
Abstract
Flat folksonomy uses simple tags and has emerged as a powerful instrument for classifying and sharing a huge amount of knowledge on Web 2.0. However, it has semantic problems, such as ambiguous and misunderstood tags. To alleviate such problems, researchers have built structured folksonomies with a hierarchical structure or relationships among tags. Structured folksonomies, however, also have some fundamental problems, such as limited tagging of pre-defined vocabulary and time-consuming manual effort required to select tags. To resolve these problems, we suggested a new method of attaching a tag with its category, which we call a categorized tag (CT), to web content. CTs entered by users are automatically and immediately integrated into a collaboratively built structured folksonomy (CSF), reflecting the tag-and-category relationships supported by the majority of users. Then, we developed a CT-based knowledge organization system (CTKOS), which builds upon the CSF to classify organizational knowledge and enables us to locate appropriate knowledge. In addition, the results of the evaluation, which we conducted to compare our proposed system with the flat folksonomy system, indicate that users perceive CTKOS to be more useful than the flat folksonomy system in terms of knowledge sharing (i.e. the tagging mechanism) and retrieval (i.e. the searching mechanism).
1. Introduction
Knowledge organization systems (KOS) are used as a means of organizing and retrieving a huge amount of information (e.g. in books, articles and documents) [1–3]. The term KOS represents systems that encompass many types of schemes to organize information and promote knowledge management [3]. KOS has evolved from systems that use a set of simple terms without any hierarchy (e.g. keywords, glossaries, dictionaries, gazetteers) to systems that use a limited set of terms with a shallow hierarchy (e.g. taxonomies, classification schemes) and systems that use of a set of concepts and their relationships, including semantic relationships (e.g. thesauri, semantic networks, ontologies) [3–7]. One of the characteristics of schemes with a structure is that the structure is pre-defined with a limited set of terms by domain experts or by authorized groups so that users can retrieve relevant information more easily and quickly [1, 3, 4].
Recently, with the emergence of Web 2.0, enormous amounts of web content are being produced because more users willingly participate in creating such content. As such, in Web 2.0, more flexible schemes are required for indexing and retrieving various types of web content from rapidly changing, overloaded online environments [8, 9]. Current schemes used in KOS, however, are not sophisticated enough to create new concepts captured from the social web as an index for retrieving all of the available web content [4, 10–13], because the schemes classify content using pre-defined terms or vocabularies with a limited indexing range. To compensate for the shortcomings of these schemes, KOS adopted a new classification scheme called folksonomy, which provides Internet users with a way to organize various types of content by attaching meaningful tags [1, 14]. Compared with the schemes of previous KOS, folksonomy can be built from any keywords that users provide, not those defined by domain experts. Folksonomy can be either flat or structured. Flat folksonomy has no structure among the keywords, whereas structured folksonomy has a hierarchical structure among keywords.
In a flat folksonomy, users are free to attach a tag (or tags) to their web content (e.g. documents, web pages, bookmarks, images, videos) according to their own needs; indeed, no pre-defined tags exist to categorize the content. As more users participate in creating web content, the set of user-generated tags on the content forms a flat folksonomy [15, 16]. Currently, most popular social websites, including Flickr (http://www.flickr.com), Del.icio.us (http://www.delicious.com) and CiteULike (http://www.citeulike.org), are using flat folksonomies. Although flat folksonomy has the significant advantage of offering a flexible and easy choice of tags to organize and share user-generated content [10, 11, 17], it presents the fundamental problem that tags may be potentially ambiguous and misunderstood among users, stemming from semantic [10] or cognitive difficulties [18]. The former issue occurs because of ambiguous tags (e.g. ‘KMA’ may refer to the Korea Military Academy or to the Korea Management Association) or because tags are synonymous (e.g. automobile and car). On the other hand, cognitive difficulties arise because of homonymous tags (e.g. one person may define Java as a programming language, while another may define it as coffee produced on the island of Java in Indonesia). These problems result in users retrieving undesirable web content when searching the web.
Knowing that the main cause of these problems is a lack of semantics among tags, researchers have built a structured folksonomy by augmenting the semantics of tags and building a hierarchical structure or relationships among tags [19–21]. In these systems, users individually and manually define the meaning of their own tags by linking each tag to a term in a pre-defined hierarchy of vocabularies or to a concept that appears in ontologies [22–26]. Alternatively, the systems enable machines to define tags automatically by capturing the relevant semantics from the entire tag space using machine processing techniques, such as similarity computation, clustering and network analysis [27–31]. These structured folksonomy systems contribute to removing the ambiguity and misunderstanding of tags by resolving both the semantic and the cognitive problems of flat folksonomy. Structured folksonomy systems, however, still have fundamental problems that occur when users try to enter new tags that do not exist in the pre-defined hierarchy of vocabularies or concepts of ontologies. In such cases, users or machines have difficulty finding the proper meanings of the tags. This problem may prohibit users from using a tagging system as a powerful instrument to organize and retrieve knowledge.
In the present paper, we proposed a new type of structured folksonomy, called a collaboratively built structured folksonomy (CSF). CSF not only offers a flexible choice of tags, as in the flat folksonomy, but also augments the semantics of tags by building a hierarchical structure as occurs in structured folksonomy. When users classify their content in CSF systems, they enter a tag with the category to which the tag belongs. We call this type of tag a categorized tag (CT). As more users enter CTs freely, without limitations in choosing vocabularies or terms as tags, the CTs are integrated into a CSF dynamically, reflecting the tag-and-category relationships that the majority of users perceive. There is no ambiguity problem in CSF, because the hierarchical structure among tags confines tags’ meaning to a specific meaning in the structure. While the structure of the existing structured folksonomy is statically fixed, the structure of CSF dynamically changes as new tags are entered. Note that the structure of CSF is developed collaboratively among users, not by domain experts. In addition, we implemented a CT-based KOS (CTKOS) to demonstrate how CSF can be used to classify organizational knowledge and locate appropriate knowledge. We also conducted a usability test of CTKOS, in which we analysed the differences in tagging and searching mechanisms between CTKOS and the typical flat folksonomy system. Results from several evaluations showed that users perceive CTKOS to be more useful than the flat folksonomy system in both sharing and retrieving organizational knowledge.
The remainder of the present paper is organized as follows. Section 2 reviews several tagging systems that are closely related to our study. Section 3 describes CTKOS and explains how CSF helps users find more relevant documents than flat folksonomy does. Section 4 describes the usability test and results, and Section 5 provides a summary and some limitations of our approach as conclusions.
2. Previous work
In this section, we review the existing structured folksonomy systems and research studies that have attempted to resolve the problems of flat folksonomy, address their problems collectively and explain our approach to resolving the problems.
Based on who assigns the proper meaning to a tag, two categories of existing structured folksonomy systems can be identified – one that depends on human intervention and another that depends on machine-processing techniques. In the case of systems or research studies that belong to the first category, these systems share a similar feature: humans define the meanings of tags by linking them to terms in the pre-defined hierarchy of vocabularies or to concepts of ontologies [32]. In the DogmaBank, a social bookmark system in which a user enters a keyword as a tag to a web page, the user receives a list of concepts associated with the keyword from WordNet ontology [22]. The user then selects one of the concepts in the ontology as a tag to the web page. If the user cannot find a relevant concept, the user can suggest new tags and definitions to domain experts, who later add new tags as new concepts to the ontology. In a similar but somewhat extended way, Semkey, which uses semantic collaborative tagging, allows users to select the meaning of tags from one of two sets of pre-defined terms: a WordNet and Wikipedia category [23]. In the semantic blogging system, ambiguity of tags is removed by linking the tags to the concepts defined in domain ontologies [24]. When entering a keyword in this system, a user must select a concept defined within the ontologies associated with their blog post. In SweetWiki, which supports social tagging to categorize Wiki documents, community experts relocate keywords that users enter into a more refined structure [25]. Peters and Weller described a prototype system to show how semantic relationships between tags are defined into user-created ontologies [26]. After retrieving a Flickr photo and its associated tags, the system determines co-occurrences of the tags. Then, users can specify the semantic relations (e.g. has_shape, is_located_in, synonymy, meronymy) between the tags manually.
Systems or research studies belonging to the second category define the meanings of tags from the tag space constructed by machine processing techniques, such as similarity computation, clustering and network analysis. In the T-ORG system, users select ontologies associated with categories of resources to be tagged [27]. Then, they modify ontologies by pruning unwanted concepts, refining redundant concepts and adding missing concepts. Finally, the remaining concepts in the modified ontologies are used as categories, which, together with the tags, are used as input to T-KNOW, which classifies the tags into the categories. FAsTA, which is a folksonomy-based automatic metadata generator, extracts sets of tags from Del.icio.us and conducts a normalization process to clean up the noise in them [28]. Based on the normalized tags, the system generates semantic metadata by mapping the tags onto ontological instances in one of the three ontologies (i.e. Web Design Ontology, CSS Subject Ontology and Resource Type Ontology). In a research project titled ‘Integrating folksonomies with the semantic web’, Specia and Motta proposed an approach to making the semantics of tags explicit, which is based on the tag spaces in social tagging systems such as Flickr and Del.icio.us [29]. First, they filtered out unusual tags and then built clusters of similar tags. Finally, they defined the relationships among tags in each cluster. Cattuto et al. analysed three similarity measures (i.e. cosine similarity, co-occurrence and FolkRank algorithm) to find a set of closely related tags [30]. They then proposed a semantic grounding method to link the found tags to WordNet words according to the semantic distance between the tags. Cosine similarity is a more proper measure to discover synonyms, and the other two measures are useful for making taxonomic relationships between the tags. In another research project titled ‘Ontologies are us’, Mika suggested a new tripartite model of folksonomy, consisting of concepts, actors and instances [31]. The model is also represented as a hyperplane, which in turn is reduced to two bipartite graphs, that is, {concepts, actors} and {concepts, instances} by co-occurrence analysis between tags and users or tags and content. These graphs are used to identify emergent ontologies automatically, such as community-based ontologies and item-based ontologies by network analysis. As a result, this approach can use user-generated tags to derive a social network among users and the ontologies, including concepts for items in which the users are interested.
Table 1 compares the results of previous research projects with respect to defining the meaning of a tag, target document and the type of ontology used. Although the structured folksonomy systems in the above two categories may solve the ambiguity problem of the flat folksonomy, they are known to present some problems in terms of flexibility and ease of choice of tags that provide the greatest advantages in flat folksonomy. We will elaborate further on these problems below.
Comparison of related research projects

In the first category of systems that require human intervention, when users enter a tag, they must make additional effort to find and select the tag from a list of potential concepts suggested in the ontologies. In addition, when a user enters a new tag that does not match the concept defined in the ontologies, a flexibility problem occurs because the scope of individual tags is restricted to the pre-defined concepts in the ontologies. In this case, if users want to define the semantics of a new tag, they must request that the ontology engineers add the concepts related to their tags on the existing ontologies. In other words, new tags that users generate cannot be immediately reflected in the ontologies until another human intervenes. Such time-consuming manual efforts and inflexibility in tagging may prohibit users from using such tagging systems as a powerful instrument for organizing and retrieving knowledge. Thus, a more flexible and simple tagging method is required that reflects the semantics of tags.
In the second category of systems that depend on machine-processing techniques, it is not guaranteed that the techniques correctly match the tags’ meanings to the concepts or relationships in the ontologies, because the ontologies may not include relevant concepts or relationships for the tags. In addition, manual intervention by domain experts is sometimes required for decision-making, such as selecting and modifying the ontologies and checking the possible relationships among the mapped tags. As more and more tags are added to tag spaces, these interventions for attaching meaning to all tags become tedious and time-consuming. Furthermore, the results of defining the meanings of tags that are derived automatically from tag spaces frequently do not sufficiently reflect users’ consensus. Thus, it is necessary to match new, simple tags to existing meaningful tags correctly based on users’ consensus with minimum interventions by domain experts.
As mentioned in the introduction, the objective of the present paper is to propose a new type of structured folksonomy – CSF – to alleviate problems within existing systems of both flat and structured folksonomy. CSF, which is built dynamically from the CTs that users enter, allows us to match the tags to their semantics exactly. This capability makes it possible to classify web documents into the proper place within the structure of CSF and makes it possible to retrieve the content that is appropriate to a tag of interest. The next section describes our approach in more detail.
3. CTKOS
3.1. Overview of the system
CTKOS is a web-based prototype system developed to demonstrate how CSF is created by users and is used to classify and share various types of organizational knowledge. In our planned application scenario, users who are members of a certain organization can register their organizational knowledge into the CTKOS using their name (or ID) and password. By using the user’s name (or ID), more reliable knowledge sharing is possible in organization. In general, any type of organizational knowledge can be stored in the CTKOS, including manuals and reports. For the convenience of experiments, however, the types of organizational knowledge are limited to online documents in this study, such as books, journal articles, conference articles and technical papers. Its main characteristic is that it uses the enhanced semantics of a tag that is embodied in a hierarchically structured folksonomy. CSF provides users with multiple potential entry points to search for or browse through organizational knowledge. Figure 1 depicts the overall architecture of the system. Its main components are summarized as follows.
Registration – when users register an organizational knowledge they wish to share, they should attach a new CT or select a specific CT among CTs suggested by the system from the CSF in order to categorize it (see Section 3.2).
Database – organizational knowledge is stored in the resource table, and its CTs are stored in a CT table according to CT storing rules (see Section 3.3).
CSF – when users enter organizational knowledge and its new CTs in the CT table collaboratively, CSF is built instantly according to the folksonomy creating rules (see Section 3.4).
Suggestion – when users register or search among organizational knowledge, they are shown a list of CTs extracted from the CSF to help them select appropriate CTs (see Section 3.5).
Search – this function enables users to search tagged organizational knowledge using either a keyword or CT. The keyword-based search supports the simple matching of keywords. The CT-based search supports a semantic search of documents by creating a hierarchy from tag search rules (see Section 3.6). It does this to provide various entry points for navigating documents and by referencing WordNet to select a tag of more relevant semantics.
Exporter – this capability exports a tag hierarchy in the form of the CSF in a file format (e.g. a file in Web Ontology Language [33]) for its reuse (see Section 3.7).
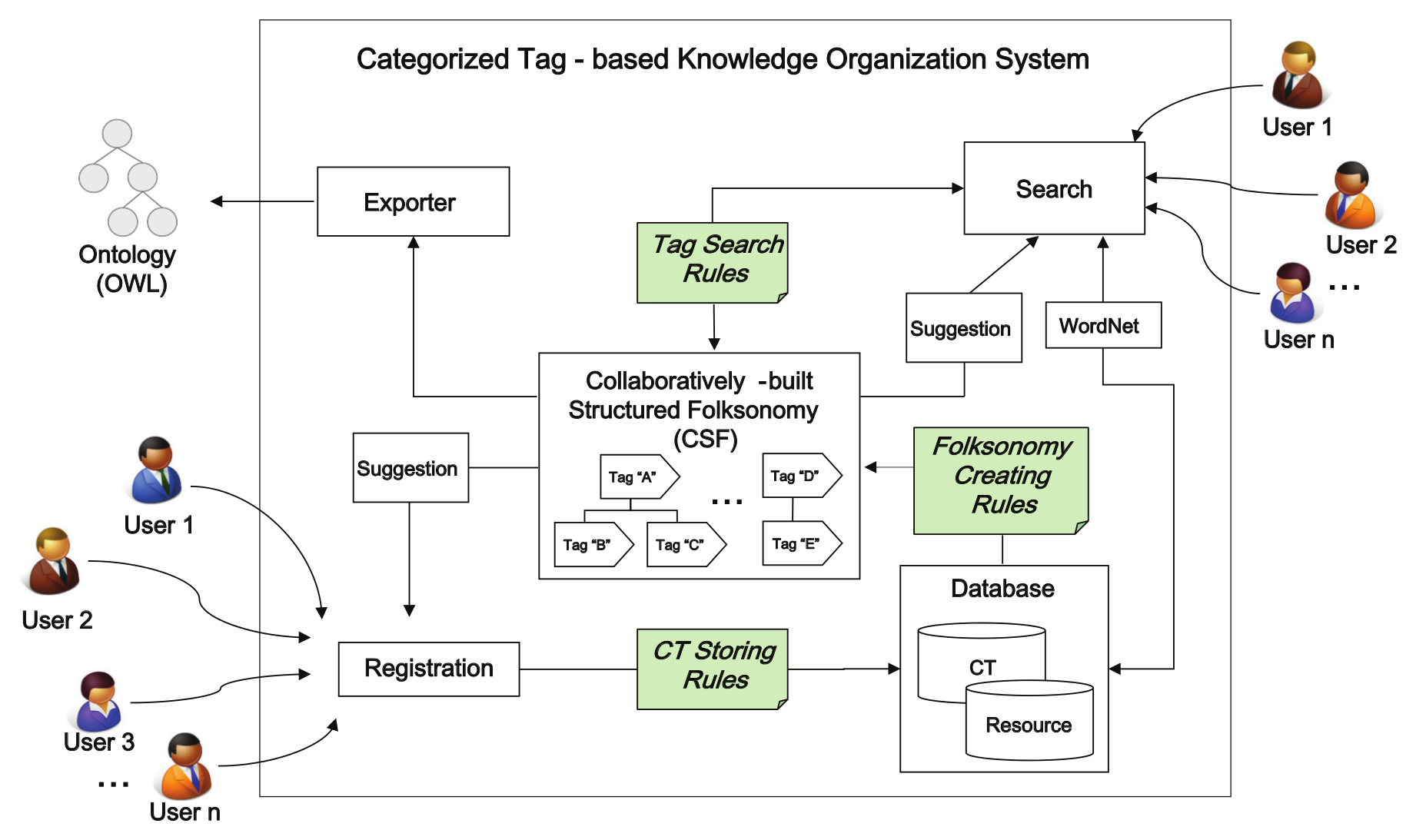
CTKOS architecture.
3.2. Registering organizational knowledge
Users who want to store their organizational knowledge in CTKOS should enter a CT, which consists of two parts: a tag and a category. The tag is related to the category in that the scope of the latter contains that of the former. In the present paper, we called this relationship a ‘belongs-to’ relationship. Users should enter a CT in the following form:

Or, users may enter two CTs in the following form:
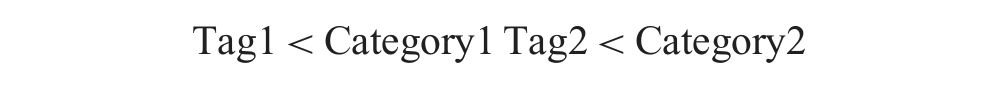
When a tag is entered this way, its meaning becomes more specific than it would otherwise be, because its category limits the context of the tag. CT would be more helpful in this case, especially when tags have polysemy. For example, Bank < Financial_Institution implies that the term bank is used as a tag to mean a kind of financial institution, while Bank < Building implies that bank is used as a tag to mean a kind of building. When users register the document they wish to share, they should input CTs through the registration page in CTKOS.
Figure 2 shows a screenshot of a document registration page. First, a user enters various metadata about a document, such as title, authors and document type. The user then attaches one or more CTs to classify the document. As the user types CTs in the Categorized Tag field, an auto-completion mechanism suggests a list of potential CTs extracted from the CSF in the Categorized Tag field. The user can either select a particular CT from the list or enter a new CT. If a user enters an incomplete CT, which is a tag entered without a category, the system displays a message such as ‘please check the CT’, ‘please check the first CT’ or ‘please check the second CT’, depending on the situation. Through the registration page, the document’s metadata is stored in the resource table, and CTs are stored in the CT table.

Registration page and auto-completion in the text field of a CT.
3.3. CT storing rules
According to CT storing rules, CTs are stored in the CT table, the schema of which consists of {ID, Level_1_Tag, Level_2_Tag, Level_3_Tag, Count}, assuming that users can enter two CTs or one at a time. The CT storing rules are described as follows:
When a user enters one CT in the form of tag < category, the system checks to determine if there is an entry for the CT in the CT table. If there is, it just increases the count field of the entry by 1. Otherwise, a new ID is assigned to the CT, tag of the CT is stored in Level_1_Tag, category of the CT is stored in Level_2_Tag in the CT table, and count field is set to 1.
When two CTs are entered in a row, which may look like tag1 < category1 tag2 < category2 and category1 is not equal to tag2, the system stores each CT in the CT table, as is done in the previous step.
When two CTs are entered in a row, which may look like tag1 < category1 tag2 < category2 and category1 is equal to tag2, they are combined into a three-level CT in the form of tag1 < category1 < category2. If this type of three-level CT is already stored in the CT table, only the count field of the three-level CT will increase by 1. Otherwise, each concept in the three-level CT is stored in Level_1_Tag, Level_2_Tag, and Level_3_Tag, respectively, and the count field is set to 1.
Figure 3 illustrates an example of storing CTs in which four different users entered into the CT table according to the CT storing rules described above. When user 1 enters Semantic_Web < Web, a new ID (e.g. 1) is assigned to the CT, the tag (e.g. Semantic_Web) is stored in Level_1_Tag, the category (e.g. Web) is stored in Level_2_Tag in the CT table, and the count field is set to 1, indicating its first occurrence. Similar actions are taken for the input of user 2. If user 3 enters RDF < Semantic_Web OWL < Semantic_Web, the count field of the first CT RDF < Semantic_Web, which was already stored in the table, is increased by 1. Then, one new entry in the table is made for the second CT OWL < Semantic_Web. When user 4 enters OWL < Semantic_Web Semantic_Web < Web, the system checks whether the two CTs look like tag < category category < super_category. In this case, they can be combined into one three-level CT, OWL < Semantic_Web < Web, and are stored as shown in Figure 3. Note that Count implies the degree of users’ agreement for the category of a tag.

Example of storing CTs in the CT table.
3.4. Folksonomy creating rules
From the CT table, where two-level CTs and three-level CTs are stored, a hierarchical CSF is built automatically according to the folksonomy creating rules, which are explained as follows:
If there are two nodes and an arrow in the CSF graph, corresponding to a two-level CT in the CT table, just add the value of count field to the label of the arrow. Otherwise, create a node for each tag and connect them with an arrow from the Level_2_Tag to the Level_1_Tag and label the arrow with the value of the count field.
If there are nodes and an arrow in the CSF graph corresponding to a two-level CT that is part of a three-level CT, just add the value of the count field to the label of the arrow. Otherwise, create a node for each tag, connect them with arrows from Level_3_Tag to Level_2_Tag and from Level_2_Tag to Level_1_Tag, and label the arrows with the value of the count field. In addition, connect the node representing the Level_3_Tag to that representing the Level_1_Tag with a dotted arrow.
If a cycle exists in the resulting graph, temporarily ignore the arrow with the smallest count among the arrows that makes a cycle. Note that the existence of a cycle in the graph implies that the relationship by the arrow with the smallest count is weaker than others in the cycle. If the ignored CT is entered later again by other users, then its count is incremented to be considered again.
Figure 4 illustrates an example of creating CSF from a CT table. The first three stages are trivial. Since the first CT OWL < Semantic_Web for the fourth entry of the CT table is already represented in the graph, its count is just added to the corresponding label. Its second CT is processed similarly, as indicated at stage 4 of Figure 4. Stage 10 in Figure 4 represents the result of processing the tenth entry in the CT table. Also note that the resulting CSF graph has two cycles: the first among the nodes Web, Semantic_Web and OWL, and the second among the nodes Bird and Eagle. As such, for the time being, we can ignore the arrows with the smallest counts, which is the arrow from OWL to Web in the first cycle, and the arrow from Eagle to Bird in the second cycle, which is shown in the final CSF.

Example of creating a CSF from the CT table.
According to the CT storing rules and folksonomy creating rules, CSF is updated immediately when new CTs are entered in the table. If several users enter related CTs at the same time, the folksonomy-creating rules may incorrectly ignore an arrow among the arrows that make a cycle in CSF. Suppose that there is a cycle among three CTs, such as OWL < Semantic_Web, Semantic_Web < Web, and Web < OWL, and that their label values are 1, 2 and 3, respectively. Then, although the first two CTs are correct and the last CT is obviously incorrect, the arrow corresponding to the first CT will be ignored tentatively. This potential error, which may occur as a result of the user’s cognitive mistake, can be resolved as more users who register CTs correctly participate in category tagging. In this way, CSF reflects more common user recognition for the relationship between each tag and its category, following the principle of the wisdom of the crowds (i.e. collective intelligence) [34–36].
3.5. Suggesting CT
When entering CTs, a user can choose one of several potential CTs extracted and suggested from the CSF or freely enter new CTs. The overall procedure for suggesting CTs is as follows:
If a user enters a keyword that is a tag part of some CT, the suggestion function finds nodes of CSF that represent the entered keyword.
Retrieve parent nodes of each node found in step 1.
Make candidate CTs by combining the keyword and each of its parent nodes.
Suggest candidate CTs in descending order of label values.
In the case of the final CSF in Figure 4, if a user enters the keyword OWL, the suggestion function finds node OWL and retrieves two parent nodes such as Semantic_Web and Bird. Then, two candidate CTs are created, such as OWL < Semantic_Web and OWL < Bird. Finally, OWL < Semantic_Web is suggested first before OWL < Bird, because the former has a higher label value than the latter. CT table and CSF are updated instantly based on the CTs that users enter. This function not only saves the time required to enter CTs, but also shows which tag-and-category pairs were used most often.
3.6. Tag search rules
Tag search for document search is CT-based. It returns a tag hierarchy from the CSF by following the tag search rules explained below, so that users can navigate the space of documents along each tag hierarchy. Tag search rules follow either of the two ensuing cases:
Case 1. If a user enters a keyword, then Retrieve the sub-tree of CSF whose root represents the keyword (if a node that was once checked by the tag search rules is retrieved again later, it is ignored). For each node at the third level of the sub-tree, ignore it from the sub-tree if the node is not linked to its root node by the dotted arrow. Repeat step (b) with the new sub-tree, whose root is the child node of the current sub-tree, when the current sub-trees have children nodes. Return the remaining nodes from the root to each leaf of the sub-tree as a tag hierarchy that consists of one or more sub-tag hierarchies.
Case 2. If a user enters a CT that represents tag < category, then Retrieve the sub-tree of CSF whose root represents the category part of the CT and the child node of the sub-tree represents the tag part of the CT. Follow steps (b)–(d) of the first case.
As an example of the first case, suppose that a user enters a keyword Semantic_Web to find documents related to Semantic_Web when the current CSF is used in Figure 4. In step (a), a sub-tree that contains nodes Semantic_Web, RDF, OWL, OWL_DL, and Bubo with the root being Semantic_Web is retrieved from the CSF. In step (b), nodes OWL_DL and Bubo, which are the nodes at the third level of the sub-tree, are checked to determine whether they are linked to their grandparent node, Semantic_Web, by the dotted arrow. Because node Bubo is not linked to its grandparent node by the dotted arrow, it is ignored. As a result, we get a sub-tree that has two leaf nodes, RDF and OWL_DL. Then, in steps (c) and (d), we get two sub-tag hierarchies, Semantic_Web → RDF and Semantic_Web → OWL → OWL_DL. In the second case, suppose that a user enters a CT, OWL < Semantic_Web. In step (a), a sub-tree that contains nodes Semantic_Web, OWL, OWL_DL, and Bubo is retrieved. Note that, in step (b), node Budo is also ignored in this case for the same reason as is explained in the first case. As a result, in steps (c) and (d), we get one sub-tag hierarchy, Semantic_Web → OWL → OWL_DL. From the two cases, we can see that entering a CT (e.g. OWL < Semantic_Web) results in a smaller number of sub-trees (e.g. one tag hierarchy in this specific example) compared with the sub-tree returned when entering a keyword (i.e. Semantic_Web). This implies that, in the second case, the scope of navigation to search for documents becomes reduced, allowing us to find documents of interest in less time, which is one of the benefits of the CT-based search.
The overall process of the CT-based search function of CTKOS, which includes the tag search and document search, is explained in Figure 5. After entering a CT (e.g. application < system) in the text field of the search page, a user clicks the search button (stage 1). Then, CTKOS returns a tag hierarchy. The sibling tags in the tag hierarchy are shown in descending order of the label value of the corresponding arrow (stage 2). There are two types of icons in the tag hierarchy. One is a tag with a folder icon, implying that it includes many sub-tags, whereas the other is a tag with a document icon, which implies that it represents a document. Here, each tag in a tag hierarchy provides a potential entry point for searching documents. In particular, when a user selects one of the leaf tags in the tag hierarchy, the different meanings of the tag are extracted from WordNet and listed on the screen (stage 3). WordNet allows users to select the correct meaning of a tag from a list of choices. For example, if a user selects a leaf tag browser from the tag hierarchy, then a list of different meanings of browser is suggested from the WordNet database. If the user selects the second entry in the list (i.e. browser, web browser), all documents related to the tag having the semantics of the selected meaning are shown to the user (stage 4). Consequently, CT-based search gives more opportunities to find web documents that better match the user’s interest semantically.
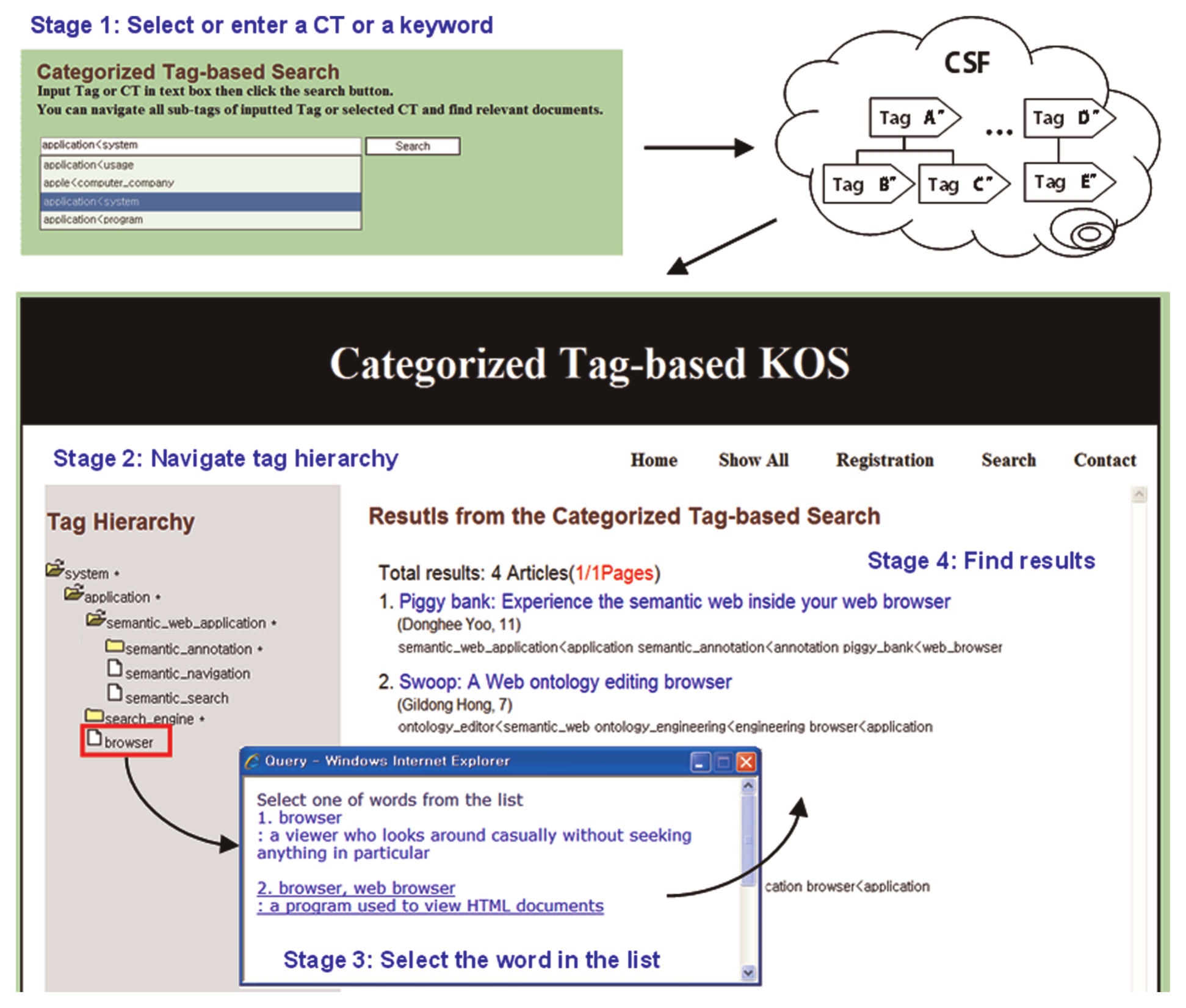
An overview of the process of a CT-based search.
In addition to the CT-based search, CTKOS also provides a simple, keyword-based search, which is used most frequently when searching documents in other systems. Given keywords by users, the keyword search uses simple text-matching algorithms to find text, such as creator, title, author and content.
3.7. Exporter and implementation
The exporter is a very simple function of CTKOS, which exports the tag hierarchy retrieved from CSF according to a user’s keyword or CT in a structured format (e.g. XML) or in a machine-understandable format (e.g. OWL). In our system, the XML is a default file format for this simple function of the exporter. Note that it is worthwhile to share and reuse the tag hierarchy in other XML-based systems or Semantic Web applications, because the tag hierarchy represents user consensus about the belongs-to relationship between a tag and its category.
We used various web applications and open-source software to develop CTKOS. For example, we used a tomcat server to provide web-based interaction, and graphical interfaces and functions were implemented using JSP (Java Server Pages), Java Script, XML, XSLT, Xalan-Java processor and Ajax. In particular, the notification functions (e.g. pop-up message) of the registration page are developed in Java Script and the auto-completion mechanism is implemented in Ajax. Three rules, that is, CT-storing rules, folksonomy-creating rules and tag search rules, were all implemented in Java. In the CT-based search, the function for retrieving terms from WordNet (http://wordnet.princeton.edu) was developed using the Java API for WordNet Searching, called JAWS (http://lyle.smu.edu/~tspell/jaws/). All metadata and CTs for documents were stored as tables of MySQL.
4. Evaluation
4.1. Evaluating the design
To examine whether users have a favourable impression of our CTKOS, we compared CTKOS and a flat folksonomy system (FFS) with respect to tagging and searching mechanisms. To this end, we also implemented an FFS with an overall user interface similar to that of the CTKOS (except the tagging and searching functions) to eliminate the effect of external factors on the results of the test. As a measure for comparing the two systems, we used the Technology Acceptance Model (TAM), which is known as a key theory of information technology acceptance [37–39]. TAM has been widely used to measure the acceptance of information systems by users. Even if a system shows excellent performance, it is of no use if the system is not accepted and thus employed by users. It is therefore important to know the degree of acceptance of the system, which can be evaluated using TAM. Although TAM cannot be used to show the system’s objective performance, we think that it is sufficient for our purpose to compare our system (i.e. CTKOS) with an FFS. According to TAM, perceived usefulness and perceived ease of use affect a user’s behavioral intention to use.
Thirty-two students who had experience tagging documents on the Web participated in our evaluation over a two-month period, from December 2010 through January 2011. The evaluation was undertaken as follows:
Instruments for constructs.

4.2. Evaluation results
We measured and compared the response scores of CTKOS and FFS in terms of three constructs: perceived usefulness, perceived ease of use and behavioral intention to use (following the TAM model) in which each construct consists of two or three instruments for operationalization. The instruments of constructs are given in Table 2. To test whether differences in the response scores between the two systems were statistically significant, we conducted a paired t-test. In addition to the response scores, we measured the negative response rate, which was defined as the fraction of users who assigned scores lower than 4 on the seven-point Likert scale. Through the evaluations, we compared the two systems with respect to both tagging and searching mechanisms (see Table 3).
Comparison between CTKOS and FFS in terms of response score and negative response rate.

p < 0.1; **p < 0.05; ***p < 0.01.
First, for the tagging mechanism, the response scores of CTKOS in all three instruments (T.1, T.2 and T.3) of the perceived usefulness construct were 5.22, 5.34 and 5.44, respectively, and were higher than those for FFS (4.59, 4.59 and 4.63, respectively). The differences in the response scores between the two systems were also statistically significant (at p < 0.1, p < 0.1 and p < 0.05, respectively). CTKOS also achieved lower negative response rates (9.38, 9.38 and 9.38%, respectively) than FFS (25, 28.13 and 25%, respectively) in the three instruments mentioned above. Users also commented that they could categorize documents systematically and grasp the categorized documents at a glance using CTKOS. These results indicate that the users perceived CTKOS as more useful than FFS when tagging documents. CTKOS, however, achieved a lower response score than FFS in all three instruments (T.4, T.5, and T.6) on the perceived ease of use construct. The response scores of CTKOS on the three instruments were 4.78, 3.75 and 4.25, respectively, and those of FFS were 5.50, 5.44 and 5.78, respectively. The differences between them were also statistically significant (at p < 0.05, p < 0.01 and p < 0.01). CTKOS also achieved higher negative response rates (18.75, 50 and 31.25%, respectively) than FFS (6.25, 6.25 and 3.13%, respectively). These results indicate that the users believe FFS is easier to use than CTKOS. We think the reason why FFS was perceived as easier to use than CTKOS is that participants seemed unfamiliar with the new tagging mechanism of CTKOS. More specifically, they may have found it difficult to define the categories of their tags. This difficulty may be reduced by CTKOS’s function of suggesting CTs for a tag that a user enters. We expect that the function will work well after many users have used CSF for a long period of time. This was not the case in our evaluations, however, because our evaluation was conducted with a limited number of users, which resulted in a low score on the perceived ease of use construct. Furthermore, the current user interface, which is not user-friendly, may be another contributing factor to the low score in the perceived ease of use construct. In the case of behavioral intention to use, the two systems did not show statistically significant differences in all instruments.
Second, for the searching mechanism, the response scores of CTKOS in all three instruments (S.1, S.2 and S.3) of the perceived usefulness construct were 5.28, 5.38 and 5.44, respectively, and were higher than those of FFS (5.06, 4.72 and 4.72, respectively), as in the case of the tagging mechanism. The differences in the response scores between the two systems were also statistically significant except S.1 (p < 0.1). CTKOS also achieved lower negative response rates (9.38, 9.38 and 12.50%, respectively) than FFS (3.13, 25 and 21.88%, respectively) in the above instruments again, except for S.1. Users also commented that, although defining the category of documents in tagging mechanism was not easy, they could search the documents both quickly and accurately using CTKOS. These results show that the CT-based search of CTKOS can be more useful than the tag-based search of FFS when searching documents. Although the response scores of CTKOS were lower than those of FFS in all three instruments (S.4, S.5 and S.6) of the perceived ease of use construct, the differences in the response scores between the two systems were not statistically significant (p < 0.1), unlike the case of the tagging mechanism. In addition, the differences in the negative response rate between the two systems regarding the searching mechanism were reduced compared with those in the tagging mechanism. These results show that users believe the CT-based search of CTKOS is as easy to use as FFS when searching documents. In the case of behavioral intention to use, the response scores of CTKOS were higher than those of FFS in all instruments, but the two systems did not show statistically significant differences (p < 0.1).
In sum, we can conclude that the users perceive our proposed system, CTKOS, as more useful than FFS in both the tagging and searching mechanisms. As mentioned in Section 4.1, both perceived usefulness and perceived ease of use affect a user’s behavioral intention to use. Therefore, although CTKOS and FFS did not show statistically significant differences in behavioral intention to use, we expect that this aspect of CTKOS may be improved after CSF has been built by many users for a longer period of time, and when CTKOS is improved in terms of perceived ease of use as a result.
5. Conclusions
Currently, flat folksonomy is known to be effective for classifying a huge amount of web content regardless of a limited set of terms. However, it has severe problems related to semantics and cognitive processing, because flat folksonomy consists of only a set of simple tags. Many studies have been conducted to build structured folksonomy to resolve the problems of flat folksonomy. However, they still have some problems in terms of flexibility and ease of use in the choice of tags.
To alleviate the problems of existing flat folksonomy and structured folksonomy, we have proposed a new type of structured folksonomy called CSF. CSF, which is built from the CTs users enter, has a hierarchy of tags. Our approach provides the following contributions. First, users can freely input their tag with its category, without being limited to a pre-defined set of tags. Second, CSF is built from users’ CTs collaboratively, so that CSF always reflects user consensus for the relationship between each tag and its category. Third, we implemented a CTKOS to demonstrate how CSF can be used in document tagging and retrieval. CSF helps users navigate document space beginning at one of the multiple potential entry points for searching. Fourth, through an experiment to analyse how users are likely to accept our proposed system compared with an FFS, we found that the users perceive CTKOS as more useful than the FFS in the aspects of knowledge sharing (i.e. tagging mechanism) and retrieval (i.e. searching mechanism).
Our approach has some additional desirable features. CSF in CTKOS reflects only the belongs-to relationship between each tag and its category, among many other potential relationships between tags. To make the CSF more useful semantically, it will be necessary to add other relationships (e.g. part-of, same-as, and inverse-of) with CSF. Representing such relationships in CSF in a way that is useful for searching, however, is another research problem. Also, the users indicated that the process of defining CT was somewhat more difficult in CTKOS than in FFS. Therefore, the interface design of the CT-based tagging mechanism must be made more user-friendly to help users feel better about using it. Additional testing related to a real-time system will be required to make the CTKOS more practically useful, such as entering new CTs at the same time by many users. Even with these limitations, we contend that we have shown how CSF can be used to add structure to tags freely, collaboratively and usefully.
Footnotes
Acknowledgements
This research was funded by Hwarang-dae Research Institute research programme of the Korea Military Academy in 2012.