
Abstract
An experiment investigated the effect of tonal language background on discrimination of pitch contour in short spoken and musical items. It was hypothesized that extensive exposure to a tonal language attunes perception of pitch contour. Accuracy and reaction times of adult participants from tonal (Thai) and non-tonal (Australian English) language backgrounds were recorded as they discriminated intact and low-pass filtered Thai and English items that differed in rising/falling contour (speech task), and musical items that differed in rising/falling contour, major/minor interval, and contour plus interval features (music task). As hypothesized, the tonal language group was significantly faster and more accurate at discriminating intact speech items on the basis of pitch contour. The tonal language group was also significantly faster in response to musical contour and intervals, although accuracy was equivalent across language groups. The results provide some support for the contention that a tonal language environment fosters perceptual attunement to contour in spoken items and this can generalize to relatively fast responding to contour in a more musical setting.
Music and speech are auditory forms of communication that draw on common processing resources. Thus, much can be learned about each domain by investigating relations between them. One way to compare music and speech perception is to consider aspects of speech that are analogous to melodic contour in music; that is, the shape of the melody line or pattern of ups and downs in pitch. Results from experiments using recognition tasks indicate that melodic contour is a psychologically valid feature extracted by infants and adults in a broad range of musical contexts (Cupchik, Phillips, & Hill, 2001; Dowling, 1994; Dowling & Fujitani, 1971; Edworthy, 1985; McDermott, Lehr, & Oxenham, 2008; Trehub & Trainor, 1993; Wayland, Herrera, & Kaan, 2010). Various lines of evidence suggest that the processing of contour is distinct from the processing of specific intervals and chords (Deutsch, 1999). The experiment reported here investigates the hypothesis that early exposure to, and acquisition of, a tonal language attunes perception of pitch contour not only in the context of speech in the native language but also in perceiving pitch contour in other languages and in musical items. Specifically, the effect of a tonal language background (Thai), compared with a non-tonal language background (Australian English), is investigated in the context of discriminating pitch contour in short spoken items and musical items.
The prosodic structure of speech consists of the non-segmental or suprasegmental aspects that include vocal tone or pitch (fundamental frequency), stress (a combination of fundamental frequency, amplitude and relative duration), and timing (syllable duration and pause) (Bollinger, 1986; Cutler, Dahan, & van Donselaar, 1997; Handel, 1989). In speech, contour refers to the trajectory of the fundamental frequency over time (de Cheveigné & Kawahara, 2002). Contour in speech marks boundaries, distinguishes categories of utterance (e.g., distinguishing a statement from a question), signals focus, and communicates affect (Cutler et al., 1997).
Linguistic contour specialization in tonal languages
In a tonal language, such as Thai or Vietnamese, differences in pitch contour serve to distinguish word meaning (Clark & Yallop, 1990); the spoken language is characterized by a variety of changes and contrasts in contour. Thus, the pitch contour of the word can change the meaning of the word—not only nuance but also core meaning (Yip, 2002). For example, in Cantonese, the syllable [yau] can be uttered with six different pitch contours and has six different meanings: high level tone—‘worry’; high rising tone—‘paint’; mid level tone—‘thin’; low level tone —‘again’; very low level tone—‘oil’; and low rising tone—‘have’ (Yip, 2002, p.2). Tone consists primarily of variations in the level or contour of the fundamental frequency of syllables (Gandour & Harshman, 1978), helps to distinguish lexical categories (de Cheveigné & Kawahara, 2002). The Thai language has five lexical tones made up of three level tones (low, mid, and high) and two contour tones, rising and falling (Abramson, 1962; Mattock & Burnham, 2006).
Stimuli derived from tonal languages are useful for disentangling contour analysis in the presence of speech versus music. Pitch change or intonation in a non-tonal language occurs most often across relatively large temporal structures such as phrases, sentences, and sometimes within a word. Intonation to produce a question generally involves a pitch change of around one octave (Schön, Magne, & Besson, 2004), and the minimum pitch change that can be detected in spoken communication, according to t’Hart (1981), is approximately three semitones.
It is plausible that perception and production of tones in tonal languages is comparable in some ways with pitch analysis characteristic of music perception (Chen-Hafteck, 1998, 1999; Deutsch, 1991, 1997; Deutsch, Henthorn, & Dolson, 2004; Peretz et al., 2002; Peretz & Hyde, 2003; Schön et al., 2004; Van Lancker, 1980) and, for speakers of a tonal language, that contour is relevant for both spoken and musical stimuli. In domain-general pattern recognition or perceptual attunement terms (Gibson, 1969; McDermott et al., 2008; Pfordresher & Brown, 2009; Stevens & Latimer, 1992, 1997), features of rising and falling pitch are extracted and weighted strongly in both tonal-language speech and musical contexts in which contour serves to differentiate between items that are otherwise similar. By contrast, there will be less sharing of perceptual resources for non-tonal language speakers: extraction of pitch rise/pitch fall features occurs readily in response to musical but relatively less so to spoken stimuli. There are exceptions, as noted earlier, in the perception of large-scale intonation variation across phrases in speech, such as distinguishing semantically identical content when it is expressed as a statement compared with when it is expressed as a question (e.g., Astésano, Besson, & Alter, 2004). However, the present study concerns pitch change over relatively short durations, that occurs across a syllable or the two notes that form a musical interval.
Pitch perception in speech and non-speech by speakers of tonal versus non-tonal languages
Although it is estimated that 60–70% of the world’s languages are tonal languages (Yip, 2002), only recently has there been concerted interest in the relationship between tonal language background and sensitivity to pitch in speech and non-speech material. To scrutinize evidence for and against specialization or modularisation of music and language processes, music and linguistic materials have been used as stimuli presented to speakers of tonal and non-tonal languages. Early studies of hemispheric lateralization supported a modular view; Thai speakers showed a right ear (left hemisphere, language-based) preference for pitch stimuli but only when the contrasting pitches corresponded to linguistic tones. Other pitches or hums elicited a left ear preference (Van Lancker & Fromkin, 1973). Thai speakers showed no ear advantage for the same pitch contrasts in a non-linguistic context (Van Lancker & Fromkin, 1978). More recent positron emission tomography (PET) data are consistent with this picture. In discrimination of pitch patterns in Mandarin words, both Mandarin speakers and English speakers showed common areas of cortical blood flow increase as measured by PET (Klein, Zatorre, Milner, & Zhao, 2001). However, only Mandarin speakers showed additional activation in left hemisphere regions. English speakers showed activity consistent with a right hemisphere role in pitch perception. Taken together, the results imply specialization of pitch processing according to language background.
Extensive studies by Gandour and colleagues have also shown specialized language effects on pitch perception in linguistic contexts. For example, when presented with pitch patterns in Thai words, Thai speakers but not English speakers showed activation of left frontal operculum. Such activation being near to Broca’s region suggested to Gandour, Wong, and Hutchins (1998) that the brain detects linguistic properties of such stimuli rather than more general auditory properties. Xu, Krishnan, and Gandour (2006) concluded that sensitivity to pitch depends on specific dimensions of pitch contours that native speakers are exposed to in speech contexts. Krishnan, Xu, Gandour, and Cariani (2005) argued for neural plasticity at the brainstem induced by language experience that may enhance linguistically relevant features of speech input.
Recent investigations of effects of both linguistic and musical experience point to less of a modular view and more to attunement. For example, Chandrasekaran, Krishnan, and Gandour (2007, 2009) used mismatch negativity (MMN) as a tool to investigate the relative influence of musical and language experience on pitch processing at automatic early preattentive stages of cortical processing. Preattentive processing of pitch contours reflected in MMN is influenced by pitch experience in both language (Chandrasekaran et al., 2007) and music (Chandrasekaran et al., 2009). Additionally, as amateur musicians showed less robust MMN compared with native Mandarin speakers, Chandrasekaran et al. (2009) concluded that domain specificity can influence the degree of modulation of the MMN response.
Pfordresher and Brown (2009) report better imitative production and discrimination of pitch by speakers of tonal languages compared with speakers of English. They conclude that language acquisition refines the processing of auditory dimensions in speech and such attunement (Gibson, 1969) can transfer to non-linguistic contexts. The view is similar to that espoused by Patel (2008): rather than sharing representations, music and language share processing resources, especially with respect to the integration of structure in relatively complex music and language tasks.
Also supporting a non-modular view, Wong, Skoe, Russo, Dees, and Kraus (2007) propose that there is domain-general processing at the brainstem for musicians relative to non-musicians in the processing of linguistically relevant pitch contours. Either speech- or music-related experience tunes sensory encoding in the auditory brainstem via the efferent pathway. Brainstem encoding differences are likely best distinguished when spectrally and temporally complex acoustic contours are used. To investigate whether contour analysis is facilitated by tonal language background, it is essential to select speech and music stimuli in which contour serves a functionally similar role. Therefore, in the present experiments, musical items analogous to the spoken items were created in an effort to minimize differences between the functions of contour in the two stimulus domains. Specifically, we employed a direction of pitch change which was associated with referential meaning differences in spoken Thai and which distinguished question from proposition in spoken English.
An approach suited to the comparison of pitch perception in speech and music is that of Bent, Bradlow, and Wright (2006). In a discrimination task, speakers of Mandarin outperformed English-speaking participants on identifying Mandarin tones but did not differ on fine-grained pitch discrimination of simple non-speech sounds (Bent, Bradlow, & Wright, 2006). A contour identification task used sine waves that were flat, rising, or falling in frequency varying from 5 to 10 Hz, with durations of 400 ms.
We developed similar methods to investigate effects of language background on perception of material that is slightly more musical, reasoning that the use of musical intervals with rising or falling contour may be more engaging for listeners. Additionally, low-pass filtering speech stimuli allows for retention of speech-like and prosodic quality with the necessary control of semantic content. In low-pass filtered speech, the pitch contour is retained, but other linguistic components (e.g., phonological, syntactic, or semantic) are no longer present. While filtered speech is not strictly musical, fewer language-specific processes should be engaged when listening to filtered speech. The presentation of these stimuli acts as an important control when testing contour perception in another domain (music), because the pitch contours in filtered speech are exactly the same as those of the intact speech.
The hypothesis to be investigated is that perceptual attunement developed from exposure to the auditory environment, specifically the lexically contrastive pitch contour features of a tonal language, generalizes to the perception of contour in non-native linguistic events and in musical events. If a tonal language environment fosters the development of general feature extraction processes for pitch contour, then we would expect tonal language speakers to be more sensitive to pitch change than non-tonal language speakers, in response to items from their native language as well as to items from another language (such as English). Furthermore, if this sensitivity to contour is general then a similar advantage for tonal speakers should be obtained with low-pass filtered versions of the stimuli. Similarly, if contour perception is a general process, then speakers with a tonal language background should also be more accurate and respond more quickly to pitch contour manipulations in music relative to speakers with a non-tonal language background. By contrast, if contour analysis is speech-specific, then there would be no effect of tonal language background on discrimination of non-speech items such as musical intervals, and if the advantage for tonal language speakers is one of finer frequency discrimination, then difference thresholds for frequency will be lower in the tonal language group than difference thresholds obtained from speakers in the non-tonal language group.
The first task examined the effect of tonal language background (tonal, non-tonal) on discriminating contour in linguistic items. Both groups of participants performed a pitch discrimination task with Thai words and with English words (stimulus language) and with low-pass filtered versions of those intact items (stimulus quality). The dependent variables were discrimination accuracy (hit rate minus false alarm rate) and reaction time. The second task investigated the effect of tonal language background on discrimination of pitch change in musical intervals. A third task—frequency discrimination—was used to investigate whether speakers of a tonal language have lower difference thresholds for frequency.
Method
Participants
The sample consisted of 48 female and male adult participants. Twenty-four were native speakers of Thai studying at Chulalongkorn University in Bangkok (11 males and 13 females; M = 23.8 years, SD = 3.9). The remaining 24 participants had English as a first language and were recruited from Psychology 1 at the University of Western Sydney (one male, 23 females; M = 23.8 years, SD = 8.9) and received course credit for participating. All participants had self-reported normal hearing and most had virtually no musical training (Thai group mean years musical training: 1.5 years, SD = 1.7, English group mean: 1.5 years, SD = 2.6); no participants reported having absolute pitch. Tasks were conducted in one session and, to ensure that attention was not drawn to musical pitch, the speech task was always completed first.
Stimuli
Speech task stimuli
Spoken-word stimuli consisted of spoken two-syllable Thai and English items with weak-strong (iambic) stress patterns. Two versions of each English word were elicited from a female native speaker of Australian English, first with rising intonation and then with falling intonation (see Table 1). There were 12 English items (selected from Pitt & Samuel, 1990) and 12 Thai items; the 13th item ‘defect’ was used in practice trials only. The Thai items were matched as closely as possible to the structure of the English words in terms of stress pattern and tonal contour, and were elicited from a female native speaker of Thai. As expected when comparing across natural languages, there was some variability in the pitch change (rising, falling) across items within each language set and across speakers. The fundamental frequency range in the English items was 22.89–34.89 Hz compared with 13.09–49.16 Hz for the Thai words or 2.18–3.22 semitones and 1.14–4.42 semitones, respectively. The mean absolute difference across English items was 2.74 semitones (SD = 0.37) and across Thai items, 2.62 semitones (SD = 1.21).
English and Thai stimulus items spoken with weak–strong stress pattern
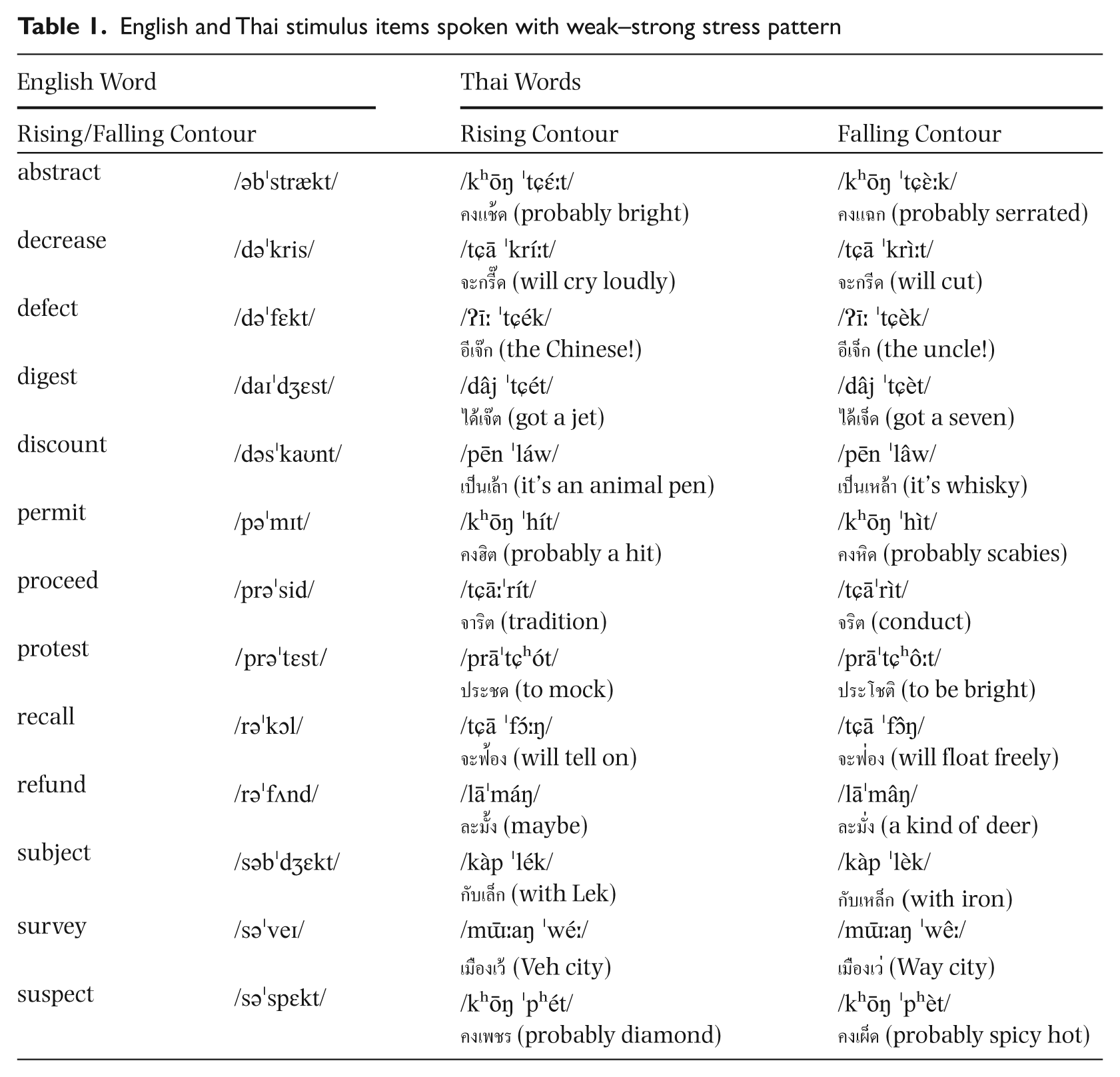
English and Thai items were comparable in overall length (Thai words mean duration = 558 ms, SD = 121 ms, range: 362–735 ms; English words mean duration = 639 ms, SD = 83 ms, range 453–778 ms), and were normalized for intensity. The overall mean duration ratio for English item syllables was 2.84 (SD = 1.19) and for Thai item syllables 2.06 (SD = 1.43). The mean duration ratio was calculated by dividing the duration of syllable 2 by the duration of syllable 1 and shows broad comparability but some variability of the English and Thai items with respect to durational cues. To eliminate the semantic content of the words but retain their speech-like quality, low-pass filtering the word stimuli at 400 Hz created a second set of items. Low-pass filtering removed the upper formants while leaving fundamental frequency intact.
Individual trials consisted of pairs of word items where the same word, intact or low-pass filtered, was paired with the same word and same intonation (rise–rise or fall–fall—same trial) or with the same word with different intonation (e.g., rise–fall or fall–rise—different trial). There were equal numbers of same and different trials, and each item appeared in the first and second position in each pair. This combination of same and different trials (2), pair position (2), item quality (2), and item (12), yielded 96 Thai intact trials, 96 Thai filtered trials, 96 English intact trials, and 96 English filtered trials. The inter-stimulus interval (ISI) within item pairs was 500 ms and 3 s between pairs.
Musical task stimuli
Music stimuli consisted of descending and ascending major and minor third musical intervals. An interval of a third (3rd) was chosen as it was similar in magnitude to the variation in pitch in the rising and falling contours of the spoken items used as stimuli in the word task while also constituting a recognizable musical event. To emulate the iambically stressed spoken items, the musical intervals were played with a weak–strong pattern with the first note of the interval lasting for 200 ms and the second note lasting for 400 ms (eighth note—quarter note pattern). Like the spoken items, the musical intervals consisted of a complex waveform, in this case a sawtooth. Ascending intervals began on G4 (392 Hz) and descending intervals ended on G4. There were 12 ’same’ and 12 ‘different’ interval combinations. The 12 different trials consisted of four trials wherein the contour or direction of the interval differed (e.g., ascending major 3rd paired with descending major 3rd); four trials in which both contour and interval differed (e.g., ascending major 3rd paired with descending minor 3rd); and four trials in which only the interval differed (e.g., ascending major 3rd paired with ascending minor 3rd). Four practice trials consisting of major and minor 3rds from D4 (293.66 Hz) preceded the experimental trials.
Frequency discrimination task stimuli
Tones 400 ms in length were generated as sine waves sampled at 22 kHz, 8-bit resolution. The tones ranged from 392 Hz (G4) to 416 Hz (~ G#4) and were separated by steps of 2 Hz yielding 13 different tones. All tones were paired with the lowest tone in both a rising and falling combination, for example, 392 Hz–394 Hz and 394 Hz–392 Hz. A gap of 100 ms separated presentation of the two 400 ms tones. Sound level was 50 dB SPL.
Equipment
Speech stimuli were recorded digitally using a Tascam DA-20 MKII DAT recorder through a RØDE NT2 microphone. The fundamental frequency and length of each speech item were checked and items normalized for loudness using Macromedia SoundEdit 16. Speech items were low-pass filtered at 400 Hz using the Butterworth filter in Matlab (The MathWorks, Inc). Auditory stimuli and written instructions were sequenced and presented using SuperLab 1.74 (Haxby, Parasuraman, Lalonde, & Abboud, 1993), and presented in both Sydney and Bangkok on a Macintosh Powerbook G3 with external keyboard, mouse, and AKG K270S stereo headphones. The digit keys 0 and 1 on the keyboard’s numeric pad were used to indicate ‘same’ and ‘different’ responses.
Procedure
Written informed consent was obtained. Word stimuli were presented in four blocks of 96 trials each: Thai-intact, Thai-filtered, English-intact, and English-filtered. The presentation order of blocks was counterbalanced across participants, and there was a new random order of trials within blocks for each participant. Participants were instructed to attend to the acoustic properties of the items and judge whether items in a pair were exactly the same or different. They could respond at any time after the onset of the second item in a pair. Each block was preceded by practice trials to familiarize participants with the task and the nature of the stimuli.
In the music task, pairs of musical intervals were presented in a different random order for each participant. Participants were asked to listen to each pair and decide whether the pairs were exactly the same or different. There were 24 trials, 12 in which ‘same’ was the correct response and 12 in which ‘different’ was the correct response. There was a 1 s ISI within interval pairs and between trials.
In the frequency discrimination task, participants were presented with a pair of sine tones and asked to decide as quickly and as accurately as possible whether the tones were the same or different. Trials were presented in a new random order for each participant. There were 30 trials in total, 24 consisting of pairs of frequencies that differed, and six trials where the pairs of frequencies were the same (to maintain vigilance). There was a 3 s pause between trials in which time participants made their response. The experiment took 60 minutes.
Results
Speech task
Three-way mixed analyses of variance (language background (2) x stimulus quality (2) x stimulus language (2)) were conducted separately for reaction time (RT) and accuracy with alpha set at .05. Reaction time was measured from the onset of the second item in each trial and analyses were based on times recorded for correct responses only. Outlying item scores +/– 3.29 z units from mean accuracy and reaction time scores were discarded (Tabachnick & Fidell, 2001); there were no missing cells in the analyses. Accuracy was computed as a discrimination index consisting of hit rate minus false alarm rate. Hit rate referred to the number of correct ‘different’ responses to pairs of items that were different, divided by the number of different trials; false alarm rate referred to the number of incorrect ‘different’ responses when, in fact, the items were the same, divided by the number of same trials. The maximum score attainable was + 1 and a score of 0 reflected chance level responding.
Mean reaction time (RT) results are shown in Figure 1 as a function of stimulus language, language background, and stimulus quality. There was a main effect of language background with the tonal language background group (M = 603.08, SD = 182.33) significantly faster than the non-tonal language group (M = 917.72, SD = 729.05), F(1,46) = 7.17, p < .05, Cohen’s d = 0.59. There was a main effect of stimulus quality, F(1,46) = 5.81, p < .05, Cohen’s d = 0.45, with significantly faster RTs recorded in response to filtered stimuli (M = 646.75, SD = 238.76) than intact (M = 874.05, SD = 672.63) stimuli. There was also a main effect of stimulus language, F(1,46) = 8.77, p < .05, Cohen’s d = 0.56, with significantly faster RTs recorded in response to English (M = 624.21, SD = 310.42) than Thai (M = 896.59, SD = 600.97) items. There was a significant interaction between language background and stimulus quality, F(1,46) = 6.11, p < .05, with faster responding by tonal language speakers which was more pronounced in response to intact than filtered items. The stimulus language x stimulus quality interaction was significant, F(1,46) = 4.27, p < .05; descriptively, responding was faster to filtered than intact items with a greater effect of stimulus quality when the stimulus language was Thai than when it was English. The language background x stimulus language x stimulus quality interaction approached significance, F(1,46) = 3.85, p = .056; descriptively, the tonal language background group is faster overall and especially on English items that are intact.
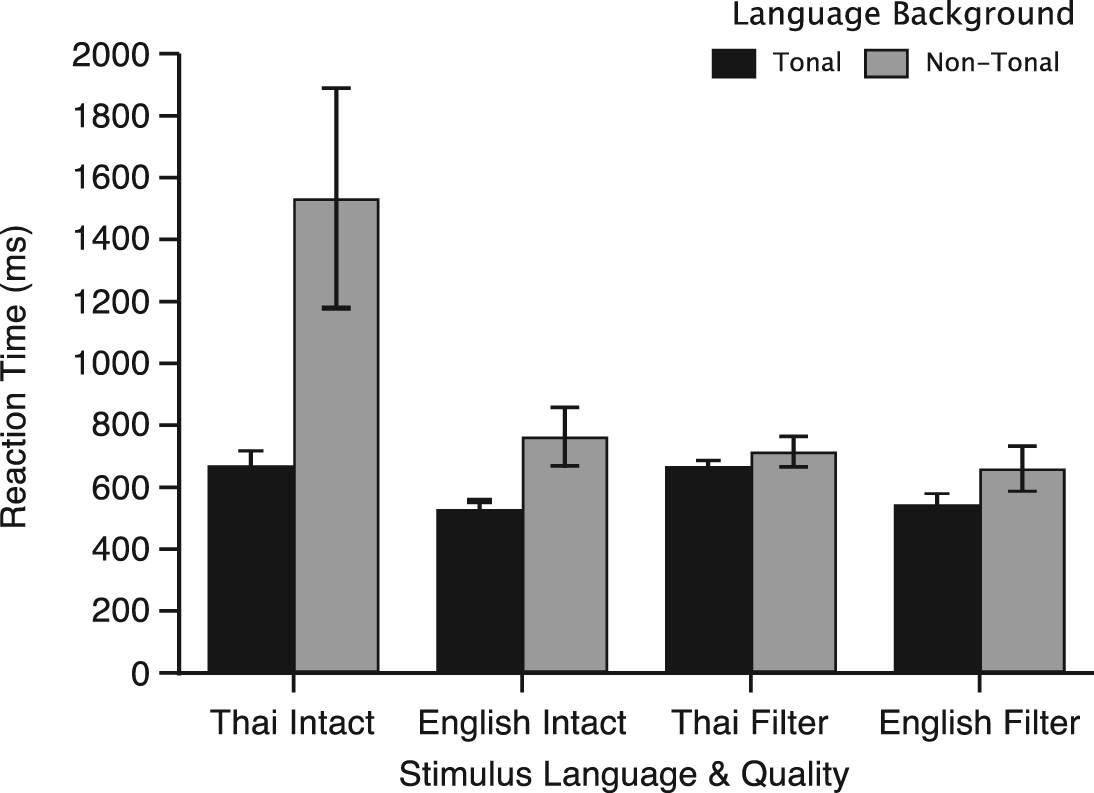
Speech task mean reaction time (in ms) as a function of language background, stimulus language, and stimulus quality. Errors bars refer to standard error of the mean.
With respect to accuracy (Figure 2), there was a significant main effect of language background, F(1,46) = 29.98, p < .05, Cohen’s d = 1.3, with the tonal language background group recording higher accuracy than the non-tonal group, M = .96, SD = .06 and M = .72, SD = .25, respectively. Both language background groups performed significantly above the chance level (tonal: t (23) = 72.21, p < .05, d = 2.66; non-tonal: t (23) = 5.04, p < .05, d = 0.52). There was a significant effect of stimulus language, F(1,46) = 8.59, p < .05, Cohen’s d = 0.38, with significantly greater accuracy recorded in response to Thai (M = .87, SD = .13) compared with English (M = .81, SD = .18) items. There was no significant interaction between language background and stimulus quality; above-chance performance on accuracy was maintained for both groups with Thai (tonal: t (23) = 43.19, p < .05, d = 2.02; non-tonal: t (23) = 7.22, p < .05, d = 0.65) and English items (tonal: t (23) = 45.76, p < .05, d = 2.08; non-tonal: t (23) = 2.39, p < .05, d = 0.27). There were no other significant main effects or interactions.
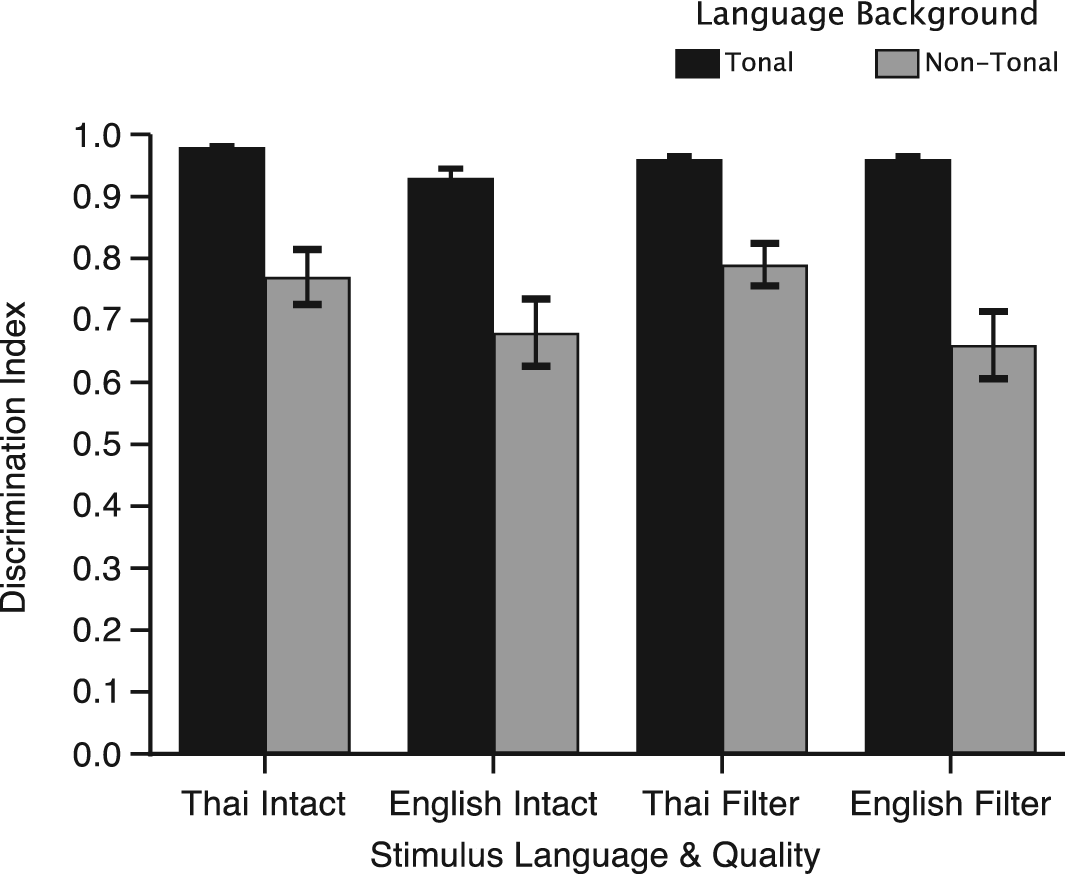
Speech task mean discrimination index (HR-FAR) as a function of language background, stimulus language, and stimulus quality. Errors bars refer to standard error of the mean.
In the speech task items paired in a ‘same’ trial were identical samples. It is possible that the use of identical items led to a ceiling effect, evident in the tonal language participant condition. A second version was conducted to investigate whether listeners are able to recognize similarities in contour when presented as different recorded versions (tokens) of the same items from the original speech task. Similar results and significant effects were obtained in the presence of a token-based discrimination paradigm.
Musical task
Two-way mixed analyses of variance (language background (2) x pitch change (3)) were conducted separately for RT and accuracy data. RT was recorded from the onset of the second interval item in each trial and analyses refer to trials that attracted correct responses only. Accuracy was calculated as a discrimination index consisting of hit rate minus false alarm rate.
Mean RTs for musical stimuli are shown in Figure 3. There was a main effect of language background with tonal language speakers responding significantly faster than non-tonal language speakers to pitch change in all music items, F(1,46) = 5.56, p < .05, Cohen’s d = 0.7, M = 532.32, SD = 294.52 and M = 770.45, SD = 430.08, respectively. There was no other significant main effect or interaction for RT.
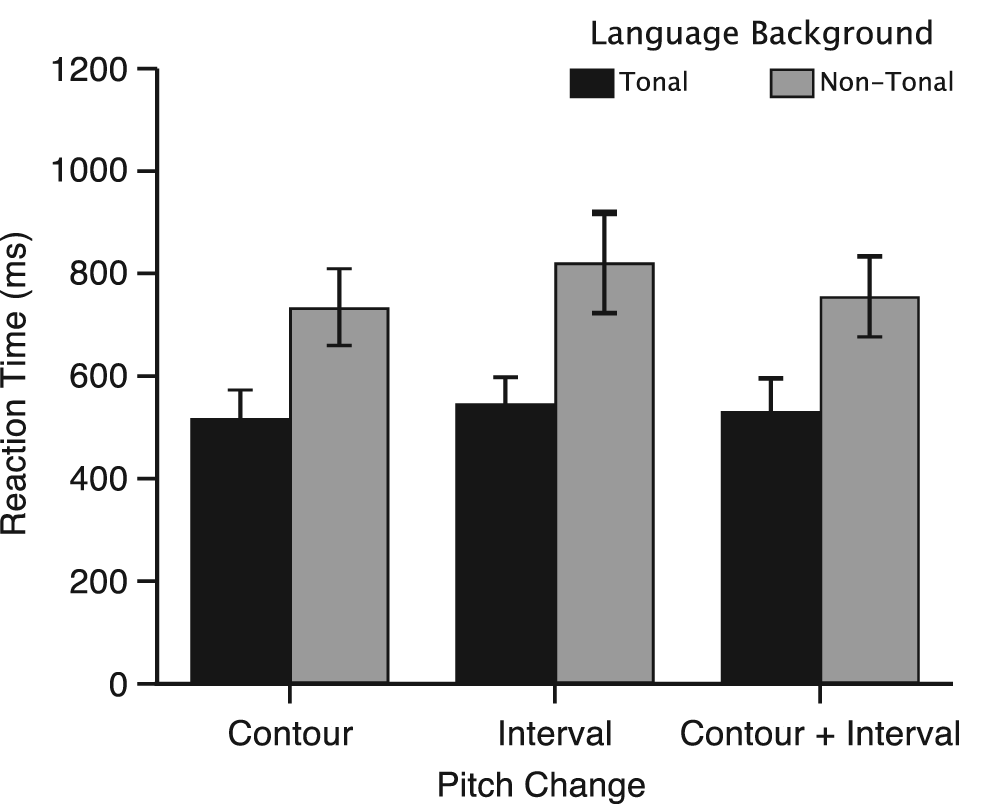
Music task mean reaction time (in ms) as a function of language background and pitch change. Errors bars refer to standard error of the mean.
There was no main effect of language background with respect to accuracy: tonal group M = .91, SD = .09, non-tonal group M = .89, SD = .11. Above-chance performance was obtained across each pitch change type for the tonal group (contour: t (23) = 42.33, p < .05, d = 2.05; interval size: t (23) = 10.78, p < .05, d = 0.79; contour + interval size: t (23) = 24.20, p < .05, d = 1.51) and for the non-tonal group (contour: t (23) = 9.43, p < .05, d = 0.88; interval size: t (23) = 5.78, p < .05, d = 0.76; contour + interval size: t (23) = 9.94, p < .05, d = 0.93). There was a main effect of pitch change: contour M = .96, SD = .08; interval M = .79, SD = .14; contour + interval M = .96, SD = .09, F(1,46) = 47.19, p < .05, with poorest accuracy recorded in response to interval. There was no significant interaction.
Musical intervals of a major and minor third are characteristic of Western tonal music and they convey information about whether a musical piece is in a major or minor mode. Thai classical music is influenced by the tuning of Thai indigenous instruments and contains seven equally spaced tones per octave (Sethares, 2005). In order to investigate enhanced discrimination of whole tone intervals by tonal language speakers and/or poorer discrimination by non-tonal language participants, a second version of the music task was devised. The procedure was identical to the original music task and the pattern of results unchanged.
Frequency discrimination task
A general index of difference threshold was calculated based on the point at which two correct (‘different’) responses were given to a frequency difference. Only trials with a difference between frequencies were scored. The minimum possible difference (and therefore lowest threshold) was 2 Hz and the maximum possible difference was 24 Hz. An independent samples t-test revealed no significant difference between the minimum difference discernible by tonal language participants (M = 11.08 Hz, SD = 6.08) and non-tonal language participants (M = 13.4 Hz, SD = 6.96).
Discussion
The results of the speech task support the hypothesis that experience acquiring a tonal language facilitates extraction and discrimination of pitch contours conveyed through spoken language. Specifically, those from a tonal language background recognized pitch change in spoken items more quickly and accurately than those from a non-tonal language background, regardless of whether the items were spoken in their native Thai or in English. The tonal language advantage can also be seen in the standard errors of the mean for both RT and accuracy. Tonal language speakers were not only faster and more accurate at responding, but there was less variation in responding. The high level of discrimination in tonal language speakers for intact Thai items could be argued to be due to simple word recognition. Nevertheless, the tonal language group outperformed the non-tonal group even with English words, and still obtained a very high score on the discrimination index (.92), giving support to the hypothesis that contour perception occurs in response to linguistically diverse stimuli. Importantly, speakers from a non-tonal language background performed above chance—they too, when necessary, can extract pitch contour from spoken items. As Berkovits (1980) noted, ‘native and non-native speakers alike can make use of intonation if they explicitly listen for it’ (p. 271).
To test further the notion that contour discrimination is a general process, filtered versions of the same stimuli were presented. While the filtered stimuli were not ‘musical’, they retained the continuous pitch contour of the intact speech items and, given that the phonemic and semantic information had been removed, they were less likely to engage language-specific processes. Again, tonal language participants were more accurate than the non-tonal group for stimuli derived from both Thai and English, but there was no longer an RT advantage. The tonal language group used pitch contour to discriminate items that were explicitly speech and they were able to ignore semantic content. Filtered speech, however, did not elicit an RT advantage for tonal language speakers suggesting that perception of contour in speech is language-bound.
The relatively high accuracy scores obtained by the tonal language group in discriminating contour of intact spoken items can be explained in terms of the nature of pitch variations that occur in their language. Production of lexical tone in tonal language involves subtle contrasts in tone such as rise and fall, and perception of the contrasts likely relies on detection of relative but not absolute changes in frequency (Abramson, 1978; Burnham, 2000; Zatorre, Belin, & Penhune, 2002; but see Deutsch et al., 2004 for results indicating absolute pitch when enunciating words in a familiar tonal language). A future study could transpose intact and filtered speech as a means to elicit differences between language groups in response to relative rather than absolute pitch of spoken items.
A musical task investigated the effect of language background on contour discrimination using musical intervals and pitch contours derived from the speech task stimuli. In the music task, the tonal language group was significantly faster than the non-tonal language group but not more accurate. Notably, RT of the tonal language group did not increase in this non-linguistic task.
Both language groups were significantly more accurate in response to contour (direction) than interval manipulations. One explanation is that discriminating interval size is a more music-specific task with an emphasis in the present experiment on discrimination of major 3rd versus minor 3rd intervals. Tonal language background has relatively little influence on accuracy in the interval discrimination task just as it had relatively little influence on perception of filtered speech items. Pfordresher and Brown (2009), by contrast, report an effect of tonal language background on interval discrimination. The present experiment differs in that intervals of a major 3rd and minor 3rd were used based on approximations to pitch change in the spoken items of Experiment 1. Pfordresher and Brown’s stimuli covered a wider range of frequency differences with a standard (comparison) interval of a perfect 5th (C5 and G5). Pairs of intervals were generated from a sine wave whereas in the present experiment a complex wave was used in keeping with the spectral complexity of speech stimuli. Differences in our results then may be related to variations in the musical stimuli. Another possible explanation can be gleaned from the conclusion of Chandrasekaran et al. (2009) that experience-dependent effects in response to contour are domain-general but that differences in long-term experience in pitch perception between domains such as speech versus music may lead to gradations in cortical response to pitch contour.
The faster responding of tonal language speakers to detecting contour in the speech and music tasks could be the result of a lower threshold for detecting frequency change which, in turn, is the result of exposure and experience with subtle changes to tone in their first language. However, this possibility can be ruled out as the estimate of difference thresholds revealed no significant difference between language groups. The frequency discrimination task was an important addition to the present suite of tasks because, unlike musical intervals, changes in utterance frequency are not mean-tempered. The frequency discrimination task therefore illuminates the effect of tonal versus non-tonal language background on perception of non mean-tempered intervals in a microtonal range.
There may be differences in abilities and/or motivation across the two language samples who were recruited in different countries and institutions. That the frequency discrimination task revealed no difference between groups counters any claim that differences in motivation explain the faster reaction times of the Thai group in the speech and music tasks. Nonetheless, future investigations might follow the lead of Pfordresher and Brown (2009) and match participants on a range of potentially influential variables. Cross-cultural research that draws on diverse participant groups and ideally uses diverse musical materials is overdue but there are logistical and philosophical challenges in selecting appropriate matching and/or control conditions (Huron, 2008; Stevens & Byron, 2009; Stevens, submitted).
Future research could also consider the influence of culture-specific musical tuning systems on perception and production of tone in music and speech contexts. An analysis of the production of tone in singing (e.g., Swangviboonpong, 2003; Tanese-ito, 1988) and subsequent perception, as well as relationships between scale, tuning, and spoken language may redress the often Eurocentric assumptions of cross-cultural studies and shed light on influences of the tonality of the language on music composition. For example, one could analyse pitch structure in the indigenous music and language of Thailand analogous to the analysis of rhythmic pattern applied by Patel and Daniele (2003) to the language and classical instrumental music of England and France. Tone languages can be distinguished between those that have level tones—register tone languages—and those that also have contour tones (Gussenhoven, 2004). If music and language are intimately related, then the register tone or contour tone basis of a tonal language may leave an imprint on the associated traditional music (or vice versa). In the present tasks, stimuli were necessarily controlled to be comparable across speech and music but there is also scope for the introduction of increasingly complex, temporally extended musical contours.
Perceptual attunement, specifically feature extraction and feature weighting, is a likely mechanism that underpins refined contour analysis via learning (Elman, 1990; Gibson, 1969; Pfordresher & Brown, 2009; Stevens & Latimer, 1997; Wayland et al., 2010). The development of language in a tonal environment attunes feature analysis to suprasegmental, tonal contrasts and pitch contour cues. Features that distinguish events from other events in a particular context and/or according to task instructions and user expectations/knowledge are weighted strongly. The present experiment has illustrated the effect of this linguistic experience and its generalization to musical contours that differ in ways resembling pitch contrasts in a tonal language. It should also be the case that extensive musical training refines pitch analysis (Chandrasekaran et al., 2009; Nan, Friederici, Shu, & Luo, 2009) perhaps tuning sensory coding in auditory brainstem (e.g., Patel & Iversen, 2007; Wayland et al., 2010; Wong et al., 2007). Musically trained, non-tonal language participants should perform at a level comparable with tonal language speakers in the present speech task, and the musicians’ well-developed interval analysis processes should ensure that they excel at pitch discrimination in the music task. Using singing to produce musical intervals and contours (e.g., Pfordresher & Brown, 2009) or using sung speech should also produce ambiguous and diagnostic stimuli that will bring into relief differential activity of music processes—contour analysis, tonal encoding, interval analysis—as a function of linguistic or musical experience, instructions, and context.
Footnotes
Acknowledgements
This research was supported by a grant from the Australian Research Council awarded to the first author. The second author assisted in the conduct of this study in his capacity as Research Assistant in MARCS Auditory Laboratories; he is now at the Max Planck Institute for Human Cognitive and Brain Sciences in Leipzig, Germany. We thank Dr Sudaporn Luksaneeyanawin for her advice and assistance in recording the Thai stimuli, Dr Luksaneeyanawin and Professor Denis Burnham for facilitating the cross-institutional testing, Melinda Gallagher and Colin Schoknecht for their assistance, and Roger Dean and Caroline Jones for comments on an earlier draft. Results have been reported at the Japanese Society for Music Perception & Cognition, Spring 2001, 28th Annual Australasian Experimental Psychology Conference 2001, 18th International Congress on Acoustics 2004, and 8th International Conference on Music Perception & Cognition, 2004.
Author biographies
![]() ).
).