
Abstract
To satisfy a user’s complex requirements, Resource Description Framework (RDF) Stream Processing (RSP) systems envision the fusion of remote RDF data with semantic streams, using common data models to query semantic streams continuously. While streaming data are changing at a high rate and are pushed into RSP systems, the remote RDF data are retrieved from different remote sources. With the growth of SPARQL endpoints that provide access to remote RDF data, RSP systems can easily integrate the remote data with streams. Such integration provides new opportunities for mixing static (or quasi-static) data with streams on a large scale. However, the current RSP systems do not offer any optimisation for the integration. In this article, we present an adaptive plan-based approach to efficiently integrate sematic streams with the static data from a remote source. We create a query execution plan based on temporal constraints among constituent services for the timely acquisition of remote data. To predict the change of remote sources in real time, we propose an adaptive process of detecting a source update, forecasting the update in the future, deciding a new plan to obtain remote data and reacting to a new plan. We extend a SPARQL query with operators for describing the multiple strategies of the proposed adaptive process. Experimental results show that our approach is more efficient than the conventional RSP systems in distributed settings.
1. Introduction
With a proliferation of stream-based sources such as sensors, feeds and vehicle activity streams (e.g. global positioning system (GPS) locations), many applications face new challenges in acquiring, processing and managing streaming data. In response to this flood of information, several researchers propose solutions for processing streams of information on-the-fly according to registered rules or queries [1]. Data stream management systems (DSMS) [2] and complex event processing (CEP) [3] systems handle data streams, providing a one-at-a-time processing in the presence of infinite flows of information generated at a high rate. All of the systems are based on a data model like a relational model, which supports operations on streams with a fixed structure. However, in a distributed environment where sources operate autonomously and independently, data streams are extremely heterogeneous both structurally and semantically. For example, Facebook streams are different from a stream produced from Twitter. Both streams are expressed using different formats and contain different types of information.
Recently, Resource Description Framework (RDF) Stream Processing (RSP) applications use a common model for continuously querying an RDF stream, 1 which consists of a potentially infinite sequence of RDF 2 triples. They extend both RDF and SPARQL 3 to incorporate the semantics of streaming data. RSP applications may evaluate continuous queries over a stream and background data [4]. Background data identify the RDF data that do not change (static) or change gradually (quasi-static) [5]. The usage of background data improves the quality of the results from a complex query. For example, in the case of a traffic congestion control application [6], traffic information can be categorised as an RDF stream and social events (e.g. music or political events) can be collected as static background data. By integrating the streaming traffic data with the background data about social events, the result of a complex query on a real-time traffic diagnosis would be improved since social events may be the main reason behind traffic congestion.
With the growth of SPARQL endpoints 4 in which services enable users to access background data in a remote repository, RSP systems can easily integrate the sematic data with their semantic streams. In particular, a federated SPARQL extension, 5 as introduced in SPARQL 1.1, enables a query author to invoke the service corresponding to the endpoint and obtain its response through a SERVICE clause. Such federated extension shifts the paradigm of query processing to a federated approach over distributed sources, commonly known as federated query processing [7]. This means that we can integrate heterogeneous sources as if they are residing in the same database. Obviously, to satisfy a user’s complex requirements in RSP applications, a SPARQL federated extension can achieve the on-the-fly integration of streaming data and the static background data distributed on the Web.
The current RSP engines like C-SPARQL [8], CQELS [9], SPARQLSTREAM [10] and EP-SPARQL [11], which extend the SPARQL language with operators to handle semantic streams, allow for registering continuous queries and evaluating the queries over RDF streams. The extended RSP query languages support the SPARQL federated extension. Thus, they support a set of services of SPARQL endpoints whenever evaluating a query with SERVICE clauses. However, they do not provide any optimisation for processing federated queries. In particular, since a set of services is delegated to a certain query processor similar to that of Jena automatic repeat request (ARQ), 6 they send a number of service requests to endpoints for each query evaluation. Endpoints may even regard the service requests as an attempt of denial-of-service attack. Consequently, we need an efficient optimisation technique of reducing the number of service requests.
The conventional methods suggest diverse optimisation techniques for a federated query with SERVICE clauses [12–16]. However, it is difficult for the existing RSP engines to embrace the existing optimisation techniques. First, while federated query processing utilises an RDF graph at a fixed time, RSP requires a sophisticated method of handling an RDF graph with a temporal annotation like a timestamp. Second, the existing RSP engines utilise push-based polices, in which streaming data are pushed quickly. While their policies work well on a fixed number of sources, they do not scale to a large number of remote sources like SPARQL endpoint federation. Third, due to scalability and administrative autonomy, sources operate independently and provide information based on an explicit request. For example, a SPARQL endpoint returns a response only when it receives a service request.
To cooperate with the existing optimisation techniques for a federated query, a poll-based protocol executes queries progressively over time and generates a stream of answers. Here, a materialised view [17] stores an intermediate result of a remote service and speeds up the query processing by obtaining the stored result. The protocol can utilise the data stored in the materialised view without a service request. Therefore, it is important to specify how often a query runs in response to an update of a remote source. It is difficult to designate a change rate of an update explicitly since updates occur randomly, for example, new posts in Web blogs. Such problem results in out-of-date remote data in a materialised view and decreases the satisfaction level of a user about the answers.
In this article, we propose an adaptive plan-based approach to continuously integrating remote RDF data with a semantic stream. Given multiple SERVICE clauses in a query, we present an execution plan based on temporal constraints among constituent services. A plan consists of a sequence of segments, and each segment in a plan represents a time interval that a query should be executed and an answer is produced. The start time of each segment indicates the expected time when the source corresponding to a remote service updates. However, an execution plan may produce a wrong answer over time by falsely using an out-of-date (or stale) data stored in a materialised view, due to the update of a remote source. The staleness of data should increase gradually if the view would not reflect the update of remote data. To maintain remote data to be up-to-date (fresh) in a materialised view in real time, we propose an adaptive process of detecting a source update, forecasting the update in the future, deciding a new execution plan to obtain data from a forecasted update and reacting to a new plan. Our framework includes a new RSP language for describing the proposed adaptive process and components for building an execution plan. We conduct experimental studies on the efficiency of our approach. Experimental results show that our approach is more efficient than the conventional RSP systems in distributed settings.
We organise the rest of the article as follows. Section 2 discusses the related approaches. Section 3 introduces an overview of background knowledge such as RSP and the federated SPARQL extension. A motivating scenario and the problem statement of this work are also described. Section 4 proposes our solution in which a plan-based protocol creates an execution plan in distributed SPARQL endpoints and the proposed RSP language expresses multiple strategies of a proactive adaptation (PA). In Section 5, our PA optimises an execution plan in response to various change rates of remote data. Experimental results show an effectiveness of the proposed solution against the conventional RSP engines in Section 6. Finally, the article closes with conclusions and a brief outlook on our future work in Section 7.
2. Related work
The studies related to plan-based approaches [18–20] share a common goal of obtaining a lower latency for detecting data while guaranteeing a reduced cost for transmitting data. Akdere et al. [18] find multi-step-based data processing to leverage temporal relationships among events and generate a candidate plan with a cost-latency model. Gao et al. [19] propose a semantic service composition model and complex composition plans with event patterns to guarantee the lowest network traffic demand. Teymourian and Paschke [20] present event detection with semantic enrichment that integrates external knowledge and meets user-specified latency expectations. However, in distributed federated sources, these researches produce a plan, which quickly becomes less optimised due to various changing rates in dataset updates.
The conventional RSP engines are based on a push-based protocol of generating an RDF stream. Due to a tightly coupled stream with their RSP languages, a request on the remote data should rely on the stream whenever data are pushed from the stream. C-SPARQL provides a language and a continuous processing engine [8]. CQELS utilises a white box–based continuous query processor, which implements a naive query operator [9]. ETALIS is a rule-based engine for semantic event processing and stream reasoning with EP-SPARQL [11]. SPARQLSTREAM, which supports operators over RDF streams, is utilised in accessing an ontology-based streaming data service [10]. While most of these systems can support the federated SPARQL extension, there is no serious consideration for optimising the joins among evolving remote data and streams.
In the research works on federated query processing, many researchers have proposed various optimisation techniques. Buil-Aranda et al. [12] suggest various strategies of executing a federated query to obtain complete answer to a query to overcome the size limits of the result returned from a SPARQL endpoint. In order to select an optimised source, Grlitz and Steffen present a system of monitoring SPARQL endpoints and utilising quality of service (QoS) parameters [13]. SPLENDID provides an optimal source selection and efficient query routing for federating endpoints with VoID 7 [14]. FedX minimises the number of remote requests and selects a source without pre-processed metadata [15]. ANAPSID is an adaptive and federated query engine, which produces an answer as soon as a response is received from available SPARQL endpoints [16]. However, the existing optimisation techniques focus on an instant result, which is obtained from a static dataset and a fixed dataset description at that time, regardless of the change of remote data.
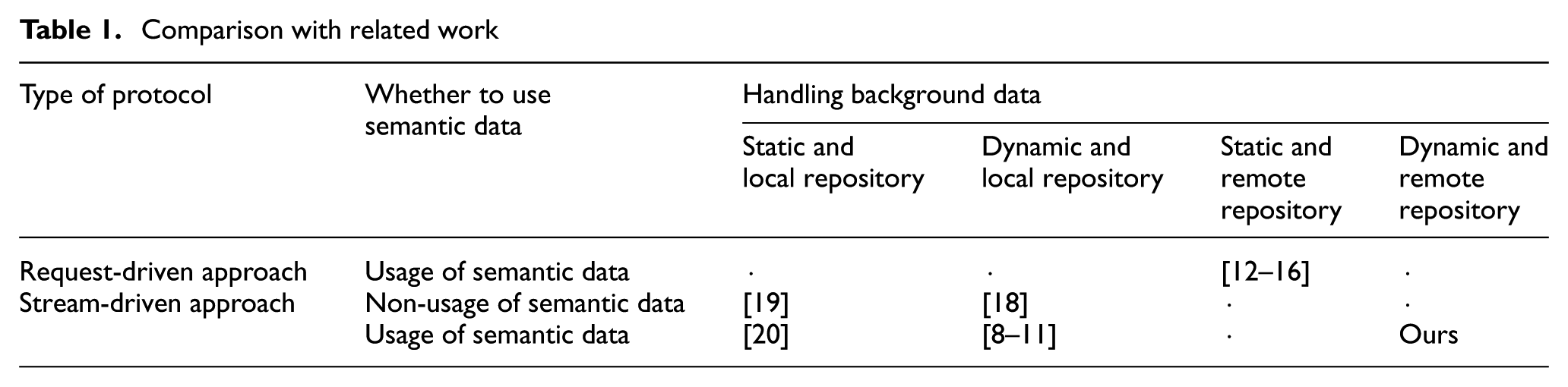
Table 1 summarises the comparison among several relevant research efforts in handling background data. The type of protocol indicates whether they are a request-driven approach or a stream-driven approach. The request-driven approach is pull-based. A query executes once and the output is generated at that point in time. In contrast, the latter is push-based and continuous, that is, new data are continuously pushed to a query processor whenever the data are produced. The second column in the table indicates whether to utilise semantic data model or not, that is, RDF or Web Ontology Language (OWL). If not use the semantic data, it means that the research works use a relational data model. The column of handling background data focuses on two criteria: whether the data are fixed (static) or changing (dynamic) over time and whether the data are located in local repositories or in remote repositories. Here, remote repositories are geographically decentralised and managed by diverse owners. As seen from the table, our proposal is a stream-driven approach and handles the dynamic background data in remote repositories.
Comparison with related work
3. Background and problem analysis
3.1. RDF stream processing with materialised view
RDF stream S is a potentially unbounded sequence of temporal triples. A temporal triple is an RDF triple (s, p, o) with a timestamp t ∈ T, which can be written as (s, p, o) [t]. In a SPARQL query, graph pattern expressions process RDF triples. They combine and join triples and operators. The evaluation of graph pattern expressions produces the bag of solution mappings, which is essentially the function that maps variables to RDF terms.
An RSP query language [7–9] allows for RSP engines to construct continuous queries, which evaluate streams and obtain different results at a different time. In general, RSP query languages have their own query features for dealing with streams. As for one of the query features, a window operator extracts temporal triples of interest from the stream. Here, the temporal triples are a subset of the stream for each query evaluation. In this article, we focus on an interval-based window, which represents a portion of temporal triples within a time interval and slides consecutively by a given execution interval (i.e. a time interval between consecutive windows).
A federated query indicates that a SPARQL 1.1 query involves SERVICE graph patterns (referred to as SERVICE pattern) on the basis of the federated SPARQL extension. The extension allows a query author to direct a part of a query to a remote SPARQL endpoint using a SERVICE clause. In other words, graph pattern expressions in the SERVICE clause have to be forwarded to and evaluated by a SPARQL endpoint. It is possible to integrate RDF data across remote sources transparently as if they are residing in the same database. Most of the RSP query languages support the federated extension.
A materialised view [17], which stores and manages the result of a query, can speed up the processing of federated queries. If the relevant remote RDF data are stored in the view, an RSP engine can access the stored data without an additional service request at each query evaluation. However, the data in the view may be out-of-date (namely, stale) due to the fact that the source may change over time. It is costly if the view is frequently updated whenever the data are retrieved from the source. Consequently, it is important to determine the appropriate time of invoking a remote service at which the corresponding source is updated.
3.2. Scenario
This section explains a hurricane observation as a motivating scenario. A hurricane is a rapidly rotating storm, which is characterised by a low-pressure centre, strong winds and thunderstorms near the surface. Although a limited number of meteorological stations observed a stream of data internally regarding hurricanes in the past, recent open ecosystems such as the Internet of Things (IoT) [21] and Web of Data [22] enable the hurricane observation by collaborating with the distributed and third-party sensor sources owned by diverse organisations. Diverse sensor sources, which provide sensor profiles and measurements, are publicly accessible through services such as SPARQL endpoints. The federation of the services improves the accuracy of hurricane observation by utilising the remote data retrieved by the services.
Due to the various change rates of source updates, it is difficult to obtain updated data in time. For example, if a system wishes to observe a sudden change in wind-speed values from many remote sources, it is important to know how frequently a request on the values should be performed. If a certain source has a likelihood of a sudden change, the system should monitor the source closely by asking for the updated wind-speed data. Although a smaller value of the interval between consecutive service requests discovers the changes in time, a service provider may reject the requests due to a high volume of service requests. Inversely, a larger value of the interval may result in a late detection of the changes in remote data. Therefore, it is necessary to configure the interval according to the fluctuations in the updates of diverse sources.
3.3. Problem analysis
Despite the importance of continuously integrating remote RDF data from diverse sources, current RSP engines do not provide any optimisation for evaluating a query with SERVICE clauses. There are two strategies to join remote RDF data with data streams: nested loop join and symmetrical hash join. The former invokes a remote service whenever solutions are obtained by a window operator. However, this strategy results in critical problems (like denial-of-service) due to many invocations to the sources. The latter evaluates triple patterns and joins them. However, whenever joining the results transferred through SERVICE clauses, many results may be discarded. Therefore, it is important to optimise the query evaluation in order to reduce the number of service requests while maximising the accuracy of the answer.
Moreover, RSP engines are both limited in scalability and compatibility due to their push-based policy that observes and actively notifies new data. While their policy works well on a fixed number of sources, they do not scale to a large number of remote sources like SPARQL endpoint federation. The administrative autonomy that sources operate independently requires providing information based on an explicit request. For example, a SPARQL endpoint returns a response only when it receives a service request that contains a SPARQL query.
A poll-based approach to generating a RDF stream uses a straightforward protocol, which executes a federated query repeatedly per time unit (e.g. hour, minute and second) and produces a stream of solutions. The protocol supports the compatibility of a SPARQL query so that it interacts with federated query processors such as FedX [17]. However, the staleness of remote data in a materialised view increases over time if updates are not reflected in the view. The stale data result in a network overhead due to many service requests regardless of the change of source updates. Therefore, we need an adaptive process of identifying and refreshing out-of-date remote data.
4. The proposed approach
In this section, we introduce a plan-based approach to generating a RDF stream progressively. First, we present a plan-based stream generation protocol, which integrates remote RDF data continuously and produces RDF streams. Second, we propose a basic framework for SPARQL endpoints federation. Third, we present a new RSP language as an extension of a SPARQL query, handling static (or quasi-static) remote RDF data. Finally, we explain how to generate and execute queries based on the proposed protocol.
4.1. Plan-based stream generation protocol
The proposed plan-based stream generation protocol integrates remote RDF data continuously and produces RDF streams. Given a query with SERVICE clauses, the proposed protocol creates an execution plan on the basis of temporal constraints among the constituent services and their execution intervals. Each execution interval indicates a time interval between two consecutive executions of services. Here, assigning an interval to a SERVICE clause is a basic alternative for acquiring an up-to-date remote data when the data constantly change at a fixed rate.
In particular, the proposed protocol creates a plan to execute a query progressively as a sequence of segments, each representing a period of executing the query. Each segment must contain an identifier, startTime, query and executable services. In detail, the identifier identifies the segment, and startTime indicates the time at which the query is executed. The executable services correspond to the services that must be invoked at startTime. Note that each SERVICE clause in a query is identified as an executable service.
Here, executable services can differ from segment to segment due to the gap among the execution intervals of services. Some executable services, which are excluded from the segment, usually pull the data from a materialised view. This means that the number of service requests is limited at a specific query evaluation if the rate of change in a source update equals to an execution interval of the service.
Equation (1) formally defines the semantics of a sequence as follows

where I denotes a set of execution intervals of services, k = 1, 2, …, K (K = ∞), and
4.2. The proposed framework
Figure 1 shows the overall process of the proposed framework. First, a query author writes a query using our RSP language (see Section 4.3) and registers it to our engine. The parser divides the query into three parts: SPARQL, service and proactive action. Then, a plan generator (PG) receives both the SPARQL and SERVICE patterns. After that, a proactive adaptor (PA) accepts the proactive action pattern in order to compose an adaptive process. The PG, then, creates an execution plan according to the execution intervals extracted from the SERVICE patterns. Next, the plan scheduler (PS) loads the new plan and transmits it to the plan executor (PE). The PE sends a query to a specified SPARQL engine like ARQ and waits for a response. Consequently, our RSP engine produces an RDF stream continuously over time if each response is successfully retrieved in time.
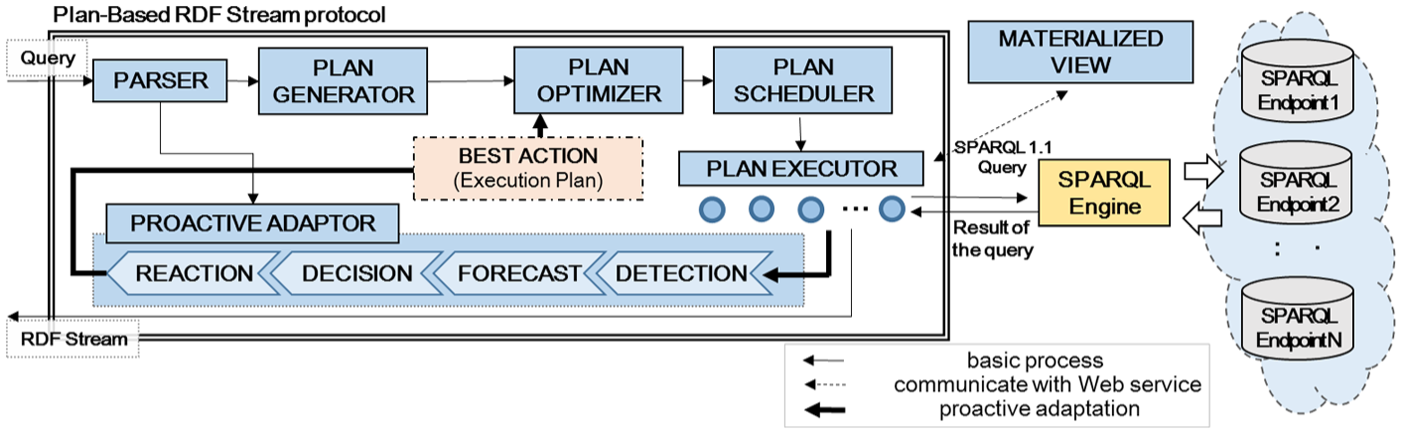
The proposed framework.
To perform the adaptive process, the PA initialises four phases, namely, detection, forecast, decision and reaction. The first detection phase observes a portion of the answer to detect a change in a source update. The second phase forecasts future updates with a prediction service, estimating whether an update will occur or not in the near future from the change detected. The third phase determines the best action for improving the freshness of the data through a decision-making process. The final reaction phase conveys the best action to optimise the current execution plan. The plan optimiser (PO) replaces a part of the current execution plan with the best action.
4.3. Language extension
To provide an RSP language support for the proposed protocol, we present the syntax of a new RSP query language as described in Listing 1. We extend the SPARQL 1.1 grammar and describe it here using Extended Backus–Naur Form (EBNF) notations. The proposed syntax expresses how to perform the PA process. The PA determines the time at which a service request obtains an updated remote data timely. Similar to the Oracle predictive analytics, 8 our language enables a query author to design a proactive action and compose its components like a Web service to predict a change in a remote source.

Specifically, we extend a SERVICE pattern of SPARQL 1.1 to build service requests periodically. The cyclic-service graph pattern (referred to as a cyclic-service pattern) expresses a service request per time unit using the EVERY keyword and configures a maximum response delay using the MAXDELAY keyword. In other words, the EVERY keyword indicates how frequent a service is invoked per time unit and the MAXDELAY keyword indicates how long a query processor waits for a response.
A proactive action pattern has four sub-patterns starting with the ON PROACTIVELY keyword. The DETECT clause defines variables, denoted by Var, which detect an intermediate result retrieved from a remote service. The FORECAST clause defines a predictor variable for predicting a change in a source update (with the PREDICTOR keyword), a response variable of the prediction result and a variable for specifying the service that forecasts the change. The DECIDE clause defines variables for an expected update (with the REWARD keyword), the forecasted change (with the PATTERN keyword) and a service (following the DECIDE keyword). Then, the result of the service is the appropriate time at which the enhanced freshness of the data is guaranteed. Finally, variables in the REACT clause describe the best action. Also, Var denotes a variable with prefix ‘?’ and VarOrIRI denotes Var or International Resource Identifier (IRI).
4.4. Plan generation and execution
In this section, we describe how to create an execution plan. A PG performs the following three stages: pattern extraction, sequence creation and query reformation. First, PG extracts both the SERVICE and cyclic-service patterns from a given query. Second, in order to create a sequence, PG then multiplies each execution interval of the cyclic-service pattern by numbers such as 1, 2 and 3. Each startTime of a segment is computed by adding the multiplied values to the time at which a query is registered. All of the segments are integrated into a sequence and arranged in an ascending order of startTime. Third, PG reforms a query with the executable SERVICE patterns that invoke a remote service at startTime. The remote service is assigned to the corresponding segment if its execution interval falls in the range of startTime. PG converts the SERVICE patterns that are not invoked at startTime into a triple pattern, which then acquires remote data from a materialised view.
Algorithm 1 depicts the generation process of a plan, which composes a sequence of segments. In Line 1, a sequence is initialised with the size of the queue that contains parts of an execution plan. A registration time of the sequence is set to the time that a query is registered. The cyclic-service patterns are extracted from a query in Line 3. Next, in Lines 4–11, segments are generated and inserted into the sequence. Each segment contains a startTime, query and a set of executable SERVICE patterns. The startTime is generated by multiplying an execution interval by numbers. If the number of executable SERVICE patterns is not equal to the total number of SERVICE patterns, PG builds a query with a materialised view as shown in Lines 15 and 16. Otherwise, all remote services in query q should be invoked given that the executable SERVICE patterns in a segment are null (Lines 17 and 18). Finally, the execution plan is returned in Line 21.

The generated sequences are optimised by a PO and are added to a PS. The runtime of inserting a new plan to PS requires no more than O(log(N)) because it is based on a tree set structure, in which segments are always sorted according to their startTimes. Here, PS has a cursor that points to a target segment and the cursor is initially set to be 0. When a cursor is located at a particular segment, a query in the segment is transmitted to a PE. After that, PE delegates the evaluation of the query to a SPARQL engine and receives the query result.
5. Plan optimisation with PA
To cope with evolving sources in which data are updated on an irregular basis, the proposed PA detects RDF data retrieved from a remote source, forecasts a future update of the data and decides the best action of obtaining the update. The best action refreshes the stale data in order to obtain the data updated.
5.1. Proactive adaptation
When accessing a materialised view, our plan-based protocol may produce a wrong answer by falsely using an out-of-date remote data. Remote sources have different rates of updates and the rates vary with time. In order to notify whether remote data are updated or not, most of the SPARQL endpoints contain the statistics and features of datasets in a uniform way (see Note 4). However, the descriptions do not support metadata about changing data such as an update interval. While a SPARQL ASK request can also check whether relevant triples exist or not in an endpoint, the request for each evaluation results in high traffic on the endpoint.
To solve the problem, we propose the PA that detects remote data, forecasts an update of the data in the future, decides a new execution plan and takes an action on it. The proactive computing model [23] motivates our approach. However, unlike the conventional model, PA requires six components: future update, predictive pattern, the probability of occurrence, decision-making process, the best action and an expected benefit. Future update µ denotes a specific time at which remote data will be updated in the future. Predictive pattern π denotes a known pattern for detecting future updates. The relationship between µ and π is represented with probability ρ at the occurrence time of µ. Given ρ, the decision-making process chooses the best action ω from candidate actions. A specific remote service should be invoked if the value of ρ is greater than a certain threshold. Furthermore, the result of the best action ω affects the expected benefit τ, that is, a high accuracy of an answer or a lower cost of transmitting the data.
Thus, in our approach, the best action enables our protocol to obtain an updated remote data in time while minimising the number of service requests. Note that the best action must contain an execution interval, an action time and its duration. Here, an execution interval indicates how frequent a remote service is requested. An action time indicates when to execute the service and the duration defines how long the service execution lasts.
5.2. Plan optimisation through a PA
The proposed PA proactively creates the best action. The process of PA consists of four phases: detection, forecast, decision and reaction. At the beginning of the phase, PA prepares to accept a result from a remote source. When the result arrives at the PE, PA receives a portion of the data that are specified by a query author through the DETECT keyword. He or she designates one or more variable(s) to be detected. PA accepts the variables as the input values. In the prediction phase, PA loads the input value as predictors and predicts an output value as a response. Here, the response would be probability ρ at the occurrence time of future update µ in a specific remote source. In addition, the predictive pattern π for expressing the relationships between predictors and solutions is processed using a prediction Web service such as linear regression.
In the decision phase, the best action ω is determined from the candidate actions when probability ρ is given. The result of each candidate action results in a different expected benefit τ. For instance, PA can communicate with a decision-making Web service, for instance, which includes a Markov decision process (MDP) model [24]. The model may define possible states of candidate actions and commitment to a future course of actions. The MDP contains (S, A, R(s, a), T(s, a, s′)), where S denotes a set of possible states, A denotes a set of possible actions, R(s, a) denotes a reward function which takes action a in state s and T(s, a, s′) denotes a transition function which signifies the effects of each action in each state.
We discuss an example of a simple MDP based on service request latency or data transmission cost. The latency for requesting a service would be a time interval between next future update µ′ and the updated time in a materialised view. If the value of the latency is high, the data may be stale. Also, the cost for transmitting remote data to a RSP engine would be a total amount of data retrieved from services through SERVICE clauses.
A simple MDP is composed of (S, A, R(s, a), T(s, a, s′)). Here, S represents the possible execution intervals corresponding to a cyclic-service pattern and A represents an action of increasing or decreasing a size of the execution interval. The R is a set of reward values that an RSP engine gets for being in state s. Then, T(s, a, s′) is a probability of going to state s after taking an action a in state s′. So, the model aims at selecting the best action ω in order to maximise the total reward that guarantees either a low-service request latency or an efficient data transmission cost.
Finally, PA groups all of the best actions in the reaction phase. A group of the best actions is transmitted to the PO. Upon completing each adaptation, PO receives the best action and evaluates whether it conflicts with the current execution plan or not. PO discards some of the best actions if their startTimes are overdue or they are duplicated. After this, PO accepts the best action and applies it to the current sequence.
Algorithm 2 describes the optimisation of the current sequence with a set of the best actions derived by the PA. In Lines 2 and 3, a current sequence is obtained and a new sequence is initialised. In Lines 4–12, the startTime of each segment is calculated depending on both an execution interval and an action time. After that, a query is also assigned to the segment and they are inserted into a new sequence. We then utilise the merge function that integrates the current sequence with the new one at Line 12. Consequently, the merged sequence is optimised to obtain the updated remote data in time.

6. Evaluation
In this section, we conducted an exhaustive experiment to verify our approach using a real-world dataset. Moreover, we compared our approach with the conventional approaches, namely, C-SPARQL [8] and CQELS [9]. We also virtually constructed a federation of SPARQL endpoints and evaluated the approaches in terms of data adaptability (DA), detection latency and transmission cost. Finally, we proved the necessity of PA through comparative evaluation with the conventional approaches.
6.1. Experimental settings
To evaluate our approach, we utilise the Charley 9 RDF dataset as a Linked Data sensor dataset that records data about hurricanes in the real world. We first synthetically selected a portion of the dataset such as data occurrence frequency, data size and the period of data observation. To virtually set up a federation of SPARQL endpoints, we assigned each sensor system to a SPARQL endpoint. The endpoint is built on a Fuseki 2 Web server, 10 which allows querying remote data using a SPARQL query.
While our original purpose was to compete against similar plan-based approaches [18–20], we could not have access to their prototypes. Therefore, we selected both C-SPARQL and CQELS as the conventional systems of RDF stream processing, especially that support a federated extension. As mentioned earlier, these systems do not provide any optimisation for a query involving a SERVICE clause.
To compare our approach with poll-based and push-based approaches, we set up a C-SPARQL query with a logical window and a CQELS query with a physical window. The C-SPARQL query uses a logical window, which extracts all triples within a given time interval. Meanwhile, the CQELS query uses a physical window, receiving all triples whenever new data are generated. CQELS thus can produce more service requests than C-SPARQL when evaluating their queries with a SERVICE clause. Consequently, we identified CQELS as the push-based approach and C-SPARQL as the poll-based one, respectively.
In the experiments, we used an example query described in Listing 2. The query collects the wind-speed data from several sensor systems, especially the one that includes a cyclic-service pattern (starting with the EVERY keyword) which executes every 30 min but waits for a response for 20 min. The proactive action pattern (starting with ON PROACTIVELY) defines four sub-patterns. The DETECT pattern detects the variables to be observed. The FORECAST pattern predicts a change in the update of wind-speed data with a prediction Web service. The prediction service deals with the relationship between wind-speed data and its update time. Furthermore, the DECIDE pattern decides the best action with a decision-making Web service, which determines the best action to obtain the updated data in a specific time when predicting the source update. Finally, in the REACT pattern, variable reward contains the values of adjusting the execution interval, for example, 20 or 40 min. The getCurSegmentStartTime and getNextSegmentStartTime indicate the startTimes of the current and next segments, respectively.

6.2. Experimental result
In this section, we evaluated the proposed approach named PPRSP, which is compared with the conventional RSP systems in terms of DA, service request latency and the efficiency of data transfer volume (DTV). We also showed that our PA reduced the number of service requests significantly while minimising the staleness of remote data.
6.2.1. DA over SPARQL endpoints
Figure 2(a) shows the comparisons in terms of DA about a SPARQL endpoint. Each SPARQL endpoint, which contains a distinct sensor dataset, is intuitively represented by CSPARQL-* and PPRSP-*, that is, PPRSP-A. The endpoint also has various update rates and the rates vary with time. In PPRSP, DA indicates how well each execution interval is adapted for obtaining the updated data even if a user designates a wrong value to the endpoint, that is, the interval is greater (or less) than the change rate of update. We utilised CSPARQL as a comparison group because CSPARQL did not support any technique for adapting to evolving remote sources. The higher value of DA indicates the ability to escape an unknown situation, which does not recognise an occurrence frequency of data in a remote source. Here, we define the meaningful data as the newly received data that do not overlap with the previously received data. DA indicates the ratio of meaningful data among all received data and is defined by equation (2) as follows

where td is all received data and md is the meaningful data.
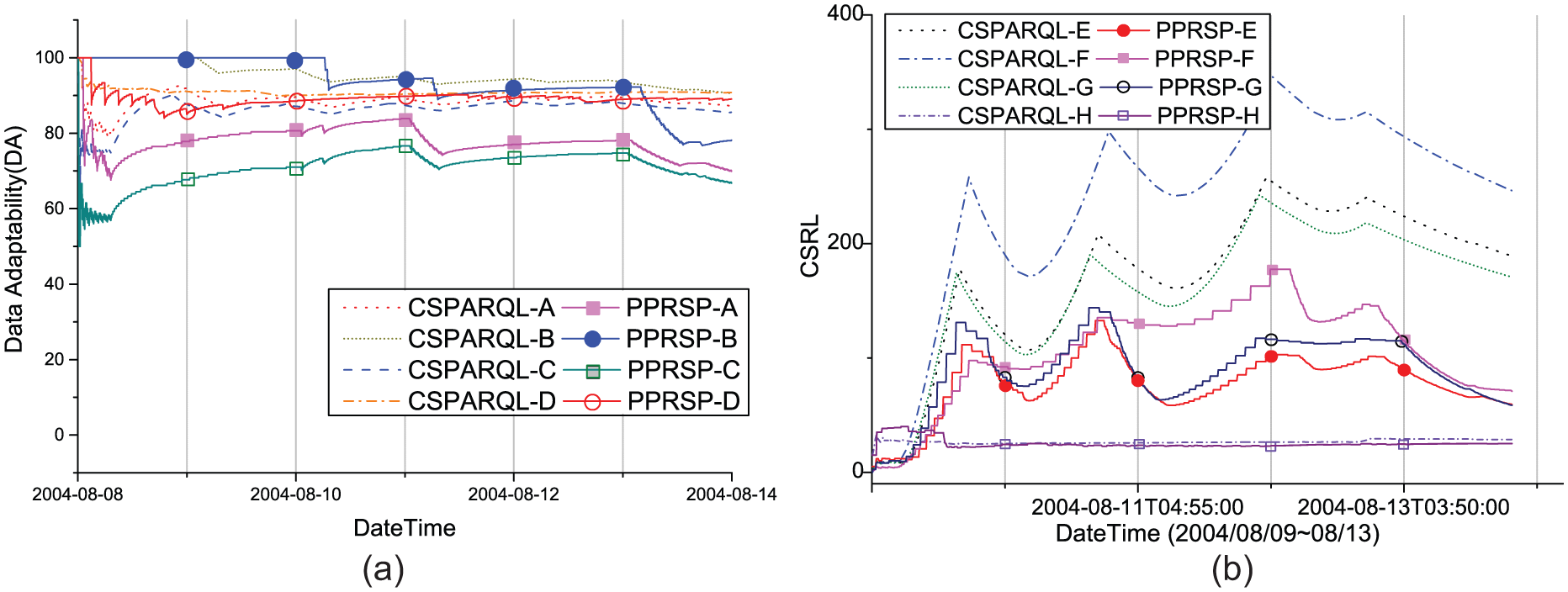
Experiments on (a) data adaptability and (b) cumulative average of service request latency.
The higher value of DA means that the majority of data returned by the endpoint are duplicated due to the difference between the query execution and the change rate. The lower DA means that the execution interval of a service adapts to a change rate of a source update. For example, in the case of PPRSP-B, it continuously produced a lot of duplicated data from endpoint B until 10 August 2004. At this point, PPRSP recognised the change rate of source update and re-adjusted the execution interval between the query evaluations corresponding to the endpoint B.
6.2.2. SERVICE request latency
Figure 2(b) shows the cumulative average of service request latency (CSRL) in PPRSP and C-SPARQL engines. The service request latency indicates a time interval between a service request and updated times. CSRL indicates the average of the service request latencies accumulated until the updated data are received. The CSRL at certain timestamp tk is computed by

where L(tk) denotes the latency at timestamp tk (k = 0, 1, 2,…).
A large CSRL value means that a service invocation to a SPARQL endpoint is delayed for a significant amount of time even if the endpoint is updated. Both solid and dotted lines represent CSRL for the duration from 8 August 2004 to 13 August 2004. Note that a line that ascends to a local peak indicates that the latency is increasing, and a line that descends from the peak indicates that the CSRL value is reducing. As one can see, the solid lines, when applied with the PPRSP approach, had lower local peaks and gradual slopes than the dotted lines. This means that our approach re-adjusted an execution interval to avoid higher latency. In the case of both PPRSP-H and CSPARQL-H, their lines were continuously flat because the update of endpoint H was published on almost equivalent change rate.
6.2.3. Efficiency of DTV
Figure 3(a) shows the distribution of DTV. DTV indicates the amount of data being retrieved from an endpoint per request when using a query involving the SERVICE clause. Each point in Figure 3(a) indicates the amount of data to be processed by an RSP engine. We then specified a time interval between the query evaluations of a specific RSP engine, for example, CSPARQL-20 indicates that its query should be executed every 20 min. AVG-20 denotes the average amount of the data collected per 20 min within 1 day.
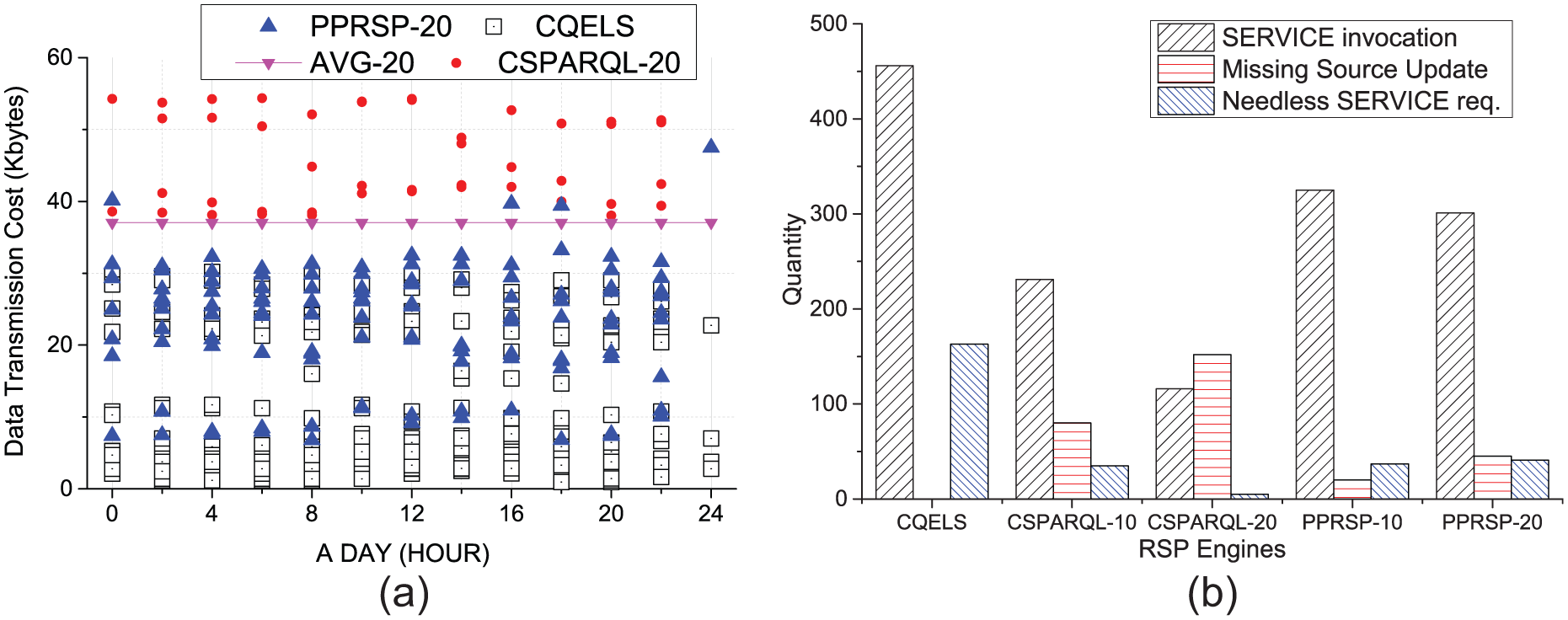
Experiments on (a) data transfer volume and (b) performance of proactive adaptation.
If DTV is larger than the value of AVG-20, a large amount of data is to be processed at a time. For example, due to a large value, which exceeds the average rate of DTV per hour, CSPARQL-20 required a higher system throughput per time unit whenever a query was executed. On the other hand, due to a value that is lower than the average rate of DTV per hour, CQELS processed a small amount of data frequently whenever the data were generated. PPRSP-20 showed an efficient data processing per 20 min with a lower DTV because it could partially re-adjust the next segment in response to the amount of data being returned.
6.2.4. Performance of PA
To prove the necessity of PA, we utilised the dataset of wind-gust sensors from 8 August 2004 to 14 August 2004. We also used various queries with cyclic-service patterns, including fixed time interval for each query evaluations such as 10 and 20 min. After that, we configured the best action that adjusts a smaller execution interval when occurring with a great difference between the values of wind gust in previous and current segments (i.e. more than or equal to 10 knots).
Figure 3(b) shows that our PA reduces the number of service requests while minimising the number of missing source updates. The number of invocations to a SPARQL endpoint indicates how many service requests are executed during a given time period. The number of missing updates indicates how many times an RSP engine misses a source update by waiting for the next execution even if a remote source is updated. The number of needless SERVICE requests indicates how many remote services are invoked unnecessarily even if the relevant dataset is unchanged.
As a result, PPRSP reduced about 130 service requests and removed about 130 needless requests, respectively, compared with CQELS, which generated 456 service requests. Furthermore, PPRSP had 25% of the number of missing updates of C-SPARQL and especially acquired 116 source updates on average in the two evaluations. Specifically, CQELS had the highest number of SERVICE invocations because it had to call remote services whenever the data were pushed from the stream. On the other hand, PPRSP permitted the invocations additionally when a source update was forecasted in the next segment. Whereas C-SPARQL did not recognise a change of remote data due to a fixed execution interval, PPRSP adjusted the intervals to adapt to a future update in the endpoint through the PA.
7. Conclusion and future work
In this article, we proposed the adaptive plan-based approach to integrating semantic streams and remote RDF data. Specifically, first, the proposed plan-based protocol continuously integrates the RDF data retrieved from remote sources. Second, in order to cope with an evolving source, in which data change with time, we proposed the PA technique that limits service requests while maintaining the freshness of remote data. The proposed method predicts the future updates and performs decision-making based on four processes: detect, forecast, decide and react. Third, we also extended the SPARQL 1.1 language with operators to support the multiple strategies of the PA. The experiment results on a real-world dataset show that our approach is more efficient than the conventional methods in terms of DA, service request latency and DTV in distributed settings.
As a future work, we plan to concentrate on integrating the plan-based protocol with RDF streams. We focused on the continuous integration of evolving remote data in this article. We believe that it is extremely important to manage (quasi-)static RDF data in a remote SPARQL endpoint. Therefore, we plan to study RDF stream processing for effective integration among streams and remote RDF data on a large scale. This would enable an RSP engine to handle fast-changing streams as well as static remote data in SPARQL endpoints. Moreover, we plan to relieve the workload overhead of the PA. In connection with our previous work [25], we will improve an RSP engine in the perspective of large-scale applications such as IoT.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work was supported by the ICT R&D programme of MSIP/IITP, Republic of Korea (B0101-16-1276, Access Network Control Techniques for Various IoT Services).