
Abstract
It is important to obtain public opinion about a news article. Microblogs such as Twitter are popular and an important medium for people to share ideas. An important portion of tweets are related to news or events. Our aim is to find tweets about newspaper reports and measure the popularity of these reports on Twitter. However, it is a challenging task to match informal and very short tweets with formal news reports. In this study, we formulate this problem as a supervised classification task. We propose to form a training set using tweets containing a link to the news and the content of the same news article. We preprocess tweets by removing unnecessary words and symbols and apply stemming by means of morphological analysers. We apply binary classifiers and anomaly detection to this task. We also propose a textual similarity-based approach. We observed that preprocessing of tweets increases accuracy. The textual similarity method obtains results with the highest recognition rate. Success increases in some cases when report text is used with tweets containing a link to the news report within the training set of classification studies. We propose that this study, which is made directly in consideration of tweet texts that measure the trends of national newspaper reports on social media, has a higher significance when compared to Twitter analyses made by using a hashtag. Given the limited number of scientific studies on Turkish tweets, this study makes a contribution to the literature.
1. Introduction
The Internet has an extensive influence on society, as social networks provide individuals with the opportunity to communicate on a virtual platform by using Internet access technologies. Microblogs, one type of social network, are used especially by professionals to share knowledge and news. Twitter is a popular microblogging service that quickly spreads information about any incident occurring anywhere in the world.
Choeng and Lee [1] state that Twitter and related microblogging technologies emerged in 2006 and academic studies on Twitter gained significance between 2008 and 2009. Together with the increase in research about Twitter, studies are conducted in disciplines such as social media, the web, human-computer relationships, data mining, etc. [2]. The National Institute of Standards and Technology added a microblog track for the first time at the Text Retrieval Conference in 2011 and selected Twitter as the source of microblog data [3].
Twitter is one of the indicators that shows the effect of news in print sources or electronic media reports. The availability of tweets about an incident or news story is important. First of all, it will show the popularity of a subject on social media. It is also possible to make more detailed sentiment analyses of these tweets and find whether people have positive or negative opinions on the subject. A user may tweet about a news article by means of the ‘Share on Twitter’ button on news websites. Twitter stores the data (the URL of the news report) so that this tweet is associated with the article. Kwak et al. [4] found in their study on Twitter that most (over 85%) of top trending topics on Twitter were newspaper headlines or general news during the active period when the study was in progress. Therefore, news reports share a significant part of Twitter content.
In this study, our aim was to find tweets related to news reports by exploiting tweets shared via the tweet button for news articles on the websites of various national newspapers. We denote this task as a classification problem and tried various methods: binary classification, single-class classification (anomaly/outlier detection) and textual similarity. This study contributes to the literature regarding the following points:
This is the first work, to the best of our knowledge, which uses tweets sent by the ‘Share on Twitter’ button on a newspaper website as the training set and uses classification techniques to find other tweets related to news articles.
This study tries to determine the success of outlier/anomaly detection (one of single-class classification methods) and textual similarity methods tried in different fields but have not yet been used in the classification of news-related Turkish tweets.
Training sets for a news article should include both relevant and irrelevant tweets. We denote tweets containing the URL of the news article as the relevant set. On the other hand, it is not possible to automatically include irrelevant examples because there is a large pool of tweets not related to the news. Therefore, we propose to include artificial instances to represent the irrelevant set. As another solution, we investigate techniques (single-class classification and textual similarity) requiring only the relevant instances.
It is also a challenge to form test sets on which we run our experiments. It is difficult to determine relevant tweets for a news article by manually checking millions of tweets. We propose to make search on tweet datasets using titles of news articles as our queries. It is not a trivial task to form a representative sample of irrelevant set for a news article since there are millions of irrelevant tweets. We propose to form this set in two ways. Tweets that have at least one word from the news title and were irrelevant to the news form one portion of our set. The remaining portion consists of tweets randomly selected from the tweet pool that do not have any word from the news title and were irrelevant in terms of meaning.
We investigated the effects of various preprocessing techniques (spell correction, stemming, etc.) on classification performance.
This paper is organised as follows: the second section includes previous studies related to microblogs and tweet classification. We present the background information about text classification and anomaly detection in the third section. The fourth section describes our methods for finding news-related tweets. The fifth section presents our experimental results. We discuss and summarise our findings and conclude the paper in the last section.
2. Related work
Twitter has become a large social networking site with an increasing number of users throughout the world since 2007. On such a large social network, it is not an easy task to make a specific analysis in a short period of time. There are various studies on such microblog data and each of them is detailed in the following paragraphs.
Castillo et al. [5] defined relationships between tweets, users, subjects and the spread of retweets in order to classify reliable and unreliable news on Twitter. Through these relationships, they sought to determine misinformation or false rumours and thus showed the effectiveness of user- and sentiment-based features. In his study, Jung [6] used the named-entity recognition method in order to understand whether two short texts (tweets) on Twitter are related to each other in terms of content. Fang et al. [7] proposed to find similarity among tweets using multiple relations between tweets such as semantic relations (content similarity), social tag relations (hashtags) and temporal relations. These relations were extracted for clustering in order to detect hot topics. They also proposed a document similarity measure based on a suffix tree to better measure similarity of tweets.
There has been a lot of work on the classification of Twitter messages. Vilares et al. [8] categorised Spanish tweets into 10 different topics such as films, soccer, economics, entertainment, etc. They used the TASS 2013 dataset that contains around 68,000 Spanish tweets and each tweet was manually assigned to at least one of the topics. (A tweet may belong to more than one topic.) They extracted various features related to bag-of-words, n-grams, part of speech tags and psychometric knowledge. The contribution of each feature group and the feature selection stage was analysed. They employed a sequential minimal optimisation (SMO) classifier in WEKA software. Dilrukshi et al. [9] took related tweets from several active news groups on Twitter. They manually classified each tweet into 12 groups and used this data as a training set. Assuming that each word was a feature, a feature vector was established with a bag-of-words model. They preferred SVM, as it supports large datasets.
Phuvipadawat and Murata [10] presented a method to find content similarity in microblogs. Twitter data were processed especially for the detection and tracking of breaking news using named entities in tweets to exploit content similarity. They also propose a network structure consisting of named entities and similar messages for this task.
Efron [11] presents problems encountered by developers of IR systems and researchers working on microblog platforms. He describes different problems on microblog data such as sentiment analysis, opinion mining, entity search, the modelling authority of people and the quality of tweets. One of the problems mentioned in that study is finding microblog users who are worth following among millions of users. For example, following even 1000 users creates an information overload and, in this case, it might be difficult to find the most relevant messages. In that study, a collection consisting of 2.3 million tweets was used. Opinions on users’ purpose for using microblogs are expressed; for example, searching questions about a product they will buy and reading answers to these questions.
There has been a lot of effort in sentiment analysis of microblog messages. Martínez-Cámara et al. [14] constructed a corpus of Spanish tweets containing 34,634 tweets classified as positive and negative based on emoticons. They analysed the performance of support vector machine (SVM), logistic regression and Naïve Bayes classifiers with different word weighting mechanisms on sentiment classification. They found that a SVM classifier with term frequency weighting achieves the best F-measure. Torunoğlu et al. [15] claims that, according to their sentiment analysis on tweets, it is possible to improve the relative performance of Naïve Bayes by using Wikipedia data for the classification of emotions. If a word used in a tweet was available in article titles in Wikipedia, other words in the relevant title were added to the tweet, which was thus enriched.
2.1. Studies on Turkish tweets
Studies made on Turkish tweets are summarised as follows.
Şimşek and Özdemir [16] selected sentimental words from the tweet set they formed by means of data mining techniques, and performed an analysis to determine whether there was a correlation between sentiments of tweets and the Turkish stock market index. In a similar study, Kayahan et al. [17] tested the consistency of rating results of TV shows on the basis of tweets using the sentiment analysis method. They expressed that the most significant part of the study was to polarise tweets and process words in tweets. They stated that handling abbreviations used in tweets is a problem and, to eliminate this problem, they used the edit distance method and many regular expressions.
Çetin and Amasyalı [18] made a sentiment analysis with two datasets consisting of Turkish tweets from a private company in the telecommunication sector. These sets were manually grouped into three different classes: positive, negative and neutral. They made a comparative analysis of supervised and unsupervised term-weighting methods used in text classification. In their comparison, they analysed the performance of various classification algorithms with word roots and character n-grams. They found that, among the algorithms they used, SMO had the highest classification accuracy.
Cengiz and Diri [19] targeted their study to find and reveal tweets with real questions among all tweets in Turkish. Their primary purpose is to develop a system that automatically finds these questions and generate automatic answers. In order to measure the success of the system, precision, recall and F-measure values were computed. They achieved a 0.80 F-measure on this classification task.
Ozdikis et al. [20] tried to develop methods for event detection (an application of data mining aiming to automatically discover unknown events) on Twitter. They used document similarity and clustering algorithms for this purpose. Küçük et al. [21] analysed the performance of a named-entity recognition system developed for news articles on Turkish tweets. They built a Turkish tweet dataset and manually tagged named entities. Their experimental results show that there is a need for further study to improve the performance of named-entity recognition tasks for Turkish tweets.
2.2. Studies on the relationship between tweets and news reports
There are several other studies that focus on the relationship between tweets and news reports. McCreadie et al. [12] tried to measure the influence of integrating news-related tweets into the search results of a news-related query. They also compared this approach with the integration of results from a news-oriented vertical search engine. They determined possible news articles by using Google Trends, bit.ly news sources and then manually selected 199 queries related to these news reports. They hired people and asked them about the extent to which the results of searches in Bing, Twitter and Wikipedia are related to the query/news and to what extend it was satisfactory.
Phuvipadawat and Murata [13] determined breaking news on Twitter, thanks to users who tweeted with the hashtag #breakingnews, and developed a method that gathered, grouped, ranked and followed them up. Since it was difficult to compare the similarity of short messages, they used proper nouns and ranked each group in terms of popularity and reliability. At first, the target set was downsized by determining users who used the hashtag #breakingnews and then the messages of only these users were analysed. News-related tweets were found on the basis of emotional expressions (awesome, oh my God, etc.) or 5W1H data about the news in English. The most common things users do on Twitter (use tagging, share a link, retweet, hashtag) were also analysed. Conversation between users is found by means of user tagging. They state that hashtags help to group similar tweets.
Bandari et al. [22] try to predict the popularity of news topics in social media before their release. They utilise features extracted from news. In a recent work, Wu and Shen [23] also try to predict news popularity on Twitter. They first analyse how news is propagated from new media sources (from CNN, BBC etc. accounts in Twitter). Then they propose a popularity prediction model in order to identify, within a few seconds after publishing, whether news will be popular or not on Twitter. They find that news with negative sentiment tends to become more popular. In this study, we also analyse the popularity of news but we analyse tweets after news has been released (1–3 days). We exploit features extracted from both news and relevant tweets. Two recent studies [24, 25] try to link tweets and related news articles in order to enrich short text tweet messages. Guo et al. [24] propose a graph-based approach where tweets and news are interconnected by hashtags, named entities and common words. Their aim is to find the related news report for a tweet. On the other hand, in our problem setup, we have the news article and we produce a training set of tweets referring to this news. We formalise our problem as a classification task and try to find other related tweets using our training tweet set and news content. Abel et al. [25] also propose methods to find a related news article for a particular tweet. Their URL-based and content-based strategies are similar to our work. We also use a URL-based strategy but only for constructing the training set. In this study, we define the task of finding relevant tweets for a news report as a classification problem. Our textual similarity approach is also different from the content-based strategy in [25]. While they use only the news content in their study, we represent relevant tweets and their related news content as a single document and compute the textual similarity to tweets. Finally, we work with Turkish tweets and apply preprocessing techniques required for the Turkish language before the feature extraction step.
3. Background
In this section, we give background information about text classification approaches in the literature and also present the basics of anomaly/outlier detection.
3.1. Text classification approaches
Text classification is a well-known problem for many years and there are a lot of efforts to solve this problem. There are various survey studies [26–28] reviewing text classification approaches in the literature. Text is a high dimensional and sparse data [27]. Words are used as features most of the time. Each distinct word in a text collection forms the feature space. Since the total number of distinct words in a collection can reach to millions, feature dimensionality reduction is an important step. Two trivial steps towards this aim are stopword removal and stemming. It is also possible to apply other filtering mechanisms based on frequency of words in the collection or by using feature distinctiveness measures such as information gain, gini index, chi-square test [27], etc. Decision trees, rule based classifiers, support vector machines, neural network classifiers and Bayes classifiers are used for text classification tasks in the literature [27]. We briefly mention three of them we applied in this study in the following paragraphs.
Naïve Bayes classifier estimates the probability of each class, given an instance with several features [29]. Assume that we try to classify a document di represented by words [w1, w2, …, wn] into classes C1 and C2. Naïve Bayes classifier applies the following formula to calculate probabilities:
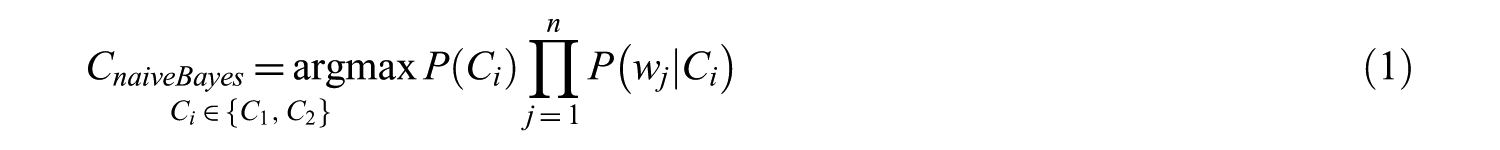
In this formula (Eq. 1), prior probabilities (P(Ci)) can be estimated based on the frequency of documents in C1 and C2 in the training set. The conditional probability of each word appearing in a document given that the document belongs to a class is estimated by the ratio of frequency of that word in the class to the frequency in all training instances. If continuous values are used with different feature weighting approaches such as term frequency (TF) or term frequency-inverse document frequency (TF-IDF), then conditional probability can be estimated by fitting values into a Gaussian (normal) distribution.
Decision tree classifiers are also used for text classification tasks. In this type of classifier, feature space is decomposed into a hierarchical structure (tree) where each node represents a test on an attribute. In text classification, each node in the decision tree tests absence or presence of words in a document. Leaf nodes represent the class label based on the majority class among the training instances reaching to this node. Decision tree classifiers are used as baselines in text classification experiments [27].
SVM classifiers [30] try to find a separating hyperplane between different classes in the training data. This type of classifier is applied to text classification and it is shown that SVM can cope with high dimensional and sparse textual data [31].
3.2. Anomaly/outlier detection
In the ‘anomaly/outlier detection’ problem in the literature, there are generally many examples from the class named ‘normal’, while the number of examples accepted as ‘anomaly/outlier’ is considerably low. Since the number of examples from normal and anomaly classes is very different, different methods are used instead of binary classification [32]. If a training set includes both examples from the normal class and examples from the anomaly/outlier class, supervised anomaly detection methods are used. If, however, it includes only examples from the normal class, as in this study, semi-supervised anomaly detection methods are used.
In the semi-supervised anomaly detection method, examples from the normal class are used and a probability distribution function is extracted from this set. Probability for a test instance to be included in the normal class is calculated on the basis of this function and those below a certain threshold value are classified as ‘anomaly/outlier’. In order to find the overall probability distribution function, each feature is individually evaluated as an independent variable. The distribution of values for each feature is identified with a Gaussian (normal) distribution and mean and standard deviation values are found. The probability density function of a normal distribution with mean (
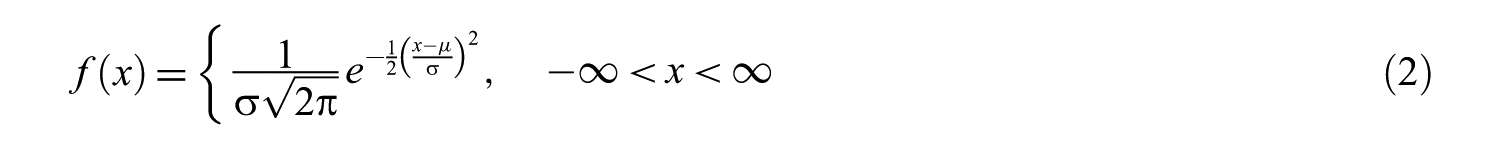
4. Finding news-related tweets
It is important to obtain public opinion about a news article. Twitter is an important medium for people to share ideas. Our aim is to find tweets about newspaper reports and measure the popularity of these reports on Twitter. This also enables sentiment analysis techniques on news-related tweets so that public opinion about news/events could be obtained.
We define our research problem to obtain our aim as follows: given a news report published in a website, find all tweets related to this news. We formulated this task as a classification problem. We build classifiers that predict whether a tweet is related to a news article or not. Our solution consists of three stages. In the first stage, we form our training set, which consists of tweets that are known/expected to be news-related. We also add news content into our training set. In the next stage, we preprocess tweets by applying stopword removal, tweets keyword processing (for hashtags, re-tweets), and stemming. In the final stage, we apply binary classification, anomaly detection and propose textual similarity approach. Thus, the popularity of current newspaper articles on Twitter is determined. In the following subsections, we present each stage of our method.
4.1. Forming the training tweet set
A two-stage method is determined in order to find tweets that are definitely related to a news report. Tweets that are linked to any URL are found in the first stage. In the second stage, within this dataset, only the ones with a news URL are selected. Additionally, each sentence in the news text is considered as a tweet related to the news.
Figure 1 shows the general procedure of forming the training tweet set. Tweets drawn from Twitter by means of search API are recorded in the database. Tweets linked to a news URL are determined and used as the training set. News content is divided into sentences, which are considered tweets about the news (as shown in Figure 1), and added to the training dataset.
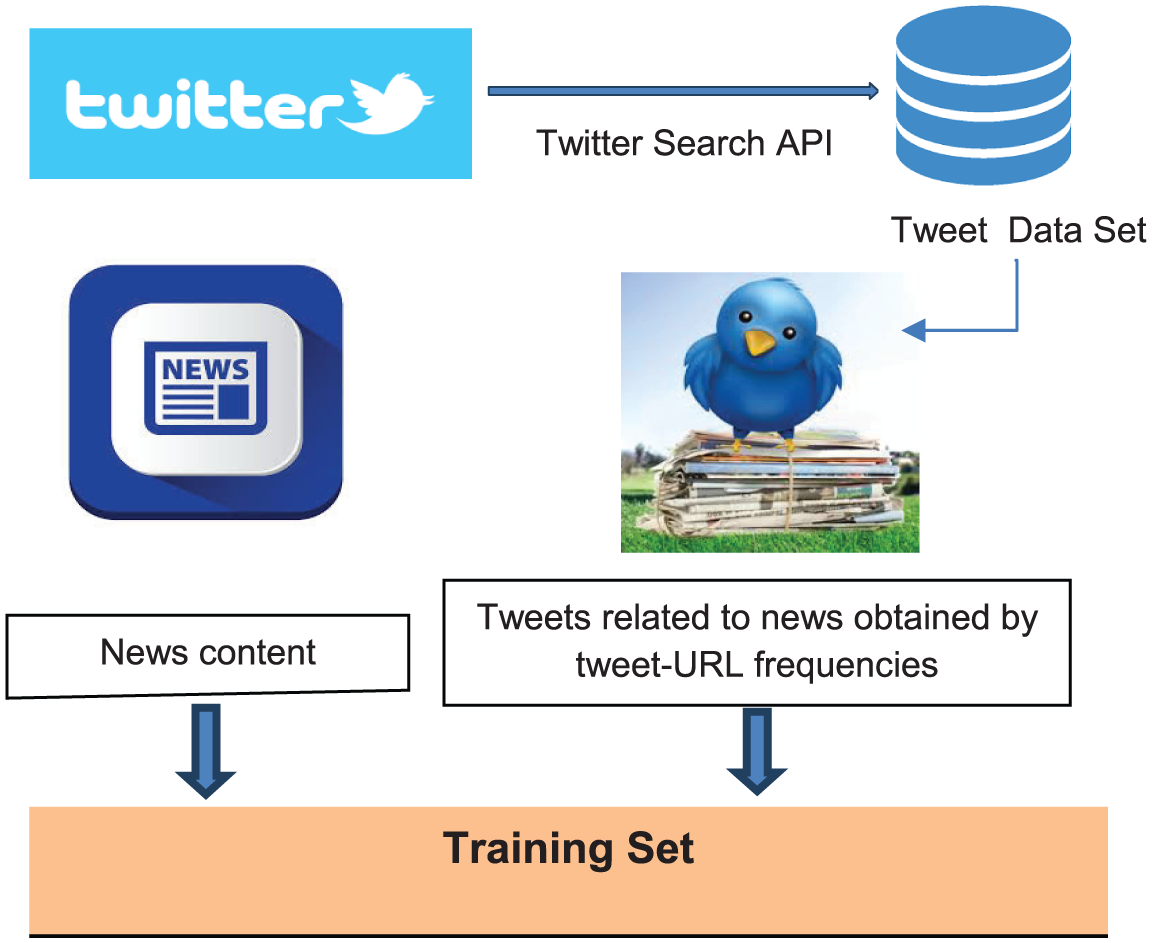
Forming the training set.
A news report may be linked to a tweet by means of the URL link of the newspaper article included in the tweet content. Due to the 140-character limitation, Twitter uses shortened URLs in the form of ‘http://t.co/’ instead of the long URL (http://www.hurriyet.com.tr/teknoloji/29784440.asp) 1 . Long URL versions of this shortened format are provided by Twitter API as ‘expanded URL’ data. An example is given Figure 2. There are two ways to add a news link to a tweet. In the first method, the user may share the news article by means of the ‘Share on Twitter’ button on the news page on the newspaper’s website. With this button, the title and URL of the news report is automatically added to the tweet as shown in Figure 2. In the second method, the user may copy the URL of the article to a manually written tweet.
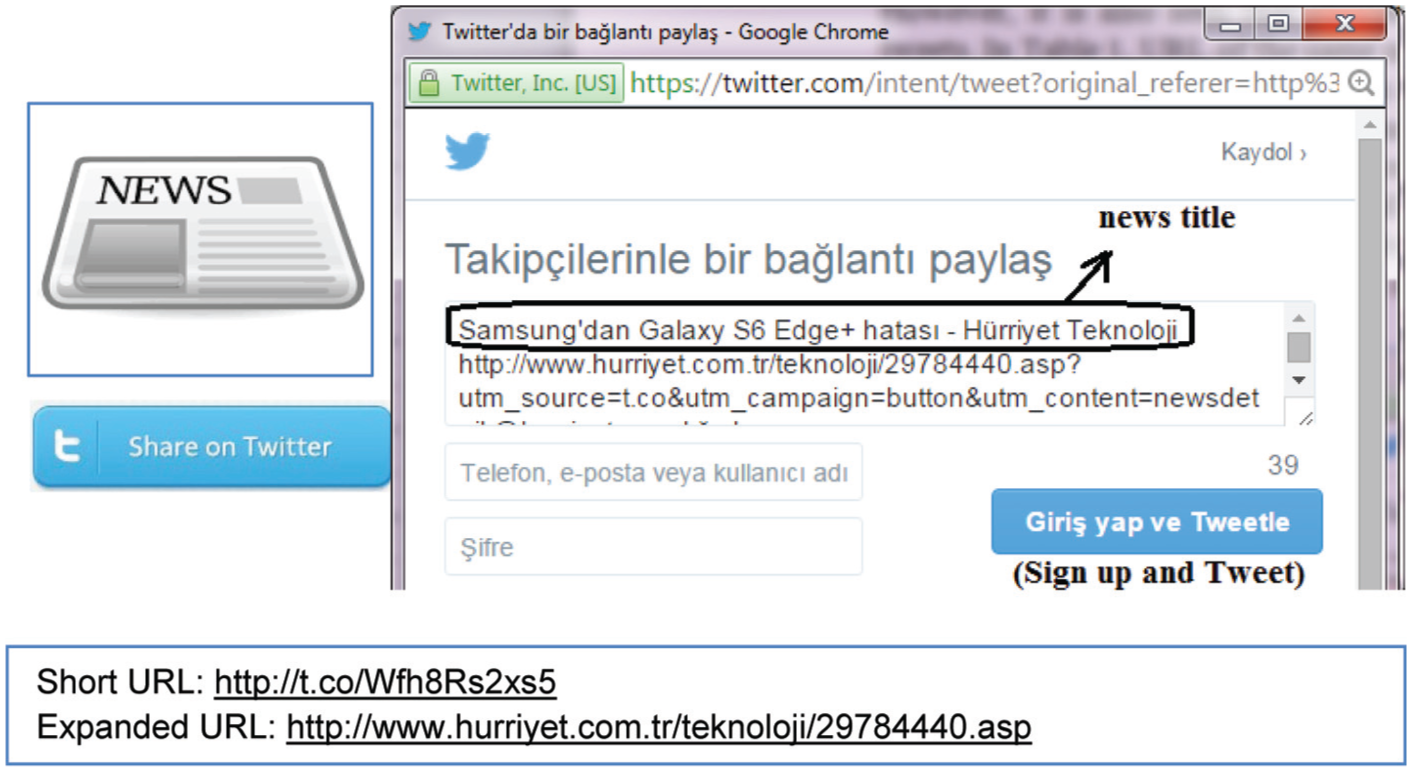
An example tweet sent by the ‘Share on Twitter’ button.
However, it is also seen that shortened URLs are used in the expanded URL areas of some tweets. In Table 1, the URL of the same newspaper article is used as different shortened URLs in each tweet. While the news link is accessed from the expanded URL area in the first three tweets, this area contains the shortened URL in the last tweet. Finding tweets related to the same news article requires the standard long versions of these URLs. For this purpose, the shortened URLs in the expanded URL area are determined in the whole dataset. They are turned into long URLs, and the dataset is updated. Thus, different URLs of a news link are turned into standard URLs.
Expanded URL versions of shortened URLs.

Popular news candidates among newspaper articles to be used in classification tests are determined through the tweet dataset. First, all tweets are grouped according to the expanded URL area (after obtaining the long version of short URLs) and the number of tweets in each group is calculated. As shown in Figure 3, these URLs are listed from high to low, based on the number of tweets. A list of national newspapers in Turkey is determined in order to select only the tweets related to news articles published by newspapers on this list. Tweets containing URL addresses in this list are filtered, and articles are ranked by the number of tweets as shown in the figure. By means of this process, the most popular news articles are found.

Finding popular news article candidates.
While relevant tweets needed for forming the training set in classification processes may be found by the URL method, irrelevant examples are difficult to determine. There are millions of tweets with varying contents that are not relevant to a news report. Therefore, it is difficult to obtain tweets representing the negative class (tweets not related to targeted news reports) and so our aim is to ‘teach’ the system by using only those tweets related to a particular news article (positive class). Each news report is considered to be a different class and classification experiments are performed separately. We determined that tweets related to a news report obtained from the dataset and used in the training set mainly have repeated contents. If a user does not add or remove something to or from the existing content of tweets shared by means of the ‘Share on Twitter’ button (as shown in Figure 2), tweet content remains the same. Another reason for content repetition is that a tweet is shared on Twitter by other users through retweet. In this case, tweets with the same content are repeated. After data preprocessing on tweet contents, the number of different tweets to be used in the training set decreases. Therefore, we plan to use news texts to increase the number of tweets with distinct contents. The content of a news article is divided into sentences and are considered to be tweets and then used in the training set. Thus, it is possible to form a training set for a news article in three different forms. The first one is formed with tweets obtained from the news-related dataset by the URL method, the second one is formed with the text of the news article and the third one is formed by the combination of these two.
4.2. Feature extraction
This section describes preprocessing to be performed on tweets during the formation of training and test sets to be used in tweet classification processes and feature extraction methods. Using correct features in classification processes makes a significant impact on success. Generally, words are used as features in automatic text classification literature and it is claimed that more complex features do not make a significant difference [26]. Tweets used in our study have Turkish texts. Various classification studies on Turkish tweet datasets [33] also show that word-based features are successful. A word-based method is preferred in the feature extraction of tweet texts. Each word in a tweet text is accepted as a feature. As seen in Figure 4, tweet text is first turned into lowercase and divided into words. Then, Turkish stopwords that do not have a direct influence on the meaning of the sentence are removed. Twitter jargon (#, @, http, rt), punctuation and similar special characters are deleted. Considering that words may have been misspelled, a spell correction function is performed. This process involves a dictionary reference that contains correct versions of misspelled words. For example, the word written as ‘traınıng’ is corrected to ‘training’. Another significant point is that several different words have the same root due to the agglutinative nature of the Turkish language. A word with the same meaning may be written in different forms. For example, the word anayasa (constitution) may be used as anayasam (my constitution), anayasamız (our constitution), anayasamızın (of our constitution), anayasamızda (in our constitution), etc. Stemming allows the use of all words with the same meaning as a single feature. This process is performed by means of the Nüve morphological analyser 2 developed for Turkish and it contains around 1.2 million words. Thus, each word in tweet texts (unigram) is used as a feature and included in the training set. Feature vectors are calculated by returning a ‘1’ if these features are available in each tweet or ‘0’ if they are not. Classification processes are performed by using these feature vectors. Note that it is also possible to use other feature weighting approaches such as TF or TF-IDF instead of binary weighting. Since tweets are very short texts like one sentence, it is very unlikely that a word appears more than once in a tweet. Therefore, we can assume that our binary weighting also corresponds to TF weighting. We also try IDF weighting in our experiments but we could not obtain better results than binary weighting.

Tweet preprocessing steps.
4.3. Binary classifiers for tweet classification
In this section, different classification algorithms are studied by using the training set formed for finding news-related tweets. Training sets needed for classification are separately prepared for each news article. Different classifier models are learned for each article. Thus, binary classification is used in this study instead of multi-class classification. As described in the previous section, the training set of an article is automatically formed by using tweets obtained from the relevant dataset by the URL method, the text of the article, or a combination of both.
It is not possible to automatically include irrelevant examples in the training set because there is a large pool of tweets not related to the news. Therefore, we add artificial instances that are denoted as vectors with only ‘0’ feature values to the training set file. These instances represent irrelevant examples. The number of artificial instances is half of the number of relevant examples. We experimented with different numbers, but this configuration gives the best result. At this point, by virtue of the feature extraction method, a feature existing in the vector is expressed by ‘1’ and a non-existing feature is expressed by ‘0’. As the number of ‘1’s in a feature vector of a tweet in the training set decreases, its relevance to the article decreases. In other words, a higher number of ‘0’s indicates lower relevance. In this way, after irrelevant examples are included in the training set to be used for training, we performed binary classification tests with different algorithms. It should be noted that artificial irrelevant examples are added only to the training set; they are not added to the test set. Therefore, there will be no impact on the real tweet data, from which performance measurements will be extracted.
Alternatively, when building a classifier for a news article, it is also possible to use tweets of other news in our dataset as irrelevant instances. However, this approach yields lower accuracy.
4.4. Anomaly/outlier detection for finding news-related tweets
As explained in the previous section, there are problems with automatically determining tweets not related to a news article (negative examples) within the whole tweet pool. Therefore, the study was conducted using methods that find whether tweets posted on Twitter are related to the news by using only the news-related (positive) examples. We use anomaly detection for this purpose.
In our study, by using the function in Eq. 2 (Section 3.2), mean (
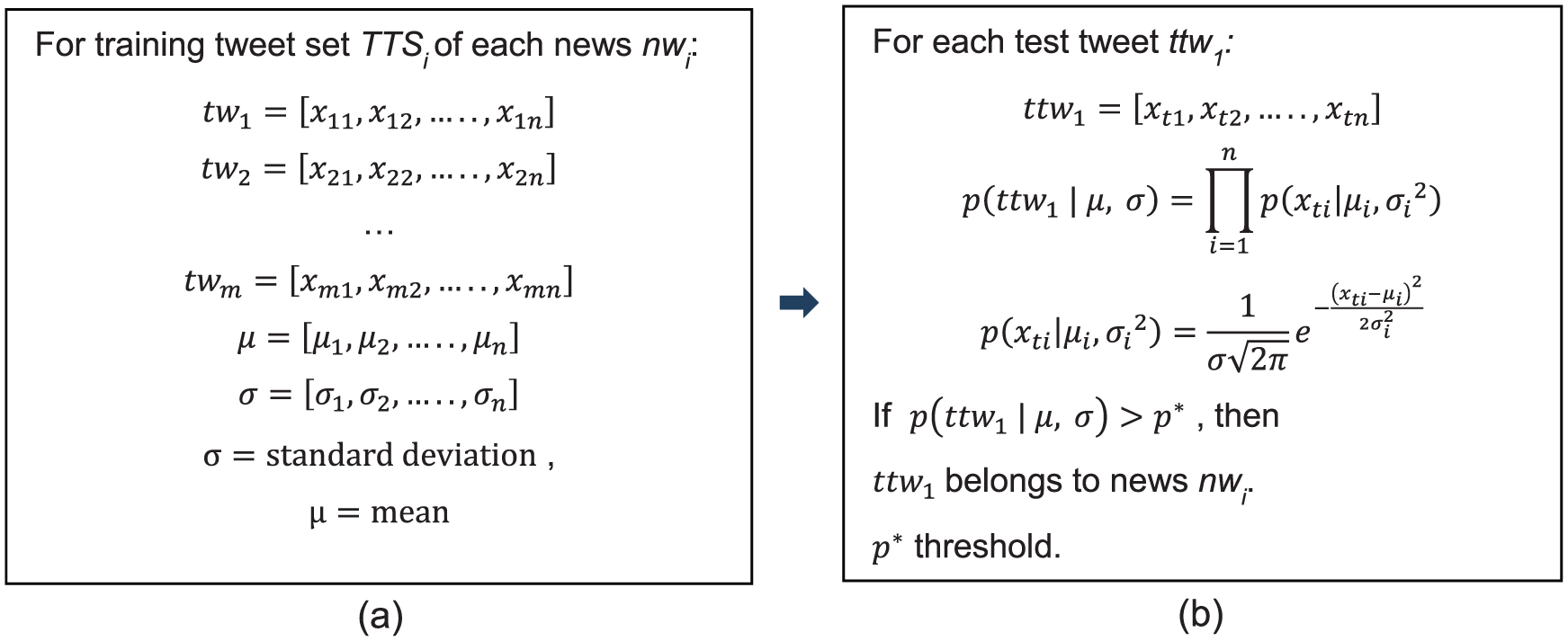
(a) Finding a probability distribution function from news-related tweets. (b) Calculating probability for test tweets to be included in the distribution.
4.5. Textual similarity approach
In this subsection, we propose a textual similarity based approach for finding tweets related to a news article. The whole training set is considered to be a document and each tweet in the test tweet set is considered to be a query. The Vector Space Model, a method frequently used in finding the most relevant answers to a query in the information retrieval literature, is used in this method. In this model, documents and queries are expressed as a vector and the most relevant documents of a query are found by calculating the cosine similarity of the angle between query vector and document vectors. For a news nwi, the training tweet document is the union of all n tweets in the training tweet set (TTSi) of this news as shown below.
Training tweet set (TTSi) of news nwi = {twi1, twi2, twi3, … twin}
Training tweet document (TTDi) of news nwi =
The similarity of any test tweet twtest to news nwi is calculated by means of cosine similarity between the training tweet document of the news and twtest as shown below (Eq. 3).
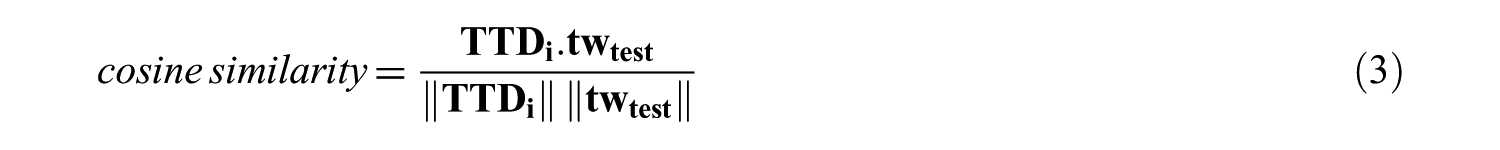
The training tweet document vector
In this method, a certain threshold (as in the case of anomaly detection) is chosen to determine news-related tweets among test tweets. Test tweets above this threshold are considered to be related to the news.
As a theoretical view of this problem, the textual similarity approach actually tries to compute the probability of a test tweet twtest to belong to the relevant set R as following formula in Eq. 4. For a threshold τ, if

5. Experimental results
In this section, we first explain how we obtain our tweet dataset and how we preprocess the data and conclude with our experimental results.
5.1. Twitter data retrieval and processing
A dataset used for the experiments in the study is constructed by means of a software program we have developed. The Twitter Search API library (provided by Twitter) is used in this software. In this library, there are some constraints imposed by Twitter. A maximum of 100 tweets per user may be retrieved in a query and a maximum of 180 queries may be processed in 15 min. With regard to these constraints, various tweet retrieval trials were performed in our study. During these trials, the ideal query period is determined considering that each query period is important, because tweets are repeated when the period is short, and the number of tweets decreases when the period is long. Besides period, we try to adjust filters for the Twitter search API library. Only tweets posted in Turkey and in Turkish are intended in the tweet dataset. In the case of tweets retrieved with only a geocode filter, the number of tweets whose source is the ‘Share on Twitter’ button, is very low. In this regard, retrieving data simultaneously with two different filters gives better results. The first filter is ‘geocode:38.963745,35.243322,500mi lang:tr’‘source:tweet_button’, and the second filter is ‘geocode:38.963745,35.243322,500mi lang:tr’. The first filter retrieves tweets posted in Turkey (in Turkish) and via the ‘Share on Twitter’ button (so that we can obtain most of the news-related tweets sent by this button), and the second filter retrieves all tweets posted in Turkey and in Turkish.
Two different datasets were formed for the 3 days prior to and following local elections held on 30 March 2014 in Turkey, when Twitter was used intensively there. The first tweet dataset, which is formed by combining tweets retrieved with two different filters on 27–29 March 2014 and making them distinct, contains 1,317,266 tweets; the second dataset covering the period 31 March to 2 April 2014 contains 1,456,935 tweets.
As described in section 4, the dataset includes tweets where data in the expanded URL area is given as shortened URLs. In this area, shortened URL data are turned into long URLs. For example, the shortened URL http://bit.ly/1rVSQLb is turned into the long URL format ‘http://www.hurriyet.com.tr/gundem/26116908.asp’. A total of 13,899 tweets are updated in the first dataset and 16,601 tweets are updated in the second one, after this process. As a consequence of these updates, we observed that there is an increase in the number of tweets with a URL of newspaper articles. It increases the number of news-related examples to be used in the training set.
As explained in section 4.1, tweets in the dataset are grouped on the basis of URLs and the number of tweets in each group was obtained. They were filtered by 11 national newspapers listed in Table 2 and listed on a decreasing basis according to the number of tweets (Figure 3). After preprocessing during the formation of the training set, the number of different tweets related to the news decreased due to tweets which are shared by different users but have the same content. Table 3 shows the dramatic decrease in the number of tweets of the first 10 news articles (N1 … N10).
List of national newspapers.

Number of news-related tweets with different content after preprocessing stage.

Articles without an adequate number of relevant tweets to be used in the training set were not used in our experiments. On the basis of these criteria, tests are performed on 15 news reports from the first dataset and 12 news reports from the second dataset.
5.2. Formation of training set and test set
The primary aim of our study is to use tweets with the same URL of a news article within a tweet dataset and thus find other tweets related to this article in terms of content in the tweet pool. The training set to be used in our experiments is formed in three different ways: tweets obtained via the URL method, the text of this news article or a combination of the two (Figure 1).
The following steps were taken to form the test set for each news report used in our experiments. First, tweets found to be related to the news with the relevant URL were filtered (to exclude tweets used in the training set from the test set) and the remaining tweets were indexed by means of Lucene 3 , an open-source search engine library, known in the information retrieval literature. In the next stage, news title was used as the query and tweets were obtained as the query result from Lucene. These tweets were manually checked and marked as relevant and irrelevant. A test set consisting of 100 tweets for each news article included 50 relevant and 50 irrelevant tweets. (So the total number of test tweets for all 27 news articles in our dataset was 2700). Relevant tweets were then selected manually among top-ranking search results on the Lucene index and relevant to the news. Irrelevant tweets were selected in two ways, being ‘hard’ irrelevant and ‘easy’ irrelevant. Among the query results from Lucene, 25 tweets that had at least one word from the news title and were irrelevant to the news were considered to be hard irrelevant. We constructed an easy irrelevant set by randomly selecting 25 tweets from the tweet pool that do not have any word from the news title and were irrelevant in terms of meaning. Considering that different individuals may post tweets with the same content, tweets with the same content were eliminated and identified as a single tweet.
5.3. Tweet classification results
This section includes results of our experiments performed with three different methods, which are binary classification, anomaly detection and textual similarity, by using the same test set. As described in the feature extraction step, words are used as features in the training and test sets. The use of all different words as features and the exclusion of words with low frequency is tried, and the best result is obtained from the use of words that are found at least twice. Results in this study are obtained from experiments performed with training and test sets formed with this method.
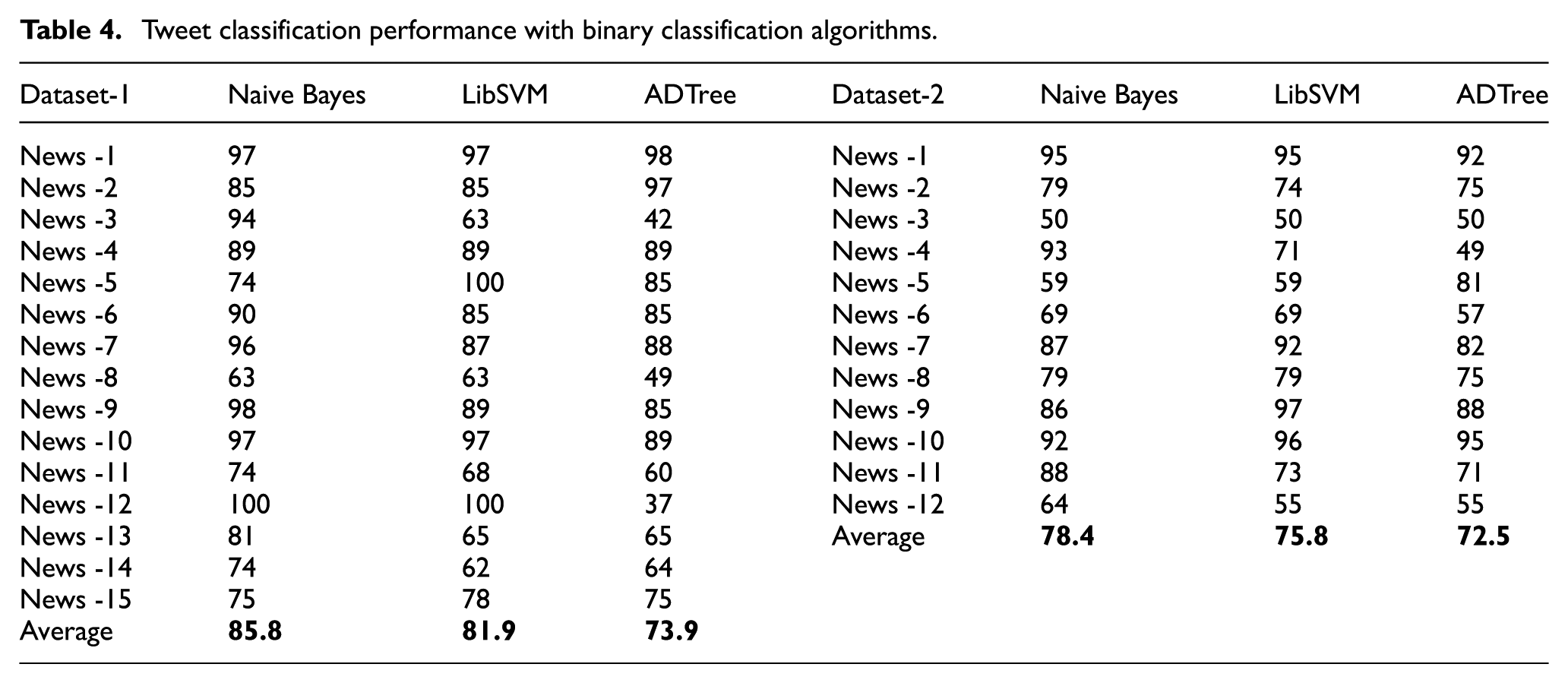
Tweet classification experiments are first made with binary classification algorithms. In these tests, only tweets with URLs are used as the training set. Table 4 shows results obtained with Naïve Bayes, libSVM (with linear kernel) and ADTree algorithms, which give the best results in this approach where many algorithms included in the WEKA [34] tool are tested. As shown in Table 4, two different datasets are evaluated within themselves and average recognition rates of algorithms are specified. We observed that Naïve Bayes algorithm has the best classification success rate (85.8%). The first dataset performance of this classifier is in the range of 63–100% for different news reports. The trend is similar for the second dataset, Naïve Bayes being the best, but accuracies are lower. We use the Naïve Bayes classifier as the binary classifier for comparison with other methods (anomaly and textual similarity) since it achieves the highest accuracy.
Tweet classification performance with binary classification algorithms.
We performed additional experiments (Table 5) in order to measure the effect of preprocessing on tweet classification results. Our tweet preprocessing stage (as shown in Figure 4) includes tokenisation and lowercase, stopword removal, tweet keywords (#, @, http, rt) processing, spell correction, and stemming. All stages up to spell correction and stemming are low level preprocessing and very straightforward. Therefore, we only measure the effect of spell correction and stemming in this experiment. So, the column entitled ‘Without preprocessing’ in Table 5 actually includes low level preprocessing steps (tokenisation and lowercase, stopword removal, tweets keyword processing). Table 5 shows the effect of preprocessing on Naïve Bayes classifier with training set including only Tweets. It is seen that preprocessing step improves the classifier accuracy by about 2–3%.
The effect of preprocessing step on tweet classification accuracy.
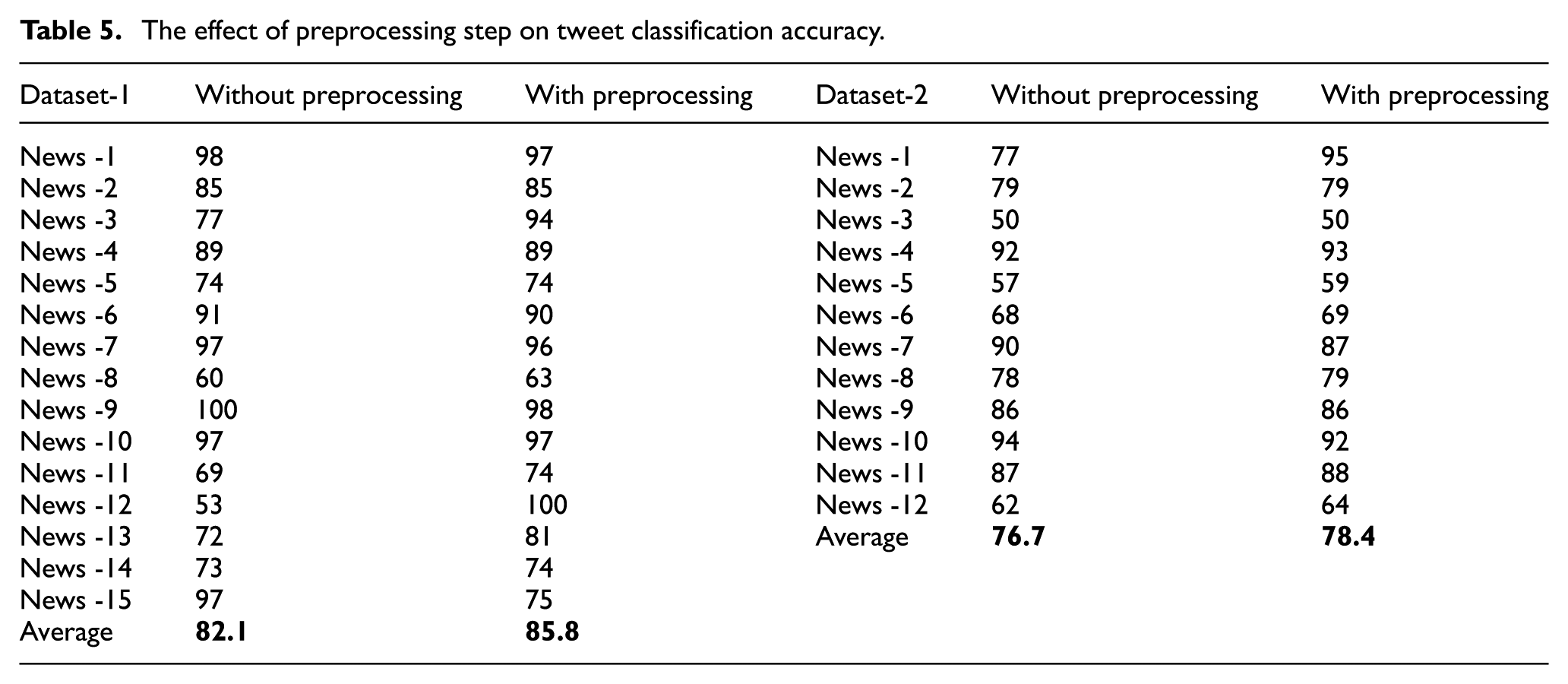
Table 6 shows the results of classification made with anomaly detection and textual similarity methods, where the training set includes only the news-related tweets and the test set includes relevant and irrelevant tweets. To compare three different methods, Naïve Bayes, anomaly and similarity results are given together in Table 6. As seen in the table, the success rate is 80.1% for classification with anomaly detection, while it is 94.3% for the similarity method. This result shows that even though Naïve Bayes classifier achieves higher accuracy than anomaly, textual similarity method on tweet texts provides the best result (Table 6). The results for the second dataset have the same trend but classification performance of methods is better for Dataset-1.
Tweet classification performances with Naïve Bayes, anomaly and similarity methods.
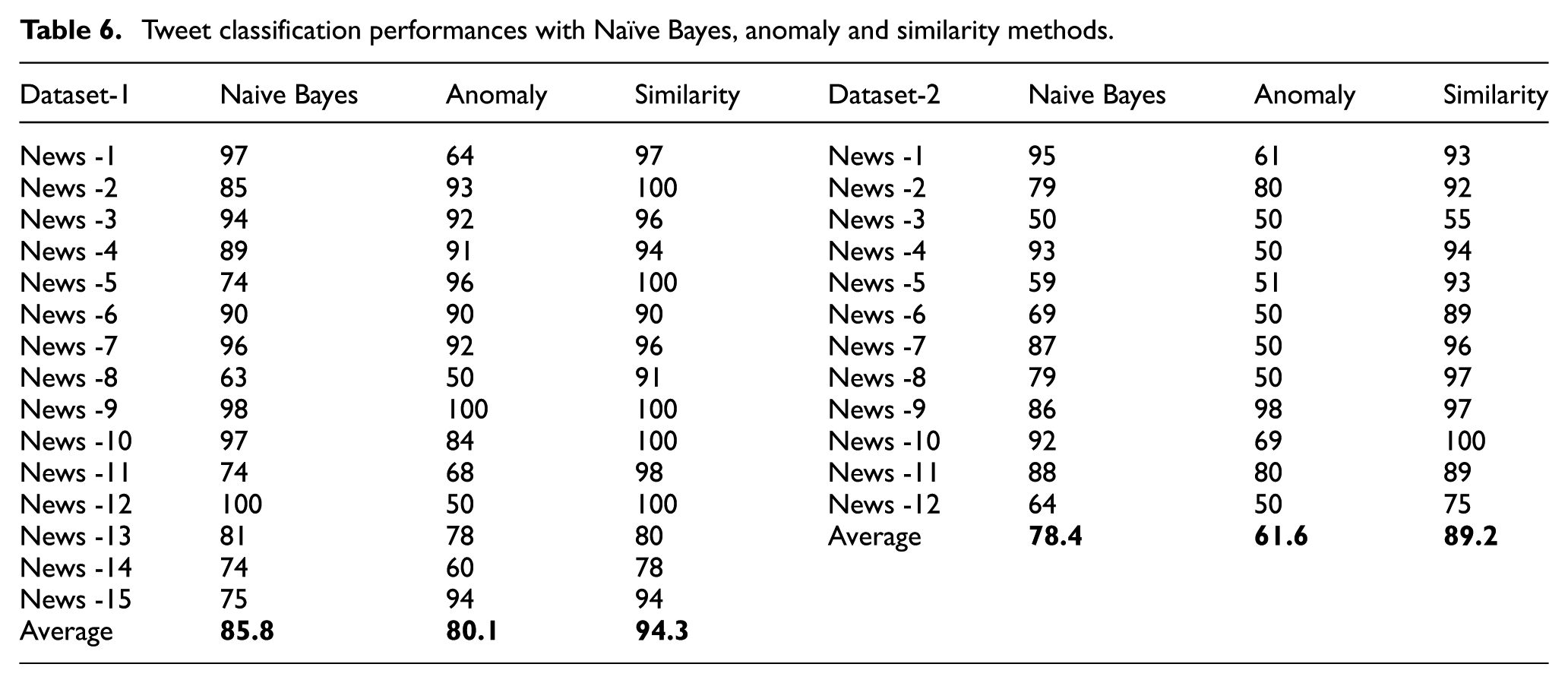
As specified before, a threshold parameter is used in deciding whether each test tweet is related to the news (sections 4.4 and 4.5). Results given in Table 6 are obtained by using the ideal thresholds for both methods (anomaly detection and textual similarity). Even when ideal thresholds are used in anomaly methods, results with low recognition rates are obtained. Therefore, detailed examinations are made only on our textual similarity method in the following sections.
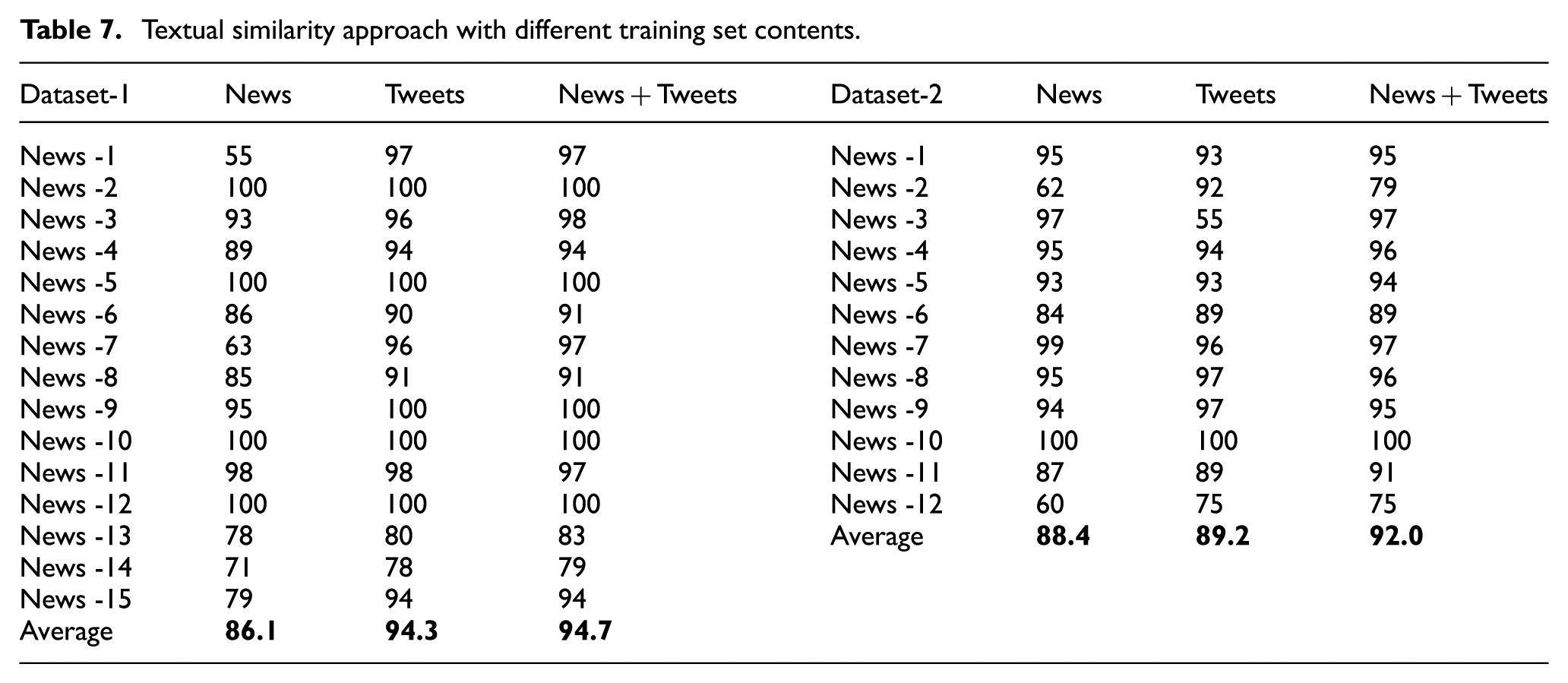
In the above-specified experimental results, we use only tweets that have news URLs. In section 4.1, we propose adding sentences extracted from news content as tweets to our training set. Here, the impact of these two different information sources (tweets and news content) is analysed in detail. For this purpose, the success of tweet classification by using only news content and News+Tweets is measured. Table 7 contains the recognition rates of textual similarity approach for only news content, only tweets and News+Tweets for the first and the second dataset. These results show that the success of tweets with a news URL in the first dataset is higher than those with news content. Even though, both information sources have similar success rates in the second dataset, tweets are slightly better than news content. It is expected that formal news text is not very successful since it is difficult to match with tweets containing informal language. However, differences in accuracies are not very large especially for the second dataset. We observe that our news-related tweets use more formal language than the language used in general tweets. Therefore, we believe that news content is also an important resource for finding news-related tweets. On the other hand, the combination of these two sources (News+Tweets) gives the best result (absolute increases of 0.4% and 1.8% in the first and second datasets, respectively). This result shows that the problem of a considerable decrease in the number of tweets in the training set due to many tweets with the same content may be solved to some extent by adding the news content.
Textual similarity approach with different training set contents.
We experiment with fixed threshold values instead of an ideal threshold with the textual similarity method. Figure 6 shows average recognition rates in the first dataset with different thresholds. As is known, cosine similarity used in our similarity method is in the range of 0–1. According to results shown in Figure 6, the highest recognition rate is obtained with a threshold of 0.25 is 87.67%.

Recognition rate of the textual similarity method using different threshold parameters.
Finally, we also plot the receiver operating characteristic (ROC) curve for our textual similarity approach (for the first dataset) in Figure 7. We also show the random guessing performance as dashed line. It is seen that our approach performs far better than a random classifier. We also show the best threshold point with a star on the figure. We found that the best threshold in this case is also 0.25 as we found in Figure 6 using recognition rate as metric. Area under curve (AUC) of this ROC plot is computed as 0.93 while AUC curves for each different news are in the range of 0.87–1.
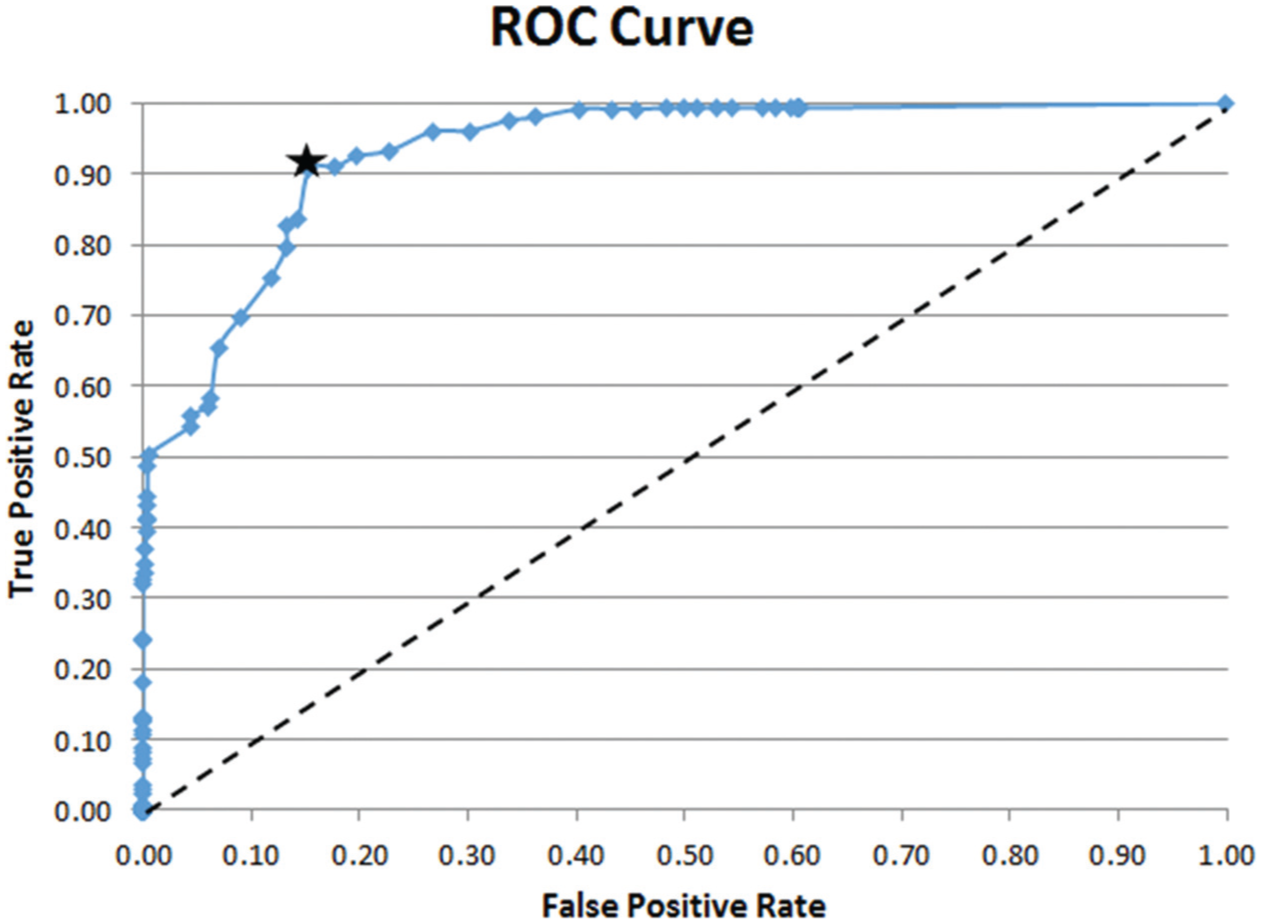
ROC curve of the textual similarity method.
6. Conclusion and future work
There were certain problems in our attempt to measure the popularity of national newspaper articles by using Twitter. First of all, we encountered some constraints in Twitter service when we try to obtain the dataset for the study. Furthermore, there were problems in forming the training set because of the repetition of the same content in tweets related to popular news. Another point is that tweets not related to the news had a very wide range of topics and it was difficult to determine examples needed for the training set. There were also problems caused by the structure of the Turkish language.
In this study, we attempted to find solutions to the above-mentioned problems and we applied various methods to increase success. We tried to reach our research goal through methods detailed in the fourth section. First of all, popular news article candidates on Twitter were obtained by means of the ‘Share on Twitter’ button. Then, methods were developed to find other tweets that were not shared in that manner, but still had the content of the news. Tweets which were obtained via classifications with a training set formed by using the news text and tweet content were important for determining Twitter-based interest levels in the news. This approach, which takes tweet content into consideration, might give more reliable results when compared to methods like hashtag used in Twitter analyses.
In this study, tweets were classified by using a word-based natural language processing approach on Turkish Twitter data. Three classification methods (binary classification, anomaly detection and textual similarity) were tried in order to find other tweets that might be related to a news article by using tweets automatically detected to be related to the news article in the training set. The best result was obtained via the textual similarity method with a success rate of 94.7% (upper bound) with an ideal threshold; it was followed by using a Naïve Bayes algorithm with a success rate of 85.8%.
Classification with tweets containing a link to a news were more successful when they were used alone in determining news-related tweets, and the recognition percentage increased when news text was added to the training set and used together with tweets containing a link to news. Considering the irregularity of Twitter data, character limitation and the constraints of the Turkish language, the performance obtained was considered to be successful.
There are some possible directions for future work. A spell correction mechanism specific to Turkish tweets could improve overall performance. Applying sentiment analysis techniques on news-related tweets could be another direction.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.