
Abstract
Background
An accurate diagnosis of children's self-care problems significantly matters in the growth and development of children. However, various and extensive disorders make the self-care problems classification extremely complex and require much effort and time to solve.
Objective
To deal with the above challenge, a deep learning model is proposed to classify the children's self-care problems intelligently and precisely.
Method
The proposed deep learning model contains two sub-deep neural networks. The first sub-network employs a technology of representing learning named triplet loss. It aims to compress the dimensions of the feature of the children with self-care problems to extract the useful information and exclude the noise, in order to improve classification performance. The second sub-network utilizes a technology for handling the class imbalance problem called focal loss to further improve the classification accuracy.
Result
The experimental results show that the proposed deep learning model outperforms. The averages of accuracy, precision, recall, and F1 score can achieve 99.78%, 0.99, 0.99, and 0.99, respectively.
Conclusion
To the best of our knowledge, the proposed method achieves state-of-the-art results. That can significantly support the rehabilitation and growth of children with self-care issues. Furthermore, this study also provides a demonstration and experience of the application of the deep learning model in the healthcare field.
Introduction
Self-care refers to the behaviors and activities a person undertakes to maintain and improve their physical, mental, and emotional wellbeing.1,2 Self-care is able to help individuals increase their self- awareness, self-esteem, confidence, and independence. It not only helps to cope with the challenges and stresses of life, but also presents and alleviates a range of lifestyle-related disorders such as anxiety, depression, and stress. 3 Self-care is not a one-time act, but requires consistent and determined effort, and becomes a part of everyday life.4,5
For children and youth with certain functioning or disabilities, self-care is important for their physical and mental developments.6,7 An accurate assessment of children's self-care problems plays an essential role in the subsequent occupational therapy and professional medical services. 8 Therefore, a conceptual framework named International Classification of Functioning, Disability, and Health for Children and Youth (ICF-CY) has been developed and released by the World Health Organization (WHO), in order to help evaluate, assess, and classify the corresponding functioning, disability, and health problems of children. 9 In accordance with the ICF-CY, WHO aims to help the healthy growth of the child physically and mentally.10–13
However, due to the complexity of disability itself14,15 and the extensive varieties of disorders,16,17 it is a hard, labor-intensive, and time-consuming work to accurately assess the children's disabilities and disorders. 18 Besides, the diagnosis of the corresponding self-care problem is also a challenge. A vast wealth of corresponding knowledge, experience, and collaboration among physicians, therapists, special educators, neuropsychologists, and other professionals in relevant fields would be required to conduct a precise diagnosis.
Therefore, in this paper, a deep learning model is proposed to accurately and effectively diagnose and classify children's self-care problems, in order to determine a corresponding appropriate occupational therapy and professional medical services to guarantee the children grow healthily.
Related work
The issue of self-care was initially studied as early as 1980. Twenty-six women were recruited and kept health diary, which consisted of a structured sheet to record health upsets, for four weeks, in order to conduct an exploratory study of self-care. 19 It indicated that self-care was necessary on more than 80 percent of days when medical issues were present. Moreover, the women reported that numerous “nonmedical” actions or events provided therapeutic benefits. The study not only confirmed that the self-care significantly impacted on both physical and mental well-being, but also highlighted that the self-care necessitated a holistic assessment of intricate interplay among social, psychological, and medical elements.
Then, different from the qualitative study way, such as “diary” 19 and “interview”, 20 the statistics method is employed to quantitatively analyze the self-care problem and conduct further research.21,22 Given the children's abilities of manual dexterity and gross motor functioning, the development of self-care and mobility skills in children with cerebral palsy was examined by Ohrvall AM et al.. 23 The data of 195 children diagnosed with cerebral palsy were collected and utilized. The collected data were evaluated using the Pediatric Evaluation of Disability Inventory's self-care and mobility functional skill scales, according to the Manual Ability Classification System (MACS) and the Gross Motor Function Classification System (GMFCS). Through the analysis of stepwise multiple regression, it can be found that the most influential predictor of self-care skills was MACS, and the most influential predictor of mobility skills was GMFCS. Besides, it also observed that children classified as MACS level I or II showed a significant correlation between age and self-care ability.
With the development of modeling technology, data size, and computing power, automatic expert systems based on data science are increasingly prevalent in medical and healthcare research.24–33 Meanwhile, these methods have also been applied to the study of children's self-care problems. Zarchi MS et al. innovatively introduced SCADI (Self-Care Activities Dataset based on ICF-CY), which was a new standard dataset for children's self-care problems analysis, to contribute to the children's self-care research. 34 To comprehensively study children's self-care issues, the SCADI contains the corresponding information as much as possible, and 29 self-care activities are included. In order to assess the applicability and universality of the SCADI, Zarchi MS et al. employed two distinct types of expert systems for classifying self-care problems among children who had physical and motor disabilities. In the first expert system, an Artificial Neural Network (ANN) was used as a classifier and achieved an accuracy of 83.1% in classifying children's self-care problems. In the second expert system, a Decision Tree (DT) algorithm known as C4.5 was employed to accurately extract classification rules for children's self-care problems. Zdrodowska M et al. considered the features contained in the SCADI and their impacts on the accuracy of children's self-care problems classification. 35 The correlation method, information gain method, and Chi-Square test-based method were employed to find and select the features that play primary roles in categorizing a child into a specific group with certain self-care problems. Then, the JRip, PART, C4.5, Random Tree (RT), and CART were used to build the classification model. The experiments showed that the accuracy of JRip increased by 4.28% with the 17 selected features, while the performances of other methods all decreased. The motivation for using the above method was to leverage a few key features to achieve satisfactory classification performance for children's self-care problems while keeping computational costs relatively low. Within the same conceptual framework, Choudhury A et al. used the Boruta algorithm to select the useful features, then utilized Random Forest (RF), Support Vector Machine (SVM), Naive Bayes (NB), and Hoeffding Tree (HF) to classify the children's self-care problems based on the selected features. 36 The experiment suggested that RF achieved the best performance with 84.75% accuracy. Fatemi et al. introduced a classification model for children's self-care problems that the Genetic Algorithm (GA) was applied for selecting features, and the Probabilistic Neural Network (PNN) was employed as a classifier. 37 The experiments demonstrated that the proposed model could classify children's self-care problems with 94.28% accuracy using the selected features across 34 dimensions. Syafrudin M et al. proposed an effective classification model for children's self-care problems by leveraging the Principal Component Analysis (PCA) to extract important features and the Decision Trees (DT) to construct the corresponding classification model. 38 The experiments demonstrated that PCA-based feature extraction yielded positive results, enhancing the model's performance by achieving 1.70% increase in accuracy. The proposed classification model achieved 94.29% accuracy. In a recent study, Putatunda S introduced a novel deep learning-based model, which was named Care2Vec, to classify the corresponding self-care problems of physically disabled children. 39 In Care2Vec, autoencoders and deep neural networks were employed to construct a two-step modeling process. Firstly, the autoencoders were used to learn the low-dimensional representation of the feature of the self-care problem. Subsequently, the learned low-dimensional representation of the feature was used as the input data that were fed into the deep neural networks to complete the training procedure. The experiments showed that the proposed Care2Vec can achieve 91.43% accuracy in the children's self-care problems classification.
Review of literature
Based on the above review, it can be seen that self-care contributes significantly to improving physical, mental, and emotional well-being, especially in promoting the healthy growth of children with certain functioning and disabilities. An accurate self-care diagnosis and classification can significantly contribute to the subsequent occupational therapy and professional medical services.
However, diagnosing and classifying self-care problems is a complex challenge due to the diverse range of disorders and disabilities. In practice, achieving a precise diagnosis of self-care problems often necessitates a broad range of knowledge, experience, and collaboration among physicians, therapists, and other related professionals. As a result, numerous studies are being conducted to automatically and accurately diagnose and classify self-care problems. Firstly, qualitative study methods, such as “diary” and “interview”, are used. Then, to obtain a more quantitative description of the self-care problem, the statistics method is employed. Nowadays, modeling methods, computational technology, and deep learning methods with increasing computing power have made great progress and achieved impressive performances in the expert system, image processing, and natural language processing fields. To utilize the outstanding ability of these new emerging methods, researchers have introduced them to the field of self-care.
As far as we know, the best performance of children's self-care problems classification achieves 94.29% accuracy. 38 The study treats the self-care problem classification as a two-step modeling process. The first step is to use the PCA to select the most related features. The second step is to utilize the selected feature to categorize the children's self-care problems using the DT method. The advantage of the two-step modeling process is that the feature selection procedure is able to make the classifier only focus on the most related factors and exclude other interfering factors which could lead to a decrease in accuracy and efficiency. 40 As a result, studies that employ the feature selection procedure achieve rather good performances. Such as Bushehri and Zarchi, 37 Syafrudin et al., 38 and Putatunda 39 achieve 94.28%, 94.29%, and 91.43% accuracy of children's self-care problems classification, respectively.
Despite achieving rather good performances, the information among feature dimensions and the correlation between different instances are neglected. Fatemi BS et al. and Syafrudin M et al. use GA 37 and PCA 38 to select the related features, respectively. However, they all neglect the information among the feature dimensions. Putatunda S realizes the information among the feature dimensions and uses the autoencoders to compress the dimensions of the feature instead of only selecting certain dimensions of the feature. 39 But the correlation between different instances represented by features is still not considered. All these factors can result in the degeneration of the classification performance of children's self-care problems. Furthermore, the class imbalance problem in children's self-care problems classification, which may lead to a decrease in classification accuracy, has not been considered.
Contributions
In order to deal with the above problems (i.e., considering the information among the feature dimensions and the correlation between the different instances, as well as the class imbalance problem), we propose an artificial neural network model, which is based on deep learning, represent learning, and focal loss technology, to furthermore improve the accuracy and efficiency of the classification performance of the children's self-care problems. The contributions are as follows: The classification of children's self-care problems is treated as a two-step modeling process and the model is consisted of two sub-deep neural networks. The first sub-deep neural network utilizes the triplet loss method to compress the dimensions of the feature that is to exclude the noise, preserve information among different dimensions, and maintain the correlation between different instances, simultaneously. The second sub-network employs a technology called focal loss to deal with the class imbalance problem to further improve the classification performance of children's self-care problems.
The remaining paper is structured as follows: In Section 2, the proposed method is presented. In Section 3, numerical tests are performed. Section 4 gives discussions about the proposed method. In Section 5, limitations of the proposed method are presented. Section 6 summarizes the paper.
In this paper, the classification of children's self-care problems is viewed as a two-step modeling procedure, which contains two sub-deep neural networks. The first sub-network employs triplet loss to enhance feature separability by enforcing intra-class compactness and inter-class distinctiveness, while the second sub-network adopts focal loss to mitigate class imbalance by focusing on hard and minority-class samples. The integration of these two complementary loss functions leads to improved classification performance. The overall structure diagram is presented in Figure 1.

The overall structure of the proposed children's self-care problems classification method.
The complete proposed method for classifying children's self-care problems is based on the deep neural network. It is one of the most popular artificial methods these days and achieves impressive performances in image processing and natural language processing. For example, the amazing stable diffusion model, the segment anything model, and the ChatGPT are all based on the deep neural network. Because of the outstanding modeling ability of the deep neural network, we have applied it to our children's self-care problems classification model. The basics of the deep neural network are presented in Figure 2. The deep neural network contains three parts which are the input layer, hidden layers, and output layer. The approach involves using the probability theory to model the relationship of the inputs denoted as
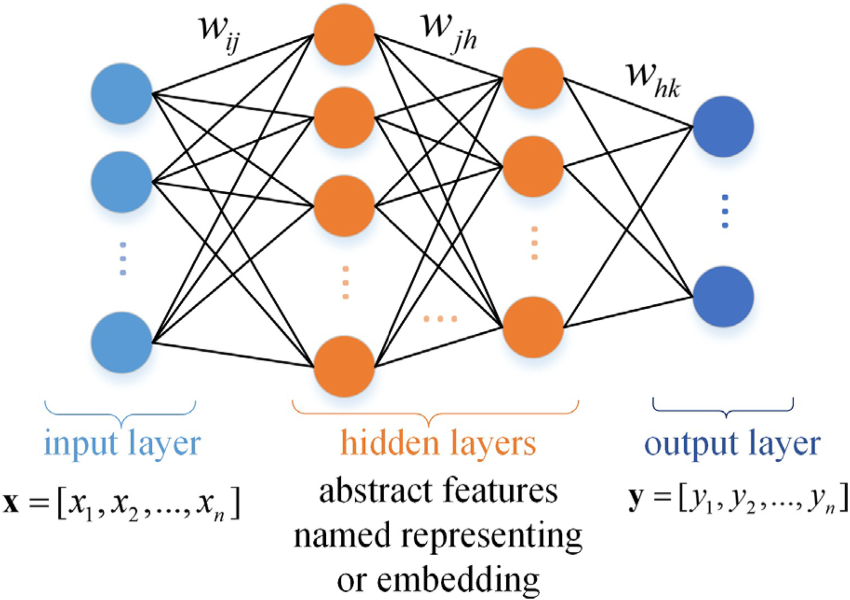
The structure of the deep neural network.
The deep neural network is a kind of supervised machine learning method and can be trained by the backpropagation method that the weight parameter w is updated by the stochastic gradient descent method according to the loss function L as

Where
The first sub-deep neural network is responsible for compressing the feature dimension to obtain its corresponding representation also named embedding. The purpose is to help the classifier pay more attention to the important useful information contained in the feature to further improve the classification accuracy as well as the computational efficiency.
Besides, in order to utilize the correlation between different instances, the triplet loss technology 45 is used. The main idea is to learn the map from the original feature to the embedding in a compact Euclidean space where distances measure the similarity. The flowchart is presented in Figure 3.

The flowchart of the first sub-deep neural network. The triplet loss is employed to generate the embeddings considering the correlation between different instances.
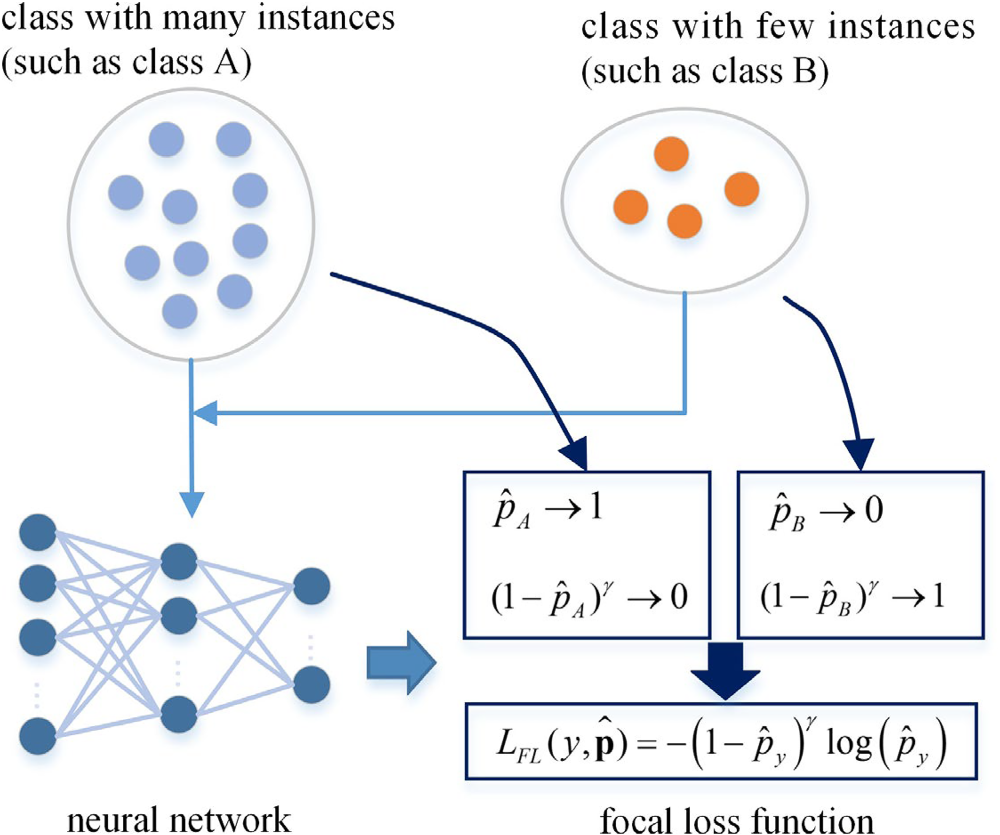
The objective of triplet loss is to ensure that instances with the same label have their embeddings placed closely together in the embedding space, whereas instances with different labels have their embeddings positioned far apart. To achieve this objective, the loss function can be defined using triplets of embeddings, consisting of an anchor, a positive instance from the same class, and a negative instance from a different class. The triplet loss function can be represented as
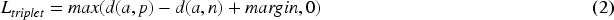
In the context of the triplet loss function, the distance between the anchor and the positive instance in the embedding space is represented by
The second sub-deep neural network is used for classifying the children's self-care problems utilizing the embedding of the feature. Considering the class imbalance problem in the children's self-care problems classification that would result in an accuracy decrease, the focal loss method 46 is used. The class imbalance problem arises from the disparity in the number of instances across different classes in the dataset. And it can lead to a decrease in the performance of the neural network. To handle the above problem, we combine the focal loss technique with the softmax cross-entropy function.
In the training process, the multiclass classification loss function based on softmax cross-entropy is as

Where
The focal loss is used to handle the above problem. The main idea of focal loss is to reduce the loss contributed by a certain class (such as class A) with a large number of instances, while emphasizing the impact of the loss from another class (like class B) with a small number of instances, simultaneously. The specific approach is adding a factor

The explanation of the second sub-deep neural network. The focal loss is employed to handle the class imbalance problem by adding a weighted factor
Additionally, the algorithm of the proposed method for the children's self-care problems classification is presented in Algorithm 1.

The proposed method for the classification of children's self-care problems is tested on the SCADI dataset which is generated from the ICF-CY framework published by the WHO. Compared with up-to-date references, the experimental tests show that the proposed method outperforms.
Datasets
The SCADI dataset includes data with 205 features of 70 children who have various physical and motor disabilities. There is a roughly equal sex distribution, with 29 boys (41.4%) and 31 girls (58.6%). The total median (interquartile range) age of the 70 children is 12 (9–15) years old. For boys, the median (interquartile range) age is 10 (9–14) years old. For girls, the median (interquartile range) age of the girls is 13 (10–15) years old. 29 activities related to the physical and motor disabilities of the children's self-care problems are considered in the SCADI dataset. These activities with the corresponding descriptions and feature codes are shown in Table 1. Table 2 presents all the feature codes used in the SCADI dataset. The feature codes are defined according to the ICF framework. 9 Furthermore, the children's self- care problems are categorized into 7 distinct classes. Class 1: Caring for body parts problem; Class 2: Toileting problem; Class 3: Dressing problem; Class 4: Washing oneself and caring for body parts and dressing problem; Class 5: Washing oneself, caring for body parts, toileting, and dressing problem; Class 6: Eating, drinking, washing oneself, caring for body parts, toileting, dressing, looking after one's health, and looking after one's safety problem; Class 7: No self-care problem. These classes are also presented in Table 3. More details of the SCADI dataset can be found in the reference. 34
Self-care activities considered in the SCADI.

Self-care activities considered in the SCADI.
The feature codes used in the SCADI.
The feature codes are defined according to the ICF framework and the details can be found in reference. 9
Classes of the children's self-care problems.

Figure 5 shows the statistics of the data. Figure 5(a) presents the proportions of different ages, and Figure 5(b) shows the instances of different classes. Besides, there are a few instances in class 1, class 3, and class 5. For example, class 1, class 3, and class 5 only have 2, 1, and 3 instances, respectively. Since the triplet loss requires at least two positive instances and one negative instance to serve as the anchor, positive, and negative in the embedding space, we doubled the SCADI dataset by augmenting the gender field. The assumption is in line with the fact that the gender field cannot affect the diagnosis of children's self-care problems in the vast majority of cases. Table 4 displays the class distribution, including the number of instances for each class.

The statistics of children with self-care problems contained in the SCADI dataset. (a) The proportions of different ages in the SCADI dataset; (b) The instances of different classes in the SCADI dataset.
The distribution of the classes and instances.

As a multiclass classification problem, the classification performances of children's self-care problems can be evaluated by common metrics such as accuracy, precision, recall, and F1 score, respectively.

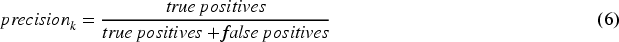
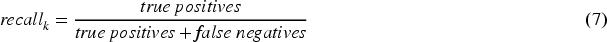

In addition, 10-fold cross-validation 47 is employed to comprehensively and reliably assess the classification performances. The 10-fold cross-validation is a kind of statistical method. It divides the whole dataset into 10 subsets. The training process is conducted on nine of these subsets, while the remaining one subset is used to validate the classification performances. The above process is repeated 10 times until each one subset has been used once as the validation set. Table 5 presents the split of the training and validation datasets in the 10-fold cross-validation.
The split of the training and validation datasets of 10-fold cross-validation.

(140) represents that the total size of the SCADI dataset is 140.
(14) denotes that the size of the validation dataset is 14.
(126) means the size of the training dataset is 126.
Several trials have been carried out to select the reasonable hyperparameters of the first sub-deep neural network (which is employed to extract useful information from the features) and the second sub- deep neural network (which is used to handle the imbalance problem).
Given that the classification of children's self-care problems is a multiclass classification problem, the activation function used in the proposed model is set to be the ReLU. The loss function of the first sub- deep neural network is chosen as the triplet loss function, while the loss function of the second sub-deep neural network is selected as the focal loss function.
For both sub-deep neural networks, the selection criterion is to choose the simplest architecture that achieves the best validation performance. The triplet loss margin is set to 0.1 to balance between intra-class compactness and inter-class separability, while the focal loss parameter gamma is set to 2.0 to effectively down-weight easy samples. The dropout regularization technique 48 is not used in this approach. The Adam optimizer 49 is employed to train the deep neural networks. The number of training epochs is set to be 50 for stable convergence. The hyperparameters and architecture of the proposed model are determined and presented in Table 6.
The hyperparameters and architecture of the model.

The hyperparameters and architecture of the model.
The performances of the proposed method for classifying the children's self-care problems are investigated and compared with other methods in the up-to-date references such as probabilistic neural network (PNN), classification and regression tree (CART), genetic algorithm combined probabilistic neural net- work (GA-PNN), 37 naive Bayes (NB), support vector machine (SVM), k-nearest neighbor (KNN), principal component analysis based decision tree (PCA-DT), 38 and a deep learning based approach named Care2Vec. 39 Besides, two scenarios are considered. In the first scenario, feature dimension compression is not implemented. The feature dimension remains unchanged which is 205. In contrast, the second scenario considers the feature compression procedure. The feature dimension is compressed from 205 to 34 and 56.
The experimental environment comprises Python 3.6 with TensorFlow 2.0, running on a 64-bit version of Microsoft Windows 11. The system is equipped with an AMD Ryzen 75800H processor, Nvidia GeForce RTX 3060 GPU, and 16 GB DDR4 RAM. Additionally, the dataset and code have been up-loaded to GitHub, and the URL is https://github.com/yangyugit/self-care_problems_classification.
The numerical results are presented in Table 7. It can be seen that the proposed method outperforms in both scenarios (with and without the feature compression procedure). In the first scenario, CART has the worst accuracy which is 76.82%. PNN obtains an accuracy of 78.56%. Care2Vec and MLP achieve the accuracy rate of 90.00% and 90.47%, respectively. Furthermore, the proposed model obtains 98.41% accuracy, when only employing the triplet loss function in the first sub-deep neural network. Based on this, we are capable of achieving 100% accuracy by incorporating the focal loss in the second sub-deep neural network. In terms of precision, recall, and F1 score, CART outperforms PNN, with 0.90 precision, 0.81 recall, and 0.85 F1 score compared with PNN's 0.81 precision, 0.75 recall, and 0.77 F1 score. Care2Vec and MLP obtain the same precision, which is 0.94. However, Care2Vec exhibits better recall and F1 score than MLP, with 0.88 recall and 0.91 F1 score compared with MLP's 0.85 recall and 0.89 F1 score. The neural network with only the triplet loss function achieves a precision, recall, and F1 score of 0.98. Lastly, the proposed method incorporating both the triplet loss function and the focal loss function achieves a precision, recall, and F1 score of 1.00.
The performances of the children's self-care problems classification.

The performances of the children's self-care problems classification.
The proposed method is compared with the state-of-the-art approaches from recent studies,37–39 which introduce GA-PNN, PCA-DT, and Care2Vec, respectively. The comparison is conducted under the condition that each of these methods achieves its best performance. Additionally, these studies also evaluate other methods, such as CART, PNN, PCA-PNN, GA-SVM, NB, KNN, and SVM, which are likewise included in our comparisons.
MLP represents a multi-layer perceptron that has the same structure as the second sub-deep neural network in the proposed method.
Triplet denotes the first sub-deep neural network with the triplet loss function.
Focal represents the second sub-deep neural network with the focal loss that has been used based on the first sub-deep neural network (i.e., the entire proposed method).
In the second scenario (the feature has been compressed to 34 dimensions), PCA-PNN has the lowest accuracy, recall, and F1 score, which are 81.42%, 0.85, and 0.87, respectively. GA-PNN performs better by obtaining 94.28% accuracy, 0.94 precision, 0.98 recall, and 0.95 F1 score. Care2Vec achieves 91.42% accuracy, 0.92 precision, 0.90 recall, and 0.91 F1 score. Compared with the performances of PNN and Care2Vec in the first scenario, these results indicate that the feature compressing procedure can extract useful information, eliminate noise, and be beneficial for improving the classification performance. However, GA-SVM performs moderately with 87.64% accuracy, 0.86 precision, 0.89 recall, and 0.87 F1 score. The reason could be attributed to the limited modeling capability of the SVM model compared with the PNN model. The neural network with only triplet loss technology achieves 98.41% accuracy, 0.98 precision, 0.98 recall, and 0.98 F1 score. Lastly, the proposed method with both the triplet loss function and the focal loss function achieves 100.00% accuracy, 1 precision, 1 recall, and 1 F1 score. When the feature is compressed to 56 dimensions, NB performs worst with 78.57% accuracy, 0.91 precision, 0.78 recall, and 0.85 F1 score. KNN and SVM perform similarly, and both outperform NB. Specifically, KNN obtains 87.14% accuracy, 0.91 precision, 0.95 recall, and 0.91 F1 score, while SVM achieves 88.57% accuracy, 0.87 precision, 1.00 recall, and 0.93 F1 score. PCA-DT achieves the third best performance with 94.29% accuracy, 0.98 precision, 0.94 recall, and 0.95 F1 score. Moreover, the neural network with only the triplet loss technology outperforms PCA-DT with 98.41% accuracy, 0.98 precision, 0.98 recall, and 0.98 F1 score. Lastly, the proposed method incorporating both the triplet loss function and the focal loss function achieves the best performance with 100.00% accuracy, 1 precision, 1 recall, and 1 F1 score.
Besides, the execution time of the proposed neural network model is investigated, considering the real-time diagnostic issues. The dataset loading time is 0.0648 s. The training time of the proposed neural network is 61.9405 s. And the classification time is only 0.0013 s. That satisfies the requirements for real-time on-site diagnosis to assist doctors.
Despite the proposed method achieving excellent performance in the classification of the children's self-care problems, its outstanding performance (i.e., 100.00% accuracy, 1 precision, 1 recall, and 1 F1 score) inevitably raises doubts and concerns. Generally, the primary cause of overly good performance is overfitting. Overfitting refers to when a deep neural network model performs well on the training dataset but poorly on the test dataset. This can be understood as the deep learning model overly focusing on the details of the data and neglecting to extract knowledge from the data. Although the excellent performance mentioned above is obtained under 10-fold cross-validation, we still want to further confirm whether overfitting occurs. Therefore, we independently repeat 10 sets of 10-fold cross-validation. This is equivalent to randomly partitioning the dataset 100 times and creating separate training and test datasets each time. Then, the proposed method is tested in the separated datasets. The testing results are presented in Table 8 and Figure 6.

The testing results of the proposed method repeating 10 sets of 10-fold cross-validation.
The 10-fold cross-validation performances.

Without feature compression (i.e., feature dimension is 205), we observe that out of 100 experimental trials, accuracy, recall, and F1 score could not achieve 1 in 6 trials, precision could not reach 1 in only 5 trials. The mean and standard deviation of accuracy, precision, recall, and F1 score are 98.98% (SD = 0.04), 0.99 (SD = 0.04), 0.99 (SD = 0.04), and 0.99 (SD = 0.04), respectively. When the feature is compressed to 34 dimensions, we observe that out of 100 experimental trials, accuracy, precision, and F1 score cannot reach 1 in only 3 trials, recall cannot reach 1 in only 2 trials. The mean and standard deviation of accuracy, precision, recall, and F1 score are 99.53% (SD = 0.03), 0.99 (SD = 0.03), 0.99 (SD = 0.03), and 0.99 (SD = 0.03), respectively. When the feature is compressed to 56 dimensions, we find that out of 100 experimental trials, accuracy cannot reach 100% in 8 trials, precision cannot reach 1 in 5 trials, recall cannot reach 1 in 9 trials, and F1 score cannot reach 1 in 9 trials. The mean and standard deviation of accuracy, precision, recall, and F1 score are 98.73% (SD = 0.04), 0.99 (SD = 0.03), 0.99 (SD = 0.05), and 0.99 (SD = 0.04), respectively. These mean the proposed method maintains consistently impressive performance across 10 sets of 10-fold cross-validation runs. This indicates that overfitting does not occur. At the very least, it demonstrates that, for this children's self-care problem dataset, the proposed method exhibits impressive and stable classification performance.
To further validate the performance of the proposed method and examine whether overfitting occurs, we also conduct numerical experiments on two additional external datasets in related domains. The first dataset is the breast cancer dataset 50 which is about the classification of the radiation therapy to treat the breast cancer. It contains 286 instances, each with 9 features, and includes two classification results (i.e., radiation therapy and non-radiation therapy). The second dataset is the nursery dataset 51 which is developed to the rank applications for nursery schools. It contains 12960 instances, each with 8 features, and includes three classification results (i.e., recommended, not-recommended, and priority). Table 9 presents the performance of the proposed method tested in the breast cancer dataset and the nursery dataset. It can be seen that the proposed method achieves a moderate performance in the breast cancer dataset with 82.79% accuracy, 0.83 precision, 0.83 recall, and 0.83 F1 score. However, compared with the Xgboost classification, SVM classification, RF classification, neural network classification, and logistic regression methods, the proposed method outperforms with the state-of-the-art results. 50 In the nursery dataset, the proposed method achieves outstanding performance with 98.89% accuracy, 0.99 precision, 0.99 recall, and 0.99 F1 score. These testing results in the additional external datasets verify the excellent performance of the proposed method.
The performances of the proposed method testing in the two additional external datasets.

Additionally, we perform a Shapley Additive Explanations (SHAP) analysis 52 to interpret the proposed method for children's self-care problems. Figure 7 and Figure 8 present the results of SHAP analysis. Figure 7(a) presents the mean SHAP values, which are computed as the average of the absolute SHAP values across the seven classes, representing the overall feature importance in classifying children's self-care problems. It can be seen that Feature 1 has the highest SHAP value, indicating its dominant influence on the model's decision-making process. Several other features, such as Feature 186, Feature 102, and Feature 184, also exhibit relatively high SHAP values, suggesting their significant contributions to classification accuracy. Furthermore, the color distribution along each feature axis highlights the impact of high and low feature values on the model's predictions, where red indicates higher feature values and blue represents lower values. This visualization demonstrates how specific features affect the decision boundaries of the model, reinforcing the interpretability of the proposed approach. Figure 7(b)–(d) and Figure 8 show the feature importance for each of the classes of the children's self-care problems. Each subgraph illustrates the impact of different features on the model's classifications for a specific class. It can be observed that Features 1, 186, 102, 116, 74, 99, 185, 55, 199, 97, 135, 104, 65, and 184 contribute more significantly to the classification of children's self-care problems across classes 1 to 7, respectively.

The average feature importance across all classes and the feature importance for classes 1-3. (a) Average feature importance across all classes. (b) The feature importance for class 1. (c) The feature importance for class 2. (d) The feature importance for class 3.

The feature importance for classes 4-7 (continued from fig. 7). (a) The feature importance for class 4. (b) The feature importance for class 5. (c) The feature importance for class 6. (d) The feature importance for class 7.
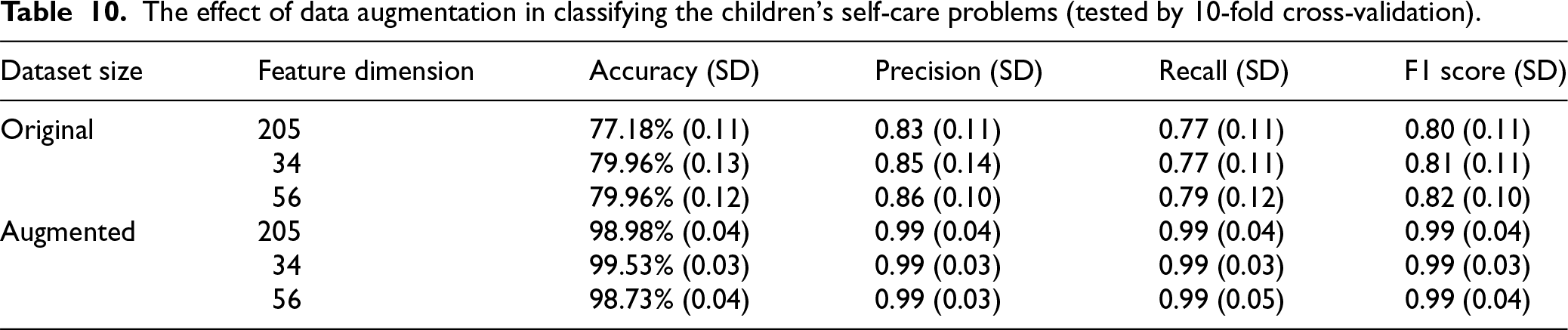
Lastly, the effect of data augmentation on the SCADI dataset in classifying the children's self-care problems is evaluated. From Table 4, it can be seen that, when the gender information, which is less relevant to the classification of the children's self-care problems, is excluded, the SCADI dataset can be doubled in size. Furthermore, Table 10 presents the effect of the data augmentation on the classification performance. It can be seen that clear and consistent performance improvements are achieved across all evaluation metrics (i.e., accuracy, precision, recall, and F1 score) after applying the augmentation method to the SCADI dataset. For example, without the feature compression procedure, the accuracy increases from 77.18% to 98.98%, the precision increases from 0.83 to 0.99, the recall increases from 0.77 to 0.99, and the F1 score rises from 0.80 to 0.99, in the original dataset to the augmented dataset, respectively. When the feature dimension is compressed to 34, the accuracy improves from 79.96% to 99.53%, the precision improves from 0.85 to 0.99, the recall improves from 0.77 to 0.99, and the F1 score improves from 0.81 to 0.99, respectively. When the feature dimension is compressed to 56, the accuracy improves from 79.96% to 98.73%, the precision improves from 0.86 to 0.99, the recall improves from 0.79 to 0.99, and the F1 score improves from 0.82 to 0.99, respectively. Besides, the standard deviations across all metrics are also significantly reduced after the dataset augmentation. That demonstrates the higher model stability and generalization capability. These results highlight that the proposed data augmentation strategy can effectively enrich the SCADI dataset size and enable more accurate and reliable classification of the children's self-care problems, regardless of the feature dimension. It is worth noting that, due to the fact that the class 3 contains only a single instance, it is not feasible to apply the triplet loss function in the original SCADI dataset. Therefore, we adopt an autoencoder network with the same structure as the first sub-neural network used in the proposed model to extract representative embeddings of the instances. These embeddings are then fed into the same second sub-neural network and trained with the focal loss function for a fair comparative experiment.
The effect of data augmentation in classifying the children's self-care problems (tested by 10-fold cross-validation).
To furthermore quantitatively verify the effects, which are contributed by the triplet loss (employed by the first sub-deep neural network) and the focal loss (used in the second sub-deep neural network), in improving the classification performance of the children's self-care problems, several trials that consider different dimensions of feature extraction are conducted. Figure 9 presents the improving effects contributed by triplet loss and focal loss, respectively.

The improving effect contributed by the triplet loss (used in the first sub-deep neural net- work) and focal loss (used in the second sub-deep neural network). MLP denotes the multi-layer perceptron with the same structure as the second sub-deep neural network. Triplet represents the performance obtained by the triplet loss used in the first sub-deep neural network. Focal denotes the performance achieved by the focal loss used in the second sub-deep neural network with the first sub-deep neural network (i.e., the entire proposed method). (a) The accuracy; (b) The precision; (c) The recall; (d) The F1 score.
It can be seen that both the triple loss and the focal loss can improve the classification performances of the children's self-care problems. Furthermore, based on the triplet loss which is employed to extract useful information from the feature, the focal loss is able to further improve the classification performance. As an illustration, we can observe that the triple loss improves the accuracy from 90.47% to 98.41%, the precision from 0.94 to 0.98, the recall from 0.85 to 0.98, the F1 score from 0.89 to 0.98, with compressing the feature to 34 dimensions, respectively. Additionally, the focal loss can further improve the accuracy from 98.41% to 100.00%, the precision from 0.98 to 1, the recall from 0.98 to 1, and the F1 score from 0.98 to 1, respectively. By contrast, when we compress the feature dimension to 56, we find the triple loss also can improve the accuracy, precision, recall, and F1 score from 90.47% to 98.41%, from 0.94 to 0.98, from 0.85 to 0.98, and from 0.89 to 0.98, respectively. Besides, the focal loss is capable of further improving the accuracy, precision, recall, and F1 score to 100%, 1, 1, and 1, respectively. It can be seen that the triplet loss and the focal loss can improve the classification performances (evaluated by accuracy, precision, recall, and F1 score) of the children's self-care problems about 10% totally, when the feature has been compressed to 34 and 56 dimensions. Furthermore, to comprehensively investigate the improving abilities of triplet loss and focal loss on the classification performances of the children's self-care problems, we conduct more experimental trials from 20 to 205 feature dimensions. It can be found that the triplet loss is able to at most improve 9.53% accuracy (from 90.47% to 100.00% with feature compressed to 80 dimensions), 0.06 precision (from 0.94 to 1 with feature compressed to 80 and 100 dimensions), 0.15 recall (from 0.85 to 1 with feature compressed to 80 dimensions), 0.11 F1 score (from 0.89 to 1 with feature compressed to 80 dimensions). Moreover, based on the triplet loss, the focal loss is capable of further improving at most 3.17% accuracy (from 96.83% to 100.00% with feature compressed to 20, 30, 90, 125, and 175 dimensions), 0.03 precision (from 0.97 to 1 with feature compressed to 90, 125, and 175 dimensions), 0.03 recall (from 0.97 to 1 with feature compressed to 20, 125, and 175 dimensions), 0.03 F1 score (from 0.97 to 1 with feature compressed to 125 and 175 dimensions). At worst, the focal loss may not further improve the classification performances. When we compress the feature to 80 dimensions, it can be seen that the focal loss cannot further improve the accuracy, precision, recall, and F1 score. The improvements in accuracy, precision, recall, and F1 score contributed by the focal loss are all 0, whereas relying solely on the triplet loss has resulted in improvements in all metrics to 1. When we compress the feature to 70 dimensions, we can observe that the focal loss only improves 1.59% accuracy (from 98.41% to 100.00%), 0.02 precision (from 0.98 to 1), but decreases the recall by 0.01 (from 0.98 to 0.97). However, in the whole range of the dimension of feature extraction, the effects of improving the classification performances of the triplet loss and focal loss are prominent. The averages of accuracy, precision, recall, and F1 score achieved by the triplet loss are improved from 90.47%, 0.94, 0.85, and 0.89 to 97.77%, 0.98, 0.97, and 0.97, respectively. Additionally, based on the improving effect of the triplet loss, the focal loss improves the averages of accuracy, precision, recall, and F1 score to 99.78%, 0.99, 0.99, and 0.99, respectively. Therefore, we can observe that the triplet loss technology is able to improve 7.30% accuracy, 0.04 precision, 0.12 recall, and 0.08 F1 score. The focal loss technology is capable of improving 2.01% accuracy, 0.01 precision, 0.02 recall, and 0.02 F1 score, respectively. According to the above analysis, we can conclude that the triplet loss and the focal loss can contribute to improving the classification performances of the children's self-care problems.
In a nutshell, the numerical tests verify the following: The triplet loss improves accuracy by 7.30%, precision by 0.04, recall by 0.12, and F1 score by 0.08, while the focal loss improves accuracy by 2.01%, precision by 0.01, recall by 0.02, and F1 score by 0.02. Together, these two sub-networks complement each other and lead to the state-of-the-art performance. The first sub-deep neural network, equipped with the triplet loss, contributes by learning discriminative feature embeddings through dimensionality compression, key information extraction, and noise reduction, thereby enhancing intra-class compactness and inter-class separability. The second sub-deep neural network, equipped with the focal loss, addresses the class imbalance problem by down-weighting easy samples and emphasizing hard and minority-class samples, which further boosts the classification performance.
This study proposes a novel neural network that integrates the representation learning and the focal loss technique to accurately classify the children's self-care problems. The numerical tests validate its state-of-the-art classification performances that achieve average accuracy, precision, recall, and F1 score of 99.78%, 0.99, 0.99, and 0.99, respectively.
Compared with previous studies, the superior performance of the proposed method could be attributed to two factors i.e., the two sub-deep neural networks with the triple loss and focal loss technologies, as well as the augmentation method.
The first contributing factor is the utilization of the triplet loss and focal loss technologies. Fundamentally, triplet loss, which is used in the first sub-neural network, is a representation learning technique. Its objective is not merely to reduce dimensionality but to learn a meaningful and highly discriminative embedding space. The principle lies in learning feature embeddings based on the relative similarity of data instances. For each training sample (the “anchor”), the model considers a “positive” sample (from the same class) and a “negative” sample (from a different class). This process compels the model to discern and learn the most critical underlying features for distinguishing between different classes of children's self-care problems, rather than focusing on superficial or irrelevant features. In complex diagnostic tasks such as classifying children's self-care problems, the initial high-dimensional feature space is often contaminated with irrelevant or redundant features (i.e., “noise”). Such noise can mislead a standard classifier, causing it to learn spurious correlations and thereby degrading its generalization performance. Triplet loss inherently facilitates noise reduction through its learning paradigm. The second sub-neural network, which utilizes the focal loss function, can deal with the class imbalance problem to further improve the classification performance. The ablation experiment verifies that the improvement in classification performance can be attributed to the triplet loss and focal loss. The second contributing factor is the augmentation method of the SCADI dataset.
To the best of our knowledge, this is the first application of the data augmentation method on the SCADI dataset for studying the classification of children's self-care problems. We also conduct the corresponding experiment to verify the effect of data augmentation on the classification performance.
Besides, the proposed method can be easily transferred or applied to other datasets in related fields to deal with the classification problem. We have already conducted the classification experiments on two additional external datasets (i.e., the breast cancer dataset and the nursery dataset) to validate the performance of the proposed method. The experiments provide valuable insights into the model's generalizability, accuracy, and the inherent characteristics of the datasets themselves. First, the high performance on the large nursery dataset (12,960 instances) strongly indicates that our model architecture is robust and generalizes well to new data. Achieving nearly 99% accuracy on a completely different domain task confirms that the model does not simply overfit to the specific characteristics of the SCADI dataset. The core architecture, which combines triplet loss for discriminative feature learning and focal loss for classification, proves to be effective across different problem spaces. Second, the 82.79% accuracy on the breast cancer dataset suggests it is an intrinsically more challenging problem. This can be attributed to the small sample size. This dataset is relatively small, containing only 286 instances. Deep learning models are data-intensive, and with limited samples, it is significantly more challenging to learn complex, non-linear decision boundaries without overfitting. While 82.79% is numerically lower than the results on the other datasets, our method still outperforms other established machine learning models (such as Xgboost, SVM, RF, etc.) and achieves the state-of-the-art result. This insight is critical. It demonstrates that even when faced with a more challenging, smaller dataset, our proposed method is powerful enough to push the performance boundary and excel relative to other baselines.
Additionally, the experimental environment includes Python 3.6 with TensorFlow 2.0, an AMD Ryzen 7 5800H, an Nvidia GeForce RTX 3060 GPU, and 16GB DDR4 RAM. Given that software like Python 3.6 and TensorFlow are free, the primary costs are associated with the CPU, GPU, and memory. Based on current market prices, the estimated cost of the hardware components for the experimental environment ranges from approximately $1360 to $2150 USD, depending on the specific laptop model and configuration. If the user already owns a desktop computer and is only considering a GPU upgrade, the cost would be approximately $350 to $450 USD. Cloud computing services from providers like Amazon and Google can also be considered to further reduce costs.
Limitation
Despite the promising performance of the proposed model, there are still several limitations that need to be addressed.
First, the performance of deep learning models is highly dependent on the size and quality of the dataset. In this study, the SCADI dataset is relatively small and potentially suffers from class imbalance and data bias. In particular, the limited demographic diversity, such as underrepresentation of certain age groups, genders, and socio-cultural backgrounds, may introduce potential biases and restrict the model's ability to generalize across broader populations. This raises concerns about the equity, especially in healthcare-related applications where biased decisions could have critical consequences.
Although the corresponding data augmentation method is applied to mitigate these issues, generating diverse and realistic instances for tabular data remains a challenging task compared with image or text domains. In essence, the most effective solution is to collect more comprehensive and demographically balanced data. Expanding the dataset to include a wider range of representative samples can significantly improve the model's generalization ability and reduce bias. In future work, we also plan to explore the use of generative models to enrich tabular datasets in a more robust way.
Second, like many deep learning-based methods, the proposed model functions as a black box. That limits its interpretability. Understanding the mechanism of why the model makes certain classifications is crucial in healthcare-related applications. Incorporating explainable AI techniques to interpret the learned embeddings and classification outcomes would be a valuable direction for future research.
Conclusion
An accurate classification of children's self-care problems has important implications for the corresponding subsequent treatment. In this study, we propose a novel deep learning-based model to precisely classify the children's self-care problems. The proposed model includes two sub-deep neural networks. The first sub-deep neural network employs the triplet loss to extract key information from the feature, considering the correlation between the different instances. Then, the embedding is used by the second sub-deep neural network to classify the children's self-care problems. Meanwhile, considering the imbalance problem, the focal loss is used to further improve the classification performance. The numerical tests show that the proposed model achieves the state-of-the-art classification performance of the children's self-care problems. In all ranges of the dimension, the averages of accuracy, precision, recall, and F1 score are 99.78%, 0.99, 0.99, and 0.99, respectively. Besides, according to the ablation experiment, the triplet loss technology is able to improve 7.30% accuracy, 0.04 precision, 0.12 recall, and 0.08 F1 score. The focal loss technology is capable of improving 2.01% accuracy, 0.01 precision, 0.02 recall, and 0.02 F1 score, respectively. In future work, we plan to further investigate the application of the proposed model on larger and more diverse datasets, including different age groups and cultural backgrounds. Additionally, we aim to integrate temporal data to explore the evolution of self-care abilities over time, which could potentially support early intervention strategies. Finally, incorporating expert knowledge and clinical guidelines into the model design could further enhance its interpretability and applicability in pediatric rehabilitation.
Footnotes
Acknowledgements
The authors would like to thank the editor and the anonymous reviewers for their valuable comments and constructive suggestions, which have greatly improved the quality of this article.
Ethical approval
This study did not involve direct experimentation with human or animal subjects. All data used were obtained from public datasets or previously published studies. Therefore, ethical approval was not required.
Author contributions
Yang Yu and Jieqiong Liu conceived and designed the study. Yang Yu implemented the algorithm. Yijia Tang, Xiaoyan Zhang, and Tingyu Zhang performed the validation. The manuscript was drafted by Yang Yu, and all authors contributed to reviewing, editing, and final approval. Jieqiong Liu supervised the project.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Shanghai Pujiang Program, (grant number 22PJC074) and the General Project of the Education Department of Zhejiang Province, (grant number Y202352869).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Copyright and originality
The authors declare that this manuscript is original, has not been published previously, and is not under consideration for publication elsewhere. All authors have read and approved the final version of the manuscript.