
Abstract
Community question answering sites (CQAs) are often flooded with questions that are never answered. To cope with the problem, experienced users of Stack Exchange are now allowed to mark newly posted questions as closed if they are of poor quality. Once closed, a question is no longer eligible to receive answers. However, identifying and closing subpar questions takes time. Therefore, the purpose of this article is to develop a supervised machine learning system that predicts question closibility, the possibility of a newly posted question to be eventually closed. Building on extant research on CQA question quality, the supervised machine learning system uses 17 features that were grouped into four categories, namely, asker features, community features, question content features and textual features. The performance of the developed system was tested on questions posted on Stack Exchange from 11 randomly chosen topics. The classification performance was generally promising and outperformed the baseline. Most of the measures of precision, recall, F1-score and area under the receiver operating characteristic curve (AUC) were above 0.90 irrespective of the topic of questions. By conceptualising question closibility, the article extends previous CQA research on question quality. Unlike previous studies, which were mostly limited to programming-related questions from Stack Overflow, this one empirically tests question closibility on questions from 11 randomly selected topics. The set of features used for classification offers a framework of question closibility that is not only more comprehensive but also more parsimonious compared with prior works.
Keywords
1. Introduction
Over the years, community question answering sites (CQAs) such as Baidu Zhidao, Stack Exchange and Yahoo! Answers have cemented themselves as key avenues to search for information. Whenever individuals with Internet access face an information need, they have an easy option to ask questions on CQAs that can be answered by other online users. If the asker chooses an incoming answer as satisfactory, the question is said to be resolved [1–6].
Despite the undoubted benefit of CQAs, a downside is that these sites have long been flooded with questions that are never answered. For example, by 2010, 42.8% of questions posted on Baidu Zhidao were reported to remain unanswered [7]. By 2012, the volume of unanswered questions on Stack Overflow, a CQA site within Stack Exchange that is dedicated to computer programming, mounted to approximately 300,000 [8]. About one-fifth of unresolved questions on Yahoo! Answers are known to remain completely ignored [9].
To cope with the problem of unanswered questions, experienced users of Stack Exchange are now allowed to mark newly posted questions as closed. Specifically, a question can be closed if it is deemed to be duplicate, off-topic, opinion-seeking, unclear or vague. A question that is closed is not possible to be answered but can be updated for reopening (Stack Exchange, 2018). Clearly, this functionality helps nurture the quality of questions on the platform.
Even with this development, under-cooked questions continue to serve as a thorn in the flesh of Stack Exchange’s question-answering cycle. Identifying and closing them manually takes time, which experienced users would have rather spent on more meaningful questioning and answering activities. Furthermore, the queue of inappropriate questions on CQAs seems to be continually growing [2,7,9–12]. A review of questions on various topics such as Golf and Mathematics available on Stack Exchange confirmed that closed questions are indeed ubiquitous (see Table 1).
Statistics of closed questions for the selected topics of Stack Exchange.
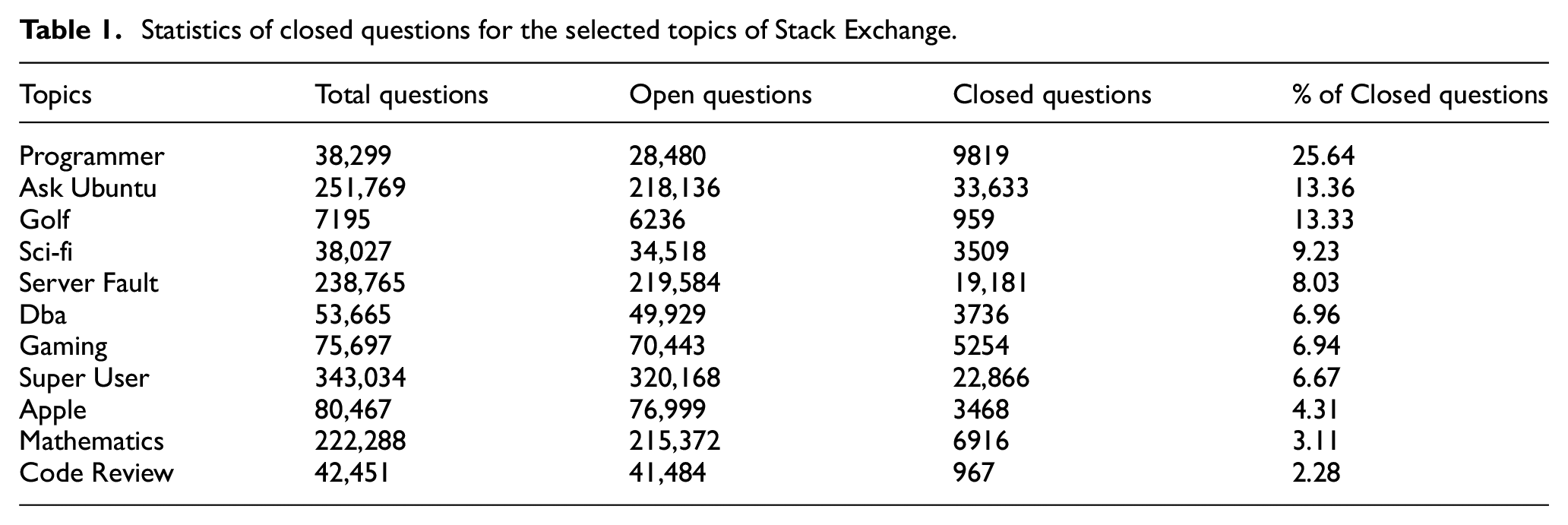
A potential remedy is to automatically identify questions that are likely to be closed before they are actually closed in reality. If the possibility for questions to be closed (henceforth referred to as closibility) can be conveyed to askers automatically soon after they write their questions without human intervention, the volume of likely-to-be-closed questions on Stack Exchange will be reduced. This in turn will minimise the time that experienced users, who are valuable information sources in the CQA community, would spend in closing subpar questions. Instead, they could focus on asking and answering, thereby resulting in more efficient use of the CQA platform for all and sundry.
Therefore, the purpose of this article is to develop a supervised machine learning system that predicts the closibility of questions on Stack Exchange. Existing research on question closibility has used a large number of features [13] but achieved a 0.71 F1-score [14]. Roy and Singh [15] used deep learning frameworks and achieved very low prediction accuracy. Deep learning-based models automatically extracted features from the input, and hence, interpreting the reasons for question closibility was not feasible. The model proposed in this research uses a fewer number of manually extracted features and outperforms the baseline models. Moreover, the proposed model also helps to identify the reason for question closibility through a feature analysis.
This article particularly builds on prior research that has been shedding light on reasons due to which several questions remain unanswered on CQAs [9,16]. In doing so, this article is significant in two ways. First, it represents one of the earliest works to conceptualise what is referred to as the closibility of questions. Using the body of CQA research on questions’ likelihood to remain unanswered as a stepping stone, this article deepens the scholarly understanding of factors that predict questions’ likelihood to be closed. Second, the developed system to predict closibility is meant to be generic so that it can be applied to questions on a variety of topics. Its performance was evaluated by testing it on data from a range of 11 topics available on Stack Exchange. This extends previous research that has been mostly restricted to programming-related questions drawn from Stack Overflow [9,14]. The classification performance was generally promising.
The rest of this article is organised as follows: The next section reviews the literature. The methodology is described thereafter. This is followed by the results and discussion. The final section closes out this article by highlighting its limitations and future scope.
2. Literature review
Since their inception, CQAs have been garnering and archiving huge volumes of user-generated content from their community of users. Their proliferation has continued to attract sustained scholarly interest over the years [1,12,17,18]. In particular, CQAs have been widely investigated to resolve answer-related issues such as examining the quality of answers [9,19–23] and finding the best answer among a pool of responses [24,25]. Much attention has also been devoted to identifying expert users who are capable of producing high-quality answers [4,26–34].
More recently, research has started to cast the spotlight on question-related issues such as clustering similar questions coupled with identification of hot topics [35–37], identification of questioning motivation [38] and detecting duplicate questions [39–45]. Particularly relevant to this article, scholars have also started to examine the quality of questions posted on CQAs [9,12,16,46,47].
For example, Shah et al. [48] used a dataset of 5000 questions posted on Yahoo! Answers to classify question quality as either good or bad. With the help of support vector machine (SVM) classification, they achieved an accuracy of 93.08%. The excellent performance notwithstanding, a limitation of the work was that some of the features required human intervention. Hence, it does not offer a logistically viable strategy to predict question quality on the fly. Ponzanelli et al. [41] proposed a model to minimise low-quality content on CQAs using textual and non-textual features extracted from a Stack Overflow dataset. They achieved a precision of 41.9% for high-quality questions and 64.91% for low-quality questions. Correa and Sureka [49] found that around 8% of the total questions were subpar on Stack Overflow. They used 47 different textual and non-textual features for classification. The model achieved a modest accuracy of 66%.
Srba and Bielikova [50] claimed that the quality of questions on Stack Overflow had been deteriorating over the years. They reported that the low-quality content of the site was 4.11% in 2011, which increased to 16.84% in 2016. They further showed that a particular group of users was continuously posting duplicate questions or definition-type questions on the site. Ahasanuzzaman et al. [39] proposed a system to find duplicate questions on Stack Overflow. They used cosine similarity, WordNet Similarity, Entity Overlap and Entity type overlap on a dataset of some 1.3 million Stack Overflow questions to classify whether an enquiry was duplicate or not. Their system achieved a recall value of 66.10%. Yang et al. [46] analysed unanswered questions on Yahoo! Answers, and proposed a supervised machine learning model to classify them. With a dataset containing 76,251 questions out of which 10,424 were unanswered, their model achieved an F1-score of 32.5%. Dror et al. [51] extended the work of Yang et al. [46] to predict the number of answers a question might receive. They achieved an F1-score of 40.3%.
Most closely related to the current article is the work of Correa and Sureka [14]. It proposed a model to predict closed questions on Stack Overflow. Several textual and non-textual features were extracted from the dataset to achieve a classification accuracy of 73%. This article extends [14] in at least two ways. First, instead of confining the dataset to only programming-related questions, it draws data from 11 randomly chosen topics. This serves to enhance research generalisability. Second, informed by recent works such as Chua and Banerjee [9], this article incorporates several new features such as up votes, down votes and interrogative words. Moreover, it drops variables such as a number of short words, upper case and lower case characters. For one, the conceptualisation of short words was unclear from Correa and Sureka [14]. Besides, there is no reason to assume that the proportions of upper and lower case characters will determine question closibility. Therefore, this article makes a modest attempt to present a more parsimonious set of features for predicting question closibility compared with previous works.
3. Methodology
Figure 1 depicts the complete framework of the proposed model to predict question closibility. The steps are explained below:
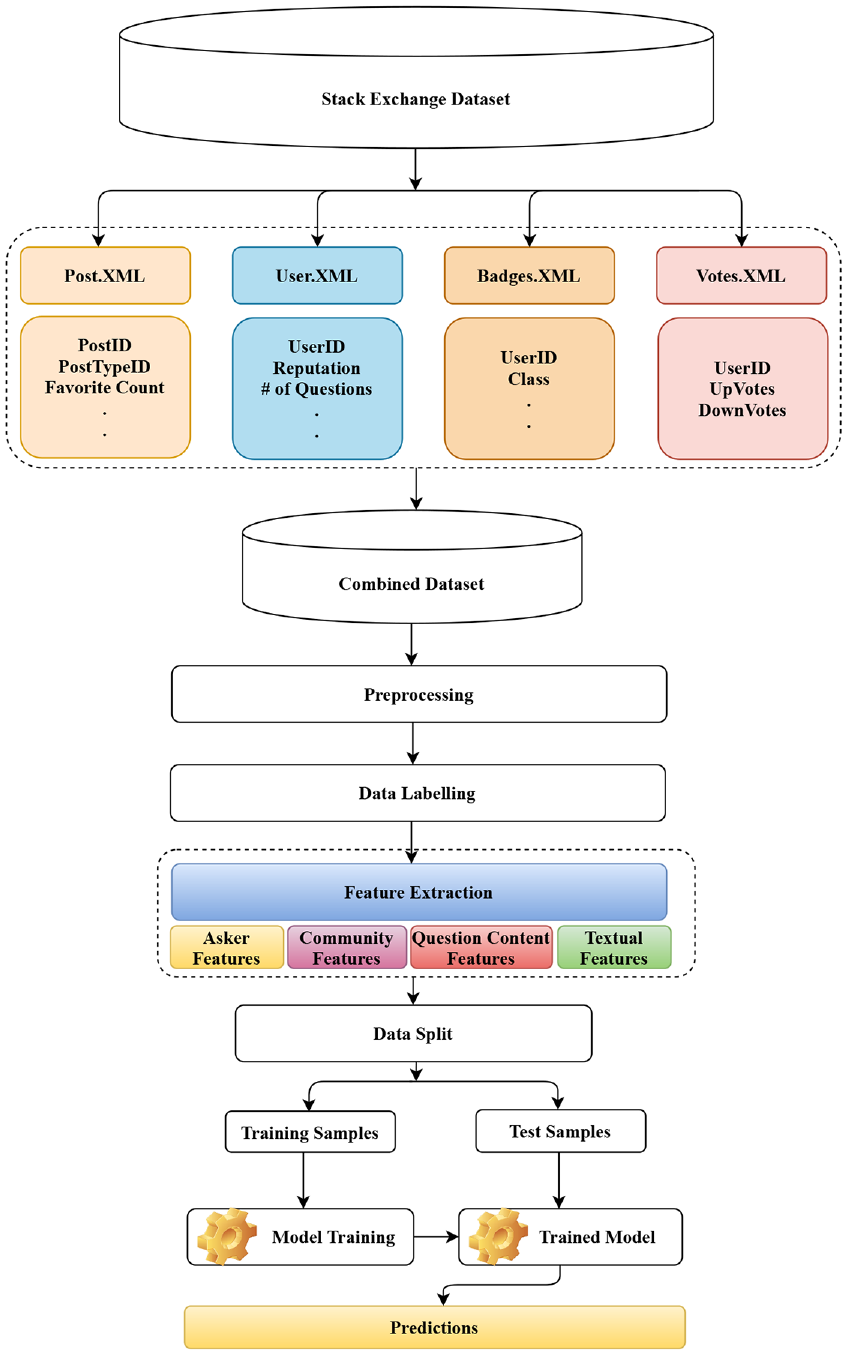
Proposed model to predict question closibility.
Asker features include account age [1] and badge score [2]. These were relevant because questions contributed by long-standing askers with high badge scores are likely to have less closibility than those posted by new and novice individuals [9,52].
Community features include post score [3], reputation [4], favourite count [5], comment count [6], view count [7], answer count [8], up votes [9] and down votes [10]. All of these reflect how well the CQA community accepts a user [16,53]. Obviously, the more whole-heartedly a user is accepted in the community, the less is the likelihood for the community to close a question submitted by the individual.
Question content features include the number of URLs [11] and the number of tags [12]. These have been shown to play a part in determining question closibility [14].
Textual features include question body length [13], question title length [14], the number of special characters [15], the number of punctuation marks [16] and the number of interrogative words [17]. These textual features are known to determine the clarity with which questions are articulated [9,14,16]. Hence, they may also shape question closibility.
All the 17 features are described below, and listed in Table 2.
1.
2.

3.

4.
5.

6.

7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
List of selected features.

3.1. Model setting and evaluation metrics
To evaluate the performance of the supervised machine learning system with the selected features, several classifiers were experimented [54–56]. For the sake of brevity, this article reports the results for Gradient Boosting, Logistic Regression, Naive Bayes and Random Forest. XGBoost, for example, was omitted because it yielded very similar results to Gradient Boosting.
In the dataset, the proportions of closed and open questions were never comparable. Table 1 conveys that closed questions were consistently fewer than open questions for all the 11 topics. For example, of 38,299 questions from the topic of Programmer, only 9819 (25.64%) questions were closed.
Therefore, to study the effect of data imbalance, the classification was conducted in two phases: first with the imbalanced dataset, and next with its balanced version created by applying what is known as SMOTE–synthetic minority over-sampling technique [57]. In SMOTE, the minority class data are oversampled by creating synthetic examples instead of over-sampling with replacement. This is known to result in realistic newly created samples, and is superior to other techniques such as random over-sampling, which increases the sample of minority classes by creating multiple copies of the same data points. With such repeated instances in the dataset, classifiers tend to be over-fitted during the training process. Another over-sampling technique known as ADASYN (ADAptive SYNthetic method) builds on SMOTE. Nonetheless, initial experiments on two datasets Programmer and Ask Ubuntu yielded similar results with both the SMOTE and ADASYN techniques on Gradient Boosting and Random Forest classifiers; however, Naive Bayes and Logistic Regression classifiers performed better with SMOTE compared with ADASYN. Hence, we proceeded with SMOTE to balance the datasets. These were executed in Python on a machine having Intel Xeon(R) CPU 16 cores and 32 GB RAM.
The classification performance was evaluated in terms of precision, recall, F1-score and area under the receiver operating characteristic curve (AUC) [58]. These are explained as follows:
Precision: It is defined as the fraction of closed questions among the retrieved closed questions. It is computed as

where
Recall: It is the fraction of closed questions that have been retrieved over the total amount of closed questions in the system, recall is computed as

where
F1-score: It is the harmonic mean of Precision and Recall, F1-score is computed as

AUC: Receiver operating characteristic curve (ROC) is the plot between the true positive rate and the false positive rate of the classifier for different thresholds


where
4. Results
This section presents the experimental results obtained using the various machine learning algorithms on both the imbalanced and the balanced datasets. The datasets were divided into two parts. One part contained 67% of the data, and was used for model training. The other part contained the remaining 33% of the data, and was used to test the model performance.
4.1. Results with imbalanced datasets
The experiment commenced with questions from the topics of Programmer and Ask Ubuntu. This was because they contained the highest proportions of closed questions. The results are presented in Table 3.
Results with the imbalanced dataset for the topics of Programmer and Ask Ubuntu.
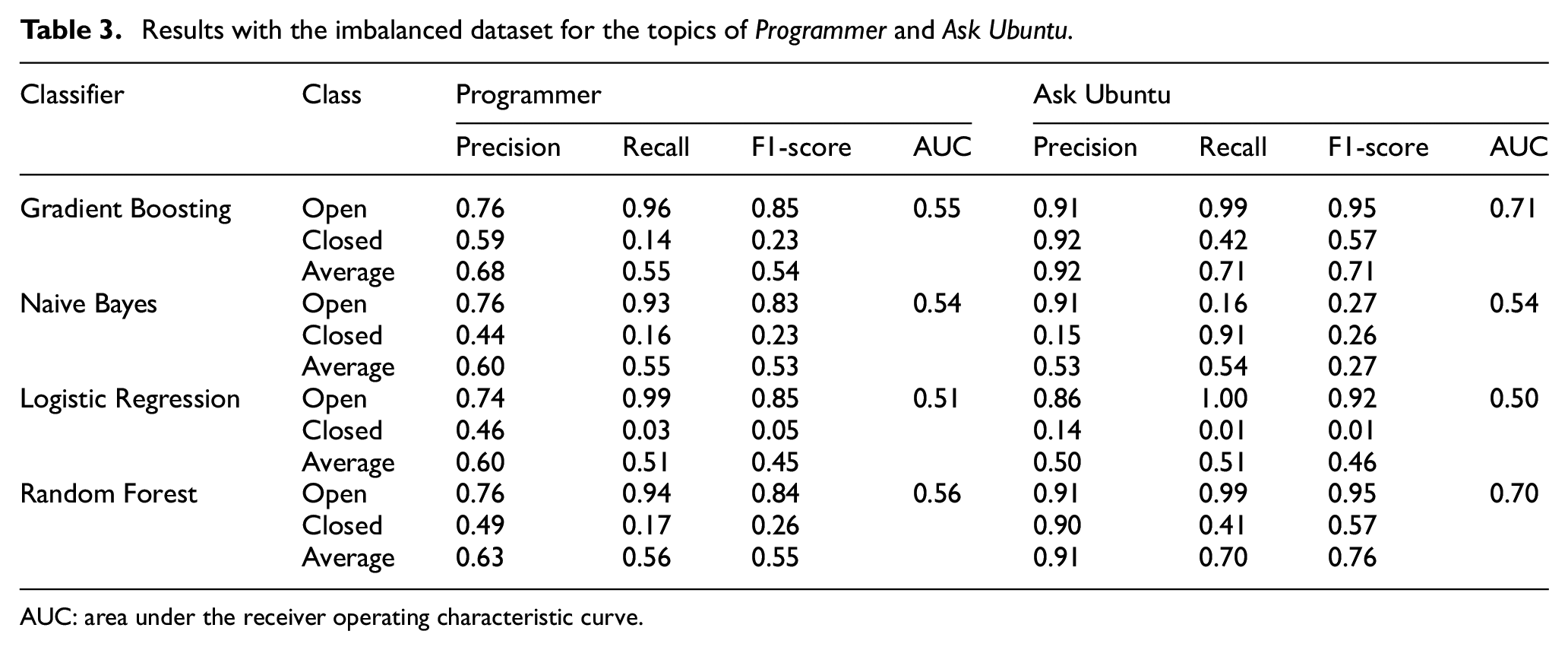
AUC: area under the receiver operating characteristic curve.
Two interesting observations were made. First, Naive Bayes yielded antagonistic results for questions from the two topics. For the topic of Programmer, recall was higher for open questions (0.93) vis-a-vis closed ones (0.16). In other words, a better recall was achieved for the class having a greater number of data instances. For the topic of Ask Ubuntu, however, a better recall was achieved for closed questions (0.91) vis-a-vis open ones (0.16). Put differently, a better recall was obtained for the class having fewer data instances.
Second, none of the classifiers yielded very promising results consistently in terms of precision, recall, F1-score and AUC across questions from both the topics. The imbalance in the dataset was identified as a possible reason. Therefore, these data were balanced to recheck the classification performance. As indicated earlier, SMOTE was applied for this purpose [57].
4.2. Results with balanced datasets
The performance of the proposed model was now checked using the balanced datasets from the topics of Programmer and Ask Ubuntu. The detailed results are presented in Table 4. There were two notable observations. First, even with balanced datasets, Naive Bayes continued to yield antagonistic results for questions from the two topics. For the topic of Programmer, recall was higher for open questions (0.88) vis-a-vis closed ones (0.26). For the topic of Ask Ubuntu, however, a better recall was achieved for closed questions (0.94) vis-a-vis open ones (0.12). Given the poor performance, the data distribution was checked. The features were not normally distributed. As mentioned by Lewis [59], the Naive Bayes classifier performs well with datasets that are normally distributed or categorical in nature. This was the reason for the anomaly.
Results with the balanced dataset for the topics of Programmer and Ask Ubuntu.
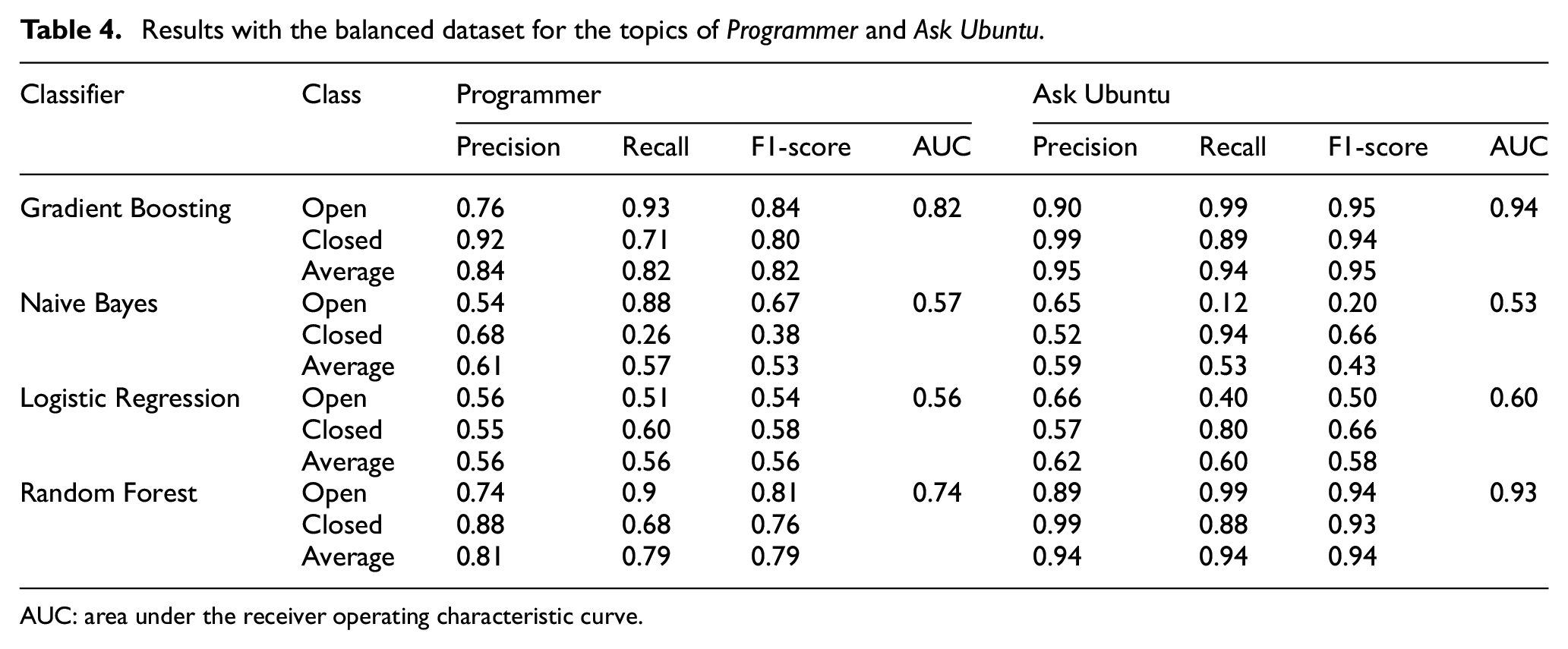
AUC: area under the receiver operating characteristic curve.
Second, Gradient Boosting outperformed the other classifiers in predicting question closibility. This was true across both the topics in terms of all the four selected performance indicators: precision, recall, F1-score and AUC [58]. The confusion matrix detecting the true distribution of the data instances over the different classes and the ROC curves for the topics of Programmer (AUC = 0.82) and Ask Ubuntu (AUC = 0.94) are shown in Figures 2 –5.
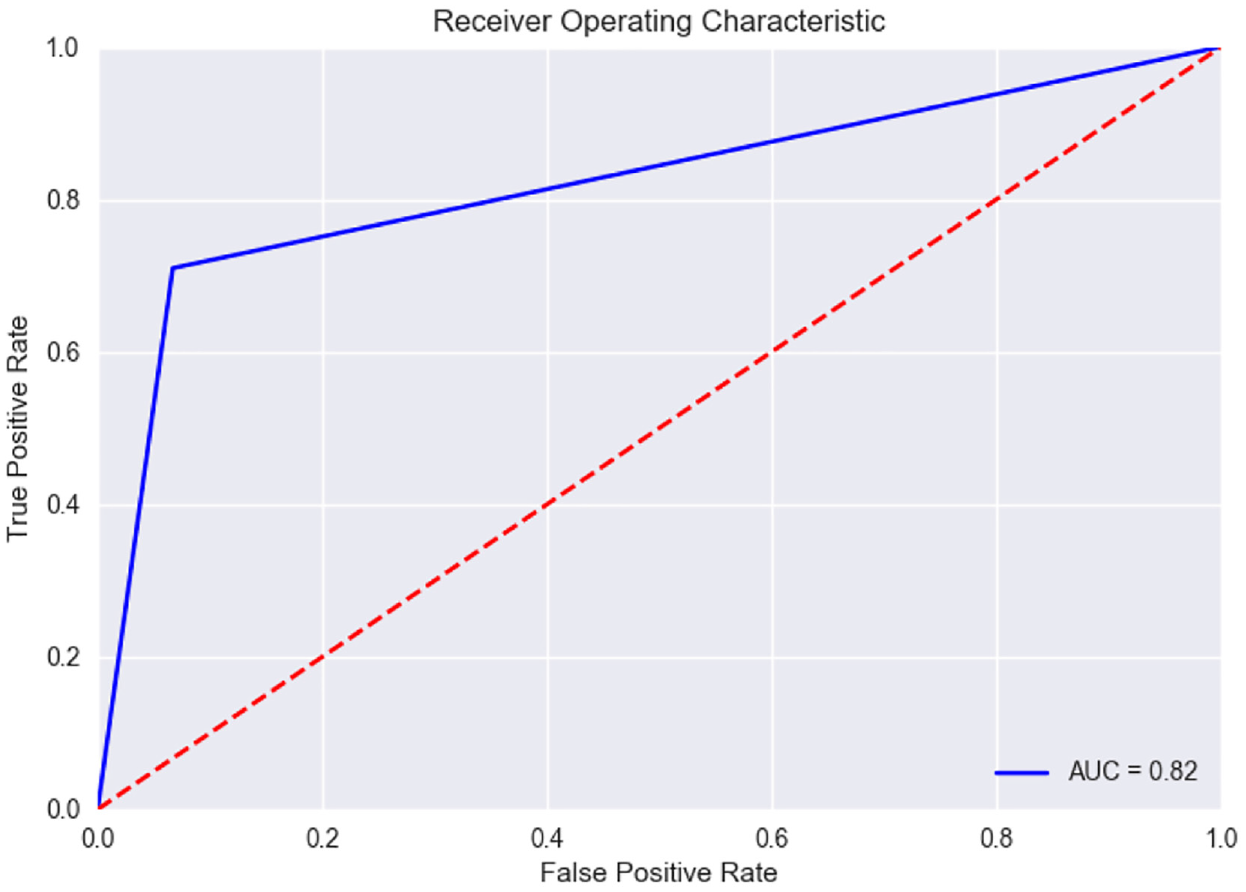
ROC curve for Programmer topic.
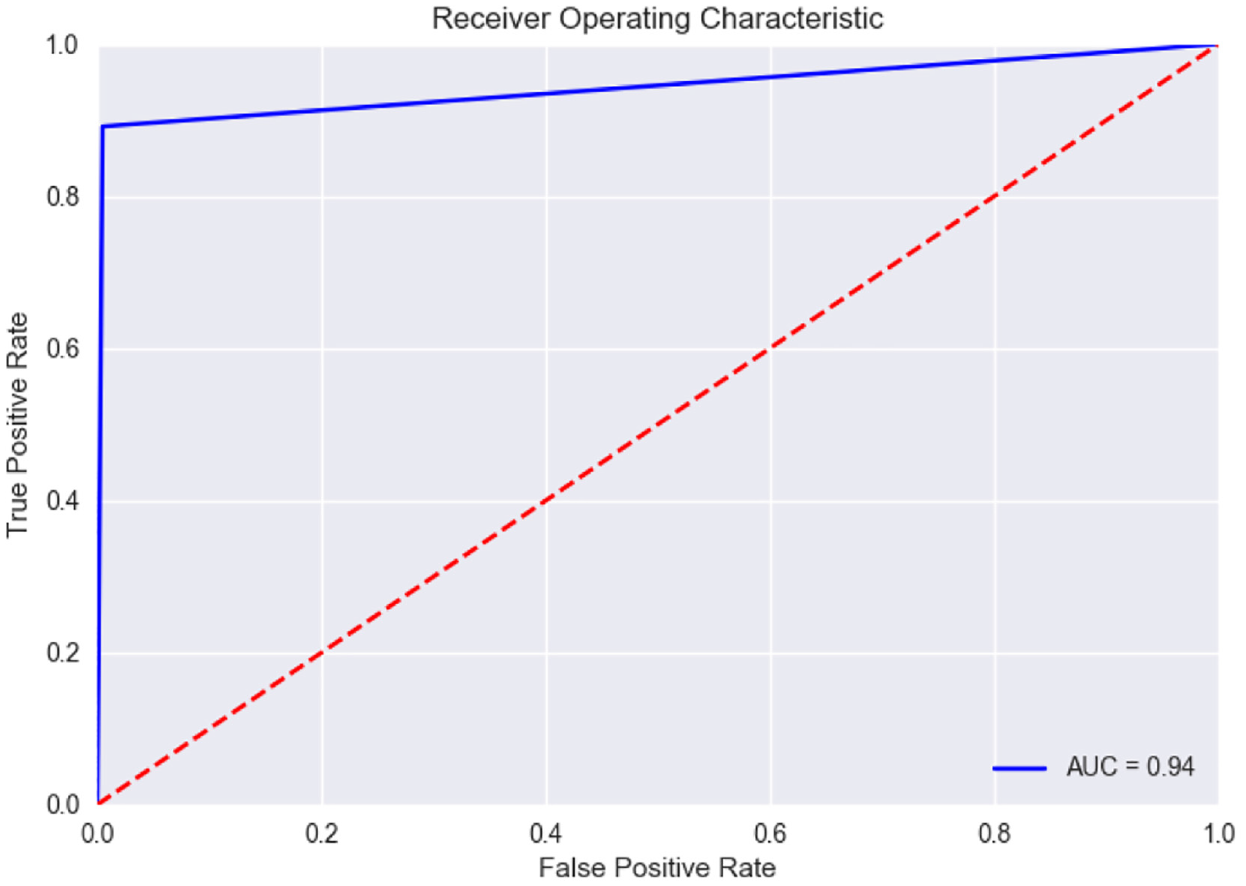
ROC curve for Ask Ubuntu topic.
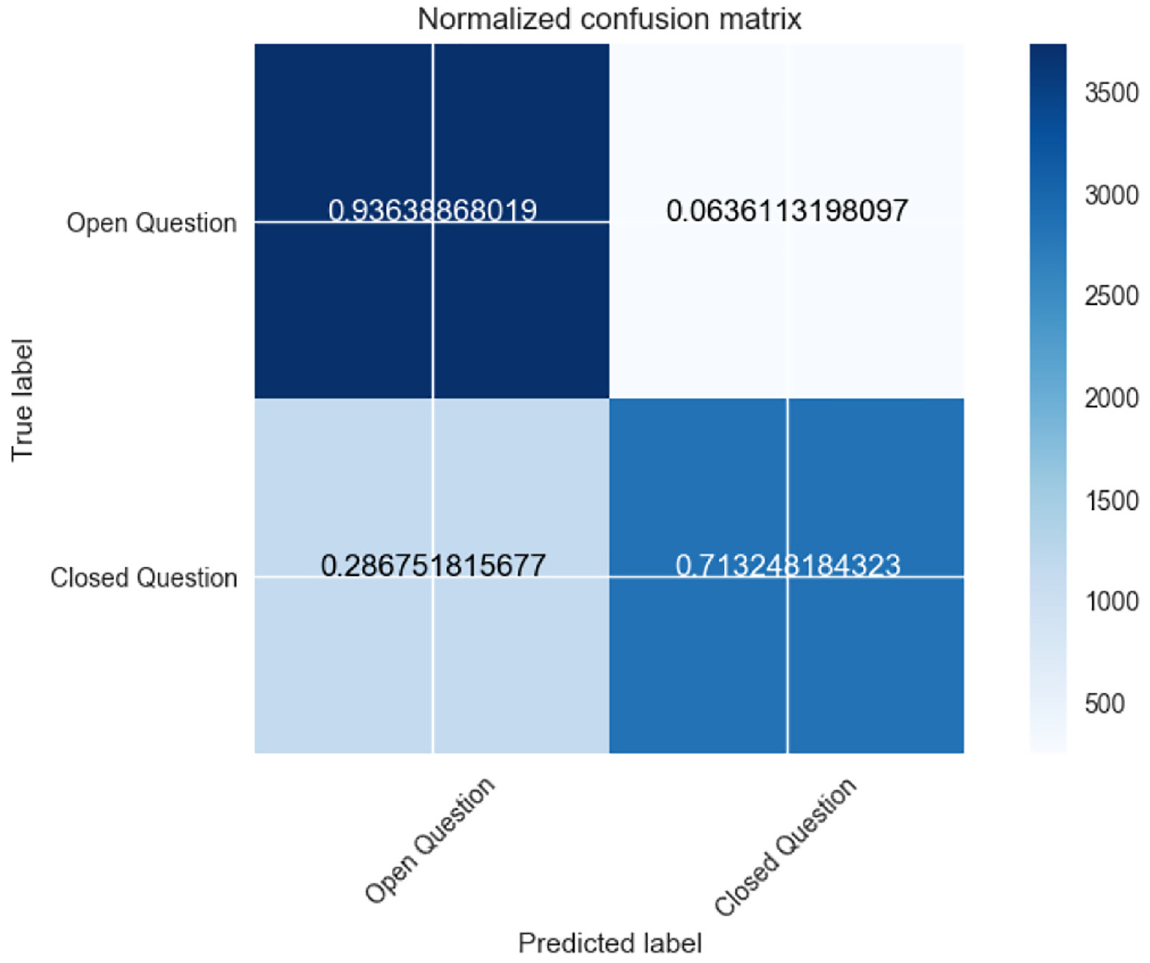
Confusion matrix for Programmer topic.
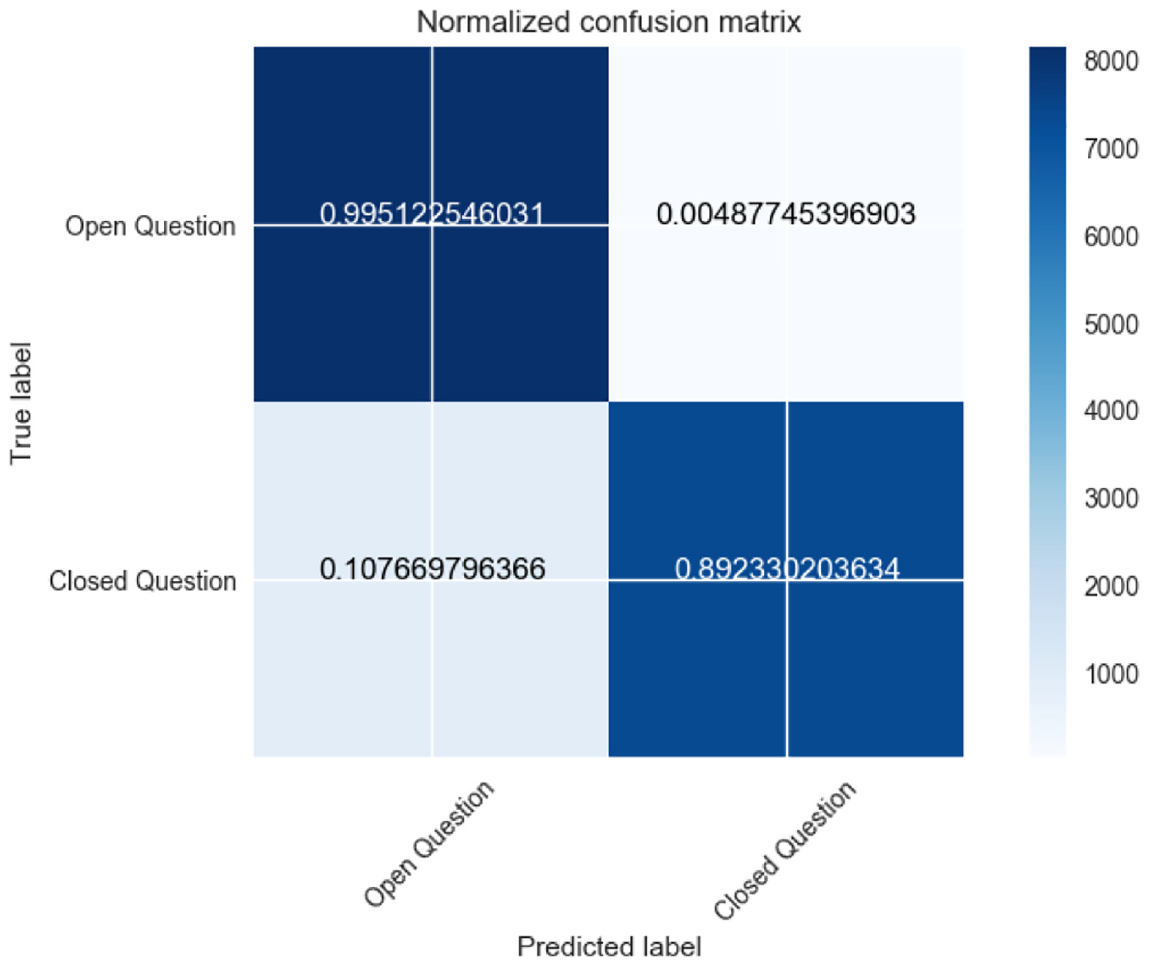
Confusion matrix for Ask Ubuntu topic.
Given that Gradient Boosting emerged as the best performing classifier, it was therefore employed on the balanced datasets for all the topics to predict question closibility. The results are summarised in Table 8. The classification performance was generally promising.
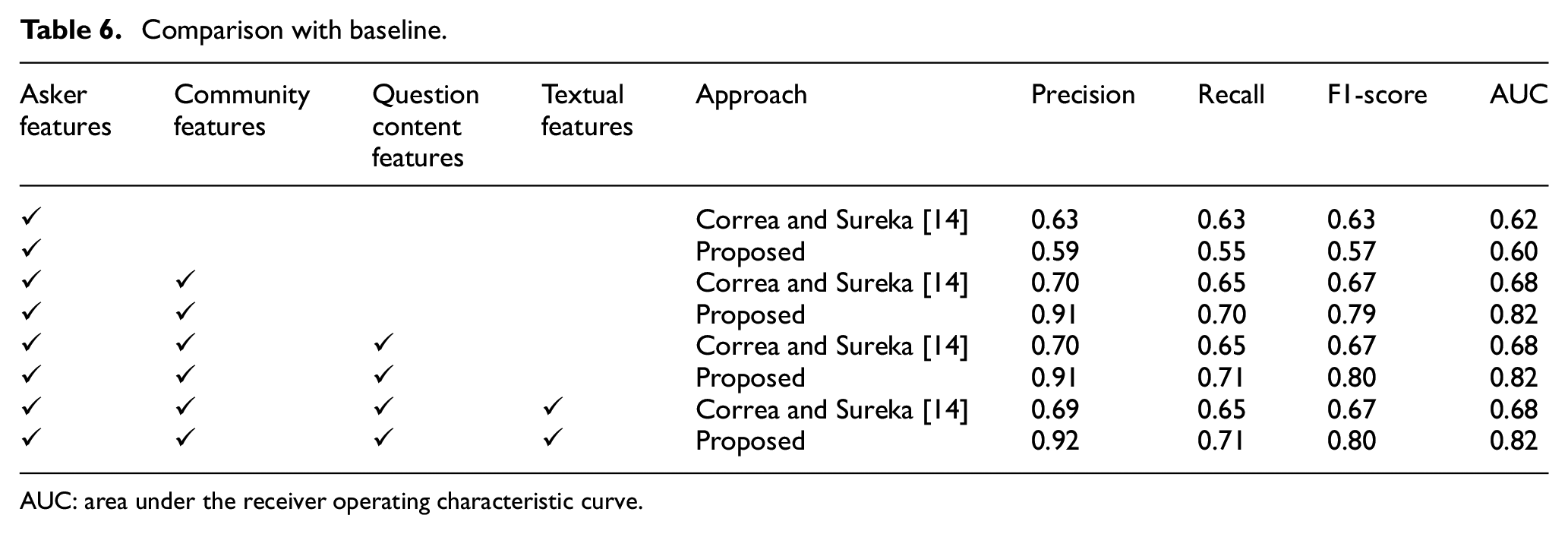
As indicated earlier, the most pertinent prior work for this article is Correa and Sureka [14]. It proposed a model to predict closed questions from a dataset of programming-related questions drawn from Stack Overflow. Therefore, using questions from the topic of Programmer, this article uses Correa and Sureka [14] as a baseline for comparison. The comparative outcomes are shown in Table 6. The classification performance using Gradient Boosting was traced in terms of precision, recall, F1-score, and AUC. To afford a granular analysis, the classification was performed in four steps that involved including asker features, community features, question content features and textual features one by one. The proposed model mostly outperformed the baseline with the selected feature set as shown in Table 6. The proposed model also outperformed Roy and Singh’s [15] deep learning model as shown in Table 5.
Comparison with deep learning.

AUC: area under the receiver operating characteristic curve.
Comparison with baseline.
AUC: area under the receiver operating characteristic curve.
4.3. Results with deep learning
Of late, deep learning-based models such as convolutional neural network (CNN), long- and short-term memory (LSTM) and the transformer-based Bidirectional Encoder Representations from Transformers (BERT) models are widely being used in natural language processing. These models are often preferred to traditional machine learning as they are capable of finding hidden contextual patterns from the dataset using their complex architecture. Hence, we decided to explore deep learning.
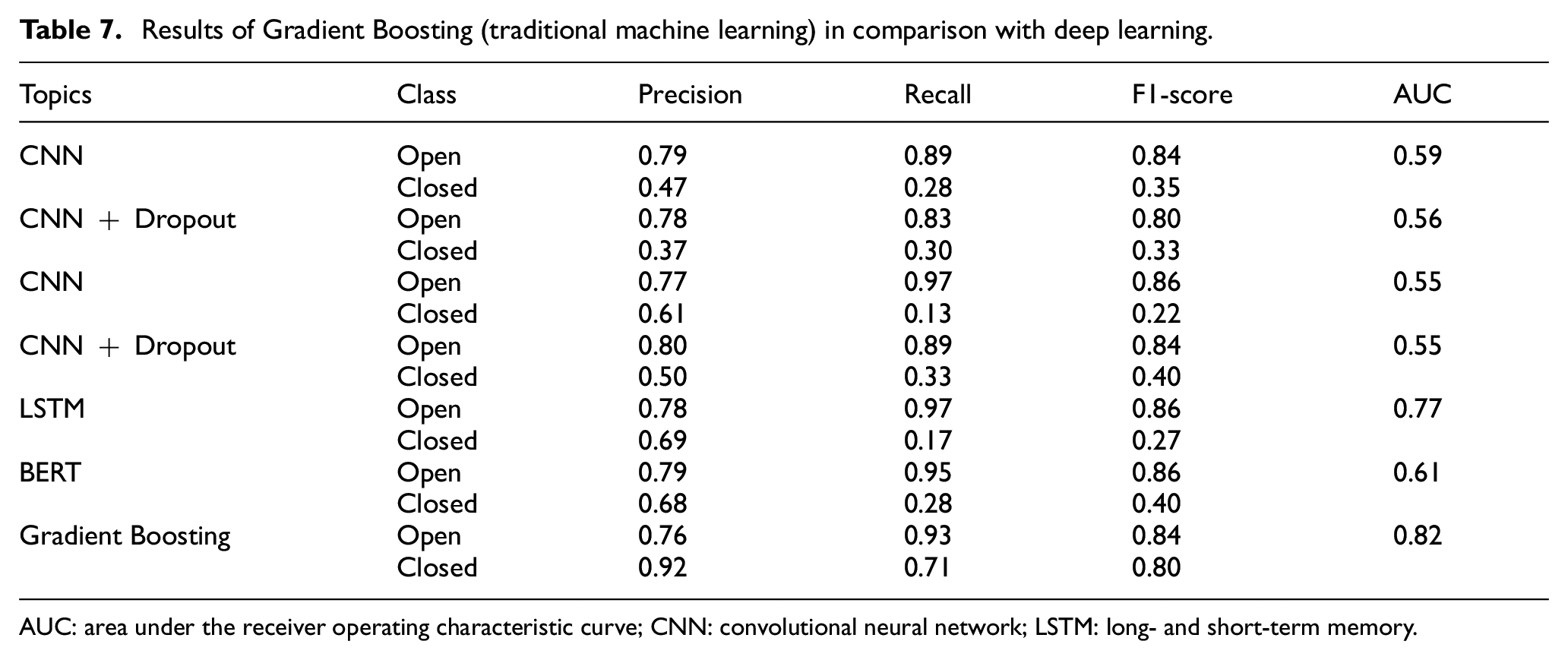
The experiments were conducted on Programmer topic using the Google Collabotary platform, where all required libraries are pre-installed. First, we experimented with the CNN model with two variations (1) without using the dropout layer and (2) using the dropout layer. The outcomes are presented in Table 7. The CNN model with a single layer of convolution worked well for the open category question prediction but performed poorly for the closed category. Even adding a dropout layer did not substantially improve model performance. The F1-score was only 0.33 for closed questions. This shows that most closed questions remained untraceable by the CNN model.
Results of Gradient Boosting (traditional machine learning) in comparison with deep learning.
AUC: area under the receiver operating characteristic curve; CNN: convolutional neural network; LSTM: long- and short-term memory.
Next, we increased the convolution layer from one to two and repeated the experiments. The outcomes of the two-layered CNN model improved slightly but were still lower than what was achieved using traditional machine learning. The LSTM and BERT models also exhibited similar performances. The AUC value using the LSTM model was 0.77 and using the BERT model was 0.61, indicating that the LSTM model performed better among all the deep learning and transformer-based models.
4.4. Feature importance
To dig deeper, the relative strength of the features was assessed for the topics of Programmer and Ask Ubuntu. Using Gradient Boosting, the feature importance graphs are shown in Figures 6 and 7, respectively.
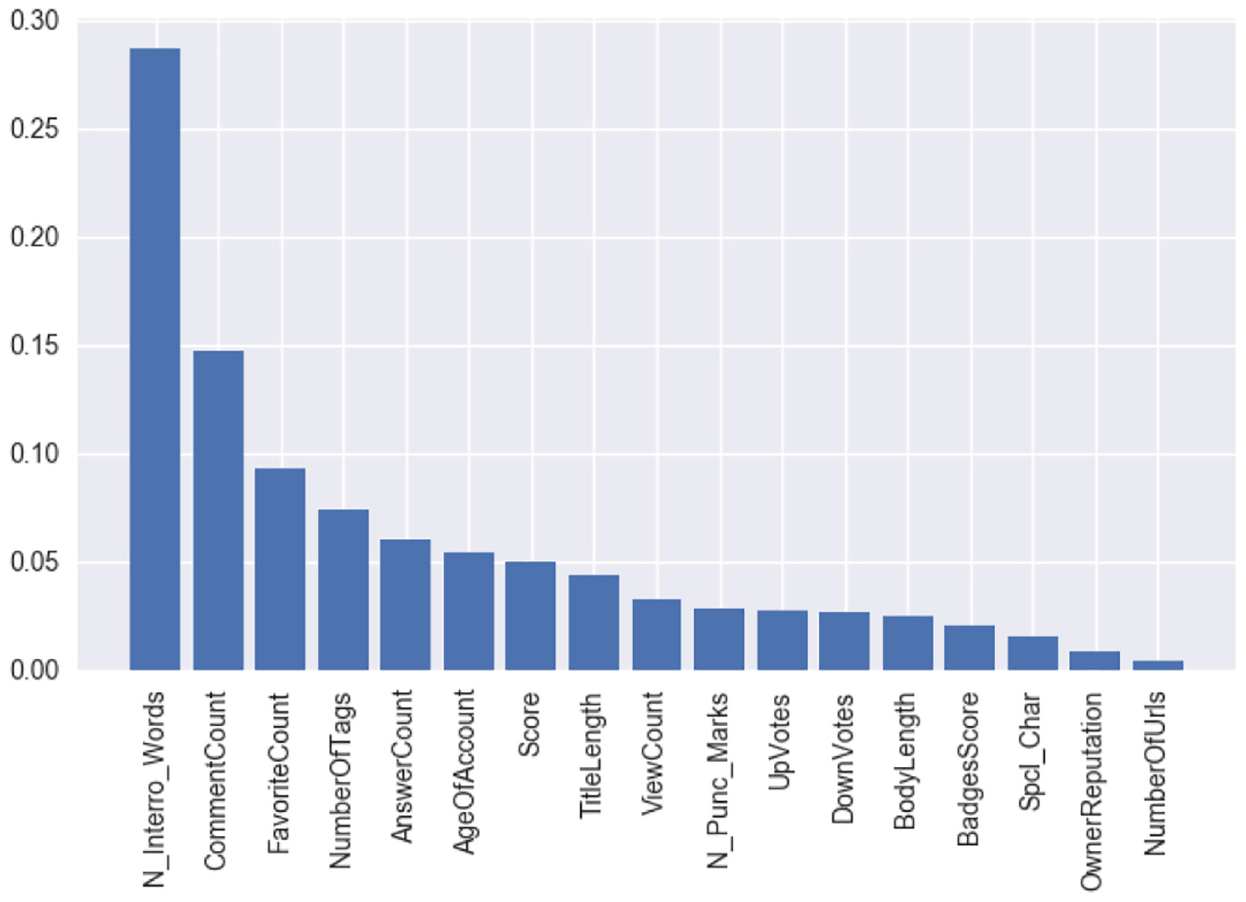
Feature importance graph for the topic of Programmer.
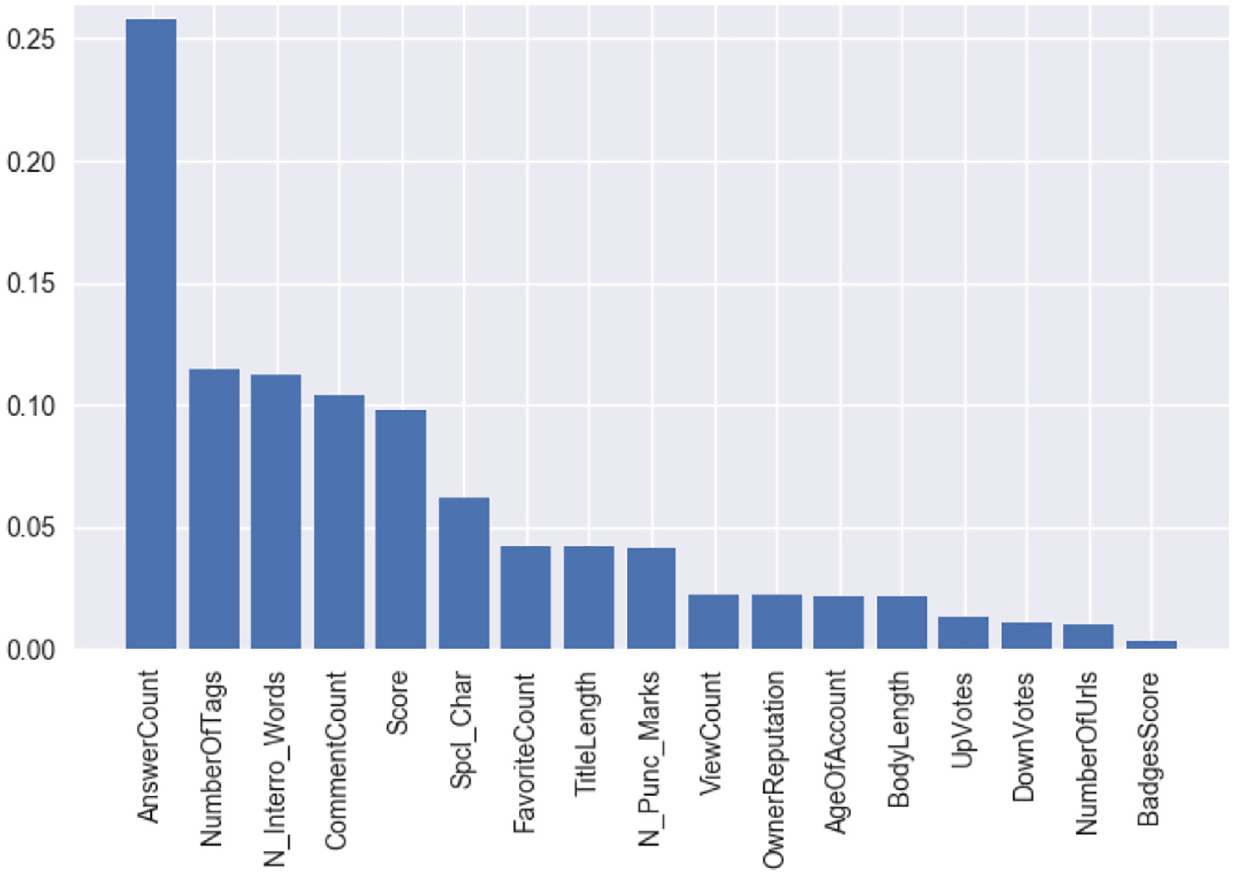
Feature importance graph for the topic of Ask Ubuntu.
For the topic of Programmer, the top three contributing features were number of interrogative words, comment count and favourite count. For the topic of Ask Ubuntu, the top three features were answer count, number of tags and number of interrogative words. Across the two topics, the top three features were mostly dominated by non-textual features. The only exception was number of interrogative words.
The effect of the selected features can also be seen in Table 6, in which the model performance is shown as a function of the feature subsets. Each subset of features, namely, asker features, community features, question content features and textual features, was useful as the values of the performance measures continued to rise progressively.
5. Discussion
This section deals with the experimental outcomes and the major finding of the research, including theoretical contributions and implications for practice [60]. CQAs are known to be flooded with questions that are never answered [7,9,10]. To cope with the problem, experienced users of Stack Exchange are now allowed to mark newly posted questions as closed if it is duplicate, off-topic, opinion-seeking, unclear or vague. However, identifying and closing subpar questions manually takes time.
To this end, this article developed a supervised machine learning system that predicts question closibility – the possibility of a newly posted question to be eventually closed. It leveraged the body of literature that has been shedding light on reasons due to which several questions remain unanswered on CQAs [9,16]. The system was tested on questions posted on Stack Exchange from 11 randomly chosen topics. Gradient Boosting emerged as the best-performing classifier. As shown in Table 8, the classification performance was generally promising. Most of the measures of precision, recall, F1-score and AUC were above 0.9 with minimum values of 0.76, 0.71, 0.80 and 0.82, respectively.
Results with datasets after balancing with Gradient Boosting.
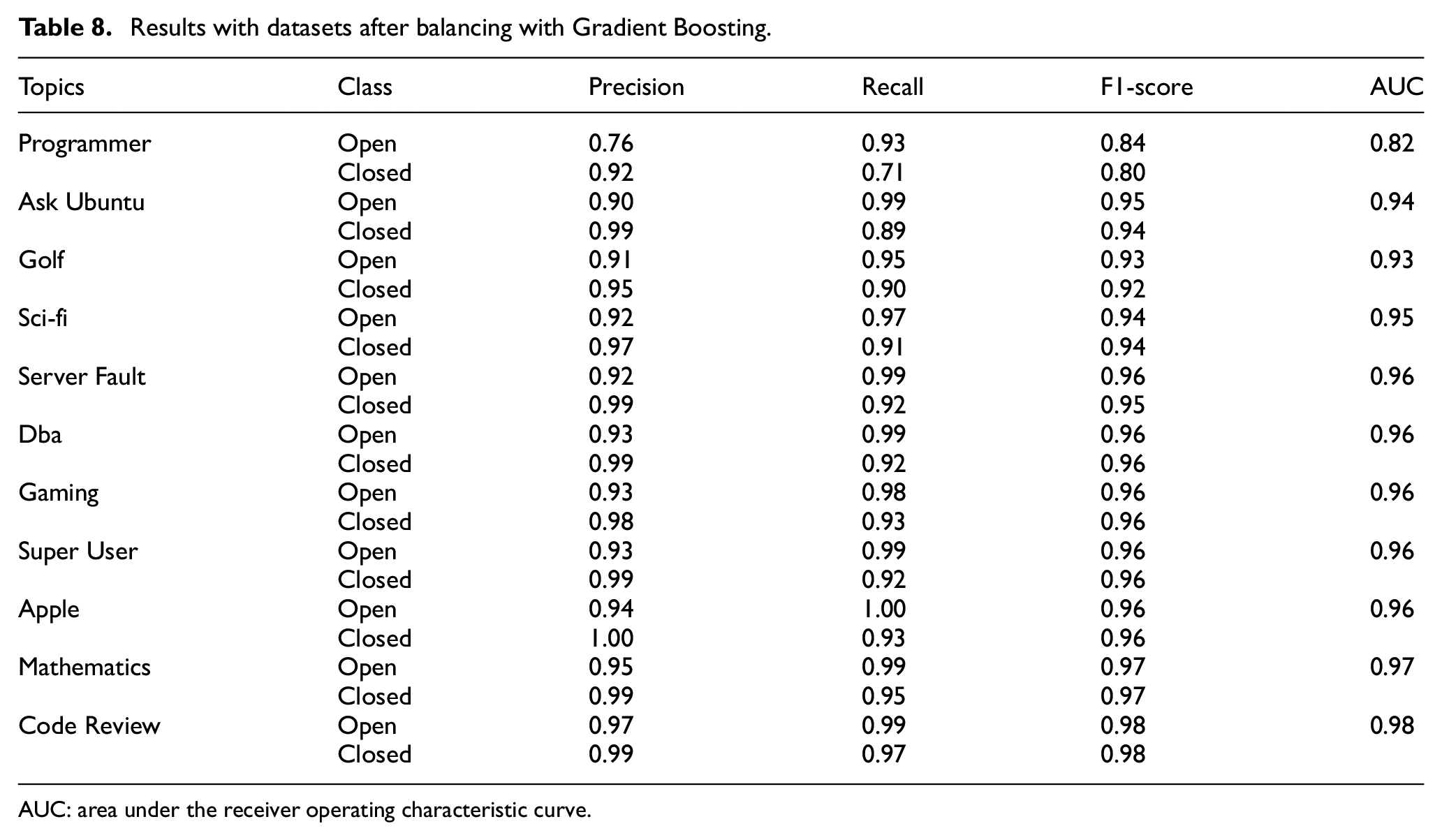
AUC: area under the receiver operating characteristic curve.
The system was found to outperform the baseline, an earlier model to predict closed questions proposed by Correa and Sureka [14]. As shown in Table 6, the best F1-score obtained by the baseline Correa and Sureka [14] was 0.67, whereas our model achieved 0.80 in a similar setting. This article also supplements previous related works. Yang et al. [46], for example, only analysed unanswered questions, and achieved an F1-score of 32.5%. Again, Ahasanuzzaman et al. [39] achieved a recall of 66.10% in identifying duplicate questions. These factors such as being unanswered and duplication can all lead to a question being closed. This research combines all such factors of question closibility, and achieves an average F1-score of 0.92 with a minimum of 0.82 for the topic of Programmer, and a maximum 0.97 for the topic of Mathematics. Moreover, unlike works such as Shah et al. [48] that used features requiring human annotation, the system developed in this article employs features that could be readily obtained. Therefore, it offers a viable strategy to predict question closibility on CQAs in real time.
5.1. Theoretical contributions
The theoretical contributions of this article are four-fold. First, it conceptualises what is referred to as the closibility of questions. It also develops a supervised machine learning system that predicts the possibility of questions on Stack Exchange to be closed. This serves to deepen the scholarly understanding of factors that predict questions’ likelihood to be closed on CQAs. It serves as a call for scholars to explore the theme of question closibility more granularly in the future.
Second, this article builds on the literature on question quality [9,16] to identify new features for predicting question closibility. Features such as the use of interrogative words were not used in earlier works to distinguish between closed and open questions [14]. However, number of interrogative words was among the top three features for the topics of both Programmer and Ask Ubuntu (Figures 6 and 7). It should be incorporated in related future research. In sum, the 17 features identified in this article seem more comprehensive than prior works.
Third, the supervised machine learning system developed to predict question closibility was intended to cater to questions on a variety of topics. For this reason, features such as code snippet – commonly used in prior works that focus solely on programming-related questions – were dropped. This serves to enhance the parsimony while widening the applicability of the classifier. The classification performance was evaluated by testing the system on questions from a range of 11 topics available on Stack Exchange. As evident from Table 8, the majority of the measures of precision, recall, F1-score and AUC were above 0.90. This extends previous research that was mostly restricted to programming-related questions drawn from Stack Overflow [9,14].
Fourth, this article has implications for the usage of supervised machine learning on CQAs. For one, it demonstrates the utility of SMOTE to predict question closibility [57]. Previous CQA studies focusing on question quality did not mitigate the data imbalance problem before feeding datasets to classifiers. This article confirms that classification performance would be inadequate if the dataset is overly imbalanced. It also echoes previous research [59] that the Naive Bayes classifier does not work well if the features are not normally distributed. Gradient Boosting emerged as the best classifier regardless of questions’ topic.
5.2. Implications for practice
On the practical front, this article demonstrates the possibility of screening new questions while they are being submitted on CQAs [61]. Moderators and administrators of CQAs could use the system developed for the purpose of this article as a preliminary filter to weed out questions with high closibility. The current system may be placed just beneath the user interface to work silently and screen all incoming questions. Besides, this automated system could be employed on the archives of previously posted questions on CQAs to evaluate question quality at regular intervals.
Overall, the system is able to free users from the tedious task of manually closing subpar questions on CQAs. It will reduce not only the community participation time in marking questions as closed but also the moderation job time. These in turn will pave the way for more efficient use of the CQA platform as an information-seeking avenue.
6. Conclusion, limitations and future scope
On CQAs, the number of closed questions has been rising. This article presents a machine learning method to predict question closibility, which is defined as the possibility of a question to be closed, as a first step towards solving the problem. A supervised machine learning system was developed and tested on data from Stack Exchange on as many as 11 topics. The feature set was more parsimonious compared with those used in prior works. Even then, the system fared better than earlier studies. Gradient Boosting emerged as the best performing classifier regardless of the question topics. Therefore, the key takeaway message from this article is this: using supervised learning, it is possible to automatically identify questions that are likely to be closed before they are actually closed, with reasonably high accuracy. This holds immense promise for the future of CQAs.
Nonetheless, a limitation of the proposed system is that the features were selected manually. It was difficult to find the optimal number of features when the system was tested on 11 different topics. The current system could be enhanced by replacing the manual feature selection method with an automated approach. For this purpose, future research may consider neural network-based frameworks such as CNN, LSTM and BERT. Also, the same can be tested by drawing data from other CQAs such as Quora and Yahoo! Answers.
Another limitation of this article lies in the use of only English questions. As many CQAs allow question-answering in non-English languages, future research could develop a language-independent model. In addition, there can be several grammatical errors in questions, making it tough for the model to identify the exact context. A model that is able to auto-correct grammatical mistakes could be developed in the future to address these issues. Hopefully, such research efforts will further enhance the value of CQAs to Internet users in the long run.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.