
Abstract
Accurate wind speed prediction is of great significance to the stable operation of the power grid when large-scale wind power is connected to the grid. This article proposes a new multi-step wind speed combination prediction model based on gray correlation analysis. First, the gray correlation analysis is performed on wind speed–related attributes, the more relevant attribute factors are selected as the input set of the prediction model, and the regularized extreme learning machine improved by the cuckoo optimization algorithm is used to perform multi-step prediction of wind speed. Then, an error self-tuning model is established to further improve the prediction accuracy. Finally, the measured results of different wind farms and seasons are selected to simulate the prediction effect of the proposed model, and the prediction accuracy and generalization ability of the proposed model are verified through comparative analysis.
Keywords
Introduction
Wind speed prediction of wind farms can improve the dispatching economy of grids with renewable energy sources and the operational safety of wind farms (Liu and Dong, 2016; Pan et al., 2019), but the characteristics of wind speed fluctuation, indirectness, and low energy density will also reduce power systems’ reliability of operation (Yang et al., 2018). Therefore, accurate wind speed prediction becomes more and more important for wind power grid connection and the operation of power systems (Zhang et al., 2018).
Existing wind speed prediction methods include physical methods (Feng et al., 2011,), mathematical methods (Yang et al., 2017), and artificial intelligence methods (Wang et al., 2018; Zhang et al., 2017). At present, most scholars around the world pay more attention to wind speed prediction methods based on artificial intelligence. Among them, the parameter setting of the extreme learning machine (ELM) is simple, the learning ability is strong, the calculation speed is fast, and it is easy to converge (Li and Li, 2016; Ye et al., 2017). But its interlayer weights and offsets are generated randomly, which has a greater impact on the prediction effect. Wang et al. (2015b) used the cuckoo optimization algorithm (COA) to optimize the parameters of the support vector machine (SVM). The results show that COA can effectively improve the accuracy of the prediction model. Xiang et al. (2019) analyzed a variety of wind speed hybrid prediction models and found that the ELM can obtain better prediction results in both single-step and multi-step prediction. Zhu et al. (2017) improved the accuracy of the ultra-short-term wind power prediction model by analyzing the correlation between various attribute factors and wind power and taking attribute factors as one of the considerations for wind power modeling. In Yang et al. (2017), the relationship between wind speed and power was analyzed using gray relational decision-making, and a wind power prediction model was established using the gray relational relationship and the wind speed–power curve.
This article proposes a new wind speed prediction model based on gray relational analysis (GRA) and an improved regularized extreme learning machine (RELM). Based on the gray correlation theory, the correlation between various attribute factors and wind speed are calculated. In order to reduce the complexity of the model, the multi-attribute time series is selected to reduce the input data. The COA was used to optimize the parameters of RELM in order to construct a combined wind speed prediction model. The obtained prediction results are corrected through error self-tuning mode to reduce prediction errors and obtain more accurate prediction results. Finally, the prediction results are compared with the actual wind farm data to verify the effectiveness of the proposed model.
Attribute optimization based on gray correlation analysis
GRA
Gray system analysis judges the correlation by determining the geometric similarity between the reference data column and the comparative data column (Zhang et al., 2011). The wind speed reference sequence is

where s0(t) represents the measured wind speed value at time t in the reference sequence and n is the total number of time points.
The comparison sequence Sij is

The specific steps are as follows:
1. Initialize each sequence

2. Find the absolute value sequence of the difference between the reference sequence and the initial value of the comparison sequence as

3. Calculate the correlation coefficient to characterize the correlation between two groups of sequences

where
Define the time series correlation coefficient to characterize its correlation degree

Through the above steps, the wind speed sequence and the attribute sequence data are quantified and analyzed to obtain the characteristic coefficient of the target S0.
Analysis of related attribute selection
Taking the measured data and related meteorological data of a wind farm in the Northeast as an example to conduct the correlation analysis, the typical monthly original wind speed sequence for each quarter is shown in Figure 1.
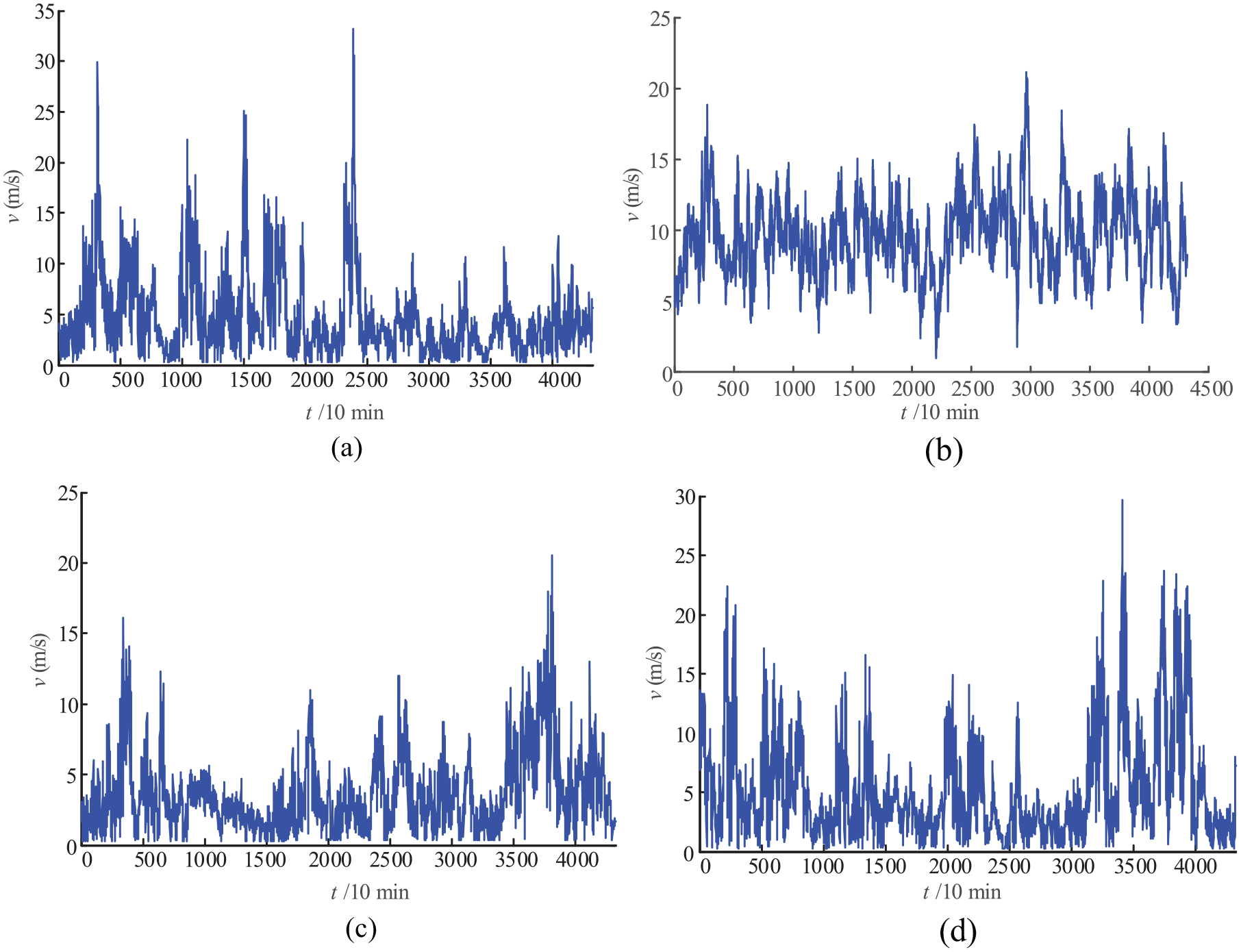
Original wind speed sequence of the northeast wind farm: (a) typical spring month—April; (b) typical summer month—July; (c) typical autumn month—October; and (d) typical winter month—November.
It can be seen from Figure 1 that winter has the most severe fluctuations and the wind speed difference is large at different times. However, the fluctuation of wind speed in spring is more regular, which increases or decreases periodically. The changes of wind speed in summer and autumn are similar and the fluctuation is relatively flat. Because wind power is generated by wind speed, there is a certain similarity between the fluctuations of the two. In this article, wind power fluctuations in different seasons are selected as an attribute factor to train the prediction model.
There are many attributes related to wind speed, including wind power (seasonal wind power fluctuations), wind direction, temperature, standard deviation of air pressure, and air density (Wang et al., 2015a). It has been confirmed that there are obvious deficiencies in predicting future values based on historical wind speed information alone. And the model’s ability to learn random fluctuations in wind speed is poor. Therefore, this article selects the above five attribute factors for the analysis and reasonably selects the input variables of the model. The correlation analysis of each time series is performed according to the gray correlation theory, and the results are shown in Table 1.
Results of the correlation of various attribute factors.

As can be seen from Table 1, the correlation between the wind speed sequence and the wind power sequence is the highest, reaching 0.9513. The correlation degree with air density is the second highest, and the correlation coefficient is 0.5781. In addition, the correlation degree between wind speed and wind direction as well as wind speed and temperature is low, and the correlation coefficients are 0.2945 and −0.1591, respectively. Due to the special monsoon climate in the Northeast, when the temperature is high in summer, the wind speed is usually smaller than that that in spring and autumn, so it shows a negative correlation with temperature.
Attribute optimization based on the improved RELM combination prediction model
RELM

where G is the activation function,
In order to improve the prediction accuracy of the ELM network, a regularization coefficient is introduced to minimize the structural risk.
1. Establish the objective function

where η is the regularization coefficient, ||ξ||2 is the empirical risk, ||
2. Constructing Lagrange’s equation

where α is a Lagrangian multiplier.
3. Calculate the output weight matrix

where
4. Substituting equation (10) into equation (7), a mathematical model of wind speed prediction based on RELM can be obtained

COA
The input-hidden interlayer weights and biases of RELM are randomly generated after the number of hidden layer neurons is determined. To avoid the randomness of parameter selection, the COA is used to optimize the input-hidden interlayer weights and biases. In order to achieve a more ideal prediction effect (Huang, 2015), the steps are as follows:
1. The population is initialized.
2. New solutions are generated by Levy flight. The new solution for each bird’s nest can be calculated as


where
3. Find the strange egg and randomize the bird’s nest. Assume that the probability that the mother will find a strange egg in the nest is Pa. When a strange egg is discovered, a new solution will be generated as follows


where l2 is a random number uniformly distributed between 0 and 1. lp1 and lp2 are random perturbations when the optimal solution of the bird’s nest is

4. When the maximum number of iterations is reached, the algorithm ends.
Compared with optimization algorithms such as particle swarm optimization, the COA has the advantages of high accuracy and fast convergence. In this article, the absolute average error of six single-step predictions is used as the fitness function of COA. The parameter optimization training of RELM is performed to construct a multi-step wind speed prediction combination model. For short-term prediction, historical wind speed data and Numerical Weather Prediction (NWP) data are selected as training data, and C-C method (Letellier, 2017) is used to reconstruct phase space of historical time series.
Model self-tuning algorithm
Based on the COA-RELM model, in order to further reduce the model prediction error and improve the prediction accuracy of the combined model, this article adds error self-tuning. At present, most of the error correlation linear analysis methods are selected to reduce the prediction error (Tang et al., 2019). The combined forecasting model is modified by solving the functional relationship between the historical forecasting error and the input. In this article, the mean absolute percentage error (MAPE) is selected as the self-tuning standard

where εM is the MAPE representing COA-RELM and f(x1, …, xn) is a linear function about the input (x1, …, xn represent the input wind speed data). The term coefficient k is obtained by the least-squares method.
The combined prediction model obtained after error self-tuning is as follows

where y(x1, …, xn) is the COA-RELM prediction model and Y is the final prediction result. Experiments show that the error value of the prediction model after error self-tuning is lower and the prediction effect is better.
Combined wind speed prediction model
Data processing
In order to avoid the influence of different attribute dimensions on the prediction effect, the data in the input COA-RELM are normalized as follows (Pan et al., 2018)

where max{x} and min{x} are the maximum and minimum values of the original data x, respectively.
The predicted value output by COA-RELM is subjected to the following inverse normalization processing, and then an error self-check is performed to calculate the error value

Prediction model process
The specific flow of the combined wind speed prediction model proposed in this article is shown in Figure 2.
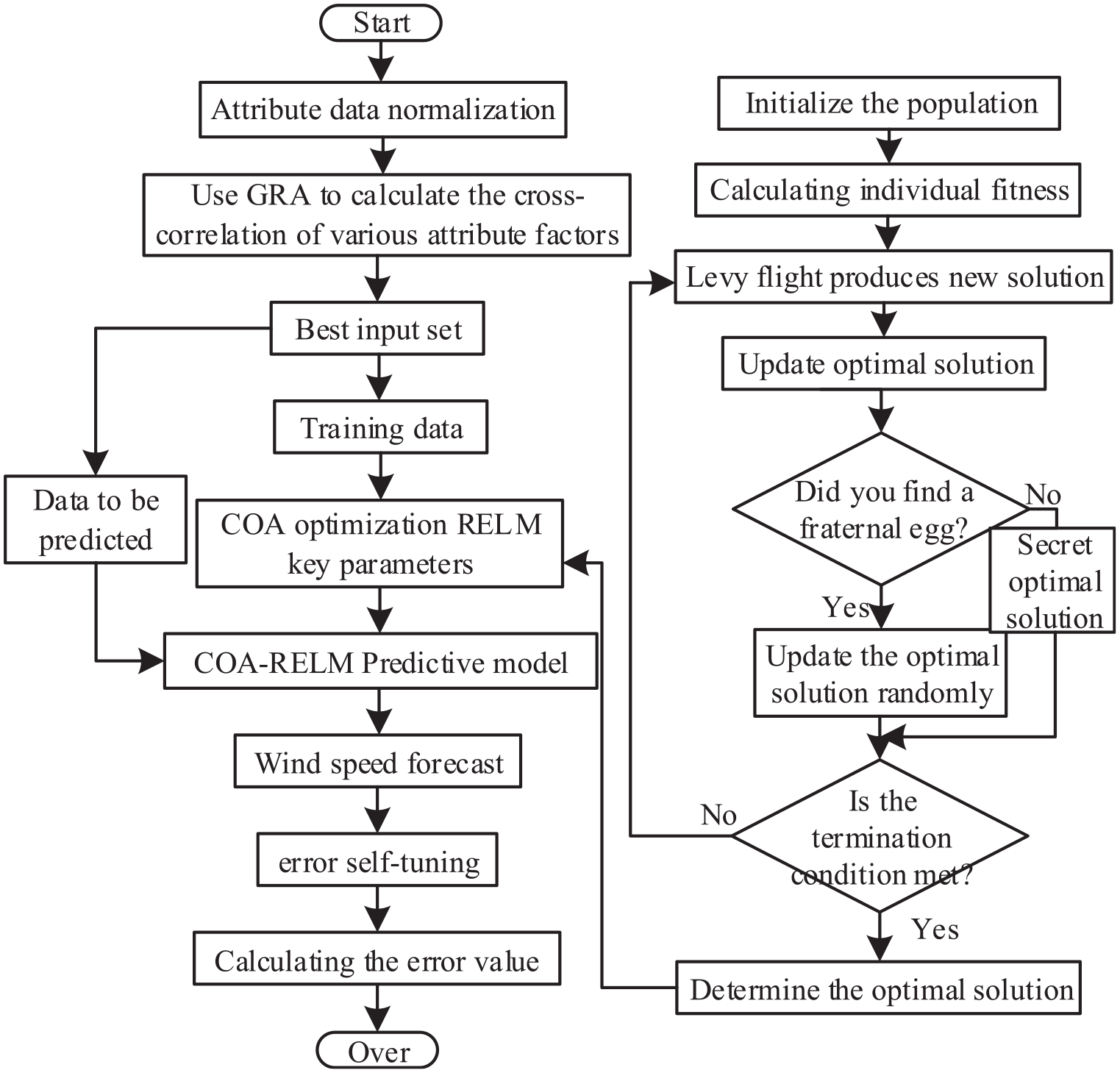
Flowchart of the combination model.
Evaluation index
In order to verify the effectiveness of the proposed model, the following two evaluation indicators are selected to evaluate the prediction results


where Yt is the predicted value at time t, xt is the actual value at time t, and N is the total number of time points in the prediction set.
Simulation analysis
The actual wind farm in the northeast region, and the actual monthly wind speed data and relevant attribute factors of the typical month of the wind farm in each quarter of 2019 are selected for the simulation analysis. The sampling interval of the original data every month is 10 min, a total of 4320 points, the data for the first 20 days are taken as the training set, the data for July 21–25 are the test set, and the data for July 26–30 are inspection set (used to check whether the model parameter settings are appropriate).
Analysis of RELM forecast results
Each attribute factor is screened based on GRA, and power, wind direction, and atmospheric pressure are selected as inputs to the model based on the results. Based on this, a rolling prediction model of 1–6 steps is established to predict the wind speed of the wind farm.
Three algorithms, namely, ELM, back propagation (BP) neural network, and SVM, were selected to perform a single-step rolling prediction of the wind speed on July 21 in the prediction set to verify the effectiveness of the method in this article (Figure 3). The training and test sets in this article were run in the MATLAB 2016b environment using Intel Core™ i5-8500, CPU@3.00 GHz, microcomputer platform with 8.00 GB RAM.

Comparison of single-step prediction results of different methods.
Each model provides a better prediction effect when the wind speed fluctuates gently. However, when the wind speed fluctuates sharply, ELM and SVM have a weak learning ability for non-linear sequences and are easy to overfit. BP has a weak learning ability for the randomness of wind speed sequences, which leads to a large deviation between the prediction result and the actual value. It has a good fitting effect on the random fluctuation of wind speed.
Analysis of prediction results of comparative models
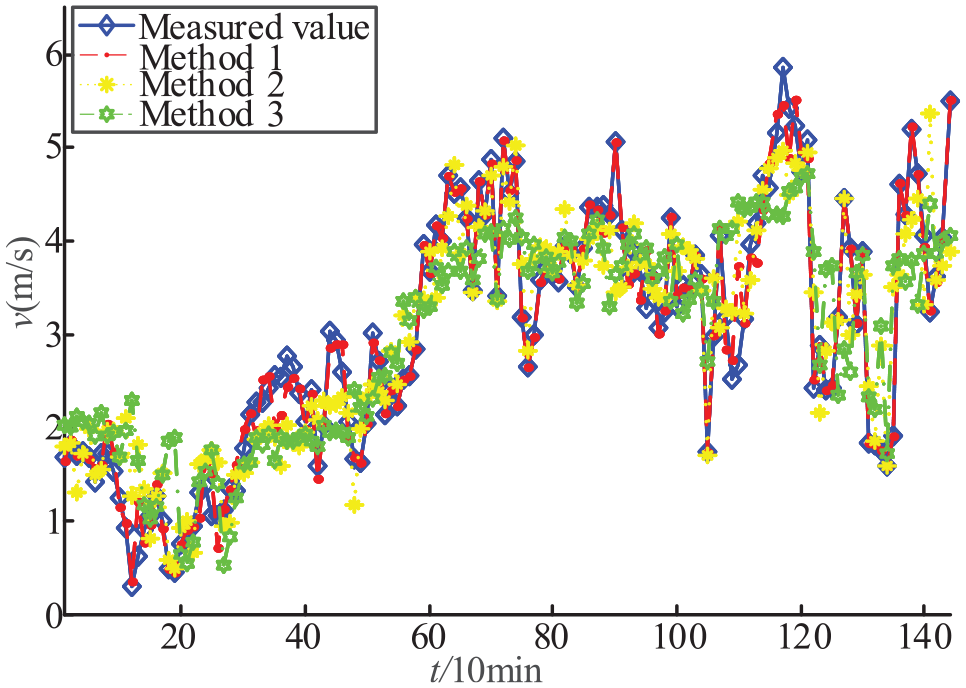
In order to verify the accuracy of the combination model proposed in this article, different combination models were selected for rolling prediction of wind speed on the 25th of July. Among them, method 1 is COA + RELM + e (error self-tuning mode), method 2 is RELM + e, and method 3 is RELM. The results are shown in Figures 4 and 5.

Single-step prediction results.

Comparison of multi-step prediction results of different methods: (a) two-step prediction, (b) three-step prediction, (c) five-step prediction, and (d) six-step prediction.
It can be seen from Figures 4 and 5 that method 1 can provide a good effect in the prediction of different step sizes, and the prediction advantage is obvious. As the step size increases, the forecasting trend is still consistent with the single-step forecasting with small changes. It has a good multi-step forecasting effect. With methods 2 and 3, as the prediction step size increases, the deviation between the prediction result and the measured data increases significantly. The specific error calculation results are shown in Table 2.
Multi-step prediction error results of different methods.
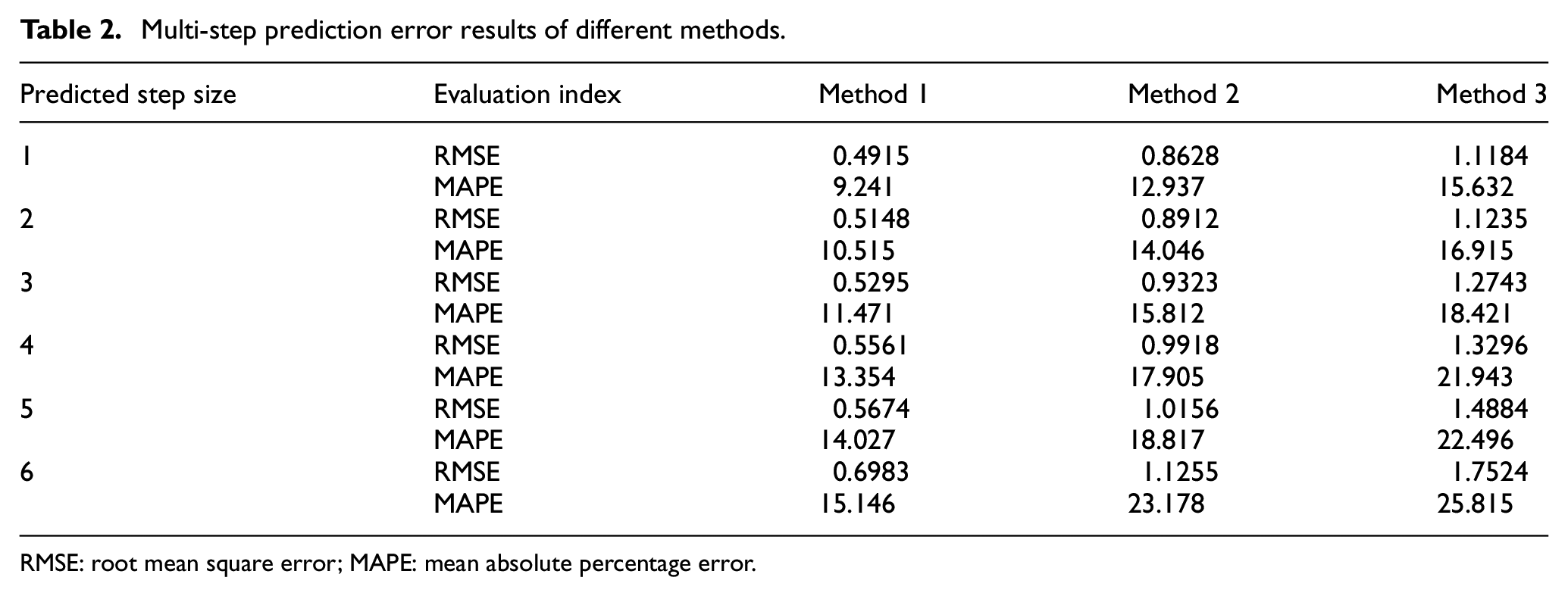
RMSE: root mean square error; MAPE: mean absolute percentage error.
It can be seen from Table 2 that, in the multi-step prediction with different step sizes, the error of method 1 is smaller than that of the comparison method. Because method 2 does not optimize the RELM parameters, the prediction model’s generalization ability to different wind speed fluctuations declined. The smaller error of method 2 compared to method 3 is because method 3 does not perform self-tuning of the preliminary prediction results, thus resulting in a decrease in prediction accuracy. It is not difficult to observe certain error accumulation in the prediction results of each method. In the one-step to six-step prediction of method 1, the root mean square error (RMSE) increased by 5.505%, while that for method 2 increased by 8.681%, indicating that the optimization of the RELM parameters by COA can effectively improve the prediction accuracy and fitting effect of the model. The RMSE in method 3 at step 1 is 2.695%, which is higher compared to method 2. And the RMSE increased 2.637% in the six-step prediction. However, the effect of the error checking ability is not affected by step size, which verifies the applicability of the error self-tuning model in multi-step prediction.
In order to further verify the prediction effectiveness of the method in this article, single-step rolling prediction results are selected for typical months of the wind field in other seasons as shown in Figures 6 to 8.
Spring (April) single-step prediction results.
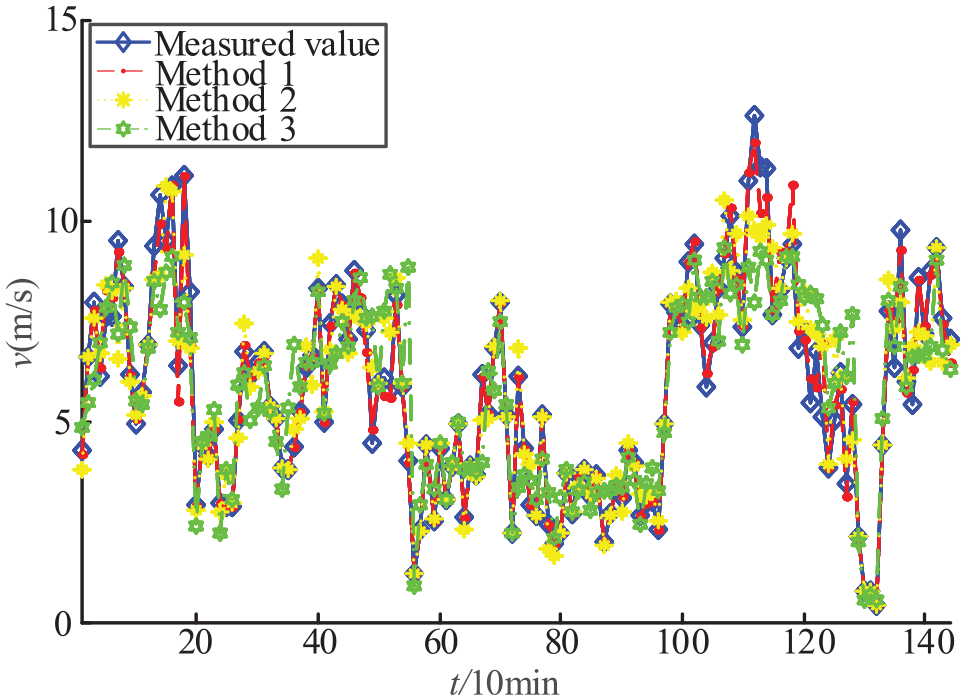
Autumn (October) single-step prediction results.
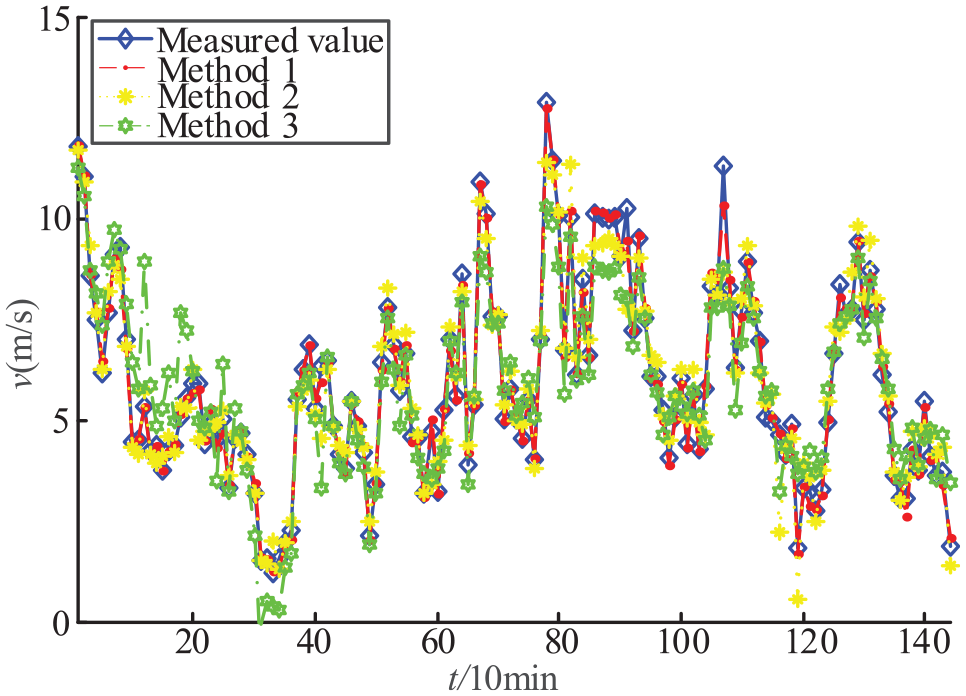
Winter (November) single-step prediction results.
It can be seen from Figures 6 to 8 that the prediction effect of method 1 in each season is better than those of methods 2 and 3, which proves the effectiveness of parameter optimization and error self-tuning models. Among them, when the wind speed in spring (April) is large and regular fluctuations, the prediction performance of the method without error self-tuning is significantly weaker than the method 1 and method 2 that pass the error check, indicating that the verified model has a stronger non-linear expression ability, can effectively reduce the generalization error. Compared with method 1, because method 2 does not optimize the parameters, although it can predict the change trend of wind speed very well, it is easy to appear in the details (such as between 110 and 120 in autumn and 105 and 110 in winter). The combination phenomenon leads to a large deviation of the predicted results from the measured data.
Error self-tuning
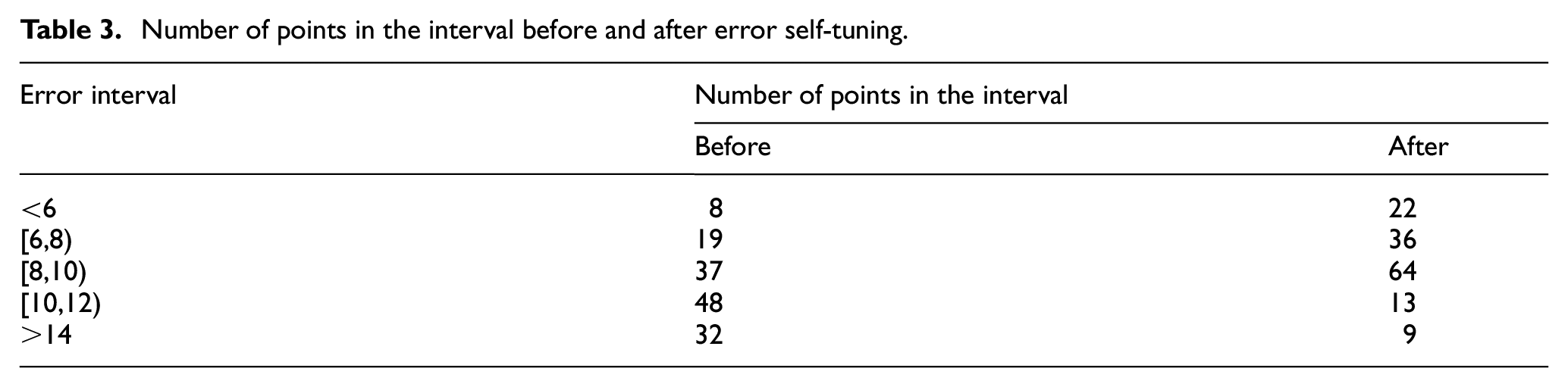
To further illustrate the effectiveness of error self-tuning, the MAPEs of the single-step prediction results before and after verification are selected for comparison. The selection results are shown in Table 3. It can be seen from Table 3 that, after verification, the number of points in the interval [10,12) is significantly reduced. Most of the points are concentrated in the interval [8,10). Statistics of 10 single-step prediction results show that the average absolute percentage error of the prediction model after verification is reduced by about 39.7% compared with the previous one. The analysis results show that the error self-tuning mode can effectively reduce the model prediction error and improve the prediction accuracy.
Number of points in the interval before and after error self-tuning.
Generalized verification analysis
In order to avoid the influence of the latitude, longitude, and climate of the selected area, combined with the data provided by a wind farm in Yunnan, China, the applicability of the model proposed in this article is further verified. Taking the historical wind speed data and various attribute data in January 2010 as an example, the data sampling interval is 10 min (Figure 9).
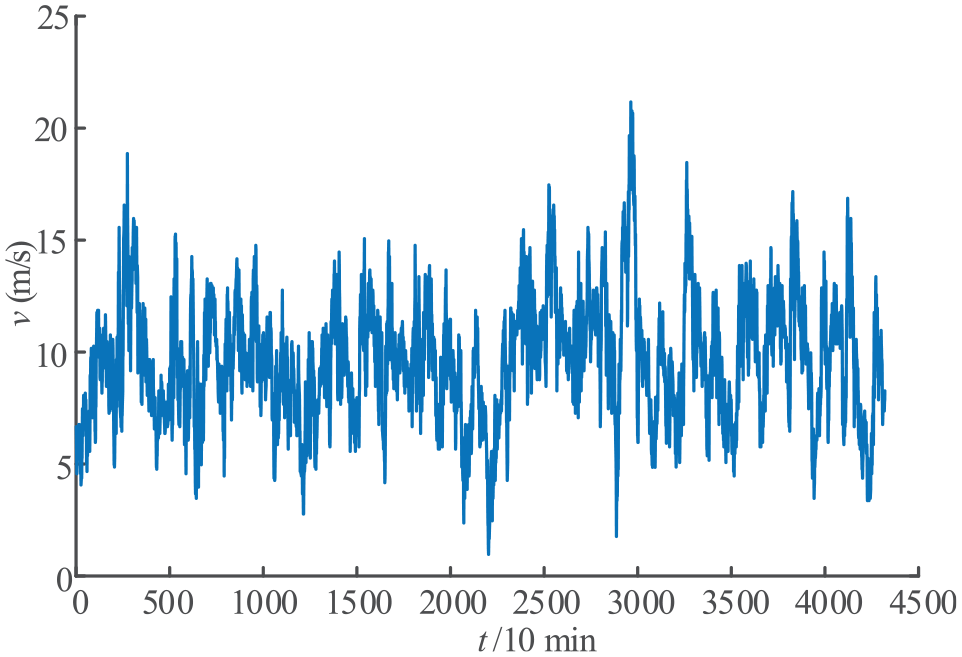
Schematic diagram of wind speed.
The wind farm is affected by geographical location and climatic environment, and the wind speed fluctuation characteristics in different quarters are quite different from those in northeast China. Correlation of each attribute sequence was calculated based on the locally measured historical meteorological data. The results are shown in Table 4. The model parameters and input set of RELM were revised, and this method is used to construct a combined model to predict wind speed. Among them, the prediction results by one-step prediction and six-step prediction are shown in Figure 10.
Results of the correlation of various attribute factors.

Multi-step prediction evaluation index.

RMSE: root mean square error; MAPE: mean absolute percentage error.
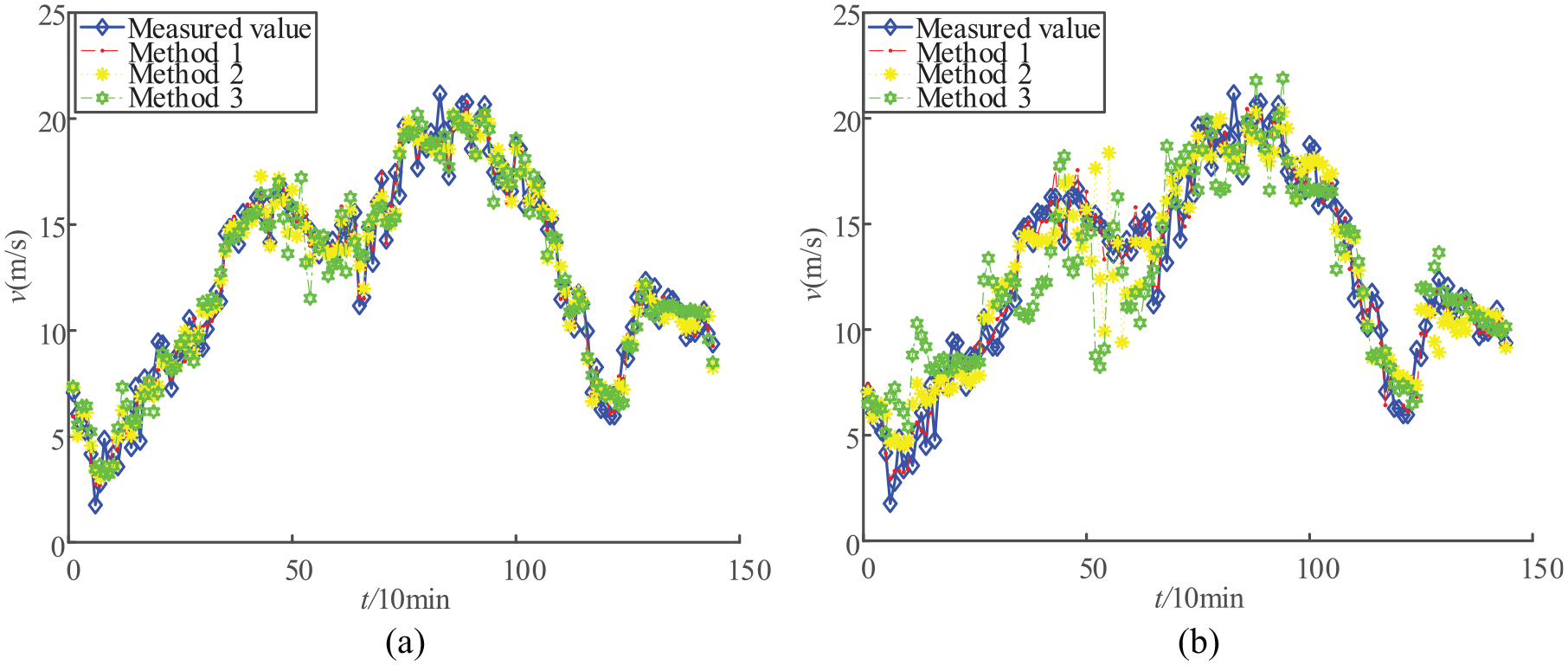
Multi-step prediction wind speed results: (a) one-step prediction and (b) six-step prediction.
From the data shown in Figure 10 and Table 4, it can be seen that the prediction results of method 1 can more accurately reflect the trend of wind speed changes, and each forecast index meets the standard requirements, which proves that the method has strong applicability and generalization ability.
Conclusion
Based on the attribute correlation degree of wind speed, a combined forecasting model is proposed to perform multi-step rolling prediction of the actual wind farm, and the following conclusions are drawn:
Analyze each wind speed attribute sequence based on gray correlation, select attribute factors with high correlation with wind speed, remove redundant information with low correlation, and improve prediction accuracy under the premise of ensuring computational efficiency.
RELM based on parameter optimization can reduce the randomness of model parameters and improve prediction performance. Combined with the wind speed fluctuations in different regions and seasons, the wind speed prediction model that conforms to the actual fluctuation conditions can be constructed through parameter modification, which has good prediction accuracy and generalization ability.
The error self-tuning model selected in this article can effectively reduce the model prediction error and is not affected by the increase in step size, thereby verifying the validity and applicability of the model proposed in this article.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.