
Abstract
Online calibration is a technology-enhanced architecture for item calibration in computerized adaptive tests (CATs). Many CATs are administered continuously over a long term and rely on large item banks. To ensure test validity, these item banks need to be frequently replenished with new items, and these new items need to be pretested before being used operationally. Online calibration dynamically embeds pretest items in operational tests and calibrates their parameters as response data are gradually obtained through the continuous test administration. This study extends existing formulas, procedures, and algorithms for dichotomous item response theory models to the generalized partial credit model, a popular model for items scored in more than two categories. A simulation study was conducted to investigate the developed algorithms and procedures under a variety of conditions, including two estimation algorithms, three pretest item selection methods, three seeding locations, two numbers of score categories, and three calibration sample sizes. Results demonstrated acceptable estimation accuracy of the two estimation algorithms in some of the simulated conditions. A variety of findings were also revealed for the interacted effects of included factors, and recommendations were made respectively.
Keywords
Invented about three decades ago (Stocking, 1988), online calibration is a technology-enhanced item calibration framework that pretests and calibrates new items on the fly during the continuous administration of computerized adaptive tests (CATs; Chang, 2014). Traditionally, CAT item banks are constructed using items calibrated from a separate pretesting event, usually administered under the paper-and-pencil testing mode, and there is a concern over the differential functioning of the items from the paper-and-pencil pretest to computerized adaptive operational mode. Now with the online calibration framework, after a CAT begins to operate using the initial item bank, new items can then be embedded inconspicuously within the operational tests and be pretested and calibrated within the same testing environment. This not only is cost-effective but also enhances the consistency in both the mode of testing and examinee motivation.
Another important feature of online calibration is that it offers great flexibility in individual treatment for each pretest item. Analogous to what individual examinees experience in an operational CAT, any single pretest item can enter the online calibration process at any time, be assigned to a specific sample of examinees, and exported from the calibration phase flexibly. During the operational test, the parameter values of the pretest items are constantly updated, based on which the sampling scheme can be dynamically adjusted. Online calibration is in fact an application of optimal design in the education setting (Berger & Wong, 2005).
Traditional statistical parameter estimation algorithms in item response theory (IRT) have been adapted into the novel setting of online calibration (e.g., Ban, Hanson, Wang, Yi, & Harris, 2001; Ban, Hanson, Yi, & Harris, 2002; Stocking, 1988; Wainer & Mislevy, 2000). The most popular estimation methods proposed for online calibration are the one EM cycle method (OEM; Wainer & Mislevy, 2000) and the multiple EM cycle method (MEM; Ban et al., 2001). These algorithms make use of the existing parameter values of the operational items and naturally put the calibrated parameter values of the new items on the existing IRT scale without linking procedures, which is a highly favored feature. However, the parameter estimation algorithms for online calibration have only been developed and studied for dichotomously scored items such as multiple-choice questions and true/false questions. Online calibration of polytomously scored items, that is, items scored in more than two categories, is yet to be explored.
Polytomously scored items are becoming increasingly important in educational assessments due to the growing emphasis on non-multiple-choice items such as performance-based items. In the past, multiple-choice items have been the most common item type in large-scale tests because of their ease in scoring and conducting other psychometric procedures. Nowadays, computers and other digital devices have made rich response data readily available, such as click streams and the corresponding time duration of examinees’ interaction with computers, and will continue to generate more and more diverse and informative “big data.” This allows for and also encourages many new item types to be incorporated in current and future assessments. Consequently, psychometric procedures must also be extended to these new item types, and one goal of this article is to extend current online calibration methods to polytomous IRT models. A number of polytomous IRT models have been developed in recent decades. This article will discuss how the OEM method and MEM method can be extended to one of the most commonly used polytomous IRT models, the generalized partial credit model (GPCM; Muraki, 1992).
This article first presents a detailed description of the procedures, algorithms, and formulae for online calibration both in general and specific for polytomous items. This offers extensive information to researchers who are interested in replicating or extending the study and practitioners who are interested using the methods. Then a simulation study is presented, which examined the calibration results from the two calibration methods under a set of conditions fully crossed by three pretest item selection methods (random selection [RAND], maximum
General Workflow of Online Calibration
The general procedures of online calibration can be summarized by Figure 1. First, a pretest item bank is formed by items to be calibrated. Then, during the operational test, when an examinee reaches a seeding location (i.e., an item position in the operational test allocated for pretest items), a pretest item is selected from the pretest item bank based on certain item selection rules. Examinees’ responses to these pretest items are not included in the scoring procedure, but only used for calibrating the item parameters. When the examinee finishes the test, the parameters of those administered pretest items are updated through statistical estimation. Sampling and parameter update are repeated for every new examinee or every new batch of examinees, where the sampling parameters are constantly adjusted based on the updated item parameter values. The sampling process of each pretest item can be terminated and the item can be exported from the pretest item bank individually once a satisfactory accuracy of the parameter estimation is achieved or the maximum sample size is reached. Finally, the exported pretest items are reviewed and, if approved, put into operational use.

Flowchart of online calibration.
Computation Logistics of Online Calibration
Because online calibration embeds item calibration in the continuous administration of the operational CAT, its data handling logistics and algorithms are different from those used for traditional item calibration with “static” response data. In traditional item calibration, all necessary response data are collected in full as the first step, and then a response matrix, which can be sparse sometimes, is prepared. This response matrix is then entered into a calibration program, which outputs the calibrated parameter values for all items of interest. In contrast, online calibration is an evolving process. More response data accumulate as more examinees take the test sequentially. To facilitate a sequential optimal design, the parameters of a pretest item need to be updated each time a new data point is received (termed fully sequential) or each time a batch of new data points is received (termed group sequential). Another complexity of online calibration is that each pretest item is taken by a different sample of examinees, and these examinees also take different sets of operational items. To calibrate any pretest item, data from all examinees who received this item are needed, which include both their responses to this item and their responses to all the varied operational items they took.
To facilitate online calibration, as each incoming examinee finishes the test, the following data must be stored in the database immediately. First, for each pretest item
The item parameters of all the operational items in the operational item bank, denoted by
If a fully sequential design is used, every time an examinee finishes the test, all pretest items administered to him or her will be estimated one by one. For a pretest item
The GPCM
A variety of polytomous IRT models have been developed to model item response data scored in more than two categories. Among the available models, the GPCM (Muraki, 1992) is especially appropriate for and, thus, popular in education settings. More details on polytomous IRT models are given in online appendices.
As described by Muraki (1992), GPCM was developed based on the assumption that the conditional probability of selecting the
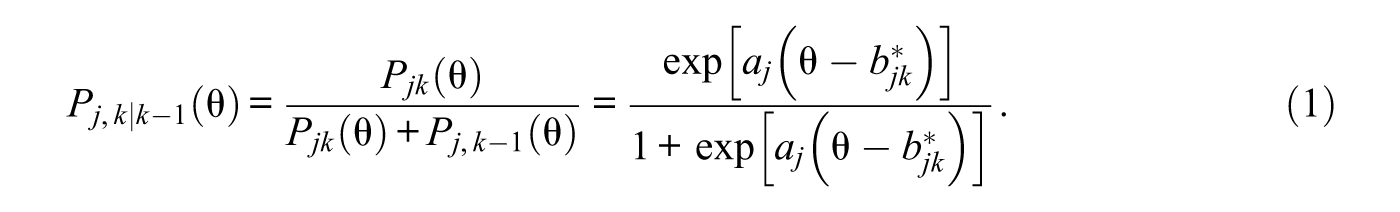
Assuming there are a total of

where
After fusing with Rating Scale Model (RSM) (Andrich, 1978), Muraki (1992) finally formulated GPCM into the following ICRF, which was used in this simulation study:
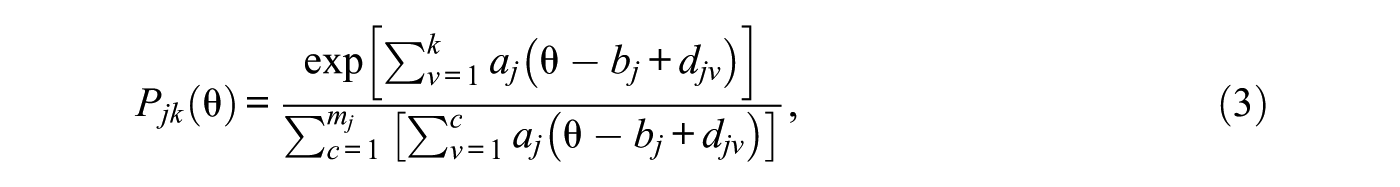
where
OEM and MEM: Marginal Maximum Likelihood Estimation (MMLE) With Expectation-Maximization (EM) Algorithm
With necessary examinee response data and operational item parameter data, a variety of estimation algorithms can be utilized to generate item parameter estimates for pretest items. This article focuses on two popular algorithms: OEM and MEM. Both OEM and MEM are based on the framework of MMLE with the EM algorithm. This framework integrates out (i.e., marginalizes) the examinee ability parameter
Simulation Study Design
A simulation study was conducted using a Fortran program written by the author to investigate the performance of the online calibration procedures and algorithms under various conditions. The program simulated the entire online calibration workflow including the operational CAT and the sequential sampling and calibration of the pretest items, replicated for 100 times. The study included five factors: estimation method (OEM and MEM), number of score categories (3 and 4), pretest item selection method (RAND, MTFI, and MATB), seeding location (early, middle, late in the test), and calibration sample size (approximately 200, 500, 1,000).
Generation of Item Parameters
In each replication, 300 operational items were randomly generated under the GPCM model from the following distributions:


The pretest items were fixed at 20 prechosen parameter combinations to examine conditional results for items with distinctive characteristics. The

Category characteristic curves for the simulated pretest items with
As shown in Figure 2, in both the three-category and four-category conditions, the first combination of
The
CAT Workflow
In each replication, 4,000 examinee ability
During the test, operational items were selected from the operational item bank using the maximum Fisher information method, a typical operational item selection method in CAT. The Fisher information of a GPCM item
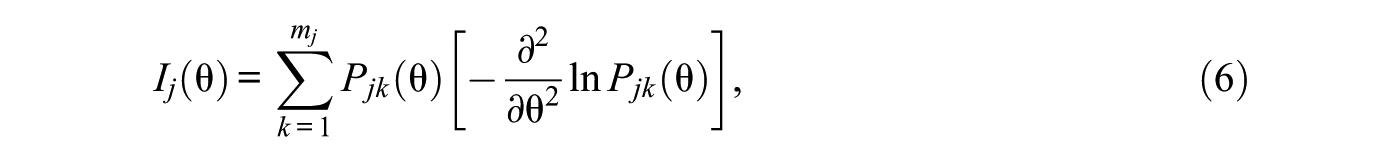

where
When an examinee reaches a seeding location, one of the pretest items in the pretest item bank was selected and administered. Examinees’ responses to pretest items were not used to update
Pretest Item Selection Methods
Three pretest item selection methods were included in this simulation study: RAND, MTFI, and MATB. In RAND, one pretest item was randomly selected from the pretest item pool when an examinee reaches a seeding location.
In MTFI, the pretest item that maximizes the Fisher information for
MATB is a model-based heuristic item selection method. This method matches the mean of provisional estimates of
Seeding Locations
Although in the proposed online calibration workflow, pretest item parameters are not updated until the end of any examinee’s test, seeding location may still influence calibration results when pretest items are selected adaptively, because adaptive item selection methods involve
Thus, seeding location was included as a factor in the simulation study, and three levels were chosen for seeding location: (a) early in the test (Items 6 through 10), (b) in the middle of the test (Items 19 through 23), and (c) late in the test (Items 32 through 36). For each examinee, five different pretest items were seeded in one of those seeding ranges. In real practice, a seeding strategy with more randomness may be more acceptable than this fixed seeding because the latter may lead to differentiated motivation if the seeding locations are known by examinees. However, the seeding locations were fixed in this simulation study to better reveal the effect of seeding locations.
Calibration Sample Sizes
In this simulation study, item parameter estimates were recorded at three different time points when 800, 2,000, 4,000 examinees have taken the test. With random pretest item selection, given that each examinee takes five pretest items and there were a total of 20 pretest items, these chosen conditions corresponds to an average of roughly 200, 500, and 1,000 calibration samples per pretest item.
Evaluation Criteria
The simulation results were evaluated through the root mean square errors (RMSEs) of the estimates of each item parameter, formulated by Equation 8.
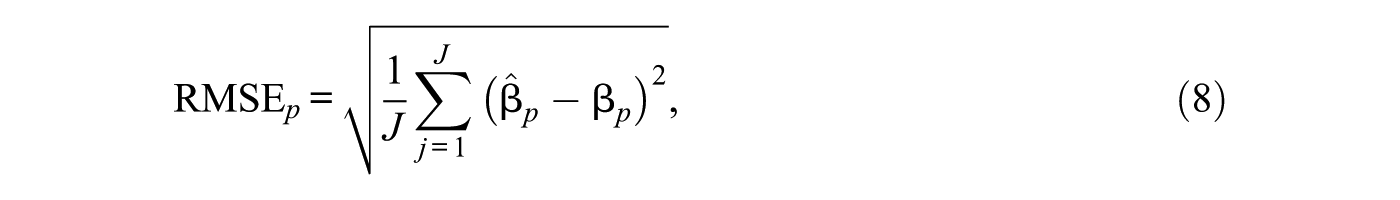
where
Simulation Results
Results of the simulation study were averaged across the 100 replications and are presented in Figures 3 to 8.

The RMSE of the
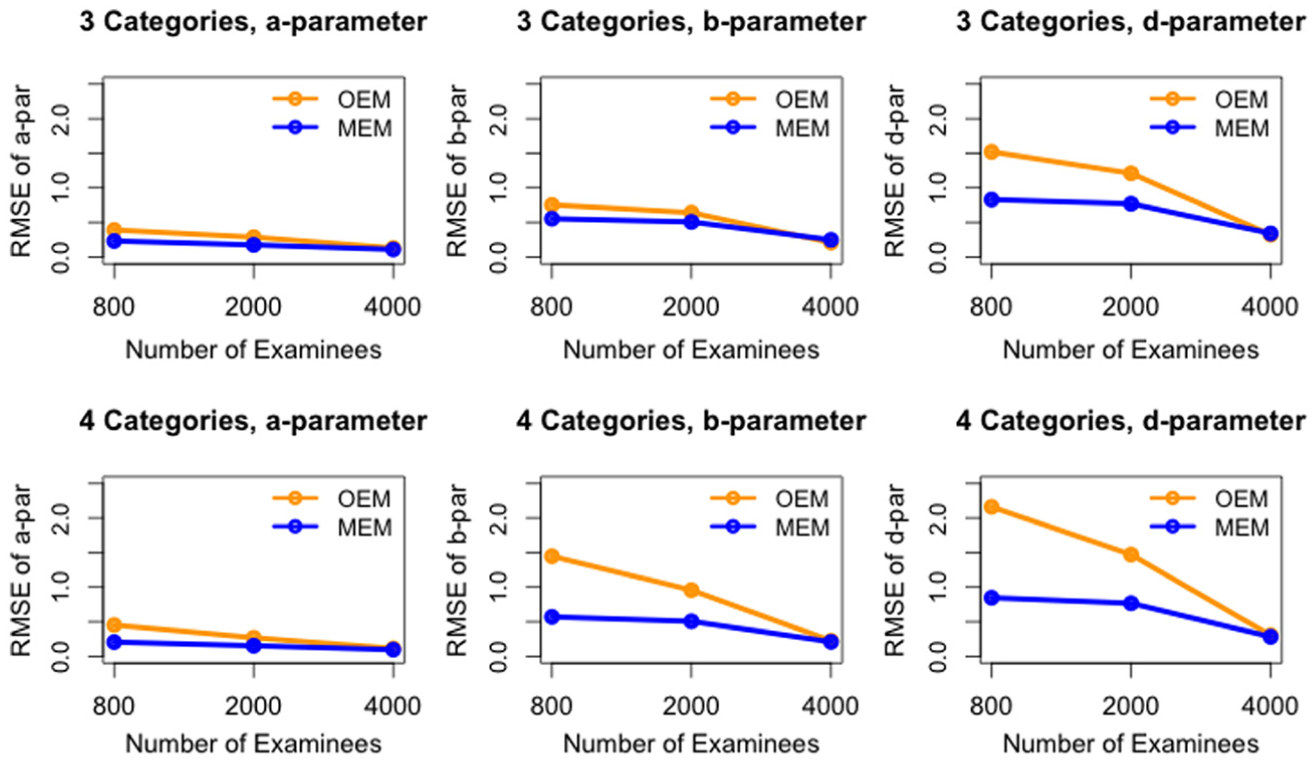
The RMSE of the
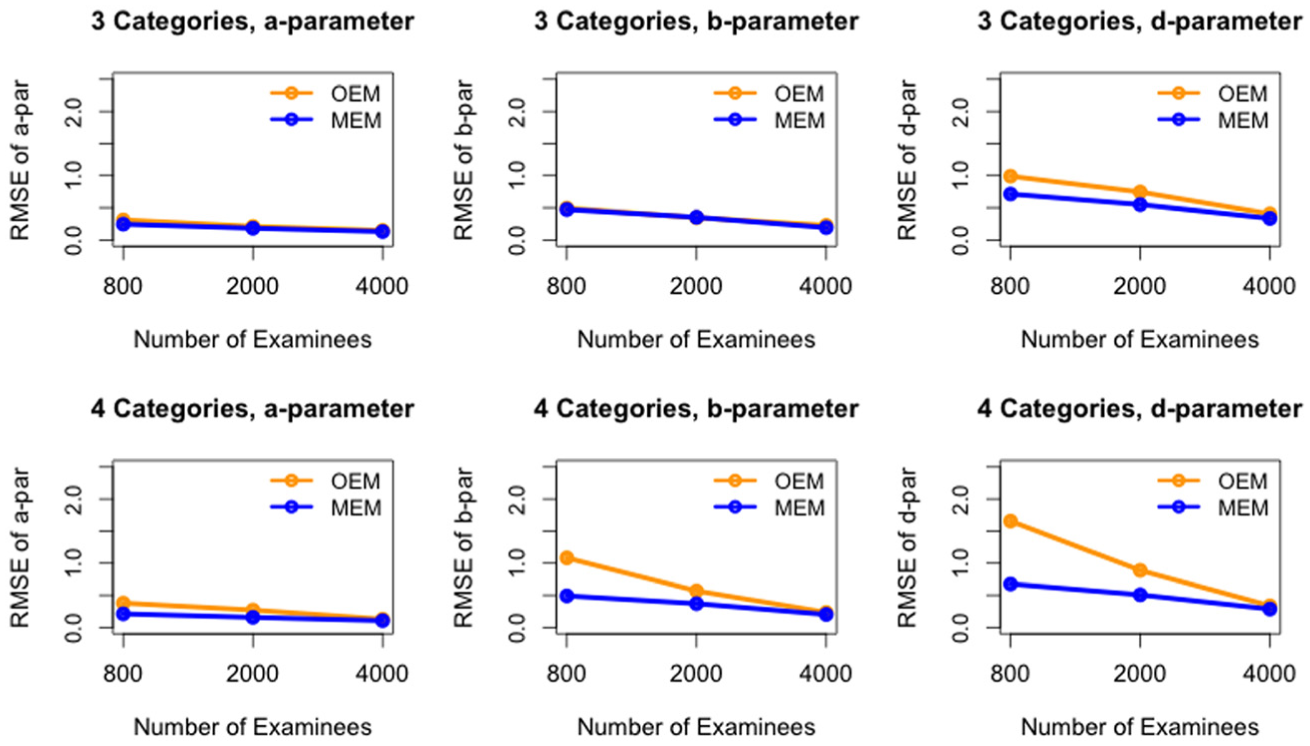
The RMSE of the

The RMSE of the

The RMSE of the
The RMSE of the
Effect of Seeding Locations
Effects of seeding locations were almost unnoticeable from results of the simulation. In other words, graphs of the RMSEs of item parameter estimates look fairly similar for early, middle, or late seeding locations under various conditions with regard to other factors. This may suggest that, on overall, seeding location does not make much difference in the eventual calibration outcome in the highly complicated online calibration system, which could provide test developers with more flexibility in randomly seeding pretest items throughout the entire test so that it is less predictable by the examinees, resulting in less contaminated calibration data.
Because of the similarity among seeding locations, to provide a clearer and more focused presentation, only results from late seeding location are presented in the article. Results from early and middle seeding locations are given in online appendices.
Interacted Effects of Sample Sizes, Number of Categories, Estimation Algorithms, and Pretest Item Selection Methods
Figures 3 to 5 present the effect of calibration sample size under various conditions. As described in the “Simulation Study Design” section, item parameter estimates were recorded 3 times in each replication—when 800, 2,000, and 4,000 examinees finished the test. With random pretest item selection, these correspond to calibration sample sizes of about 200, 500, and 1,000 for each pretest item. For the other two item selection methods, the actual sample sizes can vary for different items. For all conditions, calibration accuracy (as reflected by low values in RMSE) increases as sample size increases, which empirically verifies the consistency of the estimation algorithms.
Across all conditions, 200 seems too small a sample size for a reasonable calibration accuracy. When the sample size gets to about 1,000 per item, all conditions seem to have reasonable and similar average RMSE values across all items. (Yet conditional results are different for individual items. See the next section for details.) When the sample size is about 500 per item, pretest item selection methods and estimation algorithms make a difference. For RAND with both OEM and MEM, and MATB with MEM, there was only small improvement in calibration accuracy from the sample size of 500 to 1,000, so 500 could be an economic sample size with reasonable calibration accuracy for these settings. However, for MATB with OEM, and MTFI with both OEM and MEM, RMSE with the sample size of 500 was still noticeably larger than with sample size of 1,000. Therefore, it is recommended that appropriate calibration sample sizes should be chosen with respect to both the pretest item selection method and the parameter estimation approach.
The estimation of the three-category model was noticeably more accurate than the estimation of the four-category model for OEM conditions. For MEM conditions, the two models did not show noticeable difference. In both models, the estimation of
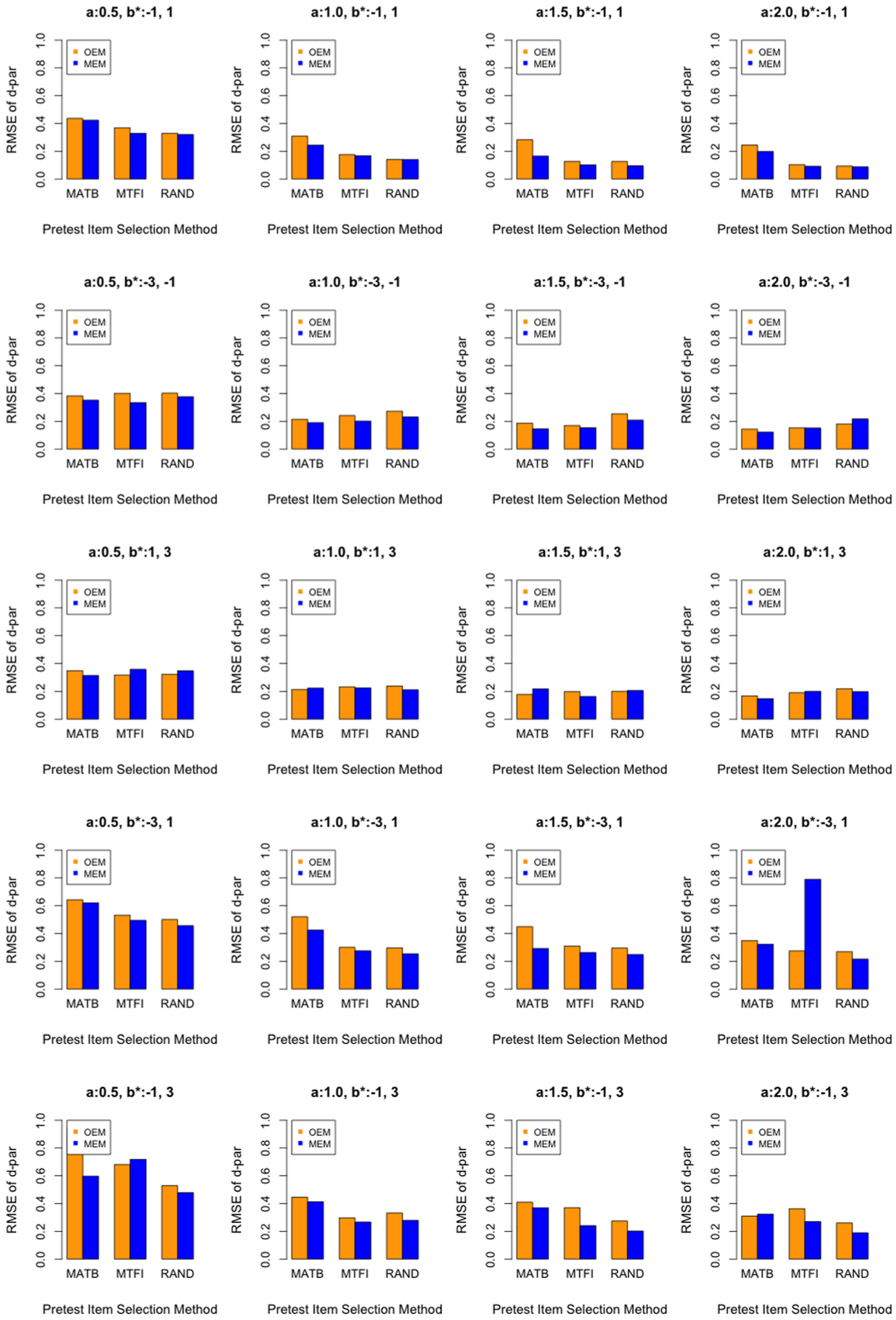
Conditional RMSE Results for Individual Items
Figures 6 through 8 summarize RMSE values of each individual pretest item under various conditions when the average sample size was 1,000 per item. As explained earlier and shown in Figure 2, the 20 pretest items were generated by crossing four typical and distinctive
Comparing calibration algorithms
Comparing OEM and MEM, when the sample size was as large as about 1,000 per item on average, OEM and MEM generated quite comparable RMSE values. Most of time, MEM was slightly more accurate than OEM. Considering that MEM takes considerably longer time than OEM in computation, OEM may be a viable option when sample size is large. But remember from Figures 3 to 5 that when sample size is small, MEM was significantly more accurate than OEM.
Comparing different items
Regarding
Regarding
Interesting observations emerge from the patterns in calibration accuracy of
Comparing pretest item selection methods
Comparing the three pretest item selection methods, the most common trend across the three investigated item selection methods is that RAND generated slightly more accurate item parameter estimates than MTFI, which is in turn slightly more accurate than MATB. This trend is reversed only in
This seemingly counter-intuitive result can be further understood by examining the distributions of
The inferior performance of MTFI is no surprise because the operational item selection method, which is the maximum Fisher information method in this study, is typically designed to optimize the measurement accuracy for the examinee ability parameter
These results also suggest that a more spread
Discussion
This study extended two estimation algorithms for online calibration, OEM and MEM, which were originally developed for dichotomous IRT models, to the GPCM, a popular IRT model for polytomously scored items. Detailed description of the algorithms and the unique computation logistics of online calibration were given in the article, which may assist researchers and practitioners in applying these methods or replicating or extending the study.
A simulation study was conducted to investigate the performance of the developed OEM and MEM algorithms under a variety of conditions. Results showed that both OEM and MEM were able to generate reasonably accurate parameter estimates with a sample size of about 1,000 per item. MEM was more accurate than OEM when sample size was smaller, but took longer to complete because of the multiple EM cycles.
This study also revealed the following key findings. (a) All seeding locations generated similar results. Thus test developers may have more flexibility to embed pretest items throughout the entire test. (b) When OEM was used, parameter estimation was noticeably more accurate for the three-category model than the four-category model; when MEM was used, the two models do not show noticeable difference. (c) In most conditions RAND generated more accurate parameter estimates than MTFI and MATB, and this may be attributed to the difference in distribution of
Cautions should be used in interpreting or generalizing the findings from the study, because the findings are limited by the specific test design, calibration design, numbers and distributions of the simulated item parameters,
Also note that the item parameters calibrated through online calibration not only can be used in subsequent operational CAT tests, but they may also be useful in assembling tests in other formats, including linear tests (e.g., Veldkamp, Matteucci, & de Jong, 2013) and multistage tests (e.g., Zheng, Wang, Culbertson, & Chang, 2014). If format difference is of concern in using these item parameters for scoring, the items can be re-calibrated with response data collected in the actual delivery format, but still these item parameters obtained from online calibration can provide reasonable approximation in the test assembly step.
There is a great need for more research in online calibration. For example, more research is needed to investigate the methods in similar or new settings to corroborate or compare with the findings from this article. In addition, this article revealed many interesting empirical patterns in conditional results—more theoretical work is needed to find explanations for these patterns.
Furthermore, because neither of the two adaptive pretest item selection methods investigated in this study showed superior performance than RAND, it is of great interest to develop optimal-design-based, “item-centered” pretest item selection methods (Zheng, 2014; Zheng & Chang, 2014) for polytomous IRT models to hopefully better capitalize on the power of online calibration. Here item-centered pretest item selection methods refer to those that rely on criteria derived for item parameter estimation, such as the D-optimal criterion (i.e., determinant of item parameter information matrix), as opposed to examinee-centered criteria, which are derived for examinee parameter estimation, such as maximum
The algorithms discussed in this article can also be extended to other polytomous IRT models. Also along this line are termination rules—termination rules originally developed for multidimensional CAT (Wang, Chang, & Boughton, 2013) may be adapted into online calibration settings. Finally, using online calibration to build vertical scales (Li & Lissitz, 2012; Tong & Kolen, 2007) and detect item parameter drift (Babcock & Albano, 2012; Guo, Zheng, & Chang, 2015) remains promising future directions.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.