
Abstract
The wind resources have been estimated by using physical models, statistical models, and artificial intelligence models. Wind power calculation helps us measure the annual energy that will sustain the balance between electricity generation and electricity consumption. Wind speed plays a significant role in calculating wind power, due to which here we focus on wind speed prediction. In this paper, hybrid models for wind speed forecasting have been proposed. The hybrid models are formed by combining the time series decomposition technique, that is, discrete wavelet transform (DWT), with statistical models, that is, autoregressive integrated moving average (ARIMA) and generalized autoregressive score (GAS), respectively. These hybrid models are referred to as DWT-ARIMA and DWT-GAS. DWT decomposes the original series into sub-series. After that, statistical models are applied to each sub-series for prediction. In the end, aggregate the prediction results of each sub-series to get the final forecasted series. For experimentation purposes, statistical and hybrid models are applied to various datasets that are taken from the NREL repository. In our studies, the hybrid version demonstrates better results in terms of accuracy and complexity, which indicates superior performance in most cases compared to the existing statistical models.
Introduction
Wind energy is a renewable energy source; the demand is high as it is environmentally friendly and easily available in nature. Due to a renewable source, it is beneficial for economic development and environmental issues. It is also essential to manage wind energy on the trade-off for consumption (including establishment) and production. Research published in Morshedizadeh et al. (2017), Wadhvani and Shukla (2018), and Dongre and Pateriya (2019) concluded that there is a strong relationship between wind power and wind speed at the site. A useful wind speed prediction model can increase power forecasting accuracy. However, accurate wind speed forecasting for wind energy is an important task. It is challenging to get accurate predictive results due to the irregular wind speed behavior Liu et al. (2015). Wind speed forecasting is a type of time series prediction issue that provides valuable information that helps established wind power plants, scheduling, power distribution, and related activities Erdem and Shi (2011). There are currently several forecasting methods available, which can be classified into four classes: physical approach, statistical approach, artificial intelligence approach, and hybrid approach Lei et al. (2009). In the physical model, more complex variables are used; therefore, it takes more time to obtain the results, and it is generally considered for long-term predictions. It is mainly used by the numerical weather prediction models that establish a relationship between the factors affecting the wind speed forecasting and weather data such as temperature, pressure, altitude, and humidity Pelikán et al. (2010). Whereas, in statistical models, a relationship is maintained between the dependent and independent variables on the basis of historical data. Various statistical models are available, such as autoregressive (AR), moving average (MA), autoregressive moving average (ARMA) Yang et al. (2015), autoregressive integrated moving average (ARIMA) Torres et al. (2005), and generalized autoregressive score (GAS) Creal et al. (2013), which use past data to obtain the seasonal and trend components of wind time series data used for wind speed prediction. It is widely used in practice for getting the forecasting result because they are quick and straightforward. Besides, various factors impact the wind speed series and require a complex function to detect relationships between variables. Therefore they are not capable of handling the more complicated signal.
In recent years artificial intelligence models are frequently employed to develop the model for time series forecasting Barbounis and Theocharis (2007). These techniques include artificial neural network (ANN) Zhou et al. (2011), support vector machine (SVM) Pinto et al. (2014), and support vector regression (SVR) Santamaría-Bonfil et al. (2016). These models can maintain the relationship between the input and output data and have excellent error tolerance due to their outstanding performance in handling nonlinear and complicated signals Li and Shi (2010). The hybrid model is formed by combining the two or more above-mentioned models Xiao et al. (2016). Besides, an excellent hybrid model can only be obtained by the best combination of two or more different types of the model; the simple combination can result in a poor hybrid model. So, the structures of the hybrid model are essential Okumus and Dinler (2016). The above details indicate that a better-designed hybrid model can perform better than a randomly designed hybrid model Salcedo-Sanz et al. (2014). In recent years, various hybrid models are proposed for wind speed forecasting. Kushwah and Wadhvani (2019) have constructed a hybrid model by combining the GAS model and the neural network-based modeling techniques for wind speed forecasting on the 5-minute time interval. The results show that the hybrid model performs better as compared with the conventional statistical models. Shukur and Lee (2015) proposed the hybrid model, which is obtained by combining the Kalman Filter (KF) and the ANN models. In this model ARIMA model is also used to pick the KF’s preliminary parameters. The experimental results show that the hybrid version improves the accuracy of wind speed forecasting further. Cadenas and Rivera (2010) proposed a hybrid model based on the ARIMA version and ANN model. ARIMA model was first constructed here to forecast the wind speed and then produce the expected errors, which are given to the ANN models as an input. The results indicate that the hybrid version had better accuracy than the unbiased versions of ARIMA and ANN. Kushwah et al. (2020) suggested a hybrid model consisting of statistical models and trend-based clustering. Compared to statistical models used alone, the hybrid model performs better. Su et al. (2014) have proposed a hybrid model for wind speed prediction using particle swarm optimization (PSO), ARIMA, and KF. The PSO is used to refine the ARIMA version’s parameters, and the ARIMA variant is used to get the Kalman filter’s parameters. The experimental result showed that the hybrid model’s efficiency is better than that of ARIMA and ARIMA models optimized by PSO.
Another approach to handling the linear and nonlinear time series data is to use the time series decomposition techniques and apply the existing forecasting models. However, the decomposition-based prediction technique is a kind of hybrid approach that combines the various decomposition algorithms with forecasting models. Decomposition algorithms such as empirical mode decomposition Zhang et al. (2008), discrete wavelet transform Lei and Ran (2008), and ensemble empirical mode decomposition Wang et al. (2013) are generally used. There are many applications where hybrid models have performed better as compared to the different models used individually. Meng et al. (2016) have proposed a hybrid approach for forecasting time series by merging the wavelet packet decomposition and the artificial neural networks. The experimental results showed that the hybrid model performs better than the ANN alone. In this paper, a hybrid model for wind speed forecasting is proposed by combining the decomposition technique of discrete wavelet transform (DWT) with statistical models (ARIMA and GAS). This work proposed two hybrid models, namely, DWT-ARIMA and DWT-GAS. DWT is used to reduce the non-stationarity of wind time series data. DWT decomposes the original wind time series data into sub-series of low and high frequency. These sub-series are stationary as compared to the actual wind time series. The statistical model is applied to each sub-series and then aggregates each sub-series’ forecasting results to get the final forecasted series. The performance of statistical models and hybrid models are evaluated using the metrics Mean Absolute Error (MAE) and Root Mean Square Error (RMSE).
Statistical models for wind speed forecasting
This section describes the detail of statistical models used for wind speed forecasting. Wind speed is a type of time series forecasting problem which are used for wind power development. There are numerous statistical methods available for forecasting the wind time series, and the model ARIMA and GAS are commonly used.
ARIMA model
Ait Maatallah et al. (2015) have suggested the ARIMA model, which can represent different types of time series models such as the autoregressive (AR) model, the moving average (MA) model, and the ARMA model. These models have become very popular because of their flexibility and simplicity in representing the different time series. The ARIMA model is incorporated to handle the non-stationary time series data, whereas AR, MA, and ARMA models are used for stationary time series data. Here, the primary constraint is to assume the linear form of models that shows the direct connection structure for the time series data. ARIMA model can not capture the nonlinear pattern that is presented in the time-series data. The notation ARIMA (p; d; q) implies that the ARIMA model has p autoregressive terms, q moving-average terms, and d represents the differencing term’s degree. This model is described as:
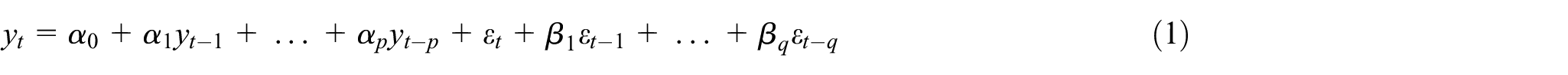
Where
GAS model
Creal et al. (2013) and Harvey (2013) have proposed the generalized autoregressive score (GAS) model, which is the new class of observation-driven model. The GAS model uses wind time series data to accommodate the varying density present in the time series data. A conditional observation density P

Where μ is a constant vector, ϕ is the coefficients of autoregressive terms, α represents the scaling parameter, s is the scaling factor which is multiplied with conditional observation density P. The scaling factor depending on
Naive model
The Naive model is the most straightforward forecasting technique used in various data fields, such as economic and financial time series data Hyndman and Athanasopoulos (2018). This model assumes the data’s future value, which is equal to the last observed data value. This model is described as:
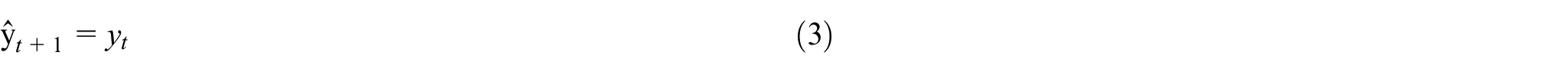
Where
Time series decomposition
The original series of wind speed is decomposed into a collection of sub-series for better and more reliable behavior using the wavelet transform Percival and Walden (2000). Generally, there are two types of the wavelet transform, namely, continuous wavelet transform and discrete wavelet transform. An X(t) signal’s continuous wavelet transform (CWT) is shown as follows.

Where a is the scale factor, b corresponds to the translation parameter and

Where t is the discrete-time index, T is the length of the given time series, a =

Wavelet Transform method with three decomposition levels: A is the approximate component, and D is the detail component.
Proposed hybrid approach for wind speed forecasting
The framework of the proposed hybrid model for wind speed forecasting is illustrated in Figure 2. The hybrid model is formed by combining the decomposition technique DWT and the following Statistical Models: ARIMA and GAS. First, DWT decomposes the original time series into a set of sub-series. These sub-series have both low frequency and high-frequency components, known as the approximation (A) and the detail components (D). These components are forecasted using ARIMA and GAS models, respectively. After predicting all the sub-series, forecasted results are aggregated to obtain the final wind speed forecasted data. The two-hybrid models are called the DWT-ARIMA and the DWT-GAS model. For the experimentation, the dataset is drawn from NREL’s wind prospector (National Renewable Energy Laboratory (NREL), 2012). The performance of proposed hybrid models is estimated using the criteria MAE and RMSE.

The proposed hybrid (DWT-ARIMA/GAS) model.
Results and discussion
The full section describes the experiments carried out on different datasets and then examines the experiments’ results. The first section deals with the details of the datasets used for the experiment. Performance evaluation criteria are discussed in the second section. The third section analyses the results.
Dataset
In this section, we will explain the practical implementation of the modeling techniques described earlier. We use NREL sites such as 68003, 124693, 36363, 44402, 45208, 9687, 33423, 74664, 94404, and 72509. Among these sites, twenty datasets are obtained for our experiments. The geographical position of site id 68003 has −99.7579° longitude and 41.86517° latitudes. Table 1 includes a detailed overview of all datasets.
Dataset description.

Performance measuring criteria
The performance of proposed hybrid models and existing statistical models are calculated using the required parameters to determine the models’ potential. Mean absolute error (MAE) and root mean squared error (RMSE) is used for our experiments to calculate the wind speed forecasting performance. The measurement parameters, such as MAE and RMSE, are further defined as:


In this case, N is the cumulative number of observations, y indicate input variable and
Outlier detection in the dataset
There are several methods used for outlier detection in the dataset, such as boxplot, local outlier factor, etc. Boxplot is the most commonly used outlier detection method, which shows the distribution of numerical data of time series among with the minimum value, first quartile (


Where,

Figure 3 shows the boxplot with outlier for dataset #2. Here the outliers are detected after the maximum value of the boxplot. After removing these outliers, our dataset is cleaned, which is shown in Figure 4.
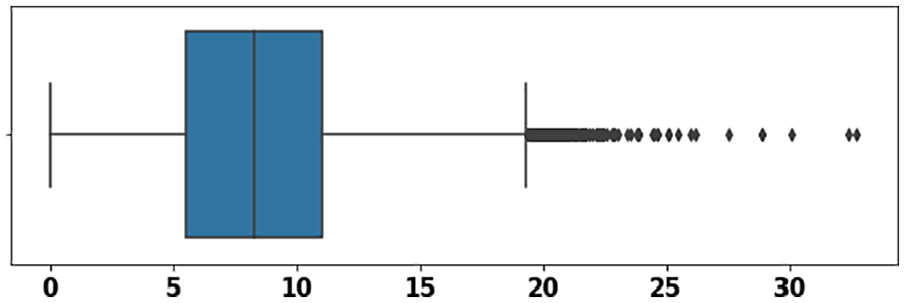
The boxplot with an outlier of wind time series data using dataset #2.
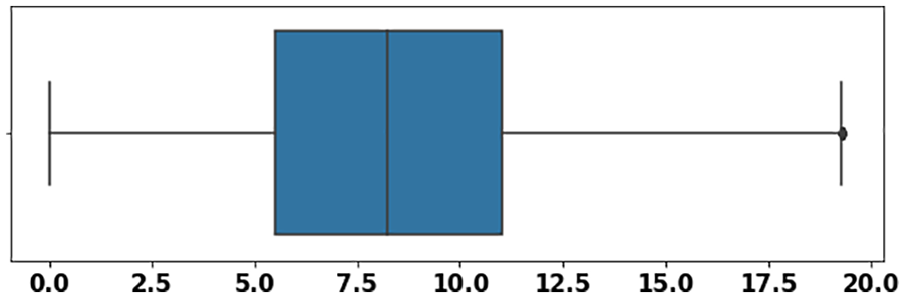
The boxplot after removal of the outlier of wind time series data using dataset #2.
Analysis of results
Statistical and the proposed hybrid models (ARIMA, GAS, DWT-ARIMA, and DWT-GAS) are applied for wind speed prediction on all the datasets. Figures 5 and 6 show the original and decomposed series. The original series is decomposed into sub-series using DWT with five decomposition label. Figure 4 shows one approximation component (
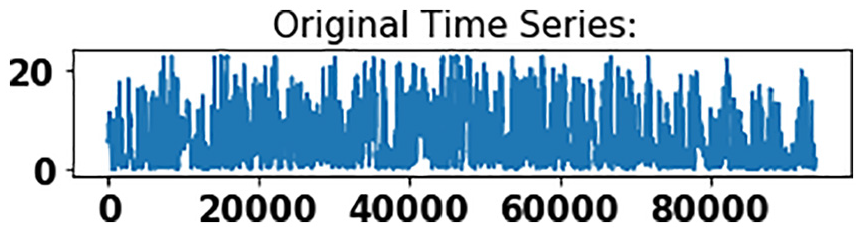
Original wind speed time series.
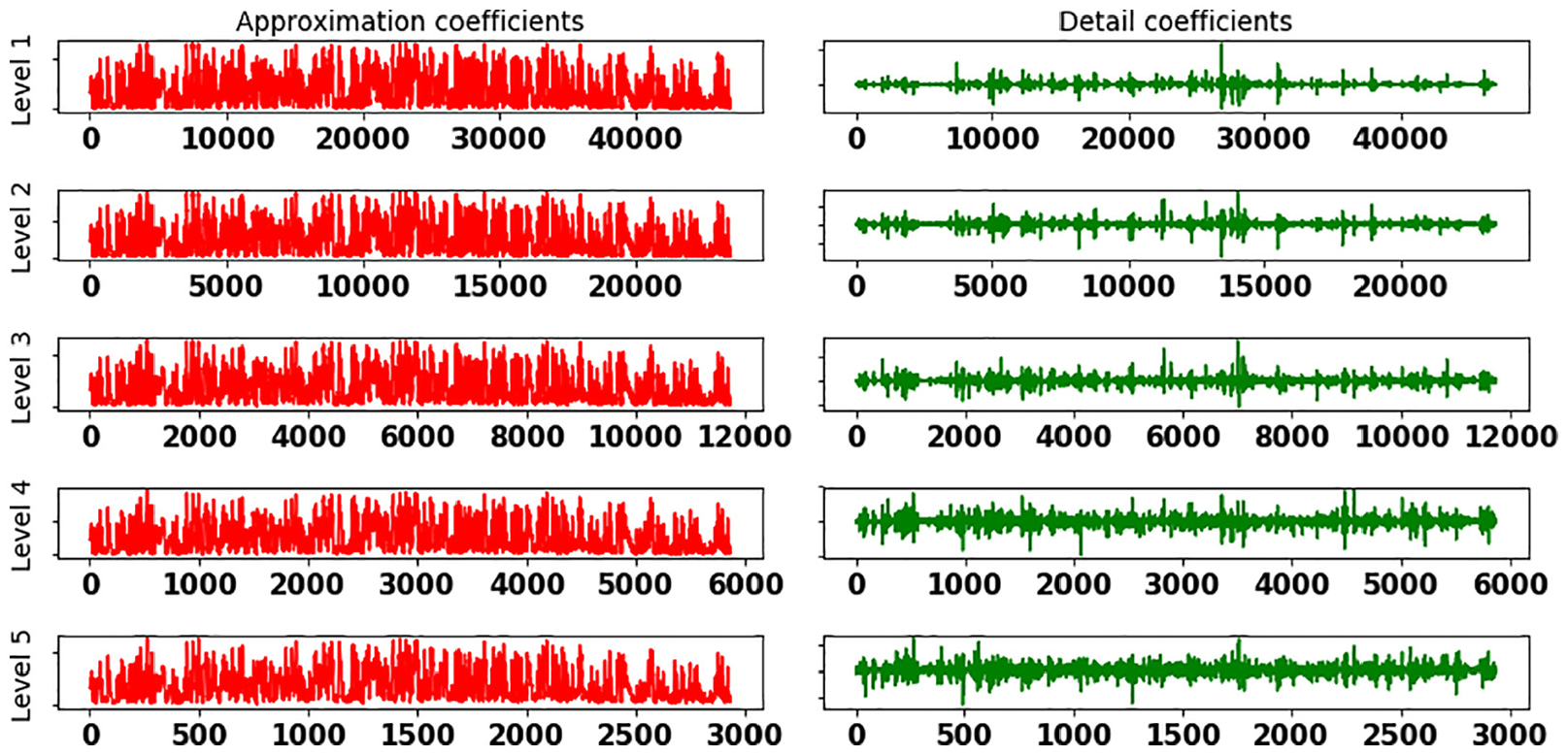
Wind speed time series decomposition using DWT with five labels.
The datasets used for experimentations are divided into training-testing pair. The training set contains 90% of the data, and the testing set contains 10% of the data. Figures 7 and 8 illustrate the wind speed prediction using ARIMA and GAS model applied separately on dataset #2. Here the GAS model shows better accuracy than the ARIMA model because the ARIMA model does not capture varying density present in this dataset, whereas the GAS model easily handles it and shows better accuracy.
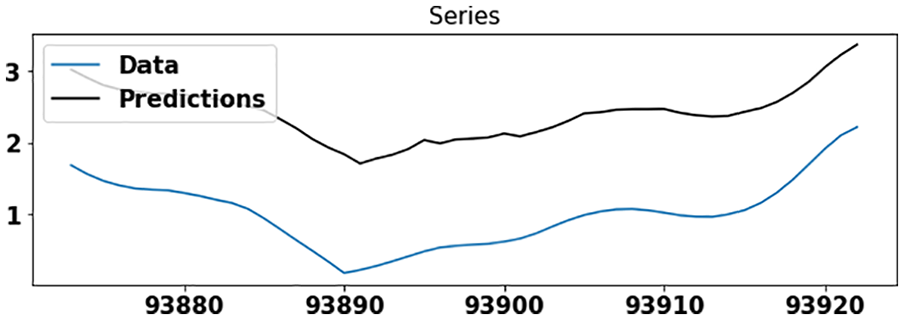
Wind speed prediction using the ARIMA model for dataset #2.
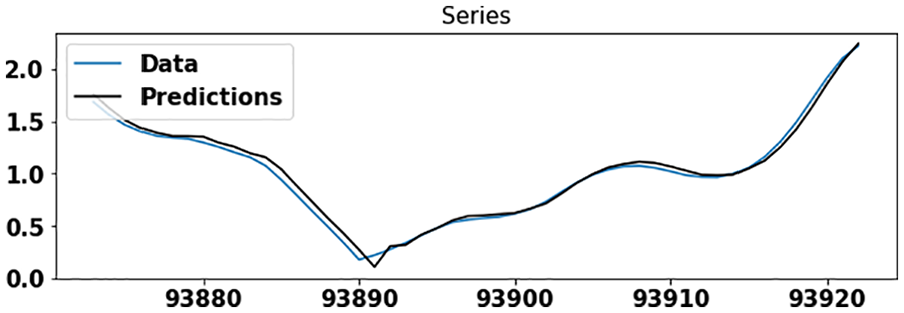
Wind speed prediction using the GAS model for dataset #2.
The training results of all models in terms of MAE (maximum absolute error) and RMSE (root mean squared error) are shown in Table 2. In each row of the table, a “bold numeric value” of MAE and RMSE indicates that the prediction model corresponding to the column has the least prediction error and performed better on the Dataset representing that row.
Training Errors in terms of MAE, RMSE values of the proposed hybrid models compared with the existing methods.
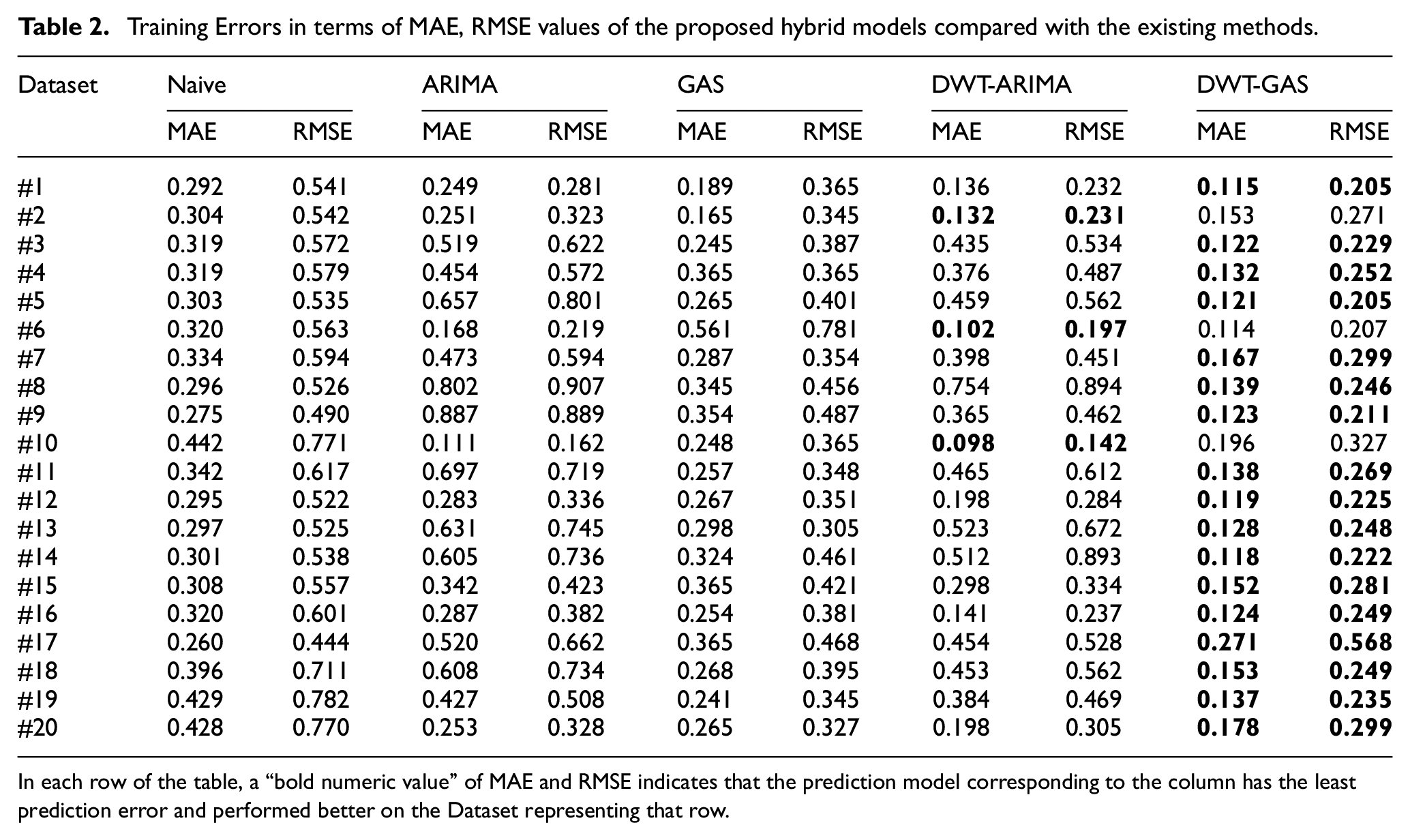
In each row of the table, a “bold numeric value” of MAE and RMSE indicates that the prediction model corresponding to the column has the least prediction error and performed better on the Dataset representing that row.
The testing results of all models in terms of MAE and RMSE values are given in Table 3. As shown in the table, the model DWT-ARIMA has minimum MAE and RMSE values compared to the ARIMA, GAS, and DWT-GAS models for series #1. For dataset #2, the model DWT-GAS has minimum MAE and RMSE values compared with the ARIMA, GAS, and DWT-ARIMA models. Therefore, it is concluded from our experimentations that the hybrid models perform superior to the existing ARIMA and GAS model.
Testing Errors in terms of MAE, RMSE values of the proposed hybrid models compared with the existing models.

Note: The minimum values of MAE and RMSE for the prediction model are indicated in bold is referred as best performing model corresponding to the dataset representing that row.
Figures 9 and 10 demonstrate the wind speed prediction using the DWT-ARIMA and DWT-GAS model, which is applied individually on each component of dataset #2. The DWT-GAS model shows better accuracy compared to the DWT-ARIMA model. Therefore, it can be concluded that

Wind speed prediction using the DWT-ARIMA model for dataset #2.
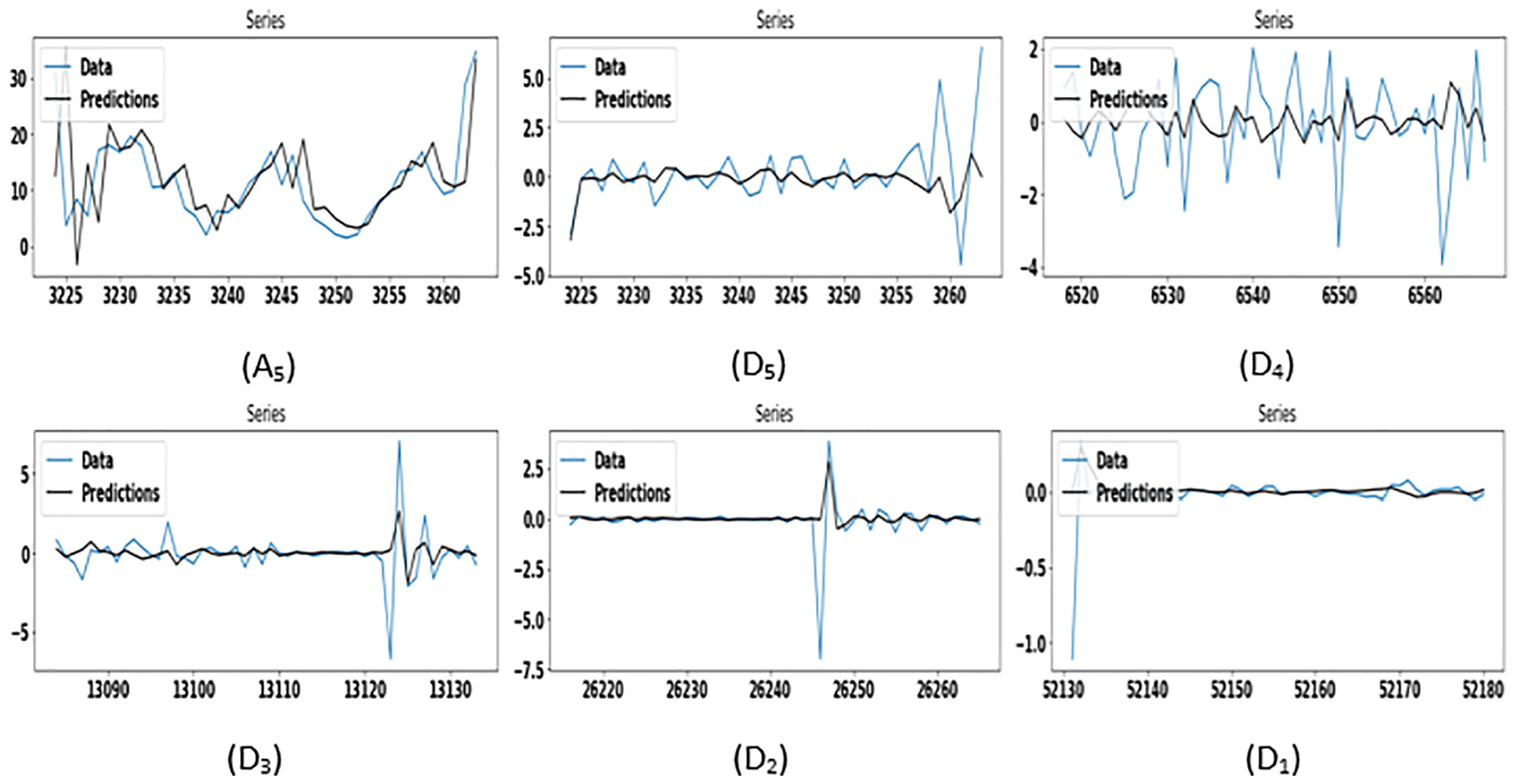
Wind speed prediction using the DWT-GAS model for dataset #2.
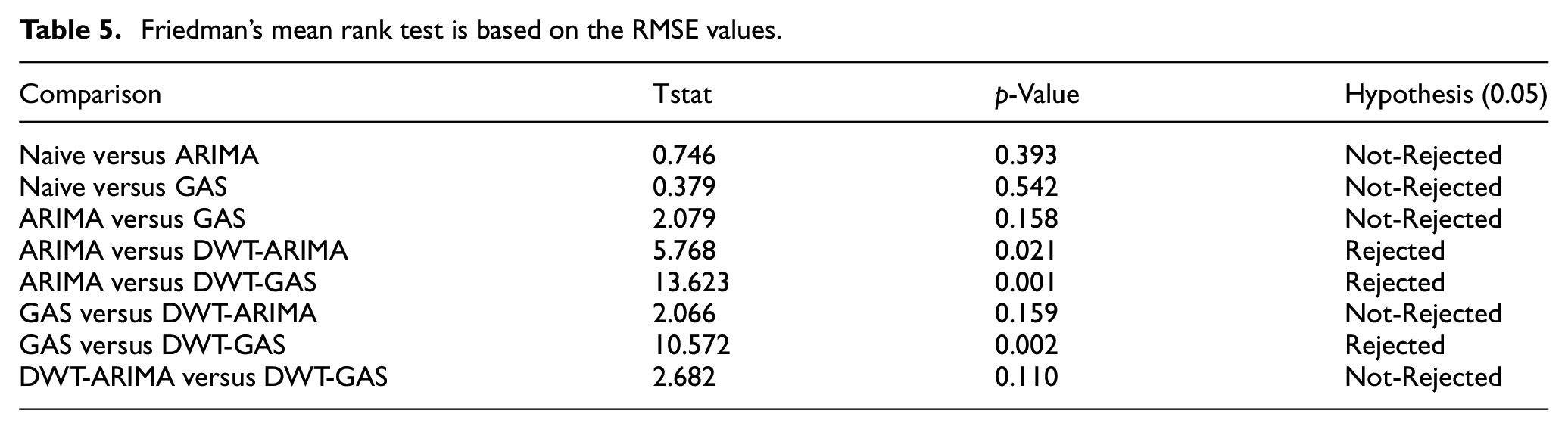
This research conducts the statistical t-test and Friedman’s mean rank test with a significance point of α = 0.05 on all the statistical models used for wind speed forecasting to evaluate the proposed model further. The statistical t-test results using MAE values calculated by statistical models have been shown in Table 4. The smaller p-value indicates a higher significant difference between the two models. The model ARIMA versus DWT-GAS has a more considerable difference in p-values relative to the other models. The Naive versus GAS model shows the least significant difference; hence, the null hypothesis is not rejected because of p-value > α. Similarly, Naive versus ARIMA, ARIMA versus GAS, GAS versus DWT-ARIMA, and DWT-ARIMA versus DWT-GAS show the least significant difference; hence the null hypothesis is not rejected. The statistical t-test results using the RMSE value are shown in Table 5. The ARIMA and DWT-GAS model has a more significant difference, whereas the Naive versus GAS model has the least significant difference in the p-value. Here, the null hypothesis for the models ARIMA versus DWT-ARIMA, ARIMA versus DWT-GAS, and GAS versus DWT-GAS are rejected.
Friedman’s mean rank test is based on the MAE values.

Friedman’s mean rank test is based on the RMSE values.
The proposed hybrid approach based on the GAS model and DWT techniques (DWT-GAS) has the least mean-ranks in the Friedman test, shown in Figures 11 and 12, respectively. The Friedman test computes the rank of each model on the 20 datasets. In our experimentation, the DWT-ARIMA and DWT-GAS models outperform the ARIMA and the GAS models, respectively.
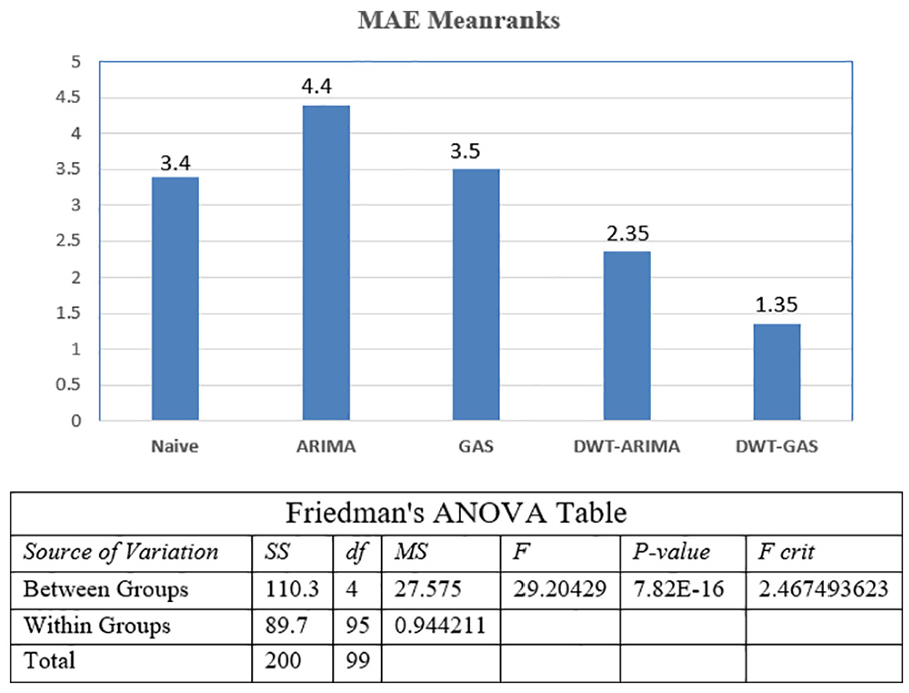
Friedman’s mean ranks and ANOVA table for MAE with α = 0.05.
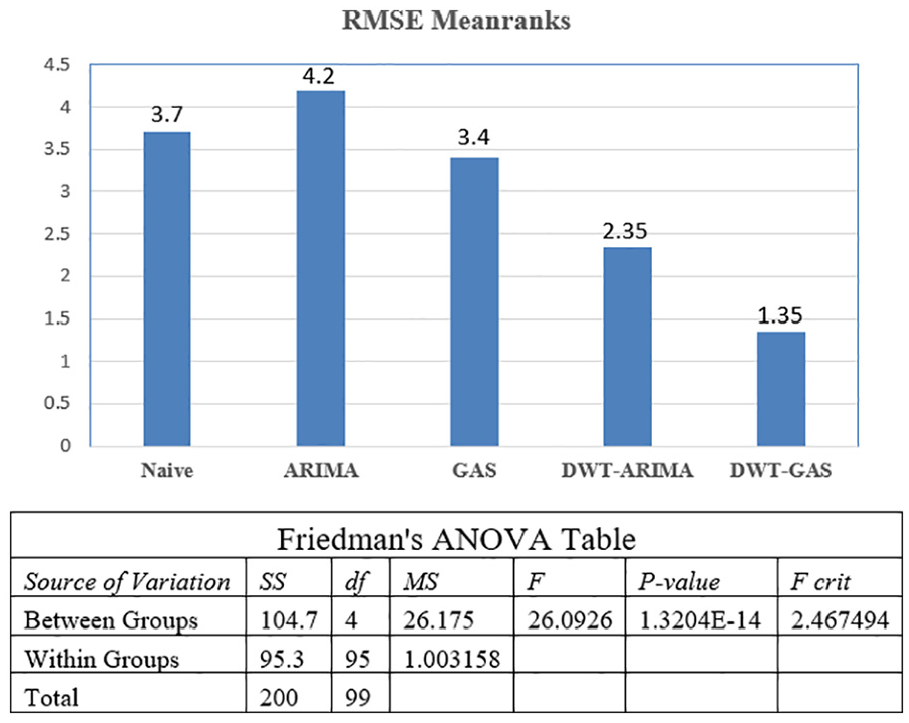
Friedman’s mean ranks and ANOVA table for RMSE with α = 0.05.
Conclusions
The present work focuses on selecting the best suitable modeling approach to wind speed forecasting. This study has proposed the hybrid models and applied the existing statistical models to predict the wind speed time series on 20 different datasets. For each dataset in the proposed hybrid approaches, the DWT technique is used to decompose the original series into a set of sub-series. Then the ARIMA and GAS model is applied to each sub-series. These sub-series are relatively stationary as compared to the original series. Finally, predicted wind speed is aggregated to get the overall predicted series. In our experiments, the hybrid model performs better as compared to the existing Naive, ARIMA, and GAS models. The wind speed series data has both high-frequency variants and low-frequency variants, which depict long-time period trends. The ARIMA and GAS models are not effective in capturing all the detail in wind speed data. The hybrid approaches take care of both the high-frequency variants and the low-frequency variants in wind speed series data, making it a powerful forecasting technique. In the future, advanced neural network-based approaches for sequential modeling along with decomposition techniques can be applied to achieve higher accuracy.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.