
Abstract
One of the fundamental issues in social networks is the influence maximization problem, where the goal is to identify a small subset of individuals such that they can trigger the largest number of members in the network. In real-world social networks, the propagation of information from a node to another may incur a certain amount of time delay; moreover, the value of information may decrease over time. So not only the coverage size, but also the propagation speed matters. In this paper, we propose the Time-Sensitive Influence Maximization (TSIM) problem, which takes into account the time dependence of the information value. Considering the time delay aspect, we develop two diffusion models, namely the Delayed Independent Cascade model and the Delayed Linear Threshold model. We show that the TSIM problem is NP-hard under these models but the spread function is monotone and submodular. Thus, a greedy approximation algorithm can achieve a 1 − 1/e approximation ratio. Moreover, we propose two time-sensitive centrality measures and compare their performance with the greedy algorithm. We evaluate our methods on four real-world datasets. Experimental results show that the proposed algorithms outperform existing methods, which ignore the decay of information value over time.
Keywords
1. Introduction
A social network is made up of social actors (such as individuals or organizations) and the relationships between them. The advent of online social networks in the last decades provides unprecedented opportunities for social network analysis [1]. One of the main research interests in this expanding area is the analysis of influence and information propagation in social networks. Social influence is a well-known phenomenon in networks and is defined as the changes in an individual’s behaviours, opinions or actions that result from interaction with others [2]. Social influence has broad applications in different fields, including viral marketing [3–6], information dissemination [7, 8], recommendation systems [9, 10] and trust propagation [11, 12].
One of the fundamental issues with information propagation is to find a small subset of influential nodes such that they can attract the largest number of members in a social network, according to a diffusion model. This problem is called influence maximization, which is proved to be NP-hard [13, 14]. Different approximation algorithms [13–18] and heuristic methods [18–23] have been proposed to solve this problem. However, in most studies, the role of time in influence propagation is ignored. Only some recent works have considered the temporal aspects in information diffusion [24–29]. In Saito et al. [24], Goyal et al. [25] and Gomez-Rodriguez et al. [26] the underlying graph is inferred from real propagation data by considering a time delay factor. Chen et al. [27] and Liu et al. [28, 29] independently studied the influence maximization problem with a deadline constraint.
In all of the previous works, the aim was to maximize the number of influenced nodes, either until a deadline is reached or without using any time constraint. In fact, previous studies value all activated nodes equally, regardless of their activation time. However, in real-world applications, the value of propagated items may decrease over time. Therefore, a node that is activated later may worth less. As an application, consider the dissemination of hot topics or urgent information. In these situations, the value of propagated information is dependent on activation time of influenced users. For example, in the event of an epidemic it is important to inform more people as soon as possible. As another application, in viral marketing, the sooner a company sells its product, the faster it receives a return on investment. This means that not only the number of activated customers, but also the rate of activation matters.
In this paper, we define the Time-Sensitive Influence Maximization (TSIM) problem, which aims to find a set of individuals whose spread of influence in the network maximizes the total profit. The profit value of an individual is dependent on its activation time and the rate at which information decays during time. The amount of reduction in information value is determined by a freshness function, which specifies the relative importance of coverage and diffusion time in the propagation process. If the freshness value decreases quickly over time, the activation time of the nodes will have a major impact on the spread value. Conversely, if freshness value decreases slowly, the number of activated nodes will be the determining factor for the total profit.
To incorporate time delay aspect, we consider two diffusion models, Delayed Independent Cascade and Delayed Linear Threshold models. We prove that the TSIM problem is NP-hard and show that the spread function is monotone and submodular under the aforementioned models. Thus, we develop a greedy algorithm, which can guarantee a spread value within (1 − 1/e) of the optimal solution. Furthermore, we devise two time-sensitive heuristic methods and compare their performance with conventional centrality measures.
The major contributions of this paper are as follows:
We propose a new problem called TSIM, which takes into account the time dependency of information value. We incorporate freshness concept to the influence maximization problem.
We prove the NP-hardness of the TSIM problem and propose a greedy algorithm based on the submodularity and monotonicity properties of the spread function. The proposed algorithm considers time delay in estimating propagated value.
We propose two time-sensitive heuristics for influence maximization problem and compare them with the proposed approximation algorithm and conventional methods.
We verify the effectiveness of our algorithms by conducting experiments on real social networks. The experimental results show that the selected nodes by our methods can achieve higher spread value in comparison to conventional methods.
The rest of the paper is organized as follows. Section 2 reviews the related works. The problem definition and proposed methods are discussed in Section 3. The experimental results and discussion are presented in Section 4. Finally, Section 5 concludes the paper and indicates our future directions.
2. Related works
The influence maximization problem was first introduced by Domingos and Richardson [3, 4]. They modelled the problem using Markov random fields and proposed heuristics for identifying influential nodes. Kempe et al. [13, 14] formulated influence maximization as a discrete optimization problem. They proved that this problem is NP-hard under two well-known propagation models, namely the Independent Cascade (IC) and Linear Threshold (LT) models. They proposed a greedy algorithm with an approximation ratio of (1 − 1/e) that successively selects the node with the maximum marginal influence. However, their algorithm is computationally expensive and cannot scale well with large social networks. A number of studies have been carried out to address this scalability issue. Leskovec et al. [15] proposed the Cost-Effective Lazy Forward (CELF) algorithm that is a lazy forward version of the greedy algorithm. It uses the submodularity property of the influence function to reduce greatly the number of influence spread evaluations on the nodes. Goyal et al. [16] presented CELF++ based on the CELF algorithm that avoids unnecessary recomputations of marginal gain incurred by CELF.
In contrast to approximation algorithms, several studies have proposed heuristic methods to reduce the complexity of influence spread evaluation. Chen et al. [19] proposed a scalable heuristic called LDAG for the LT model, which computes the influence of each node only within its constructed local directed acyclic graph. Also a scalable heuristic algorithm called PMIA is proposed for the IC model, which exploits maximum influence in-arborescence paths to estimate the influence spread [20]. Another scalable method is IRIE that is proposed under the IC model. It uses a fast iterative ranking algorithm with a fast influence estimation method to achieve scalability while maintaining good influence coverage [21]. All of the above heuristics are proposed for a specific diffusion model; on the other hand, there are centrality heuristics including degree heuristic, betweenness and closeness centrality that are not dependent on the diffusion model [22, 23]. Goyal et al. proposed an alternative approach that directly uses past propagation data to estimate expected influence spread [30].
Some recent works have studied the role of time in the diffusion of information. Saito et al. proposed continuous time diffusion model and addressed the problem of estimating the parameters of the model from the observed data [24]. Goyal et al. [25] presented algorithms for learning the parameters of both static and time-dependent models from propagation data. The proposed methods in Gomez-Rodriguez et al. [26] find the optimal network and transmission rates that maximize the likelihood of temporal propagation data.
Chen et al. [27] and Liu et al. [28, 29] independently studied the problem of influence maximization under a deadline constraint. Given a deadline T, the aim of these works is to find a set of nodes that maximizes the expected number of influenced nodes until T. In Chen et al. [27] a meeting event is added to diffusion models that determine the probability of meeting the neighbours in a specified time. Their proposed model is a special case of the model proposed in Liu et al. [28, 29]. However, all of the above works ignore the devaluation of propagated items during time and overlook its effect on the influence maximization problem. Therefore, in this paper we incorporate this aspect into the influence maximization problem and define the TSIM.
3. Material and methods
A social network can be modelled as a directed graph G = (V, E), where V is the set of nodes and E is the set of edges or relationships. As stated in the previous section, influence maximization is a fundamental problem in social networks. Given the graph G and a number k as input, the influence maximization problem aims to find a set of k influential nodes, called the seed set, such that, by activating them, the expected spread of influence according to a diffusion model is maximized. Diffusion models define how the information propagates on the network. Two widely used diffusion models are the IC and LT models. After selecting a set of initial nodes, the items propagate based on the given diffusion model. When a node adopts the item, it will switch from inactive state to active state. In progressive models, once a node becomes active it will remain so forever.
It is shown in Kempe et al. [13] that the influence maximization problem is NP-hard under IC and LT models, but a greedy algorithm is employed that achieves (1 − 1/e) approximation by exploiting the monotonicity and submodularity properties of the influence function. Submodularity and monotonicity are two key theoretical properties for optimization problem and are defined as follows.
In other words, adding an element to the input of a monotone function does not decrease its value.
Intuitively, a function is submodular if it satisfies the diminishing return property. This property states that the marginal gain from adding an element to a set S is at least as high as the marginal gain from adding that element to the superset T.
The conventional influence maximization problem does not consider the time sensitivity of information. Thus, to incorporate time sensitivity of propagation process, we extend the IC and LT models to the Delayed Independent Cascade (DIC) model and Delayed Linear Threshold (DLT) model and propose the TSIM problem. In the next subsection, we formally define TSIM and study its properties under the DIC and DLT models.
3.1. Problem definition and properties
As we mentioned earlier, the value of propagating items may decrease over time. The amount of reduction in the value of propagated items is determined by a freshness function that is given as an input. The freshness function ff(t) specifies how the value of an item varies with time. It can be any positive decreasing function of time such as exponential, polynomial or piecewise linear function. The value of a node is determined by the freshness function, giving as input the activation time of that node. Thus, we define the value of node v as fval(v) = ff(v.acttime), where v.acttime is the activation time of v.
Taking into account the diminishing value of propagating items, we formally define TSIM problem as follows.
In the above definition, PV(S) is the spread function that is equal to the expected value of activated nodes given S. Formally we define it as:

where A(S) is the set of activated nodes at the end of diffusion process initiated by S and fval(i) is the value of activated node i.
In the following sections, we discuss the properties of the TSIM problem under DIC and DLT models.
3.1.1. TSIM problem under DIC model
In the IC model, each edge
As discussed before, in real-world social networks the propagation of influence from one node to another may incur a certain amount of time delay. Consequently, we extend the IC model to the DIC model, which takes into account the propagation delay. As in the IC, each edge
In contrast to the IC model, each node in the DIC model can be in one of three different states, active, inactive or latent active. A set of nodes are selected as seed at t = 0. By activating these nodes, the items propagate in discrete time steps as follows. At any time step t, each node
Taking the expectation over all possible worlds, we can rewrite PV(S) as:

where pr(w)is the probability of w and PVw(S) is the value of activated nodes given S over the determined graph w. Based on this redefinition, we prove the monotonicity and submodularity of PV(.).
Let S and T be two arbitrary sets such that
To verify the submodularity property, let S and T be two arbitrary sets such that
3.1.2. TSIM problem under DLT model
In the LT model, each edge
As discussed before, in real-world social networks the propagation of influence from one node to another may incur a certain amount of time delay. Consequently, we extend the LT model to the DLT model, which takes into account the propagation delay. In the DLT model, in addition to threshold and influence weights, each edge
In contrast to the LT model, each node in the DLT model can be in one of three different states, active, inactive or latent active. A set of nodes are selected as seed at t = 0. Each active node u affects its out-neighbour v after delay duv. Hence, if u becomes active at time step t, its impact time for v will be t+duv. For each node v, its active in-neighbours and their impact time are saved in a list called ANv. If v is in inactive state and the weighted sum of its active in-neighbours becomes greater than or equal to
In the TSIM problem, the values of activated nodes are computed based on their activation time and freshness function. Thus, the PV is equal to sum of the value of activated nodes at the end of propagation. The propagation process terminates, if and only if
Kempe et al. [13] showed that the Linear Threshold model is equivalent to reachability via live-edge paths as defined above. In our case, instead of computing the number of activated nodes, the value of nodes is calculated based on their activation time. Therefore, we incorporate the time delay aspect to live edges. In this case, the effective in-neighbours of node v at time t are those whose impact time on v is smaller than t.
Let At be the set of nodes that are active at time t. Suppose

where
For the live-edge process, the probability that an inactive v will be activated at t + 1, given that it has not been active yet by the end of t, can be computed as follows. We start with a set of initial nodes A0. For each node v, if its incoming live-edge is incident to a node in At and impact time of that node on v is less than or equal to t+1, then v will be reachable at stage t+1. Therefore, At+1 is the union of At and new reachable nodes. If node v is not reachable by time t, then the probability that v becomes reachable in t + 1 is the probability that v’s effective live-edge is incident on some node in

This probability is exactly same as
Considering this equivalence, the arguments will be similar to the proof of Theorem 4. Using the live-edge process, we obtain a possible world. For two arbitrary sets S and T such that
Also, in a deterministic graph w,
3.2. Approximation algorithm for the TSIM problem
As we showed in Theorems 3 and 5, the TSIM problem is NP-hard under both the DIC and DLT models. However, a celebrated result by Nemhauser et al. [31] states that for any monotone submodular function f with f(∅) = 0, the problem of finding a set S of size k that maximizes f(S) can be approximated within a factor of (1−1/e) by a greedy algorithm. Based on this theorem, we adapt the greedy algorithm [13] to solve the TSIM problem.
3.2.1. Time-Sensitive Greedy algorithm
We have proved the monotonicity and submodularity of PV(.) function under DIC and DLT models in Theorems 4 and 6, respectively. Based on these theorems and the theorem stated by Nemhauser et al. [31], in this section we propose the Time-Sensitive Greedy algorithm to approximately solve the TSIM problem with (1 − 1/e) approximation guarantee.
As shown in Algorithm 1, the greedy algorithm iteratively selects a node with the largest marginal gain and adds it to the seed set S, until k seeds are selected. The marginal gain is the difference of the propagated value initiated by S and the propagated value initiated by S union the selected node.

It is proved that computing the marginal influence is NP-hard for the IC and LT models [19, 20]. Thus, Monte-Carlo simulation is used as a common approach for estimating influence spread. This leads to a (1 − 1/e − ϵ) approximation ratio, where ϵ depends on the accuracy of Monte-Carlo estimation [13]. Since IC and LT are special cases of DIC and DLT models, respectively, computing a marginal value for these models is NP-hard as well. To estimate marginal gain for the TSIM problem, we adapt Monte-Carlo simulation to accommodate time sensitivity of information value in the computation of propagation value. The main idea of Monte-Carlo simulation is to run the diffusion model by selected nodes for many times and take the average of obtained values at each iteration.
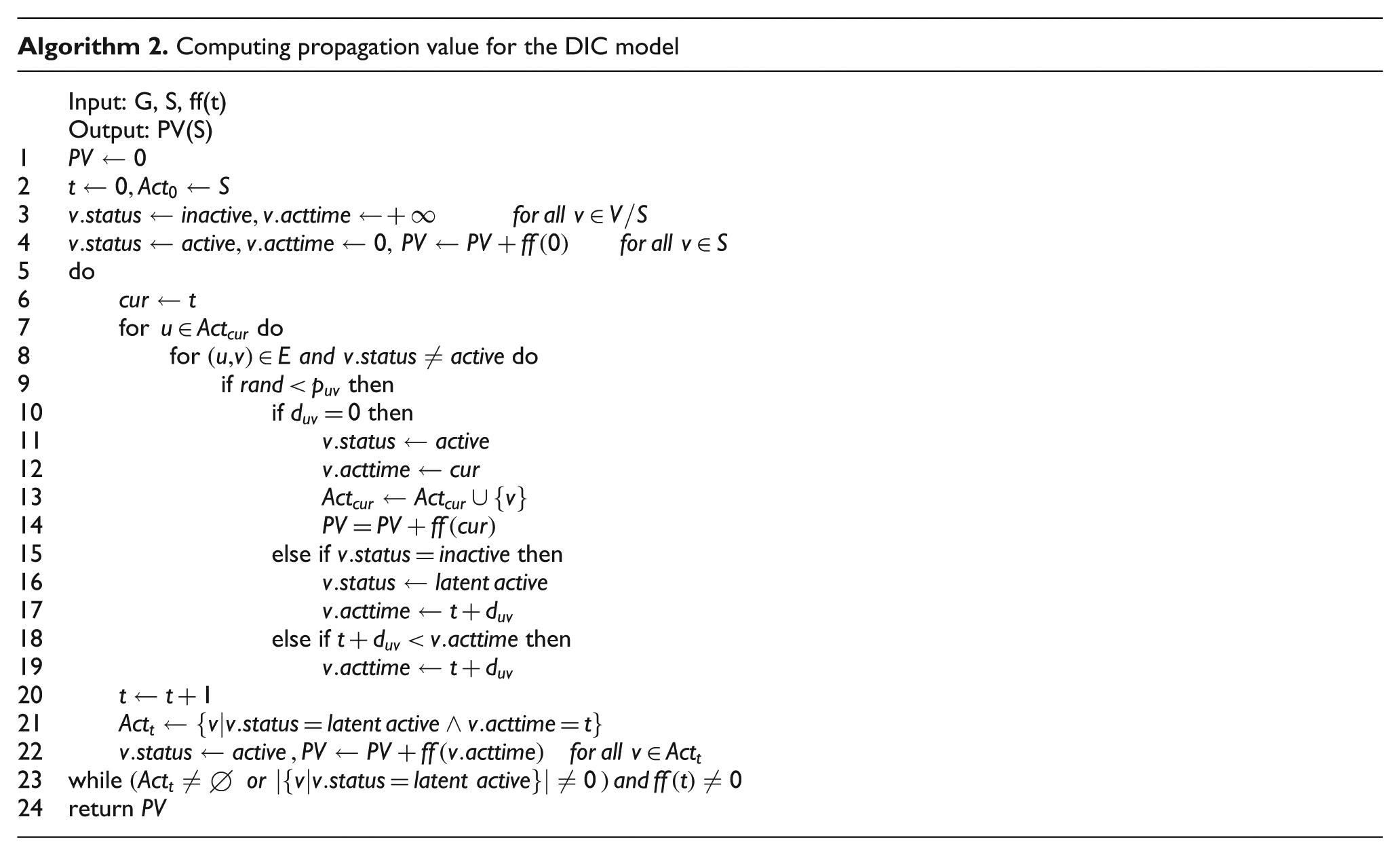
Each simulation run is the same as what we described before in Sections 3.1.1 and 3.1.2 about influence propagation in the DIC and DLT models. Algorithms 2 and 3 present the computation of propagation value in DIC and DLT models, respectively.

3.3. Heuristic methods for the TSIM problem
Although the greedy algorithm guarantees an approximation ratio for the TSIM problem, the running time is large. A possible approach is to use heuristic methods. Since in this paper the TSIM problem is discussed under two different diffusion models, namely DIC and DLT, we apply model-independent heuristics for comparison. Consequently, we propose two time-sensitive heuristic methods, which are described in this section.
3.3.1. Time-Sensitive Degree heuristic
The Degree heuristic is frequently used for selecting seeds in the influence maximization problem [22, 23]. It selects the k nodes with the highest degrees in the social network as initial nodes. Experimental results have shown that degree centrality has good performance in the influence maximization problem [32]. However, it does not consider the time aspect in the diffusion of information.
Since the value of propagating items is dependent on the activation time, a node that can activate more nodes in a shorter time is more desirable. In other words, a node that activates its neighbours with high freshness value can be a good spreader. Therefore, we define the Time-Sensitive Degree of node u as:

where v is out-neighbour of u and duv is the propagation delay from u to v. We sort the nodes in descending order based on their Time-Sensitive Degree and select the first k nodes as seed set.
3.3.2. Time-Sensitive Betweenness heuristic
Betweenness centrality is an indicator for the importance of a node in the network. The betweenness of a node is defined as the number of shortest paths from all vertices to all others that pass through that node. It has shown good performance in identifying influential nodes in social networks [22]. In this paper, we extend the betweenness measure to capture the dependency of propagated value to time delay. Considering the time aspect, a path with less delay can be more valuable.
As we discussed before, the value of a propagated item is defined by a freshness function. Thus, we weight each edge (u, v) by 1/(ff(duv) + 1) and define Time-Sensitive Betweenness of node u as:

where nsp(x, y) is the number of shortest paths from node x to y, and nspu(x, y) is the number of shortest paths from node x to y that pass through node u. The shortest paths between nodes are computed on the weighted graph we defined above.
4. Results and discussion
We evaluated the efficiency and the effectiveness of our approximation algorithms and the proposed heuristics on four real-world social networks for both the DIC and DLT models. In addition, we compared our time-sensitive methods with conventional influence maximization methods. The experimental setups and the corresponding experimental results are presented in Sections 4.1 and 4.2, respectively.
4.1. Experimental setups
In this section, we describe the datasets we used and the configurations of the conducted experiments.
4.1.1. Datasets
We used four real networks for our empirical study, namely Twitter, WikiVote, HEP-PH and Epinions. Twitter is one of the most popular social networks for online communications. We used the dataset extracted by Hashmi et al. [33], which contains following relationships of 2492 users. The second dataset, WikiVote, contains all of the Wikipedia voting data from the inception of Wikipedia until January 2008. Nodes in the network represent Wikipedia users and an edge from node u to node v represents that user u voted for user v, which means that v has an influence on u. This dataset can be obtained from SNAP [34]. The third dataset, HEP-PH, is a citation graph that covers all the Arxiv Highenergy Physics papers from January 1993 to April 2003. In this graph, the nodes represent papers and the edges represent citation. If paper u cites paper v, it means that v has an influence on u. This dataset is downloadable from SNAP [34]. The last dataset, Epinions, is extracted from Epinions.com, which is a general consumer review site. It shows who-trusts-whom relationships between members. Each node represents a user of the site and an edge from u to v means that u trusts v, that is, v has an influence on u. This dataset is available at SNAP [34]. The statistics of the above datasets are presented in Table 1.
Statistics of real-world social networks.

4.1.2. Configurations
We evaluated our Time-Sensitive Greedy Algorithm (TSGreedy) and our proposed heuristic algorithms, which are, Time-Sensitive Degree heuristic (TSDeg) and Time-Sensitive Betweenness heuristic (TSBet), in terms of propagation value and running time. In addition, we compared them with conventional influence maximization algorithms including Greedy Algorithm (Greedy), Degree heuristic (Deg), Betweenness heuristic (Bet) and Random (Rnd) method, which acts as the baseline method and select k seeds randomly.
For Greedy and TSGreedy algorithm, we exploited CELF++ optimization [16]. For estimating influence spread under both the DIC and DLT models, we performed Monte-Carlo simulations 10,000 times as in Kempe et al. [13] and Goyal et al. [16] and took the average of simulations as the result. We compared the amount of propagated value of the aforementioned algorithms with different sizes of seed set, ranging from 1 to 50.
The influence probability of edges in the DIC model is set using the Weighted Cascade model [13, 20]. In the Weighted Cascade model the probability of edge (u, v) is assigned to
As the freshness function, we employed exponential decay function and constant freshness function. An exponential decay function is of the form
4.2. Experimental results
In this section, we present the experimental results of the proposed methods on four real-world datasets. We evaluated different methods with respect to influence spread (propagation value) and running time. In addition, we compared the effectiveness of our methods with conventional influence maximization methods. We examined the effect of the freshness function on the TSIM problem in Section 4.2.3.
4.2.1. Influence spread
We varied the seed set size, k, from 1 to 50 and for each k we estimated the expected value of activated nodes in different algorithms. The expected value of activated nodes measures the effectiveness of the algorithms for the TSIM problem. The larger the expected value of activated nodes returned by an algorithm, the better the algorithm is.
Figures 1 and 2 illustrate the propagation value of different algorithms achieved on four datasets with freshness function ff(t) = e−0.2t under the DIC and DLT models, respectively. We can see from the results that TSGreedy outperforms other methods in all cases and the second best algorithm is TSDeg. TSBet performs worse than TSGreedy and TSDeg, but it outperforms conventional methods. Rnd has the worst performance.
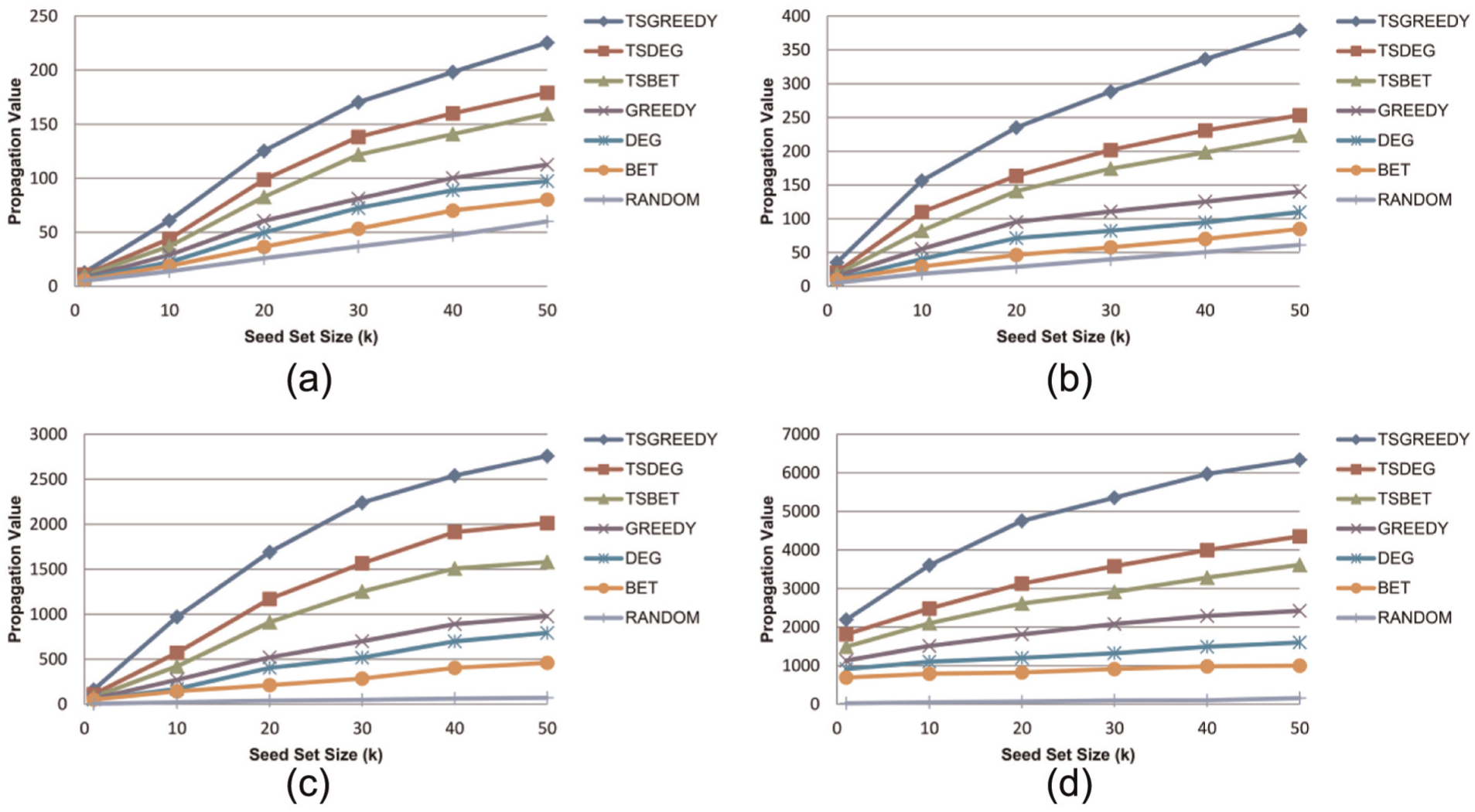
Propagation value of different algorithms under DIC model on four datasets – (a) Twitter, (b) WikiVote, (c) HEP-PH and (d) Epinions – with freshness function ff(t) = e−0.2t.
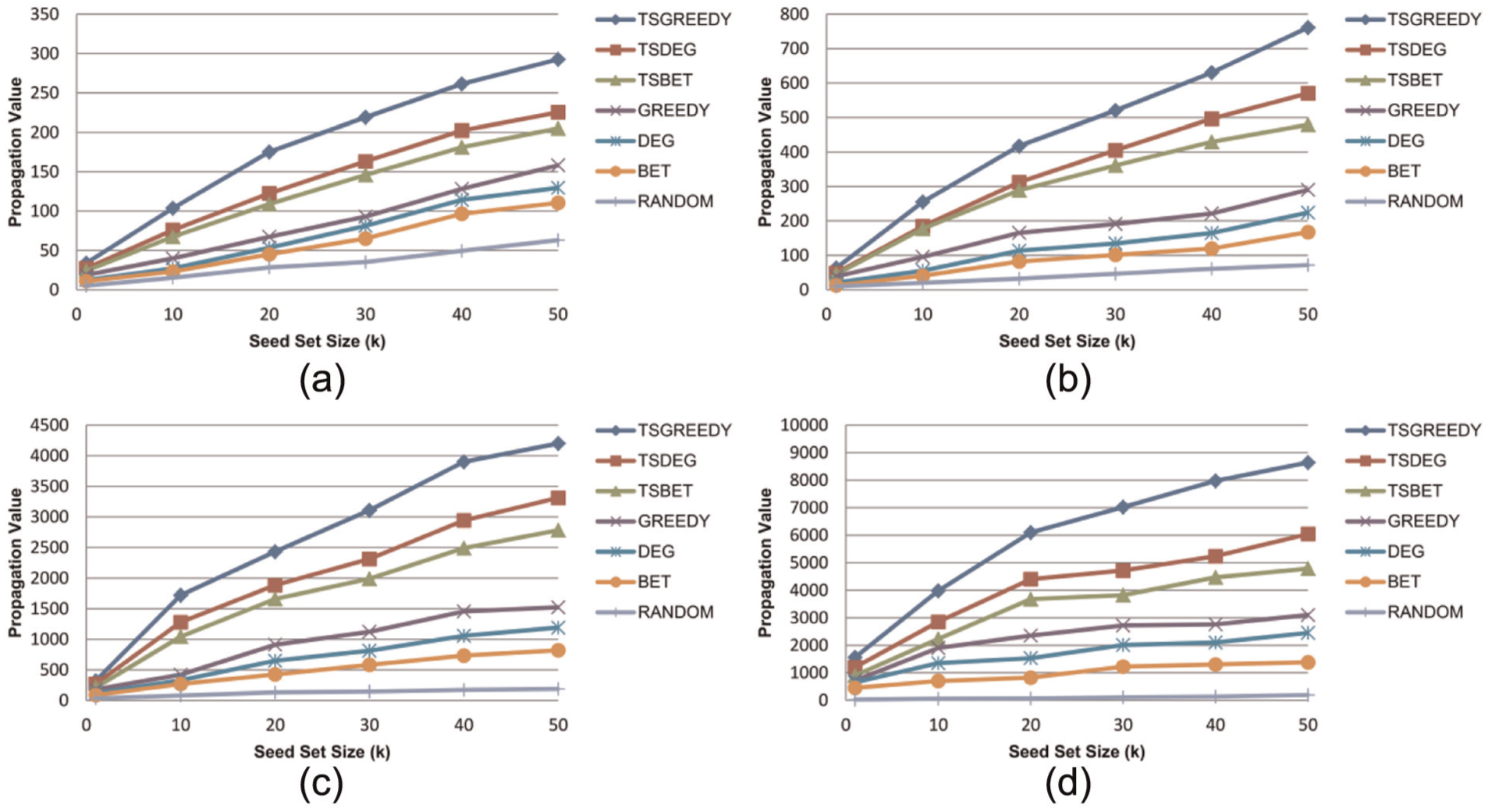
Propagation value of different algorithms under DLT model on four datasets – (a) Twitter, (b) WikiVote, (c) HEP-PH and (d) Epinions – with freshness function ff(t) = e−0.2t.
Greedy, Deg and Bet methods consistently achieve lower propagation values than our proposed time-sensitive methods. This shows that conventional influence maximization methods are not effective in the TSIM problem.
4.2.2. Running time
We compared the running time of our proposed algorithms, under both the DIC and DLT models. Table 2 shows the running times of different algorithms for selecting 50 seeds in four datasets when the freshness function is ff(t) = e−0.2t. Column 1 represents the running time of TSGreedy under the DIC model, indicated by TSGreedy(DIC). Columns 2–4 indicate the running times of TSDeg, TSBet and Rnd methods, respectively. Since TSDeg, TSBet and Rnd methods are model-independent, their running times are the same under both the DIC and DLT models. The running time of TSGreedy under the DLT model is represented in column 5 as TSGreedy(DLT).
Running times of proposed methods on four real social networks in second (k = 50, ff(t) = e−0.2t).

As the results show, TSGreedy is the slowest algorithm amongst the proposed algorithms. This is reasonable since the greedy algorithm has to calculate the marginal gain of non-seed nodes at each iteration. However, it can achieve the highest propagation values among the proposed algorithms. The running time of the TSBet heuristic is in the range of the greedy algorithm while its propagation value is much worse than the greedy algorithm. The TSDeg and Rnd run extremely fast. As the results in Section 4.2.1 show, TSDeg is the second best algorithm in maximizing expected value amongst the proposed methods. Therefore, it can be a good choice for large networks and when short running time is a major concern. On the other hand, TSGreedy outperforms other proposed methods in terms of propagation value, but it takes more time and is not scalable for large networks.
4.2.3. Effect of freshness function
We examined the impact of the freshness function on the TSIM problem. We evaluated the influence spread of TSGreedy under the DIC model on our datasets with three different freshness functions that are ff(t) = 1, ff(t) = e−0.2t, and ff(t) = e−2t.
It is obvious that, when the freshness function decreases faster, the total propagation value will reduce further. For example, the propagation value of TSGreedy(DIC) on Twitter dataset with k = 50 is equal to 448, 225.3 and 74.6, for ff(t) = 1, ff(t) = e−0.2t and ff(t) = e−2t, respectively. As the results show, when the freshness function is constant, we have the highest propagation value. This is because when ff(t) = 1 there is no decay in the value of information and all activated nodes have a value of 1, but in ff(t) = e−0.2t and ff(t) = e−2t the values of activated nodes are dependent on their activation time and decrease over time. The rate of decay in ff(t) = e−2t is greater than that in ff(t) = e−0.2t.
In addition, we investigated the overlaps of seed sets returned by TSGreedy(DIC) for different freshness functions. Table 3 represents the results for k = 50 in four datasets. Each entry in the table shows the number of common seeds returned by TSGreedy(DIC) for the two freshness functions in corresponding columns and rows.
The overlaps of seed sets returned by TSGreedy(DIC) with different freshness function when k = 50.
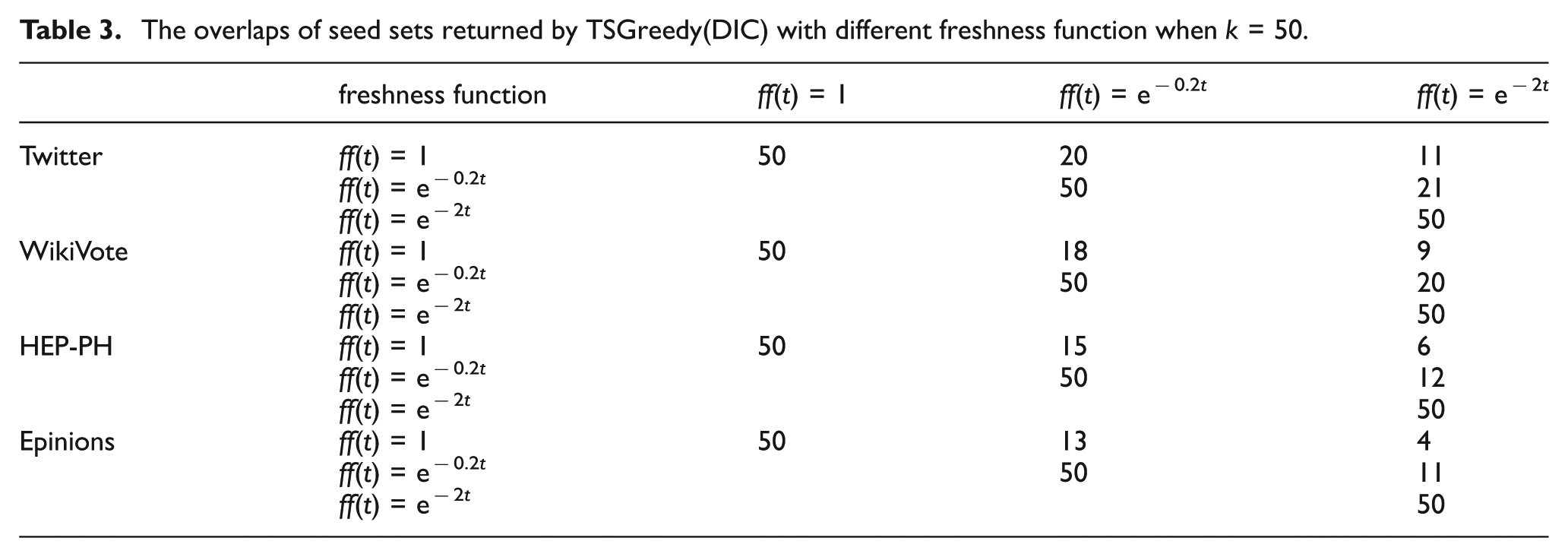
The results show that the seed sets, which maximize the propagation value, differ significantly for different freshness functions, that is, the set of nodes maximizing the propagation value for a given freshness function does not necessarily maximize the value for a different decay pattern. This indicates that considering the time sensitivity of propagation value plays an important role in the influence maximization problem.
5. Conclusions
In this paper, we introduced a novel problem, called the TSIM problem, that considers the effect of time on the value of propagated items. TSIM is important in applications where the value of propagated items decreases over time. For example, in dissemination of hot topics or urgent information, it is important to influence more people as fast as possible. Also, in viral marketing, the sooner a product is sold, the more valuable it is, because the sooner the company receives a return on investment.
To address TSIM problem, we extended the standard IC and LT models to the DIC and DLT models, respectively. We proved that the spread function of TSIM is monotone and submodular under the DIC and DLT models, and proposed a greedy algorithm with an approximation guarantee. We also modified degree and betweenness centrality to adapt to the time-sensitive nature of the propagation process. Experimental results on real datasets verified the effectiveness of our formulation and the proposed algorithms.
One drawback of the greedy algorithm is that it is computationally expensive and is not scalable for large social networks. On the other hand, the heuristic methods do not guarantee the quality of results. Therefore, one potential direction for future work is to consider the scalability issue for the TSIM problem and design effective and efficient algorithms that are scalable on large networks.
Also in this paper, we assumed that the influence probability and the influence delay of edges are given as input. However, in real social networks the edges are not labelled with influence probabilities or influence delays. Thus, learning these parameters from propagation data can be considered as another direction for future work.
Footnotes
Acknowledgements
The authors like to thank Professor David Parsons for proofreading the manuscript.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.