
Abstract
A model for multiple-choice exams is developed from a signal-detection perspective. A correct alternative in a multiple-choice exam can be viewed as being a signal embedded in noise (incorrect alternatives). Examinees are assumed to have perceptions of the plausibility of each alternative, and the decision process is to choose the most plausible alternative. It is also assumed that each examinee either knows or does not know each item. These assumptions together lead to a signal detection choice model for multiple-choice exams. The model can be viewed, statistically, as a mixture extension, with random mixing, of the traditional choice model, or similarly, as a grade-of-membership extension. A version of the model with extreme value distributions is developed, in which case the model simplifies to a mixture multinomial logit model with random mixing. The approach is shown to offer measures of item discrimination and difficulty, along with information about the relative plausibility of each of the alternatives. The model, parameters, and measures derived from the parameters are compared to those obtained with several commonly used item response theory models. An application of the model to an educational data set is presented.
Keywords
Multiple-choice (MC) exams can be viewed as being a signal detection task, in that examinees attempt to select the correct alternative (the signal) out of a set that includes incorrect alternatives (noise). From a psychological perspective, examinees are viewed as basing their decisions on their perceptions of the alternatives, with the perceptions in turn being levels of perceived plausibility for each alternative. The decision process is to select the most plausible alternative out of the set of alternatives. It is also assumed that examinees either “know” or do not know each item. It is shown here that these assumptions together lead to a signal detection model for multiple choice exams. The approach offers information about the relative plausibility of each alternative as well as measures of item discrimination and difficulty. The model is applied to an educational exam (the SAT) and the results are compared to those obtained with the widely used two-parameter and three-parameter logistic (2PL and 3PL) models, as well as the nominal response model (see, for example, de Ayala, 2009).
The basic psychological framework follows from early work by Fechner (1860/1966), with respect to the idea of using probability distributions to represent perceptions, and was further developed by Thurstone (1927) in his law of comparative judgment. The same ideas were involved and further developed in applications of signal detection theory (SDT) in psychology (Green & Swets, 1988; Macmillan & Creelman, 2005; Swets et al., 1961; Wickens, 2002). A novel aspect of the application to educational testing presented here is that an examinee component is introduced, which is whether or not an examinee “knows” an item, as has previously been done in an SDT model for true-false (TF) exams (DeCarlo, 2020), and similarly for models in psychometrics (e.g., Birnbaum, 1968; Thissen & Steinberg, 1984). The SDT TF model was shown to offer a different conceptualization of item parameters, such as difficulty and guessing, and was argued to have advantages over the 3PL model, particularly in situations where “guessing” can be high, as in TF exams or MC exams with only two alternatives. The approach is generalized here to MC exams with two or more alternatives, giving a mixture SDT choice model. The model can be viewed, from a statistical perspective, as a mixture extension, with random mixing, of the traditional choice model. Using extreme value Type I distributions (Gumbel, 1958) for the underlying SDT distributions is shown to give an extended multinomial logit (MNL) version of the model, which offers computational advantages.
First presented are basic ideas underlying the model. The model provides measures of the relative plausibility of each alternative for each item, as bias parameters, along with a measure of how well each item discriminates between the states of knowing or not knowing. It is shown that a measure of item “easiness” can be derived from the bias parameters. The approach also offers a new way to screen items. The SDT item measures are compared to difficulty and discrimination estimates obtained with the 2PL and 3PL models, and the results are also compared to those obtained with the nominal response model (Bock, 1972, 1997).
Basic Concepts
Basic ideas underlying the application of SDT to MC exams are as follows. When an examinee reads an MC item, it is assumed that she or he has perceptions of the plausibility of each of the alternatives, with the perceptions being represented as realizations from probability distributions. In addition, the perception of a correct alternative depends on whether or not an examinee knows an item; “knowing” an item is assumed to shift the probability distribution associated with the correct alternative to the right (more plausible). The decision process on each trial is to choose the alternative that is perceived as being the most plausible. Thus, as is always the case in SDT, the situation consists of a decision component, in this case “choose the most plausible alternative,” and a perceptual component, which is the perceived plausibility of each of the alternatives and the effect of knowing an alternative.
Figure 1 illustrates the above ideas for an MC item with four alternatives, say “A,”“B,”“C,” and “D.” The four distributions with solid lines (which are extreme value Type I distributions) represent distributions of plausibility for each alternative if the answer is not known, with the location of the distributions reflecting their relative plausibility, and so more plausible alternatives are located further to the right; in this case, the order of distributions is “A,”“D,”“B,” and “C” if the item is not known. The last alternative is used as the reference and so the distribution associated with Alternative D is located at zero. The “bias” parameters b1, b2, and b3 indicate the distances of the plausibility distributions for A, B, and C from D.
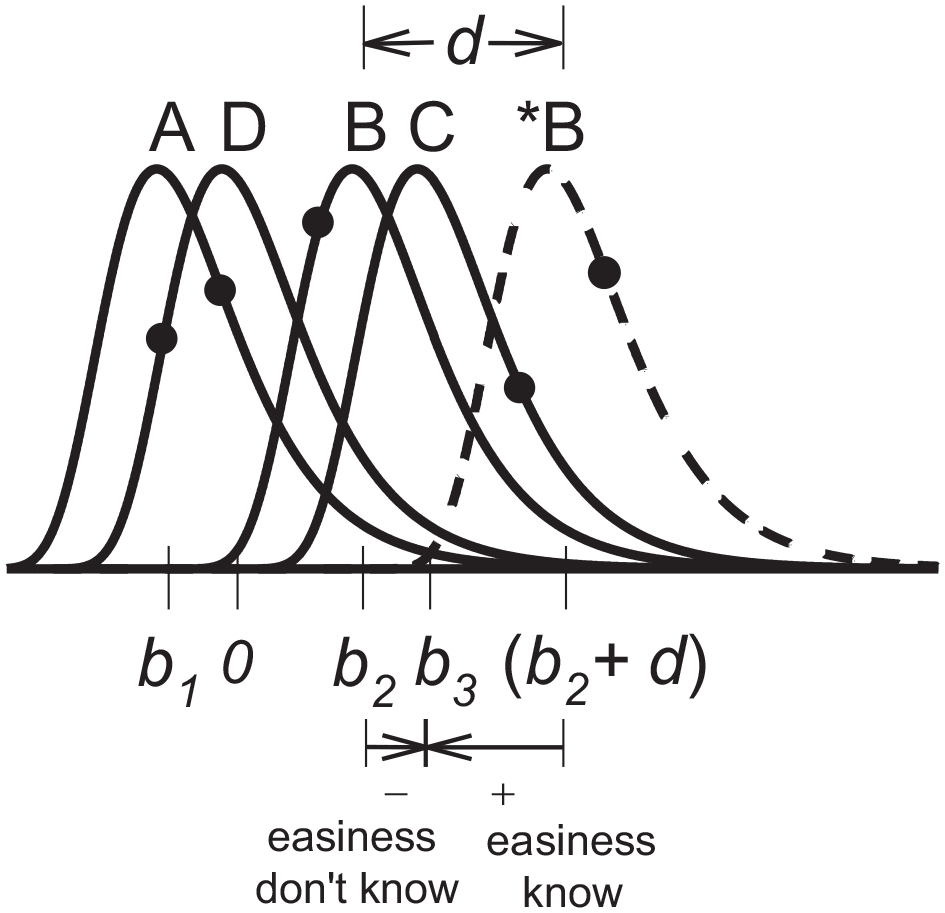
An illustration of the SDT choice model with extreme value distributions.
On any given reading, an examinee’s perceptions of the plausibility of the alternatives are realizations from each of the four distributions. The decision rule is to select the alternative with the highest perceived plausibility. For example, Figure 1 shows that, of the realizations associated with A, B, C, and D, shown as circles, the realization for Alternative C is the highest (most plausible), and so the examinee selects C, which is incorrect given that B is correct. If, on the contrary, the item is known, then it is assumed that the correct alternative is more plausible, and so the distribution is shifted to the right, as shown by the dashed distribution in Figure 1 labeled *B, where * indicates the correct answer; note that the distributions for incorrect alternatives are assumed to have the same locations. In this example, if an examinee knows the item, then the realization associated with *B is the highest of the realizations from A, *B, C, and D, and so the examinee chooses B, which is correct.
An important aspect of the above conceptualization in terms of underlying distributions is that it suggests simple measures of item discrimination and item difficulty, which are basic aspects of item response theory (IRT), and which are placed in a somewhat different perspective by SDT.
Item Discrimination
The amount that the distribution is shifted if an item is known gives a measure of item discrimination, d, as shown in Figure 1. Clearly, positive values of d are desirable, in that the item then discriminates between the states of knowing and not knowing, giving a higher probability of a correct response if the item is known. A negative value of d would mean that the correct answer is less plausible if the item is known, which suggests that the item is problematical and should be revised or dropped, as done with items that show negative (or zero) discrimination in IRT.
Item Easiness
A measure of item easiness can be defined as the distance of the distribution for the correct answer from the highest or next highest distribution. Clearly, if the other alternatives (distractors) are all much less plausible than the correct alternative, then the item is relatively “easy.” On the contrary, if one or more of the distractors is almost as plausible, or more plausible, than the correct alternative, then the item is relatively “difficult.” The easiness measure is denoted here as eDK (easiness don’t-know) to indicate that it is easiness for an item that is not known. Note that a zero or negative value means that there is an incorrect alternative that is as plausible, or more plausible, than the correct alternative. There is also an easiness measure for when the item is known, denoted here as eK, with
Figure 1 illustrates the easiness measures; the arrows show that, when the item is not known, the easiness
It is interesting to note that, in addition to using d to detect problematical items (i.e., zero or negative discrimination), as in IRT, an additional possibility is to use estimates of eK to detect problematical items. In particular, a negative value of eK means that even if the item is known, one of the incorrect alternatives is still more plausible than the correct alternative, and so it seems reasonable to suggest that items with negative estimates of eK be dropped or revised (or at least inspected!); a benefit of the SDT approach is that the bias parameter estimates will likely indicate which alternative or alternatives are causing the problem. The use of eK presents a new way to possibly uncover problematical items, even if the item discrimination is greater than zero; an example of this is shown in the application below.
Guessing
A common view of “guessing” is that it refers to the situation where an examinee does not know an item. Thus, the easiness parameter eDK can also be viewed as being a measure of how easy it is to guess the correct answer when the item is not known. However, the view of “guessing” in SDT differs from that in IRT (see DeCarlo, 2020), in that guessing in SDT is not viewed as involving a separate process. Instead, examinees in SDT are viewed as always choosing the most plausible alternative (assuming the alternatives are actually read), and so the decision process is the same irrespective of whether or not an item is known; a benefit of this view is that additional item parameters for guessing are not needed (guessing depends on the examinee know/don’t know variable). In contrast, an additional item parameter for guessing is added in the 3PL model (the c parameter) and in extensions of the nominal response model (see below) because guessing is viewed as reflecting a different process.
Thus, the SDT choice model follows from three basic ideas: examinees have perceptions of the plausibility of each alternative in an MC exam; they make their decision by choosing the most plausible alternative; and the plausibility of the correct alternative differs when an item is known. As shown above, the approach yields item parameters that are analogous to those used in 2PL and 3PL models, that is, item easiness (or difficulty) and discrimination, although also with some interesting differences. In addition, the bias parameters of the SDT choice model provide measures of the relative plausibility of each of the alternatives, and so, compared with the widely used 2PL and 3PL models, the model offers more detailed information about each item, which is useful for item diagnosis and refinement. The next section shows that the above ideas lead directly to an extended SDT choice model.
The SDT Choice Model
Structural and Decision Components
As noted above, the model follows directly from earlier approaches in psychology, such as the work of Thurstone (1927) and work in SDT (Swets et al., 1961). The main components of an SDT model are a decision component, which in this case is to simply choose the most plausible alternative, and a structural component, which involves examinees’ perceptions of the alternatives and the effect of knowing or not knowing an item. Given that MC tests commonly include four or five alternatives, the model for four alternatives, as illustrated in Figure 1, is shown here; the general model immediately follows.
Let
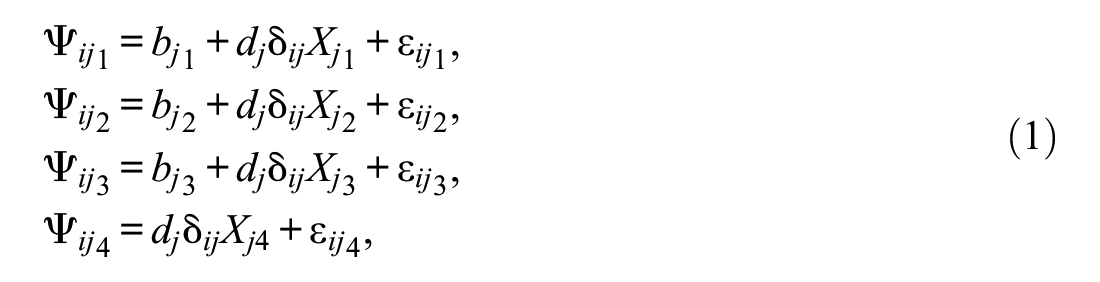
where
It is useful to start with a simple version of the model, in terms of SDT, without the dichotomous latent variable

Equation 2 corresponds to the four distributions shown in Figure 1 labeled A, B, C, and D, where the bias
The decision rule is to choose alternative m if its plausibility is the largest compared with the other alternatives. Thus, for four alternatives, the decision rule is given as follows:
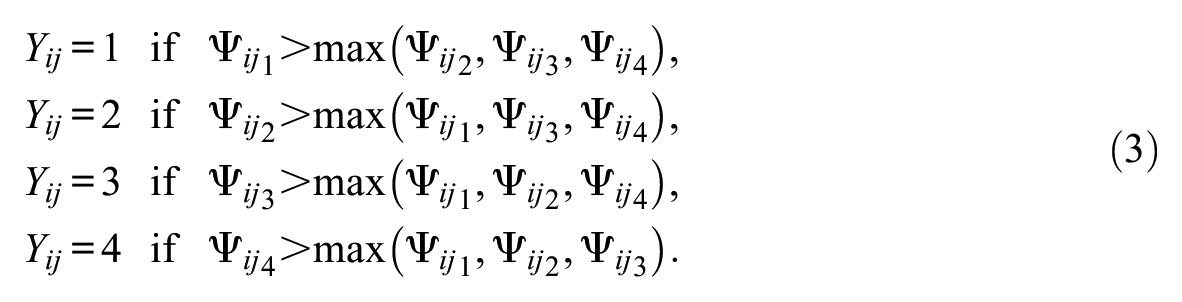
Note that it must be kept track of which option was chosen for each item, and not simply whether the choice was correct or incorrect, which loses information.
The SDT choice model follows from the structural model of Equation 2 and the decision rule of Equation 3. For example, from the decision rule, the conditional probability of a response of “1” is given as follows:
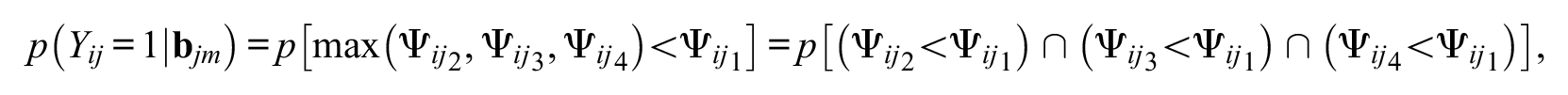
where
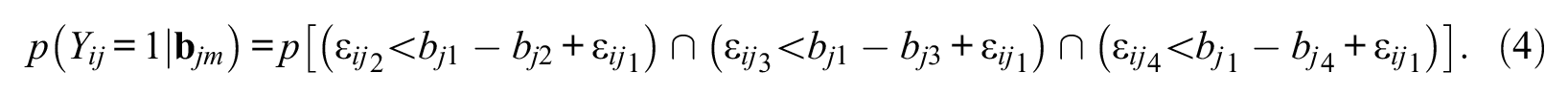
In terms of error differences,
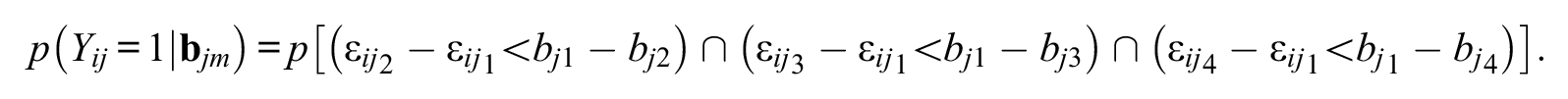
The development is the same for the other choices. One can use a joint cumulative distribution function (CDF), such as the multivariate normal, for the above probabilities, which gives a multinomial probit model. It is well known that the multinomial probit model presents computational challenges because of high-dimensional integrals when there are four or more alternatives, although some advances have been made (e.g., with maximum simulated likelihood and Bayesian estimation; see Train, 2009).
Note that, assuming that the ε ijm of Equation 2 is independent, the terms of Equation 4 are not independent. However, the terms are conditionally independent for a given realization of εij1 = eij1, and so,
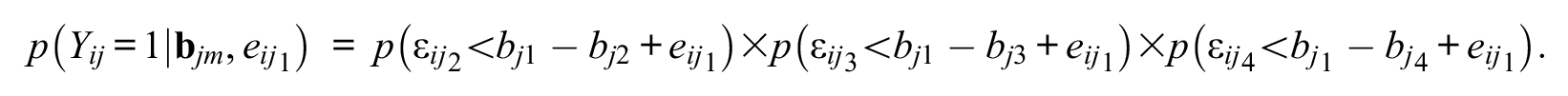
The unconditional probability can then be found by integrating over all values of

where F is a CDF, f is a probability density function (PDF), and d is the derivative. The above is the model for a choice of alternative ‘1’; the same approach is used for the remaining alternatives of 2, 3, and 4 in this example, giving,
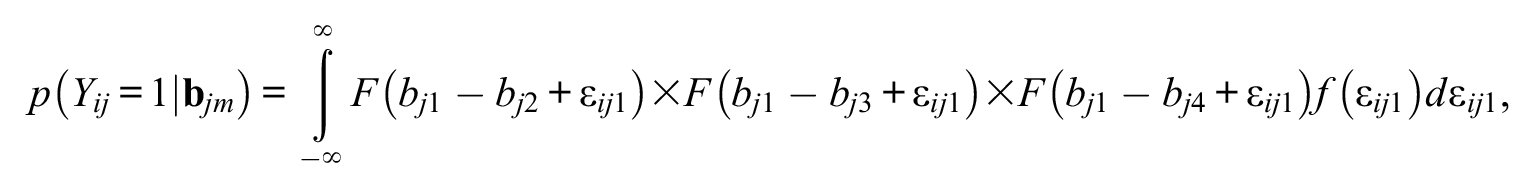

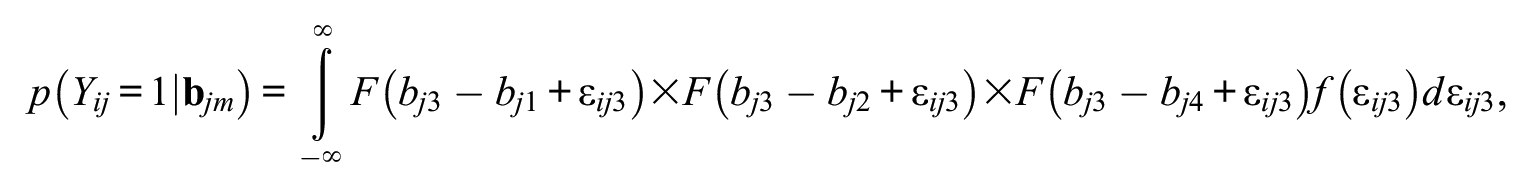
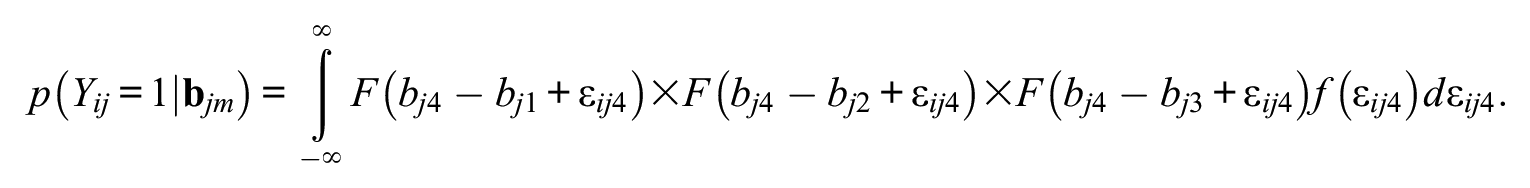
The above can be written more compactly and generally for M alternatives as follows:

Equation 5 is a general form of the basic SDT choice model; it is the same (with the addition of an alternative-specific signal variable) as the m-alternative forced choice model with bias discussed in mathematical psychology (e.g., DeCarlo, 2012) and the maximum utility model discussed in econometrics (e.g., Train, 2009).
With respect to a choice of a cumulative distribution for F and density for f, an attractive option is the extreme value Type I distribution, a distribution of smallest extremes, also known as the Gumbel distribution (Gumbel, 1958), F(x) = exp(−exp(−x)), given that it leads to simplifications. As was recognized by Luce and Suppes (1965, attributed to Holman and Marley), Yellot (1977), and McFadden (1974, Yellot and McFadden also independently showed that the extreme value solution was unique), the use of the extreme value Type I distribution in an integral such as Equation 5 leads to an MNL version of the model. Equation 5 with an extreme value distribution is given as follows:

As shown in the Online Appendix, the above integral has a closed-form solution:
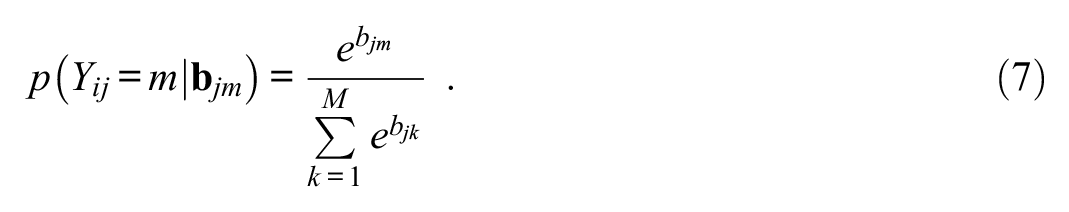
Equation 7, with bias bjm replaced by “value,” is known in psychology as Luce’s (1959) choice model and has been the starting point for developments in psychometrics (e.g., Bock, 1972, 1997) and in econometrics (e.g., McFadden, 1974, 2001). The use of the term bias here follows from the SDT conceptualization of the situation in terms of underlying perceptual distributions, as shown above. Luce (1959) actually developed the model from axiomatic ideas, such as independence from irrelevant alternatives and transitivity, but the connection of the model to Thurstonian models was later recognized.
For the generalization of the SDT structural model suggested here for MC tests, Equation 1 replaces Equation 2:
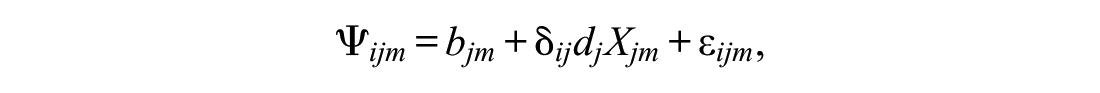
where
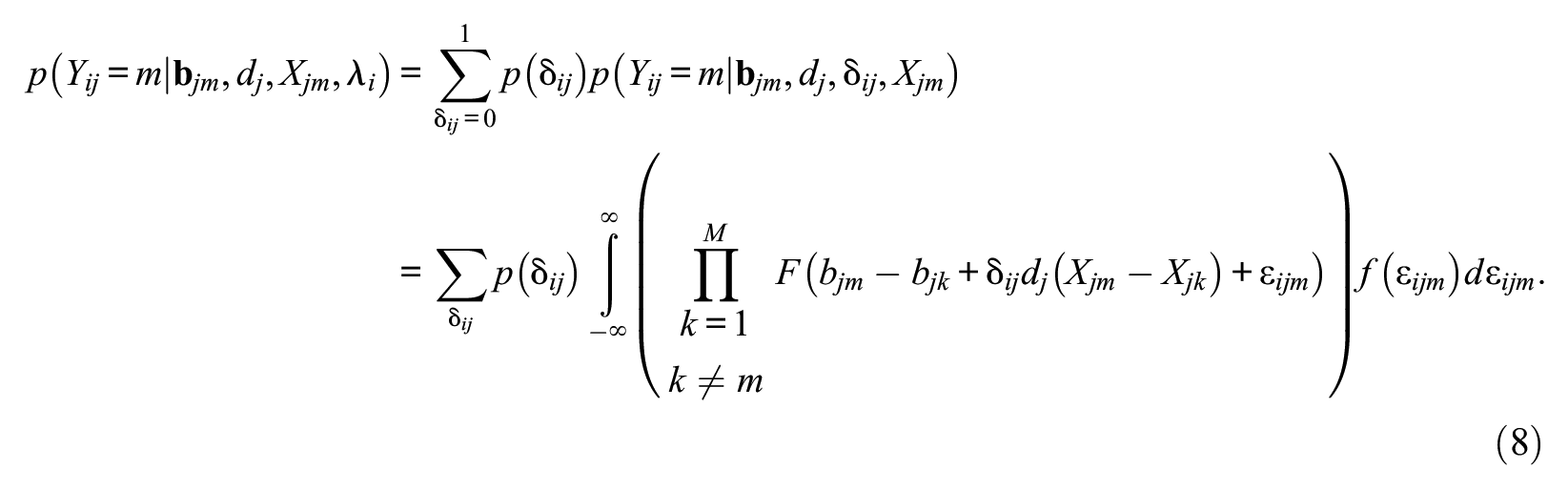
Using the extreme value distribution again gives a closed form solution, and so,
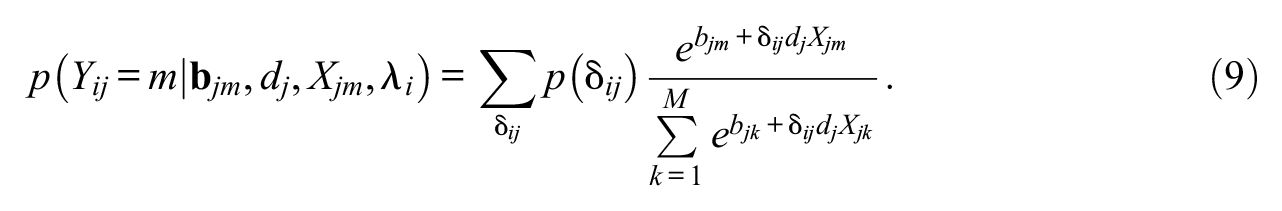
Equation 8 is a general SDT choice model for MC exams that follows from the basic ideas shown in Figure 1. Equation 9 is the version that follows with extreme value distributions. The latter model can easily be fit using maximum likelihood or posterior mode estimation (PME), with fast computational times, and so it is practical for use with large-scale exams with many items and examinees.
It is assumed that the latent variable
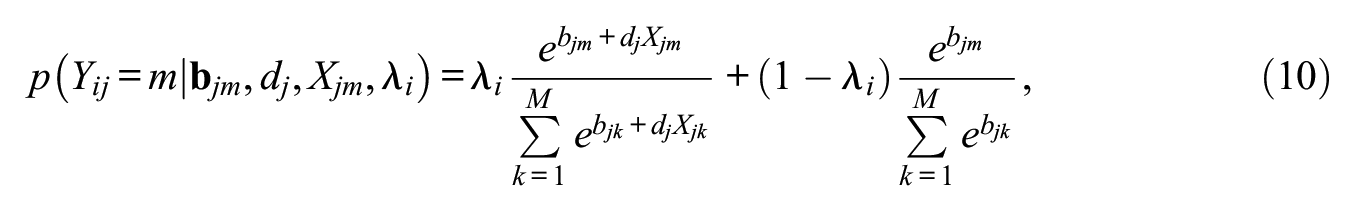
which shows that the SDT choice model is a mixture model with a random mixing parameter,
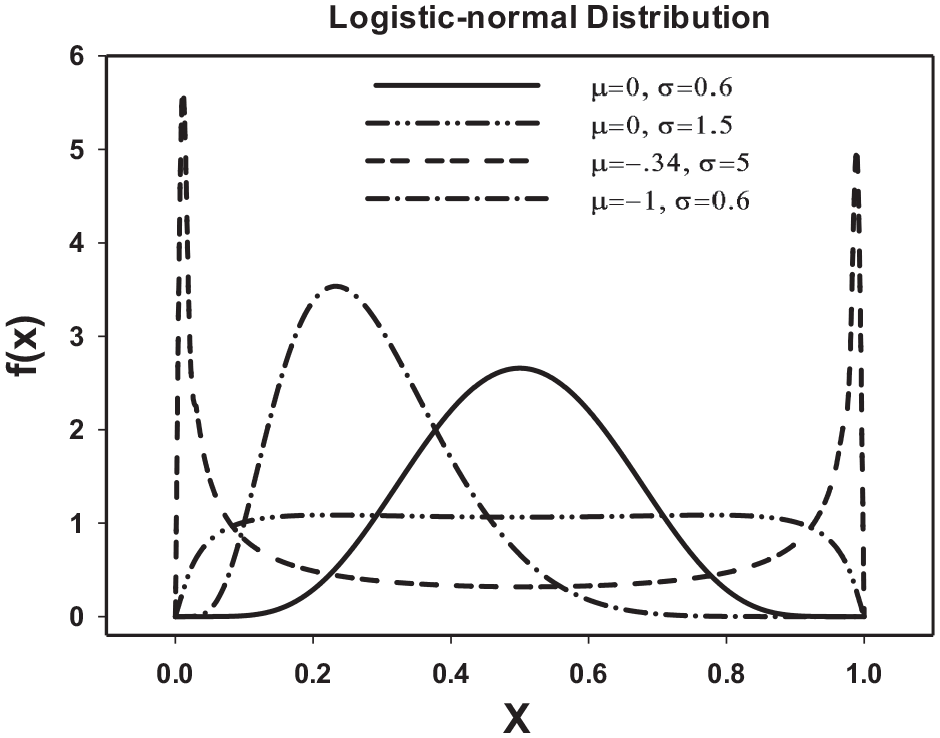
Logistic-normal density for several values of μ and σ.
The random mixing parameter
To allow for a flexible distribution for

with 0 ≤x≤ 1. Several examples of the logistic-normal distribution, with parameter values similar to those found here for the analysis presented below (and in other analyses), are shown in Figure 2.
An advantage of the logistic-normal distribution is that it keeps the model within the framework of generalized linear models (GLMs) and so it can be fit with standard software, using maximum likelihood or PME. The logistic-normal model can be implemented by specifying a logit model (at the examinee level) for λ
i
with a continuous latent predictor, say

and so
Note that in the SDT choice model, the latent dichotomous variable
Equation 10 can be viewed, statistically, as an extended latent class MNL choice model with random mixing (random class sizes) and is similar to a grade-of-membership (GoM; Erosheva, 2002) extension. From the GoM perspective,
Bock’s Nominal Response Model
The SDT choice model is related to, but also differs from, approaches to MC items previously developed in psychometrics. It is closely related to Bock’s (1972, 1997) nominal response model, and so some similarities and differences are briefly discussed in this section.
The nominal response model generalizes Luce’s choice model by replacing “value” (bias in Equation 7) with item trace functions from IRT, that is,
An important difference between the models is that the nominal response model includes discrimination parameters,
A common criticism of the nominal response model (e.g., Nering & Ostini, 2010) is that it does not deal with guessing, like the 3PL model. To address this, Thissen and Steinberg (1984) generalized Bock’s nominal response model by assuming that there is a category of “don’t know” examinees. Using this idea leads to an extended nominal model which adds a latent proportion of examinees who do not know an item, sometimes denoted as dh, which adds an additional J× (M−1) guessing parameters. Thissen and Steinberg (1997) recognized an overparameterization problem: “The focus of the problem is the large number of parameters involved . . .” (pp. 57–58) and “The solution to the problem is obviously to reduce the number of parameters; but it is not clear, a priori, which parameters are needed to fit which items” (p. 58). In contrast, additional guessing parameters are not needed in SDT because guessing is viewed as involving the same decision process—choose the most plausible alternative—which is an important advantage. The SDT approach provides, a priori, a way of reducing the number of parameters and provides a conceptual basis for what is restricted and why, with a straightforward interpretation.
An Application: SAT12 Data
The data are given in the R package MIRT as an example application of the nominal response model (Chalmers, 2012) and consist of 32 SAT items with five alternatives per item and 600 examinees. For the 32 × 600 = 19,200 observations, 69 were missing the choice response and were not included, leaving 19,131 observations.
Parameter Estimates
The SDT choice model and nominal response model were both fit using LG; note that for the SDT model, the discrimination parameter
For the SDT model, for each item, there are four estimates of
Parameter Estimates for the SDT Choice Model, SAT12 Data, Five Alternatives, N =600, bj5 = 0.
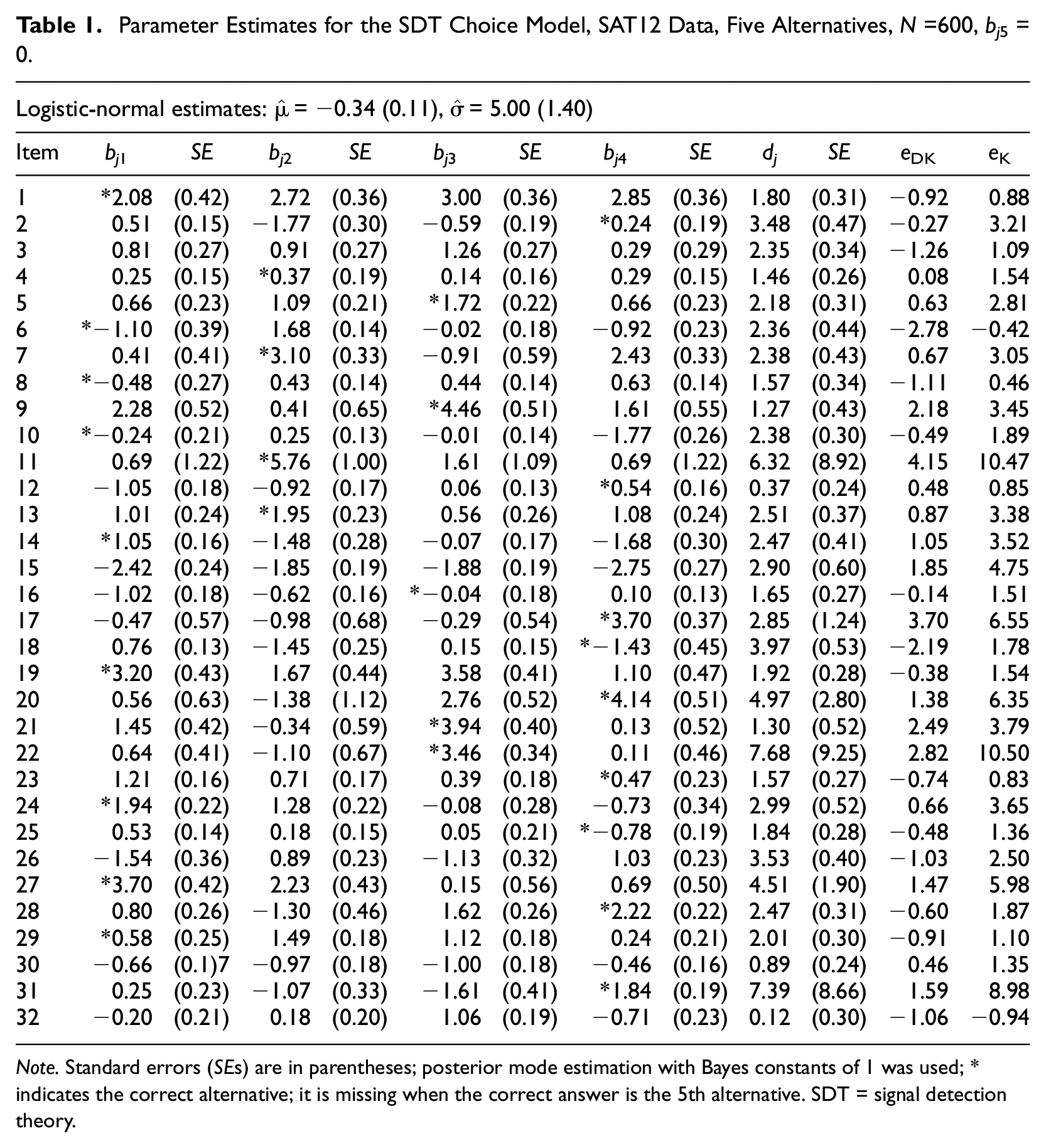
Note. Standard errors (SEs) are in parentheses; posterior mode estimation with Bayes constants of 1 was used; * indicates the correct alternative; it is missing when the correct answer is the 5th alternative. SDT = signal detection theory.
The estimates of
Nearly half of the 32 estimates of
A problem with Item 32 has previously been noted in the MIRT manual (Chalmers, 2012): “careful analysis using the nominal response model suggests that the scoring key for Item 32 may be incorrect, and should be changed from 5 to 3” (p. 158). The problem with Item 32 is immediately apparent in the SDT analysis, given that a negative estimate of eK appears in Table 1.
The SDT analysis, however, also suggests that another item might be problematical, Item 6, because Table 1 shows that
What about simply inspecting response proportions for each alternative? The potential problem with that approach is that, according to the mixture SDT model, the response proportion for the correct alternative is actually a mixture of proportions for those who know and those who don’t know the item and so ignoring this can lead to incorrect conclusions. Item 8 provides a nice example. The proportions for this item are (*0.20, 0.21, 0.21, 0.25, 0.13), and so Alternative 4 is the most often selected (0.25) even though Alternative 1 is the correct answer. Does this mean that the item is problematical? A fit of the SDT choice model readily answers this question. If the item is not known, then from Table 1, the bias estimates are (*−0.48, 0.43, 0.44, 0.63, 0.00), which shows not only that Alternative 4 has the highest plausibility (0.63) but also that the correct answer of Alternative 1 has the lowest plausibility (−0.48) compared with the remaining three alternatives. If the item is known, on the contrary, then the plausibility for Alternative 1 is −0.48 + 1.57 = 1.09, and so Alternative 1 is now the most plausible (and
With respect to discrimination (dj), Table 1 shows that the estimates are all greater than 0; however, Items 12 and 32 have small, insignificant estimates of 0.37 and 0.12, respectively (this is also true for the 2PL model, but not for the 3PL model). Estimates of discrimination for Items 11, 22, and 31 are large (6.32, 7.68, 7.39) with large standard errors (8.92, 9.25, 8.66); larger standard errors often occur for large values of the parameters (dj > 6 is high discrimination) and so there is weak information about some of the estimates of discrimination.
The estimates of
2PL and 3PL Models
Given that the SDT choice model provides estimates of discrimination and easiness, it is of interest to compare them with those obtained using the 2PL and 3PL models (fit here using PROC IRT of SAS). As found earlier, the results for the SDT choice model are similar to those found for the 2PL model (DeCarlo, 2020). The Spearman correlations of −êDK with estimates of bj for the 2PL and 3PL models are .86 (2PL) and .84 (3PL); the correlations of −êK with estimates of bj are .94 (2PL) and .92 (3PL). The Spearman correlations of estimates of dj with estimates of aj are .97 (2PL) and .04 (3PL). Thus, as found earlier, estimates of difficulty and discrimination from the SDT model are correlated with those found for the 2PL model; however, discrimination differs for the 3PL model. This also holds for a comparison of the 2PL and 3PL models—the Spearman correlation of the estimates of difficulty (
Estimates of the guessing parameter for the 3PL model range from 0.00 to 0.48 and is 0.00 (or 0.02) for nine of the 32 items. This strongly suggests that the parameter does not reflect a process of guessing—if one is randomly choosing among five alternatives, then the choice should be correct about 20% of the time, and not 0% in many cases (or 48%); this problem does not arise for the SDT model because of the different conceptualization of guessing.
With respect to detecting the possibly problematic Items 6 and 32, discussed above, neither the 2PL nor 3PL parameter estimates suggest a problem for Item 6; estimates and standard errors for the 2PL are
It is also of interest to compare the predictions of examinee ability across the models. Posterior estimates of θ
i
for the 2PL model and 3PL models, and the proportion correct (PC), were highly correlated with posterior estimates of
Note that information criteria, such as the Bayesian information criterion (BIC; Schwarz, 1978) or Akaike’s information criterion (AIC; Akaike, 1974), cannot be used to compare relative fit of the SDT choice model to the 2PL or 3PL models because the models use different data—the choice model is fit to the original 1 to 5 responses—whereas the 2PL and 3PL models are fit to responses recoded as 0 or 1 for incorrect or correct, and so the log-likelihoods are not comparable. Bock’s nominal response model, however, applies to the original 1 to 5 responses, like the SDT choice model, and so BIC and AIC can be compared across the models, as done next.
Bock’s Nominal Response Model
For Bock’s nominal response model, there are eight parameters per item, four
Information criteria for the SDT choice and nominal response model, respectively, are BIC = 40,035.7 and 40,376.3, which favors the SDT model, and AIC = 38,762.5 and 38,363.5, which favors the nominal model. This type of pattern is often found with these criteria—BIC tends to favor simpler models (i.e., fewer parameters, as in the choice model, because BIC has a larger penalty for parameters), whereas AIC tends to favor more complex models (such as the nominal response model). One could argue for the SDT choice model on the basis of parsimony (i.e., favor the BIC); however, the important question is not relative statistical fit, but rather is whether anything is gained by introducing 128 discrimination parameters in the nominal response model, as compared with 32 in the SDT choice model.
Table A1 shows that estimates of
As discussed above, the SDT analysis tagged Item 32 as being problematical. Table A1 shows that for the nominal model, the estimate of
This is not the case, however, for Item 6. Item 6 is tagged as being problematical by the SDT analysis because of the negative estimate of
A different pattern across estimates of
Spearman correlations of estimates of
Discussion
A signal detection model for multiple choice exams is presented. The approach views examinees as choosing, for each item, the alternative that is perceived as being the most plausible. It is also assumed that knowing an item shifts the perception in the direction of greater plausibility for the correct alternative. These assumptions together lead to a mixture SDT choice model. The choice model offers information about the items that is comparable with that offered by the 2PL model, in terms of discrimination and difficulty, but it also offers important information about the plausibility of the distractors. This in turn can reveal possible problems with alternatives in an item. For example, an application shows that the SDT model detects possibly problematical items that are missed by an analysis using the nominal response model, the 2PL or 3PL models, or simple inspection of response proportions. An important aspect of the SDT approach is that it also suggests how to obtain evidence of validity—if one could inspect the actual item and its’ alternatives in the above examples, then that would help to determine whether the problems suggested above by the SDT analysis have validity. Another advantage is that the interpretation of the results in terms of SDT is simple and straightforward, which is important for practitioners. The benefit of adding a large number of discrimination parameters, as in the nominal response model, was called into question. The mixture SDT choice model provides a simple unified model that can replace the 2PL, 3PL, and nominal response models, or a simple analysis of proportions.
The most basic (and strictest) version of the SDT model is presented here; there are of course many possible extensions and issues for further examination. For example, a version of the model with random discrimination parameters across examinees was examined in DeCarlo (2020). Another option is to use response times to obtain collateral information to improve estimation (van der Linden et al., 2010). Yet, another interesting possibility is to use covariates to allow the random mixture parameter
Supplemental Material
sj-pdf-1-apm-10.1177_01466216211014599 – Supplemental material for A Signal Detection Model for Multiple-Choice Exams
Supplemental material, sj-pdf-1-apm-10.1177_01466216211014599 for A Signal Detection Model for Multiple-Choice Exams by Lawrence T. DeCarlo in Applied Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplementary material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.