
Abstract
Scholars routinely search relevant papers to discover and put a new idea into proper context. Despite ongoing advances in scholarly retrieval technologies, locating relevant papers through keyword queries is still quite challenging due to the massive expansion in the size of the research paper repository. To tackle this problem, we propose a novel real-time feedback query expansion technique, which is a two-stage interactive scholarly search process. Upon receiving the initial search query, the retrieval system provides a ranked list of results. In the second stage, a user selects a few relevant papers, from which useful terms are extracted for query expansion. The newly expanded query is run against the index in real time to generate the final list of research papers. In both stages, citation analysis is involved in further improving the quality of the results. The novelty of the approach lies in the combined exploitation of query expansion and citation analysis that may bring the most relevant papers to the top of the search results list. The experimental results on the Association of Computational Linguistics (ACL) Anthology Network data set demonstrate that this technique is effective and robust for locating relevant papers regarding normalised discounted cumulative gain (nDCG), precision and recall rates than several state-of-the-art approaches.
1. Introduction
This article addresses the problem of finding relevant papers that researchers face every day while using scholarly search engines on a given topic [1]. By harnessing the related work regarding a research topic, researchers aim to put new ideas into proper context. Therefore, they search, retrieve and understand the baseline approaches for their strength and weaknesses. This results in new types of publications, and the process goes on resulting in a continuous process of recording the newly discovered information in scholarly databases for online accessibility around the globe [2]. However, the large expansion in the number of scholarly publications results in the well-known problem of information overload, where finding relevant papers is challenging [3,4].
To mitigate this issue, several popular scholarly retrieval systems, including Semantic Scholar, 1 CiteSeerX, 2 Microsoft Academic Search, 3 Google Scholar, 4 and Xueshu Baidu, 5 offer query-based interfaces to their indexed collections. However, at the beginning of a new research inquiry, researchers have limited knowledge and are unable to formulate the search query for increasing accuracy and completeness of the relevant search results. They may get a scholarly paper from their supervisors or colleagues to choose appropriate keywords as the search query, but it may also give less useful results. Several publications have appeared in recent years to satisfy user’s information need in the domain of scholarly search [1,5–14]. To support academic searchers in a scholarly exploration, researchers emphasise the use of query expansion (QE) methods, in which besides other aspects such as term frequency–inverse document frequency (TF-IDF), citation networks could be potentially exploited in generating more relevant results. However, so far, due to the complexity of citation networks [15] and the growth rate of research publications, it is challenging and a hot area of research being active towards the ideal scholarly search engine.
We hypothesise that a user search query if expanded in real time by considering the initially top relevant results selected by a user as well as the citation graph can produce more relevant results than traditional content-based (CB) approaches. To support this hypothesis and to demonstrate the effectiveness of this novel technique, we propose a user real-time feedback query expansion (RTFQE) technique for supporting scholarly search which uses QE and citation analysis in light of some important facts: (a) the academic Web is growing and the most widely used models like TF-IDF, BM25 and vector space model (VSM) are almost unable to address the user intent from a user search query because of polysemy and synonymy, which leads to low precision and recall, respectively [16]. (b) In a scholarly search, the query keywords are mostly technical and almost present in many papers; it may be difficult to fetch the most influential papers as per user intent.
One solution to this problem used in the current approaches is known as QE via user relevance feedback (URF) [17]. Based on this approach, our proposed framework further enhances the relevance of search results by performing citation network analysis. The citation networks can play a vital role in the identification of influential papers [18]. We used BM25 as the primary ranking function and retrieval model. We run-through the ACL Anthology Network (AAN) [19] data set released in 2016 for evaluation, which reveals that RTFQE technique in academic search can find the most relevant papers effectively and comparatively in a nuance robust way. The following are the key contributions of this article:
Index formulation: we formulate the index in a more nuanced way to leverage the proposed framework while ranking the results.
Effective retrieval model using RTFQE: we develop an algorithm that uses RTFQE with BM25 for retrieval.
Performance comparison: we evaluate the proposed framework on ACL data set using standard evaluation metrics including recall, precision and normalised discounted cumulative gain (nDCG) to present and evaluate our results.
The rest of the article is organised as follows: the ‘Related work’ section presents a brief overview of the literature in scholarly retrieval systems. The ‘Proposed framework’ section explains how RTFQE works and algorithmic details. The ‘Experiments’ section presents detailed information about experimental settings, evaluation, and discussion on performance. The ‘Conclusion’ section concludes the results.
2. Related work
Several approaches have been proposed in the literature for identifying relevant scholarly articles in both scholarly retrieval systems and research paper recommender systems. The former takes user query as input and checks its relevance with the scholarly literature using different ranking methods [20,21]. The latter employs information filtering algorithms for locating users’ interest; however, sometimes, their underlying techniques overlap with each other. This section discusses the state-of-the-art literature relevant to the proposed technique.
2.1. Citation-based methods
The references connect the papers, which form the citations graph (citation network). In citation network, if paper
2.2. CB methods
The CB method is commonly used in scholarly search engines for ranking articles [28]. The method processes the textual content of the papers, which can be title, abstract, introduction, keywords and main content. The text-based methods weigh the relevant articles by the frequency and position of the terms in the article. Based on the term weight, several techniques have been developed to estimate the relatedness of articles. A typical approach is the VSM, which represents each article as a vector of terms weight and the relatedness is measured merely using the cosine similarity. Many retrieval systems practice VSM (e.g., Lucence, 6 Java-based indexing and search library), even though, the cosine similarity is unable to perform well in many situations [29,30]. The vector representation of VSM is further improved by latent semantic analysis (LSA) using singular value decomposition (SVD) [31,32]. However, LSA is unable to perform well comparatively [30]. To improve the performance and to get more nuanced ranking results, BM25 was developed.
BM25 [33] is used most widely in scholarly retrieval systems for indexing, searching and ranking scholarly articles [28]. For a given query Q, BM25 uses equation (1) to rank-related articles
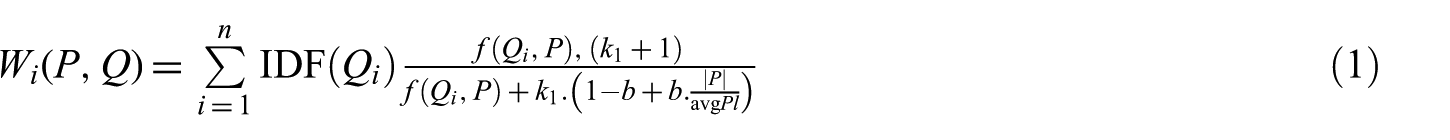
where Qi is the term frequency in paper P, |P| is the length of the paper P in words and avgPl is the average paper length in the text collection from which articles are drawn. k1 and b are free parameters usually chosen in the absence of advanced optimisation, that is, k1 ∈ [1.2, 2.0] and b = 0.75. IDF(Qi) is the inverse-document frequency weight of the query term Qi computed as

where N is the total number of documents in the collection and
PubMed 7 is a popular scholarly retrieval system primarily designed for the biomedical literature [28]. It considers many factors of article for indexing and retrieval of relevant documents including (a) stemming, (b) number of terms in the article (TF), (c) position of terms (i.e. title, abstract and body-content), (d) weight of the terms in the article and (e) key terms of the article in a domain-specific databases (e.g. MeSH Database). 8 However, none of these state-of-the-art approaches consider QE through user real-time feedback and citation network analysis in retrieval model for identifying relevant papers in academic search.
2.3. Hybrid methods
Most of the recently published approaches are hybrid [34–37] by combining the techniques mentioned above in different ways as well as adding additional features of their own. To some researchers [38,39], the proximity of citations helps locate the related article. They proposed that two articles are probably similar to each other if many articles in nearby areas cite them. Likewise, Liu et al. [40] proposed that the context passage around the citation indicates the main content of the cited paper. However, the cited paper may focus on different dimensions of context passage [40,41]. The context passages are also used for several other different purposes in the literature – like for inter-article similarity estimation [42], disambiguation of named entities [43], topic-based retrieval [44,45], identification of biomedical articles [46] and newspaper citations in scholarly search [47]. However, due to the unavailability of the full text of the papers and the complexity of citation networks, these approaches cannot be optimally reflected in the scholarly domain. Comparatively, our proposed technique identifies more nuance papers based only on title and abstract through user RTFQE and citation network analysis, and therefore, is more effective in such circumstances. The next section describes the proposed framework.
3. Proposed framework
3.1. Indexing formulation
The document indexing is designed in a manner that leverages the retrieval system to consider the user real-time feedback and citation network analysis while searching relevant papers. In our experiments, we used ACL data set of research papers [19], which contains article details including title, authors, publication date, main content, incites and outcites which are indexed using the multicore architecture of Apache Solr. 9 Table 1 explicates some of the fields’ status after index formulation. Also, our indexing scheme yielded paper citation networks for feeding into citation networks analyzer to leverage the framework in user real-time feedback.
Index field status.
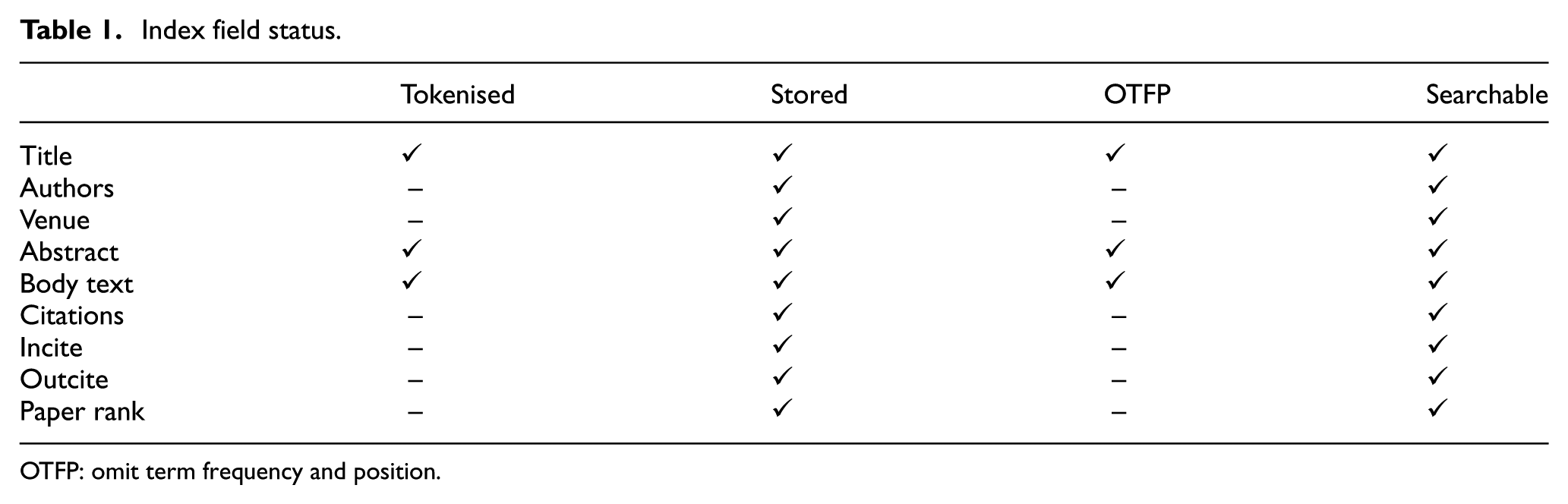
OTFP: omit term frequency and position.
3.2. Model structure
Consider the citation network as a directed graph GP = (V, E), where V is the set of nodes representing papers

Papers in citation networks.
The framework uses citation network analysis along with BM25 while computing the base weight of each paper for generating the first result. It allows the user to select relevant papers as real-time feedback from the first round search results list. The selected papers are then processed in a Rocchio [48] style to revise the search query using citation analysis and tf.idf score of top k words from title and abstract. In this way, the revised query is executed again using citation network analysis along with BM25 to produce a revised result. The high-level view of the system is visually presented in Figure 2, which demonstrates the actual theme of the framework, that is, the results before and after the QE. Experimental results show that RTFQE technique can bring more relevant papers to the top of the results list. The original titles of the documents with relevance to the user query are explicated in Figures 4–6 as a general retrieval scenario.

General view of RTFQE before and after query expansion.
3.3. Materialisation of the framework and algorithm
The framework addresses the above-mentioned task in three steps represented logically by three processing pipelines/flows, clearly indicated by the legend at the bottom of Figure 3. The blue arrows represent the pre-processing steps, including information extraction/parsing of the research papers as well as extracting their metadata and different networks including, for example, citation networks and author–affiliation networks. The green lines represent the search flow regarding the retrieval of initial results, which starts from the search interface, passes through query processing, base weight computations and citation network analysis, and finally generating the list of initially suggested papers to be displayed to the user. The brown lines demonstrate QE, which starts from the search interface, where the user selects some papers from the available list of suggested papers. The important terms are extracted and used in revising the query. The revised query is again matched against the available collection and candidate documents are ranked based on BM25 and citation network analysis, and a ranked list of finally suggested papers is displayed on the user interface. These steps are briefly discussed in the following sections.
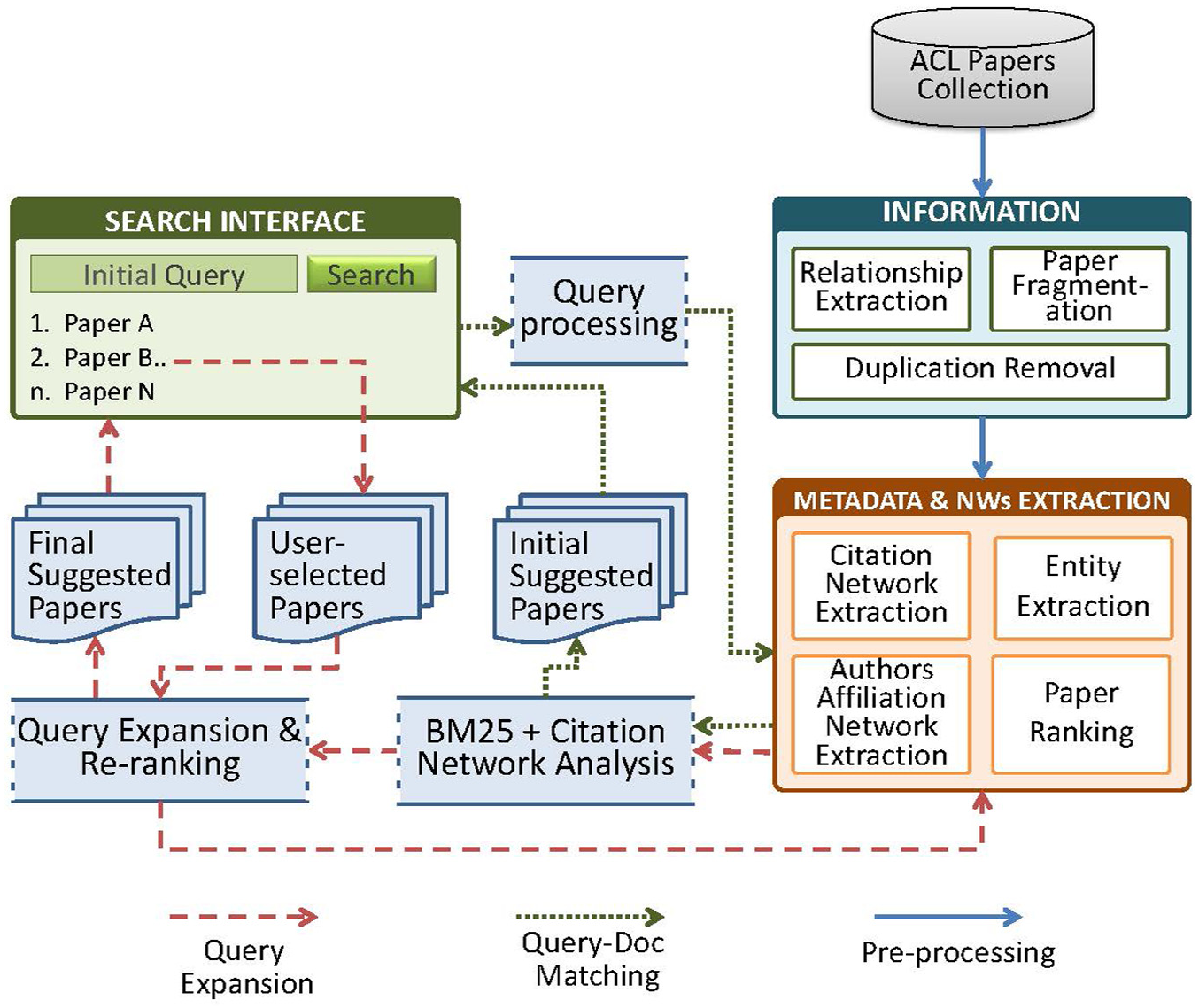
Scholarly retrieval system proposed architecture.
3.3.1. Metadata and network extraction
The system preprocesses the corpus to extract metadata (e.g., authors, publisher, date, incites and outcites), to construct different networks (e.g., citations network, authors network and author collaboration network) and to fragment papers into different desired fields (title, abstract, and content). The extracted data are then indexed in multi-core architecture for efficient retrieval.
3.3.2. Base weight computation
In the second step, the framework computes the base weight of each paper for the initial query using BM25 and citation analyzer in terms of different indexed fields (e.g. title, abstract and main content). BM25 [28,33] computes the weight of each paper, according to equations (1) and (2).
3.3.3. RTFQE
The framework processes a few relevant papers (user-selected) from top-ranked papers of the first round results set as real-time feedback for QE. Algorithms 1 and 2 delineate how the system obtains and refines the final results list using BM25, QE via URF, and citation analysis.


Algorithm 1 is the main algorithm that implements the proposed RTFQE technique. It calls Algorithm 2 in step 1 for the initial search query to retrieve the first set of search results. Algorithm 2 computes the BM25 score of all the papers against the initial search query, which is combined with the citation analysis score to compute the final base weight of the candidate papers to rank the initial search results from step 1 to step 9 of Algorithm 2. The formula used in step 7 of Algorithm 2 computes paper rank (PR) of each paper

First round results list for real-time feedback.
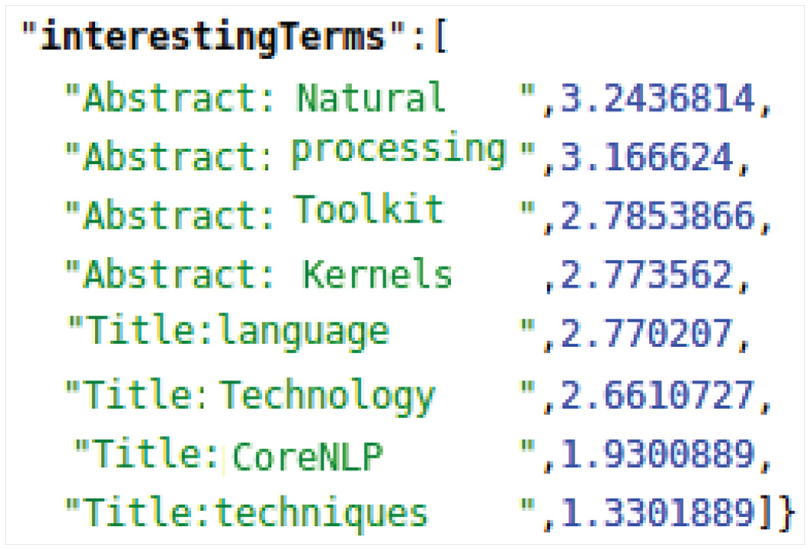
Terms from the selected fields as real-time feedback.

Final result after query expansion.
4. Experiments
The method is evaluated on ACL data set. We measure the effectiveness of the proposed approach in the scholarly search by comparing with BM25 and VSM, using full-fledged index generated in Solr. Moreover, we treat title and abstract as separate fields to use different boosting factors during retrieval, that is, the title is considered the most important followed by abstract and then the main content.
4.1. Data set
The 2016 release of AAN 10 data set, after pre-processing has 23,058 papers. Some of the statistics of the data set are shown in Table 2.
AAN data set statistics.

AAN: ACL Anthology Network.
For extracting abstract, we wrote our python script, which efficiently extracts abstracts for the abstract field. Apache Tika Parser 11 was utilised for core content and other metadata extraction. Also, from text to XML, we utilised our python script to index the metadata resourcefully in Solr. Moreover, the citation analyser was built to compute incites, outcites and PR during indexing using the formula described in step 2, the retrieval algorithm.
4.2. Evaluation criteria
Generally, for the relevance judgements of scholarly search systems, two different methods are used. The first method considers the reference list of the paper as ground truth to check whether the system can re-identify these or not. In the second method, the scholars’ relevance judgements are considered. The scholar checks that whether the retrieved papers are relevant or not. The first method is rather prejudiced towards the citation networks and does not address the use case we have in mind. Therefore, we adopted the second method and involved users to check the relevance of the system. We compare the proposed approach with BM25 and VSM models in terms of nDCG [50], recall and precision, defined as follows

Discounted cumulative gain (DCG) is used in a situation when the result is graded as per position, as in our case. It can measure the quality of the resultant set by checking the position number of the relevant paper. DCG gives high weightage to the relevant paper if it appears at the top position and penalises when it appears at the lower position. In equation (3), p is the position and

Here, IDCG (Ideal DCG) is calculated over the ideal ranking in which the most relevant items are ranked on the top. In equation (4), p is the position where the DCG and IDCG are calculated. Hence, using nDCG we can know how close the retrieval results are to the actual ones. Regarding precision and recall, we consider 1, 2 and 3 as relevant and 0 as not relevant in 4-point scale and are calculated using equations (5) and (6)


For relevance judgements, we take into account the analysis of three PhD scholars and for about 60 different queries on average, related to each student subject area in term of (perfect, relevant, marginally relevant and not relevant).
4.3. General retrieval scenario
In the proposed system, we provide an interactive interface to the users, where they can enter an initial query and get the first result using BM25 and citation network analyzer. In this example-query, we use ‘natural language processing technique’ as a user query shown in Figure 4.
A few relevant papers of the initial query (user-selected) are considered for QE to better understand the user intents as real-time feedback, from which interesting terms from selected fields are extracted for QE as shown in Figure 5. The retrieval system then adjusts the query relative to the relevant papers using Roccio algorithm [17,48] with citation network analysis and BM25. In this manner, the system can understand the user intent in a more insightful way and can find more relevant papers, as described in Figure 6. The final result of the revised query is then evaluated using precision at top 5, 10 and 20, nDCG at 10 and recall at top 15.
5. Results
The results of approximately 23,058 papers, 17,695 authors and 121,137 citations using different retrieval models in terms of standard retrieval effectiveness measures (i.e. nDCG, precision and recall) are reported in Table 3.
Performance comparison at top 5, 10 and 15.

VSM: vector space model; RTFQE: real-time feedback query expansion.
5.1. Performance comparison
We use a 4-point scale for measuring nDCG, that is, 3 for highly relevant, 2 for relevant, 1 for marginally and 0 for non-relevant. Moreover, as recall needs to have expected relevant papers and can be computed on any k, we take the hypothesis that a researcher would often not consider more than top 40 related papers for a given single paper.
To have a closer look and investigate the generalisability, we present the precision, recall and nDCG graph of three models in Figure 7.
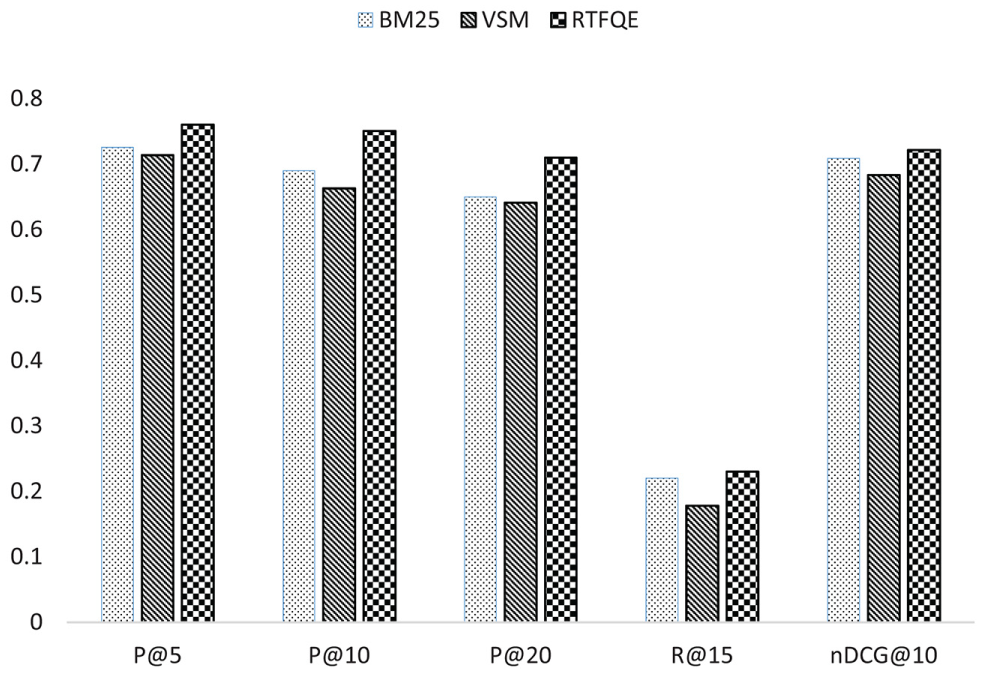
Performance comparison of RTFQE, BM25 and VSM.
The participants assessed the system through two-step criteria. In the first step, they provide feedback by selecting the papers from the initial search results set. Second, the revised results were evaluated in light of the 4-point scale. Each participant evaluated the framework for 20 different input queries, for each query top 20 results were checked, that is, in total one participant evaluated about 400 papers excluding feedback. The paper suggested by BM25, VSM and our proposed approach vary highly. Out of all evaluated papers, approximately 37% results were found highly relevant (perfect), 21% relevant, 20% marginally relevant and 22% not relevant at all to the given input queries. The nDCG@10, precision@5, 10, 20 and recall@15 of the proposed framework are presented in the fourth row of Table 3. The results show that user real-time feedback along with citation analyzer improves precision, recall and nDCG in all of the cases comparatively. Overall, the graph in Figure 7 shows that the proposed technique can improve scholarly search effectively as compared with BM25 and VSM. For more explication, we present a microscopic analysis.
5.2. Microscopic analysis
In this section, we focus on the retrieved results regarding different indexed fields, that is, title, abstract and main content. Here, the performance of RTFQE is analysed from the three perspectives.
First, we query only the title field along with the citation analysis to evaluate and highlight the importance of citation analysis in the scholarly search. In the second perspective, we probe and check the significance of abstract in the scholarly search. The third perspective is concerned with boosting both the title and abstract interchangeably. The analysis given in Figure 7 clearly illustrates the fact that good nDCG, precision and recall rate can be obtained with the integration of both citation network analysis and QE in retrieval model. Furthermore, boosting is also evaluated in real-time feedback. In the first case, we gave high weight to the keywords of the title. Likewise, in the second case, we gave high weight to the abstract as shown in Figure 8 (Title + Abstract(12, 4) and Title + Abstract(4, 12), respectively). Finally, the approach is statistically significant than the baseline approaches in scholarly search, improving efficiency by almost 30% regarding nDCG@10% and 20% when measured by MAP@15, respectively. The approach has a performance penalty; the query is executed twice. However, this can be partially mitigated through the intelligent cache, and the academic searchers usually spend more time in query reformulation to obtain the intended result comparatively [51]. Moreover, the production of the initial result is also somewhat relevant because of the integration of citation analysis in a scholarly retrieval system. The recall is also statistically improved by 10% when measured using the entire rich index through different boosting factors. Figure 8 shows that the framework can provide more relevant papers for academic searchers at the top of the results list. We believe that our proposed approach is effective and the integration of citation analysis in both QE and scholarly retrieval model can obtain comparatively more relevant papers.

Microscopic analysis.
6. Conclusion
Scholarly search engines attempt to reduce the manual effort of researchers while finding relevant papers. However, the huge expansion and the complexity of academic Web make it a very hot and challenging area of research. We have presented a new RTFQE technique for retrieving relevant papers. The mechanism includes paper fragmentation, building citation networks, paper ranking score computation using citation network analysis and effective extraction of metadata for supporting scholarly search. The framework uses QE via URF and citation network analysis, and is capable of filtering and ranking the relevant papers through the integration of both in the retrieval model. It can help scholars to locate relevant papers in scholarly published documents. The experimental results illustrate that the framework can produce more nuanced ranking results. An exciting and distinctive aspect of this framework from a practical point of view is that it only uses the metadata of the papers and does not require any user information, that is, only publicly available data can retrieve best results. However, the framework executes the query twice, which is a performance penalty, but this can be partially mitigated through the use of the intelligent cache. There are several opportunities for future work. We would like to combine our framework with most sophisticated recommender systems in case of unsupervised feedback. Considering other factors like publication venue, user log, and the scholarly social network may further improve the ranking of the top most relevant papers.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.