
Abstract
Relevance feedback (RF) has been studied under laboratory conditions using test collections and either test persons or simple simulation. These studies have given mixed results. Automatic (or pseudo) RF and intellectual RF, both leading to query reformulation, are the main approaches to explicit RF. In the present study we perform RF with the help of classification of search results. We conduct our experiments in a comprehensive collection, namely various TREC ad-hoc collections with 250 topics. We also studied various term space reduction techniques for the classification process. The research questions are: given RF on top results of pseudo RF (PRF) query results, is it possible to learn effective classifiers for the following results? What is the effectiveness of various classification methods? Our findings indicate that this approach of applying RF is significantly more effective than PRF with short (title) queries and long (title and description) queries.
1. Introduction
When interacting with information retrieval systems, the user’s first query formulation usually acts as an entry to the search system and database, and is followed by browsing and query reformulations [1]. Because the selection of good search keys is difficult but crucial for good results, query modification is often necessary. Initial query results can be improved through the user’s explicit reformulations, relevance feedback (RF) or pseudo RF where the first initial results are assumed relevant. In the latter two techniques, a new query is constructed on the basis of feedback. Query expansion (QE) typically is the technique for constructing the new query. Efthimiadis [2], Ruthven and Lalmas [3] and Ruthven et al. [4] provide useful reviews of the techniques. In the present paper we propose a novel approach to applying RF where the user’s RF on the top of the pseudo RF search results, Top-10 in effect, is used to learn classifiers to classify the subsequent results, that is, Top-11–50.
We simulate a search scenario, where users point out relevant documents on the first result page (Top-10) and the retrieval system trains a classifier with relevant and non-relevant document clusters from this feedback and then classifies the rest of search result list, in effect Top-11–50. In this way we utilize both relevant and non-relevant feedback from the user. Onoda and colleagues [5] have experimented with Support Vector Machines (SVMs) in RF for document retrieval and shown the potential of the approach. Recently, Chen and colleagues [6] proposed a text classification based method for RF. However, both studies applied a large number of RF iterations in order to show the effectiveness of the suggested approaches. In the present study, we assume just one round of RF and classification. We believe this is more realistic regarding user behaviour. We employ an extended version of text classification based RF. We run our experiments on a large collection (TREC 1-2-3-/7-8 test corpus with 250 topics).
In traditional RF, knowledgeable experienced searchers may benefit more of RF because they recognize relevant vocabulary and are better able to articulate their needs initially [7]. Users also seem more likely to identify highly relevant documents than marginal ones [8]. Baskaya and colleagues [9] showed that slightly incorrect recognition of relevant documents is not detrimental to RF effectiveness, in particular if the searcher identifies the best documents correctly. Earlier findings based on simulation [10, 11] suggest that RF is most effective when little feedback is given as early as possible followed by immediate reformulation, rather than extensively browsing the initial results. Therefore we limit the feedback to the Top-10 in our experiments; this corresponds to what users see at a glance in typical search environments.
However, there are two difficulties in providing feedback: searcher’s capability and willingness [3]. Pseudo-relevance feedback (PRF) [3] avoids these challenges by assuming that the first documents of an initial search result are relevant. Long documents and non-relevant documents, however, introduce noise in the PRF process, thus causing query drift. To counteract this, one may use query-biased summaries [10, 12] for the identification of expansion keys. Yet another challenge to PRF is that real users tend to issue very short queries [13, 14] and employ shallow browsing and active query reformulation. As a consequence, the results of PRF tend to be of poor quality. In the present paper we examine the effectiveness of RF with result classification over the PRF results, as well as of PRF, both for short (title) and long (title and description) initial queries.
Our approach, learning classifiers to utilize RF for re-ranking results, differs from other learning to rank algorithms [15]. Hang [15] has given a concise description of learning to rank methods for information retrieval and natural language processing. Even though both approaches, the current study and learning to rank methods, employ machine learning techniques for re-ranking the documents, our approach utilizes the first page of the respective result sets as training data and consequent pages as test data. On the other hand, learning to rank methods try to find a model from some pre-labelled training data with the help of machine learning techniques and exert it on test data for ranking predictions. Xiubo Geng and colleagues [16] studied query-dependent ranking and applied the K-nearest neighbour (KNN) method for it. They, however, created a ranking model for a given query using the labelled neighbours of the query in the query feature space. In a broad sense, our approach can be seen as a variation of learning to rank for re-ranking retrieved documents. Our method learns a model for every query from RF supplied by a simulated searcher, and applies it on the following results in order to improve the ranking of the documents by discarding the non-relevant documents from the list.
We base our experiments on searcher simulation (like Baskaya et al. [9] and Keskustalo et al. [11]) rather than tests with real users. Simulation has several advantages, including cost-effectiveness and rapid testing without learning effects, as argued in the SIGIR SimInt 2010 Workshop [17]. In addition, the simulation approach does not require a user interface. The informative aspects and realism of searcher simulation can be enhanced by explicitly modelling those characteristics of searchers and RF that pertain to RF effectiveness.
Our evaluations are based on four standard information retrieval (IR) evaluation metrics (P@20, P@30, NDCG@20 and NDCG@30). The main role is given to P@20/NDCG@20 and P@30/NDCG@30 as clearly user-oriented measures – users frequently avoid browsing beyond a couple of results page, that is, 10 links/documents [13]. After giving RF and already browsing up to 10 documents, the P@20/NDCG@20 can be seen as evaluation for quasi-first page and the P@30/NDCG@30 for quasi-second page.
2. Study design
2.1. Research questions
Our main research question is: given RF on Top-10 results of pseudo RF query results, is it possible to learn effective classifiers for the following results, at ranks 11–50? More specifically:
2.2. Test collection, search engine and query construction
We used the TREC 1-2-3/7-8 ad-hoc test collection including 250 topics, topic numbers 51–200 and 351–450, with binary relevance assessments. The topics have, on average, 189 relevant documents in the recall base. The document database contains 741,865 documents indexed under the retrieval system Lemur Indri (http://www.lemurproject.org/indri.php). The index was constructed by stemming document words by Porter stemmer.
The research questions do not require any particular interactive method to be employed. We simulate interactive RF that takes place at document level: the simulated users point to relevant documents and the RF system then automatically trains the classifiers. The simulated user examines the entire Top-10 of the initial query result and marks each relevant document; the rest are assumed to be non-relevant. This decision is based on the relevance of each Top-10 result in the recall base of each topic.
The initial title queries are on average 3.1 words and title and description queries 17.8 words long. When constructing the queries, the topic words are stemmed. Queries are constructed as bag-of-words queries.
2.3. Classifiers and term space reduction
We studied several standard classification and clustering methods for the classification process [18, 9]:
KNN (K-nearest neighbours);
KMeans;
naive Bayes;
SVM (Support Vector Machine).
These are suitable choices because they are widely used and well understood. Therefore one may assess whether the RF with a classification approach is at all useful. All the classification algorithms except SVM are implemented in Python programming language by the researchers. SVMLight [20] is utilized for SVM experiments.
Often in text classification, term space reduction methods may be utilized to improve the efficiency of classification without a loss in effectiveness. We experimented with the following reduction methods: Fisher exact test, Pearson’s chi-square test, Kendall–Tau rank correlation coefficient, Spearman rank correlation coefficient, information gain, and odds ratio. These are standard methods [21]. Having observed in initial tests that the other methods delivered comparable results, we focused on Kendall–Tau and information gain as the reduction methods in training the classifiers.
2.4. Experimental protocol
Figure 1 illustrates the overall experimental protocol. TREC topics are first turned to initial short and long queries (stemmed) and executed with Lemur Indri, followed by feedback document selection. This is based on the simulated searcher’s feedback scenario (in the present experiments browsing first 10 documents and returning the relevant documents as positive RF). The feedback documents for each query are used to learn classifiers, and the rest of the result list for that query is classified. No new query is executed, and both the original ranked results as well as PRF results and re-ranked results classified by feedback go to evaluation and comparison.
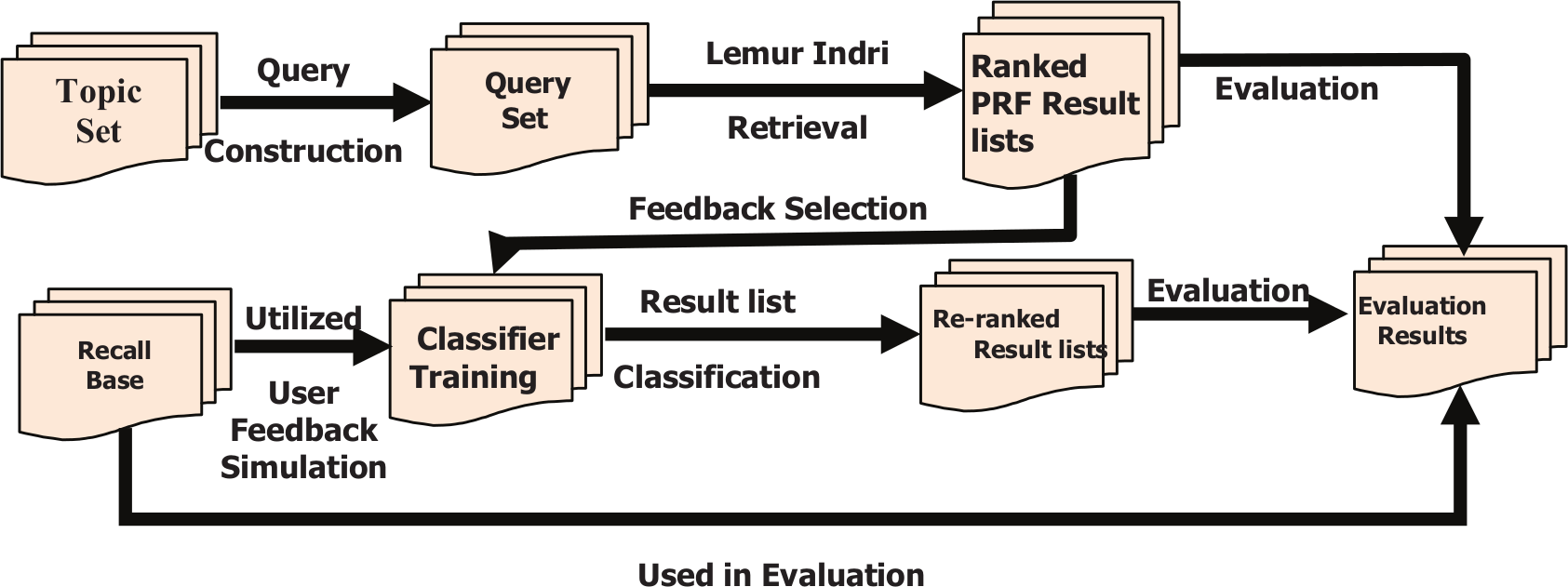
Classification-based RF retrieval process.
The detailed process of training classifiers and classification of each document in a result set is depicted in Figure 2. Up to 40 documents from subsequent pages are classified as relevant or non-relevant. The non-relevant ones are discarded and the entire list is moved forwards. Evaluations are executed on the second and third pages. This process takes place for every query.
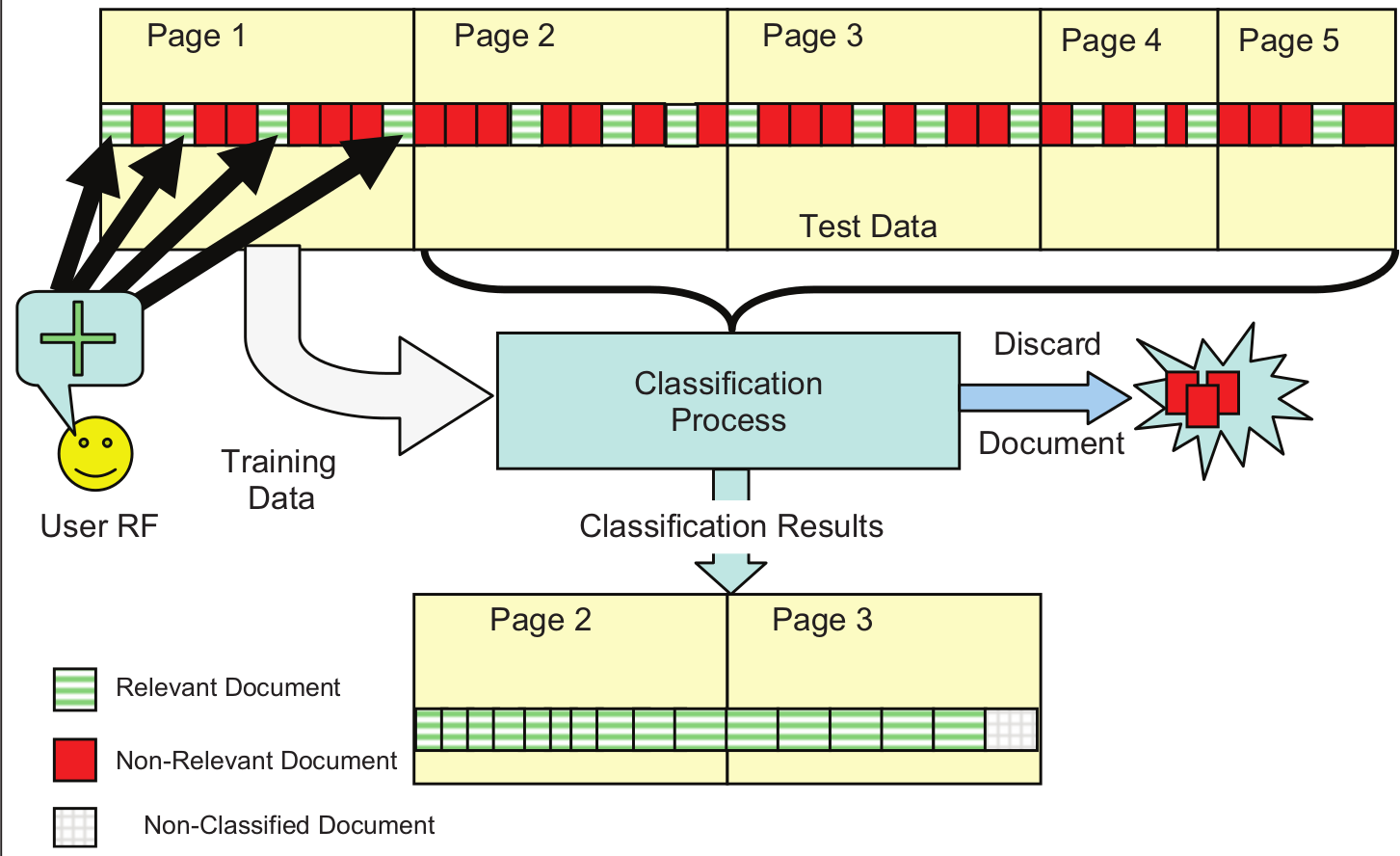
Classification of search results after RF by user.
2.5. Evaluation and statistics
We use standard evaluation metrics available in the TREC-eval package and report evaluation results for P@20 and P@30 documents, NDCG@20 and NDCG@30 documents. These are motivated by real life findings – people often are precision-oriented and avoid excessive browsing – great results beyond the first couple of pages are of no importance.
Statistical testing is based on Friedman’s test comparing the RF with classification runs and PRF. PRF on the initial query result provides the stronger baseline, and therefore PRF is used as the baseline when (pairwise) statistical significance is evaluated. We ran several PRF experiment with 30–100 extension terms. We report results for PRF with two documents and 100 extension terms because they delivered better results.
3. Experimental results
3.1. When to apply classification?
Before classifying the search results, we analysed the precision on the first and second page of the search results. This was done in order to learn how many relevant documents the Top-10 initial results provide and how their number is correlated to the number of relevant documents in the rank range 11–20. The former informs about the possibilities to learn classifiers and, from the user viewpoint, about the need to obtain more results. Very few relevant documents makes learning of classifiers challenging, whereas very many increases the probability that the user’s need is satisfied in the Top-10 already. The latter informs about the density of relevant documents to be identified in classification when learning the classifiers from Top-10 RF is worthwhile. There need be both relevant and non-relevant documents in the ranks 11–20 for the classification to be worth the effort.
We compared P@10 with P@11–20. In Figure 3, the horizontal axis represents the P@10 values and the vertical axis P@11–20. The test collection is TREC, topics 151–200. Not surprisingly, the general trend is that, the more precise the first result page, the more precise the following page.
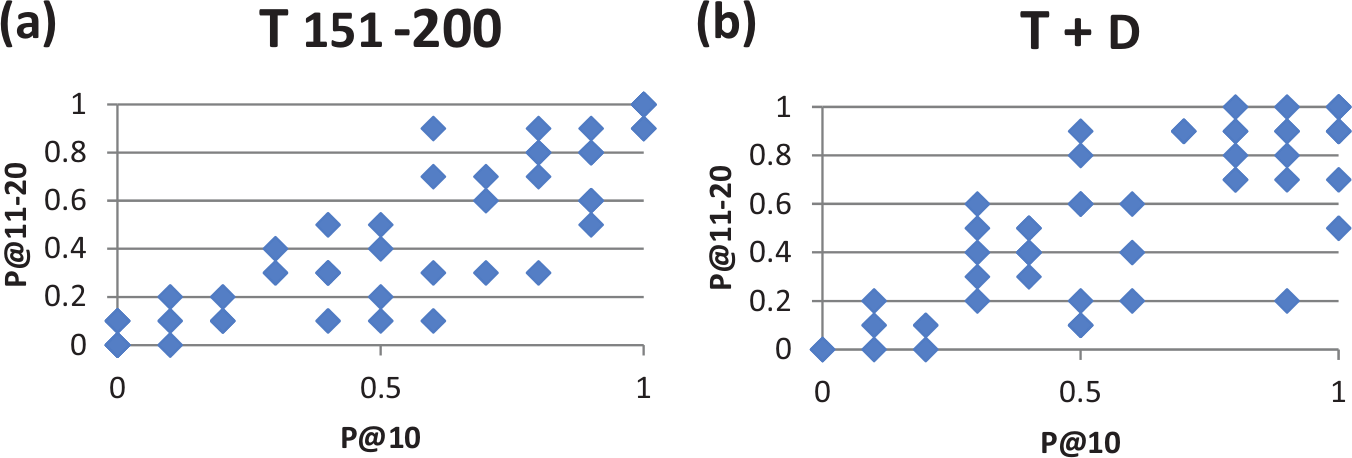
Scatterplots of correlation between P@10 vs P@11–20. (a) Title queries, only for TREC topics 151–200. (b) Title-and-Description queries, only for TREC topics 151–200.
In Figure 4, the matrices have the same axes and the numbers in each cell represent the number of occurrences of the respective precision pair (P@10, P@11–20, values ranging from 0.0 to 1.0). Therefore the value ‘4’ in Figure 4(a) on line 0.2 and column 0.3 shows that there were four queries in the data set where the initial query P@10 was 0.3 and P@11–20 was 0.2. The data clearly concentrate along the diagonals. The correlation coefficients in the range 0.78 < r < 0.85 confirm this.

Correlation between P@10 vs P@11–20. (a) Title queries, all 250 TREC topics, r = 0.845. (b) Title-and-Description queries, all 250 TREC topics, r = 0.782.
The findings in Figures 3 and 4 lead us to the conclusion that we exclude the queries with both the worst and the best precision in Top-10 from the classification effort. If a searcher finds no relevant documents on the first page, she will probably reformulate her query rather than examine the second page. In addition, learning a good classifier with no relevant documents would be difficult and the second result page probably would have only a few relevant documents to identify. On the other hand, if the searcher finds 10 relevant documents on the first page, it is highly probable that her information need is already satisfied. In addition, learning a good classifier would be difficult and the second page probably would have many relevant documents, making their classification-based identification futile.
The two arguments, on the probable searcher behaviour and on the learnability of classifiers, support the view that efforts in classifying the second result page should be focused on cases where the first page precision is 0.1–0.9. In our experiments, we do not apply the classification approach, and exclude the original result, when the initial Top-10 precision is 0.0 or 1.0. Note that such a decision can be done in real life as well by examining the searcher’s RF.
3.2. Training results
The search space for the best classifiers is large because we examine three basic approaches (KMeans, KNN and naive Bayes); all can be used with the full or reduced feature set, there are several feature set reduction methods (Fisher exact test, information gain, Kendall–Tau correlation, Pearson’s chi-square test, Spearman correlation coefficient and odds ratio), and various levels of feature set reduction can be applied. We employed extensive manual hill-climbing to explore the search space and to identify the best classification methods for reduction and associated feature selection methods and feature set sizes. The results are given in Table 1.
Training phase results for reduction method.
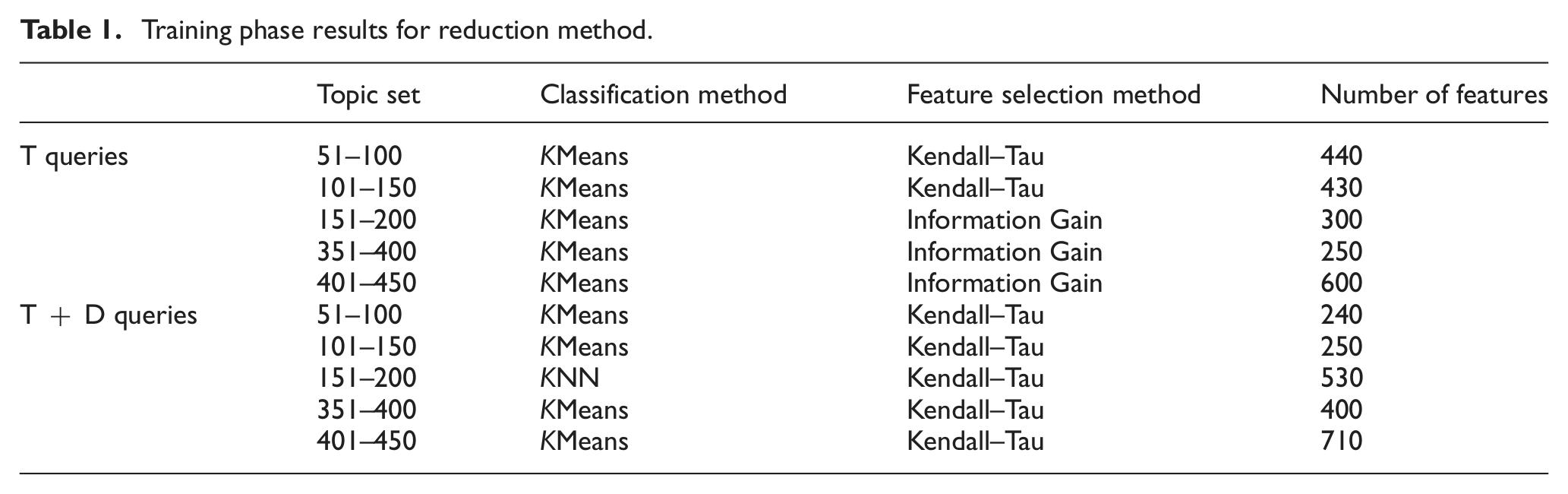
Table 1 gives for T, T + D queries and the indicated TREC topic sets the best performing classification method, the best performing feature selection method for the classifier, and the best number of features identified in training experiments. From Table 1 one may conclude that, overall, KMeans with information gain or Kendall–Tau feature reduction down to about 300–500 features is a reasonable choice for reduction method. KMeans with Information gain reduction with 300 features is applied for T queries. For the T + D queries, KMeans with Kendall–Tau reduction with 500 features is utilized. These selections of the number of features can be interpreted as arbitrary, but the main point is to reduce huge space of the features to some manageable and convenient size. This in turn improves the efficiency of the employed method. Moreover, selection of the number of features can be seen as an indication of the robustness of the reduction method.
In addition to the training for reduction method, we executed experiments with KMeans, KNN, naive Bayes and SVM methods without reduction. We report the results in Table 2 and Table 3 for three of them. Naive Bayes delivered inferior results in comparison to the others; therefore it was excluded from further experiments.
Comparative experiment results (%) for Title queries.
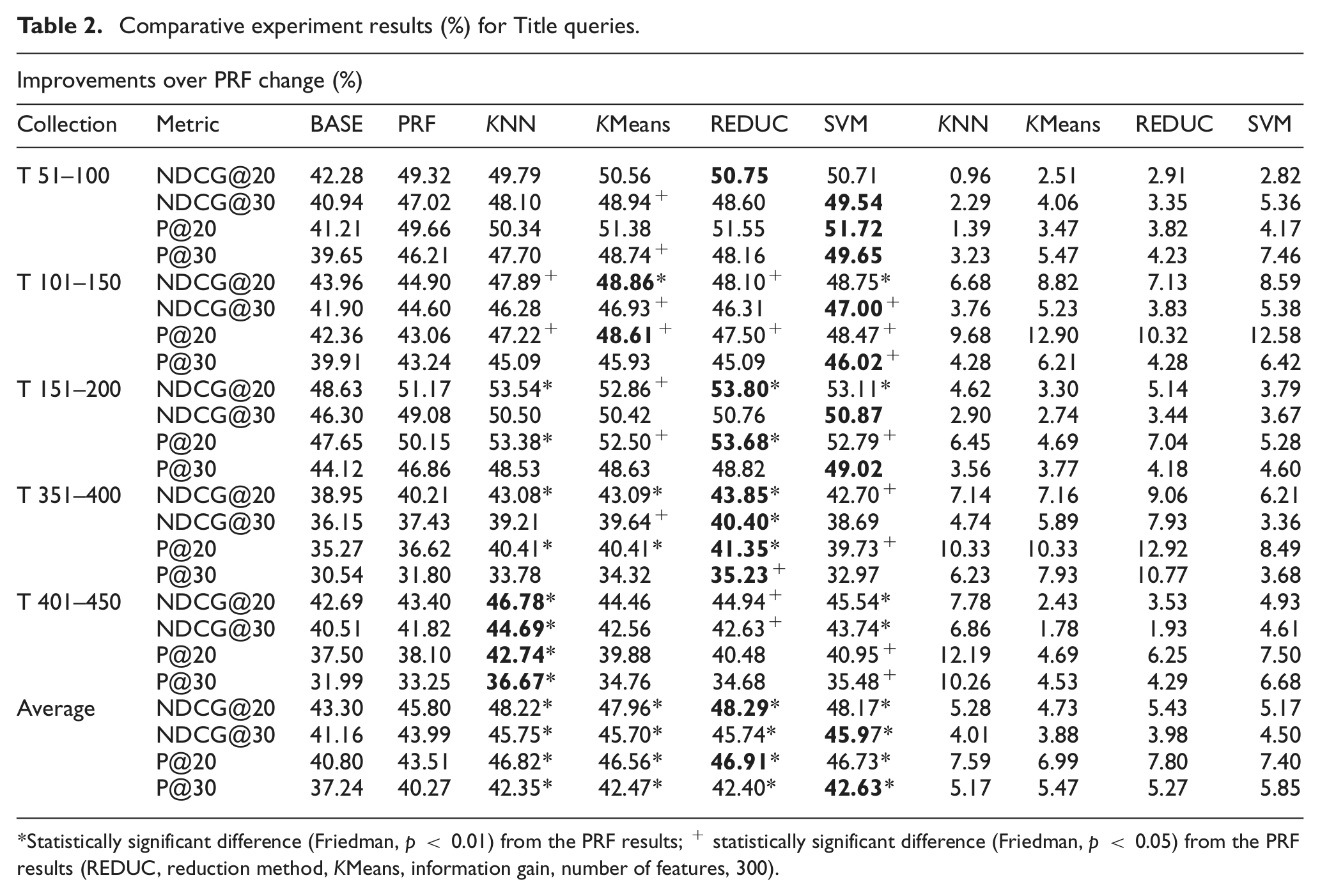
Statistically significant difference (Friedman, p < 0.01) from the PRF results; + statistically significant difference (Friedman, p < 0.05) from the PRF results (REDUC, reduction method, KMeans, information gain, number of features, 300).
Comparative experiment results (%) for T + D queries.
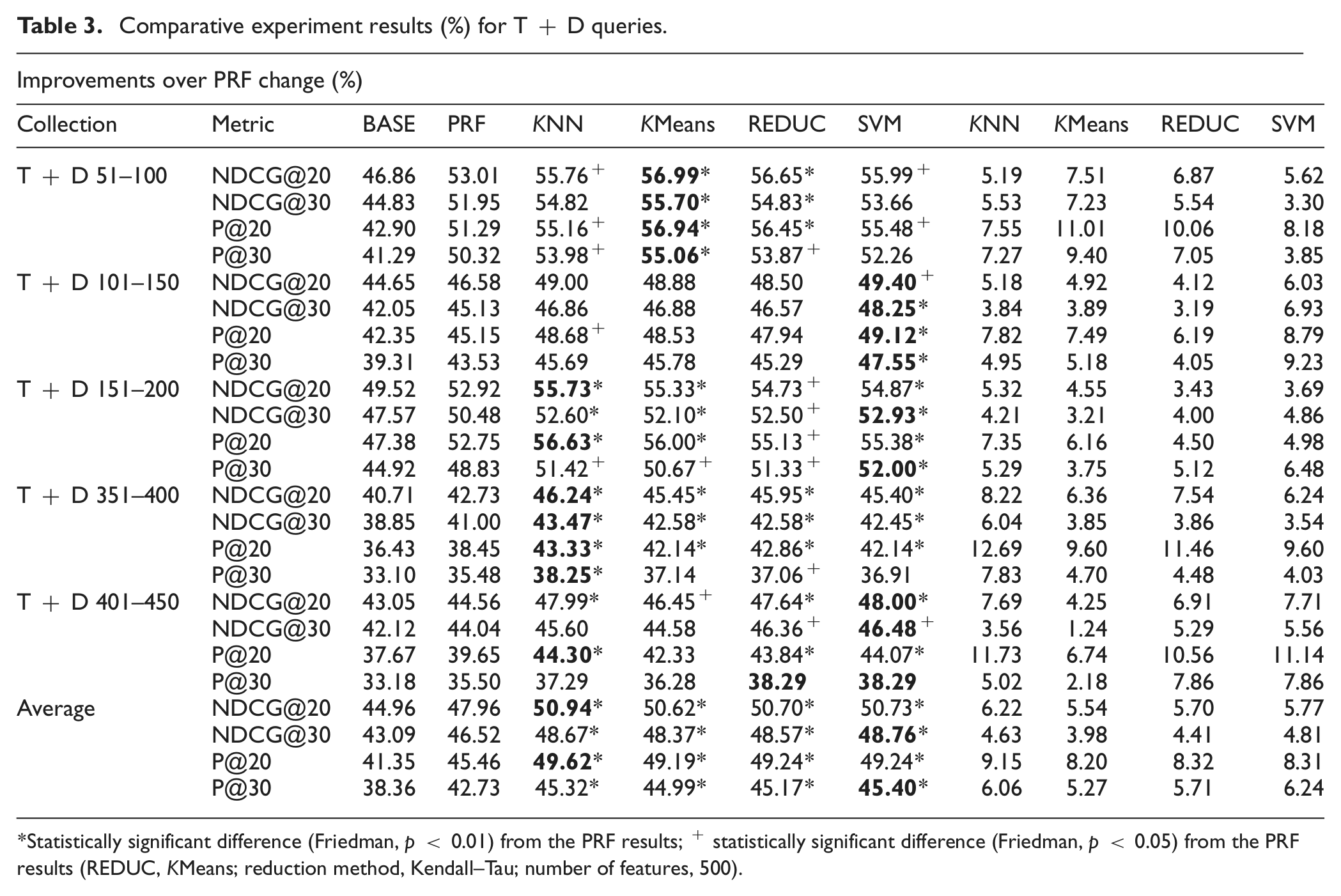
Statistically significant difference (Friedman, p < 0.01) from the PRF results; + statistically significant difference (Friedman, p < 0.05) from the PRF results (REDUC, KMeans; reduction method, Kendall–Tau; number of features, 500).
Regarding the KMeans clustering method parameters, we utilized two centroids, a maximum of 30 iterations and a convergence threshold 0.001. For KNN classification method K was set to one. A multinomial version of naive Bayes with Laplace smoothing was implemented for the naive Bayes classification method. Further, Euclidean distance was used as a distance metric between documents, and all documents were normalized before further processing by the respective algorithms.
During SVM training phase we could not achieve better results than what the other methods delivered. Having observed the classification results, the poor quality of the SVM could be attributed to data imbalance. The first page of the IR experiment results usually has a varying number of relevant and non-relevant documents. This could not be alleviated with the cost factor parameter in spite of many experiments conducted. The problem could be circumvented by balancing the training document numbers. We included in the training set only the minimum number of relevant and non-relevant documents for each set. That is, for example, if only two relevant and eight non-relevant documents were available in the first result page, the SVM training set was established by two relevant and two first non-relevant documents.
3.3. Test results
The test results are reported in Table 2 (for T queries) and Table 3 (for T + D queries). In Table 2, the first block (T_51-100) reports results for the TREC topic set 51–100. The rows within this block report results for the four metrics employed. The columns are the initial query, the PRF baseline (with top two documents and 100 extension keys) and the classification-based results. PRF was applied as provided by Lemur Indri. The columns KNN, KMeans and SVM give results for the three classification methods without feature reduction. The column REDUC indicates the results for the selected classification method with a feature reduction indicated in the table caption – in this case KMeans/Information Gain with 300 features. The effectiveness values for each metric in the block T_51-100 are the average effectiveness values obtained for the topic set T_51_100. The other blocks have analogous content; just the test sets vary. The final block in Table 2 shows the total average of the all test sets for each metric. The maximum value for every row is highlighted in bold type. The asterisks mark statistically significant differences of classification results compared with the PRF results. Almost all experiment results are statistically significant in comparison to the initial query results, but these are not marked separately. We employed Friedman tests with p < 0.01 indicating high statistical significance. In addition, Friedman tests were also conducted with p < 0.05. In this case most of the results are statistically significantly different from PRF; these are marked separately on the tables with a plus sign.
Table 2 suggests that, in the case of short T queries, one of the classification approaches provides the best average performance. Most often the top approach is the reduction-based approach or SVM without feature set reduction. All classification-based methods constitute a statistically significant difference at the level of p < 0.01.
Table 3 has the same structure; the only difference is that queries here are longer (T + D). The results indicate that the maximum values for average appear in both the KNN and SVM columns. Even though all these methods have a statistically significant difference with regard to PRF baseline queries, they do not show any significant difference to each other.
4. Discussion and conclusion
We have proposed an alternative approach to implement RF. Instead of query reformulation based on query expansion provided by RF documents, one learns classifiers from the PRF top results after simulated user RF. These classifiers are then applied to identify relevant documents among the subsequent documents in the result list. We addressed three research questions in the present paper (Section 2.1).
RQ1: Tables 2 and 3 indicate the effectiveness of the proposed classification approach. In case of the short T queries (Table 2), classification improves retrieval effectiveness over the initial query results by almost 11% at NDCG@20 and NDCG@30. For P@20 and P@30 the corresponding readings are >14% and almost 14%, respectively. Over the PRF baseline, the improvements are smaller: >5% at NDCG@20 and >4% at NDCG@30. For P@20 and P@30 the corresponding readings are >7% and >5%, respectively. This suggests that short initial query results can be improved to a useful degree by the proposed classification approach.
In case of the long T + D queries (Table 3), classification improves retrieval effectiveness over the initial query results by >12% at NDCG@20 and NDCG@30. For P@20 and P@30 the corresponding readings are around 19% and >17%, respectively. Over the PRF baseline, the improvements are smaller: almost 6% at NDCG@20 and >4% at NDCG@30. For P@20 and P@30 the corresponding readings are >8 and >5%, respectively. Even though long initial queries provide so much evidence to a modern search engine, classification methods can still improve the results by learning through top document RF.
In all, both the short and the long queries can be improved by the classification approach. Furthermore all classification methods provide statistically significantly better results over PRF and initial queries.
RQ2: Tables 2 and 3 indicate that feature set reduction is not more effective than using the full feature set in T + D queries but provides a marginal boost in the shorter T queries. The best classification methods for short queries are the reduction method and SVM with a full feature set most of the time, while the differences from the other classification methods are minor and statistically not significant. For long queries the best classification methods are KNN and again SVM with full feature set, but even this one provides only a minor advantage over other classification methods.
RQ3: the probable searcher behaviour, the learnability of classifiers and the high correlation of P@10 with P@11–20/30 supported the view that efforts in classifying the second/third result page should be focused on cases where the first page precision is between 0.1 and 0.9. In the case of T-queries, there were 178 (Figure 4) topics for which the initial query result fell in the P@10 range of 0.1–0.9. Therefore this 71% of the topics was responsible for the observed overall improvement. In the case of T + D queries, there were 190 topics for which the initial query result fell in the P@10 range of 0.1–0.9. So in this case about 76% of the topics were responsible for the observed overall effects.
Our findings are based on searcher simulation. Simulation entails using a symbolic model of a real-world system in order to study real-world problems. The model is a simplified representation of real world. The relevant features of the real world should be represented while other aspects may be abstracted out. We modelled searcher interaction features during RF and assumed feedback on the Top-10 of the PRF search results. Browsing only the Top-10 is quite realistic while the assumption on RF for all documents in Top-10 may be little optimistic compared with observations on searcher behaviour in the IR literature. On the other hand, if the searcher broke off variably after identifying three relevant documents (on average before scanning the entire Top-10), the classification results might be better than what we report above. Other simulations with RF [22] have indicated this at least for the traditional query reformulation based RF.
Our experimental evaluation was based on user-oriented metrics, P@20/P@30 and NDCG@20/NDCG@30. Compared with explicit query reformulation, RF and scanning one or two pages of classification-based results may be an option for the user, if RF is made convenient and classification is fast. Therefore the metrics @20 and @30 are relevant. In the future we aim to developing simulation of user interaction in IR towards more fine-grained models of user interaction. Namely we apply the ideas of user fallibility [9] in RF with a classification approach. We also plan to apply classification process and compare this approach with RF with various query expansion methods.
Footnotes
Funding
This research was funded by Academy of Finland grant number 133021.