
Abstract
User-generated content has been an increasingly important data source for analysing user interests in both industries and academic research. Since the proposal of the basic latent Dirichlet allocation (LDA) model, plenty of LDA variants have been developed to learn knowledge from unstructured user-generated contents. An intractable limitation for LDA and its variants is that low-quality topics whose meanings are confusing may be generated. To handle this problem, this article proposes an interactive strategy to generate high-quality topics with clear meanings by integrating subjective knowledge derived from human experts and objective knowledge learned by LDA. The proposed interactive latent Dirichlet allocation (iLDA) model develops deterministic and stochastic approaches to obtain subjective topic-word distribution from human experts, combines the subjective and objective topic-word distributions by a linear weighted-sum method, and provides the inference process to draw topics and words from a comprehensive topic-word distribution. The proposed model is a significant effort to integrate human knowledge with LDA-based models by interactive strategy. The experiments on two real-world corpora show that the proposed iLDA model can draw high-quality topics with the assistance of subjective knowledge from human experts. It is robust under various conditions and offers fundamental supports for the applications of LDA-based topic modelling.
Keywords
1. Introduction
User-generated content is reshaping the way of online user behaviour. By posting contents on social media platforms, users communicate with others and state their views about political, social and economic events. In the fourth quarter of 2016, 319 million and 1.8 billion monthly active users generate unstructured contents on Twitter and Facebook, respectively. Since abundant contents imply rich information about user interests, user-generated content offers a great opportunity for sociologists, managers and marketing people to understand user behaviours deeply. Enterprises such as Dell.com and Amazon.com have introduced various social media services to help organisations across a variety of industries develop user insights, engage with customers and understand the markets. Analysing user-generated content has become the new must-have ability for organisations in different fields.
Extracting insights from user-generated content is a challenging job because user-generated content is usually presented in the style of unstructured text. To extract hidden semantic information from the unstructured text, topic modelling technique has been developed to summarise user views into topics. Topic modelling is a kind of method that discovers hidden semantic structure from text corpus. It assumes that a document is a mixture distribution of topics, where the topic is a multinomial distribution about vocabulary. Latent Dirichlet allocation (LDA) model [1] is one of the most popular strategies for its explicit representation of a document and flexible exchangeability assumption. LDA is a complete generative probabilistic topic model for collections of discrete data. It is a powerful tool for discovering topics from documents without any keywords or labels [2–4]. Although LDA and its variants are unsupervised and can automatically discover topics, a significant limitation is that topics discovered by these methods do not always make sense to people and some words are not useful for the recognition of topic meanings. For example, the word ‘fruit’ co-occurs with the words about basketball games. Therefore, some topics discovered by these methods are occasionally confusing and not coherent with human judgements [5,6].
The intuition behind LDA is that a document exhibits multiple topics and a topic is composed of words with different probabilities. The problem of topic coherence exists in two granularities. In the topic granularity, the LDA models may generate some meaningless topics because the words with highest probabilities in these topics are very puzzling. In the word granularity, although we can understand the meaning of a topic by the words with highest probabilities, confusing words like ‘fruit’ in topics about basketball games still exist.
Figure 1 illustrates two topics discovered from Reuters corpus [7] with the LDA model. As shown in Figure 1, the meaning of topic (a) is not sensible because the topic is mixed by words about disease, life, economic and so on. Although people may classify topic (b) to be bio-medical news, the words like ‘right’ and ‘float’ are still puzzling.

(a) Meaningless topic and (b) meaningful topic with puzzling words.
In the environment of online social media, topic coherence is an intractable problem for LDA and its variants because free speech is the basic feature of online social media and user expressions are always irregular. To mine coherent topics, Newman et al. [8] introduced a novel method to evaluate topic coherence whereby words in topics are rated for coherence or interpretability. Mimno et al. [6] analysed the reasons incoherent topics generate, designed an automated evaluation metric for incoherent topics and proposed a statistical topic model to find low-quality topics. Although these methods can help us filter low-quality topics, they cannot tell us what to do when flaw topics generate.
Human knowledge is widely documented as a useful factor to improve the performance of theoretical models. This article integrates knowledge from human experts into topic models and proposes new interactive strategies to mine high-quality topics. Framework of the proposed interactive latent Dirichlet allocation (iLDA) model is shown in Figure 2. Figure 2 shows that, after topics are discovered and the objective topic-word distribution is generated by LDA, our model allows human experts to integrate their knowledge to generate a subjective topic-word distribution. The objective and subjective topic-word distributions are then merged to generate a comprehensive topic-word distribution, which is used to explore the next generation of topics. The interactive process is repeated until coherent and high-quality topics are obtained.

Framework of iLDA.
To improve topic quality with the iLDA model, the following three issues should be addressed:
In LDA-based generative models, many topics are usually generated together with a large number of probable words. It is impossible for human experts to provide probabilities for each word in each topic completely by themselves. This article proposes a strategy which allows human experts to offer their subjective knowledge by adjusting a partial of the probabilities generated by LDA. Therefore, the first issue of the iLDA model is from a large number of topics and words, which of those should be selected and presented to human experts for adjustment.
When human experts decrease the probabilities of the puzzling words in a topic, we obtain some surplus probabilities which are the differences between the original probabilities and the adjusted probabilities by human experts. Because a fundamental assumption of LDA is that the probability sum of all words in a topic equals 1, we should allocate the surplus probabilities to the rest of words in the topic. Therefore, the second question of the iLDA model is how to allocate the surplus probabilities generated by expert’s adjustment.
The basic idea of topic models is to draw words for topics automatically based on the joint distribution and the conditional distribution. The iLDA model aims to combine subjective knowledge from human experts with the objective knowledge mined by LDA to improve topic quality. Therefore, the third question of the iLDA model is how to draw words for topics automatically based on subjective and objective topic-word distributions.
The model in the existing literature that is most similar to iLDA is the interactive topic model proposed by Hu et al. [5]. In the interactive topic model, a mechanism was proposed to encode users’ feedback to topic models. The interactive process is simple enough because users just need to merge or split topics. Because their purpose is to make topic models easy to use even for political scientists who have little data mining knowledge, users are not required to adjust probabilities the words have in topics. The contributions of our proposed iLDA are two folded:
To the best of our knowledge, this is the first effort to integrate human knowledge with topic modelling by allowing human experts to adjust topic-word probabilities. We propose a new interactive framework to integrate subjective and objective knowledge. The framework theoretically contributes to the topic modelling field and has more opportunity to generate fine-grained and explainable topics.
This article proposes a novel indicator to determine which topics should be adjusted by human experts, designs two strategies to allocate the surplus probabilities and proposes new method to draw words for topics by deriving new joint and conditional distributions. These methods guarantee that the proposed iLDA model can integrate the knowledge of human experts and implied information mined by general LDA model to obtain coherent and meaningful topics.
The rest of the article is organised as follows. Section 2 reviews the related literatures on topic models. Section 3 proposes the iLDA model and its inference algorithm. A computational study is conducted in section 4 to test the proposed iLDA model. Conclusions and future researches are given in section 5.
2. Literature review
In the big data era, knowledge discovery from massive data is always a challenging task and need innovation of methodology and technology [9,10]. The topic model is a generative statistical model which provides a simple way to analyse unstructured text data. In topic modelling, a document is often considered as a bag-of-words which is a vector of words without orders. A topic model seeks to map high-dimension of documents to a lower latent semantic space [11,12]. In this section, we will review related work from LDA which has served as a springboard for many other topic models.
2.1. LDA and topic modelling
The general LDA model, proposed by Blei et al. [1], is a useful method to explore topics in documents in the fields such as business and public policy [13,14]. There are two generation processes in the LDA model: one is the generation of document-topic distribution and the other one is the generation of topic-word distribution. Suppose




Since LDA is an unsupervised model which does not require information about topics within documents and documents are also not labelled with topics or keywords, it is widely used to solve various problems. For example, Hu et al. [15] employed LDA-based method to mine customer opinions and identify top-k most informative sentences from online hotel reviews. Hyung et al. [13] developed music descriptors using LDA model to extract keywords from a large collection of user-generated documents. Ling et al. [16] developed an interpretable LDA model to mine customer preferences from ratings and online reviews so as to obtain accurate recommendation for customers. Büschken and Allenby [17] designed a sentence-based LDA model to improve the inference and prediction of consumer preference. Jacobs et al. [18] took customer heterogeneity into account and developed a novel LDA model which considers a product as a word and the products a customer purchased as a document the customer created. LDA and topic modelling are also widely used to analyse other unstructured data (e.g. picture and image) and obtained satisfactory results [19–25].
Although the general LDA model provides a powerful tool for discovering and exploiting the hidden thematic structure [26], the most probable words for each topic are not always sensible to users. Lu et al. studied the method to improve topic quality [27]. They designed various vocabulary reduction strategies and tested the influence of each strategy on topic modelling.
2.2. Evaluation of topic models
A natural evaluation metric for statistical topic models is the probability of held-out documents given a trained model [28]. Since topic models are generally used to understand documents, it is typically evaluated by either measuring performance on some secondary tasks, such as document classification, or by estimating the log-likelihood probability of unseen held-out documents. Thus, the evaluation probability for held-out document needs to estimate normalisation constants of posterior distribution over topics [28]. A common situation for the probabilities of held-out documents is that it is often inconsistent with human judgement. To measure semantic meaning of topic models, Chang et al. [29] designed two human evaluation tasks to explicitly evaluate the topics inferred by topic models: one is word intrusion and the other one is topic intrusion. Based on the observation that the size of topics usually has a strong relationship with the probability of topics judged by domain experts, Mimno et al. [6] proposed a coherence indicator to identify flawed topics. Because the indicator does not rely on human annotators and is a good predictor of human judgements, it has been widely used to measure topic quality in topic models [30–32]. This article will design a new method based on the coherence indicator to evaluate the quality of topics generated by iLDA.
2.3. Interpretability of topic models
Topics inferred by LDA are not always sensible to users. Many enhanced topic models are proposed to improve the coherence and interpretability of LDA through incorporating external knowledge. Newman et al. [31] proposed QUAD-REG and CONV-REG strategies for regularising topic models to generate more coherent and interpretable topics. They characterised external data by the ‘covariance’ matrix and treated the matrix as the word dependencies for prior. Meanwhile, they considered coefficients to leverage external information. Another principled approach to incorporate domain knowledge into LDA is inspired by constrained clustering methods [33]. Andrzejewski et al. [34] proposed a method which uses the Must-Links and Cannot-Links in topic modelling. The authors consider all domain knowledge as Must-Links and Cannot-Links which represent words that may have large probability occur within a topic and not. To incorporate these two links into the LDA model, they used Dirichlet Tree distribution [35,36] as the conjugate prior distribution of topic-word distribution. They treated Must-Links as the transitive closure and transformed Cannot-Links as an alternative form that amenable to Dirichlet Tree. Inspired by this work, Chen et al. [37] proposed the MDK-LDA method to simulate human judgement. The authors argued that human gain new knowledge gradually based on old knowledge. Therefore, they add a new latent variable in LDA which is the result from multi-domain knowledge. To improve the interpretability of topics, researchers also present models such as biterm topic model (BTM) [30] to utilise the co-occurrence patterns.
Domain knowledge and other co-occurrence patterns are actually the external data derived from other works and may not be proper for specific corpus. To discover topics with high quality, researchers also seek help from human feedback. Since topics are finally used to help people to understand documents, it may be useful to incorporate human judgement directly. Hu et al. [5] proposed a new mechanism which considers user voices by encoding their feedback to topic models as correlations between words into a topic model. The authors focused on the correlations among words within a topic and used tree-priors to encode these correlations straightforwardly. The mechanism allows users to evaluate whether words within a topic correlated with each other or not. The authors finally build a system that can learn and adapt from users’ input. Topic interpretability is a fundamental problem even if in a well-designed model. Although many enhanced topic models have been proposed to solve the problem, controlling words correlation precisely within a topic based on user feedback is still an unsolved issue.
The current literature shows that, although the LDA model proposes a useful framework for topic analysis, many issues still exist to obtain high-quality topics. The significant limitations of the LDA model are that topics discovered are inexplicable and some words are not useful to recognise topic meanings. Also, new methods are required to measure topic quality and provide guidelines for quality improvement of topics. To deal with these problems, this article allows human experts to integrate their knowledge to generate a new topic-word distribution after topics are discovered by LDA. We design a new formula to measure topic quality and experts can adjust the topic-word distribution of the low-quality topics to generate subjective distributions. The topic-word distributions generated by LDA and human experts are then merged to explore topics from documents. Figure 3(a) and (b) illustrates the difference between the LDA model and the proposed iLDA model. We will provide the details of iLDA in next section.
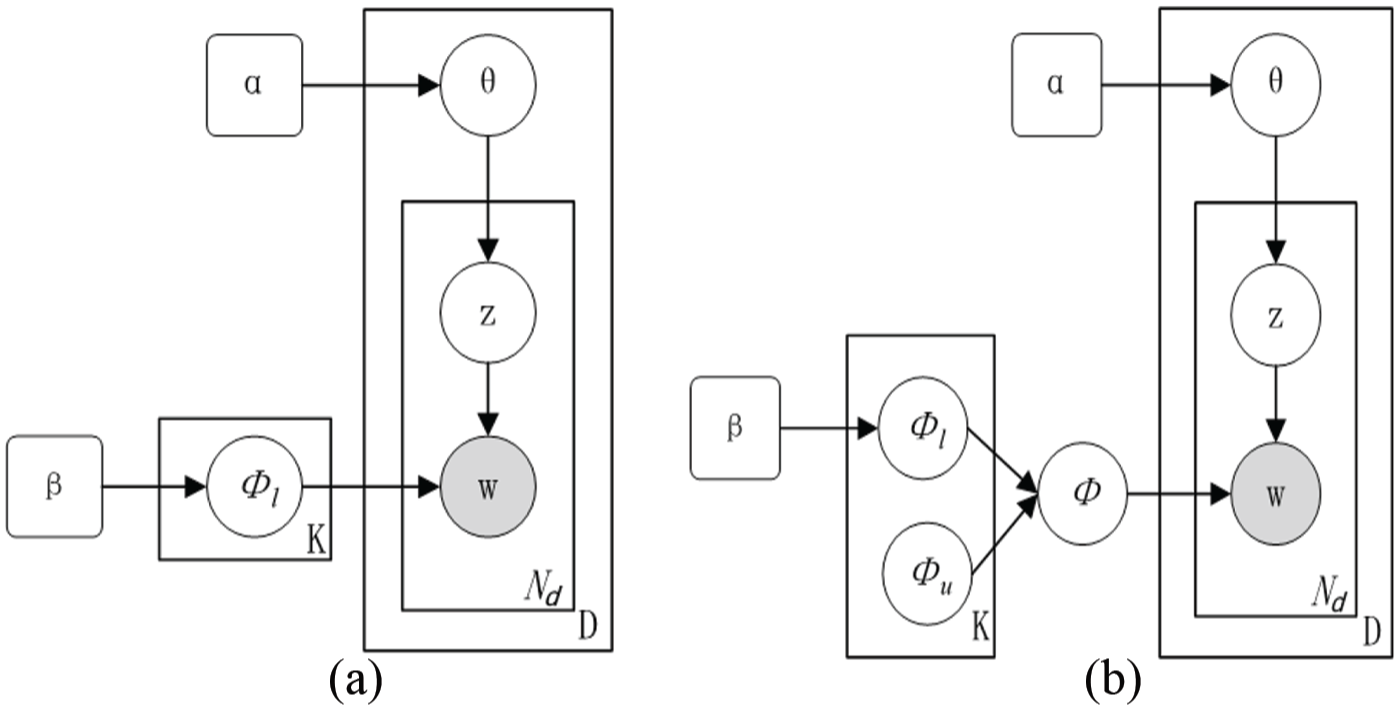
Comparison between LDA and iLDA: (a) latent Dirichlet allocation and (b) interactive latent Dirichlet allocation.
3. iLDA model
3.1. Model framework
Suppose we have a collection of
To make topics more understandable, the proposed iLDA model focuses on the integration of knowledge from human experts. The graphical model of iLDA is represented in Figure 3(b). Based on the general LDA model, the iLDA model introduces a new variable
Notations of iLDA model.

LDA: latent Dirichlet allocation.
Suppose

where

The generation process of iLDA model.
3.2. Inference
To draw words according to the distribution of
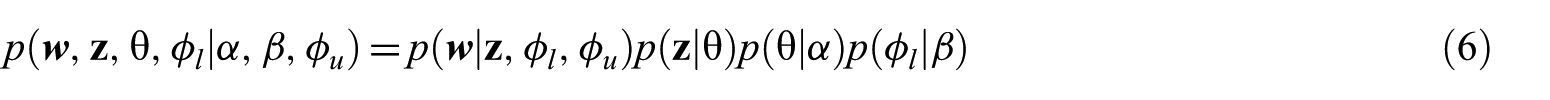
Suppose we sample topic

Here,

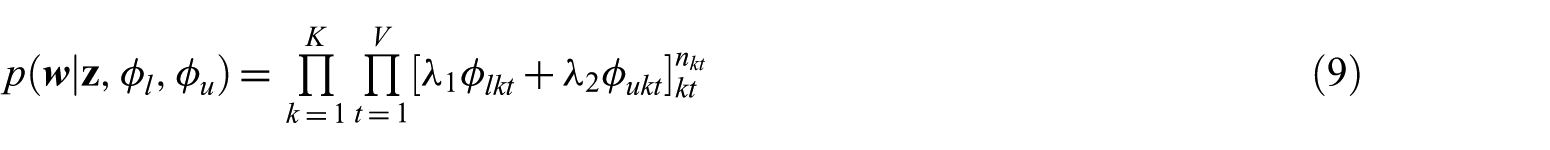
where
After we obtain the joint distribution, we can use Markov Chain Monte Carlo (MCMC) algorithm to infer the unknown parameters. Since topic






Therefore, we have the conditional probability
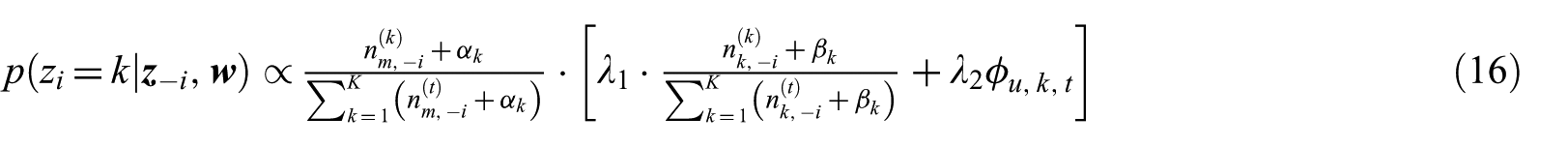
With the conditional probability
In the estimation step of LDA, we need sample topic index of each word in documents. In an iteration, we need to compute each word with a topic and update the topic distribution and document-topic distribution. Thus, the complexity of LDA for each iteration is O(D*N*K) where D is the number of documents, K is the topic size and N is the vocabulary size. For iLDA, we compute linear combination of objective distribution and subjective distribution before sampling topic index. Thus, the complexity of iLDA is O(D*N* (K + 1)).
3.3. Derivation strategy of human knowledge
As shown in formula (16), the subjective topic-word distribution is required to derive conditional probabilities and draw topics from documents. Because massive topics and words exist in unstructured texts, it is an impossible task for human experts to provide subjective probabilities for each word in each topic. This article employs a compromising strategy to derive expert knowledge. We run the general LDA model for preset iterations, show human experts the results and invite them to adjust the probabilities based on their knowledge. The topic-word distribution generated by experts is considered to be the subjective topic-word distribution. In this process, the key issues to obtain knowledge from human experts are two folded. The first issue is which topics and words should be presented to experts for adjustment. The second issue is how to calculate the subjective topic-word distribution
3.3.1. Selection of topics and words need to be adjusted
To determine which topics should be adjusted, we propose an indicator inspired by topic coherences which are useful indicators for topic quality and word consistency in topic models [6]. We employ Figure 5 to demonstrate our motivation. Figure 5 illustrates three topics with good, inter and bad quality, respectively. The horizontal axis is the coherence value of the topic. We can see that the higher the coherence value, the more likely it is a good topic. If we add a vertical line in Figure 5, we can see that there are almost all good topics when the line is near to highest value of coherence. Therefore, to decide whether a topic should be adjusted, we calculate the difference between its coherence value and the first moment of the coherence values of all topics to obtain the adjustment indicator

Here,

where

Topic coherence.
After the topics with low qualities are recognised and presented to human experts, they are asked to evaluate which words in the topics are not correlated with the topic meaning and then make adjustment decisions for the probabilities of the words. Because the probability sum of all words within a topic equals 1, we propose two strategies to allocate the surplus probabilities generated by expert adjustment next.
3.2.2. Calculation of subjective topic-word distribution
When the topics and words are presented to human experts, the iLDA model allows human experts to decrease the probabilities for the flawed words according to their knowledge. Suppose topic k with topic-word distribution
Deterministic strategy
The deterministic strategy adjusts the objective topic-word distribution according to the degenerative probabilities completely. The topic-word probabilities for the words adjusted by human experts are calculated as

To make sure the sum of the probabilities of all words in a topic is 1, the surplus probabilities from the adjusted words are distributed to other most probable words, that is, WT – WT′, rather than all of the remained words, that is, WV – WT′, in the topic. The weighted redistribution method of the degenerative probabilities to the words in WT – WT′ is
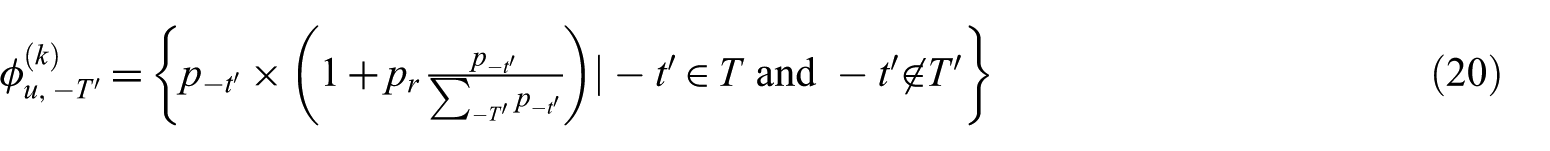
where
Suppose the topic-word distribution of the words in WV – WT′ is
Stochastic strategy
The deterministic strategy considers human experts’ knowledge is always accurate and reliable. Therefore, it adjusts the objective topic-word distribution based on the degenerative probabilities given by experts to obtain the subjective topic-word distribution. The stochastic strategy, however, takes expert confidence into account to generate the subjective topic-word distribution. In the stochastic strategy, the degenerative probabilities are considered to reflect the belief human experts have to adjust the objective distribution. A higher degenerative probability means human experts largely accept the objective probabilities while a smaller one means the objective probabilities are likely to be adjusted according to human experts’ knowledge. We introduce a stochastic variable u to determine whether the probability of a word should be adjusted. With the objective topic-word distribution for topic k,

where
4. Experiment
4.1. Data
In this section, two real-world text corpora are used to test the effect of the proposed iLDA model. The characteristics of the corpora are summarised in Table 2 and we give brief descriptions of the two corpora as follows:
Dataset statistics.

Reuters [7]. Reuters corpus was released by Reuters Ltd. in 2000 and was used widely in the field of natural language process, machine leaning and information retrieval. The original corpus, known as ‘RCV1’, has been used and relabelled by many researchers. The dataset used in this article was labelled by Moschitti and Basili [38].
Weibo. This dataset is collected from Weibo.com which is a famous social media website in China. On the website, users post, repost and make comments to messages. We collect Weibo messages by a web crawler for our experiment.
Reuters and Weibo are two different datasets in terms of corpus generation. Reuters corpus is official news with regular expressions. Weibo corpus, however, is more open and irregular because Weibo.com is an open forum where users with different backgrounds post a large number of contents without specific forms.
4.2. Experiment on model performance
4.2.1. Topic quality
To study the quality of topics discovered by the proposed iLDA, we compare it with the following baseline methods:
Mixture of unigrams (MU). The MU [39] assumes that each document is generated by only one topic and words are drawn from the topic independently. In this article, we use jLDADMM (https://github.com/datquocnguyen/jLDADMM) to implement MU algorithm.
Probabilistic latent semantic analysis (pLSA). pLSA [40] is also known as a probabilistic latent semantic indexing (pLSI) strategy. It models each word in a document as a sample from a mixture model, where the mixture components are multinomial random variables that can be viewed as representations of ‘topics’. We use mltool4j (https://code.google.com/archive/p/mltool4j) to implement pLSA.
LDA. As one of the most classical topic models, the general LDA model can induce topic-word distributions from a large number of documents without labelling. Because iLDA is constructed based on LDA by integrating expert knowledge, we employ LDA as a baseline method to test the influence of expert knowledge on topic modelling. In this article, we use jGibbLDA model (http://jgibblda.sourceforge.net) [41,42] as a baseline method which uses Gibbs Sampling technique for parameter estimation and inference.
BTM. BTM [30] learns the topics by directly modelling the generation of word co-occurrence patterns in the whole corpus. The model learns topics over short texts by modelling biterms where a biterm is an unordered word-pair co-occurred in a short context. We use the code released by the authors to implement BTM (https://github.com/xiaohuiyan/BTM).
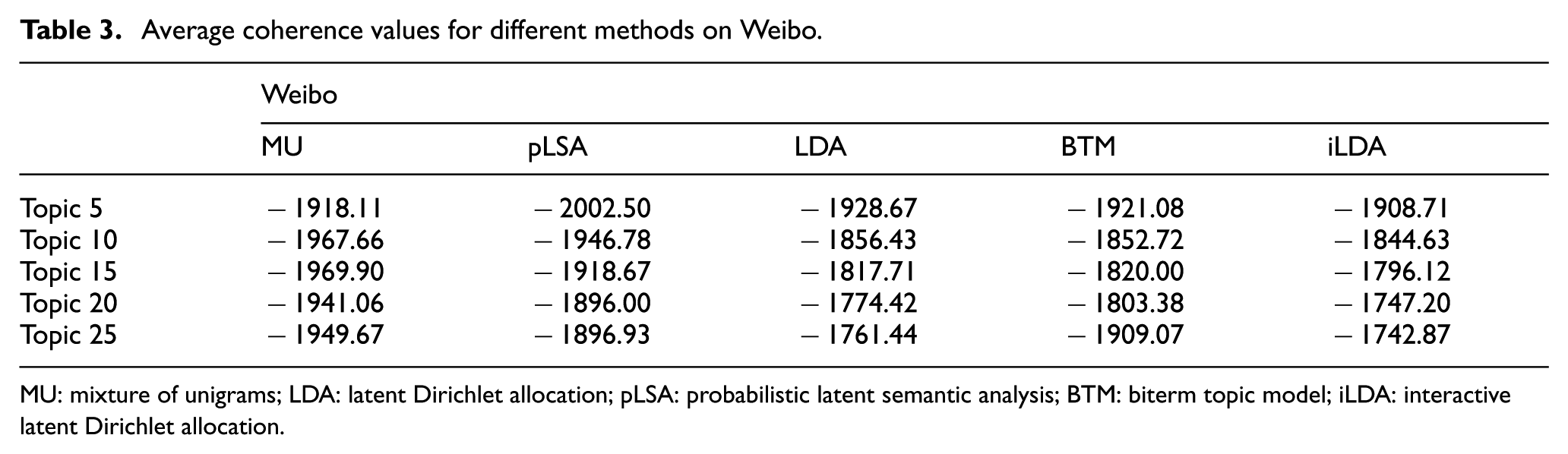
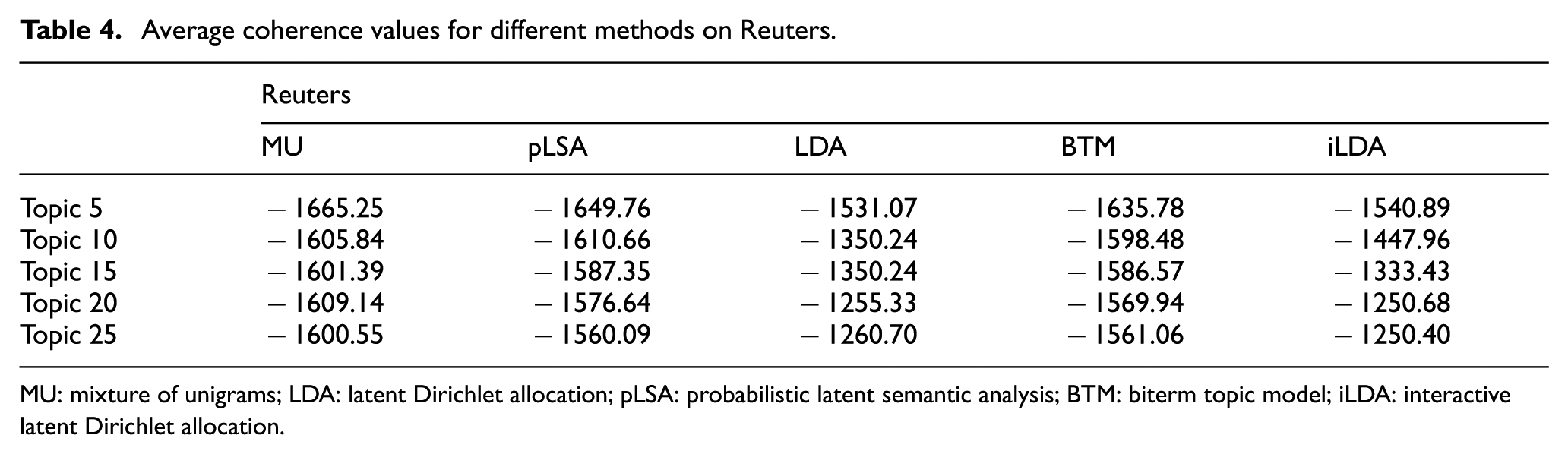
We run five experiments for each model on each corpus by fixing the number of topics as 5, 10, 15, 20 and 25, respectively. The average coherence values of the five models on the two corpora are shown in Tables 3 and 4.
Average coherence values for different methods on Weibo.
MU: mixture of unigrams; LDA: latent Dirichlet allocation; pLSA: probabilistic latent semantic analysis; BTM: biterm topic model; iLDA: interactive latent Dirichlet allocation.
Average coherence values for different methods on Reuters.
MU: mixture of unigrams; LDA: latent Dirichlet allocation; pLSA: probabilistic latent semantic analysis; BTM: biterm topic model; iLDA: interactive latent Dirichlet allocation.
As shown in Tables 3 and 4, the proposed iLDA outperforms the baselines in all the experiments except for the experiment on Reuters with five topics. In the five models, MU and pLSA have worst performances and LDA dominates them. Compared with the coherence on Weibo, the LDA model obtains much better coherence on Reuters. It indicates that data sparsity has significantly negative influence on LDA’s performance. BTM performs slightly better than MU and pLSA on Reuters, while it achieves reasonable results on Weibo. It also obtains better performance than LDA in some cases (e.g. experiments with 5 and 10 topics on Weibo). The results suggest that BTM can alleviate the influence of data sparsity.
To study whether the performance of iLDA is statistically robust, we conduct pairwise t-test to compare the topic coherence values obtained by iLDA and other baseline methods. We compare the coherence values of 75 (= 5 + 10 + 15 + 20 + 25) topics for each method and present the p values in Figure 6. From Figure 6, we can see that all the coherence improvements from the baseline methods to iLDA are statistically significant at the 0.05 level. The performance of the proposed iLDA model is statistically better than the baseline methods.
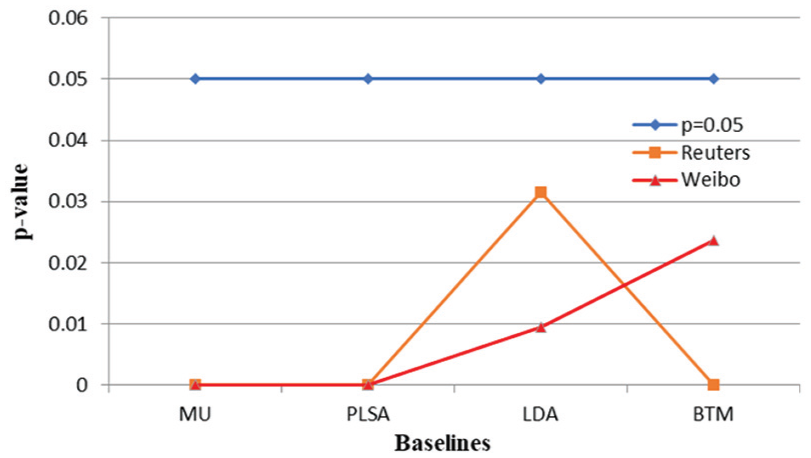
Results of t-test between iLDA and baselines.
4.2.2. Detailed comparisons between iLDA and LDA
Because the proposed iLDA model is inspired on LDA by integrating subjective knowledge, this section compares the topic quality derived by iLDA and LDA. Based on topic coherence formula (18), this article uses the defeat ratio from iLDA to LDA in formula (22) to compare their performances

where
To calculate the defeat ratio, we do not consider the topics which are not modified by experts to make sure the defeat ratio is larger than 50% if iLDA performs better. A 100% defeat ratio means from iLDA to LDA that all of the topics drawn by iLDA are better than those drawn by LDA. Since LDA is not sensitive to prior information, we set
We conduct 5×4×4 experiments in which the corresponding factor levels are as follows: number of topics = [5, 10, 15, 20, 25], number of probable words in topic = [20, 30, 40, 50] and reliability degree of human expert = [0.2, 0.4, 0.6, 0.8]. Topic-K in Tables 5–7 represents the experiments in which the size of topics is set to be K. The average defeat ratios of all experiments are shown in Table 5. Table 5 shows that the proposed iLDA model can significantly improve topic quality compared with the LDA model. The defeat ratio is 75.6% for Reuters and 89.1% for Weibo corpus, respectively, if five topics are explored, which are much higher than 50% when iLDA and LDA have equivalent performance. We also provide the detailed results when the number of probable words is fixed to be 20 (Table 6) and the reliability degrees of human experts is fixed to be 0.8 and 0.2 for Reuters and Weibo corpus, respectively (Table 7). Both tables show that we can obtain positive improvement if we integrate expert knowledge. Tables 6 and 7 also indicate that the factors such as topic size and reliability degree impact the performance of iLDA. We will examine the influence of these factors on the performance of iLDA in the sensitivity analysis.
The average defeat ratios.

The defeat ratios when number of probable words is 20.

The defeat ratios when fixing reliability degree.

4.2.3. Document clustering
Besides topic-word distribution, topic models also generate document-topic distributions for the corpus and each document can be denoted by a vector of topics. Therefore, decent topic models should have ability to draw topics to approximate document content. This section employs document clustering as an indirect strategy to test the performance of the proposed iLDA model and the baselines. The motivation behind the experiment is that, if a model can draw high-quality topics, the document clustering based on the topics should obtain better results because the topics are the accurate approximate of document content.
The k-means method is employed to cluster documents. With the k-means method, each document is considered as a data point which is represented by the corresponding document-topic distribution. The method randomly chooses k documents from corpus and uses these documents as the initial means. Other documents are then assigned to a nearest cluster. After the initial clustering step, the centroid of each cluster is calculated and the update step is iterated. Because the purpose of k-means is to maximise the between-group dispersion and minimise the within group dispersion of the samples, we use between_SS/total_SS to measure the clustering effectiveness. Here, between_SS is the weighted sum of squares between two cluster centres and the total_SS is the sum of squares assignment. The results are shown in Table 8.
The between_SS/total_SS values for document clustering.

MU: mixture of unigrams; LDA: latent Dirichlet allocation; BTM: biterm topic model; pLSA: probabilistic latent semantic analysis; iLDA: interactive latent Dirichlet allocation.
Table 8 indicates that the proposed iLDA model obtains better clustering results than the baselines on both of the two corpora. The results prove, from an indirect perspective, that iLDA can discover high-quality topics from documents. By integrating the subjective and objective knowledge, iLDA can draw topics which can summarise document contents accurately and thus result in better results of document clustering.
4.3. Sensitivity analysis
4.3.1. Influence of adjustment indicator
In section 3.3, we introduce the adjustment indicator to determine which topics should be adjusted by human experts. This section designs two experiments to test the influence of the indicator on the performance of iLDA. We classify the discovered topics into two categories: the first category consists of high-quality topics with top 20% indicator values and the second category includes the rest 80% topics. In the first experiment, we show human experts the topics in the first category and invite them to change the probabilities of the words while the second experiment invites human experts to adjust the probabilities of the words in the second category. Table 9 provides the coherence improvement from LDA to iLDA when we use these two adjustment strategies in the iLDA model. Table 9 shows that probability adjustments of the topics with low indicator values lead to coherence increase (experiment 1), but the coherence value may decrease if we change the probabilities of the topics with top 20% of the indicator values (experiment 2). For the topics with high indicator values, their qualities are mostly reasonable based on the generative mechanism of LDA. The adjustment by human experts brings conflicting information and thus results in the decrease of coherence values. For the topics with low indicator values, however, human experts can identify the puzzling words and improve topic qualities by decreasing their probabilities. Table 9 proves that, while reducing workload and saving time for human experts, the proposed adjustment indicator is also useful to improve topic quality.
The validity of adjustment indicator.

4.3.2 Influence of degenerative probabilities
In the iLDA model, human experts are invited to provide degenerative probabilities for the unrelated words according to their knowledge. Although more efforts are required from human experts, our experiments show that it is worthy to draw high-quality topics. Figure 7 illustrates the comparison results of iLDA_f and LDA. With the iLDA_f model, human experts are not required to provide degenerative probabilities for words. They are only invited to indicate that a word is related or not to a topic. Once human experts select an unrelated word from a topic, we set a fixed degenerative probability from 0.0 to 0.8 to decrease its probability in the topic. Experimental results in Figure 7 show that, even with the fixed degenerative probabilities, the iLDA_f model still outperforms the LDA model. The defeat ratio is 54.92% and 54.76% on Reuters and Weibo, respectively, which prove the value of expert knowledge to discover high-quality topics.

Results with different degenerate-probability: (a) Reuters and (b) Weibo.
Figure 7 also proves that there are no perfect fixed probabilities for all datasets and topics. When the fixed probability is set to a specific value, iLDA_f is able to outperform LDA but cannot achieve the best performances in all topic sizes. For example, on Reuters corpus, the iLDA_f is better than LDA in all topics when the fixed probability is set to 0.0. However, the highest defeat ratio on topic 10 and topic 15 is obtained when the fixed probability is 0.6. On Weibo corpus, the iLDA_f outperforms LDA in all size of topics when the fixed probability is 0.6, but topic 15 and topic 20 achieve the best result when the fixed probability is 02 and 0.8, respectively. Thus, in reality, the trade-off between best performances and robust performances is an important thing to be considered when the strategy of fixed probability is employed.
We now evaluate the value of the flexible degenerative probabilities employed in the iLDA model. We also utilise the defeat ratio from iLDA to iLDA_f to illustrate the comparison. We set the reliability of human judgement to 0.4 and 0.8 on Reuters and Weibo, respectively, of the iLDA model and compute the average defeat ratios from iLDA to iLDA_f. As shown in Figure 8, compared with iLDA which uses flexible degenerative probabilities, the iLDA_f model results in decrease of topic qualities on both corpora. In most of the cases, the iLDA generates better topics compared with the iLDA_f model. The defeat ratio from iLDA to iLDA_f is 64.2% and 63.35% on Reuters and Weibo, respectively. From the figures we can see that all of the defeat ratios from iLDA to iLDA_f are no less than 0.5 on Reuters corpus. It is also shown that iLDA_f outperforms iLDA on Weibo in only two cases.
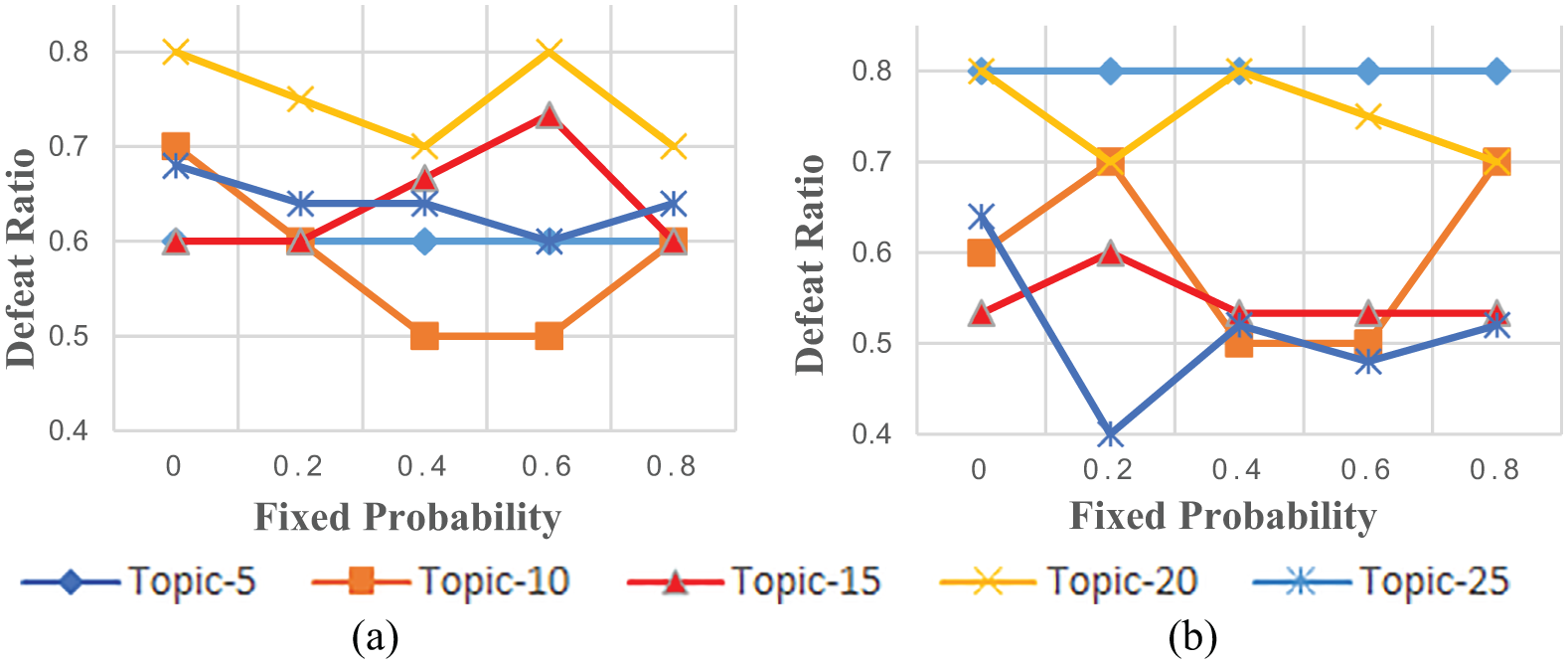
Defeat ratio from iLDA to iLDA_f: (a) Reuters and (b) Weibo.
4.3.3. Influences of reliability degree
In the proposed iLDA model, human experts have significant roles for model performance. Because the expertise of human experts varies in different fields and the professional levels usually differ among experts, the reliability degree human experts have should be considered to conduct the interactive process.
To examine whether the iLDA model remains valid under different reliability degrees, we vary the reliability degrees of human experts from 0.2 to 1. The model will reflect human’s judgement totally when the reliability degree equals 1. The comparison of experimental results between iLDA_r and LDA in Figure 9 shows that the reliability degree has obvious influence on the model performance. Taking the model performance of Topic 5 on Weibo, for example, the defeat ratio is 100% when the reliability degree is 0.8% and 75% when the reliability degree is 0.6. The average defeat ratios of the two corpora from LDA_r to iLDA are 72.50%, 65.00%, 61.26%, 56.88% and 59.42%, respectively, when the topic number varies from 5 to 25. Figure 9 indicates that an optimal reliability degree exists to mine specific number of topics on different corpora. The optimal reliability degree is 0.8 on Reuters corpus except for Topic 15.

Defeat ratio from iLDA_r to LDA: (a) Reuters and (b) Weibo.
Our experiment also shows that complete dependence on human experts results in negative influence on model performance. Figure 10 illustrates the results when the reliability degree of human experts is set to be 1. The average defeat ratio from iLDA to LDA on Reuters and Weibo decreases to 39.72% and 48.31%, respectively. Figures 9 and 10 indicate that the subjective and objective knowledge are both essential for the iLDA model.

Experiments when reliability degree is 1.
4.3.4. Influences of deterministic strategy and stochastic strategy
The iLDA model proposes two strategies, that is, the deterministic strategy and stochastic strategy, to get the subjective topic-word distribution. This section conducts experiments to test the influence of the two strategies. As shown in Figure 11, the defeat ratios from stochastic strategy to deterministic strategy are no less than 0.5 in most cases on the two corpora. The stochastic strategy performs worse than the deterministic strategy only in 7 and 8 cases in the 25 experiments on the two corpora. Figure 12 illustrates a detailed comparison of the two strategies when reliability degree is 0.8.

Influences of deterministic and stochastic strategy: (a) Reuters and (b) Weibo.
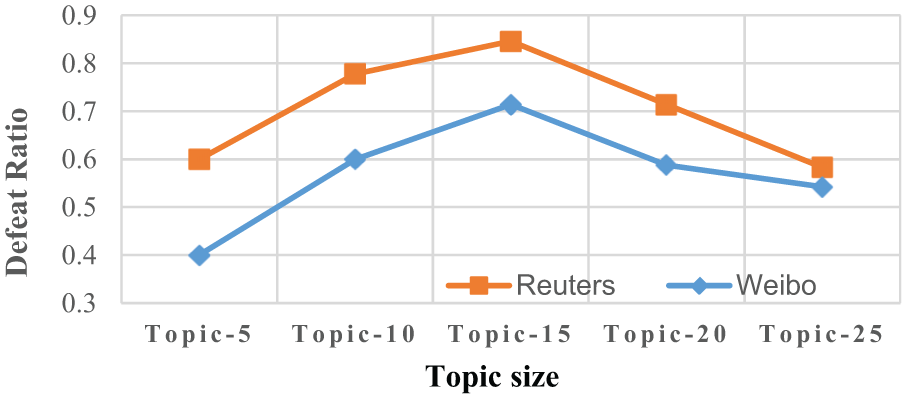
Defeat ratio when reliability degree is 0.8.
From Figure 12, we can see that the stochastic strategy outperforms the deterministic strategy except for Topic 5 on Weibo corpus. The defeat ratio from the stochastic strategy to the deterministic strategy is 70.42% and 56.88% on Reuters and Weibo, respectively. With the deterministic strategy, although the integration of human knowledge helps us find high-quality topics, a potential defect is that the topics are apt to converge towards local best themes. The stochastic strategy, however, can be treated as a selector variable for the words to be adjusted. It will encode the uncertainty of human judgement into the model which captures the power of the iLDA model better. The experiment indicates that integrating human knowledge and overstepping local best themes are both critical for the iLDA model.
The experimental results show that the proposed iLDA model outperforms other methods in terms of topic qualities and document clustering. In the proposed model, low-quality topics are selected and experts are invited to adjust the topic-word distributions of these topics. Because the LDA model can extract topics from unstructured texts and expert knowledge can eliminate the negative influence of low-quality topics, the integration of subjective knowledge from experts and objective knowledge from LDA model leads to the accurate results in the experiments.
5. Conclusion and future work
Knowledge discovery from user-generated content has been a commodity much sought after by industry and academic research. To discover high-quality knowledge, this article proposes an interactive strategy of the LDA topic model which aims to integrate subjective knowledge from human experts and objective knowledge mined by the LDA model. The proposed iLDA model employs a new indicator to measure topic quality, provides two (deterministic and stochastic) methods to derive subjective topic-word distribution and proposes guidelines to draw words for topics automatically based on both the subjective and the objective topic-word distributions. Our experiment shows that the proposed iLDA model can mine high-quality topics and is robust under various conditions.
Topic modelling based on LDA has been a frequently used tool to detect instructive knowledge in data such as genetic information, images and networks. While useful to various fields and industries, LDA-based topic modelling still suffers from inherent limitations such as topic quality, coherence and stability [43,44]. Different from the applied researches of LDA-based topic modelling, this article focuses on the inherent limitations of the LDA methodology and proposes strategies to improve topic quality. The proposed iLDA model offers fundamental supports for the applications of LDA-based topic modelling.
This article employs deterministic and stochastic strategy to obtain expert knowledge and uses linear sum-weighted method to integrate objective and subjective knowledge. In terms of future research, one possibility is to study new strategies to obtain subjective knowledge from human experts and new methods to integrate the subjective and objective knowledge. In real application, massive corpora from multiple sources determine that it is an impossible task to deal with the unstructured text by one expert. Another extension of the proposed model is to design interactive strategies for multiple experts to achieve better analysis performance.
Footnotes
Acknowledgements
We appreciate the constructive comments from the anonymous reviewers. We also thank Prof. Chunhua Sun for his contribution.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work was supported by the Major Program of the National Natural Science Foundation of China (71490725), the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (71521001), the National Natural Science Foundation of China (71722010, 91546114, 91746302, 71501057) and The National Key Research and Development Program of China (2017YFB0803303).