
Abstract
These experiments examined the common practice of allowing students to revise and resubmit papers after receiving feedback. Blind graders evaluated students’ first and second drafts of an introduction in American Psychological Association (APA) format. Across experiments, just over 50% of students’ scores improved across drafts when evaluated by blind graders compared to over 80% improvement for the scores assigned by the graduate student lab instructors. In examining the effects of the source of feedback on first drafts, no difference between self-critique, peer review, and feedback from the lab instructor was found in blind graders’ scores. The results suggest that high scores obtained through the review–revise–resubmit procedure do not reflect good writing in an objective sense, but rather an ability to satisfy a particular reviewer.
“Certainly, it MUST work.” “It’s always been done that way.” Psychologists are trained to reject these kinds of justifications for the use of behavioral treatments. Yet, when teaching scientific writing to undergraduates, many instructors adhere to the convention of providing feedback to students on their writing and allowing students to resubmit a revision to be graded, what we call the review–revise–resubmit procedure. Intuitively, telling students what is wrong with their papers and allowing students to rewrite them must have beneficial effects on students’ writing, but does this practice actually have the effects that we assume? In the experiments described herein, we addressed this question by examining the effects of the review–revise–resubmit procedure on the writing quality of students as judged by both instructors and blind graders, and by comparing the effects on student writing of feedback from the instructor, student peers, and self-critique by the student–authors themselves.
Teaching future psychologists to write scientific manuscripts typically focuses on teaching them to write in an appropriate format and style. In terms of format, this usually refers to guidelines published by the American Psychological Association (APA, 2010). As far as style, the art of writing is such that there are many subjectively evaluated characteristics that are not easily specified, although it may involve certain conventions in word usage and compositional style such as those published by the APA. Although many rules of grammar are clearly defined, the subjectivity associated with evaluating writing style can lead to variability among different graders even when a carefully developed grading rubric is used (Stellmack, Konheim-Kalkstein, Manor, Massey, & Schmitz, 2009). We will see that the subjectivity of grading writing has a substantial impact on our assessment of the effects of the review–revise–resubmit procedure.
Some universities require academic departments to offer courses that include a review–revise–resubmit component. The experiments described here were run in an introductory research methods course at the University of Minnesota that is designated as “writing intensive.” According to information published by the university about writing intensive courses (http://onestop.umn.edu/faculty/lib_eds/guidelines/writing_intensive.html), the university recognizes writing as an important part of a liberal education curriculum. The stated purpose of writing intensive courses is to distribute the responsibility for the teaching of writing to departments other than the English Department and related departments, which typically have been responsible for such instruction. Among the guidelines for the design of a writing intensive course, students must be permitted to revise and resubmit at least one writing assignment after receiving feedback from the instructor. Although not explicitly stated, it is implied that such an activity will be instructional and potentially lead to generalized, long-term improvement of writing. One question regarding the review–revise–resubmit procedure is whether it truly results in improved writing.
The evaluation or review of early drafts of writing can come from many sources, including the instructor, fellow students, or the student–author who wrote the draft. One obvious potential benefit to having reviews performed by someone other than the instructor is that it can relieve the instructor of some of the burden of evaluation. In addition, peer review can potentially serve an instructional purpose for the reviewers themselves in that it can allow them to compare their own writing to the writing of others. As Hughes (1995) pointed out, reading unclear and unintelligible writing from another student can lead the reviewer to realize that their own work might be seen in a similar way by others. In spite of its potential benefits, one possible shortcoming of peer review is that students may not be able to provide feedback of the same quality as the instructor, making the review process less beneficial to student–authors. This may have been what the students who participated in White and Kirby’s study (2005) had in mind when they reported that reviewing others’ papers was more helpful than getting reviews of their own papers. In analyzing the effects of peer feedback on student writing, McGroarty and Zhu (2001) saw no improvement across drafts of essays that were written by university students in a first-year composition course in which student–authors received feedback from fellow students on their first drafts.
These studies raise a second question with respect to the review–revise–resubmit procedure in addition to whether it improves writing quality: Is feedback from different sources equally beneficial to student–authors? A number of studies have compared the effects of review by an instructor, peer, or the student–author. Hughes (1995) compared the effects of feedback from these three sources on writing performance across four lab reports in a pharmacology course. Hughes found that student writing improved most across the four reports in the peer review condition. However, Hughes’s comparison was based upon the marks given by the respective reviewers rather than evaluation by objective observers. Other studies have found that training peer reviewers improves the quality of the peer reviews (Kinsler, 1990; McGroarty & Zhu, 2001; Stellmack, Konheim-Kalkstein, & Massey, 2008; Zhu, 1995) and that students give positive comments about their experiences in peer-review activities (Cathey, 2007; Haaga, 1993; White & Kirby, 2005), but these studies did not evaluate the effects on student revision of the reviewed writing (see Topping [1998] for a review of the literature on peer review and its effects on many different target behaviors).
The present experiments assessed the effectiveness of several aspects of the review–revise–resubmit procedure. In Experiment 1, we compared the effects of receiving a review from a fellow student (peer review) to the effects of performing a self-critique of one’s own writing. In Experiment 2, we examined the effects of feedback from the lab instructor (a graduate teaching assistant), who also graded the student writing for course credit. Both experiments also addressed the general question of whether the review–revise–resubmit procedure leads to improvements in writing across drafts of a single-writing assignment. In addition to grading by the lab instructors, writing quality was assessed by blind graders who were unaware of whether the papers they were grading were first or second drafts or what type of feedback the individual students may have received. Experiment 3 addressed the possibility of bias by comparing grades of lab instructors for the same set of papers graded at different times. The general hypothesis in all experiments was that the review–revise–resubmit procedure would lead to improvements in writing between first and second drafts. We could not predict what effects the source of feedback prior to revision might have on student writing; therefore, the general research hypothesis in each experiment was that significant differences would be seen across levels of the remaining independent variables.
We ran these experiments in a research methods course that was structured such that all students registered for a single large lecture section with one instructor (the first author). This large lecture section met twice per week for 50 min each meeting. Students also registered for one of eight lab sections, each of which met weekly for 2 hr for the entire semester. Every lab section had approximately 22 students. The instructor of each lab section was a graduate teaching assistant. There was a different lab instructor for each section. Experiments 1 and 2 were run during different semesters using different groups of students.
Experiment 1: Effect of Self-Critique and Peer Reviews
Method
Participants
We conducted this experiment using the papers of students who were enrolled in an introductory research methods course at the University of Minnesota in the fall of 2008. The course in that semester had a total of 161 students, of which 73% were female; 89% were of junior or senior standing and 11% were sophomores; 73% were declared psychology majors; and the remainder were nonpsychology majors or had not declared a major. The papers of 80 students were chosen randomly from the course for use in this experiment with the restriction that the papers had no extraneous written marks and there was no apparent explicit indication of whether a paper was a first or second draft.
Design and procedure
Students wrote an introduction in APA format describing an experiment that they designed in small groups. Students designed studies in groups of three or four students, but each student had to write his or her own introduction independently. Students wrote first drafts of their introductions, then received feedback on their writing and were required to submit a second draft that incorporated changes based on the reviews they received. Prior to writing their first drafts, all students received several instructional lectures on proper scientific writing style, identifying writing errors and shortcomings in the writing of others, and APA format.
Students were unaware of the review–revise–resubmit procedure when they submitted their first drafts. Students were led to believe that the first draft would be graded. They were not told about the review process so that they presumably would put forth their best efforts in writing their first drafts. When the students submitted their introductions to be graded for the first time, they were told that the first draft would not be graded, but rather some students were told the first draft would be reviewed by another student, whereas other students were instructed to critique their own papers. Students also were told that upon receiving the peer feedback or completing their self-critique, they would have an opportunity to revise their first drafts before resubmitting them for grading.
The eight lab sections of the course were scheduled such that two lab sections were conducted at the same time in different classrooms. One lab section at each time period was randomly chosen to be a self-review section, and the remaining section was a peer-review section. Thus, the students in four of the lab sections evaluated their own papers. In the remaining four lab sections, students blacked out or otherwise made their names unreadable on their papers. The lab instructor collected the papers and redistributed them to the students in such a way that no student received his or her own paper or the paper of a student in his or her research group. Each student then provided anonymous feedback for the paper he or she received. Students were not told that different lab sections were performing the activity differently.
All evaluations were based upon the grading rubric that eventually would be used to grade the students’ papers. The grading rubric (see Stellmack et al., 2009) consisted of eight dimensions (listed in Table 5), each scored on a scale of 0–3 in whole numbers, yielding a maximum possible score of 24 points. Students were instructed to perform their self-critique or peer review by indicating in writing how the paper met or failed to meet the criteria described for each dimension of the rubric. To encourage thorough evaluations, students were told that the self-critiques and peer reviews would be graded. Upon completion of the review procedure, copies of the peer reviews were given to the original authors. The lab instructor graded copies of the self- and peer reviews, but data regarding the content of those reviews was not collected for this study. Students did not receive grades or feedback on their self- or peer reviews until after the second drafts of their papers were submitted for grading.
Students were permitted to revise the first drafts of their papers based on their self- or peer reviews. One week later, students submitted both the first and second drafts of their papers. The lab instructors graded only the second drafts for course credit using the grading rubric. The scores assigned by lab instructors were not analyzed in this experiment.
To evaluate the quality of the student writing in this experiment, first and second drafts of a subset of students were graded separately and independently by a group of four blind graders consisting of the instructor of the large lecture section of the research methods course (the first author), a graduate student (the second author, who was an experienced lab instructor for the research methods course), and two former undergraduate students who previously were students in the research methods course (the third and fourth authors, who were chosen on the basis of the quality of their writing in previous semesters of the research methods course). Prior to grading papers in the present experiment, the graders graded numerous sample student papers over the course of several weeks using the same grading rubric that was used by students and lab instructors. The graders compared and discussed the scores that they assigned to the sample papers in order to come to agreement on their application of the rubric with the goal of maximizing interrater agreement in the assigned scores. This essentially was the procedure that was followed in the original development of the rubric (Stellmack et al., 2009).
For this experiment, the graders graded the first and second drafts of 80 students. The graders all evaluated papers from 20 different students, with each grader evaluating both the first and second drafts of a given student’s paper. Each grader graded papers from 10 students who critiqued their own first drafts and 10 students whose first drafts were peer reviewed. Other than satisfying the criteria for numbers and types of papers described above, the students whose papers were graded were chosen randomly. The graders knew the nature of the experimental manipulation (i.e., first and second drafts written by students who may have received feedback from peers), but they were blind as to which papers were first or second drafts and the source of the feedback that each student–writer received prior to writing the second draft. Students’ names were removed from all papers before they were distributed to the graders. The blind graders graded all papers using the 24-point rubric.
Because the grading rubric that was used did not exhibit extremely high interrater reliability in the past (Stellmack et al., 2009), after all papers were graded, they were swapped among graders and graded a second time to permit an assessment of interrater reliability in this experiment. Thus, each paper was graded independently by two different graders, with each grader grading the first and second drafts of a given student’s paper. This yielded two sets of scores for all of the papers, Grade Set A and Grade Set B, which are the two levels of another variable in our research design. Each pair of first and second drafts of a single student’s paper was graded by one grader in Grade Set A and by a different grader in Grade Set B. All four graders contributed grades to the papers in Grade Sets A and B.
To summarize, the independent variables in the 2 × 2 × 2 factorial design of Experiment 1 were source of feedback (self-critique vs. peer review, manipulated between subjects), draft number (first vs. second, manipulated within subjects), and grade set (Grade Set A vs. Grade Set B, manipulated within subjects). The dependent variable was the score assigned to each paper by the blind graders.
Results
Across all 160 papers that were graded, the correlation between the grades assigned by different graders for the same papers (Grade Set A vs. Grade Set B) was not extremely high but it was statistically significant; Pearson r(158) = .40, p < .001; Spearman rank-order rS (160) = .343, p < .001. The Spearman rank-order correlation for this set of papers is somewhat lower than that reported by Stellmack et al. (2009) in the development of the rubric, but the larger sample size of the present experiment is likely to result in many more ties in the rankings of the papers within graders, which will tend to decrease the rank-order correlation. Because of the somewhat low agreement across sets of grades, the grades for papers in Grade Set A and Grade Set B were kept separate for the remaining analyses.
The mean scores (of the 24 points) and the standard deviations are shown in Table 1. A mixed model 2 × 2 × 2 analysis of variance (ANOVA) was performed to test the significance of the results, with the between subjects factor of self versus peer review and the within subjects factors of draft number and grading time. Only the main effect of draft number was statistically significant, F(1, 78) = 13.66, p < .001, η2 = .041. The difference between the means of all first draft scores (M = 14.17) and second draft scores (M = 15.14) corresponds to a change of 4% for the 24-point assignment. No significant effects were observed for the self versus peer review variable or the grading time variable and none of the interactions was significant. All values of η2 were less than .01 for the remaining nonsignificant effects.
Means (and Standard Deviations) of Grades Assigned to Papers in Experiment 1
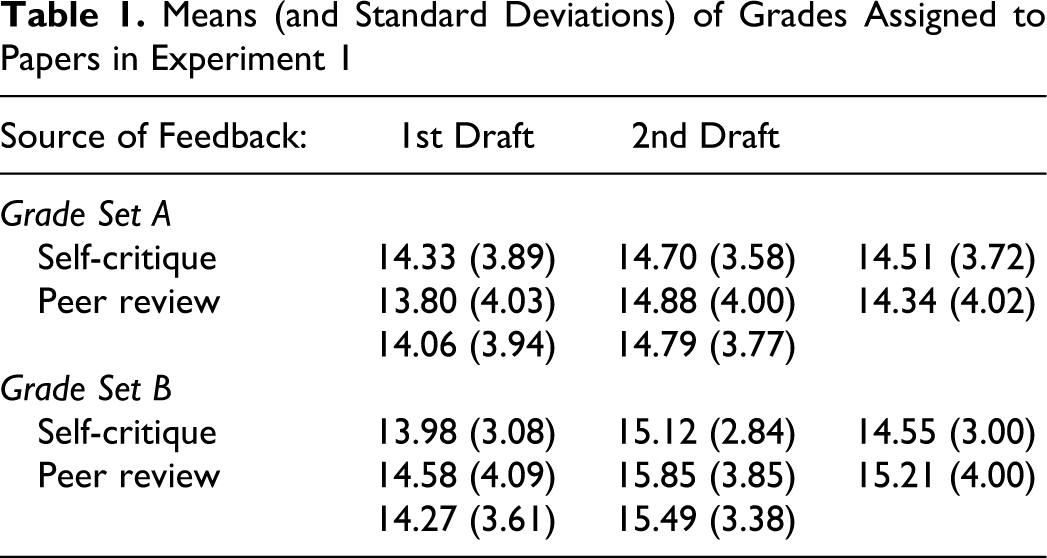
It is useful to consider the proportions of students whose scores increased, decreased, or were unchanged between drafts. For Grade Set A, across drafts, scores increased for 41 students (51%), decreased for 26 students (33%), and were unchanged for 13 students (16%). For Grade Set B, scores increased for 45 students (56%), decreased for 22 students (28%), and were unchanged for 13 students (16%). These distributions were not significantly different from one another, χ2(2) = .52, p = .77. The changes in score across drafts in Grade Set A ranged from −7 to +7 and in Grade Set B, from −8 to +9. The first and second draft scores are plotted in Figure 1, where each point represents the second draft score of a given student plotted against that student’s first draft score. Because the distributions in Grade Set A and Grade Set B were not significantly different, data from both sets of grades are plotted in the same panel; thus there are 160 data points in Figure 1. Filled triangles above the diagonal line represent students whose scores improved between the first and second drafts. Gray squares on the diagonal represent students whose scores were unchanged between drafts. Open circles below the diagonal represent students whose scores decreased between drafts.
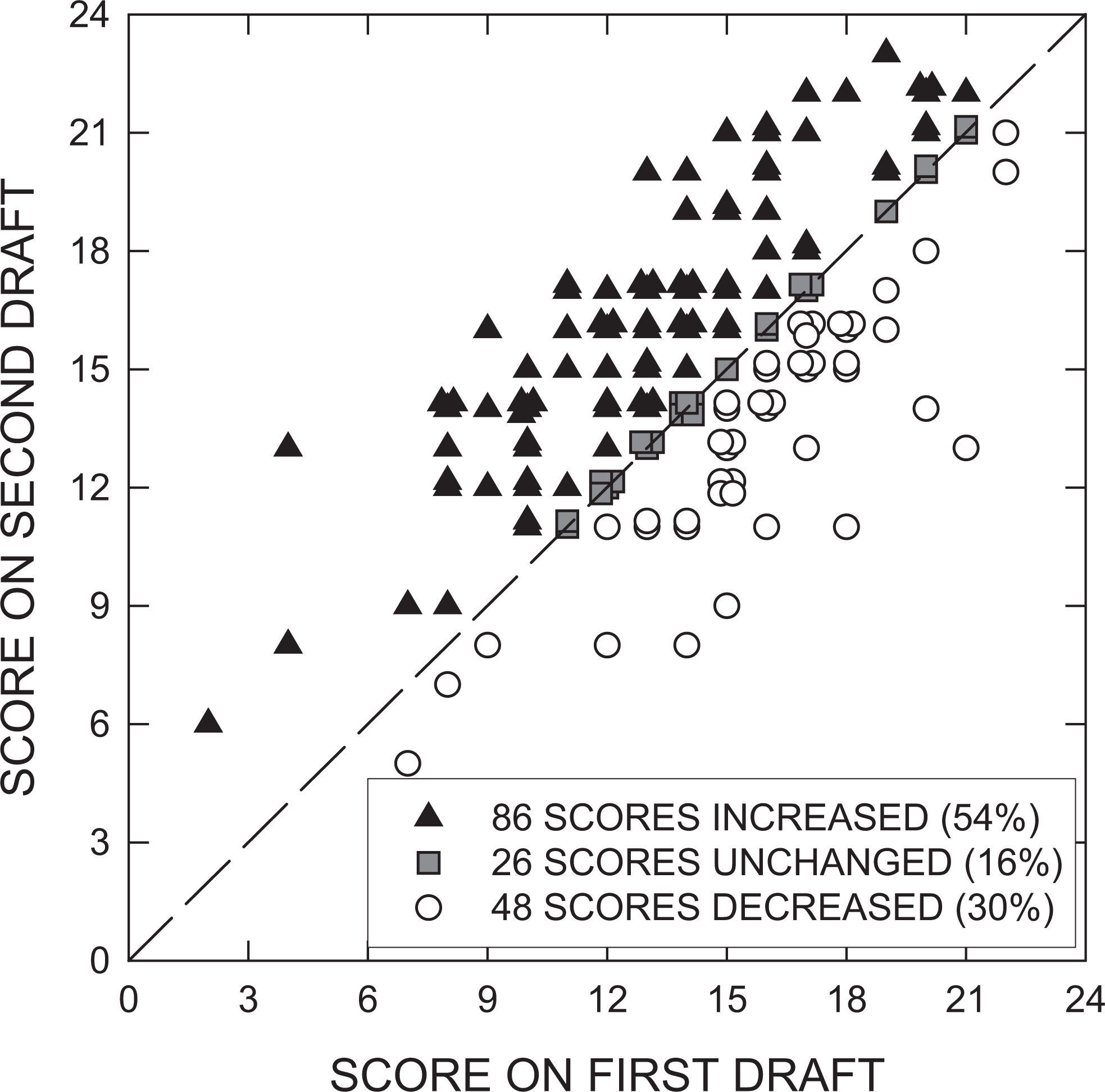
The results of Experiment 1. Each point represents the first and second draft scores for a single student. Black triangles represent students whose scores increased across drafts, gray squares represent students whose scores were unchanged, and white circles represent students whose scores decreased across drafts. Overlapping points have been offset slightly for clarity.
Table 2 shows the numbers of students whose scores increased, remained unchanged, or decreased across drafts in the self-review and peer-review groups for the grades obtained in Grade Set A and Grade Set B. The distributions for the self-critique and peer-review groups were not significantly different in Grade Set A, χ2(2) = .10, p = .95, or in Grade Set B, χ2(2) = 1.00, p = .60, suggesting no effect of the source of feedback.
Number of Students Whose Scores Increased, Remained Unchanged, or Decreased Across Drafts in the Self-Review and Peer Review Groups for Grade Set A and Grade Set B in Experiment 1

Returning to the issue of interrater agreement, the graders in Grade Set A and Grade Set B agreed on the direction of change across drafts for 36 of the 80 students (45%). The grades for 28 students increased across drafts for both graders, the grades for seven students decreased and the grade for one student was unchanged for both graders.
Brief Discussion
Although the mean change in scores across drafts was statistically significant, it was a small effect. Perhaps more importantly from a practical standpoint, only slightly more than half of the students showed an increase in score across drafts within each set of scores obtained in Grade Set A and Grade Set B. There was no difference between the effects of self-critique and peer review in terms of the mean change in score or the proportion of students whose scores increased across drafts. Furthermore, there was a low level of agreement between graders in terms of both the scores that were assigned and the direction of change in score across drafts (we consider the implications of low interrater agreement in all of the experiments in the General Discussion section).
One factor that may have limited the improvement across drafts is that the comments generated through self-critique or peer review may not have been useful due to the reviewers’ inadequate experience or knowledge. All of the reviewers were students in the same introductory research methods course, who simply may have had insufficient knowledge regarding writing research papers, particularly in APA format. If that were the case, one might expect that feedback from a more knowledgeable source, such as the lab instructor, might have more beneficial effects. To explore this possibility, in Experiment 2, students submitted a first draft of an APA-style introduction to be graded. Students then were instructed to revise and resubmit their papers based on the feedback they received from their lab instructors, who graded both the first and second drafts. Thus, Experiment 2 differed from Experiment 1 in that students received feedback from the instructor of the lab section, a graduate teaching assistant, prior to revision and resubmission of a second draft. In addition, both the first and second drafts were graded for course credit.
Experiment 2: Effect of Instructor Reviews
Method
Participants
This experiment used papers that were written by students enrolled in an introductory research methods course at the University of Minnesota in the spring semester of 2009. The course in that semester had 173 students; 73% were female; 80% were Juniors or Seniors, and 20% were Sophomores; 71% were declared Psychology majors and 29% were non-Psychology majors or had not declared a major. The papers of 48 students were randomly chosen for use in this experiment.
Design and procedure
Students were instructed to write an introduction based on a research project designed in small groups, as in Experiment 1. Prior to the writing assignment evaluated here, students received the same writing instruction as the students in Experiment 1.
Students submitted first drafts of their introductions to be graded by the instructor of their lab. The lab instructor in each section graded the introductions using the standard grading rubric and returned the rubrics and papers with editorial comments to the students. Students then revised their manuscripts and, two weeks after submitting the first draft, submitted a second draft to be graded. All papers were graded by the lab instructors during the week following their submission. The lab instructors were fully aware of the identity of each individual author and whether a paper was a first or second draft. Within the context of the course, the first draft was graded for “half points”, that is, students could score 0, 0.5, 1.0, or 1.5 points in each of the eight rubric grading dimensions for a maximum possible score of 12 points. The second draft was graded based on a maximum possible score of 24 points, with each of the eight rubric dimensions scored in whole numbers from 0 to 3.
As in Experiment 1, the first and second drafts of randomly selected students were graded independently by a group of three graders (the instructor of the large lecture section of the research methods course and the two former undergraduate graders of Experiment 1), who were blind as to whether each paper was a first or second draft and to the identities of the students. All three graders graded first and second drafts of 16 students. All of the papers that were graded by blind graders had been graded already by lab instructors in the context of the course. As in Experiment 1, after all of the papers were graded by the blind graders, the papers were exchanged among the three graders. Each grader then graded the first and second drafts of 16 different students. Thus, we used a total of 96 papers (first and second drafts of 48 students) and each paper was graded independently by two different blind graders (in addition to being graded by the lab instructor).
Due to practical limitations, such as the time commitment for which the lab instructors were employed and the time available during the semester, lab instructors received substantially less training in using the grading rubric than did the blind graders. Prior to using the rubric, lab instructors were given a single APA-style introduction that was written by a former student in the research methods course. The categories and criteria of the rubric were described to the lab instructors and the lab instructors independently graded the sample paper using the rubric. The course instructor (the first author, who participated in development of the rubric) then provided the scores that he assigned to the same paper and discussed his reasoning behind his scoring decisions in order to illustrate the intended use of the rubric to the lab instructors. Although the lab instructors received less formal training than the blind graders, the majority of the lab instructors had substantial prior experience in using the rubric because they had served as lab instructors in previous semesters, during which they used the same rubric.
To summarize the design of Experiment 2, a 2 × 3 factorial design was used in which one independent variable was draft number (first vs. second, manipulated within subjects) and the second independent variable was the grader, with each paper graded by two blind graders at different times (which we refer to as Grade Set A and Grade Set B, where each set represents a different level of the grader variable) and the graduate lab instructor, who was not blind in that he or she knew the student-authors’ identities and whether each paper was a first or second draft (scores assigned by eight different lab instructors were used in this experiment.) The dependent variable was the number of points assigned to each paper by the graders.
Results
As indicated earlier, the first drafts were graded out of 12 points by the lab instructors in the context of the class. The criteria of the rubric were unchanged across drafts; therefore, the point values assigned by the lab instructors for the first draft were doubled to facilitate comparisons in the present experiment.
The mean scores (of the 24 points) and the standard deviations for Experiment 2 are shown in Table 3. A repeated measures 2 × 3 ANOVA revealed that both of the main effects were statistically significant, but the interaction was not significant; for the main effect of draft number, F(1,47) = 27.50, p < .001, η2 = .044; for the main effect of grader, F(2,94) = 153.34, p < .001, η2 = .590; and for the interaction, F(2,94) = 1.51, p = .23, η2 = .003.
Means (and Standard Deviations) of Grades Assigned to Papers in Experiment 2
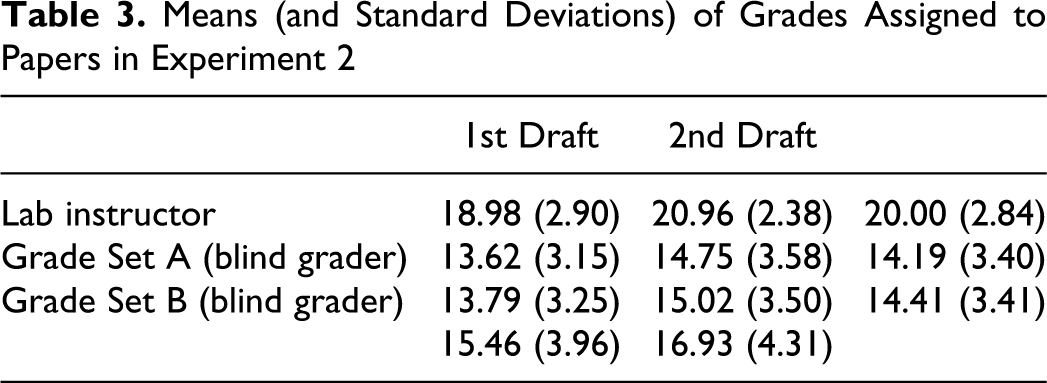
Post hoc t-tests showed that the difference between the mean scores across all papers (first and second drafts) was significant for the lab instructor and Grade Set A, t(47) = 15.97, p < .001, Cohen’s d = 2.30, and for the lab instructor and Grade Set B, t(47) = 15.54, p < .001, Cohen’s d = 2.24. The difference between mean scores across all papers for Grade Set A and Grade Set B was not significant, t(95) = .60, p = .55. Pearson product–moment correlations and Spearman rank-order correlations between scores for all pairs of graders were statistically significant, with all p < .001. For the lab instructor and Grade Set A: r(94) = .56, rS (96) = .51. For the lab instructor and Grade Set B: r(94) = .45, rS (96) = .37. For Grade Set A and Grade Set B: r(94) = .46, rS (96) = .34. Thus, although the mean grades for the lab instructor were higher than those for the blind graders, the ordering of students based on their grades was somewhat similar across graders.
Figure 2 shows the scores on the second draft plotted against the scores on the first draft for the blind graders (left panel) and the lab instructors (right panel). As in Figure 1, the blind graders’ grades in both the Grade Set A and Grade Set B sets are plotted in the left panel of Figure 2. The numbers of students whose scores increased, remained unchanged, or decreased are shown in the figure. These distributions were significantly different between the blind graders and lab instructors, χ2(2) = 8.21, p = .017.
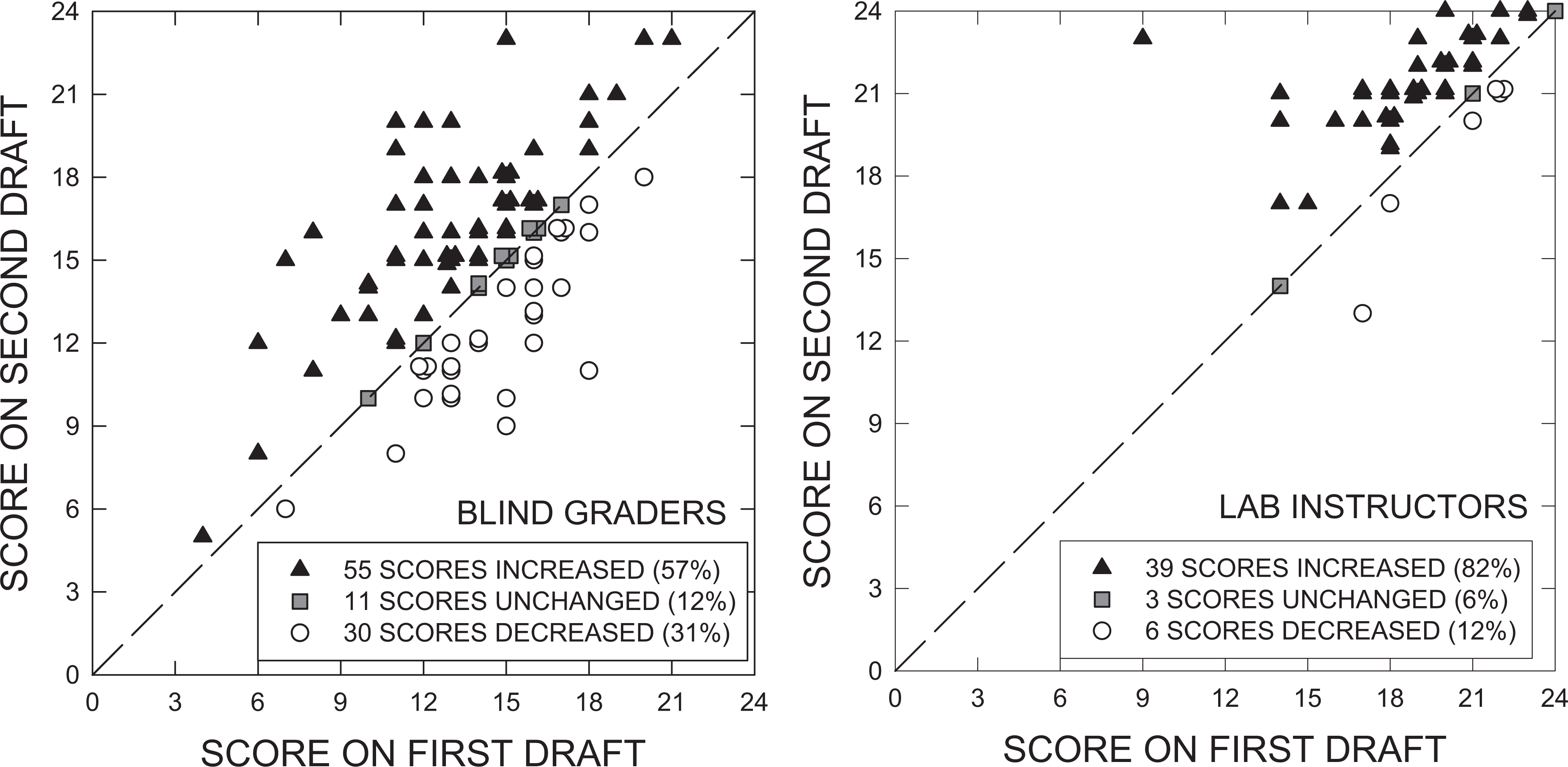
The results of Experiment 2 plotted in the same format as Figure 1. The left-hand panel represents scores assigned by the blind graders. The right-hand panel represents scores assigned by lab instructors for the same set of papers as was graded by the blind graders. Overlapping points have been offset slightly for clarity.
We evaluated the effects of the source of feedback by comparing the results of this experiment, Experiment 2, to those of Experiment 1. Recall that in Experiment 1, students reviewed their own papers or received feedback from other students. In Experiment 2, students received feedback from the lab instructor, who was a graduate teaching assistant. Therefore, these analyses assess the effects on students’ grades of feedback from a more experienced source (the graduate student lab instructor) versus a less experienced source (a fellow student or self-evaluation). For these analyses, we considered only the scores assigned to students’ papers by the blind graders in the two experiments. A mixed-model 2 × 2 ANOVA was performed with the factors of draft number (manipulated within subjects) and source of feedback (self or peer vs. instructor, manipulated between subjects). The Grade Set A and Grade Set B scores were grouped together within each experiment. There was a main effect of draft number, F(1, 254) = 28.66, p < .001, η2 = .10, but no main effect of source of feedback, F(1, 254) = .74, p = .39, η2 = .003, and no interaction, F(1, 254) = .27, p = .60, η2 < .001 (these results hold if we adjust the level of significance of .05 downward to control for multiple comparisons). For the data of Experiment 1, 86 students’ scores (54%) increased across drafts, 48 (30%) decreased, and 26 (16%) were unchanged. For Experiment 2, 55 students’ scores (57%) increased across drafts, 30 (31%) decreased, and 11 (12%) were unchanged. There was no significant difference between these distributions, χ2(2) = 1.12, p = .57. Thus, the source of feedback appears to have had no significant effect on writing scores or on the direction in which students’ scores changed across drafts when evaluated by blind graders.
Brief Discussion
As in Experiment 1, average scores increased significantly between drafts. However, the average change in scores from first to second draft was larger for the grades assigned by the lab instructors (+1.98) than for the grades assigned by blind graders (+1.18), although the difference between graders did not reach statistical significance. Furthermore, a larger proportion of students showed improvement across drafts in terms of their grades received from the lab instructors compared to the grades received from blind graders. The fact that greater improvement was seen in the grades assigned by the lab instructors could be due to two factors. First, students made changes to their first drafts based on comments from the lab instructor who also graded the papers. It is reasonable to assume that the grader would make recommendations for improvements in the papers that would be likely to increase the grades assigned by that grader. The blind grader might not agree with all of the recommendations of the lab instructor, so changes consistent with those recommendations might not result in improvement from the perspective of the blind grader. Second, the lab instructors were fully aware of which drafts were first and second drafts and they may have expected performance to improve on the second drafts, which may have biased the grading by the lab instructors. The influence of these two factors cannot be separated based on these data.
In addition to there being a larger change in grades for papers graded by the lab instructors, as described above, there was a main effect of grader in the present experiment such that lab instructors gave substantially higher grades overall than blind graders. This may reflect the fact that the lab instructors received less training in the use of the rubric than the blind graders. Another possibility, once again, is that the lab instructors’ personal familiarity with the students introduced a more generous grading bias.
Experiment 3: Effect of Instructor Bias
Because bias on the part of the lab instructors may account for much of the significant results of Experiment 2, a third experiment tested this possibility. Two of the lab instructors who originally graded the papers during the semester in which they were written (with full knowledge of the authors’ identities and of which papers were first and second drafts) regraded some of the papers with the authors’ names removed and no overt indication of draft number. The lab instructors regraded the papers more than 2 years after they first graded the same papers. The lab instructors graded hundreds of other papers during the intervening time, which decreased the likelihood that the lab instructors would recall these specific papers.
Method
Participants
This experiment used APA-style introductions that were written by students enrolled in an introductory research methods course at the University of Minnesota in the spring semester of 2009. Most but not all of the papers also were used in Experiment 2.
Design and procedure
In the spring of 2011, two of the lab instructors from the research methods class in spring of 2009 were each given the first and second drafts of introductions from 10 of their former students. The lab instructors were blind as to the students’ identities and whether each paper was a first or second draft. The lab instructors regraded all of the papers in a random order using the 24-point grading rubric. This experiment used a 2 × 2 repeated-measures design with the factors of draft number and time.
Results and Brief Discussion
Table 4 shows the mean scores (out of 24 points). The main effects of draft number and time were both significant; draft number: F(1, 19) = 12.80, p = .002, η2 = .16; time: F(1, 19) = 14.09, p = .001, η2 = .15. The interaction was not statistically significant, F(1, 19) = .003, p = .96, η2 < .001. Based on the Time 1 grades, 14 students’ scores increased across drafts, 1 was unchanged, and 5 decreased. At Time 2, 15 students’ scores increased, 3 were unchanged, and 2 decreased. These distributions were not significantly different, χ2(2) = 2.32, p = .31. The mean score across all papers was lower at Time 2 than at Time 1, which supports the suggestion that the lab instructors’ scores overall were biased upward when the papers were first graded.
Means (and Standard Deviations) of Grades Assigned to Papers in Experiment 3
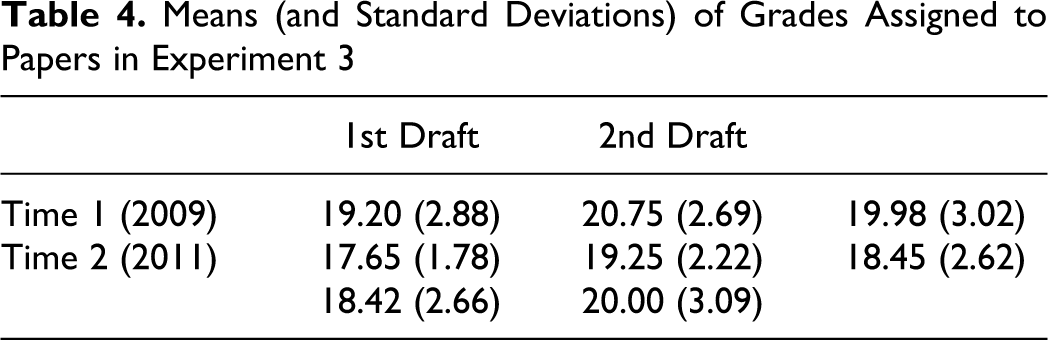
As in the previous experiments, there was an increase in scores across drafts but the effect was small. The mean change in score across drafts was 1.58 points (7%) of the 24. In addition, there was no interaction; the change in score across drafts was not significantly different at the two different times. This argues against the idea that explicit knowledge of whether a paper was a first or second draft led to a greater change in scores across drafts due to grader bias. Instead, these results suggest that the lab instructors truly perceived an improvement in writing across drafts, perhaps because students revised their papers based on the specific comments made by the lab instructor on the first drafts.
As in the previous experiments, these results are overshadowed by the somewhat low reliability of the grades. Scores for all drafts at Time 1 were significantly but modestly correlated with scores at Time 2: Pearson r(38) = .48, p = .002; Spearman rS (40) = .58, p < .001. In considering the direction of change of score across drafts, the lab instructors perceived a consistent change in direction at Time 1 and Time 2 for only 12 (60%) of the 20 students. Indeed, the effect size associated with change in score across drafts was essentially equal to the effect size associated with the reliability of scores across time (the difference between scores at Time 1 and Time 2).
General Discussion
In the present experiments, we examined the common practice of allowing students to revise and resubmit their writing after receiving feedback on a draft of that writing. We also examined the effects on writing quality of feedback from various sources prior to revision and resubmission of the writing. To summarize the experiments and the primary findings:
Experiment 1
Students either received feedback from a fellow student on a first draft of their writing or students critiqued their own first drafts. Students then revised and resubmitted their papers. Blind graders evaluated both drafts of each student’s writing. Main results: (1) With respect to the average improvement in writing score from first to second draft, there was no difference between receiving feedback from a fellow student versus critiquing one’s own paper. (2) Overall, 54% of the students’ scores improved across drafts and the remaining students’ scores either were unchanged or decreased across drafts.
Experiment 2
Graduate lab instructors graded and provided feedback on first drafts of student writing. Students were permitted to revise and resubmit their papers in light of the feedback they received. The graduate lab instructors then graded the second drafts. Blind graders also graded the first and second drafts. Main results: (1) There was no difference between lab instructors and blind graders in the average change in score from first to second draft. (2) The lab instructors found improvement across drafts for 82% of the students while the blind graders judged that there was improvement for only 57% of the students. (3) The graduate lab instructors, who provided feedback and who were aware of which drafts were first or second drafts, assigned higher grades overall to the papers than the blind graders did. (4) When papers were evaluated by blind graders, there was no difference between the improvements across drafts when peer or self-review was conducted versus when the lab instructor provides feedback.
Experiment 3
Two lab instructors blindly regraded papers that they had previously graded with full knowledge of the draft number and the authors’ identities. Main results: (1) The lab instructors assigned lower scores overall to the papers when grading them blindly. (2) The average change across drafts was the same for scores assigned at the two different times.
Across all experiments
(1) There was a small but significant change in score from first to second drafts ranging from 4% to 7%. (2) The scores of only 50–60% of the students increased from first to second draft across these experiments when blind graders evaluated the writing.
To further organize the results across experiments, we can consider them in terms of whether the writing quality is evaluated by someone other than the person providing feedback or by the same person who provided the feedback. When a grader who did not provide any feedback to the writer and who was blind as to whether a paper was a first or second draft evaluated writing quality, there was a small average increase in writing score across drafts. Just over 50% of the students showed an increase in score, whereas the remaining students’ scores were unchanged or decreased. The average change in score and the proportion of students whose scores increased did not depend on whether feedback between drafts was given by a peer, a graduate teaching assistant, or if students critiqued their own papers. From this perspective, it did not matter who provided feedback on early drafts; the effects on writing quality were nearly the same in all cases.
However, a different conclusion is reached when writing quality was evaluated by the lab instructor who provided feedback. In this situation, there also was a slight increase in average performance between first and second drafts, but the increase in average performance was larger when evaluated by the lab instructor than when evaluated by a blind grader (although not significantly so). In addition, a greater proportion of students’ scores improved between first and second drafts when evaluated by the person who provided feedback. This argues that it does matter who provides feedback on early drafts, but not in terms of whether the reviewer is a student or instructor. In particular, there is a much higher probability that a student will show improvement (positive change in score across drafts) when the grader provides feedback prior to revision.
These experiments were designed to compare the effects of different types of feedback on revisions of student writing and significant increases in mean score were found across drafts regardless of the source of feedback. Because there was not a “no feedback” control condition in the present experiments, it is possible that any change in score across drafts was simply due to the students undertaking revisions of their first drafts rather than utilizing the feedback or evaluation that was given in these experiments. In other words, similar changes in score across drafts may have been obtained if the students simply were instructed to revise and resubmit their papers without undergoing any sort of formal review process. However, the fact that scores increased more when graded by the person who provided feedback suggests that students did respond in some way to the feedback.
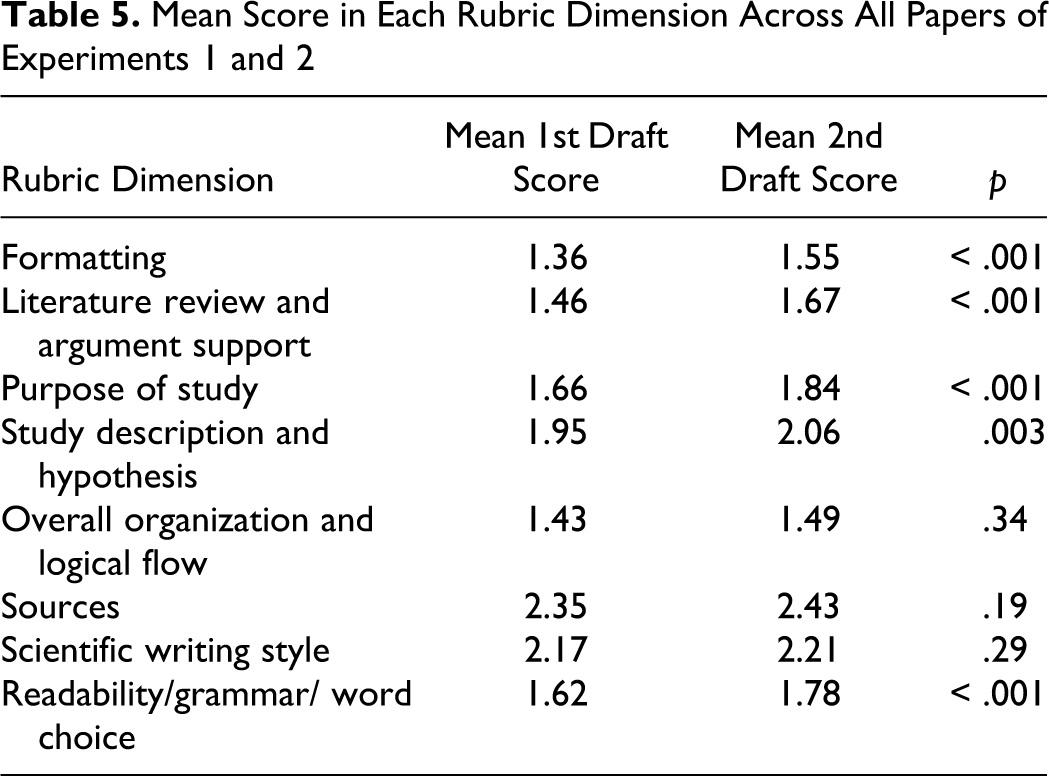
Given that a consistent effect across all experiments was an increase in scores between drafts, we considered whether increases in score were more likely in some rubric dimensions than in others. Table 5 shows the results of an analysis of the changes in score across drafts for each of the eight dimensions of the rubric. In this analysis, the first and second draft scores of all papers in Experiments 1 and 2 for all of the blind graders were combined into a single dataset consisting of 256 pairs of first and second draft scores (Thus, two scores for each paper appear in this dataset because each paper was graded by two blind graders). Repeated-measures t tests were performed to compare mean scores across drafts. In Table 5, the mean score for the first and second draft in each category is shown along with the p value of the associated t test. The results of this analysis should be interpreted with caution, keeping in mind that the score for each dimension was a whole number ranging from 0 to 3. The mean score in five of the eight dimensions increased significantly. The dimensions that showed significant improvement are those in which problems seemingly could be identified and addressed somewhat easily in a single round of review and revision, such as APA Formatting, Literature Review (e.g., whether a background article is adequately described), and Grammar. Two of the categories that did not show significant improvement, Sources and Scientific Writing Style, had high mean scores on the first draft and may have shown little improvement due to a ceiling effect. The dimension that conspicuously had a low mean score and no significant improvement across drafts was Overall Organization and Logical Flow. This dimension addresses the global organization of the paper, the construction of a coherent argument throughout that leads to a statement of the hypothesis, and smooth unified transitions between topics. It is our informal observation that students have particular difficulty with these aspects of writing and the data seem to bear this out.
Mean Score in Each Rubric Dimension Across All Papers of Experiments 1 and 2
As noted in the introduction, the rationale behind the use of the review–revise–resubmit procedure is that it improves writing. The evaluation of this claim depends upon an objective measure of writing quality. The grading rubric that we used in these experiments represents our attempt to develop such an objective measure. Despite our efforts, the rubric exhibited what some might consider to be low interrater reliability in the present experiments, although the level of interrater reliability was comparable to that which was reported when the rubric was originally developed (Stellmack et al., 2009). We are not aware of reports of reliability and validity for writing rubrics that have been similarly assessed so we cannot compare our rubric to others. Although these experiments represent our best attempt at objectively evaluating writing quality and the change in writing quality across drafts, we believe that the low interrater reliability underscores the inherent subjectivity in grading writing. Graders can agree upon the criteria that are important in evaluating writing, as when we developed the rubric, but there seems to remain low agreement in the application of those criteria, which in turn can result in differences in the perceived improvement of writing across drafts. Our results show that when different graders evaluate the same writing, the grader who provided feedback on a first draft is more likely to perceive improvement in a second draft. It remains the case that a rubric that exhibits higher reliability might show greater benefits of the review–revise–resubmit procedure.
It is possible that the higher grades assigned by the graduate lab instructors relative to the blind graders in the present experiments reflect inadequate training in the use of the rubric rather than bias by the nonblinded lab instructors. Future research might examine the effects of increased training of the graders who provide feedback to determine whether those higher grades are due to lack of training or to bias stemming from familiarity with the students, although the results of our Experiment 3 suggest that the latter does play a role. In the present experiments, the graduate lab instructors received less training because of practical limitations (e.g., limited time within the semester and competing obligations on the part of the graduate students). The fact that the lab instructors assigned substantially higher scores overall than blind graders certainly is a noteworthy result and warrants further research. However, for our purposes of assessing the utility of the review–revise–resubmit procedure, the change across drafts is of more interest than the absolute scores, and the change across drafts, particularly the direction of change, indicates that graders who also provided feedback perceive greater improvement in writing than blind graders who did not provide feedback.
An important consideration that we did not address in our experiments is the nature of the feedback provided to students on their first drafts. Students conducted peer and self-reviews by indicating how the writing met or failed to meet the criteria of the grading rubric. The graduate lab instructors effectively did the same by grading the papers with the rubric, but they also made written comments on the papers intended to instruct the authors as to how they could improve their papers. The graduate lab instructors were not trained in this process in the context of the course and their feedback was not analyzed in these experiments. Presumably, the way in which they provided feedback was influenced in part by the form and depth of feedback that they had experienced over the course of their careers as well as their own subjective judgments of writing quality. We found minimal change across drafts in these experiments, but some type of formal training in the process of giving feedback might yield greater improvement. In this regard, these experiments represent a first attempt to assess the effects on writing of any type of feedback. Clearly, the question of the optimal form of feedback to students is ripe for future research but we believe that whatever system of training is undertaken, the evaluation of writing by blind graders, as we did in these experiments, is necessary for demonstrating the efficacy of the training.
The results of these experiments along with those of our previous research (Stellmack et al., 2009) raise important questions about the utility of the review–revise–resubmit procedure. If a student receives a high grade after revising and resubmitting a paper, what does it indicate? Presumably, the intended goal of the review–revise–resubmit procedure is to improve students’ writing skills. However, given that high variability exists in the scores assigned to the same writing by different graders, a high grade cannot be taken as an indication that a student has produced a good sample of writing in any objective sense. Rather, our results suggest that a high grade (or large improvement across drafts) after the review–revise–resubmit procedure indicates that a student has successfully responded to the feedback of the grader and has satisfied the grader to some extent in revising the paper (assuming that the grader also provided feedback on the first draft). The present results show that a grader who did not provide the original feedback often perceives less improvement across drafts and frequently perceives no change or a decrement in writing quality across drafts. Therefore, the review–revise–resubmit procedure should be viewed as targeting students’ skills in responding to editorial feedback rather than skills associated with producing quality writing. In other words, high scores following the procedure do not necessarily identify better writers; they identify better revisers.
Although it may not be the intended goal of the review–revise–resubmit procedure, developing revision skills is a worthwhile goal. In most real-world contexts, writing produced for any purpose is rarely assigned a grade or a rating on a continuous scale. Instead, written work is considered to be acceptable or unacceptable, whether it is a scientific manuscript submitted for publication, a progress report prepared in a business setting, or other types of formal writing. The writing usually must be revised until it is suitable for its intended purpose. A prudent writer in the real-world will rarely disseminate his or her writing before receiving feedback from one or more reviewers. The writer can produce truly polished writing to the extent that he or she can successfully understand and respond to the feedback of others.
Within the context of coursework in psychology, the benefits of the review–revise–resubmit procedure simply may be the training of future psychologists to deal with the realities of the publication process. In order to publish a manuscript, an author must satisfy the reviewers who are, in effect, the author’s “graders.” Readers may not always agree with the compositional choices that appear in the final published version of a journal article, but the author cannot expect to please all readers. Authors must aim to please the reviewers who are giving their manuscripts a final “pass/fail” grade. Therein may lay the true value of giving students the experience of revising a paper after review.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.