
Abstract
Due to the noise uncertainty, the conventional point prediction model is difficult to describe the actual characteristics of wind speed and lacks a description of the wind speed fluctuation range. In this paper, the kernel density estimation according to its error value is given, and then its fluctuation range is found to combine the prediction results of the test set to get its prediction range. Firstly, the singular spectrum analysis (SSA) is introduced to conduct the noise reduction, and variational modal decomposition (VMD) is performed to handle the sequences, then an improved slime mold algorithm (SMA) is proposed to optimize the VMD, and the stochastic configuration networks (SCNs) is applied to perform the prediction. Finally, the interval prediction results are calculated by fusing the point prediction error and kernel density estimation. The experimental results demonstrate that the proposed method can effectively reduce the noise interference in the wind speed prediction.
Keywords
Introduction
Research background
Wind energy is a new type of energy with sustainability, which is conducive to the development of a low-carbon economy, and has attracted much attention worldwide in recent years with its great potential. The accurate wind speed prediction is beneficial to the large-scale application of wind resources to power systems (Cui et al., 2020). However, wind power generation depends to a large extent on the variation of wind speed, which is difficult to be used effectively due to its short duration, poor sustainability, and lack of stability, and also makes it more difficult to integrate wind power into the grid (Memarzadeh and Keynia, 2020). Short-term wind speed prediction is the key to alleviating this problem; therefore, improving the accuracy of wind speed prediction is beneficial for wind power system scheduling and is important for the application of wind energy (Li et al., 2018).
Machine learning is a popular field of artificial intelligence research, and models such as neural network (BP) (Emeksiz and Tan, 2022), support vector machine (SVM) (Yousuf et al., 2022), and random forest (RF) (Han et al., 2018) can enhance the extraction of nonlinear features of wind speed series with their powerful nonlinear fitting ability, and compared with the above two methods, artificial intelligence methods can effectively improve the prediction accuracy of short-term wind speed. The combination of prediction models and other algorithms has become the mainstream direction in the field of wind speed prediction research. However, the actual wind speed detection devices are affected by the environment, and the collected data are often mixed with a large amount of noise, which seriously interferes with the prediction accuracy of wind speed. In this paper, a wind speed prediction method to reduce noise uncertainty is developed.
Related works
Data preprocessing methods are becoming increasingly popular in models for predicting wind speeds. The main purpose of data preprocessing is to decompose the wind speed data to reduce the effect of nonlinear effects. Zheng et al. (2021) achieved the decomposition of wind speed signal by the VMD method, which further extracted the time-frequency information to achieve wind speed prediction. Wang et al. (2021) proposed a two-stage data preprocessing method by VMD and Sim Geometric Mode Decomposition (SGMD), and the proposed method is experimentally demonstrated to be suitable for nonlinear wind speed analysis. In addition, signal decomposition methods have also been applied to noise reduction. Liang et al. (2022) decomposed the signal by the VMD method and extracted feature vectors based on IMF signals, and finally, it was experimentally demonstrated that the VMD method not only effectively reduces noise interference but also effectively differentiates time-frequency information.
Nowadays, swarm intelligence optimization algorithms have been studied more deeply, and more and more emerging algorithms have been proposed: sparrow search algorithm (SSA) (Xue and Shen, 2020), arithmetic optimization algorithm (AOA) (Agushaka and Ezugwu, 2021), slime mold algorithm (SMA) (Li et al., 2020), fruit fly optimization algorithm (FOA) (Pan, 2012) and its combination with honey badger algorithm (Li et al., 2024) etc. Based on the continuous development of swarm intelligence optimization algorithms, research on optimized prediction models has received extensive attention. Li et al. (2022b) applied the improved gray wolf optimization algorithm (IGWO) to optimize the parameters of the LSTM model and verified that the proposed hybrid prediction model has the good predictive capability. Han et al. (2022) performed an optimized convolutional neural network (CNN) and bidirectional long and short-term memory network (Bi-LSTM) by grid search (GS) method to complete the prediction. Li et al. (2022a) decomposed the wind speed by VMD and used the particle swarm optimization (PSO) method for each modal component to the Bi-LSTM prediction model to the optimization, proving that the PSO-VMD-Bi-LSTM model is robust to the uncertainty prediction. Wang et al. (2022) decomposed the wind speed series by CEEMDAN, followed by RLMD for the quadratic decomposition of the unsteady series, and constructed the improved whale optimization algorithm (IWOA) optimized LSTM prediction model for each subsequence. Zhang et al. (2022a) decomposed the wind speed time series into multiple intrinsic modal functions (IMFs) by VMD, and used IWOA to optimize the QRGRU model.
However, some machine learning methods in wind speed prediction still have shortcomings. Li and Han (2018) proposed that SVM has problems with poor generalization performance and serious overfitting; BP neural network, as one of the traditional neural networks, has the defects of complex network structure, a large number of hidden layers, long training time, poor generalization ability; Deep learning models CNN and LSTM have high prediction accuracy, but their operation time complexity is too high. Therefore, these prediction models are not the optimal choice for us. Wang and Li (2017) proposed a stochastic configured network in 2017, which gradually increases the hidden layer nodes through the supervision mechanism to ensure the general approximation ability. As a kind of random weight vector network, it has the advantages of efficient operation and strong generalization ability. Therefore, compared with the above models, SCNs are more suitable for wind speed prediction.
Our works
To address the problem that wind speed data containing uncertainty noise can affect the prediction accuracy, this paper proposes an interval prediction method. Firstly, the SSA combined with the improved SMA is used to optimize the VMD to decompose the wind speed sequence into some subsequences, then the SCNs is used to predict each subsequences, and the prediction results are aggregated, and finally, the prediction interval is constructed by the point prediction error and kernel density distribution fitting strategies. The main contributions of this paper are as follows:
(1) An interval prediction method based on point prediction error and kernel density estimation is constructed to reduce the influence of noise uncertainty and improve the prediction accuracy.
(2) An improved slime mold algorithm with multi-strategy fusion (TASMA) is proposed, which has a faster convergence speed and a higher optimization-seeking accuracy.
(3) A data decomposition method based on SSA combined with optimal VMD is designed, to solve the problem that the parameters of VMD are difficult to be determined accurately.
The rest of the framework of this study is organized as follows. Section 2 details the problem and solution proposed in this paper, and presents the wind speed data hybrid prediction model. Sections 3-5 introduce the model principles, SMA fundamentals, improvement mechanisms, and interval prediction principles. Section 6 provides a discussion related to the experimental prediction of the data for the one seasons. Finally, Section 7 concludes the paper.
Propose solutions
Problem statement
In practical application, the wind turbine signal contains mechanical noise, aerodynamic noise caused by weather, sensor transmission interference and other influences. Wind speed noise is generally a kind of data with low amplitude and more intense vibration, which will make the original data bias, increase the complexity of the sequence. Wind speed noise will disrupt the hidden information of the entire data set, and it is difficult to estimate. Its data has unknown, complex and other characteristics, which will increase the difficulty of the later wind speed prediction.
Solutions
Wind speed is affected by the noise disturbance, and the conventional point-based prediction models lack a description of the range of future wind speed fluctuations. Wind speed interval prediction can give confidence intervals, thus reducing the uncertainty of such disturbances. In this paper, we will estimate the kernel density of the training set error, set the confidence interval, calculate the upper and lower bounds of the speed interval, and finally obtain the interval range of wind speed prediction. The predicted model components are combined and superimposed to find their training errors, and the confidence intervals are set according to the kernel density estimation to find their wind speed interval ranges. Finally, the resulting interval is used to describe the wind speed affected by the noise, minimizing the effect of its randomness and uncertainty.
Methodology
The methods involved in this study, such as SSA, VMD, and SCNs, are briefly described below.
SSA
A finite-length one-dimensional time series

The covariance matrix of the trajectory matrix is firstly calculated according to equation (2).
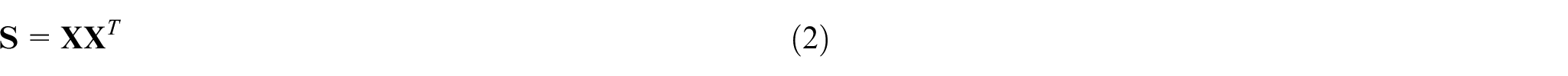
Find the matrix

where
Divid the set of subscripts {1,2,…,

The grouping matrix

VMD
VMD defines the eigenmode function (IMF) as an amplitude-modulated frequency modulated signal

where

where
The Lagrange multiplicative operator
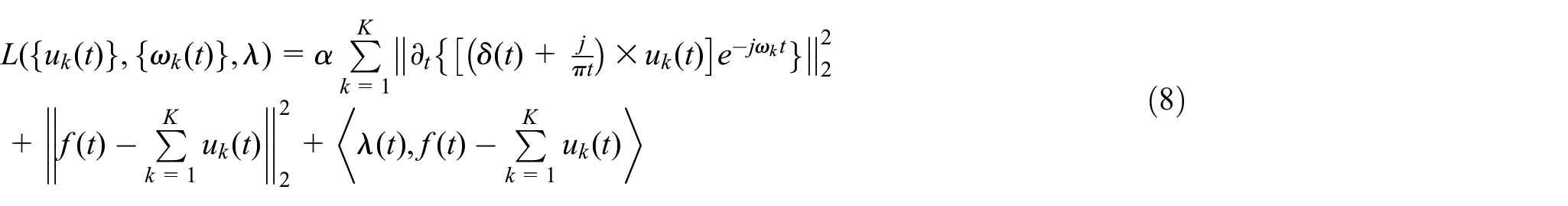
After the iteration, the expressions of



where

where
Stochastic configuration networks (SCNs)
SCNs proposed by Wang and Li (2017), are incremental stochastic learning neural networks of the RVFLN, which solves its problem of inappropriate settings for random parameters. The structure of the SCNs is shown in Figure 1.

The flow chart of SCNs.
Given a training set dataset

where
Based on the objective function

SCNs require random assignment of input weights

where

Finally, based on the obtained

where
Improved SMA with multi-strategy fusion
SMA
The position update formula of slime mold in the near food stage is:

where

where
The value of

where
The weight coefficient


where
Based on the above theories, the position update formula of slime molds is as follows:

where
Some improvements
Population initialization based on Fuch mapping backward learning
Swarm intelligence algorithms usually use a random strategy of distribution, which can lead to uneven distribution of populations and poor diversity. Fuch mapping can enrich the diversity of populations and enhance the traversal of population initialization. Using the Fuch chaos mapping to generate

where

where
Then the reverse learning is used to generate the reverse population by:

where
Adaptive adjustment of random selection
The original SMA randomly selects two individuals from the population for position update with the parent to generate children, and this random selection increases the global search ability of the algorithm in the early stage but is not conducive to the later convergence of the algorithm. To enhance the convergence of SMA, the selection range of individuals should decrease with the increase in the number of iterations. The selection range parameter

where
Whale spiral mechanism
To better balance the development and search of the SMA, a whale spiral search strategy is introduced by

Depending on the parameter conditions, the modified position update equation is defined by

Expanding global search capability
To enhance the development capability of the underlying artificial swarm, the optimal position guidance strategy is chosen to improve the update mechanism, and there is:

where
According to equation (30), the late search capability is expanded and the effect of falling into local extreme value points is reduced.
Main steps of improved SMA with multi-strategy fusion (TASMA)
Main steps of TASMA algorithm are shown in the below.
Step 1. Parameter initialization: set the search upper bound
Step 2. Initialize the population: the Fuch mapping reverse learning generates the initial population.
Step 3. Calculate the fitness of each individual of the population and rank them, record the best fitness
Step 4. Select the range of population with better fitness according to equation (27).
Step 5. Update the candidate solution positions according to equation (29).
Step 6. Update the population according to equation (30) and retain the better individuals according to the greedy strategy.
Step 7. Terminate the algorithm if the iteration condition is satisfied, otherwise repeat Steps 3–6.
Step 8. Output the optimal value and the algorithm ends.
The pseudocode of the improved TASMA algorithm is shown in Algorithm1 .
TASMA algorithm

The flow chart of the improved TASMA algorithm is shown in Figure 2.
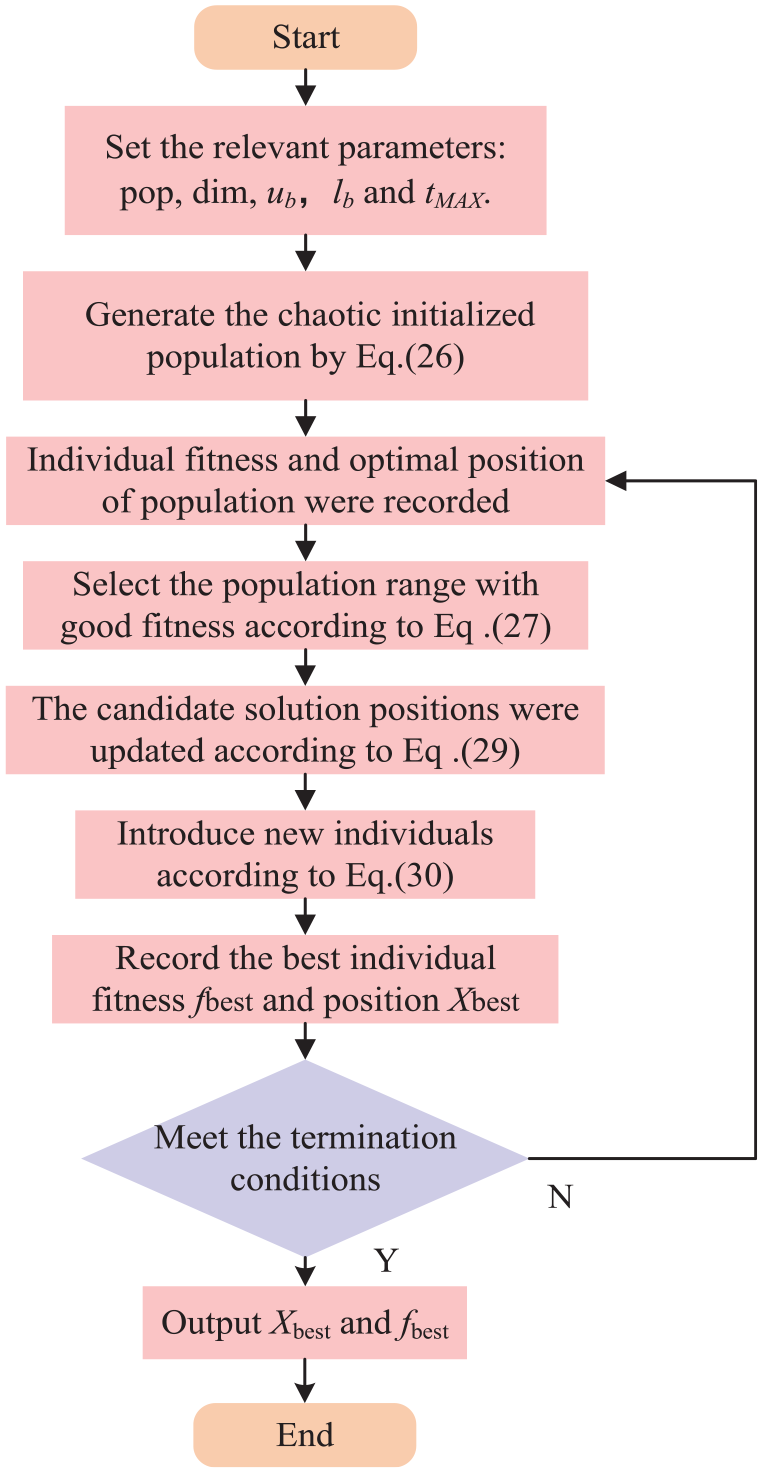
Flow chart of the improved TASMA algorithm.
Interval prediction model
Principle of interval prediction
The traditional point-based prediction models have difficulty in describing the actual characteristics of wind speed and lack the description of the range of future wind speed fluctuations. Wind speed interval prediction can give confidence intervals, which can describe the variation of future wind speed. Parametric estimation requires prior assumptions that the data obey some distribution, whereas nonparametric estimation does not require prior assumptions about the data distribution and can directly fit its distribution based on the data characteristics Zhang et al. (2022b). Although the wind speed prediction error is close to the Gaussian distribution, its wind speed time series is nonlinear in nature, the error of wind speed prediction is not inferred with sufficient a priori knowledge, and the error will also have a certain skewness asymmetry, so the nonparametric kernel density estimation method is used. The interval prediction range can be obtained based on the probability density curve, as follows:
1) Calculate the prediction error of the training set. Find the error between the predicted and measured values of wind speed
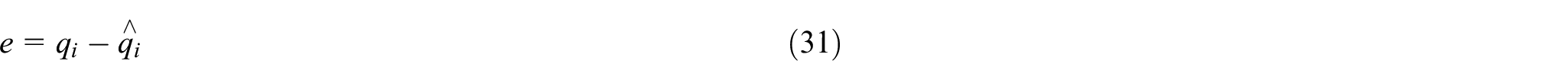
where
2) Estimation of the distribution of errors. A nonparametric kernel density estimation is used to obtain the probability density curve of the prediction error:

where
3) Given the confidence level 1-

where
Finally, the closed interval enclosed by its upper and lower boundaries is the prediction result of the model, and it is judged whether the actual value falls in the interval, and if it falls in the interval, the prediction is proved to be valid.
System structure
The structure diagram of the designed system is shown in Figure 3.
Step 1: Obtain wind speed data, and simulate the data set affected by noise.
Step 2: Data pre-processing is performed using SSA to extract different components of the data.
Step 3: The main parameters
Step 4: The model components of the signal decomposition are predicted by SCNs, and then the training set errors are obtained.
Step 5: Based on the kernel density estimation error, and the wind speed prediction results of the test set, the wind speed interval is obtained.
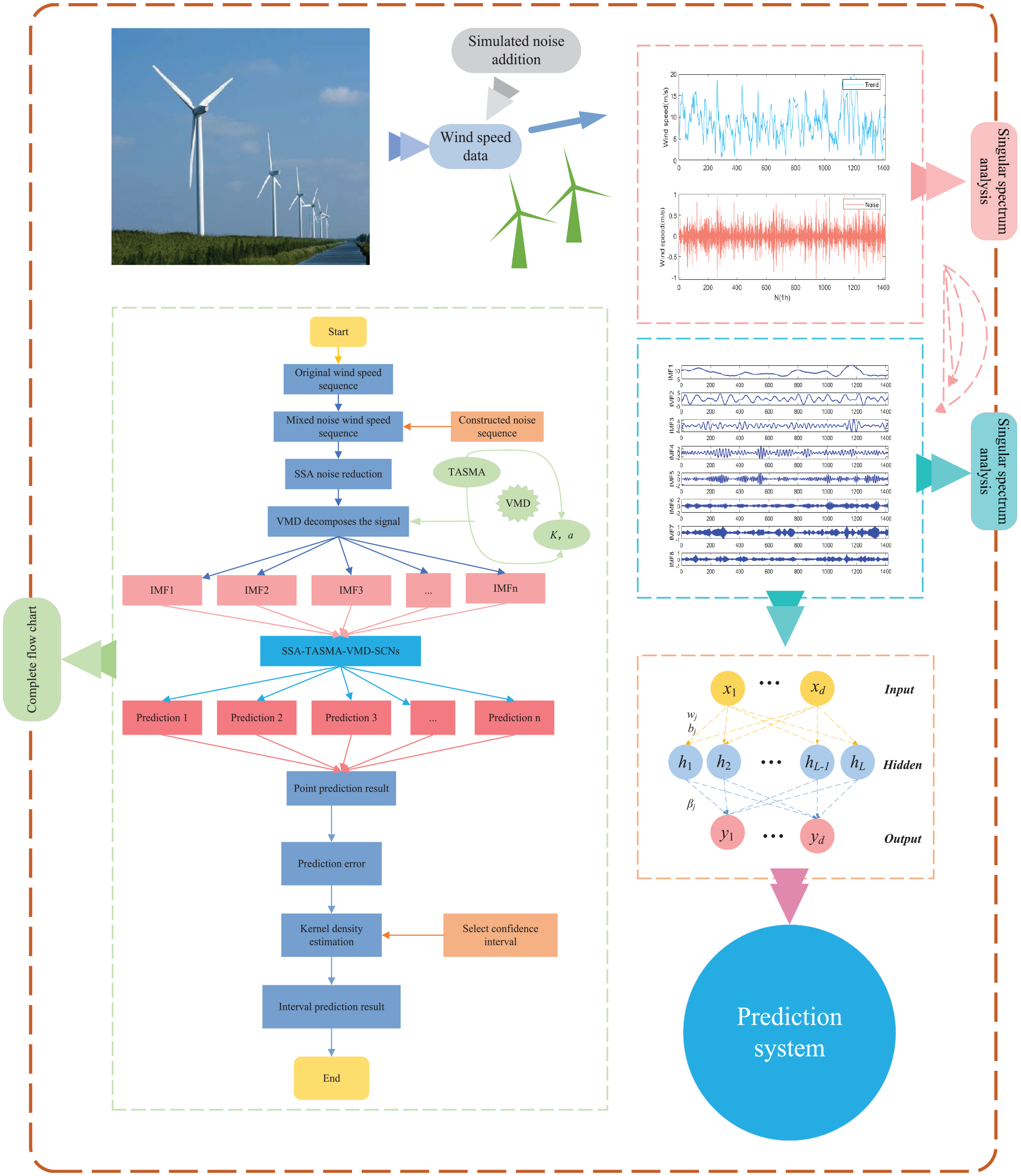
Block diagram of system structure.
Experiments and analysis
In this research paper, the wind speed data from Chicago, USA, 2022 was used, https://www.glerl.noaa.gov/metdata/chi/, in which, 1 hour time interval wind speed series and one seasonal partial data (spring) were used to do the following experiments. The training set and test set are divided according to the ratio of 85%:15%. The wind speed dataset information is shown in Figure 4.

Infographic of wind speed dataset.
Evaluation metrics
Coverage probability
The prediction interval coverage represents the probability that the true values fall in the prediction interval. The larger the
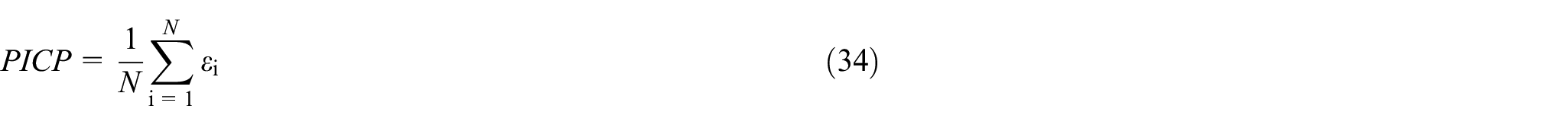
where
Average width of prediction interval
The average width of the prediction interval indicates the width of the interval results. Since a large width due to the simple pursuit of high interval coverage makes the prediction interval lose its meaning, the average width is added as another measure, and its formula is:

where
Predictive interval score
The clarity of the prediction interval is a necessary indicator to assess the merit of the prediction interval Gao et al. (2022).

The interval fraction of PI denoted by


where
Simulation experiments
The parameter settings of the algorithm used in the experiments are shown in Table 1, and for the simulated noise data, the common noise addition coefficients for each season are shown in Table 2, and the proportion of mixed noise addition is shown in Table 3, and it should be noted that the parameters of VMD-SCNs are selected according to the decomposition results (Li et al., 2017).
Model parameter setting.

Noise addition scheme.

Mixed noise addition ratio.

The noise parameter settings for the uniform and normal distributions are shown in Table 2. For example, in Table 2, the data for January and February are dataset 1, the Mean value of adding Normal noise is 0, the variance is 0.2, the proportion of noise is 0.1, and record its noise data number is serial number 1. The Mean value of the Uniform noise is −0.3, the variance is 0.5, the proportion of the noise is 0.1.
The mixed noise settings are shown in Table 3. For example, in Table 3, the data of January and February are data set 1, and the Uniform and Normal noise in Table 2 are added together. The proportional coefficient of uniform distributed noise is 0.6, the normal distributed noise coefficient is 0.4, and the noise proportional coefficient is 0.1.
After adding the serial number 1 noise in Table 2 to the January–February wind speed data, the signal decomposition and singular spectrum decomposition were performed according to the parameter settings of Table 1, and the decomposition plots are shown in Figure 5.

Data curve of several key production parameters: (a) EMD, (b) VMD, (c) SMA-VMD, and (d) TASMA-VMD.
Interval prediction results of SCNs, SCNs-Epane (Epanechnikov kernel function), SCNs-Trian (Triangular kernel function), GRU, LSTM, GRNN, EMD-SCNs, VMD-SCNs, VMD-SCNs-res (VMD decomposition with residual sequence), SSA-VMD-SCNs, SSA-SMA-VMD-SCNs, and SSA-TASMA-VMD-SCNs after adding the serial number 1 noise are shown in Figure 6.
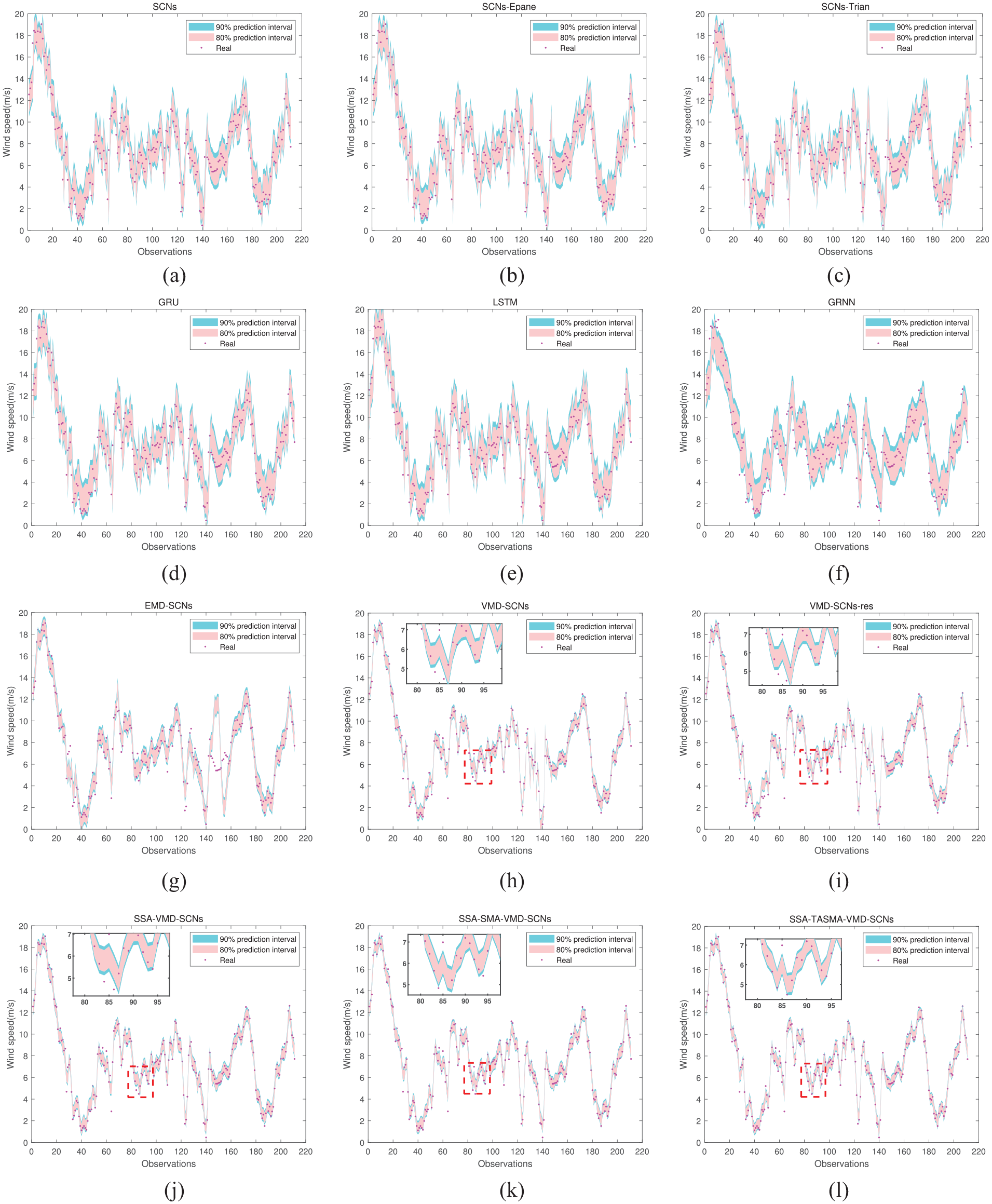
Comparison results of different models after adding serial number 1 noise to dataset 1: (a) SCNs, (b) SCNs-Epane, (c) SCNs-Trian, (d) GRU, (e) LSTM, (f) GRNN, (g) EMD-SCNs, (h) VMD-SCNs, (i) VMD-SCNs-res, (j) SSA-VMD-SCNs, (k) SSA-SMA-VMD-SCNs, and (l) SSA-TASMA-VMD-SCNs.
Through adding serial number 1 noise in Table 2 to the dataset 1, the results of the predictions of the 12 different methods, with 90% and 80% interval coverage and average width of the intervals compared are shown in Figure 7.
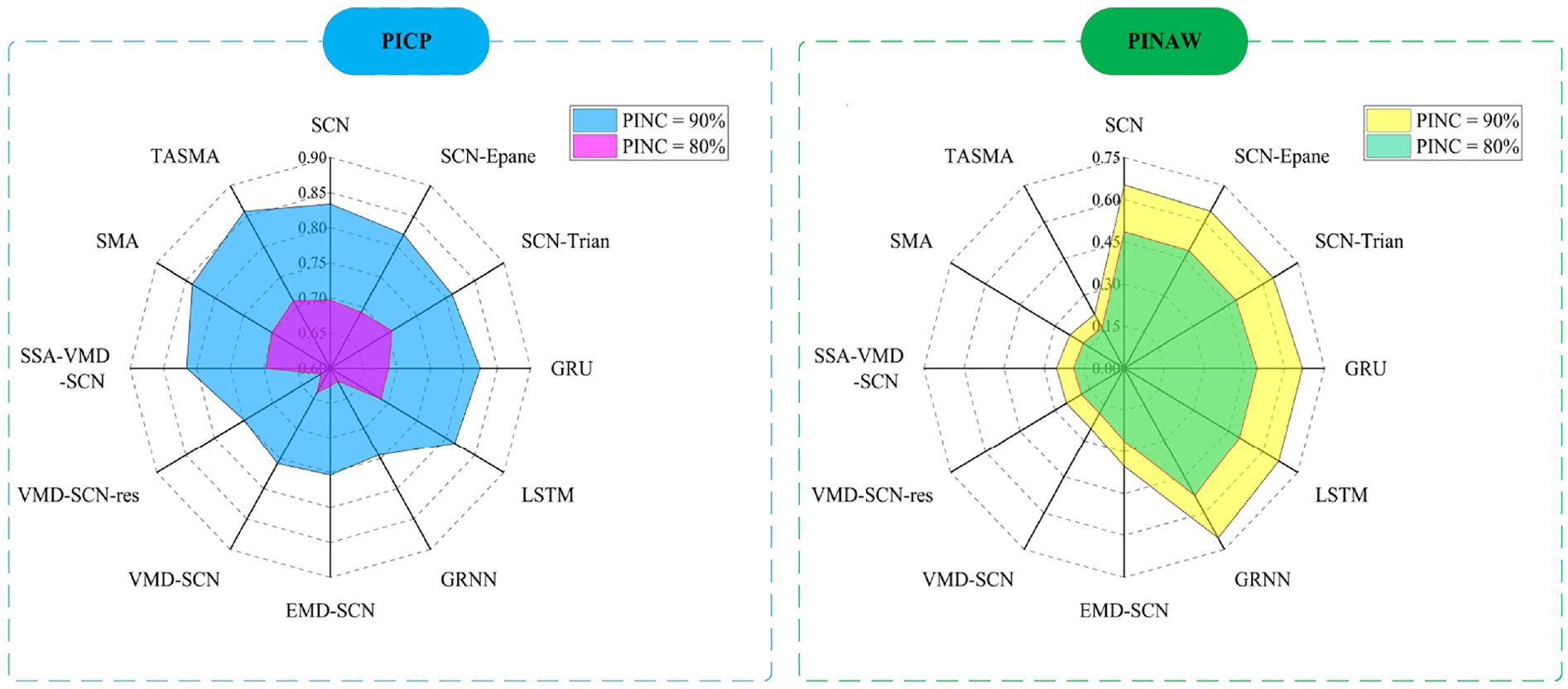
Comparison of the evaluation metrics of different models after adding serial number 1 noise to dataset 1.
In Table 4, the prediction results of wind speed data with serial number 1 noise show that by the comparison of model 1, model 2, and model 3, it can be seen that the Gaussian kernel density estimation predicts the obtained intervals with higher performance than the Epanechnikov kernel function and Triangular kernel function. Comparison of model 1, model 4, model 5 and model 6 shows that the SCNs-based interval prediction performance is better. Comparison of model 7 and model 8 shows that the adding of the residual sequence reduces the performance of interval prediction. The average width of the intervals of the model proposed in this paper is reduced by 66.1% and the fraction of the intervals is improved by 66.5% compared to SCNs at 90% confidence interval, and the average width of the intervals of the model proposed in this paper is reduced by 65.9% and the fraction of the intervals is improved by 66.7% compared to SCNs at 80% confidence interval.
Interval prediction results after adding serial number 1 noise in Table 2.

Through adding serial number 2 noise in Table 2 to the dataset 1, the results of the predictions of the 12 different methods, with 90% and 80% interval coverage and average width of the intervals compared are shown in Figure 8.
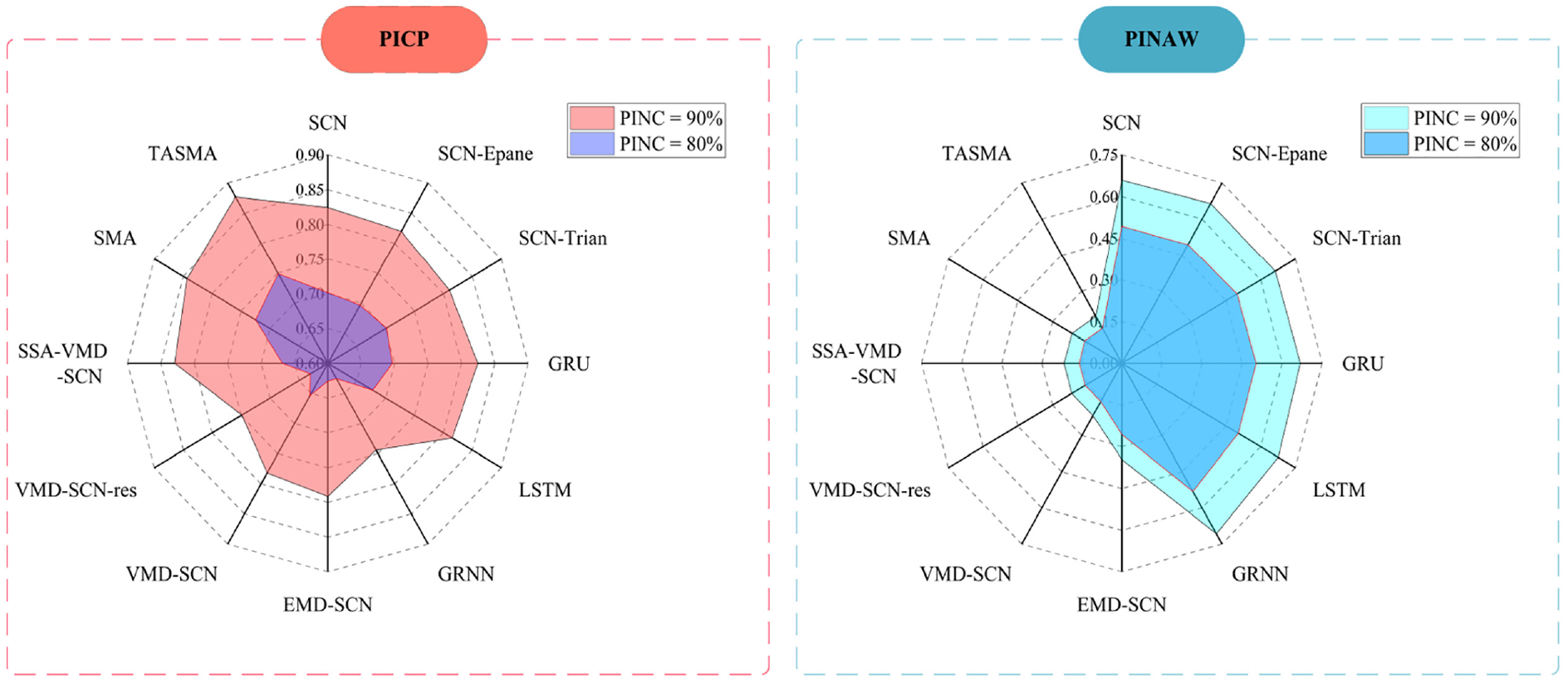
Comparison of the evaluation metrics of different models after adding serial number 2 noise to dataset 1.
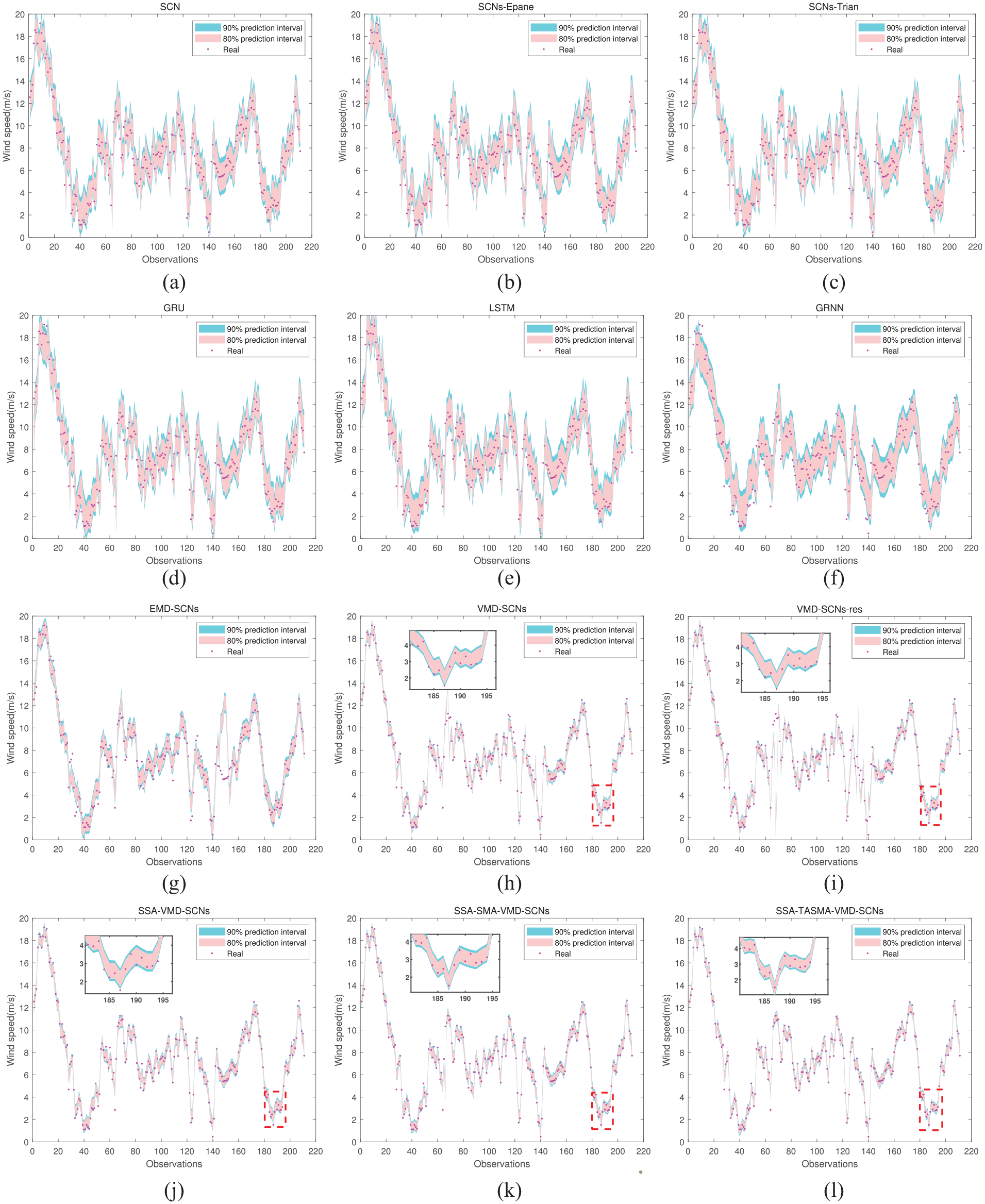
The interval prediction results of different models after adding the serial number 2 noise are shown in Figure 9.

Comparison results of different models after adding serial number 2 noise to dataset 1: (a) SCNs, (b) SCNs-Epane, (c) SCNs-Trian, (d) GRU, (e) LSTM, (f) GRNN, (g) EMD-SCNs, (h) VMD-SCNs, (i) VMD-SCNs-res, (j) SSA-VMD-SCNs, (k) SSA-SMA-VMD-SCNs, and (l) SSA-TASMA-VMD-SCNs.
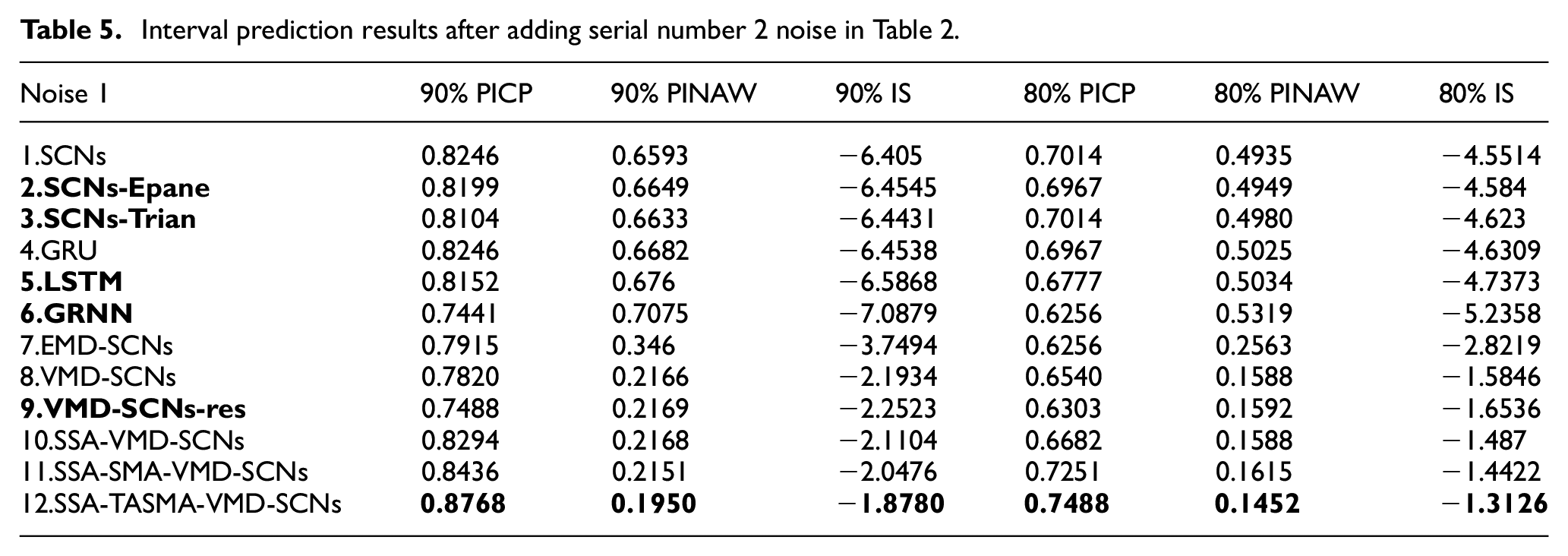
In Table 5, the prediction results of wind speed data with serial number 2 noise show that by the comparison of model 1, model 2, and model 3, it also can be seen that the Gaussian kernel density estimation predicts the obtained intervals with higher performance than other two kernel functions. Comparison of model 1, model 4, model 5, and model 6 shows that the SCNs-based interval prediction performance is also the better. Comparison of model 7 and model 8 also shows that the adding of the residual sequence reduces the performance of interval prediction. The average width of the intervals of the model proposed in this paper is reduced by 70.4% and the fraction of the intervals is improved by 70.7% compared to SCNs at 90% confidence interval, and the average width of the intervals of the model proposed in this paper is reduced by 70.6% and the fraction of the intervals is improved by 71.2% compared to SCNs at 80% confidence interval.
Interval prediction results after adding serial number 2 noise in Table 2.
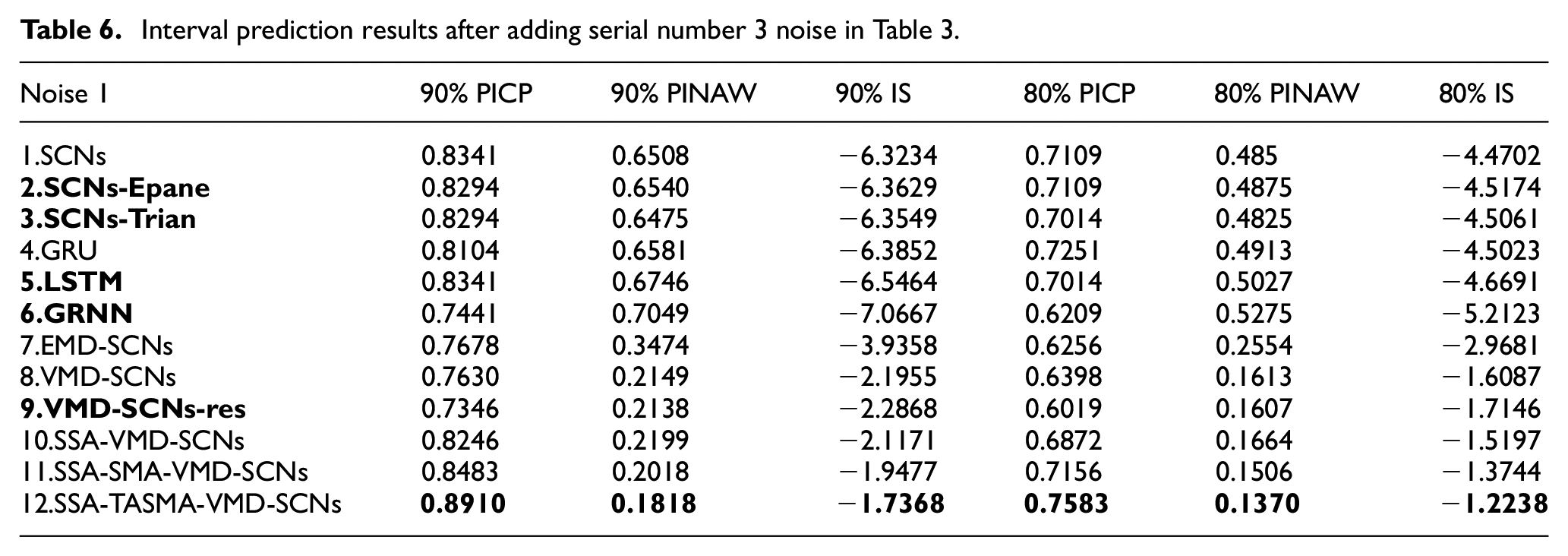
The interval prediction results of different models after adding the serial number 3 noise are shown in Figure 10.
Comparison results of different models after adding serial number 3 noise to dataset 1:(a) SCNs, (b) SCNs-Epane, (c) SCNs-Trian, (d) GRU, (e) LSTM, (f) GRNN, (g) EMD-SCNs, (h) VMD-SCNs, (i) VMD-SCNs-res, (j) SSA-VMD-SCNs, (k) SSA-SMA-VMD-SCNs, and (l) SSA-TASMA-VMD-SCNs.
Through adding serial number 3 noise in Table 3 to the dataset 1, the results of the predictions of the 12 different methods, with 90% and 80% interval coverage and average width of the intervals compared are shown in Figure 11.
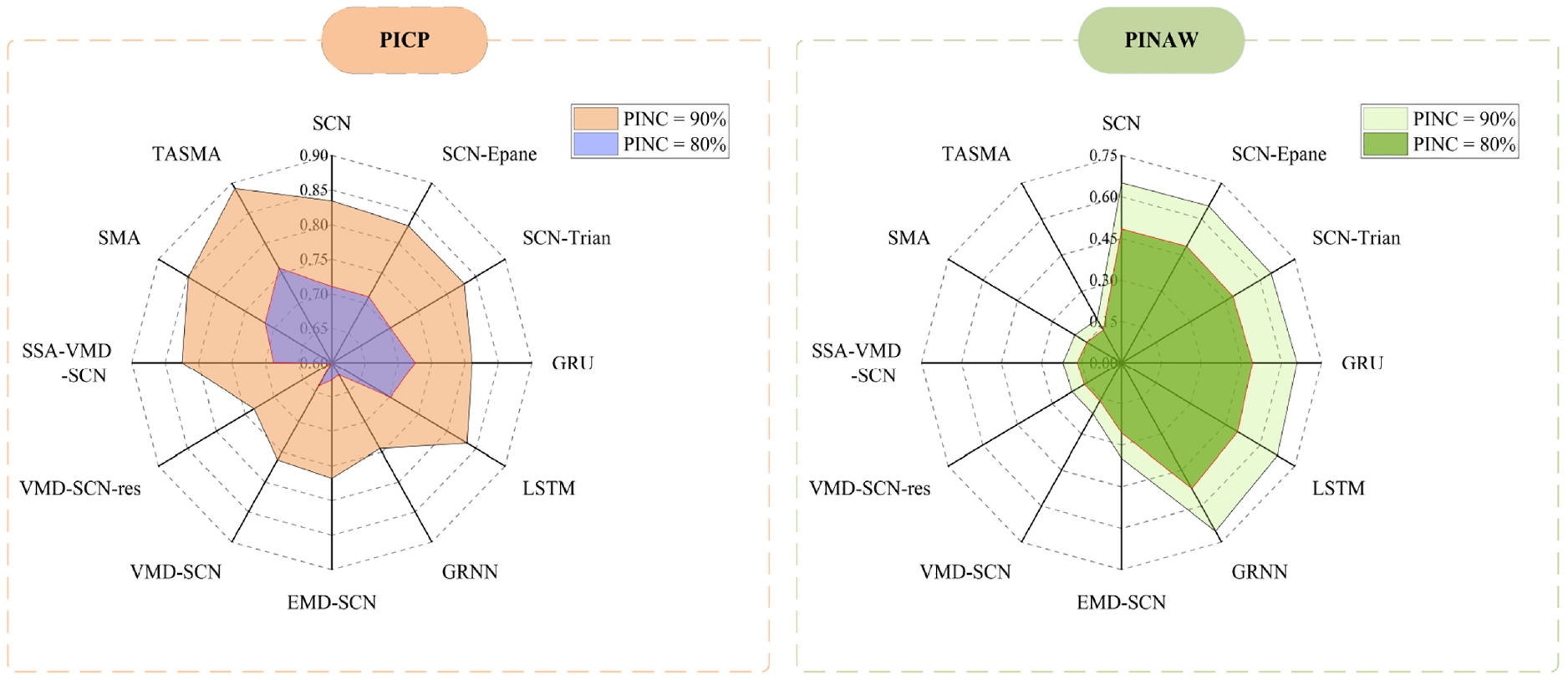
Comparison of the evaluation metrics of different models after adding serial number 3 noise to dataset 1.
In Table 6, the prediction results of wind speed data with serial number 3 noise show that by the comparison of model 1, model 2, and model 3, it also can be seen that the Gaussian kernel density estimation predicts the obtained intervals with higher performance than other two kernel functions. Comparison of model 1, model 4, model 5 and model 6 shows that the SCNs-based interval prediction performance is also the better. Comparison of model 7 and model 8 also shows that the adding of the residual sequence reduces the performance of interval prediction. The average width of the intervals of the model proposed in this paper is reduced by 72.1% and the fraction of the intervals is improved by 72.5% compared to SCNs at 90% confidence interval, and the average width of the intervals of the model proposed in this paper is reduced by 71.8% and the fraction of the intervals is improved by 72.6% compared to SCNs at 80% confidence interval.
Interval prediction results after adding serial number 3 noise in Table 3.
From above, the prediction results of wind speed data containing serial numbers 1–3 noises show that the coverage, mean width, and interval fraction of 90% and 80% confidence intervals of the method proposed in this paper are better than other methods, and the proposed method can reduce the noise uncertainty and achieve effective prediction.
Conclusions
In this paper, we propose a hybrid wind speed prediction system and the hybrid model combines data denoising, signal decomposition optimization, model prediction, and interval conversion to improve the performance of wind speed prediction in a noisy interference environment. The proposed hybrid system achieves good results in short-term wind speed prediction by using the interval prediction method to reduce the interference from noise in wind speed prediction through point prediction error and kernel density estimation fitting strategy. Based on the experimental proof, the hybrid wind speed prediction model after optimizing the parameters can better reduce the wind speed prediction interference by noise.
The complexity of the model in the optimization process will inevitably cause an increase in the prediction time cost, so it is one of our next work plans to further reduce the prediction time while ensuring the prediction accuracy.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the LiaoNing Revitalization Talents Prograrn (Grant Number XLYC2007091); this work was also partly supported by the National Natural Science Foundation of China (Grant Number 62203197).