
Abstract
Pseudo-relevance feedback (PRF) is a very effective query expansion approach, which reformulates queries by selecting expansion terms from top k pseudo-relevant documents. Although standard PRF models have been proven effective to deal with vocabulary mismatch between users’ queries and relevant documents, expansion terms are selected without considering their similarity to the original query terms. In this article, we propose a method to incorporate word embedding (WE) similarity into PRF models for Arabic information retrieval (IR). The main idea is to select expansion terms using their distribution in the set of top pseudo-relevant documents along with their similarity to the original query terms. Experiments are conducted on the standard Arabic TREC 2001/2002 collection using three neural WE models. The obtained results show that our PRF extensions significantly outperform their baseline PRF models. Moreover, they enhanced the baseline IR model by 22% and 68% for the mean average precision (MAP) and the robustness index (RI), respectively.
1. Introduction
User queries are usually too short to describe the information needs accurately, often leading to vocabulary mismatch between queries and documents and poor retrieval performance of relevant documents. In order to deal with these problems, query expansion techniques have gained interest in the last decades [1–5]. Pseudo-relevance feedback (PRF) has been proven to be an effective query expansion approach to deal with vocabulary mismatch between users’ queries and documents. This approach expands users’ queries by selecting relevant terms from the top retrieved documents, called top pseudo-relevant documents. Although PRF techniques can yield good performance [1,4,6,7], they primarily depend on the distribution of expansion terms in the set of pseudo-relevant documents; the similarity between the expansion terms and the original query terms is usually not explicitly taken into account. Ideally, however, expansion terms should be selected based on their similarity to query terms as well as their distribution in the set of pseudo-relevant documents. Some studies have indeed proposed to do so with mutual information [8–10]. We propose here to use word embedding for this task and focus on the Arabic language. This last choice is motivated by two aspects: first, this language has been less studied for information retrieval (IR) purposes than most European (and to a certain extent Asian) languages, and second, words in Arabic have a higher degree of ambiguity justifying the use of disambiguation techniques based on similarities on top of standard pseudo-relevance methods.
Recent advances in neural language models have introduced effective methods for learning word embedding. These methods represent words by vectors in low-dimensional semantic vector space relying on contextual information (representing a word by means of its neighbours) or/and word co-occurrence [11,12]. An evaluation of neural word embedding against traditional word count-based approaches, including the positive pointwise mutual information (PMI), the singular value decomposition (SVD) and the non-negative matrix factorisation (NMF) methods [13], demonstrated the success of the former on a variety of natural language processing (NLP) tasks, such as semantic relatedness, synonym detection and concept categorisation. The main advantage of the latter approaches lies in easy adaptation to any domain where a sufficiently large corpus is available. Furthermore, they showed promising results on several similarity tasks compared with knowledge-based methods using the WordNet ontology [14].
In the last few years, there has been a growing interest in using word embedding as a representational basis for NLP applications and particularly for IR. Previous research has demonstrated that incorporating word embedding similarities into existing IR models improves the performance of IR [15–18]. Moreover, several researchers have showed the effectiveness of using word embedding for query expansion [5,19,20].
Despite the recent advances in exploiting word embedding in IR, using such word representation for Arabic IR remains yet under-explored. In fact, the rich and complex morphology of Arabic language is the most studied area in Arabic IRs [21–27]. Although the field of Arabic IR has achieved a tangible progress, most stemming algorithms produce a noisy representation of documents and queries. On the one hand, root-based stemmers conflate words with different meaning to the same root. On the other hand, most light stemming algorithms, which have been proven to be effective to deal with the Arabic morphology in the context of IR, do not deal with broken plural and fail to discriminate conjunctions and prepositions from the core words [28,29]. Hence, light stemmers may conflate words with the same meaning to different stems. Thus, dealing with term mismatch between document and queries is of particular interest for Arabic IR.
The hypothesis of this article is that word embedding can be exploited in PRF framework for Arabic IR to deal with term mismatch since similar words, as well as words that should be grouped to the same stem, will be close to each other in the vector space. To illustrate the latter hypothesis, Figure 1 presents the two-dimensional (2D) projection using principal component analysis (PCA) for word ‘ ’ (lessons) and its top 100 related words where the word embedding is trained using the continuous bag-of-words (CBOW) model on stemmed Arabic text corpora applying Farasa stemmer [26]. Performing stemming before learning word embedding for Arabic IR is motivated by the fact that Arabic has a rich and complex morphology and previous studies showed that stemming is a key preprocessing step to deal with its morphology for IR. The figure shows that not only similar words appear close to each other in the vector space, but also words that should be grouped into the same stem (broken plurals, stemming errors, etc.).
’ (lessons) and its top 100 related words where the word embedding is trained using the continuous bag-of-words (CBOW) model on stemmed Arabic text corpora applying Farasa stemmer [26]. Performing stemming before learning word embedding for Arabic IR is motivated by the fact that Arabic has a rich and complex morphology and previous studies showed that stemming is a key preprocessing step to deal with its morphology for IR. The figure shows that not only similar words appear close to each other in the vector space, but also words that should be grouped into the same stem (broken plurals, stemming errors, etc.).
2D projection of Arabic word ‘’ (lessons) and its top 100 related words using PCA using the CBOW word embedding model.
In this article, we propose a method to incorporate word embedding similarities into existing PRF models for Arabic content retrieval. The main goal is to boost weights of semantically related terms to the original query terms. The present work investigates three neural word embedding models, including the Skip-gram, the CBOW and the Glove models, that represent each word by a single vector in low-dimensional vector space. Moreover, the word embedding similarities are incorporated into four PRF models, including the Kullback–Leibler divergence (KLD) [1], the Bo2 of the family of divergence from randomness (DFR) models [7] and the log-logistic (LL), as well as the smoothed power law (SP) of the information-based family of PRF models [4]. Our goal in this work is to study how word embeddings may be exploited in PRF techniques for Arabic IR. Specifically, we are looking for answers to the following main questions:
Does incorporating word embedding similarity into existing PRF models improve the performance of Arabic IR?
Which word embedding model performs better for incorporating term similarity into PRF models for Arabic IR?
The rest of the article is organised as follows. We discuss the related work in Section 2 and briefly review the neural word embedding models used in this work in Section 3. Then, we present our proposed method to incorporate word embedding semantic similarities into existing PRF models in Section 4, and we discuss the experiment results in Section 5. Finally, we conclude in Section 6.
2. Related work
For several years, great effort has been devoted to the study of Arabic query expansion. Shaalan et al. [30] introduced a method to incorporate semantic similarity into Arabic query expansion using expectation–maximisation (EM) algorithm. The EM algorithm is used to select relevant expansion terms out of top retrieved documents. Experiments are performed on INFILE test collection of CLEF 2009. The results showed that their method improves the recall. In another work, Mahgoub et al. [31] proposed a method for semantic query expansion using a domain-independent ontology built from Wikipedia. Experiments are performed on Arabic TREC 2002. The results showed better results against the baseline keyword matching method. In a different study, Belalem et al. [32] introduced a technique for interactive and automatic query expansion using the Arabic WordNet (AWN) to enhance Arabic IR. The main contribution consists of using word’s part-of-speech to select the appropriate synonyms. More recently, Atwan et al. [9] presented an automatic corpus-based expansion technique combining AWN and corpus-based semantic similarity to select expansion terms. The results showed that the automatic expansion technique enhances the accuracy of Arabic IR on TREC 2001 dataset.
One of the most significant current discussions in IR is word embedding. Vulić and Moens [16] introduced a unified framework for Bilingual Word Embedding Skip-Gram (BWESG) for monolingual information retrieval (MoIR) and cross-lingual information retrieval CLIR) from comparable data. The latter framework relies on estimating document vectors using single word embedding through a compositional approach based on word occurrence in the target document and the vocabulary size of the collection. Significant improvements are obtained by linear combination of the proposed documents embedding and the baseline language model for both MoIR and CLIR tasks. The authors have also reported a significant improvement over latent Dirichlet allocation (LDA)-based IR models. In another work, Ganguly et al. [15] have proposed a word-embedding-based generalised language model (GLM). The GLM estimates transformation probabilities (events) for a given term and its semantically related terms based on three transformation events sampling: direct term sampling, that is, language model (LM) baseline, transformation via document sampling and transformation via collection sampling. The three sampling transformations are linearly combined in the scoring function. The obtained results on TREC data sets show a significant improvement over the baseline LM and the LDA-based IR models. Zuccon et al. [17] have proposed a neural translation language model (NTLM) for exploiting word embedding in IR. The latter are used to estimate translation probabilities between words. The results show that the NTLM significantly improves the baseline language model and achieves a better performance than the state-of-the-art translation language models on most test sets. In the context of Arabic language, El Mahdaouy et al. [18] have introduced a modified term frequency scheme to incorporate word embedding similarities for Arabic IR. The main idea consists of computing the within-document term frequency based on the number of occurrences of a given query term and its similar terms. The results showed that incorporating the enhanced term frequency to standard probabilistic IR models significantly improves their baseline bag-of-words models on the standard Arabic collection TREC 2001/2002. Moreover, El Mahdaouy et al. [33] have proposed a method to incorporate word embedding similarities into existing probabilistic IR models to deal with term mismatch for Arabic document retrieval. The main idea consists of selecting the most related terms, for each query term following the approach defined by Li and Gaussier [34] in the context of CLIR, either from the collection vocabulary or from each document. The obtained results on the standard Arabic TREC 2001/2002 collection, using three neural word embedding models, showed that their proposed IR extensions significantly outperform baseline bag-of-words models and three state-of-the-art word-embedding-based language models [15–17] and the AWN-based semantic indexing method for IR [35].
For PRF using word embedding, Zamani and Croft [36] have proposed an embedding-based relevance model. The latter model is an extension of the relevance model approach. The obtained results on TREC test collection show a significant improvement over the baseline relevance model. Moreover, Kuzi et al. [19] have presented a suite of query expansion methods using CBOW model. The obtained results show that the proposed query expansion methods improve the baseline IR models and the baseline relevance model. According to Zahran et al. [37], exploiting neural word embedding models for query expansion, including the two word2vec models and Glove model, perform slightly better than the semantic query expansion that is introduced in Mahgoub et al. [31].
In this article, we incorporate word embedding similarity into existing PRF models for Arabic IR. The main goal is to boost expansion weights of semantically related terms to the original query. We integrate word embedding similarities into four PRF models, including the KLD [1], the Bo2 of the family of DFR models [7] and the LL, as well as the SP of the information-based family of PRF models [4]. Moreover, we evaluate three neural word embedding models, including the CBOW, the Skip-gram and Glove models.
3. Neural word embedding
Most NLP applications involve word representation step and could benefit from word representations that reflect similarities and dissimilarities between them rather than treating individual words as independent symbols. Hence, there has been a lot of work proposing to represent words as dense vectors in a low-dimensional vector space obtained using various training methods inspired from neural-network language modelling. These vectors’ estimation is based on the idea that words in similar contexts have similar meanings.
3.1. CBOW
In the CBOW model [11], the context is represented by surrounding words for a given target word. The word representation is constructed by maximising the log probability to predict the target word given its context. The CBOW model uses a simple neural architecture where the nonlinear hidden layer is removed and the projection layer is shared for all words. For a given target word
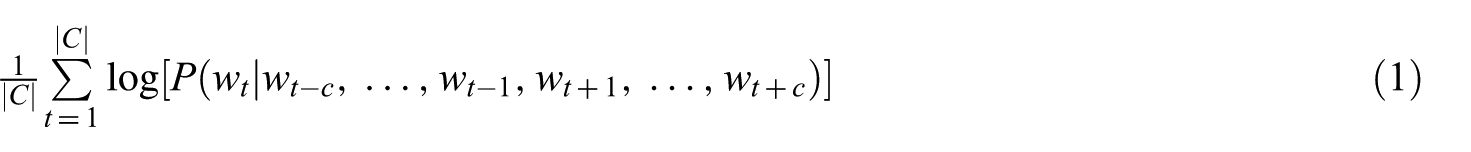
where
3.2. Skip-gram model
Instead of predicting the current word using its surrounding words (context), the Skip-gram model uses a similar architecture by reversing the input and the output of the neural network [11]. Each word vector is trained to maximise the log probability of neighbouring words in a corpus. Given a sequence of training words

where
3.3. Glove model
Glove model is a global log-bilinear regression model that combines the advantages of global matrix factorisation, as well as local context window methods. The underlying model is trained on the non-zero entries of global word-word co-occurrence matrix [12]. The model constructs a word-word co-occurrence matrix X, whose element
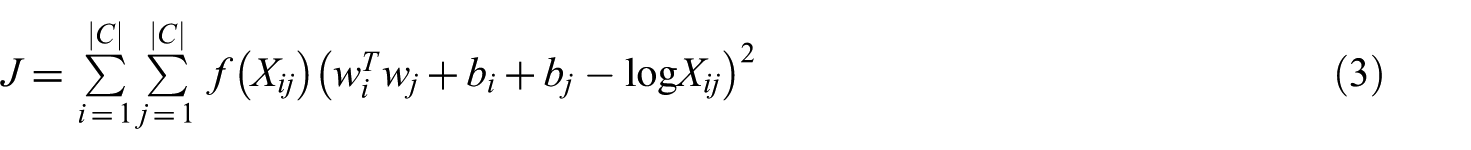
where f is a weighting function to avoid weighting all co-occurrences equally

where
4. Proposed method
To enhance the performance of Arabic IR, we propose a word-embedding-based PRF method, which incorporates word embedding similarity into existing PRF models. The main idea of our method consists of combining the distribution of expansion terms in the set of pseudo-relevant documents and their similarity to the original query in unified PRF framework. The process of our method is composed of seven main steps:
Step 1. Select a set
Step 2. For each term in F, we compute their word embedding similarities to the original query and transform them into probabilities;
Step 3. For each term in F, we compute their distribution (i.e. weight) in the set F using a standard PRF model;
Step 4. For each term in F, we compute its modified weights by multiplying its weights that are computed in steps 2 and 3;
Step 5. Select the best n terms (expansion terms) from F according to their resulting weights (computed in step 4);
Step 6. Weight the selected expansion terms and add them to the query;
Step 7. Retrieve documents using the new query;
After selecting the set of top k pseudo-relevant documents

where

The second technique relies on computing the average similarity between a candidate expansion term’s vector and the query terms’ vectors. The average similarity is computed using the following formula

Then, we use the softmax function to transform these similarities into probabilities to facilitate their incorporation into existing PRF models. The probability of a candidate expansion term w given the original query q and the set F is given by

where
The combination of candidate expansion term similarity to the original query and its distribution in the set F (step 4) is obtained simply by multiplying the probability

where
For the KLD model [1]

where
For the Bo2 model [7]
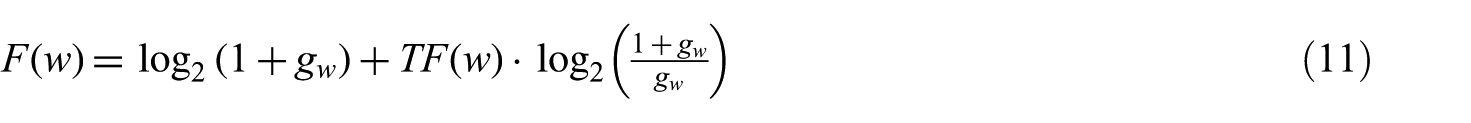
where
For the information-based family of PRF models [4]: The LL model The SP model


where
After selecting the best n expansion terms according to their modified expansion weights (equation (9)), the original query is then modified to take into account both original query terms and expansion terms. The final modified weights of the query terms and expansion terms are computed using the following equation

where
The last step of our method consists of retrieving documents for the new query using the baseline IR model.
5. Experimental evaluation
5.1. Experimental settings
All experiments are conducted using Terrier 3.5
1
IR platform on the Arabic standard TREC 2001/2002 data set. We used title-description topic fields and relevance judgements on the Arabic Newswire LDC catalogue number LDC2001T55.
2
The latter data set contains 75 topics. The corpus consists of 383,872 documents from the Agence France-Presse (AFP; France Press Agency) Arabic Newswire, containing 76 million tokens for 666,094 unique words. These documents are newspaper articles covering the period from May 1994 until December 2000. Our extensions are tested and evaluated mainly using the mean average precision (MAP), the precision at 10 documents (P10), and the robustness index (RI) [2]. The RI is defined as
Cross-validation parameter values.
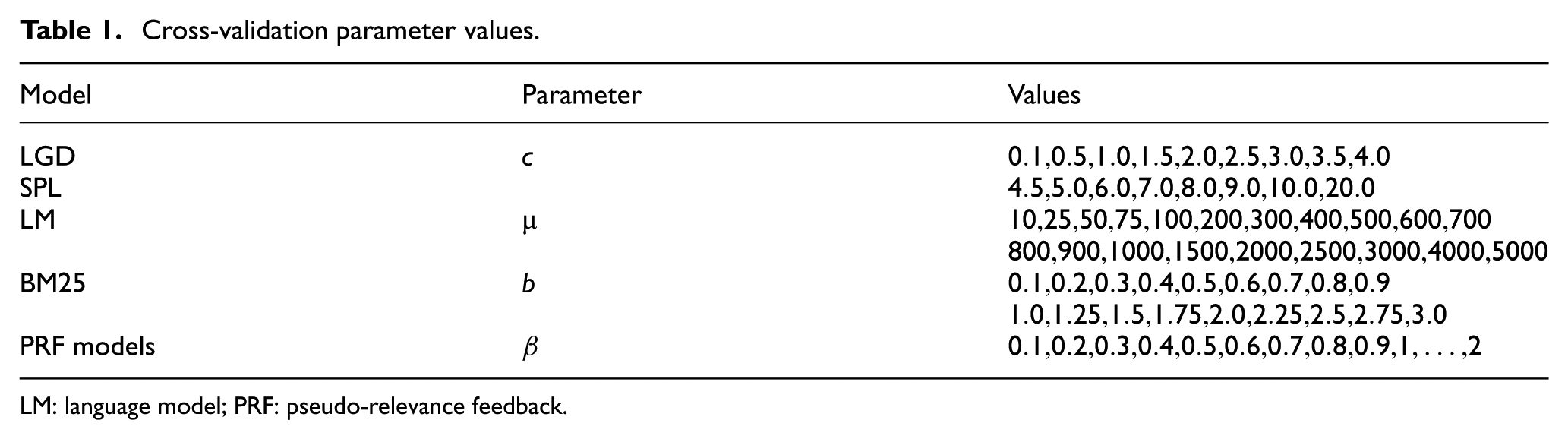
LM: language model; PRF: pseudo-relevance feedback.
To train the word embedding models, we collected a 2.03-gigabyte raw Arabic texts, containing about 216 million tokens, including Arabic BBC, CNN, OSAC corpora, 3 Arabic Newswire LDC catalogue number LDC2001T55 and other sentence corpora collected from WORTSHATZ. 4 Since stemming is a key component in any Arabic IR system and plays a key role in reducing morphological variants, we used the Farasa stemmer [26] on the collected corpora to train the neural embedding models. The latter stemmer is selected since our comparison results show that Farasa significantly improves the light and the root-based stemming approaches [43,44]. For training all word embedding models (CBOW, Skip-gram 5 and Glove models 6 ), we fix the context size and the word vector dimension to 10 and 300, respectively. The training time of each word embedding model, using an Intel Xeon 4 CPUs E5-2407 machine with 48Go of RAM, is as follows
155 min for the Skip-gram model;
52 min for the CBOW model;
93 min for the Glove model.
Even though the Glove model is three times faster than the Skip-gram model (the slowest here), all these models can be used, their training time remaining reasonable on the collection considered.
5.2. Experimental results
5.2.1. Comparison of Arabic text preprocessing approaches
First, we evaluate the impact of several text preprocessing methods on the performance of Arabic document retrieval. To do so, our experiments are performed using the following approaches:
Light stemming:
Lemmatisation:
Heavy stemming: Khoja root-based stemmer (RS); [44]
Text normalisation (Norm).
In fact, the Arabic language is morphologically rich and there is no real consensus, in past experiments, on which stemmer or lemmatiser to use for IR [23,27,47–49]. We tackle this problem by conducting an extensive comparison of different stemming and lemmatisation approaches, coupled with four different IR models, from different families. In order to perform Arabic text lemmatisation, we used SAFAR API sentence splitter [50] to segment the collection’s documents and feed the obtained sentences to Farasa and MADAMIRA lemmatisation modules [46,45]. Since MADAMIRA lemmatiser produces vocalised lemmas, we used the SafeBW transliteration scheme of the underlying system in order to preserve diacritics representation for vocalised lemma-based indexing method (M vocL).
Table 2 presents the indexing time and the vocabulary size of the Arabic TREC 2001/2002 collection for the different text preprocessing approaches using the same machine.
Comparison of indexing time and vocabulary size for the different Arabic text preprocessing approaches.

FS: Farasa stemmer; FL: Farasa lemmatiser; M unvocL: MADAMIRA unvocalised lemma; M vocL: MADAMIRA vocalised lemma; LS: light stemmer; RS: root-based stemmer.
Not surprisingly doing just text normalisation is faster, while MADAMIRA lemmatiser, that conducts deeper analysis based on word context, leads to the worst performance. Farasa lemmatizer (FL) shows the fastest indexing time in comparison with MADAMIRA lemmatiser. The latter is explained by the fact that FL relies on a dictionary of words and their possible diacritisations ordered by number of occurrences of each diacritised form, select the lemma that corresponds to the frequent diacritisation [46]. This said, the indexing times above do not prevent the use of any of the stemming approaches. The choice for one or the other is to be based on the overall performance on the targeted task. Moreover, using roots, stems and lemmas significantly reduces the storage space in comparison with text normalisation. As expected, the root-based (RS) indexing method has the smallest vocabulary size. Farasa stemmer (FS) has the smallest vocabulary size among the light stemming and MADAMIRA lemmatisation approaches. Indexing vocalised lemma (M vocL) increases the vocabulary size in comparison with unvocalised lemma (M unvocL). Furthermore, Farasa lemmatizer (FL) shows a small reduction in the storage size in comparison with MADAMIRA lemmatiser and the light stemmer (LS). The latter can be explained by the fact that Farasa lemmatizer showed a better lemmatisation accuracy than MADAMIRA [46]. In addition, FL uses Farasa stemmer/segmenter to deal with out-of-dictionary words by removing prefixes and some suffixes to get either their lemmas (if their segmented forms are found in the lemmatiser’s dictionary) or stems [46].
Table 3 summarises the obtained results for the three stemmers, the three lemma-based indexing methods and text normalisation without query expansion. The results show that all stemming and lemmatisation approaches significantly improve the text normalisation. Farasa stemming approach significantly outperforms the classical stemming approaches and both MADAMIRA lemma-based indexing methods (M unvocL and M vocL) for Arabic IR, which is explained by the high accuracy of word segmentation with Farasa [29]. Moreover, Farasa stemmer yields to a better performance than Farasa lemmatizer (FL). The latter lemmatiser shows significant improvement over MADAMIRA vocalised lemma-based indexing method (M vocL) and a better performance over MADAMIRA unvocalized lemma-based indexing method (M unvocL). This is explained by the fact that Farasa lemmatizer achieves a better lemmatisation accuracy than MADAMIRA lemmatiser [46]. Furthermore, the unvocalized lemma-based indexing method (M unvocL) achieves a better performance than vocalised lemma-based indexing method, which increases the vocabulary size (see Table 2). Thus, vocalised lemmas lead to another form of term mismatch. In addition, M unvocL achieves the best P10 performance in comparison with the other lemma-based indexing methods (FL and M vocL). In line with previous studies [43,51], the light stemming approach significantly improves the heavy stemming approach. The low performance of the heavy stemming approach is explained by the fact that the root-based stemmer conflates words with different meanings into the same root. Furthermore, the overall comparison results show that the SPL and BM25 models achieve better performances than the LGD and the LM models. Thus, we select Farasa stemmer for Arabic text preprocessing and the SPL model as a baseline IR model for the rest of our experiments.
Summary of the results for bag-of-words IR models using Farasa, light and heavy stemming approaches, and text normalisation without query expansion.
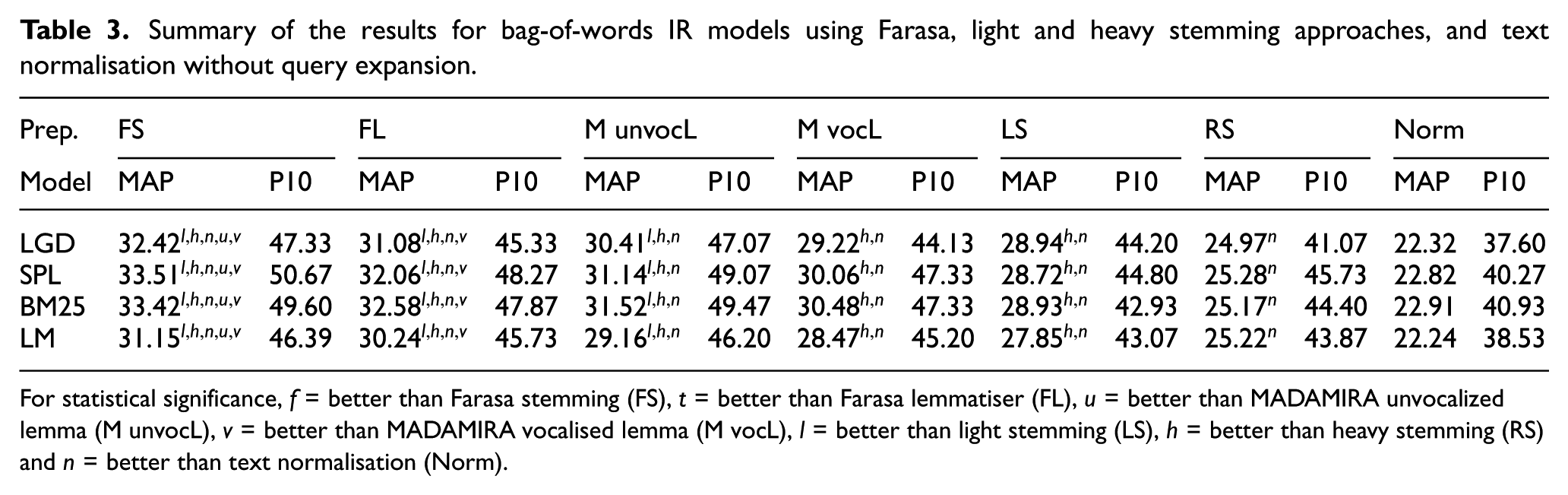
For statistical significance, f = better than Farasa stemming (FS), t = better than Farasa lemmatiser (FL), u = better than MADAMIRA unvocalized lemma (M unvocL), v = better than MADAMIRA vocalised lemma (M vocL), l = better than light stemming (LS), h = better than heavy stemming (RS) and n = better than text normalisation (Norm).
5.2.2. Evaluation of word-embedding-based PRF models
Second, we conduct several experiments to compare our proposed extensions for incorporating word embedding similarities into existing PRF against their baseline PRF models and the baseline IR model (SPL model). The main goal of these experiments is to answer the following question: does incorporating word embedding similarity into existing PRF models improve the performance of Arabic IR? The PRF extensions are evaluated using both similarity functions (
Table 4 shows the obtained results for our PRF extensions, their baseline PRF models and the baseline IR model (SPL), using the Farasa stemming approach. The proposed extensions significantly outperform their baselines using both similarity functions for the KLD and Bo2 PRF models. Although our LL and SP extensions improve their baseline PRF model, the difference is not statistically significant. The best results are obtained by incorporating word embedding similarity into the Bo2, LL and SP PRF models. Our Bo2, LL and SP extensions enhance the baseline IR model by 22% and 68% for the MAP and the RI, respectively. Furthermore, computing the average similarity between expansion terms and the original query terms yield to a slightly better performance than using a single embedding vector for the query.
Evaluation of the proposed PRF models against their baseline PRF models and the baseline IR model (SPL).
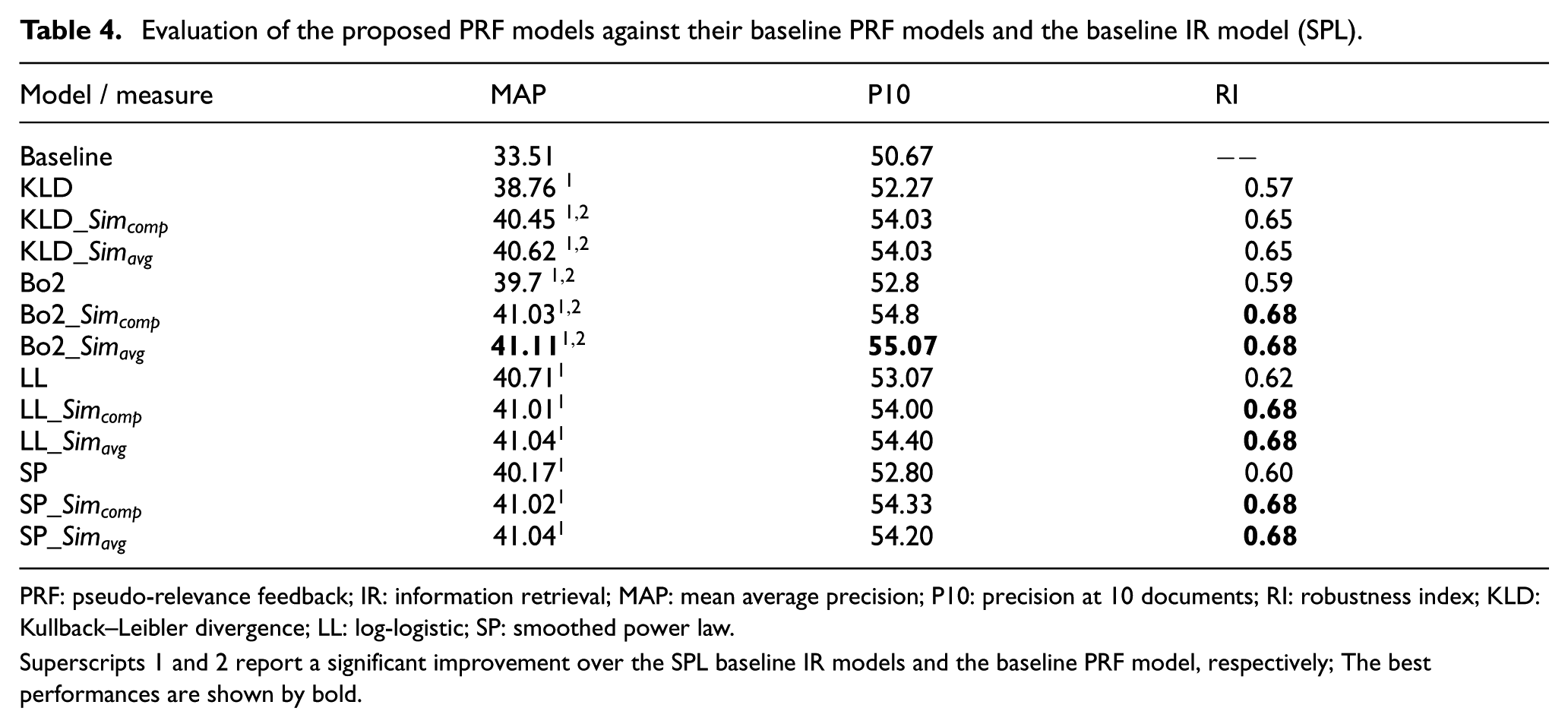
PRF: pseudo-relevance feedback; IR: information retrieval; MAP: mean average precision; P10: precision at 10 documents; RI: robustness index; KLD: Kullback–Leibler divergence; LL: log-logistic; SP: smoothed power law.
Superscripts 1 and 2 report a significant improvement over the SPL baseline IR models and the baseline PRF model, respectively; The best performances are shown by bold.
5.2.3. Impact of the number of expansion terms
Third, we evaluate the impact of the number of expansion terms on the proposed PRF extensions and their baseline models. The aim is to study the sensitivity of the proposed extension to the number of expansion terms. To do so, we fixed the number of pseudo-relevant documents to 10 and vary the number of expansion terms between 10 and 100.
Figure 2 illustrates the sensitivity of the proposed extension to the number of expansion terms. According to this figure, the performance of the PRF extensions and their baselines generally increases by increasing the number of expansion terms for the used 100 best expansion terms. Moreover, for all ranges of expansion terms, the proposed extensions improve their PRF baselines. The
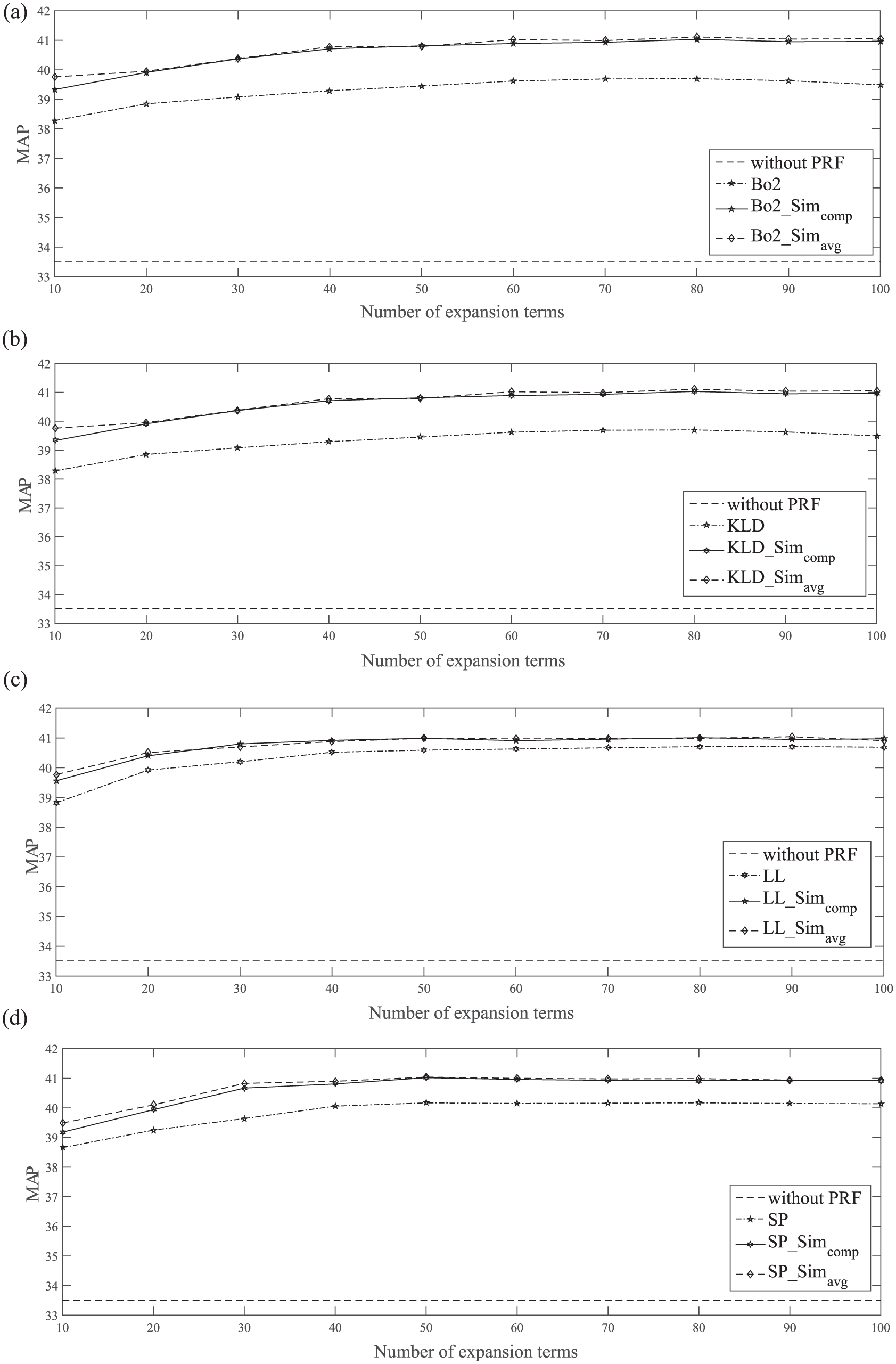
Effect of the number of expansion terms on the MAP of the proposed PRF extensions and their baselines: (a) KLD PRF model, (b) Bo2 PRF model, (c) LL PRF model and (d) SP PRF model.
The processing time, again using an Intel Xeon 4 CPUs E5-2407 machine with 48Go of RAM, of documents retrieval employing the SPL baseline IR model, the LL PRF baseline model (the most complex PRF model we consider) and our extensions for the whole set of queries (75 queries) is as follows (k is set to 10):
10.46 s for the baseline SPL models (without query expansion);
26.10 and 65.44 s for the baseline LL PRF model using
28.94 and 67.21 s for LL_
31.59 and 70.18 s for LL_
As one can note, if the processing time increases, it remains below 0.5 s/query for
5.2.4. Comparison of word embedding models for PRF
Finally, we compare the three word embedding models (CBOW, Skip-gram and Glove) for incorporating term similarity into PRF models (KLD, Bo2, LL and SP). The main goal of this comparison is to answer the question: Which word embedding model performs better for incorporating term similarity into PRF techniques for Arabic IR?
Table 5 presents the comparison results for the proposed word-embedding-based PRF extensions using Glove, CBOW and Skip-gram models. The optimal values of the number of top pseudo-relevant documents and the number of expansion terms are selected according to the best MAP value for each PRF model. The overall comparison results show that the difference in terms of MAP performance between the three word embedding models for each PRF extension is not statistically significant. Although the best MAP and P10 values are obtained by incorporating the Skip-gram word similarity into the Bo2 PRF extension (Bo2_
Summary of the comparison results for the proposed word-embedding-based PRF extensions using Glove, CBOW and Skip-gram models.
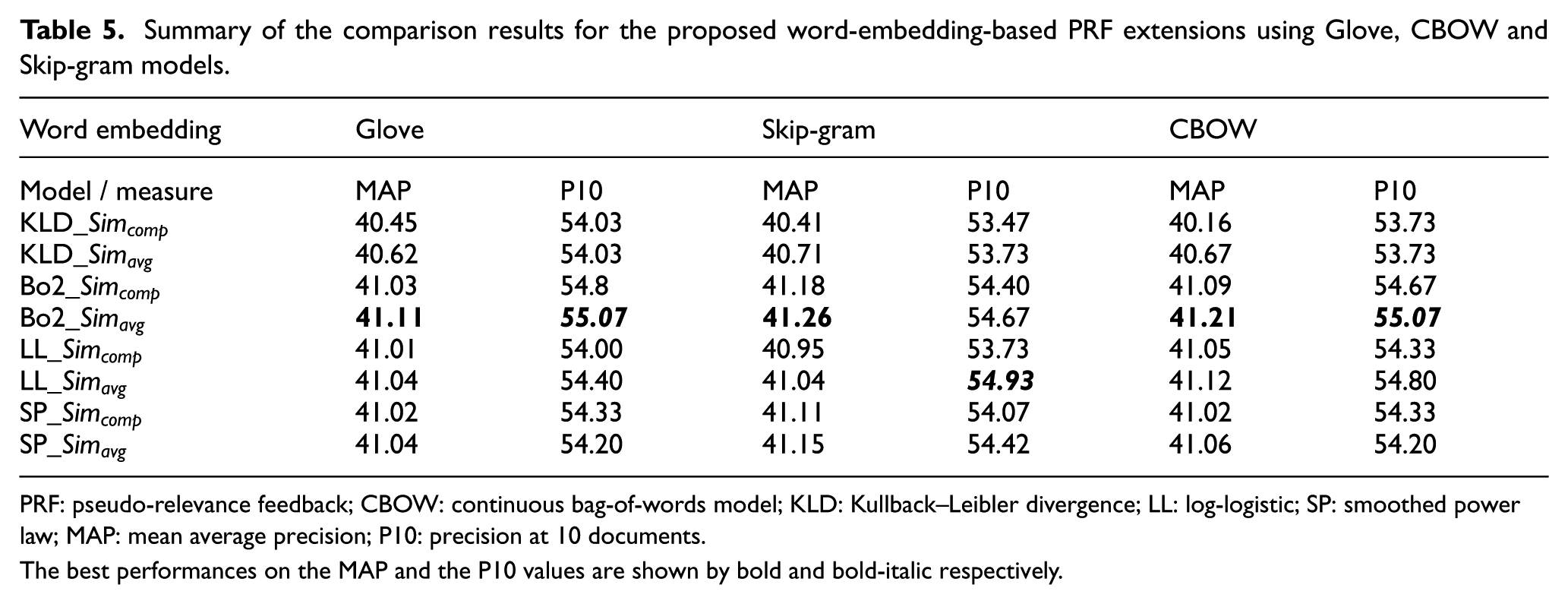
PRF: pseudo-relevance feedback; CBOW: continuous bag-of-words model; KLD: Kullback–Leibler divergence; LL: log-logistic; SP: smoothed power law; MAP: mean average precision; P10: precision at 10 documents.
The best performances on the MAP and the P10 values are shown by bold and bold-italic respectively.
6. Conclusion
In this article, we proposed a method to incorporate word embedding similarity into existing PRF models (KLD, Bo2, LL and SP) for Arabic IR. The main idea of our method consists of combining the distribution of expansion terms in the set of pseudo-relevant documents and their similarity to the original query terms in unified PRF framework. To do so, we used two word similarity functions that compute the similarity between a candidate expansion term and the original query. Evaluations are performed on the standard Arabic TREC 2001/2002 test collection using three neural word embedding models, including the Glove, the CBOW and the Skip-gram models. Our method improved the baseline IR model by 22% and 68% for the MAP and the RI, respectively. The analysis of the obtained results led us to conclude that
Incorporating word embedding similarity into existing PRF models significantly improves the performance of their baselines (KLD and Bo2) and the baseline bag-of-word IR models (SPL model);
The difference in terms of performance between the three word embedding models (Glove, CBOW and Skip-gram models) is not statistically significant;
Computing word similarity using either a query embedding using query terms vectors (
The Farasa stemmer is in general preferable to the classical light, the root-based stemming, the evaluated state-of-the-art lemmatisers (MADAMIRA and Farasa) and text normalisation approaches;
The results showed that the difference in terms of performance between the three word embedding models (Glove, CBOW and Skip-gram models) is not statistically significant. A straightforward path of future research is to study the impact of parameters that are used to learn word embedding, such as the context size and the dimension of word vectors, and to rely on other word-embedding-based IR models as the one proposed in El Mahdaouy et al. [33]. We also plan on comparing our PRF approach to other query expansion methods as [5,19,20].
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.