however, the parameter estimate associated with gender is 4.79, suggesting that, on average, the probability of a female applicant being approved for a loan is actually 4.79 percentage points higher than that of an otherwise comparable male. The estimated effect of gender appears even larger if we ignore whether or not applicants were denied mortgage insurance in the past. In most cases, however, the estimated effect of gender tends to be more modest, lying between 2.37 and 2.77 in four of the eight models. As YH correctly note, our assessment of the relationship between gender and the probability of being approved for a mortgage is sensitive to the choice of controls, with race and marital status emerging as the most influential. This type of variation inevitably raises questions about the idea of committing to any one estimate in particular.
What is to be done? As is the case with model averaging, the YH procedure attempts to quantify the degree of uncertainty resulting from variation in the value of parameter estimates across models. Toward this end, the two sets of procedures draw on a common framework. Given a set of J models, we calculate the mean estimate:

and the total variance
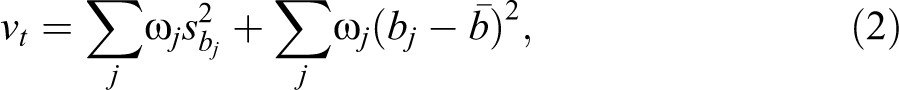
where bj
refers to the estimated value of the parameter of interest b associated with model j, with the estimated sampling variance given by
For any given model j, we thus need to calculate three quantities—bj,

where L* refers to some form of penalized likelihood and τj refers to the prior probability assigned to model j. In most cases, L* refers to either a marginal likelihood or some approximation thereof, with
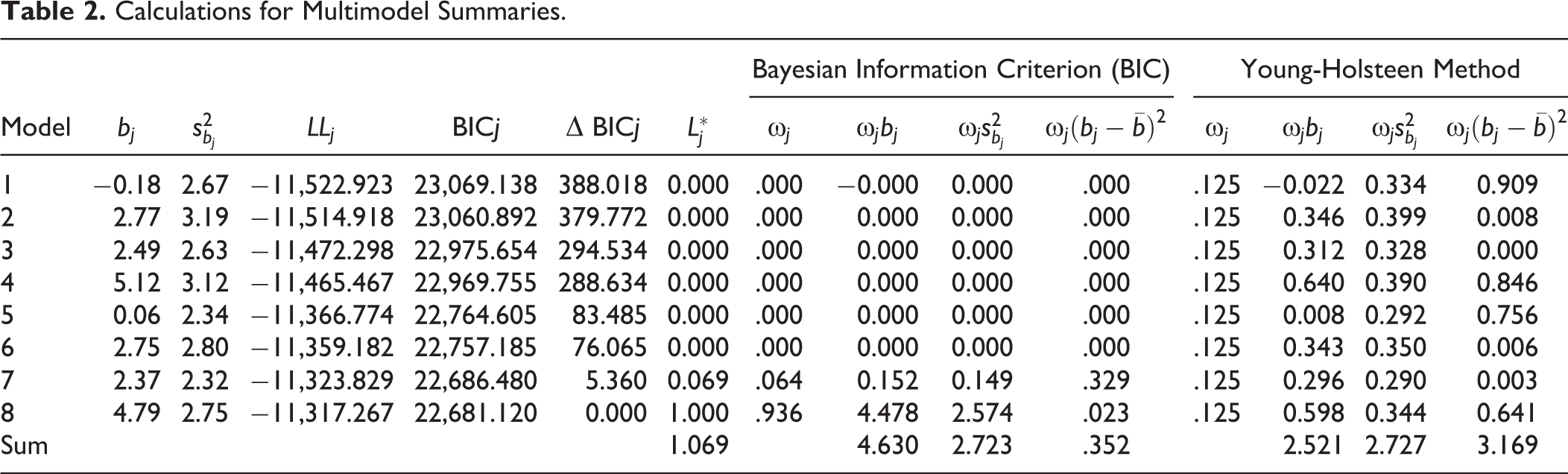
To see how model averaging and the YH procedure work in practice, consider the results shown in Table 2, which compares the results of model averaging using the Bayesian information criterion (BIC) to results using the YH procedure.
1
For each model, we see the estimated effect of gender bj, along with the estimated sampling variance
Calculations for Multimodel Summaries.
If we assign a uniform prior to the model space such that

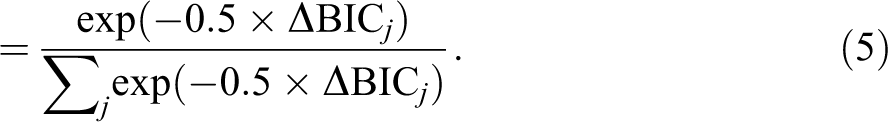
This definition follows naturally from equation (3), with the exact value of the model prior τj determined by the number of models under consideration. Yet as the above formulation suggests, the effect of the model prior τj on the model weight ωj cancels out by the virtue of the fact that the value of τj happens to be constant across models. As it turns out, the YH method also begins with a uniform prior on the model space. The difference is that whereas traditional forms of model averaging allow priors to be revised in light of the data, the YH method commits to the equality assumption throughout. This is evident in the choice of model weights which, in this particular case, are defined as
Using the above quantities, we compute estimates of
The results produced using the YH method are noticeably different, especially when looking that the mean point estimate
Numerical Variation Versus Statistical Uncertainty
The basic intuition behind both model averaging and the YH procedure is that numerical variation in a given parameter estimate is indicative of statistical uncertainty. This relationship is formally captured by the formula for modeling variance
Toward this end, I use simulation to construct hypothetical pairings of estimates and weights. Assuming a preferred model with one independent variable and 10 controls, each pass of the simulation begins by generating 210 = 1, 024 coefficients bj. The simulated coefficients are constructed by drawing a set of J = 1,024 values from a standard normal distribution and then rescaling the resulting values to ensure that the degree of numerical variation is constant from one run to the next. The degree of numerical variation is, by definition, equal to the unweighted modeling variance given by
Using the above method, I generated 10,000 sets of coefficients, along with 10 sets of weights for each. For any given combination of coefficients and weights, the effect of weighting can be measured in terms of the ratio of the weighted modeling variance to the unweighted modeling variance produced using the weights in question. Insofar as the distinction between the weighted and unweighted modeling variance corresponds to a distinction between statistical uncertainty and numerical variation, respectively, the ratio in question can be said to capture the rate at which numerical variation is converted into statistical uncertainty. A conversion rate of less than 1 indicates that the degree of statistical uncertainty is less than the degree of numerical variation. This exercise is admittedly artificial, in the sense that both the estimates and the weights exist independently of a given set of data. This setup is useful in two respects. First, it allows me to directly manipulate the level of concentration. Second, it allows me to remain completely agnostic about the origin of the weights. In this context, calculating statistical uncertainty is a purely mathematical operation, carried out without regard for principles of inference. The purpose is simply to describe what happens to our calculations as we begin to assign higher weights to a smaller number of models.
The results of the analysis are shown in Figure 1, which depicts variation in the central 50 percent of the distribution of conversion rates across weighting schemes. For ease of interpretation, weighting schemes are depicted in terms of the average concentration of weights associated with the underlying scale parameter as measured by the average Herfindahl–Hirschman index (HHI), which can range anywhere between 1/J and 1. The first thing to note is that there are conditions under which weighted modeling variance exceeds the unweighted modeling variance, as evidenced by the fact the upper bound of the central 50 percent of the distribution of conversion rates is clearly above 1 in many of the weighting schemes considered here. At the same time, the estimated modeling variance was more likely than not to be higher in the unweighted condition, even at the lowest levels of concentration. The conversion rate tends to be negatively associated with the degree of concentration, which makes this outcome even more likely as the degree of concentration increases.
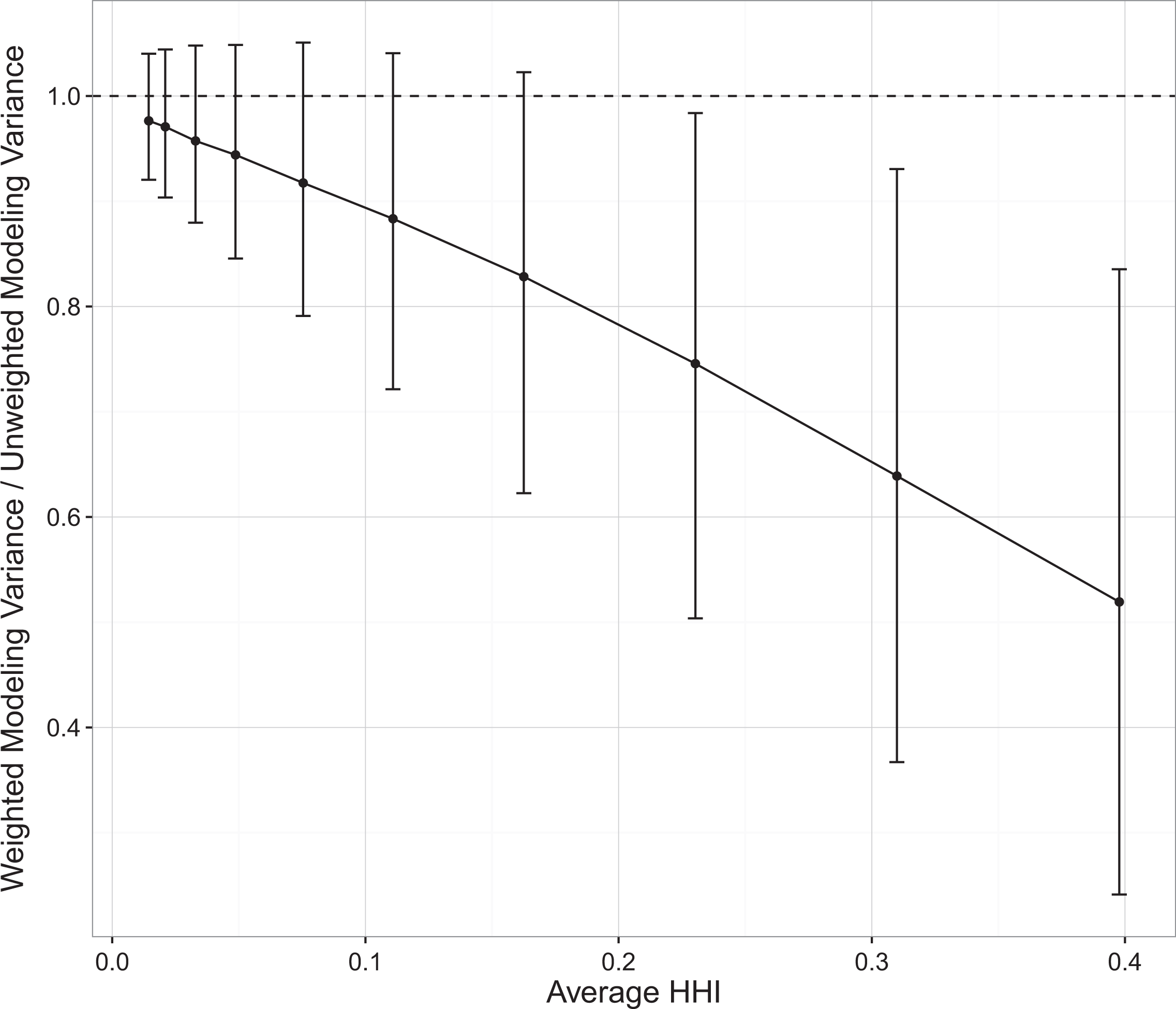
Distribution of conversion rates by concentration.
We find that the magnitude of the divergence between numerical variation and their weighted counterparts can be quite large. Considering only the middle 50 percent of estimates, we find cases where the weighted modeling variance (i.e., statistical uncertainty) is two, three, and even four times lower than the unweighted modeling variance (i.e., numerical variation). As one can imagine, the effects of weighting appear even more extreme once we consider the full range of the distribution. 2 In general, the results shown here not only indicate the conditions under which model averaging and the YH method are likely to produce different results but provide us with a sense of the nature of the differences in question. Insofar as traditional forms of model averaging assign weights on the basis of fit, the results of model averaging will typically differ from the results of the YH procedure when there are some models that fit better than others. Under these conditions, estimates of statistical uncertainty produced using the YH method will tend to be higher than those produced using traditional forms of model averaging. Given that few models are truly equal, we should expect to observe this type of divergence in most real-world scenarios. The question is not so much about whether model averaging and the YH method will produce different estimates of modeling variance; rather, the question is how much larger the variance will be under the YH method as compared to traditional forms of model averaging.
Examples
Using the data provided by YH as part of their mrobust package, I reran the analysis from the first two examples in YH, the first of which examines the relationship between wages and union membership and the second of which examines the relationship between mortgage approval and gender. In addition, I conducted a similar exercise using YH’s data on interstate migration. The resulting analysis is much simpler than that of YH, who use the migration example to show how their method can be used to simultaneously address questions regarding robustness with respect to the choice of controls, the choice of functional form, and the choice of data. For the purposes of the current discussion, I focus exclusively on the uncertainty resulting from the choice of controls. Toward this end, I use linear regression to model the relationship between the log of the number of interstate migrants and the difference in the income tax rate between the destination and the origin, with estimates of the number of interstate migrants come from the Internal Revenue Service. Following YH’s example, controls for the population size of both origin and destination are included in every model. Unlike YH, I did not adjust the standard errors. 3
In each case, I compared the results produced using the YH method to the results produced using a range of model averaging procedures, including Akaike information criterion (AIC)-based averaging, approximate Bayesian averaging using the BIC, and fully Bayesian model averaging using both a Zellner–Siow prior, as well as a hyper-g prior (a = 3) . Note that in the case of the latter two procedures, the priors in question refer to the priors on the parameters not the model space. Details of these procedures are provided by Montgomery and Nyhan (2010). In the context of model averaging, it is fairly standard to average over all possible models. For the sake of comparability, however, I follow YH and focus exclusively on models containing the parameters of interest, thus bracketing out the question of whether these variables should be included in the first place. I also follow the example of YH in assigning a uniform prior to the model space. Calculations were carried out using the bas.lm routine included as part of the BAS package in R (Clyde 2016). 4
The results of the analysis are summarized in the Figure 2, which depicts the decomposition of variance by prior. The results are quite striking. In all three cases, the estimated modeling variance under the YH procedure tends to exceed that of other methods. This trend is especially pronounced in the union membership and gender examples, where the modeling variance—which is more or less nonexistent when using standard forms of model averaging—virtually doubles the size of the total variance! The discrepancy is less sizable in the case of tax advantage, the only example of the three in which the mean estimated sampling variance appears to exceed the modeling variance. Our expectation is that the degree of discrepancy between results produced using the YH method and results produced using standard forms of model averaging should roughly correspond to the extent to which the weights used for model averaging tend to concentrate on a single model.
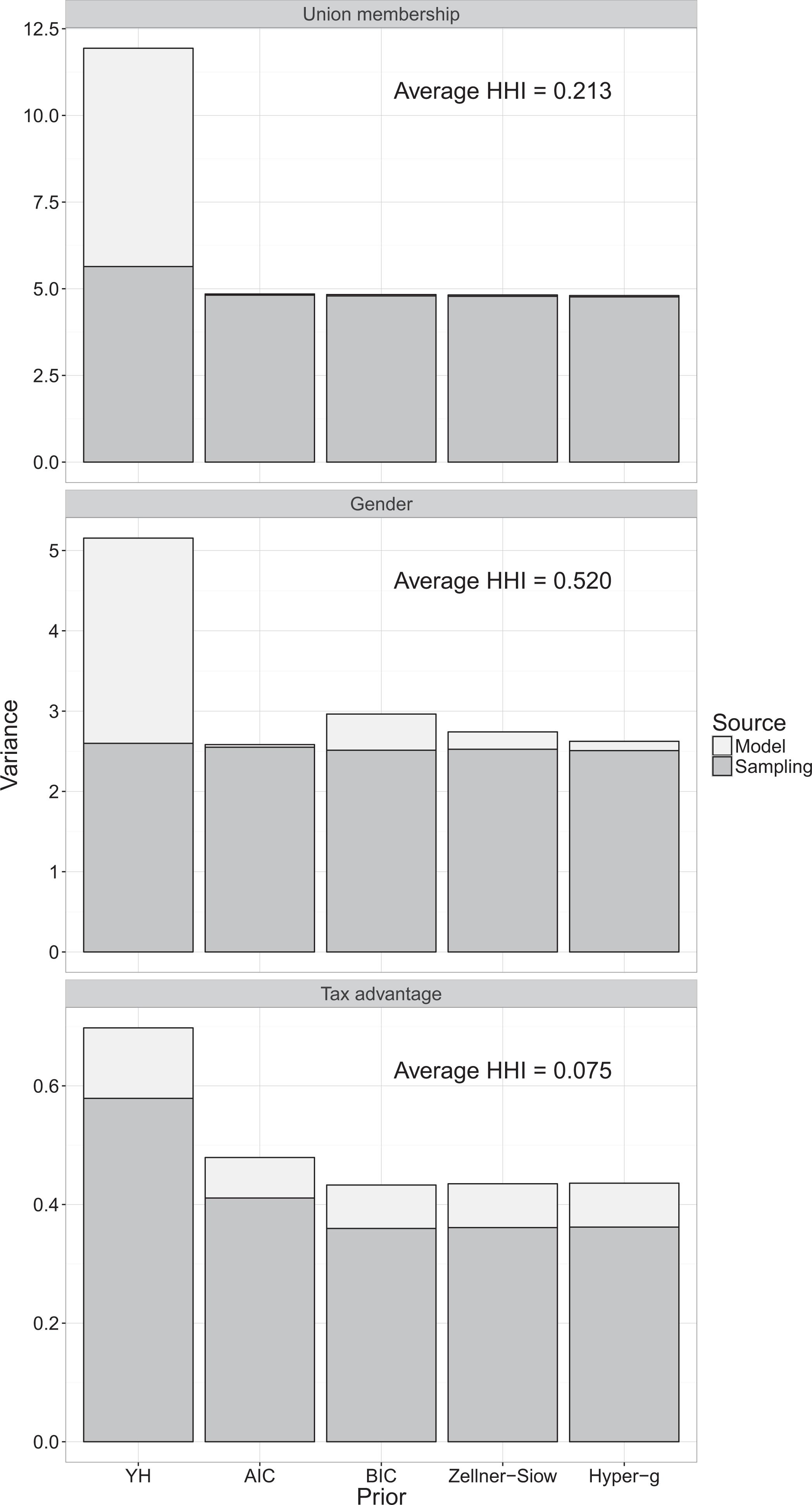
Decomposition of variance by prior.
To measure the degree of concentration, I calculated the average HHI value associated with the distribution of weights resulting from each of the model averaging procedures. I then took the average for each example. As we might expect, the distribution of estimated model weights in the tax advantage example is less concentrated than the other two. At the same time, we see that the relationship between discrepancy and concentration is less than perfect, as evidenced by the comparison between the union wage and gender examples, which produce comparable levels of discrepancy in spite of the fact that the estimated level of concentration in the gender example is almost 2.5 times higher than that in the union wage example. This is consistent with the results of the simulation, which showed that while the divide between weighted and unweighted estimates clearly increases along with the level of concentration, there is a considerable amount of variation around this trend. The key point here is that the potential for discrepancy between the YH procedure and standard forms of model averaging is apparent in real-world examples, with the YH procedure producing a higher estimated modeling variance than conventional forms of model averaging, as we would tend expect given the results of the simulation. The question is whether this increased uncertainty is warranted.
Why Weight?
Up to this point, we have focused exclusively on the effects of weighting, setting aside the question of why one would weight in the first place. The simple answer is that weighting is what gives us inferential traction. This line of argument is not tied to any particular philosophy—it follows naturally from basic probability theory. When working with a single model, inferences are based on a distribution whose properties are, in effect, conditional on the choice of model in question. This is true regardless of whether we think about inference in terms of the sampling distribution of the estimate or the posterior distribution of the parameter. Multimodel inference addresses the problem of model dependence by combining these conditional results to generate a statement about the unconditional distribution of a given quantity of interest.
To help fix ideas, we can start with an analogy to a one-way analysis of variance (ANOVA) in which in the unconditional distribution of some random variable Y can be understood as a mixture of conditional distributions, each of which is associated with a particular group of observations. Here we are concerned not so much with ANOVA as a formal test but as a way of thinking about the world. From this perspective, the question is, how much does each of the conditional distributions contribute to the unconditional distribution? If we think about any standard ANOVA problem, it should be fairly intuitive that groups do not necessarily contribute equally. We find instead that a group’s contribution is proportional to its share of the population, which is the same thing as saying that a group’s contribution is proportional to the probability of selecting a member of that group at random.
If group membership is represented by a discrete random variable X, then the law of total probability says that the unconditional distribution of the outcome Y can be expressed as follows:
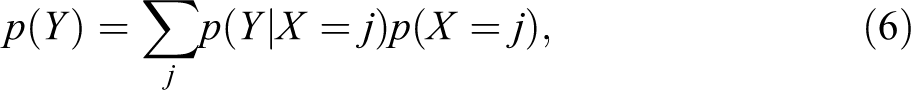
where
Applying the law of total probability to the problem of Bayesian regression, Leamer (1978:117-18) famously proposed that

where D refers to a given set of data, Mj refers to model j,
The practical difficulty lies in the fact that in order to weight our estimates, we need to be able to calculate the probability of the models from which they were drawn. For the moment, we will focus exclusively on the Bayesian case, where the probability in question can be ambiguously interpreted in terms of the posterior model probability
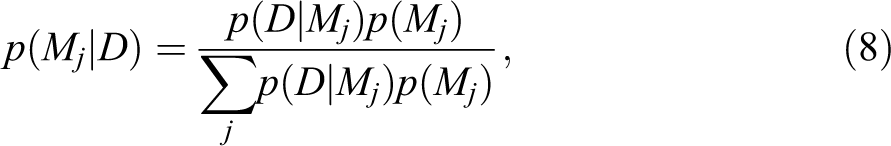
where
This approach can be used to motivate the derivation of the BIC, which, under certain conditions, is roughly proportional to the log marginal likelihood (see Raftery 1995:145). If we assume that all models are equally likely a priori, the posterior model probability of any given model can then be calculated as follows:
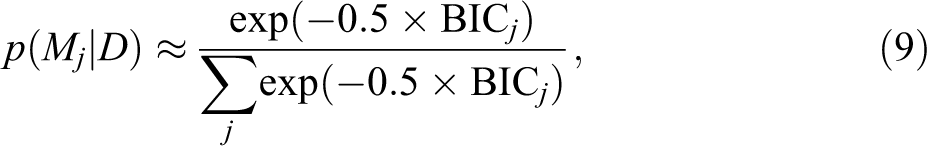
with the latter quantity serving as the model weight ωj, as per the example from which we began. Starting with the law of total probability, we can now see very clearly how and why models come to be weighted by fit, whether that be understood in terms of the marginal likelihood itself or some approximation thereof. Non-Bayesian approaches to the problem proceed in a similar fashion. Burnham and Anderson (2002:74-77), for example, propose using variants of the AIC in place of the (approximate) marginal likelihood. While the resulting weights can technically be recast as posterior model probabilities, they are more directly interpretable as estimates of the probability that a given model is the Kullback–Leibler best model in the set.
Endogeneity and Other Misguided Fears
According to YH, standard forms of model averaging weight estimates in one of the two ways—by model fit or by Bayesian prior. They balk at the practice of weighting by fit on the grounds that measures of fit are only valid under the assumption of exogeneity. It is hard to know what to do with this claim. Measures of fit—marginal likelihood and approximations thereof being among the most important—are meaningfully defined without regard to the quality of the predictors. So while there may be conditions under which the inclusion of an endogenous predictor causes a better fitting model to produce worse estimates than would otherwise be the case, it is not as if there is a systematic relationship whereby measures of fit are necessarily subject to upward bias in the presence of endogenous predictors. This is not to suggest that the question of endogeneity is somehow irrelevant. The point is that to the extent that the assumption of exogeneity is a problem, we need to be clear about the fact that the assumption in question applies to the model itself and thus holds regardless of whether we chose to weight the resulting estimates by fit.
The idea of using unweighted estimates to address concerns regarding endogeneity was first proposed by Sala-i Martin (1997). Introduced in the context of work on economic growth where the threat of endogeneity due to reverse causation—which might lead to a spuriously high fit—happens to loom especially large (see Brock and Durlauf 2001:237-38), the use of unweighted estimates does not appear as a refutation of standard forms of model averaging but as an ad hoc check designed to deal with the specific empirical problem at hand. Indeed, not only did Sala-i Martin continue to contribute to the development of standard model averaging procedures (see Sala-i Martin, Doppelhofer, and Miller 2004), he would also go on to suggest in passing that model averaging might be the solution to the endogeneity problem (see Sala-i Martin 2001:281). This suggestion has been borne out by a growing body of work showing that standard approaches to modeling endogenous regressors extend naturally to the case of model averaging (e.g., Durlauf, Kourtellos, and Tan 2008; Karl and Lenkoski 2012; Koop, Leon-Gonzalez, and Strachan 2012; Lenkoski, Eicher, and Raftery 2014), thus alleviating any lingering concerns as to whether an otherwise remediable problem is somehow damning in a multimodel setting.
This is all to say that endogeneity is neither inherently at odds with the prospect of model averaging nor is the use of unweighted estimates an unambiguous solution. Insofar as the inclusion of endogenous predictors leads to biased estimates, the problem with endogeneity in the context of multimodel inference is that we might overweight bad estimates, an outcome that seems just as likely when we assign the same weight to each model. Certainly, some of our models are better than others, however that may be defined. Again, whatever problems there are with a model, these adhere at the level of the model itself and need to be handled accordingly. Endogeneity and causality in particular have been highlighted as areas that are not in and of themselves addressed through standard forms of model averaging (Montgomery and Nyhan 2010:266). Model averaging can, however, be used to improve existing solutions to the problems in question as noted above with respect to the issue of endogeneity. We have seen similar progress in the area of causality and counterfactual inference as evidenced by an emerging line of work that combines model averaging with propensity score matching (e.g., Kaplan and Chen 2012; Zigler and Dominici 2014).
In terms of the question of Bayesian priors, YH contend that weighting models on the basis of one’s priors privileges model assumptions emanating from the private beliefs of the researcher, thus giving rise to an asymmetry of information between audience and analyst. This line of critique is largely out of step with how priors work in practice. In the first place, it is common to report one’s priors, so while these may begin as private beliefs, they are eventually made public. In this sense, Bayesian methods tend to be fairly transparent. More importantly, when it comes to assigning weights, priors do not exist independently of fit as YH seem to let on. As shown in equation (8), the assignment of weights is consonant with a process of Bayesian updating in which prior assumptions are revised in light of the data as captured by some measure of fit. In this setting, failure to account for fit is tantamount to a refusal to learn from the data.
This is where the YH procedure really diverges from conventional forms of model averaging. It is not uncommon to begin—as YH do—from the assumption that all models are equally likely. In most cases, however, prior equality quickly gives way to posterior distinction. Once we look at the results, we usually have a pretty good sense of which models seem to work and update our priors accordingly. In the context of the YH procedure, on the other hand, the assumption of equality effectively supersedes the traditional distinction between prior beliefs and posterior estimates. The irony is that in attempting to avoid the assumptions that come with standard forms of model averaging, the YH method makes a stronger and even less plausible assumption of its own. To paraphrase a reviewer, the YH method is, in effect, a degenerate form of Bayesian model averaging in which we never update our priors. From a technical perspective, this is unambiguously true, in the sense that one can replicate the results of YH’s mrobust command using existing model averaging routines by simply replacing the posterior weights with their corresponding priors.
Coverage, Bias, and Out-of-Sample Prediction
The argument above suggests three things. First, the relationship between numerical variation and statistical uncertainty is systematically affected by the extent to which the assigned weights are concentrated in a single model, with the conversion rate tending to decline as concentration increases. Second, the propensity for divergence has practical implications insofar as the YH method and conventional forms of model averaging tend to produce different results in real-world applications. Third, to the extent that they approximate the probability of a given model, weights are integral to the process of estimation and inference. We thus have every to think not only that we should weight, but that the decision to weight is likely to have a very real bearing on the quality of the results. To illustrate this point, I turn to simulation. The advantage of using simulation is that we know the value of the underlying parameters ahead of time, thus allowing us to quantify the extent to which any given procedure captures the characteristics of the data generating process.
To put it another way, simulation helps us to evaluate a method’s inferential capacity, by which I mean the capacity of a method to translate descriptive statements about the data in front of us into claims about the larger population from which those data were drawn. The role of inference in the YH method is, however, somewhat ambiguous. Motivated in large part by the threat of false positives, the tools proposed by YH are designed to assess the extent to which one’s preferred estimate depends on a particular model or assumption set. So while allowing for the prospect of inference at the level of the individual model, YH ultimately stop short of multimodel inference. At the same time, the inferential properties of a measure such as the robustness ratio can easily be evaluated using standard methods. More specifically, if we recast the robustness ratio in terms of a confidence interval, we can objectively asses its inferential performance in terms of coverage probability or the percentage of trials in which the interval captures the true value of the parameter of interest.
The analysis below focuses in particular on the relationship between the independent variable x and the outcome y associated with the model:
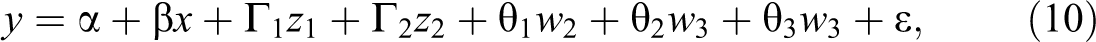
where α refers to the intercept, β refers to the coefficient of interest, and ε refers to a random disturbance. We assume that α = 0, β = 1, and
The vector of predictors
For each case, I generated 10,000 samples of size N = 1,000. Using these data, I assess the relative performance of the YH procedure in terms of not only coverage but bias and out-of-sample prediction as well. The discussion of bias follows naturally from the discussion of coverage, in that bias in the point estimate inevitably carries over to the resulting interval. Together, measures of coverage and bias are used to quantify the ability of the YH procedure to speak to the parameter of interest β. Moving beyond the traditional YH framework, I also consider the effect of weighting on out-of-sample prediction. Although not especially common in sociology, out-of-sample performance is a standard metric in fields such as machine learning, where ensemble methods—including model averaging—are commonly used for the purpose of prediction. Lack of familiarity aside, out-of-sample performance is an intuitive measure of a method’s ability to capture the basic properties of the data generating process.
Results
The results of this exercise are shown in Table 3. I consider two types of intervals, the first of which is the traditional model-specific interval given by
Coverage, Bias, and Predicton Error by Method.

Note:
For each combination of case and interval, I report the average point estimate
When it comes to assessing the inferential properties of the YH method, the primary point of reference is the coverage probability (CP) which, as per the discussion above, measures the proportion of trials in which the confidence interval associated with a given estimate captures the true parameter value. In an effort to depict the typical interval, I have included information on the average lower bound
Looking across the four cases, we find that the coverage probability associated with the non-YH intervals holds steady between 0.952 and 0.956. In contrast, coverage under the YH method ranges from anywhere between 0.86 and 1, meaning that the resulting coverage probabilities can be either well above or well below the nominal rate depending on the nature of data generating process. To understand how this plays out, we need to consider the behavior of the estimated variance as well as the corresponding point estimate. As we move away from the case of orthogonal predictors where the expected modeling variance is equal to 0 by definition, the width of the YH interval increases accordingly. Comparing the average width of the interval produced using the full model to the average width of the interval produced using the YH method, we find that the typical YH interval is 1.11 times larger in case 1, 2.64 times larger in case 2, 3.14 times larger in case 3, and 2.86 times larger in case 4. 7 In other words, the results suggest that the use of the YH interval in this context entails doubling and tripling the width of intervals that already reproduce the nominal coverage rate. The variation in excess width across cases corresponds with variation in the average modeling variance, as we would expect. 8
Whether the coverage rate under the YH interval falls above or below the nominal rate depends on the extent to which the unweighted average of model-specific estimates deviates from the true parameter value. Much like the inflation of the standard error, the degree of bias in the YH point estimate depends on the underlying correlation structure. Unlike the width of the interval, however, the deviation between the point estimate and the true parameter value does not necessarily correspond with the expected value of the unweighted modeling variance. This can be seen by examining changes in the observed bias B representing the difference between the average estimate across samples and the true value of the parameter being estimated. Looking at the results for the YH method, we see the degree of bias increase as we move away from orthogonal predictors in case 1, toward moderate correlation in case 2, and strong correlation in case 3.
In these cases, the propensity for an upward bias in coverage due to the use of inflated standard errors is tempered by the bias in their respective point estimates, resulting in subnominal coverage rates. This is what we would usually expect from a biased estimator. The issue in this case is that in order to produce a downward bias in coverage, the bias in the point estimate needs to be severe enough to counter the inflation in the standard error. Note that a correlation between x and the members of
To this point, I have focused on inference with respect to a single parameter. I also consider overall performance as measured by the capacity for out-of-sample prediction. With this goal in mind, I simulated a second set of data for each trial using the same data generating process as before. For any given trial, the question is how well a model or ensemble based on the first set of data—the data that produced the results described above—predicts outcomes in a second set of data that were omitted from the estimation process. The correspondence between the observed and predicted values associated with a given sample can be measured in terms of the mean squared prediction error
When constructing average parameter estimates, I consider models both with and without the variable of interest x. The resulting model space is comprised of a total of J = 64 models. As before, the model weights ωj are set to 1/J when using the YH method and freely estimated otherwise. When a variable is omitted from a model, the corresponding parameter estimate is assigned a value of 0. Allowing variables to be omitted in this manner causes the average parameter estimate to be shrunk accordingly. In the case of the YH method, the estimate is simply cut in half. In all other cases, the estimate is shrunk by a factor equal to the inverse of the sum of the weights associated with the models in which the variable is included. In this formulation, a variable is, in effect, only as good as the models in which it appears. The implication is that variables that are weak or uncertain have less of an influence on the predicted value than they would otherwise.
Table 3 reports the average MSPE value across samples. Not surprisingly, the true model outperforms its competitors in all four cases. We find that conventional model averaging procedures do as well, if not slightly better than the full model, with only modest variation in predictive performance across cases. The performance gain due to model averaging is admittedly slight, though that is to be expected, given how close the full model is to the true model. The performance of the YH method, however, deviates quite a bit from that of the other methods. As was true before, the results differ considerably across cases. In the presence of orthogonal predictors, the performance of the YH method is only slightly worse than that of the other procedures. Outside this case, however, the YH method predictions are noticeably worse than those of the other methods, with the exact degree of divergence depending on the specific correlation structure at hand.
Discussion
The results above are clear. In all four cases, the coverage probability for the YH interval deviates from that of its competitors, all of which—including conventional forms of model averaging—produce coverage rates around the nominal level. This deviation is a product of a case-specific interplay between the width of the interval and the accuracy of the point estimate. While the YH interval tended to be much wider than any of the alternatives considered here, this only translated into above-nominal coverage when coupled with an unbiased point estimate. In the presence of a biased point estimate, coverage could be either above or below the nominal rate depending on whether the degree of bias was enough to offset the size of the interval. There is no reason to think that any of the model-averaged point estimates—either weighted or unweighted—should necessarily approximate the true parameter value. In the simple cases above, however, we only observe sizable bias when looking at the unweighted estimates associated with the YH method.
It might be argued that when it comes to the YH method, what you lose in precision and accuracy, you make up for in flexibility and ease of use. Insofar as any methodological choice is subject to scrutiny within the YH framework, there are almost certainly scenarios covered by YH that do not fall under the umbrella of standard forms of model averaging. 10 As the discussion above makes clear, the inferential cost of using unweighted estimates is far from trivial, especially when there is a discernible difference in the quality of the underlying models. Fortunately, the bulk of the tools introduced by YH already have some direct alternative in the model averaging literature. Readers are directed to the work cited in Table 4, which provides a list of relevant citations related to carrying out YH-style analysis using existing tools, focusing in particular on techniques that extend beyond traditional forms of variable selection. I have included a list of relevant R packages where applicable. Versions of these programs have been available since at least 2012, with the oldest of the three—BMA (Raftery et al. 2015)—first appearing in 2005. A quick search suggests that the earliest incarnations of what became BMA have been available as an S routine since 1995, if not earlier.
Key Features of the Young-Holsteen Method and Their Model Averaging Analogs.
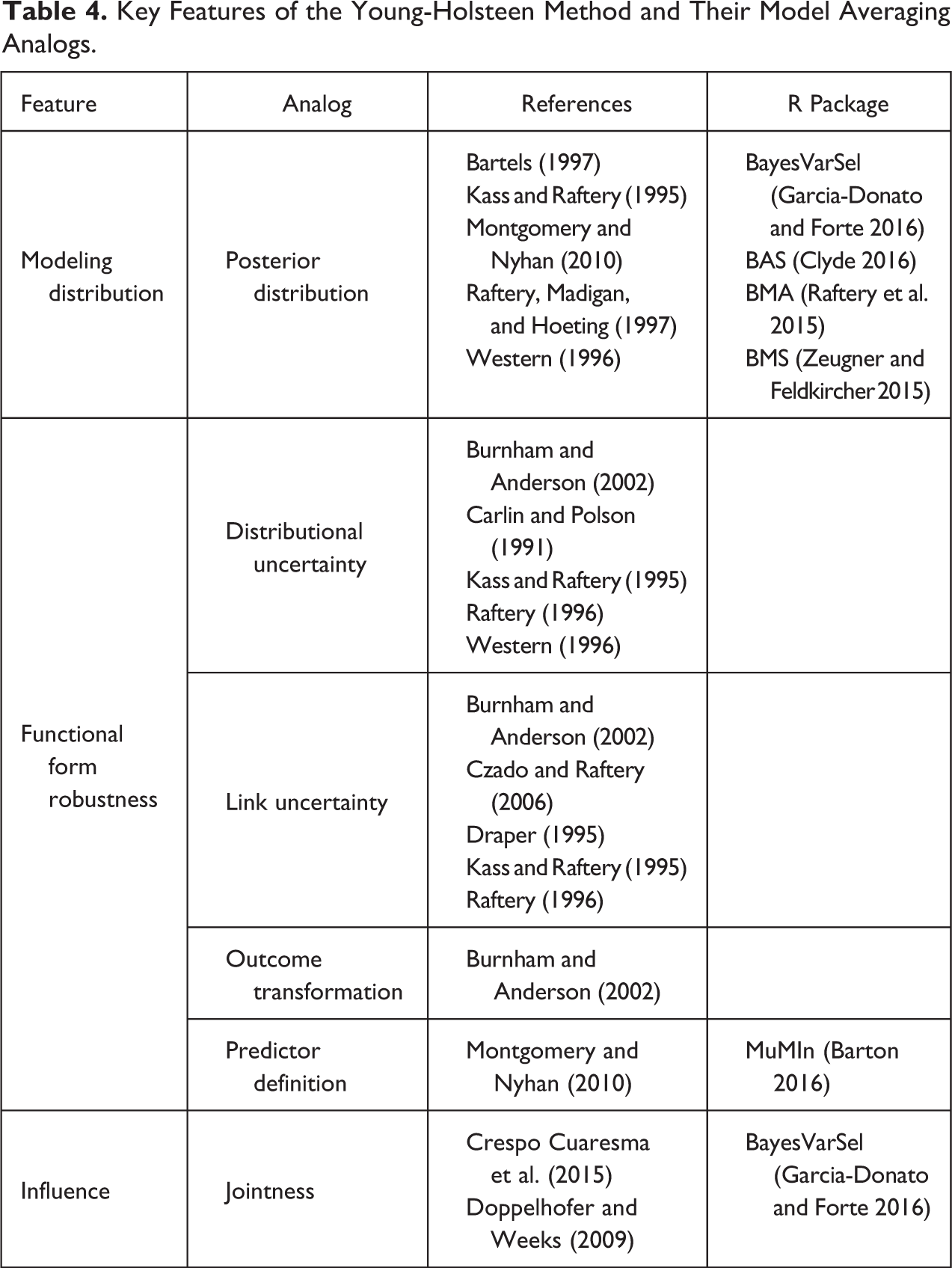
A full discussion of the intricacies of these various methods is well beyond the scope of this article. 11 For the purposes of the present discussion, the key point is that, contrary to YH’s claim, conventional forms of model averaging are by no means uniquely concerned with the choice of variables. Indeed, discussions regarding the distribution of estimates as well as uncertainty in the choice of family and link are evident in seminal papers such as that of Kass and Raftery (1995) who, along with Raftery (1995), helped to popularize the use of the BIC in the mid-1990s. 12 Since then, we have seen work touching on topics such as the transformation of outcomes (Burnham and Anderson 2002), the definition of predictors (Montgomery and Nyhan 2010), and the extent to which predictors work in combination with one another (Crespo Cuaresma et al. 2015; Doppelhofer and Weeks 2009). When it comes to implementation, however, the primary focus is still on variable selection. Yet, this is as true of the mrobust package provided by YH as it as of most other model averaging routines. To replicate YH’s work on functional form robustness, for example, one has to combine estimates across multiple rounds of variable selection and then summarize the results in the usual way. The main point of difference among available packages lies in the choice of priors, with minor differences in the availability of convenience functions related to tasks such as the construction of posterior plots (Clyde 2016; Garcia-Donato and Forte 2016; Raftery et al. 2015; Zeugner and Feldkircher 2015), the construction of jointness statistics (Garcia-Donato and Forte 2016), and the omission of models from the model space (Barton 2016).
In the spirit of full disclosure, it is worth noting that I provided comments on an earlier version of YH’s paper, though the comments I offered then looked quite a bit different than the comments offered here. At the time, I was not fully aware of the possibility of model averaging, though I realize in retrospect that the concept appeared in Young’s earlier work (see Young 2009:382-83). I remain confident that the methods proposed by YH can help us make sense of general patterns in the data in front of us. My concern, simply stated, is that these patterns do not necessarily translate into meaningful statements about the underlying quantities of interest. The benchmarks proposed by YH assume a probabilistic framework that no longer applies once we insist on the equality of models. While I have a hard time recommending YH’s method as an inferential procedure, the motivating principle is absolutely correct and I remain inspired by their commitment to improving methodological practice. Regardless of whether we think about the issue in terms of robustness or inference, model uncertainty is a real concern that applies to the vast majority of quantitative research in sociology. We are well-served by following YH’s lead in trying to find tools to help us address this problem.
Footnotes
Acknowledgment
Thanks are due to John Levi Martin and three anonymous reviewers for forcing me to clarify the argument. I would also like to acknowledge Jon Kropko for encouraging me to write this in the first place. Andrew Hayashi provided helpful comments along the way.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.