
Abstract
The fourth edition of the Wechsler Adult Intelligence Scale (WAIS-IV) has been used extensively for assessing adult intelligence. This study uses Mokken scale analysis to investigate the psychometric proprieties of WAIS-IV subtests adapted for the Egyptian population in a sample of 250 adults between 18 and 25 years of age. The monotone homogeneity model and the double monotonicity model were consistent with the subtest data. The items of all subtests except Matrix Reasoning, Information, Similarities, and Vocabulary formed a unidimensional scale. The WAIS-IV subtests have discriminatory and invariantly ordered items, although some items violated the invariant item ordering and scalability criteria. Therefore, the WAIS-IV subtests—with the exception of some items—are hierarchical scales that allow items to be ordered according to difficulty and subjects to be ordered using the sum score. In conclusion, the current study provides evidence of the dimensionality and hierarchy of the WAIS-IV subtests in the framework of Mokken scaling, although care should be taken when interpreting or including certain items.
The Wechsler Adult Intelligence Scale (WAIS) is one of the most widely used scales for assessing the cognitive abilities of adults and older adolescents (Benson, Hulac, & Kranzler, 2010; Salthouse & Saklofske, 2010). The most recent version of the WAIS (Wechsler Adult Intelligence Scale–Fourth Edition [WAIS-IV]; Wechsler, 2008) updates the base theory of the intelligence construct, assuming it to be a general concept comprising four indices: Verbal Comprehension (VC), Perceptual Reasoning (PR), Working Memory (WM), and Processing Speed (PS; Saklofske et al., 2012). The WAIS-IV takes into consideration current concepts of fluid reasoning, WM, and PS from the Cattell–Horn–Carroll model and contains 15 subtests, five of which are supplemental (Bowden, Saklofske, & Weiss, 2011a; Kaufman, Salthouse, Scheiber, & Chen, 2016). For each subtest, it is assumed that items are administrated in ascending order of difficulty; consequently, the start points, reversal rules, basal rules, and discontinue rules are used to reduce the administration time and estimate participants’ sum scores without having to apply all the test items (Climie & Rostad, 2011; Weiss, Saklofske, Coalson, & Raiford, 2010).
Several recent studies, including Abdelhamid, Gómez-Benito, Abdeltawwab, Abu Bakr, and Kazem (2019); Bowden, Saklofske, and Weiss (2011b); Miller, Davidson, Schindler, and Messier (2013); Nelson, Canivez, and Watkins (2013), have explored the validity of the WAIS-IV using statistical tools based on classical test theory such as the internal consistency reliability, factor analysis, and confirmatory factor analysis. Together, this body of studies provides important insights into the statistical properties of the WAIS-IV, but their conclusions depend on the total score for the subtests in the framework of classical test theory, which has many acknowledged limitations. One such limitation is that the item parameter is dependent on the sample properties and the person parameter is dependent on the specific selection of items in a test (Embretson, 1996).
Sijtsma, Emons, Bouwmeester, Nyklíček, and Roorda (2008) argued that an instrument should achieve two requirements to be an efficient measure. First, the true number of dimensions measured must be clear (e.g., one dimension or multidimensional). In the light of this requirement, if each subtest of the WAIS-IV assesses one dimension, the sum score of subtest items can be calculated to determine the adult level of the latent trait being measured. However, if the subtest encompasses two or more dimensions, it is necessary to estimate the sum score for each dimension that reflects a feature of the latent trait measured. The second requirement is that the psychometric properties of the items must be accurately estimated, as they are necessary in ensuring that the difficulty and discriminatory power are accurate.
In the literature, there is no discussion of the properties of WAIS-IV subtests adapted for Arabic speakers (Abdelhamid et al., 2019) in terms of individual item scores or, in particular, the dimensionality of each subtest. To our knowledge, no study has focused on item statistical properties or dimensionality in each of the WAIS-IV subtests using modern psychometric theory, such as item response theory (IRT) or Mokken scale analysis (MSA), which represents the main aim of the current study.
MSA is a nonparametric procedure that provides a series of methods for examining the relationship between items and the latent traits being measured and for investigating hierarchies of items in measures (Watson et al., 2012). It has some advantages over other parametric procedures. First, MSA is less restrictive about the data with regard to the item response function (IRF) than parametric IRT models (specific shape, logistic like S; Sijtsma & Van der Ark, 2017). This helps researchers to retain items that would otherwise be omitted from a measure in restrictive parametric IRT models. Second, MSA provides a set of exploratory tools for dimensionality analysis, which is not possible in parametric IRT models (Emons, Sijtsma, & Pedersen, 2012).
Nonparametric Item Response Theory (NIRT) Models
MSA uses a set of methods that assesses the fit of two NIRT models. These NIRT models are known as the monotone homogeneity model (MHM) and, its special case, the double monotonicity model (DMM). The MHM and DMM share a number of assumptions, including unidimesionality, monotonicity, and local independence, whereas the DMM adds nonintersecting item response nonintersection of IRFs (Sijtsma & Van der Ark, 2017).
The MHM indicates that each item exhibits a monotonic and positive relationship with the latent variable (Emons et al., 2012). The MHM uses the sum score
MSA uses three scalability coefficients: item scalability coefficient (
Assumptions of NIRT Models
The unidimensionality assumption indicates that all items measure the same latent variable (denoted by
Numerous studies have used MSA to examine the psychometric properties of various tests, but despite the advantages of the MHM and its special case, the DMM, described above (e.g., Sijtsma & Van der Ark, 2017), to our knowledge, there is no published calibration of the WAIS-IV scale using MSA. As such, as far as we are aware, the current study is also the first to examine IIO and dimensionality of WAIS-IV subtests adapted for an Egyptian sample (Abdelhamid et al., 2019) using those of the two NIRT models. As such, this study was an important opportunity to advance the understanding of Mokken analysis and to assess the fit of IRT models for the WAIS-IV subtests analyzed. Therefore, our study has three purposes: (a) to evaluate the dimensionality of each of the WAIS-IV subtests using MSA, (b) to estimate whether the hierarchy of the items in each of the WAIS-IV subtests could be established with IIO, and (c) to check the ability of the items in each of the subtests analyzed to identify individual differences on the latent trait measured.
Method
Participants
Two hundred fifty normal adults agreed to participate voluntarily in this study. Once informed consent had been received, the participants were tested from 2015 to 2016 across Egypt. Participants were aged between 18 and 24 years, with an overall mean age of 20.6 years (SD = 1.7 years), and just more than half the sample (62.7%) was female. Respondents participated voluntarily. All participants were native speakers of Egyptian Arabic. All participants were evaluated individually by psychologists and educators who had received prior training in the application of the scale, based on guidelines explained in the administration manual (Wechsler, 2008). The research reported in this study was part of a project to adapt the WAIS-IV to Arabic speakers, and permission was obtained from the ethics committee of Fayoum University.
Measures
The WAIS-IV Arabic version was used (Abdelhamid et al., 2019), which, like the English version, has 10 core subtests and five supplemental subtests that generate a score for four indices: VC, PR, WM, and PS. Some of these subtests are scored 0, 1 (e.g., dichotomous data). For PR, the subtests analyzed were Visual Perception (26 items), Figure Weights (27 items), Picture Complete (24 items), and Matrix Reasoning (26 items); for WM, Arithmetic (22 items); for VC, Information (26 items); for PS, Symbol Search (60 items) and Coding (135 items). Others are scored polytomously (i.e., 0, 1, 2, etc.): for VC, the subtests Similarities (18 items) and Vocabulary (30 items); for PR, Block Design (14 items); for WM, Digit Span, which has three subscales (Digit Span-Forward [eight items], Digit Span-Backward [eight items], and Digit Span-Sequencing [eight items]), and Letter–Number Sequencing (10 items); for PS, Cancelation (two items).
The WAIS-IV subtests can also be classified as verbal and nonverbal. The verbal tests, such as Similarities, Vocabulary, Arithmetic and Information, contain some changes to ensure that they are suitable for the Arabic-speaking population. By contrast, nonverbal tests such as Visual Puzzles, Figure Weights, Picture Completion, Matrix Reasoning, Block Design, and Symbol Search were unchanged. In the Letter–Number Sequencing subscale, the English alphabet and numbers were converted to Arabic script, taking into account the order of letters and numbers during items adaptation. For the Digit Span-Forward, Digit Span-Backward, and Digit Span-Sequencing subscales, which only contain numbers, the numerals were converted to the Arabic equivalents. It should be noted that the WAIS-IV subtests contain a set of easy items that do not fit the sample used in this study and are, therefore, omitted from the analysis.
Data Analysis
The R package Mokken V 2.8.2 (Van der Ark, 2016) was used to analyze the data for WAIS-IV subtests. The Mokken scalability coefficients
Thus, the statistic HT was reported as an indicator of the accuracy of the IIO on the basis of the following criteria:
To assess the reliability of the scale, we estimated three reliability coefficients for each subtest of the WAIS-IV: the lambda-2 statistic (Sijtsma, 2009), as an alternative to Cronbach’s alpha; the Molenaar–Sijtsma statistic, as a reliability estimator with a smaller bias for MSA (MS; Sijtsma & Molenaar, 2002); and the latent class reliability coefficient (LCRC), an unbiased statistic of test-score reliability (Van der Ark, Van der Palm, & Sijtsma, 2011).
Results
Descriptive Statistics and Reliability
The majority of participants were students who were not employed and were not married; only around 22% were employed and married. With regard to education achievement, the participants were at different stages of undergraduate study (first year, 22%; second year, 34.8%; third year, 9.2%; and fourth year, 8.8%; or held an undergraduate or postgraduate degree, 25.2%).
As shown in Table 1, the normality assumption held for the WAIS-IV subtests; skewness and kurtosis values were within the rule of thumb. Table 1 also provides the results obtained with the three reliability coefficients for the WAIS-IV subtests. Overall, the subscales were shown to have good internal consistency: The values of the three coefficients ranged from .68 to .99.
Descriptive Statistics and Internal Consistency for the Wechsler Adult Intelligence Scale-IV Subtests.

Note. MS = Molenaar–Sijtsma; λ2 = lambda-2; LCRC = latent class reliability coefficient; VP = Visual Puzzles; PR = Perceptual Reasoning; FW = Figure Weights; PC = Picture Completion; MR = Matrix Reasoning; AR = Arithmetic; WM = Working Memory; INF = Information; VC = Verbal Comprehension; SIM = Similarities; V = Vocabulary; BD = Block Design; DS = Digit Span; LN = Letter–Number Sequencing; SS = Symbol Search; PS = Processing Speed; CD = Coding.
MHM Analysis
Tables 2 and 3 provide an overview of Mokken analysis for the WAIS-IV subtests. It should first be noted that item-pair scalability (Hij) and item scalability (Hj) were positive for all subtest items. However, Hj > .3 was only achieved for all items of the subtests Visual Puzzles, Arithmetic, and Block Design, whereas total scalability (H) was .48, .55, and .59, respectively, which indicated medium and strong scales. In the case of the other subtests, some items failed to achieve the Hj > .3 criterion: one item in Figure Weight and Digit Span; three items in Picture Completion, Information, and Letter–Number Sequencing; five items in Matrix Reasoning; six items in Similarities; 11 items in Vocabulary; and 19 items in Symbol Search. The total scalability (H) of these subtests was between .30 and .65 when no items were deleted (see Table 2). These results indicate that Similarities, Vocabulary, and Symbol Search are weak; Picture Completion, Matrix Reasoning, Information, Letter–Number Sequencing, and Digit Span are medium; and Figure Weights and Coding are strong. However, when those items that failed to satisfy the Hj criterion were deleted, the total scalability H was greater than or equal to .5 (strong scales) for all subtests except Matrix Reasoning, which was medium. These increases in total scalability show a trend toward greater unidimensionality of subtests.
Summary of the Mokken Scaling Analysis Results for the Wechsler Adult Intelligence Scale-IV Subtests.
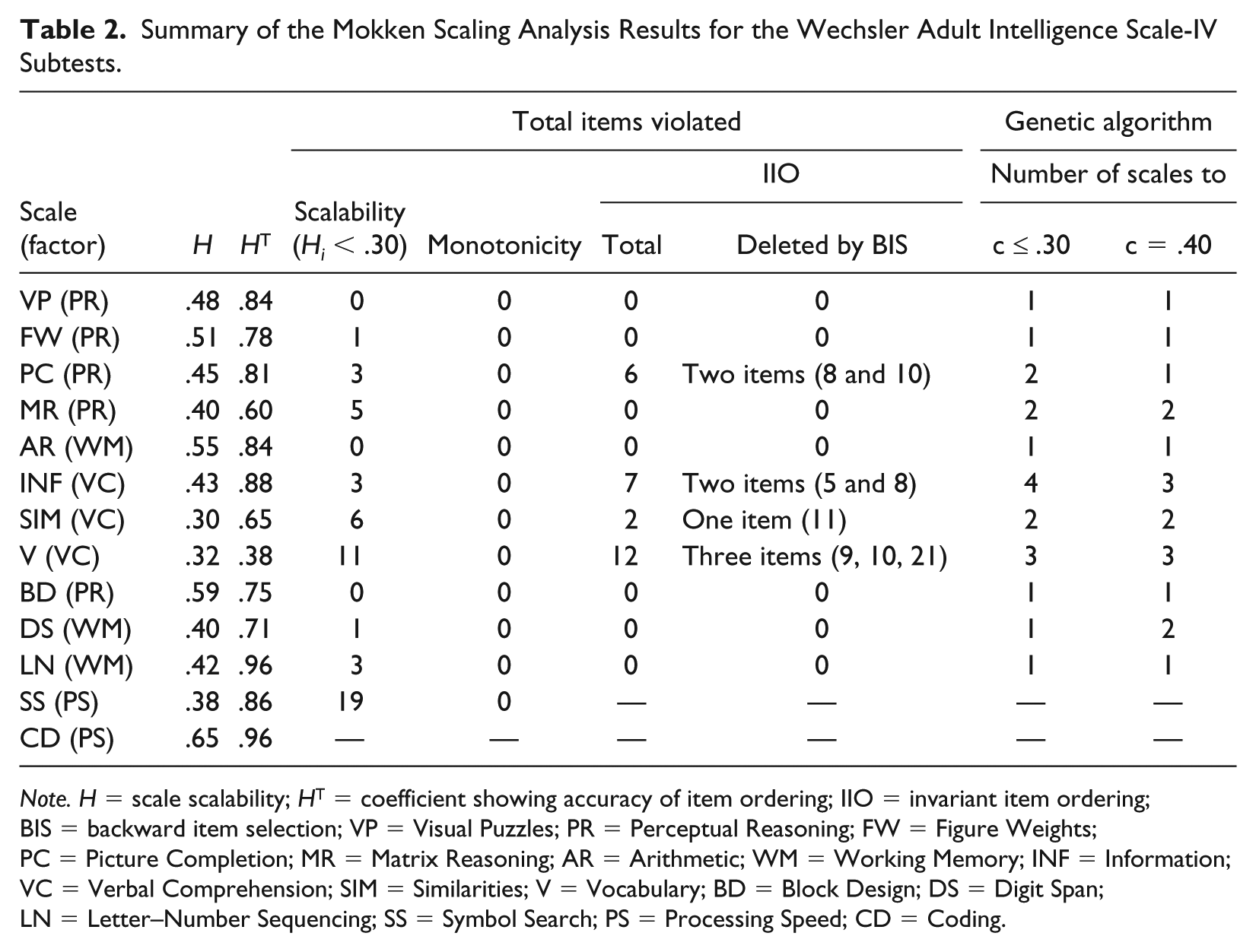
Note. H = scale scalability; HT = coefficient showing accuracy of item ordering; IIO = invariant item ordering; BIS = backward item selection; VP = Visual Puzzles; PR = Perceptual Reasoning; FW = Figure Weights; PC = Picture Completion; MR = Matrix Reasoning; AR = Arithmetic; WM = Working Memory; INF = Information; VC = Verbal Comprehension; SIM = Similarities; V = Vocabulary; BD = Block Design; DS = Digit Span; LN = Letter–Number Sequencing; SS = Symbol Search; PS = Processing Speed; CD = Coding.
Fit Statistics of MSA Models for Wechsler Adult Intelligence Scale-IV Subtests.
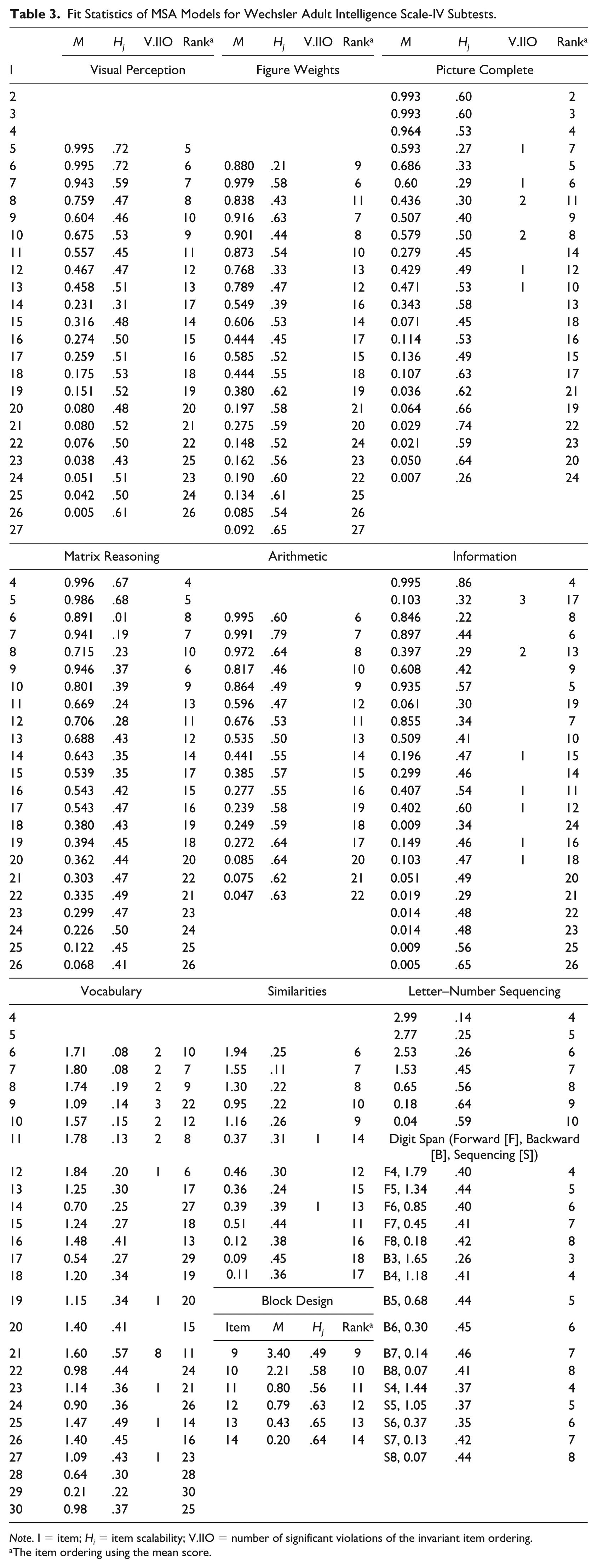
Note. I = item; Hi = item scalability; V.IIO = number of significant violations of the invariant item ordering.
The item ordering using the mean score.
Additional information about dimensionality can also be found in Table 2, particularly in the last two columns; we report only the results for c ≤ .30 and c = .40 (the other values did not show interesting results), which show the results using the genetic algorithm for each WAIS-IV subtest. In general terms, we found that the items of the subtests Visual Puzzles, Figure Weights, Arithmetic, Block Design, Digit Span, and Letter–Number Sequencing were selected to form a scale in each subtest with lower bounds in the range .0 ≤ c ≤ .3. For the subtests Picture Completion, Matrix Reasoning, and Similarities, with lower bounds in the range .0 ≤ c ≤ .3, not all the items were selected for the same scale, suggesting that the items can be divided between two scales for each subtest. Finally, for the subtests Information and Vocabulary, using the same criterion (.0 ≤ c ≤ .3), the items can form up to four and three scales, respectively.
Using a slightly more restrictive lower bound criterion of c = .4, the items of the subtests Visual Perception, Figure Weights, Picture Completion, Arithmetic, Block Design, and Letter–Number Sequencing formed a single scale in each case, whereas the items of the subtests Matrix Reasoning, Similarities, and Digit Span formed two scales and those of Information and Vocabulary formed three scales. In summary, the results fitted the expected pattern of a unidimensional scale for Visual Puzzles, Figure Weights, Picture Completion, Arithmetic, Block Design, Digit Span, and Letter–Number Sequencing, as described by Sijtsma and Molenaar (2002), whereas the Matrix Reasoning, Information, Similarities, and Vocabulary subtests were multidimensional.
No significant violations of the monotonicity assumption were detected for the items of each subtest, but one item of the Matrix Reasoning and Vocabulary subtests had a Crit value in the range 40 ≤ Crit < 80, showing a nonserious degree of misfit. In addition, strong evidence of monotonicity was found when inspecting all IRFs of the subtests for all items across the range of ability. In summary, the results under the MHM indicate that the monotonicity assumption held for each of the WAIS-IV subtests and that unidimensionality was achieved by all subtests except Matrix Reasoning, Information, Similarities, and Vocabulary, which reported Mokken multiscales (i.e., multifactor).
DMM Analysis
Tables 2 and 3 (V.IIO column) display the statistics for IIO applied to the subtests. The IIO assumption was also visualized using the Mokken package. The results revealed no significant IIO violations for any items of the Visual Puzzles, Figure Weights, Matrix Reasoning, Arithmetic, Block Design, Digit Span, and Letter–Number Sequencing subtests, and the HT coefficient was greater than .50, indicating a strong ordering.
But, six items (5, 7, 8, 10, 12, and 13) of the Picture Completion subtest violated the IIO assumption, and Crit values were in the range 40 ≤ Crit < 80, although the backward item selection method reported only two items (8 and 10) to be removed. Once the two items had been removed from the Picture Completion subtest, HT was .81 (strong ordering) and the test scalability H was .48, indicating a medium scale. The Information subtest showed significant violations of IIO for seven items, but only one item (8) had a Crit value greater than 80, of approximately 90. Backward item selection confirmed that two items (5 and 8) should be removed. Once these items had been removed, the HT coefficient for the remaining Information items was .88, which is a very high value according to Ligtvoet et al. (2010) and H was .48, indicating a medium scale.
For the Similarities and Vocabulary subtests, the HT coefficient was .65 (strong ordering) and .38 (weak ordering) and backward item selection confirmed that only one item (11) and three items (9, 10, and 21) should be removed, respectively. As shown in Figure 1, Item 11 violated the IIO and nonintersection assumptions with Item 15 for the Similarities subtest, and depicted the intersection between item-pairs 20 and 9, and 21 and 10 for the Vocabulary subtest. For the Coding and Symbol Search subtests, although strong ordering was achieved, the backward item selection procedure reported violations by some items, which should be deleted.
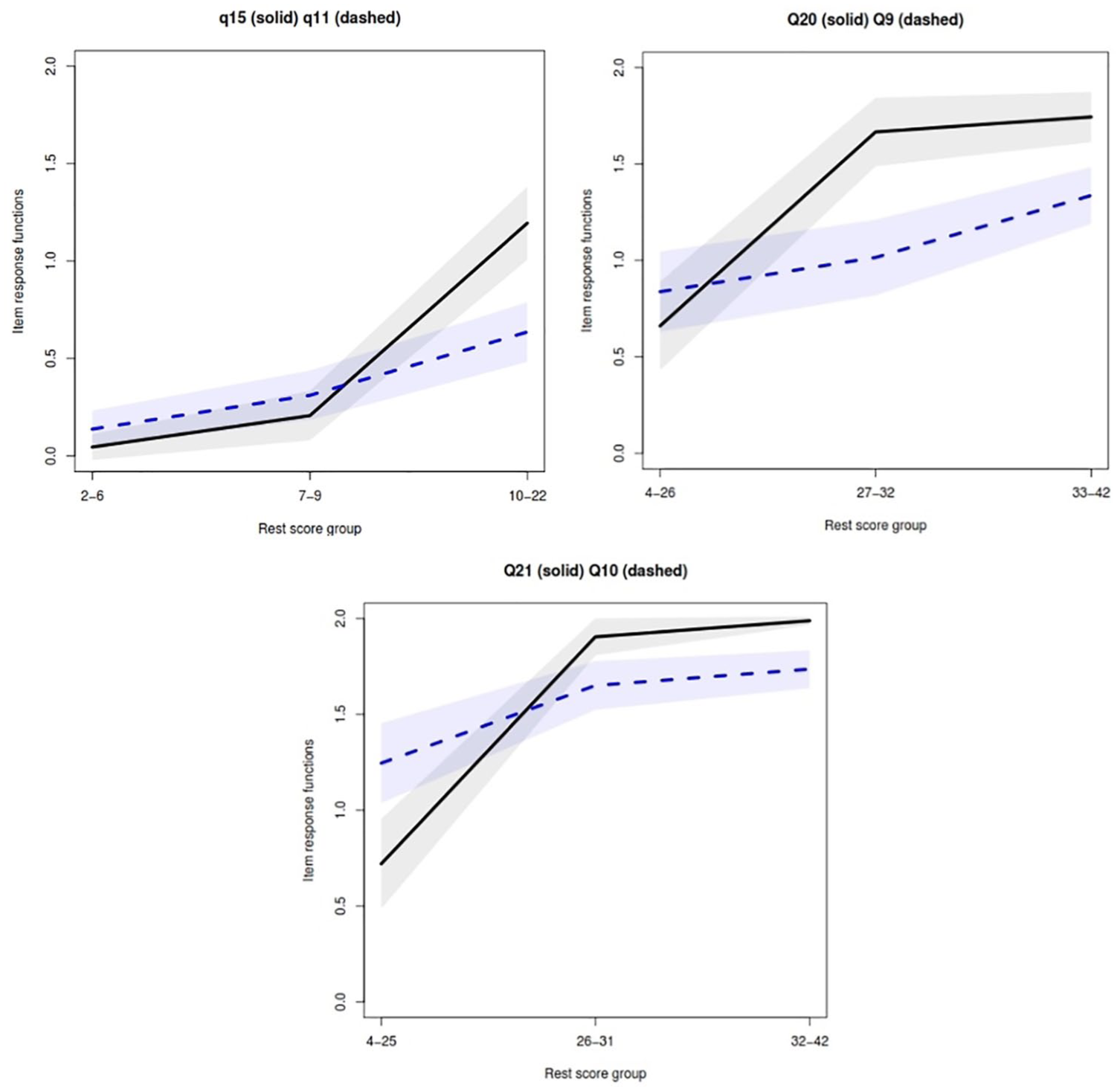
Example violations of the IIO assumption for item-pair 15 and 11 for the Similarities subtest and item-pairs 20 and 9, and 21 and 10 for the Vocabulary subtest using the manifest IIO method.
Table 3 (Rank column) displays the item ordering for each subtest using the mean score. Using this approach, items with a lower mean score are reflected as more difficult. Interestingly, the ordering was different for some items with respect to the original ranking described in the WAIS-IV manual.
It can, therefore, be concluded that the MHM and DMM fitted well to the subtest data, although caution is required with certain items for which a poor fit was reported: In the MHM, those items that failed to satisfy the Hj criterion, and in the DMM, those items that were removed following backward item selection.
Discussion
This study uses two NIRT models to assess the psychometric properties of WAIS-IV subtests. In reviewing the literature, no data were found on the application of MSA to WAIS-IV data. The most interesting finding was that MHM fitted all items of the subtests, although a small number of items fitted poorly as measured by the scalability coefficient. Sijtsma and Molenaar (2002) noted that a similar fit of the MHM to the one reported in this study suggests that the sum score of each subtest is a good indicator of the latent trait. From a practical perspective, the sum score of each subtest can be used to order adults on the latent trait. This is reinforced by the results obtained with the item scalability coefficient Hi for the WAIS-IV subtests, which indicate that the subtest items discriminate well between levels of adults on the latent trait, such that adults with a higher level of intelligence will score higher for each subtest. In any case, although the results also showed that care should be taken with those items with a scalability coefficient less than .30 when interpreting the total scores, it was not essential to remove these items as H was greater than .4, indicating that they fitted well to the MHM.
Moreover, strong IIO (HT ≥ .50) was recorded for all WAIS-IV subtests with the exception of Vocabulary, according to the criteria established by Ligtvoet et al. (2010). One of the issues that emerges from these findings is that WAIS-IV subtests present hierarchical information based on the difficulty of each item, and items can be administered in ascending order, using their difficulty to reduce administration time and applying the discontinue rule if the individual fails to answer several consecutive items; for example, the matrix subtest is discontinued if the individual fails to correctly answer three consecutive items. This also makes it possible to apply the starting rule according to the age of each individual. As expected, there are differences in item order between the WAIS-IV subtests adapted to Arabic and those detailed in the U.S. WAIS-IV manual, although the original subtest structures have been maintained as far as possible. For verbal subtests, the order of item administration should be changed. For instance, in the Information subtest, most of the items pertain to the Western canons of geography, science, history, and literature. Specifically, Item 5, “Martin Luther King,” is very easy for a U.S. sample, whereas individuals from Egypt may find it more difficult to answer correctly, so it was ranked 17th, whereas Item 10, “Cleopatra,” is very easy for our sample and was ranked fifth. Similarly, the administration order of some items in the nonverbal subtests should also be reexamined. For instance, Item 14 in Visual Puzzles was ranked 17th in our study, and Item 17 in Figure Weights was ranked 15th. On the basis of these results, applying the WAIS-IV subtests for Arabic speakers as ordered in the U.S. WAIS-IV manual may have a negative impact on overall scores due to the presence of the lowest ranked items and their implications for the application of the discontinue rule. In general, it seems that WAIS-IV subtest items should be resequenced for Arabic speakers to obtain more accurate scores. These results match those reported by Suwartono, Hidajat, Halim, Hendriks, and Kessels (2016), who found that the orders established in the U.S. WAIS-IV manual were unsuitable for Indonesia.
Moreover, according to Watson et al. (2012) and Ligtvoet et al. (2010), the lack of IIO was due to the measurement of many items at the same level of latent trait. Therefore, we can infer from the IIO of WAIS-IV items that they measure different levels of cognitive construct, and this is confirmed by the variation in mean item scores; for instance, for the Visual Puzzles subtest, mean scores ranged from .005 (Item 26; very difficult) to .995 (Items 1-5; very easy). From this, and considering the IIO of the WAIS-IV, we can conclude that the ordering of subjects based on the total score of each WAIS-IV subtest is invariant (Ligtvoet et al., 2010; Sijtsma & Van der Ark, 2017).
Interestingly, the dimensionality results using the genetic algorithm indicated that the WAIS-IV subtests analyzed in this study are unidimensional except for Matrix Reasoning, Information, Similarities, and Vocabulary, which are multidimensional. The appearance of more than one scale for some of the WAIS-IV subtests using Mokken analysis may explain the findings of previous studies such as Abdelhamid et al. (2019), Bowden et al. (2011a), Weiss, Keith, Zhu, and Chen (2013a, 2013b), which suggested that some of these subtests were loaded on more than one factor. As such, the total score of each the WAIS-IV subtests (except multidimensional subtests) can be computed to determine the adult’s level on the latent trait being measured. For the multidimensional subtests (e.g., Matrix Reasoning, Information, Similarities, and Vocabulary), it is necessary to calculate the total score for each dimension that reflects features of the latent trait being measured.
Moreover, the current study used the reliability coefficients (Molenaar–Sijtsma, lambda-2, and latent class reliability), which revealed high reliability for the subtests, which is an indication of good quality. These findings are in the line with those of previous studies such as Glass, Ryan, and Charter (2010).
From an empirical perspective, this study provides new understanding of how to apply Mokken analysis to intelligence scales and how to assess the fit of NIRT models. Our analysis has shown that the MHM and DMM fit the WAIS-IV, giving evidence of their highly successful application in intelligence scales. The current findings should be extrapolated only to the 18 to 24 years age group. Although the sample is expected to be representative of the 18 to 24 years age group and the data satisfied the normality assumption, care should be taken when drawing inferences with regard to other age groups and regions. It is unfortunate that our study did not include the Comprehension and Cancelation subtests. Symbol Search and Coding are speeded subtests, so the results should be approached with caution; as such, we did not discuss these results at the item level.
In conclusion, the present study provides several interesting findings on the dimensionality and hierarchy of WAIS-IV subtests in an MSA framework. In future research, it may be of interest to use different WAIS-IV data (samples from other countries, or extending the current sample, to include other socidemographic characteristics) to compare NIRT models and establish their statistical properties. Moreover, the use of a variety of IRT models may yield useful information from which to draw conclusions about item fit or item weakness. The current findings offer many suggestions that may improve the WAIS-IV subtests adapted for Arabic speakers. First, consideration should be given to reordering the items of some subtests to obtain more accurate mean score estimates using modern theoretical approaches such as Mokken analysis. Second, some WAIS-IV items that did not fit well to the NIRT models could be revised, and some could be omitted in the construction of a shortened version of the WAIS-IV, which was suggested by previous studies such as Denney, Ringe, and Lacritz (2015) and Meyers, Zellinger, Kockler, Wagner, and Miller (2013).
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Egyptian Ministry of Higher Education, Management of Supporting Excellence, Competitive Excellence Project of Higher Education Institutions (grant 2016), and by the Agency for the Management of University and Research Grants of the Government of Catalonia (grant 2017SGR1681). The funders played no role in the study design, data collection and analysis, decision to publish, or preparation of the article.