
Abstract
This study explored graduate teaching assistant (GTA) grading on 480 papers across two writing assignments as integrated into large Introductory Psychology courses. We measured GTA accuracy, consistency, and commenting (feedback) quality. Results indicate that GTA graders improved, although unevenly, in accuracy and consistency from Time 1 to 2 when compared to professional graders who scored the same papers. GTA commenting on papers improved from Time 1 to Time 2 as well, as indicated by seven measures of feedback effectiveness. However, subsequent to training GTAs gave higher grades than professional graders, and significant interactions between GTAs and time were evident in terms of both grading and commenting improvement. Conclusions for GTA training and professional development are discussed.
Dunn has argued that faculty in Psychology should pay heightened attention to student writing (Goddard, 2002), but there are difficult challenges associated with providing valid grading and effective feedback on formal papers (e.g., Cooper & O’Dell, 1999; Huot, 2002; Phelps, 2000; Smith, 1997; Sommers, 1982; Straub, 1996; Straub & Lunsford, 1995). At the same time, increased understanding of response, or feedback on writing, suggests that effective feedback can be a pedagogical tool that guides students toward sustained independent thought (Anson, 1999; Beason, 1993; Brannon & Knoblauch, 1982; Freedman, 1987; Hodges, 1997; Huot, 2002; Lunsford, 1997; Metcalfe & Kornell, 2007). It is also widely understood that feedback differs from evaluation, or the assignment of a fair and just grade, but defining precisely what constitutes more or less effective feedback remains a challenge. For instance, the question of whether facilitative or directive feedback (i.e., asking questions vs. giving specific corrections) is inherently more effective is subject to debate (Straub, 1996).
One widely accepted facet of effective feedback is restraint or a grader's conscious decision to limit feedback to that which is most instructional and of highest priority to the student, rather than giving diffuse feedback or feedback that primarily justifies the grade (Anson, 1999; Sommers, 1982). To achieve effectively restrained feedback, a clear sense of both assignment and student learning priorities is needed. It is also important to discern patterns of both weakness and strength in the individual student’s written work. Effective feedback is unified and coherent, connecting marginal comments to end comments. It is forward looking, working less to justify a grade and more to coach the student toward improved performance.
Whether done by faculty, graduate teaching assistants (GTAs), or peer reviewers, effective feedback is not only difficult to achieve (Cho, Schunn, & Charney, 2006; Connors & Lunsford, 1988; Connors & Lunsford, 1993; Stern & Solomon, 2006) but difficult to measure. Research on feedback has generally focused on the ethical implications of the awarding of grades in the absence of feedback or alongside weak feedback (Connors & Lunsford, 1988, 1993; Lunsford, 1997; Smith, 1997; Sommers, 1982). Underwood and Tregidgo (2006) reviewed existing empirical research on feedback and reported that one demonstrated factor of feedback effectiveness is timing; particular types of feedback are important to writers at specific times. In other words, writing and feedback are iterative and evolving. Stern and Solomon (2006) found in an examination of just under 600 papers graded by faculty that although these instructors provided substantial feedback on grammatical and technical deficiencies, they provided little guidance to students in regard to substance and only rarely applied other principles of effective feedback, such as explaining how the student might prioritize effort in order to improve. These findings reinforce not only the complexity of the feedback task, but the assumptions at work when GTA graders are deployed to grade and respond to student writing, a common way of utilizing GTA labor (Prostko, 1998).
In recent decades, undergraduate courses have increasingly been taught by GTAs or had some type of significant instructional responsibilty assigned to them (Marincovich, Prostko, & Stout, 1998). Although Norcross, Hanych, and Terranova (1997) reported that most psychology departments provide graduate teaching assistantships, neither the American Psychological Association nor the Division Two (Society for the Teaching of Psychology) maintains data on the number of GTAs working in Psychology courses as teachers or graders. Furthermore, although many Psychology graduate programs report offering some sort of GTA training (Meyers & Prieto 2000a), little is known about the substance or effectiveness of these methods. Training may include review of a TA manual (Lowman & Mathie, 1993), a teaching seminar or pedagogy class (Hogan, Norcross, Cannon, & Karplak, 2007), workshops, orientations, and retreats (Meyers & Prieto, 2000a) or faculty mentoring, including GTA observation of faculty teaching, followed by conversation on teaching issues (Lowman & Mathie, 1993). A survey of training programs (Meyers & Prieto, 2000a) also suggested that GTA training typically involves activities such as the review of sample syllabi. However, many have argued for the integration of more active forms of learning, such as guided practice teaching, so that GTAs rehearse and reflect upon their work (Meyers & Prieto, 2000b; Prieto & Meyers, 1999). In general, grading and feedback training has been inadequate, especially when compared to graduate student preparation for other parts of the academic career such as research (Meyers & Prieto, 2000a; Mueller, Perlman, McCann, & McFadden, 1997). Certainly, more attention needs to be paid to the systematic training of GTAs who grade and respond to writing.
Despite the apparent shortcomings of GTA preparation, many instructors believe that providing GTAs with a rubric means they can be assured that grading will be consistent with the rubric and the instructor’s intentions. Some have even characterized GTAs as “expert graders” against whom others can be compared (Pare & Joordens, 2008). Moreover, the dearth of research on faculty accuracy, consistency, and effectiveness in grading and feedback reveals the casual approach that is generally taken to grading and responding to student writing in the disciplines.
The current study explored three areas of GTA grading for which the research literature is scarce. First, we were interested in how accurate GTA graders are with respect to a rubric. In large psychology classrooms such as those involved in this study, graders may have more than 100 papers to assess and respond to for any graded event. It is impractical for faculty to check each paper, so instructors often do not know whether GTA grades are accurate yet often trust that they are. Second, this study explored the consistency of grading across graders. Faculty often hear students say that their grade depends on which grader they are assigned. Yet, if all the graders use the same rubric and receive the same training, the belief is that they should grade accurately and consistently. This study addressed whether or not they do. Finally, there is the important issue of feedback quality. This study explored whether the quality of grader feedback can be improved during the course of one semester when accompanied by a training program.
Method
Participants
GTA participants were eight (66%) women and four (33%) men between the ages of 23 and 35 (M = 26.33, standard deviation [SD] = 3.50). All participants were native speakers of English. They were graduate students in their first (92%—11 participants) or third (8%—1 participant) year of a doctoral program in Counseling (42%), Industrial–Organizational (42%), Cognitive (8%), and Applied Social Psychology (8%) at a large Midwestern university. All participants were novice graders with paid assistantships as writing graders for large Introductory Psychology courses. Half of the graders had been awarded a 10-hr/week assistantship, and the other half had a 20-hr/week position. Each participant was responsible for grading between 70 and 140 papers for each assignment, depending on the assistantship award.
Materials
Grading Rubric
Graders utilized a 5-point grading rubric, developed by a professor in the University Writing Program, within the Department of English. Similar to rubrics used in university writing placement grading, the rubric used in this study was “holistic,” as it evaluated the overall level of accomplishment of the writing in terms of the assignment requirements and objectives (White, 1988). As this particular assignment required students to draw upon course information to evaluate a claim about behavior in a popular press article, a score of 2 on the 5-point rubric indicated that a student did not use information learned in class and/or did not provide an evaluation (typically, a “2” paper provided only a summary of the article, or an evaluation based solely on personal experience). A paper earning a score of “3” on the 5-point rubric demonstrated at least a minimal ability to evaluate, and the “4” paper needed to demonstrate the use of content knowledge (related to what had been taught about research methods) in a well-developed evaluation. Papers earning a “5” were especially well-supported and well-written evaluations that effectively applied course content.
Quality Indicator Instrument
The quality of participant comments (written feedback) on each paper in the sample was evaluated using seven indicators of effectiveness, each rated on a 5-point scale. The feedback evaluation instrument was the one used in the University Writing Program’s teacher preparation for GTAs in composition courses. It results in an Overall Quality Indicator score (summed across all seven subscales) for each paper as well as separate ratings for seven key indicators of feedback effectiveness. The seven indicators were (1) Strengths/Weaknesses, or providing an accurate overall assessment of the paper’s strengths and weaknesses; (2) Hierarchy of Rhetorical Concerns, or prioritizing psychology content and analytic/evaluative approaches over grammar; (3) General Advice, or offering broad suggestions for improved writing; (4) Connected Comments, or the connecting of marginal to end comments to focus and unify the feedback; (5) Positive Feedback, or the acknowledgment of good writing, rather than merely the noting of deficiencies; (6) Professional Tone, or maintaining a collegial and professional approach in the commenting; and (7) Offers Suggestions, or providing suggestions that are forward looking or applicable to future papers.
Procedure
During a 16-week semester, GTA participants graded and provided feedback on six writing assignments in large Introductory Psychology classes (125–175 students per section). After an initial orientation to grading and commenting, they attended a 5-week course on theory and best practices associated with grading and responding to writing as well as five experiential workshops. Workshops focused on two areas: accurate scoring/calibration of grades on the 5-point rubric mentioned previously and providing instructive written feedback on each student paper.
More than 1,900 Introductory Psychology students completed writing assignments during the semester in which the study was conducted. At both Time 1 and Time 2 (approximately 3 months apart), students found a popular press article in which a research study was described, leading the author of the article to make a claim about behavior. The primary task of the assignment was to evaluate the author’s claim, drawing upon knowledge students acquired in the research methods module of their Introductory Psychology text. For example, in an article claiming that people are happier if they participate in athletic activity, students evaluated that claim based on the information provided in the article about how the study was conducted. Using what they had learned about the elements of experimental and correlational studies, they made a case for whether or not a claim appeared to be credible, with thorough development and explanation of their judgment. Although the articles (and their claims) in Times 1 and 2 were different, the writing task and grading rubrics remained the same.
GTA participants provided grades on the Time 1 and Time 2 papers, as well as thorough, instructive comments aimed at helping students improve their ability to write an evaluative essay. Twenty papers were randomly selected from each of the 12 GTA participants’ stacks of graded papers at Times 1 and 2, resulting in a sample of 480 papers.
To establish a standard of comparison for grader accuracy and consistency, the same sample of papers was graded by professional graders. The professional graders were seven (88%) female and one (12%) male writing instructors in the Department of English. Two held terminal degrees, and the others held the MA in English. They had between 5 and 20 years of experience as university writing instructors and between 5 and 10 years of experience as paid placement graders in a university setting. The role of the placement grader is to score incoming first-year students on essays written purely for the purpose of accurately placing them in the writing course that best matches their capabilities. Three also had several years of experience grading Advanced Placement essays for the Educational Testing Service. For the purposes of this study, the grading of these experienced, professional graders was considered the standard.
With student names and grades removed, we distributed papers randomly among the professional graders, and two professionals graded each paper with the same rubric utilized by the GTAs. The professional graders were unaware of whether papers were from Time 1 or from Time 2. In the rare event of discrepant grades (less than 3% of the time), a third professional grader scored the paper, and the more common grade was retained. There were no cases of a three-way discrepancy. Interrater reliabilities were calculated for papers graded by professional graders at Time 1 (r = .89) and Time 2 (r = .91).
To examine the quality of grader comments on student papers on the Time 1 and Time 2 papers, each paper was evaluated with the quality indicator instrument described previously. Raters included two professors from the Department of English’s Rhetoric and Composition program. One rater had more than 35 years and the other more than 30 years of teaching experience in the teaching of college writing, with particular expertise in written feedback on student papers. To obtain a subsample of papers for establishing interrater reliability, 24 papers (10%) were randomly selected and scored by both the raters; individual scores on the seven indicators were calculated for each paper. Interrater reliabilities for the seven indicators were as follows: strengths/weaknesses (r = .92), hierarchy of rhetorical concerns (r = .69), general advice (r = .82), connected comments (r = .78), positive feedback (r = .90), professional tone (r = .85), and offers suggestions (r = .71).
Results
Comparison of GTAs and Professional Graders
To assess the accuracy of GTA grading, we compared the grades assigned by GTAs to those assigned by professional graders on the first and second evaluative essays. Repeated measures analyses were completed as indicated. Partial η2 assessed effect size and was interpreted within Cohen’s (1988) criteria (i.e., η2 of .01 to .04 = small effect size, .05 to .14 = moderate effect size, and >.14 = large effect size).
A 2 (Type of Grader) × 2 (Time) Repeated Measures analysis of variance (ANOVA) revealed significant effects for type of grader, time, and the interaction, Fs(1, 950) = 165.19, 83.40, and 10.90, ps < .001, .001, and .01, η2 s = .15, .08, and .01, respectively. GTA M grades were 3.47 and 4.07 (SDs = 0.62 and 0.69) and professional grader M grades were 3.00 and 3.29 (SDs = 0.82 and 0.85) at Times 1 and 2, respectively.
GTAs gave significantly higher grades at both Time 1 and Time 2 as compared to professional graders. Both the groups provided higher grades on the second essay. Although the prior analysis suggested that GTAs provided higher grades at both assessments, GTA and professional grader grades correlated positively at Time 1 (r = .44) and Time 2 (r = .57). This finding suggested that even though there was a difference in the distribution of grades between GTAs and professional graders, there was concordance in the relative grades that the students earned. That is, professional graders gave lower grades than GTAs in general, but GTAs and professional graders generally agreed on the relative quality of student essays. A test for the difference between independent correlations supported this notion, as the correlation between GTA and professional grader graders was higher at Time 2 than Time 1, z = −1.92, p < .05 (one-tailed test).
Differences Within GTA Graders and Across Time
To assess consistency across graders and time, a series of 2 (Time) × 12 (Grader) repeated measures ANOVAs and multivariate analysis of variance (MANOVA) with a Bonferroni correction were conducted, where MANOVA employed Wilks’s λ.
An ANOVA on GTA grades revealed a significant effect for Time, F(1, 225) = 141.16, p < .001, η2 = 0.38, grader, F(11, 225) = 2.12, p < .001, η2 = 0.09, and the interaction, F(11, 225) = 4.52), p < .001, η2 = 0.18. Grades increased from the first to the second paper, some graders differed across assessments, and graders changed differentially from the first to the second grading assignment. Effect sizes were large, moderate, and large, respectively.
The Quality Indicator Instrument was used to assess effectiveness of GTA feedback on students. An ANOVA on the Overall Quality Indicator score (Table 1) demonstrated large significant effects for time, grader, and the interaction. Total scores improved from the first to the second assignment across graders. There were also meaningful differences between GTAs on both the grading assignments. That is, some GTAs provided better feedback initially and over time, and although GTA feedback skills improved, GTAs did not consistently rise to similar levels of performance. Additionally, grader comment and feedback skills changed differentially over time; that is, there were not uniform grader and time-related changes in feedback behavior.
Comparisons Within Graduate Teaching Assistants across Time.
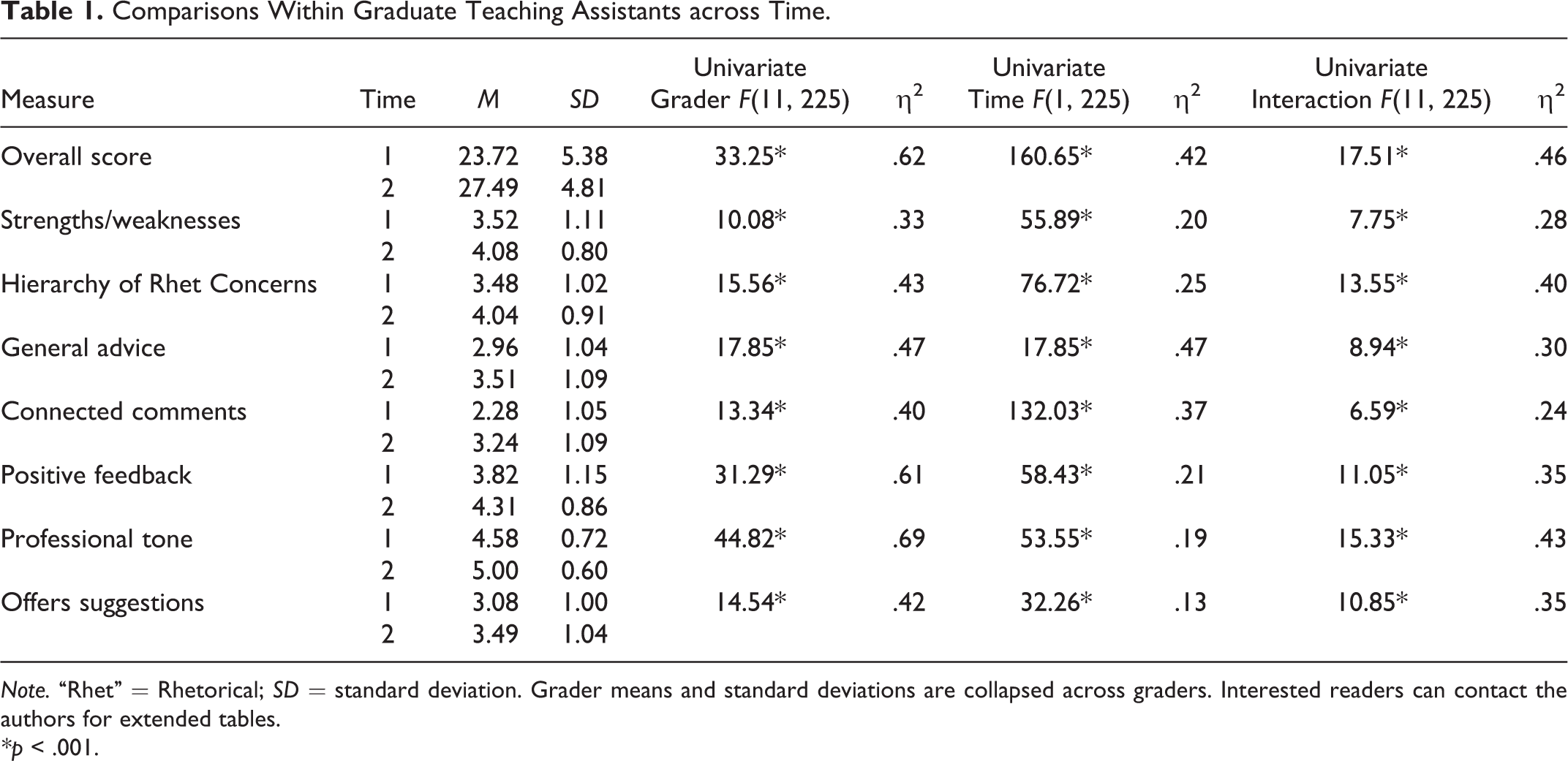
Note. “Rhet” = Rhetorical; SD = standard deviation. Grader means and standard deviations are collapsed across graders. Interested readers can contact the authors for extended tables.
*p < .001.
Given significant findings for the overall feedback score, we conducted a MANOVA on subscales of the Quality Indicator Instrument (Table 1). This analysis revealed large, significant multivariate effects for time, F(7, 219) = 27.82, p < .001, η2 = 0.47, grader, F(77, 1319) = 9.45, p < .001, η2 = 0.31, and the interaction, F(77, 1319) = 3.88, p < .001, η2 = 0.22. Follow-up univariate analyses (Table 1) revealed a consistent pattern. All measures showed large time effects, reflecting significant improvement from the first to the second assignment on all seven assessed feedback dimensions. Thus, graders showed marked improvement in commenting practices such as providing positive feedback, offering specific suggestions for improvement, connecting comments made throughout the paper, and maintaining a professional tone. Both assessments revealed significant between-grader differences, as GTAs differed on the dimensions of commenting on papers and providing feedback. Effects were large, except for the moderate grader effect on Offers Suggestions. Interaction effect sizes were large for all measures.
Discussion
This study suggests that although GTAs are ultimately neither fully accurate nor wholly consistent after a semester of training, their accuracy and consistency can improve. Ratings between professional and GTA graders were significantly and positively correlated at both Time 1 and Time 2, indicating a high degree of agreement between these groups’ assessments of student performance, but GTAs’ and professional graders’ scoring of student performance at Time 2 were significantly closer than that at Time 1 (i.e., GTAs and professional graders were in greater agreement about the quality of student performance at Time 2). GTAs may thus have improved as a result of practice and familiarity with the rubric, developed greater clarity in the goals of the assignment, and/or developed greater grading and responding skills as a result of their training.
However, the findings also show that GTA performance still falls short of the standard of a significantly more experienced grader after a semester of training and practice. The absolute ratings of student performance by GTAs remained higher than those of professional raters. That is, GTAs consistently gave higher grades than did the professional raters. Paradoxically, the degree of difference in grades was actually higher at Time 2 than at Time 1. Thus, although the degree of concordance in ratings increased, so did the degree of discrepancy in actual grades. Stated differently, over time GTAs may have reached greater agreement with professional graders in evaluating the relative quality of students’ papers, but GTAs were also significantly more generous in their grading as the course neared its end.
There are several possible explanations for their relatively inflated grading. GTAs may have been biased toward seeing improvement after working with students over the course of the semester, whereas the professional graders never directly interacted with students. GTA sensitivity to that improvement could have been exaggerated, resulting in overreaction and excessive reward for slight improvement. They might have also developed bias in grading due to their awareness of in-class efforts to teach research processes and critical thinking skills. Another possibility is that the timing of the Time 2 assessment may have influenced GTA accuracy. Time 2 came near the end of the semester when GTAs were under great pressure to not only complete their grading but also finish work on their own graduate courses. These pressures may have led to more cursory review and elevated performance ratings. In other words, high grades may represent a form of expediency. Whatever the source(s) of the grade discrepancies, it is worrisome that students would have generally received higher grades from GTAs than they did from professional graders, even after significant training.
Our second concern, grader consistency, showed overall improvement from Time 1 to Time 2 but was clearly affected by the interaction of time and grader. This interaction illustrates the widely discussed person–situation debate as discussed in many subfields of psychology (Mischel, 1968). Multiple individual and situational factors likely affect grading, such as motivation and personality factors, workload, time allotted for grading, fatigue, previous grading experience, writing expertise, and interest in writing. This finding suggests the importance of identifying predictors of GTA effectiveness in grading and responding; that is, effort should be directed toward selection processes that identify GTAs who are motivated to learn to do this work as a facet of their professional development, rather than primarily as a form of support for their graduate studies. Once selected, GTAs with responsibility for grading undergraduate writing might be further encouraged to improve their skills through mentorship that underscores the importance of writing in the disciplines. In particular, faculty mentors should more often state the relevance of feedback to overall learning, reinforcing the centrality of grading and feedback to the instructional enterprise. Faculty mentor-supervisors might also point out the benefits that GTAs themselves can derive from increased understanding of writing.
Third, the quality of commenting also improved, but again there were interactions between graders and time. Some GTAs improved in their feedback more than others, a finding which suggests that differences in GTA knowledge, writing ability, motivation, and perseverance may be complicating factors that make it difficult to train-in effective grading and responding approaches or train-out ineffective ones in all GTAs. This finding also suggests that providing feedback through written comments on papers is a highly skilled act, further reinforcing the call for better, more nuanced training. Given the complexity of the work of providing meaningful and effective feedback as well as the uneven internalization of training, it is clear that there are dangerous assumptions at work when no training or inadequate training is provided to GTAs as is too often the case. Even among faculty, grading and feedback are considered challenging work, the goals of which are often derailed by a variety of communication and time problems; such highly complex skills may be deserving of additional professional development for all who engage in this work (Hodges, 1997).
Despite evidence that GTA graders remain to some degree inaccurate and inconsistent after a semester of training, this study supports the continued training and support of GTA graders because their scoring accuracy and quality of response generally improve over time and because the impact of doing this work effectively can have important implications for student learning. Although GTAs represent a relatively expensive approach to grading and feedback, especially when compared to machine scoring and calibrated peer review (Carlson & Berry, 2007; Chisholm, 1991; Cho & Schunn, 2007; Cho, Schunn & Wilson, 2006; Liu & Hansen, 2002; Nelson & Schunn, 2009; Pare & Joordens, 2008; Patchan, Charney, & Schunn, 2009; Volz & Saterback, 2009), they also represent an opportunity for providing deeper, more refined levels of instructional feedback to undergraduate writers in the disciplines, but only if they do their job well. GTAs also gain opportunity to learn distinct professional abilities that can serve them as members of the future professoriate and elsewhere. Although we cannot assume that GTAs arrive on campus ready to provide this type of meaningful feedback on papers, we can influence their performance through sustained support.
Limitations and Future Research
This study was undertaken in a real-world context in which actual and recorded grading and feedback needed to occur even as the study was occurring. Although this necessity allowed for high levels of ecological validity as a function of a real-world context, less clear is the extent to which student gains in writing performance were affected by the feedback they received from GTAs or the types of feedback that were most productive of student improvement. For instance, students were taking other courses that required writing, including, for instance, the first-year composition course. They also had access to the Writing Center, to roommates, and to other forms of review. Practice effects from Time 1 to Time 2 also undoubtedly contributed to the the improved writing of some students. Simple maturation may explain certain gains as well. Therefore, many factors almost certainly had an effect on student writing, and it would be valuable to tease out the degree to which various factors, including feedback, contributed to student growth.
Also, GTA differences in terms of time spent on task, relevant personality factors, workload, and other constraining variables (e.g., family obligations, motivation, or writing ability) were not measured in this study. Therefore, future research might evaluate such factors as the role of personality and the role of past experience with writing as predictors of GTA grading effectiveness. Research might also seek to identify those attributes of graders who are more likely to improve and the forms of training that best facilitate their learning. Additional research might compare GTA performance to other grading solutions such as machine scoring and calibrated peer review, or at the opposite extreme, faculty grading and response. It might also be valuable to study varied types of feedback and student perceptions about the feedback they receive. Additionally, research similar to that of Malouff, Emmerton, and Schutte (2013) might elucidate ways to reduce grader bias and clarify whether such bias is related to the grader's level of professional experience. Finally, it would be interesting to investigate whether GTA grading and feedback on undergraduate writing has an effect upon graduate students’ own writing and hence toward their timely completion of the graduate degree. These efforts would advance the current study by refining our understanding of the factors that contribute to better grading and feedback on undergraduate writing while also investigating additional benefits that may derive from GTAs’ improved grading practice.
Footnotes
Acknowledgment
We are grateful to Jerry Deffenbacher for his helpful insight on this project.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.