
Abstract
Many educational testing programs require different test forms with minimal or no item overlap. At the same time, the test forms should be parallel in terms of their statistical and content-related properties. A well-established method to assemble parallel test forms is to apply combinatorial optimization using mixed-integer linear programming (MILP). Using this approach, in the unidimensional case, Fisher information (FI) is commonly used as the statistical target to obtain parallelism. In the multidimensional case, however, FI is a multidimensional matrix, which complicates its use as a statistical target. Previous research addressing this problem focused on item selection criteria for multidimensional computerized adaptive testing (MCAT). Yet these selection criteria are not directly transferable to the assembly of linear parallel test forms. To bridge this gap the authors derive different statistical targets, based on either FI or the Kullback–Leibler (KL) divergence, that can be applied in MILP models to assemble multidimensional parallel test forms. Using simulated item pools and an item pool based on empirical items, the proposed statistical targets are compared and evaluated. Promising results with respect to the KL-based statistical targets are presented and discussed.
In educational measurement there are many cases where different sets of items (i.e., test forms or item pools) are required to be parallel. That is, test forms 1 are required to be equivalent in terms of both their statistical and content-related properties. Without being exhaustive, the need for parallel test forms can arise in the following situations. High-stakes educational testing programs may require multiple parallel test forms with minimal or no item overlap for fair, secure, and valid test scores. Computerized adaptive testing (CAT) administrations may need multiple parallel item pools, which can be applied at different time points. Multistage testing may require the subtests at each stage to be parallel with an ideal, preconceived subtest to meet measurement precision and content-related requirements. Large-scale low-stakes assessments that apply a balanced incomplete block design often require item blocks that (a) are nonoverlapping, (b) have a prespecified expected overall response time, and (c) meet a specified precision across a predefined ability range. Yet, regardless the situation, constructing these parallel test forms is not straightforward.
Assembling multiple parallel test forms out of a calibrated item pool has proven to be a complicated combinatorial optimization problem. Rather than by hand, test forms are comonly assembled automatically. Different automated test assembly (ATA) methods are available; some are based on sampling-and-classification methods such as the Cell Only and the Cell and Cube methods (Chen, Chang, & Wu, 2012), and others rely on constrained combinatorial optimization techniques (e.g., Finkelman, Kim, & Roussos, 2009; Luecht, 1998; van der Linden, 2005). The most commonly used optimization technique involves translating the ATA problem to a mixed-integer linear programming (MILP) model (Diao & van der Linden, 2011; Theunissen, 1985; van der Linden, 2005). This article focuses on the MILP approach for ATA problems, and specifically on the Minimax approach for the assembly of parallel test forms (Boekkooi-Timminga, 1990; van der Linden, 2005) within item response theory (IRT) framework.
The literature on parallel test assembly is currently limited to unidimensional IRT (UIRT). Yet multidimensional test administrations may also require parallel test forms. Therefore, the main aim of this article is to extend the Minimax approach to multidimensional IRT (MIRT; Reckase, 2009). To bridge this gap, the authors propose new statistical targets and evaluate their performance in both unidimensional and multidimensional cases. Although the article focuses on assembling multiple test forms with parallel expected score distributions and parallel measurement error, the proposed methods can also consider different targets (e.g., testing time and precision) or even assemble one optimal test form.
The remainder of this article is organized as follows. First, the authors introduce the item response and Fisher information (FI) functions in MIRT. Then, they discuss the MILP model approach for ATA, with a focus on Minimax models (van der Linden, 2005). Subsequently, they explain the challenge that arises with ATA of parallel test forms in the multidimensional case and propose six approaches that mitigate this issue. They first translate the two approaches proposed by Veldkamp (2002) to the case of parallel test assembly. Then, they introduce the Kullback–Leibler (KL) divergence and subsequently propose four KL-based approaches. These sections can be found in Online Appendices A and B. In the “Method” and “Results” sections, the six approaches are evaluated using simulated one- and two-dimensional item pools, as well as a three-dimensional bifactor model case that is based on data from an operational language aptitude test. The article ends with a discussion of the results.
MIRT
Due to its diagnostic feature and potential for exploiting correlated subskills, MIRT has gained more attention recently. Many certification and admission boards want to enhance their high stakes tests with multidimensional scale scores that can be used as a diagnostic service to inform candidates (Mulder & van der Linden, 2009b), but also for decision making. MIRT reflects testing for diagnosis by viewing ability as a
According to the multidimensional extension of the two-parameter logistic model (2PLM; Birnbaum, 1968), the probability of a correct response on item
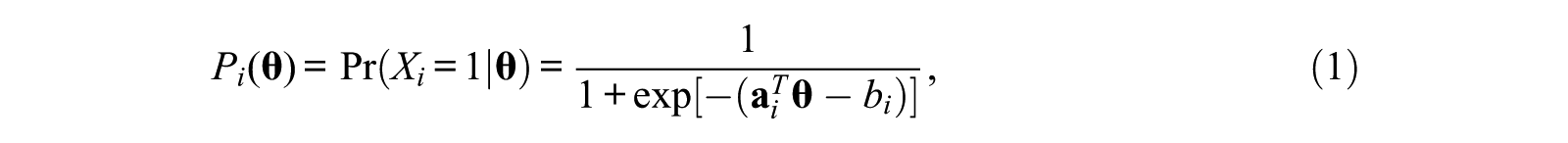
where
The test characteristic curve (TCC) for a test with n items describes the expected test score for a given ability

In addition, under local independence, the likelihood of a response pattern
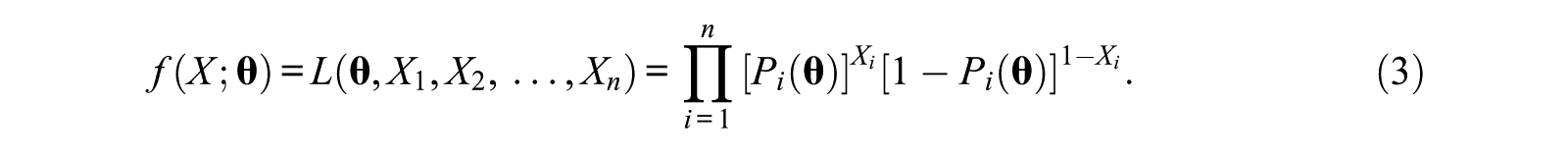
Fisher Information
In maximum likelihood theory, the variance of the score function is referred to as FI. It is a measure of the information that a random variable carries about an unknown parameter. In MIRT, with

The inverse of this
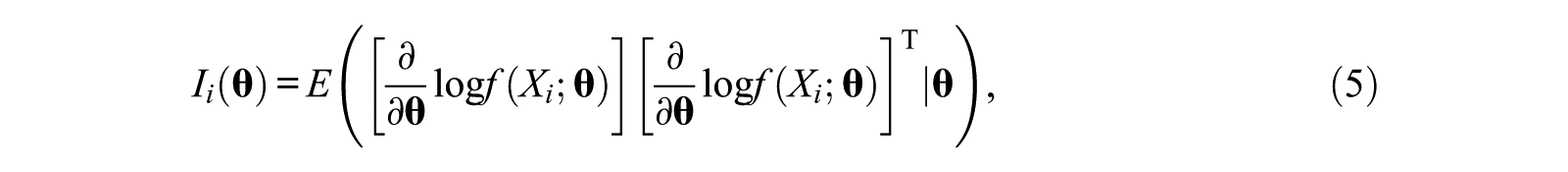
where
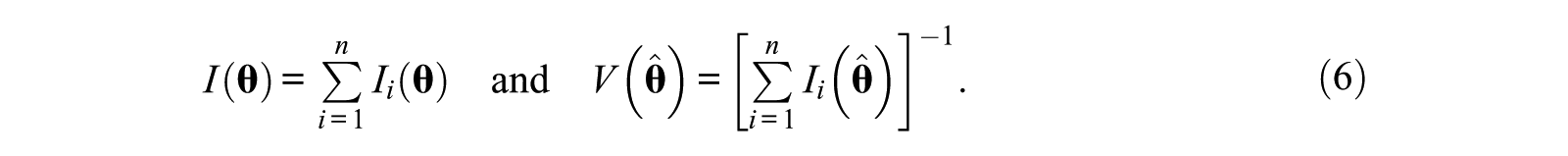
Test Assembly via MILP
Translating the ATA problem to a MILP model is a common technique (Diao & van der Linden, 2011; Theunissen, 1985; van der Linden, 2005). Because MILP and linear programming models are widely used in various industries, efficient algorithms have been developed and various software packages (usually referred to as “solvers”) are available. For an overview of both commercial and open source solvers that can be used for ATA problems, see Donoghue (2015).
MILP models are linear programming models for which (some of) the variables are restricted to integer values. When variables in a MILP model are further restricted to be binary, they can be interpreted as decision variables. In the context of ATA, each decision variable relates to whether or not a specific item from the pool is selected into a specific test form. In general, a MILP model includes two main parts (Ali & van Rijn, 2016; Diao & van der Linden, 2011): (a) the objective function,

and (b) a set of inequality constraints,

where
The specifications that assembled test forms should satisfy, such as the number of items from a specific content domain, can also be divided into objectives and constraints (van der Linden, 2005). Constraints require a test or item attribute to satisfy an upper or lower bound. Objectives require an attribute to take a minimum or maximum possible value. Translating the constraints and the objectives from the ATA problem to a MILP model with inequality constraints and an objective function is generally straightforward.
Minimax Models
Although there are other MILP approaches available for the ATA of parallel test forms, the authors only focus on the Minimax approach (Boekkooi-Timminga, 1990; van der Linden, 2005). The Minimax approach is one of the most commonly used MILP approaches and it works as follows. First, the desired reference or target test form, which can be based on either an existing or an ideal test form, is decided. Then, after choosing the statistical target (i.e., the statistic that is used to attain parallelism), the Minimax model minimizes the maximum distance between the statistical targets of each assembled test form and the statistical target of the reference test form (Chen et al., 2012).
If
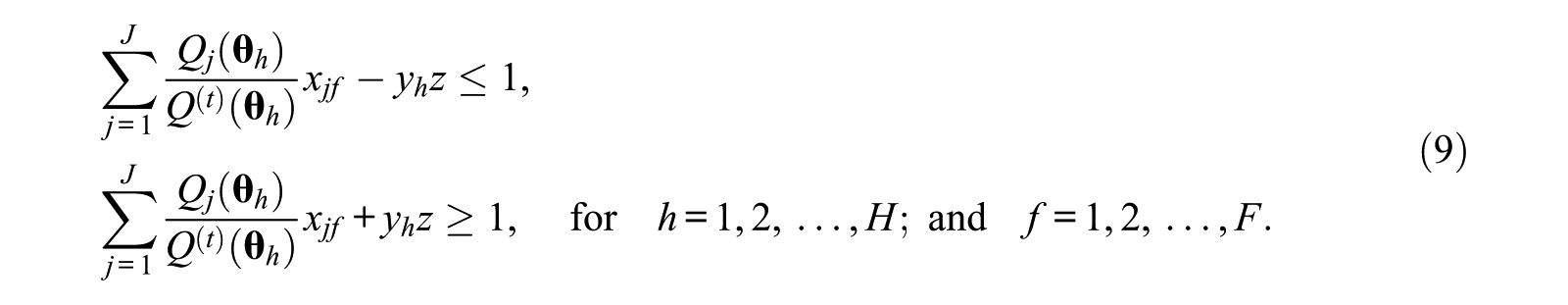
where
When all

results in
Statistical Targets in Minimax Models
As can be seen in Equation 9, there is an important restriction for a statistical target
The Multidimensionality Issue
Regardless the dimensionality of the ability
Previously proposed strategies to mitigate this multidimensionality issue mainly focus on MCAT, where the item selection procedure is based on sequentially selecting the next item. These MCAT item selection criteria either transform the test information matrix into a scalar using a function (e.g., D-optimality), or define a new (scalar) statistical target that is derived from other information measures, such as Shannon’s Entropy (Wang & Chang, 2011), mutual information (Mulder & van der Linden, 2009a), or the KL divergence (Veldkamp & van der Linden, 2002). The item selection criteria from MCAT are, however, not directly transferable to the ATA of linear test forms. In addition, the few strategies that have been proposed specifically for the ATA of multidimensional linear tests (a) require interventions from the test assembler (van der Linden, 1996) or (b) focus on the construction of one optimal test, rather than multiple parallel test forms (van der Linden, 1996; Veldkamp, 2002). Therefore, our main aim is to contribute to the literature by presenting and evaluating six statistical targets that mitigate the multidimensionality issue, with a focus on the assembly of multiple parallel test forms. The authors first extend the approach proposed by Veldkamp (2002) to parallel test assembly. Then, they propose four new statistical targets based on KL divergence.
Scalar Aggregates of FI Matrix and Its Inverse
In MCAT, several strategies have been proposed to reduce the FI matrix (or the variance-covariance matrix) into a single scalar. Two of these methods are A-optimality and D-optimality. These strategies are, however, not directly applicable in MILP. To overcome this issue, Veldkamp (2002) proposed to use linear approximation of the A-optimality and D-optimality constraints. The work of Veldkamp (2002) was limited to the assembly of one optimal test. In this article the authors extended it to the assembly of multiple parallel test forms. For both D-optimality and A-optimality the resulting constraints are
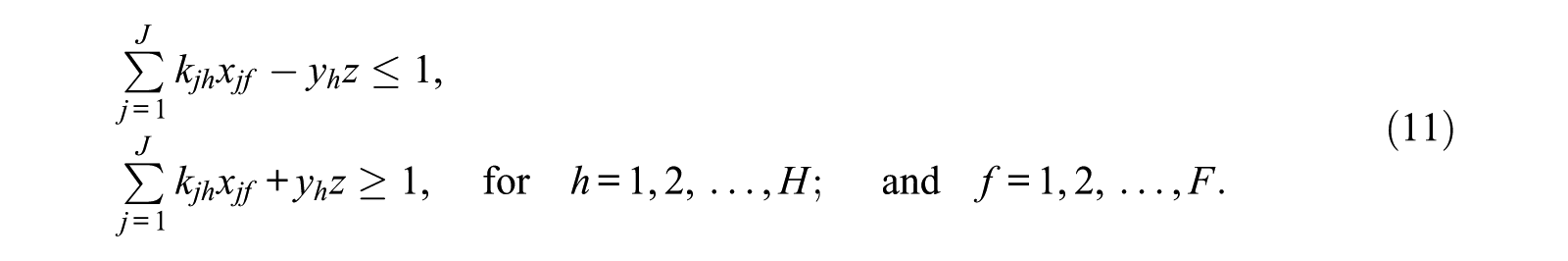
The principle behind A-optimality and D-optimality, and the formulae and derivations of the linear approximations
KL-Based Statistical Targets
The FI is not the only measure that can be used to quantify the information contained in a random variable or in a distribution. Alternative information measures have been proposed, such as the KL divergence, which expresses the divergence (i.e., nonsymmetric distance) between two probability distributions
Online Appendix B discusses how an KL Index (KLI) can be derived from the KL divergence and applied in CAT and MCAT. From this starting point, it is explained how KL-based statistical targets can be defined. Three KLIs that can be applied as statistical targets in ATA using MILP are proposed: the
Method
In this section the authors describe the design and the technical details of three simulation studies. Simulation 1 focuses on the unidimensional case and compares the performance of the proposed KLIs with the performance of the FI and TCC as the statistical targets in Minimax models. Simulation 2 applies the KLIs, the linear approximations of D- and A-optimality, and the TCC to two-dimensional item pools. Finally, Simulation 3 is based on an operational language aptitude assessment and focuses on a three-dimensional bifactor model.
Simulation 1: Unidimensional Item Pool
In the first simulation, five 30-item test forms are assembled out of an item pool with
Item pool
In each replication an item pool was generated by sampling the item discriminations from a uniform distribution
Reference test form
Because a simulated rather than an empirical item pool was used, each reference test was proportional to the corresponding item pool. The target values for the statistical targets

Minimax models
In total, for each generated item pool, 2 sets of
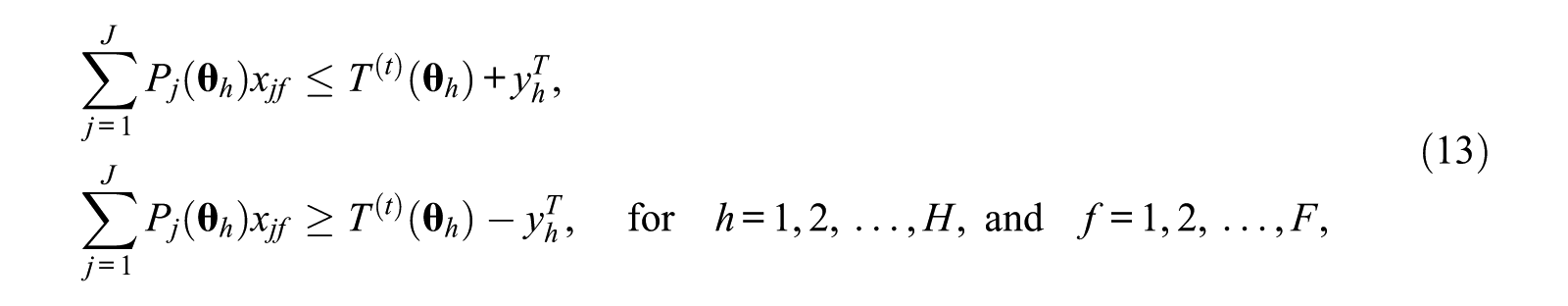
so that the TCCs of the assembled test forms were constrained to be within an absolute distance of
Constraints with respect to item content/format were added to all the Minimax models:

where
Simulation 2: Two-Dimensional Item Pool
In the second simulation study, the authors focused on a scenario where five 30-item parallel test forms are assembled out of an item pool with
Item pool
In each replication the item pool consisted of three types of items, from each item type 150 items were generated. Type 1 items were generated by sampling the slope parameters for the first and second dimension from respectively a uniform distribution between
Reference test form and Minimax models
As in Simulation 1, the target values were obtained using Equation 12. The number of
As in Simulation 1, item content and item format constraints (cf. Equation 14) as well as item-overlap constraints (cf. Equation 10) were added to each Minimax model. Note that there were no constraints related to the three item types.
Simulation 3: Three-Dimensional Bifactor Item Pool
The third simulation study was based on empirical data from an operational language aptitude assessment. Twenty item pools with
Item pool
Data from an operational language aptitude assessment consisting of 79 items were fit to several IRT models. A bifactor model with one common dimension and two orthogonal group dimensions provided the best relative fit. For each of the 20 item pools 750 new binary items were generated in two steps. First, 750 items were randomly drawn (with replacement) from the 73 binary items. 4 Second, for each drawn original item a new item was generated by sampling its parameters from normal distributions using the parameter estimates and standard errors of the original item. Online Appendix C lists the calibrated item parameters and standard errors of the 73 binary operational items.
Reference test form and Minimax models
As in Simulations 1 and 2, the target values were obtained using Equation 12. The number of theta-points per dimension was either three
Evaluation Criteria
The parallelism of the constructed test forms in each simulation study was evaluated using different statistics. First, for each test form the root mean square deviation (RMSD) statistic was computed with respect to the target TCC (RMSD
T
). For a assembled test form

where the superscript
Second, with respect to the variance of the MLE estimate (i.e., the error variance) in dimension
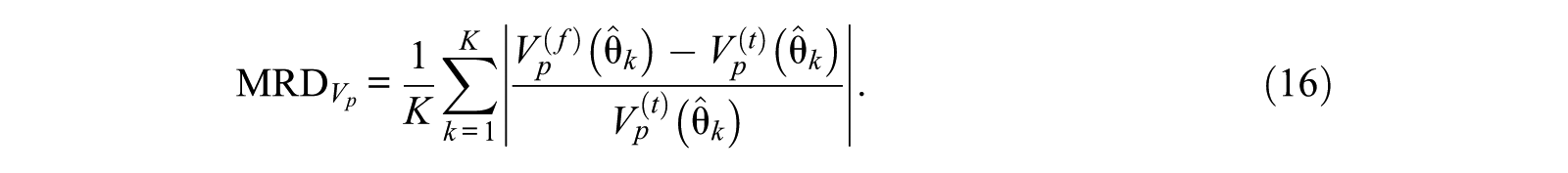
Third, as a more locally oriented evaluation criterion with respect to the TCC, the maximum score gap (MSG) was computed for each Minimax model. The MSG is the maximal absolute difference between the conditional expected test scores of the assembled forms, within a specified ability range:
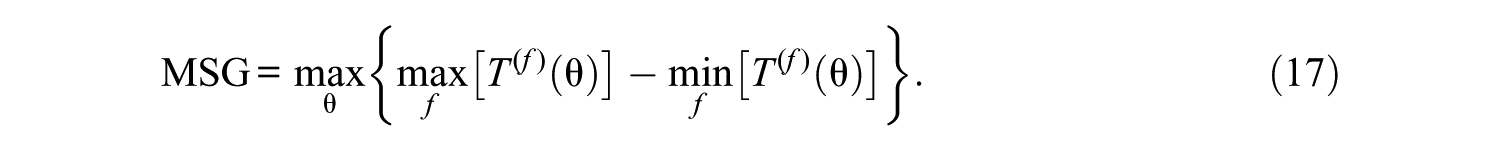
Finally, the maximum relative error variance gap (MREVG) was computed (per dimension). That is, the maximal relative difference in conditional error variance in dimension
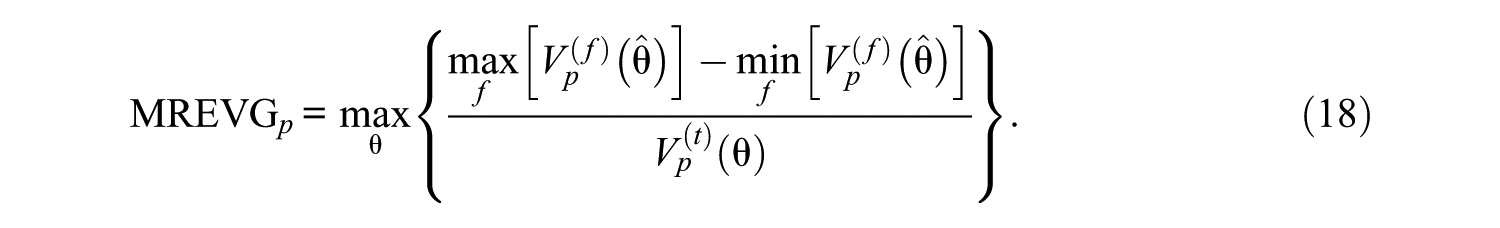
In the unidimensional case,
In addition, as more global measures of performance, the RMSD
T
and the
Technical Details
To compute the
Results
In the three simulation studies, GUROBI found at least one feasible solution (satisfying all constraints) for all Minimax models, after 20 min of computing time. For each study, a graphical representation of the results can be found in Online Appendix D.
Simulation 1—Unidimensional Item Pool
As can be seen in Online Appendix D, the following was observed. First, as could be expected giving previous research (cf. Ali & van Rijn, 2016; Debeer et al., 2017), using the TCC as the statistical target results in a better performance with respect to the TCC, but a worse performance with respect to the error variance. Second, for all the other Minimax models the difference in performance with respect to the error variance is limited, but the combined approach with additional TCC constraints performs better with respect to TCC parallelism (cf. Ali & van Rijn, 2016; Debeer et al., 2017). Third, increasing the number of
These results indicate that in the unidimensional case, the proposed KLIs are valuable replacements for the commonly used TIF as statistical targets in Minimax models.
Simulation 2—Two-Dimensional Item Pool
With respect to Simulation 2, the following was observed (cf. Online Appendix D). First, the combined approach with additional TCC constraints outperforms the single approach, both with respect to the error variance and the TCC evaluation criteria. Second, although increasing the number of
Overall, the results suggest that for two-dimensional item pools, the six proposed targets are applicable, preferably using a combined approach. When using the single approach there is a preference for the trace of the FI, the
Simulation 3—Bifactor Item Pool
Overall, the results are similar to the results in the two-dimensional case (i.e., Simulation 2; see Online Appendix D). First, the combined approach with additional TCC constraints outperforms the single approach, but the difference in performance seems small. Second, although increasing the number of
The performance with respect to the measurement error on the third dimension is overall worse than those on the first and second dimensions. At the same time, only minor differences are present between the error variance performance on the first and second dimension. The worse performance on the third dimension, especially by the
Conclusion
The results of the three simulation studies combined show that the proposed KLIs can be used as statistical targets for assembling test forms using Minimax models via MILP. In the unidimensional case the three proposed KLIs’ performance is similar to the performance of FI. In the multidimensional cases, the parallelism achieved by using the KLIs was at an overall satisfactory level. The performance of the linear approximations of the A- and D-optimality criteria was similar, but these statistical targets are limited to the two-dimensional case.
Although some differences were found in the performance of the KLIs, when applied in the single approach, these differences mostly vanished when they were applied in the combined approach with the additional TCC constraints. Moreover, the combined approach generally outperformed the single approaches, with the exception of the single approach with the TCC as the statistical target, for which the performance in the multidimensional cases was remarkably good. Hence, in practice, including the TCC (e.g., in a combined approach) in the Minimax model is recommended, especially when number-correct scoring is to be used.
Discussion
Many testing scenarios require multiple test forms that are parallel with respect to their content and statistical properties. A popular and efficient way to automatically assemble parallel test forms is to write the assembly problem as a Minimax model and solve this model via MILP. In this article the authors focused on the ATA of multidimensional parallel test forms. The statistical targets that are commonly applied in UIRT are not directly applicable in MIRT. Therefore, they proposed six statistical targets that can mitigate the multidimensionality issue. Two of those are based on linear approximations of either the A- or D-optimality criterion (cf. Veldkamp, 2002), and are limited to the two-dimensional case. The other four statistical targets are based on the KL divergence. They can be interpreted as alternative information indexes, and they can be applied to both uni- and multi-dimensional cases.
Using simulated item pools, of which some were based on operational items, the performance of the proposed statistical targets was compared in a uni-, a two-, and a three-dimensional bifactor case. The results indicated that (a) the KLIs can replace the traditional TIF as statistical target in the unidimensional case, (b) the proposed statistical targets can be successfully applied in two- and three-dimensional cases (note that the linear approximations are limited to the two-dimensional case), (c) the combined approach with additional TCC constraints (Ali & van Rijn, 2016; Debeer et al., 2017) outperforms the single approach regardless of the item pool or the chosen statistical target, and (d) in contrast with the unidimensional case, using only the TCC as the statistical target also results in good parallelism with respect to the error variance in the multidimensional case.
In the remainder of this discussion, the practical implications related to the proposed statistical targets and their performance are discussed. Subsequently, the limitations of our study are critically discussed and suggestions for future extensions are provided.
Practical Implications
Given the findings in the simulation studies, the authors would advise to use one of the proposed KLIs in multidimensional situations combined with constraints with respect to the TCC when this is applicable. Depending on the situation, other combined approaches (cf. Debeer et al., 2017) may also be appropriate. When it is not possible or not advisable to include constraints with respect to the TCC (see below) in the Minimax model, the
The simulation study suggests that, when applying the combined approach with additional TCC constraints, the performance of the different KLIs is similar. Therefore, the choice for a specific KLI can be driven by factors other than the performance with respect to parallelism. First, the interpretation of the KLIs can be a deciding factor. Practitioners responsible for the assembly of new parallel test forms can decide on which KLI to use, based on which type of information index they find most appropriate. Should the used information measure quantify how well an item/test can discriminate ability values from (a) other abilities in a very small region around the ability value (cf.
A second factor that may guide the choice for a specific KLI is computation speed. First, in the multidimensional case, and when appropriate, using the TCC is a straightforward and good performing alternative. Second, the trace of the FI, which is the (proportional) linear approximation of the
In situations where there is ample time for the ATA, the authors would suggest to implement the assembly using different statistical targets. Then, the parallelism performance with respect to the relevant statistics (i.e., measurement error, expected test score) can be compared across the different solutions, and the best performing solution can be chosen.
In contrast with the undimensional case (Ali & van Rijn, 2016; Debeer et al., 2017), the performance of the TCC as the statistical target in Minimax models in the multidimensional case was very good. Therefore, it seems advisable to include constraints with respect to the TCC in the ATA Minimax model. However, this may not always be appropriate. First, when pattern scoring methods (e.g., maximum likelihood estimation, expected a priori estimation) are used, and when the expected testing time is the target, rather than the number of items, constraints with respect to the TCC may be undesirable. Such situations are not unlikely when assembling multi-stage assessments, where modules should have equal testing time but not necessarily equal number of items. In these cases, constraining the TCC could result in harder MILP models and suboptimal test assembly. Second, previous research indicated that in the unidimensional case the performance of using only the TCC decreases when the item pool consist of mixed format items (Debeer et al., 2017). A similar deterioration could also be present in multidimensional mixed format item pools.
Although the focus of this article was on the assembly of parallel test forms, the described approaches also apply to cases where only one test form is assembled to be as close as possible to some ideal or existing reference test form. For instance, when only one test form/item set needs to be assembled, rather than using optimal test assembly—which usually involves maximizing the precision—one can specify an ideal test form and and apply the Minimax approach to approximate this ideal form as accurate as possible. The advantage of this approach is that the assembled test satisfies the required properties, without depleting the item pool. Especially when the item pool will be used in the future, the Minimax approach should be preferred over the optimal test assembly.
Finally, when optimal test assembly is the preferred option, both the
Limitations and Extensions
Simulation studies can never completely cover all the practically relevant situations, nor provide an exhaustive evaluation of methods. In that sense, the present simulation study is also limited. In addition, due to the computational demands of assembly problems, we were required to limit the number of conditions and replications to keep the overall computing time reasonable. Therefore, additional simulations are desirable, as they will be able to provide evidence that the proposed statistical targets are also feasible in bigger/smaller item pools, for different reference test forms (for instance, with a flat information surface), for other numbers of test forms, and for mixed format item pools.
In the operationalization of the different KLIs, there were several tuning parameters for which the authors attempted to use sensible values. First, to compute the
According to the rationale behind the
As an alternative for the trace of the FI, which the authors introduced as an proportional approximation of the
In our simulation studies, the authors assumed that the ability dimensions were orthogonal. However, in certain MIRT models ability dimensions may be correlated (e.g., simple-structure models). Although it is not impossible to incorporate them into FI-based statistical targets, the
Also, the authors did not take into account the uncertainty in the item parameter estimates. This can impact the TCC-, FI-, and KL-based statistical targets and, in practice, lead to assembled test forms, whose true FI and TCCs are less parallel than expected. Future research could assess whether or not the Minimax approach is more robust against these uncertainties than optimal test assembly, and whether the approach of Veldkamp, Matteucci, and de Jong (2013) can be extended to the Minimax approach and the statistical targets proposed in this article.
Finally, in this article the authors focused on the unidimensional and multidimensional versions of the 2PLM. The current methods could be extended for application to other commonly used compensatory IRT models, but also to noncompensatory MIRT models. From a theoretical perspective, there are no obstacles to compute and apply the KLIs to other IRT models. Yet from a practical viewpoint, the R-code provided in the online appendix needs to be extended.
Supplemental Material
Appendix_A_long – Supplemental material for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information
Supplemental material, Appendix_A_long for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information by Dries Debeer, Peter W. van Rijn and Usama S. Ali in Applied Psychological Measurement
Supplemental Material
Appendix_B_long – Supplemental material for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information
Supplemental material, Appendix_B_long for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information by Dries Debeer, Peter W. van Rijn and Usama S. Ali in Applied Psychological Measurement
Supplemental Material
Appendix_C – Supplemental material for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information
Supplemental material, Appendix_C for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information by Dries Debeer, Peter W. van Rijn and Usama S. Ali in Applied Psychological Measurement
Supplemental Material
Appendix_D_long – Supplemental material for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information
Supplemental material, Appendix_D_long for Multidimensional Test Assembly Using Mixed-Integer Linear Programming: An Application of Kullback–Leibler Information by Dries Debeer, Peter W. van Rijn and Usama S. Ali in Applied Psychological Measurement
Footnotes
Declaration of Conflicting Interests
Funding
Supplemental Material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.