
Abstract
The microblog has become a new global hot spot. Information retrieval (IR) technologies are necessary for accessing the massive amounts of valuable user-generated contents in the microblog sphere. The challenge in searching relevant microblogs is that they are usually very short with sparse vocabulary and may fail to match queries. Pseudo-relevance feedback (PRF) via query-expansion has been proven in previous studies to successfully increase the number of matches in IR. However, a critical problem of PRF is that the pseudo-relevant feedback may not be truly relevant, and thus may introduce noise to query expansion. In this paper, we exploit the dynamic nature of microblogs to address this problem. We first present a novel dynamic PRF technique, which is capable of expanding queries with truly relevant keywords by extracting representative terms based on the query’s temporal profile. Next we present query expansion from external knowledge sources based on negative and positive feedbacks. We further consider that the choice of PRF strategy is query-dependent. A two-level microblog search framework is presented. At the high level, a temporal profile is constructed and categorized for each query; at the low level, hybrid PRF query expansion combining dynamic and external PRF is adopted based on the query category. Experiments on a real data set demonstrate that the proposed method significantly increases the performance of microblog searching, compared with several traditional retrieval models, various query expansion methods and state-of-art recency-based models for microblog searching.
1. Introduction
Microblogging has attracted attention from all over the world in recent years. For example, Twitter – the most popular microblog platform – produces approximately 50 million tweets per day by billions of users, as reported by The Daily Telegraph in February 2010. The contents in the microblog sphere are generated and updated by online users. They cover a wide range of topics. Furthermore, most microblogs contain valuable first-hand reports on real events (e.g. crisis situations and disasters). Hence the microblog has emerged as an important information source for online users, scientists and media employees.
The extremely high volume of contents in microblog sphere makes evident the need to develop an efficient microblog search engine. Microblog search is still an open problem. Existing systems fall into two categories: ‘asking’ and ‘retrieving’ [1]. In this paper, a microblog search is conducted through the paradigm of traditional information retrieval (IR) – the goal of microblog search is to fetch relevant tweets for given queries.
Although many information retrieval systems have been developed in other domains, most of them still suffer from ‘the vocabulary problem’, which refers to the difficulty of matching the underlying information need expressed by a short and vague query to several relevant documents within a large, complex and noisy corpus. In the scenario of a microblog search, the ‘vocabulary problem’ is more severe owing to some inherent weaknesses. First, the microblog is short in content with a maximum of 140 characters, which limits the information capacity of each tweet. Second, as an instant broadcast platform, the microblog produces streams of tweets to report a series of updates instead of long detailed descriptions. During this process, diverse vocabularies are adopted to describe an identical topic. Third, microblogs contain not only texts but also users, tags and replies, which are important components for understanding the content and context of microblogs.
Pseudo-relevance feedback (PRF) via query expansion is a well-studied technique to overcome the vocabulary problem in IR literature [2]. The key idea of PRF is to expand the original queries with keywords selected from some relevant feedback. Usually the relevant feedbacks are generated from top results retrieved in a naive run (pseudo-relevance). Hence relevant documents can be matched to the expanded query more effectively. While PRF is in general an appropriate solution for microblog retrieval, one critical problem is that the top retrieved results may not be relevant. We illustrate how the sparse and dynamic nature of the microblog may harm the performance of conventional PRF in Figure 1.

PRF for microblog search.
In the left-hand side of Figure 1, the top results with their creation timestamps are ranked according to their relevancy score computed by traditional retrieval systems. For simplicity, the relevancy score is measured mainly based on the number of matched query terms. In the right-hand side, we list expanded terms generated by several PRF strategies. Generally PRF strategies select statistical significant keywords, for example, the most common/possible term in top results, the most divergent term in top results compared with the background corpus, the term in top results with maximal co-occurrences with query terms, etc. We can see that, since the top results are not all truly relevant, the expanded term is not correctly chosen. However, if we know in advance that the event related to the given query is active from 25 January to 11 Fegruary 2011, the second tweet can be filtered since it is outside the active period of the query, and by analysing the temporal distribution of expansion candidates, ‘curfew’ appears to be a dynamic relevant keyword. The user-defined tag ‘#jan25’ can be also discovered to be relevant by analysing the temporal distribution of annotated tweets.
Therefore we propose a dynamic PRF query expansion strategy, which exploits the dynamic nature of microblogs to identify truly relevant feedback. By building a temporal profile for each query, the active phases of the query are detected. The proposed technique is capable of selecting representative keywords in different active phases from pseudo-relevant tweets. To the best of our knowledge, this is the first work on employing query-specific temporal information for PRF query expansion.
Furthermore, we consider that the characteristics of queries are determining factors for choosing PRF query expansion techniques. Different from previous studies on selective query expansion techniques, we do not attempt to directly predict the performance of PRF [3–6] or the semantics of queries [7]. Instead, the temporal profile for each query is employed for predicting the query category through a supervised learning process. We explore two different PRF mechanisms in this work. One is the proposed dynamic PRF; the other is query expansion from external knowledge sources based on positive and negative feedback. A hybrid query expansion strategy incorporating external and internal dynamic information is implemented, where the combination weights are intelligently assigned based on the category probability of the given query.
The paper is organized as follows: Section 2 briefly reviews some related work about microblog searching and PRF query expansion techniques. Section 3 presents dynamic PRF query expansion. Hybrid PRF is presented in Section 4. Comparable experiments and analysis of experimental results are shown in Section 5. Section 6 concludes this paper and prospects for future work.
2. Related work
2.1. Microblog search
With the emergence of Twitter, more and more studies have investigated the value of microblogs. Microblog search plays a fundamental role in building efficient microblog applications. It is defined in Efron [1] that there are two distinct types of microblog search; one is broadcasting a query in the hope of getting an answer from someone, and the other is conducting ad hoc IR in the microblog sphere. In this paper, microblog search refers to the latter type. As studied in Teevan et al. [8], queries issued to a microblog search engine show remarkable differences from web queries: ‘People search Twitter to find temporally relevant information (e.g., breaking news, real-time content, and popular trends) and information related to people (e.g., content directed at the searcher, information about people of interest, and general sentiment and opinion).’
To improve the performance of microblog search systems, a few works have been proposed in the literature. Most of them make use of the unique features of microblog, for example, hash-tags, re-tweets, influential tweets and timestamps. In Efron [9], hash-tag is used to construct relevance feedback for query expansion. The transfer latent semantic learning model is presented in Zhang et al. [10] to learn the hidden topics of abbreviated tweets based on annotated tweets. Tweet-LDA is presented in Zhao et al. [11] to model the relation between tweets and re-tweets. The retrieval model in Massoudi et al. [12] incorporates a quality indicator of microblogs. Similarly, conversational tweets are filtered in Huang et al. [13]. The recency problem of microblog search is studied in Massoudi et al. [12] and Efron and Golovchinsky [14], where the timestamps of tweets are employed to aggressively smooth older tweets. TI [15] presents a different mechanism – an adaptive indexing scheme to combine users and tweets for a new ranking system. Instead of ranking, in Sakaki et al. [16], tweet features are employed by SVM to classify relevant and non-relevant tweets. In 2011, Text Retrieval Conference (TREC) launched a new track, namely the microblog track, to motivate research efforts in this area [17]. Several approaches are presented to promote recent tweets using the temporal tweet prior.
2.2. PRF query expansion
Query expansion is an effective IR technique. Early systems adopted manual query expansion, which is not applicable to massive data. Pseudo-relevance feedback was then proposed to improve retrieval effectiveness on large collections. Query expansion techniques implemented on language model are surveyed in Zhai [2]. A parameter-free expansion strategy is presented in Tao and Zhai [18] by regularizing the estimation of the language model parameters. Common distribution statistics of expansion candidates are utilized in Cao et al. [3] in a classification process to predict good expansion terms. Some researchers exploit the global information of the corpus to discover word relationships in addition to locally analysing pseudo-relevant documents [19]. In the meantime, instead of documents within the corpus, some researchers explore the utility of external resources in query expansion. Most of them are based on Wikipedia [5, 6, 20].
There have been works on query-dependent expansion strategies. One main idea of pseudo-relevance expansion is to select ‘good’ terms in higher-ranked documents by the initial search, and integrate these terms into original query and re-assign the weights of query terms. The ‘goodness’ of expansion terms can be measured by information theoretic criteria [21]. Most of them propose a decision process based on the predicted query performance. For example, selective query expansion is only carried out in easy queries in Amati et al. [4]; adaptive query expansion is implemented in Teevan et al. [8] on either the corpus or on the external collection with highest predictive performance. Similarly, Li et al. [6] suggest expanding weak queries on external collection rather than pseudo-relevance. Different from these strategies, queries are categorized based on their semantics in Xu et al. [7] to entity queries, ambiguous queries and other queries. Then Wikipedia entity pages are collected to select expansion terms on the corresponding senses of the query.
2.3. Conclusion
There are only a few research systems dedicated to microblog search. Most of them focus on the characteristics of microblogs. The work in Efron and Golovchinsky [14] is the most similar to us, and proposes various ranking schemes for recency queries and non-temporal queries. However, the goal of Efron and Golovchinsky [14] is to return most recent tweets given the query issue time. Favouring only the most recent tweets, the recency-based model [14] is not able to capture related keywords in different active phases of an event. As we will show in later sections, the proposed method can obtain more accurate results than the recency-based model.
3. Dynamic PRF
In this section, we first illustrate the intuition of dynamic PRF by analysing a typical type of information need in microblog search: query for event-specific information. We show that, for highly dynamic queries such as event queries, relevant keywords are correlated with query terms as a function of time. Then we show how this assumption can be modelled in dynamic PRF.
3.1. Intuition
PRF strategies select statistically significant terms in the pseudo-relevance as expansion terms. However, since pseudo-relevance is not truly relevant, PRF may not generate good expansion terms.
In microblog search, this problem is even more severe. A major portion of information need in microblog searching is fetching tweets related to dynamic queries. In fact, since microblogs are quickly updated, it is natural for users to seek information related to changing topics, for example, an on-going event or the daily life of a celebrity. For simplicity of intuition, we use event query as an example of the large group of dynamic queries, which produce huge volumes of rapidly updating relevant contents in certain periods and little relevant content in other periods.
On one hand, queries are short, containing only basic descriptive terms. For example, event queries usually only contain the location of the event, the person involved, and the main theme. However, an event may last for several weeks. There may be various keywords related to the event during this period. As shown in the left-hand side of Figure 2, the timeline of the event ‘Egypt Revolution’, which lasted from 25 January to 11 February 2011, consists of four active phases (by active phases, we mean that during these phases the event encounters major progress and discussion bursts out). The term ‘curfew’ is a relevant keyword in phase 2 (around 28 January 2011), and ‘Tahrir’ is relevant in phases 1 and 3. Both ‘curfew’ and ‘Tahrir’ are dynamic relevant keywords, but they are not provided as query terms. On the other hand, since the length of tweets is restricted, a user is likely to use abbreviated expression – only the representative keywords in the current phase, without elaborate description of context and background. As shown in Figure 1, a relevant tweet published on 26 January 2011 only contains the keyword ‘curfew’, while an irrelevant tweet published on 1 January 2011 contains both ‘Egypt’ and ‘revolution’. The above two reasons would lead to a lower position of truly relevant tweets and a higher position of irrelevant tweets in pseudo-relevance.
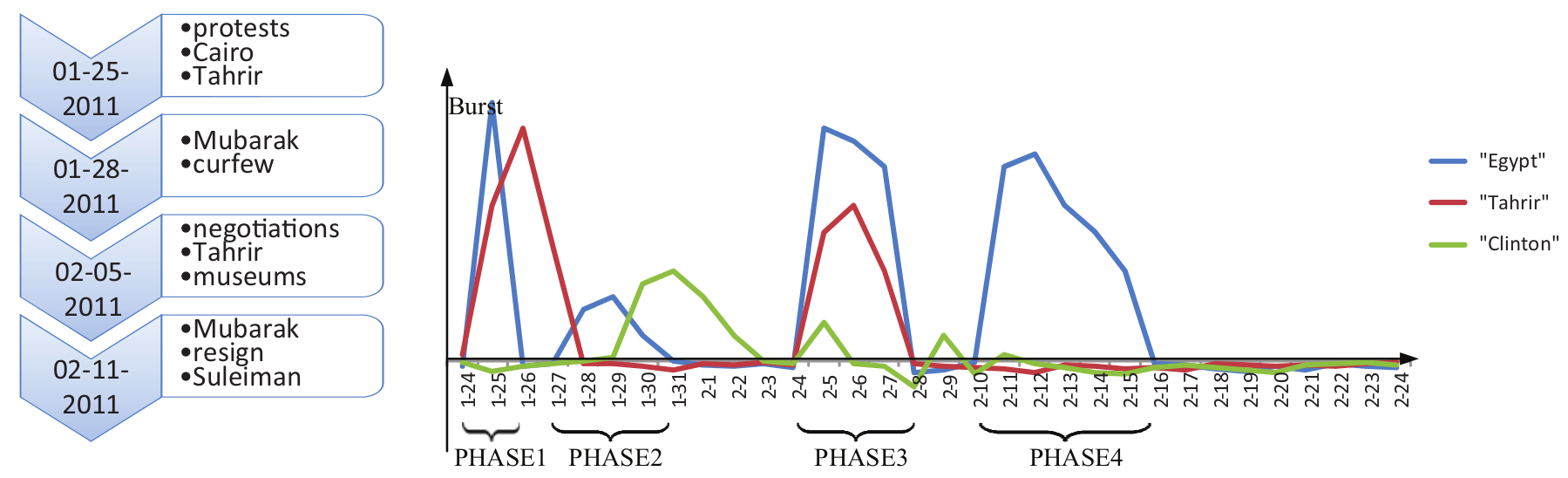
Dynamic correlation patterns of relevant keywords in event queries.
The motivation of dynamic PRF is to enhance the quality of query expansion by utilizing the temporal information of query and tweets. Assume that active phases of the corresponding event are already detected by building the temporal profile for each query; then the truly relevant tweets are more likely to be published around active phases.
Intuitively, we can measure the relevancy of expanded terms in pseudo-relevance by incorporating the timestamps of their occurrences. If we analyse the temporal distribution of all expansion candidates, their correlations with query terms are some function of time. As shown in the right-hand side of Figure 2, the zero point is set to be the average frequency of a term. In two of the active phases of the query term ‘Egypt’, the term ‘Tahrir’ is significantly frequent, which suggests that ‘Tahrir’ is a dynamic relevant keyword in phases 1 and 3. On the contrary, ‘Clinton’ is irrelevant to the event, because its temporal distribution has nothing in common with ‘Egypt’. Therefore, ‘Tahrir’is a proper expansion term, while ‘Clinton’ is not.
3.2. Query temporal profile
Building a temporal profile of query consists of detecting event phases, which can be implemented in two stages. In the first stage, we partition the timeline of an event to meaningful intervals. In the second stage, we obtain the most active phases from all intervals.
There are a number of systems developed for detecting an event in the literature, almost all of which are frequency-driven approaches. Intuitively, a measurement is needed to quantify to what degree the term appears abnormally frequent during a given time interval. It should be comparable among different time intervals. Therefore the measurement should be based on term frequency in the time interval, the length of the time interval and the global term frequency. We borrow the definition of a term’s ‘bursty score’ from [22]. Suppose
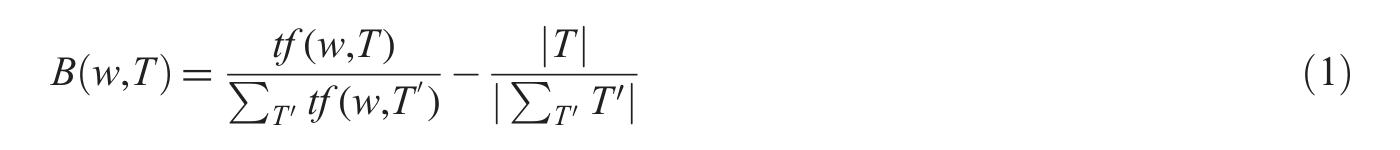
where
For each query term
Next, to choose K active phases, we present equation (2) to compute the score of each unit time segment:

where
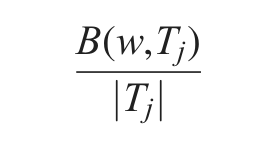
is the bursty score of W in the discovered maximal interval Tj, which is a super segment of t. Hence
3.3. Dynamic pseudo-relevance feedback query expansion
We therefore state the procedure of dynamically selecting expansion terms from pseudo-relevant feedback as follows. Suppose the original query generates a ranking list of tweets, each tweet is associated with a timestamp and the top N tweets are considered to be pseudo-relevant to the query. We collect all appearing terms in pseudo-relevance. Then each expansion candidate is measured by its temporal distribution in relevant tweets.
We present a selective score function

We present a base function
Exponential score function

Polynomial score function

Both base functions are controlled by a single parameter
The definition of distance function
Therefore two strategies of distance computation are presented, one is based on the centroid of active phase, and the other is based on the boundary of active phase. As illustrated in Figure 3, for a certain tweet, the four combinations of base functions and distance measures cause different proportional change in the selective score.
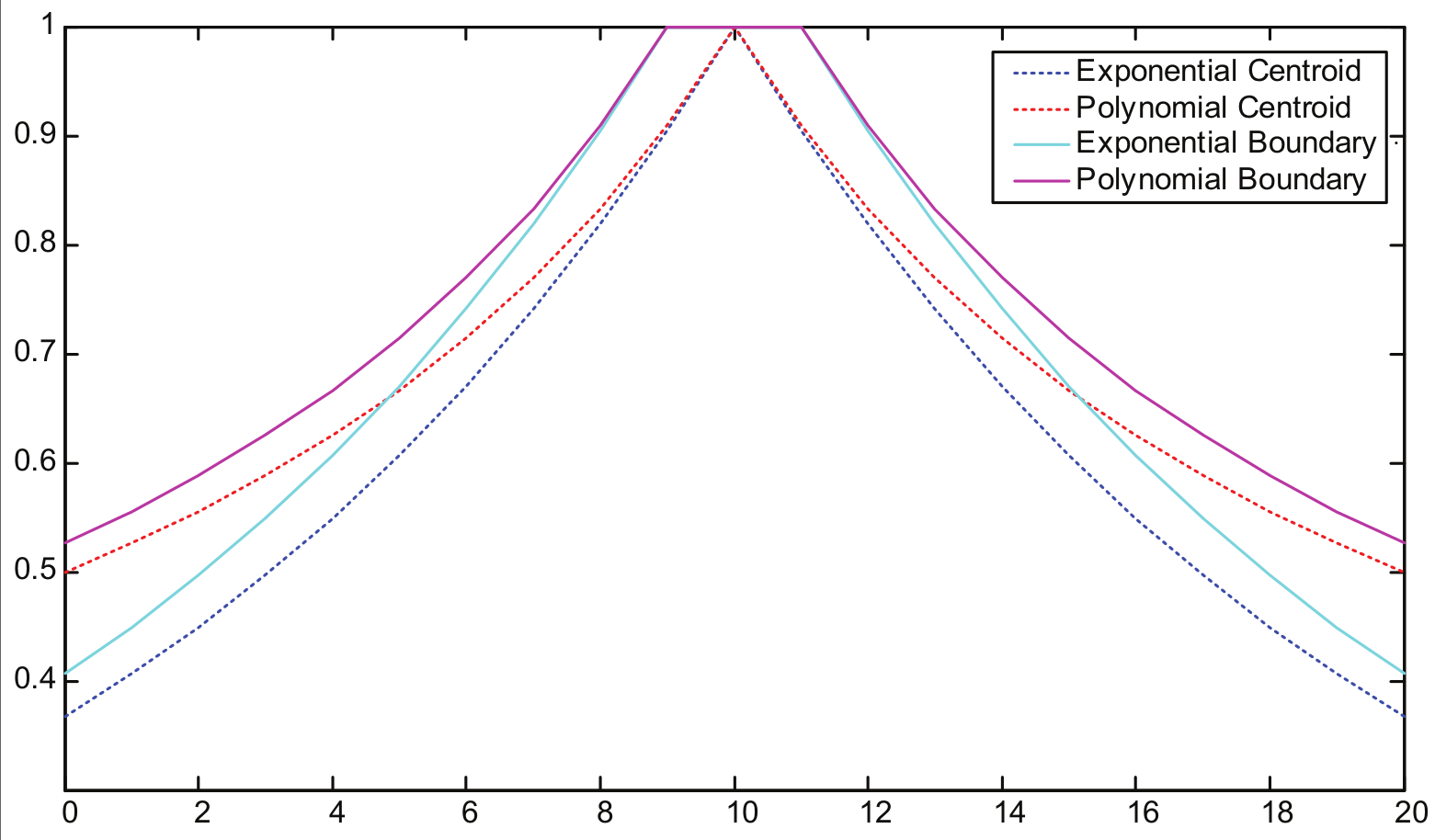
Illustration of four expansion scores.
3.3.1. Centroid
In this strategy, we choose K distinguishing time points

3.3.2. Boundary
In this strategy, we choose K time segments
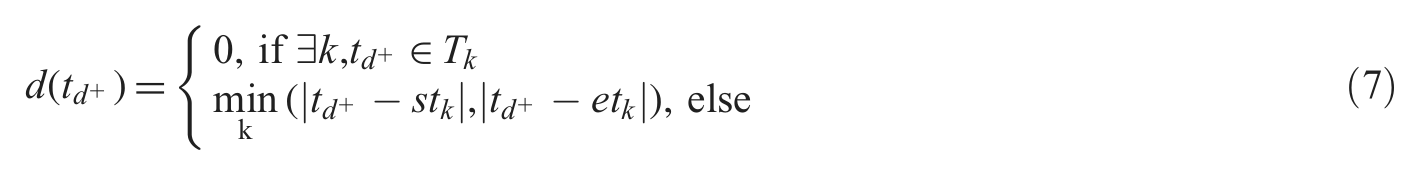
4. Hybrid query expansion
4.1. Framework overview
The dynamic PRF introduced in Section 3 is particularly designed for dynamic queries. In microblog search, despite requiring dynamic information related to real-time events, people also seek information related to more static topics. We present a hybrid query expansion framework in this section, to benefit microblog searching on different kinds of information needs. As shown in Figure 4, the microblog search system consists of two components. In the offline component, all terms are indexed. In the online component, each query is first categorized to two classes: for dynamic queries, dynamic PRF is adopted based on the query temporal profile; for static queries, external knowledge (such as Wikipedia) is utilized to expand query terms. Query expansion candidates by the above two strategies are aggregated and re-weighted in the hybrid query expansion process according to the query category distribution. Finally, through a default ranking module, the resulting relevant tweets are presented to the user. We present the technical details of query classification, query expansion by external knowledge and hybrid query reweighting in Sections 4.2–4.4, respectivey.
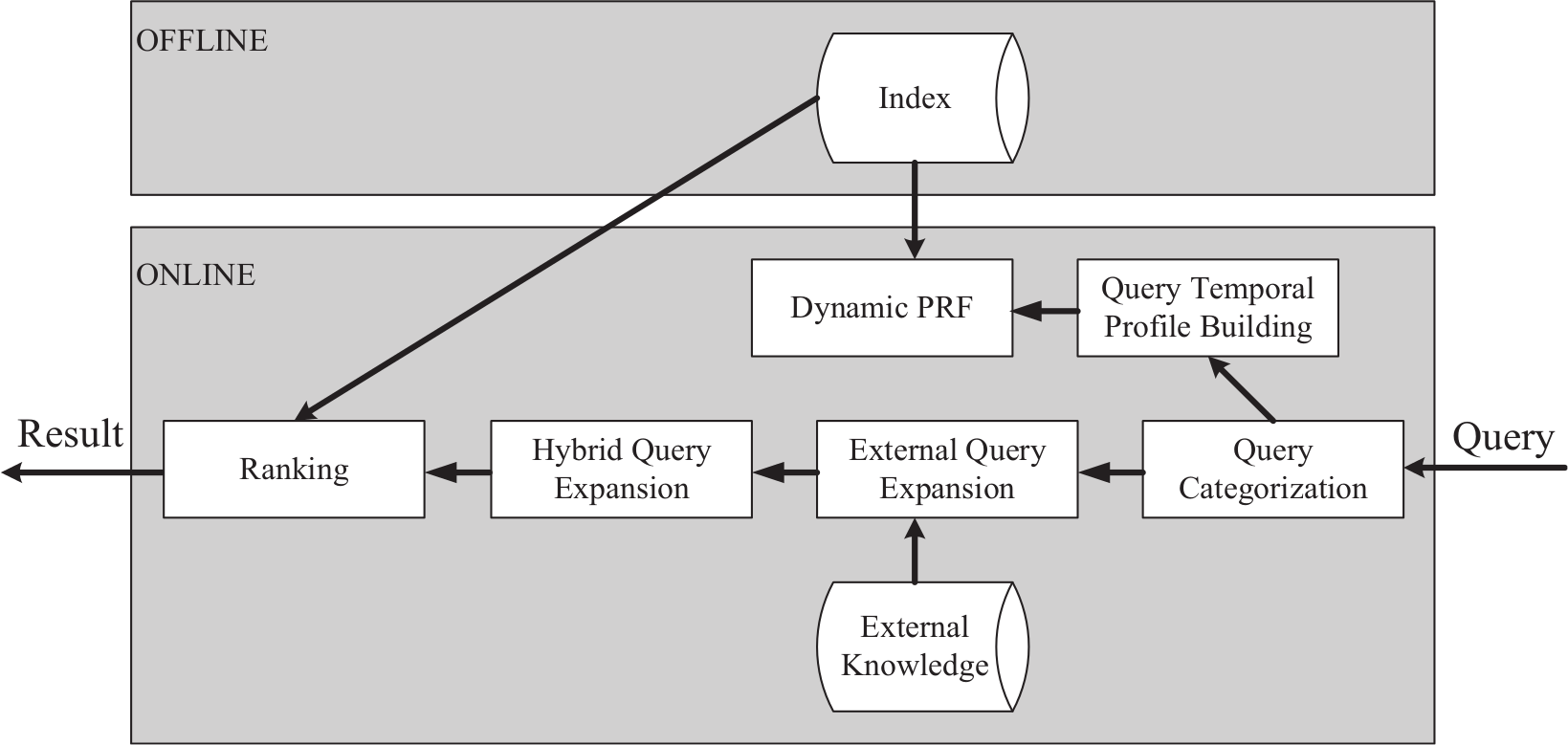
System overview.
4.2. Query classification
In this paper, we consider the simplest case: classify microblog queries into two classes based on temporal profiles; the positive class consists of dynamic queries (such as event queries and celebrity queries) and the negative class consists of static queries (including knowledge queries). This assumption is simple but reasonable. In Teevan et al. [8], a comparative study shows that Twitter users frequently seek temporally relevant information or information related to people. However, the classes of queries can be expanded for convenience.
A natural method is to develop an appropriate query expansion strategy for each query type. In this section, we provide the classification framework to identify whether a query is a dynamic query or a static query. Each query Q consists of several query terms. The features used for classification are mainly grouped into five types. As briefly listed in Table 1, we use frequency features, entropy features, entity features, POS features and timestamp features.
Features for query classification.

Intuitively, frequency features measure how statically and dynamically the query terms appear in the collection, including the query temporal profile, maximal bursty score and average bursty score of all query terms, document frequency and term frequency. Entropy features measure to what degree the query terms vary around the average level, including the average and maximal entropy of all query terms and maximal and average standard deviation of all query terms. Entity features and POS features comprise the number of extracted name entities and entity phrases, including location, person name, organization, abbreviations with all capital characters and ‘the-x’ phrases. Timestamp features comprise information related to the time of the query, including the normalized length of the presenting period of all query terms and the number of timestamps (of certain format) in the external knowledge. Based on the above features, the classifier will calculate the category probability of a query. We can choose any probabilistic classifier.
4.3. Expansion by external knowledge
In addition to dynamic PRF, we also propose an external knowledge-based query expansion strategy dedicated to microblog searching. Intuitively, existing knowledge databases have exact definitions on many topics. Expansion by external knowledge takes advantage of external knowledge sources such as Wikipedia and other online ontologies. Wikipedia is the best knowledge source since it is the largest and most popular general reference work on the Internet. Therefore, Wikipedia is used as a major source of external knowledge to expand querying in our work.
In this work, we attempt to use both positive and negative feedback in external knowledge in query expansion. Negative feedback is adopted in very few previous PRF studies [24] as its performance is not stable. In the PRF framework, negative feedback is usually defined as the bottom results or the unreturned results in the first search. However, negative feedback in PRF is not accurately identified in the first search. We believe that the use of external knowledge can benefit query expansion in two aspects: (1) the contents of external knowledge are edited and verified, and thus can be seen as truly (positive) relevant feedback; and (2) external knowledge sources provide certain confidence in negative feedback, as the intra-page links can help to cluster relevant topics.
The expansion steps are as follows. (1) Use Google search engine for every query to discover the relevant Wikipedia page. Usually Google will return the Wikipedia page in the first place if there exists a Wikipedia entry about the query. Therefore we empirically extract the first Wikipedia page from the top fivedocuments returned. If none of the top five documents is from Wikipedia, we assume that there is no related Wikipedia entry, so we extract the first document returned by Google as an alternative relevant page. (2) Remove stop-words and html tags from the relevant pages. Follow the intra-page links to crawl other Wikipedia pages. (3) Wikipedia pages are hyperlinked to each other. Intra-page links are usually indicators of related topics. The positive and negative feedback used in this work comes from relevant Wikipedia pages for all queries and their linking pages. For each query, the relevant Wikipedia page and linking Wikipedia pages form positive cluster
The statistical measurements are
TF. We only use positive feedback
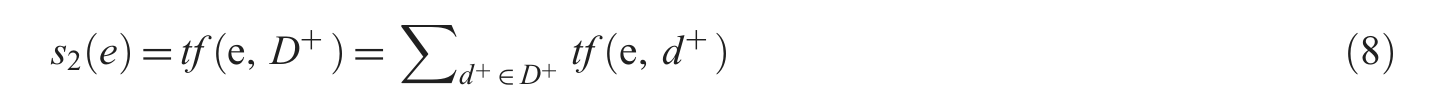
Chi-square. We borrow the classic feature extraction formula in classification to investigate the divergence between negative and positive feedback. Here,
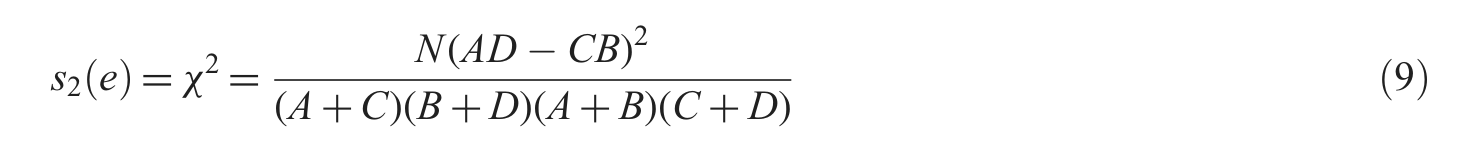
where A is the times of term e appears in cluster
Mutual-information. We also borrow another feature extraction formula in classification for negative feedback expansion. The mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables. Intuitively, mutual information measures the information that two variables share. Formally,

where the definitions of A, B, C, D and N are the same as those mentioned in equation 9.
4.4. Hybrid query reweighting
Intuitively, dynamic pseudo-relevance expansion is more appropriate for dynamic querying. Static querying is more biased towards querying basic facts; therefore it is better to use external knowledge-based expansion. In this paper, we want to focus on query expansion techniques and minimize the effect of retrieval models. Therefore we adopt a heuristic re-weighting process, which is independent of the retrieval model. We rank expansion candidates from dynamic pseudo-relevance expansion and external knowledge-based expansion, according to the new selective score

Suppose the best candidate ranked in the first position is assigned selective score

where
5. Experiment
5.1. Experimental setup
We evaluated our method on the Tweets2011 corpus, which was used in the TREC 2011 microblog track. Since it is difficult to obtain human relevance judgement on microblog searching, the Tweets 2011 corpus was the only corpus we used in this study. The corpus comprises two weeks (23 January 2011 to 8 February) of sampled tweets. Different types of tweets are presented, including replies and re-tweets in the corpus. The languages of tweets vary, including English, Japanese and others. More details of the collection are illustrated in Table 2. We can see that, although the time-span of data is limited, the corpus is ‘dynamic’. Tweets are short with an average of 10 English characters, which suggest that tweets are streams of short texts. Averagely the variance of term frequency is very large (280), which suggests that the contents of tweets are changing over time. As Figure 5 shows, the term frequency each day follows a power-law distribution, which also suggests that the topics of tweets are time-sensitive.
Statistics of data set.

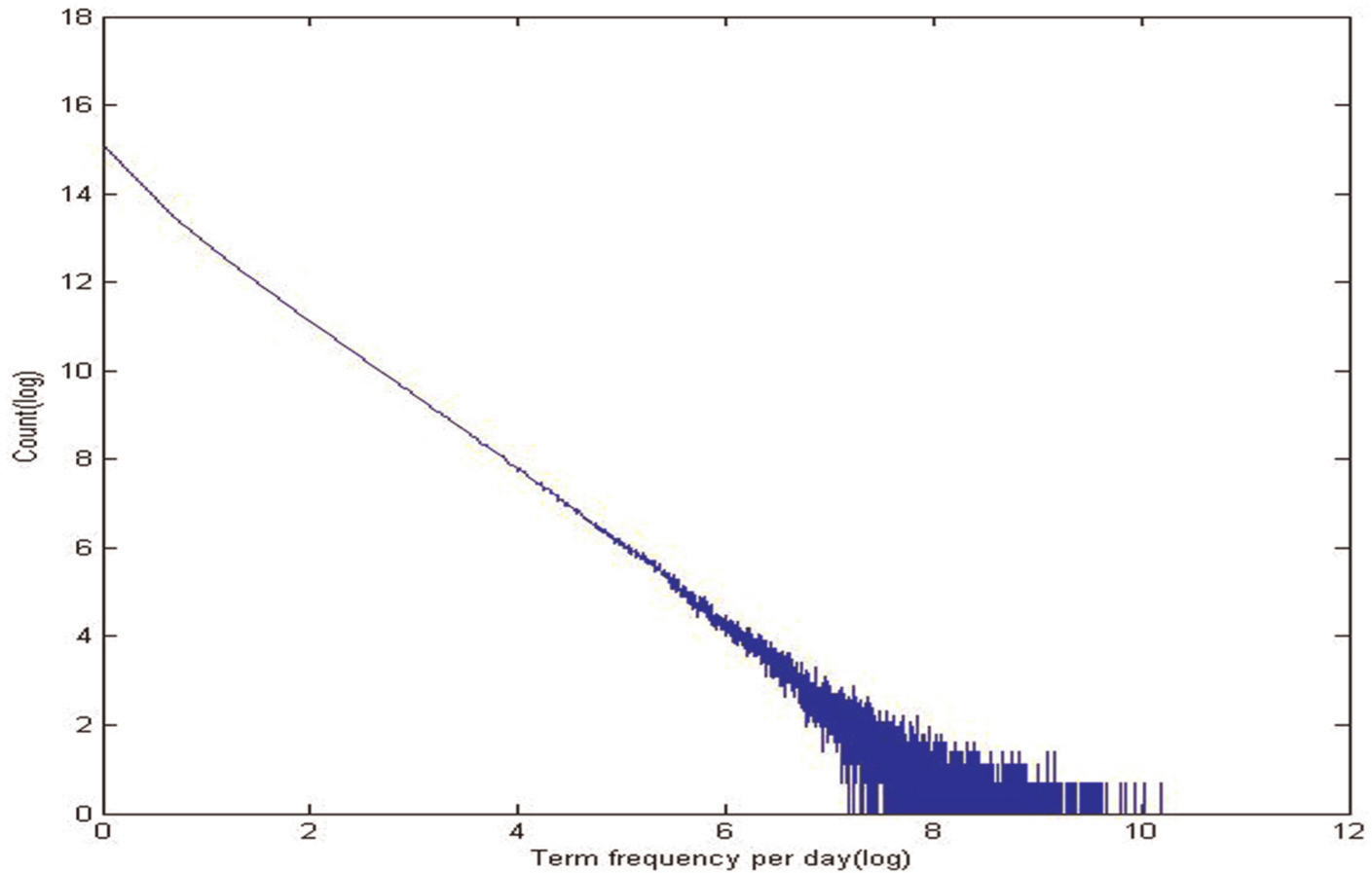
Log–log term frequency distribution.
We used the 49 queries and relevance judgements provided by TREC 2011 microblog track. The queries were also dynamic: 32 out of the 49 queries were event queries. In our experiment, we found that removing stop words decreased the performance of all retrieval models; therefore we did not remove stop words. Porter Stemmer was adopted. For hash-tags, we collected annotated tweets for each hash-tag, and then selected the best representative terms for each hash-tag to replace them in plain text. Experiments showed that the best performance was achieved by selecting one or two terms based on TFIDF for each hash-tag. However the differences among hash-tag representation strategies were minute.
5.2. Query classification
We manually annotated 12 sample queries and 49 official queries provided by TREC. The annotation was carried out by three authors independently. The label of the training query was assigned by voting of the three authors of this paper. We removed all stop-words in the queries. After stop-word removal, each query was no longer than five query terms. For shorter queries, we automatically filled in the feature for the ‘empty’ query term with the average amount of the given feature type in this query. Named entity recognition and POS tagging were implemented by LingPipe. Timestamp phrases in Wiki pages were extracted by a few manually generated patterns. A total set of 45 features was used. WEKA was adopted to generate predictions.
First we quantified the effectiveness of features in Table 1. One concern wass that a small training set may cause over-fitting. Therefore we used leave-one-out in classification. We randomly used 60 queries as a training set, and one as the test sample. This procedure was repeated 50 times; the average precisions for several WEKA-embedded classifiers are reported in Table 3. As shown in Table 3, almost all classifiers generated satisfactory results, which demonstrates the robustness of the proposed features.
Performance of query classification, feature effectiveness.

Another concern in our experiment was that we discovered that most of the TREC queries have a certain degree of temporal inclines. Classification in such an unbalanced data set may reduce precision. Hence we conducted a comparative experiment to verify if the proposed features can correctly capture the degree of temporal inclines. We manually ranked the queries by their potential temporal inclines. This ranking list was set as the ground truth. Then the queries were ordered by three main features in Table 1, such as the average entropy of all query terms, average frequency in the most active phase of all query terms, the standard deviation of query terms, and the probability predicted by SVM that the query was a dynamic query. Compared with the ground truth, the Spearman correlation
Finally we used the 12 sample queries as a training set to predict the category of 49 test queries by SVM. Thirty-two queries were categorized as dynamic queries. The top-five queries in each category are shown in Table 4. Although, owing to the over-fitting problem, some queries may not be categorized properly, we can see that the sample queries are meaningful. Dynamic queries are usually queries acquiring information about events occurring over a short period, while static queries relate to long-term, historical or future events.
Performance of query classification, sample queries.

5.3. Comparative study
We implemented an extensive comparative study to verify the enhancement of the proposed query expansion technology. The baseline was obtained by searching the original query using LUCENE. We conducted a recency-based model using the original query, removing all re-tweets and promoting recent tweets as in Efron and Golovchinsky[14]. We also compared several pseudo-relevance feedback expansion strategies as in Cao et al. [3]. The pseudo-relevance feedback expansion strategies were carried out in the following three steps: (1) the origin query was input into LUCENE and the stop-words and URLs removed from returning tweets; (2) top 30 tweets returned by step 1 were regarded as pseudo-relevant feedback set
TF: we chose expansion terms based on the average frequency in pseudo-relevance feedback.
DF-ratio: intuitively, a good expansion word frequently occurs in relevant documents but rarely appears in irrelevant documents. Hence the quotient of the average frequency of term

Max-co-occurrence: a good expansion word for query should co-occur frequently with some query word. The maximal rate of the co-occurrence of any query word and expansion word in the entire corpus is denoted as

Co-occurrence-ratio: similar to equation (14), a good expansion word should co-occur frequently with all query words. We define

Chi-square: we selected centroid terms in the pseudo-relevant feedbacks as expansion terms. The chi-square score was computed for any term in both pseudo-relevant feedback and pseudo-nonrelevant feedback. The CS value of the term
TFIDF: a common approach in document summarization is to select the centroid word in a cluster. We applied this idea to choose the most representative word in
Bo1: we implemented the Bo1 expansion in language modelling framework provided by Terrier [25]
Negative: after a first ranking by the PL2 model in Terrier, we collected 100 bottom tweets for each query. The negative feedback model
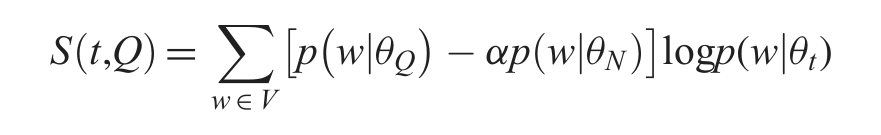
We used JM smoothing for estimating the language model
Temporal: this is another query expansion strategy that is based on temporal distribution over tweets. The selective score for each expansion candidate
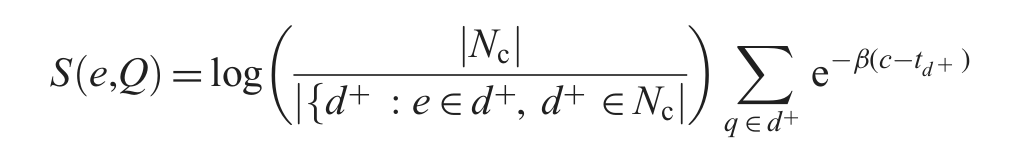
In this strategy, we only computed the score for tweets published before query time, where
We also tested the performance of
In dynamic PRF, we also used LUCENE as a baseline. This was because we wanted to minimize the effect of retrieval models; for example, even for a weak baseline that may fetch irrelevant documents, how much the dynamic PRF will increase the performance? For fair comparison, the dynamic pseudo-relevance feedback query expansion strategy also selected the top 20 expansion terms from 30 pseudo-relevant tweets returned by LUCENE for the original query. The unit time of temporal profile was set at day. The scoring function was polynomial, with centroid based strategy and parameter set at
The proposed query expansion technique by external knowledge used a slightly different setting. Since we only used one Wikipedia page as relevant feedback, the number of expansion terms should be reasonably smaller. We selected five terms, because we experimented with
Hybrid expansion re-weighted the expansion terms generated by dynamic PRF and external PRF based on chi-square, according to the class distribution probability of each query predicted by SVM on 12 training queries. We should note that, since dynamic PRF and external knowledge may produce identical expansion terms, the number of expansion terms in hybrid expansion is usually not larger than 20.
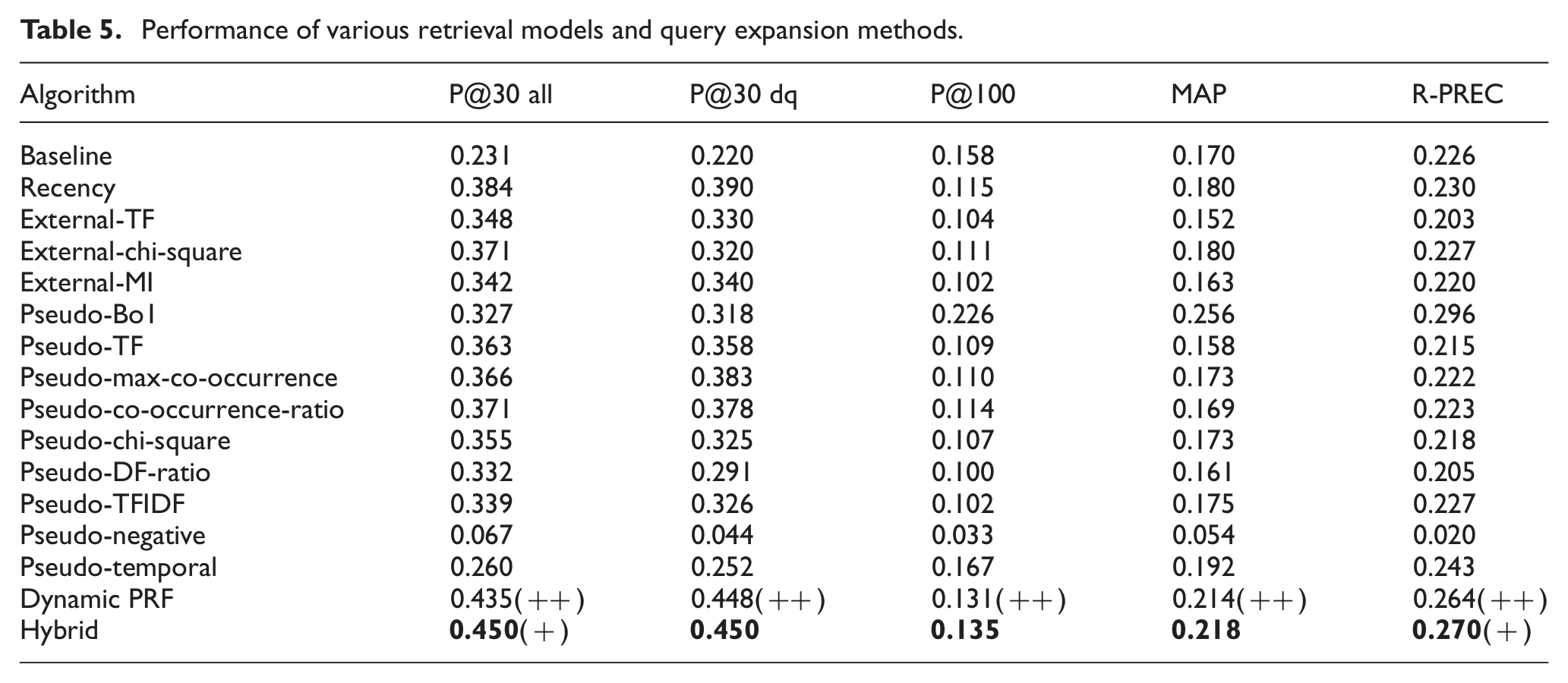
The dominant evaluation metrics was precision in the top 30 tweets (P@30 all). However we also provide mean average precision (MAP), precision in the top 100 tweets (P@100) and R-precision as supplementary measures. In theory, (1) dynamic PRF will work well if the data is dynamic, for example, streams of short texts. In such cases, the contents are time-sensitive; therefore dynamic PRF can utilize the timestamps of data to identify true relevance feedback. (2) Dynamic PRF will work well if the queries are dynamic, for example, event querying. In such cases, information related to the query will be massive in certain periods and small in other periods; therefore dynamic PRF, which is not solely on static information, can fully exploit the underlying information needs in dynamic queries. To show the benefit of ‘dynamic’, we also report the P@30 of all comparative methods on dynamic queries (P@30 dq).
From Table 5, we note the following observations. (1) The hybrid method performs best in terms of P@30, MAP and R-PREC. It boosts the P@30 performance of naive baseline nearly 2-fold. It also outperforms the recency-based method by nearly 20%. (2) Traditional PRF methods do not work well for microblogs. The reason is that a fair baseline is essential for PRF. (3) The recency-based model performs well in terms of P@30, P@100 and R-PREC. This indicates that, in microblog searching, temporal information is a critical factor. However, since the recency-based model promote tweets published shortly before the query issue time, the global performance such as P@100 may be harmed. (4) The dynamic pseudo-relevance expansion strategy yields the second best performance. Note that the expansion strategy is built on a naive baseline; hence it is a stable improvement. (5) Although the baseline generates best P@100 result, the gap is tiny. The proposed dynamic pseudo-relevance expansion strategy and the hybrid strategy are robust in all other measures. (6) Negative feedback can benefit PRF methods, but should be combined with positive feedback. External-chi-square and pseudo-chi-square are both based on both negative and positive feedback, and they achieve better results than PRF based on only positive feedback, such as external-TF and pseudo-TFIDF. Pseudo-negative yields very low accuracy, which suggests that only negative feedback in PRF cannot guarantee a good performance. External-chi-square outperforms pseudo-chi-square, which suggests the negative feedback in external knowledge has higher quality. We also discovered that the expanded queries generated by negative feedback and positive feedback are highly different. (7) Temporal distribution of tweets captures the dynamics of topics in Twitter. Pseudo-temporal distribution generates good R-PREC performance. (8) In general, most comparative methods perform less well on dynamic queries than on static queries. However, dynamic PRF better suits information retrieval tasks for dynamic queries. (9) The significance test showed that dynamic PRF is significantly better than the baseline in all five measures with confidence levels larger than 99% (indicated by ++), while the proposed hybrid method is significantly better than dynamic PRF in R-PREC with confidence level larger than 95% (indicated by +).
Performance of various retrieval models and query expansion methods.
5.4. Parameter tuning
In this subsection, we compare the p@30 performance of four combinations of distance measurements and scoring functions on various parameters. The parameters needing to be tuned are the number of active phases, n, and the decreasing factor,

P@30 of various dynamic PRF scoring functions with different parameters.
6. Conclusion
The proposed hybrid expansion framework for microblog search generates very good results. It is better than the best in the TREC 2011 microblog track. The novelty of the proposed framework is two-fold. On the one hand, the framework is a two-class feedback model. On the other hand, by incorporating temporal information, the proposed dynamic PRF technique is capable of selecting representative keywords in different active phases of an on-going event; thus, it can eliminate the negative effect of falsely matched documents in conventional PRF.
In the future, we would like to further study the nature of micro-blog queries. The implementation of query expansion is somehow heuristic in this paper. We would like to further explore how to embed it in a language model framework. The mechanism of negative feedback is also not yet fully explored in this work.
Footnotes
Funding
This work was supported by National Natural Scientific Foundation of China, under grant no. 61102136, 61001013, the Natural Scientific Foundation of Fujian Province of China, under grant no. 2011J05158, the Shanghai Key Laboratory of Intelligent Information Processing under grant no. IIPL-2011-004 and the Base Research Project of Shenzhen Bureau of Science, Technology and Information under grant no. JCYJ20120618155655087.