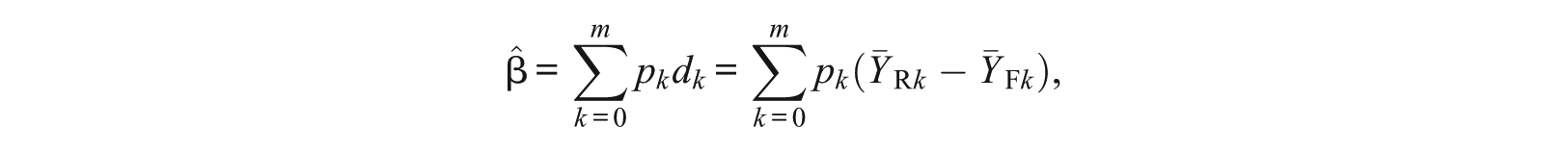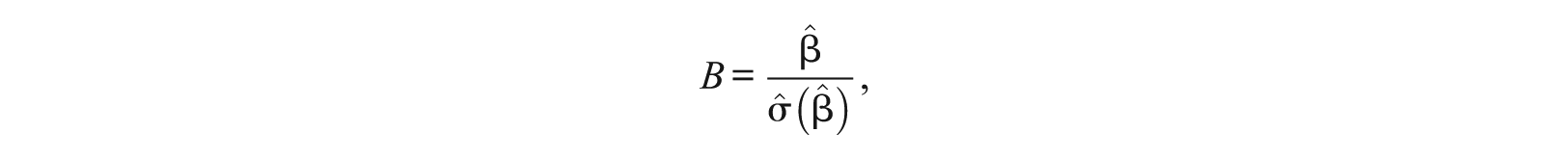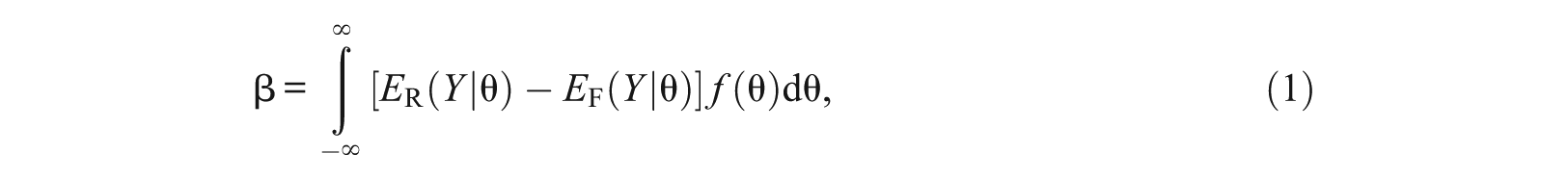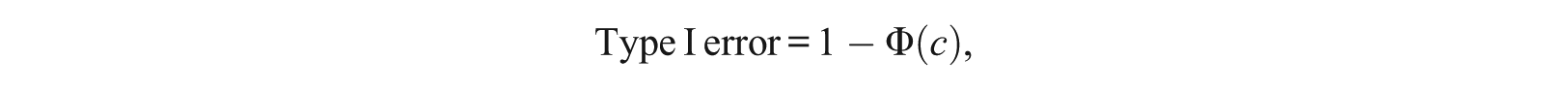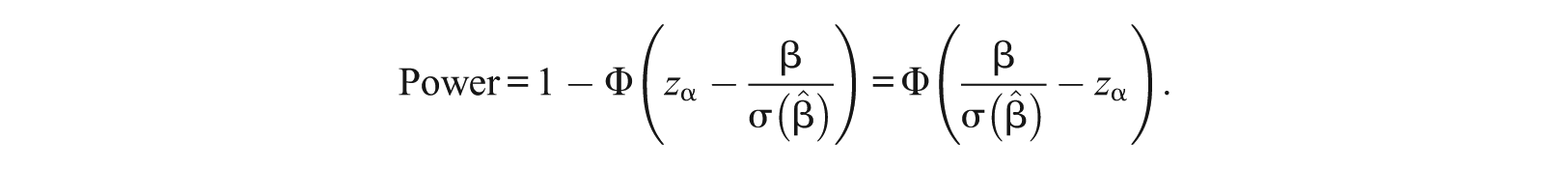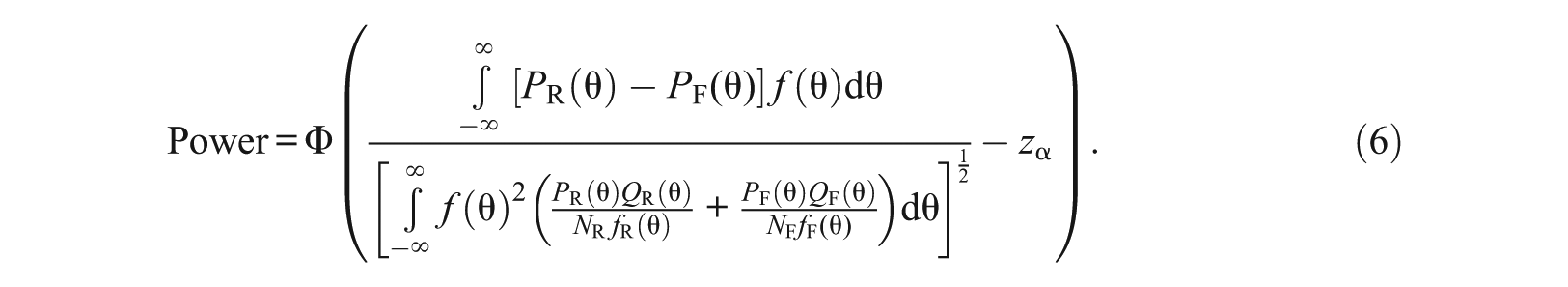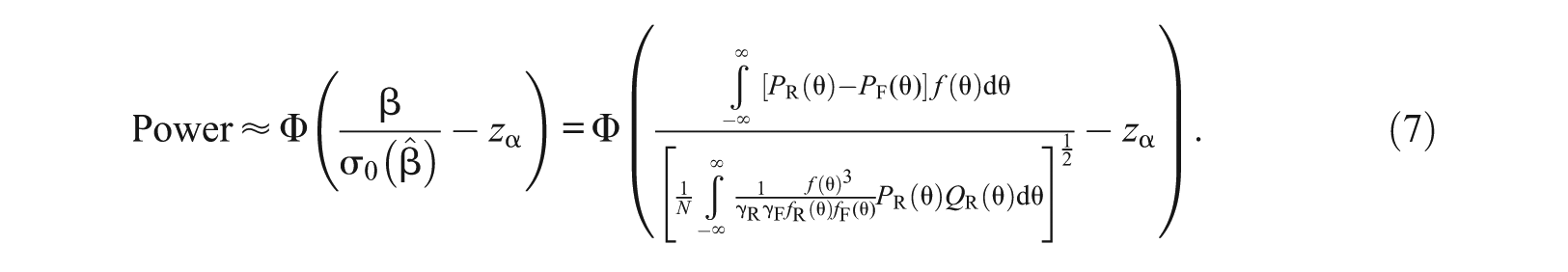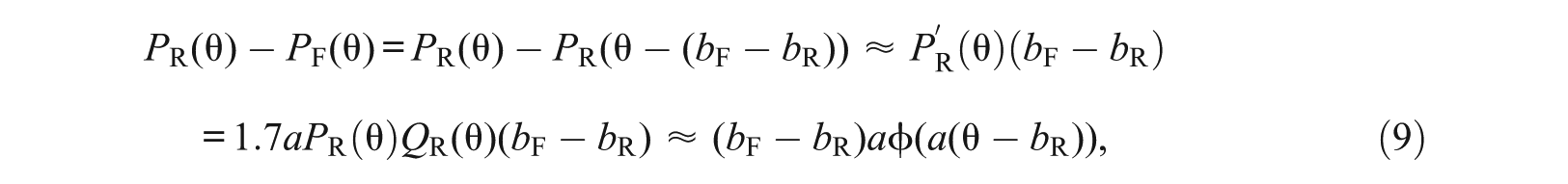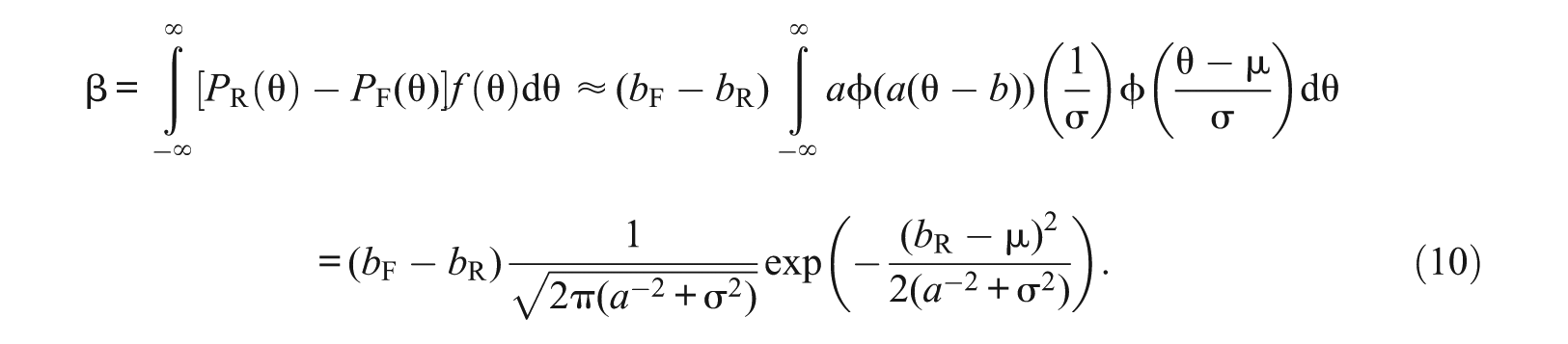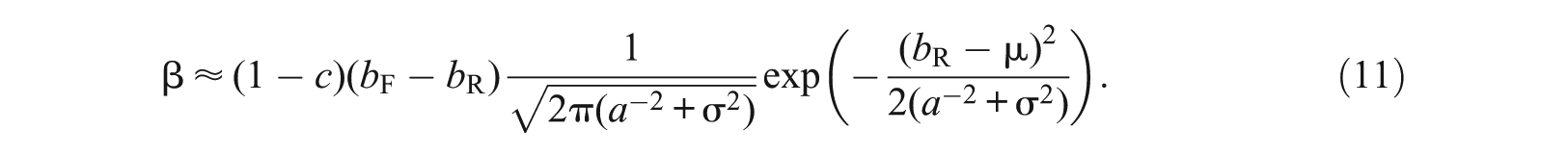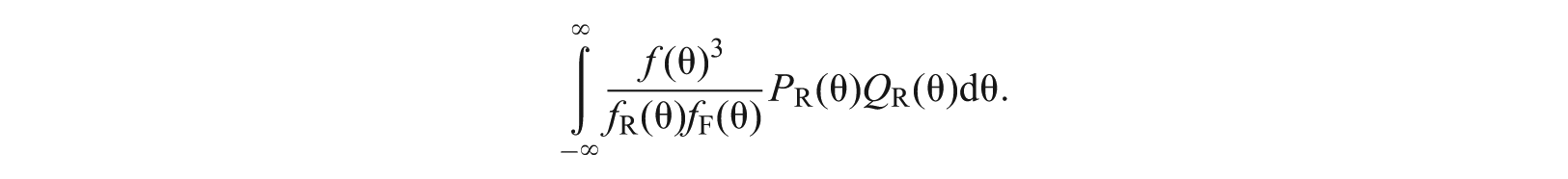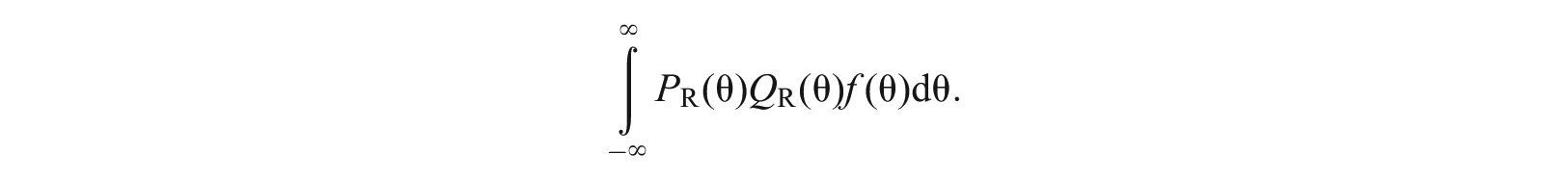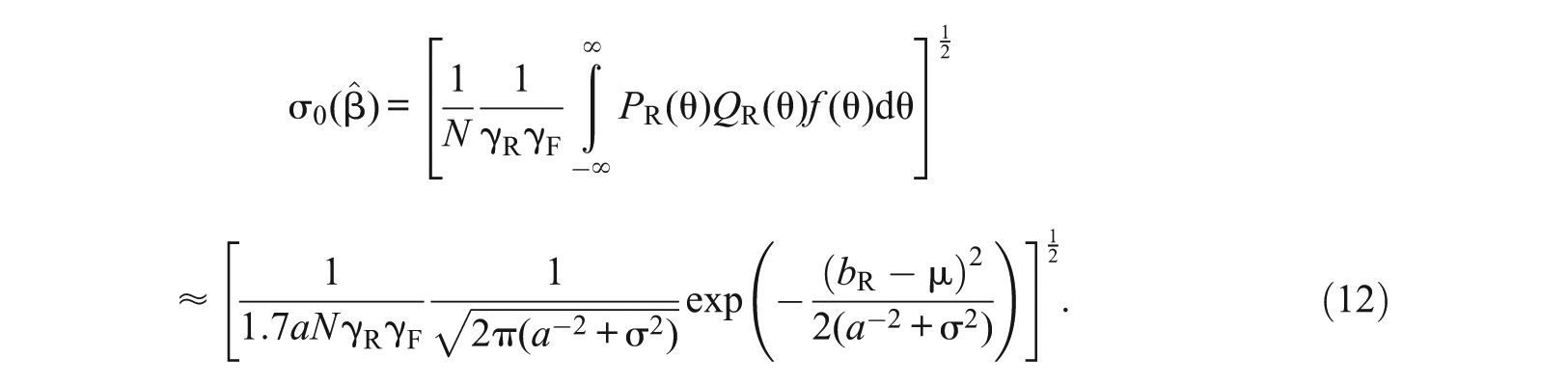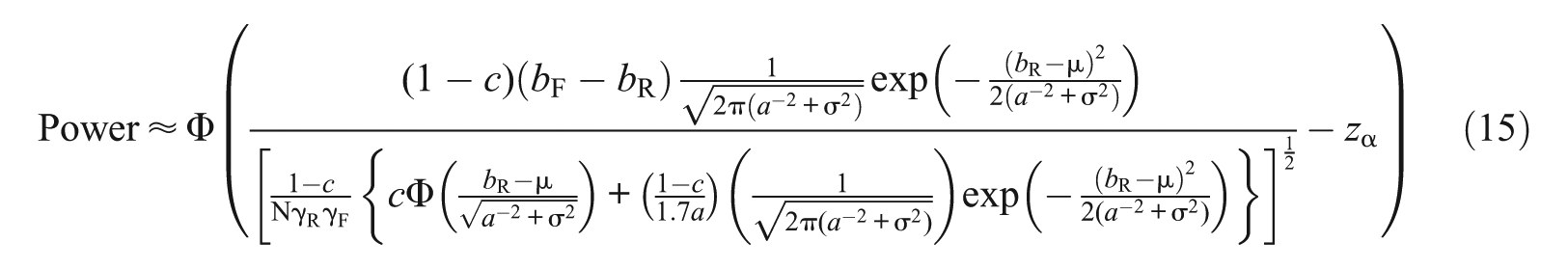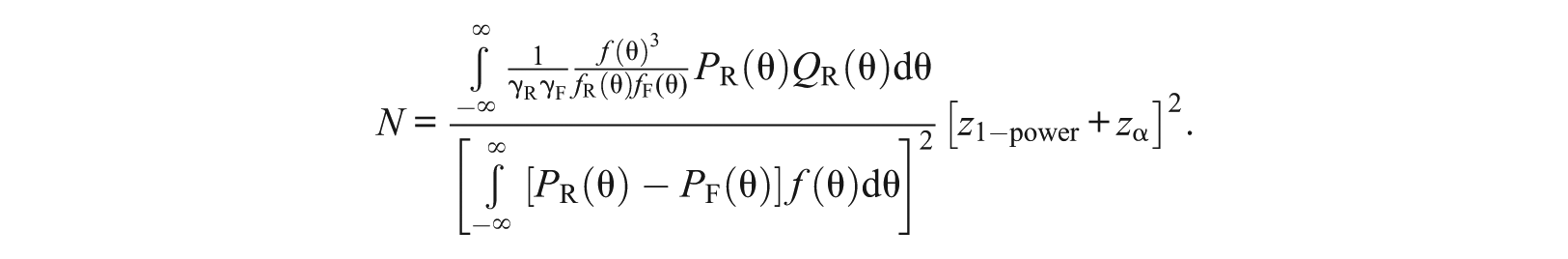A power formula for the SIBTEST procedure for differential item functioning (DIF) is derived. The power of SIBTEST is related to the item response function (IRF) for the studied item, the latent trait distributions and the sample sizes for the reference and focal groups, and the proportion of each group in the sample. Based on the power formula, a method for calculating the sample size for a desired power level is presented. Monte Carlo simulation studies show that the theoretical values calculated from the formulas derived in the article are close to what are observed in the simulated data.
A fair test should consist of items for which the probability of getting the correct answer is solely determined by an examinee’s ability on the construct that the test is designed to measure. If people from different groups (e.g., gender, ethnicity, etc.) with the same ability have different probabilities of getting a correct answer on an item, then this item displays differential item functioning (DIF). Statistical procedures have been developed to detect DIF items (Holland & Wainer, 1993). When a statistical test is conducted on an item and the null hypothesis of no DIF is not rejected, there are two possibilities: (a) the item does not have DIF, and the test correctly identifies that, or (b) the item has DIF, but the test does not have enough power to identify it. The latter may occur if the sample size is not large enough. For example, a target population may be a minority group such that the size of the sample drawn from that population is rather limited. In such situations, one may cast doubt on the validity of the DIF study. Therefore, an essential part of the validity argument for a DIF study is to show that the power of the DIF test on the data is above a certain value (a common choice is 0.80). While in other areas of behavioral sciences where t tests, ANOVAs, and so on, are conducted, power analyses are routinely done or recommended at the research planning stage, however, power analyses are seldom conducted for DIF studies mainly due to the lack of tools available to practitioners.
The main purpose of this study is to derive a formula for the power of the SIBTEST procedure (Shealy & Stout, 1993), so that it can be used by the practitioners for power and sample size calculation. No similar work has been done on SIBTEST. Without a power formula, one can still study the power of a statistical test by conducting simulation studies, where the power is obtained by calculating the rate at which the null hypothesis is rejected by the test over many replicates of simulation data. For example, some simulation studies related to SIBTEST where the rejection rates are calculated are Roussos and Stout (1996); Jiang and Stout (1998); Bolt (2000); Gierl, Gotzmann, and Boughton (2004); Nandakumar and Roussos (2004); Woods (2011); and so on. In practice, however, simulation studies have the disadvantage of being conducted on a specific setup of the models and parameters, so it is often unclear how well the results can be generalized; and practitioners may lack the skills and resources needed to conduct a simulation study tailored to their problems. The formula derived in this article is very general. It can be applied to the most general forms of item response theory (IRT; Lord, 1980) models, including, but not limited to, the most popular models used in practice: the Rasch model (Rasch, 1960), the two-parameter logistic (2PL) model, and the three-parameter logistic (3PL) model.
In the following sections, we start with a review of the SIBTEST procedure. Next, we present a theoretical derivation of the power formula for SIBTEST, followed by a discussion, based on the derived formula, of the factors that may influence the power in some common IRT models. Then, the formula for sample size calculation is presented and an example is given. We resort to simulation studies to confirm that the derived power formula is indeed correct by comparing what is predicted from the formula and what is observed from the simulated data.
DIF and SIBTEST
Consider a test of length I with the first m items being the anchor items and the remaining I−m items being the studied items. Let Ui be the score for item , be the total score for the anchor items, and be the total score for the studied items. Let be the average score of the studied items for all group g (g = R or F; R for the reference group and F for the focal group) examinees for which X = k. Let NR and NF be the number of examinees in the reference and the focal groups, respectively, and N = NR+NF be the total sample size. An intuitive local measure for DIF is
the group difference on the studied items among examinees with the same observed matching score on the anchor items. If the studied items have no DIF, one would expect . A global DIF statistic can be defined by the weighted sum of the local group differences by
where is the proportion of examinees (from the reference and focal groups pooled together) getting score . A standardized version of is defined by
where
is the standard error of the estimator , and is the sample variance of the studied item scores for examinees in group g (R or F) with matching score X = k. However, under the null hypothesis that for all θ, and when there is difference in the two latent trait distributions (or impact, ), will lead to an inflated Type I error rate because the true asymptotic distribution is no longer N(0,1) (DeMars, 2010; Roussos & Stout, 1996; Zwick, 1990). Therefore, a modified SIBTEST test statistic by a regression correction method was proposed by Shealy and Stout (1993) and later improved by Jiang and Stout (1998). Using the regression correction, a corrected version for is given by , where is the corrected average score for examinees matched on the true score, instead of the observed score. The SIBTEST hypothesis testing statistic is now given by
where is the corrected version of . Under the null hypothesis that , has an asymptotic distribution of N(0,1).
If the test length and the number of examinees are large, tends to the population parameter
where is the density function for the population latent trait distribution; and is an estimate of the population parameter:
In practice, the modified SIBTEST statistic is always used and the regression correction is a part of the SIBTEST procedure. To simplify the notation, we will drop the asterisks in and . And from now on, and B refer to the corrected version of the corresponding statistics.
The Power Formula for SIBTEST
Under the null hypothesis, B has an asymptotic distribution of N(0,1). And under the alternative hypothesis, B has an asymptotic distribution of . The null hypothesis can be written as . Based on the sign of β, there are three types of alternative hypotheses: (a) one-sided ; (b) one-sided ; and (c) two-sided .
For now, consider the one-sided hypothesis testing problem of versus , where the null hypothesis is rejected if the SIBTEST statistic B is greater than a certain cutoff value c. By definition, the Type I error rate is the probability of rejecting the null, given that the null hypothesis is true: ; the power rate is the probability of rejecting the null, given that the alternative hypothesis is true: . Therefore, based on the asymptotic distribution for B under the null hypothesis,
where is the cumulative distribution function of the standard normal distribution. Let Type I error be fixed at α (e.g., α = .05). Solving for the cutoff value, we get c = zα, where zα is the (1 −α) quantile in the standard normal distribution, such that the tail area to its right is α (e.g., z.05 = 1.645). Based on the asymptotic distribution for B under the alternative hypothesis,
Now substituting the values for and as shown in Equations 1 and 2, we get
Similarly, for the other one-sided hypothesis testing problem of versus , one rejects the null hypothesis if , and the power formula is given by
For the two-sided hypothesis testing problem of versus , one rejects the null hypothesis if , and the power formula is given by
In the discussions that follow, we consider the power formula under the one-sided hypothesis testing versus , and the results can be easily extended to the other two testing problems.
Power Formula for SIBTEST With a Single Studied Dichotomous Item
SIBTEST was originally developed with the capability of testing the joint DIF effect of multiple studied items (differential bundle functioning [DBF]), and it was later extended to polytomous items (Chang, Mazzeo, & Roussos, 2005). The power formulas in Equations 35 are applicable for all the cases where SIBTEST can be applied: whether it is on a single studied item or a bundle of multiple items simultaneously and whether it is on dichotomous or polytomous items. We leave the discussions on the power of SIBTEST for DBF and polytomous items for future work. In this article, we focus on the case where DIF detection is conducted for each item one by one and the items are dichotomously scored, as this situation is most commonly found in practice. Also note that the power formulas in this article are only applicable for the SIBTEST procedures for unidirectional DIF, but not for the extended procedure for crossing DIF (CSIBTEST; Li & Stout, 1996).
In the situation where there is only one studied item and the studied item is dichotomous, , or F, where is the item response function (IRF) for group g; and , where . By substituting these in Equation 3, we get the power formula for SIBTEST with a single studied dichotomous item:
The Formula With Standard Error Evaluated Under Null Hypothesis
In the derivation of the power formula (Equation 6), the standard error as shown in Equation 2 is evaluated under the alternative hypothesis. It is possible to approximate with its value evaluated under the null hypothesis:
where , , and . Using in the place of in the power formula (Equation 6), we get
Using in place of does not change the asymptotic behavior in large sample theory, and this technique is often used in the derivation of the power formula (e.g., see Lehmann, 1999, Theorem 3.3.3). Therefore, Equation 7 is still a valid power formula as is, of course, Equation 6.
In this case, one advantage of using is that its integral (as shown in the denominator in Equation 7) does not involve the IRF for the focal group. In practice, this removes the burden of specifying . Very often, practitioners have no idea what is. Note that the numerator is simply the effect size β. That is, one may simply specify the desired effect size level to be detected.
A practitioner can ask the following question: What is the power of the SIBTEST to detect a DIF effect if the average difference in probability of getting correction response between the reference group and the focal group (i.e., β) is .10? To answer that question, one can use the standard error calculated under the null model, and the given β value to calculate the power.
Note in this formula, actually refers to “the IRF under the null hypothesis”; thus, it does not have to be the reference group IRF, sometimes it can also be the combined population IRF. One example is a DIF analysis on females versus males when the items are calibrated to the whole population. In this case, the whole population IRF can be used to evaluate the standard error under the null hypothesis.
Factors Influencing the Power of the SIBTEST
Based on the power formula (Equation 7), we can see that the power of SIBTEST is related to
the size of the DIF effect ,
the standard error parameter , which is determined by the following factors:
the sample size N,
the proportion of the focal group and reference group in the population and ,
the distributions of the latent trait and , and
the IRF of the studied item, , for the reference group.
the Type I error rate α.
It is obvious that an increase in power can be achieved in three ways: increasing the effect size β, decreasing standard error , and getting smaller (i.e., larger Type I error α). For a given studied item, the item characteristic (IRF) is considered fixed and cannot be manipulated. Similarly, for the reference and focal populations, the distributions of the latent trait cannot be manipulated. The Type I error rate α is always a controlled value and usually fixed at .05. Therefore, in practice, once the studied item and reference and focal populations are determined, the only factors that can be manipulated are the sample size and the proportion of the focal group in the sample. One can always increase the sample size (including the total sample size or the sizes from either group) to reach the targeted power, and we defer the discussion on sample size calculation to a later section. When the total sample size N is fixed, a balanced design of = .5 will have higher power than an unbalanced design. Therefore, in the situation where the total sample size has to be fixed due to limited resources, efforts to balance the group sizes, such as oversampling the smaller group (usually the focal group), will often increase the power.
For those factors that cannot be manipulated, the power formula can be used to understand how these factors influence the power. Note that in the power formula there is no specific requirement for the forms of the IRF and the latent trait distribution. In what follows, we discuss some of the most commonly used models, including the Rasch, 2PL, and 3PL models. Furthermore, we assume that the reference and focal group latent traits follow normal distributions.
Effect Size β Under IRT Models
The effect size β used by SIBTEST is a global measure of the DIF effect and can be seen as a weighted average of the local DIF effect , where the weight is the density of the latent trait distribution in the population from which the reference and focal groups are sampled. For dichotomous items, it is the same as the standardized p-difference statistic by Dorans and Kulick (1986). A discussion on the relationship between β and other popular DIF effect size measures including the area between IRF (Raju, 1988), Mantel-Haenszel log-odds ratio (Holland & Thayer, 1988), and Delta-b (difference in difficulty) is provided in Appendix C in the online supplementary document.
The IRF for the IRT 3PL model is given by
where θ is the latent trait, a is the discrimination parameter, b is the difficulty parameter, and c is the guessing parameter. The IRF for the 2PL model is obtained by setting c = 0. And the IRF for the Rasch model is obtained by setting c = 0 and .
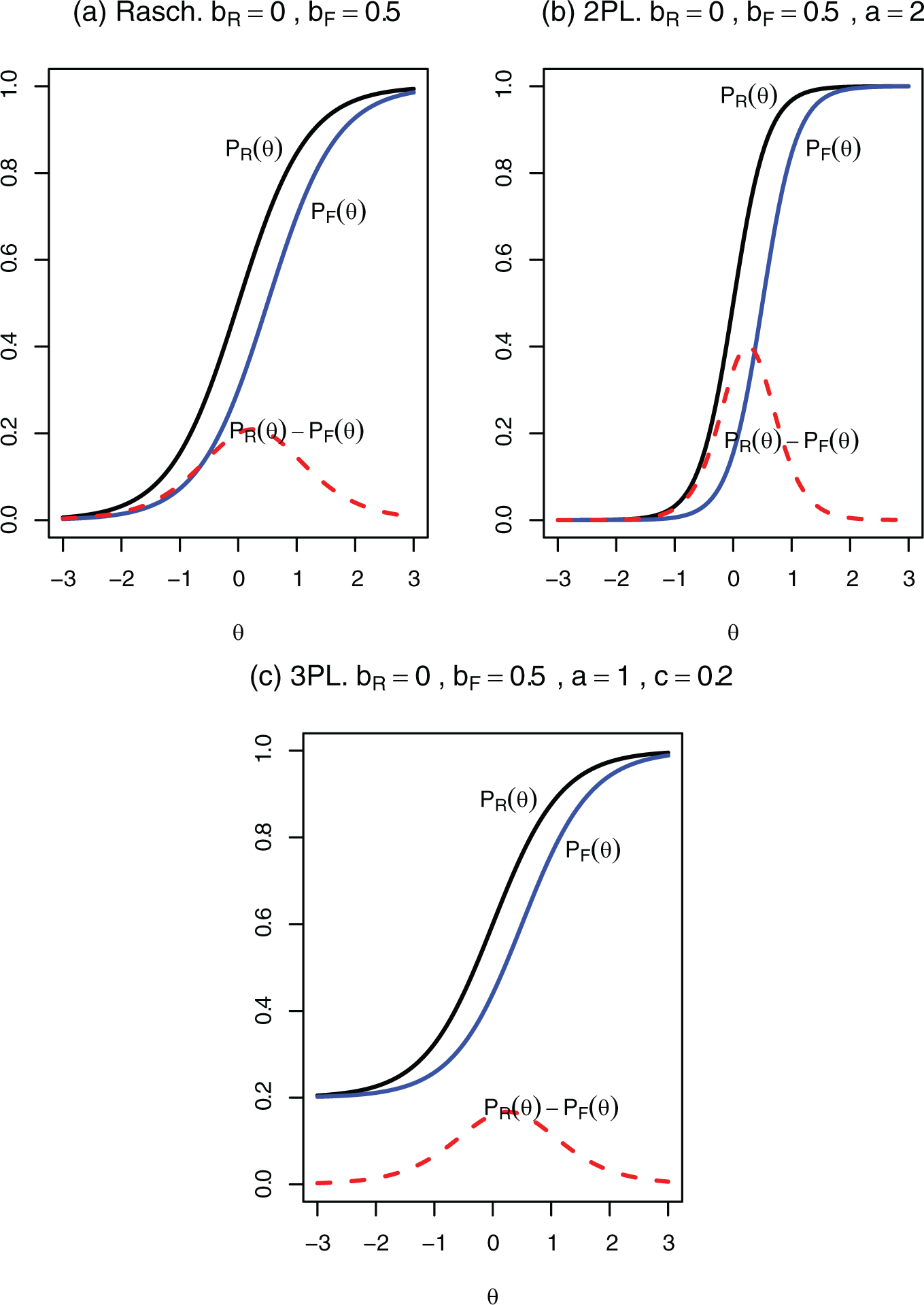
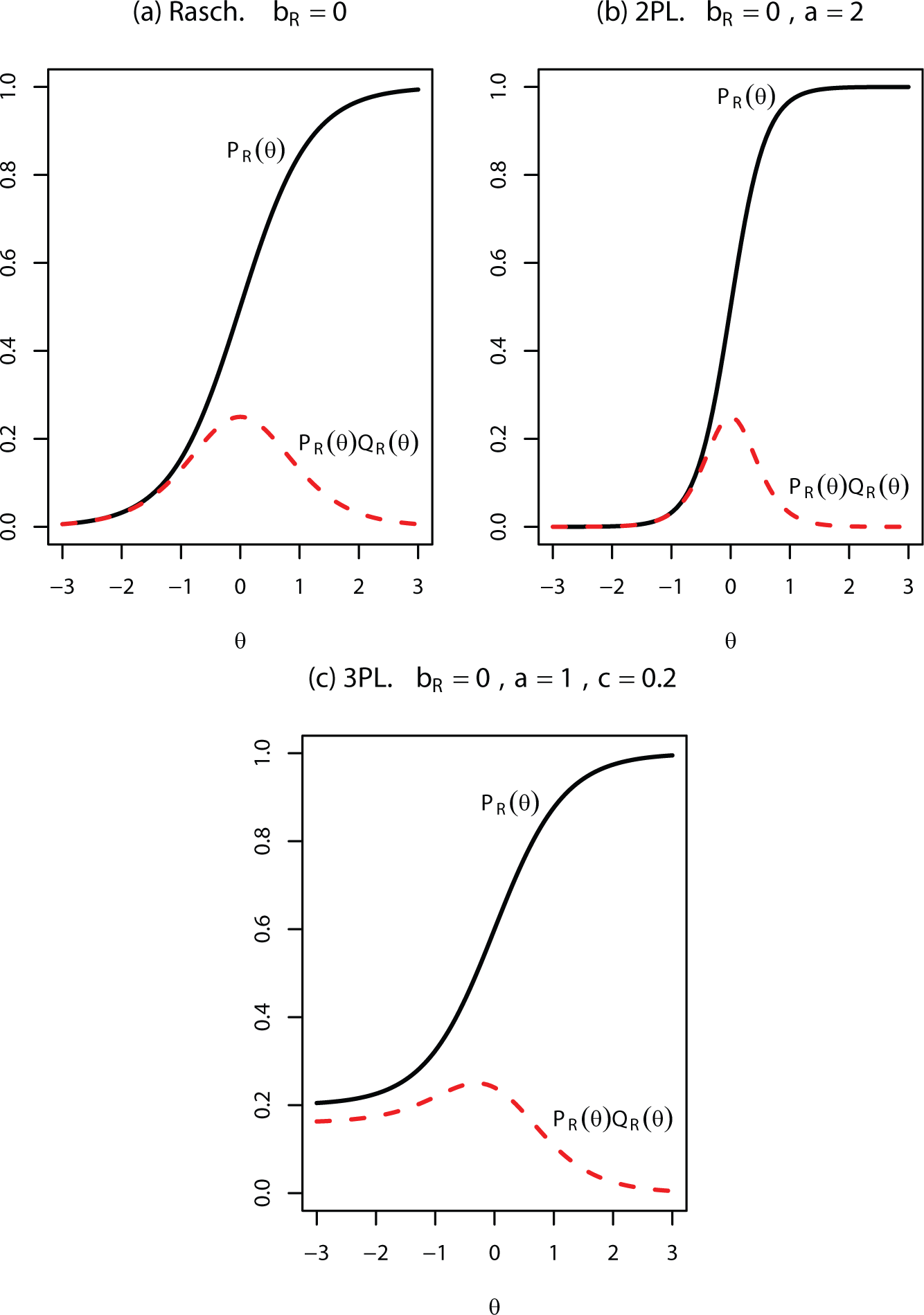
Figure 1 shows examples of the shape of the curve under the Rasch, 2PL, and 3PL models. The curve under the Rasch or 2PL model has a bell shape that resembles a normal density curve. It turns out that a normal approximation does exist for . Consider the 2PL models for and where and , so that . By Taylor expansion, we have the linear approximation
under Rasch, 2PL, and 3PL models.
where the second approximation is based on the logistic-normal approximation (see Online Appendix A, Equation 21).
Now consider the effect size β when is the density of the normal distribution with mean µ and standard deviation σ. By applying the normal approximation (Equation 9) and Equation 22 in Online Appendix B, the integral has a closed form approximation:
For the 3PL model with , , and , and , the effect size β has been shown (proof is given in Online Appendix B) to have a closed form approximate formula
From Equations 10 and 11, effect size β is the product of (1 −c), and the difference in difficulty , and the normal density function evaluated at , with mean µ and variance . Effect size β is large when an item’s difficulty is close to the mean ability of the population; that is, is small. It is hard to detect the DIF for an item that is too easy or too difficult relative to the target population because of the small effect size β.
How effect size β is influenced by a and σ is more complicated. Intuitively, a higher discrimination a will lead to a narrower shape for , which may change the size of β in different ways depending on the difficulty of the item that determines the relative location between the curve and the curve. If the item difficulty is close to the mean ability, a higher a will lead to a higher effect size because of increased overlap between the two curves. However, if the item is too easy or too difficult, a higher a may lead to a lower effect size because of decreased overlap. Online Appendix D provides a detailed discussion based on Equation 11.
Standard Error Under IRT Models
Beside the sample size N and the proportion , other factors that influence the standard error are reflected in the integral
To simplify the discussion, let us consider the situation where the reference and focal groups have the same latent trait distribution and the integral becomes
The integrand has two parts: is related to the item characteristics and is the latent trait distribution. Figure 2 shows the shape of the curve under Rasch, 2PL, and 3PL models. For the Rasch or 2PL models, the curve has a symmetric bell shape peaked around , whereas for the 3PL model, it has an asymmetric bell shape. For the 2PL model, the derivative of the IRF = ; therefore, has a bell shape as reflected by the logistic-normal approximation, and the area under the curve is
under the Rasch, 2PL, and 3PL models.
Under the 2PL model with a common discrimination a and the assumption that , by applying the logistic-normal approximation, we obtain the closed form solution in the same way Equation 10 was derived, resulting in
Together with Equation 10, a closed form solution for the power formula under the 2PL model is
Note that if is fixed, is not related to the standard error . When is given, will influence the integral in a similar way to how it influences β: As gets farther away from the mean of , the integral will become smaller, and, thus, the standard error will also get smaller. In this case, both β and get smaller, but the ratio gets smaller, because the numerator dominates the denominator with exponent 1 versus 1/2, as shown in the power formula Equation 13.
A larger discrimination parameter a tends to lead to a smaller standard error. However, as the behavior of the ratio is dominated by the numerator β, the power is influenced by a in a similar fashion as β influenced by a.
For the 3PL model, as , it can be derived that . Compared with the 2PL model with the same parameters and , a non-zero guessing parameter will lead to a larger standard error, and together with a smaller effect size, resulting in a smaller power for SIBTEST.
For the 3PL model with and , and assuming , a closed form approximation for the standard error has been derived (Online Appendix B):
Accordingly, the power formula is
When and Differ
In previous discussion, we assumed that the reference and focal groups have the same latent trait distribution. If the two distributions differ, the DIF effect size β can be written as
The effect size is large if the high value regions in both and overlap with the high value region in , which is unlikely to happen as the difference between the mean of reference and focal distributions increases. Therefore, as the size of the difference in population means increases, the power of SIBTEST tends to decrease.
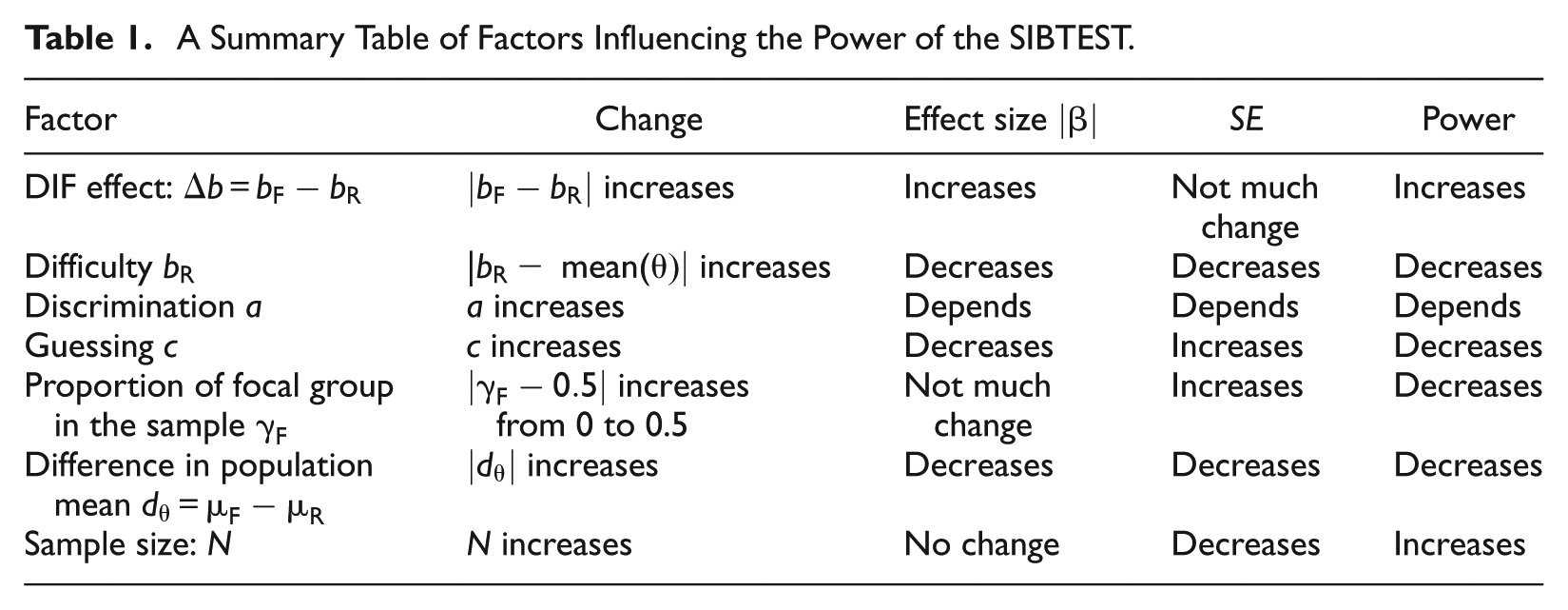
Table 1 summarizes what has been discussed so far. It lists the factors that may influence the power of SIBTEST, and how the change in each factor affects the DIF effect size, the standard error, and the power of SIBTEST. The situations we have discussed involve some typical factors in some typical setups. And we even derived some closed form formulas in these situations. However, the power formula (Equation 6 or 7) is very general, and its applicability should not be considered as only restricted to the situations we have discussed. For example, one situation we have not discussed is when the discrimination parameter in the 2PL or 3PL model has different values with regard to the reference and focal groups. Furthermore, there is no restriction that the IRF has to be 2PL or 3PL IRT models; it can be any form, for example, a normal ogive model, and so on. Also, the distribution of the latent trait may take forms other than the normal distribution.
A Summary Table of Factors Influencing the Power of the SIBTEST.
Factor
Change
Effect size
SE
Power
DIF effect:
increases
Increases
Not much change
Increases
Difficulty
|− mean( increases
Decreases
Decreases
Decreases
Discrimination a
increases
Depends
Depends
Depends
Guessing c
increases
Decreases
Increases
Decreases
Proportion of focal group in the sample
increases from 0 to 0.5
Not much change
Increases
Decreases
Difference in population mean
increases
Decreases
Decreases
Decreases
Sample size: N
increases
No change
Decreases
Increases
Sample Size Calculation
The most practical use of the power formula is probably the sample size calculation. Very often, one would like to calculate the minimal sample size N to achieve a certain power level (a well-accepted power value is 0.80). From the power formula, one can solve for N. For the one-sided test versus , the sample size formula is
For the two-sided test, the power formula does not have a closed form solution for N, but one can find the solution using numerical methods such as trial and error or a binary search algorithm.
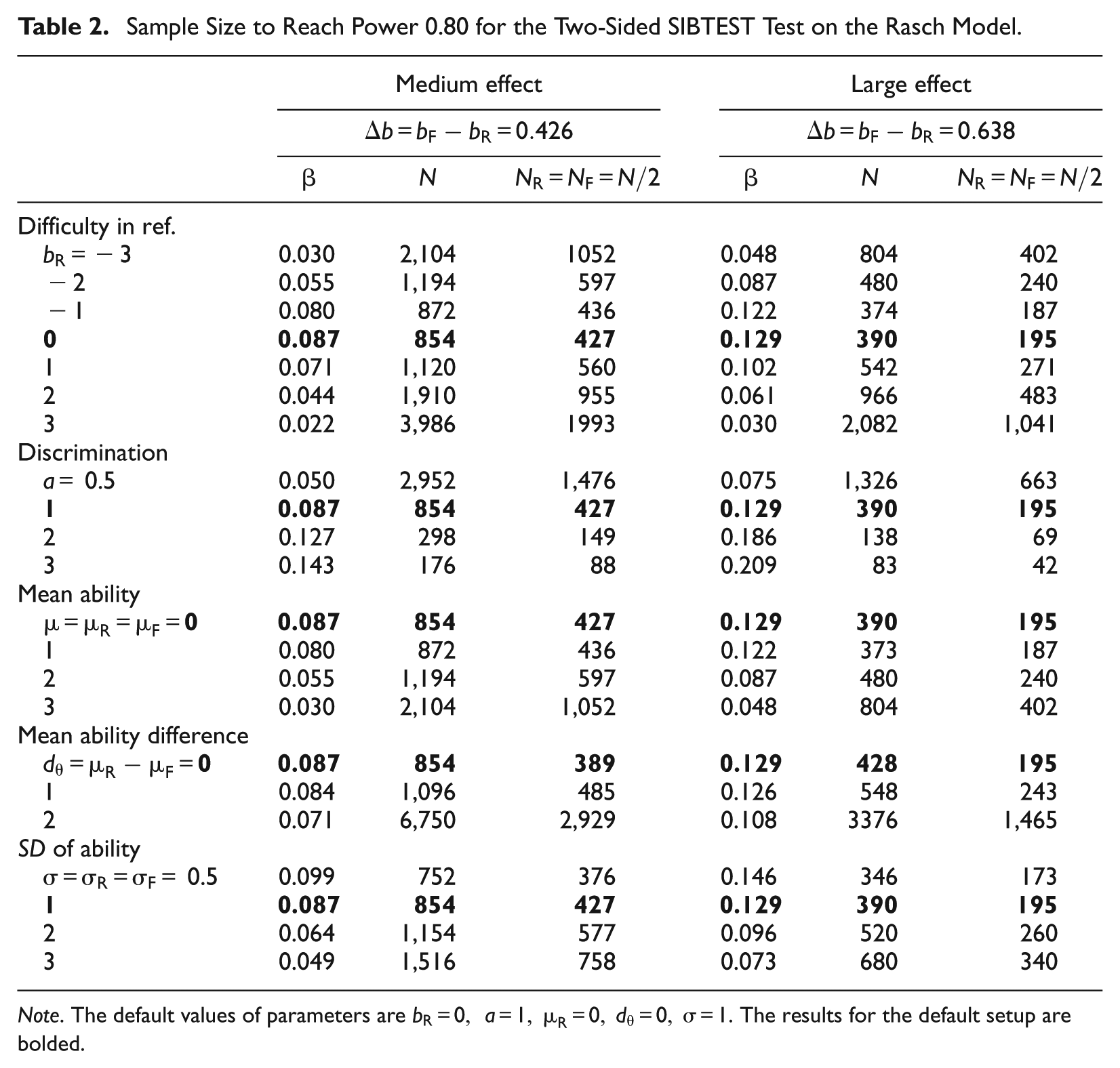
As an example, for the two-sided SIBTEST with a Type I error rate of 0.05, Table 2 shows the results of minimum sample size needed to achieve 0.80 power when the studied item follows the Rasch model. The default setup is that the reference difficulty for the studied item is 0; the latent trait distributions for both the focal and reference groups are N(0,1); and the group sizes are balanced . We consider two values for : a medium effect value of and a large effect value of (Paek & Wilson, 2011; also see Appendix B in the supplementary document on why these two values were chosen). Under the default setup, the required sample size is 854 () for ; and the required sample size is 390 () for . The table shows sample sizes in the cases when one of the following factors changes while keeping the rest fixed at default values: the reference difficulty bR, discrimination α, the mean ability µ, mean difference in ability , SD of the ability σ. In each case, the effect size β is also reported. Note that the sample size is related not only to the effect size β but also to the standard error ; therefore, different cases with similar β values may still have very different results for sample sizes.
Sample Size to Reach Power 0.80 for the Two-Sided SIBTEST Test on the Rasch Model.
Medium effect
Large effect
N
N
Difficulty in ref.
−3
0.030
2,104
1052
0.048
804
402
−2
0.055
1,194
597
0.087
480
240
−1
0.080
872
436
0.122
374
187
0
0.087
854
427
0.129
390
195
1
0.071
1,120
560
0.102
542
271
2
0.044
1,910
955
0.061
966
483
3
0.022
3,986
1993
0.030
2,082
1,041
Discrimination
0.5
0.050
2,952
1,476
0.075
1,326
663
1
0.087
854
427
0.129
390
195
2
0.127
298
149
0.186
138
69
3
0.143
176
88
0.209
83
42
Mean ability
0
0.087
854
427
0.129
390
195
1
0.080
872
436
0.122
373
187
2
0.055
1,194
597
0.087
480
240
3
0.030
2,104
1,052
0.048
804
402
Mean ability difference
0
0.087
854
389
0.129
428
195
1
0.084
1,096
485
0.126
548
243
2
0.071
6,750
2,929
0.108
3376
1,465
SD of ability
0.5
0.099
752
376
0.146
346
173
1
0.087
854
427
0.129
390
195
2
0.064
1,154
577
0.096
520
260
3
0.049
1,516
758
0.073
680
340
Note. The default values of parameters are . The results for the default setup are bolded.
Monte Carlo Simulation Study
For simulation study, we adopted a design that is very similar to the simulation study conducted by Uttaro and Millsap (1994). Their simulation study looked at the factors that influence the detection of DIF by the Mantel-Haenszel procedure; while, in this article, we generate simulated data in a very similar design to study the behavior of SIBTEST, comparing the results with those predicted by the power formula. Each simulated data set is generated from the IRT 3PL model. Two test lengths are used: a short test with 20 items and a long test with 40 items. In a test form, only 1 item is the studied item, and the rest (19 or 39 items) are anchor items. For anchor items, the difficulty parameters were randomly picked from a N(0, 1) distribution; the discrimination parameters were randomly chosen from values 0.5, 1.0, and 1.5; and the guessing parameters were randomly chosen from values 0, 0.1, and 0.2. The same set of 19 or 39 anchor items were used in all the simulated test forms. For the single studied item, the item parameters for the reference group were , , and . For the focal group item parameters and also the latent trait distributions, 36 conditions were considered by varying the following factors in a 3 × 3 × 2 × 2 factorial design with (a) three levels of discrimination parameter a: 0.5, 1.0, 1.5; (b) three levels of difficulty parameter b: 0.0, 0.3, 0.5; (c) two levels of guessing parameter c: 0.0, 0.2; and (d) two levels of differences in latent trait distribution means : 0.0, −1.0. In each data set, 1,000 reference group examinees and 1,000 focal group examinees were sampled from the distributions , and , respectively. Each case was replicated 10,000 times. In the SIBTEST analysis, the total score of the 19 or 39 anchor items was used as the matching variable to stratify the examinees, and the SIBTEST procedure with a two-sided alternative hypothesis was conducted on studied items.
Table 3 summarizes the parameters used in the 36 cases, and the results for β, SE, B statistic, and the power for the simulated data sets. Under each quantity, three values were reported: the theoretical value as given by the formula presented in this article, the summary value from the SIBTEST results on the simulated data sets with 20 items, and the summary value for the 40-item data sets. The summary values for β and B are the mean of the corresponding estimates from 10,000 replicated data sets, the value for SE is the Monte Carlo SE, and the power is the observed rejection rate based on the p < .05 criterion. From the table, we observe that the theoretical values for β agree very well with the observed Monte Carlo mean values from both 20-item and 40-item simulation data. The root mean square difference between the theoretical value for β and the Monte Carlo mean of the β estimates is .0036 for 20-item tests, and .0046 for 40-item tests. The root mean square difference between the observed rejection rate and the theoretical power is 0.031 for 20-item tests, and 0.016 for 40-item tests. These results confirm that the power formula is accurate and is useful in estimating the power, even for short test forms. For SE, the theoretical values are very close to yet consistently slightly lower than the observed values (differences range from 0.002 to 0.005, about 5% to 10% of the SE value). Also note that the observed SE values for 40-item tests are very slightly yet consistently lower than those from 20-item tests (differences less than 0.002). One explanation for this is that the SE formula assumes a perfect match in θ when comparing the difference in response probability between the reference and focal groups, thus it ignores the small variability introduced by matching on the total score of the anchor items instead of matching on . This variability is larger for short tests than for longer tests. The power of the 36 cases ranges from 0.05 (the cases where there is no DIF) to near 1. Note that over the 36 cases, the SE values are actually similar: The values are all around 0.030, which means that the main driving force in the variability of the power over the cases is the differences in the effect size β.
Note. Item parameters for reference group: , , = 0.2. Sample Size: , . Latent trait distribution: , Number of replicates in each case: 10,000. DIF = differential item functioning.
Cases with no DIF.
Discussion
In this article, we have derived a formula for calculating the power of the SIBTEST procedure for detecting DIF. The derivation is based on the asymptotic normal distribution of the SIBTEST test statistic, which assumes that the test length and the sample size are large. A comparison of the theoretical power from the formula and the observed rejection rate in the simulation studies has shown that the formula provides a close approximation to the true power and can thus be used in practical applications.
Several forms of the power formula for SIBTEST have been given in this article. For a dichotomous studied item, Equation 6 is a very general formula. In that formula, the IRFs, and can take either parametric or non-parametric forms, and so are the latent trait distributions, and . To conduct a power calculation, practitioners need to identify the models for the studied item and the distributions of the target populations, and have to make assumptions on some aspect of the item models. By using the standard error under the null hypothesis, the formula in Equation 7 releases practitioners from the burden of specifying the focal group IRF , which is usually unknown beforehand. And practitioners only need to specify the level of effect size β they care about.
In some cases, practitioners may still want to make assumptions on , that is, how should be different from . Does have the same type of IRT model as in the reference IRT model? If both and follow IRT 3PL model, shall we assume ? Shall we assume ? What values of to choose? The simulation study is a vivid example of the ramification of different choices of model for , while is the same, the different choices for in the 36 cases produce different power values. The good news is that the power formula can be applied to all these cases. Practitioners have to make decisions on what assumptions look reasonable or are of interest to their problem. For example, it is often reasonable to assume that and , and focus on the power calculation on different choices of . In this case, the closed form formulas in Equations 13 and 15 can be used.
The formulas for power and sample size calculation presented in this article have been implemented in an R package that is available to public at the author’s website.
Footnotes
Acknowledgements
The author thanks Dr. Louis Roussos for his suggestions. She also thanks the editor, the associate editor, and three anonymous reviewers for their constructive comments and feedback on the manuscript.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Boston College research expense grant.
Supplemental Material
The online appendices are available at
References
1.
BoltD. M. (2000). A SIBTEST approach to testing DIF hypotheses using experimentally designed test items. Journal of Educational Measurement, 37, 307-327.
2.
ChangH. H.MazzeoJ.RoussosL. (2005). Detecting DIF for polytomously scored items: An adaptation of the SIBTEST procedure. Journal of Educational Measurement, 33, 333-353.
3.
DeMarsC. E. (2010). Type I error inflation for detecting DIF in the presence of impact. Educational and Psychological Measurement, 70, 961-972.
4.
DoransN. J.KulickE. (1986). Demonstrating the utility of the standardization approach to assessing unexpected differential item performance on the Scholastic Aptitude Test. Journal of Educational Measurement, 23, 355-368.
5.
GierlM. J.GotzmannA.BoughtonK. A. (2004). Performance of SIBTEST when the percentage of DIF Items is large. Applied Measurement in Education, 17, 241-264.
6.
HollandP. W.ThayerD. T. (1988). Differential item performance and the Mantel-Haenszel procedure. In WainerH.BraunH. (Eds.), Test validity (pp. 129-145). Hillsdale, NJ: Erlbaum.
7.
HollandP. W.WainerH. E. (1993). Differential item functioning: Theory and practice. Hillsdale, NJ: Erlbaum.
8.
JiangH.StoutW. (1998). Improved Type I error control and reduced estimation bias for DIF detection using SIBTEST. Journal of Educational Statistics, 23, 291-322.
9.
LehmannE. L. (1999). Elements of large-sample theory. New York, NY: Springer.
10.
LiH.-H.StoutW. (1996). A new procedure for detection of crossing DIF. Psychometrika, 61, 647-677.
11.
LordF. M. (1980). Applications of item response theory to practical testing problems. Hillsdale, NJ: Erlbaum.
12.
NandakumarR.RoussosL. (2004). Evaluation of the CATSIB DIF procedure in a pretest setting. Journal of Educational and Behavioral Statistics, 29, 177-199.
13.
PaekI.WilsonM. (2011). Formulating the Rasch differential item functioning model under the marginal maximum likelihood estimation context and its comparison with Mantel-Haenszel procedure in short test and small sample conditions. Educational and Psychological Measurement, 71, 1023-1046.
14.
RajuN. S. (1988). The area between two item characteristic curves. Psychometrika, 53, 495-502.
15.
RaschG. (1960). Probabilistic models for some intelligence and attainment tests. Copenhagen, Denmark: The Danish Institute of Educational Research.
16.
RoussosL. A.StoutW. F. (1996). Simulation studies of the effects of small sample size and studied item parameters on SIBTEST and Mantel-Haenszel Type I error performance. Journal of Educational Measurement, 33, 215-230.
17.
ShealyR.StoutW. (1993). A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DTF as well as item bias/DIF. Psychometrika, 58, 159-194.
18.
UttaroT.MillsapR. E. (1994). Factors influencing the Mantel-Haenszel procedure in the detection of differential item functioning. Applied Psychological Measurement, 18(1), 15-25.
19.
WoodsC. M. (2011). DIF testing for ordinal items with poly-SIBTEST, the Mantel and GMH tests, and IRT-LR-DIF when the latent distribution is nonnormal for both groups. Applied Psychological Measurement, 35, 145-164.
20.
ZwickR. J. (1990). When do item response function and Mantel-Haenszel definitions of differential item functioning coincide?Journal of Educational Statistics, 15, 185-197.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.