
Abstract
X-ray imaging technology, as the core non-invasive inspection method, plays an irreplaceable role in industrial non-destructive testing and medical diagnosis. However, during signal acquisition, the imaging system faces multiple interferences, such as the quantum effect and electronic noise. This leads to a significant decrease in the image’s signal-to-noise ratio, seriously affecting the accuracy of hazardous material identification and lesion detection. Existing X-ray image denoising methods have two major limitations. First, in physical model-driven denoising methods, the existing noise models deviate significantly from realistic ones, resulting in poor denoising results. Second, in mainstream deep learning-based methods, Convolutional Neural Networks (CNNs) have limitations in capturing long-range dependencies, while the Transformer model with a global receptive field has high computational complexity. To address these challenges, a physically grounded noise model is designed for synthesizing realistic X-ray images, trained on the public mainstream X-ray image security inspection datasets and augmented with hybrid real-synthetic data. Based on this, a novel denoising model, XDenoiser, is proposed in this paper. It incorporates a linear attention complexity Receptance Weighted Key-Value (RWKV) into a Transformer-based image restoration structure and combines it with CNNs to support both global and local receptive fields. Experiments on the expanded mainstream X-ray image security inspection datasets demonstrate the reasonableness and effectiveness of the XDenoiser algorithm.
Introduction
X-ray imaging is a mature non-destructive testing technique. It is widely used in medical diagnosis and industrial inspection due to its rapid imaging capability and non-invasive nature.1–3 However, image quality is often compromised by complex noise in practical applications. This noise arises from multiple sources. These include quantum statistical fluctuations of X-ray photons, electronic noise from detectors, and the low signal-to-noise ratio inherent in low-dose imaging which is commonly employed to protect patients and operational staff. Such noise not only degrades visual quality but also impairs the accuracy of subsequent quantitative analysis and diagnosis. Therefore, effective denoising is an essential preprocessing step in X-ray image analysis.
At present, research on X-ray image denoising confronts several key challenges. The primary difficulty involves the complexity of the noise model. X-ray image noise does not follow a simple additive Gaussian model. Instead, it typically exhibits Poisson-Gaussian mixture characteristics.4–6 This complexity substantially limits the effectiveness of traditional denoising algorithms designed for simpler noise models. A second challenge lies in the inherent trade-off between detail preservation and noise suppression. In medical imaging, excessive smoothing during denoising can obscure subtle structures indicative of early-stage lesions. Such obscuration increases the risk of misdiagnosis and missed diagnoses. 7 Furthermore, the widespread adoption of low-dose imaging imposes additional demands on denoising algorithms. A critical practical problem involves reconstructing diagnostically useful images through post-processing while maintaining reduced radiation exposure. 8 This challenge requires particular attention in clinical applications.
Given these challenges, the development of advanced X-ray image denoising techniques is critically needed. In medical applications, image quality directly influences diagnostic accuracy. Effective denoising methods are essential to unlock the clinical potential of low-dose imaging while ensuring patient safety. In industrial inspection, particularly in high-precision sectors such as aerospace and new energy, defect tolerance is extremely low. Reliable denoising algorithms serve as crucial safeguards against missing subtle internal defects in structural components. 9
Recent advances in deep learning have demonstrated remarkable success in image denoising. These data-driven approaches learn complex nonlinear input-output mappings through extensive training on large datasets. However, their superior performance typically requires massive amounts of high-quality annotated data. For X-ray applications, the scarcity of such datasets significantly limits denoising model performance. Challenges in obtaining large-scale real X-ray images stem from medical privacy concerns, industrial data sensitivity, and high annotation costs. To address this limitation, researchers have developed synthetic data-driven methods that generate realistic noise-clean image pairs based on physical noise characteristics. 10 The accuracy of these noise synthesis models is critical, and they must precisely simulate the noise distribution present in actual X-ray imaging. In real X-ray systems, image noise primarily originates from equipment physics and environmental conditions, including sensor quantum noise and electronic thermal noise. 5 Poisson noise constitutes a major component, exhibiting photon-count-dependent behavior. This results in weak noise in low absorption regions and strong noise in high absorption areas, creating a significant non-uniform noise distribution across the image. Another dominant component is Gaussian noise, caused by random signal interference from irregular electron motion in electronic systems. This noise type commonly appears in physical systems, electronic devices, and signal transmission processes. Therefore, these noise patterns severely degrade image quality and compromise subsequent analysis accuracy.
Current X-ray noise modeling approaches often demonstrate limited accuracy, compromising the validity of data-driven denoising results. Most existing denoising methods based on physical models rely exclusively on Gaussian noise assumptions. While some studies incorporate Gaussian-Poisson mixture models, these still fail to capture the complete noise complexity in real-world scenarios, particularly neglecting key physical characteristics of X-ray noise. 11 Consequently, developing accurate noise representations remains a critical challenge in X-ray denoising. To address this limitation, a more realistic X-ray image noise modeling approach is needed. Previous work 5 demonstrates that Poisson-Gaussian distributions can effectively approximate both signal-dependent and stationary noise components. Building upon this foundation, a novel noise model in this paper is developed through integration with the original datasets. This solution helps mitigate the detrimental effects of inadequate noise modeling on training performance.
Recent deep learning denoising methods primarily employ either convolutional neural networks (CNNs)12–14 or transformer architectures15,16 to learn noise-to-clean signal mappings through data-driven approaches. While CNNs utilize fixed convolution kernels for feature extraction, they struggle to capture long-range dependencies. In contrast, transformers excel at extracting global contextual features through self-attention mechanisms. Hybrid architectures combining both approaches 17 demonstrate superior performance in balancing global denoising and local detail preservation. However, the quadratic computational complexity of standard self-attention presents significant limitations when handling complex noise distributions while maintaining computational efficiency. Recent advances in sequence modeling, particularly linear attention mechanisms like the Receptance Weighted Key Value (RWKV) model, 18 have shown promise for efficient long-sequence processing in natural language tasks. This work investigates the integration of linear-complexity RWKV attention with image denoising models to achieve an optimal balance between computational efficiency and denoising performance. The key challenge lies in designing an effective hybrid architecture that optimally combines local feature extraction with global structure preservation. Inspired by Restore RWKV, 19 a novel dual-branch RWKV-CNN architecture is proposed for X-ray image denoising. This framework combines convolutional networks with linear attention mechanisms, leveraging CNNs for local feature enhancement while maintaining RWKV’s global dependency modeling. A dynamic fusion module is introduced to maximize the integration of global and local information while providing effective training supervision. Experimental validation on the mainstream X-ray image security inspection datasets demonstrates the proposed XDenoiser’s effectiveness compared to state-of-the-art denoising methods.
The main contributions of this paper are summarized as follows:
The mainstream X-ray image security inspection datasets are expanded by integrating original and composite images using a newly proposed physical noise model. To the best of our knowledge, this represents the first work on X-ray image synthesis incorporating noise modeling. A global receptive field denoiser, XDenoiser, is introduced to enhance denoising efficiency with linear computational complexity. This is the first X-ray image denoising model based on the RWKV architecture. While pure global modeling may degrade local details, a dual-branch architecture combining RWKV and convolution is designed to strengthen local dependency modeling. This yields a novel denoising model with both global and local receptive fields. Additionally, a dynamic fusion module is proposed to effectively combine global and local information. By analyzing regional noise characteristics and structural complexity, the module adaptively adjusts the fusion weights of the global and local branches.
Related work
Traditional filtering methods
Spatial domain methods were the first widely adopted strategy for image denoising, suppressing noise by smoothing pixel neighborhood information. Representative techniques include the median filter 20 and Gaussian filter. 21 The median filter effectively removes salt-and-pepper noise, while the Gaussian filter is suitable for smoothing Gaussian noise. Both methods benefit from computational simplicity and high efficiency. However, they often blur image details, particularly in edge regions, leading to structural information loss. Transform domain methods utilize sparse image representations in domains such as frequency or wavelet space to enhance significant information while suppressing noise. Wavelet transform 22 is widely used in multi-scale image processing, effectively distinguishing between image details and noise for threshold-based denoising. Additionally, principal component analysis (PCA) 23 is frequently employed to reduce image redundancy, improving the separation between signal and noise.
Model-based denoising methods
Model-based image denoising methods construct interpretable optimization objectives by explicitly modeling the statistical properties or physical mechanisms of noise and signals. These methods can be categorized into four main approaches: (1) Total Variation (TV) Models: Based on gradient sparsity, TV methods suppress noise by penalizing the total gradient magnitude while preserving edge structures. The classical TV denoising method proposed by Rudin et al. 24 is a representative example. (2) Matrix Modeling Methods (Low-Rank & Sparse Decomposition): The Non-Local Means (NLM) algorithm 25 improves texture and structure preservation by searching for structurally similar patches across the image and performing weighted averaging. However, NLM is noise-sensitive and prone to matching failures in complex textures or high-noise conditions, degrading reconstruction quality. (3) Block-Matching Methods: BM3D 26 (Block-Matching and 3D Filtering) achieves strong denoising performance while preserving details through patch matching and collaborative 3D filtering. It is widely used in image processing, particularly for scenes with repetitive structures. However, BM3D suffers from performance degradation under non-uniform noise or blurred edges, and its multi-stage pipeline incurs high computational costs, limiting efficiency. (4) Sparse Representation & Dictionary Learning: Methods like K-SVD 27 employ trained dictionaries for sparse coding, performing well under additive white Gaussian noise (AWGN). However, they heavily depend on training data, and their iterative optimization processes are computationally intensive.
In summary, while model-based methods provide strong theoretical guarantees and interpretability, they face challenges in handling complex real-world noise patterns and meeting efficiency requirements.
Deep learning based methods
Recent advances in deep learning-based image denoising can be broadly categorized into supervised and self-supervised approaches. Supervised methods utilize paired noisy-clean images to train end-to-end networks. CNN-based techniques like RED-CNN 12 and FFDNet 28 employ local convolutional operations for efficient feature extraction, offering fast convergence but limited performance on long-range structures and weakly textured regions due to constrained receptive fields. To address this limitation, Transformer architectures have been introduced, leveraging self-attention mechanisms for improved global modeling. Methods such as Restormer 15 demonstrate superior performance in natural image denoising while preserving spatial details. However, Transformer-based approaches face challenges including high computational costs, significant memory requirements, and slow inference speeds, hindering deployment on resource-constrained devices.
Self-supervised denoising methods eliminate the need for clean reference images, making them suitable for real-world scenarios where ground truth data is unavailable. Noise2Noise 29 trains models using pairs of independently noisy images, leveraging statistical averaging of noise patterns. Noise2Void 30 generates pseudo-supervised signals from single noisy images by masking central pixels and predicting their values from surrounding neighborhoods. However, these approaches typically require specific noise assumptions (e.g., zero-mean, independent noise) and demonstrate limited effectiveness for structural or signal-dependent noise. Their reconstruction fidelity generally underperforms supervised methods. Consequently, integrating explicit noise modeling with strongly supervised frameworks represents a critical research direction for enhancing X-ray image denoising performance.
Methods
Modelling X-ray image noise
Recently, deep learning methods have made significant progress in image denoising, particularly through CNN and Transformer-based networks. Guo et al. 31 demonstrate that accurate noise modeling plays a critical role in enhancing denoising effectiveness. When noise models fail to precisely characterize actual noise distributions, even sophisticated neural networks may achieve suboptimal results. This understanding has prompted increasing research into hybrid approaches combining physical modeling with deep learning, including Poisson-Gaussian distribution-based neural networks and self-supervised methods that adapt to real noise patterns. Effective noise modeling not only improves denoising quality but also ensures more reliable data for downstream X-ray image analysis tasks.
Conventional denoising methods, such as DnCNN, 32 are mainly for the world image of visible light imaging. The imaging process is different from X-ray imaging, and the noise model based on it is also different. This difference makes the method applied to visible light image denoising less effective in X-ray image denoising. As shown in Figure 1, it is the result of directly using the Gaussian noise model, the area of complex structure information shown by the green ellipse may become too smooth. Most X-ray image denoising methods 11 mainly focus on Gaussian or Poisson noise with a single fixed parameter. However, in X-ray images, the noise level of the output image is not constant, which is caused by random physical processes. In X-ray imaging, image noise originates from two independent physical processes within the imaging process. First, the arrival of X-ray photons at the detector follows a random process governed by Poisson statistics from quantum physics. The resulting photon-counting fluctuations produce Poisson noise. A key characteristic of this noise type is its signal dependence—noise intensity correlates with signal intensity. Second, the electronic readout circuitry of the imaging system introduces additive Gaussian noise. This noise component arises from electronic disturbances such as thermal noise and dark current. Unlike Poisson noise, it remains independent of the signal. Consequently, an accurate noise model for X-ray image degradation must account for both of these fundamental noise sources. The Poisson-Gaussian mixture noise model employed in this paper builds upon this physical mechanism. Its validity is established at two levels. In X-ray imaging, the model has been directly verified and adopted through multiple physics-based studies and experiments.4–6 Furthermore, this model extends beyond X-ray imaging. As a classical framework for handling mixed signal-dependent and signal-independent noise, the Poisson-Gaussian model has been widely validated across various imaging domains. These include fluorescence microscopy 33 and general digital imaging. 34 Collectively, this evidence confirms the model’s effectiveness and accuracy in characterizing real noise behavior in X-ray imaging.
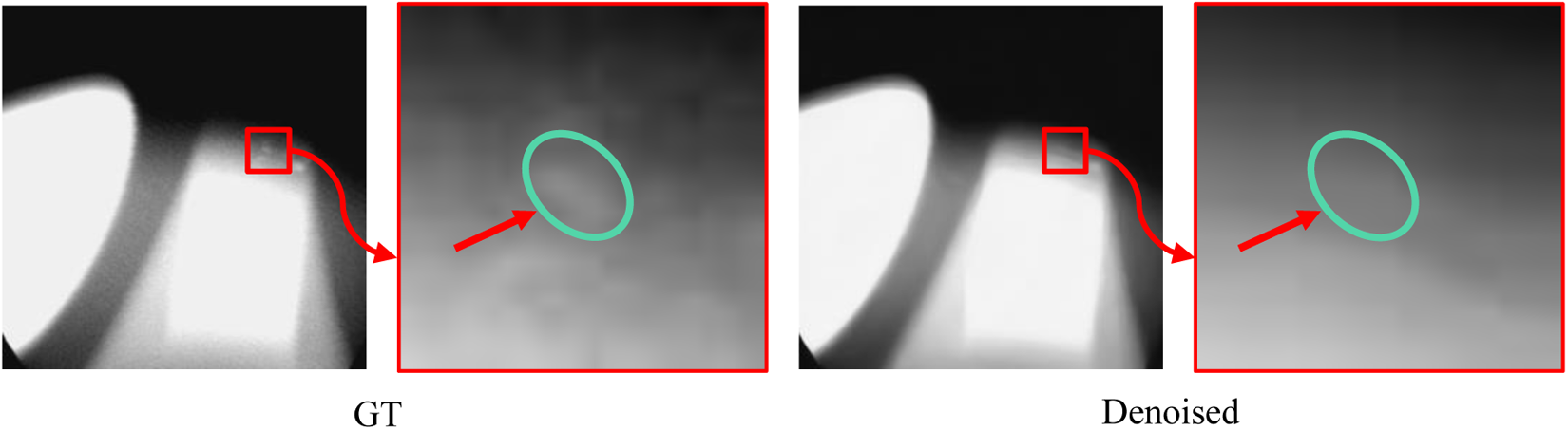
Results of the denoising method based on a simplified noise model.
In X-ray imaging, Poisson noise arises from the quantum nature of photon detection. The number of incident photons at each pixel location adheres to Poisson statistics. For a pixel with an expected photon count of

Although the true photon count
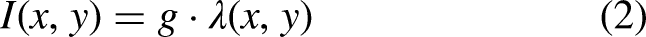

Therefore, the observed image
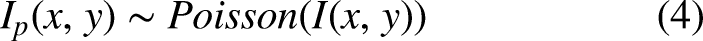
The expected value
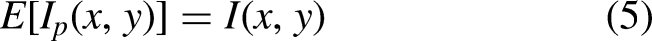
To enable finer control over noise intensity, a dimensionless scaling factor
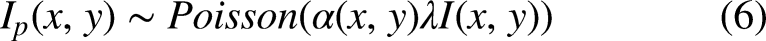
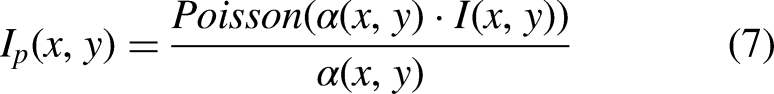
In addition to Poisson noise, X-ray imaging systems also exhibit electronic noise that primarily follows an additive Gaussian distribution. This noise typically originates from three sources: sensor thermal noise, amplifier circuit noise, and quantization noise during digitization. These components collectively demonstrate uniform distribution characteristics. Let
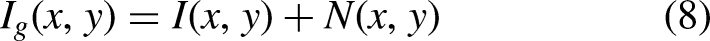
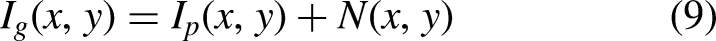

The results of different noises on the original image. (a) Original image, (b) Poisson noise, (c) Gaussian noise, (d) Combined noise.
Network structure
During X-ray image acquisition, image quality is often affected by the presence of Poisson noise and Gaussian noise. To address these two types of noise, the XDenoiser network proposed in this paper employs a dual-branch parallel structure to model degradation characteristics caused by different noise types. Figure 3 illustrates the XDenoiser architecture, which employs a dual-branch parallel structure comprising three core modules: (1) Global Linear Attention Branch (GLAB), (2) Local Convolution Branch (LCB), and (3) Dynamic Fusion (DF). The GLAB centers around the rwkv module with linear complexity. It has global modeling capabilities similar to a transformer and can capture long-range dependencies in images within a large receptive field. This feature gives it an inherent advantage in restoring the global structure damaged by Poisson noise. For instance, in weak signal regions where Poisson noise masks the complete object contour, Glab can reconstruct missing structural features using context information. The LCB is based on the CNN architecture. It uses multilayer local perception convolution operations to enhance image details. Since Gaussian noise is a local spatial disturbance, LCB can effectively remove high-frequency noise and restore texture details with its efficient local smoothing and edge-preserving abilities. The DF module is designed to coordinate complementary information from the two branches. By learning a pixel-level weight map related to the content, the output ratio of GLAB and LCB is dynamically adjusted to handle different regional noise types. For example, in areas with a clear global structure but local interference, the system automatically favors LCB output. In areas with a fuzzy structure, it relies more on GLAB for structural restoration.
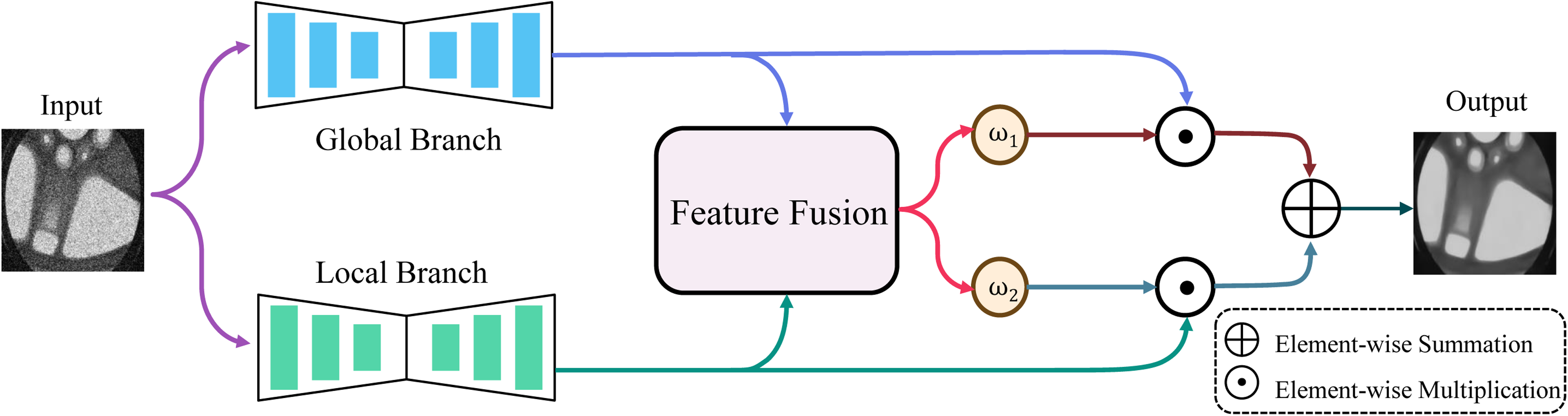
The Overview architecture of the XDenoiser.
Global linear attention branch
The attention mechanism has demonstrated strong performance in computer vision (CV) and natural language processing (NLP). However, its scalability is constrained by the quadratic computational complexity of the self-attention mechanism in Transformers. Recent studies have explored linear-complexity operators18,35 to optimize global attention mechanisms. The Receptance Weighted Key Value (RWKV) model,
18
originally developed for NLP, serves as an efficient alternative to Transformers. Unlike standard Transformers,
36
RWKV combines the linear complexity of recurrent neural networks (RNNs) with the parallel processing benefits of Transformers. Recently, Vision RWKV
37
extended this architecture from NLP to visual tasks, achieving superior performance over Vision Transformers while maintaining lower computational complexity. The linear complexity enables activation across a broader range of pixels, making it well-suited for image denoising tasks. The proposed GLAB framework is illustrated in Figure 4. The global branching follows a three-level U-shaped encoder-decoder architecture. Initially, shallow base features are extracted using a

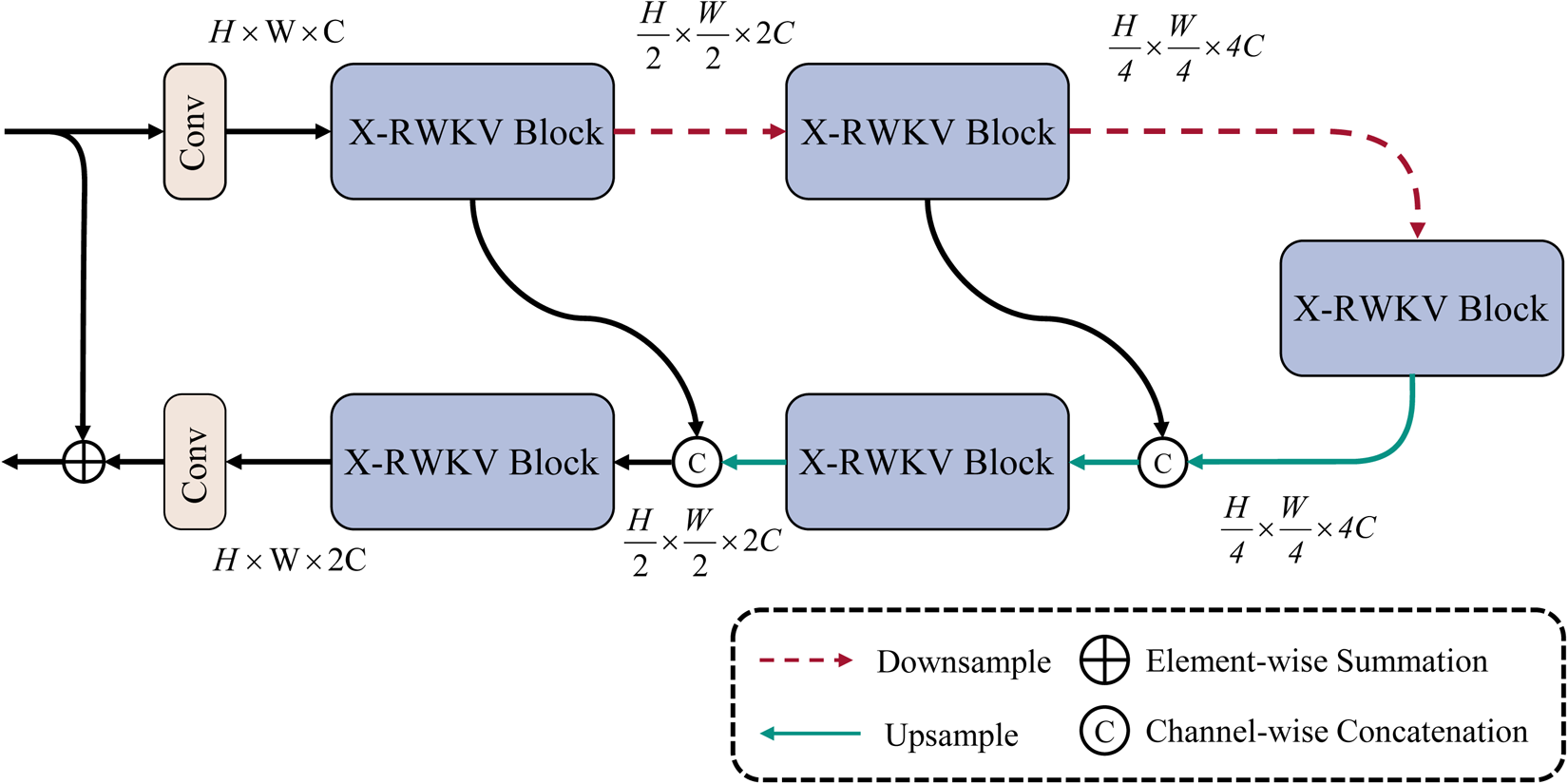
The global linear attention branch architecture.
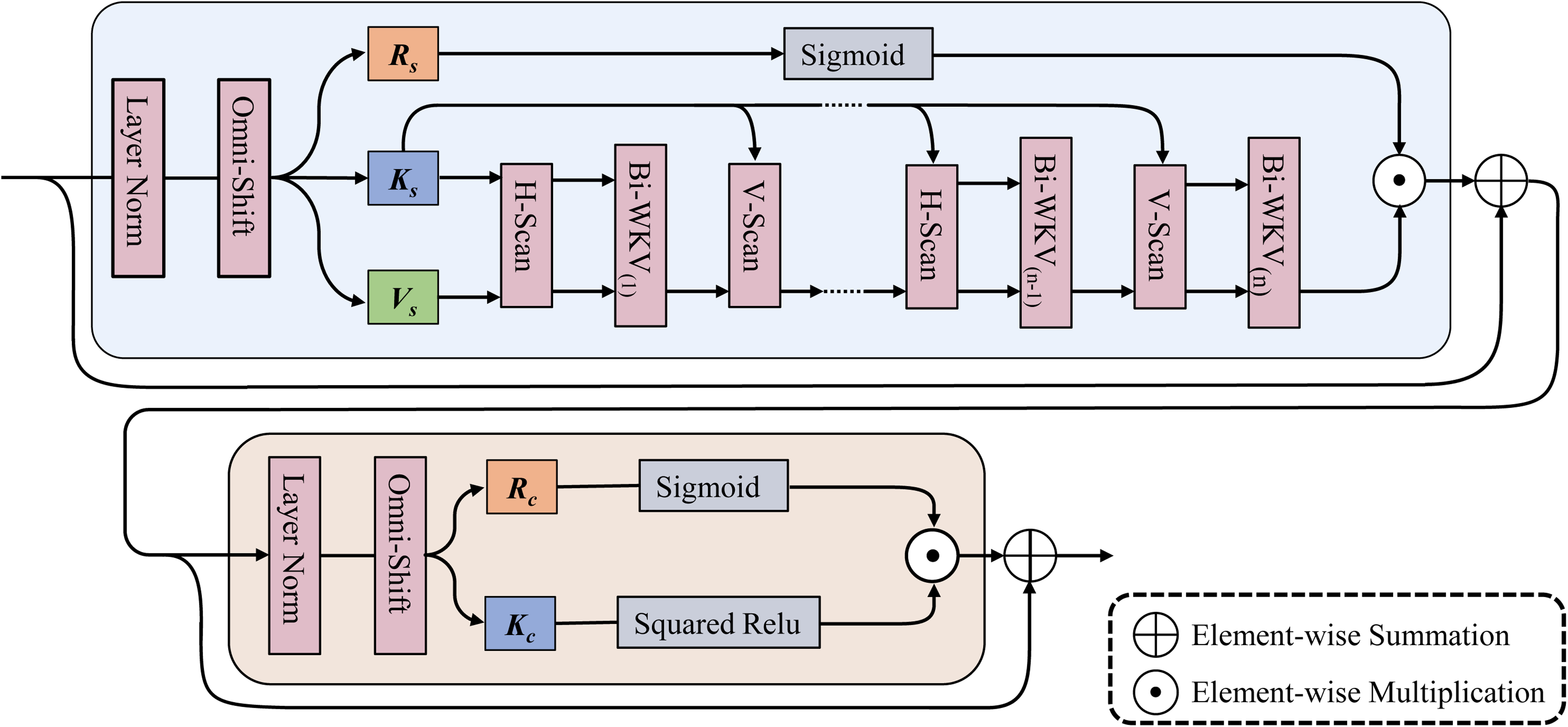
The X-RWKV block structure.
Local convolution branch
Restore RWKV 19 employs a single-branch encoder-decoder architecture. Its core components include RWKV spatial mixing and channel mixing modules. Efficient recurrent attention computation is achieved through custom CUDA kernels. A key advantage of this model is its use of RWKV units for global dependency modeling and efficient feature propagation. Additionally, an OmniShift module enables multi-scale convolutional reparameterization to expand the spatial receptive field. However, three main limitations were identified. First, the single-path design requires the RWKV module to handle both global features and local noise modeling, lacking specialized mechanisms for noise estimation and detail recovery. Second, the large parameter count reduces computational efficiency. Third, training instability can occur with larger batch sizes. To address these limitations, significant improvements were made to the Restore RWKV framework. A parallel convolutional branch was introduced, comprising a noise perception module and a detail enhancement denoising module. This branch specializes in estimating input image noise distribution and restoring local textures and high-frequency details. Combined with the original RWKV backbone, this forms a global-local dual-branch architecture that effectively compensates for the original model’s shortcomings in local noise detail modeling. Additionally, a computationally efficient and easily optimizable convolutional structure is adopted to balance denoising performance and computational cost, ensuring better global-local information trade-offs. Consequently, a Convolutional Denoising Network is proposed, as shown in Figure 6, comprising a Noise-Aware Module and a Detail-Enhanced Denoising Module, designed to improve both local feature extraction and overall denoising efficacy.
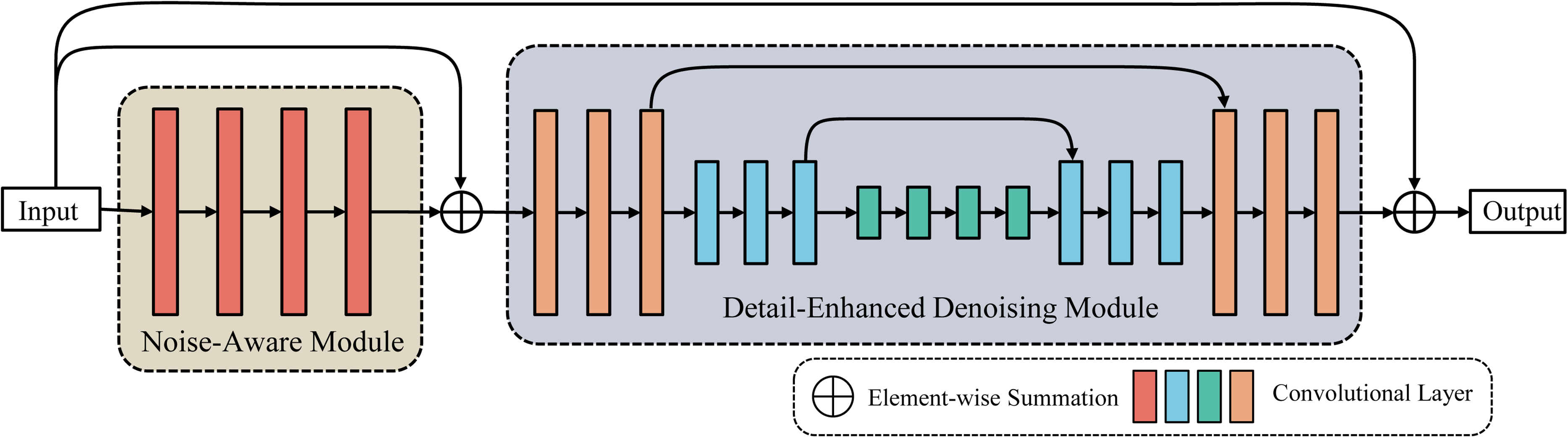
Overview of the local convolution branch architecture.
The Detail-Enhanced Denoising Module employs a U-Net architecture to extract multi-scale features. By integrating skip connections and local convolutional operations, it strengthens local dependencies while preserving texture details, enabling high-quality denoising. A key challenge in denoising is the variability of noise levels across input images. Fixed-parameter denoising methods often struggle to adapt to different noise intensities, resulting in either insufficient denoising (noise residue) or over-smoothing (texture loss). To address this, a Fully Convolutional Network (FCN) is introduced, utilizing a lightweight pixel-wise regression network to dynamically estimate noise levels for adaptive denoising.

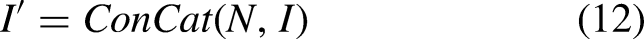
The detail-enhanced denoising branch employs a modified U-Net architecture for denoising. Unlike conventional U-Net designs, this implementation uses only two downsampling stages to minimize high-resolution information loss while maintaining an adequate receptive field. In the encoder pathway, local features are extracted through
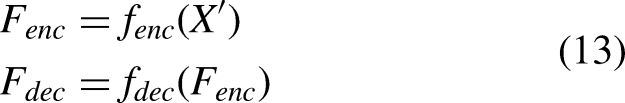
where

where
Dynamic fusion module
To fully utilize the complementary advantages of different feature representations in the dual branch structure, a lightweight adaptive fusion module was designed for weighted fusion of the output results of the two denoising branches, as shown in Figure 7. This module can adaptively generate the weight map based on the input image features and achieve fine dynamic feature integration. Compared to the fixed convolutional fusion in Restore RWKV, the proposed fusion mechanism significantly enhances model generalization and stability across diverse noise scenarios. First, the outputs of the two branches are concatenated into a channel tensor
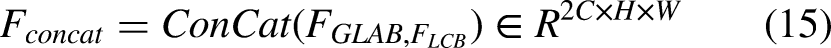
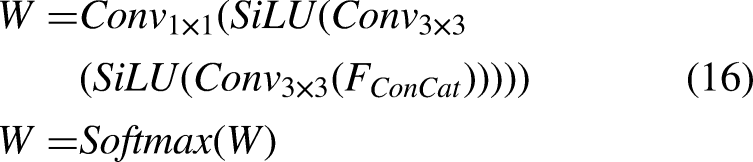
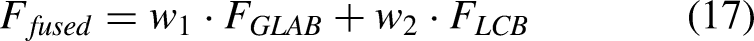
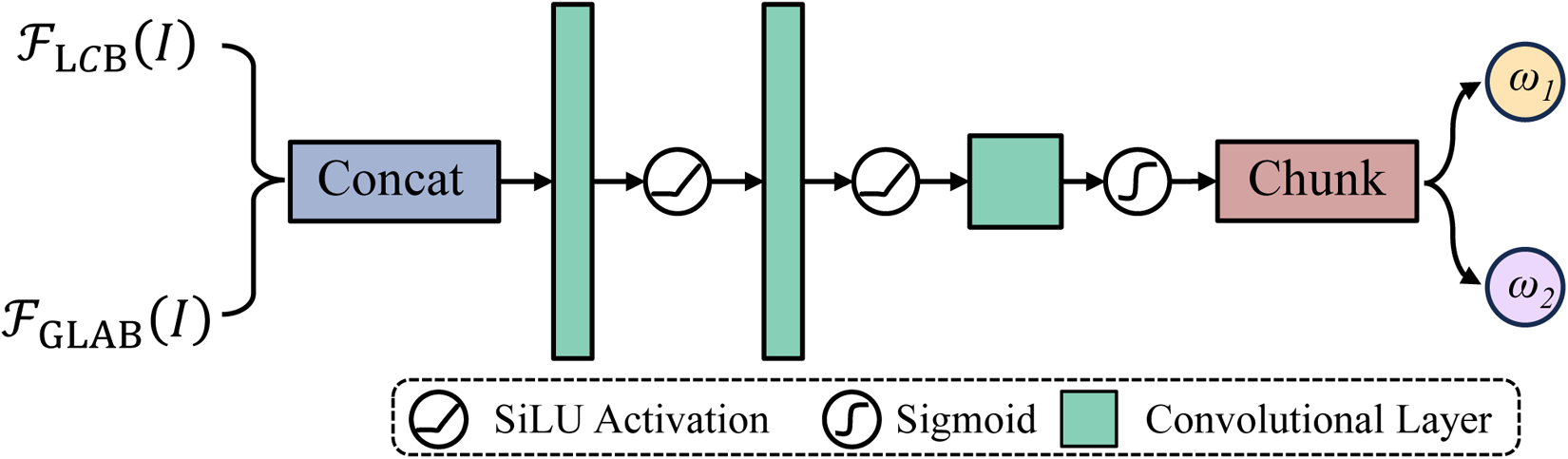
The flow chart of dynamic fusion module which takes the outputs of the global and local branches as input and generates weighted fusion weights for the two branches.
Loss function
To optimize the network’s denoising performance, the loss function incorporates errors from the global branch, local branch, and final fused output. The total loss is defined as follows:
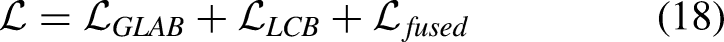
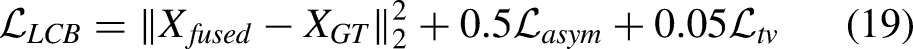
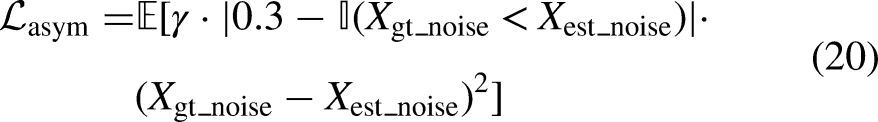
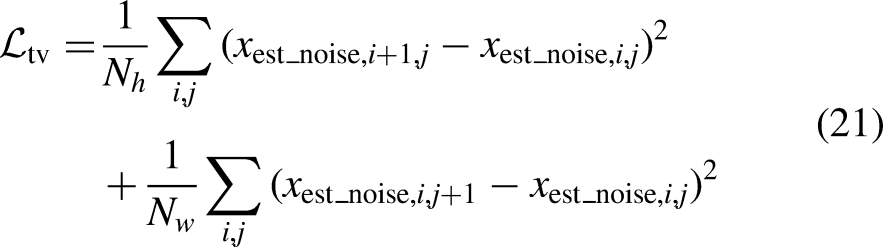
Experimental results and analyses
Dataset setting
This paper utilizes three publicly available datasets, including GDXRay,
38
HiXray
39
and SIXray.
40
The GDXRay is a widely recognized benchmark library for X-ray images in industrial applications. GDXRay offers diverse cross-domain samples suitable for multi-target detection tasks in security screening scenarios. The dataset comprises five distinct categories: castings, welds, baggage, natural objects, and scenes. The baggage subset was selected for training, consisting of

Examples of noise setting.
Evaluation metrics
Objective evaluation metrics play a critical role in quantifying the performance of image denoising algorithms. This paper employs three core metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Root Mean Square Error (RMSE). These metrics assess denoising performance from different perspectives, including pixel-level accuracy, structural fidelity, and perceptual quality.
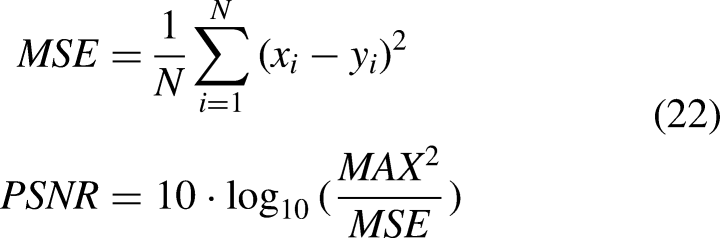
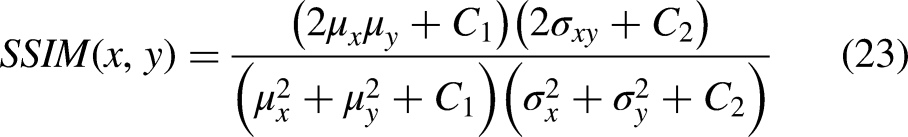
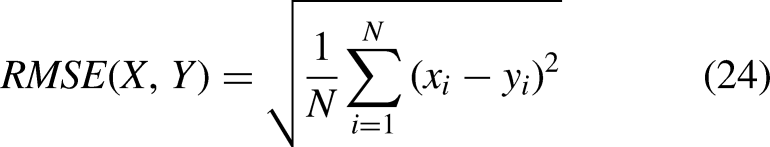
Experimental setup
The model is trained with an initial learning rate of
Ablation study
A set of ablation studies was designed to evaluate the impact of the local branch and fusion modules on model performance. Three key modules—the Noise-Aware Module (NAM), Detail-Enhanced Denoising Module (DEDM), and dynamic fusion modules (DFM)—were sequentially removed. The performance of each ablated model was then compared against the complete model and a benchmark. As shown in Table 1, the absence of any module leads to a decline in overall performance, confirming the indispensability of each component. The most significant drop occurs when the Detail-Enhanced Denoising Module is removed, with performance falling slightly below the benchmark level. This result highlights the distinct roles and collaborative mechanism of the modules. In the proposed architecture, the Noise-Aware Module predicts noise distribution but does not directly reconstruct the image. The Detail-Enhanced Denoising Module then uses this prior noise information to actively restore key texture and detail components. Removing this module causes the local convolution branch to lose its core denoising capability. The remaining noise estimate from the perception module can no longer be utilized effectively and instead interferes with the global branch’s output via the fusion module, leading to significant performance degradation. This finding underscores the critical role of the detail enhancement module within the denoising pipeline. Furthermore, the Noise-Aware Module enables a more targeted detail enhancement process, as evidenced by the performance drop following its removal. Finally, ablating the dynamic fusion module also resulted in a performance decline, emphasizing its importance as an adaptive coordinator that effectively balances and integrates features from different branches to achieve superior global denoising.
Ablation study of the GDXray dataset under the conditions of noise level

In summary, these ablation studies clearly demonstrate that the Noise-Aware Module, Detail-Enhanced Denoising Module, and dynamic fusion module perform distinct yet complementary functions, forming the foundation of XDenoiser’s effective denoising capability.
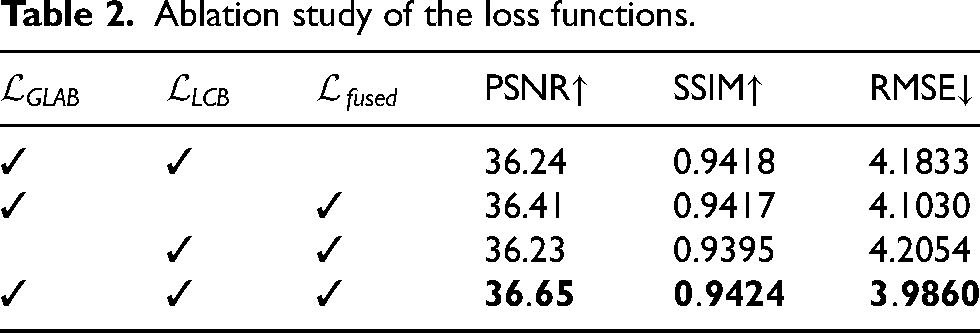
To validate the design of the loss function, ablation experiments were conducted as summarized in Table 2. The results show that removing any loss component—whether
Ablation study of the loss functions.
Experimental analyses
Xdenoiser is compared with five representative methods, including both model-driven and deep learning-based approaches. For the model-driven method, BM3D 26 is selected. For deep learning-based methods, CBDNet, 31 Restormer, 15 DCANet, 41 and Restore-RWKV 19 are chosen. CBDNet represents convolutional denoising, Restormer is a widely used self-attention-based method, DCANet combines convolution and attention, and Restore-RWKV adopts linear attention mechanisms. Tables 3 to Table 5 present a quantitative comparison of the proposed Xdenoiser against those methods on the GDXray dataset, HiXray dataset and Hixray dataset, respectively. The best results are highlighted in bold, while the second-best are shown in underline.
Comparative results of denoising methods on the GDXray.
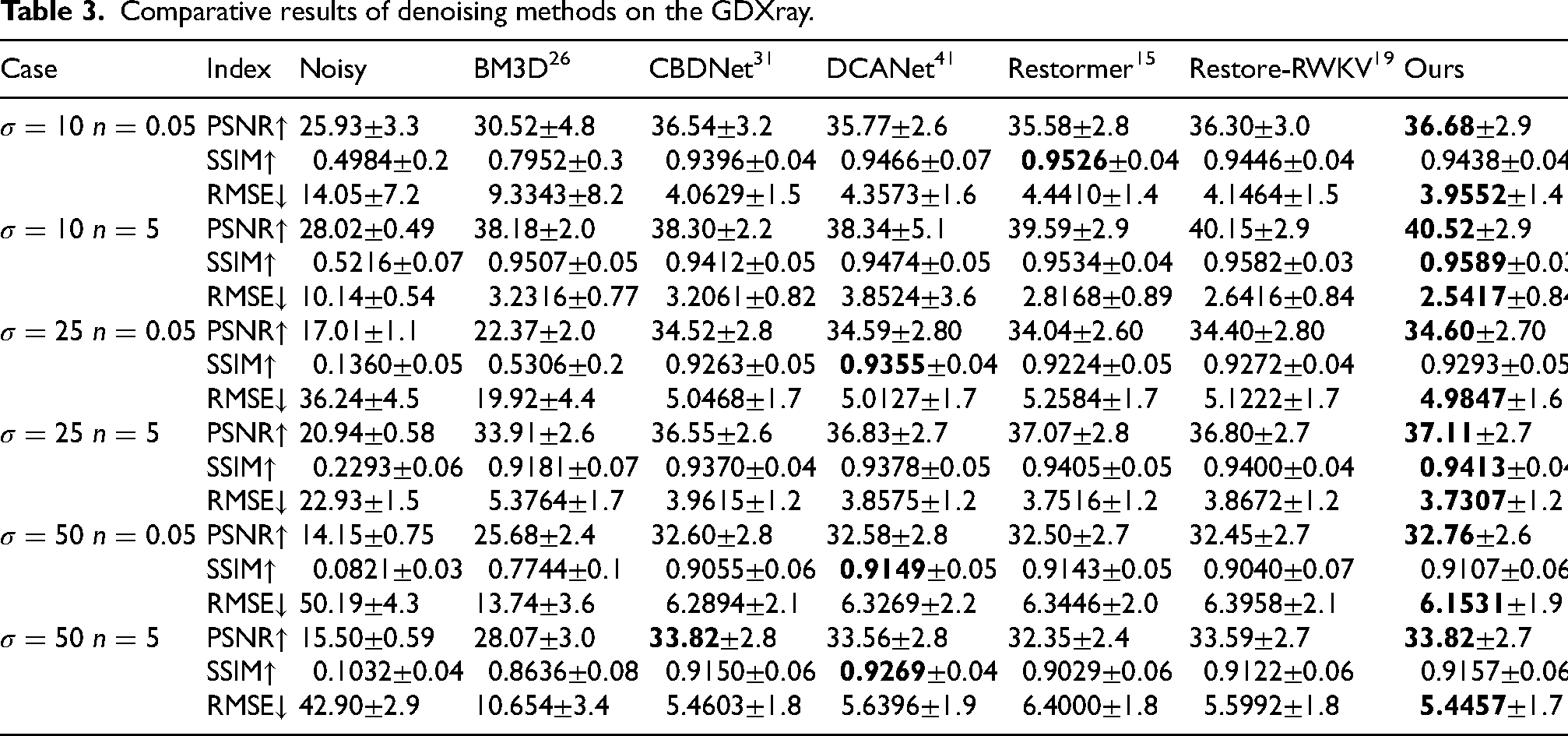
As shown in Tables 3 to Table 5, the proposed method demonstrates superior performance across various noise levels compared to mainstream algorithms. It achieves the best or near-optimal results in most test configurations for PSNR, SSIM, and RMSE metrics, indicating strong capabilities in structural consistency preservation and detail restoration. Standard deviation results further confirm the model’s output stability. Across most experimental settings, the proposed method exhibits significantly lower performance fluctuations than other approaches, demonstrating insensitivity to input noise variations and robust generalization characteristics. To validate the reliability of performance improvements, paired t-tests were conducted under identical noise configurations. The performance advantage proves statistically significant (
Comparative results of denoising methods on the sixray.

To further validate the denoising effectiveness of each method, visual results are presented in Figure 9, Figures 10 and 11, which shown some results of GDXRay, SIXray and Hixray, respectively. In the black-box region highlighted in Figure 9, numeric characters are displayed. This area is highly susceptible to blurring due to Gaussian-Poisson hybrid noise, making it a challenging region for detail recovery. The comparison shows that BM3D, CBDNet, and Restore-RWKV fail to preserve the character shapes effectively. Their denoised outputs exhibit distorted contours and broken strokes, resulting in illegible digits.
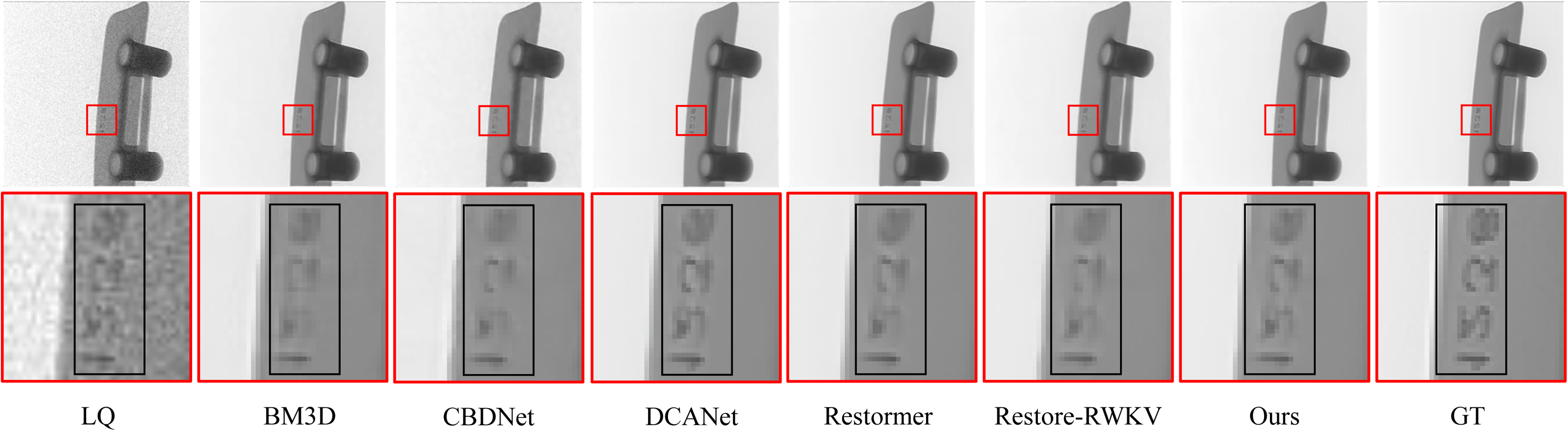
Noise removal results of the GDXRay dataset at Poisson noise level

Noise removal results of the SIXray dataset at Poisson noise level

Noise removal results of the Hixray dataset at Poisson noise level
Although DCANet improves edge clarity to some extent, it introduces pseudo-structures and false strokes at certain pixel locations. This adds high-frequency information that was not originally present, compromising the structural authenticity of the image. In contrast, the proposed Xdenoiser accurately restores the digit contours and stroke structures without introducing artifacts or false details, while effectively suppressing noise. The numeric regions appear clear and natural, exhibiting higher readability and realism. This improvement is attributed to the dynamic fusion mechanism, which allows global structure modeling and local detail enhancement to complement each other, resulting in more robust feature reconstruction in high-noise areas.
Figure 10 presents denoising results on the SIXray dataset with Poisson noise level
Figure 11 presents denoising results on the HiXray dataset with Poisson noise level
To systematically assess differences in computational resource consumption and inference efficiency, five image denoising models are compared based on the number of parameters (Params, in millions), which is the total number of learnable weights and biases in the model, measured in millions (M). The number of parameters influences the model’s capacity, storage requirements, training cost, and generalization ability. Computational complexity (FLOPs, in gigaflops), which is the total count of floating-point operations required during model inference, measured in gigaflops (G). Higher FLOPs indicate greater computational complexity and increased processing demands. and Average Inference Time per Image (AIT, in milliseconds), which is the average time taken to perform inference on a single image, measured in milliseconds (ms). The reported AIT values exclude data transfer time between CPU and GPU. Timing starts when the input tensor becomes available in GPU memory and ends upon completion of model computation. All AIT measurements were obtained at an input resolution of
Comparative results of denoising methods on the hixray.
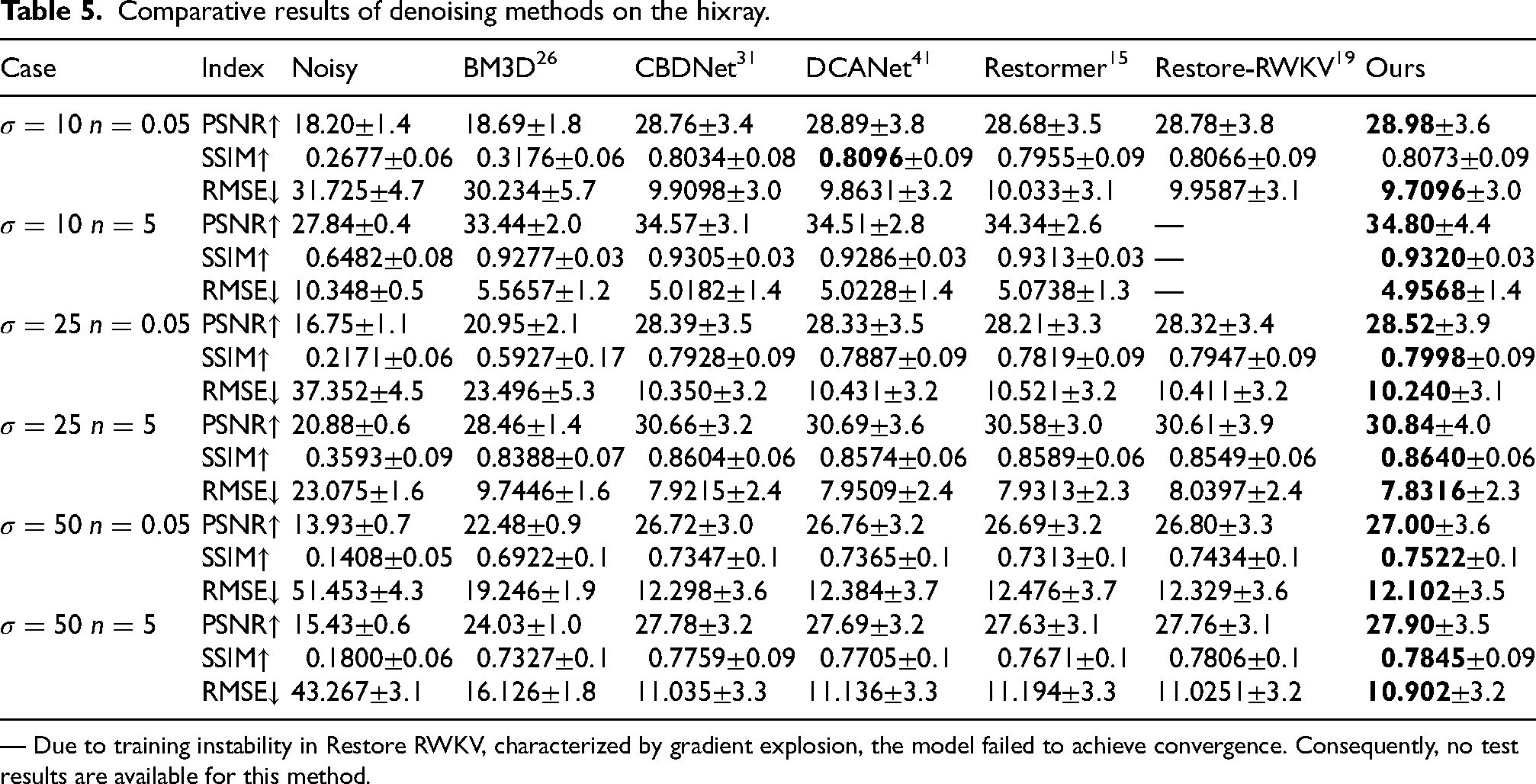
— Due to training instability in Restore RWKV, characterized by gradient explosion, the model failed to achieve convergence. Consequently, no test results are available for this method.
Comparative analysis of model computational complexity.
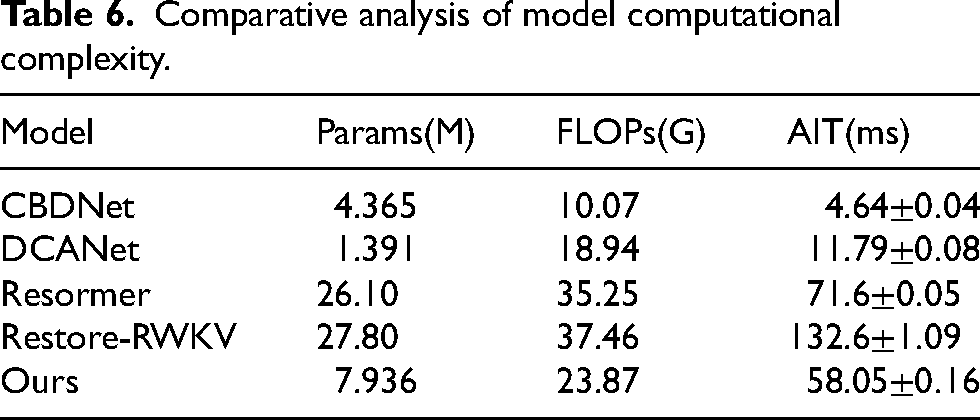
Xdenoiser, the method proposed in this paper, integrates global modeling with local structure enhancement. It employs a linear attention mechanism to address Poisson noise typical of low-dose imaging, while lightweight local branches suppress detail perturbations dominated by Gaussian noise. Although its inference time is slightly higher than that of pure CNN models, Xdenoiser significantly reduces model parameters and FLOPs compared to large Transformer architectures. This demonstrates a favorable balance between computational efficiency and denoising performance.
Conclusion
In this paper, a Poisson-Gaussian hybrid noise model is designed to reflect the noise characteristics of X-ray images, addressing the bias found in traditional synthetic noise distributions. Additionally, a two-branch cooperative denoising model is proposed, which balances global noise modeling and local detail preservation by integrating a linear-complexity RWKV module with a local convolutional branch. The model’s effectiveness in handling the complex noise distributions typical of X-ray images is demonstrated. Extensive experiments confirm that the proposed method achieves significant improvements in both quantitative metrics and the visual quality of reconstructed images.
Footnotes
Acknowledgements
This work was supported by the Key R&D Program Project of Zhejiang Province (2024C01232).
Ethical approval
Not applicable.
Authors’ contributions
Funding
This work was supported by the Key R&D Program Project of Zhejiang Province (2024C01232).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The datasets employed in this study were obtained from publicly available repositories, accessible via their corresponding references.