
Abstract
Markov chain Monte Carlo (MCMC) methods enable a fully Bayesian approach to parameter estimation of item response models. In this simulation study, the authors compared the recovery of graded response model parameters using marginal maximum likelihood (MML) and Gibbs sampling (MCMC) under various latent trait distributions, test lengths, and sample sizes. Sample size and test length explained the largest amount of variance in item and person parameter estimates, respectively. There was little difference in item parameter recovery between MML and MCMC in samples with 300 or more respondents. MCMC recovered some item threshold parameters better in samples with 75 or 150 respondents. Bias in threshold parameter estimates depended on the generating value and the type of threshold. Person parameters were comparable between MCMC and MML/expected a posteriori for all test lengths.
Keywords
Accurate recovery of model parameters from response data is a central problem in item response theory (IRT). Marginal maximum likelihood (MML; Bock & Aitkin, 1981; Bock & Lieberman, 1970) is a popular parameter estimation technique in IRT. The marginal probability of a response vector

where p(θ) is the (assumed) distribution of the latent trait in the population, typically θ˜N(0, 1). The marginal probability of an N×L response matrix

This marginal likelihood is maximized to obtain item parameter estimates. In turn, these item parameter estimates can be used to estimate person parameters using maximum likelihood (ML), expected a posteriori (EAP), or maximum a posteriori (MAP). EAP and MAP are essentially Bayesian methods and estimate θ based on the posterior distribution p(θ|
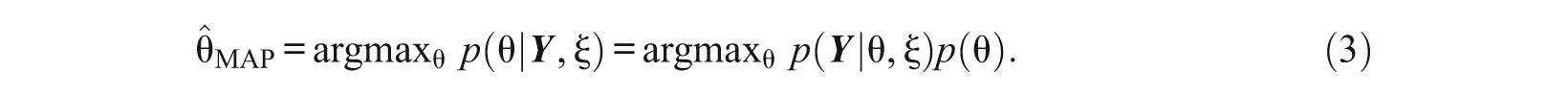
Bayesian Parameter Estimation
A natural extension of EAP and MAP person parameter estimation is to use a fully Bayesian approach for all parameters. Contrary to the classical approach, in Bayesian statistics all parameters are treated as probability distributions. These distributions directly reflect the uncertainty in the parameter estimates. Bayesian parameter estimation is based on the posterior distribution p(θ, ξ|Y) of the model parameters θ, ξ given the data
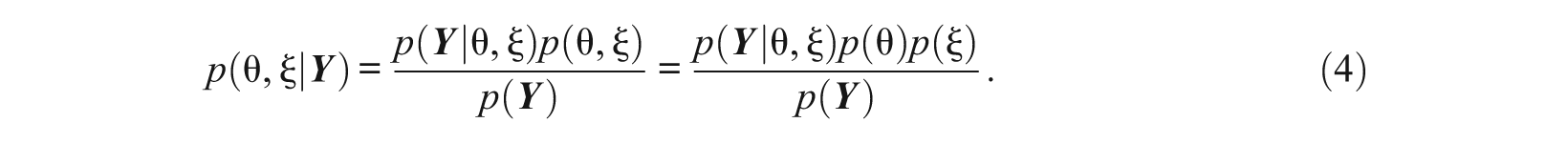
Here, assume that the joint prior p(θ, ξ) factors as p(θ)p(ξ) due to independence of person and item priors. The mean of the posterior distribution (EAP) is usually taken as a point estimate of the parameter. The posterior standard deviation is a measure of the standard error of estimation.
Lord (1986) recommended Bayesian parameter estimation because it prevents parameter drift. Swaminathan and Gifford (1982) stated that it allows parameter estimation from extreme response patterns and improves accuracy with smaller samples. A Bayesian framework also allows a unified treatment of complex modeling issues such as missing data and multiple raters (Patz & Junker, 1999a), multilevel structures (Fox & Glas, 2001; Janssen, Tuerlinckx, Meulders, & de Boeck, 2000), multidimensional models (Béguin & Glas, 2001), and testlet structures (Bradlow, Wainer, & Wang, 1999). Moreover, extensive information about parameters can be obtained through various summary statistics of the posterior distributions, which can be computed during parameter estimation (see, for example, Fox, 2010). Prerequisite to using Bayesian estimation to the fullest extent is that the point estimates derived from posterior distributions are at least as accurate as point estimates from MML.
In practice, the joint posteriors of complex models are analytically intractable, and Markov chain Monte Carlo (MCMC) methods (Hastings, 1970; Metropolis, Rosenbluth, Rosenbluth, Teller, & Teller, 1953; Metropolis & Ulam, 1949) are used to simulate draws from the posterior. In particular, Gibbs sampling (Gelfand & Smith, 1990; Geman & Geman, 1984) uses conditional posterior distributions to obtain a chain of draws of the model parameters ω = (ω1, …, ωP). The algorithm starts with initial values
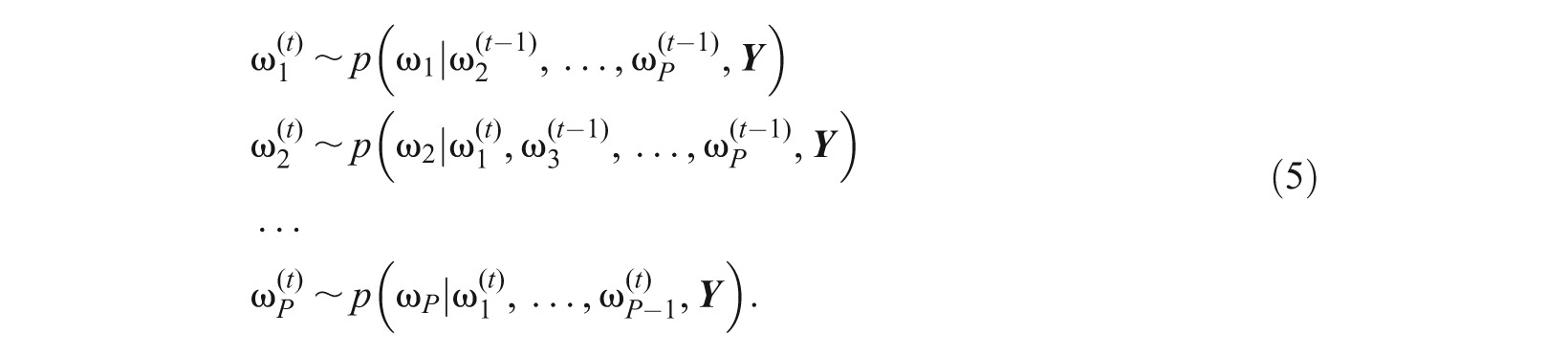
The distribution of ω(t) converges to the posterior distribution p(ω|

Albert (1992) used Gibbs sampling to estimate normal-ogive two-parameter models. Patz and Junker (1999a, 1999b) presented (closely related) Metropolis-within-Gibbs algorithms to estimate two-parameter logistic (2PL) and generalized partial credit model parameters.
Several studies have compared the performance of MML and MCMC estimation in dichotomous models (e.g., Albert, 1992; Baker, 1998; S.-H. Kim, 2001; S.-H. Kim & Cohen, 1999). Comparing an implementation of Albert’s (1992) Gibbs sampling scheme with BILOG, Baker (1998) concluded that the estimates were similar except in case of shorter tests and smaller samples where the BILOG estimates were superior. BILOG was also better at estimating item discrimination parameters. S.-H. Kim and Cohen (1999) compared the performance of marginalized Bayesian and Gibbs sampling for the 2PL model and found that marginalized Bayesian sampling performed better than the Gibbs sampler. It must be noted that S.-H. Kim and Cohen (1999) used very vague priors for the difficulty parameter (SD of 10,000), which may have affected the parameter estimates. S.-H. Kim (2001) compared the estimates from MML (and other methods) and Gibbs sampling for the Rasch model, and found no difference between the item parameter estimates, apart from the longer estimation time for MCMC. Because the true parameters were not known in this study, it is difficult to conclude which method was better at estimating person ability parameters.
S.-H. Kim and Cohen (1999), Kim (2001), and S.-H. Baker and S.-H. Kim (2004) suggested that Gibbs sampling and MCMC techniques may perform better with more complex models, for instance, polytomous item response models. Wollack, Bolt, Cohen, and Lee (2002) compared MML and MCMC parameter estimation for the nominal response model. They found that the two methods are similarly accurate in samples of 300 and 500 persons with test lengths of 10, 20, and 30 items. De la Torre, Stark, and Chernyshenko (2006) concluded that MML and MCMC parameter estimates in the generalized graded unfolding model (GGUM) were comparable; standard errors were more accurately recovered by MCMC. Roberts and Thompson (2011) found that MCMC had an advantage over MML for GGUM items with less than four response categories.
Purpose of the Present Study
The purpose of the present study was to compare the accuracy of MML and MCMC in recovering item and person parameters in Samejima’s (1969) graded response model (GRM) under varying conditions of latent trait distribution, test length, and sample size. In particular, the present study considered the recovery of item and person parameters with smaller test lengths and sample sizes where Bayesian estimation may be advantageous. This is particularly important because GRMs are commonly used in measurement of attitudes, where subscales with as few as five items administered to fewer than 300 respondents are not uncommon. Practitioners could benefit from recommendations regarding minimum sample size and test length required for adequate item and person parameter recovery in GRMs. The present study primarily investigated (a) the accuracy of MCMC in recovering item and person parameters compared with MML, (b) the factors which contribute the most to accurate parameter recovery, and (c) the minimal conditions required for adequate parameter recovery.
The secondary purpose was to test the effectiveness of OpenBUGS (Lunn, Spiegelhalter, Thomas, & Best, 2009), a general purpose Gibbs sampling software that allows practitioners to use MCMC estimation without (extensive) programming. J.-S. Kim and Bolt (2007) presented an introduction to fitting item response models using OpenBUGS. Curtis (2010) provided OpenBUGS codes for common item response models and described how these codes can be adapted for more complex models, in particular longitudinal designs. OpenBUGS provides a flexible way to fit a wide variety of item response models, in contrast to software such as MULTILOG (Thissen, Chen, & Bock, 2003), which can only be used for a fixed set of models. However, before practitioners can confidently use OpenBUGS for more complex models, they need to know its accuracy in parameter recovery and the factors that influence the recovery the most.
Previous Studies on MML Estimation of GRMs
Whereas the nominal response model (NRM) can be used to analyze unordered categorical responses, Samejima’s (1969) GRM is used for ordered categorical data, for example, Likert-type scales. An item i with K categories is modeled by a discrimination parameter a i and K − 1 threshold parameters bi1, …, bi(K − 1). The probability that person n with latent trait parameter θ n will select category 1 ≤k≤K in response to item i is given by
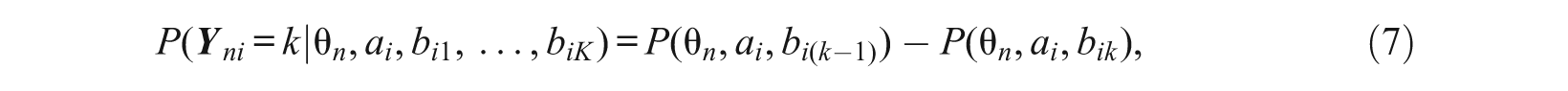
where bi0 = − ∞, b iK = ∞, and with b i equal to bi(K − 1) or b ik ,
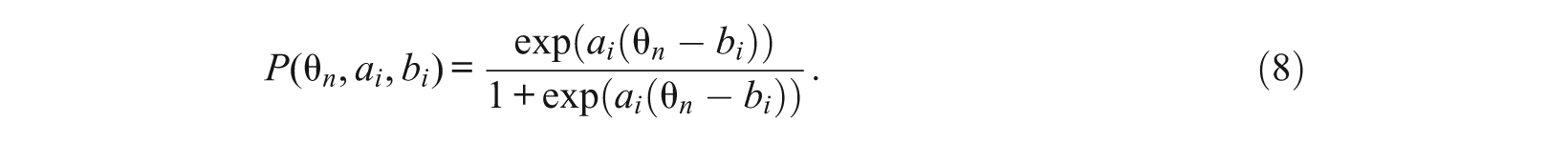
Reise and Yu (1990), Ankenmann and Stone (1992), DeMars (2003), and Lautenschlager, Meade, and Kim (2006) investigated the accuracy of MML parameter recovery for the GRM for various latent trait distributions, test lengths, and sample sizes.
Reise and Yu (1990) studied parameter recovery for three different types of tests based on their item discrimination parameter values. Based on factor loadings, they selected a poor test with discrimination parameters between 0.44 and 0.75, an average test with discrimination parameters between 0.58 and 0.98, and a good test with discrimination parameters between 0.75 and 1.33. Each test had a fixed length of 25 items with five response categories each. For the most discriminating test, the average root mean square errors (RMSEs) were 0.08, 0.16, and 0.35 for item discrimination, item difficulty, and person parameters, respectively. Recovery was better at larger sample sizes (500 or more vs. 250) and slightly better for samples in which the latent trait was uniformly distributed rather than normally distributed or skewed.
Ankenmann and Stone (1992) extended the study of Reise and Yu (1990) by including test length as a design factor. Longer tests improved person parameter estimation with average RMSEs of approximately 0.5, 0.4, and 0.3 for 5, 10, and 20 items, respectively. Test length did not affect item parameter estimation. Lautenschlager et al. (2006) reported similar results. DeMars (2003) examined (among other issues) MULTILOG’s and PARSCALE’s recovery of GRM parameters. For sample sizes of 250 and 500, she reported average RMSEs for item discrimination as 0.14 and 0.10 and for category threshold parameters as 0.26 and 0.17. In addition, DeMars analyzed the variance in the logarithm of the absolute difference between generating parameters and parameter estimates accounted for by software package, latent trait distribution, and sample size. The latter accounted for 3% of the variance with other factors accounting for less than 1%. In all studies, the second and third thresholds, b2 and b3, were recovered slightly better than the first and last thresholds, b1 and b4. Sample size had an impact on item parameter recovery but little effect on person parameter estimates. This can be explained by the fact that in the MML framework, parameters are estimated for each examinee separately after item calibration. However, in a fully Bayesian framework, person parameters are estimated jointly with item parameters, and therefore, sample size could possibly affect person parameter estimation in MCMC.
Reise and Yu (1990) and Ankenmann and Stone (1992) recommended a minimum sample size of 500 to accurately estimate GRM parameters and samples as large as 1,000 or 2,000 in situations where structural parameter recovery is crucial; Lautenschlager et al. (2006) concurred, recommending against using fewer than five items and 300 respondents. Unfortunately, none of these studies presented a full analysis of variance to quantify the contribution of different factors toward the accuracy of GRM parameter estimation.
Method
The primary purpose of this study was to compare the performance of MML versus MCMC in parameter recovery. Therefore, the main factor in the study design was estimation method (MML, MCMC). Although the authors primarily compare MML/EAP with MCMC (EAP) person parameter estimates, they also included MML/MAP estimates. Based on previous studies, they varied latent trait distribution (normal, skew-normal, and uniform), test length (5, 10, 15, and 20 items), and sample size (75, 150, 300, 500, and 1,000 persons). The specific levels of the independent variables were selected to facilitate comparison with other studies. The independent variables were fully crossed resulting in 120 conditions (2 estimation methods×3 latent trait distributions×4 test lengths×5 sample sizes).
Data Simulation
For each of the 60 combinations of latent trait distribution, test length, and sample size, 100 data sets were generated. Person parameters were simulated from (a) a unit normal distribution N(0, 1), (b) a uniform distribution on the interval (−3, 3), and (c) a skew-normal distribution with skewness = 1.25 and kurtosis = 1.5. These different distributions allowed the investigation of the impact of a person parameter prior that may be “mismatched” with the population latent trait distribution. Random variates θ′ from the skew-normal distribution were generated by transforming unit normal variates θ according to Fleishman’s (1978) power transformation method; specifically, θ′ = a + bθ + cθ2 + dθ3 with a = −0.282, b = 1.037, c = 0.282, and d = −0.042 (see Fan, Felsovalyi, Sivo, & Keenan, 2003). A new set of person parameters was simulated for each replication.
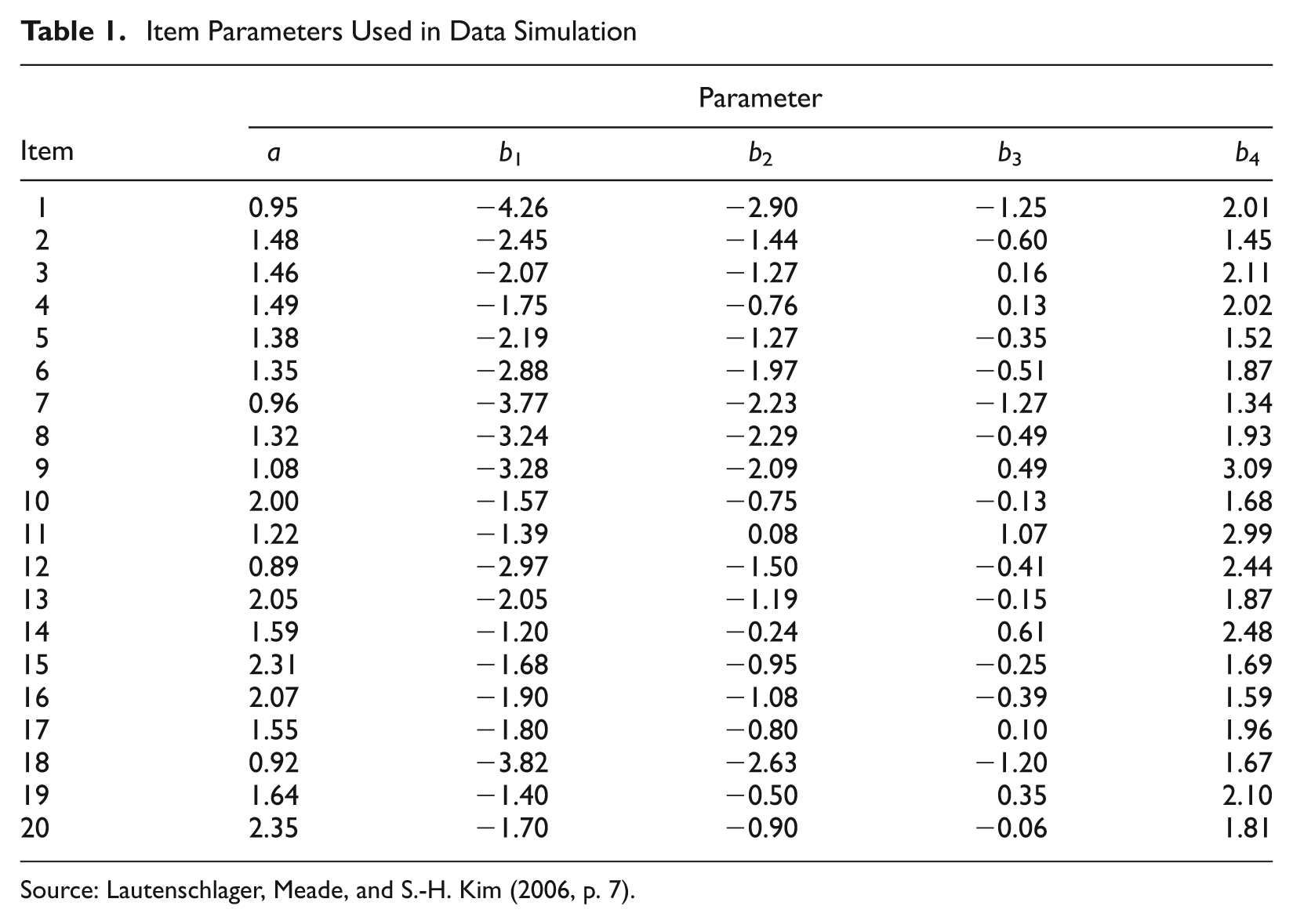
Common item parameters between replications help to minimize the effects of random error on parameter estimates. Therefore, response data were generated using item parameters for 20 items measured on a 5-point scale (see Table 1). These items have been calibrated from the Minnesota Satisfaction Questionnaire and were used by Lautenschlager et al. (2006). Using these item parameters ensured simulation of realistic items as advocated by Harwell, Stone, Hsu, and Kirisci (1996). A simulated test of length L contained the first L items.
Item Parameters Used in Data Simulation
Parameter Estimation
MULTILOG was used to obtain MML item parameter estimates and MML/MAP person parameter estimates. The default starting values for item parameters were used (a = 1, b1 = −1.39, b2 = −0.405, b3 = 0.405, and b4 = 1.39). Based on the MML item parameter estimates, EAP person estimates (with unit normal prior) were computed using the authors’ Mathematica (Wolfram, 2011) code. MCMC model parameters were estimated using OpenBUGS. Following recommendations by Albert and Chib (1993) and Albert and Johnson (1999), a log-normal prior was used for the discrimination parameters, that is,
Initial values were provided for item parameters (a = 1, b1 = −2, b2 = −1, b3 = 1, and b4 = 2), whereas OpenBUGS generated initial values for person parameters. The first 1,000 iterations were allowed to burn in to reduce the effect of these initial values on the estimates. A further 10,000 iterations were used to estimate the parameters. To confirm the adequacy of this setup (which was also used by Wollack et al., 2002), the authors inspected one data set for each condition for nonconvergence. Specifically, two chains were run, and the multivariate potential scale reduction factor (Brooks & Gelman, 1998), estimated potential scale reduction (Gelman, 1996), and half-width test (Heidelberger & Welch, 1983) were computed using BOA (Smith, 2007). The 0.975th quantiles of both scale reduction factors were less than 1.2 for all conditions and all conditions passed the half-width test. This is commonly taken as an indication that the samples are drawn from the stationary distribution (see, for example, Smith, 2007). However, convergence assessment of Markov chains remains a difficult subject (see, for example, Sinharay, 2004). When analyzing a single data set, it may be prudent to allow more iterations to burn in.
MML and MCMC parameter estimates were equated to the metric of the generating parameters using the test characteristic curve method (Baker, 1992; Stocking & Lord, 1983) programmed by the authors. The accuracy of parameter recovery was then evaluated using RMSE, conditional bias, and correlations. With λ representing either discrimination a or one of the thresholds b1, …, b4, these were computed for each combination E×D×N×L×R (estimation method×distribution×sample size×test length×replication) as
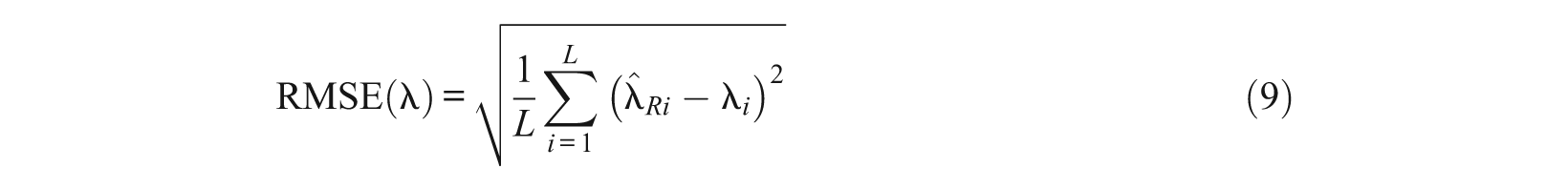
and
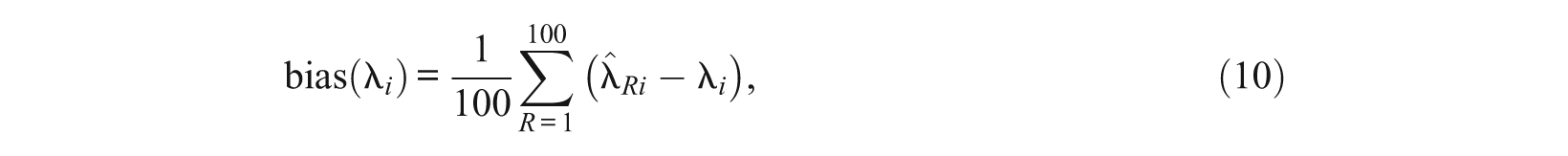
where
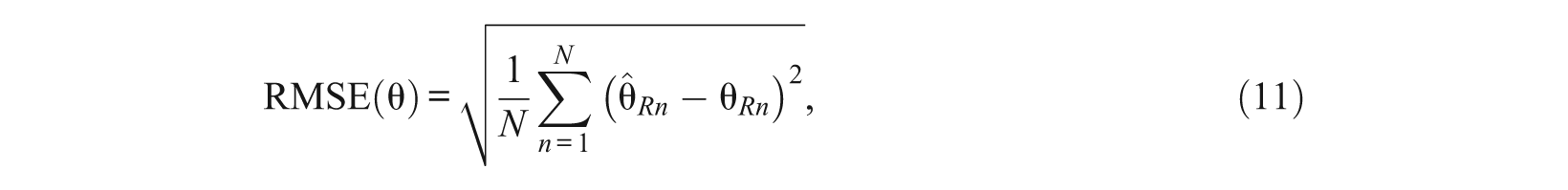
where
Fractional factorial analyses of variance of RMSEs and correlations were conducted by estimation method, latent trait distribution, sample size, and test length. Because the aim was to identify those conditions that contribute the most toward RMSE and correlations, the authors refrained from interpreting p-values and considered only η2 effect sizes. They performed orthogonal planned contrasts to study differences in effect sizes between the levels of each factor. Because the authors deemed interaction effects between three or more factors difficult to interpret, only the four main effects and their six two-way interactions were considered.
Results
Tables 2 and 4 show the contribution of the design factors to the variance in RMSE and correlations of parameter estimates. Following Cohen (1988), effect sizes less than 1% were characterized as small, around 6% were characterized as medium, and greater than 14% were characterized as large were characterized. RMSE of item parameters was affected much more by sample size (η2 > 35%) than by test length (η2 < 1.65%). Similarly, RMSE of person parameters was affected by test length (η2 = 86.30%) but not by sample size (η2 = 0.32%). The interaction effect between sample size and test length was small for discrimination parameters (η2 = 1.99%) and negligible for other parameters. Therefore, the authors present their results more succinctly by reporting RMSE averaged over test length for item parameters and over sample size for person parameters (see Tables 3 and 9). Test length had an effect on the correlation of discrimination, fourth threshold, and person parameters, so the authors report correlation by test length (see Tables 5-7). In the following sections, they sequentially discuss item parameter recovery (including the impact of sample size ratio [SSR]), person parameter recovery, conditional bias, and computational time.
Effect Sizes (η2) of the Simulation Design Factors Explaining the Variabilities in RMSE of Parameter Estimates in Percentages

Note: RMSE = root mean square error.
Mean RMSE in Item Parameter Estimates Under Different Conditions

Note: RMSE = root mean square error; MML = marginal maximum likelihood; MCMC = Markov chain Monte Carlo. RMSE averaged over items. Latent trait distribution: N = normal N(0, 1); S = skew-normal: skewness = 1.25, kurtosis = 1.5; U = uniform U(−3, 3). Absolute differences larger than .1 are boldfaced.
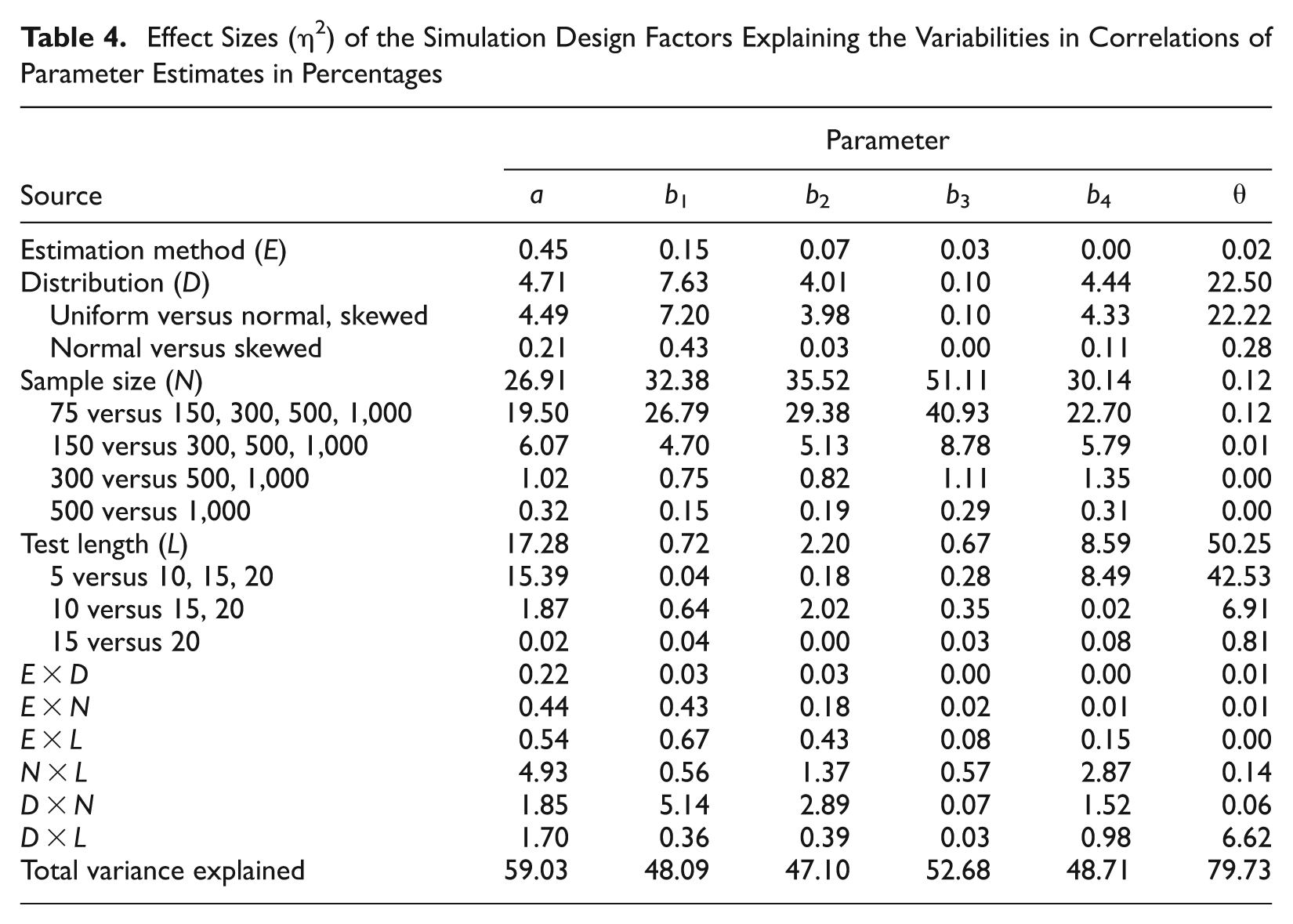
Effect Sizes (η2) of the Simulation Design Factors Explaining the Variabilities in Correlations of Parameter Estimates in Percentages
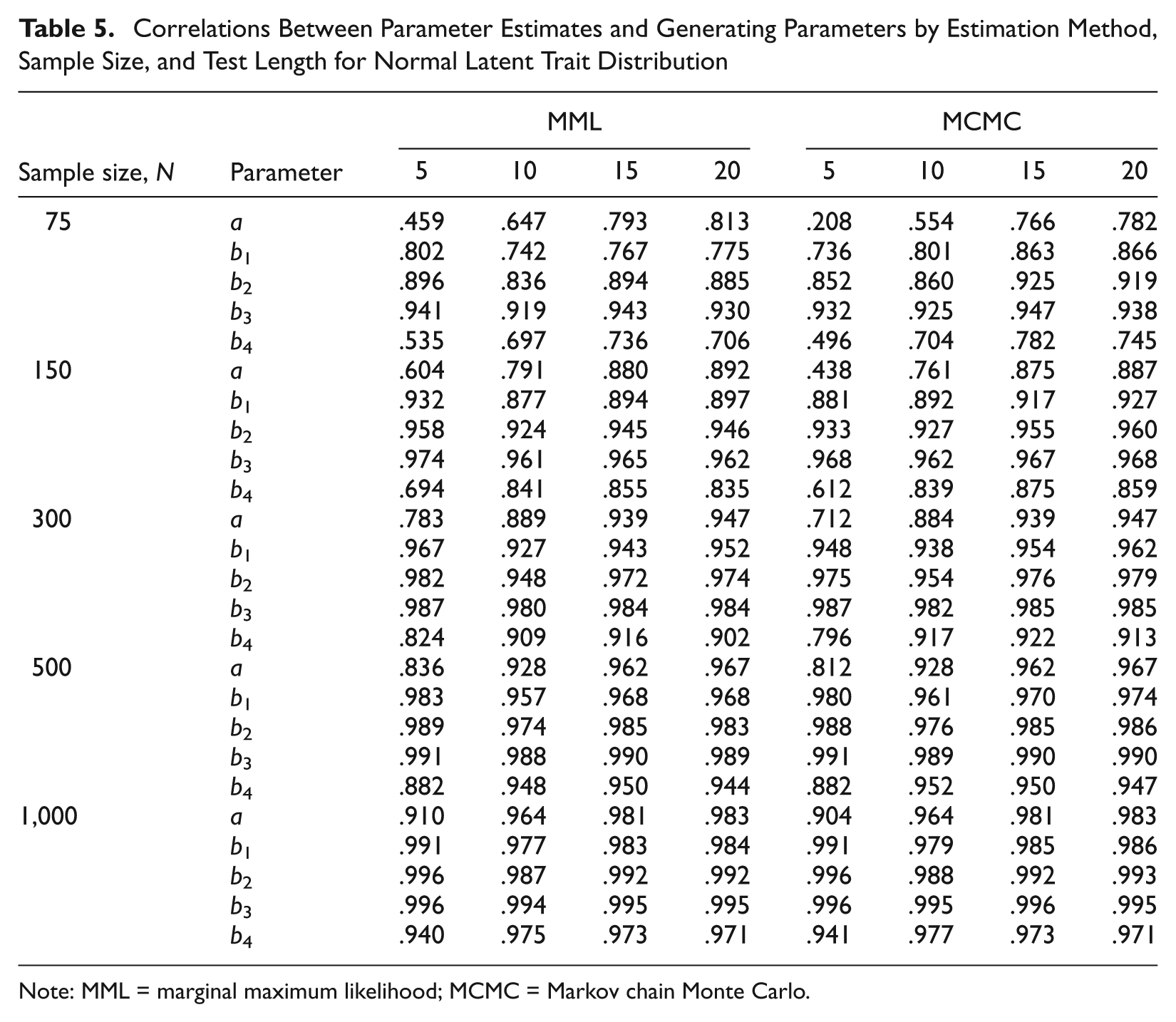
Correlations Between Parameter Estimates and Generating Parameters by Estimation Method, Sample Size, and Test Length for Normal Latent Trait Distribution
Note: MML = marginal maximum likelihood; MCMC = Markov chain Monte Carlo.
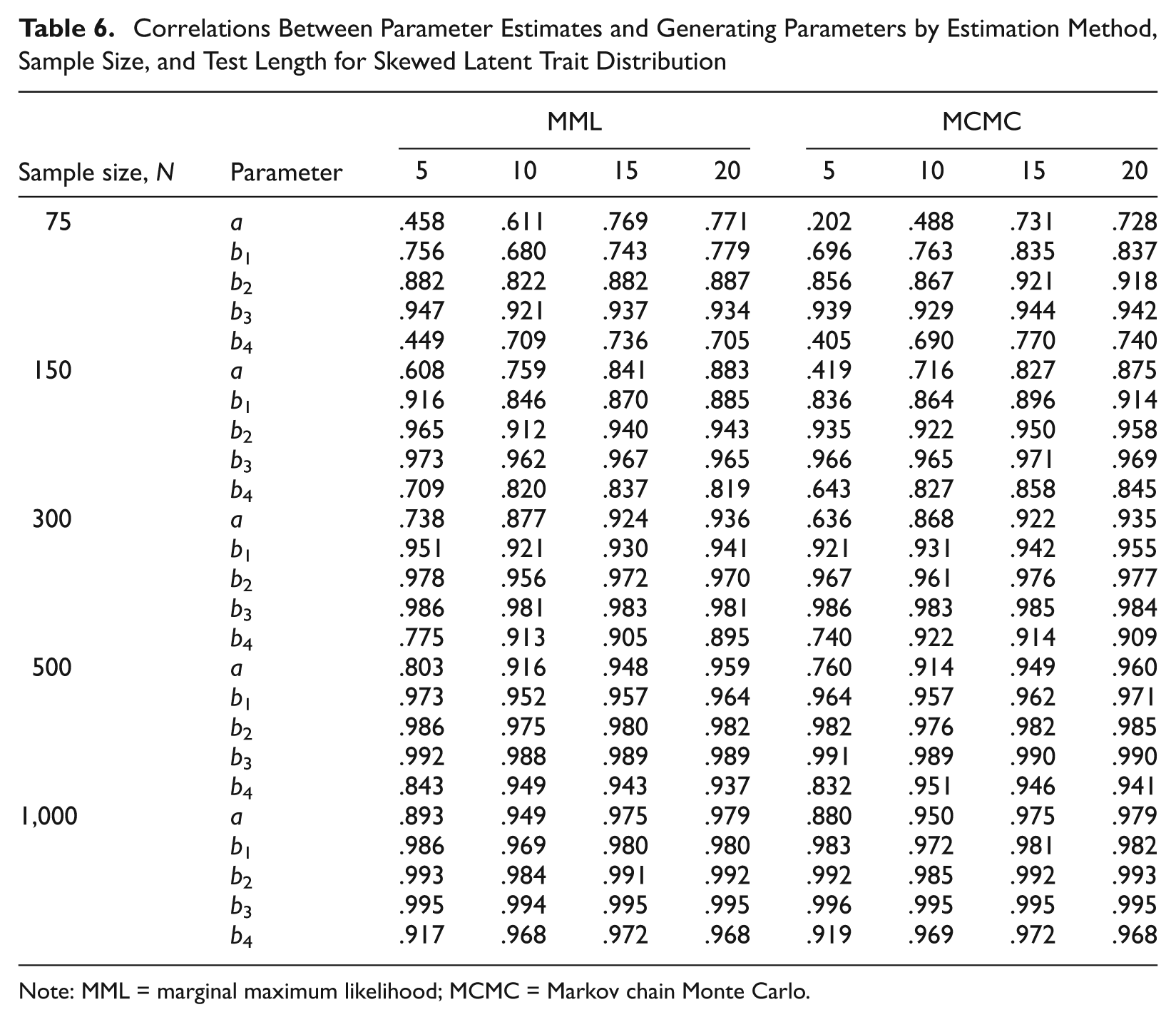
Correlations Between Parameter Estimates and Generating Parameters by Estimation Method, Sample Size, and Test Length for Skewed Latent Trait Distribution
Note: MML = marginal maximum likelihood; MCMC = Markov chain Monte Carlo.
Correlations Between Parameter Estimates and Generating Parameters by Estimation Method, Sample Size, and Test Length for Uniform Latent Trait Distribution
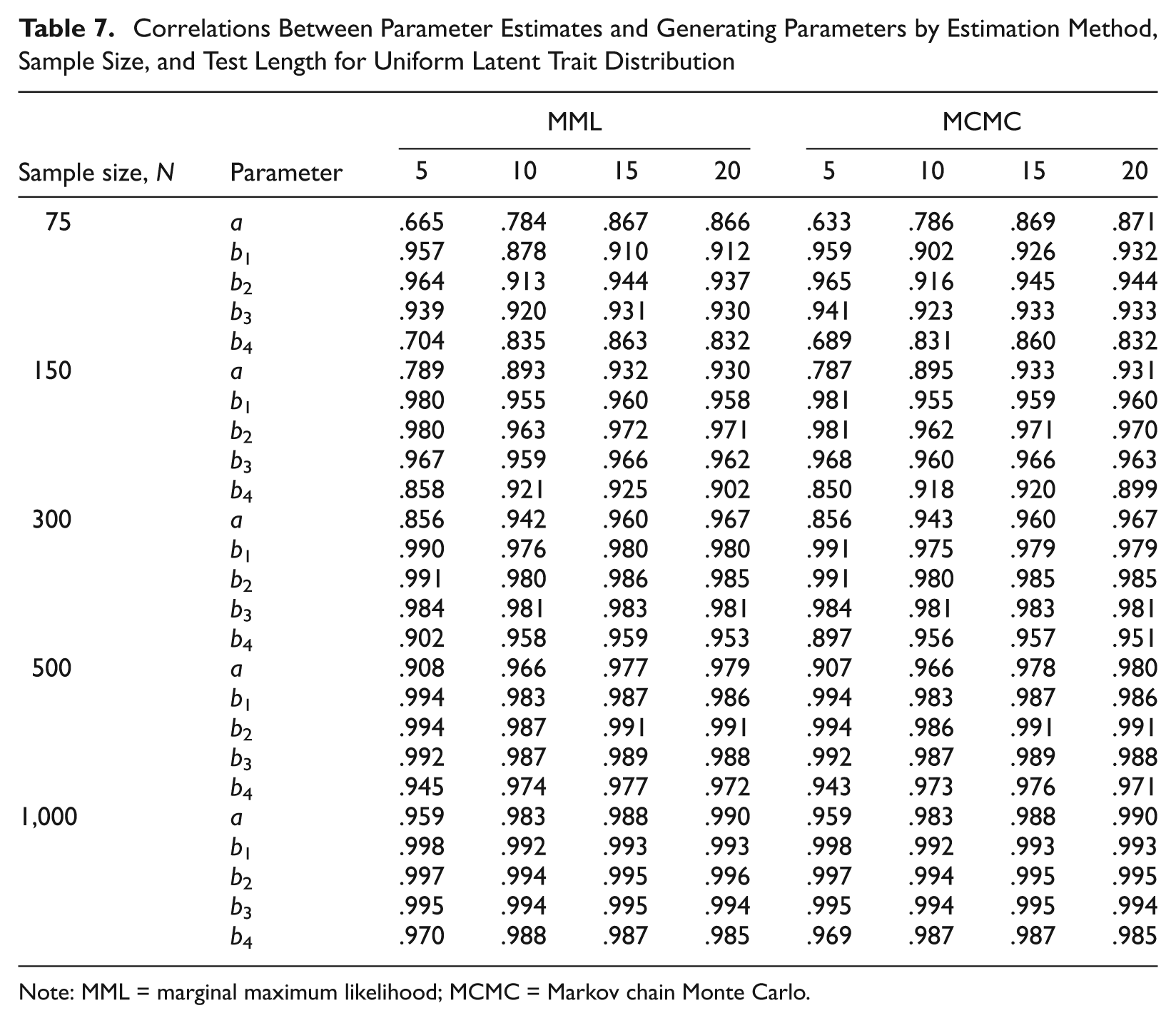
Note: MML = marginal maximum likelihood; MCMC = Markov chain Monte Carlo.
Mean RMSE in Item Parameter Estimates for Normal Distribution by SSR
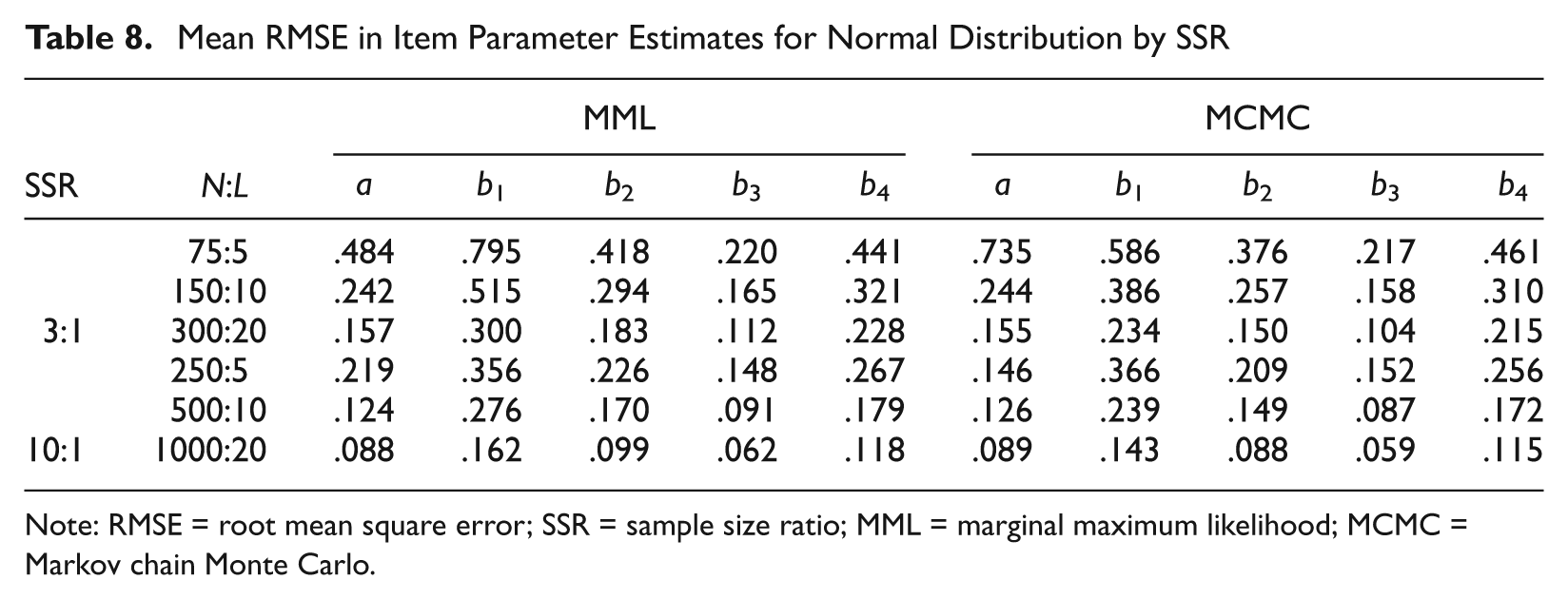
Note: RMSE = root mean square error; SSR = sample size ratio; MML = marginal maximum likelihood; MCMC = Markov chain Monte Carlo.
Mean RMSE in Person Parameter Estimates by Estimation Method, Latent Trait Distribution, and Test Length
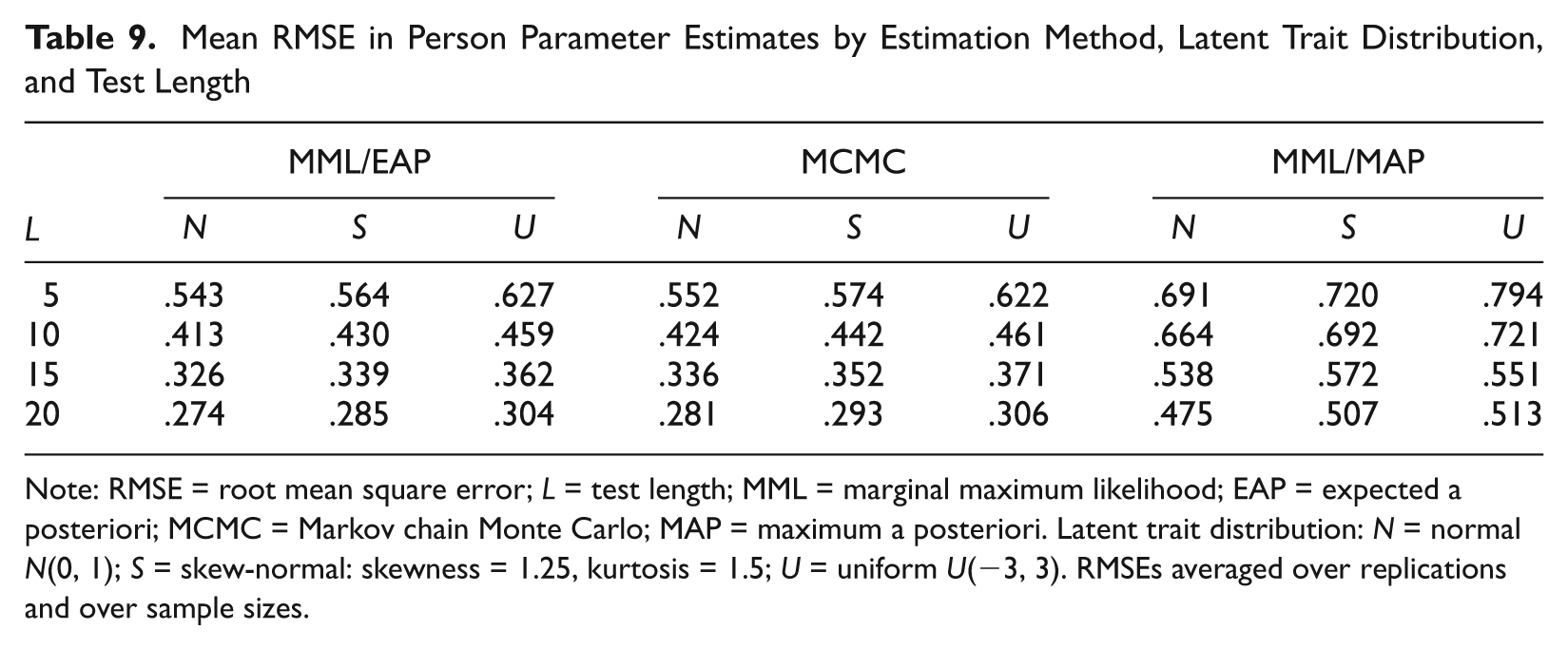
Note: RMSE = root mean square error; L = test length; MML = marginal maximum likelihood; EAP = expected a posteriori; MCMC = Markov chain Monte Carlo; MAP = maximum a posteriori. Latent trait distribution: N = normal N(0, 1); S = skew-normal: skewness = 1.25, kurtosis = 1.5; U = uniform U(−3, 3). RMSEs averaged over replications and over sample sizes.
Item Parameter Recovery
Sample size is the most important factor in item parameter recovery with effect sizes ranging from 35% to 68%. Orthogonal planned contrasts over various levels of sample size indicate that the maximum difference occurs between 75 versus (150, 300, 500, and 1,000), with a medium to large difference between 150 versus (300, 500, and 1,000). The gain in accuracy was smaller (η2 < 3.91%) between samples of size 300 versus (500 and 1,000). Test length played a very small role in item parameter recovery.
Estimation method explained a small portion of the variation in RMSE for the first threshold parameter. MCMC recovered the first threshold better when N≤150, and additionally, the second threshold parameter when N = 75. For other conditions, RMSEs of the threshold parameters tend to be comparable between the two methods, with the first and last threshold parameters recovered less accurately than the middle two thresholds, probably because fewer respondents select these extreme categories (see Table 3). In general, MCMC did not recover discrimination parameters better than did MML. This echoes Baker’s (1998) study in which BILOG recovered discrimination parameters better than Gibbs sampling. Latent trait distribution explained a small percentage of the variation for discrimination parameters and threshold parameters, b1, b2, and b4. Estimates from both methods were better for uniform latent trait distributions than normal and skew-normal. This is probably because a broader range of the latent trait in the sample provides more variation in responses. Note that for uniform distributions, MCMC did not recover item parameters any better than did MML.
Correlation is affected by latent trait distribution, sample size, and test length but not by estimation method (see Table 4). Correlations for item parameters (except the third threshold) are higher in uniformly distributed samples than in normally or skew-normally distributed samples (see Tables 5-7). Sample size affects correlation primarily for samples of 75 and 150 persons. The effect of latent trait distribution and sample size on correlation can probably be explained by the fact that parameters are more accurately recovered in uniform and/or larger samples. Test length has a large effect on correlations of discrimination (η2 = 17.28%) and fourth threshold (η2 = 8.59%) parameters. Being an effect size, correlation should not be sensitive to the number of observations. Correlation may be affected by sample variance. For the generating item parameters, the SDs for a and b4 increase with test length—for instance, SD(a) = 0.229, 0.309, 0.418, 0.454 for L = 5, 10, 15, 20—but the SDs of b1, b2, and b3 remain relatively similar—for instance, SD(b1) = 0.992, 0.889, 0.914, and 0.913 for L = 5, 10, 15, and 20, respectively. This could be a possible explanation for the test length explaining variation in the correlations of a and b4.
SSR
De Ayala and Sava-Bolesta (1999) found that the recovery of item parameters in the nominal response model is affected more by SSR than by sample size alone. One might conjecture that this holds for the GRM as well. However, the impact of SSR over sample size is not apparent in Table 2. To investigate this issue further, RMSE for SSRs of 3:1 and 10:1 was compared with normal latent trait distribution but with different sample sizes. Because each item has five parameters in the present study, a SSR of 3:1 corresponds to conditions with sample size N to test length L ratios of 75:5, 150:10, and 300:20. Similarly, a SSR of 10:1 corresponds to N:L of 250:5, 500:10, and 1000:20. As N = 250, L = 5 was not among the authors’ original conditions, they additionally estimated 100 replications for this particular condition. Table 8 shows that even when SSR remains the same, item parameter estimates improve when the sample size increases. Doubling the sample size improves item parameter estimates by 159% on average.
Person Parameter Recovery
Test length explained the highest variance in RMSE of person parameter estimates (η2 = 86.30%). The highest gain in accuracy was between test length of 5 versus 10, 15, and 20 (η2 = 66.54%), followed by 10 versus 15 and 20 (η2 = 17.00%); the gain between 15 items versus 20 items was much lower (η2 = 2.75%). Correlation also improved with an increases in test length, probably because person parameters are estimated more accurately with longer tests. The distribution of the simulated person parameters explained a small amount of variance in RMSE (η2 = 2.62%) but a large amount of variance in correlations (η2 = 22.50%). RMSEs and correlations were a little higher in uniformly distributed versus normal and skewed samples, probably because the variability in parameter values is larger in that case.
Table 9 shows that RMSE in the MML/EAP and the MCMC person parameter estimates was comparable. However, the MML/MAP estimates were inferior to the other two estimation methods. RMSEs for MML/EAP and MCMC were approximately 50% to 70% lower than MML/MAP RMSEs. The MML/MAP estimates seem to be in line with the results of Reise and Yu (1990), who found an average RMSE in MAP person parameter estimates of 0.35 with a 25-item test of highly discriminating items. (Note that MML/EAP and MCMC produced better results even for tests with 5 fewer items.) Lautenschlager et al. (2006) also reported MML/MAP person estimates comparable with those obtained in the present study. DeMars (2003) reported an average RMSE of 0.67 using ML estimates from a 10-item test. In contrast, Ankenmann and Stone (1992) found substantially better RMSEs of approximately 0.5, 0.4, and 0.3, respectively, for 5-, 10-, and 20-item tests using MML/MAP.
The authors subsequently computed MML/MAP estimates using their own implementation of a MAP algorithm. The mean RMSEs for these MAP estimates were 0.53, 0.44, 0.37, and 0.38 for test lengths L = 5, 10, 15, and 20, respectively. These RMSEs are more comparable with the MML/EAP and MCMC results (but perhaps somewhat larger for L = 20). Moreover, Table 10 shows that there are essentially no differences in correlation between MML/MAP, MML/EAP, and MCMC person parameter estimates. Lautenschlager et al. (2006) also noted that person parameter estimates tend to correlate well with generating values, despite estimation errors that can be large with shorter test lengths.
Mean Correlation Between Person Parameter Estimates and Generating Parameters by Estimation Method, Latent Trait Distribution, and Test Length

Note: L = test length; MML = marginal maximum likelihood; EAP = expected a posteriori; MCMC = Markov chain Monte Carlo; MAP = maximum a posteriori. Latent trait distribution: N = normal N(0, 1); S = skew-normal: skewness = 1.25, kurtosis = 1.5; U = uniform U(−3, 3). Correlations averaged over replications and over sample sizes.
Conditional Bias
Bias in the ML estimates of GRM item parameters is known to be very small with samples larger than 300 persons (Lautenschlager et al. 2006; Reise & Yu, 1990). However, Bayesian estimates are regressed toward the mean of the prior distributions. This regression is stronger in smaller samples because, in these cases, the effect of the prior is larger relative to the likelihood. Moreover, more extreme values tend to regress more toward the mean.
Figures 1 and 2 show the conditional bias in item parameter estimates by sample size. In samples of 300 persons, maximum absolute bias in the item parameter estimates was 0.056, 0.296, 0.187, 0.080, and 0.115 for a, b1, b2, b3, and b4, respectively. This maximum absolute bias is roughly halved in samples of 500, except that there is no reduction in bias for b4. Almost all discrimination parameters were overestimated. This may be due to the fact that the mean of the log-normal prior was larger than any of the generating discrimination values. In samples of 75 persons, the bias was particularly large compared with the bias in larger samples. The value of discrimination parameters seems to have no systematic effect on bias.

Conditional bias in MCMC discrimination parameter estimates by sample size
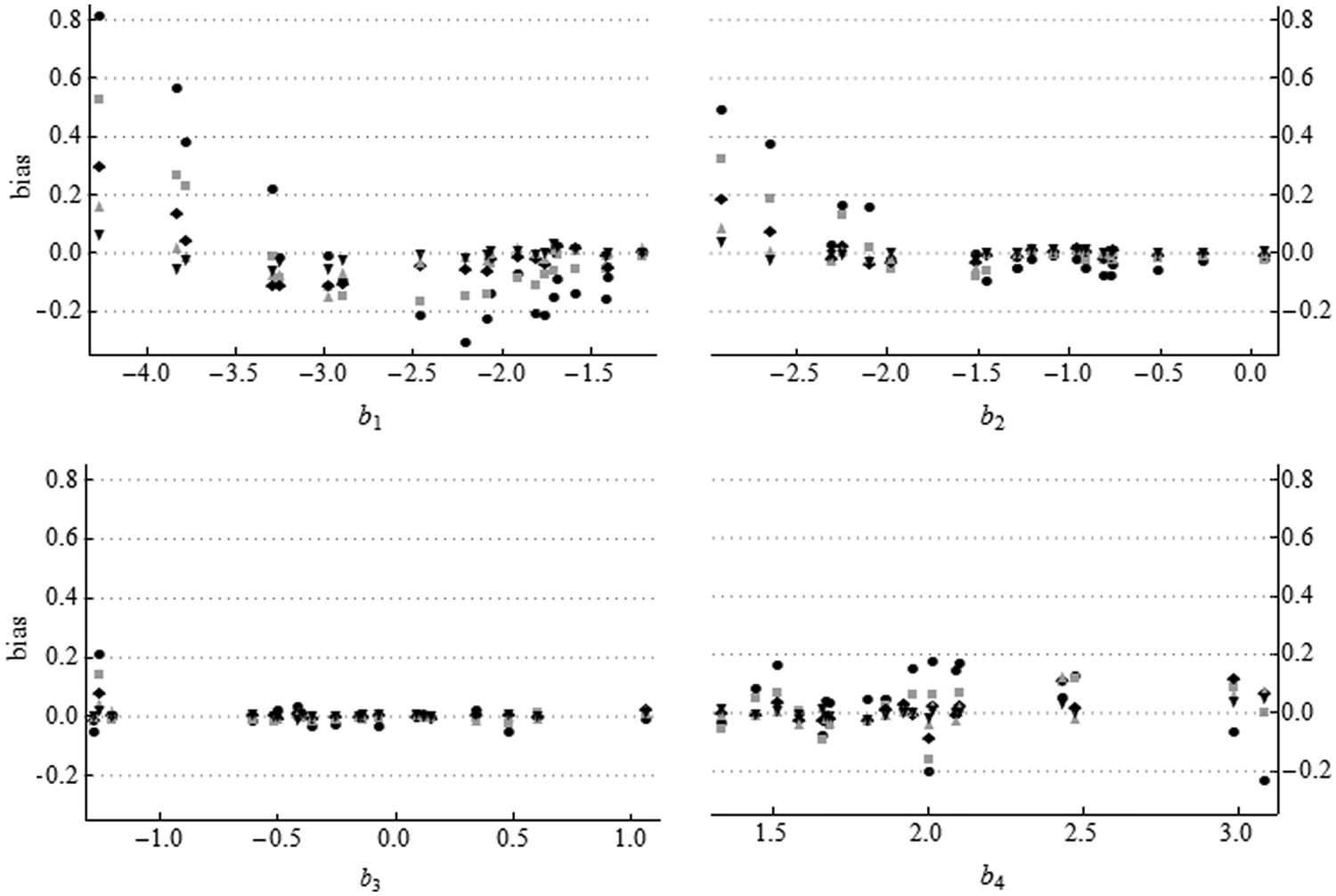
Conditional bias in MCMC threshold parameter estimates by sample size
However, the value of the threshold parameters has an effect on the bias in threshold parameters: The bias is lower in estimates of threshold parameters between −1.5 and 1.25. This is probably due to the fact that more responses are available to estimate these thresholds. In addition, the type of threshold parameter (first, second, etc.) also has an effect. For example, the first threshold of the sixth item b61 and the second threshold of the first item b12 are almost equal (about −2.9), but the biases in their estimates (when N = 300) are −0.109 and 0.187, respectively. The first thresholds are underestimated and the second thresholds are overestimated in the region where they overlap. This effect may be caused by the fact that the second threshold is forced to be above the first in the model specification.
Figure 3 shows bias in person parameters averaged over evenly spaced intervals of length 0.25 from −3 to 3 with least-square best-fitting cubic curves superimposed. The regression toward the mean is clearly visible. Bias in the MML/EAP estimates was slightly smaller than the bias in the MCMC estimates. Average absolute bias in the MML/EAP person estimates was 0.433, 0.330, 0.260, and 0.218 for test lengths L = 5, 10, 15, and 20, respectively, and 0.437, 0.333, 0.263, and 0.221 for MCMC person parameter estimates. Seong, S.-H. Kim, and Cohen (1997) found that EAP estimates were slightly less biased than MAP estimates for the GRM. Given that RMSE in MML/EAP estimates was considerably lower than in the MML/MAP estimates, the authors do not consider the bias in ML/MAP estimates further.
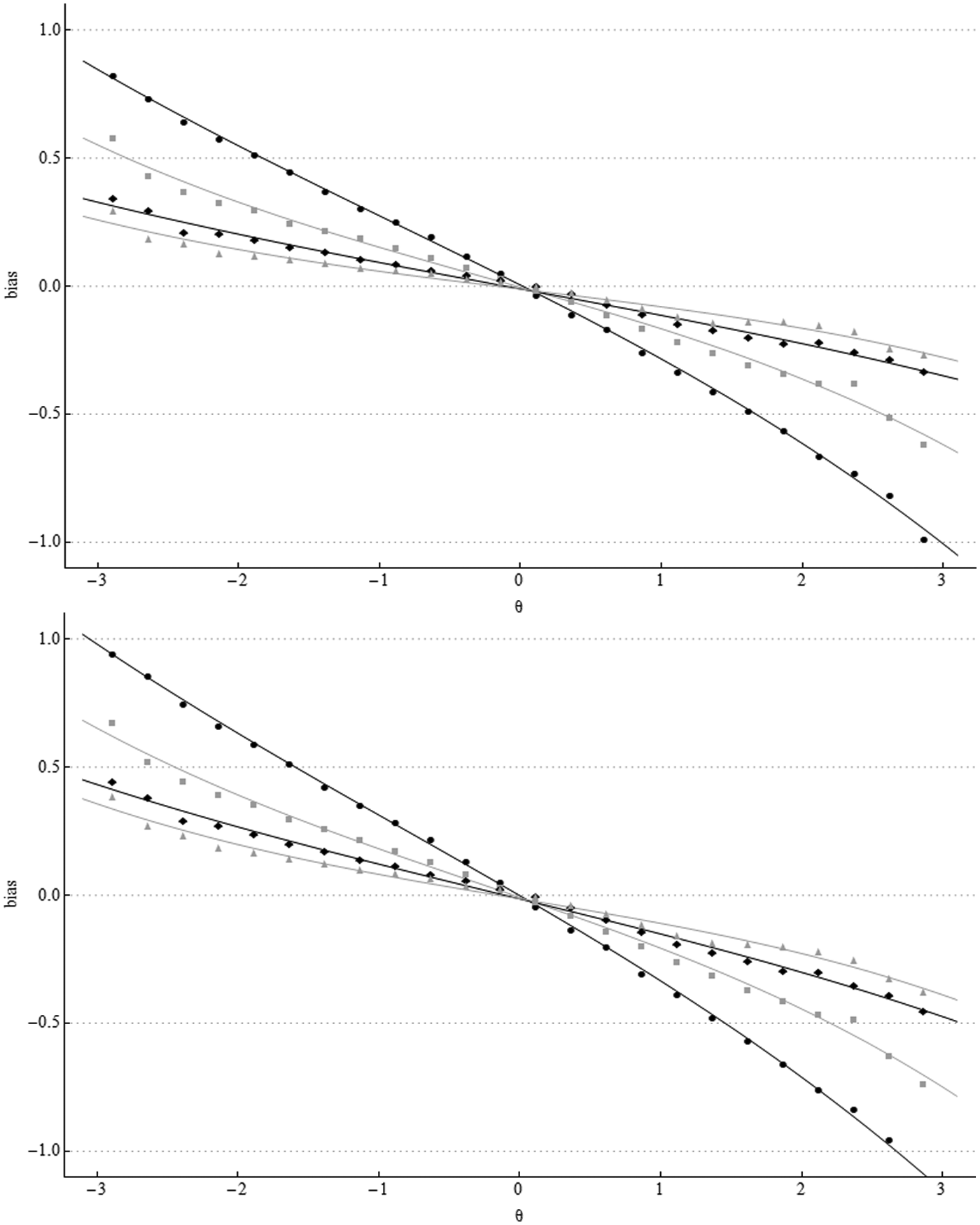
Conditional bias in MML/EAP (top) and MCMC (bottom) person parameter estimates by test length.
Estimation Time
Longer estimation time is a drawback of the MCMC estimation using OpenBugs (see Table 11). Modern hardware alleviates this problem to a certain extent. Wollack et al. (2002) reported that estimation of NRM parameters with 300 persons and 10 items took 4 hrs and 10 mins on a Pentium 450 MHz PC. This is considerably longer than the 7 min and 40 s it took on an Intel i3 3.2 GHz PC to estimate the GRM parameters for the same sample size and test length. Doubling the sample size increases the MCMC estimation time by a factor of 2.25 on average; doubling the test length multiplies estimation time by 2.17 on average. In comparison, the MML estimation with MULTILOG only takes a few seconds, even with larger samples.
Mean Estimation Time in Minutes for MCMC Estimation

Note: MCMC = Markov chain Monte Carlo. A total of 11,000 iterations in OpenBUGS on an Intel i3 3.2 GHz PC with 4 GB RAM.
Discussion
Several researchers have suggested that Bayesian (MCMC) parameter estimation may be more accurate than MML with smaller samples and test lengths, and with more complex models (S.-H. Kim, 2001; S.-H. Kim & Cohen, 1999; Swaminathan & Gifford, 1982). The present simulation study compared MML/EAP and MCMC parameter estimation in the GRM investigating (a) the accuracy of MCMC in recovering item and person parameters compared with MML/EAP, (b) the factors which contribute the most to accurate parameter recovery, and (c) the minimal conditions required for adequate parameter recovery.
Sample size is the most important factor in the accurate recovery of item parameters. Test length does not influence item parameter recovery. This concurs with results of Ankenmann and Stone (1992), among others. Improved item parameter recovery was associated with larger sample sizes, rather than higher SSRs, in contrast to findings by De Ayala and Sava-Bolesta (1999) for the nominal response model. The recovery of item parameters improved considerably when sample size increased from 150 to 300 examinees, to a lesser extent when sample size increased from 300 to 500 examinees, and even less when sample size increased from 500 to 1,000 examinees. It seems that 300 examinees are a necessary minimum; 500 persons are better. In practice, the limited increase in accuracy between samples of 500 and 1,000 persons may not be worth the additional costs. Practitioners may see considerably improved item parameter estimates if they select a sample with a broad range of latent traits. There is likely to be little negative effect of skewness in sampled latent traits.
Comparing the accuracy of MCMC with MML, there is little difference in item parameter recovery with samples of 300 persons or more, even in a polytomous item response model. This finding concurs with Wollack et al. (2002) and de la Torre et al. (2006) who also found no difference between samples of 300 persons and more for the nominal response model and the GGUM, respectively. The positive bias of MCMC in discrimination parameter estimates means that discrimination is likely to be overestimated, although this effect was small for large samples. The overestimation is probably caused by the choice of prior. Although a log-normal distribution seems a natural choice as prior for discrimination parameters, the mean of the prior was much larger than was the generating discrimination parameters. A prior better matched to the specific generating parameters used in this study probably would have improved the accuracy of the estimates. The authors are cautious about recommending another prior for discrimination parameters because a generic prior is needed when, in practice, the item parameters are unknown. This seems an important topic for further study.
Although the RMSEs are smaller for sample sizes of 500, the difference between samples of 300 versus 500 and 1,000 explained a low-medium amount of variance in the RMSE of the item parameters. Perhaps a more prudent selection of priors can make accurate recovery of the GRM item parameters feasible in samples of 300 persons. MCMC recovered the first and second threshold parameters better than did MML/EAP in samples of 75 persons, and the first threshold in samples of 150 persons. The authors note that the size of the RMSEs makes the use of IRT in such small samples debatable.
Person parameter recovery was influenced most by test length. When accurate estimation of person parameters is important, at least 10 items (preferably 15) should be used. Given a need for shorter instruments, 15 items seems to be a reasonable option as more items do not lead to much improvement. Overall, MML/EAP and MCMC person parameter estimates were much better than MULTILOG’s MML/MAP estimates, irrespective of test length. At the same time, there was essentially no difference in the correlations between parameter estimates and generating parameters. This seems to indicate that the larger RMSEs for the MML/MAP estimates produced by MULTILOG are due to scaling issues. However, all parameter estimates were put on the metric of the generating parameters using the same equating procedure, and the implementation of MML/MAP gave estimates comparable with MML/EAP and MCMC. Therefore, it seems more likely that the differences are caused by variations in the implementation of the MAP procedure.
MCMC and MML estimation differ in the choice of item priors (always flat for MML, more possibilities for MCMC). Bayesian parameter estimation is sometimes presumed to work better in smaller samples because priors provide additional information. However, the flat priors used in this study for the threshold parameters conveyed no information beyond the restriction to the range (−5, 5), and the prior (used following Albert & Chib, 1993, and Albert & Johnson, 1999) for the discrimination parameter was in fact ill matched to the actual parameter values.
Moreover, the unit normal person parameter worked well even when it did not match the uniform or skewed latent trait distribution in the sample. Further research is needed to see if item parameter estimates can be improved (especially discrimination parameters), for example, by using more informative or hierarchical priors.
Mislevy (1986) extended MML to marginalized maximum a posteriori (MMAP) by incorporating item priors within MML. MMAP and MCMC differ in the details of the marginalization of person parameters. In MMAP, person parameters are marginalized with respect to the prior distribution before item parameter estimation. In MCMC, parameters are estimated jointly and the marginalization is with respect to the posterior distribution of the person parameters. Recently, Roberts and Thompson (2011) compared MML, MMAP, and MCMC estimates for the GGUM. They found evidence that MMAP gives better estimates than does MCMC, noting that MMAP may offer one of the advantages of MCMC (use of item priors) without its disadvantage (computational burden). It may be worthwhile to investigate MMAP estimation of GRM parameters.
At the same time, the main benefit to MCMC estimation is more complete information about model parameters in the form of a sample from their posterior distributions. How the posterior draws given by MCMC estimation can be used to address psychometric issues such as model assessment, item and person fit, and equating is currently an active area of research (see, for example, Baldwin, 2011; Sinharay, Johnson, & Stern, 2006; Zhu & Stone, 2011). In conclusion, the present study shows that MCMC parameter recovery is comparable with MML in most cases with advantages to MCMC in smaller samples. Given the accuracy of estimates, the use of OpenBUGS to estimate GRM parameters seems viable. The software allows great flexibility in modeling, even without extensive programming skills, and could be useful for more complex models for which MML may not have been implemented.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their useful comments that helped them to improve this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.