
Abstract
Latent Dirichlet allocation (LDA) is one of the probabilistic topic models; it discovers the latent topic structure in a document collection. The basic assumption under LDA is that documents are viewed as a probabilistic mixture of latent topics; a topic has a probability distribution over words and each document is modelled on the basis of a bag-of-words model. The topic models such as LDA are sufficient in learning hidden topics but they do not take into account the deeper semantic knowledge of a document. In this article, we propose a novel method based on topic modelling to determine the latent aspects of online review documents. In the proposed model, which is called Concept-LDA, the feature space of reviews is enriched with the concepts and named entities, which are extracted from Babelfy to obtain topics that contain not only co-occurred words but also semantically related words. The performance in terms of topic coherence and topic quality is reported over 10 publicly available datasets, and it is demonstrated that Concept-LDA achieves better topic representations than an LDA model alone, as measured by topic coherence and F-measure. The learned topic representation by Concept-LDA leads to accurate and an easy aspect extraction task in an aspect-based sentiment analysis system.
1. Introduction
The Internet, which has become an important source of information to millions of people in the world, has opened the new doors for its users to share their opinions about their purchases. In this sense, online review web sites with millions of users are used to express opinions and feelings towards products, companies, services and so on, and anyone can gather others’ opinion through these mediums [1]. Everywhere, users are accessing these web sites. Therefore, a growing volume of the data for analysis is piling up and intensively analysed as it exerts a powerful effect on consumers [2].
However, there is a constant and unavoidable increase in online user reviews, and, for the same product, these reviews could be posted on different web sites. Thus, for average humans and companies to extract the required information is a challenging task. In order to help both the consumers for the product they wish to purchase and the companies for their brands, there is a need for automatic analysis of such product reviews [3].
The sentiment analysis is a computational task for analysing opinions, sentiments and evaluations of people about products, topics, individuals and their attributes [4]. Recently, understanding people’s opinion from written texts via machines has become a hot research topic. This is because opinions are central to almost all human activities and are essential parts of our decision making process. The purpose of the sentiment analysis is to determine opinions through opinionated texts.
Sentiment analysis is mainly done at three different levels: document level, sentence level and aspect level. Document-level analysis is based on the overall sentiments of a review. For example, in a restaurant review, the aim is to know a general sentiment (good or bad) about the restaurant through the whole document. Sentence-level analysis is used for learning general sentiment from opinionated sentences. Although these two analyses give general sentiment about a product as mentioned above, however, with this result, we cannot say that all the product specifications are poor or good. Thus, there is a need for fine-grained analysis; as a result, aspect-level analysis has gained popularity. Aspect, which expresses the sentiment, is anything that defines and completes a product; sentiment is positive or negative feeling about an aspect [2]. In aspect-level sentiment analysis, sentiments are individually assigned to each aspect.
The automatic extraction of aspects is a very crucial step in aspect-level sentiment analysis. There are many methods of aspect extraction, which include frequent noun and noun phrases–based methods [5–9], rule-based methods [10–12], supervised learning [13], deep learning [14–17] and topic models [2,18–20]. Among these methods, topic models, such as latent Dirichlet allocation (LDA), have the ability to discover latent topics that are of extensive interest.
LDA, which is a probabilistic topic model, is based on the idea that a document is a mixture of many latent topics and each topic has a probability distribution over words [21]. A topic is described as a basic idea discussed in the whole document. One assumption that LDA makes is the ‘bag-of-words’, so the model does not consider the semantic structure of the documents.
In this study, to overcome the shortfall of LDA, we incorporate semantic knowledge into a model for aspect-based sentiment analysis. For this purpose, instead of using a bag-of-words, a bag of {words + concepts + named entities} is used. Concepts are defined as the units of knowledge, where each unit contains a unique meaning [22]. Named entities are defined as the names of real-world objects such as a person, organisation or location. In order to extract the concept and named entity, Babelfy, which carries out both multilingual word sense disambiguation (WSD) and entity linking (EL), is used [23]. Babelfy is based on the BabelNet, which is an integration of Wikipedia and WordNet, a multilingual semantic [24]. More meaningful topics are intended to obtain the related concepts and named entities. In this study, the proposed approach is empirically proved to be an effective unsupervised method for aspect-based sentiment analysis.
The rest of the article is organised as follows. Section 2 summarises the literature review about LDA. Section 3 describes the background knowledge about Babelfy and LDA. The proposed approach is exemplified in Section 4. The dataset, evaluation measures and evaluation results based on topic coherence and F-Measure are given in Section 5. Finally, discussion and conclusions for the future work are summarised in Section 6.
2. Literature review
The studies on aspect-based sentiment analysis have attracted a great attention in recent years owing to their ability to give sentiments separately for each product aspect. In this analysis, the vital step is the aspect extraction, and to design a powerful sentiment analysis system, aspect extraction process should be carried out successfully.
Aspect extraction that is one of the core tasks of sentiment analysis has been studied by many researchers [4,25,26]. Furthermore, the ongoing research has recently started addressing this problem by using topic models and its variants.
Titov and McDonald [27] considered two distinct types of topics, that is, global and local. They assumed that a word in a document is sampled either from a mixture of global topics or from a mixture of local topics. They devised Multi-Grain LDA (MG-LDA) to model local and global topics for extracting product aspects. With the local topics, they intended to capture rateable aspects, while with global topics, they intended to capture product properties. In this experiment, they used a set of 27,564 reviews of hotels taken from TripAdvisor.com. PRanking algorithm that is a perceptron-based online learning method was used as an aspect rater method. For each aspect i, a rating score was calculated by PRanking. The authors extracted topics using both LDA and MG-LDA and then combined them with unigram, bigram and trigrams in the text to represent the input features. The Gibbs sampling algorithm, for both MG-LDA and LDA, was applied and executed for 800 iterations. All experiments were evaluated with an average ranking loss that defines the average difference between the actual and predicted rating values for a given N test instances. They compared four models for the ranking loss. The first model gives a rating of 5 to each aspect, the second model applies PRanking over input features of raw data, the third and fourth models include words obtained from LDA and MG-LDA, respectively, and then apply PRanking algorithm. In making a conclusion, their method surpasses the remaining three methods. Lin and He [28] implemented an LDA-based fully unsupervised Joint Sentiment/Topic Model (JST) to extract sentiments and aspects from movie reviews simultaneously. With this model, they also classified sentiment polarities of reviews. Brody and Elhadad [29] proposed Local LDA as an unsupervised method for aspect extraction. Mutual Information was used for representative words of each aspect. For example, the representative words for ‘value’ are ‘portions, quality, worth, size, cheap and so on’. Adjective extraction was realised with conjunctions, negations and polarities of these adjectives, which were determined with a conjunction graph. Wang [30] developed a semi-supervised topic model, Co-LDA, in which aspects and sentiments are modelled simultaneously. This model considers sentiment LDA and topic LDA. Jo and Oh [31] assumed that words in the same sentence are under the same topic with Sentence LDA. Then they extended Sentence LDA, called Aspect and Sentiment Unification Model (ASUM), to model aspects and sentiments together and obtained aspect sentiment pairs. Xianghua et al. [32] extracted aspects from Chinese reviews. In order to extract global and local topics, they utilised LDA and sliding window, respectively.
Bagheri et al. [33] preferred Aspect Detection Model based on LDA (ADM-LDA). In this model, they used Markov Chain instead of the ‘bag-of-words’ assumption. Wang et al. [34] devised two new semi-supervised methods called Fine-Grained Label LDA (FL-LDA) and Unified Fine-Grained Label LDA (UFL-LDA). In FL-LDA, the aspect seed lexicon was utilised to extract the aspects in the reviews, and in UFL-LDA, unlabeled documents were used to extract high frequency aspects. Zheng et al. [35] developed Appraisal Expression Patterns LDA (AEP-LDA) for extracting product aspects from restaurant, hotel, MP3 player and camera reviews. They assumed that words in the same sentence were covered under the same topic. Yin et al. [36] proposed a new LDA-based approach, that is, Dependency Topic Affects Sentiment LDA (DTAS), where they ignored ‘bag-of-words’ and preferred the Markov Chain. Poria et al. [37] utilised Sentic-LDA, which was an improved variant of the LDA that incorporated semantic similarity. This method offered better performance compared with the baselines. Yang et al. [38] implemented CAT-LDA, which was based on LDA and used two-layer categorical information. By using the hierarchical relation between products, they constructed a general category from a subcategory. In their empirical evaluation, they preferred five general categories of Amazon.com Review Dataset. Shams and Baraani-Dastjerdi [39] used Enriched LDA (ELDA) to extract aspects by combining word co-occurrence as prior knowledge with LDA. The ELDA was evaluated with some English and Persian datasets and showed reasonable accuracy. Unlike English and other languages, there is only one study that applied the LDA method in Turkish documents. Ekinci and Ilhan [1,40] applied the LDA model for restaurant reviews in English and hotel reviews in Turkish. Besides, Atıcı et al. [41] used the LDA model to determine complaints and dissatisfactions about products, services or companies from a Turkish complaint dataset.
3. Background
3.1. Babelfy
In natural language processing (NLP), word sense ambiguity (WSA) causes poor performance and serious problems with annotation [42]. Thus, there is a need for a powerful approach to this problem.
Babelfy is the first approach that performs both multilingual WSD and EL at the same time [22]. It uncovers semantic relations between word meanings and named entities by using BabelNet [22,23]. BabelNet is a multilingual semantic network with 9 million concepts and named entities in 50 languages and lexicalisations and glosses for them. It takes advantage of WordNet, Wikipedia, OmegaWiki, Open Multilingual WordNet and Wiktionary for annotation. Babelfy completes a task in following steps: (1) for exact matching, all possible meanings of all words in a sentence are considered; (2) a partial matching is realised; (3) in order to solve ambiguity problem, all the candidate meanings are linked with each other; (4) a dense sub graph is extracted from connections; (5) at the final step, most suitable meanings are chosen; and (6) the text in any language is disambiguated [43].
3.2. LDA
Probabilistic topic modelling methods have become an important field of research and have gained a great attention in machine learning and text mining applications in recent years [21,44–46]. In fact, the probabilistic topic modelling methods are defined as a group of algorithms that discover hidden thematic knowledge in document collections by converting this knowledge into small dimensions [47]. In these methods, LDA is very popular because of its high success rate.
LDA, which is based on the bag-of-words assumption, is fully unsupervised and does not need prior knowledge. It is described as a generative probabilistic model for collections of discrete data such as text corpora by Blei et al. [45]. The generative model specifies document creation by using latent variables. The basic idea behind LDA is that documents in a collection exhibit multiple latent topics and a topic has a probability distribution over words. A topic can be defined as a collection of words that frequently occur together and are related to the same subject. In this model, it is assumed that, given the parameters, the words in a review are independent, which is known as the ‘bag-of-words’ assumption in NLP. The generative model and posterior distribution of LDA is shown in Figure 1.

Generative model for LDA.
In LDA, documents are mixtures of latent topics and each of the words that compose the document is selected from one of these topics. The topics have probability distributions over words that are coming from a fixed dictionary. At first, the generative model begins by sampling the words under a topic. In the second step, each topic is sampled from a document, and, consequently, topic proportions for each document are obtained. In the last step, each word in a document is drawn from one of the topics. Word distribution over topics and topic distribution over documents are obtained by using the Dirichlet distribution, which is a prior conjugate for multinomial.
The graphical model of the LDA is represented with plate notation. The plate notation for LDA describes the random variables and explains how these variables are generated from the propagation along the directional edges for the observed data. The plate notation of the LDA is given in Figure 2.
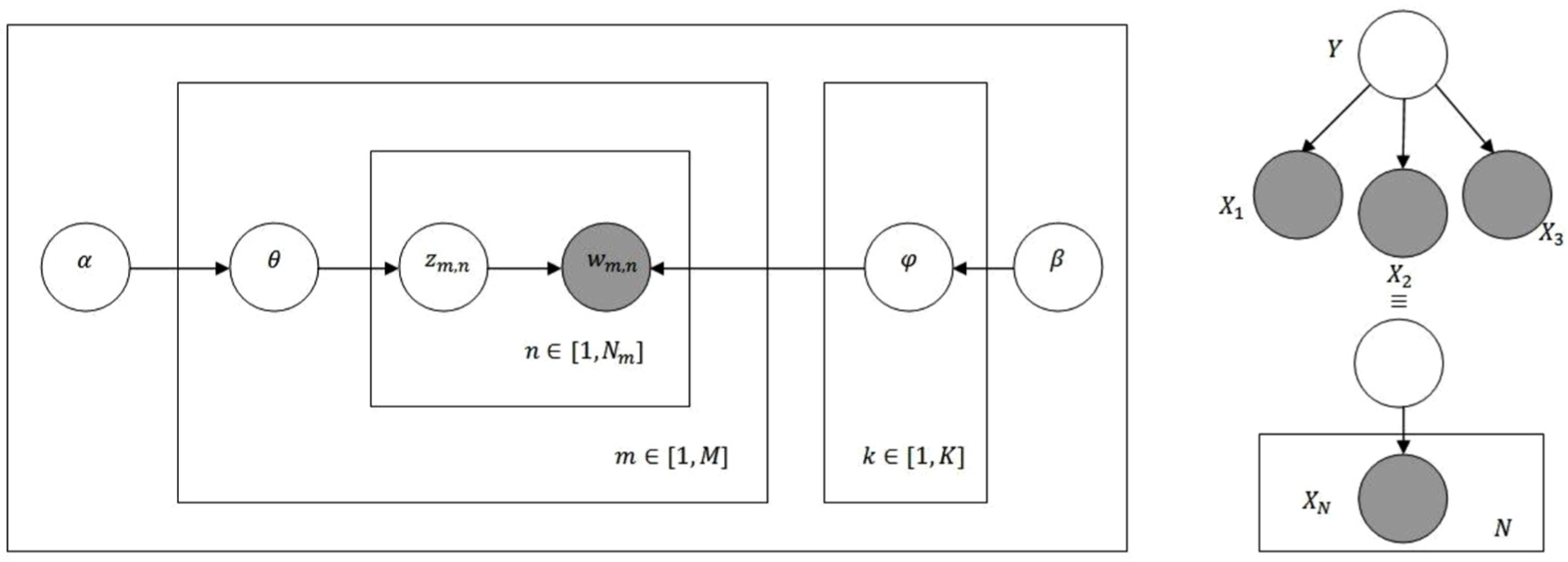
Plate notation for LDA.
In Figure 2,
In the given generative model, plates are used for indicating replicated variables. Nodes are random variables; edges indicate dependencies between these nodes. While the shaded nodes are observed variables, the non-shaded nodes are hidden variables. According to the graphical model given in Figure 2, the joint distribution of all hidden and observed random variables is given below
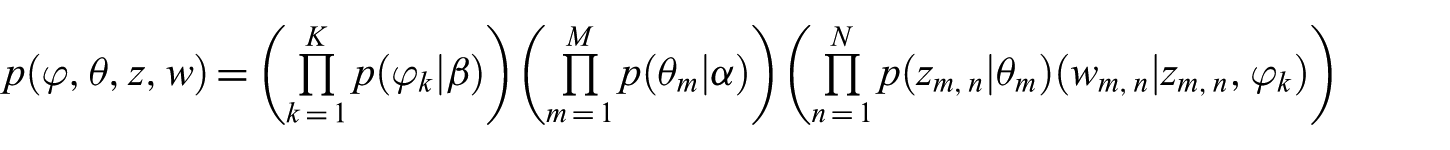
As mentioned above, the main aim of the LDA is to obtain the model parameters. For this purpose, the posterior distribution given below is used
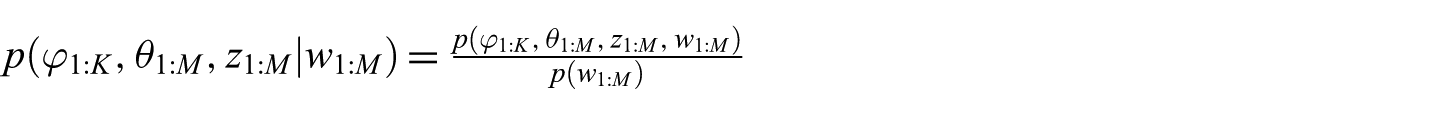
The joint probability in the numerator can easily be determined for any combination of the hidden variables. The denominator, which is the marginal probability of the observed data, is intractable to compute because it represents the probability of seeing the observed corpus under any topic model, and the possible topic models are quite large. Thus, for approximating this posterior, variational expectation maximisation or the Collapsed Gibbs Sampling (CGS) methods are preferred. In this study, to discover the latent topics, CGS is used.
3.3. CGS
CGS is a special kind of Markov Chain Monte Carlo (MCMC) sampling, which is used for the posterior distribution in the Bayesian inference and provides information about distributions. CGS was first introduced by Griffiths and Steyvers in 2004 [48]. It is performed to approximate the intractable statistics in generative models like LDA [48,49].
In this method, only the latent variable z is sampled, θ and φ are marginalised. Sampling is realised by calculating the probability that the current word is assigned to each topic and conditioned on the topic assignments to all other words, which are accepted as model parameters [21]. This process is applied iteratively for each word in the document and each word in the document collection based on the equation below

In the above equation,
4. Proposed approach
A crucial aspect of NLP is to describe semantically well-represented word vectors. LDA clusters co-occurred words together by ignoring semantic relationships between them. In order to handle this lack of semantic information, we propose a semantic word enrichment method by expanding reviews with concepts and named entities obtained from Babelfy. The current study has been inspired by our analysis that some semantically related words are not being included in the same topic in LDA. For an example, if the document collection is represented by the bag-of-words model, then ‘waiter (A person whose occupation is to serve at table) (as in a restaurant)’ and ‘waitress (a woman waiter)’ cannot be included in the same topic. However, by adding concepts of the ‘waiter’ and ‘waitress’, which are ‘person’ and ‘restaurant’ for waiter; ‘woman’ and ‘waiter’ for waitress, we obtain a more accurate topic which includes ‘waiter’ and ‘waitress’ together. The major assumption of our model is that the words that indicate the same concepts tend to have a similar meaning. Therefore, for extracting concepts and named entities based on the true sense of the words, Babelfy is used in this study. In addition, when we considered the successful and extensive usage of Babelfy for a WSA problem in NLP, this interface also offers us an advantage for solving the WSA problem for topic modelling.
The proposed model includes the following steps: (1) multi-words are learned from an original dataset by using Babelfy; (2) stemming, converting lowercase and stop word elimination are applied to the dataset; (3) Babelfy is used to extract the concepts and named entities from the pre-processed dataset; (4) the pre-processed dataset and the concepts and named entities are combined to create a final dataset; and (5) LDA is applied to obtain the semantic topics from the final dataset.
According to the steps given above, we first explain the multi-word extraction using Babelfy. Then the basic pre-processing steps such as stemming, converting lowercase and stop word elimination are presented. The Babelfy-based concept and named entity extraction are introduced in the next section. The proposed LDA is presented at the end. The basic framework of the proposed approach is illustrated in Figure 3.
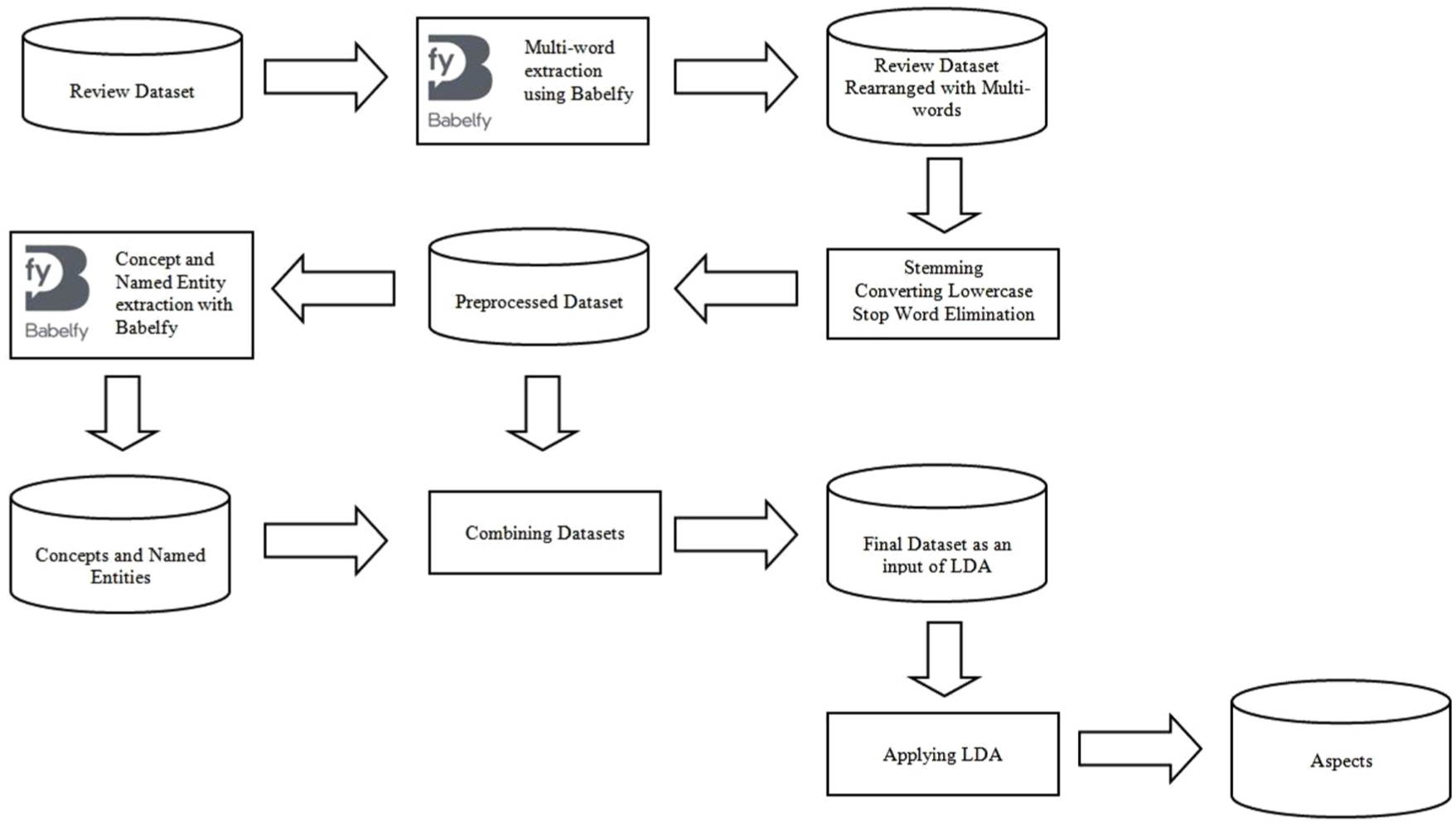
Framework of the proposed approach.
In user reviews, the product aspects can either be single worded or multi-worded, so for a depth sentiment analysis, multi-word aspects besides single-word aspects must be detected [50]. For this purpose, the first aim is to extract all the multi-words from the reviews. When the reviews are examined, four types of multi-words are observed: multi-words taking place in the dictionary, domain-based multi-words, multi-word named entity phrases and misspelled compounds. In a review sentence, ‘… it is the one with an open English muffin’, ‘English muffin’ is a multi-word and dictionary contains this word. Domain-based multi-words, such as ‘mustard sauce’, do not exist in the dictionary, ‘mustard’ and ‘sauce’ come together based on a domain and content of the sentence. Like ‘mustard sauce’, ‘poached egg’ in the sentence ‘My girlfriend had a couple of poached eggs with spinach and cheese’ is a domain-based multi-word. In the sentence ‘… along Washington Boulevard’, ‘Washington Boulevard’ is the multi-word named entity phrase. In user reviews, there are a lot of misspellings, for example, the word ‘seafood’ is written as ‘sea food’. By using Babelfy and its properties, all type of multi-words can be easily extracted from user reviews. In our study, 1982 multi-words were extracted efficiently from the restaurant reviews.
In the second stage, stemming is applied to extract word radicals contained in the dataset rearranged with multi-words. The morphological variants of a word are reduced by stemming. For this task, Stanford CoreNLP (see https://stanfordnlp.github.io/CoreNLP) library is preferably used. Then, all uppercase letters are converted to lowercase because of case sensitivity. Stop word elimination is performed to remove irrelevant words such that Babelfy does not extract concepts and named entities for them. At last, all punctuations are removed from the dataset. We use the OpenNLP (see http://opennlp.apache.org) for sentence detection.
In NLP studies, automatic acquisition of meaning from a text is the major task due to ambiguity [51]. Thus, accurate concept and named entity extraction is very crucial for capturing true meaning and semantically related topics. Even in this stage, Babelfy is used with following extraction steps: (1) concepts and named entities in the text are linked to a set of vertices by using a lexicalised semantic network, (2) possible meanings of linkable fragments extracted from text are determined by using semantic network and (3) convenient meanings for each fragment are selected by using dense sub graph [51]. Concept-LDA which is applied to a final dataset obtained from the combining dataset step is presented in Figure 4.
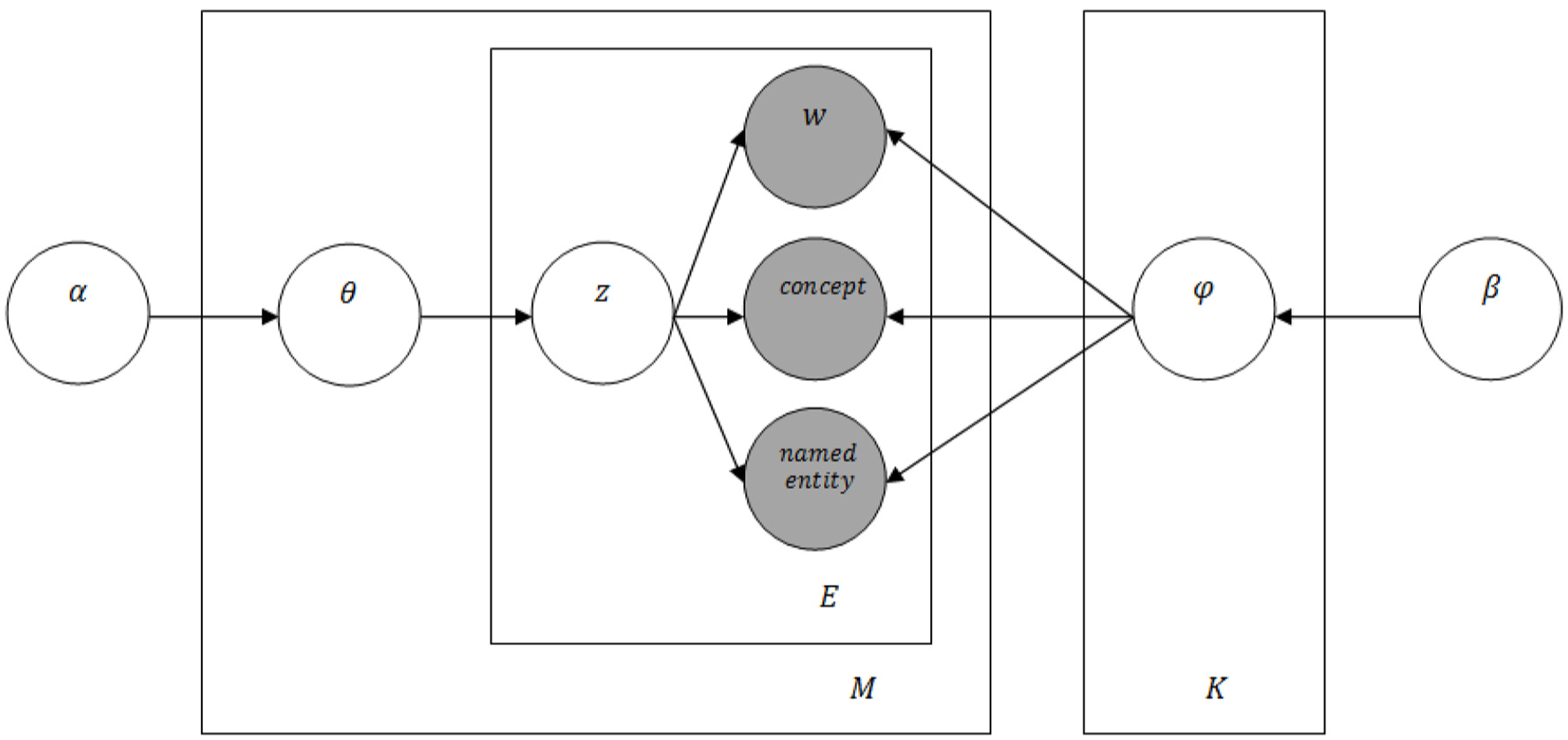
Concept-LDA model.
In Figure 4,
5. Evaluation
In this section, we describe the evaluation of Concept-LDA and compare it with LDA both qualitatively and quantitatively. For the qualitative analysis, we present aspects generated by both models in terms of semantic relation and ability to capture details. For the quantitative analysis, we use topic coherence and F-Measure as a comparing measure. In the following section, dataset, evaluation measures and evaluation results are discussed.
5.1. Dataset
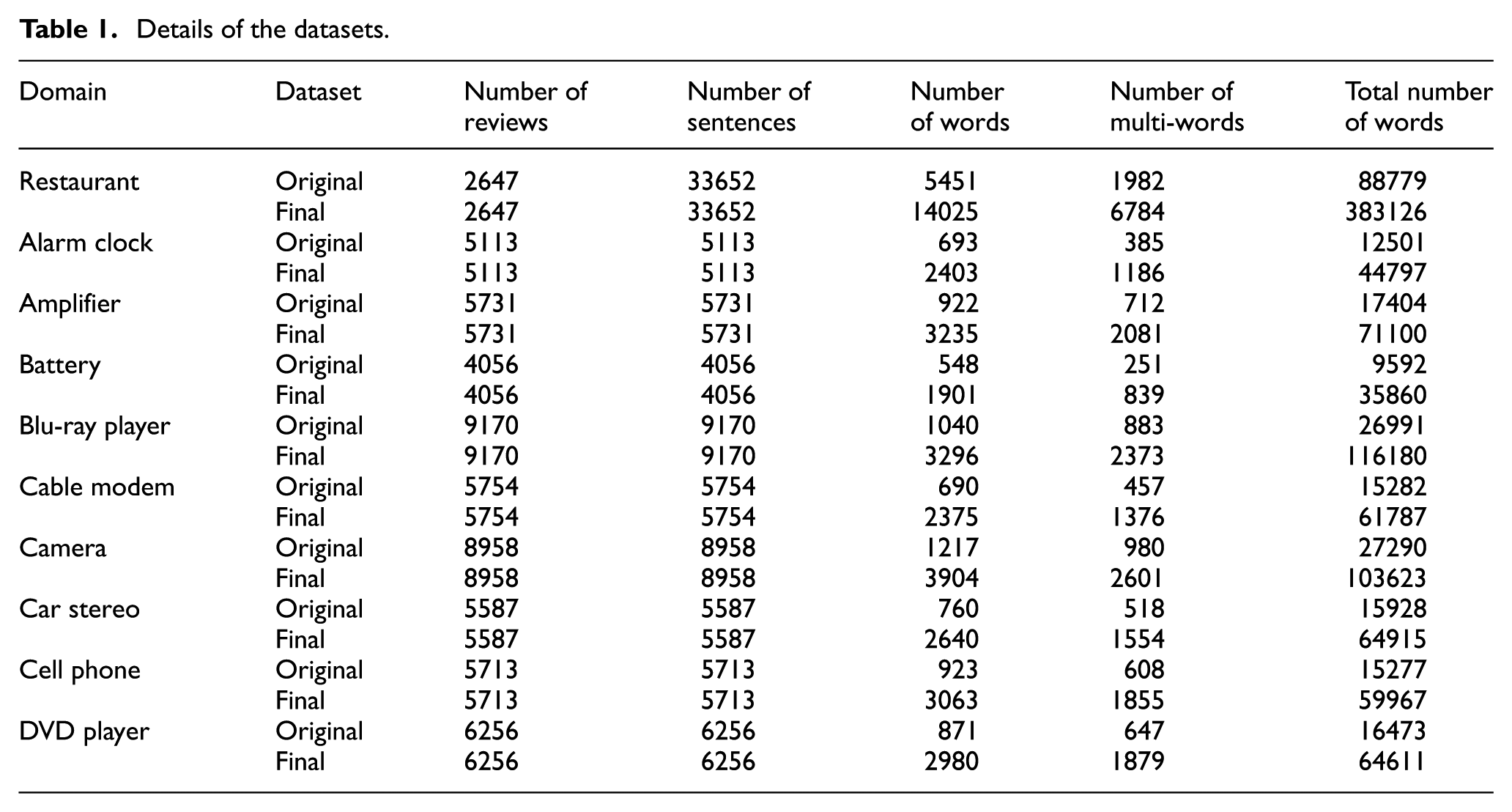
In experiments, we use 10 different public datasets. As the first dataset, we select the subset of a restaurant dataset from the popular web site Yelp (see http://www.yelp.com). The reviews in the selected subset are in American (New) category. For the remaining datasets, we select 9 domains out of 50, which were crawled from Amazon.com [52]. The standard pre-processing steps which are realised in the NLP works are applied to datasets as explained in Section 4. After applying these steps, the final datasets are enriched by expanding features with concepts and named entities as deeper semantic knowledge. The original and final datasets are enlisted in Table 1.
Details of the datasets.
5.2. Evaluation measure
In this study, topic coherence and F-Measure (based on precision and recall) are used as a performance measure. Topic coherence is used to reflect the semantic coherence of the individual topics and is computed as follows [53]

where
In order to make an accurate evaluation of the Concept-LDA, the words in the datasets are labelled as an aspect or non-aspect manually by three annotators, independently. The words are labelled as an aspect, if all of the annotators are agreed otherwise as a non-aspect. Since the topic words are extracted by both the Concept-LDA and LDA models, they are evaluated separately on the basis of annotators’ decision F-Measure used for evaluation.
5.3. Evaluation results
In many earlier studies, the model parameters are set arbitrarily without justification [44,54]. Therefore, for both models, we run 50, 100, 200, 500 and 1000 iterations of CGS and use symmetric priors
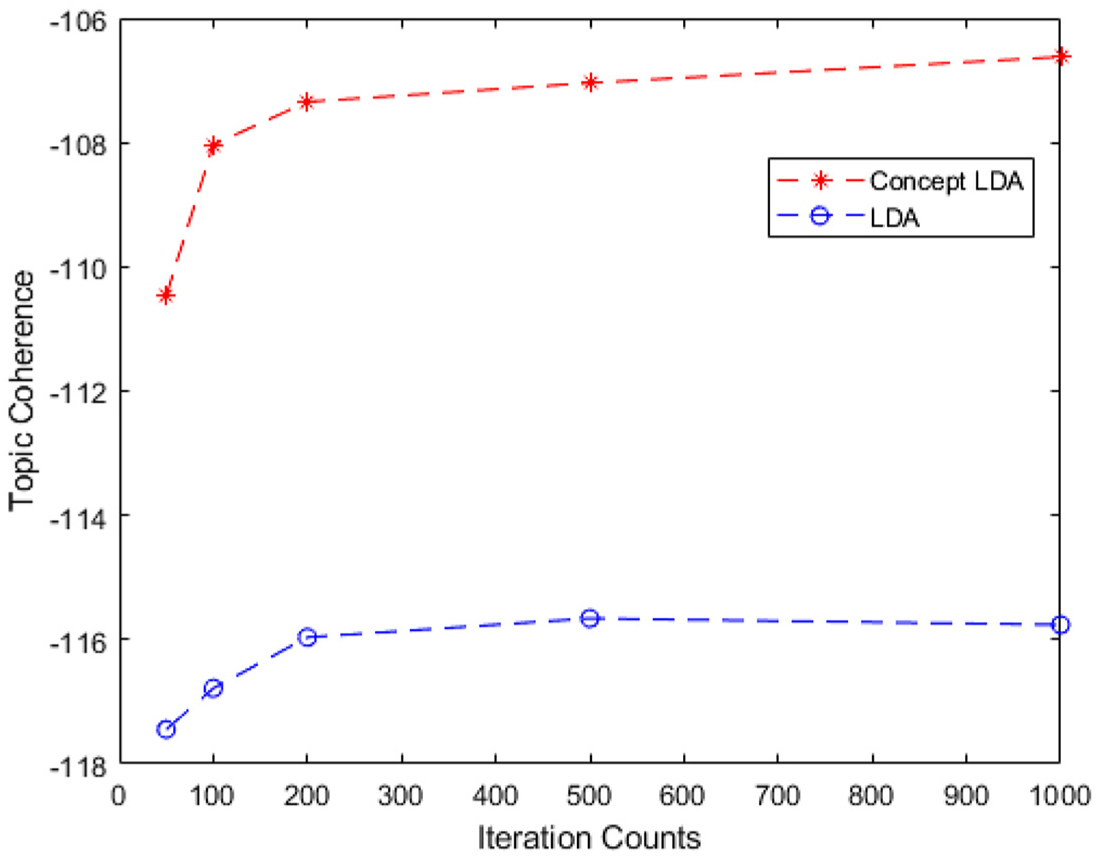
Average topic coherence with different iteration count selection.
Figure 5 shows that the topic coherence in Concept-LDA is better than that in the LDA model. Therefore, incorporating concepts and named entities into topic modelling enhances the generalisation performance significantly. As shown in Figure 6, even for a smaller number of iterations such as 50, the improvement by Concept-LDA is more than 6% on average. If the number of iterations is increased, the improvement over topic coherence increases slightly. For 1000 iterations, the improvement over coherence is more than 8%. That is, the Concept-LDA results in better generalisation performance in terms of topic coherence. As a result of these evaluations, it can be asserted that with 1000 iterations the highest average topic coherence can be obtained for Concept-LDA. Thus, we run 1000 iterations for Gibbs sampling, which is adequate to achieve best results in our experiments.
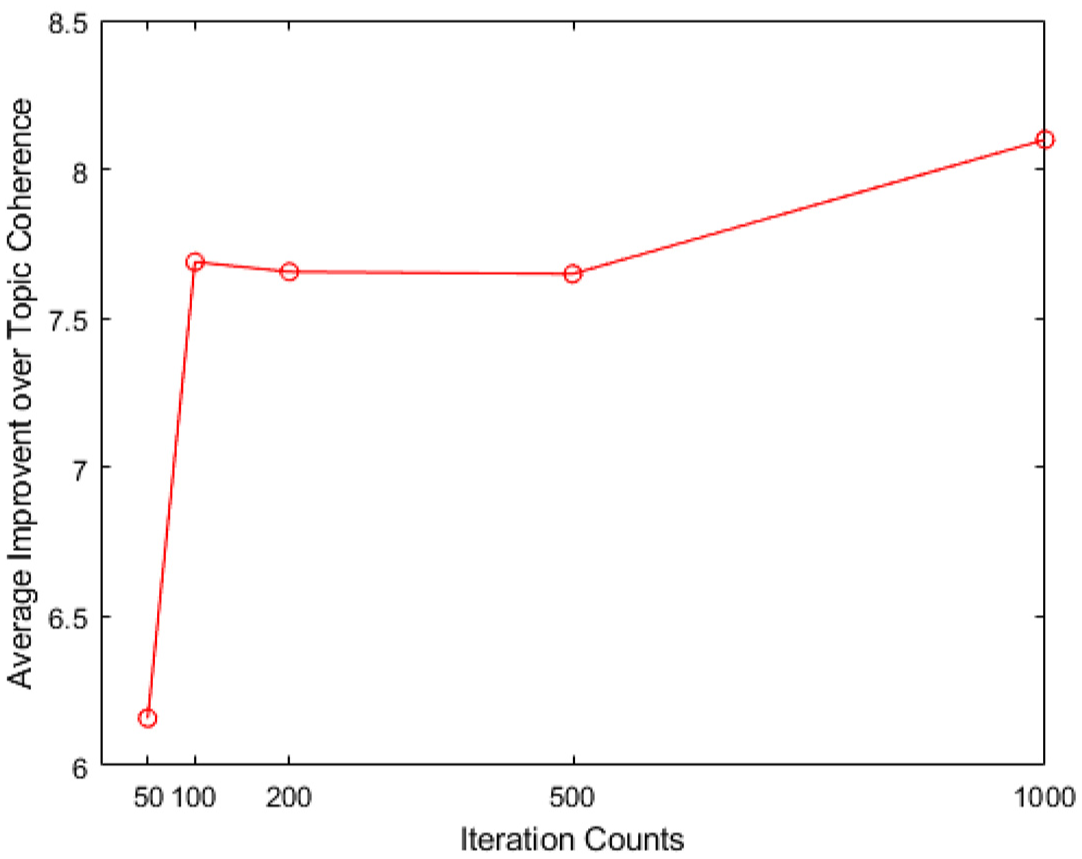
Average improvement of Concept-LDA over topic coherence with different iteration counts.
It can be gleaned from Figure 7 that Concept-LDA achieves 3% improvement on average as compared with LDA. This improvement is due to the fact that incorporating semantic knowledge could make better the extracted aspects.

Average F-measure, Precision and Recall of Concept-LDA and LDA.
The top 10 topic words, used for the qualitative analysis as the most emphasised aspects of restaurant domain, are presented in Table 2.
The example topics obtained from Concept-LDA and LDA in the Restaurant domain.
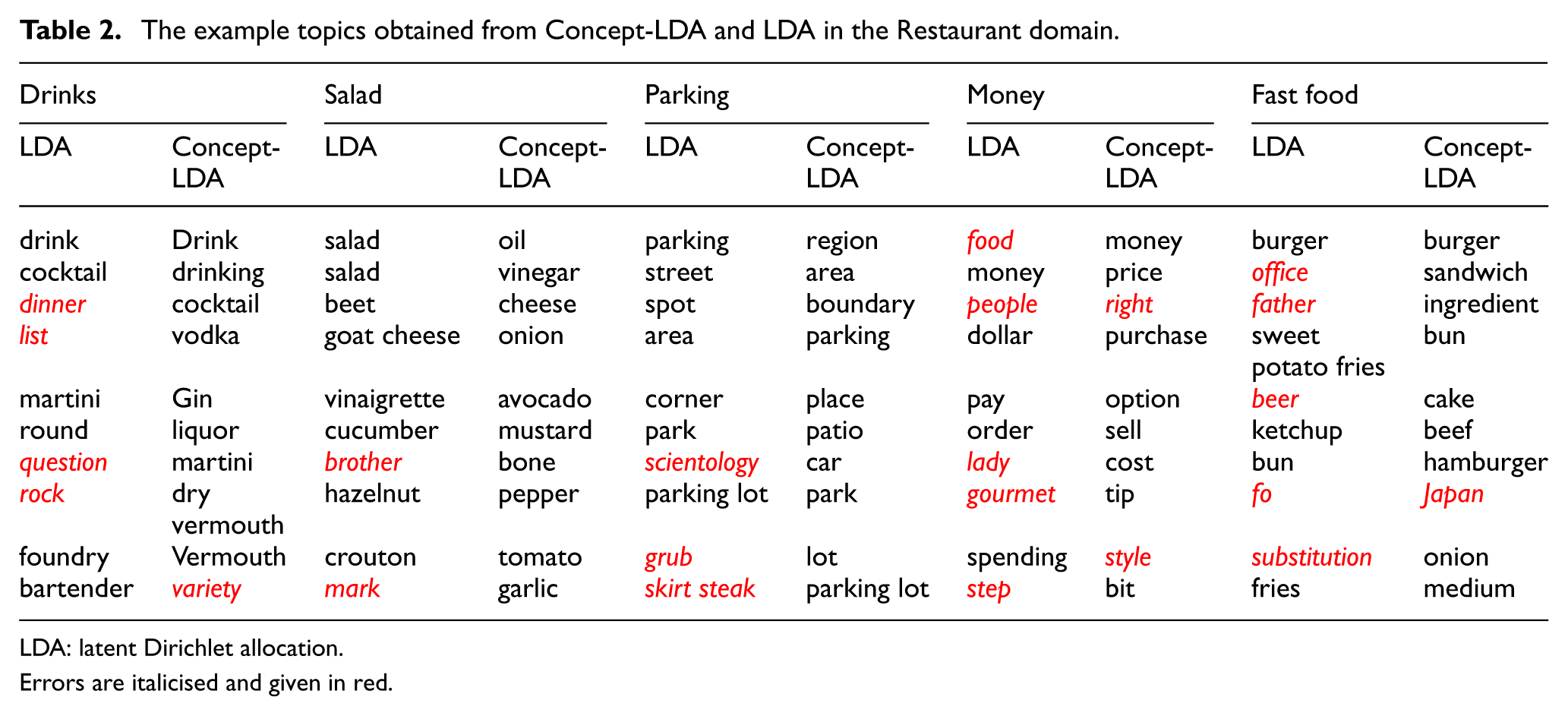
LDA: latent Dirichlet allocation.
Errors are italicised and given in red.
The topics are manually labelled on the basis of our interpretation. If Concept-LDA and LDA are compared quantitatively, it can be easily realised that all labelled topics of Concept-LDA are semantically related, are coherent and have the ability to capture the details while LDA results in quite low quality. If Concept-LDA topics are examined, it can be seen that the aspects in ‘Drinks’ topic are coherent and semantically related. Thus, the topic label can easily be determined. In spite of that, the topic words for LDA such as ‘question’, ‘rock’ and ‘foundry’ in ‘Drinks’ topic are not related to drinks. Furthermore, LDA cannot catch the topic words like sandwich, ingredient and hamburger, which are discussed significantly in the reviews. Therefore, aspects in of Concept-LDA are more informative, coherent and semantically related while those in LDA are not. Consequently, when we compare the two separate topic models of restaurant domain obtained from Concept-LDA and LDA, respectively, it is obvious that the topic words in Concept-LDA provide a better representation of the restaurant domain.
Both quantitative and qualitative results indicate that our proposed assumption about enriching the feature space with the concepts and named entities is reasonable and the quality of extracted aspects is very good.
6. Conclusion
Automatic topic detection in an unlabeled document collection is a very crucial and remarkable research problem in NLP. LDA is a highly significant and widely used method for this kind of problems. LDA represents each document as a probability distribution over topics, where each topic is modelled by a probability distribution over words in a fixed vocabulary. The success of a topic modelling in LDA is based on a fixed vocabulary and the model does not consider the semantic structure of documents. It is obvious that words in a document usually contain deeper semantic information about the topics. Thus, this kind of semantic information should be considered, while the more accurate extraction of topics is achieved from the documents. In this context, a novel method based on incorporating deeper semantic knowledge, which is obtained by using extracted concepts and named entities into the LDA model, is proposed.
Our experimental results prove that rather than bag-of-words representation in LDA, the applied bag of {words + concepts + named entities} representation in Concept-LDA offers better performance in terms of topic coherence, F-measure and quality of topics. This is the main contribution of this work. Besides, our proposed model can be used as an aspect extraction tool for a sentiment analysis system. Thus the aspect extraction problem, which is one of the core tasks of sentiment analysis, can be solved effectively by Concept-LDA. From this view point, the more accurate topic representations mean the more accurate aspects for sentiment analysis.
Furthermore, in NLP studies, the domain dependence in word semantics is a crucial point to be solved in order to disambiguate word senses. Since Concept-LDA does not depend on the domain of the corpus, it can be easily applied to any domain without any previous knowledge.
As a future work, it would be interesting to compare the improvement of concepts and named entity words used for Concept-LDA with the improvement of word embedding methods such as word2vec or doc2vec in LDA.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.