Abstract
Due to the widespread use of the internet, there are large amounts of information and documents available in several languages. The Arabic language is one of the available important languages in terms of its usage and structure. Search engines like Google and Yahoo support searching in Arabic, yet fail to get good results when slang terms are used in the query. There are difficulties associated with the Arabic language. The main goal of this research is to refine Arabic text-based searching by using Arabic slang terms in queries. This research proposed a framework to enable users to use their slang language in order to retrieve the relevant documents that have been posted in both forms – slang and classical. The framework is designed and implemented based on a context-free grammar that is used to map the user’s slang queries to the equivalent classical ones. On a classical dataset, results showed a 3% improvement on the average values of precision, recall, and F-measure achieved using classical-based queries rather than slang-based ones. Using slang-based queries gives 13% improvement on the average values of the used measures on a slang dataset and 7% improvement on the average values of the used measures on a hybrid dataset.
1. Introduction
The area of Information Retrieval (IR) includes many studies that have been proposed to help users retrieve information on their interests [1–4]. The majority of the previously undertaken work describes methods and tools to process English language based documents. Much work has been done in the field of Arabic language based documents and the need for special processing. This is due to difficulties associated with the features and structure of the Arabic language. There are several features that distinguish the Arabic language from other languages. For example, the Arabic language is written from right to left [5–7]; it has a complex morphological structure [1, 2, 4, 8]; Arabic letters change their shapes depending on their location within the word [1, 4, 9]; Arabic is polysemous, i.e. the same word may have several meanings [2], which can lead to user and author vocabulary mismatch [10, 11]. Finally, there are difficulties in finding the stem for Arabic words. To refer to a word in an Arabic dictionary, first you must extract the root of the word, and then find this root in the dictionary. Several algorithms are proposed as in [10, 12, 13] but there is no complete stemming algorithm for Arabic words until now [13].
The Arabic language is divided into slang and classical languages [14, 15]. Arabic language queries are written in the classical form, and the results, sometimes, are irrelevant because of the poor search terms used. Until now, there has been no search engine able to process slang Arabic queries.
Sometimes, it might be necessary to use slang terms to search among documents that are posted in slang (e.g. social forums). In this article a framework is introduced, in which the slang queries can be written to return the relevant documents accordingly. Slang languages differ from one country to another. Also within the same country, there are many slang languages that distinguish country provinces from each other [16]. Using the developed system, the user enters a query using their slang language, and then the system returns the related documents. In this research, a slang language of a province in Jordan is used as an example of a used slang language. Modifying the system to be applicable for different cities in different countries has become much easier than ever. The modification process can be performed based on the used slang languages.
2. Problem statement
The accuracy of searching for Arabic documents as well as other documents depends on the search terms used; these terms need to be precise in order to get the best results that fulfill the user’s needs. In reality, most of the time the user enters inaccurate terms and so irrelevant results are retrieved. The main reason for using inaccurate terms is the nature of the Arabic language, which contains complicated and complex terms that often are used incorrectly by the majority of users.
Currently, users who are familiar with the Arabic language can only use classical Arabic language to search the web. Thus far, searching for slang-based documents is not possible. Arab people study, learn and write in classical language, but slang is commonly spoken and widespread among them. Thus, slang terms are closer to Arab people than those terms learned in either school or university. Using slang terms for search and retrieval is more flexible and much easier for users who speak slang Arabic. In addition, the web content might be in slang-based language such as the material that is available in social forums. Therefore, there is a need to develop a tool to convert the terms from slang to their equivalent classical terms. This conversion is expected to give better results when users search the web using slang-based queries.
3. Research objective
The main objective of this research is to develop a framework that is specialized in converting user queries from slang Arabic into their equivalent classical forms. The main goal of the proposed framework is to enhance the Arabic-based information retrieval systems. In this context, the English translation for Arabic words is provided at the end of the article to enhance the readability of the paper.
4. Related work
Studies and experiments that have been undertaken on Arabic language processing are relatively new and limited compared to the work that has been done on English language. The proposed method in [17] is a statistical thesaurus to deal with the large number of broken plurals and synonyms in Arabic. This approach differs from other techniques in that it is probabilistically motivated and employs a parallel corpus rather than a monolingual corpus for determining word associations. Experiments show that the thesaurus can significantly improve monolingual retrieval.
In [18], a rule-based algorithm is developed to convert the Sana’ani accent to Modern Standard Arabic (MSA). The mechanism tokenizes the input dialect text and divides each token into a stem and its affixes. The stem and the affixes could be dialect or MSA stem/affix. The rules are applied to extract the dialect affixes. This algorithm achieves 77.32% of the whole used Sana’ani corpus.
Authors in [19] presented an approach that aims to find the differences between MSA and Jordanian Arabic (JA) in the future. Two markers found in MSA are ‘sa- سـ’ at the beginning of the verb to expresses approximate and ‘sawfa سوف’ to express remote future. In JA, three markers found, bad- (e.g. بدي أروح على المدرسة ) with two allomorphs (wed-) and (ad-) used by elder people. For example, أدي/ ودي أروح على المدرسة . The second marker is (Rayih رايح ) or (Rayha رايحة). For example, انا رايح/رايحة على سة. In both cases it could be replaced with ‘ RAH راح ’. The third marker is (b-) that is attached with the present verb to represent continuity of the action without having a future adverbial. For example, بكتب رسالة.
The English language has changed remarkably over centuries and the vocabulary, structure and terms used today are very different. In [20], the differences between slang and classical (modern) English are defined, and a non-referential definite has been analysed in a slang context.
In [21] the authors developed a dictionary of slang drug terms to help drug counsellors and researchers get more accurate information on client’s abuse history and patterns. In [22], a new method for retrieving evaluative documents for an item by using a slang-style coined name for an item as a query has been proposed. This method evaluates documents that cannot be retrieved by existing methods. In this method, users are allowed to select slang-style names to be used as a query; and the method automatically generates slang-style alternative names for that item and uses those names to query the internet. Otherwise, all the generated names are automatically used for retrieval purposes.
The authors of [23] studied the effectiveness of Google search results in response to 104 Arabic queries. Analysis of the results indicated that Arabic information is imprecise, and Arabic users are not very satisfied with the results. This is due to a lack of valid and reliable online information in Arabic.
In [24] the authors presented preliminary results of experiments with a corpus for MSA using data available on the internet. The selected samples were newspapers published online from different Arabic countries. The selection was driven mainly by the amount of data available for building a significant corpus for the purpose of studying the Arabic language. In [25], automatic Arabic thesauri using term–term similarity and association techniques were designed and built to be used in any special field or domain to improve the expansion process, and to get more relevant documents for the user’s query.
There are few studies that have been undertaken on the analysis of the morphological structure of Arabic language, and how this analysis could help in the Arabic-based information retrieval systems. The limited number of studies in this field is due to the complex morphological structure of the Arabic language.
With the widespread use of the computer communications, a lot of information can be obtained through public forums. There exist now a very large number of social forums where members are discussing several general or specific topics.
Much work is being undertaken on how to take advantage of the vast amount of information in these forums. Social media systems such as weblogs, photo, link-sharing websites, wikis and on-line forums are currently thought to produce up to one third of new web content.
In [26], the authors developed an approach to enhance IR over social networks extracted from scientific publications. This approach consists of the following four steps.
Theoretical foundation: justification for the usage of online information to extract social networks.
Conceptual model: develop social network analysis to enhance relevance ranking model for IR systems.
Implementation: the model is implemented.
Evaluation: to evaluate whether and how the relevance ranking based on centrality measures has an impact on the relevance ranking of the documents of the information retrieval system.
Extremist online forums are widely spread over the internet. The information posted by those people could be collected and analysed to determine their activities, communications, relationships and special information to help researchers and officials to understand their activities.
The authors of [27] developed a web mining approach to collect and monitor information from extremist forums. This approach consists of three parts.
Forum identification: define the extremist groups that are considered by the authorities to be extremist groups. The sources include government agencies. Also in this step the hosted websites and ISPs of these forums are defined.
Forum collection and parsing: web spidering approach is used to collect information.
Forum analysis: web and text mining techniques can be applied on the collected information to identify the characteristics of active participants and listeners and all multimedia files are analysed.
In [28], the author discusses a sample of spoken Jordanian time expressions and provides ethnolinguistic explanations of their meanings in the contexts in which they occur. The author divides the relevant time expressions into three categories.
Imprecise expressions, which includes expressions whose temporal specifications are somewhat vague, take the sentence ( مع فجة الضو). This glimpse of dawn is established within Arab cultural and societal norms not according to calendar calculations.
Semi-precise expressions – this type of temporal reference may be roughly defined as short-term reference co-extensive with a fairly limited period of time (e.g. لحظة من فضلك). The word ‘ لحظة’ suggests that the waiting will not be long at all; in effect, however, it may take seconds or minutes.
Precise expressions, which include clock time along with an overt or covert calendar day (e.g. منتقابل الساعة وحدة ونص بعد الظهر). The day of the meeting is shared information between the speakers, and the time is precisely given to them.
In [29], a Bayesian model has been developed to automatically align documents with different dialects (slang, common and technical) while extracting their semantics using Dialect Topic Models (diaTM). This method achieves a 25%improvement in information retrieval relevance.
5. The proposed framework
The main objective of this research is to design a framework to enhance the Arabic information retrieval using slang-based queries. There exists a fair amount of documents that have already been posted on the internet in slang. Such documents are most likely to be found in social forums that may contain very important and relevant documents. Figure 1 shows the process of converting the user’s query from slang to its equivalent classical one.
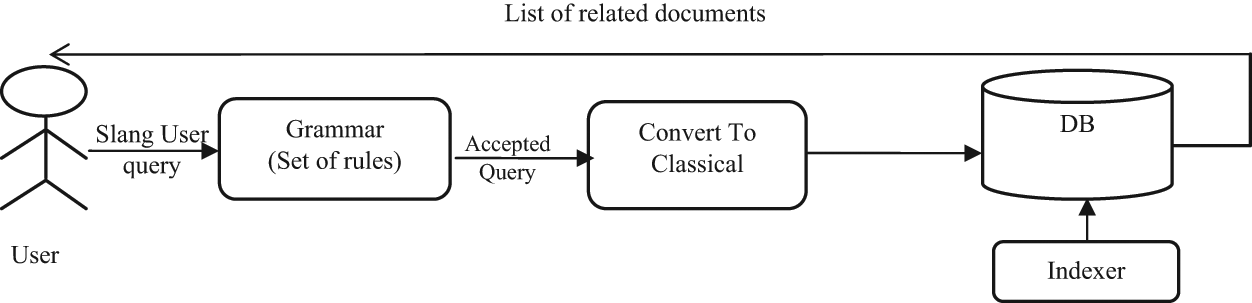
The process of converting a slang query to a classical one.
Figure 2 shows the framework of the Slang Arabic Retrieval System (SARS) and the main steps of the process of retrieving documents using slang Arabic queries. Arabic-based studies and information are often found in their classical form. The goal of this system is to retrieve Arabic information using slang-based queries. To achieve this, the system provides two approaches to deal with Arabic slang queries, but after checking their compatibility with the proposed grammar. Only accepted queries are processed.
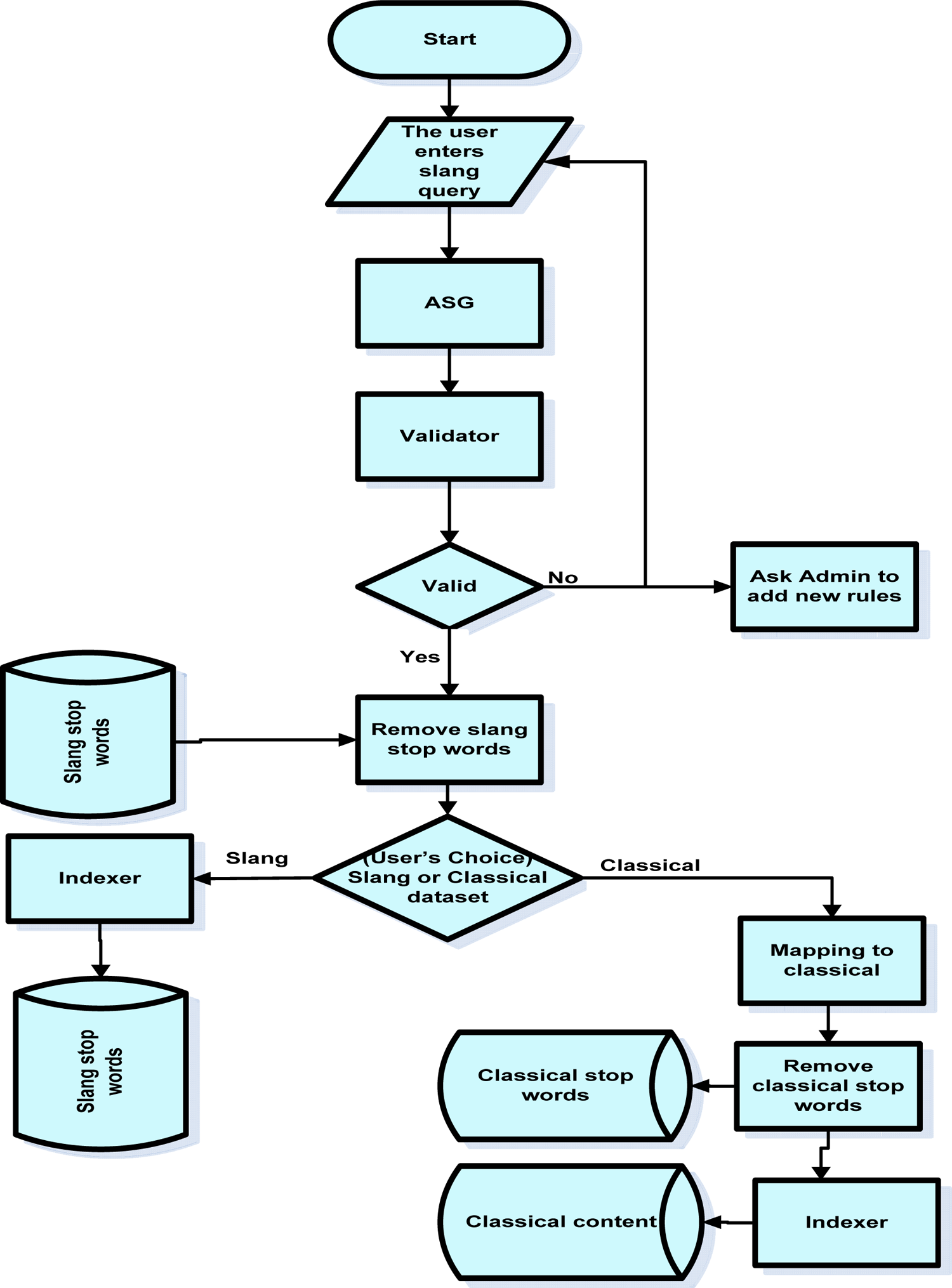
The proposed framework.
The first approach is to convert the slang query terms to their equivalent classical ones based on Arabic Slang Grammar (ASG) then to search in the traditional way after removing the stop words and applying the proper stemming algorithms. The stemming algorithms are necessary here in order to facilitate the process of transforming the slang query to its relevant classical one. The stemming algorithms are responsible for removing the prefixes and the suffixes of the slang query. The second approach is to keep the query in its slang form, then only remove stop words that are commonly used and search for the remaining terms of the query.
Removing the classical stop words is necessary for the same purpose of removing the slang stop words. Keeping the stop words degrades the search accuracy because users usually are interested in searching for non-stop words and the frequency of those words is relatively high. In addition, this process is a recommended process because sometimes the mapping process might result in classical stop words.
The indexer component is used to index the content in order to facilitate the searching process because as is known the search is performed against the indexer.
5.1. Definition of ASG Grammar
This research uses a Context Free Grammar (CFG) which is a set of rules written in the form R1 → R2, where R1 is a non-terminal symbol and R2 is a set of non-terminal and/or terminal symbols.
The grammar G consist of four parts (T, N, S, R).
T: is a finite set of terminal symbols.
N: is a finite set of non-terminal symbols.
S: is a unique starting symbol.
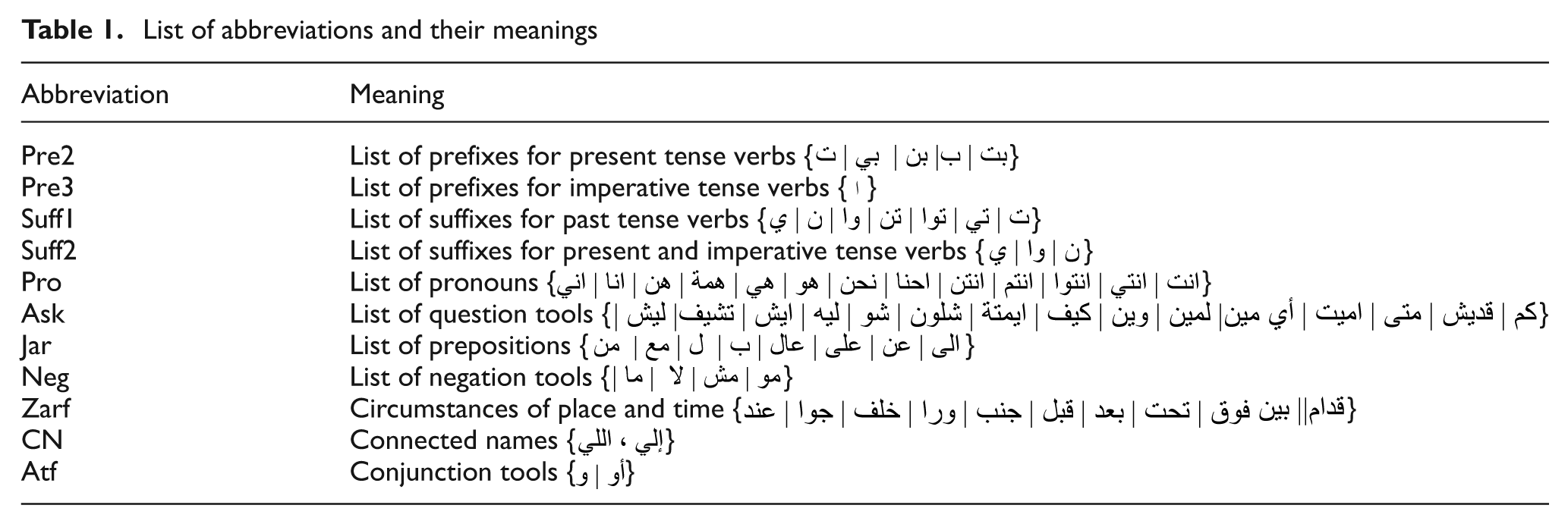
R: is a finite set of production of the form α → β, where α and β are string of terminals and non-terminals. The contents of ASG are shown in Figure 3 and the abbreviations used in ASG are listed in Table 1. The set of prefixes and suffixes is determined based on slang Arabic language. Those prefixes and suffixes contradict the classical ones that exist in Arabic classical language in which there is a known set of prefixes and suffixes. Usually, the prefixes and suffixes are collected based on the used slang language.

Arabic Slang Grammar (ASG).
List of abbreviations and their meanings
The grammar that appears in Figure 3 is a user defined grammar. This grammar is a context free grammar that is built based on the chosen slang language. Thus, any slang-based statement can be driven from the above grammar recursively (i.e. the set of production rules that produce the slang statement).
5.2. Syntax of ASG rules
The imposition of a certain format for the rules of mapping slang terms to classical ones is required in order to have better control over adding such normalization rules. If the rule format complies with ASG, the rule is added to the list of available and accepted ones. The basic sentence of the equivalent rules in slang grammar should be in the form: S: S (where S is a non-terminal symbol which represents a structure of an Arabic slang sentence). The symbol (: ) is an equivalent operator between the the two sentences. The left hand side is the sentence (i.e. query) before applying the rule of equivalence and the right hand side represents the sentence after applying the rule of equivalence [30].
5.3. Term type determination
The type of the query terms must be determined in order to check the query structure and its compatability with the predefined grammar. The type of a term can be a verb, a noun or an adjective.
Depending on the given set of prefixes, suffixes and the structure of sentences, algorithms are developed to extract the type of a term. The pseudocode to determine the verb tense appears in Figure 4, where (termi) represents the current processed term of the user’s query. A verb could be one of three tenses; past, present or imperative. For each case, the list of prefixes and suffixes that may precede or follow verbs is shown in Table 1. Notice that the minimum length for any affix is one and the maximum length is two [31]. These are the conditions for the attached prefixes and suffixes.

Pseudocode to determine the verb tense in the Arabic language.
In the case of past tense verbs, it has no prefixes but a suffix may follow it (e.g. لعبنا) or the past verb might be the root of the verb (has no affixes) (e.g. كتب). In a present tense verb, the attached affixes are known. Therefore, the present tense verb may be preceded by a prefix and followed by a suffix (e.g. بتعلبي) or it may be preceded by a prefix and not followed by any suffix (e.g. بلعب). The imperative tense verb has the same suffixes as those that follow the present tense verb (see Table 1) but the only prefix that precedes the imperative verbs is the letter ‘ا’ (e.g. العب ، ادرس ). Special verbs are imperative but do not follow the above structure, and do not have any affixes (e.g. روح, تعال). Such terms can be stored in a lookup table in order to facilitate their processing (i.e. finding their equivalent classical ones).
The best known and common nouns are people names, places, countries and objects. Generally, Arabic nouns are preceded by the article ‘the’ (الـ - التعريف). The noun can be found either after Zarf Makan or Zarf Zaman [31], which means in English the circumstances of place and time (e.g. year, month, etc.), or after Jar tools (prepositions). These are the three well known rules that can be used to determine the noun in the Arabic language.
In the Arabic language the adjective always follows nouns in contrary to the English language. Therefore, if the term is not a verb or not one of the Arabic static types and proceeded by a noun, then it is an adjective.
In this research, the CFG is used to validate the rules and the structure of the user query. Table 2 shows the symbols that are used to represent the types of Arabic words.
Symbols used to describe each type of Arabic word

For explanation purposes if the user input is ‘وين بتوجد البترا’, according to the defined format in ASG, the format ‘$*?n’ as appears in Table 3 is correct and the structure of this query is acceptable, but the format for the query ‘أميت من البيت طلع محمد’ appears in Table 4. This format ‘$@n*_n’ indicates that this query is not acceptable because of its invalid structure.
The format of the Arabic statement ‘وين بتوجد البترا’

The format of the Arabic statement ‘أميت من البيت طلع محمد’

6. The Slang Arabic Retrieval System
In this research, a system to retrieve documents based on slang queries is designed and implemented, in which it is called the Slang Arabic Retrieval System (SARS). The implementation is divided into two parts, the ‘Validation’ part and the ‘Slang to Classical Mapping’ part. Validation concerns checking whether the input query complies with the predefined grammar. Only valid queries will be accepted and processed thereafter. The main terms of the accepted query will be reformatted, if needed, to get their equivalent terms in classical language according to the predefined rules.
Testing the performance of this work is an important step. The test-bed should contain both kinds of documents – slang and classical ones. Usually, the user starts searching by entering their own query of interest. The system maps the main terms and searches for them in the database. The query is executed to retrieve the relevant items. This process works for both the original slang terms used in the query and for terms that have been mapped to classical language. This way, users who are interested with only slang-based content can retrieve and check the slang ones because users can decide whether to perform the ‘Slang to Classical Mapping’ or not.
6.1. Mapping slang to classical
The main objective of this step is to find the most appropriate classical terms that map (i.e. replace) the slang terms of the query. Achieving this step is based on removing the set of prefixes and sufixes from the slang words, Upon removing those prefixes, the stem of that word is the classical equivalent for that slang word. The highest cost method is by using lookup tables. This method is not applied because we have a very large number of terms. Thus, a very large size data repository is needed to store them. Instead, tables for static terms (i.e. terms that cannot be found using predefined rules), nouns, and a mapping method has been developed that depends on the main similarities and differences between slang and classical terms.
In general, the main difference between slang and classical Arabic is in the dialect [32] because slang is not another language that differs from the classical one. The result of the language errors produces slang terms [29, 33, 34]. For example, in verbs, they are mostly the same in writing but differ in their pronunciation. As another example, the attached affixes that precede or follow slang verbs are not the same as those attached with classical verbs [6, 31] (e.g. ‘بكتب’ in slang and ‘يكت:ب’ in classical): using ‘ب’ instead of ‘ي’ is a language error.
6.2. Verb conversion
To convert verbs from slang to classical, the affixes used in slang are replaced with an appropriate classical affix [31, 35, 36]. Tables 5–8 show examples of affixes attached to slang verbs and their equivalent classical ones [31, 37].
Examples of slang suffixes for past verb and their equivalent classical ones

The list of slang prefixes for present verbs and their equivalent classical ones

The list of slang suffixes for present verbs and their equivalent classical ones

The list of slang suffixes for imperative verbs and their equivalent classical ones

For the imperative verbs, the only prefix that precedes them is the letter (Alf ‘ا’). there is no need to replace the (Alf ‘ا’ ) in order to convert the slang form to its equivalent classical form because they are the same in both forms.
6.3. Examples of slang queries
6.3.1 Past tense verb slang query examples
شرب خالد العصير
In this sentence, the verb ‘شرب’ has no prefixes or suffixes to be replaced, so it remains the same.
لعبت مها باللعبة
In this case, the verb ‘لعبت’ is followed by the suffix ‘ت’, according to Table 3 this suffix remains unchanged. Notice that the suffixes ( ت، ن، تن، نا ) that are used in slang are the same as in classical without changing.
انتي فتحتي الباب
The suffix ‘ي’ follows the verb ‘فتحتي’, according to Arabic grammar for the past tense verb [31] if the suffix following the past tense verb is ‘ي’ (ياء المخاطبة), the suffix is omitted and replaced with KASRA ( ِ) under the last letter preceding the ‘ي’.
الشباب كتبوا قصة
When the suffix ‘وا’ is found, it is either not replaced or replaced with ‘ا’ to express the Muthanna (i.e. a group of two things).
6.3.2 Present tense verb slang query examples
خالد بلعب/بيلعب بالكرة
If the present tense verb is preceded with the prefix ‘ب’ or ‘بي’, it is mapped to classical by replacing the prefix with ‘ي’ to get ‘يلعب’.
مها بتدرس بتركيز
In this example, the subject of the verb is female. The prefix ‘بت’ represent female users in slang present tense verbs. Mapping is done by replacing ‘بت’ with the prefix ‘ت’.
احنا بنلعب كرة القدم
To convert the verb ‘بنلعب’ to its classical form, the prefix ‘بن’ is replaced with ‘ن’ to get the verb ‘نلعب’.
الاولاد بسبحوا بوقت الفراغ
The verb ‘بسبحوا’ ends with the suffix ‘وا’. First, the prefix is replaced with ‘ي’ as given above. The suffix ‘وا’ after that is replaced with ‘ون’ or ‘ان’ (both of them represent a single subject). The form of the resulting verb is one of the forms of (الافعال الخمسة) which is given with these five formats: (يفعلون ، تفعلون ، يفعلان ، تفعلان ، تفعلين). Also, if the verb ends with ‘ي’, the verb is converted to the form ‘تفعلين’.
المعلمات بدربن الطلاب على الاغاني
The ending suffix ‘ن’ is called in Arabic ‘Noon Al-neswah’. This suffix remains as is when it is converted to classical, but the prefix is changed from ‘ب’ to ‘ي’ giving ‘يدربن’.
6.3.3 Imperative tense verb slang query examples
The only prefix that is attached to the imperative tense verbs in slang Arabic is ‘ا’. To convert the verb to classical there is no change to the prefix. For the suffixes, there are three suffixes that may follow slang imperative tense verbs (ي ، وا ، ن). All of them remain the same if they follow the verb. The suffix ‘وا’ may also be replaced with ‘ا’ to represent two subjects.
Many verbs indicate the imperative tense but they do not have the same shape of imperative verbs (e.g. كسِّر الحواجز الخطيرة).
اكتب الكلمات بشكل صحيح
The verb ‘اكتب’ is written the same way for both slang and classical.
اكتبي الكلمات بشكل صحيح
The verb followed by the suffix ‘ي’. The converted verb is ‘اكتبي ’.
6.4. Noun and adjective conversion
Nouns are static; there is no need to convert them. For example, people names, places, things, animals and adjectives. In slang Arabic, there are many terms that are considered strange and vague for classical language.
7. Experiments and results
Two datasets were manually built. The first one contained 260 Arabic slang-based documents. The basic terms of the content of these documents were written as they are spoken in the slang language. The second contained 306 Arabic classical-based documents. Some of these documents were obtained from social forums or they are articles. Two lists of stop words were used; the first one contained 662 classical stop words. The other list contained a set of 100 slang stop words that were manually collected. The performance of this system has been measured by designing and implementing a test-bed that is connected to a searchable database. The searchable database has a set of slang-based and classical-based Arabic documents. The test-bed contains a set of 2600 rules in order to help in mapping Arabic slang terms to their classical ones.
7.1. Testing using slang-based and classical-based queries over a classical dataset
Using Arabic slang query to search within a classical dataset approximately gives the same results of precision and recall as those given when searching with Arabic classical query. This is due to the proposed system that converts any slang query to its equivalent classical form. Table 9 compares the average values for precision, recall and F-measure. There is a slight predominance when classical queries are used.
Precision, recall and F-measure on classical dataset.

7.2. Testing using slang-based and classical-based queries over a slang dataset
Table 10 shows that when comparing the results after searching the slang dataset, the results obtained using slang queries were better than those obtained using their equivalent classical terms. This is because there is no technique used to convert classical terms to the slang form.
Precision, recall and F-measure on slang dataset.

7.3. Testing the combined slang and classical datasets (hybrid dataset)
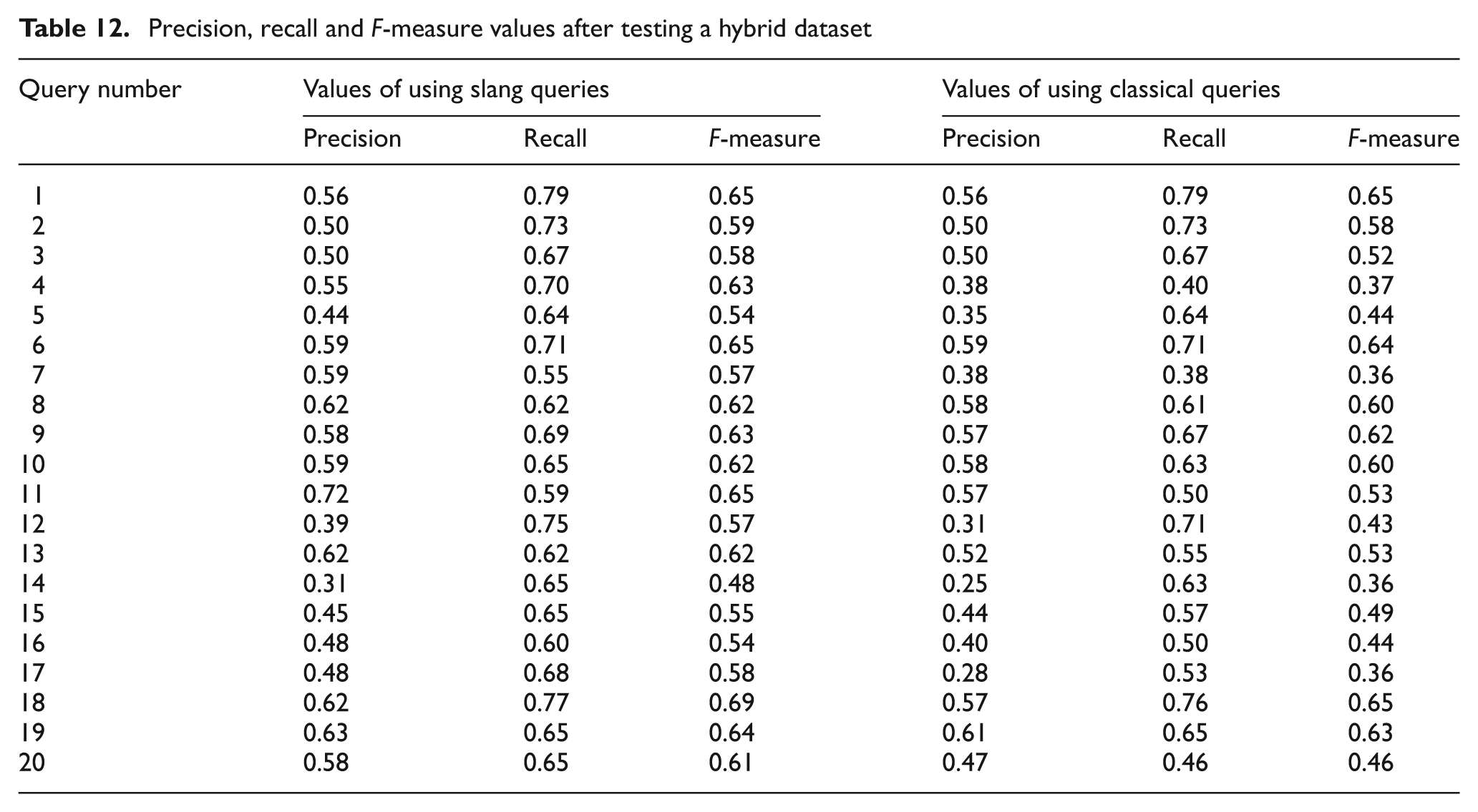
Table 12 shows a comparison between the used queries that are listed in Table 14 for testing; it illustrates that using slang-based queries is better than using classical-based ones when searching on the combined dataset that contains all slang-based and classical-based documents. The reason for this is that the system converts queries that contain slang terms to their equivalent classical terms but the opposite is not true. The average precision, recall and F-measure for the tested 20 queries appear in Table 11.
Precision, recall and F-measure on hybrid dataset.

Precision, recall and F-measure values after testing a hybrid dataset.
7.4. Comparing SARS with Google and Yahoo
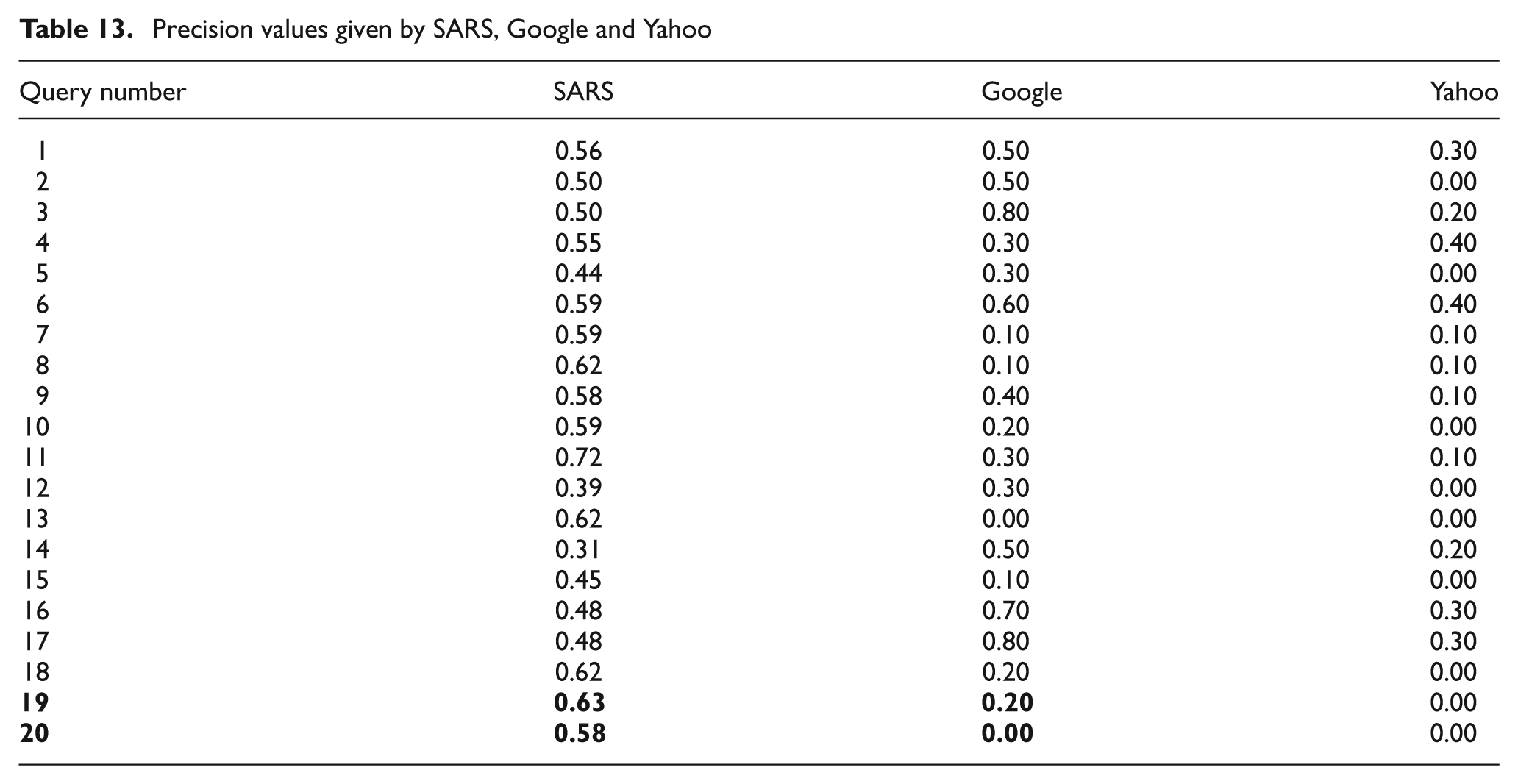
To verify the efficiency of the system, a set of slang queries that is listed in Table 14 was applied on the search engines Google and Yahoo. The precision was calculated for both of them for the first 20 retrieved results as appears in Table 13. The comparison was done between the results obtained in SARS when applying slang-based queries on a hybrid dataset. This is because the databases of Google and Yahoo contain both types of documents. Table 13 lists precision values for the queries after applying them on SARS, Google and Yahoo. In Table 14, a sample of the queries that were used to evaluate SARS are listed in slang, classical, and the English translations for them are provided.
Precision values given by SARS, Google and Yahoo.
Query Samples.
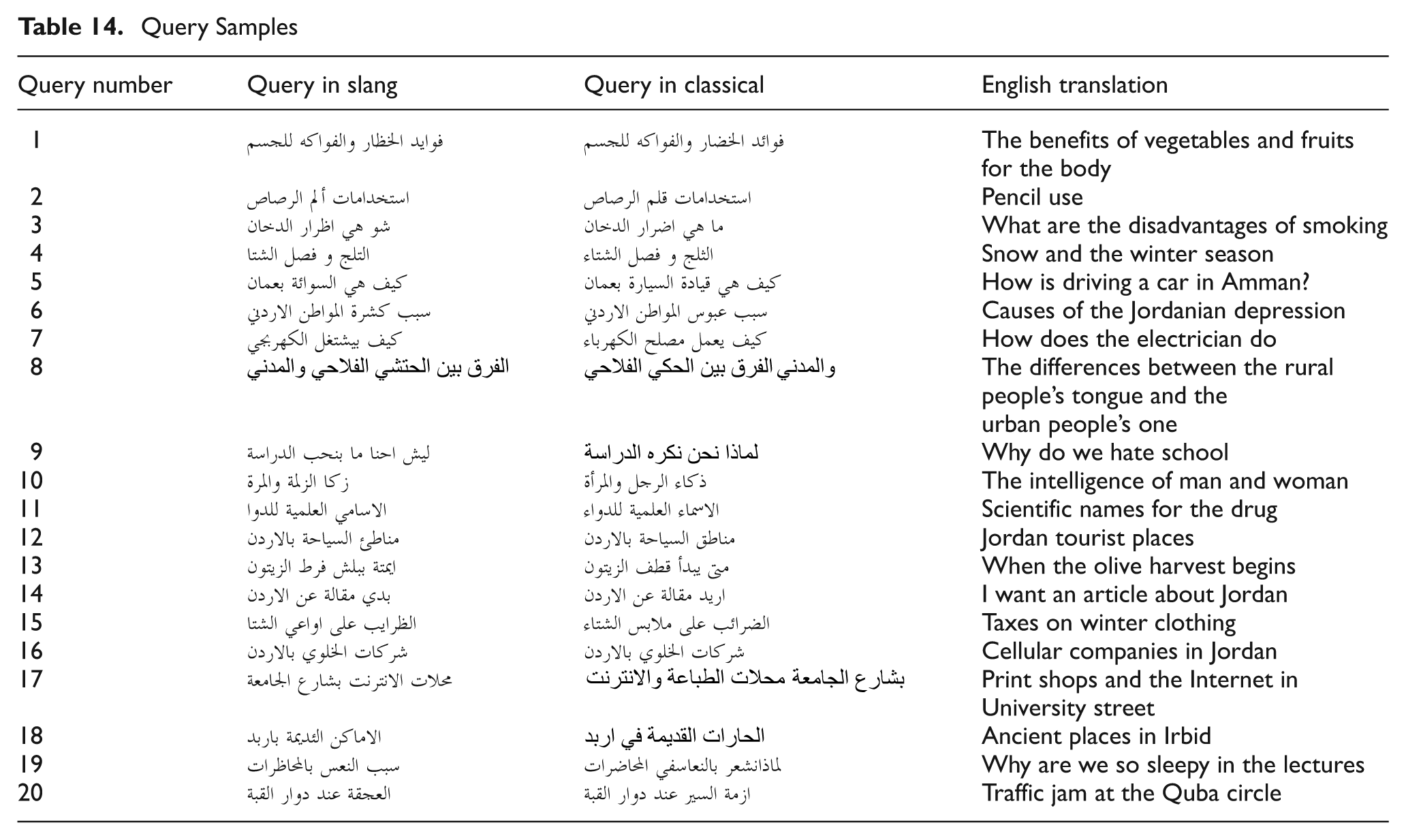
Figure 5 shows a comparison for the average precision for the results given by SARS and those given by Google and Yahoo. Despite the fact that both search engines support Arabic searches, SARS is better than Google and Yahoo in document retrieval using slang-based queries. The dataset is collected from the web and Google and Yahoo have access to it. Slang and classical queries above are run against Google, Yahoo and SARS. SARS uses the mapping process and that is responsible for increasing the precision. The low precision values for Google and Yahoo are due to the fact that the mapping process has not been undertaken. Recall and F-measure values cannot be calculated for Google and Yahoo because the number of relevant documents in the searchable database is not known.
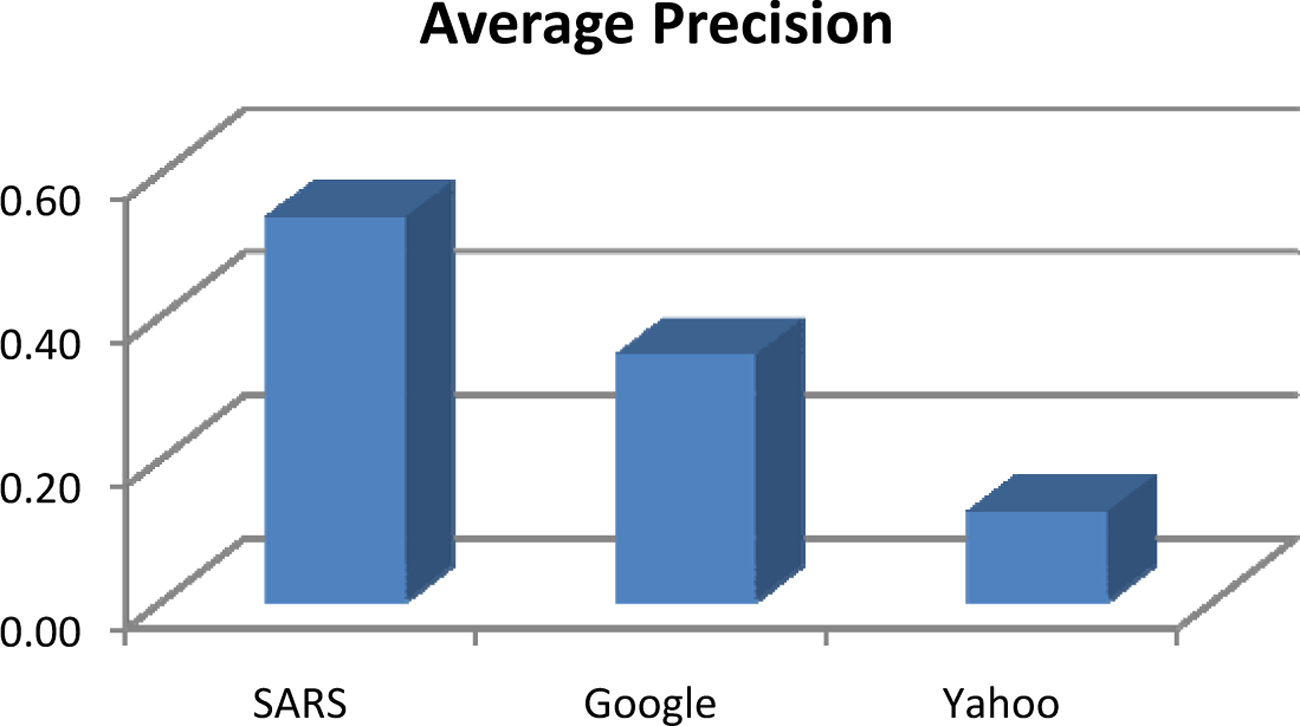
Comparison between the average precision values given by SARS, Google and Yahoo.
8. Conclusion and future directions
This research has enhanced the Arabic IR process by implementing a new search system using Arabic slang queries. Results prove that using the proposed ASG to normalize user’s queries to retrieve classical documents makes an improvement in the accuracy of the retrieved documents. Also, for documents posted in classical Arabic, the given results for the precision, recall and F-measure are very close, whether the used query is in slang form or in its classical one; this is due to the proposed conversion process that converts the slang based terms to their equivalent classical terms.
Results show that using slang-based queries is more efficient than the use of classical-based ones in some cases, but the opposite is not true. In addition, results show that, on average, using slang-based queries is better to retrieve documents from a slang dataset than using classical queries with 13% improvement. The two datasets could be accessed with one search query. Either slang or classical based terms could be used in the input query. Results show that using slang queries is better than using classical queries with 7% improvement to search in a hybrid dataset.
The following are a list of future directions for this research.
Expand the system to include other slang languages for different countries.
Searching using slang Arabic could be more specific by categorizing the field of search. For example, searching for geographical and political information.
Find a method to differentiate between typing errors and slang terms.
Improve slang-based search to include other multimedia types like images and videos.
Develop a voice recognition technique to process user’s slang queries, especially for people with special needs (e.g. visually impaired or disabled), because the effect of the slang dialect is clearly noticed when talking more than writing.
Footnotes
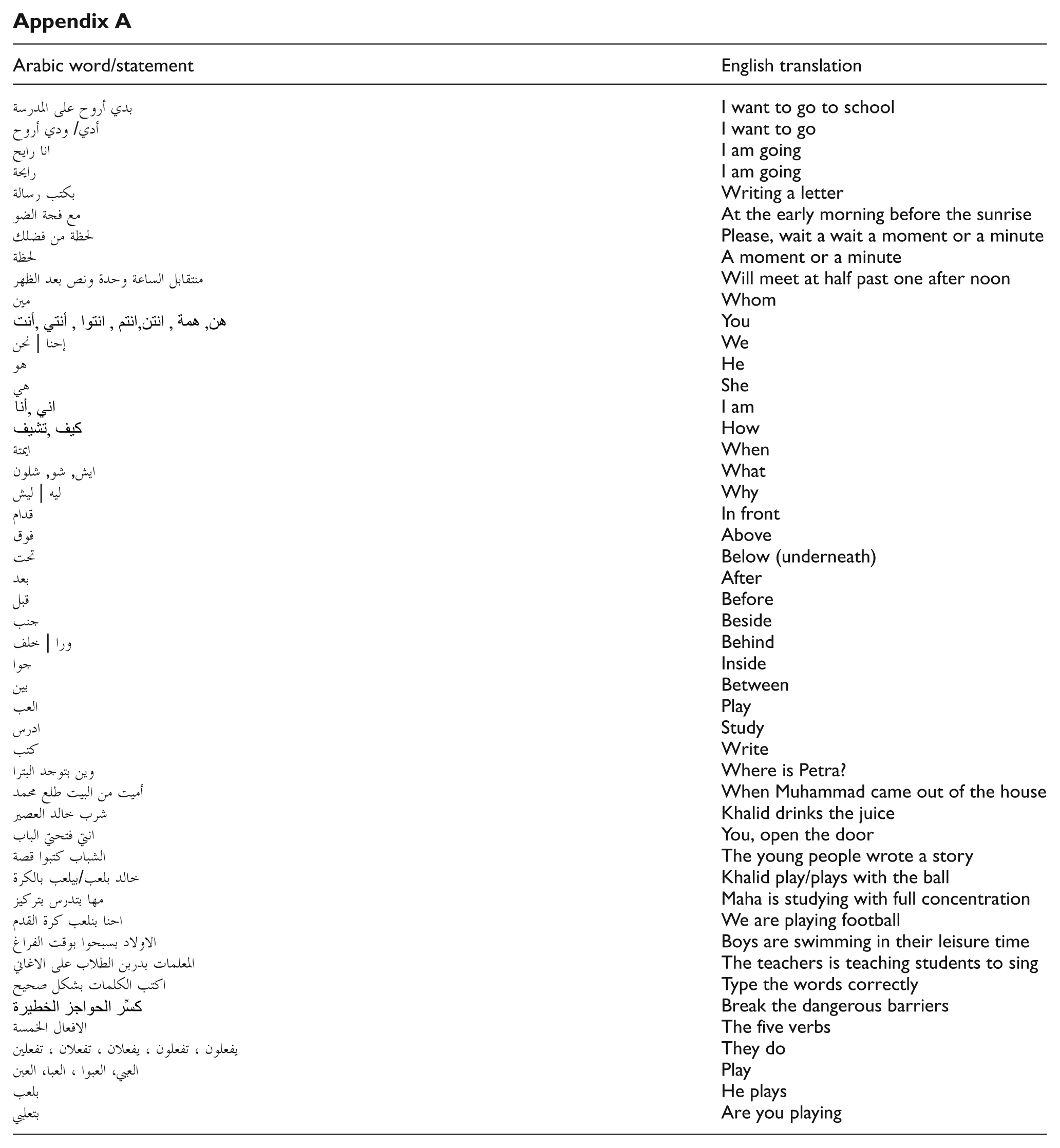
Appendix A
| Arabic word/statement | English translation |
|---|---|
| بدي أروح على المدرسة | I want to go to school |
| أدي/ ودي أروح | I want to go |
| انا رايح | I am going |
| رايحة | I am going |
| بكتب رسالة | Writing a letter |
| مع فجة الضو | At the early morning before the sunrise |
| لحظة من فضلك | Please, wait a wait a moment or a minute |
| لحظة | A moment or a minute |
| منتقابل الساعة وحدة ونص بعد الظهر | Will meet at half past one after noon |
| مين | Whom |
| أنت, أنتي, انتوا,انتم, انتن, همة, هن | You |
| إحنا | نحن | We |
| هو | He |
| هي | She |
| أنا, اني | I am |
| تشيف, كيف | How |
| ايمتة | When |
| ايش, شو, شلون | What |
| ليه | ليش | Why |
| قدام | In front |
| فوق | Above |
| تحت | Below (underneath) |
| بعد | After |
| قبل | Before |
| جنب | Beside |
| ورا | خلف | Behind |
| جوا | Inside |
| بين | Between |
| العب | Play |
| ادرس | Study |
| كتب | Write |
| وين بتوجد البترا | Where is Petra? |
| أميت من البيت طلع محمد | When Muhammad came out of the house |
| شرب خالد العصير | Khalid drinks the juice |
| انتي فتحتي الباب | You, open the door |
| الشباب كتبوا قصة | The young people wrote a story |
| خالد بلعب/بيلعب بالكرة | Khalid play/plays with the ball |
| مها بتدرس بتركيز | Maha is studying with full concentration |
| احنا بنلعب كرة القدم | We are playing football |
| الاولاد بسبحوا بوقت الفراغ | Boys are swimming in their leisure time |
| المعلمات بدربن الطلاب على الاغاني | The teachers is teaching students to sing |
| اكتب الكلمات بشكل صحيح | Type the words correctly |
| كسِّر الحواجز الخطيرة | Break the dangerous barriers |
| الافعال الخمسة | The five verbs |
| يفعلون ، تفعلون ، يفعلان ، تفعلان ، تفعلين | They do |
| العبي، العبوا ، العبا، العبن | Play |
| بلعب | He plays |
| بتعلبي | Are you playing |