
Abstract
The Journal of Information Science does not normally carry book reviews, but when the Editor received a copy of Martin Frické’s book, Logic and the Organization of Information, he thought it was too interesting to ignore. It succinctly encapsulates years of accumulated research and practice in the field, while also adding ‘logic’ into the mix. He asked me if I could think of a suitable way of acknowledging the work, and I proposed a collection of short pieces by prominent people in the information science community. This is not, then, a review; more a salute to the author for making explicit the fundamental relationship between the ancient disciplines of logic and knowledge organization.
1. A note on the International Society for Knowledge Organization
The Society (ISKO) was founded in Germany in 1989 and now has national and regional Chapters representing more than 15 countries. The UK Chapter was founded in 2007 with the mission to promote the theory and practice of organizing knowledge and information, with a particular emphasis on the building of bridges between the research and practitioner communities across the field. Knowledge organization is becoming increasingly central to the work of otherwise disparate information professionals, evidenced by a look at www.iskouk.org/events.htm, which shows the wide range of activities that have been presented and discussed at two international biennial conferences and some 20 afternoon meetings.
The pieces that follow reflect this range and have been commissioned from five people with strong associations with ISKO UK:
Marcia Lei Zeng – Professor, School of Library and Information Science, Kent State University, USA; Member ISO 25964 Committee – Thesaurus and interoperability with other vocabularies; co-author of Metadata (New York: Neal-Schuman, 2008); papers at ISKO UK conferences.
Stella Dextre Clarke – independent consultant; Chair, ISKO UK; Chair ISO 25964 Committee; winner of Tony Kent Strix Award for outstanding contributions to the field of information retrieval.
Antoine Isaac – Department of Computer Science, Free University of Amsterdam; Scientific Co-ordinator at Europeana (a unified access platform to digitized European cultural heritage); speaker at ISKO UK Afternoon Meeting.
Patrick Lambe – Co-Founder and Principal Consultant, Straits Knowledge, Singapore; author of Organizing knowledge: Taxonomies, knowledge and organizational effectiveness (Oxford: Chandos, 2007); speaker at ISKO UK conferences.
Judi Vernau – Founder and Director, Metataxis Ltd; Vice-Chair, ISKO UK.
2. Logic and knowledge organization – Alan Gilchrist
In his book Frické observes that:
The monumental and authoritative Encyclopaedia of Library and Information Sciences (Third Edition, 2009) does not have an entry for logic in its 6,856 pages despite the fact that traditional librarianship has, over the last 5,000 years, evolved data structures such as the ‘organization of knowledge’ … typically using trees, hierarchies. lattices, sets, subsets, types, parts, mereology etc. [1]
Back in the 1960s it was vital that the information scientists of that time became familiar with information technology and the people in that field of work. Many did, some becoming proficient programmers and even, like Tony Kent, writing successful and marketable information retrieval software packages. Correspondingly, it seems eminently sensible that more people working in the information professions should gain an appreciation of the theory and practice of logic, particularly symbolic logic both in its own right and as it is used by knowledge engineers in the practice of knowledge representation.
As with so much philosophy, including logic, epistemology and classification, we are indebted to the ancient Greeks for laying the foundations by posing and attempting to answer fundamental questions. One of the greatest of these philosophers was Aristotle, born some 2400 years ago. In our own field we can relate to his work in the areas noted above, and Frické makes many references to him in this respect. One of the most widely known of Aristotle’s constructs is the syllogism: connected sentences each containing a subject and a predicate, such that the premise of an argument and what ‘results of necessity’ is the conclusion. The simplest of these syllogisms is the well-known triplet:
All
All
Therefore All
By ‘conversion rules’, it can also be said, for example, that:
From All
Aristotle developed his ideas much further and for hundreds of years it was considered that he had said almost all that was needed to be said about logic. Then, Gottlob Frege, a German philosopher of mathematics and a near contemporary of Boole, devised a system of symbols to represent propositions, terms and relations to assist reasoning, which revolutionized the application of logic and helped to pave the way for the modern programmable computer. However, his ‘concept script’, as it was known, was too cumbersome and difficult to print and so later philosophers, notably the British Bertrand Russell and his collaborator AN Whitehead developed it into what became better known as formal logic, a branch of symbolic logic (the other branch being mathematical logic including set theory and Boolean algebra, a simple form of which is familiar to database searchers with the AND, OR and NOT connectors). Russell also worked with the younger Austrian Ludwig Wittgenstein at Cambridge University and these two, together with Frege, are widely regarded as the founders of analytical philosophy; all three were outstanding thinkers in logic, the philosophy of mathematics and the philosophy of language. Modern information retrieval and knowledge organization rest on the fusion of these three disciplines: logic, mathematics and linguistics – albeit with a healthy dash of pragmatism. As Frické bravely asserts:
Computers are not going to solve our information retrieval problems any time soon.
In his book, Frické carefully weaves considerations of knowledge organization with the fundamentals of predicate logic, providing the reader with a basic tutorial in the construction of statements using first order logic and Lambda calculus, extensions of Aristotle’s propositional logic. Frické quotes Sowa [2] on the strength of formal logic:
Natural languages display the widest range of knowledge that can be expressed, and logic enables the precisely formulated subject to be expressed in a comparable form. Perhaps there are some kinds of knowledge that cannot be expressed in logic. But if such knowledge exists, it cannot be represented or manipulated in any digital computer in any other notation. The expressive power of logic includes every kind of information that can be stored or programmed on any digital computer.
It is obvious that the Semantic Web, that vast enterprise of knowledge organization, needs the power of symbolic logic; it is equally clear that it will need a huge number of well-crafted structured vocabularies. Furthermore, while very many resource collections remain unlinked, there will continue to be a need for both sophisticated and pragmatic approaches to knowledge organization.
3. Approaches to knowledge organization – Marcia Zeng
Clustering things (real-world-objects or concepts), ordering groups of things, clarifying identities of things, sorting out relationships between things – these everyday and everywhere practices become methodological questions of knowledge organization (KO) through the lenses of information and knowledge professionals. These people put much effort into answering such questions that occur in different subject domains through the construction of structured vocabularies such as lists, taxonomies, classification systems, thesauri, semantic networks, ontologies, etc., that can be shared among users of different communities when communicating about things and relationships. Although arguments persist regarding the forms (and even definitions) of these vocabularies, the basic functions of these structured vocabularies, known as ‘knowledge organization systems’ (KOS), can be summarized into the following: eliminating ambiguity of concepts, controlling synonyms or equivalents of terms representing concepts, making explicit semantic relationships among concepts, and presenting semantic relationships as well as properties of concepts. Different types of KOS may emphasize, with various degrees, one or all of these functions.
At the simplest end of the KOS types are the term lists (e.g. the pull-down lists on websites), mainly used to eliminate the ambiguity of concepts in certain applications. Glossaries and dictionaries give some definitions of a concept and the synonyms of a term. In a more formalized format, the labels that represent personal names, place names, etc., are collectively managed through so-called authority files for better indexing and search purposes. They provide instances along with the concept systems. For example, web directories group vacation sites by continents, countries and cities, while also listing the sites themselves with the links. Digital gazetteers even give you the coordinates and maps of the sites and tell you the types of the places. In uncontrolled meta-searching, we can also build synonym rings (groups of terms being considered as having equal meaning when searching).
Classification and categorization are efforts to order things in this world or in our daily life. Subject headings are used to index important topics mentioned in a document so it will be easier to find all documents of the same topic in a large database. Taxonomies and classification systems are widely used to sort out the hierarchical relationships between things. A classic example is the taxonomy that differentiates between all kinds of animals; such a method has been applied to sorting out things in countless cases.
However, merely hierarchical relationships are not enough for understanding the world. Relationship models (thesauri, semantic networks and ontologies) are the types of KOS that also indicate all kinds of other relationships, for example, causes and effects, theories and applications. The semantic networks specify types of concepts in addition to presenting the relationships in hierarchies and networks. Ontologies are designed based on the semantic relationships and properties of things. Classes are established according to the properties (characteristics and relationships with others) that the class members share. They are more logical and are structured with constraints, in comparison with regular base-line classification systems. Ontologies are often used in reasoning, beyond ordinary KO applications. It is their function to represent more complex semantic relationships and properties, thus extending the role of facilitating information organization that is found in less complex KO approaches.
Overall, the more comprehensive the structures a type of KOS possesses, the more functions can it satisfy. Although various types of KOS have existed for years, the ‘Digital Age’ has brought an increased interest in them, while new applications and services are emerging. It is important that information and knowledge professionals understand how to align KOS with the academic, research, service and business goals of an institution and how to leverage navigation, searching, collaborative filtering and other approaches to achieve cost-effective, scalable solutions through KO approaches.
4. Who cares about organizing information? – Stella G. Dextre Clarke
There was a time when the study of classification lay at the heart of the curriculum of budding librarians and information scientists. Today, however, a multiplicity of other topics has crowded the curricula offered by many library and information science (LIS) departments, squeezing the principles and practice of organizing information into a shrinking corner. Could it be, now that computers are doing it all for us, that information professionals no longer care about classification?
The UK Chapter of ISKO, as the professional body most concerned with the subject, recently arranged a one-day seminar and workshop under the banner ‘I think, therefore I classify’. The object was to review the way classification is taught and learned, and breakout sessions were planned to address the problem and the opportunities.
A capacity audience showed that classification still has the power to fascinate. In the cause of proving ‘Why classification matters’, Vanda Broughton of University College London disputed Weinberger’s famous claim that ‘Everything is miscellaneous’ [3]. Since University College London has one of the few Departments of Information Studies left in the UK that still provide a thorough grounding in classification theory, she was well placed to proclaim the advantages of a structured knowledge organization system.
Although Broughton spoke from a librarian’s standpoint, she was followed by a range of speakers with very different perspectives, inter alia a botanist specializing in the taxonomy of the Solanaceae, a researcher in cognitive science, a philosopher of science and two computer scientists, specializing (respectively) in automatic classification techniques and the application of ontologies to the Semantic Web. (Their slides and audio recordings at http://www.iskouk.org/events/classification_july2012.htm are well worth a view.) The overall message was plain: the ability to categorize is fundamental to the cognitive development of every human being; more sophisticated forms of classification follow, and have applications in all walks of life, especially as society becomes more dependent on the electronic delivery of information.
And yet, when the breakout sessions arrived, very few people chose to join the discussion of how classification should be taught and learned, either in formal education or in the workplace. A much more popular topic for this audience of information professionals was the future of classification in electronic/networked environments, including the role of informal vs formal classification. Admittedly all these topics are interesting, but how will we prepare for that future if we neglect education and training in the basics?
In academic departments other than LIS, interest in classification continues and may possibly be growing. It seems safe to predict that students of philosophy will always find time for the teachings of Aristotle, as well as later logicians and philosophers. In science curricula, where classification of phenomena is needed to advance the science (for example in chemistry, where the arrangement of elements in Mendeleev’s periodic table has supported countless predictions and discoveries), the advantages of a domain-oriented classification system will not be forgotten. In computer science an expanding range of applications require class structures developed with rigorous logic, so that intelligent agents can use them for reasoning; curricula may adapt to give this aspect more attention. However, for information scientists in the UK at least, it seems that educational courses with thorough coverage of classification deserve a place in the list of endangered species.
Before much time has passed, people interested in the organization of information and knowledge may no longer take the trouble to study the contributions of Panizzi, Dewey, Ranganathan and the other pioneers of bibliographic classification celebrated in Martin Frické’s book. They may simply take a long hop from Plato and Aristotle over to Tim Berners-Lee, with brief staging posts at Leibniz, Linnaeus and Frege. Who will show them the way? If schools of librarianship and information science cease to offer studies in classification, the teachers of other disciplines may soon fill the gap, presenting the subject from a very different viewpoint.
5. KO and the Europeana service – Antoine Isaac
The Europeana service aims to provide access to digitized objects in cultural institutions from all over Europe. This raises considerable challenges, when such a service has to be built on object metadata having various scope, structure and language. Traditionally, metadata have been published and exchanged (when possible) in the form of simple flat records in which only strings are available for both human and machine consumption. Yet, metadata are often created with richer semantic information attached to them. Library cataloguers, for example, routinely base the descriptions they create using controlled and structured KOS such as thesauri, classification systems or name authority lists.
It is also possible to enrich existing object descriptions by linking them to relevant KOS. Consider, for example, a painting of a horse that has been described in Russian. Suppose this description is linked to a thesaurus like GEMET [4], which contains a structure of concepts about horses, including labels in 31 languages and a semantic link to the broader concept of ‘animals’. It then becomes possible to find this painting among the results of queries that did not include the Russian keyword ‘лoшaдь’, for example, queries for ‘cheval’ or ‘Tier’ (respectively ‘horse’ in French and ‘animal’ in German). KOS thus enables a wider range of answers derived from the metadata to better meet the demands of users of Europeana.
The potential use of KOS data has been acknowledged for some time in the Semantic Web and Linked Data community, particularly that part of it in cooperation with libraries, archives and museums, where such data is often found (see the report of the recent Library Linked Data Incubator Group, which named them ‘value vocabularies’ [5]). The value of KOS is especially high when resulting from the long and careful effort of experts who have gathered impressive bodies of conceptual and lexical data over the years. Yet sharing and exploiting these data in accord with the Linked Data vision requires solving some of the interoperability issues which too often prevented the exchange and re-use of KOS in the past. In addition to the usual rights issues (access to vocabularies is often barred by strong intellectual property-related conditions), one important problem was the lack of suitable models to express KOS data. Semantic Web technology makes available ontology languages (e.g. OWL [6]) that are designed to create rich conceptualizations of domains of interest, based on formal logics. However, these make strict assumptions on the nature of semantic axioms; for example, generic-specific hierarchical links should denote formal class subsumption. Such assumptions often do not apply in KOS, where semantic relationships can be of a much more informal nature (e.g. associative links). Expressing KOS in formal frameworks would require either processing with tedious conceptual cleaning of their semantics or inappropriate interpretation of informal data, which could lead to undesirable inferences by reasoning engines.
To solve this issue, less demanding data models have been shaped, like the simple knowledge organization system (SKOS [7]). SKOS is designed to allow a straightforward porting of KOS data onto the Web of Data, without requiring ‘over-interpretation’ of these data. SKOS focuses on basic descriptions of concepts as needed by most representative KOS application cases for Linked Data. Mostly, simple labelling (preferred and variant labels) and semantic links (hierarchical or associative). SKOS can then be extended to handle other, sometimes useful, features such as fine-grained relations between labels or combinations of concepts in pre-coordinated systems. One feature which was judged crucial to include from the start, though, is the ability to express semantic links like equivalence across different KOS. SKOS adapts the Linked Data vision where resources can be directly connected together independently from their original domain. This allows the seamless exploitation of data based on different KOS – a big move beyond traditional KOS approaches, especially useful in contexts such as Europeana where hundreds of local or more general KOS have been used to describe objects. For example, vocabularies like AGROVOC [8] or LCSH [9] are now published with links to many similar KOS from other institutional or language contexts, allowing them to be deployed as hubs between these different contexts.
6. Empiricism vs rulesets in knowledge organization – Patrick Lambe
If you wanted to build a spell-checking application before the mid 1990s, you would have tried to predict all possible keypad mis-strokes and the words probably intended. You might have run tests counting the most common types of mistakes, extrapolating from them to refine your prediction algorithms. Rules-based analysis was the game.
Then Google arrived taking an entirely different route, simply observing whenever users changed what they were typing in the search box, what they corrected and how. The billions of corrections in search queries provided a statistical database far more efficient than a rules-based predictive engine. As Gary Marcus observed in the New Yorker Blog,
The lesson, it seemed, was that with a big enough database and fast enough computers, human problems could be solved without much insight into the particulars of the human mind. [10].
The problem is in understanding which errors – and their intended correct forms – are going to be the most common, which is often context-sensitive. Predictive rulesets go with averages, not outliers – which is frustrating when using language playfully. When I type ‘mon plaisir’, Google knows I am trying to write in French and Microsoft Word thinks I am trying to write ‘mom pleaser’. Put another way, this is the problem of salience – that is, what is significant to a particular kind of user in a particular context. Salience is almost never the average. Given sufficiently large and differentiated datasets, empirical approaches are much better at identifying salience than predictive rulesets. The problem of salience is central to the work of knowledge organization in general and taxonomy development in particular. With enough energy and resources, we can build ontologies to describe the conceptual universe, and can trace conceptual relationships between entities in this universe. However, we never have enough energy and resources, and so we must guess (predict) the most common entity types and relationship types, and must scale them up using rules. Then we have to keep pace with the world’s capacity for creating novelty. Only by luck is this going to serve the specific needs of specific communities in specific situations. Tanks in refineries are different from tanks in battles. To differentiate all possible alternatives requires either massively predictive rulesets or statistically based attention to the immediate context of a query and the enquirer.
Salience – the quality of lifting relevant and important concepts and relationship types into sharp relief against the rest of the information landscape – requires something known in the library science community as warrant, an essentially empirical concept. It points to the evidence base upon which the salience choices are made, and which authorizes lifting some concepts and some relationship types into visibility in some situations and not others.
This is why general all-purpose rules-based predictively modelled taxonomies and ontologies will always frustrate, and why taxonomy development needs sometimes laborious processes for auditing the information content and contextualizing that content in terms of real (current) needs and tasks.
For years, Google Internet search has bemused taxonomists. The mysterious opacity of the Google algorithms poses a question: although it is probable that knowledge organization tools have been used to sharpen search results, most of the credit for salience was apparently due to a purely empirical behavioural observation model, sidestepping formal knowledge organization systems. In May 2012 Google launched Google Knowledge Graph. Now, when you look for a frequently searched entity keyword (e.g. a personality or a place), you get a ‘key facts’ panel to the right of your search results with links to related entities. Search just got much richer, and seems to have done so by marrying knowledge organization tools with empirical datasets to indicate salience. Behaviours associate salience features with their contexts. Curated knowledge organization structures connect entities and relationships. Ontology rules are built out as they are needed, not to cover the whole universe, but to trace empirically warranted information pathways. Google engineer Shawn Simister has explicated this novel alliance between empirically derived indicators for salience and formal knowledge organization tools in terms of ‘design patterns’ [11]. From this it is clear that Google is playing in taxonomy territory, without ever using the word. I have defined taxonomies [12] as having three functions, each of which appears to underpin one of the ‘design patterns’ that Shawn speaks about:
Taxonomies have a semantic function by providing a controlled vocabulary – in Google these are the ‘discovery patterns’ allowing them to match terms to entities, extract and disambiguate entities and reconcile terms to a single ID.
Taxonomies have a classification function to group related things together – in Google these are ‘interaction patterns’ that allow users to filter (Google explicitly uses the language of facets here) and navigate from one entity to other related entities via recommendations.
Taxonomies have a mapping function to give an overview of a knowledge domain – in Google these are ‘presentation patterns’ for displaying concepts, particularly for providing mashups (which become much more productive when working with facets) and visualizations such as network maps, trees, timelines, graphs etc.
In Google Knowledge Graph, empiricism meets rules-based knowledge organization in a hybrid approach that suggests a middle ground may be possible. Taxonomists get a salience engine. Behaviourists get strategically enriched search results.
7. Bending the rules – Judi Vernau
The ‘scientific’ sense of a taxonomy as a strict hierarchy is attractive from a distance, but rarely useful in practice when building KM taxonomies. [12]
In his book Martin Frické discusses some of the current issues relating to the classification and retrieval of digitized ‘information objects’. In particular he says ‘it is a real question whether traditional approaches are going to be good enough for the tasks that will arise’.
To my mind, the question is less about the ability of those traditional approaches to meet twenty-first century requirements for information organization, management and retrieval, but more about what organizations and individuals are willing to contribute in terms of time and effort in order to achieve, as Frické says, a ‘good enough’ outcome. I will confine myself to outcomes in the business environment.
As business people what do we know?
Our information has increased at a rate of something like 10 times over five years.
The means of communication and language itself are changing ever faster.
Businesses, needing to capitalize on information and knowledge, must facilitate access by staff who need to be able to organize and find the content they need quickly and efficiently.
However, many businesses have limited resources (money and people) to meet those needs.
As information professionals what do we know?
Users look for information in different ways.
Different approaches to information-seeking require different semantic and technical tools.
The use of controlled vocabularies such as thesauri can improve precision and recall.
However, developing these kinds of tools, especially following a rigorous, standards-based approach, needs expert help and a lot of work – and it is not just a one-off activity.
The implication of these eight statements is that the organization must identify some middle ground on which to build this aspect of its information strategy: it needs to find a practical approach that will deliver observable improvements, but which can be implemented relatively quickly and cheaply.
Some things are a given: as stated above, people look for information in different ways at different times and for different purposes. Once upon a time, some or all of these activities were carried out by information specialists who knew their way around the thesaurus or other specialist finding aids. Now, individuals in the organization are usually conducting searches for themselves, and so we need to provide them with tools to help them obtain the relevant information. However, does that need to be ISO standard-compliant thesauri containing, for example, hierarchical relationships that conform strictly to the genus/species, whole/part or instance rules? Is it necessary to present terms as unit concepts? Many traditional thesauri were created with these devices, as were the universal classifications, to provide the hospitality to deal with new topics. Many such thesauri are necessarily extensive (the MeSH thesaurus contains about 199,000 entry points), which has two impacts. The first is that it will be hard to convince the budget-holder that a big investment (as a truly compliant thesaurus is likely to need) will provide sufficient return on that investment. As information professionals we may believe that it might, but persuading others will not be easy. Furthermore, in enterprises, which are often ‘problem-oriented’, it may be more appropriate to adopt a looser structure containing compound terms, and fewer levels in which individual arrays may not contain terms that are strictly coterminous or that fully conform to the standard hierarchical relationships. Such an approach will be easier and cheaper to build and maintain. For the user, searching via some sort of taxonomy may be more congenial, and if users are also asked to index their outputs, they will almost certainly find it easier to use similar devices or folksonomies. Can we quantify the degradation in performance caused by such approaches? Or does ‘bending the rules’ provide a ‘good enough outcome’?
8. Concluding comments – Alan Gilchrist
The word ‘and’ in the title of Frické’s book, rather than ‘for’, is appropriate, particularly as much of the book dealing with KO concentrates on the more traditional ‘craft’ aspects of the construction of knowledge-based artefacts (or mentefacts as the late Brian Vickery called them). KO has its roots in this craft aspect, often based on a philosophical approach, as in the Dewey Decimal Classification or on facet analysis as in the Bliss classification. A later craft focussed more on a semantic approach as used in thesaurus construction: facet analysis and semantics coming together in the Thesaurofacet [13] designed by Jean Aitchison. Such schemes produced an ‘artificial language’ placed between the author and the searcher so that a match might be made between the language of the author and the language posed in the question. With the advent of the computer followed by distributed processing, the needs of the end-user were met by the manipulation of a range of tricks, each range varying according to the design provided by the particular software vendor. Bayesian statistics was the initial and principal technique, later supported by such adjuncts as automatic categorization, information extraction and rule-based systems. These developments were accompanied by a new generation of KOS as described by Zeng, although still all underpinned, as Dextre Clarke correctly maintains, by some form of classification or categorization. However, as Vernau points out, the combination of disintermediation and the exigencies of limited resources, often exacerbated by the relative indifference of senior management, dictates the application of a more pragmatic approach, although one that is also largely craft-based. One possible reason for Dextre Clarke’s concern that classification seems to be largely ignored in the curricula of LIS schools in the UK may be because the traditional crafts, however much they may be computer-assisted and delivered electronically, are being overshadowed by the newer engineering of knowledge, which is also developing its own crafts. The two movements, despite sharing some common goals and techniques, have largely worked separately, as may be observed from the citations in the respective literatures and the use of different terms denoting similar concepts. However, there are welcome signs of a coming together, as may be evidenced by Isaac describing one fairly typical project in knowledge engineering in language and example familiar to the earlier information professionals. Also significant is Lambe’s analysis of the thinking and techniques behind Google’s Knowledge Graph where the use of older crafts become evident and user behaviour is also factored into the search process.
As inferred above, some of the automated techniques used by knowledge engineers have been used for some time for information retrieval. Such routines are based on the elicitation of implicit semantics, the co-occurrence of words and phrases, the clustering of related documents, indeed any clues that may help to build a descriptive picture of a collection of documents.
The famous Semantic Web Stack (Figure 1) shows how the machinery is built up from the basics of Unicode, using XML and RDF through taxonomy (used here to mean the basic vocabulary rather than a website navigation tool) to the ontology manipulated by a logic inference engine such as OWL. Here, the problems of scalability and complexity begin. Isaac noted the inherent difference between the taxonomy and the ontology: ‘expressing KOS in formal frameworks … could lead to undesirable inferences by reasoning engines’. However, now the semantic problem is moved to the ontology, which is usually focussing on a relatively closed domain of knowledge. As Sheth et al. say [13]: ‘Description logics … leave no scope for the representation of degrees of concept membership or uncertainty associated with concept membership’, while when employing what they call ‘Powerful (soft) semantics’, ‘it becomes impractical as the size of the knowledge base increases or as knowledge from many sources is added’. As Lambe notes, ‘we have to keep pace with the world’s capacity for creating novelty’ or, in the words of Sheth et al., ‘It is rare that human experts in most scientific domains have a full and complete agreement. In these cases it becomes more desirable that the system can deal with inconsistencies’ [14].
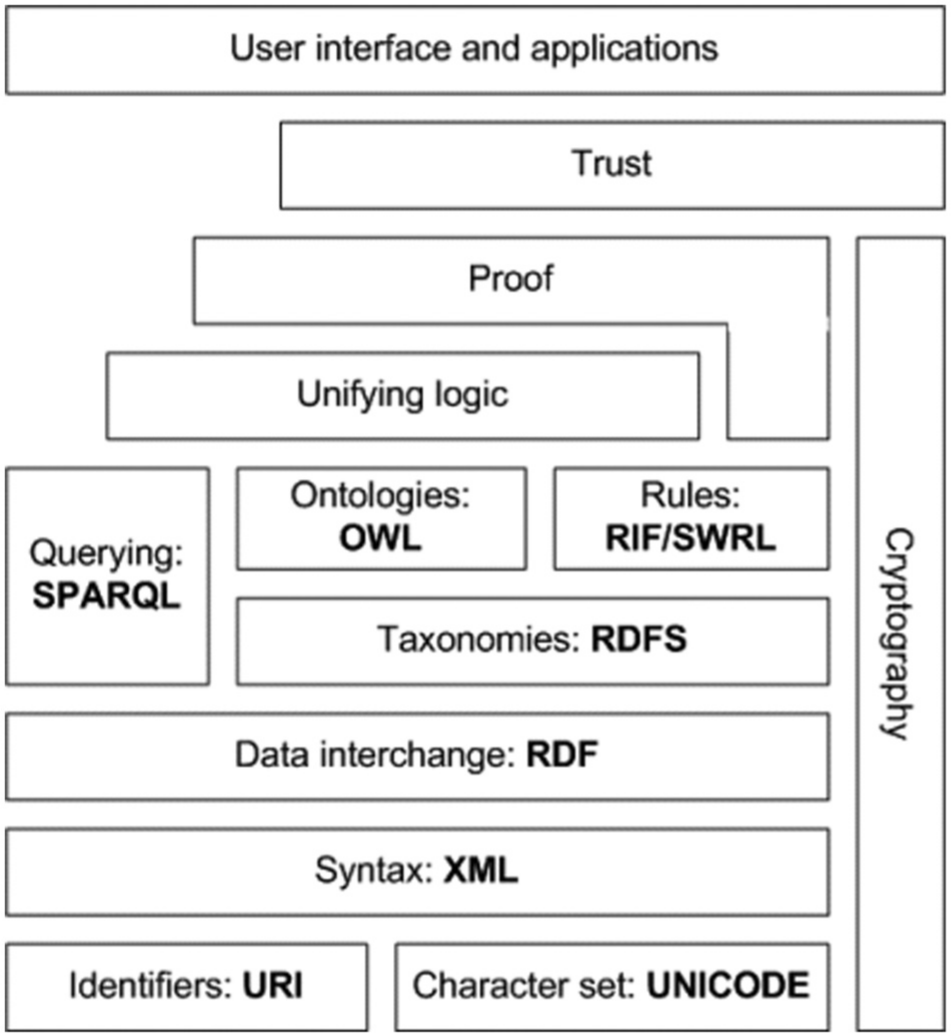
The Semantic Web Stack, also known as Semantic Web Cake or Semantic Web Layer Cake.
Humans must be brought into the complex equations. Naeve of the KM Research Group at the Royal Institute of Technology in Sweden has reported on what he calls the ‘Human Semantic Web’, and presents three levels of information systems [15]:
semantic isolation (with document-based descriptions, closed description spaces and fixed metadata sets);
semantic co-existence (with RDFs and graph-based descriptions, and open description spaces allowing joint searching);
semantic collaboration (with ontology management systems and mappings, contextualization and inter-searching with dynamic queries).
Here, the traditional craft-based community is in step with such thinking. As it happens, three of the above essayists are members of the ISO Committee that has just completed ISO Standard 25964, Thesauri and interoperability with other vocabularies. Replacing the earlier standard, which was mainly concerned with the thesaurus as the best-practice basis for construction of structured vocabularies, the emphasis of the new standard is on interoperability. Certainly, ISKO UK is keen to collaborate in the success of the Semantic Web dream, but also to help ensure that the generally poor level of information provision in many enterprises, as well as the sub-standard nature of many websites, is improved on behalf of both individuals and the knowledge economy in general.