
Abstract
In adolescence research, the treatment of measurement reliability is often fragmented, and it is not always clear how different reliability coefficients are related. We show that generalizability theory (G-theory) is a comprehensive framework of measurement reliability, encompassing all other reliability methods (e.g., Pearson r, coefficient alpha and KR-20, intraclass correlation coefficients). As such, G-theory provides the flexibility and comprehensiveness not offered by conventional reliability methods. Within the G-theory framework, the similarities and differences of different reliability coefficients can be easily understood, and planning for optimal measurement protocols in adolescence research is feasible. Using hypothetical data, we show how different conventional reliability estimates are related to G-theory estimates and how G-theory estimates are obtained in research practice. Adolescence researchers may use G-theory as the general framework for understanding different reliability estimates.
Keywords
In adolescence research, as in other social and behavioral sciences, measurement reliability is always an important concern. The meaning and interpretation of our statistical findings hinge on the quality of our measurement data, and reliability is an important aspect of the measurement quality (Wilkinson and the Task Force on Statistical Inference, 1999). As it has been widely discussed in measurement literature, validity is the most fundamental concern in any measurement situation. It is also generally understood that measurement reliability is a necessary, though not sufficient, condition for measurement validity (Brennan, 2006; Crocker & Algina, 1987). The purpose of this article is on measurement reliability, and readers interested in issues related to measurement validity should consult relevant sources in the literature (e.g., Brennan, 2006; Crocker & Algina, 1987; Worthen, White, Fan, & Sudweeks, 1999).
There are different types of reliability estimates, depending on the measurement error sources of interest, such as internal consistency reliability coefficient (Cronbach’s coefficient alpha, KR-20), coefficient of stability (test-retest reliability coefficient), coefficient of equivalence (parallel-form reliability coefficient), and interrater reliability coefficient. In adolescence research and some other areas of psychology, intraclass correlation coefficient is also a widely used reliability estimate for assessing measurement reliability across-raters or across-occasions (e.g., Maisto et al., 2011; Valen, Ryum, Svartberg, Stiles, & McCullough, 2011). Generalizability theory (Brennan, 2010; Cronbach, Gleser, Nanda, & Rajaratnam, 1972), however, has emerged as a comprehensive framework for measurement reliability.
Many adolescence researchers may not be familiar with the generalizability theory (G-theory) and its advantages over conventional forms of reliability estimates (e.g., test-retest reliability, interrater reliability, intraclass correlation, Cronbach’s coefficient α). In this article, we discuss the underlying rationale for different coefficients and present illustrative examples about how the G-theory provides a unified framework for estimating reliability in different situations. We further discuss that the G-theory approach subsumes all other seemingly different reliability coefficients (e.g., intraclass correlations, Cronbach’s coefficient alpha, test-retest reliability) as its special cases. Adolescence researchers may use G-theory as the general framework for understanding different reliability estimates.
Reliability and Its Estimates in Classical True Score Theory
In classical test theory (e.g., Crocker & Algina, 1986; Gulliksen, 1987; Traub, 1994), the observed score (X) from a measurement process (e.g., taking a test, rating provided by an observer) consists of two components: true score (T) and error (E):

Classical true score theory has one basic assumption: the measurement error (E) is random. This basic assumption leads to three resultant assumptions: (a) the mean of errors is zero (μ
E
= 0); (b) the correlation between the true score and errors is zero (ρ
T,E
= 0); (c) for a population of examinees, errors from two tests (or two forms, two occasions with the same form, two raters, etc.) are not correlated (

Reliability coefficient (
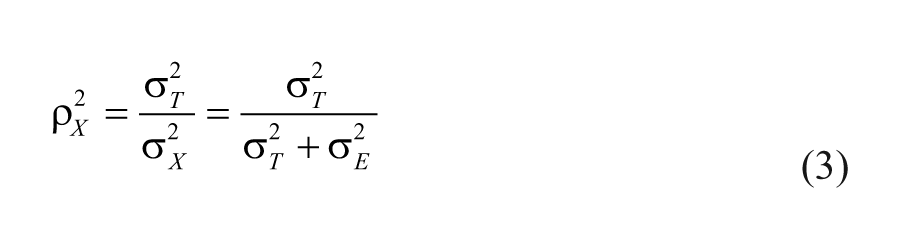
In other words, a reliability coefficient theoretically represents the proportion of the true score variance (
Equation 3, however, only represents the theoretical measurement reliability. In reality, we only know the observed score variance (
Under the assumption of true parallel forms, it can be shown (e.g., Crocker & Algina, 1986) that the correlation coefficient (
True parallel tests exist in theory only. But when we have measurements that are reasonably parallel, we can estimate reliability coefficient by computing the Pearson correlation coefficient between the two measurements. The two measurements may be obtained in different measurement contexts, such as scores obtained from two test forms (parallel forms), from two occasions (test-retest), or two ratings provided by two raters/observers (interrater), and so forth. The Pearson correlation (as a population parameter) takes the following form:
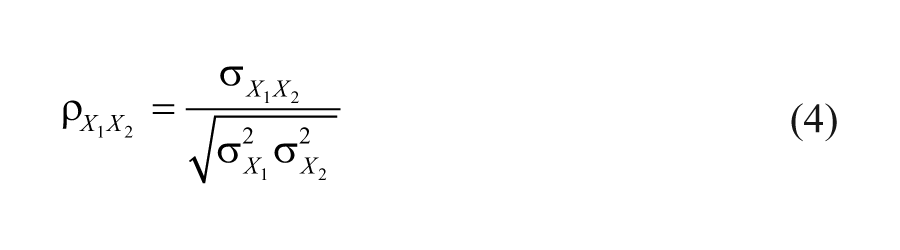
where
Major Types of Reliability Coefficients
Depending on the measurement context, a reliability estimate may take different forms. In classical test theory, there are basically two major forms that a reliability estimate may take: Cronbach’s coefficient alpha and the Pearson correlation coefficient.
Coefficient Alpha
In a situation where a test (i.e., any measurement instrument) involving multiple items is administered to a group of examinees, coefficient alpha (Cronbach, 1951) is the most widely used reliability estimate. Coefficient alpha belongs to the category of reliability estimates for internal consistency of the items, and it takes the following form:

where, k is the number of items,
Illustration of Coefficient Alpha Calculation.
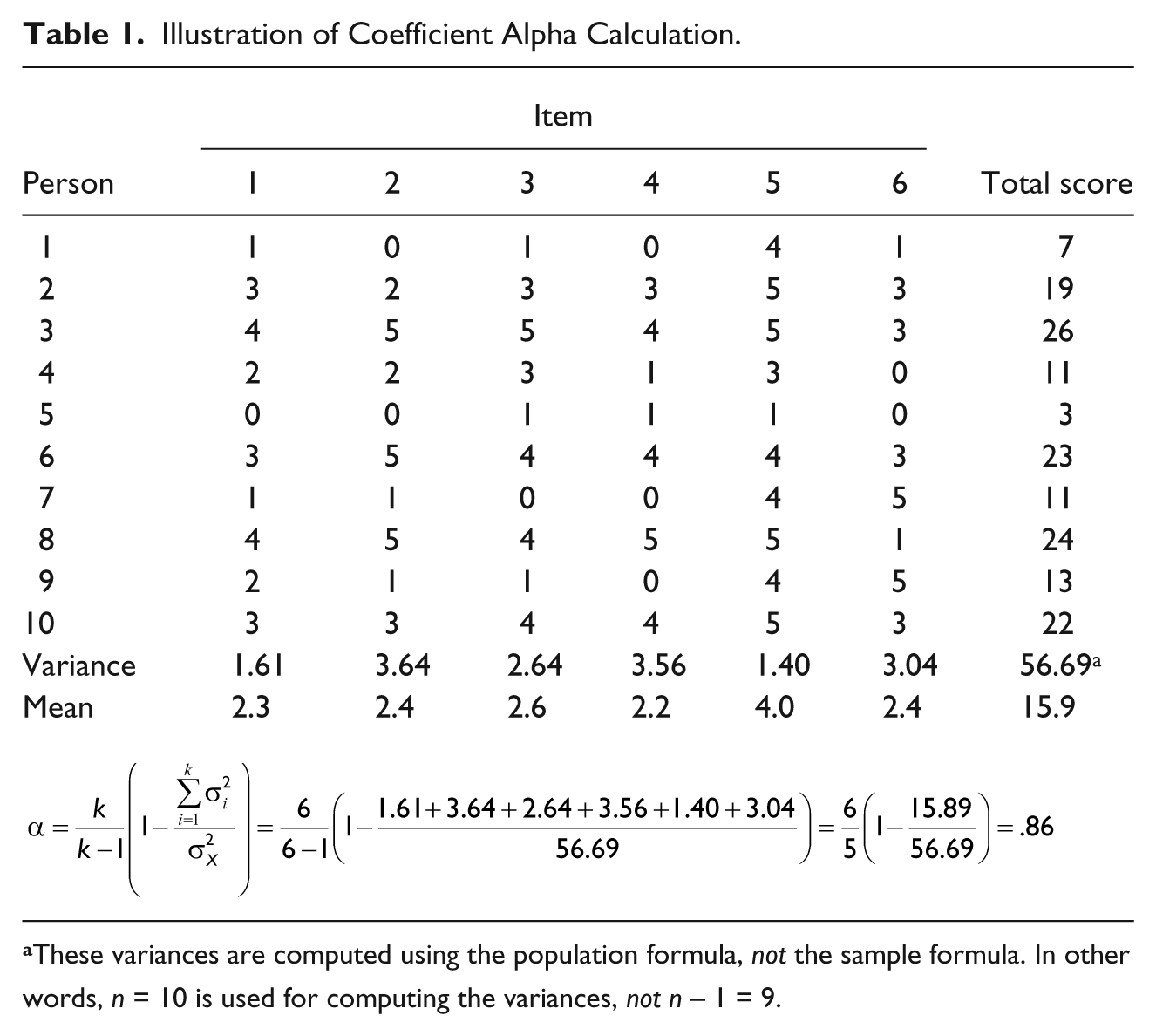
These variances are computed using the population formula, not the sample formula. In other words, n = 10 is used for computing the variances, not n – 1 = 9.
There are other approaches for estimating internal consistency reliability of a test, such as split-half method, KR-20 formula, or Hoyt’s method. Coefficient alpha is theoretically the average of all possible split-half coefficients (Crocker & Algina, 1986). Kuder and Richardson (1937) designed a coefficient (KR-20) for dichotomously scored items, which is a special case of coefficient alpha developed later by Cronbach (1951). Hoyt’s method (Hoyt, 1941) of using an analysis variance model is also equivalent to coefficient alpha algebraically.
Pearson Correlation as Reliability Coefficient
In many situations, the Pearson correlation is used as the reliability coefficient. Computationally, Pearson correlation coefficient can serve as a reliability estimate when there are two sets of scores obtained from one group of examinees (or ratees). Several measurement situations fall under this category: test-retest reliability coefficient, alternate-form reliability coefficient, interrater reliability coefficient. In these situations, the Pearson correlation coefficient between the two sets of scores is computed, and this correlation coefficient is treated as the reliability coefficient. Because reliability coefficient represents the proportion of total (observed) score variance (
Sources of Measurement Error
As discussed above, different forms of reliability estimates may be obtained, such as Cronbach’s coefficient α (coefficient of internal consistency), interrater reliability coefficient (i.e., coefficient of stability), alternate-form reliability coefficient (i.e., coefficient of equivalence), and interrater reliability coefficient. However, these different forms of reliability estimates are not conceptually equivalent because they capture the measurement error from different sources. For internal consistency (Cronbach’s coefficient α and alternatives), the main source of measurement error is content sampling. For coefficient of stability, the main source of measurement error is time sampling. For coefficient of equivalence, the main source of measurement error is content sampling across forms. For interrater reliability, the main source of measurement error is rater inconsistency (e.g., inconsistent rating criterion for different ratees). Which reliability coefficient to use in a specific measurement situation depends on what measurement error source is the most relevant concern in that situation.
Norm-Referenced Versus Criterion-Referenced Score Interpretation
Norm-Referenced Score Interpretation
Classical true score theory and its reliability procedures were developed for norm-referenced measurement of individual differences. In norm-referenced measurement, the measurement focus is the relative standings of individuals, not the absolute scores. So a typical reliability coefficient (e.g., test-retest reliability coefficient) quantifies the degree of consistency of the relative standings of individuals, but not the consistency of actual scores.
To illustrate the norm-referenced interpretation of a reliability coefficient, Table 2 presents a hypothetical data set in which 10 adolescents (Targets) were rated by two researchers (J1 and J2). The interrater reliability coefficient (Pearson correlation) between the ratings provided by J1 and J2 is .84, a moderately high interrater reliability coefficient, suggesting that the relative standings of the 10 adolescents are reasonably stable across the two raters.
InterRater Reliability Example.
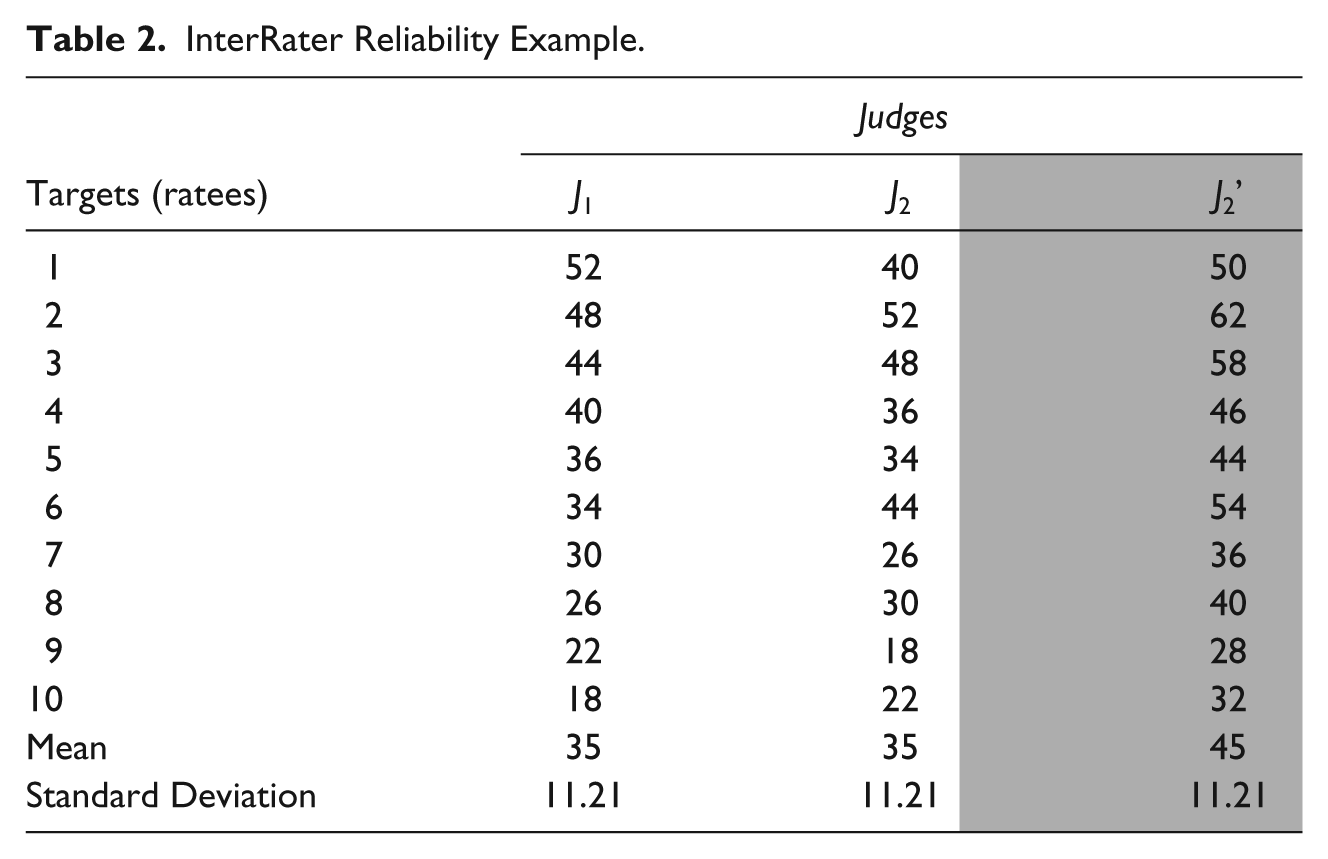
Let’s now assume that the rating from the second judge were really J2’ (the shaded column). Notice that J2’ = J2 + 1. In this situation, it is obvious that the individuals have the same relative positions on J2 and J2’, but they have higher scores on J2’ than on J2. Classical reliability coefficient only quantifies the consistency of relative standings but not the consistency of actual ratings. As a result, the score difference between J2 and J2’ is ignored in classical reliability; the interrater reliability coefficient between J1 and J2’ is the same (
Criterion-Referenced Score Interpretation
In some situations, we are not only concerned about the consistency of relative standings of the individuals (norm-referenced interpretation) but also about the consistency of actual scores (e.g., across testing occasions, across two parallel forms, or across two different raters/observers). In criterion-referenced 1 score interpretation, the measurement interest is not only in the consistency of relative standings but also in the consistency of actual scores. For example, if we are interested in understanding the reliability of the Beck Depression Inventory (BDI) as applied to an adolescent population, it would be grossly insufficient to report only interrater reliability in the form of Pearson correlation coefficient across two raters (norm-referenced reliability). It is crucial that another form of reliability estimate is available that will inform us about the consistency of actual scores across the two raters (criterion-referenced reliability), because the clinical diagnosis of depression depends on the actual score (rating) on BDI. To quantify measurement consistency of both relative standings and actual ratings, we need something different from the Pearson correlation that represents the conventional interrater reliability.
Intraclass Correlation Coefficient (ICC)
Intraclass correlations are rarely discussed in a typical measurement book. For example, a quick look at several measurement books (Crocker & Algina, 1986; Gulliksen, 1987; McDonald, 1999; Traub, 1994) showed that this topic was not covered in any of these books. In adolescence research literature, intraclass correlation coefficient (ICC) has been used widely (e.g., Cicchetti, 1994; Maisto et al., 2011; Brown, West, Loverich, & Biegel, 2011; Valen et al., 2011) although the exact meaning of ICC as used in many research articles in adolescent literature may not always be sufficiently clear. In general, unlike the Pearson correlation coefficient (interrater, test-retest, and parallel form reliability estimates), ICC takes into account both the consistency of relative standings and the consistency of actual scores. ICC relies on the analysis of variance (ANOVA) model to partition score variance into different components. Historically, there has been considerable discussion in the literature on the use of ICCs (e.g., Algina, 1978; Bartko, 1966, 1976, 1978a, 1978b; McGraw & Wong, 1996; Shrout & Fleiss, 1979). Shrout and Fleiss (1979) provided the procedural details for three “Cases” of ICC:
Case 1: ICC(1, 1) or ICC(1, J): Each target is rated by a different set of judges, randomly selected from a larger population of judges;
Case 2: ICC(2, 1) or ICC(2, J): A random sample of J judges is selected from a larger population of judges, and each judge rates all the n targets;
Case 3: ICC(3, 1) or ICC(3, J): Each target is rated by each of the J judges, and these judges are the only judges of interest (i.e., not a sample of judges).
Under each ICC case, the score for each ratee may be represented by a single judge’s rating, or by the average rating of J judges. Statistically, it is well known that the mean score based on J judges is more reliable than the score from a single judge. So reliability may be estimated for the rating of a single judge, ICC(Case #, 1), or for the average scores, each based on J judge, ICC( Case #, J).
Of the three ICC cases discussed in Shrout and Fleiss (1979), Case 2 is the most widely known and used. Case 2 represents a crossed two-way design, with targets crossed with judges, and both factors (“target” and “judge”) are random. For Table 2 data, let’s assume that we have two judges (J1 and J2) rating 10 adolescents. Let’s further assume that J2’ is J2 transformed (J2’ = J2 + 10). If we are concerned about both the consistency of relative standings and the consistency of actual ratings from the two judges, we will use an ICC as the reliability coefficient, rather than interrater reliability in the form of a Pearson correlation coefficient.
For Case 2 (two-way crossed design), the ANOVA model 2 contains both “target” (T) and “judge” (J) as the factors. The interaction term between “target” and “judge” (T*J), however, is confounded with error (e) due to insufficient degrees of freedom for separate estimates. Once the score variance is partitioned into different sources through the ANOVA model, the reliability for a single judge’s rating can be computed by the intraclass correlation for Case 2: ICC(2, 1):

where, BMS is the mean square for the targets being rated, EMS is the error (residual) mean square, JMS is the mean square for judges, n is the number of targets, and J is the number of judges. On the other hand, the reliability for the mean scores based on J judges, ICC(2, J), can be obtained from
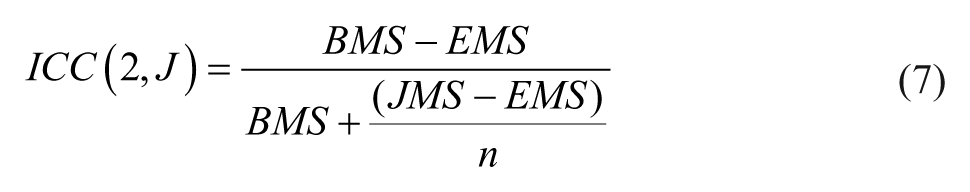
For Table 2 data, two-way ANOVA provides the needed mean squares for each hypothetical pair of ratings, as shown in Table 3.
Analysis of Variance Results for Data in Table 2.

We can compute ICCs for each hypothetical pair of ratings in Table 2:
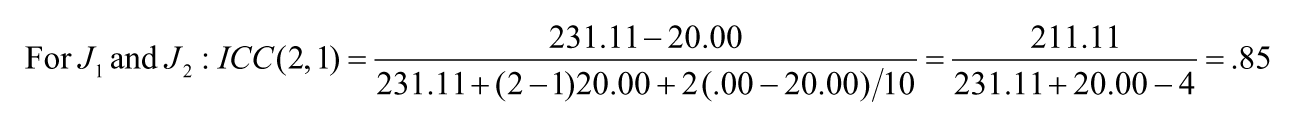
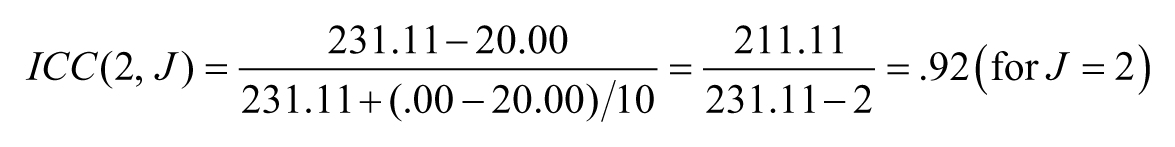
Similarly, we can obtain ICCs for the other hypothetical pairs of ratings:
For J2 and J2’: ICC(2, 1) = .72
ICC(2, J) = .83, (for J = 2)
For J1 and J2’ : ICC(2, 1) = .61
ICC(2, J) = .76, (for J = 2)
For Table 2 data, the previously computed interrater reliability estimates (Pearson correlations) and the ICCs obtained above are presented in Table 4 for easy comparison. It is shown that, because J1 and J2 have the same means, that is, as a group, there is no score change, the ICC(2,1) captures inconsistency in relative standings only; consequently, ICC(2,1) is equivalent to the interrater reliability estimate (Pearson r of .84). Between J2 and J2’, however, the relative standings of the ratees are exactly the same across the two ratings; as a result, Pearson correlation coefficient is 1.00, indicating perfect reliability. But because there is rating score change (10 points difference between J2’ and J2), the inconsistency of actual rating scores is captured by ICC(2,1) = .72, numerically much lower than interrater reliability of 1.0. Between J1 and J2’, there is inconsistency across the two ratings both in the relative standings and in the actual ratings (means of 35 and 45, respectively). As a result, the ICC for J1 and J2’ pair of ratings should be the lowest among the three hypothetical pairs of ratings (J1 vs. J2, J2 vs. J2’, J1 vs. J2’ ). ICC(2,1) for J1 and J2’ is computed to be .61, considerably lower than the interrater reliability (i.e., Pearson r) of .84.
Interrater Reliability (Pearson r), ICCs and Generalizability Coefficients (for Table 2 Data).
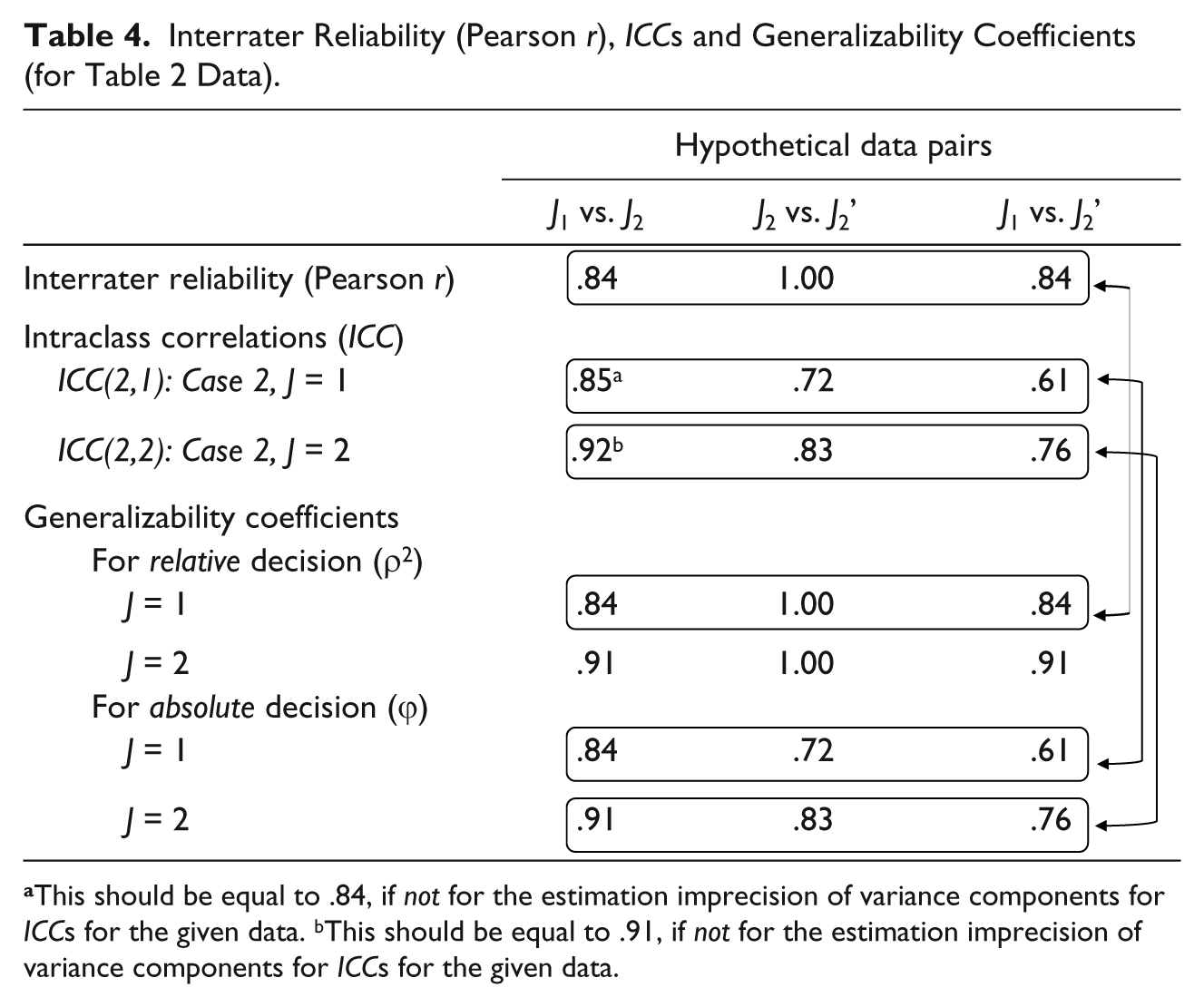
This should be equal to .84, if not for the estimation imprecision of variance components for ICCs for the given data. bThis should be equal to .91, if not for the estimation imprecision of variance components for ICCs for the given data.
ICCs for Cases 1 and 3
Because Case 1 and Case 3 ICCs are very rare in adolescence research practice, we will skip these two in this article. Interested readers may refer to Shrout and Fleiss (1979) for details.
Generalizability Theory
In adolescence research, as well as in other behavioral science disciplines, the treatment of measurement reliability is often fragmented. Researchers may be aware of different forms of reliability coefficients, but it could be difficult to understand how different reliability coefficients are related, and what the similarities/differences are among some of these reliability coefficients (e.g., intraclass correlation coefficient vs. interrater reliability coefficient). Generalizability theory (G-theory) provides a comprehensive and unified framework for measurement reliability. G-theory, although widely understood and applied in some disciplines (e.g., educational research and measurement), is not as well known among adolescence researchers. The first comprehensive treatment on G-theory was presented several decades ago (Cronbach et al., 1972). More recent presentations on G-theory (e.g., Brennan, 2010; Cardinet, Johnson, & Pini, 2009; Shavelson & Webb, 1991) have made the G-theory more accessible for research practitioners.
Partitioning Score Variance Into Variance Components
G-theory relies on the analysis of variance (ANOVA) model to partition the total score variance into variance components of different sources. For Table 1 data presented previously, the model appropriate for the data is a crossed two-way ANOVA design, with Person (P) and Item (I) as the two random factors. In this situation, our measurement interest is in the true differences among the persons (P), and this factor is called the “object of measurement.” Factors other than the “object of measurement” are called “facets,” which are potential sources of measurement error. Thus, for Table 1 data, the Item (I) factor is a “facet.” The data collection design in Table 1 is known as one-facet design.
This two-way random-factor ANOVA model means that, theoretically, there are four sources of variation for the scores: Person effect (p), Item effect (i), Person and Item interaction (pi), and finally, the residual (e). But the interaction (pi) and the residual (e) are confounded due to insufficient degrees of freedom. As a result, the total score variance,
Variance component estimation relies on the theoretical composition (often called “Expected Mean Square”) of the mean squares for each factor. For the data in Table 1, when an ANOVA is run using both Person (P) and Item (I) as random factors, the results are shown in Table 5. This is a conventional two-way ANOVA summary table, except for the additional column of “Expected Mean Square,” and the variance components derived.
Two-Way ANOVA Summary, Expected Mean Square and Variance Components.
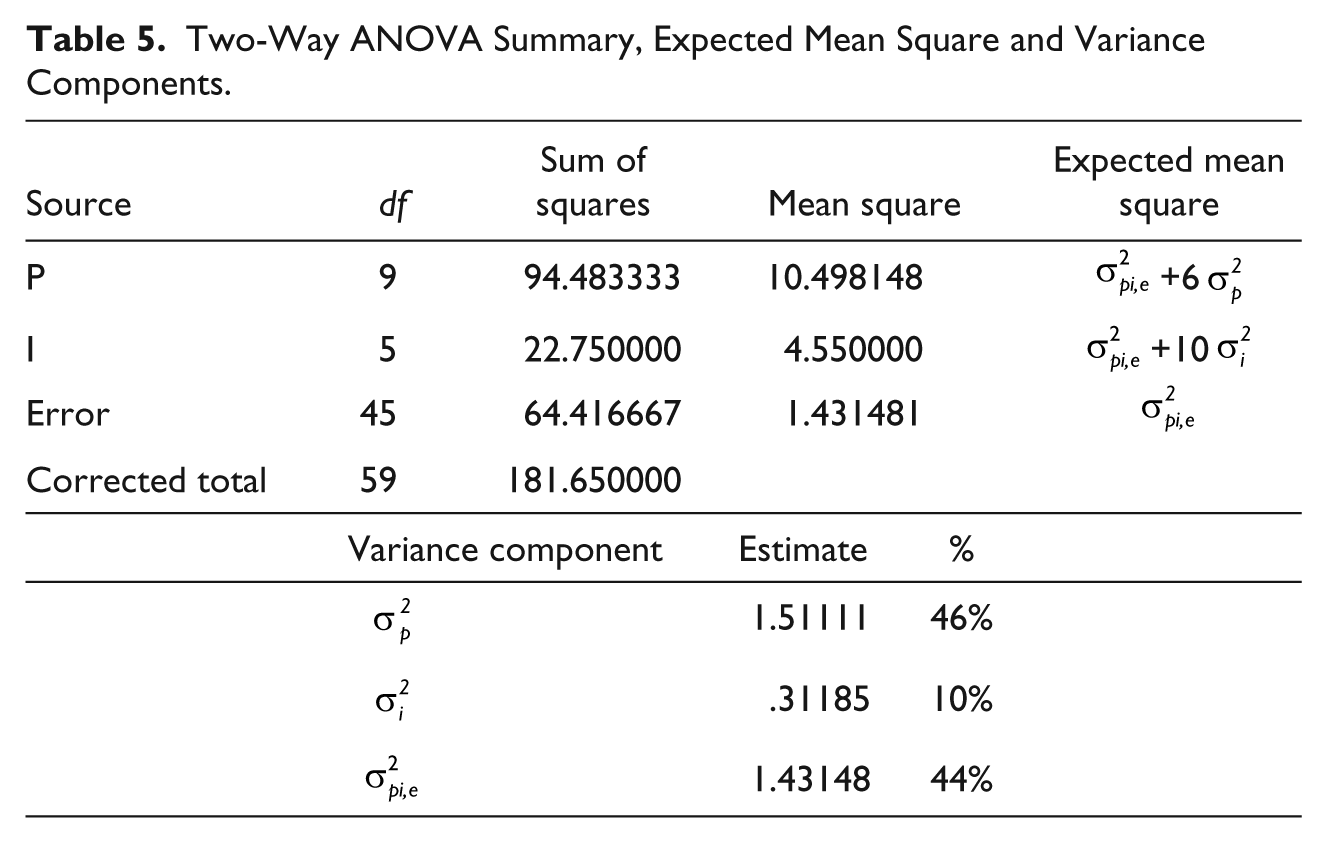
The “Expected Mean Square”
3
shows the theoretical composition of each mean square. For example, the residual mean square (
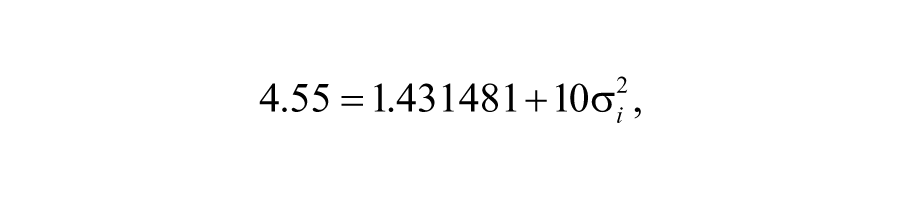
and we can solve

Similarly, the mean square for Factor p is as follows:
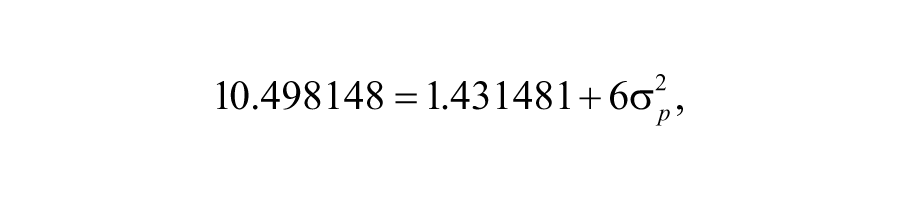
and we can solve for

Because variance components are estimated, the sum of the variance components may be slightly different from the total score variance. Also, there are different approaches for estimating variance components, such as ANOVA approach shown above, or some other method (e.g., maximum likelihood estimation). Statistical software (e.g., SPSS, SAS) provides users with these estimation options.
Similar analyses for variance components for Table 2 data (ratings of 10 adolescent Targets by two Judges)
4
were conducted, and Table 6 presents the results for the three pairs of ratings in Table 2. In Table 6,
Estimated Variance Components for Table 2 Ratings.
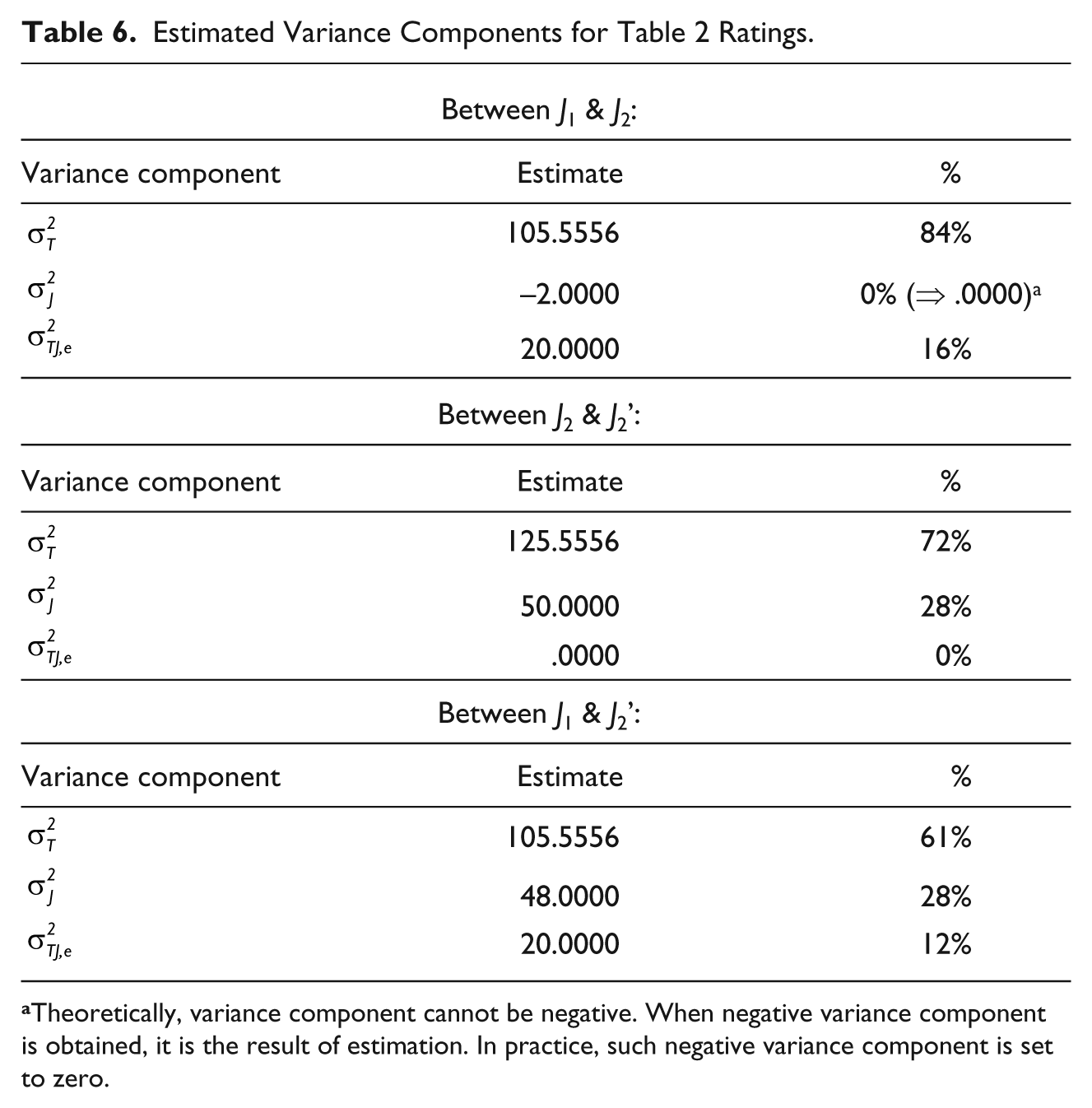
Theoretically, variance component cannot be negative. When negative variance component is obtained, it is the result of estimation. In practice, such negative variance component is set to zero.
Once the variance components are obtained, they will serve as the basis for calculating generalizability coefficients (i.e., reliability coefficients). How the variance components of different sources will be used in a specific study depends on the study design and on the purpose of the measurement interpretation, as discussed in the following sections.
G-Theory Perspectives on Reliability
Relative decision
Classical test theory focuses on norm-referenced score interpretation, that is, using measurement scores to differentiate examinees. As a result, measurement reliability is concerned about the consistency of relative standings of the individuals but not about the consistency of the actual scores. As long as the relative standings of the examinees are consistent, the actual scores do not matter. Within the G-theory framework, this type of interpretation is called “relative decision.”
Absolute decision
Criterion-referenced score interpretation is concerned about both the consistency of the relative standings of the individuals and the consistency of actual scores (i.e., possible score change). This criterion-reference perspective is called “absolute decision” in G-theory.
In a measurement situation, the type of score interpretation (norm- vs. criterion-referenced) determines whether the “relative decision” or “absolute decision” is appropriate. As a result, there are two types of generalizability coefficients: one for “relative decision” reliability and the other for “absolute decision” reliability. The “relative decision” generalizability coefficient is often called ρ2, and the “absolute decision” generalizability coefficient is often called φ (Brennan, 2010; Shavelson & Webb, 1991). The difference between the two types of coefficients is on the sources of variation that would be considered as measurement error.
Meaning of Variance Components
Reliability coefficient can be calculated once we know the true score variance (
For Table 1 data, that is, six items (I) administered to 10 persons (P), we obtained three variance components shown in Table 5 (
For Table 2 data of 10 targets (T) rated by two judges (J), the meanings of the variance components (contained in Table 6) are similar.
Measurement Error and Generalizability Coefficients
Generalizability coefficient for Table 1 data
Once we understand the substantive meanings of the variance components, it is relatively easy to construct appropriate generalizability coefficients for “relative” or “absolute” decisions by applying Equation 3. For Table 1 data, we indicated that the item effect (
We previously computed coefficient alpha for Table 1 data (α = .86). Coefficient α is a reliability estimate for norm-referenced score interpretation; as such, it reflects the consistency of examinees’ relative standings but not the consistency of examinees’ absolute scores. The generalizability coefficient for a “relative” decision is equivalent to coefficient α. If we use Equation 3, and substitute appropriate variance components, we have the following “relative decision” generalizability coefficients for k = 1 (one-item test) and k = 6 (six-item test):
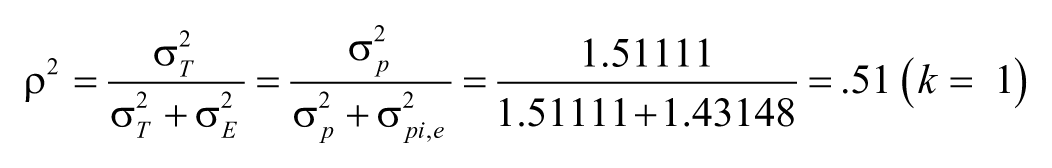

It is noted that for k = 6, the generalizability coefficient is the same as the coefficient α (.86). This is not a coincidence, and it demonstrates that generalizability theory subsumes coefficient alpha. The reason that generalizability (reliability) coefficient for k = 6 is higher (.86) than for k = 1 (.51) is that other things being equal, more items reduce measurement error and produce more reliable measurement.
Generalizability coefficients for Table 2 data
The hypothetical data in Table 2 represent several scenarios. Between J1 and J2, the average ratings from two judges are the same (35), thus there is no Judge (J) effect. But there is inconsistency in the relative standings of the ratees (Targets, T) across the two ratings. Between J2 and J2’, the ratees are perfectly consistent in their relative standings across the two ratings, but their absolute ratings are not consistent, as shown by the 10 points change from J2 to J2’. Between J1 and J2’, however, there is inconsistency both in the relative standings and in the absolute ratings.
If we are only concerned about the consistency of the relative standings of the ratees across the two ratings (J1 vs. J2, J2 vs. J2’, or J1 vs. J2’), the appropriate error term for generalizability coefficients of “relative decision” (ρ2) should be
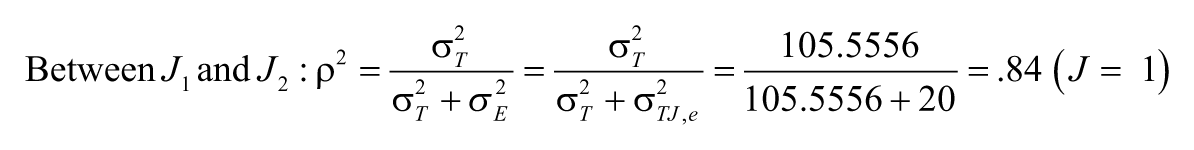

Similarly, we can obtain ρ2 for the other two hypothetical pairs of ratings:
Between J2 and J2’: ρ2 = 1.00 (J = 1); ρ2 = 1.00 (J = 2)
Between J1 and J2’: ρ2 = .84 (J = 1); ρ2 = .91 (J = 2)
These relative G-coefficients are presented in Table 4 for easy comparisons with the interrater reliability coefficients (Pearson r) and ICCs. We note that the relative generalizability coefficients for J = 1 (i.e., reliability for only one judge’s rating) and the interrater reliability coefficients (i.e., Pearson correlation coefficients) are equal. As we discussed before, the Pearson correlation coefficient (r) quantifies the consistency of relative standings; as a result, it is conceptually equivalent to the generalizability coefficient for a relative decision (ρ2). Mathematically, however, Pearson r and ρ2 are only equivalent when the two ratings have the same standard deviations, as is the case in Table 2 data (SD = 11.21). When the two standard deviations are not equal, Pearson r will be higher than ρ2, but the demonstration for this is beyond the scope of this article.
The intraclass correlations in Table 4 are about the consistency of both relative standings and actual ratings, thus they are conceptually equivalent to the generalizability coefficient for absolute decision (φ), and the appropriate error term should be
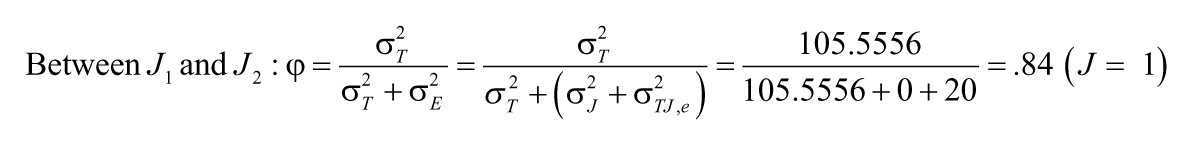
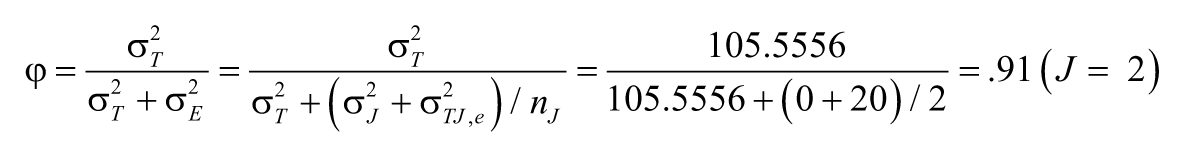
Similarly, we can obtain φ for the other two hypothetical pairs of ratings:
Between J2 and J2’: φ = .72 (J = 1); φ = .83 (J = 2)
Between J1 and J2’: φ = .61 (J = 1); φ = .76 (J = 2)
Equivalence of Generalizability Coefficients and Intraclass Correlations
It was shown above that the absolute decision G-coefficients φ are equivalent to intraclass correlation coefficients (Case 2 ICC). This is because the two types of coefficients are mathematically equivalent. For example, it is easy to show that ICC(2, J) is mathematically equivalent to absolute-decision G-coefficient φ when the mean of J = 2 judges’ ratings is used:
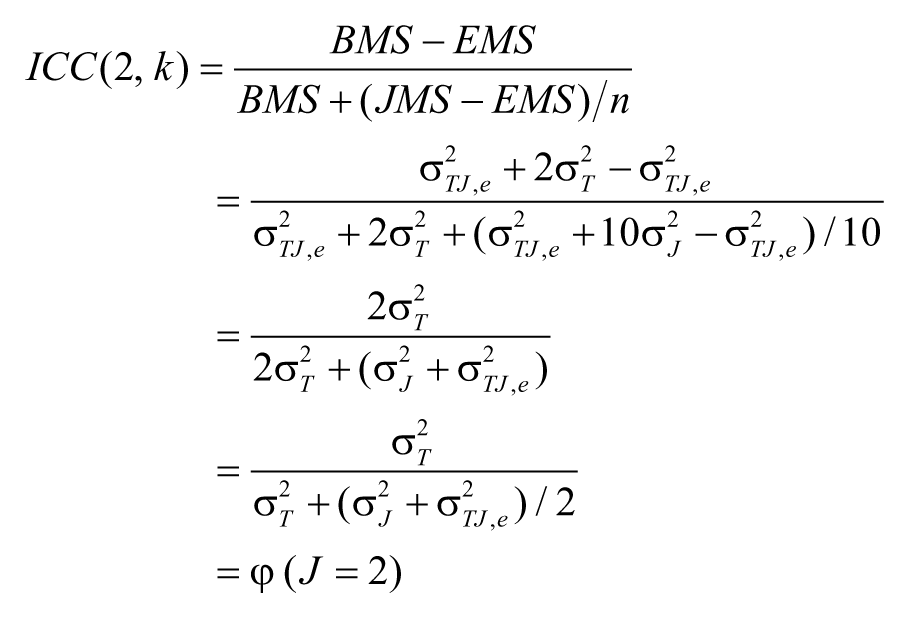
For research methodologists, the equivalence between ICC and generalizability coefficient φ has long been well known. As Shrout and Fleish (1979) discussed, ICC was a special case of the one-facet generalizability study. Although not discussed or presented in this article, it could be shown that other cases of ICC (Case 1 and Case 3) are also special cases of the generalizability coefficients involving nested (Case 1) and fixed (Case 3) factors.
Advantages of Generalizability Theory
The presentation and discussion above have shown that G-theory and its coefficients subsume other types of reliability coefficients, and it provides a unified framework for measurement reliability. It is shown that (a) the G-coefficient (relative decision) is equivalent to coefficient alpha (including KR-20 for dichotomously scored items); (b) G-coefficient (relative decision) is conceptually the same as the reliability coefficients based on Pearson r (i.e., interrater, test-retest, and parallel form reliability coefficients), and it is mathematically equivalent to Pearson r when the two scores to be correlated in Pearson r have equal variances; (c) G-coefficient (absolute decision) is both conceptually and mathematically equivalent to ICCs. However, application of G-theory compels a researcher to make a clear distinction between norm-referenced (relative decision) and criterion-referenced (absolute decision) score interpretations, thus avoiding potential confusion about the appropriateness of some seemingly similar coefficients (e.g., interrater reliability vs. ICC). In addition, G-theory also offers some other important advantages as discussed in the following sections.
Multiple Sources of Measurement Error
Up to now, we have limited our discussion to measurement situations that involve only one “facet” (one measurement error source, other than random measurement error). For example, “item” is the only facet for Table 1 data, and “judge” is the only facet for Table 2 data. Some measurement situations may involve more than one facet, that is, more than one sources of measurement error. Conventional methods for reliability estimation do not work in these situations because conventional reliability methods are all designed for one facet only, thus unable to handle multiple sources of measurement error. G-theory does not have this limitation, and it can easily accommodate multiple measurement error sources (i.e., multiple facets).
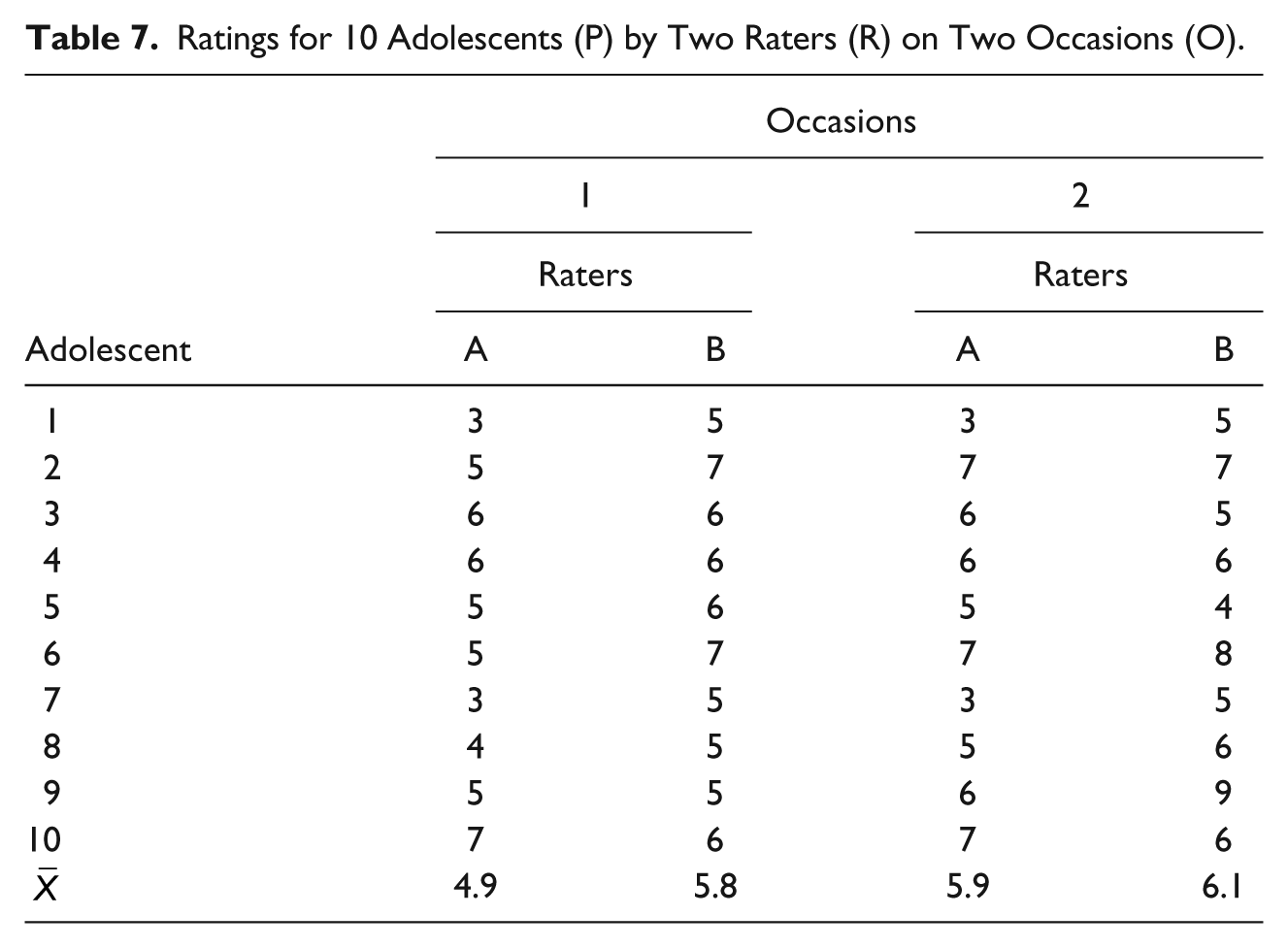
Table 7 presents the data from a hypothetical situation where 10 adolescents (P) are rated by two raters (R) on two occasions (O). In this situation, we are interested in the real differences among the adolescents (P: object of measurement), and both rater (R) and occasion (O) may introduce measurement unreliability, thus both being the facets. In this situation, we may be interested in knowing the reliability of the average ratings across the two raters and across the two occasions. ICC methods do not allow us to estimate such measurement reliability because ICC is not capable of dealing two measurement error sources (i.e., occasion and rater) simultaneously; as a result, this measurement situation is beyond what ICC is designed to do. If we only calculated the ICC for each occasion, we would only be able to capture the measurement error introduced by raters (cf. interrater reliability) but would not be able to capture the measurement error introduced by occasions (cf. test-retest reliability). Using the G-theory, we would capture the errors introduced by both sources (i.e., interrater and test-retest).
Ratings for 10 Adolescents (P) by Two Raters (R) on Two Occasions (O).
G-theory, however, handles this situation easily. Table 8 presents the estimates of the variance components for Table 7 data. Because the measurement involves object of measurement (P) and two facets (O, R), a three-way ANOVA model is called for. In this ANOVA model, there are three main effects (P, O, R), three two-way interactions (P*O, P*R, O*R), and one three-way interaction (P*O*R) confounded with error (e), due to insufficient degrees of freedom. Consequently, there are seven estimable variance components.
Variance Component Estimates for Table 8 Data.
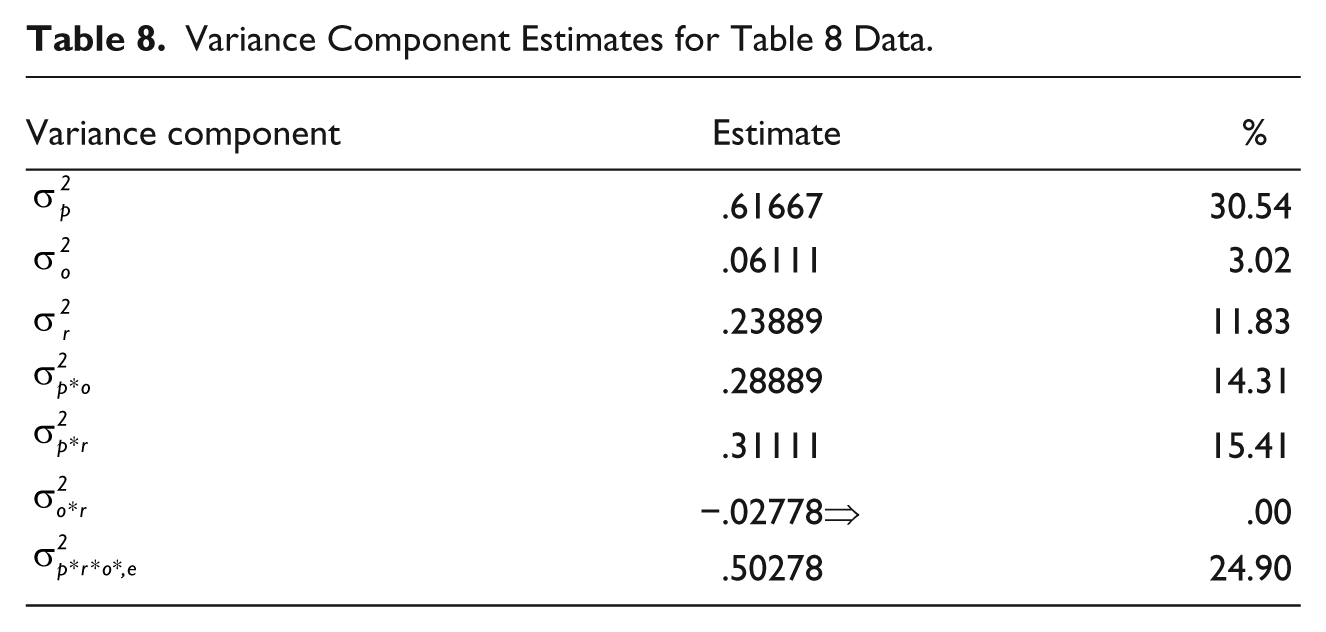
It is noted that the variance component for the object of measurement (
Once these variance components are estimated, it is relatively easy to obtain the generalizability coefficients for Table 7 ratings based on two raters (nr = 2) who provide ratings on two occasions (no = 2) for either relative or absolute decision. As discussed previously, relative decision G-coefficient is appropriate if we are only interested in the consistency of relative positions of the individuals. For relative decision G-coefficient, the error term includes all interaction components involving the object of measurement P:

Absolute decision G-coefficient is appropriate when we are interested in the consistency of both relative positions and actual scores, and the error term includes all the components except the object of measurement P:

The φ coefficient above (φ = .52) is conceptually equivalent to intraclass correlation coefficient. Because ICC is not designed for this more complicated measurement situation, we cannot compute ICC for the data. We note that for the data in Table 7, measurement reliability involving two raters and two occasions appears to be low for both relative and absolute decisions. In a real measurement situation, we would be interested in improving the measurement process and measurement protocol to achieve better measurement reliability.
Improving the Measurement Process
The partitioning of the total score variance into multiple facets provides estimation of the percentage of variance attributable to each facet, and these variance components will help us understand the magnitudes measurement error from different error sources. For example, a relatively large variance component for the facet of Rater may suggest the need for better training for raters to achieve better consistency across raters. Similarly, a systematic interaction between Person and Rater indicates that the rater(s) are not applying consistent rating criteria to different ratees.
Planning for Measurement Reliability in Future Studies
Conventional reliability approaches are typically post hoc, that is, measurement reliability is computed after the fact. 5 G-theory, however, is more proactive in planning for future measurement protocol. G-theory typically has two stages: G-study and D-study. The G-study serves as a “pilot” reliability study that provides information for planning the “real” research study. In the G-study, relevant variance components are estimated. In the D-study, the estimated variance components are used for planning for the measurement protocol of the “real” study so that the desired measurement reliability can be attained in the “real” study.
For example, for the J1 vs. J2’ data pair in Table 2, we previously (see Table 4) calculated Case 2 ICCs to be .61 (for J = 1) and .76 (for J = 2). Let’s assume that this is our “pilot” study (i.e., G-study), and we consider these reliability coefficients low and desire to attain higher measurement reliability in our “real” study. What should we do then?
In this case, we used J (J = 2) judges in our “pilot” study. If we consider ICC(2, J = 2) = .76 unacceptable, we may want to know what measurement reliability will likely to be if we increase the number of judges from two to four in our “real” study so that we may plan for our “real” study accordingly. This phase is called “D-study” in G-theory. D-study can be conducted regardless of norm-referenced or criterion-referenced score interpretation, and regardless of either a single facet (i.e., measurement error source) or multiple facets are involved in the measurement process.
Using the variance components estimated for the data pair J1 vs. J2’ (Table 6), we can “forecast” the measurement reliability in our “real” study if we plan to use the mean of four 6 judges’ rating for each target (person), and this involves the simple substitution of nj = 4 in the equation for G-coefficient for absolute decision as shown below. If we consider φ = .85 satisfactory for our purpose of study, we may plan to conduct our “real” study by using four judges to rate each target (person) and use the mean of the four judges as the rating for each target (person).
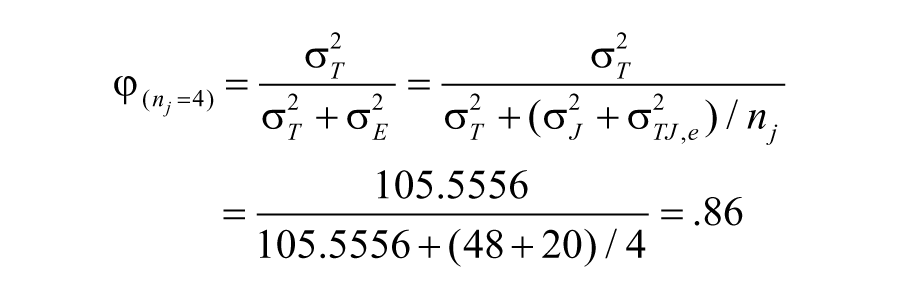
In the same vein, for the two-facet (rater and occasion) measurement data in Table 7, we previously estimated all relevant variance components (Table 8) and calculated G-coefficient for absolute decision for the mean rating based on two raters and two occasions (φ = .52). We may desire to attain higher measurement reliability in our “real” study by either increasing the number of raters, the number of occasions, or both (assuming that practical constraints, such as cost, time, etc., allow us to do so). As an illustration, we may consider a measurement scenario of using four occasions and four raters (n0 = 4, nr = 4):
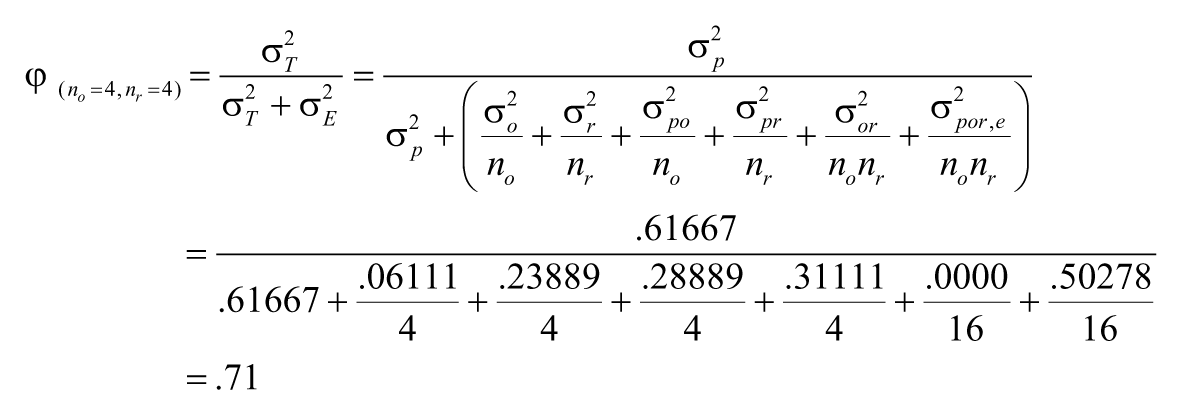
These D-studies for different measurement scenarios allow us to assess the impact of changing measurement conditions on measurement reliability, thus allowing us to design the optimal measurement protocol (considering measurement reliability, cost, time, other practical constraints) for our “real” research study. This aspect of G-theory provides researchers with the flexibility and forecasting capability that are not previously available in conventional reliability approaches.
Conclusions
In this article, we discussed that some adolescence researchers’ understanding of measurement reliability may be fragmented, and it is not always clear how different reliability coefficients are related. We have shown that generalizability theory (G-theory) is a comprehensive framework of measurement reliability, and this framework subsumes all other reliability methods (e.g., reliability coefficients based on Pearson r, coefficient alpha and KR-20, intraclass correlation coefficients). As such, G-theory provides the degree of flexibility and comprehensiveness not offered by the conventional approaches. Within the G-theory framework, the similarities and differences of different reliability coefficients can be easily understood, and planning for optimal measurement protocols becomes feasible. Adolescence researchers may move beyond the fragmented treatment of measurement reliability and consider and use generalizability theory as the general framework for different reliability estimates in their substantive studies.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.