
Abstract
A new item response theory model for count data is introduced. In contrast to models in common use, it does not assume a fixed distribution for the responses as, for example, the Poisson count model and extensions do. The distribution of responses is determined by difficulty functions which reflect the characteristics of items in a flexible way. Sparse parameterizations are obtained by choosing fixed parametric difficulty functions, more general versions use an approximation by basis functions. The model can be seen as constructed from binary response models as the Rasch model or the normal-ogive model to which it reduces if responses are dichotomized. It is demonstrated that the model competes well with advanced count data models. Simulations demonstrate that parameters and response distributions are recovered well. An application shows the flexibility of the model to account for strongly varying distributions of responses.
Introduction
Count data can be very useful in measuring abilities. Forthmann et al. (2020) mention various areas where count data arise quite naturally including memory tasks where the number of remembered items is counted, diverging thinking tasks where the number of generated ideas is of interest or verbal fluency tasks where participants name instances of broad classes like animals within a short time limit, see, for example, Jansen and van Duijn (1992), Jansen (1995), Silvia et al. (2013), Süß et al. (2002), Doebler and Holling (2016), Forthmann et al. (2017), Forthmann and Doebler (2021).
Count data item response theory models date back at least to Rasch’s early models (Rasch, 1960). The Poisson counts model proposed by Rasch assumes that counts are Poisson distributed given the ability and item parameters. The rather restrictive assumption of a Poisson distribution has been weakened by assuming a negative binomial distribution (Hung, 2012), and more recently by assuming a Conway–Maxwell distribution (Forthmann et al., 2020). All the models have in common that a fixed (conditional) distribution of responses is postulated to hold.
The model proposed here is quite different in nature. Instead of postulating a fixed response distribution to hold for the response, the probability of a response beyond thresholds is modeled by using classical binary response models. The binary models are assumed to hold for all thresholds with item parameters depending on the threshold. The item parameters for the thresholds yield an item difficulty function which varies across the possible responses and determines the form of the response distribution in a rather flexible way. There are two forms of difficulty functions, simple parametric functions with just two parameters that follow a specific form and very flexible functions obtained by approximating the unknown difficulty function by an expansion in basis functions.
A general framework of item theory thresholds models for various types of data including continuous and ordered responses has been given in Tutz (2022). The focus here is on count threshold models. Its properties are investigated theoretically and in simulations. The model is also compared to alternative approaches to modeling count data. Threshold concepts in regression, not covering item response theory, have also been used in Tutz (2021).
In Section 2, models with fixed response distributions are briefly considered. The count thresholds model is introduced in Section 3 where basic concepts and illustrations of possible response distributions are given. Estimation concepts are considered in Section 4 followed by simulation results in Section 5. Extended model versions with data-driven difficulty functions are given in Section 6. In the application (Section 7) models with fixed difficulty functions and more general versions are used to model verbal fluency tasks data.
Traditional Item Response Models for Count Data
We first consider approaches with fixed response distributions that have been proposed in the literature Let Y
pi
∈ {0, 1, 2, … } denote the responses of person p on item i (p ∈ {1, …, P}, i ∈ {1, …, I}). A classical model that has been used for this kind of data is Rasch’s Poisson count model (Rasch, 1960). In additive parameterization the model specifies the expected response μ
pi
for person p on item i by


The assumption of a Poisson distribution is rather restrictive and limits the applicability of the model to real data. In particular it implies that expected value and variance are equal, the so-called equidispersion of Poisson distributions. In more general models the Poisson distribution is replaced by a negative binomial distribution Hung (2012). More recently, Forthmann et al. (2020) proposed the Conway–Maxwell–Poisson model, which uses a more general distribution with an additional parameter ν
i

The model contains one more parameter, ν i , for each item. The strength of the model is that it can account for overdispersion and underdispersion relative to the Poisson model. If ν i < 1, the data display overdispersion and if ν i > 1, the data display underdispersion. For ν i = 1, the item response is Poisson distributed. Thus if ν1 = ⋯ = ν I = 1, the model simplifies to the Poisson model.
Count Thresholds Model
The count thresholds model (CTM) has the general form
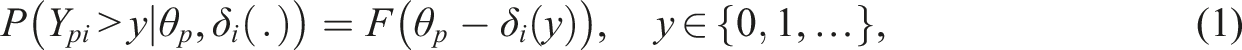
For the understanding of the meaning of parameters, it is useful to consider a fixed threshold y. Then, the probability of observing a response larger than y is determined by a familiar binary item response model, namely, the normal-ogive model if F(.) is the normal distribution and the Rasch model if it is the logistic distribution function. The parameter θ p is the ability parameter and δ i (y) the difficulty parameter in the corresponding binary model. Since the model is assumed to hold for all thresholds the item parameters of the underlying binary models form the difficulty function δ i (.), but the ability, which indicates the ability of obtaining a high score is the same for all thresholds. In the following, we consider properties of the model and the impact of difficulty functions.
Model Properties: Difficulty Functions and Monotonicity
In particular the functions δ
i
(.) determine the distribution of the responses. It is distinguished between fixed parametric functions δ
i
(.) and flexible functions that are chosen in a data-driven way. We will first consider parametric functions of the form Common slope difficulty functions; left column are difficulty functions, right column are probability mass functions for θ
p
= 0; intercepts: (δ10, δ20, δ30) = (−5, −4, −3)), slopes first row: δ
i
= 1.5, second row: δ
i
= 2, third row: δ
i
= 3.


If slopes differ across items the difficulty is determined by both values of intercepts and slopes. For illustration, the first two rows of Figure 2 show items with fixed intercepts for all items (δi0 = −4 in the first row, δi0 = −6) in the second row, but with differing slopes in the items ((δ1, δ2, δ3) = (2, 2.5, 3))). It is seen that although the intercepts are the same for all items the variation in slopes has the consequence that distributions are differing, items with larger slopes are harder than items with smaller slopes. Varying slopes in difficulty functions, first row: intercepts δi0 = −4 for all i, slopes (δ1, δ2, δ3) = (2, 2.5, 3), second row: intercepts δi0 = −6 for all i, slopes (δ1, δ2, δ1) = (2, 2.5, 3), third row: intercepts (δ10, δ20, δ10) = (−6, −4, −2), slopes (δ1, δ2, δ1) = (3, 2, 1).
In the last row of Figure 2 both slopes and intercepts vary across items. The effect is that item difficulty functions can cross, which means that items are not simply ordered in terms of difficulty. The difficulty functions show essentially how hard it is to score above a fixed threshold y. For small values of y, say 1 or 3, the probability of scoring above y is higher for item 1 than item 3. However, for large values of y, say 20, the probability of scoring above y is smaller for item 1 than item 3. Consequently, item 3 has a peak at 2 but also has a heavy tail with larger probabilities than item 1 for large values of y.
The strength of the model with common slopes, if it fits the data well, is that items are ordered, and the intercepts represent the difficulties of the ordering. Varying slopes allow for more flexible modeling, but items are not ordered, the corresponding distributions vary in means and other moments. However, one should not expect items to be ordered in a simple way. If responses were normally distributed with the same variance then (for fixed θ), the means of responses would provide a distinct ordering of items. However, for count data where means and variances vary over items, means of responses do not provide an order.
In general, it is important that the whole difficulty function determines the difficulty of an item. For parametric functions that means both parameters δi0 and δ i , determine the difficulty, large values of these parameters mean that the item difficulty is high, small values indicate easy items. It should be noted that slopes refer to the difficulty functions. This should be distinguished from the slope concept that is used, for example, in binary models. In binary models as the 2PL model, P(Y pi = 1) = F(α i (θ p − δ i )), the parameter α i is a discrimination parameter, but is also often referred to as slope parameter. It has a quite different meaning than the slope in thresholds models. Large discrimination parameters have the effect that the increase in probability is stronger when θ p increases than for smaller discrimination parameters. The slopes in thresholds models do not have these effects.
Monotonicity
Although items are not necessarily simply ordered in terms of difficulty, the ability is in a specific way linked monotonically to the responses to be expected. Let us consider the probability of an response above a specific value y as a function of θ
p
, which is considered an item characteristic function (for fixed value y)
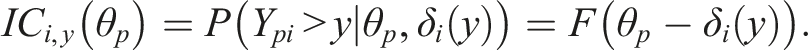
Since F(.) is strictly monotonically increasing also the function ICi,y(θ
p
) is strictly monotonically increasing. That means, the probability of scoring above y is an increasing function of the ability for any value y. For two abilities θ
p
and

It should be noted that the monotonicity of the item characteristic functions holds also if difficulty functions do cross. The essential feature is that the item characteristic functions do not cross, which is simply seen to hold.
Link to Categorical Item Response Models
Let us consider the thresholds model for a fixed threshold y0, P(Y
pi
> y0|θ
p
, δ
i
(.)) = F(θ
p
− δ
i
(y)). For the binary response defined by Y
pi
(y0) = 1 if Y
pi
> y0 and Y
pi
(y0) = 0 otherwise one obtains the binary item response model

The link between the threshold model and binary models is even stronger. If binary models P(Y pi (y0) = 1|θ p , δ i (y0)) = F(θ p − δ i (y0)) hold for all thresholds y0 ∈ {0, 1, 2, … }, then the thresholds model holds. Thus, the threshold model can also be understood as a collection of binary (normal-ogive or Rasch) models that have to hold simultaneously for fixed θ p . In this sense, it can be seen as an extension of binary models to count data, and binary models as special cases if count data are dichotomized.
There is also a link to polytomous response models. For a set of thresholds −1 = y0 < y1 < … < y
m
,


The link to polytomous models is also interesting with regard to collapsibility. It refers to the invariance of models when adjacent categories are combined, which reduces the number of response categories by collapsing. It is of importance since it is not unusual that categories are combined in an analysis although more categories have been used in data collection. In several papers, it has been argued that the number of categories should not interfere with what is being measured (Jansen & Roskam, 1986; Roskam & Jansen, 1989). That means the model should remain the same if adjacent categories are combined, a concept that has been formalized by a principle called ξ-invariance (Jansen & Roskam, 1986). By construction the threshold model is invariant under collapsing.
In addition, if responses are collapsed by using thresholds y1 < … < y m the model becomes a generalized linear model (McCullagh & Nelder, 1989), which allows to use the tools that have been developed for this class of models. A particular choice that could be useful, is y i = i, i = 1, …, m, which retains the observations up to m and collapses the responses larger than m into one category. It might be useful in particular if outliers are present.
Overdispersion and Underdispersion
Rasch’s original Poisson counts model (Rasch, 1960) assumes equidispersion, that means conditional mean and variance have to coincide. By assuming a negative binomial distribution given person ability and item parameters also overdispersion, which means conditional variances can be larger than means, is covered (Hung, 2012). Forthmann et al. (2020) made a point of considering the possibility of underdispersion in item response count models, which means that conditional variances can be smaller than means, and introduced the Conway–Maxwell–Poisson model, which is able to model underdispersion.
The same holds for the count threshold model considered here. The model can account for overdispersion as well as underdispersion regarding means and variances. For illustration, Figure 3 shows the conditional means and variances for items with intercepts from (−3.4, −2) and slopes from (2, 3). It is seen that for these parameters easy items (left corner) have conditional variances that are larger than the means but for harder items (right corner) the conditional variance is smaller than the mean. Conditional means and variances for selection of items (logarithmic difficulty functions).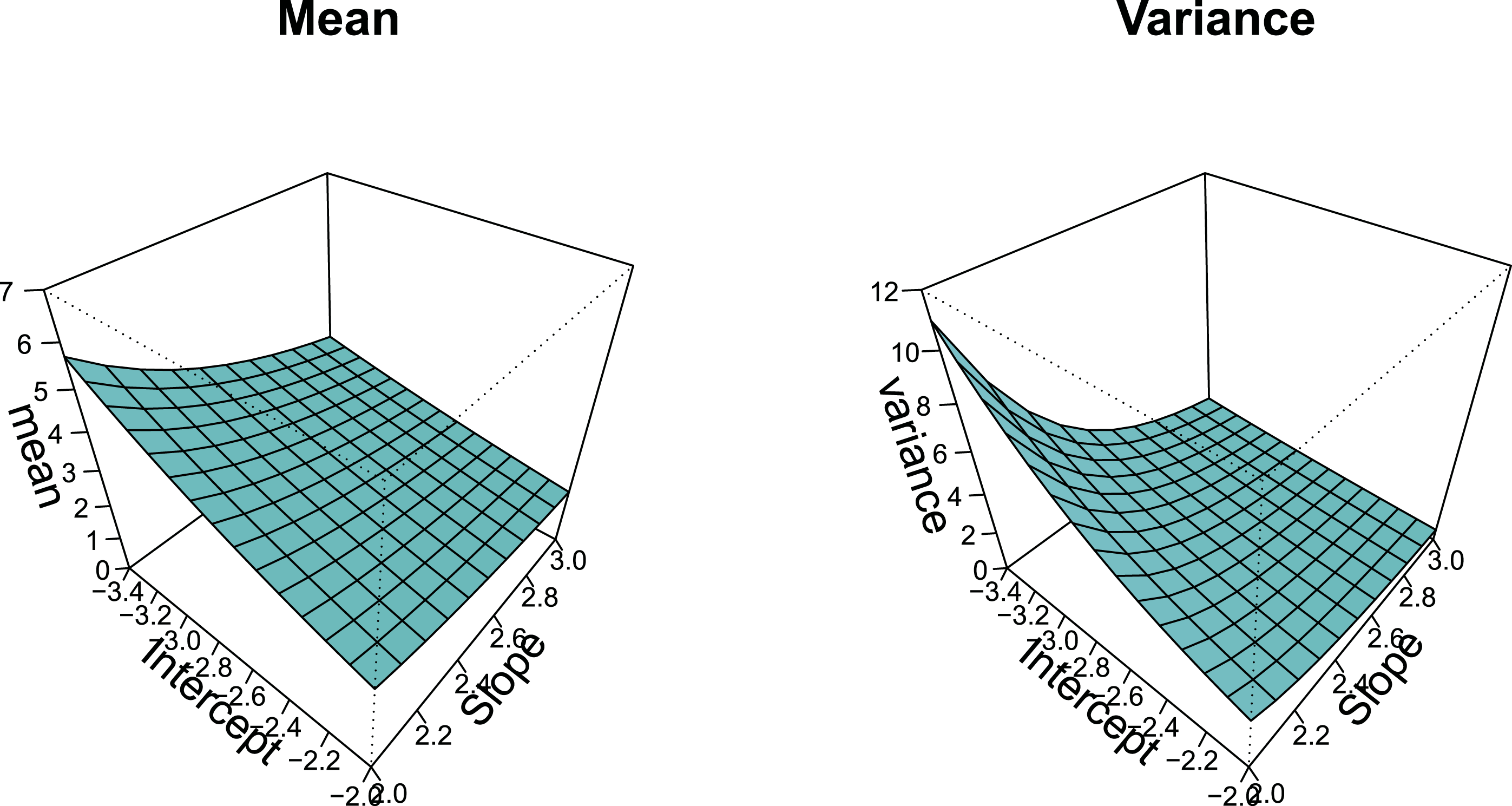
Estimation
If the general thresholds model holds the distribution function for observation Y
pi
has the form


Marginal likelihood estimation is obtained by assuming that person parameters are normally distributed,
The marginal likelihood has the form


The corresponding score function s(


Illustrative Simulation
We consider 10 items with logarithmic difficulty functions. The intercepts were δi0 = −6 + (i − 1)0.2 yielding the sequence −6, −5.8, −5.6, … , and slopes δ
i
= 2 + (i − 1)0.1 yielding the sequence 2, 2.1, 2.2, …. The items are ordered, item 1 is the easiest item and item 10 the hardest, which is also seen from Figure 4, which shows the probabilities of a response larger than y for θ
p
= 0 (only 9 items shown) and the corresponding response probabilities. Probabilities of a response larger than y for 10 items with true intercepts δi0 ∈ {−6, −5.8, −5.6, … } and slopes δ
i
∈ {2, 2.1, 2.2, … }.
Figure 5 shows the resulting parameter estimates and the true values (as dots) for P = 100 (200 repetitions), in the supplemental appendix results for P = 200 are given. It is seen that parameters are recovered very well. More important than accurate estimates of parameters is that the underlying distributions are estimated accurately. Since both parameters contribute to the difficulty even some underestimation of the slope can be compensated for by an overestimation of the intercept and vice versa. Therefore, the left picture in the third row shows the accuracy of estimates regarding the density of responses. It shows for all items the distance between the true (discrete) density and the estimated density for θ
p
= 0 Simulation results for 10 items and P = 100 respondents; first row: intercepts and slopes, dots indicate true values; second row: person threshold functions for θ
p
= 0 for items 1 and 8 and six estimated functions from the first six simulation runs; third row, first column: difference true and estimated densities for all items; third row, second column: correlation between true and estimated person parameters; forth row: standard errors, true and estimated, for item parameters.

Data-Driven Item Difficulty Functions
Fixed item difficulty functions are easy to handle but an appropriate function has to be chosen. If the form of the function is questionable it seems warranted to let the difficulty function be determined in a data-driven way from a wide range of possible functions. For illustration of the flexibility of the threshold model let us consider person p with cumulative probability mass function given by cpi(y pi ) = P(Y pi > y pi |θ p , δ i ) = F(θ p − δ i (y)). Since parameters are only identifiable up to an additive constant, one can choose θ p = 0 for this individual. Then for any function cpi(.) the item difficulty function can be computed by δ i (y) = F−1(cpi(y)). Thus, for any cumulative probability mass function one can find an item difficulty that fits this individual. Of course, if the item difficulty is determined for one individual, the model restricts the distribution of responses for all other individuals; however, it demonstrates that the choice of the item difficulty function can adapt quite flexibly to a wide range of possible distributions.
In the following, we consider a method to generate flexible difficulty functions. It can use fixed difficulty functions as a starting point or do without.
Modeling by Basis Functions
To obtain a wide range of item difficulties they can be approximated by a finite set of basis functions. We will consider two ways of using basis functions. One way is to let difficulty functions be determined solely by basis functions by assuming

The downside is that models are not nested. A model that uses basis functions is more flexible than a model with a logarithmic difficulty function, but it is not straightforward to compare the two models since the model that uses a fixed function is not a submodel of the basis functions model. A way to obtain nested models is to combine a fixed function with the basis function approach. Let the first two basis functions in (3) be given by

For basis functions the log-likelihood functions are the same as in the case with fixed difficulty function. Only the derivatives have the more general form

The strategy we use here is to choose a moderate number of basis functions, say 8 to 10. It makes the difficulty functions sufficiently flexible without increasing the numbers of parameters too strongly. An alternative strategy is to use a larger number of basis functions, say 30 to 40, but then estimation becomes unstable, reliable estimates can be obtained only if one uses penalized maximum likelihood estimates, which restrict the variation of differences of parameters for adjacent basis functions, see Eilers and Marx (1996, 2021). Although the latter strategy is more flexible, it has the disadvantage that additional tuning parameters have to be selected. Moreover, likelihood ratio tests are not available since fitting is not based on maximum likelihood but on penalized maximum likelihood. For the choice of the number of basis functions in an application see also supplemental appendix.
Flexibility of Models
In the following, we briefly investigate the flexibility of the thresholds model. Several models can be used in count data item response theory, the simple Rasch count model, the negative binomial model, Conway–Maxwell models, or the thresholds model. Since typically it is not known which model generates the data it is useful if a model can adapt to quite different data generating mechanisms.
In a simulation study, we considered several data generating models and how differing models adapt to the generated data. As an example we give the results for 50 respondents and four items. The data generating models were • (Poisson) the Poisson model with item parameters −2.4, −2.0, −1.6, −1.2 and σ
θ
= 1, • (CMGlobal) the Conway-Maxwell model with global dispersion with the same item parameters as the Poisson model, but the additional dispersion parameters ν1 = ⋯ = ν4 = 0.8, • (CMDisp) the Conway-Maxwell model with varying dispersion with the same item parameters as the Poisson model, but the additional dispersion parameters (ν1, ν2, ν2, ν4) = (0.8, 0.9, 1.1, 1.2), • (NegBin) the negative binomial model with the same expectation as the Poisson model but with strongly overdispersed items such that the variance is five times the mean of responses, • (Thresholds) the thresholds model with logarithmic difficulty functions and item parameters (−6.02.0), (−5.62.2), (−5.22.4), (−4.82.6) for (δi0, δ
i
), and σ
θ
= 1.
Figure 6 shows the log-likelihoods and the AICs obtained when these models generate the data and are also used to fit the data (100 repetitions). In addition, the thresholds model with splines was fitted (ThreshSpl). It is seen that the splines model always yields the best fit in terms of maximum log-likelihood. It shows that the model is able to fit data that were generated by any of the models that were used. The thresholds model with fixed difficulty functions fits well if it is the data generating model but is not flexible enough if the Poisson or the Conway–Maxwell model generate the data. However, it fits comparatively well if the generating model is the negative binomial model with overdispersion. It is interesting how models fit if one takes the number of fitted parameters into account by considering the AIC. Then, the splines model shows good performance for most models, in particular the fit in terms of AIC is comparable to the fits of Conway–Maxwell models if the latter are the data generating models. In the case of the negative binomial model the performance is stronger in terms of AIC. If the threshold model generates the data the threshold model with fixed difficulty functions performs best as was to be expected. Conway–Maxwell models perform worse and do not adapt very well to the probability structure of thresholds models, which is somewhat hidden by the inclusion of the Poisson fit, which in this case shows very poor performance. Simulation results for differing data generating models (P=50); first row: Poisson model, second row: Conway-Maxwell (CM) with global dispersion, third row: CM with varying dispersion, fourth row: negative binomial model; fifth row: thresholds model; left column: log-likelihood, right column: AIC.
Application
Forthmann et al. (2020) used a data set with four commonly used verbal fluency tasks, which are available at https://osf.io/38zsm/. The data set includes two semantic fluency tasks, namely, animal naming (item 1) and naming things that can be found in a supermarket (item 4) and two letter fluency tasks, words beginning with letter f (item 2) or letter s (item 3). The participants had 1 minute to complete each of the verbal fluency tasks. In our analysis, we use the 192 individuals that responded to all items.
Verbal Fluency Data.


Difficulty functions, person threshold functions, P(Y > y), for value θ = 0 and densities for verbal fluency data; left: common slope, right: varying slopes.
Log-Likelihoods, AIC, Number of Parameters, and Mixture Standard Deviations.

Figure 8 shows the posterior estimates of person abilities plotted against the total score Posterior estimates of person parameters against sum score of persons.
We also considered the more general model with data-driven choice of difficulty functions. Model 3 uses basis functions only to approximate the difficulty functions while model 4 uses a combination of the logarithmic function and basis functions. In both models the number of cubic B-splines was 8, which provides enough flexibility but does not inflate the number of parameters. Cubic splines are a natural and widely used choice since they yield rather smooth curves, splines of higher order typically yield no discernible change in fitted curves. Thus, each item has 8 parameters in model 3 (only B-splines) and 10 parameters in model 4 (8 B-splines parameters, intercept and slope on logarithmic function). The difference between the two models is negligible as is seen from Figure 9. Also the likelihood ratio test that compares the two models shows that there is no significant difference (8.70 on 8 df). Model 4 has the advantage that it can be directly compared to model 2 since model 2 is a submodel of model 4. The likelihood ratio test yields 95.12 on 32 df, which means the difference is highly significant, and the model that allows for more flexible difficulty functions is more appropriate. Difficulty functions, person threshold functions, P(Y > y), for value θ = 0 and densities for verbal fluency data; left: logarithmic plus B-splines, right: B-splines.
We also fitted the Poisson model and extensions by using the R package glmmTMB, for a detailed description of the models and how to fit them see Forthmann et al. (2020). Table 2 shows the results for three models, the Poisson Rasch model (M), the Conway–Maxwell model with global dispersion (CMG), and the Conway–Maxwell model with varying dispersion (CMV). It is seen that in terms of AIC the Poisson model and the Conway–Maxwell model with global dispersion fit the data less well than the thresholds models (3) and (4), the best fit was found for the Conway–Maxwell model with varying dispersion. The largest log-likelihood value was found for model (4) but since it has more parameters than model (3) and the Conway–Maxwell model the AIC is larger. It is worth mentioning that posterior estimates are highly correlated for the models. For example, the person parameters of the threshold model with varying slopes (shown in Figure 8) have correlation 0.9906 with the person parameters of the Poisson model, 0.9924 with the global dispersion Conway–Maxwell model, and 0.9901 with the varying dispersion Conway–Maxwell model. For the latter model, the computational effort is rather high as compared to threshold models.
Concluding Remarks
Item response count models as alternatives to fixed distribution models have been introduced. The models allow for very flexible modeling of responses that can account for a wide range of response distributions that may vary across items. It has been demonstrated that the model also fits well if data are generated by the Conway–Maxwell distribution. The item characteristics of the model are summarized in difficulty functions, which are easily accessible in the form of plots. In the simplest case, difficulty functions are ordered, indicating that items are ordered in a simple way. In the considered application more flexible modeling with crossing item difficulties turned out to be more appropriate.
It has also been demonstrated that the model yields good parameter recovery. In the simulation and application sections we used the package glmmTMB to fit the Conway–Maxwell model, see Forthmann et al. (2020). For the fitting of the threshold model an R program has been written that uses the function gauss.hermite from the package spatstat, and the package splines when fitting difficulty functions that are expanded in B-splines. Software that can be used to fit models and compute the results shown in previous sections will be made available on GitHub.
Supplemental Material
Supplemental Material - Flexible Item Response Models for Count Data: The Count Thresholds Model
Supplemental Material for Flexible Item Response Models for Count Data: The Count Thresholds Model by Gerhard Tutz in Applied Psychological Measurement
Footnotes
Acknowledgments
I want to thank Boris Forthman for providing the data set and the code to fit Conway-Maxwell type models.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental Material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.