
Abstract
X-ray ionizing radiation from Computed Tomography (CT) scanning increases cancer risk for patients, thus making sparse view CT, which diminishes X-ray exposure by lowering the number of projections, highly significant in diagnostic imaging. However, reducing the number of projections inherently degrades image quality, negatively impacting clinical diagnosis. Consequently, attaining reconstructed images that meet diagnostic imaging criteria for sparse view CT is challenging. This paper presents a novel network (CSUF), specifically designed for ultra-sparse view lung CT image reconstruction. The CSUF network consists of three cohesive components including (1) a compressed sensing-based CT image reconstruction module (VdCS module), (2) a U-shaped end-to-end network, CT-RDNet, enhanced with a self-attention mechanism, acting as the generator in a Generative Adversarial Network (GAN) for CT image restoration and denoising, and (3) a feedback loop. The VdCS module enriches CT-RDNet with enhanced features, while CT-RDNet supplies the VdCS module with prior images infused with rich details and minimized artifacts, facilitated by the feedback loop. Engineering simulation experimental results demonstrate the robustness of the CSUF network and its potential to deliver lung CT images with diagnostic imaging quality even under ultra-sparse view conditions.
Introduction
X-ray Computed Tomography (CT) is extensively employed clinically due to its superior spatial resolution and rapid imaging capabilities, particularly for traumatic and oncological diagnosis. Recent increases in CT usage have heightened concerns regarding the potential risks associated with its X-ray ionizing radiation, recognizing that prolonged or excessive exposure may elevate the risk of cancer. 1 For instance, PET/CT scans are generally associated with elevated radiation doses, 2 whereas cardiac CT frequently necessitates repeated imaging for the assessment of coronary artery disease. 3 Particularly, Periodic CT screening for individuals at high risk of lung cancer is crucial, but frequent scans may lead to the accumulation of significant radiation doses. 4 The development of technologies aimed at minimizing X-ray radiation doses, adhering to the ALARA (as low as reasonably achievable) principle, is critical in medical imaging. The primary objective of these technologies is to generate clinically diagnostic CT images while ensuring minimal radiation exposure to patients.
A straightforward way to reduce X-ray radiation dosage is to lower the number of projections in CT scans. Ref.5,6 have developed a CT iterative reconstruction algorithm based on the Compressed Sensing (CS) theory, the View-driven Compressed Sensing (VdCS) algorithm, which is capable of reconstructing images from sparse views without prior data. However, the VdCS algorithm may exhibit staircase artifacts, a common drawback in CS-based CT image reconstructions, leading to discontinuous edges and detail loss in high-frequency areas, 7 hence undermining its clinical utility. Specifically in lung CT images, the edges of small nodules or lesions may become discontinuous or exhibit a step-like appearance, which reduces the accuracy with which radiologists assess the precise shape of subtle lesions. To address this, we explore advanced techniques to enhance the quality of images reconstructed by the VdCS algorithm. Generative Adversarial Network (GAN) 8 have shown exceptional performance in medical image restoration, 9 denoising,10–12 and reconstruction 13 by exploiting the strengths of CNN. 14 The combination of GAN and CNN effectively capture intricate image features, leading to high-quality and noise-free generations, which forms the basis of our methodological improvements.
In this study, we developed an end-to-end network, CT-RDNet, with a U-shaped architecture inspired by the classic U-Net, 15 specifically designed to act as the generator in a GAN for CT image restoration and denoising. We also introduced a self-attention (SA) mechanism into the CT-RDNet to enhance its ability to capture both local features and global information, thereby improving overall performance. For the GAN training, a combined loss function that incorporates LSGAN, SSIM, and L1 losses was constructed. This combined loss function not only stabilizes the GAN training but also balances the structural similarity and overall visual quality of the generated image. Then we integrated the CT-RDNet with the enhanced VdCS algorithm through a feedback loop, developing a novel framework, the Compressed Sensing U-shaped network with Feedback (CSUF), for ultra-sparse view lung CT image reconstruction. In CSUF, the VdCS algorithm is utilized for the image reconstruction from ultra-sparse view projection data, providing enhanced features to the CT-RDNet. The CT-RDNet is used for restoring high-frequency details and denoising the images reconstructed by the VdCS algorithm. Through the feedback loop, the CT-RDNet supplies valuable priors to the VdCS algorithm, thereby improving overall performance of the VdCS algorithm.
Our main contributions are summarized as follows:
This paper proposes the CSUF network, particularly designed for ultra-sparse view lung CT image reconstruction, which has the potential to generate lung CT images with diagnostic imaging quality even under conditions of ultra-sparse views. As such, the CSUF has the potential to reduce X-ray radiation exposure for patients during CT scans. The CSUF network is a novel framework that combines the CS theory with GAN technology, comprising three key components: (1) a CS-based CT image reconstruction module (VdCS module), (2) a U-shaped end-to-end network (CT-RDNet), and (3) a feedback loop that is proposed to enable a cooperative integration between the VdCS module and the CT-RDNet. The CT-RDNet is specifically designed for CT image restoration and denoising. This paper introduces a self-attention mechanism into the CT-RDNet and also designs a combined loss function, both aimed at optimizing network performance.
This paper is organized as follows: Section 2 briefly reviews related work. Section 3 outlines the architecture and components of the proposed CSUF network. Section 4 presents the engineering simulation experiments conducted using synthetic CT projection data. The methods used are discussed in Section 5. Section 6 draws conclusions and sketches future directions.
Related work
Numerous CT iterative reconstruction algorithms have been developed to reduce X-ray ionizing radiation dose. Sidky et al., 16 for instance, proposed a Total Variation (TV) minimization algorithm for divergent-beam CT, achieving more accurate reconstruction from sparsely sampled projection data. In contrast to the discrete gradient transform used in TV minimization, dictionary learning has proven more effective for sparse representation. For instance, Xu et al. 17 incorporated a redundant dictionary into a statistical iterative reconstruction framework, to capture local structural information, which can suppress artifacts and retain detailed structural features. Differing from algorithms based on dictionary learning, the Adaptive Statistical Iterative Reconstruction (ASIR) algorithm 18 relies on adaptively captured statistical properties of the image, modeling X-ray photon statistics and electronic noise to mitigate noise and artifacts in low-dose CT images.
Compressed sensing (CS) theory, 19 a landmark advancement, enables accurate restoration of original signals from undersampled data. Chen et al., 20 building upon CS theory, proposed the Prior Image Constrained Compressed Sensing (PICCS) method, leveraging a prior image to guide the reconstruction from highly undersampled projection data for precise CT imaging. However, the clinical utility of PICCS is limited by the need to obtain accurately matched high-quality prior images. Our previous work5,6 introduced a CS-based image reconstruction algorithm, VdCS, which effectively reconstruct images from sparse projection data without prior information, demonstrating strong engineering applicability. However, CS-based iterative image reconstruction algorithms, including VdCS, frequently suffer from the loss of high-frequency details and the emergence of blur artifacts attributed to the staircase effect.
Deep learning-based image reconstruction algorithms have emerged as a new frontier in medical imaging,21,22 demonstrating superior practical efficacy compared to traditional methods. These algorithms excel at suppressing noise and artifacts, thereby enhancing image quality. A notable approach is the DL-PICCS proposed by Zhang et al., 23 which integrates deep learning with the PICCS algorithm for sparse view CT image reconstruction. This method employs a U-Net framework to eliminate artifacts in the images reconstructed from undersampled data by Filtered Back Projection (FBP) techniques. It utilizes the output of the U-Net as the prior image for the PICCS algorithm. Then, it applies an additional light U-Net to restore image details. Deep learning-based image reconstruction algorithms can be classified into three categories: image-domain reconstruction,24–26 sinogram-domain reconstruction,27–29 and hybrid-domain reconstruction.30–32
Image-domain reconstruction methods aim to establish non-linear mappings between noisy and high-quality images, primarily for artifact elimination and detail restoration. Zhang et al. 25 introduced DD-Net, combining DenseNet and a deconvolution network with shortcut connections to improve artifact suppression and detail recovery in low-quality FBP-reconstructed images. GANs have also been applied to CT image reconstruction.13,30,33 Q. Yang et al. 33 proposed a GAN-based low-dose CT image denoising method that optimizes the Wasserstein distance and employs perceptual loss for high-frequency detail restoration. Overall, since the input of the image-domain methods is an image reconstructed from sparse projections by the conventional FBP algorithm, the output inevitably suffers from artifacts.
Sinogram-domain reconstruction methods preprocess projection data prior to image reconstruction. Lee et al. 27 proposed a method that employs residual U-Net to generate missing data from sparse projection data, followed by image reconstruction using the FBP algorithm. This technique outperforms conventional interpolation methods and iterative reconstruction methods in terms of reconstructed image quality. To overcome the limitations of traditional supervised learning methods, which require sparse-full view image pairs, Guan et al. 29 proposed a fully unsupervised score-based generative model for sparse view CT image reconstruction in the sinogram domain. This method trains a score-based generative network using full-view projection data and employs a multi-channel strategy to capture prior information, delivering comparable or better performance than the supervised learning counterparts.
Hybrid-domain reconstruction methods simultaneously process projection data and reconstructed images to suppress artifacts and enhance detail restoration. Wu et al. 30 proposed the DRONE network, which integrates embedding, refinement, and awareness modules for artifact suppression, detail restoration, and measurement consistency, respectively, ultimately improving edge preservation and reconstruction accuracy. Zhang et al. 32 developed LEARN++, an extension of the LEARN framework, 34 featuring parallel sub-networks for the projection and image domains. This architecture enables simultaneous denoising and restoration while ensuring mutual interaction between domains for superior reconstruction performance.
Our work centered on accurately reconstructing lung CT images for clinical diagnosis utilizing ultra-sparse view CT scanning. The engineering simulation experiments presented in this paper demonstrate that the proposed CSUF network facilities the acquisition of sufficiently accurate lung CT images to meet clinical diagnostic standards, using only 20 view angles within the [0, 2π) interval for standard fan-beam scanning.
Theory and methods
Architecture of the CSUF network
The CSUF network, as depicted in Figure 1, comprises two modules: the VdCS module and the CT-RDNet, interconnected by a feedback loop. The workflow of CSUF is as follows: first, the VdCS algorithm is used for the pre-reconstruction of ultra-sparse view projection data, followed by the restoration of high-frequency information and denoising using the CT-RDNet. Then, the output of the CT-RDNet is fed back as prior information to the VdCS algorithm for the next reconstruction. Finally, the CT-RDNet is applied once more to generate the final reconstruction.
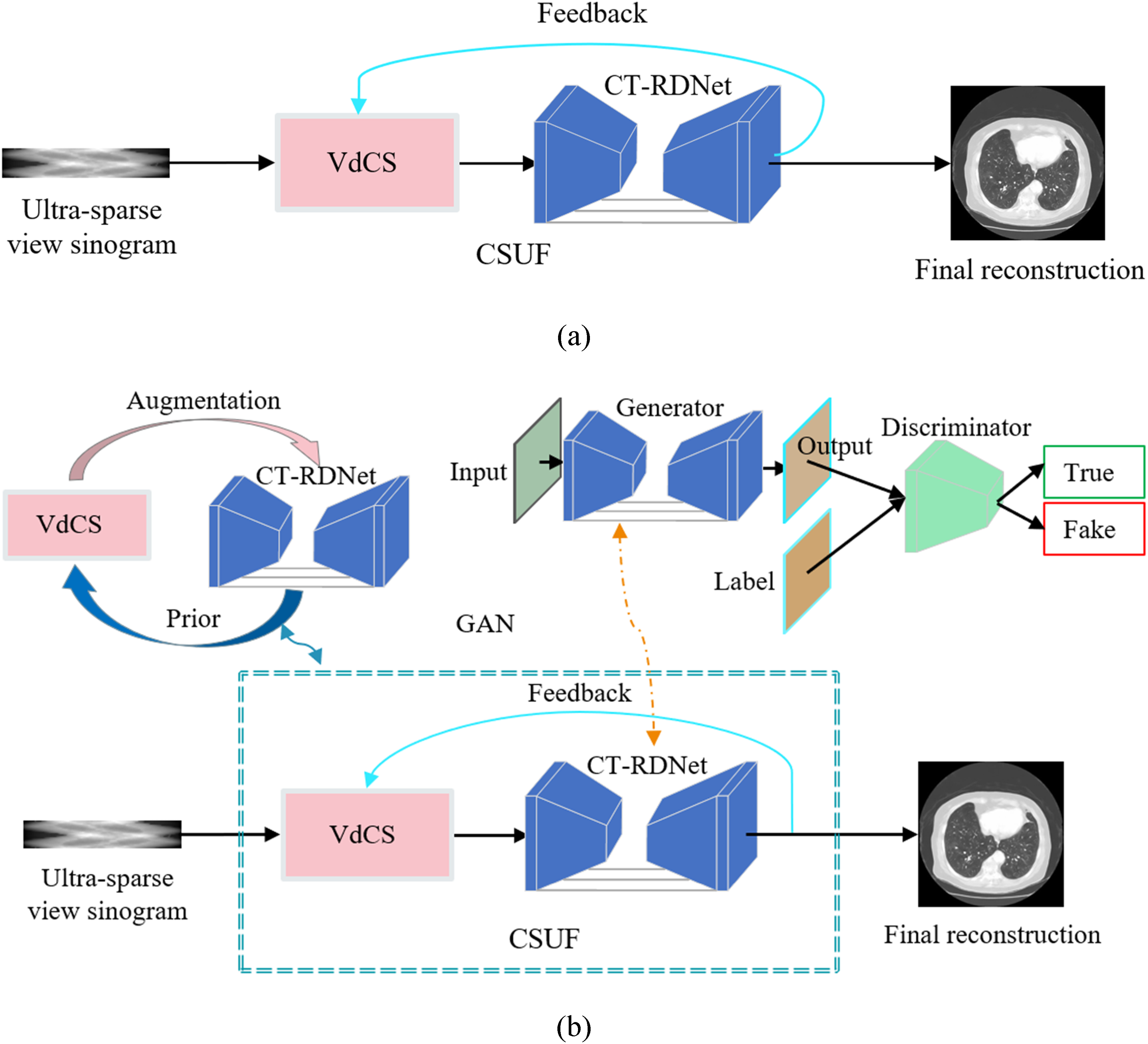
The CSUF network. (a) Architecture: Integrating the VdCS module and the CT-RDNet with a feedback loop. (b) The interaction between the VdCS module and the CT-RDNet.
The VdCS algorithm
The CT iterative image reconstruction based on the CS theory under ultra-sparse view can be regarded as solving the ill-posed linear equation:

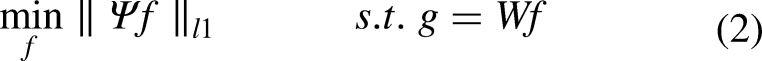
We enhance the VdCS algorithm that was proposed in Ref,5,6 which is presented in Algorithm 1 and depicted in Figure 2. The VdCS algorithm consists of two modules: rough reconstruction and optimization. The rough reconstruction module performs an initial approximation of the image, while the optimization module further refines this approximation to find the optimal solution. Specifically, the rough reconstruction module iteratively solves Equation (1) to obtain solutions that approximately meet the constraints specified in Equation (2). This iterative process involves four steps: forward projection, difference computation, backward projection, and correction, as summarized in Equation (3).
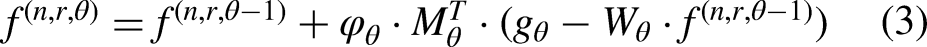
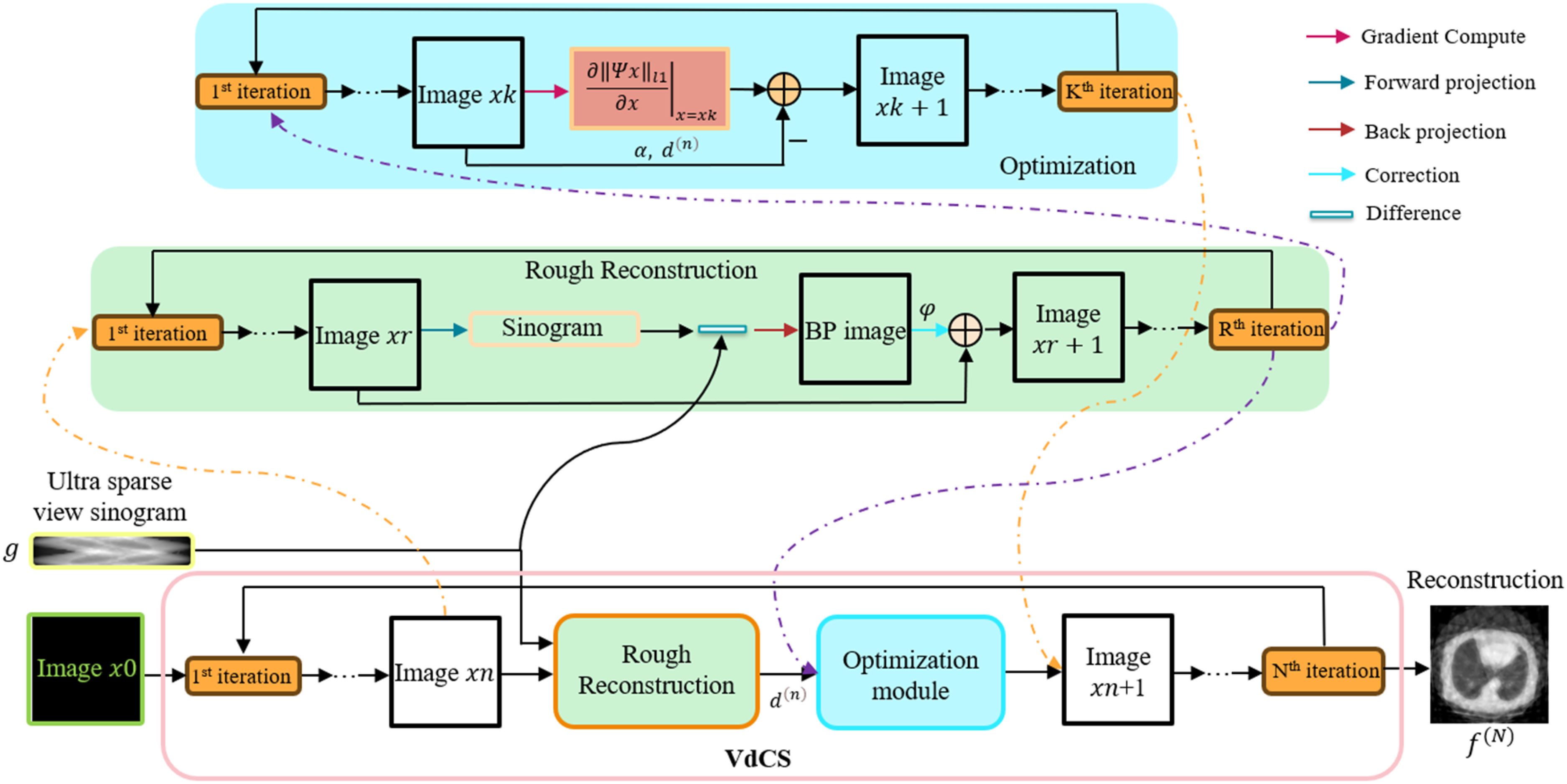
The VdCS algorithm: N is the number of the overall iterations, and R and K are the number of the rough reconstruction sub-iterations and optimization sub-iterations, respectively.
The optimization module takes
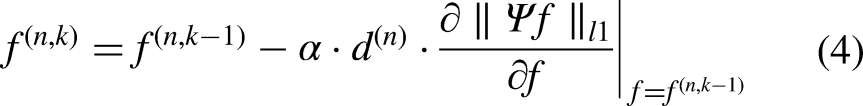
The forward and backward projection modules of VdCS are distance-drive, referred to as DDFP and DDBP module, respectively. It should be noted that, in the engineering simulation experiments of this study, the DDFP module was also used to simulate the forward projection procedure and generate synthetic projection data.
VdCS

CT-RDNet
A GAN consists of a generator and a discriminator that engage in adversarial learning to enhance the quality of generated data. The architecture of the GAN in this paper is shown in Figure 3, where the CT-RDNet is the generator. As illustrated, the CT-RDNet is a U-shaped end-to-end network specifically designed for CT image restoration and denoising.
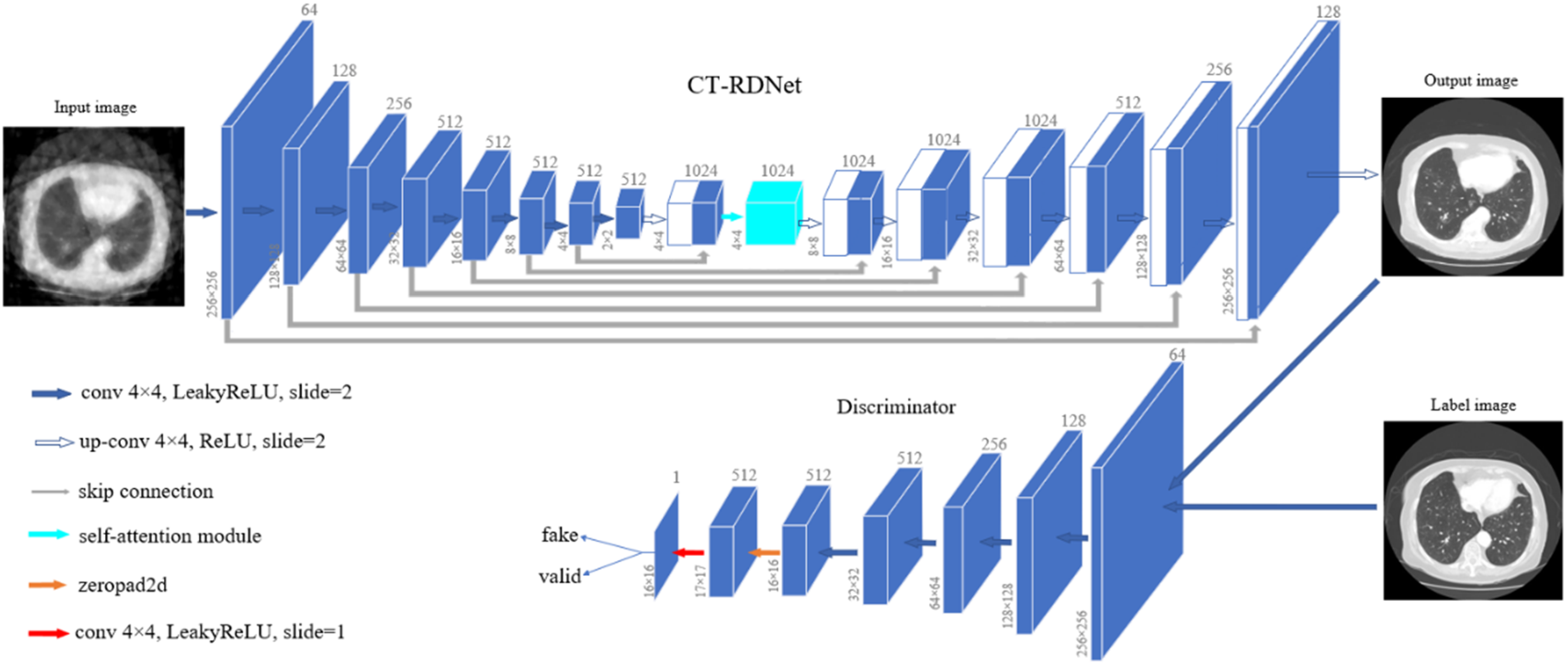
Architecture of the GAN, comprises the CT-RDNet (the generator) and the discriminator. The CT- RDNet is augmented with a self-attention module.
The design of the CT-RDNet is inspired by the conventional U-Net, retaining the advantages of its symmetrical encoder-decoder structure and skip connections. But unlike the conventional U-Net, the CT-RDNet uses convolutional layers with strides for downsampling, rather than max-pooling, to reduce noise sensitivity while preserving critical image details. The CT-RDNet's upsampling layers mirror the downsampling layers’ parameters, with a 4×4 kernel size, a stride of 2, and padding of 1, ensuring that the feature map size is doubled during upsampling and halved during downsampling.
To enhance the ability of the CT-RDNet to understand the overall image structure, we introduced the self-attention (SA)35,36 mechanism implemented with convolution into the CT-RDNet. The SA module is applied to the concatenated feature maps formed by the first upsampling-generated feature maps and the corresponding downsampling-generated feature maps of the same spatial dimensions, enabling adaptive focus on different regions and capturing global information. As shown in Figure 4, the SA module processes the feature maps through three 1×1 convolutional layers to create query, key, and value tensors. Then the query tensor is multiplied by the key tensor, normalized with SoftMax, and the product is multiplied by the value tensor. Finally, the result passes through another 1×1 convolution layer to produce the self-attention feature maps.
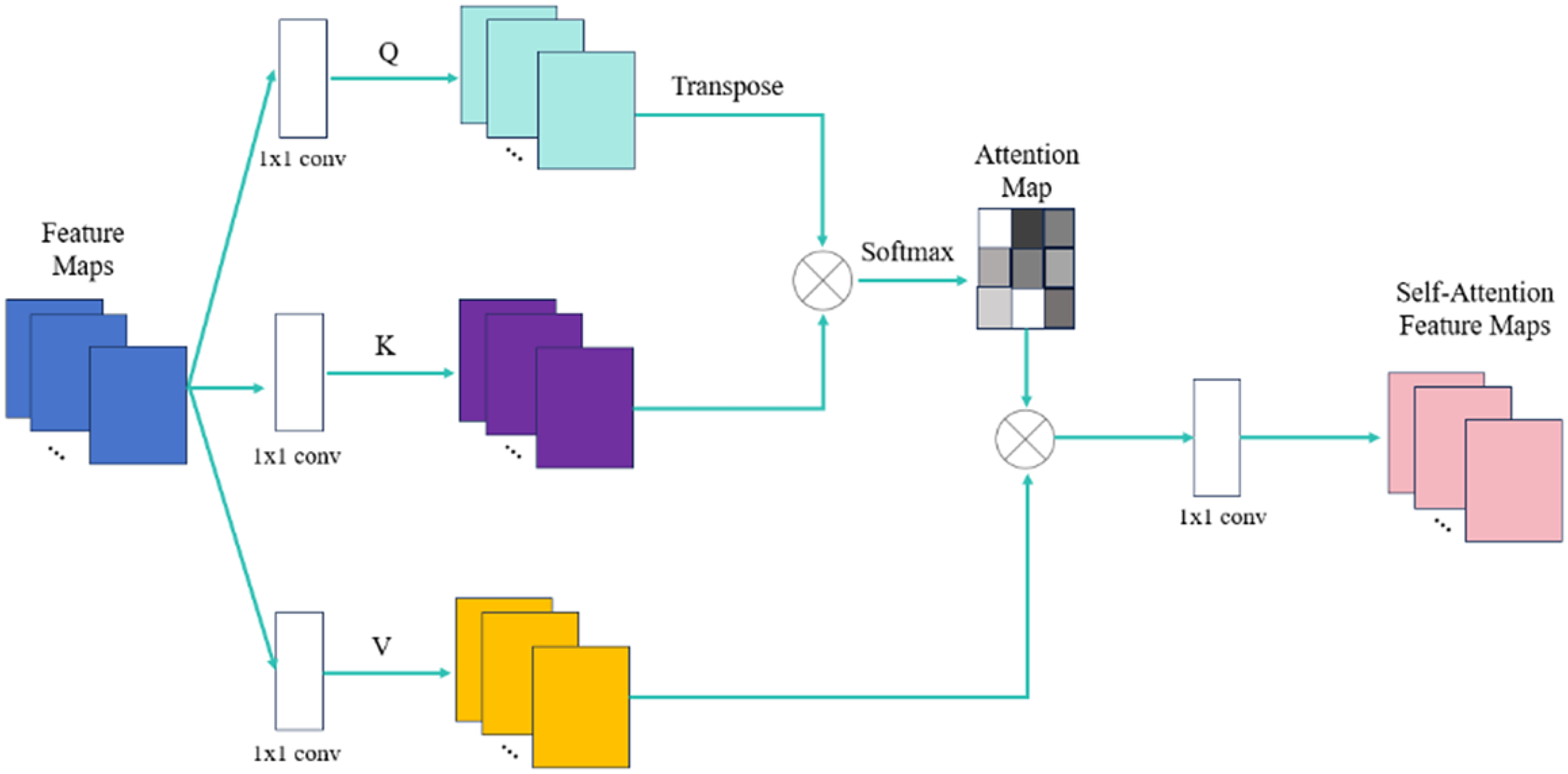
The architecture of the self-attention (SA) module, which is integrated into the CT-RDNet for capturing global information.
Feedback loop
The feedback loop plays a vital role in the CSUF network, enabling a cooperative integration between the VdCS module and the CT-RDNet. Through the integration, the CSUF network effectively reconstructs ultra-sparse view CT images, reducing noise and artifacts, and restoring detailed structures.
The VdCS module iteratively reconstructs the image from the ultra-sparse sinogram starting with a zero-pixel value image as the initial estimate. While this approach facilitates preliminary reconstruction, it is challenged by artifacts due to severe undersampling. By utilizing the feedback loop, the CT-RDNet replaces the zero-pixel value image with its output, supplying the VdCS module with rich high-frequency details and reduced artifacts as prior information, which leads to higher-quality reconstruction and augmented artifact suppression. Actually, the image generated by the CT-RDNet may exhibit artifacts, such as local distortions or strange textures, due to the inherent limitations of GAN. The feedback loop enables the VdCS module to mitigate these issues, enhancing the overall image quality.
Loss functions
The Least Squares GAN (LSGAN) loss
37
addresses issues such as mode collapse and gradient vanishing in GAN training, thereby facilitating more effective learning between the generator and the discriminator. In this paper, the CT-RDNet's LSGAN loss is defined as Equation (5).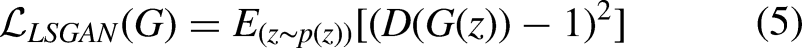
To balance training stability and the quality of the generated image, the total loss function in this study further combines the aforementioned LSGAN with L1 loss and SSIM loss,38,39 defined as Equation. (6). L1 loss focus more on pixel accuracy, while SSIM loss focus more on overall image quality. The combination enhances the denoising and restoration performance of the CT-RDNet.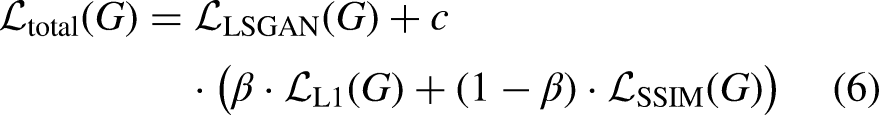
Engineering simulation experiments
Synthetic projection data
The LIDC-IDRI dataset, 40 developed as a reference for the early diagnosis of lung cancer within the medical imaging research community, was utilized to generate synthetic projection data. A total of 987 thoracic CT images from different patients were selected. Each image has a resolution of 512×512 pixels. Simulating a standard fan-beam CT scanning procedure, we generated synthetic projection data using the DDFP algorithm, with varying numbers of projections. For the training dataset (511 out of the total 987 images), projection numbers of 20, 45, 90, and 180 were selected to generate sparse projection data. For the testing dataset (476 out of the total 987 images), only 20 and 30 at ultra-sparse conditions were selected.
Preparation of the dataset for the GAN training
After obtaining the synthetic projection data for training, we use the VdCS algorithm to initially reconstruct sparse view CT images. These reconstruct images were paired with the original CT images, used as the ground truth (GT) images, to form a sparse-full image dataset for training the GAN. We randomly selected different number of images for each projection number and performed data augmentation technique to enhance the sparse-full image dataset.
Implementation details
The parameters of DDFP.

In this study, the codes for DDFP and VdCS algorithms were implemented with C++ programming language under the ISO/IEC 14882:2020 standard. And the GAN was trained on an NVIDIA RTX 3090 GPU running Ubuntu 18.04.6 LTS, while the CSUF network was tested using CPU-only. We implemented GAN with PyTorch version 1.10.0 and CUDA version 11.4.
Experimental results
Qualitative analysis
To assess the performance of the CSUF network, we respectively reconstructed images from the testing projection dataset with 20 and 30 angles and performed qualitative analysis for the quality of image. For each of the projection angles, we randomly selected two instances, resulting in four instances (Instance 1–4) in total. The CT reconstructed images at each stage are shown in Figure 5. In this context, GT represents GT images, CS denotes images generated by the VdCS algorithm, CS-U refers to the CT-RDNet enhanced images, CS-U-CS indicates the reconstructed images obtained by the VdCS algorithm with prior image, and CSUF represents the final reconstructed images.
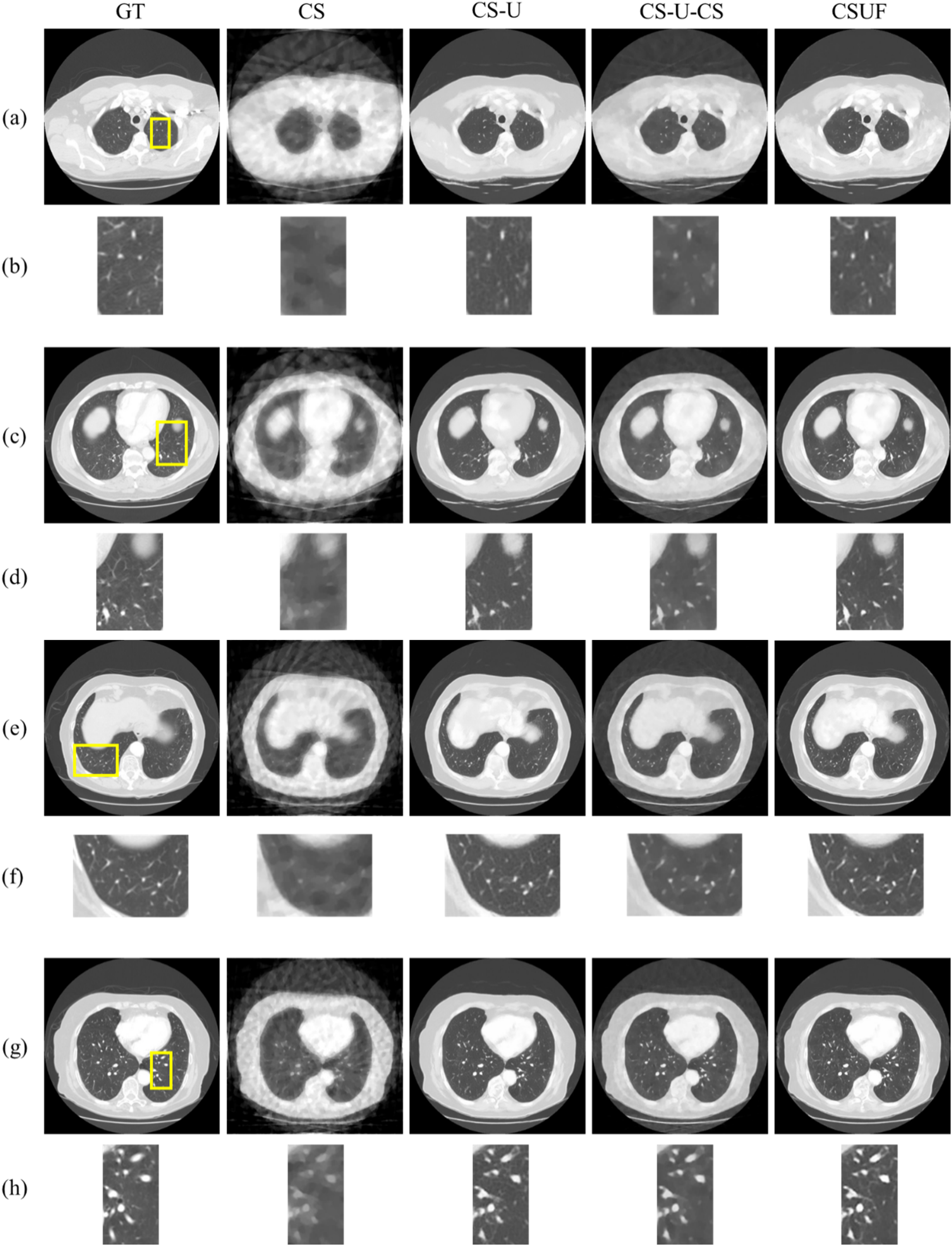
Reconstructed images at different stages (CS, CS-U, CS-U-CS, and CSUF) and corresponding region of interest (ROI) images. (a) and (b) respectively show the reconstructed images and the ROI images, for Instance 1 at 20 projection angles, (c) and (d) for Instance 2 at 20 projection angles, (e) and (f) for Instance 3 at 30 projection angles, and (g) and (h) for Instance 4 at 30 projection angles.
The CSUF network demonstrates its capability to reconstruct CT images with rich detailed structures and minimal artifacts at 30 projection angles, as shown in the corresponding ROI images of (e) and (g), where the lung textures are restored with high fidelity. Even in more sparse conditions with 20 projection angles, as illustrated in (a) and (c), the CSUF network largely restores the detailed structure of the images. By comparing CS and CS-U in (a), (c), (e), and (g), it can be found that the CT-RDNet effectively suppresses the blur artifacts caused by the VdCS algorithm and significantly restores the texture structure of the CS images. Based on a thorough evaluation of the imaging results, experts from the Department of Medical Imaging at the University of Saskatchewan and the Saskatoon Health Region concluded that the CSUF network proposed in this study has the potential to achieve clinical diagnostic standards for ultra-sparse view CT image reconstruction.
Quantitative analysis
In this study, Peak Signal-to-Noise Ratio (PSNR) and SSIM were employed as image quality metrics. we calculated the PSNR and SSIM values for some images from the testing projection dataset and presented the results in Figure 6. Figure 6(a) and (b) show the PSNR and SSIM box plots, respectively, for 20 projection angles, while (c) and (d) depict the results for 30 projection angles. The results in (a) and (b) indicate that the reconstruction performance of the VdCS algorithm is limited when the projection number is reduced to 20. However, the introduction of the CT-RDNet significantly improves both PSNR and SSIM metrics and reduces the fluctuation of the quality indices of the reconstructed images.
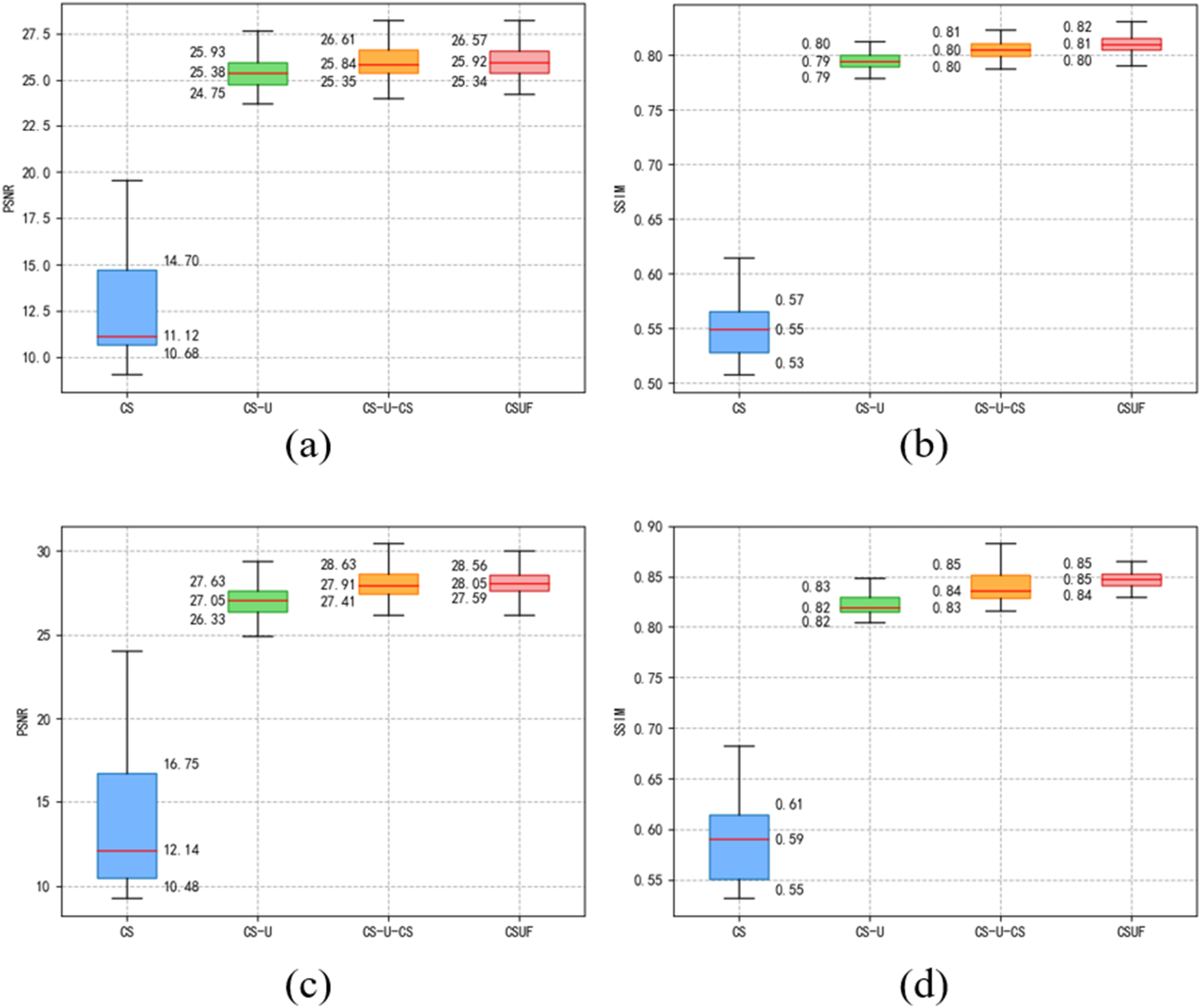
The PSNR and the SSIM metrics for reconstructed images at different stages (CS, CS-U, CS-U-CS, and CSUF). (a) and (b) show the metrics, respectively, for 20 projection angles, while (c) and (d) present the metrics for 30 projection angles.
Performance evaluation
The complexity of the CT-RDNet was evaluated by calculating its FLOPs and the parameter scale revealing that it comprises 56 million parameters and requires 71 GFLOPs for a single forward pass.
We also measured the computational efficiency of the CSUF network under the condition of 20 projection angles. The average inference time was computed across 100 test samples, and memory usage was monitored during execution. Conducting on an Intel Xeon Silver 4210R CPU @2.40GHz, the CSUF network achieved an average inference time of 40 s and utilized 203 MB of memory.
Discussion
In this study, the feedback loop, together with the self-attention mechanism in CT-RDNet, significantly enhances the performance of the CSUF network. Additionally, the design of the loss function contributes to further improvements.
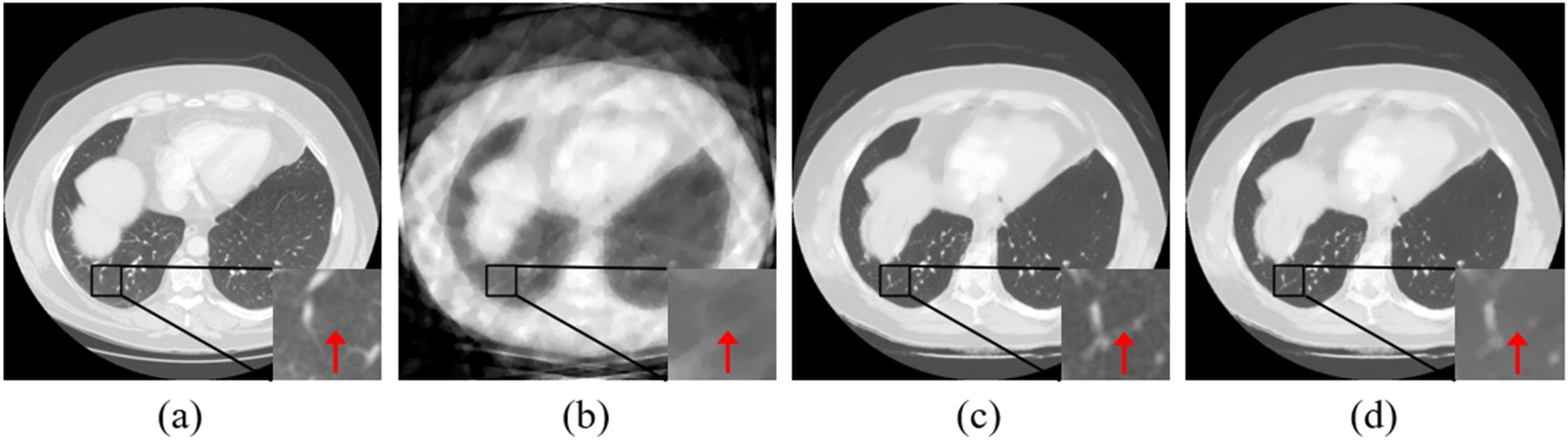
Reconstructed images at different stages for Instance 5. (a) GT, (b) CS, (c) CS-U, and (d) CS-U-CS.
The introduction of the feedback loop enhances the CSUF network's adaptability to different iteration numbers of the VdCS algorithm. We conducted experiments with different iteration numbers, selecting Instance 6 from testing projection dataset at 20 projection angles, as shown in Figure 8 (A). The PSNR and SSIM metrics are shown in Figure 8(B). Figure 8(A) and (B) reveal that both the visual quality and metrics of reconstructed image of the CSUF network remain relatively consistent across different iteration numbers.
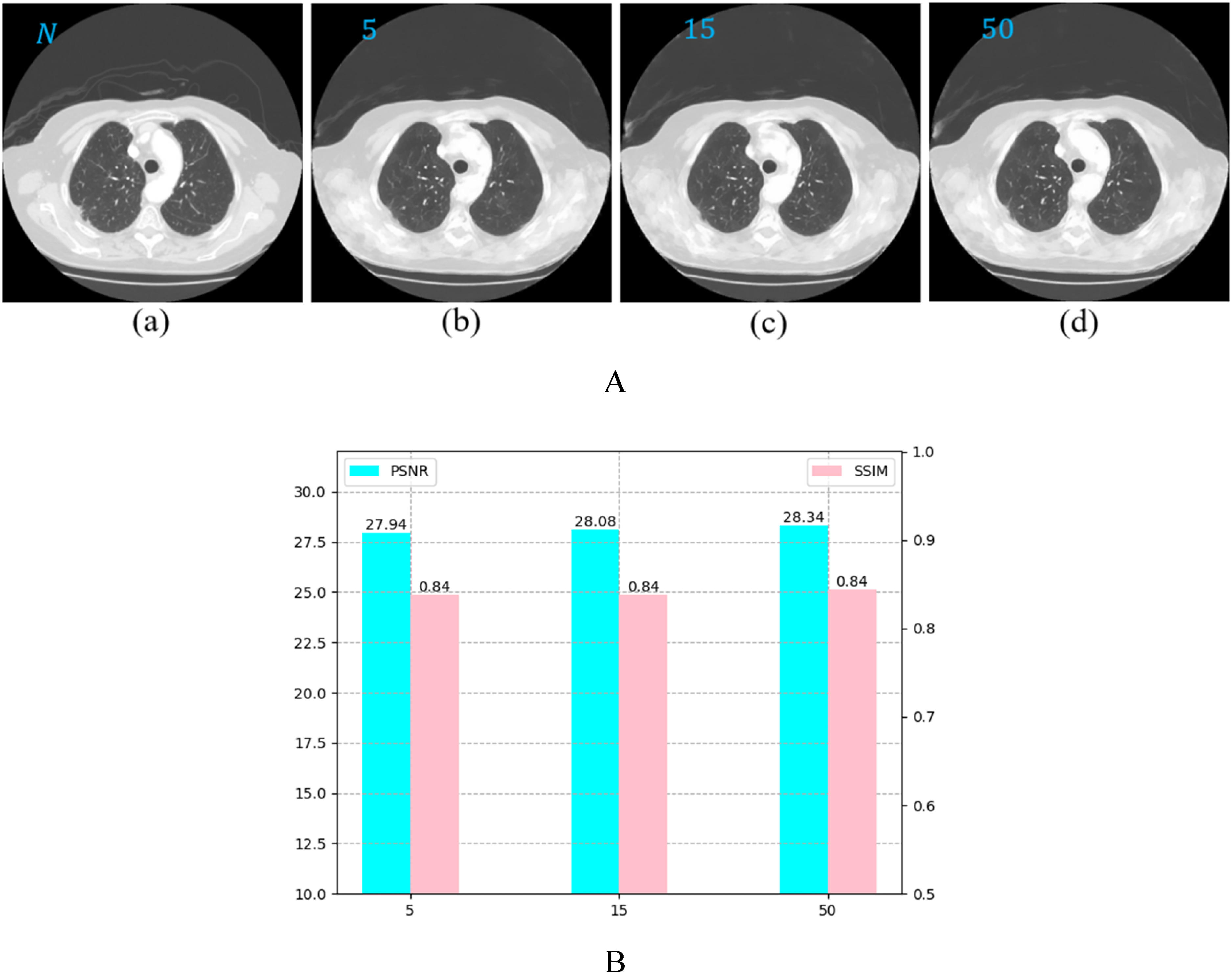
A: Ground truth and reconstructed images under different iteration numbers for Instance 6. (a) GT, (b) 5 iterations, (c) 15 iterations, (d) 50 iterations. B: PSNR and SSIM results.
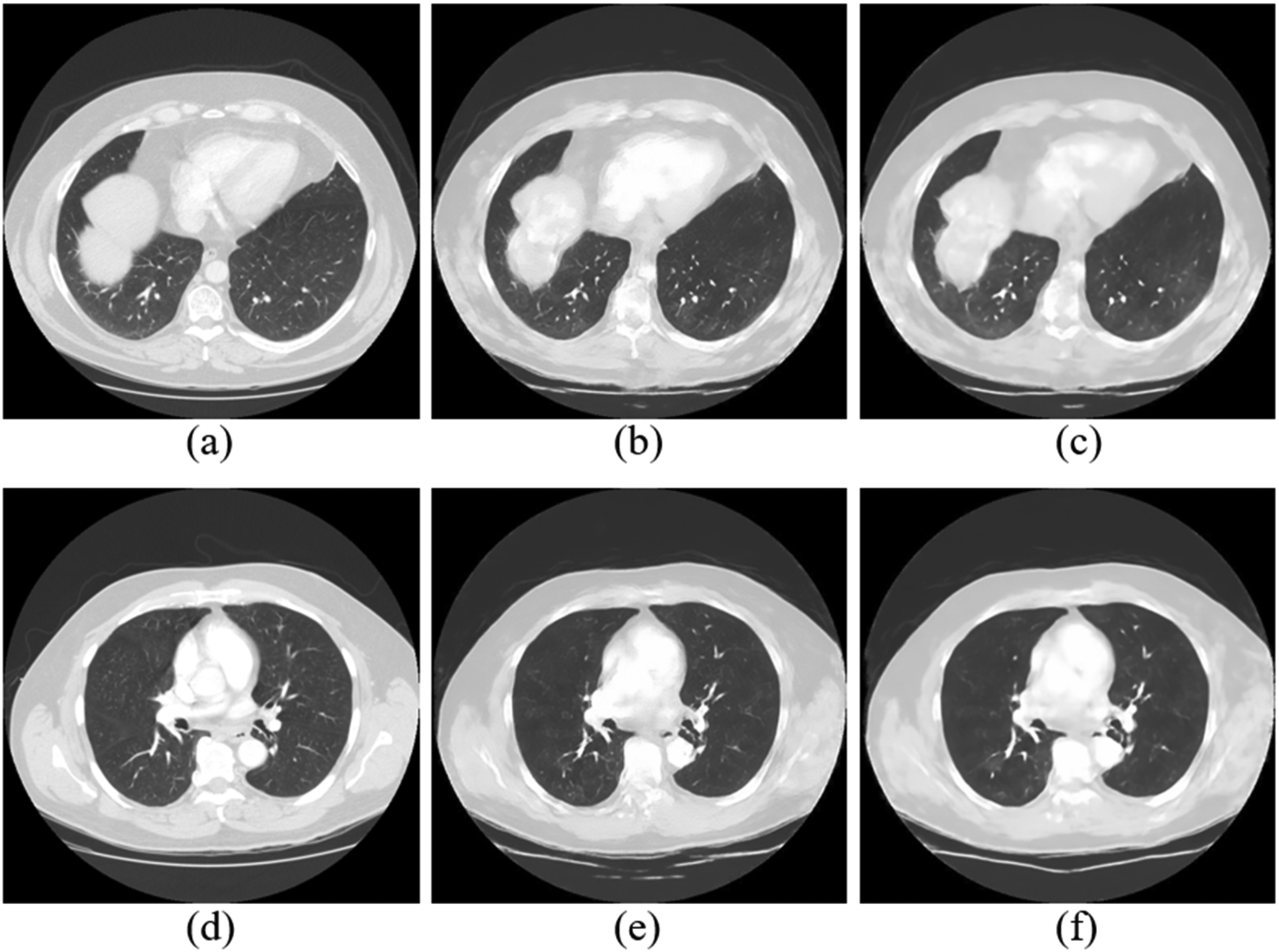
Ground truth and CSUF reconstructed images with and without self-attention (SA). Results for Instance 5: (a) GT, (b) CSUF_WithSA, (c) CSUF_WithoutSA. (d), (e), and (f) are results for Instance 7.
The comparison between Figure 9(b) and (c), as well as Figure 9(e) and (f), demonstrates that the images reconstructed by CSUF network with SA are clearer and exhibit more detailed texture structures. Subjectively, the images reconstructed by CSUF network with SA better meet diagnostic imaging needs, indicating that SA plays a crucial role in enhancing the performance of the CSUF network.
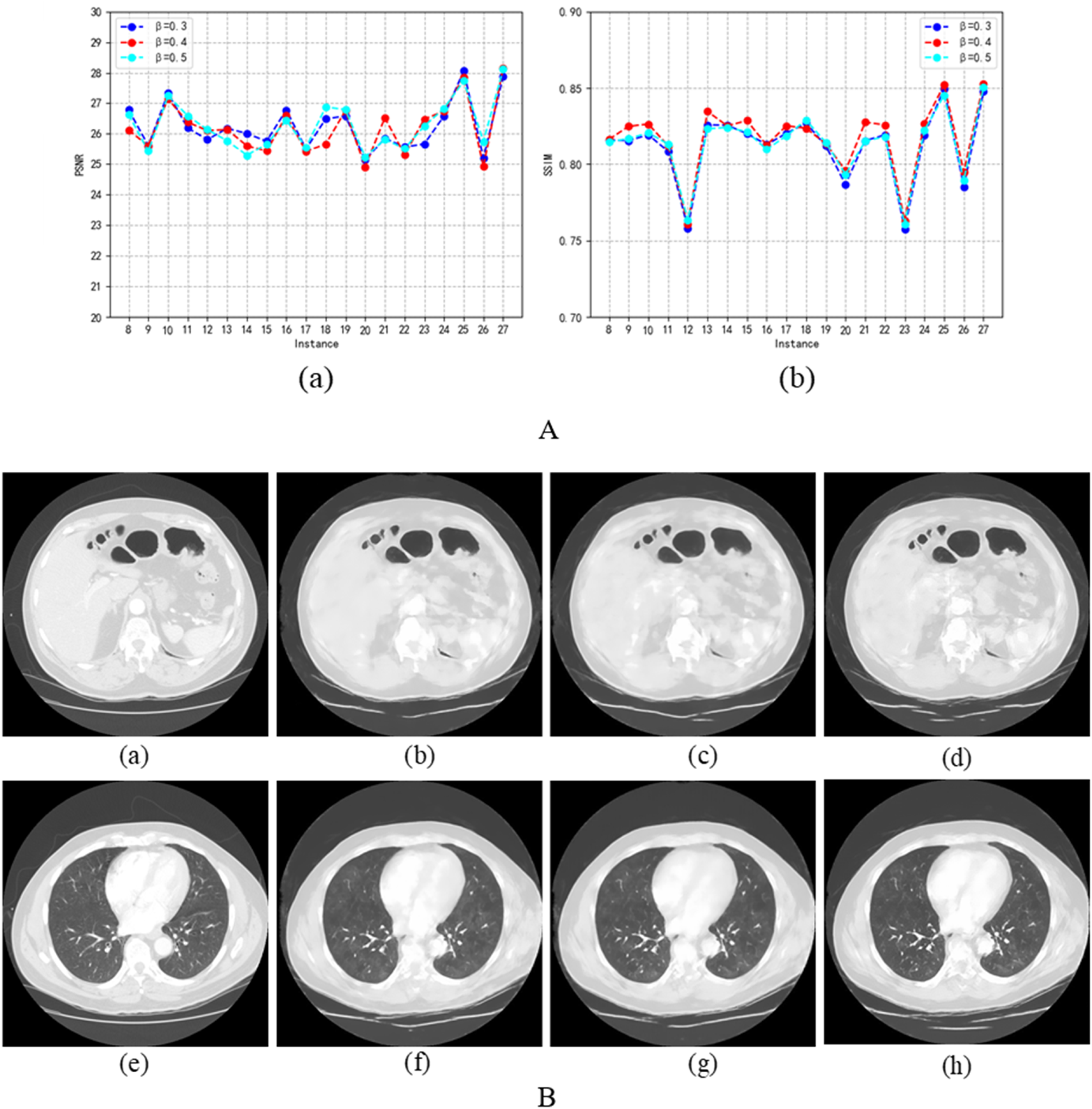
A: PSNR and SSIM metrics for the reconstructed images under different weight parameters
From Figure 10 A(a), we observe that the PSNR values fluctuate slightly but do not differ significantly when
In the future, we will also conduct detailed experimental comparisons with state-of-the-art (SOTA) methods, such as FBPConvNet and DD-Net, to provide a more comprehensive evaluation of our approach and explore the integration of other advanced deep learning techniques. Furthermore, we aim to facilitate the clinical adoption and implementation of the CSUF network.
Conclusion
CT scanning is an indispensable diagnostic imaging technique in modern medicine, and it will maintain its irreplaceable clinical status even in the foreseeable future. However, for more than half a century since CT scanning was introduced into clinical practice, concerns about the potential harm from X-ray radiation have persisted. Ultra-sparse view CT scanning can significantly reduce the hazards associated with X-ray radiation. Motivated by the goal of enhancing quality of life and ensuring health and safety, this paper focuses on ultra-sparse view lung CT image reconstruction methods that integrate emerging technologies from relevant fields. Overall, this paper contributes a robust and promising methodology to the field of ultra-sparse view lung CT image reconstruction, with potential implications for reducing the X-ray radiation exposure to patients during CT scanning.
Footnotes
Acknowledgments
This work is supported by the Nature Science Foundation of Shandong Province (Grant No. ZR2019MF048) and the Natural Science Foundation of China (Grant No. 12204273), and partly supported by the National Key R&D Program of China (Grant No. 2021YFB1407001).
The authors sincerely thank the editor and reviewers for their valuable feedback and insightful suggestions, which have greatly enhanced the overall presentation of our work.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.