
Abstract
This article analyses how a set of psycholinguistic factors may account for children’s lexical development. Age of acquisition is compared to a measure of lexical development based on vocabulary size rather than age, and robust regression models are used to assess the individual and joint effects of word class, frequency, imageability and phonological neighbourhood density on Norwegian children’s early lexical development. The Norwegian Communicative Development Inventories (CDI) norms were used to calculate each CDI word’s age of acquisition and vocabulary size of acquisition. Lexical properties were downloaded from the lexical database Norwegian Words, supplemented with data on frequency in adult and child-directed speech. Age of acquisition correlated highly with vocabulary size of acquisition, but the new measure was more evenly distributed and more sensitive to lexical effects. Frequency in child-directed speech was the most important predictor of lexical development, followed by imageability, which seems to account for the dominance of nominals over predicates in Norwegian.
Keywords
Introduction
Children’s vocabularies will be shaped by their individual dispositions and experiences, as well as properties of the language and culture surrounding them (e.g. Xanthos et al., 2011). There are nevertheless striking cross-linguistic similarities in lexical development, such as commonalities in the form (Boysson-Bardies & Vihman, 1991; Garmann, Hansen, Simonsen, & Kristoffersen, in press) and meaning (Caselli et al., 1995; Gentner, 1982; Wehberg et al., 2007) of the words that constitute early vocabularies.
Two recent Norwegian developments facilitate a closer look at the ways in which form, meaning and usage impact children’s early vocabularies. The recently launched database Norwegian Words (Lind, Simonsen, Hansen, Holm, & Mevik, 2015) offers information on a set of psycholinguistic factors, including imageability, frequency and phonological neighbourhood density, for about 1650 Norwegian nouns, verbs and adjectives. Among them are words included in the Norwegian adaptation of the MacArthur–Bates Communicative Development Inventories (Fenson et al., 2007), a parental questionnaire demonstrated to give a valid and reliable measure of early lexical development (for a review, see Law & Roy, 2008). The Norwegian CDI norms consist of data from 6500 monolingual Norwegian children (Kristoffersen & Simonsen, 2012; Simonsen, Kristoffersen, Bleses, Wehberg, & Jørgensen, 2014), and together with the database Norwegian Words, these data form an ideal basis for studies of early lexical development.
This article investigates the combined effects on lexical development from the four most relevant factors in this database: word class, frequency, imageability and phonological neighbourhood density. As elaborated below, these factors have previously been found to affect how easy a word is to acquire. Importantly, interactions have also been found between them.
Word class
Common nouns tend to dominate lexical acquisition; verbs and adjectives are scarce, and closed class items even more so. These findings are fairly consistent across a wide range of languages (Bates et al., 1994; Caselli et al., 1995; Hao et al., 2015; Kern, 2007; Schults, Tulviste, & Konstabel, 2012; Stolt, Haataja, Lapinleimu, & Lehtonen, 2008; Trudeau & Sutton, 2011; Wehberg et al., 2007), although there are cross-linguistic differences. For instance, according to Ma, Golinkoff, Hirsh-Pasek, McDonough, and Tardif (2009) and Tardif (1996, 2006), there are more verbs among the early words in Mandarin than in English.
CDI norms are typically cross-sectional, and thus cannot be used to determine when each child acquired each word, only which words she or he currently produces (or understands). Studies of lexical composition have circumvented this limitation in three different ways: by calculating mean lexical compositions by vocabulary size (Bates et al., 1994), through item analysis of the first 50 words, that is, the 50 words most frequently produced among infants (Caselli et al., 1995), or finally by calculating the age in months where at least 50% of the children are reported to produce each word (Fenson et al., 1994). The latter measure is commonly referred to as a word’s age of acquisition (AoA) (Goodman, Dale, & Li, 2008; Ma et al., 2009; McDonough, Song, Hirsh-Pasek, Golinkoff, & Lannon, 2011; Storkel, 2004a). Some studies have used other thresholds, such as Eriksson and Berglund (1999), who discuss the words comprehended by at least 80% of Swedish 16-months-olds, and the words produced by at least 20% of the same children. Interestingly, nobody has so far analysed the acquisition of each item as a function of vocabulary size, even though there is a large variation in children’s lexical development (Fenson et al., 1994), and lexical size appears to be a better predictor of general language than age (Bates & Goodman, 1997; Labrell et al., 2014).
Frequency
It is a reasonable assumption that words should be acquired earlier the more frequent they are. However, Goodman et al. (2008) reported the opposite: the higher the frequency, the later that word is acquired. This is counterintuitive, but easily explained. As languages typically have more unique nouns than verbs, and only a small set of closed-class words, a closed-class word will be more frequent than the average verb, which in turn will be more frequent than the average noun (Gentner, 1982; Goodman et al., 2008). On a scale we then find common nouns in one end (infrequent, but acquired early), and closed-class words in the other (highly frequent, but acquired late). Within each word class, highly frequent words are indeed acquired before less frequent words (Goodman et al., 2008).
Goodman et al. (2008) analysed correlation between AoA based on the US English CDI norms and three different frequency lists: Kučera–Francis (Francis & Kučera, 1967), Thorndike–Lorge (Thorndike & Lorge, 1944) based on written language, and a new frequency list compiled from child-directed speech (CDS) in 28 CHILDES corpora (MacWhinney, 2000). They found CDS frequency to correlate with AoA within all lexical categories, whereas correlations were only found within common nouns for the written language frequency lists.
Imageability
Words have been found to be acquired earlier the more imageable they are (Bird, Franklin, & Howard, 2001; Ma et al., 2009; McDonough et al., 2011), that is, the more easily they arouse a mental image or sensory experience (Paivio, Yuille, & Madigan, 1968). Imageability also appears to aid the acquisition of morphology: according to Smolík and Kříž (2015), Czech children use inflected forms earlier if the noun or verb in question is highly imageable.
Imageability is highly correlated with concreteness, but also depends on experience: words with strong emotional connotations may be abstract, but quite imageable (e.g. anger), whereas words denoting rare objects are concrete, but may still be low on imageability (e.g. antitoxin) (Bird et al., 2001; Paivio et al., 1968).
Nouns are cross-linguistically more imageable than verbs (Bird, Ralph, Patterson, & Hodges, 2000; Cortese & Fugett, 2004; Luzzatti et al., 2002; Masterson & Druks, 1998; Simonsen, Lind, Hansen, Holm, & Mevik, 2013), and Ma et al. (2009) claim that imageability can account for the many verbs acquired early in Mandarin; these verbs are more imageable than the few verbs acquired early in English.
Phonological neighbourhood density
A word’s phonological neighbourhood density (PND) consists of all the words that differ from it by one and only one segment, through substitution, deletion or addition (Luce & Pisoni, 1998). For instance, hat, scat, cats, at, cab and cut are all phonological neighbours of cat. Words residing in dense neighbourhoods are phonologically similar to many other words in the language, and Storkel (2004a) found nouns in dense neighbourhoods to have a lower AoA than those in sparse phonological neighbourhoods. This effect was robust for short words, but not for long words, and there was no evident effect for high-frequency words.
Interaction and competition between effects
The effects of word class, imageability, PND and frequency are intertwined. As mentioned, nouns are generally less frequent (Goodman et al., 2008) and more imageable (Ma et al., 2009; Simonsen et al., 2013) than verbs. Furthermore, highly frequent words tend to have a higher PND than less frequent words (Pisoni, Nusbaum, Luce, & Slowiaczek, 1985), and Simonsen et al. (2013, p. 443) report words to be less imageable the more frequent they are, assuming the cause to be semantic bleaching: frequent words might over time get a more general meaning, which in turn might increase their frequency (Bybee, 2010).
Other properties also interact with the four factors investigated here. One example is word length: short nouns have more phonological neighbours than long nouns (Pisoni et al., 1985; Storkel, 2004b), high-imageability nouns are shorter than low-imageability nouns (Reilly & Kean, 2007) and frequent words tend to be shorter than infrequent words (Zipf, 1936), possibly due to phonological reduction (Bybee, 2010). Word length may also have an independent effect on lexical development: for English, short words are reported to be acquired before long words (Storkel, 2004a), and the first words are predominantly monosyllabic (Garmann et al., in press; Vihman & Croft, 2007). However, this may not hold cross-linguistically, as Vihman and Croft (2007) report a dominance of disyllables among early words to be the most common pattern cross-linguistically. According to Garmann et al. (in press), the patterns of word length in syllables in the first English, Italian, Swedish and Norwegian words correspond to cross-linguistic differences in adult language samples. A closer look at such interactions and combined effects on early lexical development is not only important to clarify the individual contribution of each factor, but also to inform ‘about the nature of the learning mechanism’ (Ambridge, Kidd, Rowland, & Theakston, 2015, p. 244).
The aims of this article
The purpose of this article is twofold. First, the size of the Norwegian CDI norms (N = 6574) is exploited to compare the much used measure AoA to a measure based on vocabulary size rather than age. Second, data from the CDI norms, the database Norwegian Words and two corpora are combined to assess the individual and joint effects on lexical development of word class, frequency, imageability and PND. Of particular interest is the competition and interaction between the factors. For instance, imageability and frequency have been shown to be negatively correlated with each other, although both are reported to correlate positively with AoA. Based on these results, we may expect an interaction between the two: the earliest words may be both highly imageable and highly frequent. The specific research questions are:
How does AoA compare to a measure of lexical development based on vocabulary size rather than age?
How well can word class, frequency, imageability and PND, individually and in interaction, account for lexical development?
Method
The Norwegian CDI norms
The CDI consists of CDI I: Words and gestures (WG) and a CDI II: Words and sentences (WS) (Fenson et al., 2007). The Norwegian CDI study is one of the world’s largest to date, with norms based on 2359 WG responses and 4215 WS responses (Kristoffersen & Simonsen, 2012; Simonsen et al., 2014). The Norwegian study followed Bleses et al. (2008) and assessed children aged 0;8–1;8 with the WG form and children aged 1;4–3;6 with the WS form, creating an overlap (1;4–1;8) in which parents were randomly assigned to either form (Simonsen et al., 2014, p. 8). Both forms include a vocabulary checklist, but this is substantially longer in the form intended for the oldest group (WG: 395 items, WS: 731 items). In this study, data from both forms are combined, and a word is considered acquired if it is checked as produced in the vocabulary checklist.
Can WG and WS responses be combined?
Data from both forms are needed to explore the whole range of early lexical development, but the WG and WS data might not be directly comparable, as the length of the checklist may affect the responses. According to analyses of the data from the 1824 parents that were randomly assigned to either of the two forms (see Figure 1), parents given WS checked significantly more words at age 1;4 (medianWG = 23, medianWS = 31, W = 9214.5, p = .001), 1;6 (medianWG = 49, medianWS = 59.5, W = 14,869.5, p = .006) and 1;8 (medianWG = 79.5, medianWS = 149, W = 14,265.5, p < .001), but not at ages 1;5 and 1;7. Thus, the length of the checklist does indeed appear to have an effect on the reported vocabulary size. However, the data could still be comparable for the words occurring in both lists. When the WS data were recalculated including only the words common to both forms (see Figure 1), the forms differed significantly only at age 1;8 (medianWG = 79.5, medianWS = 121, W = 17,216, p = .010). It thus seems that up to age 1;7, the data may be combined.
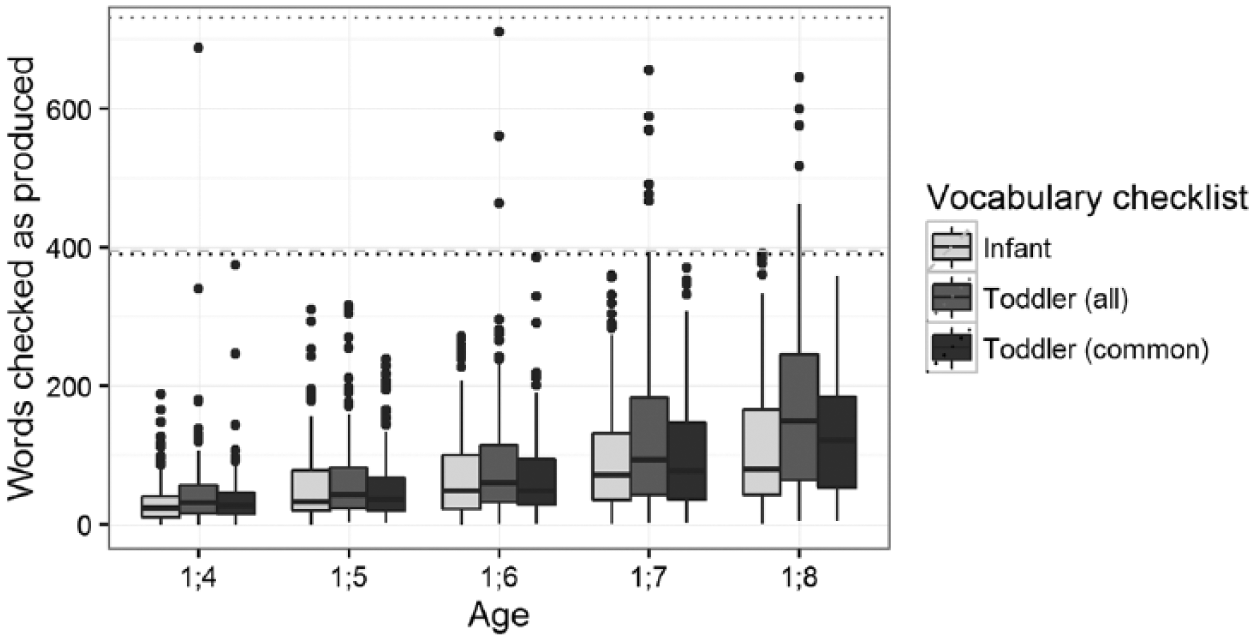
Number of words produced by children aged 1;4–1;8, by CDI form. WS data given including all words or only those common to both checklists. The horizontal lines indicate the maximum for each list.
Age of acquisition and vocabulary size of acquisition
Each word’s AoA, that is, the age when it is first produced by at least 50% of the children (Fenson et al., 1994, p. 91), was calculated based on the combined WG and WS results, apart from the WG data at age 1;8. Following Goodman et al. (2008), 36 words that never reached this threshold were excluded. AoA is widely used in the literature, even though vocabulary size has been found to be a far better predictor than age of other aspects of language development (Bates & Goodman, 1997; Devescovi et al., 2005; Fenson et al., 1994). To investigate how well AoA corresponds to development in terms of vocabulary size, a new measure was devised: vocabulary size of acquisition (VSoA), defined as the smallest vocabulary span where at least 50% of the children produce a given word. Vocabularies are grouped in spans of 20. Words reaching this threshold in the span 1–20 words are assigned a VSoA of 20, and words reaching the threshold in the span 541–560 words are assigned a VSoA of 560.
Word properties
Word class
Analyses of word class follow Caselli et al. (1995), who applied the broad lexical categories nominals, predicates and closed-class items presented in Table 1; the CDI category games & routines was analysed separately, and the category words about time was excluded because it crosses word class boundaries. For comparability with Goodman et al. (2008), frequency effects are also investigated within the CDI categories action words and descriptive words, and within common nouns, consisting of all nominals apart from sound effects, people, outside things and places to go (see Bates et al., 1994).
Broad lexical categories from Caselli et al. (1995).

Imageability and phonological neighbourhood density
The database Norwegian Words (Lind et al., 2015) offers data on a set of lexical properties, including imageability, PND and frequency, for about 1600 words. These words were selected from various assessment tools, such as the CDI, but only adult language nouns, verbs and adjectives were included in the database. Homographs were excluded, but as stated by the authors, ‘a certain level of polysemy among the words in such a database is unavoidable’ (Lind et al., 2015, p. 279). Of the 695 WG and WS words analysed here, 447 are included in Norwegian Words.
The imageability data in the database were collected by Simonsen et al. (2013), who asked participants to rate each word on a scale from 1 to 7. Due to a skewness towards high imageability, the values in Norwegian words are statistically modelled, ranging from 2.01 for the verb lyste ‘crave’ to 7.22 for paraply ‘umbrella’. Due to a strong bias towards high imageability among the CDI words, the values were exponentially transformed. PND was calculated based on the phonetically transcribed dictionary NorCompLex (Nordgård, 1998). Norwegian has a vowel length contrast, as well as two lexical pitch accents in di- and polysyllabic words. Lind et al. (2015) followed Ribu (2012) in additionally defining two words as phonological neighbours if they differ in either pitch accent or vowel length and are otherwise identical, but not if they differ in both respects. Of the 447 CDI words in Norwegian Words, five are not listed in NorCompLex. Consequently, their PND is unknown. The remaining 442 words range from zero neighbours (e.g. himmel ‘sky’) to 38 neighbours for the word ris ‘rice’.
Adult word frequency
The frequency data in Norwegian Words come from NoWaC (Guevara, 2010), a 700-million word corpus based on the no internet domain. Using the same corpus, frequencies were manually obtained for function words and phrases. Furthermore, words excluded from Norwegian Words due to polysemy where the meanings are clearly related (e.g. bad ‘bath/bathroom’) were included in this frequency search. Homonyms, proper names like ‘the child’s name’ and the CDI category words about time (see above) were still left out. Some lemmas occur more than once in the CDI checklist, such as verbs given in present tense as well as in their basic form. Here, basic forms were assigned lemma frequencies, whereas inflected forms were assigned word form frequencies. This effort added 240 words to the adult frequency list, ranging from two occurrences for gåbil ‘ride-on car’ and klappe kake ‘patty cake’ to 16.6 million occurrences of være ‘be’. The data are skewed towards low frequencies, and hence logarithmically transformed (on the formula ln(x+1)).
CDS word frequency
No Norwegian CDS frequency list is currently available, so a list was created for this study on the basis of the two available Norwegian CHILDES (MacWhinney, 2000) corpora where parents’ utterances are transcribed following an official written standard: Simonsen (1990), which contains 42,694 adult word tokens, and Garmann (Garmann, 2016; Garmann et al., in press), with 24,291 adult word tokens. 1 The children were aged 1;2–4;1 in the recordings. The Text Laboratory at the University of Oslo created lists of word form frequencies and lemma frequencies for each corpus using an automatic tagger, and the two lists were manually controlled and combined. 2 Of the 682 words in the adult frequency list, 122 did not occur in the CDS data; these were assumed to have a frequency of zero. The most frequent word was det ‘that’ with 4917 occurrences. CDS frequencies were also logarithmically transformed due to skewness towards low frequencies.
Interactions between factors
The subset for which all factors above were available numbers 437 words: 287 nominals, 139 predicates, 8 closed-class items and 3 games & routines. Due to the small number of closed-class items and games & routines, only nominals and predicates were included in analyses of correlations and joint effects between factors.
Compared to predicates, nominals are on average less frequent in both CDS (mediannom = 1.6, medianpred = 13.0, W = 13,188, p < .001) and adult language (mediannom = 8.9, medianpred = 10.7, W = 9420, p < .001), more imageable (mediannom = 788, medianpred = 262, W = 37,083, p < .001) and marginally longer, although both word classes have a median of 4 phonemes (W = 22,584, p = .02). Nominals also have fewer phonological neighbours than predicates (mediannom = 9, medianpred = 17, W = 12,646, p < .001). Table 2 gives the correlation matrix for both frequency measures, imageability, PND and word length in phonemes, revealing a high positive correlation between PND and word length in phonemes, and small or moderate correlations between all other factors, apart from between imageability and word length (see Table 2).
Correlation matrix (Kendall’s rank correlation τ) for all continuous independent variables.

p < . 001, **p < .01, *p < .05 (adjusted with Holm correction).
Statistical analyses
Statistical analyses are performed with R 3.2.3 (R Core Team, 2015). Due to skewness and ties in the data, correlation coefficients were calculated with Kendall’s rank correlation tau (τ). White tests indicated heteroscedasticity in ordinary least squares (OLS) regression models with either AoA or VSoA as the dependent variable; applying classic parametric tests on the data could hence cause loss of power, and potentially lead to erroneous conclusions (Wilcox, 2012; Wilcox & Keselman, 2012). Thus, the predictive power on AoA and VSoA from word class, frequency, imageability, PND, word length and all two-factor interactions was analysed through robust regression using the R package robust (Wang et al., 2014).
Standardised beta (β) coefficients allowing for comparisons of relative predictive power were calculated by running regression models on robust standardised values, calculated by subtracting the median from each value and dividing the difference on the median absolute deviation (Daszykowski, Kaczmarek, Vander Heyden, & Walczak, 2007), using the R package robustHD (Alfons, 2014). Analyses were carried out on all available data, counting all 695 WG and WS words for the comparison of AoA and VSoA and analysis of word class differences in AoA, 682 words for frequency effects, 447 words for imageability effects and word length, and finally 442 words for PND effects.
Results
Age of acquisition compared to vocabulary size of acquisition
There is a very high correlation between AoA and the new measure VSoA (rτ = .93, p < .001); the order of acquisition is practically identical in the two measures. However, the relationship between the measures is not completely linear, as the slope is steeper for the words acquired early and late than for the words in between (see Figure 2). This is connected to the distribution of the two factors: whereas VSoA spreads across the whole vocabulary range, half of the words have an AoA in the range 23–28 months. Since VSoA is evenly distributed across a wider scale, this measure could reveal lexical effects too small to surface in analyses based on AoA. However, due to the widespread use of AoA in the literature, the sections below will focus on AoA effects.

The relationship between AoA and VSoA (points jittered and transparent to prevent overplotting).
Word class
Games and routines (AoA median = 23 months, VSoA median = 240) are acquired earlier than nominals (AoA median = 24, VSoA median = 300), which are in turn acquired before predicates (AoA median = 25, VSoA median = 380) and closed-class items (AoA median = 28, VSoA median = 500) (see Figure 3). The differences are significant between all lexical categories, according to a pairwise Wilcoxon rank sum test with Holm correction (p = .008 between games & routines and nominals, p < .001 for all other comparisons).
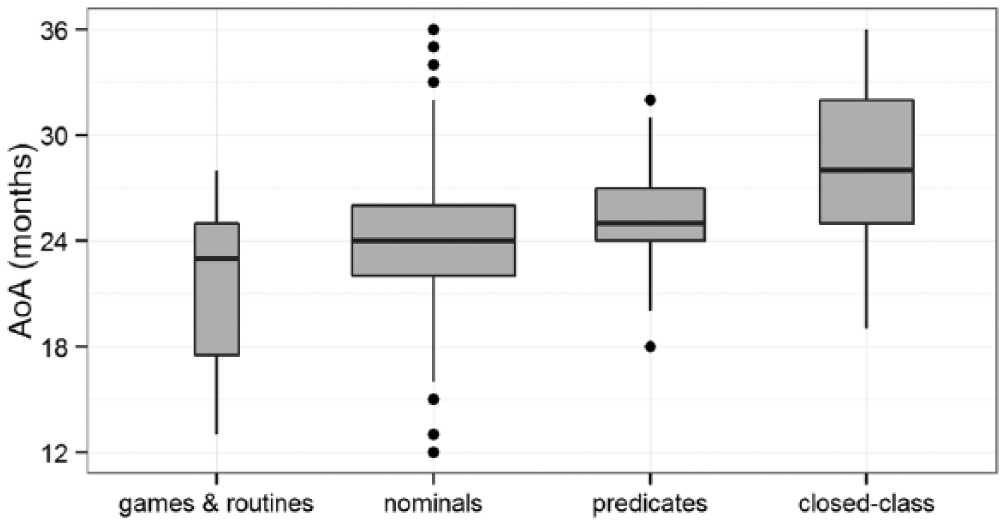
The distribution of AoA within games & routines and each of the broad lexical categories (width reflecting category size).
Frequency
There is a moderate correlation between AoA and CDS frequency within games & routines, nominals and predicates, and a small correlation within closed-class items; for adult frequency, the correlation is moderate for nominals, small for predicates and not significant for closed-class items or games & routines (see Table 3). For both frequency datasets, the correlation is higher within verbs than within adjectives, and for the adult frequency, the significant effect within nominals can be attributed to the common nouns.
Kendall’s rank correlation τ by word class for AoA and the two frequency lists.
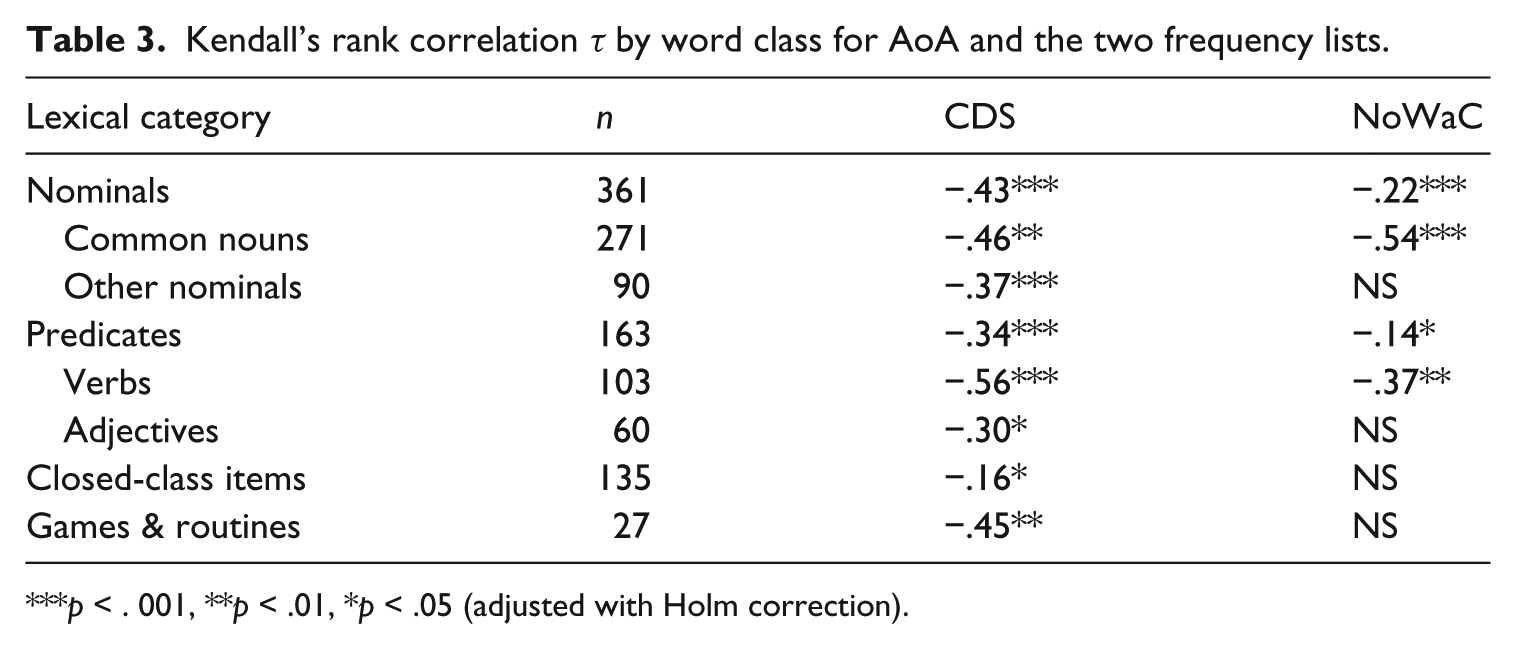
p < . 001, **p < .01, *p < .05 (adjusted with Holm correction).
The two measures were furthermore compared through robust regression of nominals, predicates and closed-class items. Analysed alone, adult frequency was a significant predictor of AoA within nominals, but not within predicates or closed-class items. CDS frequency had a significant effect within all three lexical categories, and was the only significant predictor in a regression model including both frequency lists.
Imageability
There is an moderate negative correlation between AoA and imageability (rτ = −.23, p < .001); words are acquired earlier the more imageable they are. According to a regression model including imageability and word class for the 433 nominals and predicates in Norwegian Words, there was a significant effect of imageability (β = −.28, t(430) = −3.34, p = .006), but not of word class. There was furthermore a significant effect of imageability within both nominals (β = −.24, t(291) = −3.02, p = .003) and predicates (β = −.44, t(138) = −2.32, p = .022). Notably, the relative predictive power of imageability is stronger for predicates than for nominals, according to the standardised coefficients.
Phonological neighbourhood density and word length
There is a small, negative correlation between AoA and PND (rτ = −.15, p < .001), indicating that words are generally acquired earlier the denser their phonological neighbourhood. However, words are also acquired earlier the fewer phonemes they have (rτ = .19, p < .001), and in a regression model including both variables, only word length had a significant effect on AoA. There was a close to significant PND effect on AoA within the nominals (β = −.66, t(284) = −1.93, p = .055), but contrary to Storkel (2004a), there were no effects within subgroups of high and low levels of frequency or word length, whether the words were analysed together or separated by word class.
Importantly, the new measure VSoA may be more sensitive to small effects than AoA, and in regression models with VSoA as the dependent variable, the PND effect within nominals reached significance (β = −.19, t(284) = −2.37, p = .018), with a stronger relative effect than word length (β = .12, t(284) = 1.99, p = .0473), according to the standardised coefficients.
Interaction and competition between factors
Frequency, imageability and word length in phonemes appear as robust predictors of AoA, whereas the roles of word class and PND are less clear. But which of these variables account for unique variation when combined in the same regression model? This question was investigated through robust regression models on the nominals and predicates (analysed separately and together) for which the factors were available, including all two-factor interactions.
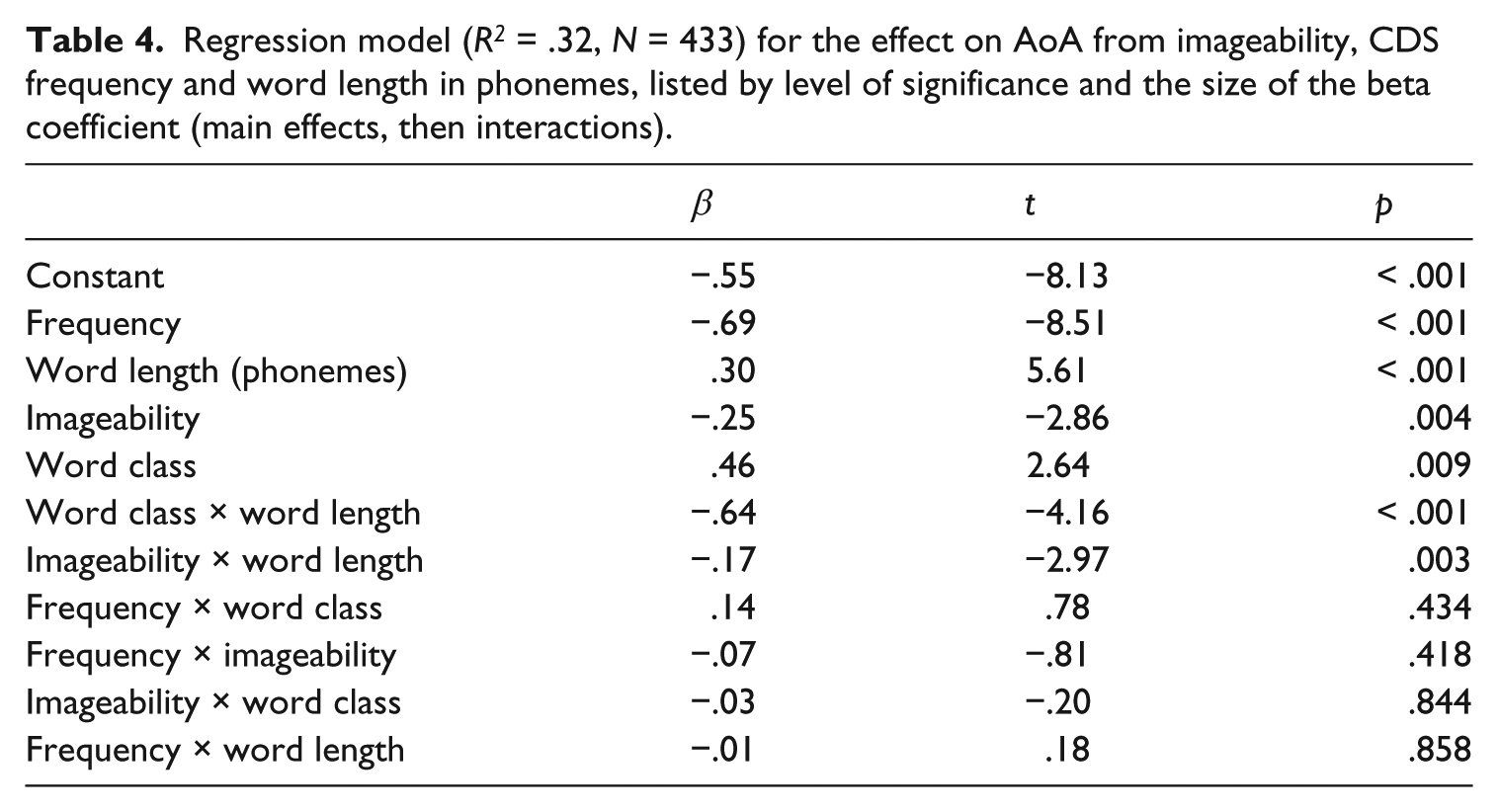
These regression models (Tables 4 and 5) could account for more of the variation in VSoA (R2 = .41) than in AoA (R2 = .31). Frequency was by far the most important predictor of both AoA (β = −.69, t(433) = −8.51, p < .001) and VSoA (β = −.62, t(433) = −9.86, p < .001). For AoA, significant interactions were found between word class and word length (short words were acquired earlier, but less so among predicates), as well as between imageability and both frequency and word length (both with an additive effect). For VSoA, two significant interactions were found: the frequency effect was smaller within predicates, and although short words were acquired before longer words, this was primarily the case among nominals.
Regression model (R2 = .32, N = 433) for the effect on AoA from imageability, CDS frequency and word length in phonemes, listed by level of significance and the size of the beta coefficient (main effects, then interactions).
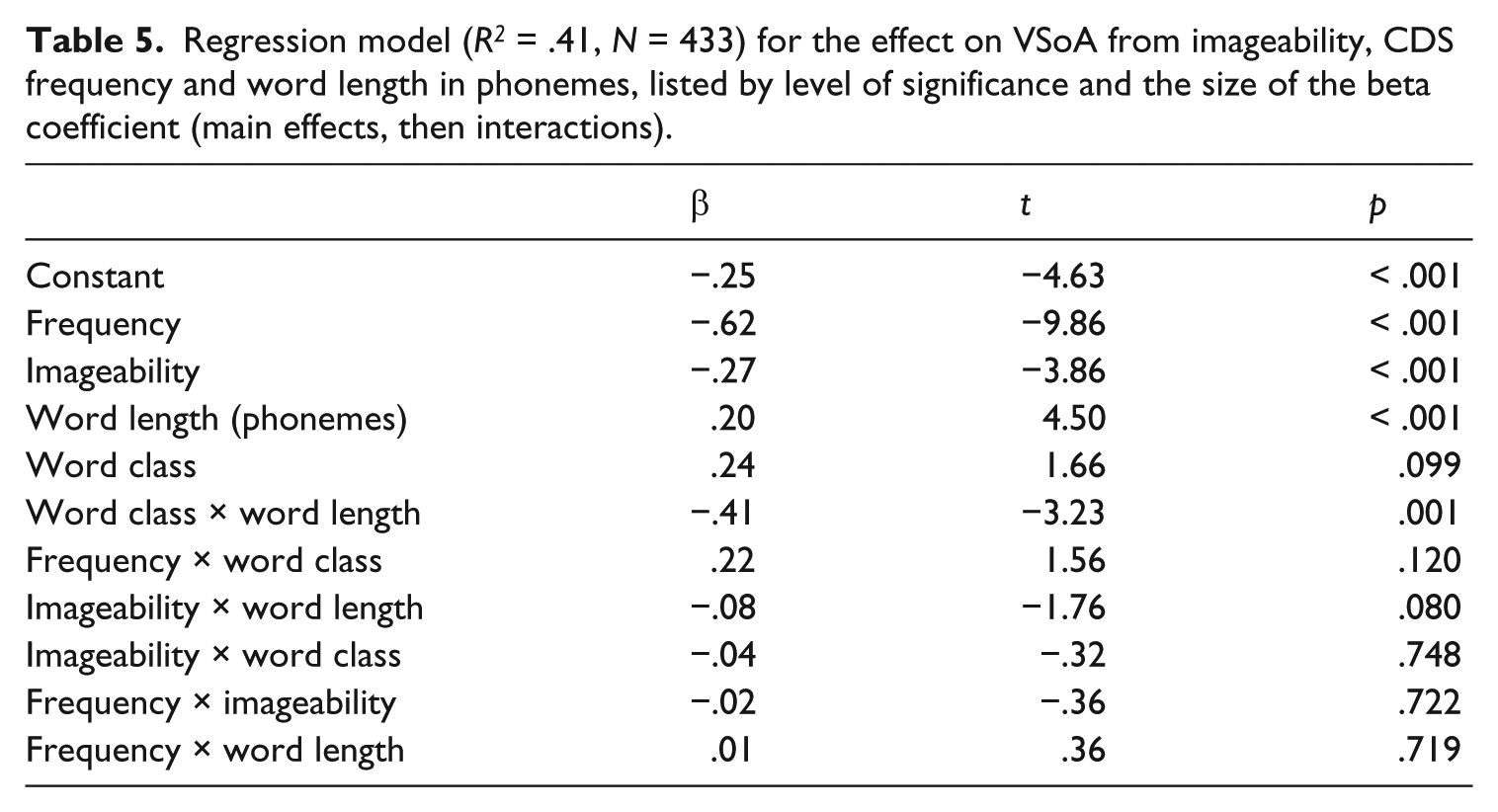
Regression model (R2 = .41, N = 433) for the effect on VSoA from imageability, CDS frequency and word length in phonemes, listed by level of significance and the size of the beta coefficient (main effects, then interactions).
The relationship between VSoA, imageability, frequency and word length is illustrated in Figure 4, with VSoA on the vertical axis and imageability on the horizontal axis. Frequency is represented by shade of grey (divided in three groups for the purpose of readability: the lowest 25%, mid 50% and highest 25%), and word length is represented by the size of the circle or triangle/diamond (also divided in three groups for readability). The three regression lines in Figure 4 represent the predicted imageability effect given a median word length and frequencies at the first, second (i.e. the median) and third quartile.
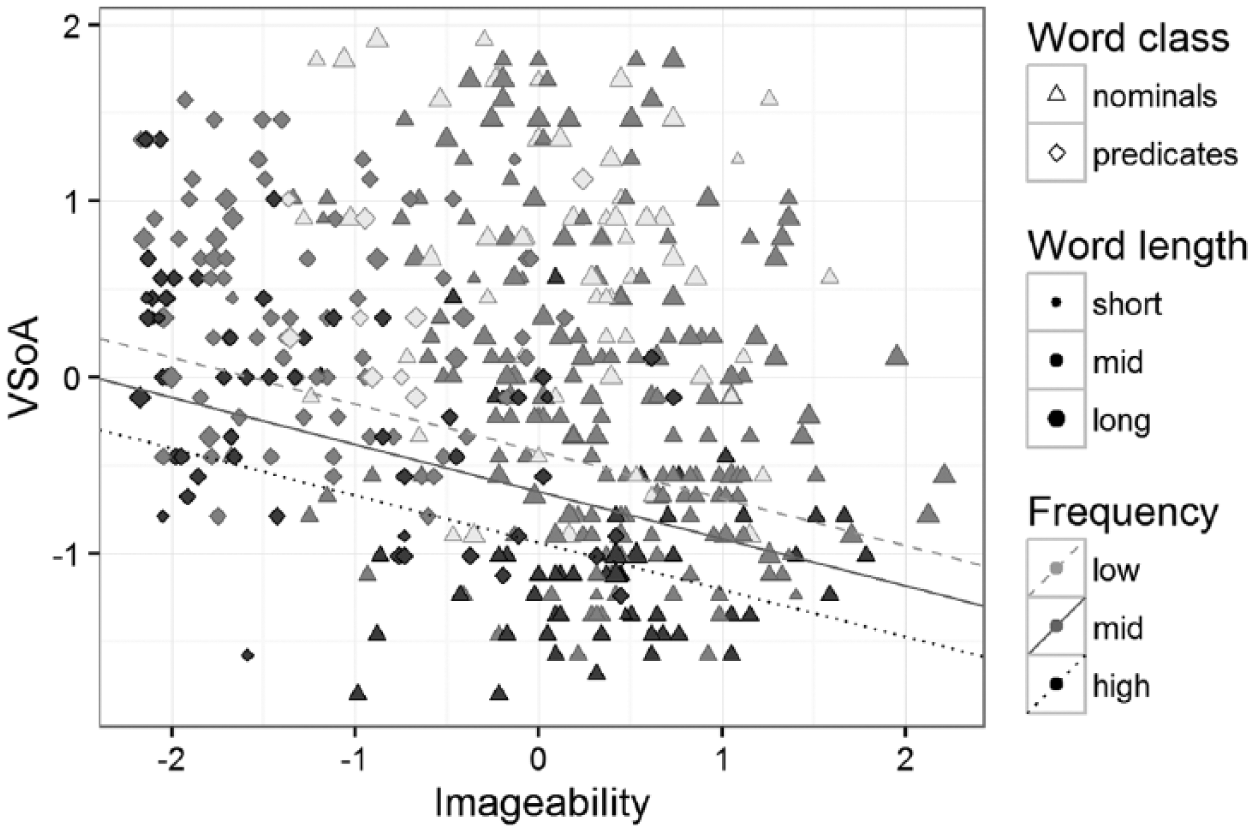
Nominals (triangles) and predicates (diamonds) by imageability and VSoA (standardized values, jittered to prevent overplotting), with frequency by shade of grey (denoting the lowest 25%, mid 50% and highest 25%), and word length by size (denoting the shortest 25%, mid 50% and longest 25%). Regression lines for imageability given frequencies at the first (low) and third quartile (high), assuming a median word length (four phonemes).
According to the models, frequency has a larger influence on lexical development than imageability does. This is apparent for the 17 words with a VSoA below 100: these are spread across the imageability scale, but most of them are highly frequent. For instance, the first acquired verb, se ‘look’, is relatively low on imageability (455 on the exponential scale), but is still the first predicate (AoA = 18, VSoA = 60). These early words are also short; only one is in the longest half of the dataset, and this word, banan ‘banana’, is only one phoneme longer than the median. The late words are typically low on frequency; the only high-frequency words not acquired by a vocabulary size over 500 are park ‘park/short-time day care’, tenke ‘think’, lang ‘long’ and rar ‘strange’. Apart from one word, park (AoA = 34, VSoA = 660), these are all low on imageability.
Discussion
The first research question addressed in the present study was how AoA compares to a measure of lexical development based on vocabulary size rather than age. The new measure VSoA was devised based on children’s vocabulary size, and the two measures were highly correlated; the order of the CDI words is practically the same. There are however differences in the distributions: half of the words have an AoA between 2;3 and 2;8, indicating a vocabulary spurt among the words in the CDI checklist. Since VSoA builds on vocabulary size, not age, this spurt is not evident in the words’ VSoA – rather the words are evenly distributed according to this measure. VSoA may as a result be more sensitive to lexical effects than AoA, and this may be why the only regression model that revealed a significant effect of PND when word length was controlled for, was a model of nominals using VSoA as the dependent variable. Also, for the final regression models in Tables 4 and 5, the factors investigated here could account for more of the variation in VSoA than in AoA.
The accumulation of AoA indicates that for the words investigated here, there is a spurt in the beginning of the second year of life. Notably, the timing of this spurt coincides with an acceleration in vocabulary growth and a sharp acceleration in grammatical complexity observed in the Norwegian CDI norms (Simonsen et al., 2014, pp. 15–16), indicating that lexicon and grammar are indeed closely connected, as demonstrated by Bates and Goodman (1997).
The second research question concerned how well word class, frequency, imageability and PND could account for lexical development. Word length in phonemes was added to the equation to control for correlations with the other factors, particularly PND. Regarding word class, games & routines are generally acquired earlier than nominals, followed by predicates, and finally closed-class items, in accordance with studies of the lexical composition of children acquiring English (Bates et al., 1994), Italian (Caselli et al., 1995) and Danish (Wehberg et al., 2007), and with a large body of research reporting nouns to be acquired before verbs. Word class was, however, not a significant predictor of AoA when imageability was added to the equation: in a regression model of the 293 nominals and 140 predicates with available imageability data, only imageability had a significant effect. Imageability thus appears to account for the early acquisition of Norwegian nouns and verbs, in accordance with the findings of Ma et al. (2009) for English and Mandarin.
Several accounts have been proposed to explain the bias towards nouns in early vocabularies. One that tallies with the findings here is the natural partitions hypothesis proposed by Gentner (1982): nouns are acquired early because they typically denote concrete objects that are stable through time, allowing for a transparent mapping between meanings and what we perceive as entities in the real world, whereas verbs are generally hard to grasp because they typically denote transient and abstract events. The same perceptual-conceptual properties may underlie imageability: Simonsen et al. (2013) argue that the observed word class difference in imageability relates to conceptual dependence; according to Langacker (1987), nouns are prototypically objects, and thus conceptually autonomous and self-contained, whereas verbs, prototypically events, cannot be conceptualised independently of the participants taking part in them. McDonough et al. (2011) suggest that highly imageable words (nouns as well as verbs) are characterised by referents that are easily perceived as separate and distinct units. However, note that the imageability effects and word class differences documented here could be an attribute of the communicative situation these words are used in, rather than a result of how words are conceptualised in the mental lexicon (Gillette, Gleitman, Gleitman, & Lederer, 1999; Tomasello, 2005).
From these accounts, we would expect differences within nouns and verbs too. Within verbs, words denoting distinct events should be acquired before those denoting abstract processes. Support for this prediction is obtained in the present data: the earliest predicates tend to denote concrete actions such as drikke ‘drink’, while tenke ‘think’ is among the latest words. Notably, drikke is the third most imageable predicate, whereas tenke is the thirteenth least imageable. In accordance with these examples and the findings of McDonough et al. (2011), imageability accounts for variation not only overall, but also within nominals and predicates.
As illustrated in Figure 4, the very first words are not highly imageable; the first predicate, se ‘see/look/watch’ (AoA = 18, VSoA = 60), is remarkably low on imageability. Interestingly, se appears as one of the first 50 words in both Danish (Wehberg et al., 2007) and Norwegian (Garmann et al., in press), while no translation equivalent is among the first 50 English or Italian words (Caselli et al., 1995). The reason could be differences in form–meaning mapping: the semantic area covered by se in these two Scandinavian languages is divided between multiple verbs in English (see, look, watch) and Italian (vedere, guardare). Since se has a more general meaning, it may also be more frequent in CDS than each of the English and Italian verbs (cf. Bybee, 2010), and thus easier to acquire. Its usage may also be easier to grasp.
Concerning frequency, the present results are in accordance with Goodman et al. (2008): frequency in written adult language was outperformed by frequency in CDS, which correlated with AoA within all word classes, even games & routines with only 27 items. However, the adult frequency list used here performed better: whereas Goodman et al. (2008) only found an moderate correlation within common nouns, the present data yielded a strong correlation within common nouns and a moderate correlation within verbs. A possible explanation is that the source of the adult frequency list, NoWaC (Guevara, 2010), is more similar to oral language than the Kučera–Francis norms (Francis & Kučera, 1967), as it consists of internet texts, including blogs and forum discussions. Also, NoWaC and the Norwegian CDI norms are contemporary: the CDI norms were gathered in the winter of 2008/2009, and the data in NoWaC were downloaded from the internet one year later.
The finding that CDS frequency outperformed adult frequency is in accordance with Goodman et al. (2008), but still remarkable: the Norwegian CDS frequency list is after all based on only two corpora with 66,985 word types altogether, whereas the list used by Goodman et al. (2008) was based on 28 corpora and 3.8 million word tokens. The cohering results are thus good news for investigators of other languages with relatively few available data from which to generate a frequency list. The success of the CDS frequency list is further underlined by the analyses of combined effects: the relative effect of CDS surpassed that of imageability and word length within both nominals and predicates. Furthermore, the same frequency data have proved to be a significant predictor of lexical skills in mono- and bilingual preschoolers (Hansen, Simonsen, Łuniewska, & Haman, in press).
One word, park ‘park/short-time day care’, stood out as acquired late in spite of a high frequency and an average imageability. The cause of this inconsistency may be a change in the Norwegian welfare system, as 15 of the 18 occurrences of park in CDS are from Simonsen (1990): in the 1980s, when these data were collected, many children attended park, a day care facility open for a few hours a day, usually outdoors. Currently, the majority of children attend barnehage, a full day care facility, and park first and foremost denotes ‘park’.
Concerning phonology, the fewer the phonemes, the earlier the words were acquired. But PND was not a robust predictor of lexical development, with a significant effect only on VSoA within nominals. When imageability and frequency were included, there was no PND effect. Why was PND not a significant predictor in this study, in contrast to the findings of Storkel (2004a)? The reason could lie with the Norwegian PND norms: using the same norms, Ribu (2012) investigated the relative effects of imageability and PND on lexical decision and picture naming results from aphasia patients and healthy ageing adults. She found imageability to facilitate lexical processing in both tasks, but no effect of PND.
The lack of PND effects could be caused by the data used to calculate PND: the transcribed dictionary NorCompLex (Nordgård, 1998) was used to search for phonological neighbours for each word in Norwegian Words. All words that fulfilled the neighbourhood criteria counted towards a word’s neighbourhood, although some of these may be quite unusual. In the literature, two measures have been used to give less weight to such words: first, Storkel (2004a, p. 205) applied familiarity ratings in the calculation of phonological neighbourhood density in order to ‘more closely approximate a child lexicon’: only words with a familiarity rating of 6 or more on a seven-point scale counted as phonological neighbours. Second, Luce and Pisoni (1998) and Vitevitch and Luce (1999) computed frequency-weighted neighbourhood densities by summing the (logarithmically transformed) frequencies for each word’s neighbours.
A revision of the Norwegian PND measure based on the first approach would not be feasible, as familiarity ratings are not available for Norwegian. Imageability or subjective age of acquisition could perhaps be used instead, but these properties are only available for the 1650 words in Norwegian Words, which is far too few for the purpose. The second approach might be feasible: the NoWaC token frequency list with over 6 million words constitutes a good starting point for automatised queries for words listed as neighbours in the lexical database.
Limitations
The study is limited to words that are acquired early in life – for words acquired later, other methods of data collection must be employed. Imageability ratings are available for a majority of the CDI nominals and predicates, but not for the social words or function words. Investigating whether imageability may account for the acquisition of these words was thus not possible with the current dataset.
Another issue that adds a caveat to the findings above is that the factors investigated here may all affect processing in adults (e.g. Bates, Burani, D’Amico, & Barca, 2001). Since the study is based on parental reports, it cannot be precluded that the reported effects are to some extent related to how parents store and process their children’s utterances. For instance, words with a high frequency in CDS may be more salient to parents, and thus easier to remember, and children’s productions that are heavily influenced by individual phonological preferences may be easier for parents to understand if the words are highly imageable.
Conclusion
In summary, the answer to the question ‘What makes a word easy to acquire?’ is compositional: CDS frequency clearly plays an important role, so does imageability and word length. Word class membership does not seem to be essential, as imageability seems to account for the dominance of nominals over predicates in Norwegian children’s early words. However, consistent with previous research, social words were acquired before nominals, nominals before predicates, and predicates before function words. Thus, as expected within a usage-based view on language acquisition, it appears that a word’s form, function and usage pattern is essential when children expand their early vocabularies. Also, no significant effect was found for PND, apart from in an analysis of VSoA among nominals including only PND and word length as possible predictors; the PND measure may however need a revision. Notably, although the order of acquisition within the two measures was close to identical, the new measure VSoA appeared to be more sensitive to lexical effects than AoA.
Footnotes
Acknowledgements
I am grateful to Hanne Gram Simonsen, Kristian Emil Kristoffersen for access to the Norwegian CDI norms, and to Nina Gram Garmann for access to the corpus Garmann-Norwegian. I thank Dorthe Bleses, Hanne Gram Simonsen, Nina Gram Garmann and two anonymous reviewers for helpful comments on the manuscript, and Elisabeth Holm and participants at several conferences, especially GURT 2014, for useful discussions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the Research Council of Norway through its Centres of Excellence funding scheme, project number 223265.