
Abstract
Taxonomy merging is an important work to provide a uniform schema for several heterogeneous taxonomies. Previous studies primarily focus on merging two taxonomies in a specific domain, while the merging of multiple taxonomies has been neglected. This article proposes a taxonomy merging approach to automatically merge multiple source taxonomies into a target taxonomy in an asymmetric manner. The approach adopts a strategy of breaking up the whole into parts to decrease the complexity of merging multiple taxonomies and employs a block-based method to reduce the scale of measuring semantic relations between concept pairs. In addition, for the problem of multiple inheritance, a method of topical coverage is proposed. Experiments conducted on synthetic and real-world scenarios indicate that the proposed merging approach is feasible and effective to merge multiple taxonomies. In particular, the proposed approach works well in the aspects of limiting the semantic redundancy and establishing high-quality hierarchical relations between concepts.
1. Introduction
A taxonomy as a hierarchical data organisation framework is the most important ontology element and is widely used to provide the sharing and exchange of content related to specific knowledge or application domain [1–3]. Nowadays, a growing number of taxonomies have been developed on the Web for resource management [4,5], intelligent information retrieval [6] and knowledge discovery system [7,8].
However, taxonomies were built by different organisations or individuals using different tools and scattered on the Web. As a result, many taxonomies refer to the same domain in different formats, which make it hard for users to fully understand the knowledge behind these taxonomies and bring great difficulties for the application of taxonomy resources. It is necessary, therefore, to merge multiple related taxonomies in order to resolve the taxonomy heterogeneity and provide a unified schema serving for the management of resources.
Currently, schema integration, including taxonomy merging, is regarded as a vital, yet challenging task. Various schema integration approaches have been proposed to deal with the problem [9–11]. The process of taxonomies merging can be symmetric or asymmetric with respect to the input taxonomies. The symmetric-based merging preserves all information from input taxonomies with the same priority but thereby introduces a large amount of redundant information and reduces the understandability of the merged result [10,11]. Comparatively, the asymmetric-based merging takes one of the input taxonomies as the target taxonomy and the other input taxonomies as the source taxonomies, and it merges the source taxonomies into the target taxonomy. In this way, the concepts and relations of the target taxonomy are fully preserved, and only the concepts and relations of the source taxonomies, that do not introduce semantic redundancy, are added.
One limitation of previous taxonomy merging approaches is that these approaches mainly focus on merging two taxonomies, while the problem of merging three or more taxonomies has not been investigated. With the increasing use of taxonomies in various domains, the merging of multiple taxonomies is encountered in numerous situations. In comparison with two taxonomies merging, the multiple taxonomies merging is more time-consuming and complicated, which is primarily attributed to the following two factors:
In general, before performing the merging of taxonomies, it is essential to measure the semantic relations between any two concepts belonging to different taxonomies. In the case of two taxonomies merging, the measures need to be carried out
Since the asymmetric-based approach can retain the structure of the target taxonomy and largely limit the semantic redundancy, it is more desirable than the symmetric-based approach. However, maintaining the structure of the target taxonomy is a great challenge in the process of merging two taxonomies. For the merging of multiple taxonomies, the increase in the number of concepts to be merged and more complicated semantic relations among taxonomies add a further dimension to the complexity of the asymmetric-based approach.
In this article, we propose a taxonomy merging approach that takes two or more domain-specific taxonomies as input and produces a merged taxonomy as output. The proposed approach is asymmetric, and it can automatically determine the merged solution. For the multiple large-scale taxonomies that should be merged, the strategy of ‘breaking up the whole into parts’ is adopted. According to the characteristics of concepts, our approach divides all concepts from source taxonomies into two parts, that is, core concepts and non-core concepts, which are the interior nodes and leaf nodes of the merged taxonomy, respectively. In the process of integrating core concepts, a block-based approach is proposed to reduce the calculating scale of measuring semantic relations between concept pairs. Specifically, non-core concepts mainly contain leaf nodes that will not modify the hierarchical structure of the target taxonomy; thus, the goal of maintaining the hierarchical structure of the target taxonomy can be achieved in the process of integrating core concepts.
The main contributions of our work are summarised as follows:
An approach of merging multiple taxonomies is proposed, which can merge multiple source taxonomies into a target taxonomy in a fully automatic and asymmetric manner.
To reduce the complexity of the multiple taxonomies merging, we propose a method to divide concepts from source taxonomies into different types and develop different integration strategies for each type.
A block-based approach is presented to decompose the symmetric merged taxonomy. The approach reduces the scale of measuring semantic relations between concept pairs and preserves the structure of the target taxonomy.
A topical coverage is provided for each parent–child pair to address the multiple inheritance problem, which can effectively reduce semantic overlap and increase the understandability of the merged taxonomy.
The rest of this article is organised as follows. In section 2, the related works are reviewed and discussed. Problem definition and relevant terminologies are presented in section 3. Section 4 gives the general overview of the proposed approach and details the step of merging multiple taxonomies. Section 5 provides the approach of generating alignment. Experiments conducted on synthetic and real-world scenarios are presented in section 6. Finally, we provide remarks along with some future research directions in section 7.
2. Related work
Taxonomy merging is a complicated and challenging task, which can be decomposed into independently solvable two subproblems, that is, identifying correspondence relations and combining the information from input taxonomies.
The identification of corresponding concepts between two or more heterogeneous schemas is an active field of current research. It is a prerequisite for the merging of ontologies and taxonomies. A number of approaches have been developed to determine different kinds of correspondences, including but not limited to equivalence, is-a and inverse-is-a correspondences.
Several methods focus mainly on identifying equivalence correspondences such as COMA++ [11], Anchor-Flood [12], ASMOV [13] and RiMOM [14], which primarily used linguistic-based strategies and structure-based strategies. COMA++ [15] provided context-dependent and segment-based approach to solve large-scale alignment problems. Similar to COMA++, Anchor-Flood [12] also took segment-based method to achieve equivalence correspondence between two ontologies of arbitrary size. ASMOV [13] derived equivalence correspondences between two ontologies by iteratively calculating an equivalence measure in conceptual and structural characteristics. RiMOM [14] proposed a multi-strategy method to align different kinds of ontologies and employed a learning-based approach to support multilingual environments.
When it comes to detect correspondences other than equivalence correspondences, there are also many studies on the identifying of more expressive relations. S-Match [16] and STROMA [17] are able to distinguish the different kinds of correspondences including equivalence, is-a and part-of correspondences between concepts of two ontologies based on linguistic characteristics and background knowledge from WordNet. COMPOSE [18] developed a three-stage alignment framework to detect equivalence and is-a correspondences. Recently, SBOMT [19] employed a statistical model to generate one-to-many alignment between two ontologies, which can discover all semantic relations for any concept pairs. Different from those approaches of identifying equivalence correspondences, the approaches of measuring enriched correspondences need to use external resources, which limit the adaptation of these approaches in special situation.
As for the process of schema merging, considerable work has investigated such research in the last 20 years. In the early stages, ontology merging approaches are mostly semi-automatic, that is, the generation of merged result requires human domain experts’ intervention [20–25]. Such semi-automatic approaches are far from realistic, obviously, when dealing with large-scale taxonomies with thousands of concepts. To overcome the limitation, several schema merging approaches with fully automatised manner have been proposed recently.
In Guzmán-Arenas and Cuevas [26], the authors proposed an automatic ontology merging approach that considers the inconsistencies, contradictions and redundancies between the input ontologies but leaves out some information in the merged result. In order to incorporate all concepts of ontologies without semantic redundancy, Rangel et al. [27] developed a novel ontology merging algorithm based on semantic similarity measure and exhaustive searching along with the closest concepts. Maree and Belkhatir [28] developed an ontology merging approach that focuses on domain-specific ontology.
Many approaches have been developed and successfully used in merging two ontologies. However, the resulting ontology as a graph-based model is not suitable for some applications that require the tree-structured taxonomy [29,30]. Furthermore, previous works paid little attention to the merging of taxonomies. Yang et al. [31] proposed a taxonomy integration approach that employs several operations, such as mapping, splitting and inserting to ensure the merged result conform to the tree structure. Likewise, Xie et al. [32] proposed a tree-structured ontology integration method to facilitate queries between ontologies. One representative approach in the taxonomies merging, called ATOM, is to employ target-driven approach to merge automatically a source taxonomy into the target taxonomy [10]. The approach largely limits the semantic redundancy, but it allows the existence of multiple inheritance in the merged output.
In summary, the review of the state of the art shows that all existing merging approaches – including ontology merging and taxonomy merging – focus mainly on merging two schemas, and little work has been done to study the multiple schemas merging. This motivates our research on the merging of multiple taxonomies in an automatic manner.
3. Terminology and preliminaries
3.1. Taxonomy
A taxonomy Tk represents a tree-based schema that consists of a set of concepts having certain relations and sharing a set of resources. It is denoted by a triple
A taxonomy
If
For any three concepts
For children
For any two children
3.2. Alignment
Alignment
If concepts
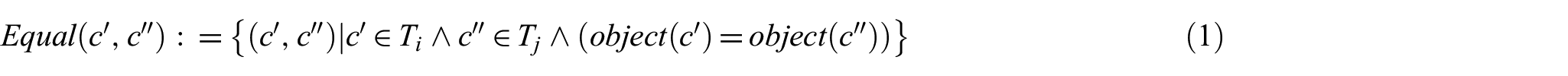
where
The semantic relation between concepts

If there exists a correspondence

In particular, if an equivalence correspondence is established between a concept pair, we can deduce other correspondence relations according to the order relation of concept pair in its taxonomy.
In Figure 1(a), concepts
The inheritance for super concept and sub-concept relations.
A special case may happen in the inheritance of semantic relations. In Figure 1(b), there exist two equivalence correspondences between concept pairs
3.3. Taxonomy merging
Given a target taxonomy
To support a good coverage and compactness of the merged result, based on the definition of two taxonomies merging introduced in [10,11], we suggest that the merged result generated in the asymmetric manner from multiple taxonomies should satisfy the following requirements:
R1. Target concept preservation: each concept coming from the target taxonomy should have an equivalent concept in the merged result.
R2. Target relation preservation: each semantic relation in the target taxonomy should be explicitly in or implied by the merged result.
R3. Equality concept preservation: the equivalent concepts in input taxonomies should be mapped to the same concepts in the merged result.
R4. Is-a relation preservation: if there is an is-a relation between a concept pair, the relation should be maintained in the merged result or evolved into irrelevant relations for reducing semantic redundancy, but translation into inverse-is-a or equivalence relation is not supported.
R5. Tree-based preservation: the merged result is a tree-based hierarchical structure, in which concepts should be connected by is-a relations, and cyclic and multiple inheritance are not allowed.
The purpose of R1 and R2 is to maintain the concepts and structure of the target taxonomy in the merged result. And, R3, R4 and R5 ensure that the merged result should remain a tree structure and not contain those concepts and relationships that would introduce semantic redundancy and incoherence.
3.4. Core concept and non-core concept
We categorise the concepts of the source taxonomies according to the equivalence correspondences between each source taxonomy and the target taxonomy: core concepts and non-core concepts:
Core concept: given a concept
Non-core concept: given a concept
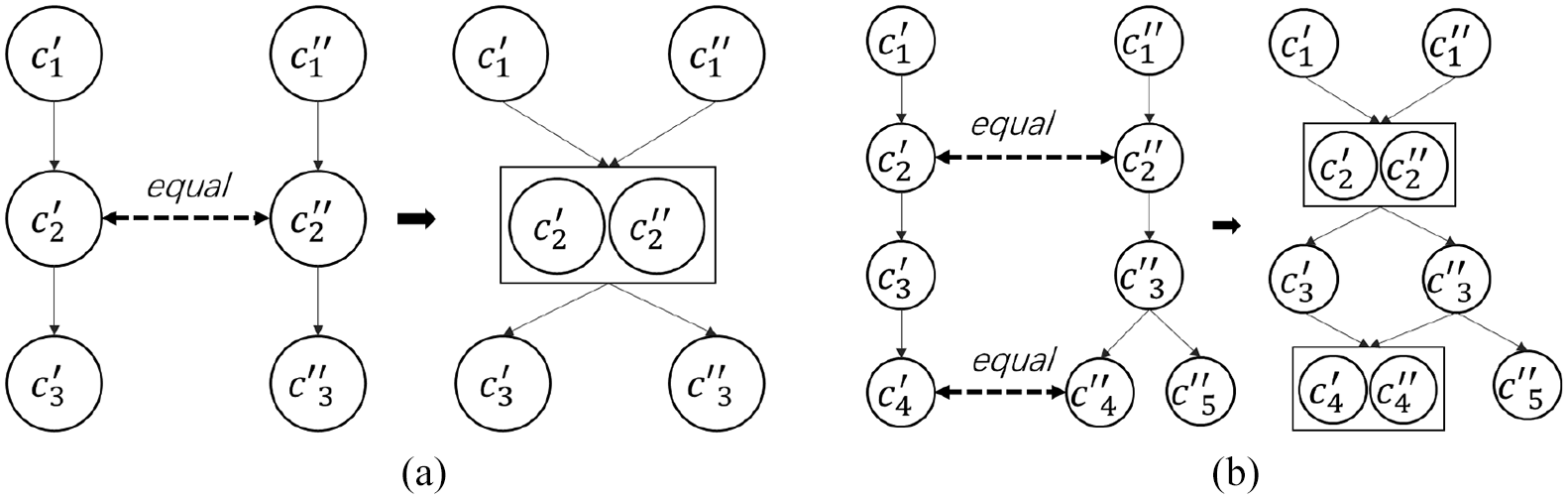
To give an example, Figure 2 shows a source taxonomy
The dividing of core concepts and non-core concepts.
The identifications of core concepts and non-core concepts are at the core of our approach. It is clear that the core concepts consist mainly of branch nodes. After integrating core concepts into the target taxonomy, these core concepts will modify and reconstruct the hierarchical structure of the target taxonomy. Conversely, non-core concepts are mostly leaf nodes and their incorporation is an extension rather than a reconstructing for the target taxonomy. And, because the semantic relations between core concepts are notably more complicated than non-concepts, this makes the process of merging core concepts harder. To reduce the complexity of taxonomies merging, we therefore classify concepts in source taxonomies into core concepts and non-core concepts and propose different merging strategies for these two categories.
4. Implemented strategies
4.1. Framework overview
The basic workflow of our approach is shown in Figure 3, which depicts the input and output, as well as three data processing steps: dividing concept sets, building core tree and adding non-core concepts.
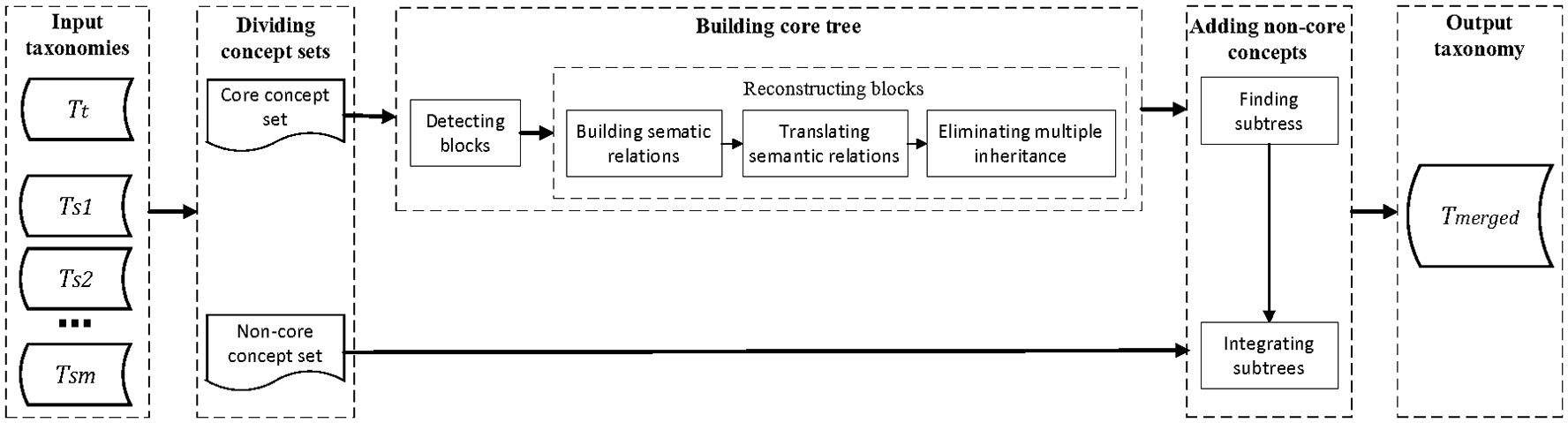
Basic workflow for merging multiple taxonomies.
First, the taxonomies to be merged are fed into the process of dividing concept sets. Dividing concept sets divides the concepts in source taxonomies into core concepts and non-core concepts based on the equivalence correspondences between each source taxonomy and the target taxonomy (see section 4.2). After dividing, the process of building core tree incorporates core concepts into the target taxonomy to generate a fully information-preserving model and invokes a detecting block method to split the fully merged model into multiple graph-based blocks (see section 4.3.1). Then, three decomposition operations – including building semantic relations, translation semantic relations and eliminating multiple inheritance– are performed to reconstruct each block into a tree structure (see section 4.3.2). Finally, the process of adding non-core concepts divides the non-core concept set into multiple independent subtrees, and then integrates them into the core tree in turn to generate a new merged taxonomy (see section 4.4).
4.2. Dividing concept sets
We first introduce the process of dividing the concepts of the source taxonomies into core concepts and non-core concepts. As the definitions of the core concept and the non-core concept point out, the core concept is the ancestor of one or more concepts in the target taxonomy, or has an equivalence correspondence with one target concept, while the non-core concepts are the remaining concepts in the source taxonomies after removing the core concepts. Some concepts in the target taxonomy are the ancestors of non-core concepts, but no concept is the descendant of non-core concepts. The equivalence correspondences between each source taxonomy and the target taxonomy can be viewed as the most distinguishing mark to identify the core concepts and the non-core concepts. Algorithm 1 illustrates the general procedure of dividing concept sets.

For each source taxonomy, the algorithm employs Postorder Traversal to determine the core concepts and the non-core concepts (lines 2 and 3). A temporary array
4.3. Building core tree
The merging of core concepts has a direct impact on the understandability of the final output, because it determines the hierarchical structure of the output taxonomy

The algorithm first generates a fully merged taxonomy with graph-based structure by a symmetric manner which retains all information from the target taxonomy and core concepts (lines 2–6). At this point, the algorithm only employs equivalence correspondences between concept pairs, in which two concepts come from the target taxonomy and source taxonomies, respectively. Each concept pair that has an equivalence correspondence is merged into one new integrated concept where the label of the integrated concept is defined by the label of the target concept (line 5).
After this process, the algorithm takes all integrated concepts
4.3.1. Detecting blocks
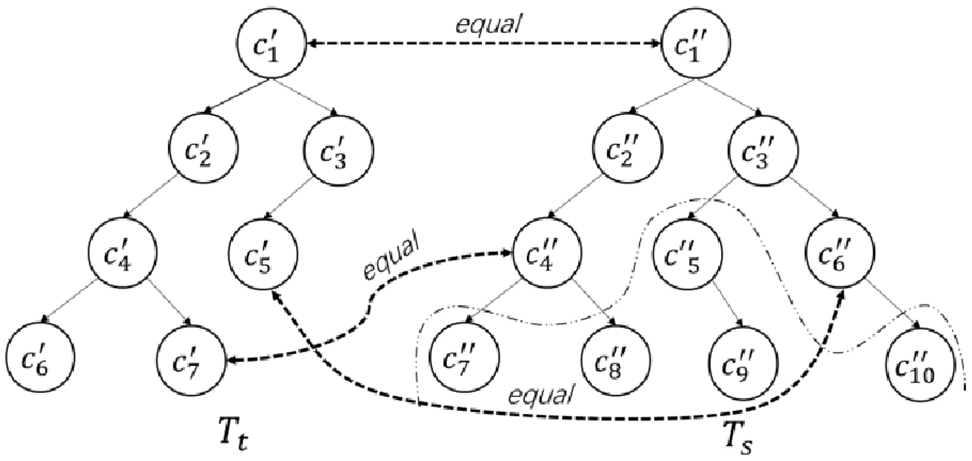
The fully merged taxonomy is a directed acyclic graph, which remains all information of the target taxonomy and all core concepts from source taxonomies. Figure 4(a) shows a fully merged taxonomy. Grey nodes represent concepts from the target taxonomy, while the white nodes represent concepts from source taxonomies. Note that the merged taxonomy may introduce a lot of redundant concepts and relations.
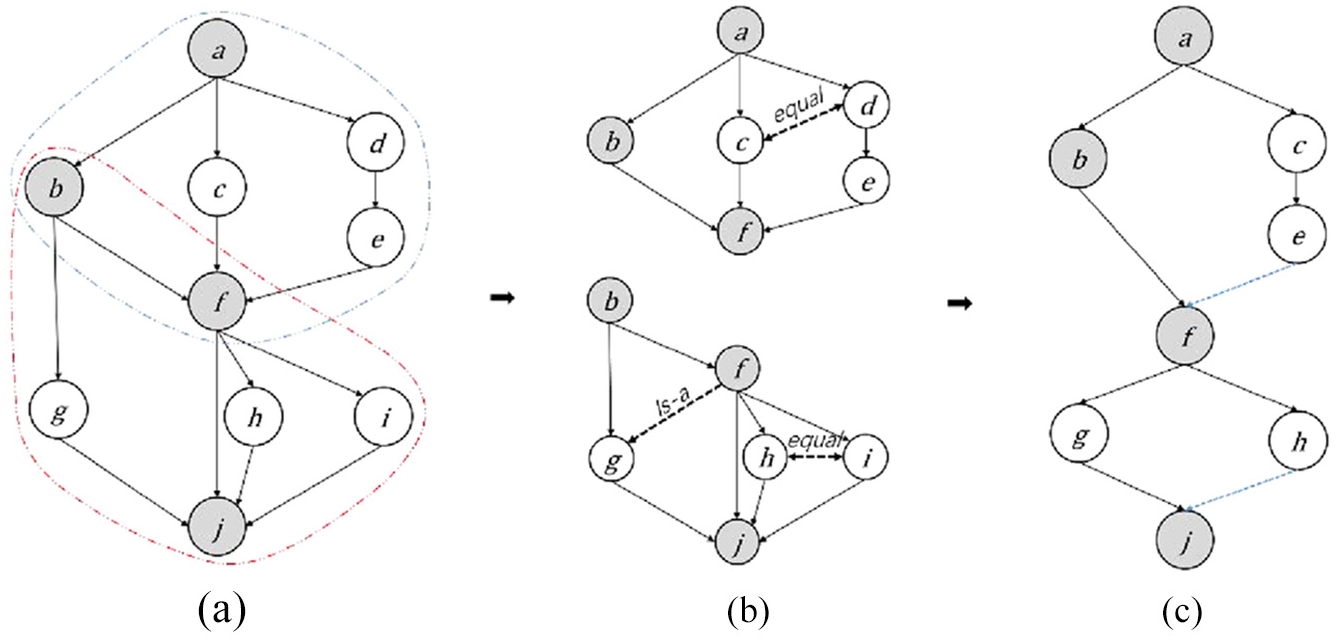
The process of detecting and reconstructing blocks.
To remove the redundancy information, a straightforward idea is to obtain the semantic relations between each concept pair in the fully merged taxonomy and then invoke merging method to eliminate semantic overlap. However, this approach can be problematic because, typically, it is computationally expensive to measure semantic relations between each concept pair, including equivalence, is-a and inverse-is-a correspondences, especially when these concepts come from multiple heterogeneous large-scale taxonomies. Therefore, we take a block-based approach to divide the fully merged taxonomy into multiple independent sub-graphs, that is, blocks. For each block, it has only one concept with zero indegree (called source point) and one concept with zero degree (called sink point) where source point and sink point are the integrated equivalent concepts
Figure 4(b) shows that a fully merged taxonomy is divided into two graph-based blocks. There exists a hierarchical structure between any two blocks divided by the integrated equivalent concepts. In the interior of each block, the semantic relations between core concepts are complicated; we get the relations and further translate the graph-based block into a tree-based pattern. Thus, the integrated tree-based taxonomy can be constructed by multiple tree-based patterns.
Algorithm 3 demonstrates the process of detecting blocks based on all integrated equivalent concepts in the fully merged taxonomy. To decompose blocks from top-down, we first sort the integrated equivalent concepts based on their hierarchical order in the fully merged taxonomy (line 1). Then, we find the sink points with multiple parents from the integrated equivalent concepts (lines 2–6). Detecting blocks is a process of searching for a source point from a sink point. The number of searching paths is equal to the number of the parents of the sink point. If the current node searched by a search path is an integrated equivalent concept, the searching will be temporarily stopped to estimate whether these searching paths have converged to a node or not (lines 10–17). If the current nodes being searching refer to a node, then the node is the source point and a block has been found; otherwise, the searching path at the highest level does not move, and the remaining paths continue to search upwards (lines 18–23). This entire process is continued until the source node is found out.

4.3.2. Reconstructing blocks
After finishing the process of detecting blocks, we deconstruct each found block into a tree structure. Three steps are executed in sequence.
Building semantic relations
It is important to highlight that section 4.2 only employed the equivalence correspondences between the target taxonomy and each source taxonomy. Here, we will build more expressive semantic relations for the concepts in the interior of each block. For each path in a block, we find that the concepts belonged to it come from the same taxonomy. Therefore, it is only necessary to measure the semantic relations between concept pairs from different paths. For example, the first graph-based block in Figure 4(b) has three paths {a, b, f}, {a, c, f} and {a, d, e, f}. For these concept pairs from different taxonomies (b, c), (b, d) and (b, e), they need to be estimated whether there exist is-a correspondences or inverse-is-a correspondences. The equivalence correspondences between them have been detected in the process of dividing concept sets. As mentioned in section 3, after obtaining the semantic relation between a concept pair, we can further deduce other existing semantic relations between the concept pair and other concepts. This enables us to reduce the number of concepts whose semantic relations need to be measured. As shown in Figure 4(b), if an equivalence correspondence between c and d is obtained, we can deduce that e is a sub-concept of c and the relation between the concept pair (c, e) does not need to be detected again.
Translating semantic relations
In this step, we discuss the process of translating semantic relations, including translating inverse-is-a correspondences, merging equivalent concepts and eliminating redundant relations. According to the requirement R5, all relations between concepts should be expressed in the type of is-a. As the translation of the inverse-is-a correspondence is much simpler than that of the other two relations, we will directly translate each inverse-is-a correspondence
For some concepts that exist equivalence correspondences with each other, we integrate them into a new concept. Relations attached to these concepts are added to the new concept. For the label of the integrated concept, section 4.3 provides a method that uses target concepts to define it. However, this method cannot be used here because equivalent concepts in a block are all from source taxonomies. At this point, each of the following approaches can be utilised:
Manually assigns a label for the integrated concept.
Randomly selects a label from the equivalent concepts.
Concatenate these labels of the equivalent concepts to form a new label.
Define the label using a common prototype of the equivalent concepts.
Let us discuss the process of eliminating redundant relations. Given two concepts with an is-a relation, if there exists one more detailed is-a relation to depict their semantic relation, then the direct is-a relation is disconnected and the detailed is-a relation is preserved. The intuition behind selecting the detailed path is that it preserves and extends the structure and relation between the concept pair.
To give an example, in the second graph-based block in Figure 4(b), the concept pair
Eliminating multiple inheritance
Due to the inadequacy of semantic dictionaries, the state-of-the-art automatic semantic alignment approaches, including linguistic-based and structure-based approaches, cannot cover all terms so that they are difficult to identify the semantic relations between any two concepts accurately. When semantic alignment approaches cannot identify the semantic relations among several concepts having one common child concept, the problem of how to eliminate the multiple inheritance for a concept, that is, the multiple inheritance problem (R5), is raised.
We conduct LDA topic model to detect topical coverage for each parent–child pair to eliminate multiple inheritance. LDA topic model [38] is a three-layer Bayesian model, including documents layer, topics layer and words layer, where each document can be represented as a probability distribution of topics and each topic can be represented as a probability distribution over words. LDA topic model is one of the most popular unsupervised machine learning techniques that can be used to identify the implicit topics and mine deep semantics of documents [39].
In this stage of our algorithm, the topic distribution for each concept

where

where

where
For a concept
4.4. Adding non-core concepts
In this section, we discuss how to automatically integrate non-core concepts into the core tree to generate a final merged taxonomy as the output. According to the definition of non-core concept, it is not difficult to find that the non-core concepts consist of subtrees from source taxonomies. Each subtree

Adding non-core concepts includes two major procedures: finding the root node for each subtree (lines 2–6) and merging each subtree into the core tree (lines 7–12). For any subtree, if we can obtain its root, then all concepts in the tree can be obtained using either breadth-first search or depth-first search to traverse a source taxonomy from the root. The rationale behind the method of identifying root concept is that for any concept in the non-core concept set, if it does not have parent concept or its parent concept is not in the non-core concept set, then it is the root of a subtree. After performing the method on each non-core concept, we get a list of root concept
4.5. The scale of measuring semantic relations
Assume that the number of taxonomies to be merged is m(m≥ 2), the average number of concepts per taxonomy is n(n≥ 1), the number of blocks in the fully merged taxonomy is r(r≥ 1) and the average number of concepts per block is (m × n)/r. Section 4.2 measured the equivalence correspondences between the target taxonomy and each source taxonomy. In this phase, the maximum number of concept pairs to be measured would be
By summing up the two phases, the total number of concept pairs to be measured in the worst case is

5. Alignment generation
In this section, we introduce the alignment approach for determining the exact correspondence between a concept pair from different taxonomies. As discussed in section 2, existing approaches for measuring semantic relations can be classified into two types: linguistic-based strategy and structure-based strategy [40].
The linguistic-based strategy relies on the concept’s label to determine correspondences between a concept pair. This strategy is able to support different types of correspondences, including equivalence, is-a, inverse-is-a and so on, by utilising linguistic techniques and background sources such as WordNet [41,42]. Due to the complexity and diversity of natural language, the linguistic-based strategy has obvious limitation. For example, the equivalent concepts expressed by different labels (synonyms) cannot be detected, and the different concepts described by same labels (homonyms) might be mistakenly detected as equivalent concepts.
Differently from the linguistic-based strategy, the structure-based strategy relies on the taxonomy structure information to determine correspondences between a concept pair. This strategy is based on the intuition that if two concepts belonging to different taxonomies are similar in semantic, their neighbours are semantically related. The structure-based strategy can detect homonyms and synonyms in taxonomies, but it cannot further identify kinds of correspondences.
Combining the advantages of the two strategies, we employ a two-phase approach to determine the correspondence between a concept pair. The structure-based strategy is used to determine whether the concept pair is semantically related in the first stage, and then the linguistic-based strategy is applied to identify more expressive correspondences, including equivalence, is-a and inverse-is-a.
5.1. Determining candidate concept pair
This stage is to identify the concept pair that is semantically related, and to roughly filter out homonyms. To compute semantic relatedness between a concept pair, the approach of information distance proposed in Jiang et al. [43] is used as follows.
Assume that there is a concept-pair
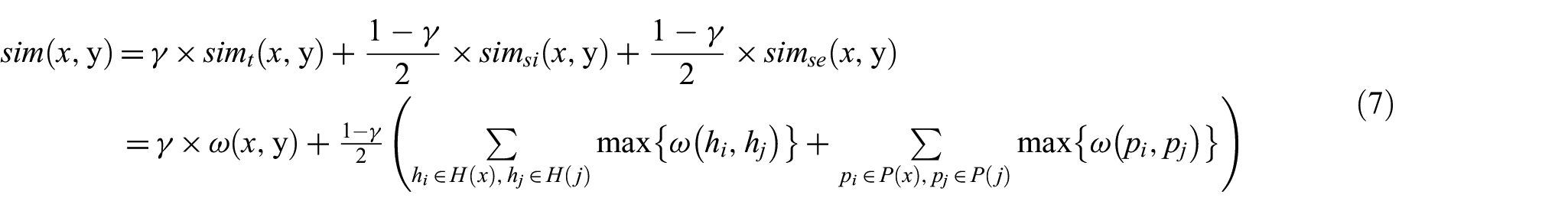
where

where
Owing to the combination of terminological similarity and structural similarity, the approach of information distance has a high performance in identifying semantic relatedness. Moreover, it is also effective to correctly detect synonyms and homonyms.
5.2. Identifying expressive relationship
The first step in our semantic alignment approach is to identify the candidate concept pair with semantic relatedness. We then apply linguistic-based strategy proposed by Arnold and Rahm [17] to determine more expressive semantic relations between the candidate concept pair. This strategy consists of four approaches: lexical-based, compound, background knowledge and itemisation.
Lexical-based approach
The approach is proposed to deal with concept pairs which share the same lexical representation or are both found in semantic lexicon like WordNet. Given two concepts
If
If If If If Type cannot be determined, return unknown.
If either
Compound approach
The approach is based on the idea that a compound c consisting of a head ch and a modifier cm expresses something more specific than its head ch, that is, c is a sub-concept of ch. Specifically, given two concepts
Background knowledge approach
The approach mainly employs semantic lexicon as external background source to identify specific correspondence types between a non-compound concept cw and an open compound cc, where the concept cw is contained in semantic lexicon, yet the concept cc = cmch consisting of a modifier cm and a head ch is not. For the compound concept cc, we gradually remove the modifier cm and check whether the remaining form
Itemisation approach
The approach is utilised to identify the correspondence types between two concepts where at least one concept is an itemisation containing a list of words or phrases, like ‘Games and Puzzles’. Given two concepts
For each set W, remove each wi∈W which is a sub-concept of wj∈W.
For each set W, remove each wi∈W which is a synonym of wj∈W.
Remove each
Remove each
Determine the semantic relation: If If If If
Since these introduced approaches will return exactly one correspondence type or ‘unknown’, a conflict may occur when four approaches return different types. In this case, we use the following priority order: equivalence, is-a/inverse-is-a and unknown.
It is noted that for the measure of equivalence correspondences in section 4.2, we only employ the lexical-based approach and do not involve the compound approach, the background knowledge approach and the itemisation approach. Although the lexical-based approach is only suitable to measure the equivalence correspondences for non-compound concepts but not for the compound concepts, the strategy can effectively reduce the complexity and time consumption of measuring the equivalence correspondence. Moreover, the equivalence correspondences utilised in section 4.2 are to divide the target taxonomy and the source taxonomies into blocks; therefore, in this stage, this strategy that we only get the equivalence correspondences between non-compound concepts does not affect the result of the whole taxonomies merging. The measures for compound concepts will be implemented in section 4.3.1.
6. Evaluation
To make a comprehensive evaluation for the performance of the proposed approach, the experiments are respectively conducted on real-world and synthetic scenarios. For the real-world scenario, we select four popular e-commerce website product catalogues as the test data to assess the proposed approach in terms of semantic redundancy. Regarding the synthetic scenario, seven groups of test cases are applied to evaluate the semantic accuracy of the taxonomy generated by the proposed approach.
The hardware device used for evaluating the proposed approach is a PC running Windows 10 system with Intel Core 2 Duo processors (2.30 GHz) and 4 GB RAM. A prototype of the proposed approach is implemented as a Java application. In our experiments, JGibbLDA (http://jgibblda.sourceforge.net) is used as the implementation of LDA topic model to discover the topic distribution of each concept. Gibbs sampling is employed in JGibbLDA to estimate and infer the document-topic probability distribution and the topic-word probability distribution. We empirically set the number of topics K = 50, hyper parameters α = 0.5 and β = 0.01, and the number of Gibbs sampling iterations = 2000.
6.1. Experiment 1: real-world scenario
As discussed in section 1, an important advantage of the asymmetric-based merging approach is that it can largely limit the semantic redundancy in the merged taxonomy. Here, we conduct experiments on real-world scenario to evaluate and verify the performance of proposed approach in limiting the semantic redundancy. For a quantitative evaluation, we follow [10,45,46] to measure the compactness and the introduced degree of semantic overlap in the merged result. The measure is defined to compare the fully merged taxonomy generated in symmetric-based manner with our solution in terms of the number of concepts and leaf paths. Besides, considering that the asymmetric-based merging approach needs to specify a target taxonomy, we conduct careful experiments to analyse how different choices of the target taxonomy affect the merged result.
We select four popular e-commerce website catalogues as input taxonomies, in which the descriptions of products are viewed as the documents attached to concepts. The product catalogues were crawled in June 2019. Table 1 shows the detailed characteristics of these catalogues, including the site name, URL, the number of concepts and leaf concepts as well as the maximum depth and the average depth.
The characteristics of experimental data for real-world scenario.

Table 2 provides the experiment results for the real-world scenario obtained by the proposed approach using different target taxonomies [10]. We find that the solutions, whether using the product catalogues of Groupon, eBay, Amazon or Walmart as the target taxonomies, have the same number of concepts, leaf concepts, leaf paths and maximum depth. Moreover, although the average depth of the four taxonomies is quite different, the four solutions using different target taxonomies achieve almost the same average depth. Similar results obtained using different target taxonomies demonstrate that the proposed approach is robust to the chosen target taxonomy.
Comparison of our solutions using different target taxonomies and the fully merged solution on the real-world scenario.
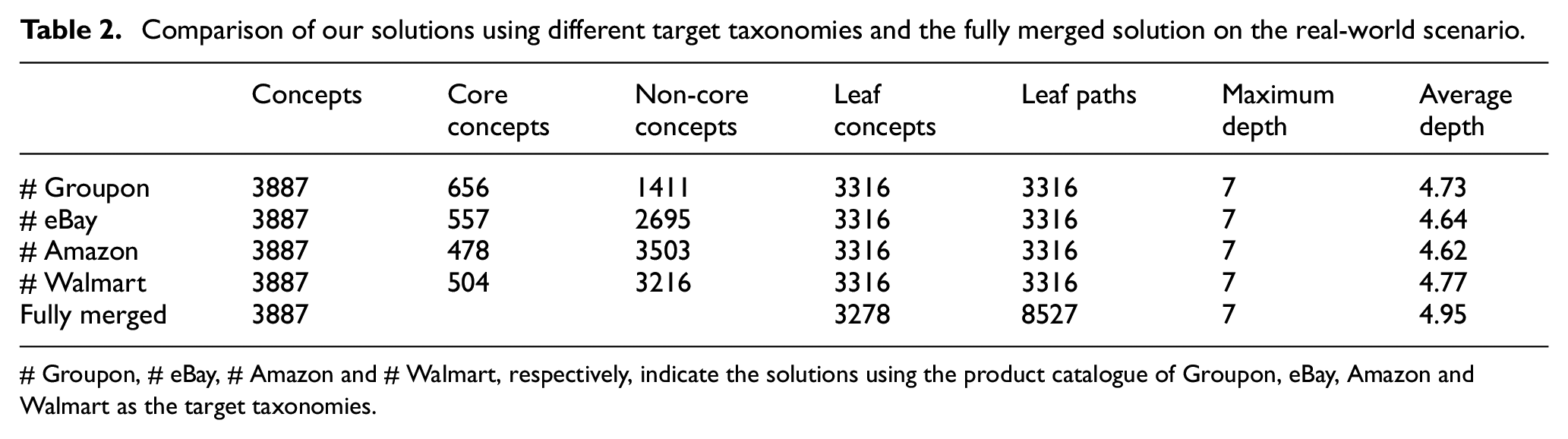
# Groupon, # eBay, # Amazon and # Walmart, respectively, indicate the solutions using the product catalogue of Groupon, eBay, Amazon and Walmart as the target taxonomies.
We further compare our solutions with the fully merged solution. The results show that our solutions and the fully merged solution have the same number of concepts indicating that our approach not only combines equivalent concepts but also maintains all the input concepts. However, the number of leaf concepts in the fully merged solution is less than our solutions, since our approach converted some branch concepts to leaf concepts in the problem-solving process of multiple inheritance. In addition, Table 2 depicts the number of leaf paths, which could act as an index to evaluate the introduced degree of redundancy. It is observed that all our solutions introduce 60% fewer leaf paths compared with the fully merged solution, and the number of leaf paths is equal to that of leaf concepts in our solutions, the reason for which is that the merged taxonomy generated by our approach does not introduce any multiple inheritance and remains a tree structure.
To summarise, the experiments indicate that the proposed approach has a good performance to preserve all concepts and relationships of the input taxonomies and can limit the semantic redundancy in the merged result at the same time. Furthermore, the experiments demonstrate the capability of our approach to merge multiple taxonomies from real world.
6.2. Experiment 2: synthetic scenario
6.2.1. Evaluation measures
The above experiments evaluate the performance of proposed approach in the degree of semantic redundancy. To evaluate the performance more holistically, in this section, we use a golden standard evaluation [47,48] as evaluation framework to systematically evaluate the precision, recall and F-measure of the proposed approach. The golden standard evaluation mainly emphasises on comparing the positions and hierarchies between two concepts belonging, respectively, to the merged taxonomy and the benchmark taxonomy (i.e. a reference taxonomy) which represents an accurate well-merged result. The evaluation usually includes two aspects: local measure and global measure.
Before describing local measure, let us introduce the common semantic cotopy

where ‘
The framework of local measure includes the local taxonomic precision


The definitions of
The local measure compares the position of a concept in the merged taxonomy with the position of the corresponding concept in the reference taxonomy. The global taxonomic precision


where
In some cases, the taxonomic precision and the taxonomic recall are contradictory. In order to balance the two measures, we introduce the taxonomic F-measure

The F-measure is the harmonic mean of the global taxonomic precision value and global taxonomic recall value. The higher of the value of F-measure, the better of the quality of the merged taxonomy.
6.2.2. Evaluation data
Virtually, all previous studies on integrating heterogeneous ontologies or schemas focus on the problem of merging two schemas. A number of benchmarks for two ontologies merging are available [46]. For instance, the Ontology Matching conference presents more than 20 data sets and their alignment (http://www.ontologymatching.org). However, little work has done for the multiple taxonomies merging, and there is no public benchmark for multiple taxonomies merging, to the best of our knowledge. To investigate the performance of our approach, seven groups of test cases that contain, respectively, 3, 4, 5, 6, 7, 8 and 9 input taxonomies are constructed by a two-stage method as follows.
In the first stage, an original taxonomy is generated from the Open Directory Project data set (DMOZ). DMOZ is the largest human-edited directory on the Web with over 5,169,995 sites listed in over 1,017,500 concepts. In this article, we just extract the taxonomy ‘Science’ from DMOZ. As the taxonomy contains many meaningless concepts and some concepts with multiple inheritance, these concepts and their sub-concepts are removed. After cleaning these concepts, the number of concepts in the taxonomy is 1187 and the depth of the taxonomy is 7. Due to the lack of corresponding resource documents for many concepts in DMOZ, each concept in the extracted taxonomy is searched by Google, and the texts of the first 100 records from the search results are collected as the documents attached to the concept.
In the second stage, the taxonomies of each test case are generated from the original taxonomy. The generation method includes two operations: copying taxonomy and removing concept.
Copying taxonomy
n copies are generated from this original taxonomy, where
Removing concept
The process of removing concepts is a vital key since it determines the unique and heterogeneous nature of each copy of a test case. Here, we take the test case containing six taxonomies (i.e. n = 6) as an example to illustrate the operation process, which comprises five (i.e. n− 1) times of removing operation. When performing the ith (i = 1, 2, …, 5) removing operation, 100 concepts are selected one by one at random from the original taxonomy (once a concept is selected, it will be marked so that it will not be selected again); after that, for each selected concept, we first randomly select i copies from the test case, and then remove this concept from the i copies. Note that to maintain the hierarchical structure of the copy, when a concept is removed from a copy, its sub-concepts become the direct sub-concepts of its super concept.
In this way, the generated test case ensures that each concept in the original taxonomy exists in at least one copy. Meanwhile, the massive and random removal of concepts from the copies guarantees the heterogeneity of each copy. Due to the stochastic nature of the generation method, 50 different test cases were constructed for each group. The general characteristics of each group are depicted in Table 3. Furthermore, the total number of concepts in a test case for the seven groups is, respectively, 3261, 4148, 4935, 5622, 6209, 6696 and 7083. As can be seen from the generation method, the total number of concepts of a test case can be calculated using the following formula

The characteristics of experimental data for synthetic scenario.

where n is the number of taxonomies in a test case and m is the number of concepts of the original taxonomy (i.e. m = 1187).
6.2.3. Evaluation results
For each test case, the first taxonomy is viewed as the target taxonomy, and the others as the source taxonomies. As pointed out in section 6.1, the original taxonomy is viewed as the benchmark taxonomy to evaluate each merged taxonomy. In order to focus on evaluating the performance of the merged taxonomy and remove the influence of the quality of alignments for the merged result, we transform the semantic relations between concepts in the original taxonomy to the correspondence relations between concepts from different taxonomies so that a near-perfect alignment is available. Figure 5 consists of seven figures depicting the detailed results of the experiments from 50 different test cases for each group in terms of the measures of GP, GR and GF. Figure 7 summarises the average performance of 50 different test cases for each group.

Performance of 50 test cases for each group: (a) group 1, (b) group 2, (c) group 3, (d) group 4, (e) group 5, (f) group 6 and (g) group 7.
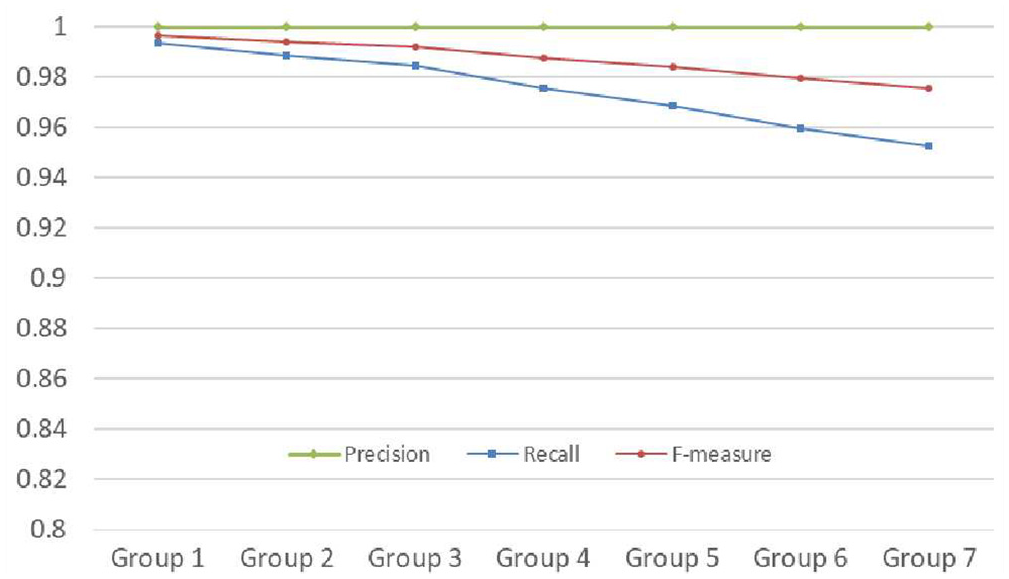
The results displayed in Figures 5 and 6 show that the precisions for each group all are 100%. It means that the hierarchical relations for the concept in each merged taxonomy are same as the benchmark taxonomy. In other words, the merged taxonomies do not introduce any incorrect semantic relations. As a general requirement, any semantic error in a taxonomy is not supported by the applications using the taxonomy [49], so that it is necessary to ensure that the precision of semantic relations of merged taxonomy reaches 100%.
Average performance of seven groups of test cases.
The average recalls for each group (all less than 100%) show that the benchmark taxonomy contains more information than these merged taxonomies. In fact, each merged taxonomy and the benchmark taxonomy have exactly the same concept set, which means that some semantic relations have been missed in the process of merging taxonomies. We find that with the increasing number of taxonomies in a test case, the recall shows a downward trend (see Figure 6). Since more concepts are removed in the test case with more taxonomies, this leads to more concepts having multiple inheritance. To deal with multiple inheritance problem, not all semantic relations between concepts coming from source taxonomies are retained, but the relations from the target taxonomy are maintained. Even so, the minimum recall of our approach in all test cases for seven groups also reaches over 93.02% (in group 7).
As can be seen from Figure 6, the average F-measures of our approach applied on each merging task show that the merged taxonomies have a high quality of hierarchical relations (99.67%, 99.41%, 99.21%, 98.75%, 98.39%, 97.94% and 97.57%). Indeed, our approach preserves not only the concepts of the target taxonomy but also the non-redundant concepts of the source taxonomies. However, we lost some semantic relations mainly coming from source taxonomies, but we did not introduce any redundancy and inconsistency in the merged result.
7. Conclusion
In this article, we present an approach to automatically merge multiple taxonomies in an asymmetric manner, which includes three procedures: dividing concept sets, building core tree and adding non-core concepts. In order to reduce the scale of measuring semantic relations between concepts, the approach decomposes a fully merged taxonomy into many graph-based blocks and further reconstructs each block into a tree structure. Moreover, the approach employs the LDA topic model to solve the multiple inheritance problem. The proposed approach is extensively tested on real-world and synthetic scenarios in a fully automatic way. Experimental results demonstrate the effectiveness of the proposed approach in merging multiple taxonomies.
As a future work, we would like to explore an automatic way to measure the accuracy of information in the input taxonomies and eliminate erroneous information from them, which will help to further increase the utility of the merged taxonomy. Moreover, we plan to investigate how to evaluate the knowledge coverage of the merged taxonomy for some specific domains, which is another important decision factor for the utility of the merged taxonomy [50].
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the National Key R&D Program of China (Grant No. 2017YFB1401300 and 2017YFB1401302), the self-determined research funds of CCNU from the colleges’ basic research and operation of MOE (Grant No. CCNU19ZN011) and the Fundamental Research Funds for the Central Universities (Grant No. 2019YBZZ010).