
Abstract
The purpose of this study is to provide evidence of reliability and validity of the Self-Efficacy for Teaching Mathematics Instrument (SETMI). Self-efficacy, as defined by Bandura, was the theoretical framework for the development of the instrument. The complex belief systems of mathematics teachers, as touted by Ernest provided insights into the elements of mathematics beliefs that could be relative to a teacher’s self-efficacy beliefs. The SETMI was developed in July 2010 and has undergone revisions to the original version through processes defined in this study. Evidence of reliability and validity were collected to determine whether the SETMI is an adequate instrument to measure self-efficacy of elementary mathematics teachers. Construct validity of the revised SETMI was tested using confirmatory factor analysis. Findings indicate that the SETMI is a valid and reliable measure of two aspects of self-efficacy: pedagogy in mathematics and teaching mathematics content.
Keywords
Mathematics has become a subject of much discussion in the past decade as results from international tests of academic achievement have shown that American student achievement in mathematics is much lower than that in many European and Asian countries (National Center for Educational Statistics [NCES], 2010). To find ways of improving student learning, the relationships between teacher factors and student achievement are often examined. There is a notable coherence between a teacher’s beliefs and their practices in the classroom (Peterson, Fennema, Carpenter, & Loef, 1989; Stipek, Givvin, Salmon, & MacGyvers, 2001). With regard to mathematics, there is a significant relationship between a teacher’s self-confidence for teaching mathematics and student’s self-confidence as mathematics learners (Stipek et al., 2001).
Ernest (1989) discerned that a mathematics teacher’s belief system has three components: ideas about mathematics as a subject, ideas about the nature of mathematics teaching, and ideas about mathematics learning. In support of Ernest’s thoughts about mathematics teacher beliefs, Beswick (2012) noted that a teacher’s experiences in teaching mathematics influence his or her beliefs about mathematics schooling and the processes related to performing mathematical tasks. A teachers’ belief system is often marked by his or her self-efficacy for specific tasks. Self-efficacy is “concerned with people’s beliefs in their capabilities to produce given attainments” (Bandura, 2006, p. 1).
Self-efficacy stems from social cognitive theory, which is best represented by a triadic model that describes the relationships between one’s behaviors, the environment, and personal factors (Bandura, 1997; Pajares, 2002). Bandura’s (1977) social cognitive theory consisted of two main constructs: efficacy expectations and outcome expectations. Current use of the term self-efficacy comes from the original construct of efficacy expectations. As integral as self-efficacy may be in many cognitive processes and subsequent behaviors, it is not an overarching measure of self-ability for each individual (Bandura, 1977). There can be no global measure of self-efficacy (Bandura, 2006). Judgments of self-efficacy are task-specific and vary in strength and magnitude (Bandura, 1977; Bong & Skaalvik, 2003; Pajares, 1997; Wang & Pape, 2007). Self-efficacy is also not solely responsible for the outcome of an event but the outcomes that one may expect are dependent on one’s judgments of how much they can accomplish (Bandura, 1986).
Phelps (2010) concluded that pre-service teachers’ motivational profiles are constructed through multiple sources such as past performance, vicarious experiences, career goals, views of mathematics as a subject and views of mathematics in teaching. Elementary pre-service teachers were motivated by their career goal to be attentive to mathematics content. This relationship between their career goals and understanding of mathematics seemed to assist in their formation of mathematics self-efficacy beliefs (Phelps, 2010).
Measuring Teacher Self-Efficacy
The measurement of teacher self-efficacy has a history of more than 30 years. The term “teacher efficacy” was first used in two reports of RAND Corporation evaluations of projects funded by the Elementary and Secondary Education Act (Armor et al., 1976; Berman, McLaughlin, Bass, Pauly, & Zellman, 1977). The RAND studies used Rotter’s (1954) social learning theory, which cites internal-external locus of control of reinforcement as a component of efficacy (Woolfolk & Hoy, 1990).
Following the RAND studies, measurement of teacher efficacy has been attempted in various ways (see Table 1). Three measurement instruments emerged in the literature that used Rotter’s (1954) theory: the Teacher Locus of Control (TLC) questionnaire (Rose & Medway, 1981), the Responsibility for Student Achievement (RSA) questionnaire (Guskey, 1981), and the Webb Efficacy Scale (Ashton, Olejnik, Crocker, & McAuliffe, 1982; Tschannen-Moran, Woolfolk Hoy, & Hoy, 1998). Gibson and Dembo (1984) took the two items from the RAND studies and attempted to expand them, while also combining them with two elements of Bandura’s (1977) newly published theory to measure the two constructs of general teaching efficacy and personal teaching efficacy on the Teacher Efficacy Scale (TES; Tschannen-Moran & Woolfolk Hoy, 2001). Other researchers used the Gibson and Dembo (1984) study as a springboard to measure self-efficacy within specific contexts by rewording the TES items to be content-specific or by creating hypothetical context-specific situations for teachers to respond (see Table 1). Although the TES is a foundational work used to create other self-efficacy measures, it is important to recall that the RAND studies used Rotter’s theory as a theoretical framework (Henson, 2001).
Complete Listing of Self-Efficacy Instruments.
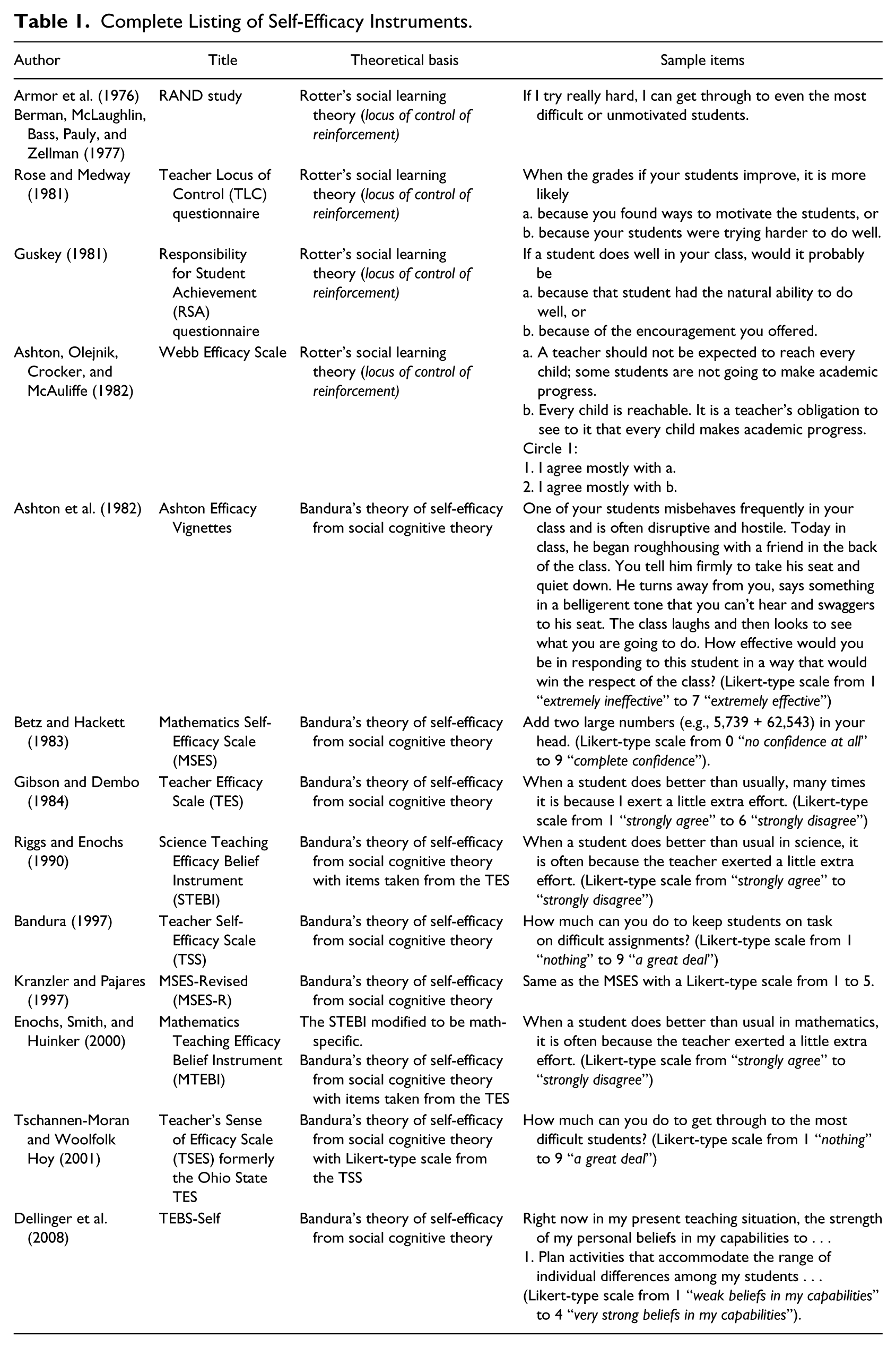
The creation of so many diverse measurement tools for teacher self-efficacy created confusion about the nature of self-efficacy itself (Pajares, 1997). In response, Bandura (1997) created his own Teacher Self-Efficacy Scale (TSS). He further outlined that locus of control and self-efficacy are not empirically related and that locus of control is a weak predictor of behavior, denouncing Rotter’s social learning theory as a basis for teacher self-efficacy. Reliability and validity information for this instrument is not available because it was never published (Tschannen-Moran & Woolfolk Hoy, 2001). Tschannen-Moran and Woolfolk Hoy (2001) therefore found it necessary to create a measure for teacher self-efficacy and created the Teacher’s Sense of Efficacy Scale (TSES).
The TSES, formerly the Ohio State Teacher Efficacy Scale (OSTES), was tested for validity in a series of studies using pre-service and in-service teachers. A careful selection of items after examinations of factor structure gave rise to both a Long Form and a Short Form of the OSTES. Further tests on both the Long and Short Forms of the OSTES revealed a four-factor structure, validating that the underlying construct of self-efficacy could be measured by giving a total score, and the three sub-scales could be given scores as well. The researchers determined that a total score was more appropriate for pre-service teachers and total and sub-scale scores appropriate for in-service teachers. The construct validity of the Long and Short Forms was tested first by correlating the total scores on the OSTES responses to the RAND items and the Hoy and Woolfolk (1993) adaption of the TES. Then, correlations were computed for the RAND items (r = .18 and .53, p < .01) and the personal teaching efficacy (r = .64, p < .01) and general teaching efficacy (r = .16, p < .01) factors of the TES. The researchers concluded that more work is needed on validation of the instrument, although the factor structure has remained stable (Tschannen-Moran & Woolfolk Hoy, 2001).
In an attempt to distinguish between concepts of teacher efficacy and teacher self-efficacy, Dellinger, Bobbett, Olivier, and Ellett (2008) created the Teachers’ Efficacy Beliefs System–Self Form (TEBS-Self). The researchers make a compelling argument for the differences between teacher efficacy and teacher self-efficacy, but the TEBS-Self items themselves are not conceptually different from those in the TSES. Therefore, the TSES remains the most widely used measure of general teacher self-efficacy (Swackhamer, 2010) and the TES is still in use as well (Henson, 2001).
Measuring Content-Specific Self-Efficacy
Mathematics self-efficacy of teachers is a complex construct, comprised of several components. Because one of the problems with measuring self-efficacy is the inability to clearly define constructs across the literature (Pajares, 1997), a distinction has to be made here between teachers’ mathematics self-efficacy and their self-efficacy for teaching mathematics. Teachers’ mathematics self-efficacy refers to a teacher’s own belief in his or her ability to perform mathematical tasks (Kahle, 2008). Teachers’ mathematics self-efficacy has been measured in several ways. Betz and Hackett (1983) created the Mathematics Self-Efficacy Scale (MSES) to measure mathematics self-efficacy by asking the participants to rate their confidence in their ability to solve mathematical problems. The MSES was later revised (MSES-R) by Kranzler and Pajares (1997). Hoffman (2010) used a self-report measure where pre-service teachers rated eight mathematical problems on an 11-point scale with 1 being “no confidence at all in solving” and 11 being “total confidence in solving.”
In contrast to teachers’ mathematics self-efficacy, self-efficacy for teaching mathematics is a teacher’s beliefs regarding his or her ability to teach others mathematics (Kahle, 2008). This construct is measured by instruments like the Mathematics Teaching Efficacy Beliefs Instrument (MTEBI). The MTEBI was created by Enochs, Smith, and Huinker (2000) by revising their earlier published Science Teaching Efficacy Beliefs Instrument (STEBI; Riggs & Enochs, 1990) to be mathematics-specific. The two constructs in the MTEBI are personal mathematics teaching efficacy and mathematics teaching outcome expectancy. It should be noted that these are a direct reference to Gibson and Dembo’s (1984) TES as well as Bandura’s self-efficacy theory. However, Bandura (2006) clearly makes the distinction between efficacy expectations and outcome expectations, noting that outcome expectations are not a component of self-efficacy, which calls these constructs into question. In addition, although the authors report that the MTEBI is both valid and reliable, they indicate that further work on validation of the instrument is needed. Validity of the MTEBI has only been explored in a few studies (Enochs et al., 2000; Kieftenbeld, Natesan, & Eddy, 2011).
Problems With Measurement of Self-Efficacy
There are fundamental issues with each of the instruments previously discussed, according to the guidelines for measuring self-efficacy that are touted by Pajares (1997) and Bandura (2006). Historically, most of the instruments that have been created to measure teacher self-efficacy with regard to mathematics fall into the categories of general teacher self-efficacy, self-efficacy for teaching mathematics, or mathematics self-efficacy. The TES (Gibson & Dembo, 1984) touts to be theoretically aligned to Bandura’s theory of self-efficacy, but in reality is more aligned to Rotter’s (1954) locus of control because it used the RAND items as a basis for creating new items (Henson, 2001). A re-examination of the MTEBI using item response theory (IRT) provided evidence that the validity of the MTEBI was not as high as previously reported (Kieftenbeld et al., 2011).
The TSES has perhaps undergone the most rigorous tests of validity and reliability than other instruments introduced in the field (Swackhamer, 2010) but it has only been re-examined a few times with regard to validity since its original publication in 2001. TSES items were intended for use with in-service teachers, but the validation of the factor structure was only performed using data from pre-service teachers (Henson, 2001). Its construct validity was measured concurrently and has not been tested using confirmatory factor analysis (CFA) techniques (Heneman, Kimball, & Milanowski, 2007; Klassen et al., 2009). The TSES constructs do seem to hold true over time and in different contexts (Heneman et al., 2007; Klassen et al., 2009) but not always when modified to be mathematics-specific (Swackhamer, 2010). Even the authors of the TSES, Tschannen-Moran and Woolfolk Hoy (2001), have postulated that teacher efficacy may vary depending on school and classroom context.
Although capturing context-specific teacher self-efficacy has been attempted (Bandura, 2006; Pajares, 1997), some still argue that measures currently in use for doing so are not completely valid (Swackhamer, 2010). One of the issues with context and content-specific measures of teacher self-efficacy is how to balance specificity and generality. Imbalanced instruments cause measures that are too specific to lose predictive power (Tschannen-Moran et al., 1998; Tschannen-Moran & Woolfolk Hoy, 2001). Having predictive power is important because most current measures of teacher self-efficacy are used as predictors of outcomes such as student performance, although prediction should be undertaken with caution (Pajares, 1997).
Another measurement issue is item wording. The STEBI and the MTEBI, both use wording more theoretically aligned with Rotter’s theory than with Bandura’s (i.e., “When a low-achieving child progresses in mathematics, it is usually due to extra attention given by the teacher”), although the authors claim to adhere to Bandura’s theory of self-efficacy. The wording “can” should be used instead of “will” or “confident” to indicate a judgment of perceived ability instead of intention (Bandura, 1997). Dellinger et al. (2008) determined that items with the wording “My belief in my ability to . . . is” had different results when comparing responses with items worded “I can” or “I am able to.” Therefore, the wording of items intended to measure self-efficacy should be carefully considered to ensure proper measurement of the construct.
Another caveat of measuring self-efficacy beliefs is the fact that best practice calls for measurement of self-efficacy at the most optimal levels of specificity relevant to the criteria task being assessed (Bandura, 2006; Pajares, 1997). Pajares (1997) indicated that to properly measure self-efficacy, the specific task in question has to be identified first. Then, the levels of that specific task have to be identified by creating items that relate to the difficulty of the sub-tasks for each level. If the task is already learned, task-specific items are relevant. If the task is novel, language about perceived self-efficacy for that task is more appropriate. This difference between learned tasks and learning future tasks has created a distinction between “self-efficacy for performance” and “self-efficacy for learning” in the literature (Pajares, 1997).
Therefore, for teachers, lack of specificity to a grade level can be an issue when measuring self-efficacy. Content and context are different at each grade level and thus, expectations of a classroom teacher and sub-tasks associated with teaching vary. Elementary education is the context for this study because elementary teachers have communicated their apprehension to researchers and teacher educators about mathematics and their own self-doubts regarding teaching mathematics (McGee, Polly, & Wang, 2013; Piel & Green, 1993; Polly et al., 2013).
Efforts to measure teacher self-efficacy have become theoretically confused (Haines, McGrath, & Pirot, 1980; Henson, 2001; Pajares, 1997; Tschannen-Moran et al., 1998) and work on validity of content- and context-specific instruments has slowed. The need for better understanding of student performance in mathematics highlights a need to examine teacher beliefs and thus self-efficacy for mathematics teaching and learning. In an effort to provide more content- and context-specific measurement of a teacher’s self-efficacy beliefs, McGee (2012) developed the Self-Efficacy for Teaching Mathematics Instrument (SETMI) as an instrument that aligns to the theoretical underpinnings of Bandura’s social cognitive theory and also the idea that a teacher’s belief system surrounding mathematics is complex (Ernest, 1989). The purpose of this study is to provide evidence of reliability and validity of the SETMI.
Method
Data collection for this study occurred during the second and third year of a 3-year federally funded US$2.4 million dollar Mathematics Science Partnership (MSP) grant from the U.S. Department of Education. The MSP grant project took place between August 2009 and June 2012. Three cohorts of elementary teachers were involved in the MSP grant, which was a collaborative partnership between two school districts and an urban research university in the southeastern region of the United States. District 1 is a large urban district with 88 elementary schools and District 2 is a neighboring suburban district with 5 elementary schools.
Participants
Teacher participants of the MSP grant in the second year (Cohort II) and the third year (Cohort III) participated in the instrument development. Cohort II participants provided data for the exploratory factor analysis (EFA) of Version 1 of the SETMI in August 2010. Cohort III participants provided data for the CFA of Version 2 of the SETMI in August 2011.
Observed differences in mathematics content understanding and use between Kindergarten teachers and teachers in Grades 1 through 5 during the grant workshops caused some question as to differences in Kindergarten teacher mathematics self-efficacy and self-efficacy of other elementary teachers (McGee, 2012). In the state where this study takes place, Kindergarten teachers can either be certified “Birth through Kindergarten” or “Kindergarten through Sixth Grade.” The certification of the Kindergarten teachers in this dataset is unknown. In addition, the academic content presented in teacher preparation programs for these certifications differs greatly. For those reasons, Kindergarten teachers were withdrawn from analysis of this data.
In Cohort II, 133 participants taught in District 1 and 18 taught in District 2. Twenty-six of the participants (17%) taught first grade, 29 (19%) taught second grade, 33 (22%) taught third grade, 27 (18%) taught fourth grade, and 36 (23%) taught fifth grade. In Cohort III, 150 participants were from District 1 and 32 were from District 2. Forty-one of the participants (23%) taught first grade, 37 (20%) taught second grade, 39 (22%) taught third grade, 38 (21%) taught fourth grade, and 22 (12%) taught fifth grade. Five teachers (3%) were Exceptional Children (EC) teachers or other mathematics school-level specialists who taught multiple grades.
Instrument Development
The SETMI was first created in July 2010. It was created in alignment with Bandura’s thoughts on self-efficacy and Woolfolk and Hoy’s (1990) proposition that teacher’s efficacy was comprised of two different unrelated factors: teaching efficacy and personal efficacy. Woolfolk and Hoy found that 18% to 30% of the variance between teachers is explained by these two factors (Tschannen-Moran & Woolfolk Hoy, 2001). The SETMI also takes into consideration the theory that a mathematics teacher’s belief system is comprised of ideas about mathematics as a subject, ideas about the nature of mathematics teaching, and ideas about mathematics learning (Ernest, 1989).
The TSES (Tschannen-Moran & Woolfolk Hoy, 2001) was used as a framework for constructs and items while Aerni’s (2008) “Teaching Mathematics in Inclusive Settings” instrument was used to consider mathematics content-specific items. The TSES was used because it is the most widely accepted measure of general teacher self-efficacy (Swackhamer, 2010). The short form of the TSES contains 12 questions that address three constructs: efficacy in student engagement, efficacy in instructional strategies, and efficacy in classroom management. Items within the classroom management construct were not included on the SETMI (McGee, 2012). The “Teaching Mathematics in Inclusive Settings” instrument uses the TSES short form, modified to be specific to teaching mathematics in inclusive settings. It also contains mathematics content items. The idea for asking mathematics content-specific items came from Aerni’s (2008) instrument, but no items from that instrument were used.
This study details validity evidence for the SETMI as well as procedures for revisions based on the collection of validity evidence over time. Part 1 of the SETMI, efficacy for pedagogy in mathematics (EPM) uses Items 2, 4, 5, 7, 9, 10, and 12 from the TSES short form, modified to be mathematics-specific (see Table 2). Part 2 of the SETMI, efficacy for teaching mathematics content (ETMC), asks teachers to rate their level of self-efficacy for teaching mathematics content-specific to elementary school (i.e., integers, rational, irrational numbers, probability, size, quantity, and capacity). Both versions contain 22 items, but there were some modifications to Part 2 made to improve response processes (see Table 3).
SETMI Part 1.

Note. SETMI = Self-Efficacy for Teaching Mathematics Instrument.
SETMI Part 2: Revisions From Version 1 to Version 2.

Note. SETMI = Self-Efficacy for Teaching Mathematics Instrument.
Data Analytical Procedures
Instead of using classic models of test validity, which divided this concept into content validity, criterion validity, and construct validity, this study uses the currently dominant view that validity is a single unitary construct (Messick, 1995). With this view, we aim to provide evidence of validity for the SETMI based on test content, response processes, internal structure, and relations to other variables.
Validity for test content was established deductively by defining what was to be measured and then creating items that sample that content. It was then determined to be valid by the judgment of those considered to be experts in the content area (Cronbach & Meehl, 1955). Reliability was explored using Cronbach’s alpha. EFA was used to see the general structure of the response patterns. It was determined a priori that any item with a factor loading greater than .40 would be considered following the suggestion of Comrey and Lee (1992). Principal axis factoring was used as a method for extraction, whereas direct oblimin was used as a method for rotation. Scree plots were also examined. The number of factors was not set before the EFA was conducted.
Correlating the two constructs measured by the SETMI provided evidence of validity for relations to other variables. The purpose of this analysis was to provide evidence that items in Part 2 were accurate measures of self-efficacy. Part 1 of the SETMI was compared against Part 2. A scale score for EPM and ETMC was computed for each participant, after missing values were imputed with the means of their respective constructs. Correlations between the factors (EPM and ETMC) were examined.
Evidence of validity for test content and response processes were provided through consultation with the state Standard Course of Study and Common Core Standards for Kindergarten through fifth grade, elementary mathematics experts, elementary education experts, and a focus group of elementary mathematics teachers. Evidence of validity for internal structure was provided by results from a CFA with data collected in August 2011.
Results
Validity of test content was carefully considered during the creation of Version 1 of the SETMI. The alignment of items on Version 1 to the TSES ensured integrity of the self-efficacy for teaching mathematics items. Before data were collected on Version 1, content experts were consulted to be sure that mathematics content items communicated clearly. One mathematics teacher educator, two elementary mathematics education directors for District 1, and the mathematics education director for District 2 were consulted as content experts.
Validity of the Version 1 of the SETMI was examined using data collected from Cohort II of the MSP grant. Reliability was explored using Cronbach’s alpha. For EPM, the reliability was .86 and for ETMC, the reliability was .91. These are acceptable reliability values and indicate moderately strong reliability of the instrument (Cronbach & Meehl, 1955). Because the reliability of the instrument was deemed to be acceptable, further examination of the factor structure was conducted.
Results from EFA showed promise of structural validity but with significant cross-loading items. As a result, the researchers met with a mathematics teacher educator from the university to revise mathematics content items. It was apparent that two content items (Items 20 and 21) needed to be revised to improve response processes of participants. Other revisions were also made to make more clear alignment to the Common Core Standards. For example, Items 11 and 15 were removed. After initial revisions were made, a focus group of five elementary teachers, who were serving as facilitators of the professional development for Cohort III, met in July 2011 to discuss the new items on the instrument. These teachers were considered experts in pedagogical content knowledge and mathematics content. The focus group provided feedback to the researchers regarding item wording. They also suggested the addition of aspects of probability to the instrument. Item 22 (Version 2) now states, “Interpret probability of outcomes.” The focus group also suggested that Item 16 (Version 2) only states, “Measurement of area and perimeter” instead of the original “Measurement of area and perimeter of rectangles.”
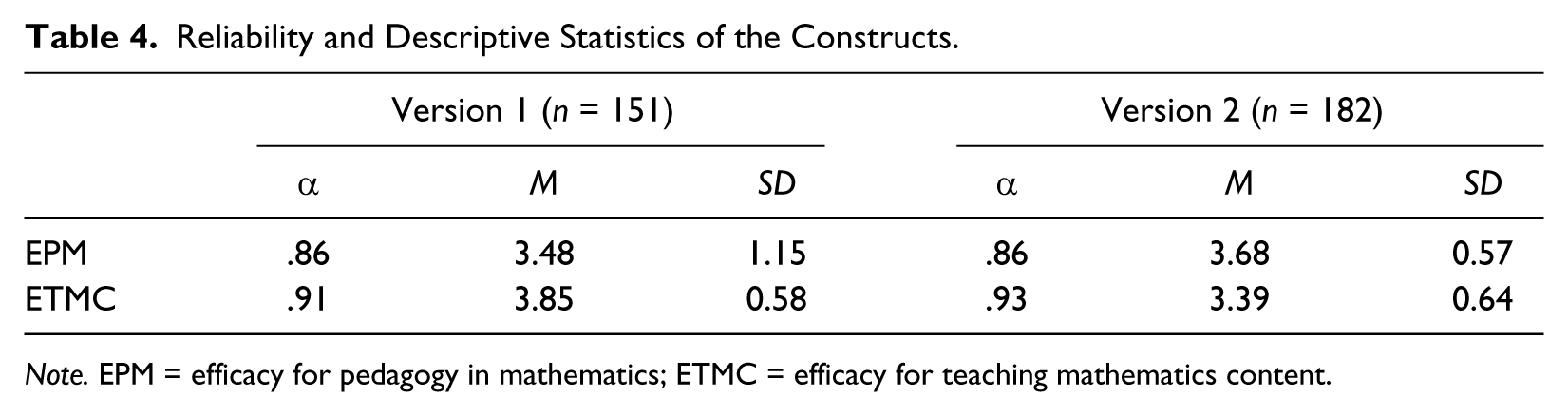
For Version 2 of the instrument, the new reliabilities for each factor were EPM (.86) and ETMC (.93). The relationship between EPM and ETMC was explored after the revisions and it was statistically significant, r = .52, p < .001. Table 4 shows the difference in reliability from Version 1 to Version 2 and also displays the means and standard deviations for each construct.
Reliability and Descriptive Statistics of the Constructs.
Note. EPM = efficacy for pedagogy in mathematics; ETMC = efficacy for teaching mathematics content.
With data collected from the revised version from Cohort III and to verify the theoretical model proposed in this study, a CFA was conducted using LISREL. The first model tested was the measurement model for EPM, containing Items 1 through 7. This model fit the data after allowing for one correlation between Items 6 and 7 (χ2 = 33.48, df = 13, p < .0001; root mean square error of approximation [RMSEA] 90% confidence interval [CI] = [.06, .13]; comparative fit index [CFI] = .98; goodness-of-fit index [GFI] = .95). The second model tested was the measurement model for ETMC, containing Items 8 through 22. This model fit the data after allowing for two modifications; one between Items 11 and 12 and another between Items 17 and 18 (χ2 = 259.80, df = 88, p < .0001; RMSEA [90% CI] = .10, .12; CFI = .96; GFI = .83). See Table 5 for detailed goodness-of-fit indices of these models. Suggested modifications were only allowed if they fit the theoretical framework of the study.
Model Fit Indices for the SETMI.

Note. SETMI = Self-Efficacy for Teaching Mathematics Instrument; GFI = goodness-of-fit index; AGFI = adjusted goodness of fit; NFI = normed fit index; NNFI = non-normed fit index; CFI = comparative fit index; SRMR = standardized root mean residual; RMSEA = root mean square error of approximation; CI = confidence interval; EPM = efficacy for pedagogy in mathematics; ETMC = efficacy for teaching mathematics content.
As for CFA, all items were loaded to the first-order latent variable as the first model (SETMI-1). A second-order factor analysis was then conducted with SETMI as the second-order latent variable and EPM and ETMC as the first-order latent variables in the second model (SETMI-2). By allowing the previously mentioned correlations between error variances with no cross-loadings, the second model fit the data better (χ2 = 404.62, df = 204, p < .001; RMSEA [90% CI] = .07, .09; CFI = .97; GFI = .83). The chi-square change from the first model (SETMI-1) to the second model (SETMI-2) was statistically significant, χ2 = 379.15, df = 2, p < .001. The fit indices for all models can be seen in Table 5. The structure of the multi-level measurement model for the SETMI can be seen in Figure 1.

SETMI model with two latent constructs: EPM and ETMC.
Discussion
The theoretical basis for this study aligns with Bandura’s (1977) ideas about self-efficacy. Self-efficacy is one’s beliefs about how his or her actions produce given future attainments (Bandura, 1977; Tschannen-Moran & Woolfolk Hoy, 2001). Currently, there is only one widely accepted measure of teacher self-efficacy, the TSES (Tschannen-Moran & Woolfolk Hoy, 2001) and one instrument to measure the mathematics self-efficacy beliefs of teachers, the MTEBI (Enochs et al., 2000). When attempting to measure the self-efficacy of mathematics teachers, both instruments fall short.
In response to the need for better measurement of mathematics teacher self-efficacy, the SETMI was created. The SETMI is comprised of two parts: EPM and ETMC. Evidence of validity has been collected using the current dominant view that validity is a single unitary construct (Messick, 1995). Therefore, evidence of validity for the SETMI has been provided in the following ways.
Evidence of validity of test content (Messick, 1995) of the SETMI can be found in the organized manner in which it was created and revised. The SETMI was created to align to Bandura’s theory by using appropriate literature as a basis and also using previously published instruments as a guide. Elementary mathematics content was also appropriately sampled to provide for specificity relevant to the task of teaching elementary mathematics. Elementary mathematics experts judged the content validity of the instrument before data were collected. Revisions to Version 1 were made in consultation with a mathematics teacher educator and then approved by a focus group of elementary mathematics teachers.
Evidence of validity of response processes can be found through reliability coefficients using Cronbach’s alpha. Validity of the internal structure was determined by conducting an EFA of the SETMI Version 1, which revealed a more complex factor structure than was anticipated. Revisions to the instrument were made to simplify the factor structure and clarify item content, and then a CFA was conducted on Version 2 of the instrument to examine the construct validity.
Ultimately, these results show evidence that the SETMI is a valid and reliable measure of two aspects of self-efficacy: pedagogy in mathematics and teaching mathematics content. Through the process of examining structural validity, it became clear that there is potential for self-efficacy to be much more complex than was initially thought. Research on self-efficacy measurement has attempted to capture the construct through the formation of instruments aligned with tightly formed constructs thought to be elements of self-efficacy. These earlier instruments clung tightly to Bandura’s ideas that self-efficacy is a component of efficacy expectations. In addition, using mathematics as a context for examining self-efficacy creates a need to examine mathematics content knowledge because this is integral to the ability to teach mathematics successfully. Bandura (1997) stated that personal attributes may or may not be relevant to their efficacy for completing a task or producing an outcome, but in the case of teaching mathematics, it seems logical that personal attributes could contribute heavily to both one’s decision to teach mathematics and to one’s self-efficacy for doing so.
The relationship between teacher’s beliefs and practices is also important to reiterate. Numerous studies have noted a relationship between teacher beliefs and practices (Beswick, 2012; Ernest, 1989; Stipek et al., 2001). Therefore, a teacher’s beliefs are important to understanding their practices. Because there is also a direct relationship between teacher practices and student learning (Darling-Hammond & Youngs, 2002), the belief system of a teacher is incredibly important to understand. If student achievement in mathematics is to improve, the nature of a mathematics teacher’s complex belief system must be understood.
Researchers in both psychological and educational contexts have a vested interest in the measurement of self-efficacy. Most instruments that are in use today within the literature are at least 10 years old, which indicates a need to re-examine both validity and reliability of previously used scales. Context-specific measurement of self-efficacy in particular has been difficult to obtain for mathematics (Swackhamer, 2010). Mathematics content and teaching practices are both broad fields that are difficult to assess at a granular level. When existing measures of self-efficacy have been modified to be mathematics-specific, it has been difficult to maintain the existing factor structure of the instrument.
Further examination of the validity of this scale is needed as only two participants groups were sampled and student outcomes were not included. Our data suggested that the two-factor model is better than the one-factor model, but this does not mean that the two-factor model is the best for teacher self-efficacy as an empirical two-factor EFA and following independent sample CFA were not evaluated. More evidence of validity of the SETMI is called for with samples from other school districts and the inclusion of student mathematics achievement data. It is also possible that content items should be added or revised to allow for a closer alignment between the participants and the specificity of the content.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.