
Abstract
It is argued in studies in which open-ended questions are used that the choice is not between human or machine coding. It is the position the investigator takes with regard to the coding process that is relevant: from whose perspective is the coding performed? This choice determines whether human or machine coding can be performed. The results one obtains when these approaches are used can be very different.
Introduction
In many quantitative text analysis studies, including the analysis of open-ended questions as used in surveys, one tries to avoid human coding as much as possible, most of all as it is thought to be time consuming and expensive. There is an alternative: the computer. However, one then needs a good dictionary and developing such a dictionary also takes time, just as updating an old dictionary. The quality an investigator wants is also highly relevant. Even more important should be the view one has concerning the coding process to be performed. Two views can be distinguished. One view encourages the use of the computer to perform the coding task. The other view however usually demands human coders or raters.
An important question in text analysis is from whose point of view the data are to be coded. In the instrumental approach, texts are interpreted according to the researcher's theory. The approach ignores the meanings that the texts' authors may have intended. When the representational perspective is applied, texts are used as a means to understand the author's meaning (Shapiro, 1997).
The instrumental approach can be illustrated with the work of Gottschalk and his colleagues (Gottschalk et al., 1975; Gottschalk, 1997). This work involves assigning psychological scores based on the results of a text analysis of speech. These scores are calculated based on word usage indicating distinctive characteristics, according to the theoretical perspective of the investigators. More generally, when an instrumental perspective is applied, texts are interpreted according to the researcher's theory. In terms of Osgood: “As a matter of fact, we may define a method of text analysis as allowing for ‘instrumental’ analysis as if it taps message evidence that is beyond voluntary control of the source and hence yields valid inferences despite the strategies of the source” (Osgood, 1959: 75). Thus, the instrumental approach to text analysis tends to use texts to identify individual and societal characteristics about which society members may be unaware. The approach works very well if one wants to catch the manifest content of text.
The representational approach can be illustrated using Carley's (1986, 1988) study of dormitory residents. Based on interviews with students, she extracted topics salient in their speech. She recorded which topics the students related to other topics. In this way, she was able to construct a cognitive map in line with what the students said. Using a representational approach the researcher focuses less on specific wording than on the context within which the texts originated. When a text is analysed representationally, the researcher attempts to map the meaning intended by its source. This mapping cannot be accomplished unless the coder or rater understands the social context within which the text originated. The approach is suited if one wants to catch the latent meaning of text.
Today, most investigators still use the instrumental approach. If the researcher using this approach knows exactly what he or she is looking for, it should to be possible to fully automate the coding task. This would give rise to a “fixed dictionary” of conceptual categories with a one-to-one correspondence with search entries – words and phrases in texts indicating the concept. Therefore, the computer can perform the coding task very well.
Researchers using the representational approach must develop ad hoc dictionaries that contain concepts that reflect the perspectives of the texts’ authors. Raters must use sympathetic “understanding” (or “Verstehen”) to encode the texts according to the meanings their sources intended. At issue is no longer “how” to encode text as in the instrumental approach, but “whether” one chooses to apply one's own theory or sources' “theories” or meaning to the texts under analysis. Here the computer is essentially used as a management tool; the coding is performed by a human being. This approach is also very helpful to overcome problems of ambiguity, like recognizing homonyms (Roberts and Popping, 1996).
These differences in view on coding usually implies that different types of decisions are made and different outcomes are found. This may be demonstrated by using an example. It has implications for the validity of the results. Converse (1964) assigned answers to the open-ended question where people could explain why they voted in the last elections for a specific party. Converse's position was that the vast majority of the voting public has no clear ideology and has little desire to understand issues which are not clearly and directly related to them as individuals. This position can also be tested in a country other than the US and also for another time period. Here we consider the Dutch election data from 2006 (Nationaal Kiezersonderzoek, NKO 2006, Dutch Parliamentary Elections Studies, http://www.dpes.nl/pages/nko_2006.php).).
What Converse Had in Mind
Converse, being interested in voter decision making, took the position that most Americans have little understanding of their beliefs, have no basis for referencing conflicting ideas, and have little desire to consider the issues. If asked to agree or disagree with the statement that "Communists are atheists," most people in the US would agree. However, if further asked why Communists are atheists, the public could rarely give a coherent and correct explanation. The statement would only turn out to be a “fact of existence” (Converse, 1964: 212). Converse noted that most Americans tend to have limited education, which is linked with traits such as “limited horizons” and "concrete thinking," which implies no ability to think past the near future and minimal conceptual scope. The most important political issues however rely on the ability to think in abstract terms and unify various information. These are skills many people seem to lack. For the Dutch, a similar reasoning can be applied. In the Dutch election study of 2006, a lot of people answered that they voted for a certain party because of a specific person (usually the leader), but a quality of that person was never mentioned, other than that he was “good”.
Ideology involves such a high level of abstraction that the man in the street does not seem to use. Most people have no underlying belief structure, just a number of random opinions. Voting behavior is hardly connected with intelligent decision-making, but most of all with lack of knowledge and emotions. Based on this, Converse developed a set of categories and classified voters according to their understanding of basic ideological differentiation between ideas:
Ideologues - These respondents relied on “a relatively abstract and far reaching conceptual dimension as a yardstick against which political objects and their shifting political significance over time were evaluated” (Converse, 1964: 216).
Near Ideologues - These respondents mentioned the liberal dimension in a peripheral way, but did not appear to place much emphasis on it, or used it in a way that led the researchers to question their understanding of the issues.
Group Interest - These respondents made choices based on whether they were favorable or unfavorable for groups that the parties tend to represent. These people tended to not understand issues that did not clearly benefit the groups to which they referred.
Nature of the Times - The respondents in this group showed no understanding of the ideological differences between parties, but made their decisions based on the “nature of the times”. Within this category two types are distinguished: one type refers to voters who praise or punish a party for its policy in general; the other type refers to voters who do this based on one or two topics. Hereafter, this distinction is not used.
No Issue Content - These were the respondents whose evaluation of the political scene had “no shred of policy significance whatever” (Converse, 1964: 217). These people included respondents who identified a party affiliation, but had no idea what the party stood for, as well as people who based their decisions on personal qualities of candidates.
These categories have also been applied to the Dutch data.
The Coding Task
To get a grip on the coding process, the respondents in the Dutch election study were placed in one of the above categories. First the respondents were asked a closed question on which party they voted for, and next they were asked in an open-ended question on why they voted for that specific party. The coding was based on the answers to this question. A typical characteristic of the answers was that actually they were very short. Nevertheless, the majority required the so called type B2 coding task 1 – coding “where the coder has not only to locate relevant information, but also to evaluate the relative importance of two or more possible responses to arrive at a single code” (Montgomery and Crittenden, 1977: 236). Many answers contained more than one argument. These were mainly single words referring to issues, personality attributes and sometimes factual propositions. The quality of these answers is summarized well by the following quote: “Responses to open-ended questions are usually less than completely clear; they often contain ambiguous words and phrases; and they are frequently ungrammatical and poorly worded” (Kammeyer and Roth, 1971: 61). Both the instrumental and the representational view of coding were applied: the first via a computer program; the second via human raters. The data set contains 2,806 respondents, 2,173 of them answered this “why” question.
The Coding Process
Representational Coding
Respondents were twice place or “coded” into one of the above categories. This “coding” or assignment from the perspective of the respondent was performed by two raters. First these raters had been trained with data from a previous election. During the actual coding or assignment, the raters operated independently. For a correct understanding of the answers, the raters were permitted to use the answer to the question regarding the party for which the respondents had voted. Such coding or assignment implies a subjective decision. Before starting their task, the raters had agreed on how to act in several situations. Such rules are indispensable (Popping and Roberts, 2009). The rules with regard to the present coding include:
- Terminology with respect to ideologues. Respondents who really mention ideology or use ideological understanding are placed in the first category. In case of doubt regarding the understanding, the second category is used.
- Christian parties. People voting for such a party tend do so because of religious persuading. Converse does not mention religion. The argument is coded in the fourth category, the party is rewarded for supporting Christian norms and values.
- Being a member of a party. Respondents who vote for a party because they are a member of that party are member of a group and therefore belong to the third category.
- One policy issue is mentioned. Respondents, mentioning one issue, are coded in the fourth category: the nature of times. They praise the party for giving attention to the topic.
- Party program. Respondents may explain they voted for a party because of the party program. This program probably is based on an ideology, but the position is taken that these voters looked at specific topics on which they agree. Therefore, they are coded to the fourth category.
- Strategic voting. This is also placed in the fourth category. The respondents have an opinion about where the country should be going, but they are afraid their voice will not be heard when they vote for their desired party.
- Political leader is mentioned. Respondents often refer to a political leader (as seen in a television debate), such a reference is coded in the category No Issue Content.
In case multiple answers were given and it was not possible to decide which part of the answer is most important, the highest category was selected (although I do not believe at the time of writing that the categories represent an order). These rules may be questionable, but they tend to provide guidelines for the raters. The raters had no problems in using them.
Instrumental Coding
In the present example, a computer program was used to perform the coding, therefore it was necessary to construct a dictionary. This implies that the coding is performed from the perspective of the investigator and no interpretation by a rater is involved. Some search entries were simple to find. The name of a political leader refers to a party affiliation and therefore fits in the fifth category. Many search entries however consisted of phrases and had to be looked for in the answers that were given by the respondents. The dictionary used was based on search entries that were constituted before the coding task started. The search entries were proposed by a potential rater, and also the first 20 percent of the answers of the Dutch election study of 2002-2003 were examined. The dictionary contained 229 search entries. Several of these entries were in prefix or suffix position; that is, they contained the beginning or the end of a word and the parts to be filled in at the end or the beginning of the word were unspecified. In this way, the entry “_minorit” refers to both “_minority” and “_minorities” (note, the underscore at the beginning of the word must be read as a space, implying that characters can only be added at the end of the word). It is assumed that the free part, the suffix part, is not such that the final word or text phrase used refers to another category than intended. In fact the investigator should be able to motivate all choices of search entries. The dictionary also included variants of an expression (“my favorite party” or “this party is my favorite”), but unique statements given by the respondents were not looked at explicitly. This means that many answers were not coded. Frisbie and Sudman (1968) previously pointed out that this is a disadvantage of machine coding where a dictionary is used. In case an answer allows choosing from two categories, the highest one is chosen, just as it was done in the situation where the representational view was followed.
Results
When the representational view of coding is followed, the coding task must be performed by at least two independently operating raters. At the end, the assignments by these raters were compared. The assignments based on decisions by the computer program can also be compared to those by the human raters. For the comparisons, Scott’s π was used (Scott, 1955; Popping, 2010). The resulting outcomes are presented in Table 1.
Interrater agreement
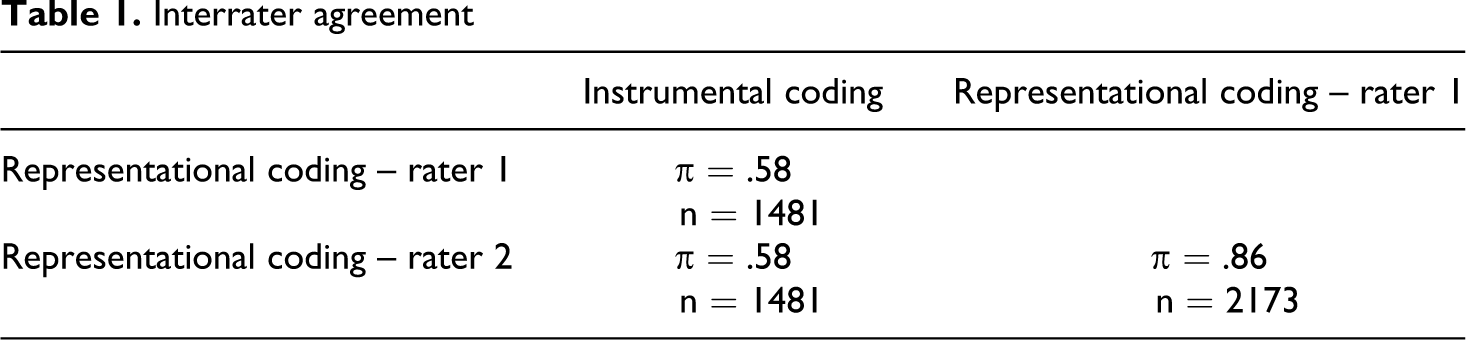
The amount of agreement among the two raters is very high. If answers that have not been coded when the computer program was used are omitted, one even finds π = .89. Most of this high amount of agreement is due to the fact that explicit rules were followed during the coding process. The comparison with the computer coding does not show such good results. With respect to the differences found, three issues need to be considered now: the quality of the dictionary, assigning differences between the two raters themselves and differences between the raters and the computer program.
Three remarks concern the dictionary. In case two or more arguments were mentioned for voting for a party, the computer program was not able to judge which one is most important (type B2 coding); the program does choose the category that is highest in the categorization. At present, the choice can only be made by a human rater. Second, the computer program is not always able to catch the answer or the intention of what was expressed by the respondent. For this, it would have been necessary to add the individual’s complete answer as a search entry into the dictionary. This involves phrases such as: “I had most with that”, “as a principle”, “standard”, “was clear”, “the only consequential party in the Netherlands”, “fresh wind”, “because this party has to remain bigger than the Socialist party”. Third, the dictionary contains inaccuracies. The Dutch language has inflected adjectives that were not all in the dictionary. Two answers were “Christian environment” and “my Christian right-wing party.” In Dutch these are “Christelijk milieu” and “mijn Christelijke rechtse partij.” The first adjective was in the dictionary, the second one was not. One way to solve this is to allow that some text can follow the part of the word that is in the dictionary. Such inaccuracies were also found in the texts, the answer “cristelijk” was not recognized by the program and therefore not coded. Writing errors, also in the names of people should have been corrected.
Looking at differences in assignments between raters, it turns out that the answer “stable party, against capitalism” was coded by one rater as Near Ideologues, the other one coded it as No Issue Content. The remark on the role of capitalism must have been judged differently. The raters also had problems with the difference between Near Ideologues and Nature of the Times. It concerns answers like “separation of church and state” and “fits best with my religious persuasion.” For Nature of the Times the first answer should be read as a topic, the second one as praise. The answer “party pays attention to minorities” was coded Nature of the Times by one rater probably because of the reference to the topic. The other rater coded Group Interest, because the answer was favorable for a certain group. However, no systematic differences in coding were found. It is impossible to overcome all differences; the relevance however of the part in the project where the raters are trained was emphasized. In that part, the raters learn how to look at the answers.
Differences in assignment between raters and the computer program – differences due to the representational or instrumental view on coding – most of all have to do with the fact that the computer program can only recognize words and cannot provide an interpretation. The computer program reads in the answer (mentioned above) “stable party, against capitalism”, and capitalism is involved and this points to Ideologues. This is closer to ideology than the Near Ideologues, for one of the raters. The answer “only decent right wing-party” was coded by the program as Nature of the Times, because of the word “right”. According to both raters in this case, there was No Issue Content. A reverse coding was found for the answer “the SGP [Christian party] expresses principles we share ourselves.” The raters noticed a relationship to the norms and values of people voting for this party, a small Calvinist group, while the computer program did not.
Both the raters and the computer program had problems especially in distinguishing between Nature of the Times and No Issue Content. The pair accounted for 65 percent of the 182 disagreements between the raters and for 78 percent of the 359 disagreements between the first rater and computer program. This holds for answers like: “want to give the CDA [Christian Democrats] another chance”, “the best party”, “did well the last year”, “let them finish the job”, or “good ideas”. In case Nature of the Times was coded, this must have been because the party was seen in a positive light.
The dictionary contains most essential words, but in the answers these words are part of a sentence and this often makes a distinction that the computer program does not catch.
All these different decisions give rise to at least two remarks. The raters followed some rules, but these still could have been more specific. Also differences between categories might have received more attention (remember the answers where a topic or praise had to be recognized). This should have been realized in the training part, where the different reading of answers should have been noticed. The dictionary might have contained more expressions; this would have reduced the number of unassigned answers. More answers of the study from which the entries were taken should have been considered, and adding synonyms would be a good start. Answers from the present study should not be used to construct the dictionary.
The computer program could not code all answers. Automatically assigning these answers to the No Issue Content category is not a good idea, the agreement index drops to .42 and .46 in the comparison with each of the two raters. The answers not coded by the computer program refer according to the raters to different categories.
The two human raters used the two final categories (Nature of the Times and No Issue Content) for 90 percent of the assignments; the computer even assigned 97 percent of the answers to these two categories. The distribution of assignments over these two categories is quite similar for the two human raters, while it is skewed for the computer. The computer program assigned almost 70 percent of these answers to the fifth category. All this is different from Converse’s 1964 outcomes in the USA, since he also had a lot of assignments to the third category. The example shows that the approach to coding can cause enormous differences in the final classification.
Conclusion
Most important with respect to the result of the coding process is the semantic validity; have the answers been coded in line with the research question and do they fit into the category to which they have been assigned? In case some interpretation is needed, the representational view allows more coding in line with these requirements than does the instrumental view. When this approach is followed, the coding task is usually performed by human raters. Answers have to be assigned to the category that fits best. To realize this coding, rules are necessary, no matter which view is followed. If two choices are equally possible, the rater again needs some guidance. For the present task, more rules might have been formulated.
The human raters assign about 90 percent of the assignments to the categories Nature of the Times and No Issue Content that are far from an ideological orientation. This finding is in line with what I have experienced when talking to others, therefore I do not ask questions about face validity. The computer program decided that more answers are in these two categories, for the greater part they are in the category No Issue Content. This finding is not what I would have expected.
The choice for approach in coding has consequences for the findings. One can follow the instrumental view, where the perspective of the investigator is followed, or the representational view, where the perspective of the respondent is followed. If the representational view is followed, the computer program serves as a management tool. If the instrumental view is followed, the computer program can also have a role, but now it is also possible (and often to be expected) that the program takes care of the coding. In this case, the investigator has to make a choice: first with respect to the view on coding; then on the role the computer program will have.
Certain investigators have argumed that machine coding is preferable as it is faster and cheaper. My impression is that these investigators refer only to the instrumental view of coding (and possibly are only aware of that view). This might be true when this type of coding is applied, but one also has costs for developing a dictionary. The dictionary used in this study could have contained more search entries. But it is questionable if assignment is that precise; certainly some interpretation is needed anyway. Besides, if a search entry is not in the dictionary, the machine is not able to come to a decision. Intelligent algorithms will become available that will suggest alternatives in case of misspellings. In this way, more of the manifest content can be captured. However, I have my doubts on whether or not this will also be possible with respect to the latent content. Here more research is needed.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.