
Abstract
The Wechsler Adult Intelligence Scale–Fourth Edition (WAIS-IV) is one of the most well-known tests in the field of adult intelligence assessment. This study explores the validity of the Egyptian adaptation for the subscales of the WAIS-IV. Confirmatory factor analysis (CFA) indicated that the first-order, second-order, and bifactor models of both the five-factor Cattel–Horn–Carroll (CHC) and the four-factor structures fitted with the WAIS-IV. When the Arithmetic subscale was pathed to Perceptual Reasoning and Working Memory, the modified four first-order factor showed a better fit than any other model. Estimates of internal consistency revealed that Cronbach’s alpha was very high (.91) for the WAIS-IV scale and for four-factor structures (ranging from .81 to .95), while
The Wechsler Adult Intelligence Scale (WAIS-IV) is the most commonly used instrument to assess the cognitive abilities of adults (Goldstein & Saklofske, 2010; Salthouse & Saklofske, 2010). Unlike previous versions, the WAIS-IV (Wechsler, 2008) is structured to be compatible with the Cattel–Horn–Carroll (CHC) theoretical conceptualization of intelligence and takes into account the concepts of fluid reasoning, working memory, and processing speed (Kaufman, Salthouse, Scheiber, & Chen, 2016; Weiss, Saklofske, Coalson, & Raiford, 2010). In addition, the WAIS-IV reduces the administration time of the previous version (Coalson, Raiford, Saklofske, & Weiss, 2010).
Several recent validity studies have explored the validity and reliability of the WAIS-IV by reanalyzing the U.S. standard sample (n = 2,200). Benson, Hulac, and Kranzler (2010) indicated that the CHC model gave a better data fit than the four-factor model. Canivez and Watkins (2010) found that the second-order general factor explained the greatest proportion of the total variance. Gignac and Watkins (2013) found that the bifactor model was a better fit to the data. In addition, Glass, Ryan, and Charter (2010) showed that discrepancy score reliabilities ranged from .55 to .88 for WAIS-IV subtests and 80 to .91 for WAIS-IV indexes. Several studies have discussed the WAIS-IV structure across various samples. Bowden, Saklofske, and Weiss (2011) concluded that invariance of subtest scores across the United States and Canada was similar for construct measurement. D. I. Miller, Davidson, Schindler, and Messier (2013) and Nelson, Canivez, and Watkins (2013) suggested that four first-order factors was suitable. van Aken et al. (2017) and Weiss, Keith, Zhu, and Chen (2013a, 2013b) indicated that both the four- and five-factor models were a good fit with the data, but the five-factor model was a better overall fit. However, Canivez and Kush (2013) questioned the results of Weiss et al. (2013b) on the grounds of theoretical, methodological, and practical problems. Furthermore, some studies compared the differences in WAIS-IV Canadian and U.S. norms (Harrison, Holmes, Silvestri, & Armstrong, 2015a, 2015b; J. L. Miller et al., 2015).
Overall, these studies highlight the need for more research to test the WAIS-IV structure with Arabic speakers. To our knowledge, no attempt was made to provide an adapted version of the WAIS-IV for this population group. Test adaptation is a strategy that may reduce bias and minimize impact on the cross-cultural equivalence of test scores (van de Vijver & Tanzer, 2004), such as adapting the WAIS-IV for Arabic speakers. Furthermore, there is no published validation of the WAIS-IV for Egyptian samples. An objective of this study was to attempt to adapt the WAIS-IV for Arabic speakers. This study, therefore, set out to assess the dimensionality of the WAIS-IV for an Egyptian sample. To investigate the dimensionality of the WAIS-IV for an Egyptian sample, confirmatory factor analysis (CFA) was performed for different models to identify the best fit with the sample data.
Method
Participants
In total, 250 participants were recruited, but only 204 adults (128 [62.7%] females and 76 [37.3%] males) were administered at least the 10 core subtests of the WAIS-IV. All participants were aged between 18 and 24 (average 20.65 years, SD = 1.71).
Instrument and Adaptation Procedure
The WAIS-IV (Wechsler, 2008) is a measure of adult intelligence for ages 16 to 90. It includes 15 subtests—10 core (Similarities [SIM], Vocabulary [V], Information [INF], Block Design [BD], Matrix Reasoning [MR], Visual Puzzles [VP], Digit Span [DS], Arithmetic [AR], Coding [CD], Symbol Search [SS]) and five supplemental (Comprehension, Figure Weights, Picture Completion, Letter-Number Sequencing, and Cancellation)—from which four index factors may be derived: Verbal Comprehension (VC), Perceptual Reasoning (PR), Working Memory (WM) and Processing Speed (PS). Ten subtest scores are used to calculate the Full-Scale Intelligence Quotient (FSIQ) where there are three subtests for VC and PR and two subtests for WM and PS (Climie & Rostad, 2011). In addition, there are five supplemental subtests, two for PR and one for VC, WM, and PS. The WAIS-IV was translated and adapted into Arabic as follows: (a) direct translation into Arabic by two expert bilingual translators (English-Arabic) with knowledge of psychology and education (working as assistant professor and lecturer, respectively, at the Faculty of Education of Fayoum University; (b) comparison of the two translations to investigate any variance in apprehension; (c) review from two experts in the Arabic language and education; (d) back translation from Arabic into English by two translators; (e) comparison of the two back-translations to identify any differences; and (f) review of differences which were resolved by consensus.
Data Analysis
Mplus 7.1 (Muthén & Muthén, 1998-2015) was used for CFA. The following configurations was tested: (a) one-factor model; (b) two-factor model (verbal and nonverbal reasoning); (c) four first-order factor model (VC [SIM, V, INF], PR [BD, MR, VP], WM [DS, AR], PS [CD, SS]); (d) four-factor loading on a higher order factor model (second-order; indirect hierarchical model); (e) direct hierarchical (bifactor) model with four first-order factors; (f) five first-order model (crystallized knowledge [GC; SIM, V, SIM], visual processing [GV; BD, VP], fluid reasoning [GF; AR, MR], short-term memory [GSM; AR, DS], processing speed [GS; CD, SS]); (g) bifactor model with five first-order factors; (h) five-factor loading on a higher order factor model (five second-order factors).
The model fit acceptance values are not statistically significant according to chi-square; a root mean square error of approximation (RMSEA) value less than or equal to 0.05; χ2/df < 3; comparative fit index (CFI), Tucker–Lewis index (TLI) > 0.95; standardized root mean square residual (SRMR) < 0.05. Comparison of Akaike information criterion (AIC) values in various models is also considered (the best model has a lower value for AIC). In addition, Cronbach’s alpha, omega, and omega H coefficients were used to assess the reliability of WAIS-IV.
Results and Discussion
Table 1 provides an overview of descriptive statistics for the WAIS-IV subscale (M = 26.36; SD = 5.5) and four-factor (M = 65.91; SD = 11.03). The skewness and kurtosis values are less than the criterion of |2.0| to prove normal univariate distribution (acceptable; George & Mallery, 2010).
Descriptive Statistics and Internal Consistency Coefficients (Cronbach’s α,
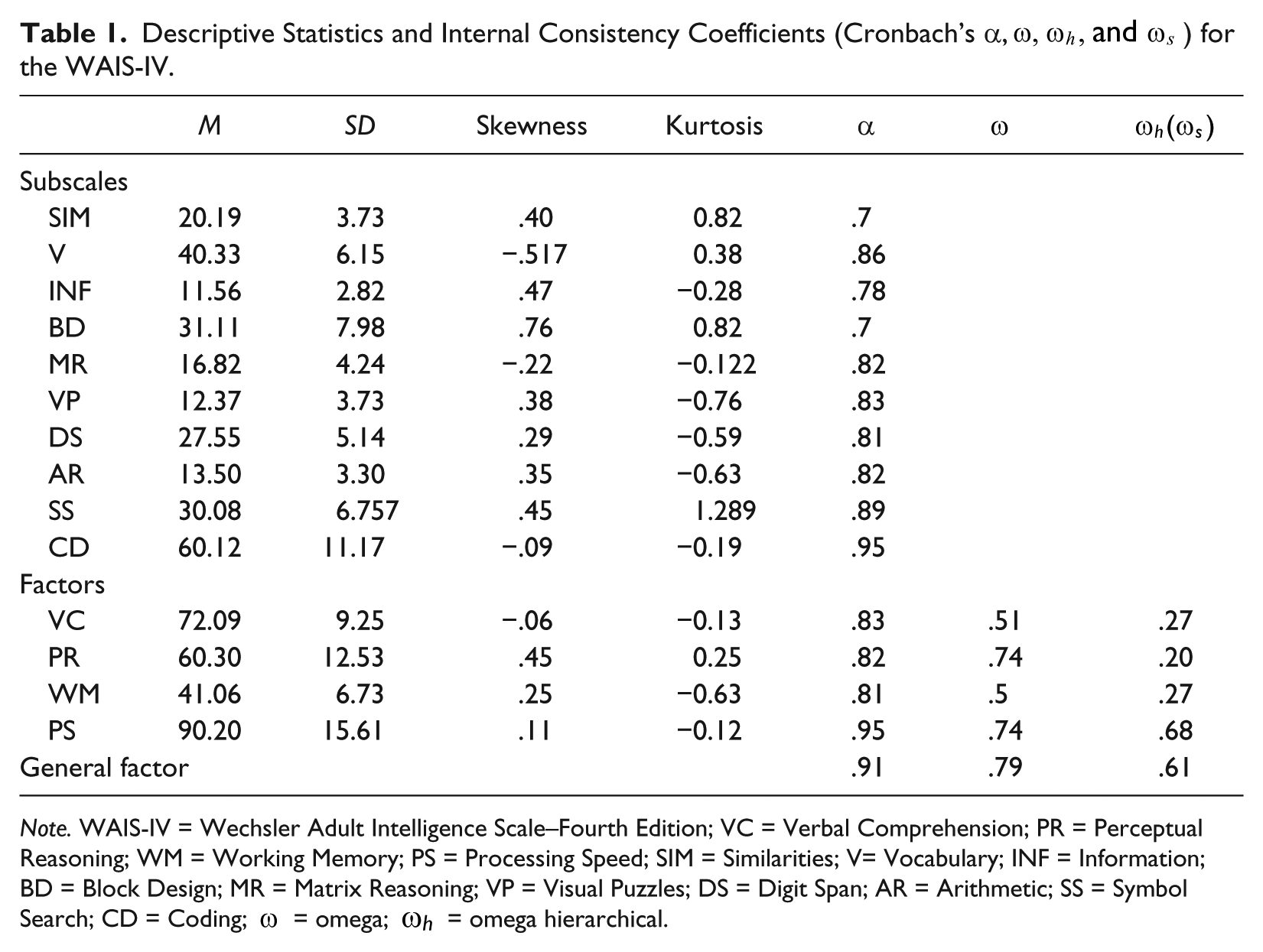
Note. WAIS-IV = Wechsler Adult Intelligence Scale–Fourth Edition; VC = Verbal Comprehension; PR = Perceptual Reasoning; WM = Working Memory; PS = Processing Speed; SIM = Similarities; V= Vocabulary; INF = Information; BD = Block Design; MR = Matrix Reasoning; VP = Visual Puzzles; DS = Digit Span; AR = Arithmetic; SS = Symbol Search; CD = Coding;
The top of Table 2 shows the fit statistics for the eight WAIS-IV models first proposed. The fit statistics suggested that the one-factor model and the two-factor model (verbal and nonverbal) were inadequate (χ2 significant, χ2/df < 2; RMSEA and >.05, TLI and CFI < .95). For the four-factor structure, the fit statistics were achieved for the correlated four first-order factor model (M3), the direct hierarchical model (Bifactor, M4), the four-factor loading on a higher order factor (second-order, M5) model. Moreover, no significant differences were found between these three models in terms of χ2 value or AIC coefficient, but M3 and M4 gave better values of CFI and RMSEA than M5.
Confirmatory Factor Analysis Fit Statistics for the WAIS-IV: Egyptian Sample.
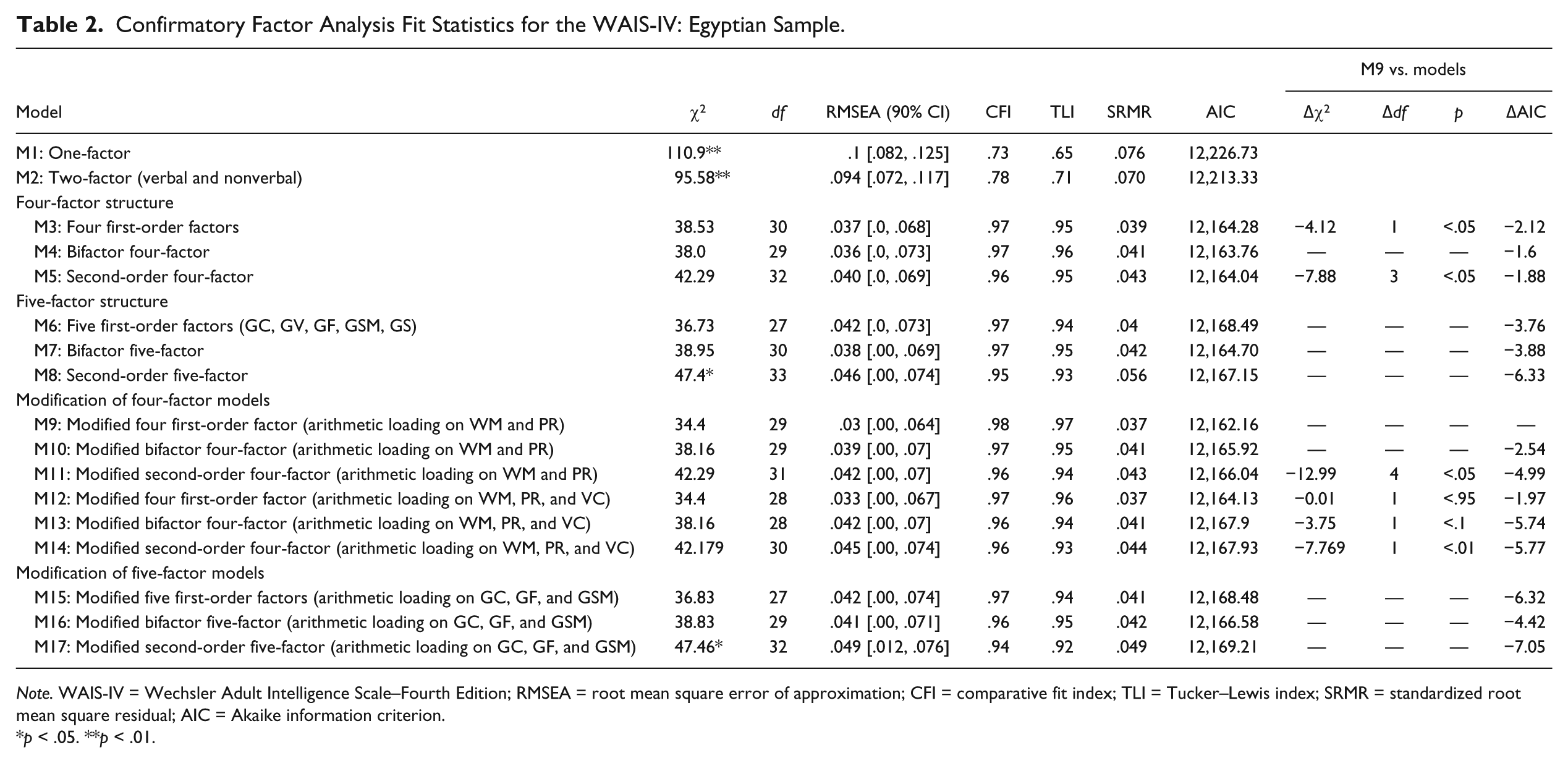
Note. WAIS-IV = Wechsler Adult Intelligence Scale–Fourth Edition; RMSEA = root mean square error of approximation; CFI = comparative fit index; TLI = Tucker–Lewis index; SRMR = standardized root mean square residual; AIC = Akaike information criterion.
p < .05. **p < .01.
The top of Table 3 summarizes the standardized loadings for the three plausible four-factor models: M3, M4 and M5. The 10 WAIS-IV subscales show a significant positive standardized loading value on the four factors (VC, PR, WM and PS) for M3 and M5 models. Similarly, the four-factor model (VC, PR, WM and PS) gives a significant positive loading on second-order factor, for M5. By contrast, in the bifactor model (M4), Matrix Reasoning yielded nonsignificant loadings on PR, and the Symbol Search subscale showed nonsignificant loading on general factor.
Standardized Loadings for Four- and Five-Factor Models.
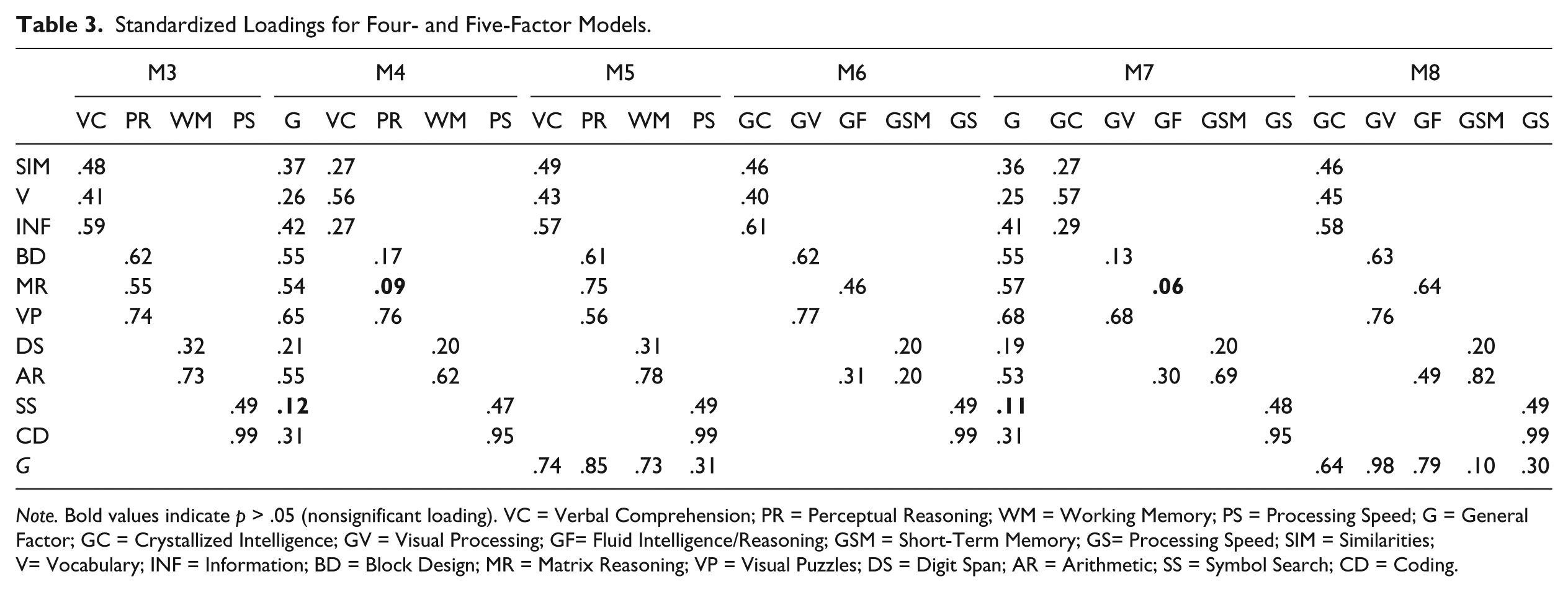
Note. Bold values indicate p > .05 (nonsignificant loading). VC = Verbal Comprehension; PR = Perceptual Reasoning; WM = Working Memory; PS = Processing Speed; G = General Factor; GC = Crystallized Intelligence; GV = Visual Processing; GF= Fluid Intelligence/Reasoning; GSM = Short-Term Memory; GS= Processing Speed; SIM = Similarities; V= Vocabulary; INF = Information; BD = Block Design; MR = Matrix Reasoning; VP = Visual Puzzles; DS = Digit Span; AR = Arithmetic; SS = Symbol Search; CD = Coding.
Regarding the five-factor CHC-based structure derived from terms of the CHC theory of cognitive abilities through (McGrew, 2009) alongside the results of previous research (van Aken et al., 2017; Benson et al., 2010; Weiss et al., 2013b), the three five-factor models again fitted the data (see Table 2). For these models, the Arithmetic subscale was loaded significantly on both the WM and GF factors. M7 was a better fit than M6 and M8, giving the lowest value of AIC. Moreover, ΔΔχ2 was statistically significant between M7 and M8 (Δχ2 = −8.45, df = 3, p < .05) but not between M6 and M7 (Δχ2 = −2.22, df = 3, p < .75). For standardized loadings of the five-factor models (M6, M7, M8), a very similar pattern is observed with respect to what is mentioned in the four-factor models, as well as the same problem on bifactor model regarding the nonsignificant loadings of specific scales (see the bottom of Table 3).
To optimize the fit, some modifications are proposed (see the bottom of Table 2). For the four-factor structure, following the addition of a path between the Arithmetic subscale and PR, in addition to WM, the fit of M9 was improved due to multiple loadings of the Arithmetic subscale on PR and WM, but M10 and M11 did not show any improvement of fit statistics relative to M4 and M5. Interestingly, the Arithmetic subscale showed nonsignificant loading on PR and VC in multiple attempts to find the best model fit when a path was added from the Arithmetic subscale to PR, WM, and VC for models M12, M13, and M14. For the five-factor structure, no improvement in fit was observed in the loadings of the Arithmetic subscale on GC, GF and GSM for models M15, M16, or M17. In addition, no significant loadings were found between Arithmetic and GC for the three modified models M15 (.11), M16 (.041), and M17 (.14).
The modified models reproduce the previous observations for the unmodified models. As shown in Figure 1 for M9, the loadings of 10 subscales on the four-factor structure were very similar to M3, which produced a significant positive standardized loading value on the four factors (VC, PR, WM, and PS). Interestingly, comparisons of M9 with nested models using Δχ2 suggested that M9 provided better overall fit (see Table 2). In addition, ΔAIC also supported the use of M9 over the other models. In summary, the best fit appeared to be obtained for Model 9 (see Table 2).

Path diagram for M9.
In addition, the 10 subscales and four factors were shown to have acceptable internal consistency (see Table 1). The mean Cronbach’s alpha values for the 10 subscales and four factors were .81 and .85, respectively. Cronbach’s alpha for the general factor was very high (.91) and Coding and Symbol Search gave the highest internal consistency values (.95 and .89, respectively), while Similarities and Block Design gave the lowest (.7). The values of
Interestingly, both the four-factor structure and five-factor CHC theory models fit the WAIS-IV with the Egyptian sample, confirming the findings of (van Aken et al., 2017; Weiss et al., 2013b). For the four-factor structure, the clearest finding was that the second-order model and the four-factor structure were the best fit for the data compared with the bifactor model. These findings are comparable with those of (Canivez & Watkins, 2010; D. I. Miller et al., 2013; Reynolds, Ingram, Seeley, & Newby, 2013). One unanticipated finding was that the bifactor model presented nonsignificant loadings of the MR subscale on PR, and nonsignificant loadings of the SS on general factor and these results are consistent with those of Gignac and Watkins (2013). Moreover, for the CHC-based structure, the five first-order factors (GC, GV, GF, GSM, GS), bifactor five-factor, and second-order five-factor models were also suitable, but the bifactor five-factor model presented nonsignificant loadings of the MR on the general factor, similar to the bifactor four-factor model. A possible explanation for this is that the bifactor model does not include mediation between a higher order factor and the observed variables by the first-order factor; the bifactor model focuses on the direct influences of a general factor on those subscales that also are loaded with nested factors directly, making the general factor closer to subscales (Gignac, 2008).
Another important finding was that adding a path from the Arithmetic subscale to the factors PR and WM for three four-factor structure models showed that the modified four first-order factor model was preferable to the other four- and five-factor models. In addition, the most obvious finding to emerge from the analysis is that Arithmetic is a complex subscale requiring multiple abilities (van Aken et al., 2017; Benson et al., 2010; Bowden et al., 2011; Ward, Bergman, & Hebert, 2012; Weiss et al., 2013b). The current study indicated that Arithmetic loaded significantly on WM (.34) and PR (.40) in the modified four first-order factor model and on GSM (.303) and GF (.689) in the bifactor five-factor model, but it showed nonsignificant when another path was added to VC, confirming with those obtained by Ward et al. (2012) who reported Arithmetic loadings of .32 and .35 on GSM and GF, in addition to slight loading on VC (.17) for the five-factor model. These results are also consistent with the findings of Weiss et al. (2013b), who showed that Arithmetic produced loadings of .36 and .27 on WM and PR, respectively, in the four-factor model. Our findings also corroborate the ideas of Nelson et al. (2013), who suggested that the bifactor model was suitable for the WAIS-IV structure using the normative data, although the correlated four first-order factor model gave a better fit. However, the findings presented here do not support those of Nelson et al., according to which the subscale loadings in the direct hierarchical model were significant. For example, the loading of Symbol Search on the general factor in the bifactor model was.362 according to Nelson et al. and 0.120 in this study, but the loading was nonsignificant on the general factor in the bifactor model. On the opposite, these results differ from the study of Benson et al. (2010) who found that the second-order model fit the data but selected the CHC model as the fittest for the data.
This study helps to disseminate knowledge of one of the most up-to-date and widely used measures in the field of intelligence testing, facilitating the development of scales that are suitable for the Egyptian community and its standards, especially Arab speakers for whom English is not a native language. The implications are important for the development of measures like the WAIS-IV that can be used by school psychologists and counselors to diagnose cognitive abilities and thus help to provide essential services for community institutions, particularly for Arabic speakers who do not speak English as a native language.
This study was limited by the absence of supplemental subscales of the WAIS-IV in our analysis. One of these subscales is Figure Weights, which showed the best loading on the GF factor in the five-factor model and also on the PR factor in the four-factor model in many studies comparing other core subscales, such as Ward et al. (2012). One additional limitation is that the WAIS-IV structure was explored with a randomly selected sample that satisfies the normal distribution criteria but was collected from a particular population and restricted by age (18-24). Caution should be exercised when generalizing the results to other age groups and regions.
In summary, the main goal of the current study was to adapt the WAIS-IV for Arabic-speaking populations. In addition, this study examined dimensionality and reliability using
Footnotes
Acknowledgements
The authors would like thank Dr. Hanaa E M Hussein, Dr. Mona A. Abdel-Tawab, Dr. Abeer E. M. Abo Zaid, Dr. Mohamed A. M. Hasan, Dr. Mohammed A. Owees, and Dr. Alsaid M. Abo Zed for their help in adapting the Wechsler Adult Intelligence Scale–Fourth Edition (WAIS-IV) for Arabic speakers.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.