
Abstract
Although virtually all Inuit children in eastern Arctic Canada learn Inuktitut as their native language, there is a critical lack of tools to assess their level of language ability. This article investigates how mean length of utterance (MLU), a widely-used assessment measure in English and other languages, can be best applied in Inuktitut. The authors seek a measure that is suitable for the structural characteristics of Inuktitut as well as the practical realities of language assessment in the Inuit context. They compare five measures of mean length of utterance/word as well as five measures of longest utterance/word using three sets of data: spontaneous speech from eight children aged 1;8–3;6, frog story narratives from 12 older children and 6 adults, and spontaneous speech from one 5-year-old with specific language impairment and an age-matched peer. The authors conclude that mean length of word in syllables is the measure that provides the best balance of reliably assessing language level while also suiting Inuktitut structure and being relatively easy to calculate.
Keywords
Introduction
Virtually all Inuit children in eastern Canada learn Inuktitut as their native language. We have a reasonable understanding of the trajectory of many aspects of language acquisition in typically-developing Inuktitut-speaking children as a result of research conducted over the past three decades (e.g., Allen, 1996, 1998, 2000, 2013, in press; Allen & Crago, 1996; Allen, Crago, & Pesco, 2006; Crago, 1988; Crago & Allen, 1997, 1998, 2001; Crago, Annahatak, Doehring, & Allen, 1991; Dorais & Sammons, 2002; Fortescue & Lennert Olsen, 1992; Parkinson, 1999; Swift, 2004; Wilman, 1988; Wright, Taylor, & Macarthur, 2000). However, as noted in a 2010 report published by Speech-Language and Audiology Canada (SAC, 2010), there is a critical lack of tools that can be used by speech-language pathologists to assess language ability and language difficulties in children who speak Inuktitut or other indigenous languages. In the present article, we use data from some of the aforementioned studies to explore the viability for Inuktitut of one of the most commonly used measures of expressive language cross-linguistically: the mean length of utterance (MLU).
The Inuktitut language
Inuit languages are spoken across Siberia, Alaska, northern Canada, and Greenland (see Dorais, 2010 for more information). Arctic Quebec Inuktitut (hereafter simply Inuktitut), the language discussed in this article, is spoken by some 11,000 Inuit throughout the 14 Inuit communities in Nunavik, the northern region of Quebec, Canada (Statistics Canada, 2011). Virtually all Inuit in this region are native and fluent speakers of the language, using Inuktitut as their main language at home and usually at work as well. In addition, virtually all children learn Inuktitut at home as their native language. Numerous studies attest to the fluent acquisition of Inuktitut by preschool Inuit children in Nunavik (e.g., Allen, 1996, in press; Crago & Allen, 1998; Swift, 2004), as well as to the strong Inuktitut abilities of school-aged Inuit children in the early grades (e.g., Allen et al., 2006; Crago et al., 1991; Wright et al., 2000).
Four structural characteristics of Inuktitut are particularly relevant for assessing MLU in this language. First, Inuktitut is polysynthetic. The central feature of polysynthesis is the possibility, “in a single word, to use processes of morphological composition to encode information about both the predicate and all its arguments, for all major clause types (i.e., one-, two- and three-place predicates, basic and derived), to a level of specificity allowing this word to serve alone as a free-standing utterance without reliance on context” (Evans & Sasse, 2002, p. 3). This possibility derives from a number of morphosyntactic phenomena including the incorporation of the noun stem within the verbal complex, derivational processes that enable the shifting from noun to verb and back within a single word, a large inventory of bound morphemes including a variety of adverbial elements, and pronominal marking of subjects and objects (as well as other core arguments) on verbal forms as well as possessors on nominal forms (Fortescue, 1994, p. 2601).
As a polysynthetic language, Inuktitut allows up to 10 or more morphemes per word and can express in one word what would be a complete sentence in a language like English (Dorais, 2010; Fortescue, 1994). The example in (1) illustrates this. It begins as a noun with a nominal root followed by adjectival and case affixes, then turns into a verb via a verbalizer, then has three verbal affixes (tense, aspect, negation) and an obligatory verbal cross-referencing inflection, and finishes with two enclitics. 1
(1) Illujuaraalummuulaursimannginamalittauq. illu-juaq-aluk-mut-uq-lauq-sima-nngit-nama-li-ttauq house-big-EMPH-ALL.SG-go-PAST-PERF-NEG-CTG.1sS-but-also ‘But also, because I never went to the really big house.’ (Dorais, 1988, p. 8)
The word in (1) is considered a single word in Inuktitut rather than a sequence of shorter words on both morphological and phonological grounds (Fortescue, 1994, p. 2601). Morphologically, none of the morphemes except the initial noun root (illu ‘house’) can stand on its own; all of the other morphemes are bound and can only appear when preceded by a stem of the relevant grammatical class. Further, words beginning with a noun root or a verb root are not considered complete without an obligatory final inflection: case for nouns (here -mut ‘ALL.SG’), and cross-referencing inflection for verbs (here -nama ‘CTG.1sS’). Phonologically, the morphemes within the word are fused together by an obligatory morphophonemic process that applies within but not across word boundaries, and the complete spoken word falls within one intonation contour.
The second relevant characteristic of Inuktitut is agglutination (Dorais, 2010). This means that bound morphemes are expressed by affixes rather than changes in vowel or stress patterns, and the form of the affix changes very little as a result of contact with other affixes. Inuktitut has some 400 word-internal derivational suffixes that represent categories of tense, aspect, emphasis, negation, and the like, for which each suffix realizes one unit of meaning (e.g., negation, distant past tense). Several of these are evident in the utterance in (1).
The third relevant characteristic of Inuktitut is its very rich inflectional system (Dorais, 2010). More than 900 portmanteau verbal inflections mark verbal modality as well as person and number of subject and object. In addition, more than 300 portmanteau nominal inflections mark case and number as well as person and number of possessor if applicable. The sentence in (2) highlights this inflectional complexity. It contains 6 words, all but one of which have an inflection.
(2) Ulla-ru-tuar-mat ta-an-na surusi-Ø morning-become-as.soon.as-CTG.3sS PRE-this.one-ABS.SG boy-ABS.SG pillitajuu-minik taku-sa-rasuar-suni pi-ta-qa-nngi-jialik. frog-MOD.4Ssg see-really-try-CTM.4sS thing-possession-have-NEG-PART ‘When it became morning the boy tried to look at his frog but there was nothing.’ (Allen et al., 2006, p. 585)
Fourth, largely as a result of the extensive verbal inflection system, ellipsis of both subjects and objects is very common in Inuktitut (Allen, 2000). This is evident in both preceding examples where most subjects are omitted (i.e., I in (1), pleonastic it and there in (2)) and most objects are incorporated into the verb (i.e., illu- ‘house’ in (1), ulla- ‘morning’ and pi- ‘thing’ in (2)).
Mean length of utterance
As its name suggests, mean length of utterance (MLU) measures the average length of a child’s utterance at a given time point. It was originally developed for English and first calculated in words per utterance (MLUw; Nice, 1925). Since Brown (1973), however, it has typically been operationalized as the mean number of morphemes per utterance (MLUm) in 100 consecutive but non-repetitive utterances in a spontaneous speech interaction. MLUm has been shown in numerous studies to be a more reliable indicator of grammatical ability than chronological age, given that children’s language develops at very different rates (Brown, 1973; Miller & Chapman, 1981; Wells, 1985). Several studies find significant correlations between MLUm and other measures of morphosyntactic development such as Developmental Sentence Scoring (DSS; Lee, 1974), Index of Productive Syntax (IPSyn; Scarborough, 1990), Language Assessment Remediation and Screening Protocol (LARSP; Crystal, Fletcher, & Garman, 1976), and other less formal measures (DeThorne, Johnson, & Loeb, 2005; Hickey, 1991; Rice, Redmond, & Hoffman, 2006; Rondal, Ghiotto, Bredart, & Bachelet, 1987; Scarborough, Rescorla, Tager-Flusberg, Fowler, & Sudhalter, 1991; Thordardottir & Weismer, 1998). For typically developing children, most studies report that MLUm is also significantly but not necessarily strongly correlated with age (rs between .30 and .80; Blake, Quartaro, & Onorati, 1993; Conant, 1987; de Villiers & de Villiers, 1973; Klee, Stokes, Wong, Fletcher, & Gavin, 2004; Miller & Chapman, 1981; Rice et al., 2006; Rondal et al., 1987; Wells, 1985), although some studies do not find a significant correlation with age (e.g., Klee & Fitzgerald, 1985). Further, some studies report considerable variability in MLUm for a given child, even within one session, depending on the context of the interaction and various other factors (e.g., Arlman-Rupp, van Niekerk de Haan, & van de Sandt-Koenderman, 1976). Widely used in English, it has also been adapted for use in many languages of varying typologies.
Calculating mean length of utterance in morphemes
The logic behind measuring MLU in morphemes (MLUm) for English is that, especially up to about 4 years of age (MLUm of about 4.0), many new developments in linguistic ability are signaled by the addition of a new morpheme to the child’s utterance. For instance, development of understanding of the concept of plural is signaled by the use of -s, development of understanding of past tense is signaled by the use of -ed, and so forth. Syntactic development is signaled by addition of a new word to the utterance which also increases MLUm; Brown (1973) lists a number of examples including growth in the number of semantic roles expressed in a sentence, the addition of negative forms and auxiliaries, and increasing use of embedding and coordinating structures.
The validity of MLUm has been questioned for MLUm values greater than 4.0 (Brown, 1973; Rollins, Snow, & Willett, 1996). For example, Brown (1973) notes that later grammatical development in English is signaled more by internal reorganization of utterance form than by addition of new morphemes or words. Further, utterance length at later ages is influenced more by the type of interaction than at younger ages, and reflects more variability as shown in larger standard deviations in MLU (Miller & Chapman, 1981). Nonetheless, studies have shown MLUm to be a reliable indicator of language development and language impairment at least until 10 years of age (Moyle, Karasinski, Weismer, & Gorman, 2011; Rice et al., 2006; Rice et al., 2010).
Although MLUm is very widely used, calculating MLUm poses a number of difficulties. These include determining morpheme productivity, applying morpheme counting rules across languages, and the time and effort required to calculate MLUm. We highlight here the major concerns for each, especially in relation to our study in Inuktitut.
Productivity
The first difficulty – determining what morphemes are productive and thus should count separately in the MLUm calculation – applies both for speakers in general and for young children in particular. For any speaker, several types of forms could logically count as either one or two morphemes, and the researcher must decide how to count them. For English, these include forms like two-word expressions and names (thank you, Mickey Mouse), irregular past tense forms (got, went), contractions (I’m, don’t), diminutives (doggie, mommy), ritualized reduplications (night-night, bye-bye) and concatenatives (wanna, hafta). Each is technically composed of two parts (e.g., thank + you, verb get + tense PAST, subject I + verb am), but is arguably treated as one unit in speech rather than productively decomposed.
For young children, the problem of determining morpheme productivity is even more complex. Forms that are assumed to be productive for adults, such as treating the verb looked as the root look and the past tense morpheme -ed, may well be one unanalyzed unit for a child at 1;6 or 2;0. Thus, the researcher ideally should judge whether each morpheme is used productively by a given child at the age when the sample is taken, and thus should be individually counted for that child. An accurate assessment of whether each morpheme is productive for a given child requires a thorough assessment of the child’s grammar at the relevant age. This is not a practical option in the majority of cases, given the sheer amount of time and data that would be required. Thus, there is necessarily some uncertainty in calculating MLUm as to whether the child really has mastery of all the morphemes attributed to him or her.
In languages such as English, these difficulties are dealt with by setting and following a list of rules such as that in Brown (1973). Even then, however, different studies often follow different sets of rules, making comparability across studies difficult (Eisenberg, Fersko, & Lundgren, 2001). But for languages like Inuktitut, it is virtually impossible to decide which combinations of the more than 1500 bound morphemes are treated by speakers as one unit vs. productively decomposed. Elsewhere we have discussed in detail this problem of productivity in the acquisition of Inuktitut, and have applied a set of tests to determine whether certain morphemes are productive (Allen, 1996, 1998; Allen & Crago, 1996). In the present study, however, we simply assumed that every morpheme, apart from clearly fossilized forms, was productive for every child that used it, since this best reflects what would be possible in the typical clinical situation.
Cross-linguistic applicability.
A second difficulty for calculating MLU by morpheme is its applicability cross-linguistically given the substantial morphological differences between languages. For example, Mandarin and Cantonese are isolating languages with almost no inflectional or derivational morphology, so counting MLU by morpheme is no different than counting MLU by word (Cheung, 1998; Klee et al., 2004; Kok, 2011; Yip & Matthews, 2006). Turkish, however, is an agglutinating language with extensive derivational and inflectional morphology, so counting MLU by word as opposed to by morpheme yields quite different results (Ege, Acarlar, & Güleryüz, 1998).
Another difference derives from patterns of packaging features into morphemes. In agglutinating languages like Turkish, each morpheme realizes one feature (e.g., separate verbal morphemes for tense, person, and number), so counting MLU by morpheme results in a one-for-one assessment of features (Ege et al., 1998). But in inflectional languages like German and Spanish, the norm is portmanteau morphemes that each represent more than one feature (e.g., one verbal inflection simultaneously represents the features tense, person, and number). If only morphemes and not features are counted in the MLU, this potentially underestimates the language ability of children speaking inflectional as compared to agglutinating languages. However, if features rather than simply morphemes are counted, this potentially has the opposite effect (Linares, 1981; Linares-Orama & Sanders, 1977; Park, 1981).
MLU research in other language types highlights additional issues. For instance, Hebrew morphology is highly synthetic due to many portmanteau morphemes as well as its root-pattern system (e.g., consonants in a verb root realize verb meaning while vowels realize tense), requiring numerous arbitrary decisions about what counts as a morpheme (Dromi & Berman, 1982). For languages like Irish where morphological features are indicated by phonological changes such as initial mutation and lentition rather than by identifiable morphemes, it is often not clear what constitutes a morpheme (Hickey, 1991). Further, caution is warranted in using MLUm for languages where there is not yet a good linguistic description because of the difficulty of identifying what constitutes a morpheme for the language, or for languages where language development has not been studied extensively because of the difficulty of knowing what morphemes are likely to be productive for the young child (Hickey, 1991; Thordardottir & Weismer, 1998).
For Inuktitut, there is enough linguistic study (Dorais, 2010) and enough knowledge about child language (Allen, in press) to warrant using MLUm. The morpheme boundaries are clearly visible, and there is little doubt as to what constitutes a morpheme. One potential concern is that, while word-internal morphology is of the agglutinative type where each morpheme represents one feature, nominal and verbal inflections are all portmanteau realizing two or three features simultaneously. Further, we are not aware of other published studies using MLUm in a polysynthetic language.
Feasibility of MLUm for Inuktitut.
Given these advantages and disadvantages, is MLU counted in morphemes likely to be a useful indicator of developmental progress in Inuktitut? The highly agglutinative morphology and extensive inflection system of Inuktitut suggests that it will. Indeed, MLUm has been used in previous studies of language development in Inuktitut (e.g., Allen, 1996) and the related dialects/languages Tununirmiut (spoken in northern Baffin Island; Wilman, 1988) and West Greenlandic (Fortescue, 1985), and found to be sensitive to grammatical development. One previous study in Inuktitut also focused on word length rather than utterance length, calculating mean length of word in morphemes (MLWm; Allen et al., 2006). In addition, there is some evidence that MLUm is ecologically valid for Inuktitut. A preliminary study of a native Inuktitut speaker’s evaluation of language samples from school-aged children found that her scores correlated well with the measures of longest word in morphemes (Crago et al., 1991).
Using MLUm for Inuktitut is not without problems, however. The most relevant drawbacks are the considerable linguistic knowledge it takes to identify individual morphemes and to determine what rules for morpheme counting to use, as well as the considerable time it takes to transcribe the language sample and divide child utterances into morphemes. In our previous studies with Inuktitut child language, we found that it took one hour to transcribe five minutes of transcript, and a further half to one hour to divide the words in the transcript into their component morphemes using a semi-automated coding system (Allen, 1996).
Clinical language assessments of Inuit children are typically done either by health professionals with limited knowledge of Inuktitut, or by native speaker assistants with limited linguistic knowledge. Further, because most assessments are done during short visits by pediatricians or speech-language pathologists to the remote communities where the children live, and because many children must be seen during these visits, time is of the essence. In clinical assessment situations, clinicians often simply do not have the time to focus on this level of detail. Assistants, who may have the time, often do not have the appropriate linguistic training. Thus, assessing MLU by morpheme is often not a practical option.
Calculating mean length of utterance in words
Several studies in other languages have investigated alternatives to MLUm. One such alternative is that originally formulated by Nice (1925): the calculation of MLU in words. At least five studies across four languages have found a very high correlation between MLUm and MLUw: Arlman-Rupp et al. (1976) for longitudinal data from four Dutch-speaking children aged 2;0–2;6 (rs for each child between .98 and .99); Hickey (1991) for longitudinal data from one Irish-speaking child aged 1;11–3;0 (r = .99); Thordardottir and Weismer (1998) for cross-sectional data from 36 Icelandic-speaking children aged 1;3–3;0 (r = .98); Malakoff, Mayes, Schottenfeld, and Howell (1999) for data from 74 English-speaking children (46 exposed to drugs in utero and 28 not exposed) aged 2;0 (r = .97); and Parker and Brorson (2005) for cross-sectional data from 40 English-speaking children aged 3;0–3;10 (r = .998). At least one study has shown a lower correlation, however: Wieczorek (2010) for longitudinal data from one English-speaking child with SLI aged 3;5–4;5 (r = .84) and one age-matched typically developing peer (r = .61).
Calculating MLU by word eliminates the need for potentially arbitrary decisions about what constitutes a morpheme for either the language or the child. As Arlman-Rupp et al. (1976, p. 269) state, ‘[c]ounting words or syllables is faster, easier, more reliable, and theoretically more justifiable than counting morphemes since no ad hoc decisions are necessary’. The problem of determining what a word is still remains for some languages (e.g., Mandarin: Cheung, 1998), and for compound words in languages like English (Arlman-Rupp et al., 1976) but that is not a serious problem for most languages. Determining what is productive vs. memorized for a child is still a problem since children often produce word clusters as fixed forms. Lieven, Behrens, Speares, and Tomasello (2003) show that a large proportion of children’s early utterances fit a ‘frame and slot’ pattern where frames such as It’s a or Where’s the may well be unanalyzed units at early ages. However, determining productivity is less of a problem for words than for morphemes, simply because there are fewer decisions to make and less likelihood of memorized units. Counting words is also more practical for clinicians given that words are already distinguished in the transcription process (assuming that the writing system for a given language leaves spaces between words, as is the case in Inuktitut), so no extra division of units is necessary for analysis.
So how useful is MLUw likely to be as an indicator of language development in Inuktitut? It is certainly easier for clinicians to calculate than MLUm, and in that sense would be an easier measure to use. A potential problem, however, is that counting MLU by words may underestimate grammatical ability in a language like Inuktitut, where many grammatical notions are instantiated in morphology within the word. In addition, Inuktitut’s extensive ellipsis of subjects and objects limits the effectiveness of calculating MLU by words because subjects and objects are usually not realized as individual words.
Calculating mean length of utterance in syllables
A few studies have calculated MLU in syllables (MLUs). Two studies examined the correlation between MLUm and MLUs: Arlman-Rupp et al. (1976) for longitudinal data from four Dutch-speaking children aged 2;0–2;6 (all rs between .91 and .99), and Hickey (1991) for longitudinal data from one Irish-speaking child aged 1;11–3;0 (r = .90). Some studies have also examined the correlation between MLUw and MLUs and found it also reasonably high: Hickey (1991) for longitudinal data from three Irish-speaking children aged 1;4–3;0 (rs for each child between .77 and .95); Cheung (1998) for longitudinal data from five Mandarin-speaking children aged 1;6–4;3 (r = .98); and Kok (2011) for cross-sectional data from 130 Mandarin-speaking children aged 1;0–6;11 (no correlation figure provided).
Calculating MLU by syllable eliminates the need for potentially arbitrary decisions about what constitutes a morpheme or word for either the language or the child, because neither units of meaning nor productivity of forms are relevant to counting by syllable. However, several new problems are introduced when calculating MLUs. First, one must determine how to deal with filler syllables – syllables that are not identifiable morphemes or words in the adult language but may well serve as protomorphemes and carry meaning for the child (e.g., /ǝ/ in /ǝ hat/ ‘__ hot’, /ǝŋǝ/ in /ǝŋǝ tep/ ‘__ tape’; Peters & Menn, 1993, p. 748). Second, one must determine how to count the extra syllables generated by reduplication (e.g., wawa for ‘water’) and diminutives (e.g., doggie for ‘dog’) that are common in child language but bear no grammatically relevant meaning (Hickey, 1991). Determining what a syllable is may also be problematic depending on the phonological patterns of the language (e.g., dutifully may be counted as 3 or 4 syllables depending on how carefully it is pronounced). In addition, one must decide how to deal with mispronunciations – whether to count the target form or the actual form produced. Finally, in some languages, longer words may reflect semantic rather than syntactic development (e.g., car/automobile; go/depart).
How useful would MLUs be as an indicator of language development in Inuktitut? Roots and affixes in Inuktitut are generally fairly uniform in length at one to three syllables each, suggesting that MLUs might have some validity as a measure. Additionally, Inuktitut has a straightforward syllable inventory (Lipscomb, 1992). The syllable nucleus contains either a short vowel, a long vowel, or a diphthong, while the onset and the coda each optionally contain a single consonant. Thus, the options for syllable form include only V, CV, VC, CVC, VV, CVV, VVC, and CVVC. This relatively simple syllable structure is made even more transparent by the syllabic writing system of Inuktitut, in which the symbols used each represent one syllable. For example, surusi ‘boy’ is written using three symbols – ᓱᕈᓯ, where ᓱ = su, ᕈ = ru, and ᓯ = si. This suggests that calculating MLU by syllable would be relatively easy, even with little linguistic training, and might be a more practical option than either MLUw or MLUm. However, each of the problems raised in the previous paragraph remains a problem for calculating MLUs in Inuktitut. We did not take filler syllables into account in our study because only recognizable words were transcribed, and because filler syllables mostly occur in younger children than the ones in our study. Reduplication is relatively rare in child and child-directed speech in Inuktitut so we did not take it into consideration. Finally, we based our analysis on the child’s pronunciation as recorded in the transcriptions.
The present study
The main goal of this article, then, was to determine a method of assessing MLU for Inuktitut that fits three criteria. It must change predictably and noticeably with development in language ability in order to discriminate children at different levels of ability, be well-suited to the structural characteristics of Inuktitut, and be practical for use in clinical assessment situations. To this end, we used existing child data to evaluate 10 different length measures. These included three measures of mean utterance length – MLUw, MLUm, MLUs – as well as two measures of mean word length – MLWm and MLWs. To investigate whether a simpler measure is viable, we also evaluated three measures of longest utterance – LUw, LUm, LUs – as well as two measures of longest word – LWm and LWs.
The first step in the evaluation was to correlate each of the measures with age, under the assumption that any suitable measure should roughly increase with age even though the relationship may not be highly correlated. As a second step, it would have been ideal to correlate each of the measures with results from some other test of language development in Inuktitut that has already been proven to be a valid measure. However, no such test exists. Therefore, we decided to take MLUm as the best proxy for a ‘gold-standard’ test of language development given three factors: MLUm is the most widely-used proxy measure for language ability in the literature, development of language ability in Inuktitut is well indicated through increasing use of morphology according to previous research (e.g., Crago & Allen, 1998), and MLUm correlates well with age in Inuktitut (as we will show in the first analysis). We then correlated the other nine length measures with MLUm to determine which of them might be a sufficiently discriminating but simpler alternative to MLUm.
These two sets of correlations – with age and with MLUm – were carried out for two sets of data. In Study 1, we used spontaneous speech data from eight children over the age range 1;8–3;6, collected at two or three time points per child for previous studies (Allen, 1996; Crago, 1988). In Study 2, we used elicited narrative data from six children at each of ages 8 and 15, as well as from six adults (Allen et al., 2006). Although these data come from participants who might be considered old for the use of MLU measures, we wanted to see whether MLU might apply nonetheless at older ages in Inuktitut given that morphology is such a key feature of the language. Also, speech-language pathologists are often called upon to test Inuktitut-speaking children in this age range, so it would be useful to have a measure of language ability suitable for this age. Finally, in Study 3 we investigated whether the 10 length measures could distinguish the language ability of one 5-year-old with specific language impairment compared to an age-matched typically-developing peer (Crago & Allen, 2001).
Study 1
In Study 1, we asked which of the measures of utterance and word length was most reliable in indicating development in language ability for Inuktitut-speaking children in the age range typically covered by MLU – from the point of the first two-morpheme utterances until about age 4.
Method
Data
We analyzed two sets of existing data from previously conducted studies of Inuktitut child language development. The first comprises four children aged 1;0–1;8 at outset, all monolingual and typically developing speakers of Inuktitut (Crago, 1988). They were videotaped every four months for one year in naturalistic spontaneous speech situations with their mothers and other family members. Only the last two sessions per child were used in the present study because utterances during the earlier sessions comprised only one-morpheme utterances. The data were originally collected for a study of communicative competence in Inuit children, in two small communities of under 400 inhabitants in Nunavik.
The second data set comprises four children aged 2;0–2;10 at outset, also monolingual and typically developing (Allen, 1996). They were videotaped every month for nine months in naturalistic spontaneous speech situations with their mothers and other family members; only the first, middle, and last sessions are used in the present study. The data were originally collected for a study of morphosyntactic development in Inuit children, and were collected in one small community of about 250 inhabitants in Nunavik.
All data had previously been transcribed by native speakers in CHAT format following the standards of the CHILDES initiative (MacWhinney & Snow, 2000), and all transcripts for the second data set were subsequently checked by the first author. The length of recordings varied across children and sessions. In keeping with other studies using MLU and to maintain consistency across participants, we analyzed the first 100 utterances in each recording that were fully intelligible, not repetitions, and not memorized units.
Dividing utterances into morphemes and syllables.
All utterances were divided into morphemes for the original studies noted earlier. All morpheme division was done by a trained research assistant using a semi-automated specially-designed computer program, and then checked by the first author. Morpheme division followed the criteria detailed in Allen and Crago (1996, p. 135), the main points of which are reiterated here.
First, following typical practice in the field, we excluded from the utterance any filler morphemes (e.g., um), any symbolic noises (e.g., vroom), and any retraced material (e.g., in I am … I am happy, the first I am would be excluded from analysis). We included exclamations (e.g., hai ‘hey’), interactional expressions (e.g., ai ‘hi’), nursery words (e.g., vuvu ‘vehicle’, used instead of the adult form nunakkuujuuq), and words in English (e.g., funny, hockey).
Second, we treated each verbal and nominal inflection as a single portmanteau morpheme, as is common in the literature on Inuktitut (Dorais, 1988). These inflections were almost certainly originally composed of individual morphemes for each of the component meanings, and many can still be separated into some or all of their component parts. For example, -nut ‘ALL.PL’ can be separated into -n- for plural and -ut for allative, while -vagit ‘IND.1sS.2sO’ can be separated into -v- for indicative, -a- for transitive, and -git for second person. However, the individual components are not systematically transparent for most of the morphemes. More importantly, there is little evidence that even adult speakers systematically recognize the individual components or treat the inflectional morphemes as other than one portmanteau unit.
Third, we treated each lexicalized nominal as a single morpheme. Many nominals in Inuktitut were formed diachronically from several morphemes (Dorais, 1983). For example, supuurutiviniqauti ‘ashtray’ is formed from four individual morphemes – supuu- ‘blow’, -ruti- ‘item used for’, -viniq- ‘former’, and -qauti ‘item.containing’ – with the literal meaning ‘that which contains the remains of that which is used to blow’. These nominals have become lexicalized and are no longer formed productively with each use, even though their component parts are transparent and are used productively elsewhere.
Finally, we counted as a morpheme for the child each item that would be considered a morpheme by adult speakers, unless there was clear evidence that a certain group of morphemes was used in a formulaic or unanalyzed sense for a particular child. Groups of morphemes that were very likely to be used as an unanalyzed unit even by adults were counted as one morpheme. Examples include qanuippit ‘how are you?’ (formed of qanu-i-ppit ‘how-be-INT.2sS’) and qatsinguppat ‘what time is it?’ (formed of qatsi-ngu-ppat ‘when-be-CND.3sS’). This means that we did not determine whether each morpheme was productive for each child at each taping session, as advocated by Brown (1973). Given the sheer number of morphemes in Inuktitut, this would have been unwieldy if not impossible. Although some studies in other languages have assessed productivity for each morpheme for each child at each time point (e.g., Spanish: Linares, 1981; Hebrew: Dromi & Berman, 1982), most studies have followed criteria very similar to ours (e.g., German: Park, 1981; Icelandic: Thordardottir & Weismer, 1998).
Data coding and analysis.
Mean length of utterance in words (MLUw) and morphemes (MLUm), as well as mean length of word in morphemes (MLWm), were all calculated using the MLU program in the CLAN tool set (MacWhinney & Snow, 2000). Mean length of utterance in syllables (MLUs) and mean length of word in syllables (MLWs) were calculated using a specially-developed Excel macro that counted each vowel or geminate pair as one syllable. Non-geminate vowel pairs were counted as two syllables. Following the same methods, we also determined the longest utterance in words (LUw), morphemes (LUm), and syllables (LUs), as well as the longest word in morphemes (LWm) and syllables (LWs) for each file. Because all of these counts were generated by computer, inter-rater agreement estimates were not obtained.
Examples of how single-word and multi-word utterances were coded for words, morphemes, and syllables are given in (3) and (4) respectively. The total set of data used for analysis of the spontaneous speech is given in Table 1.
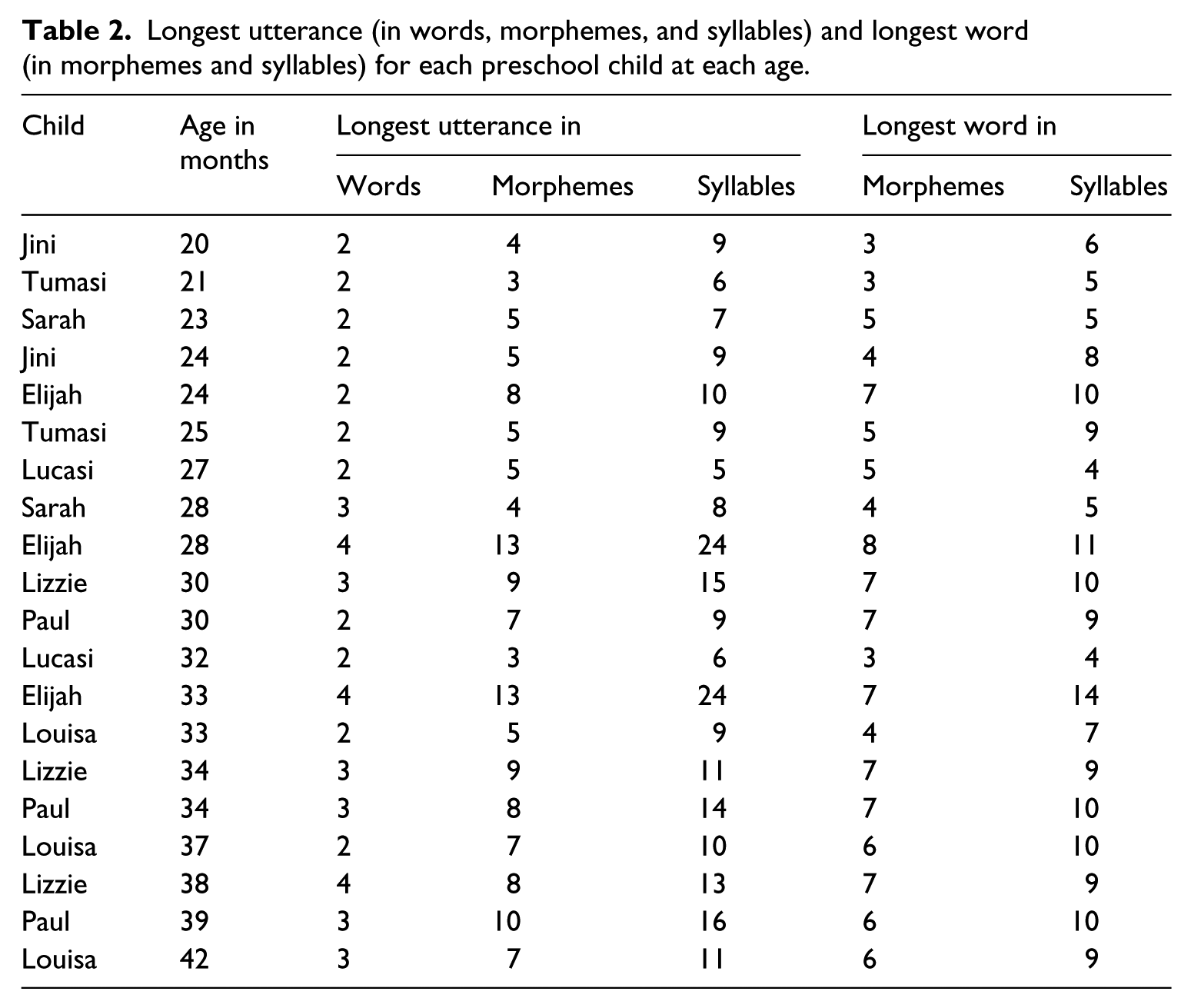
Mean length of utterance (in words, morphemes, and syllables) and mean length of word (in morphemes and syllables) for each preschool child at each age.

(3) a. Qimmiq. dog ‘Dog.’ (Jini 1;8) Coding: 1 word, 1 morpheme, 2 syllables b. Qai-git. come-IMP.2sS ‘Come here.’ (Sarah 2;4) Coding: 1 word, 2 morphemes, 3 syllables c. Miki-ju-gulum-mu-uq-langa-vita? be.small-that.which-EMPH.PEJ-ALL.SG-arrive.at-FUT-INT.1pS ‘Are we going to a yucky small place?’ (Paul 3;3) Coding: 1 word, 7 morphemes, 10 syllables (4) a. Ataataga itirtuq. ataata-ga itiq-juq father-abs.1Ssg enter-par.3sS ‘My father is coming in.’ (Lizzie 2;6) Coding: 2 words, 4 morphemes, 7 syllables b. Ataatamma kaivaluakainnatanga. ataata-mma kaivalua-kainnaq-janga father-erg.1Ssg turn-past-par.3sS.3sO ‘My father spun it.’ (Elijah 2;9) Coding: 2 words, 5 morphemes, 14 syllables c. Itsumunga aijaugavit. itsu-munga ai-jau-gavit that.one-all.sg get-pass-ctg.2sS ‘You will be brought by that one.’ (Louisa 2;10) Coding: 2 words, 5 morphemes, 10 syllables
Once these 10 measures were calculated for each file, we computed two sets of correlations. The first was between age in months and each of the length measures. The second was between MLUm and each of the other nine length measures. We used Pearson correlations because all the variables are on an interval scale. Given the large number of correlations, we also used a Bonferroni correction such that the alpha level was set at .005 (.05/10).
Results
Mean length data are shown in Table 1, and longest utterance/word data in Table 2.
Longest utterance (in words, morphemes, and syllables) and longest word (in morphemes and syllables) for each preschool child at each age.
Results of the correlation between age and each of the length measures are presented in Table 3. Notably, only MLUm, MLWm, and MLWs correlate significantly with age. (We also calculated Spearman correlations, suitable for data which are not normally distributed, and found basically the same results. MLUm and MLWm are both significant at p < .001. MLUs and MLWs are both marginally significant at p = .006. No other results are significant.)
Pearson correlations between age (in months) and length measures for preschool children (N = 20).

= p < .005, **= p < .001.
Results of the correlation between MLUm and each of the other length measures are presented in Table 4. All measures correlate significantly with MLUm.
Pearson correlations between MLUm and the other length measures for preschool children (N = 20).

= p < .005, **= p < .001.
Figure 1 shows trend lines for the relationship between age and each of the five mean length measures, while Figure 2 shows trend lines for the relationship between age and each of the five measures of longest utterance/word. Although there is noticeable variability in the data, the trend lines all slope upwards as expected: the older the age that the data sample is taken from, the longer the particular measure of utterance or word length. Although not all of these slopes reflect significant relationships (see Table 3), there are no instances where older ages are correlated with a decrease in the length measures.

Relationship between age in months and measures of mean utterance length (MLUw, MLUm, MLUs) and mean word length (MLWm, MLWs) in spontaneous speech for Inuktitut-speaking children aged 20–42 months.
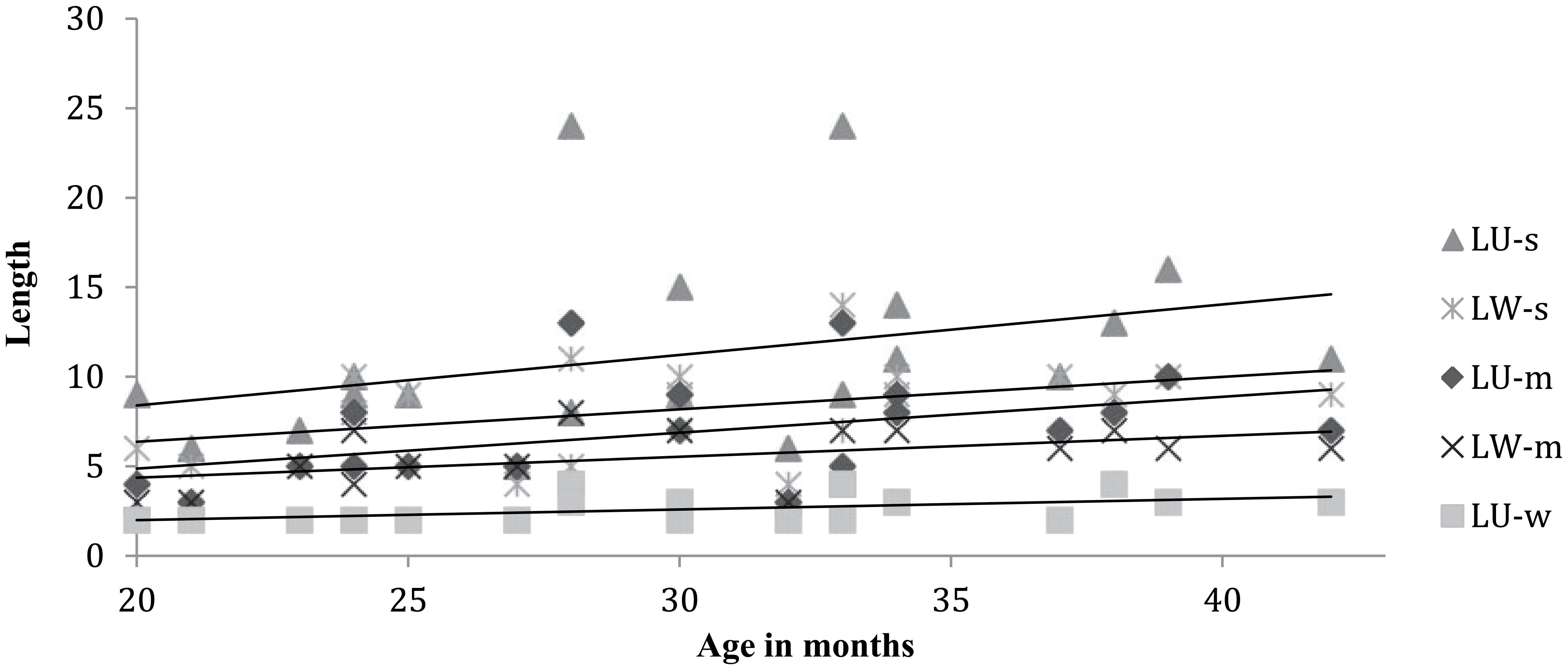
Relationship between age in months and measures of longest utterance (in words, morphemes, syllables) and longest word (in morphemes, syllables) in spontaneous speech for Inuktitut-speaking children aged 20–42 months.
Discussion
Our focus in Study 1 was to find a measure of utterance or word length that is reliable in indicating development in language ability for Inuktitut-speaking children in the age range typically covered by MLU. Additional desiderata were that the method be sensitive to the structural characteristics of Inuktitut, and that it be easy to calculate for speech-language pathologists. Taking increase in age as one rough proxy for increase in language development, we first correlated each of our 10 candidate measures with age. This resulted in three significant correlations – with MLUm, MLWm, and MLWs. Taking increase in MLUm as another rough proxy for increase in language development, in the absence of any standardized measures, we then correlated MLUm with the other nine candidate measures. Interestingly, all nine measures correlated strongly with MLUm.
Our finding that measures focused on length in words (i.e., MLUw, LUw) were not significantly correlated with age is not surprising given the structure of Inuktitut. Indeed, these measures increase very little over the 22-month range covered in our study: MLUw ranges only from 1.05 to 1.58 across this period, and LUw only from 2 to 4. This is quite different from findings in languages such as Dutch, English, Icelandic, Irish, and Mandarin noted earlier, where MLUw was shown to be equally as sensitive as MLUm to increases in language development.
It is also not surprising that the measures focused on length in morphemes (i.e., MLUm, MLWm) were significantly correlated with age given the morphological complexity in Inuktitut and the need for children to master that complexity. Over the same period, MLUm ranges from 1.27 to 3.74, and MLWm from 1.10 to 2.43. Either of these measures would be very suitable for future research studies, in the same way that they have been used in past studies (Allen, 1996, in press; Allen et al., 2006; Fortescue, 1985; Wilman, 1988). However, because these measures require considerable time and linguistic knowledge to calculate, they are impractical for the language assessment context.
MLWs, the third measure that showed a significant correlation with age, holds more promise as a practical tool. It is both sensitive to development and substantially easier to calculate than measures that require dividing words and utterances into morphemes. Further, it changes considerably over the 22-month period – from 2.09 to 3.94 – so it is easier to use as a measure of change. It also correlates significantly and highly with MLUm.
We conclude from these results that although MLUm and MLWm are likely the best measures to detect different levels in language ability of Inuktitut-speaking children, MLWs seems to be a good equivalent that is also much more practical to use.
One drawback of our data set is that there is some individual variation across children. For example, Elijah is particularly precocious while Louisa seems to be developing language a bit more slowly than her peers. Because our data come from only eight children, these variations are particularly noticeable. Future research should include data from a larger number of children, perhaps in a cross-sectional design, to control for the influence of individual differences.
Study 2
In Study 2, we asked whether any of the measures of utterance and word length would be suitable indicators of development in language ability for Inuktitut-speaking children in an older age range than that typically covered by MLU – age 8 and 15. We suspected that this might be the case in Inuktitut, because morphology is such a key feature of Inuktitut and presumably develops over a much longer time period than is the case in English. Our main motivation for investigating this is that speech-language pathologists are often called upon to test Inuktitut-speaking children in this age range, so it would be useful to have a measure of language ability suitable for this age. As in Study 1, we first correlated each of the measures with age, and then correlated MLUm with the other nine measures.
Method
Data
The data set comprises six children aged 8–9 years, six children aged 15–16 years, and six adults retelling the story of the wordless picture book Frog where are you? (Mayer, 1969). All participants grew up in Inuktitut-speaking homes, completed their first two years of schooling (grades 1 and 2) in Inuktitut, and then switched to schooling in either English or French in the third year of school (grade 3, age 8–9). The adults had varying amounts of formal schooling including some in either English or French. Thus, all of the participants were native speakers of Inuktitut but were also bilingual in English and/or French to varying degrees. These data were originally collected for a study of morphosyntactic development in Inuktitut (Allen et al., 2006). Half the data from each age group were collected in one of two small communities of less than 400 inhabitants in Nunavik, and the other half were collected from a larger community of around 1000 inhabitants in Nunavik with considerably more non-Inuit inhabitants.
The story retellings were all transcribed by native speakers of Inuktitut, and checked by the first author. The recordings varied between 22 and 164 utterances in length. To maintain consistency in data across participants, we analyzed only the first 22 fully intelligible utterances of actual story retelling for each participant. No utterances were repetitions or memorized units.
Morpheme division was done following the procedure and criteria laid out in Study 1. Analysis was also done as in Study 1, except that we used Spearman correlations because the age variable here is categorical rather than on an interval scale. Since the analysis was all computer-generated, no inter-rater reliability scores are reported.
Results
Mean length data are shown in Table 5, and longest utterance/word data in Table 6.
Mean length of utterance (in words, morphemes, and syllables) and mean length of word (in morphemes and syllables) for each school-aged child and adult in each age group.

Longest utterance (in words, morphemes, and syllables) and longest word (in morphemes and syllables) for each school-aged child and adult in each age group.

Average figures for each of the groups on each of the mean length measures are shown in Figure 3, and on each of the longest measures in Figure 4.

Mean values for each age group for mean length of utterance and word measures.
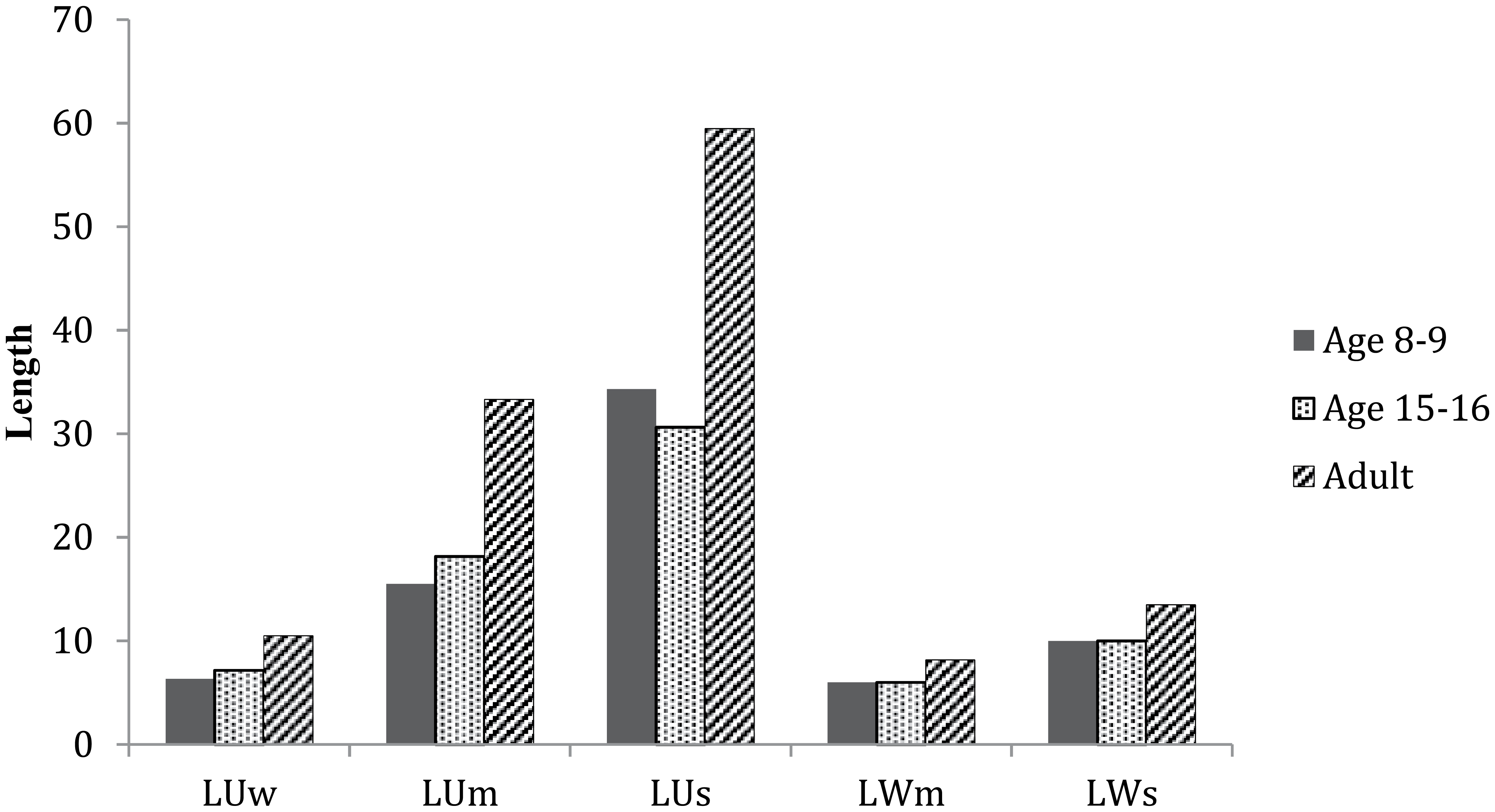
Mean values for each age group for longest utterance and word measures.
Results of the correlation between age and each of the length measures are presented in Table 7. All measures except LWm and LWs correlate significantly with age.
Spearman correlations between age (in category) and length measures for school-aged children and adults (N = 18).

= p < .005, **= p < .001.
Results of the correlation between MLUm and each of the other length measures are presented in Table 8. All measures except LWs correlate significantly with MLUm.
Spearman correlations between MLUm and the other length measures for school-aged children and adults (N = 18).

= p < .005, **= p < .001.
Discussion
Our goal in Study 2 was to determine whether any of the length measures could be used to indicate development in an older age range than for the children in Study 1. We found that all of the measures except LWm and LWs correlated highly with age, and that MLUm correlated highly with all of the other nine measures except LWs. Thus, it appears that all of the mean length measures as well as all of the longest utterance measures could suitably discriminate development in this age range. In the light of the practical consideration to have an easily countable measure, it seems that MLUs, MLWs, and LUs could all be suitable.
Study 3
In Study 3, we used the case study method to investigate whether the utterance-length and word-length measures identified in Studies 1 and 2 could be used diagnostically to discriminate children with language difficulties from typically-developing children. We focused on one Inuktitut-speaking 5-year-old child who had previously been identified as having specific language impairment (SLI).
Children with SLI have delays in language development, although their hearing and other cognitive and neurological measures are in the normal range. They typically score significantly lower on MLU measures than do age-matched typically-developing children, as revealed in studies across languages with a variety of typologies (e.g., Cantonese: Klee et al., 2004; Dutch: Bol, 2003; English: Wieczorek, 2010; Finnish: Nieminen, 2007; Spanish: Bedore & Leonard, 2001; Swedish: Hansson et al., 2000). This derives partly from producing shorter utterances overall and, in at least some languages, partly from omitting certain vulnerable morphology. The specific structures that present difficulty in SLI vary in accordance with the typology of the language, and are often those structures that are also difficult for younger typically-developing children (Leonard, 2014). In particular, verbal inflections often (but not always) emerge as vulnerable cross-linguistically for children with SLI. Depending on the language, they are sometimes omitted, sometimes replaced by infinitives, and sometimes substituted with closely-related inflections such as singular instead of plural agreement (e.g., English: Rice, Wexler, & Cleave, 1995; Finnish: Kunnari et al., 2011; Hungarian: Lukacs, Leonard, Kas, & Pleh, 2009). In Romance languages such as French, Italian, and Spanish, inflections are not particularly problematic but unstressed direct object pronouns are often either omitted or misplaced (Bedore & Leonard, 2001; Jakubowicz, Nash, Rigaut, & Gérard, 1998).
In this case study, we aimed to see if one Inuktitut-speaking child with SLI would also have significantly lower MLU measures than her typically-developing peers, and if this difference would be better revealed in some measures than others. To this end, we evaluated the 10 measures of utterance and word length in data from the child with SLI. We then performed two comparisons to determine the effectiveness of our measures at discriminating SLI. First, we compared the data from the child with SLI to data from one typically-developing age-matched peer. Given that in many languages SLI particularly affects inflectional morphology, we expected that scores for the measures related to morphemes (i.e., MLUm, MLWm, LUm, LWm), and thus also syllables (i.e., MLUs, MLWs, LUs, LWs) would be noticeably lower in the child with SLI than in the age-matched peer. In contrast, we expected scores for the word-related measures (i.e., MLUw, LUw) to be only slightly lower across the two children because morphology should not affect these measures. Second, we compared her data to data from typically-developing language-matched peers from Study 1. Here we expected that all of the measures would be broadly similar across these samples because the children are at a similar stage of language development, despite the fact that the language-matched peers are considerably younger.
Method
Data
The new data for Study 3 comes from two children aged 5;4, both monolingual, one with specific language impairment and one typically developing (Crago & Allen, 2001). Both children had normal hearing, no history of chronic middle ear disease, and no signs of social and emotional disabilities or neurological deficits. They were considered to be of normal intelligence by their families and other members of the community. In the absence of standardized tests for language development in Inuktitut, the language impairment in the child with SLI was identified by her family and community members (Inuit nursing assistant, special education teacher, and pedagogical counselor). At the time of the study, she was enrolled in a normal kindergarten and was reported to be comparable to peers motorically, socially, and intellectually. Data from the child with SLI and her age-matched peer were videotaped for about one hour while they were playing together in a naturalistic spontaneous speech situation. The data were originally collected for a study of inflection development in specific language impairment in Inuktitut, and were collected in one small community of about 350 inhabitants in northern Quebec.
Data for typically-developing language-matched children were taken from Study 1. We used all data samples from Study 1 with an MLUm up to 0.4 below or above the MLUm of the child with SLI (i.e., MLUm range of 2.07–2.87). This resulted in five samples – from Paul at 2;6 and 2;10, from Lizzie at 2;10, and from Louisa at 3;1 and 3;6. Notably, these children are two to three years younger than the child with SLI.
Data transcription, morpheme division, data coding, and analysis were done as in Studies 1 and 2.
Results
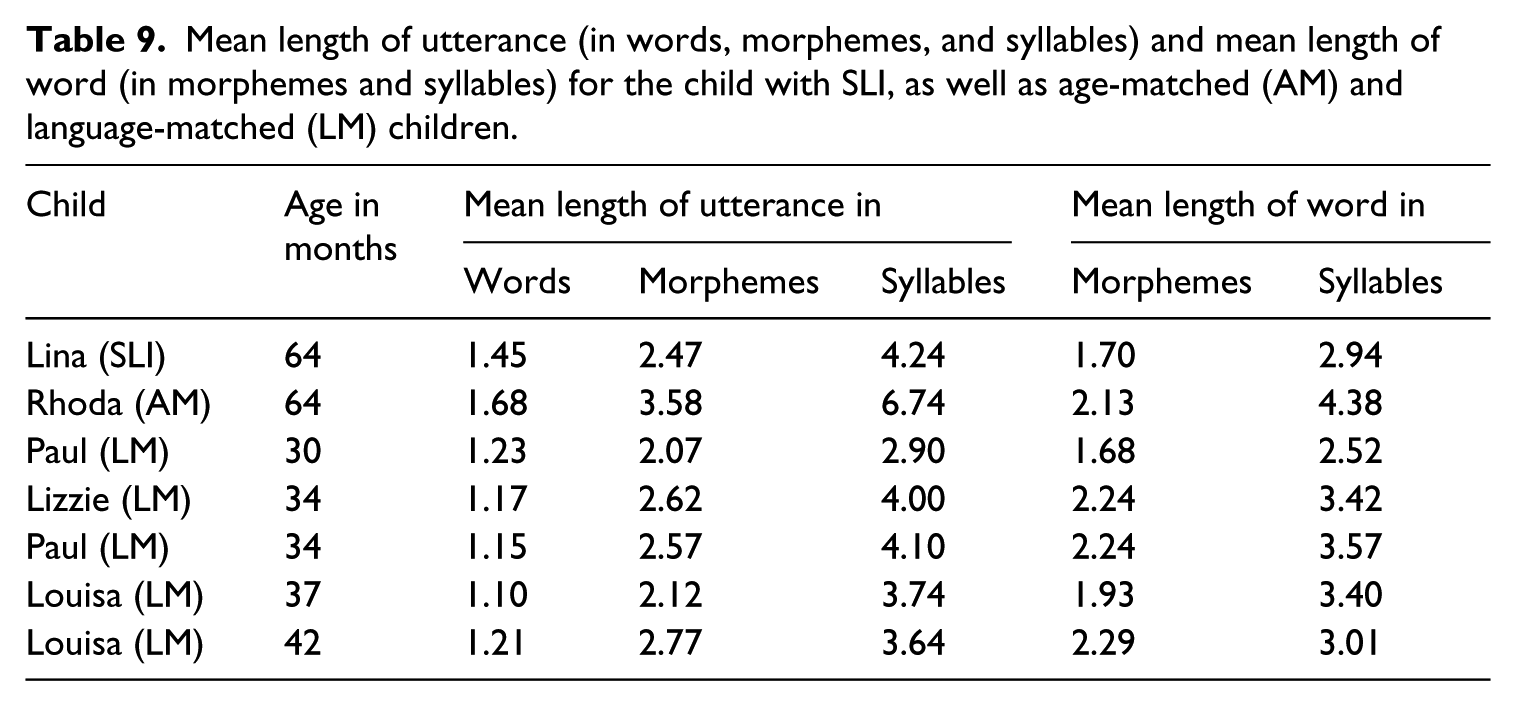
Mean length data are shown in Table 9, and longest utterance/word data in Table 10.
Mean length of utterance (in words, morphemes, and syllables) and mean length of word (in morphemes and syllables) for the child with SLI, as well as age-matched (AM) and language-matched (LM) children.
Longest utterance (in words, morphemes, and syllables) and longest word (in morphemes and syllables) for the child with SLI, as well as age-matched (AM) and language-matched (LM) children.
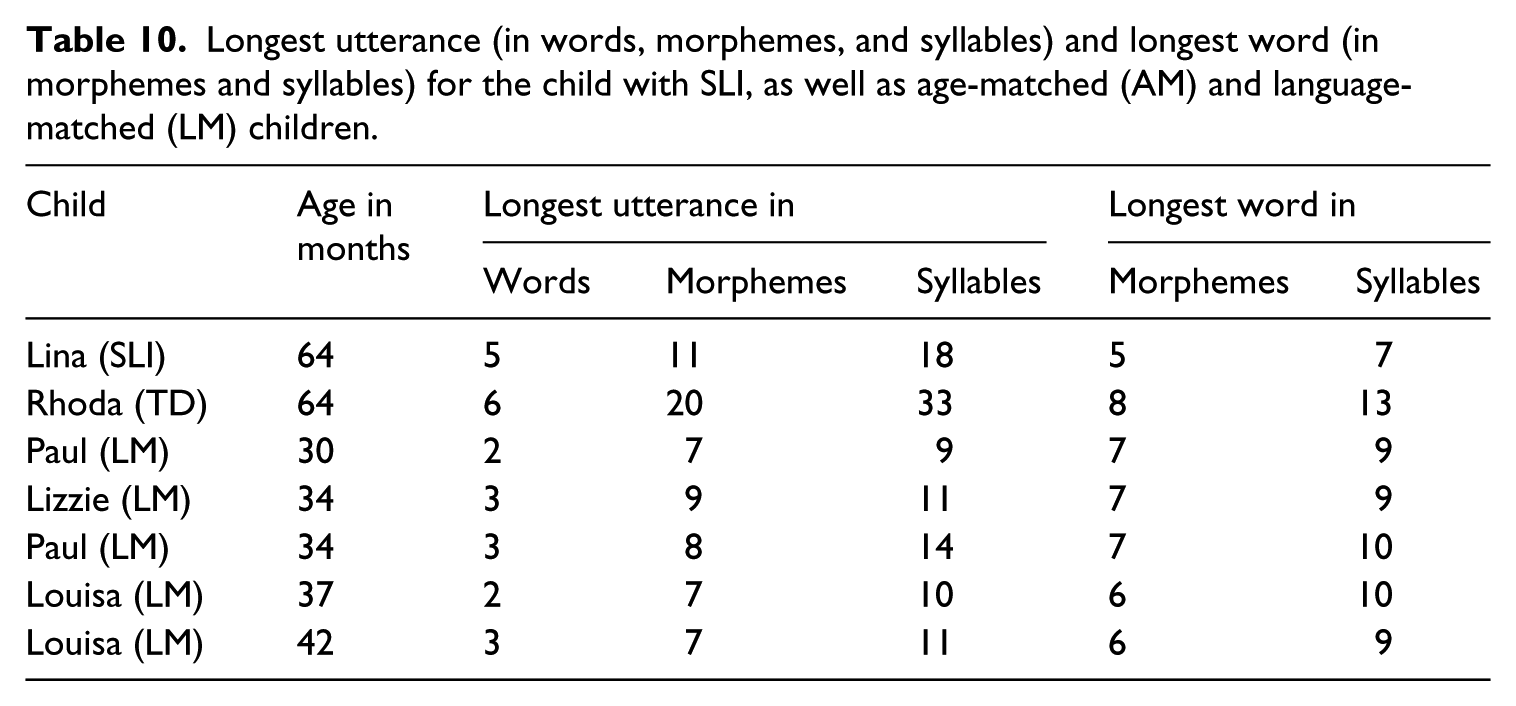
We first compared data from the child with SLI to that of her age-matched peer. As we expected, her scores were noticeably lower than those of her age-matched peer for every measure assessing length in morphemes and syllables. This was true for both the mean length measures and the longest measures. The scores of the child with SLI were also somewhat lower on the two measures assessing number of words – the MLUw score was 0.23 words lower, while the LUw score was 1 word lower. The differences for measurements in words are relatively smaller than the differences for measurements in morphemes or syllables. This pattern was predicted because only the morpheme- and syllable-based measures should be affected by omission of inflectional morphemes. However, we cannot rule out that this pattern emerged simply because there are fewer words by definition, and thus less possibility to see a large difference in the word-based measurements.
We then compared the data from the child with SLI to that of her language-matched peers. Because the data samples were explicitly matched for MLUm, we expected all the other measures to also be very similar across the SLI and language-matched data. However, we found two unexpected patterns. First, the child with SLI scored higher than her language-matched peers for all of the utterance-length measures (apart from MLUm on which the samples were matched; i.e., MLUw, MLUs, LUw, LUm, and LUs). Second, she scored lower than her language-matched peers for all of the word-length measures (i.e., MLWm, MLWs, LWm and LWs), except for the MLWm and MLWs of Paul at 2;6 which are slightly lower than those of the child with SLI. Taken together, these results reveal that the child with SLI used more words per utterance than her language-matched peers, but that these words were less morphologically complex. This was true both in terms of average usage (i.e., mean length measures) and in the limit (i.e., longest measures). Thus, it appears that the child with SLI was using extra words to compensate for what she could not convey through morphology.
Discussion
In Study 3, we compared data from one child with SLI to data from one age-matched peer and five language-matched peers with the goal of determining whether our length measures could serve to identify language impairment. The measures served well to discriminate the child with SLI from her age-matched peer, since she scored noticeably lower on all of the measures. The measures also revealed that the child with SLI used more words but morphologically less complex words than her language-matched peers.
These results for measures related to morphemes (MLWm, LUm, LWm) are not surprising given that difficulty with inflectional morphology is often a hallmark of SLI. In addition, previous research using data from the same children showed that the child with SLI produced inflections on only 43% of the verbs in her speech, while her age-matched peer produced inflections on 98% of the verbs in her speech (Crago & Allen, 2001, p. 91). Data from a language-matched peer (different from the ones used in Study 3) showed that he produced inflections on 84% of the verbs in his speech (Crago & Allen, 2001, p. 91).
The pattern of more words but less morphological complexity than language-matched peers is also consistent with the findings in Crago and Allen (2001). They found three patterns in the utterances of the child with SLI when her verbs were not inflected: the inflection was simply missing (5), a meaningless filler element was used in place of the inflection (6), and an overt pronoun was used in place of the inflection (7). The first and second patterns would lead to fewer morphemes, while the third would lead to more words. In comparing the actual utterances from the child with SLI (shown in (a) in the examples) with the target utterance that would typically be spoken by age- or language-matched peers (shown in (b)), we see the following differences. The word count would be the same for the two utterances in (5) and (6), but would be one more for the actual utterance in (7). The morpheme counts would be one less for the actual utterance in (5), and two less in both (6) and (7). The syllable counts would be one less for the actual utterance in (5), two less in (6) assuming that the filler would not be counted, and the same in (7).
(5) a. Aaa, qaisi. aaa qai-si yes come-PRSP ‘Yes, is coming.’ (Lina 5;4; Crago & Allen, 2001, p. 93) b. Aaa, qaisijuq. aaa qai-si-juq yes come-PRSP-PAR.3sS ‘Yes, he/she/it is coming.’ (target; Crago & Allen, 2001, p. 93) (6) a. Ah umiami ah sinimi. ah umiaq-mi ah sinik-MI um boat-LOC.SG um sleep-MI ‘Um on the boat, um sleep.’ (Lina 5;4; Crago & Allen, 2001, p. 94) b. Sininngualuk umiarmi. sinik-nnguaq-luk umiaq-mi sleep-pretend-IMP.1dS boat-LOC.SG ‘Let’s pretend to sleep on the boat.’ (target; Crago & Allen, 2001, p. 95) (7) a. Anaana unattinu uvanga. anaana uvatti-nut uvanga mother our.house-ALL.PL I/me/my/mine ‘Mother go home, I.’ (Lina 5;4; Crago & Allen, 2001, p. 96) b. Anaana uvattinusivunga. anaana uvatti-nut-uq-si-vunga mother our.house-ALL.PL-go-PRSP-IND.1sS ‘Mom, I’m about to go home.’ (target; Crago & Allen, 2001, p. 96)
In comparison with the languages cited earlier for which patterns in SLI have been studied, the omission (5) and substitution (6) patterns found for Inuktitut are expected. However, the pattern of replacing an inflection with a pronoun has not previously been reported for other languages. As noted by Crago and Allen (2001), this pattern may derive from the child’s overall difficulty with the polysynthetic structure of Inuktitut, given that similar errors are seen in the productions of English native speakers learning Inuktitut as a second language.
In sum, the length measures that we assessed served overall to distinguish the child with SLI from her age- and language-matched peers. Based as they are on a single case study, the results tentatively suggest that the measures focusing on morphemes and syllables (MLUs, MLUm, MLWm, MLWs, LUm, LUs, LWs) will be more effective than the measures focusing on words (MLUw, LUw).
General discussion
We had three main goals in our research. In Study 1, we investigated whether any of 10 possible length measures would serve to discriminate preschool Inuktitut-speaking children’s language development, while being both sensitive to the structure of Inuktitut and also easy to calculate for speech-language pathologists. In Study 2, we investigated whether any of these length measures would serve to discriminate language development at older ages (here ages 8–9 and 15–16), since speech-language pathologists are often called on to evaluate language difficulties in older children. In Study 3, we explored in a case study whether the measures could be used to discriminate the language of one 5-year-old child with specific language impairment from that of her age-matched and language-matched peers.
We found that three measures correlated well with age, our proxy for development, in preschool children: MLUm, MLWm, and MLWs. Each of these measures fits well with the structural complexities of Inuktitut, and thus would be suitable to discriminate children’s language development. MLUm and MLWm are the most directly related to morphology, which is the key element of complexity in Inuktitut as in other polysynthetic languages. Thus, we recommend those for research purposes where the personnel analyzing the data have both enough time and enough linguistic knowledge to appropriately prepare the data for analysis.
For day-to-day assessment in clinical situations, however, it is not realistic to take the time and effort needed to calculate MLUm or MLWm. Given that MLWs is relatively easier and faster to calculate while also discriminating children’s language development, we recommend that as a suitable method to be used in clinical language assessments in the future. One caveat is that calculating MLWs from 100 utterances is unwieldy, simply because of the time it takes to transcribe 100 utterances of child speech from audio or video recordings (likely several hours). The analyses here show that a maximally simple syllable-based measure like LUs or LWs is not a reliable indicator of language development. It would be useful in future research to determine whether a mean taken from some intermediate number of utterances – say 5 or 10 – would be a reliable indicator.
With regard to older children, we found that all 10 length measures are valid for discriminating language development, or at least for differentiating the typical language produced by an 8- to 9-year-old from that of a 15- to 16-year-old. This is a promising result, but more detailed research is warranted to see whether the measures are still valid when the age differences are smaller.
Finally, we found that the measures tested here were useful for identifying one child with SLI as compared to typically-developing peers. Her scores on all the length measures were noticeably lower than those of her age-matched peer. She was matched with her language-matched peers on the basis of MLUm, and we thus expected that she would also have similar scores for the other length measures. However, she had higher scores than her language-matched peers for all the measures of utterance length (where words and morphemes count as equivalent), illustrating that her overall messages were longer than those of her peers, which is reasonable given the almost two-year age difference. Further, she had lower scores than her language-matched peers for all the measures of word length (where only number of morphemes are relevant), illustrating that her morphological complexity was less than that of her peers. This is consistent with the fact that inflectional morphology is a particular area of difficulty for many children with SLI.
Based on these results, the three measures identified as most effective for assessing language ability in preschool Inuktitut-speaking children would also be suitable for identifying specific language impairment in Inuktitut. The measures MLUm and MLWm would be preferable for research purposes since they focus on morphology which is the key indicator of complexity in Inuktitut. However, the measure MLWs – the measure identified as the best for clinical language assessment purposes in Study 1 – would be suitable for assessing SLI as well. This child’s MLWs score was about 0.5 lower than that of her language-matched peers, and about 1.5 lower than that of her age-matched peer.
The present study also has implications for the role of language structure in determining appropriate language assessment methods. Numerous previous studies in a variety of languages have found that MLUw and MLUm correlate highly, and have advocated using MLUw as an assessment measure on the grounds that it requires fewer ad hoc decisions on the part of the researcher about identifying morphemes and about morpheme productivity for the child (Dutch: Arlman-Rupp et al., 1976; English: Malakoff et al., 1999; Parker & Brorson, 2005; Icelandic: Thordardottir & Weismer, 1998; Irish: Hickey, 1991). However, our study shows clearly that this would not be an appropriate solution for Inuktitut and thus likely for other polysynthetic languages. In these languages there is relatively little variation in the number of words per utterance, and little of the complexity of the linguistic structure is revealed through word order or word combinations. Rather, the main source of complexity in the language is the morphology, with words varying in length from 1 to 5 morphemes already at ages younger than two years, and up to 10 or more morphemes by adulthood. This should be taken into account for future studies using length measures with polysynthetic and other morphologically complex languages.
In sum, the results of the three studies reported here reveal that three measures discriminated language ability across all of the data: MLUm, MLWm, and MLWs. The first two are very suitable for research purposes since they tune into the major source of complexity in the language, the morphology. However, they are time-consuming to measure and require considerable linguistic knowledge. The measure MLWs also discriminates language ability and is sensitive to the structure of Inuktitut. But in addition, it has the major advantage that it is easier to calculate that the other two measures. Thus, we conclude that it is the best measure overall for clinical assessment purposes. Further research should determine if an MLWs taken from a smaller number of utterances than 100 would also prove a reliable measure.
Footnotes
Acknowledgements
We thank Patricia Cleave, Lindsay Coffin, Kerry Isakson, and Gunnar Jacob for assistance with data analysis. We also thank two anonymous reviewers, the editors, and the Scientific Writing Group at the University of Kaiserslautern for helpful comments on an earlier version of this manuscript.
Funding
Funding for data collection and transcription was provided by a grant from the Kativik School Board to the first author, and by grants from the Kativik School Board and the Social Sciences and Humanities Research Council of Canada to Martha B. Crago.