
Abstract
Accurate prediction of offshore wind speed is of great significance for optimizing operation strategies of offshore wind power. Here, a novel hybrid algorithm based on seasonal-trend decomposition with loess (STL) and auto-regressive integrated moving average (ARIMA)- long short-term memory neural network (LSTM) is proposed to eliminate seasonal factors in wind speed and fully exert the advantages of ARIMA processing linear series and LSTM processing nonlinear series. Moreover, wind speed are comprehensively preprocessed and statistically analyzed. Then, we handle information leakage problem. Finally, STL-ARIMA-LSTM model is applied to wind speed forecasting on 3 time-scales. The proposed model has the highest accuracy and resolution for the trend and periodicity of wind speed, and the lag problem of very shortterm wind speed prediction can be solved. This study also shows that when predicting offshore wind speed, we can handle the strong intermittence, volatility and outliers in wind speed by gradually adjusting time scale.
Introduction
The development of wind power can protect the ecological environment, improve the energy structure and achieve sustainable economic growth (Afshar et al., 2018). Compared with onshore wind power generation, offshore wind energy resources are more stable, wind turbine utilization is higher, and does not occupy land resources. However, the uncertainty, intermittence and volatility of offshore wind (Boutoubat et al., 2013) not only challenges the security of power system, but also poses a great challenge to the accurate forecasting of wind speed. Consequently, the accurate prediction of wind speed is an indispensable prerequisite for planning wind farms and dispatching power grids. In recent years, the statistical method and the machine learning method have been widely concerned and developed in the field of wind energy prediction.
In statistical methods, autoregressive moving average model (ARMA) and ARIMA are suitable for predicting very shortterm or shortterm wind speed. ARMA is utilized to calculate hourly mean wind speed at five locations in Spain (Torres et al., 2005). Even if the model is simple, they also obtained good prediction results. Erdem and Shi (2011) studied the performance of ARMA in wind speed and direction prediction for hourly mean wind by comparing vector autoregression (VAR) model. Their results showed that ARMA has good advantages in wind speed forecasting, and VAR can enhance the accuracy of wind direction prediction. ARIMA model (Box and Jenkins, 1970) was established by adding d-order difference process on the basis of ARMA model, which can make the calculation of time series more stable in theory. ARIMA model has been used in many time-series forecasting tasks because of its simple calculation, which is also popular in wind speed time series prediction (Benth and Benth, 2010; Cadenas and Rivera, 2010; Kavasseri and Seetharaman, 2009). Wind has high-frequency oscillation and seasonality, whereas ARIMA has the advantage of processing linear series. Therefore, we may first decompose the sequence, and then the decomposed components are modeled by ARIMA. For instance, Aasim et al. (2019) applied ARIMA with repeated wavelet transform (RWT) decomposition to very shortterm wind speed forecasting and studied the superiority of ARIMA with RWT decomposition by comparing with WT decomposition. Alternatively, considering that wind speed has linear trend and nonlinear trend, the linear trend component can be modeled by ARIMA, and the nonlinear part can be modeled by other suitable algorithms. Some machine learning models show their superior performance in dealing with nonlinear wind speed prediction problems.
The representative machine learning model includes random forest (RF; Lin et al., 2015), support vector machine (SVM; Mohandes et al., 2004), artificial neural network (ANN; Hur, 2021; Shboul et al., 2021), convolutional neural network (CNN; Wang et al., 2017, 2020b), deep belief network (DBN; Khodayar et al., 2019; Zhang et al., 2020), recurrent neural network (RNN) and so on. As a variant of RNN, LSTM neural network has advantages in terms of time series prediction and has made some progress in wind speed forecasting (Chen et al., 2019; Qin et al., 2019; Wang et al., 2020a). However, a single model is not competent to accurately predict complex wind speed time series. As a result, a complex time series can be decomposed into different components, combined with the advantages of each model to make predictions, which will usually achieve better prediction results than a single model (Olaofe and Folly, 2012). In recent years, some signal-decomposition methods such as wavelet packet decomposition (WPD; Liu et al., 2020), empirical mode decomposition (EMD) and variational mode decomposition (VMD) have been integrated into the hybrid model to preprocess the original wind speed signals. In addition, Wen et al. (2019) decomposed the wind speed time series by using STL and analyzed the potential characteristics of wind speed. STL decomposition method developed by Cleveland and Cleveland (1990) is a filtered seasonal decomposition method, which is simple and flexible. A few outliers do not affect the estimation of trend period and seasonal factors when processing time series data. Therefore, the paper will adopt STL method to adjust the seasonal wind speed time series.
LSTM neural network has wonderful feature in handling nonlinear wind speed due to its great ability to handle longterm correlation problem (Liu et al., 2018a, 2018b; Wang and Hu, 2015). Memarzadeh and Keynia (2020) developed a hybrid model with LSTM, which combined CSA, WT, FS and MI. Their model was used to predict wind speed and proved to be reliable. Chen et al. (2018) presented EnsemLSTM, and based on the model, the nonlinear feature of shortterm wind series was well captured. Jaseena and Kovoor (2021) applied hybrid BiDLSTM to predict wind speed, and achieved good prediction result.
Meanwhile, if the signal decomposition method is adopted in the process of wind speed prediction, the information leakage (Qian et al., 2019) is noteworthy. We can find a phenomenon that, if we normalize the data first and then divide train set and test set, high-precision results can be achieved based on the prediction model, but when this high-precision prediction method is applied to the actual working condition, its accuracy is often greatly reduced or the calculation results are incorrect. If the whole data set is decomposed first then substituted into the model to predict, the above result will also be obtained. These phenomena are the result of information leakage. Actually, the model training stage involves “future” data that should be unknown, which leads to information leakage. In this paper, we will deal with the problem of information leakage.
In this paper, combining the advantages that ARIMA model is easier to capture the linear relationship in the sequence and LSTM is easier to capture the nonlinear relationship in the sequence, a novel ARIMA-LSTM multi-scale hybrid model based on STL seasonal adjustment is proposed for wind speed time series prediction. The reason for choosing this hybrid model is that, in fact, the single ARIMA is hard to attain the accuracy results in forecasting non-linear and non-stationary time series, while the single LSTM model has the problem of forecasting lag, whereas seasonal factors in wind speed time series can not be ignored. Therefore, we first preprocess the original data, and then eliminate the seasonal factors in the data by STL decomposition. The processed data are predicted by ARIMA model to obtain the prediction results and residual values, and the residual value is predicted by LSTM. Finally, the predicted value of ARIMA is combined with the predicted value of LSTM to obtain the final prediction result. Moreover, in order to better satisfy the requirement of the actual project, multi-scale analysis of wind speed series is carried out, and original wind speed time series is divided into 3 time scales containing hour, day and month. In addition, STL decomposition of time series and data normalization preprocessing also avoid information leakage and ensure the forecasting accuracy. The main contributions of this paper are summarized as follows.
(1) In this paper, a detailed selection analysis experiment is carried out on the sample data of offshore wind speed and the problem of information leakage is fully considered, which can provide reliable prediction results;
(2) Compared with other decomposition methods, STL decomposition has better interpretability. Therefore, this paper uses STL decomposition method to extract the seasonal features in the sequence. Such feature extraction is convenient for the prediction of subsequent models, and the seasonal factors of wind speed can also be fully considered;
(3) ARIMA model can capture the linear relationship in the data, and LSTM model can capture the nonlinear relationship in the data. We use the hybrid method of ARIMA and LSTM to predict the seasonally processed data. This model is to use the prediction error to make a small linear correction to the wind speed value of the nonlinear prediction of the neural network. Therefore, the proposed model can effectively solve the lag problem in very shortterm wind speed prediction and improve the accuracy of predicting multiple time scale data;
(4) The proposed model shows the best performance and is reliable under the verification of three types of data and the comparison of multiple models. In addition, the prediction results of three different time scales of wind speed series also point out the direction for our future research.
Wind speed series preprocessing
Wind speed has the characteristics of intermittent, randomness and volatility, as well as the characteristics of data loss and data redundancy caused by the acquisition process, particularly offshore wind speed, which directly leads to the time-consuming data processing and analysis and the inability to extract useful information. This paper chooses the offshore wind speed data with a sampling interval of 1 hour and a height of 50 m in Nanhui District of Shanghai from 1993 to 2019 as the research object. The visualization of time series data can provide valuable diagnosis for determining wind speed trend and seasonal variation. Figure 1 shows a box plot where maximum and minimum values, median value, upper and lower quartile values can be clearly observed. Figure 2 illustrates the wind speed distribution curve with time. In order to accurately and fully mine the data information, it is necessary to preprocess and statistically analyze the wind speed series.
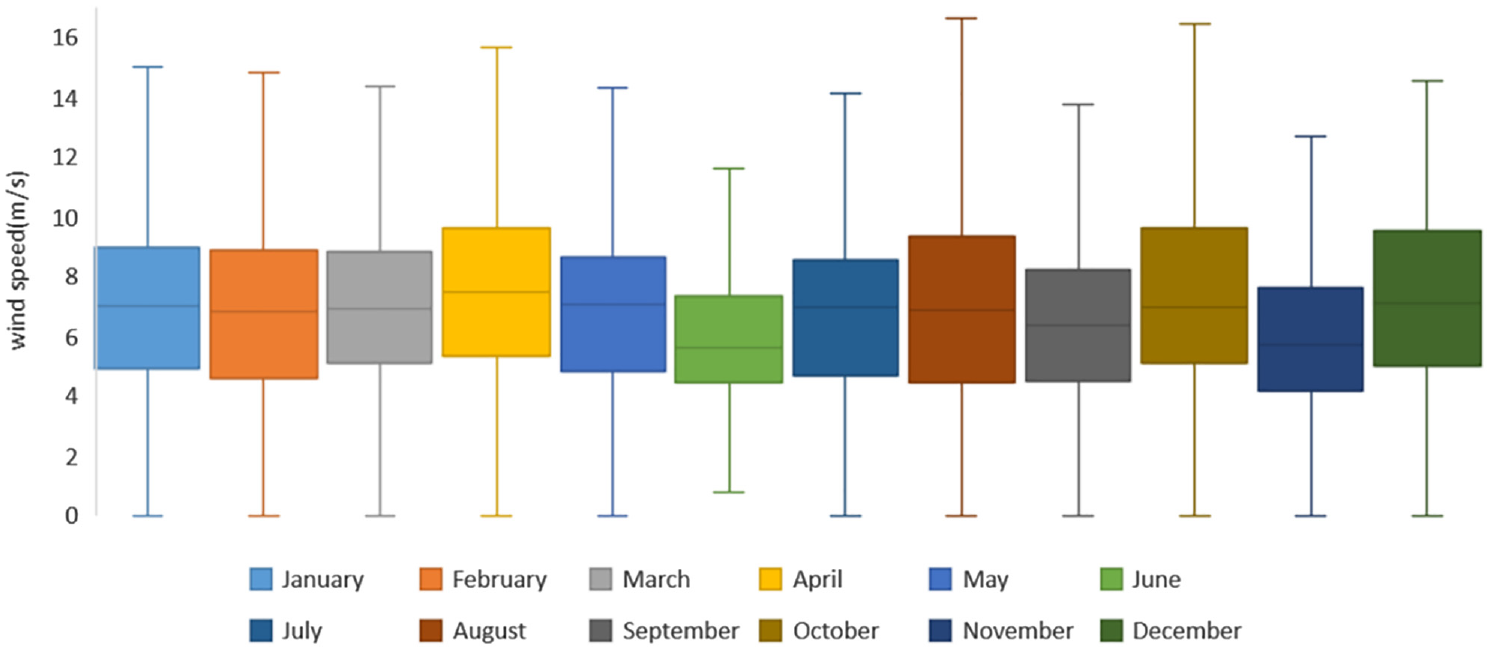
Box plot of wind speed time sequences.
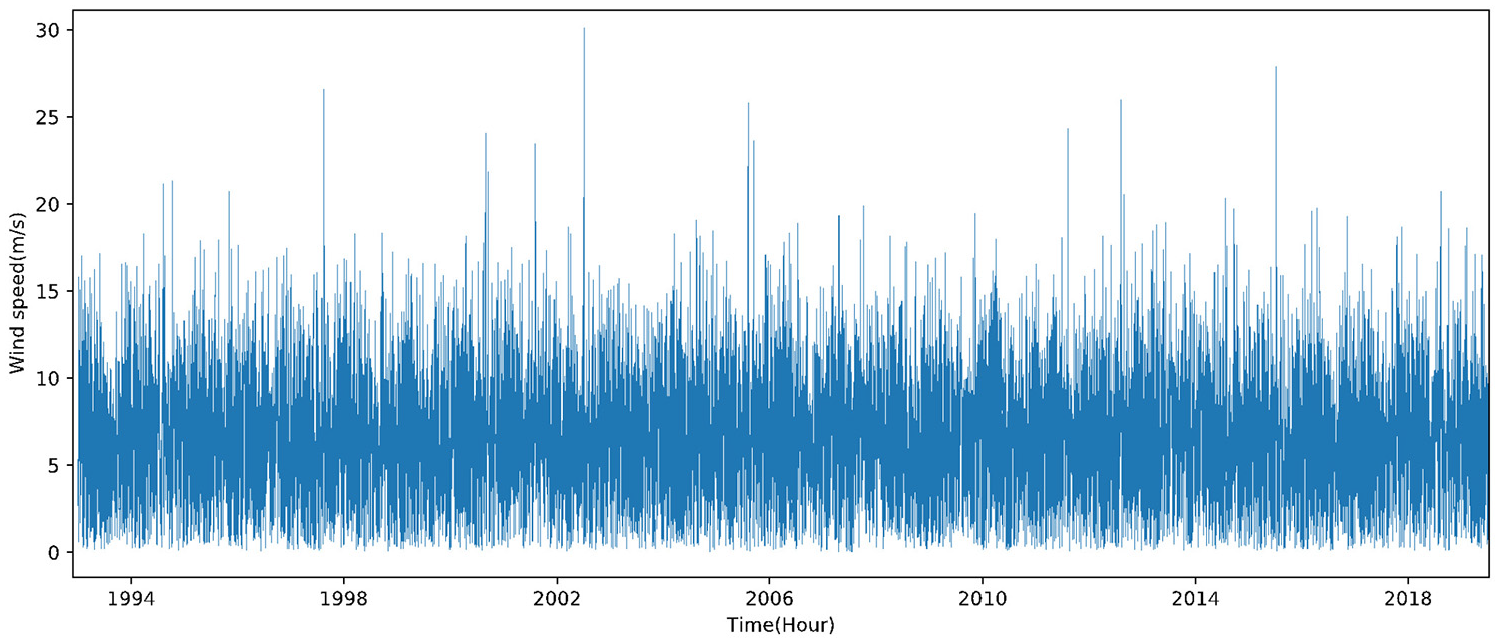
Line plot of wind speed time sequences.
Missing value and downsampling processing
First, we handle the missing values in the wind speed time series that are numeric types. Considering the missing value ratio is small and the data structure is relatively standard, the missing value is solved by using linear interpolation on its two nearest neighbors.
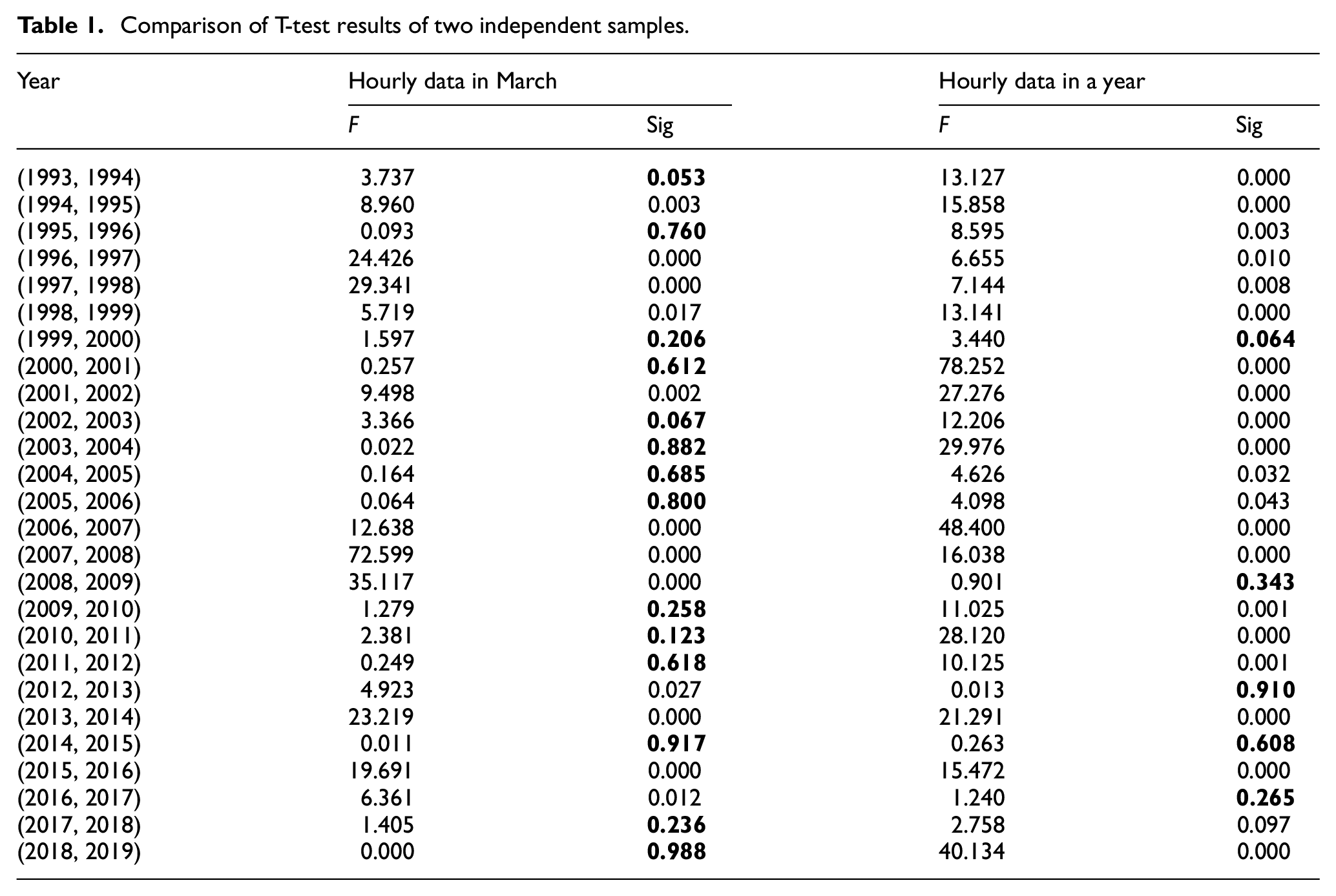
The prediction accuracy is related to the time scale of wind speed. For comprehensively investigate the proposed model, we downsample the raw wind speed sequence and converted it from high frequency sequence to the low frequency sequence, and divide it into three sub sample time series with different time scales, namely very shortterm, shortterm and longterm time series. For the very shortterm sub-sample series, we select the hourly data in March each year to calculate. In fact, affected by seasons, the annual wind speed series has strong nonlinearity, whereas the nonlinearity for the data over a short time such as a month would become weak. Here, considering the large amount of data, we adopt independent T-test method in Statistical Hypothesis Testing to test the data distribution differences between 2 adjacent years and 2 months corresponding to adjacent years respectively. The statistically significant level
Table 1 shows the T-test results of hourly dataset in March and hourly dataset in 1 year. The bold values in the table indicate that their Sig value is greater than 0.05. For the case of 1 year, the results with significant difference (Sig <0.05) are up to about 81% which is much bigger than the results of the case of March, which implies the distribution difference of hourly wind speed in March is smaller than that of a whole year. Therefore, for very shortterm time series, it is feasible to select the historical wind speed data in March rather than the data in 1 year for wind resource prediction.
Comparison of T-test results of two independent samples.
Data descriptive statistics
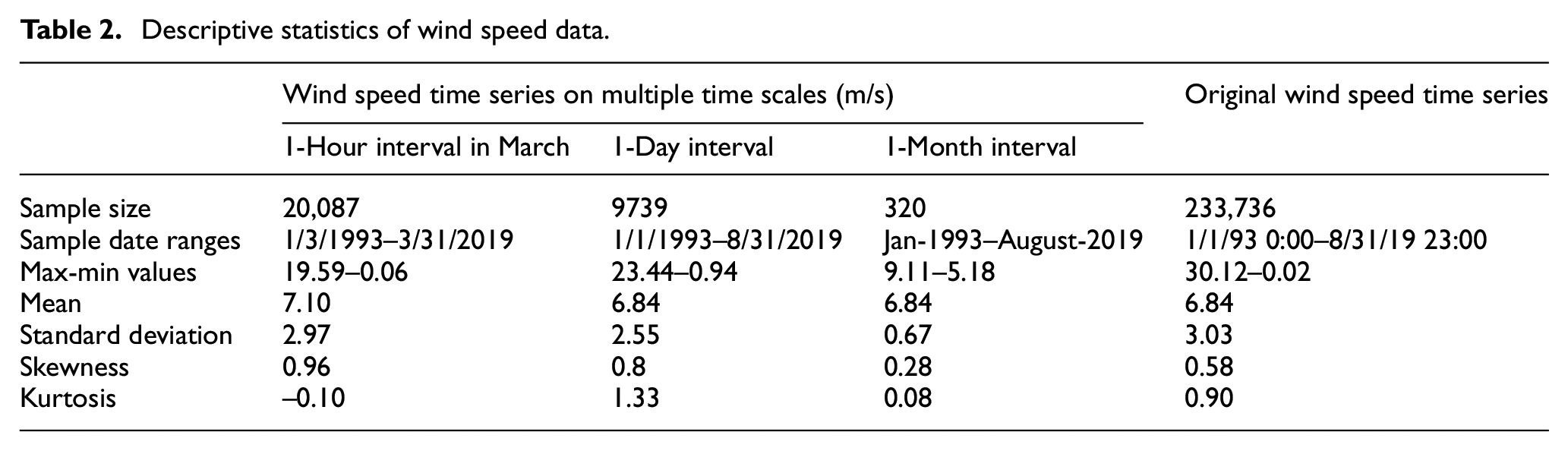
Here, we briefly give descriptive statistics of data on 3 time scales involving hours, days and months, in order to have an intuitive understanding of the samples to be studied. Table 2 shows the sample size, maximum / minimum value, expectation, root variance, coefficients of skewness and kurtosis of the 3 time scale data. It can be observed that three coefficients of skewness are positive, which indicates that their distribution patterns are all positive partial peaks. The coefficient of kurtosis of 1-hour interval in March is −0.10, which represents the peak of data distribution is wider than that of Gauss distribution. The coefficients of kurtosis of 1-day interval and 1-month interval are positive, which represents the peaks of data distribution are steeper than that of Gauss distribution. The standard deviation of hourly time scale series is the largest, followed by daily time scale series, which further shows that the wind speed time series has strong volatility.
Descriptive statistics of wind speed data.
Data normalization processing
For eliminating the influence of different ranges of the samples on the prediction accuracy, facilitate data processing and ensure faster convergence when the program runs. The data needs dimensionless normalization, which can be realized by linear mapping to the interval [0,1]

If the entire dataset is directly normalized, and then one part constitutes training set and the rest is test set, it is obvious that the data information in the training set will be leaked to the test set, which will lead to the problem of information leakage (Qian et al., 2019; Wang and Wu, 2016). This kind of information leakage will cause an illusion that the mathematical model has high accuracy.
In order to avoid the problem of data information leakage, as shown in Figure 3, the normalization of training set and test set is processed separately, where the training set accounts for 65% and the test set accounts for 35%.
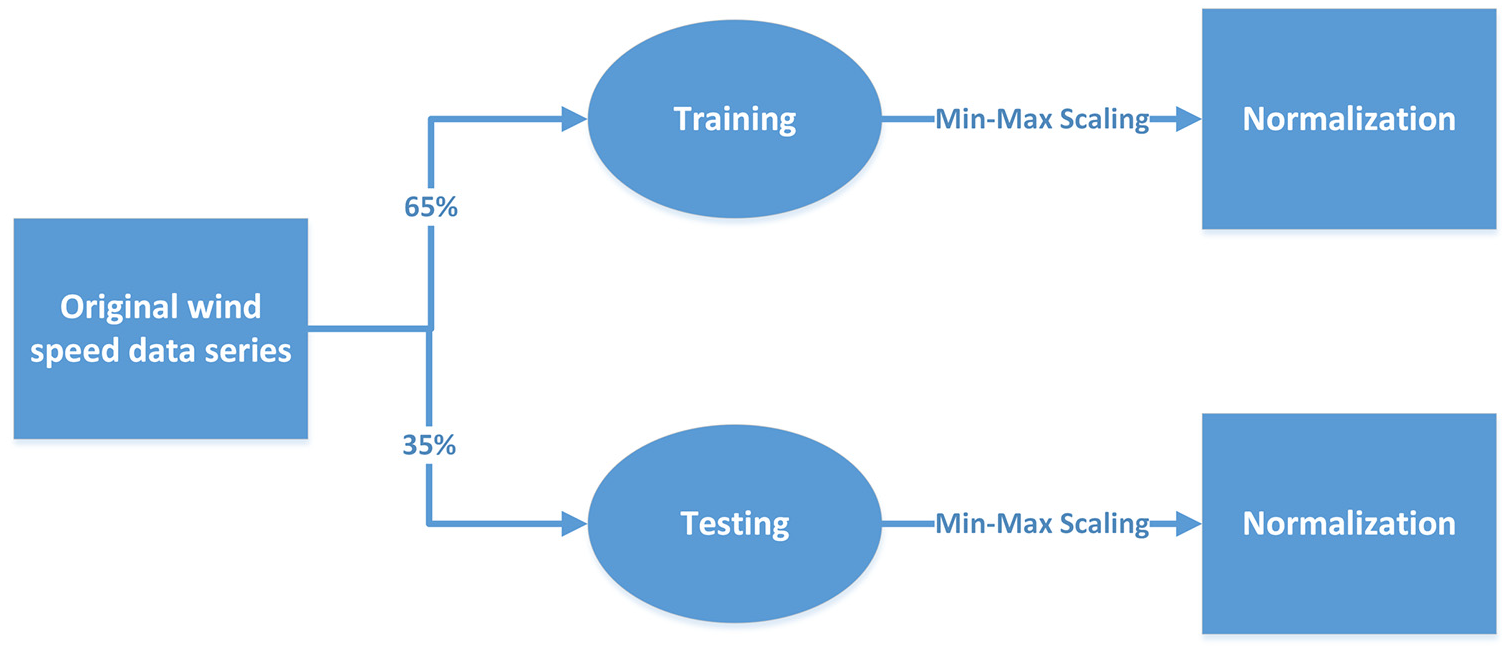
Separate normalization to avoid information leakage.
Processing of data stationarity
Time series can be classified into stationary and non-stationary sequences. Stationary sequence doesn’t basically include trend, in which trend refers to the law that the time series shows a continuous rise or decline over a long period of time, including linear trend and nonlinear trend. Specifically, if the values of mean, variance and covariance or self variance of sample time series do not change with time, which can also be considered to remain unchanged in the future, then the sample time series is called a stationary time series. Generally, we can transform non-stationary sequence into a stationary sequence with difference method.
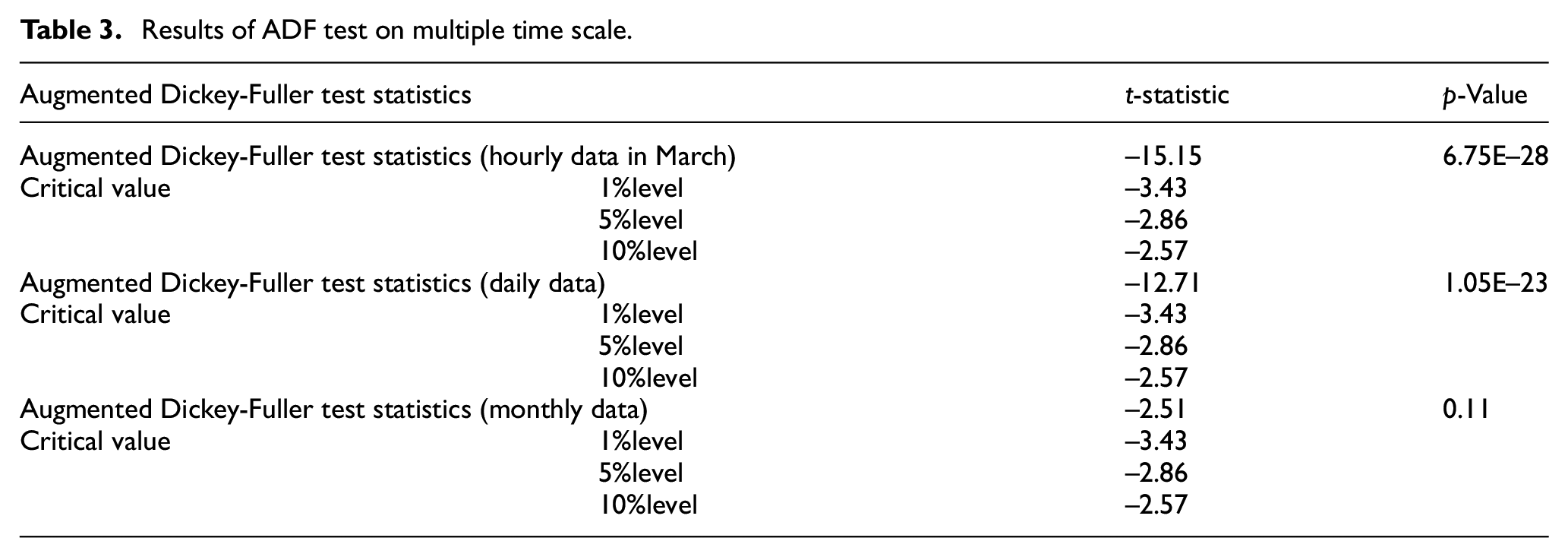
In the paper, the unit root ADF test method (Krämer, 1998) is adopted to check the stationarity. Table 3 shows the ADF test results of multi-time scale wind speed time series. It can be concluded from the table that only the p-value of monthly time scale sequence is greater than 0.05, which indicates that this time series is non-stationary. Because ARIMA is good at handling stationarity time series, a difference operation is performed as follows

Results of ADF test on multiple time scale.
until the time series is stable. And the other two stationary time series samples do not need differential processing.
Methodology
Since wind speed time series is seasonal, we use STL decomposition method to eliminate the seasonal factors. Moreover, wind speed time series has nonlinearity and randomness, which make it difficult to accurately predict future wind speed as well, so we propose to adopt the hybrid method of ARIMA and LSTM to increase the forecast precision.
The framework of the proposed model
Figure 4 shows the flow chart of our proposed model, which has the following four steps.
Firstly, as mentioned above, the raw wind speed time series are preprocessed, where the multi-scale samples involving hourly, daily and monthly data are obtained by downsampling processing.
Then, STL decomposition method is used to eliminate the seasonal components in the subsamples. In the process of STL decomposition, only the training set is used, and there is no risk of test set information leakage.
After seasonal adjustment for the 3 time scale samples, ARIMA is applied to predict the time series to obtain prediction values and residual series.
For the residual series, another part prediction results are obtained by using LSTM neural network. The final prediction results are obtained by adding the two part results computed by ARIMA model and LSTM neural network respectively.
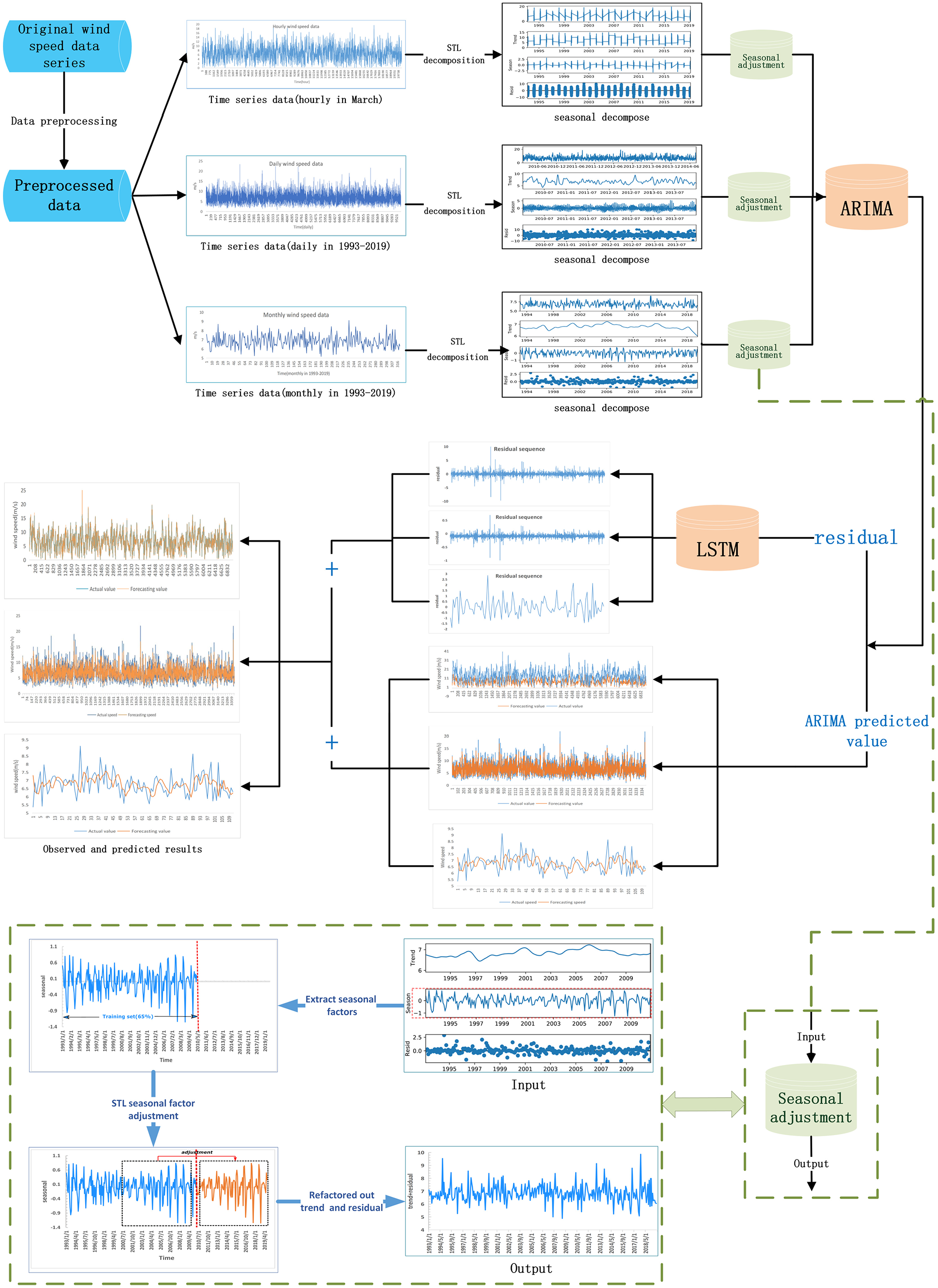
Framework of hybrid models.
STL
STL is a classical time series decomposition technique. Its significant advantage is that it can decompose the time series with outliers into robust components (Theodosiou, 2011; Yang et al., 2021). Based on STL method, the sequence can be decomposed into the following three components

where
The inner loop iteration is to update the corresponding seasonal and trend components. Each time the inner loop is completed, the robustness weights will be calculated in the outer loop, and then the weights will be used to reduce the impact of outliers on the update, which is the impact on the seasonal and trend components in the next inner loop. Figure 5 shows the steps of the inner loop (Yang et al., 2021):
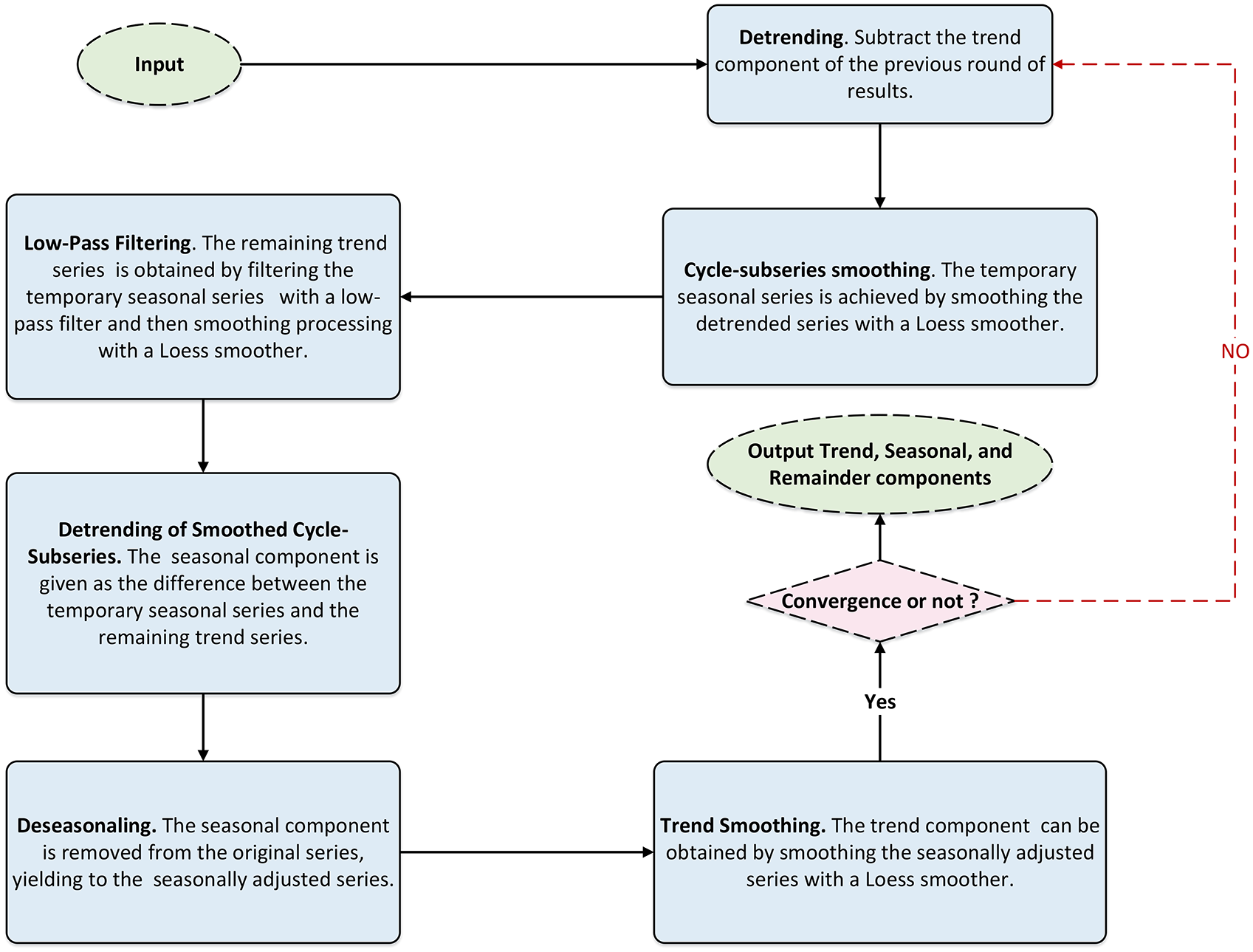
The inner loop of STL decomposition.
In the outer loop, the trend and seasonal components obtained in the inner loop are employed to calculate the remaining component through the formula
The above process is the implementation procedure of decomposing the raw sequence into seasonal components, trend components and remainder components.
ARIMA
ARIMA is a predicting technique of time sequence. ARIMA has the characteristics of differential transformation, autoregressive and moving average (Zhang, 2003). In addition, ARIMA is a method established by regressing the lagging value of dependent variables and the present value and lagging value of random error term (Box and Jenkins, 1970). Therefore, ARIMA model is usually used for wind speed prediction because it only needs endogenous variables and does not need other exogenous variables, as well as is easy to implement.
The basic idea of ARIMA is that the data sequence formed by the prediction object over time is regarded as a random sequence. Its formula is expressed as follows

The formula can also be expressed as follows

Eq.4 contains two important special cases of ARIMA model. When using ARIMA model, the most important thing is to determine the parameters of the model, that is,
LSTM
As a special RNN, LSTM proposed by Hochreiter and Schmidhuber (1997) can avoid vanishing gradient and exploding gradient problems that usually occur in initial RNN (You and Nikolaou, 1993). On this basis, Gers et al. (2000) added the forget gate to release the internal resources in the LSTM cell, so the current LSTM neuron includes three gates: inputting, forgetting and outputting gates, as shown in Figure 6. This structure can not only effectively mine and utilize the hidden information in dynamic time series, but also automatically store and delete time state information. The neuron of LSTM is like a special built-in memory block, which can extract the complex feature relationships between long-time series and short-time series (Gers et al., 2000; Hochreiter and Schmidhuber, 1997). Therefore, LSTM neural network has unique advantages in the processing of time series prediction (Chen et al., 2018).
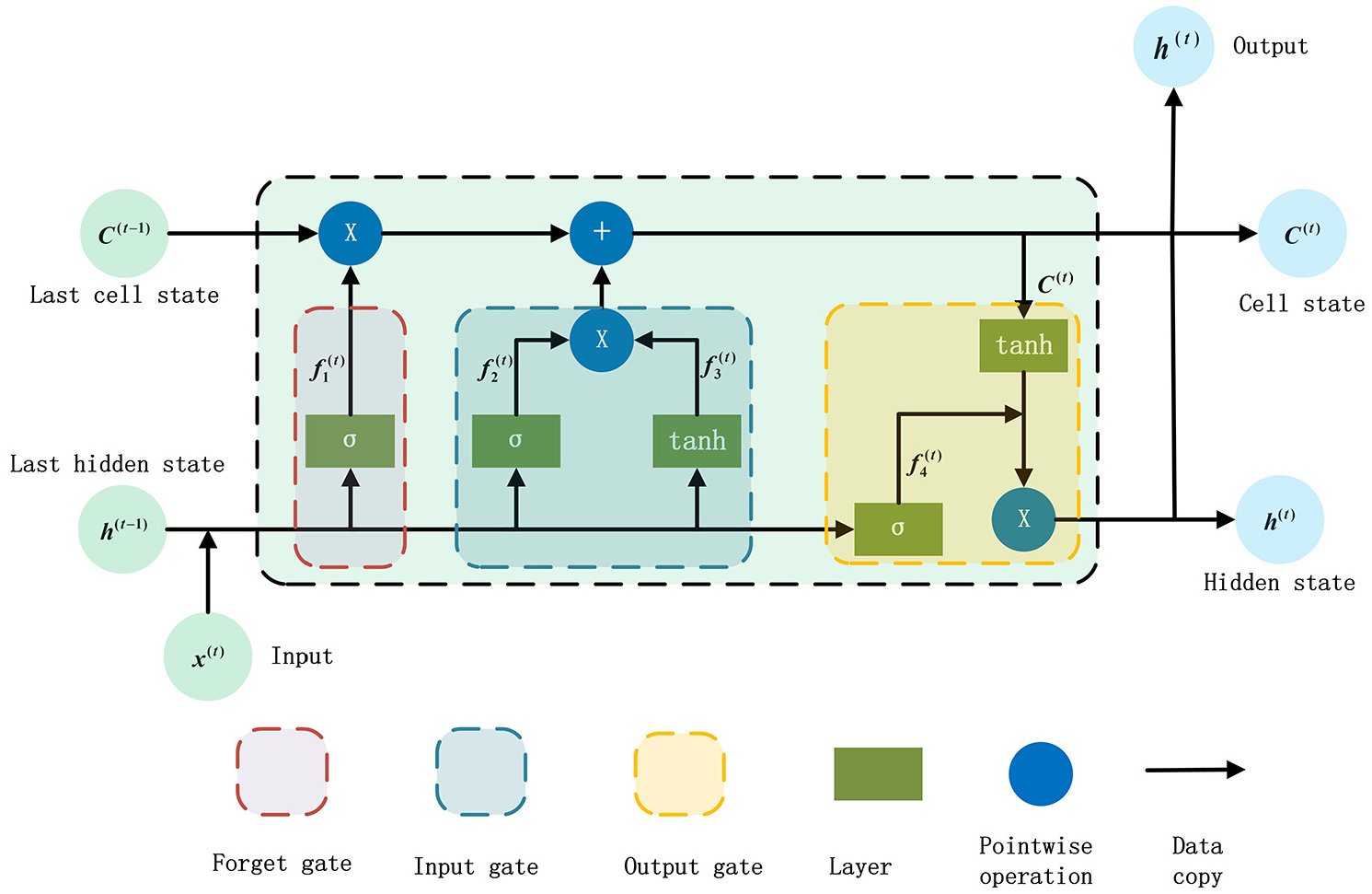
Internal structure of LSTM neurons.

where


Then, the new neuron state value



Experiments
This section briefly introduces the methods of seasonal adjustment and the configuration of each test method. In this experiment, the feasibility of the model is verified by three examples on different time scales. Training set consists of the first 65% of the data, and the remaining 35% of the data constitute the test set.
Seasonal adjustment
Monthly average wind speed distribution is shown in Figure 7, from which it can be found that the wind speed sequence has obvious seasonality. In order to make the wind speed prediction more accurate, the STL decomposition method is used to eliminate the seasonal characteristics. In the process of time series decomposition, the problem of information leakage must be paid attention to. Figure 8 illustrates our STL seasonal adjustment preprocessing data process, which can avoid information leakage. The specific implementation process is as follows. A part data from the target wind speed series

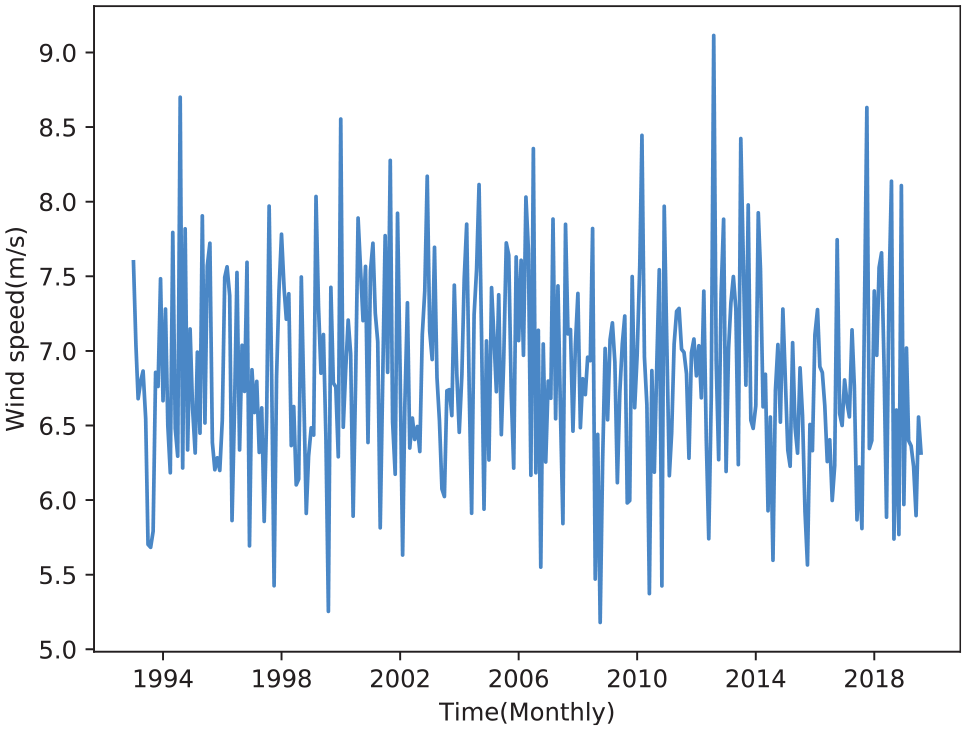
Monthly average wind speed from 1993 to 2019.
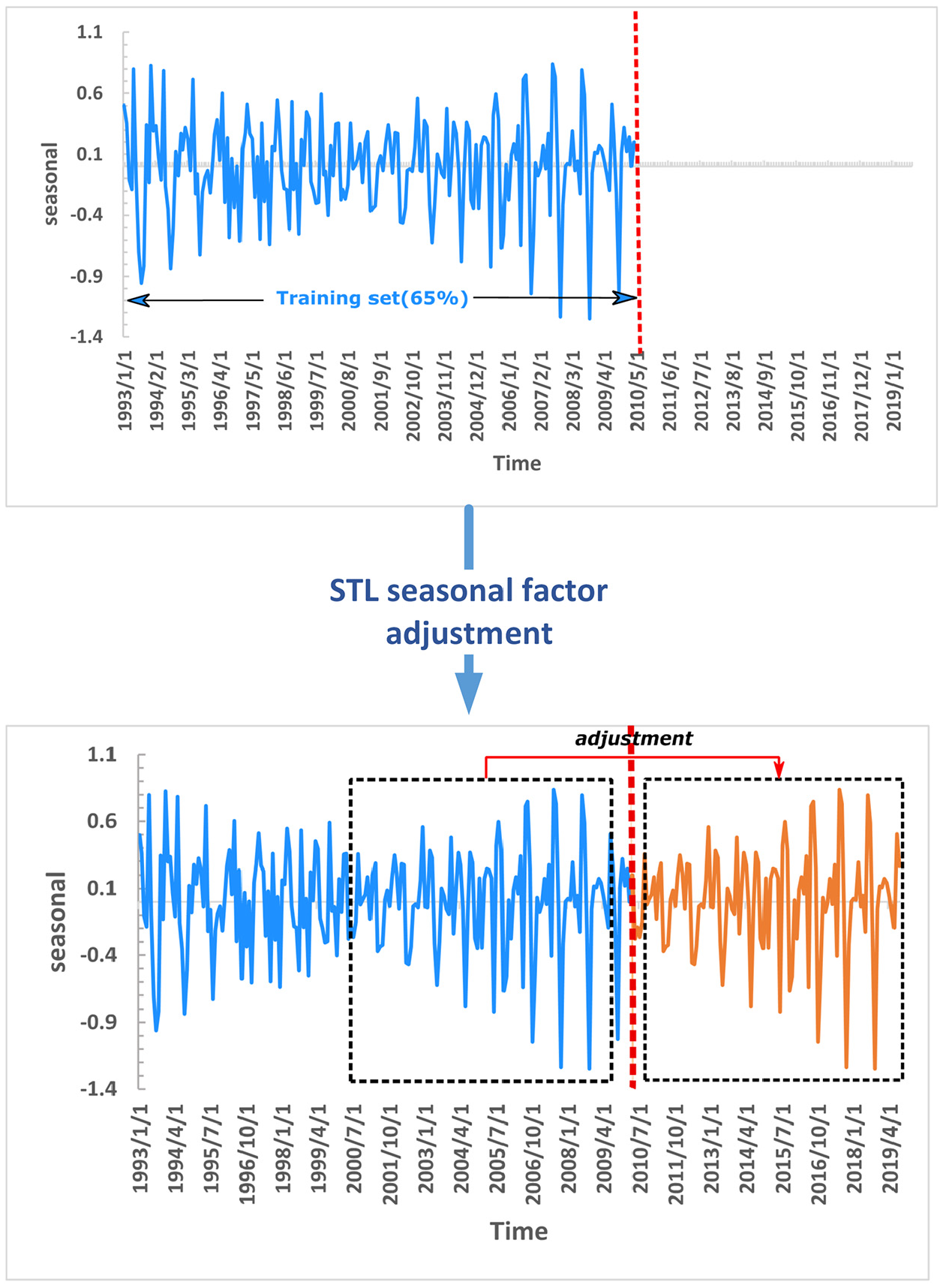
STL seasonal adjustment preprocessing data process.
STL adjustment is implemented on the training set

An example of wind speed time series for STL framework and decomposition is shown in Figure 9.
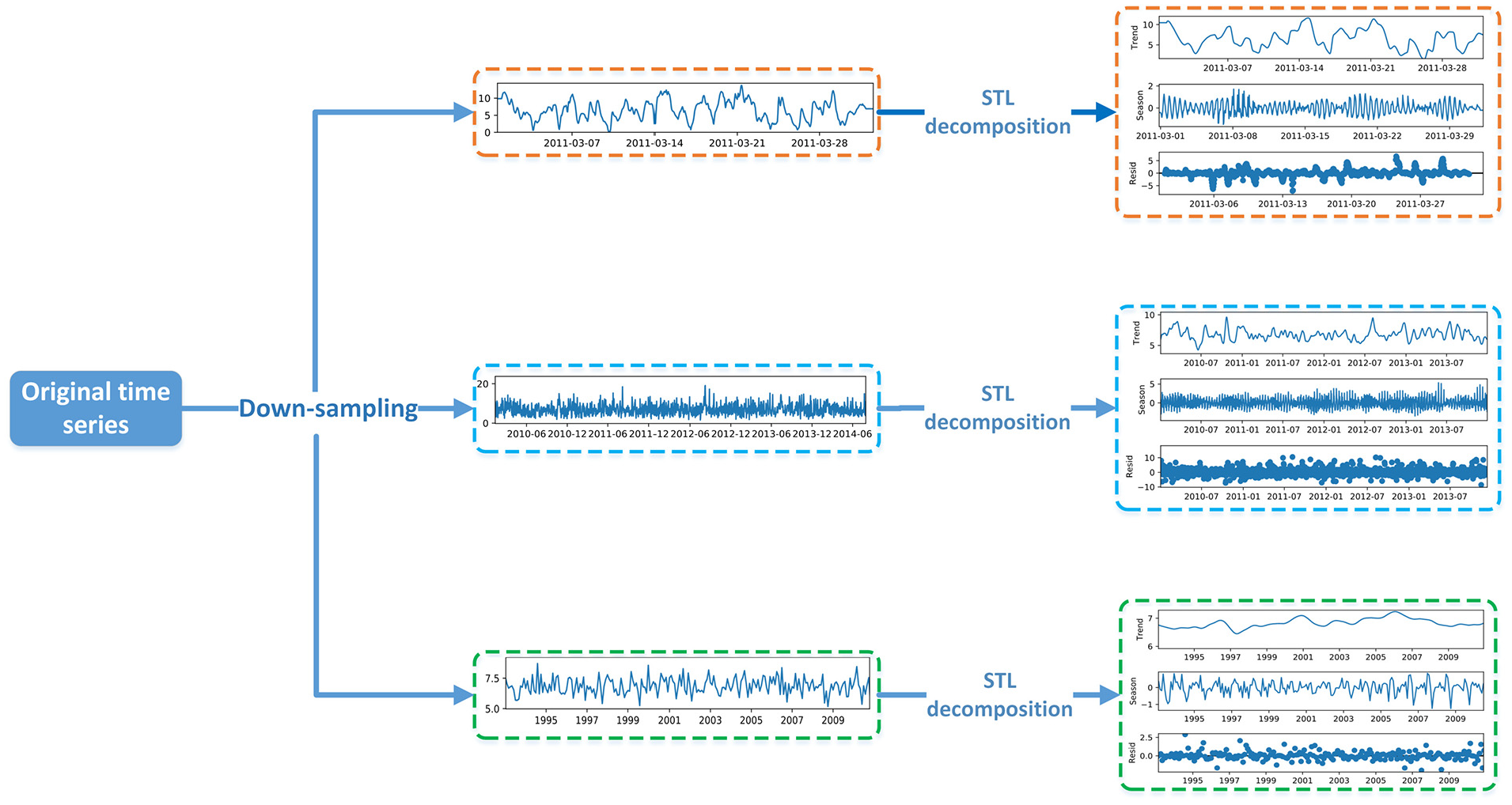
STL decomposition of wind speed series in training set.
Because the seasonal component

The output item of seasonal adjustment

After that, just substitute
Experimental parameter settings
Based on the proposed STL-ARIMA-LSTM hybrid method, this paper predicts three sub-sample data sets with different time scales. The performance of STL-ARIMA-LSTM hybrid model is comprehensively investigated by comparing with ARIMA model, LSTM model, STL-ARIMA model, STL-LSTM model, and ARIMA-LSTM hybrid model in each sample data set.
Some special parameters in the prediction model need to be determined in advance. In ARIMA model, the initial range of
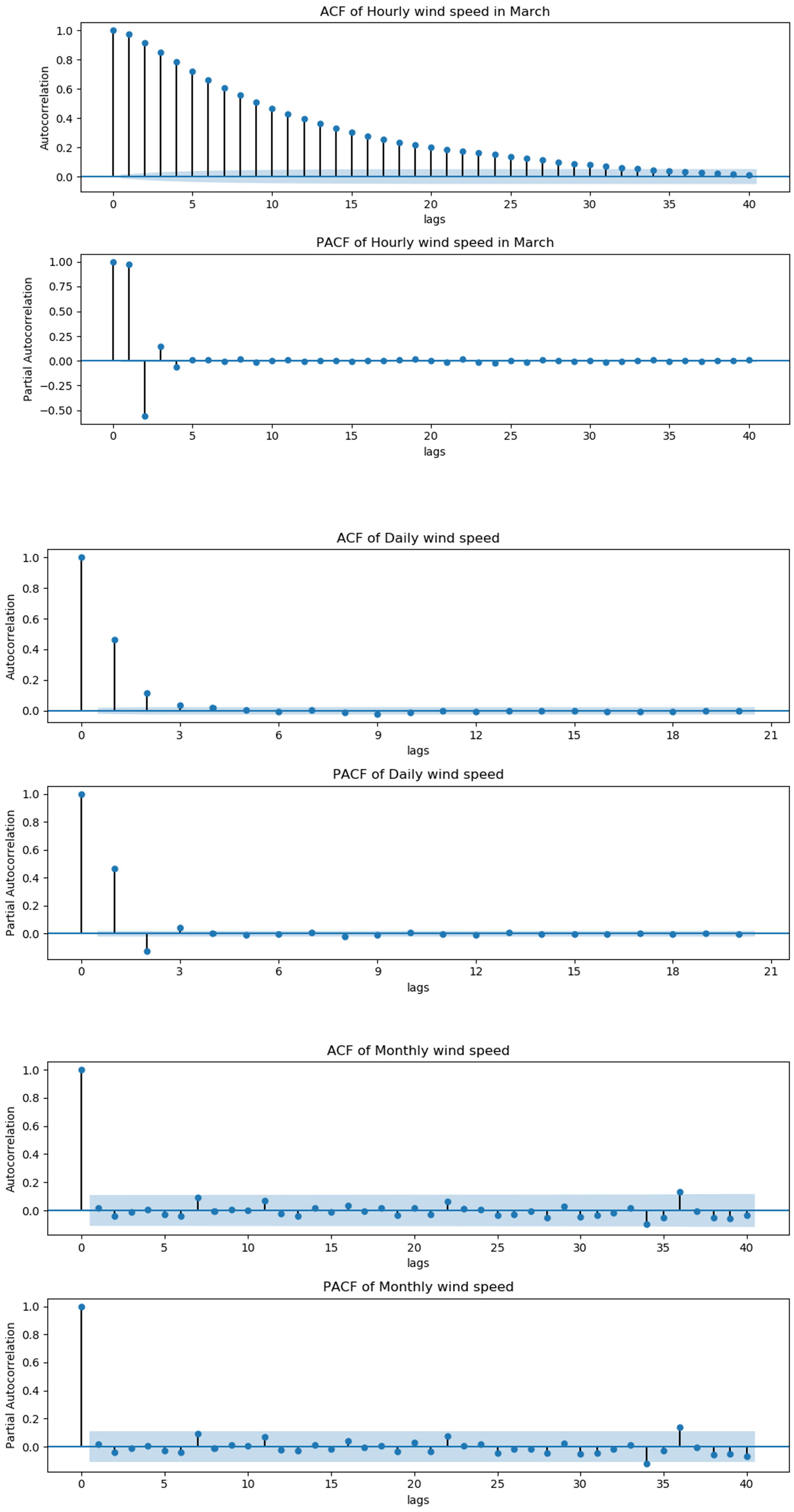
Autocorrelation and partial correlation graphs of sample time series.
Parameter values of ARIMA and LSTM models.

Results
In this article, we will use four model performance indexes, namely MSE, RMSE (Foley et al., 2012; Kavasseri and Seetharaman, 2009), MAE (Foley et al., 2012), and MAPE (He et al., 2021). These indexes can be used to evaluate the performance of the prediction model. Table 5 shows the formulas of different evaluation indexes, where
Forecasting evaluation indexes and their calculation formulas.

Case 1: Very shortterm wind speed prediction
In case 1, we selected the hourly wind speed series in March from 1993 to 2019 to constitute the data set. This wind speed series belongs to a very shortterm time scale type. Figure 11 shows the prediction results of ARIMA model, LSTM model, STL-ARIMA model, STL-LSTM model, ARIMA-LSTM model, and STL-ARIMA-LSTM hybrid model. It seems clear that the prediction results of all models are in good agreement with the actual wind speed time sequences. Compared with the other five models, the proposed model well deals with the lag of the predicted value, and fits the actual wind speed best. In particular, STL-ARIMA-LSTM hybrid model achieves the best prediction result, which can be further verified by error evaluation indexes. Figure 12 illustrates the values of error evaluation indexes including MSE, RMSE, MAE and MAPE for the six prediction models. Accordingly, these values are summarized in Table 6 which includes all evaluation index of very shortterm wind time series for eight different prediction models. And the values given in bold indicate the minimum error value. We also added the prediction results of RF and SVM models in this table. In this way, the prediction effect of this model can be more prominent.
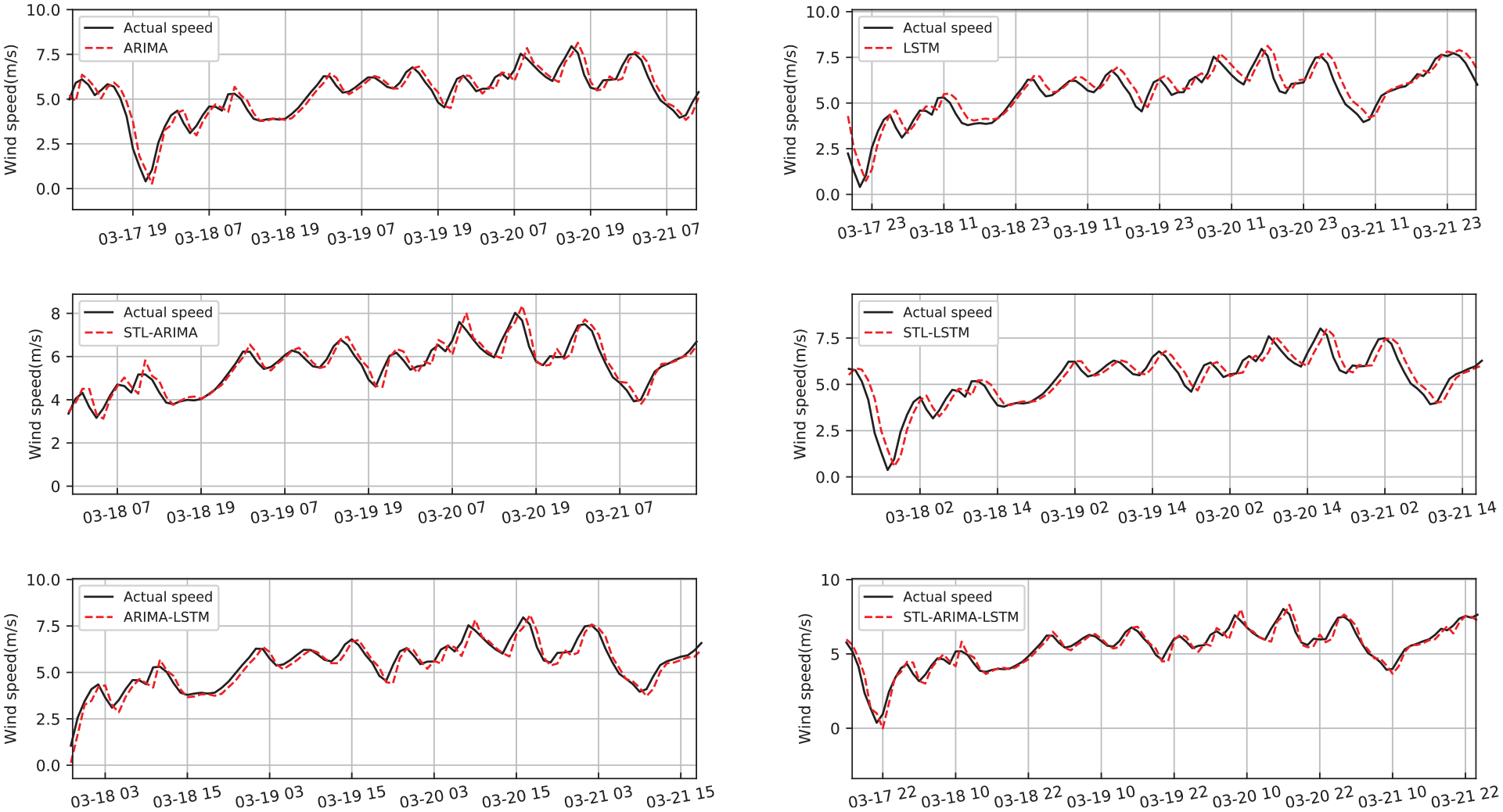
The wind speed forecasting results of very shortterm wind speed.
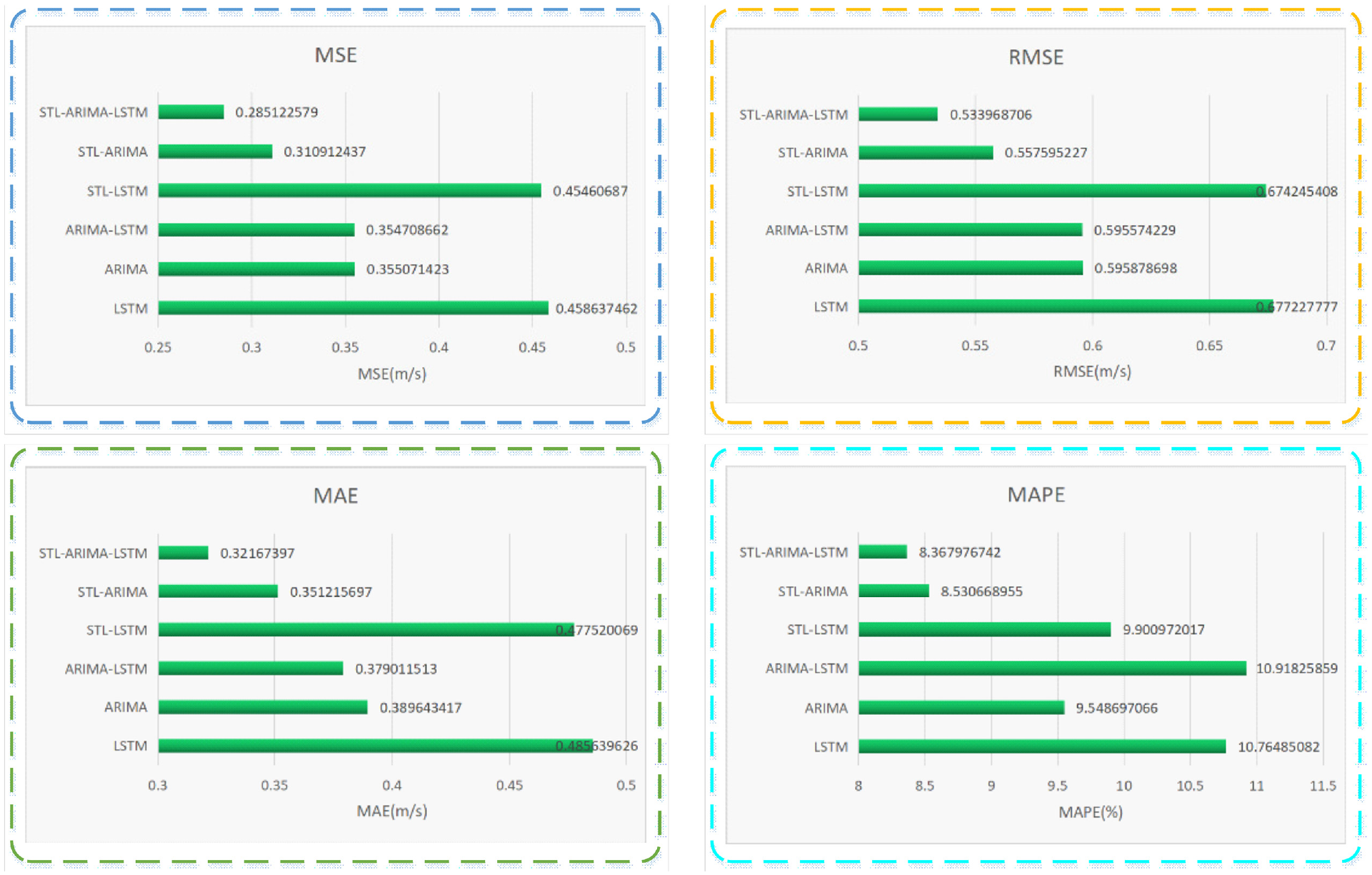
Histogram of forecast indexes of very shortterm wind speed.
Very shortterm forecasting performance indices and their definition.

From the results of evaluation indicators, the prediction results of the proposed model are better than those of RF and SVM. Therefore, in the Figures 11 and 12, we only consider the six comparison models related to this STL-ARIMA-LSTM model for comparison. In this way, the comparative analysis can be carried out layer by layer, which reflects the advantages of this model. For this very shortterm wind speed prediction, whether from Figures 11 and 12 or Table 6, we can see that the error of STL-ARIMA-LSTM hybrid model is the smallest compared with the other forecast models. In fact, MSE, RMSE, MAE, and MAPE of STL-ARIMA-LSTM model are 0.2851, 0.5340, 0.3217, and 8.3679%, respectively. The error of LSTM is the largest, where its MSE, RMSE, MAE, and MAPE are 0.4586, 0.6772, 0.4856, and 10.7649%, respectively. This also indicates that data preprocessing and seasonal component removal can greatly improve the accuracy of model prediction.
Case 2: Shortterm wind speed prediction
Case 2 investigates the daily average wind speed series from January 1, 1993 to August 31, 2019, which belongs to a shortterm time scale type. The last 35% of the data which form test set involve the wind speed time series from April 30, 2010 to August 31, 2019. Figure 13 shows the prediction results of ARIMA model, LSTM model, STL-ARIMA model, STL-LSTM model, ARIMA-LSTM model, and STL-ARIMA-LSTM model in comparison with the test data. Compared with 1-hour interval wind speed, 1-day interval wind speed fluctuates more, with more extreme values and the amount of data is also reduced, which greatly increases the difficulty of model prediction. Nevertheless, it can be observed that the change trends of the prediction results of six models are generally correct, although the wind speed prediction results of case 2 are not as good as those of case 1. Table 7 shows the results of shortterm wind speed prediction evaluation indicators for the eight models. Combined with the values of error evaluation indexes involving MSE, RMSE, MAE, and MAPE, as shown in Figure 14 and Table 7, the prediction results are all within a reasonable and acceptable range.
The wind speed forecasting results of shortterm wind speed.
Shortterm forecasting performance indices and their definition.

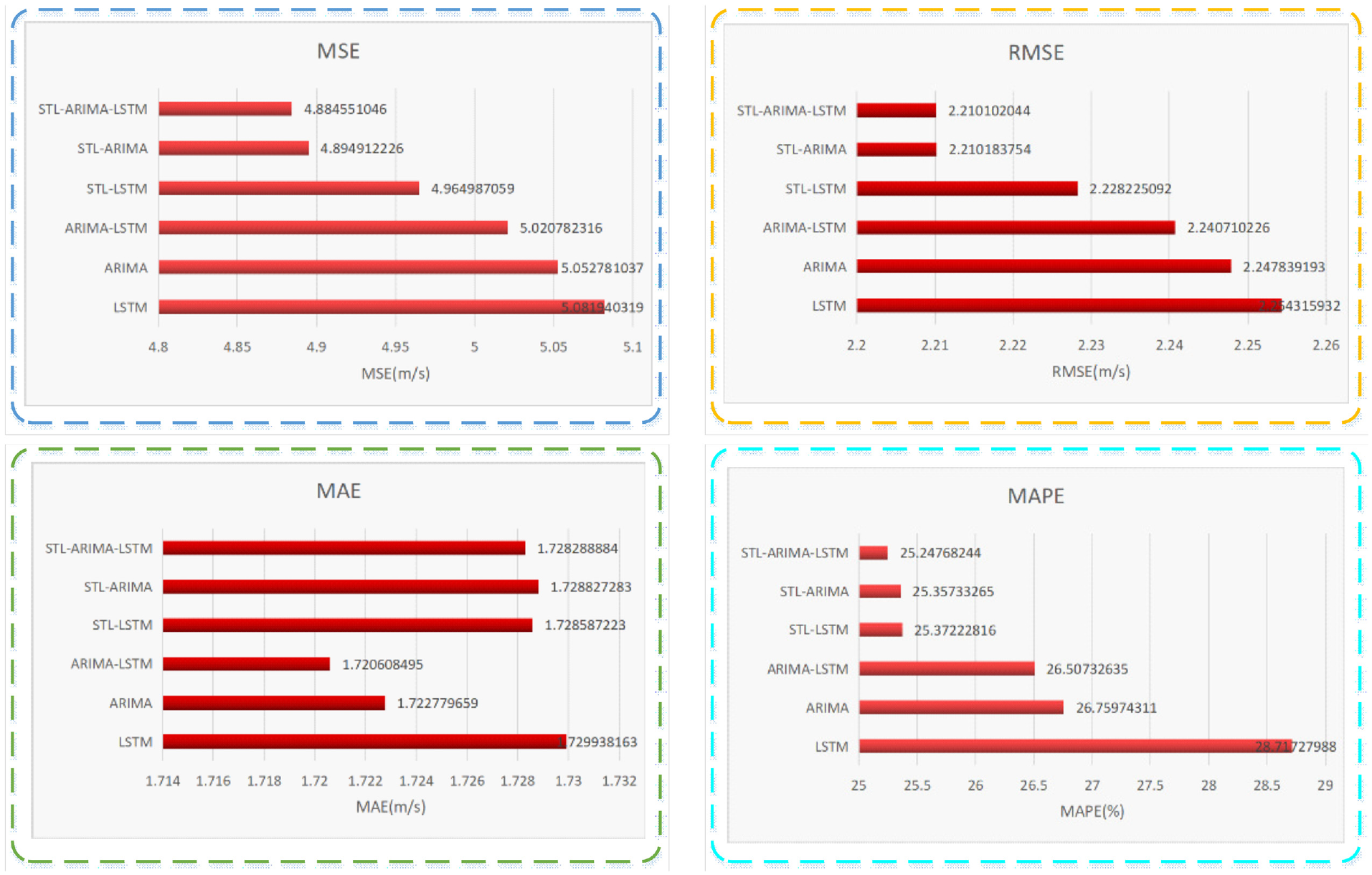
Histogram of forecast indexes of shortterm wind speed.
Among all the models, STL-ARIMA-LSTM model has the smallest error in terms of MSE=4.8846, RMSE=2.2108, and MAPE=25.25%, ignoring its MAE index with no obvious advantage. Furthermore, combined with the fitting effect between the predicted data and test data, the wind speed time series predicted by STL-ARIMA-LSTM model is closest to the actual wind speed.
Case 3: Longterm wind speed prediction
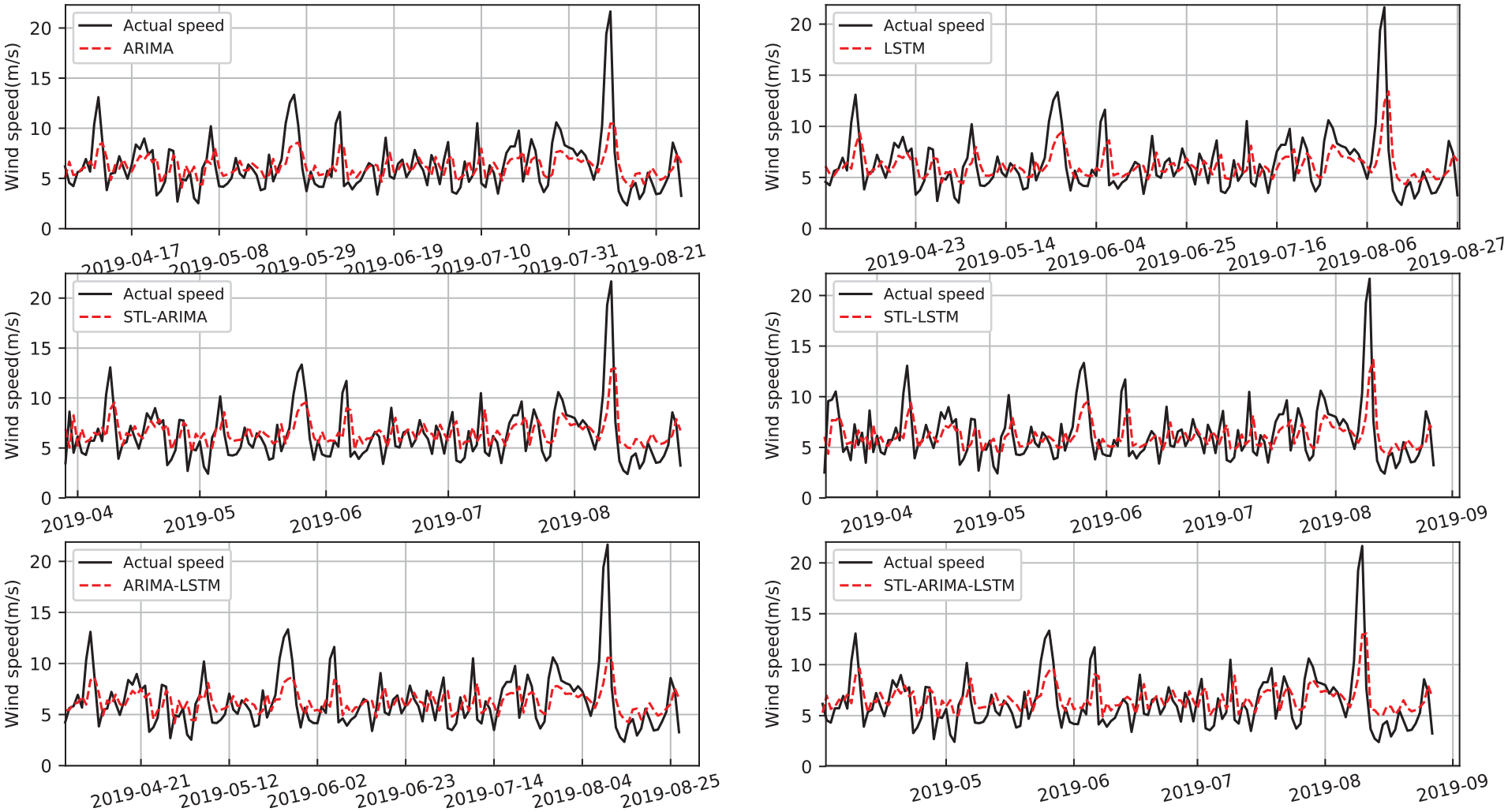
Case 3 selects the monthly average wind speed series from January 1993 to August 2019 to form the data set with longterm time scale type. The first 65% of the data which form the train set consist of the wind speed time sequences from January 1993 to March 2010. Figure 15 shows the prediction results of ARIMA model, LSTM model, STL-ARIMA model, STL-LSTM model, ARIMA-LSTM model, and STL-ARIMA-LSTM model for this longterm time sequences. Among these 3 time scales of wind speed time sequences, the uncertainty, intermittence and volatility of long-time scale wind speed series are the most sufficient and strongest, which poses a great challenge to the accuracy of prediction. Here, except that the new model STL-ARIMA-LSTM proposed better captures the periodic trend of longterm wind speed time sequences, the prediction models do not well capture the intermittence, shock and extreme value. Still, we observe that the prediction result curve of LSTM can better reflect the periodicity of time series than that of ARIMA, which indicates that LSTM has more advantage in predicting nonlinear time series, while ARIMA predicts better in linear time series.
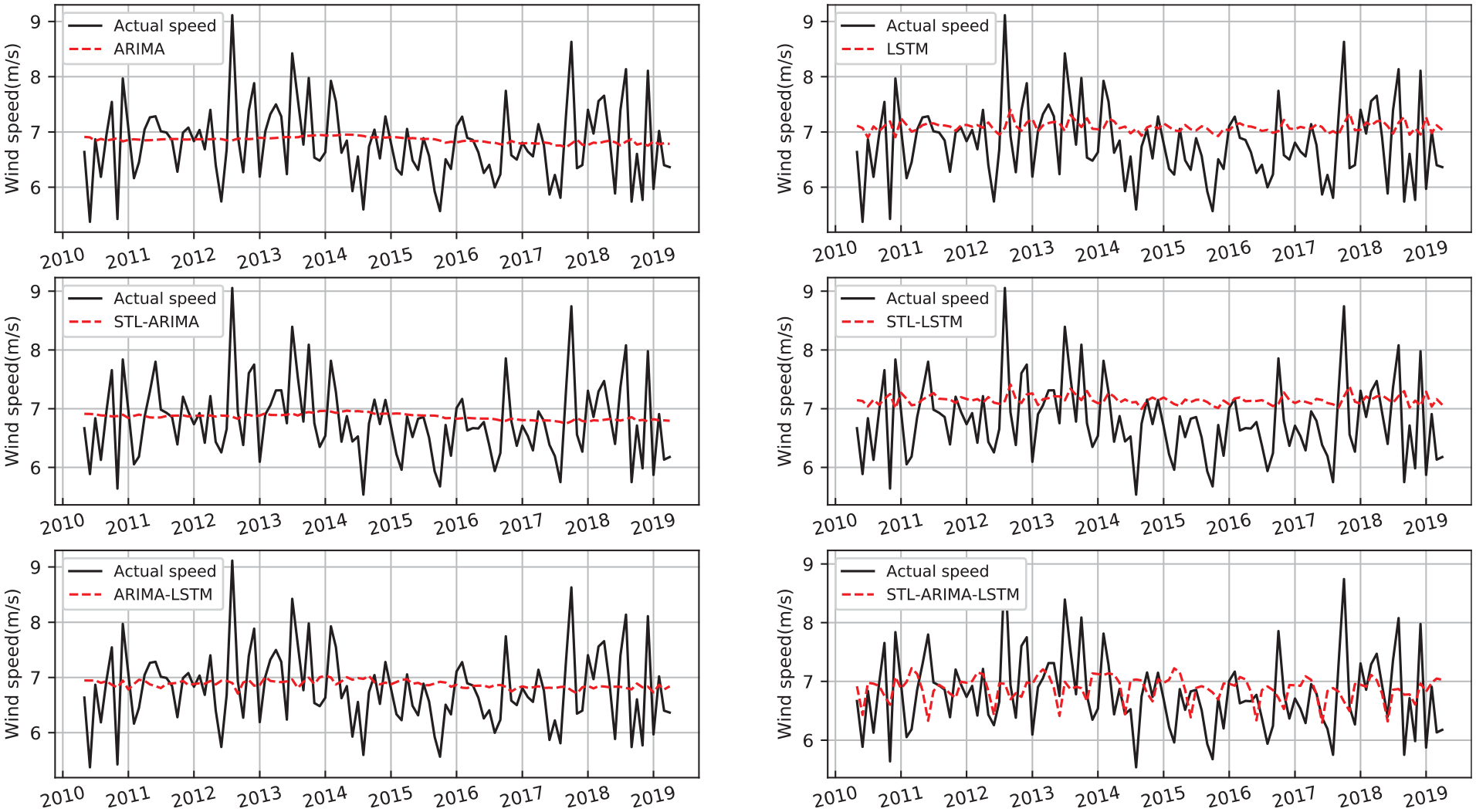
The wind speed forecasting results of longterm wind speed.
Table 8 shows the results of longterm wind speed prediction evaluation indexes for eight models. As can be seen from Figures 15 and 16 and Table 8, LSTM based on STL, namely STL-LSTM, has higher accuracy than LSTM without STL. Specifically, by comprehensively considering four performance evaluation indicators, STL-ARIMA-LSTM hybrid model has the best prediction accuracy, where the performance of STL-ARIMA-LSTM with MSE = 0.4149, RMSE = 0.6441, and MAPE = 7.1556% is obviously better than the other seven models. MAE value of STL-ARIMA-LSTM is slightly greater than those of STL-ARIMA and STL-LSTM, but the difference between the three models is not as obvious as that between the other three models without SLT. In conclusion, based on the analysis of performance evaluation indexes and prediction results, STL-ARIMA-LSTM model has the best prediction results for longterm wind speed time sequences, which has been better verified in very shortterm and shortterm wind speed predicting as well.
Longterm forecasting performance indices and their definition.

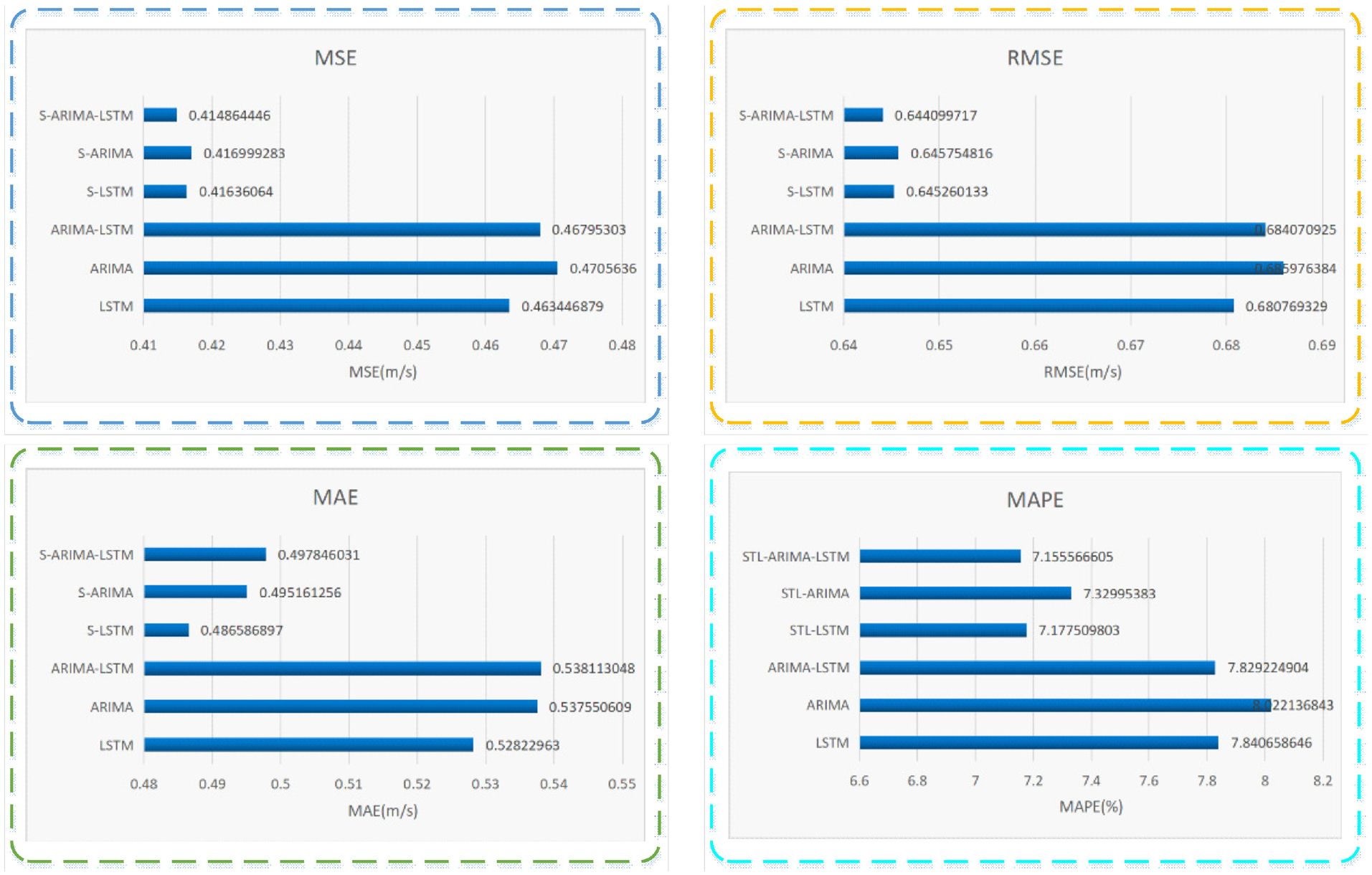
Histogram of forecast indexes of longterm wind speed.
Conclusions
This article presents a new STL-ARIMA-LSTM model for wind speed prediction on 3 time scales: very shortterm, shortterm, and longterm. The main work and conclusions are as follows.
In order to accurately and fully mine the data information, the wind speed time sequences is preprocessed and statistically analyzed. We handle the missing values by interpolation, perform the T-test to test the data differences between 2 adjacent years and 2 months corresponding to adjacent years, give descriptive statistics of data on 3 time scales to get an intuitive understanding on the distribution pattern and volatility of wind speed time sequences, and test the stationarity of dimensionless normalization data on 3 time scales by using ADF test method.
Since the wind speed time series has obvious seasonality, STL decomposition method is applied to eliminate seasonal component in wind speed time sequences, so it can achieve accurate prediction of wind speed. Especially, in the experiment, in order to avoid the problem of information leakage, we implement two strategies: (a) distinguishing the training set from the test set in the process of standardization; (b) only performing STL decomposition on the wind speed data of train set. For seasonally adjusted wind speed time series, ARIMA-LSTM hybrid model is proposed to predict the time series, which can make full use of the advantages of ARIMA in processing linear time series and LSTM in processing nonlinear time series. We refer to the proposed model as STL-ARIMA-LSTM hybrid model here.
Finally, STL-ARIMA-LSTM model is applied to compute wind speed time sequences with very shortterm, shortterm, and longterm respectively. Meanwhile, its performance has been validated by comparing with RF, SVM, ARIMA, LSTM, ARIMA-LSTM, STL-ARIMA, and STL-LSTM models. The results reveal that the STL-ARIMA-LSTM hybrid model has the highest accuracy and the highest resolution for the trend and periodicity of wind speed series on 3 time scales among eight prediction models. In the 3 time-scale wind speed time sequences prediction, the proposed model has the best prediction result on the 1-hour interval wind speed time sequences, and can solve the problem of lag in forecasting. For 1-day interval and 1-month interval wind speed time sequences, as the time interval of data increases, the uncertainty, intermittence, volatility increase sharply and the amount of data decreases. This leads to the prediction models can not well capture the intermittence, extreme value and volatility with high frequency and wide amplitude, whereas STL-ARIMA-LSTM better captures the periodic trend of different time intervals wind speed than the other seven models.
In the experimental analysis of three cases, we found that due to the different time scales of wind speed data, the fluctuation and amplitude of data are very different, which also affects the accuracy of model prediction. Therefore, when predicting the wind speed, we can first try to calculate the wind speed series on a longterm time scale to achieve an overall grasp for the problem, and then handle the strong intermittence, volatility with high frequency and wide amplitude, and outliers in the wind speed by gradually adjusting the time scale.
Footnotes
Appendix
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science and Technology Project of State Grid Shanghai Municipal Electric Power Company (No. 52090R19000C).