
Abstract
Bearings are critical components in rotating machinery and their failure can lead to catastrophic outcomes, including system downtime and financial losses. Accurate fault detection and prediction in bearings can significantly improve the reliability and efficiency of industrial systems. The reliable operation of rotating machinery is critically dependent on early and accurate detection of bearing faults. This research presents an intelligent fault classification and prediction framework utilizing Support Vector Machine (SVM) and Multinomial Logistic Regression (MLR) models applied to vibration signal data. The dataset consists of multiple fault categories including inner race, outer race, and ball defects under various severity levels. After preprocessing and feature extraction, both SVM and MLR models were trained and evaluated using a confusion matrix, precision, recall, and F1-score metrics. The SVM model demonstrated superior classification performance, particularly in accurately detecting complex fault patterns, achieving an overall accuracy of 96%, compared to 94% with logistic regression. Comparative analysis highlights the strengths of SVM in handling non-linear decision boundaries, while logistic regression offers simpler interpretability and faster training times. The results show that SVM provides high accuracy in detecting and classifying different types of bearing faults, making it a suitable method for real-time condition monitoring applications.
Keywords
Introduction
Bearings are the one who shouldered the entire load in rotating machinery and are considered as a very critical component of the machine, supporting mechanical motion and ensuring smooth operation under varying load conditions. The failure of bearings can lead to severe machine breakdowns, unplanned downtime, and costly repairs, making early fault detection and accurate prediction vital for ensuring system reliability and safety. Traditional machine condition monitoring wherein fault detection is carried out by techniques such as vibration analysis, acoustic emission, and thermography, rely heavily on manual inspection and expert interpretation, which can be time-consuming and prone to human error.
With the rapid development of Industry 4.0 and the increasing adoption of smart maintenance strategies, machine learning (ML) has emerged as a powerful tool for automated bearing fault diagnosis. ML models can learn patterns from historical sensor data—such as vibration signals—and classify or predict fault types with high accuracy. These data-driven approaches offer significant advantages, including real-time monitoring, adaptability to complex systems, and improved diagnostic precision.
Among various ML techniques, Support Vector Machines (SVM) have demonstrated excellent performance in classification tasks, particularly in cases involving high-dimensional data and limited samples. SVM’s ability to construct optimal hyperplanes makes it a robust choice for identifying the presence and severity of bearing faults from vibration signals and other condition-monitoring data.
This paper presents a comprehensive approach for bearing fault detection and prediction using machine learning algorithms, with a specific focus on SVM. Vibration datasets are processed for feature extraction, followed by classification using SVM and other comparative models. The study evaluates model performance in terms of accuracy, precision, recall, and computational efficiency etc. The study also includes performance comparison of SVM with Logistic Regression model. The results indicate that the proposed SVM-based model achieves high accuracy in classifying different bearing conditions, making it suitable for real-time predictive maintenance applications.
Literature review
Rolling element bearings are integral components in rotating machinery, and their failures often lead to catastrophic damage and costly downtime. Consequently, the early detection and classification of bearing faults have become a significant area of research in condition monitoring and predictive maintenance. Over the years, a variety of data-driven techniques have been explored to enhance the accuracy and reliability of bearing fault diagnosis.
Initial works in bearing fault detection relied on time-domain and frequency-domain analyses. Techniques such as Fast Fourier Transform (FFT), envelope analysis, and wavelet transform were widely used for feature extraction from vibration signals. 1 However, these approaches often struggled with noise sensitivity and required expert-driven feature engineering.
The emergence of machine learning (ML) introduced powerful tools for automatic fault classification. Among them, Support Vector Machines (SVMs) have been extensively applied due to their robustness in high-dimensional spaces and effectiveness with limited datasets. 2 Widodo and Yang (2007) successfully used SVM for machine fault classification, demonstrating high diagnostic accuracy even with overlapping features. 3 SVM’s ability to construct non-linear decision boundaries using kernel functions makes it particularly suitable for complex industrial datasets. While not as powerful in handling non-linear separable data, Multinomial Logistic Regression (MLR) remains a baseline model due to its simplicity, interpretability, and computational efficiency. MLR has been applied in fault diagnosis scenarios, especially where the focus is on gaining insight into the importance of each feature. 4 Its multi-class capability through a one-vs-rest or multinomial approach makes it a useful comparative model. Comparative studies, such as that by Rai and Upadhyay (2016), have evaluated the performance of SVM, LR, Decision Trees, and k-NN on bearing datasets. These studies typically find that SVM outperforms others in accuracy, particularly in noisy or complex datasets. 5 Meanwhile, hybrid models combining feature selection techniques like Principal Component Analysis (PCA) or signal decomposition (e.g., Empirical Mode Decomposition) with classifiers like SVM have shown promising results. 6 The Case Western Reserve University (CWRU) bearing dataset has become a standard benchmark for evaluating fault classification models. 7 Evaluation metrics such as accuracy, precision, recall, F1-score, and confusion matrices are commonly employed for performance comparison. Recent studies emphasize the need for balanced datasets and cross-validation to avoid overfitting and to ensure the generalizability of models.
In recent years, hybrid machine learning models have emerged as an effective solution for bearing fault diagnosis by integrating signal processing, feature selection, and intelligent classifiers into a unified framework. Hybrid approaches aim to overcome the individual limitations of single algorithms by combining complementary techniques to enhance diagnostic accuracy, robustness, and generalization capability. 6
Several studies have demonstrated that coupling advanced signal decomposition techniques with machine learning classifiers significantly improves fault classification performance. Methods such as empirical mode decomposition (EMD), variational mode decomposition (VMD), and wavelet transform (WT) are widely used to extract fault-sensitive features from non-stationary vibration signals. These features are often further optimized using dimensionality reduction techniques such as principal component analysis (PCA), linear discriminant analysis (LDA), or recursive feature elimination (RFE) before classification. The combination of signal processing, feature optimization, and classification forms the core of hybrid diagnostic frameworks. 8
Hybrid SVM-based models are among the most extensively investigated approaches. For example, VMD–SVM and PCA–SVM frameworks have been reported to significantly enhance classification accuracy by suppressing noise and retaining only dominant fault features. These models demonstrate superior performance compared to standalone SVM classifiers, particularly under variable speed and load conditions. Similarly, hybrid deep-learning-assisted models that integrate convolutional neural networks (CNNs) with traditional classifiers (e.g., CNN–SVM) have shown improved feature representation capability while maintaining the classification strength of SVM. 9
Logistic regression has also been incorporated within hybrid diagnostic structures, primarily as an interpretable classifier following optimized feature extraction. Hybrid models combining time–frequency analysis with multinomial logistic regression have shown promising results for multi-class bearing fault identification, especially when interpretability and computational efficiency are prioritized. 10
Despite these advances, most existing hybrid fault diagnosis studies either focus exclusively on deep learning–based hybrids or advanced signal-processing-driven hybrids. Comparatively fewer works conduct a structured performance benchmarking between hybrid models and classical machine learning classifiers such as SVM and multinomial logistic regression under identical preprocessing and evaluation frameworks. Moreover, limited attention has been given to evaluating the trade-off between classification accuracy, computational complexity, and model explainability within hybrid bearing fault diagnosis systems.11–13
Therefore, the present study positions itself as a foundational step toward future hybrid model development by first establishing a reliable comparative baseline between SVM and MLR using standardized preprocessing and uniform evaluation metrics. The insights gained from this comparison directly support the future integration of feature optimization and hybrid learning strategies for real-world bearing health monitoring applications.
In summary, while logistic regression offers a simple and interpretable baseline, SVM stands out in handling the complexities of bearing fault classification, especially in multi-class and non-linear domains. The comparative study in this paper builds on this foundation by evaluating both models on a real-world vibration dataset, offering insights into their relative strengths for predictive maintenance applications.
Literature gap
Despite the significant progress in bearing fault diagnosis using machine learning and signal processing methods, several key research gaps are discussed herewith. While many studies focus on a single model (e.g., SVM or Logistic Regression), few offer a detailed and fair comparison between classifiers using standardized evaluation metrics (accuracy, precision, recall, F1-score, confusion matrix) on benchmark datasets under the same conditions. Most literature emphasizes SVM, Random Forests, and Deep Learning models, whereas multinomial logistic regression is often overlooked or considered as a weak baseline. Its potential interpretability and performance in multi-class bearing fault scenarios remain underexplored. Existing work often emphasizes technical accuracy, without translating model performance into actionable insights for predictive maintenance. There is a lack of research that correlates classification accuracy with practical implications for machinery health monitoring systems. Deep learning and black-box models provide high accuracy but poor interpretability. SVM and MLR offer a trade-off between performance and explainability, which is underexplored in current literature regarding its utility in industrial decision-making.
Scope of the research
This research is aimed at bridging the above gaps through comparative analysis of Support Vector Machine and Multinomial Logistic Regression on a standard vibration-based bearing dataset (e.g., CWRU). Uniform preprocessing, feature extraction, and evaluation metrics are used to ensure fairness in comparison. Focus is given on multi-class classification covering various bearing fault types (inner race, outer race, ball defect) and severities using confusion matrix analysis. Detailed insights are provided to make a model more suitable for deployment in real-time condition monitoring systems considering both accuracy and interpretability. The study also serves as the foundation for further development of hybrid models (e.g., feature selection + SVM, or ensemble of interpretable models) tailored for industrial condition monitoring applications.
Machine learning approach in bearing fault detection
Bearing fault detection using machine learning (ML) is a powerful alternative to traditional signal processing methods. ML can automatically learn patterns in vibration data and classify different types of faults with high accuracy. The key steps in Machine Learning-Based Bearing Fault Detection are data acquisition, preprocessing, feature extraction, model selection, model training and testing, model deployment etc. Inspite of having so many advantages of machine learning, there are some challenges of using it also. Such as it requires labeled data for supervised learning, sensitive to noise and sensor placement and it may need retraining for new machines or operating conditions.
Data collection
For this study, bearing fault data was obtained from the Case Western Reserve University (CWRU) Bearing Data Center, which provides one of the most widely used and publicly available datasets for bearing condition monitoring and fault diagnosis research. The CWRU dataset was generated using an experimental setup at the university’s bearing test facility. The test rig consists of a 2-horsepower (hp) motor, a torque transducer/encoder, and a dynamometer. Ball bearings (SKF 6203) were installed on the motor shaft, and artificial faults were introduced using electrical discharge machining (EDM). The faults were induced on three key components of the bearings which are Inner race, Outer race, Rolling element (ball). Each of these faults was created with varying fault diameters (e.g., 0.007, 0.014, and 0.021 inches) to simulate different severity levels. The test conditions also varied in terms of motor load (0 to 3 hp) and rotational speed (e.g., 1797, 1772, 1750, and 1730 RPM), providing a diverse and rich dataset for analysis. The sensor used in the data acquisition was accelerometers which were mounted on the bearing housing in both horizontal and vertical directions. Time series segments contain 2048 points each with the sampling frequency being 48 kHz for a time period of 0.04 seconds. The dataset includes time-domain vibration signals under both healthy and faulty conditions. Data is stored in. csv files and also available as. txt for compatibility with various analysis tools. Each file in the dataset is named to reflect fault location (e.g., IR for inner race, OR for outer race, B for ball), fault severity (in inches), load condition (e.g., 0 hp, 1 hp), sensor location (drive end or fan end). This structured naming convention helps in easy extraction and labelling of data for machine learning applications. The CWRU bearing dataset is widely accepted in academia and industry because it provides controlled experimental conditions, contains real vibration responses from mechanical components, includes multiple fault types and severities, offers high-quality, repeatable data for benchmarking machine learning models.
Feature extraction
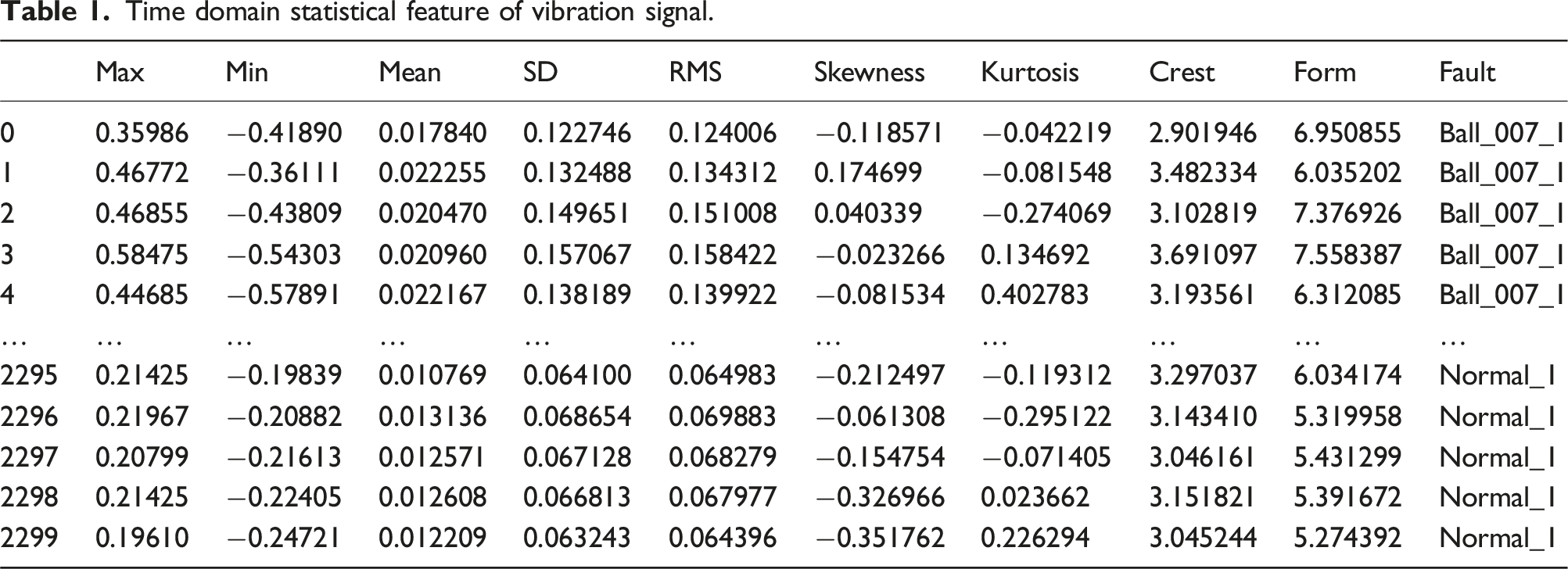
Feature extraction is a critical step in the machine learning pipeline for bearing fault detection. Raw vibration signals captured from sensors are typically high-dimensional and noisy. Directly feeding these raw signals into a machine learning model may lead to poor performance and generalization. Therefore, meaningful features must be extracted to capture the characteristics of various bearing conditions such as normal, inner race fault, outer race fault, and ball defect. In this study, features are extracted from the time domain using statistical and signal processing techniques. These features help in distinguishing different fault types and severity levels. Time-domain features are directly computed from the raw vibration signal. These are statistical descriptors that provide insight into the amplitude, variability, and shape of the signal. The time domain statistical features are max (μ\muμ, maximum of the signal values), min (μ\muμ, minimum of the signal values), Mean (μ\muμ, average of the signal values), Standard Deviation (σ, indicates the dispersion of the signal), Root Mean Square (RMS) (measures signal energy and is sensitive to changes in amplitude), Skewness (measures the asymmetry of the signal distribution), Kurtosis (Measures the “peakedness” of the signal and is sensitive to impulses), Crest Factor (ratio of peak value to RMS which is used to detect impulsive faults), form factor. These features are effective in detecting sudden changes and abnormalities in vibration patterns caused by bearing defects.
Time domain statistical feature of vibration signal.
Data standardization
Descriptive statistics of scaled test data.

Model selection
Model selection is a crucial step in the development of an effective machine learning pipeline for bearing fault detection. It involves evaluating various classifiers and selecting the one that provides the best balance between classification accuracy, robustness, generalization, and computational efficiency. In this study, the Support Vector Machine (SVM) is considered due to its proven effectiveness in fault diagnosis applications, highest classification accuracy across fault categories, and robust to overfitting. Also, it is well-suited for high-dimensional and small-sample environments, which is typical in bearing fault datasets and offers good generalization to unseen data, making it ideal for predictive maintenance scenarios. Hence Support Vector Machine (SVM) is used to train and test for bearing fault classification and prediction. To train and evaluate the machine learning model effectively, the preprocessed dataset (data_time) was divided into training and testing subsets. The split was carried out using the train_test_split function from the Scikit-learn library. A fixed number of 750 samples were allocated to the test set to ensure a consistent evaluation framework, while the remaining data was used for training the model. Stratified sampling was employed based on the target label (fault) to ensure that each fault category was proportionally represented in both the training and testing subsets. This approach helps prevent any imbalance in class distribution, which is critical for maintaining classifier fairness and reliability. Furthermore, a fixed random state (random_state = 1234) was used to ensure reproducibility of the split in all experiments. The dataset was split into 70% for training and 30% for testing. Cross-validation was used for hyperparameter tuning (C, gamma) using GridSearchCV. Data standardization was performed using StandardScaler.
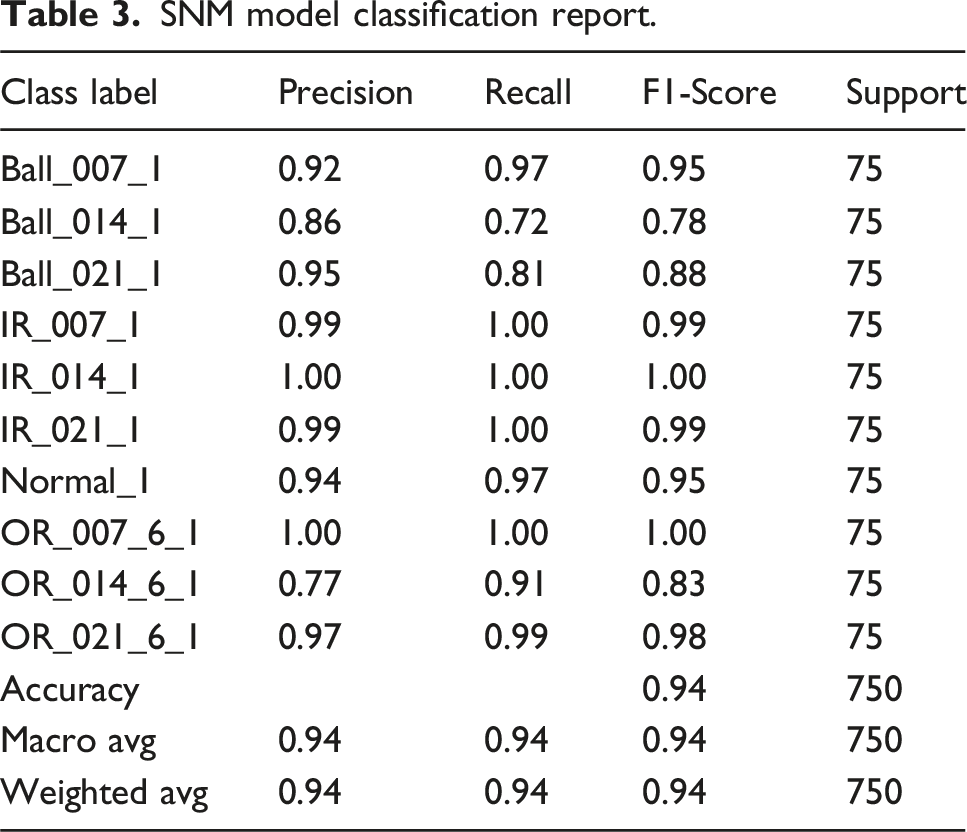
The Figure 1 shows two confusion matrices for training and testing datasets for SVM-based bearing fault classification. It compares the predicted and true fault types for the bearing dataset, using a Support Vector Machine (SVM) model. The left matrix is for the training dataset, and the right matrix is for the testing dataset. In the training confusion matrix, the diagonal elements represent correct predictions, which are predominantly high, indicating that the SVM model performs very well on the training data. Minor misclassifications are visible in classes like ‘Ball_014_1’, ‘Ball_021_1’, and ‘OR_021_6_1’, with a few samples misclassified into other categories. Overall, the training matrix shows very high classification accuracy with minimal confusion. The test confusion matrix helps evaluate the generalization of the model. Most fault classes have high correct classification rates, especially ‘Ball_007_1’, ‘IR_007_1’, and ‘Normal_1’, showing robustness of the model. Misclassifications are more visible in the testing phase, for example, ‘Ball_014_1’ has some samples misclassified as ‘Ball_021_1’ and ‘OR_014_6_1’. Similarly, ‘Ball_021_1’ and ‘OR_021_6_1’ have minor confusions. These off-diagonal values indicate where the model could be further improved. Classification Metrics with Precision, Recall, F1-Score is shown in Table 3. The classification report shows high values for all metrics (e.g., precision = 0.92, recall = 0.97 for ‘Ball_007_1’), confirming effective performance. This balance of precision and recall demonstrates that the model is not biased toward any specific class and performs well overall. Confusion matrices for training (left) and testing (right) datasets for SVM-based bearing fault classification. SNM model classification report.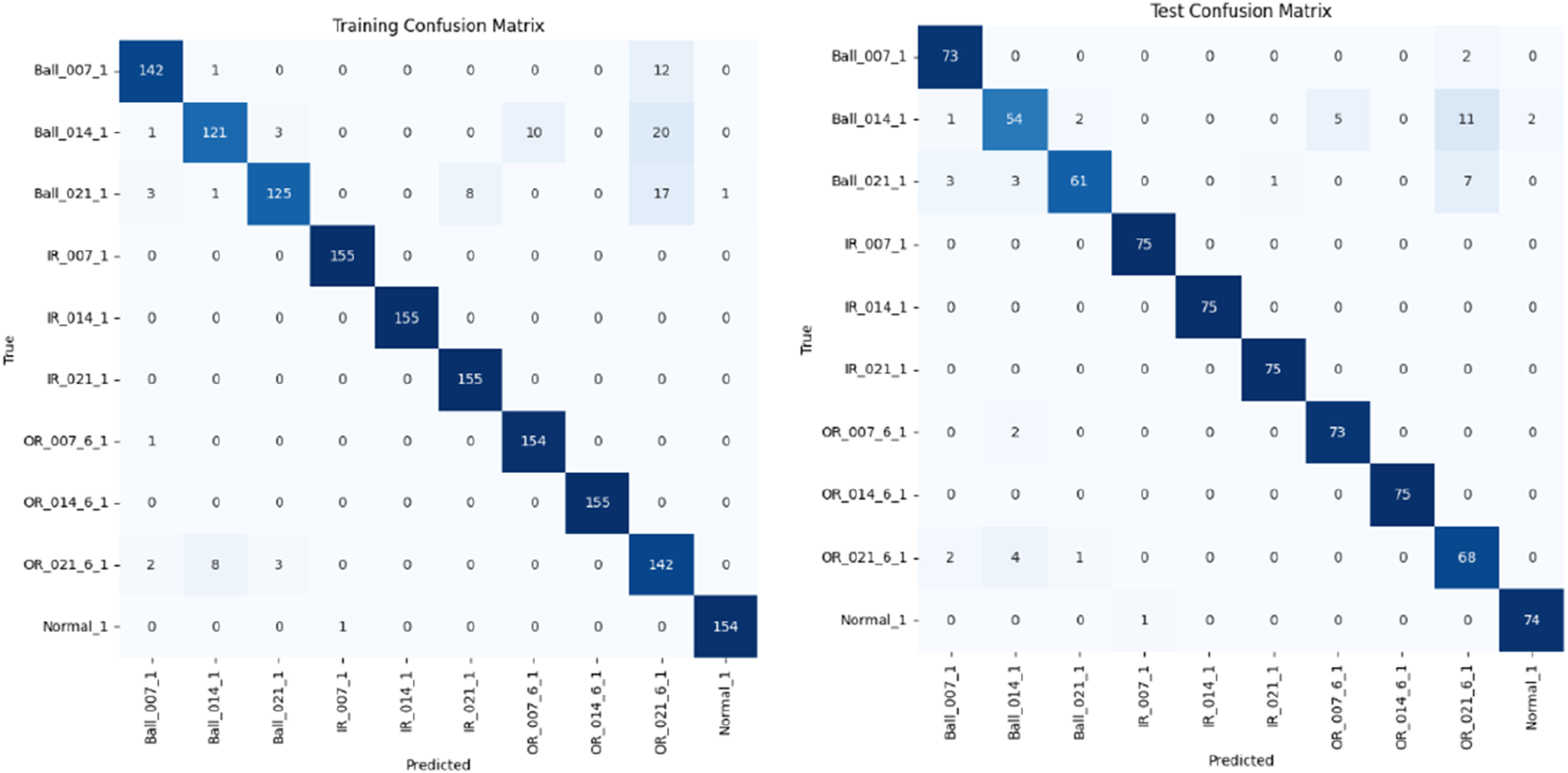
Tuning hyperparameters for model optimization
Tuning hyperparameters is a critical step in model optimization because hyperparameters significantly affect the performance, accuracy, and generalization ability of a machine learning model. Default hyperparameters may not yield the best accuracy. Tuning helps find optimal settings to increase performance metrics (accuracy, precision, recall, F1-score, etc.). Proper tuning helps balance model complexity. For example, too high regularization may underfit, and too low may overfit. The right hyperparameters ensure that the model performs well not only on training data but also on unseen (test) data. Parameters like learning rate, batch size, and number of epochs directly influence convergence speed and stability. Many ML algorithms (like SVM, Random Forest, etc.) have powerful capabilities only when the right combination of hyperparameters is used. The tuned SVM model for training and testing is shown in Figure 2. The training Confusion Matrix (Best Model) shows clear improvement in accuracy across all classes. Ball_014_1 defect improves from 121 to 147 correctly predicted samples. Whereas in Test Confusion Matrix (Best Model), drastic accuracy improvement is seen. Ball_014_1 defect is predicted correctly by 66 as against 54 in the untuned model. OR_021_6_1 defect still has some confusion with ball classes but reduced. Overall, model generalization to unseen data has improved and misclassifications reduced significantly for most classes. Confusion matrices for training (left) and testing (right) datasets for tuned SVM model.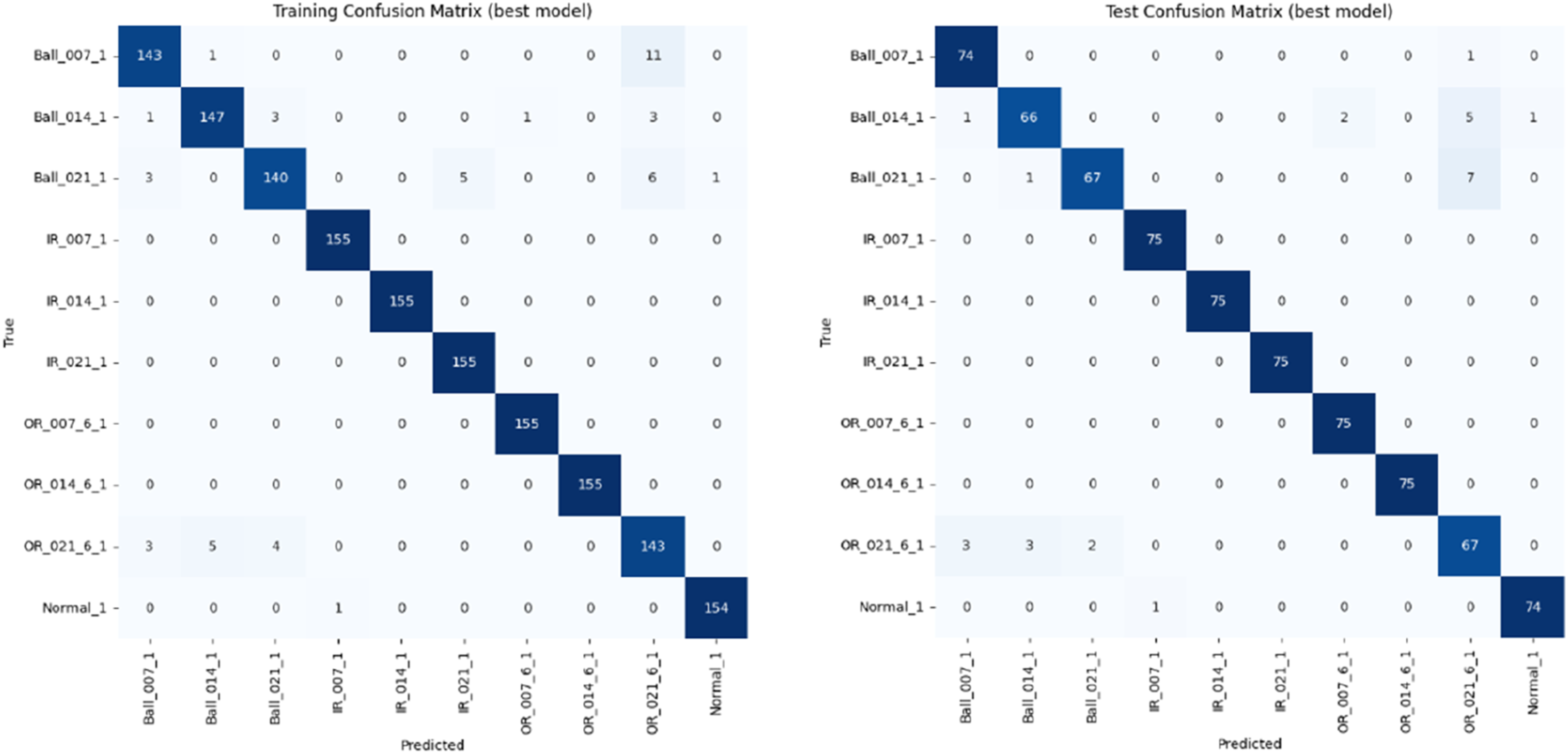
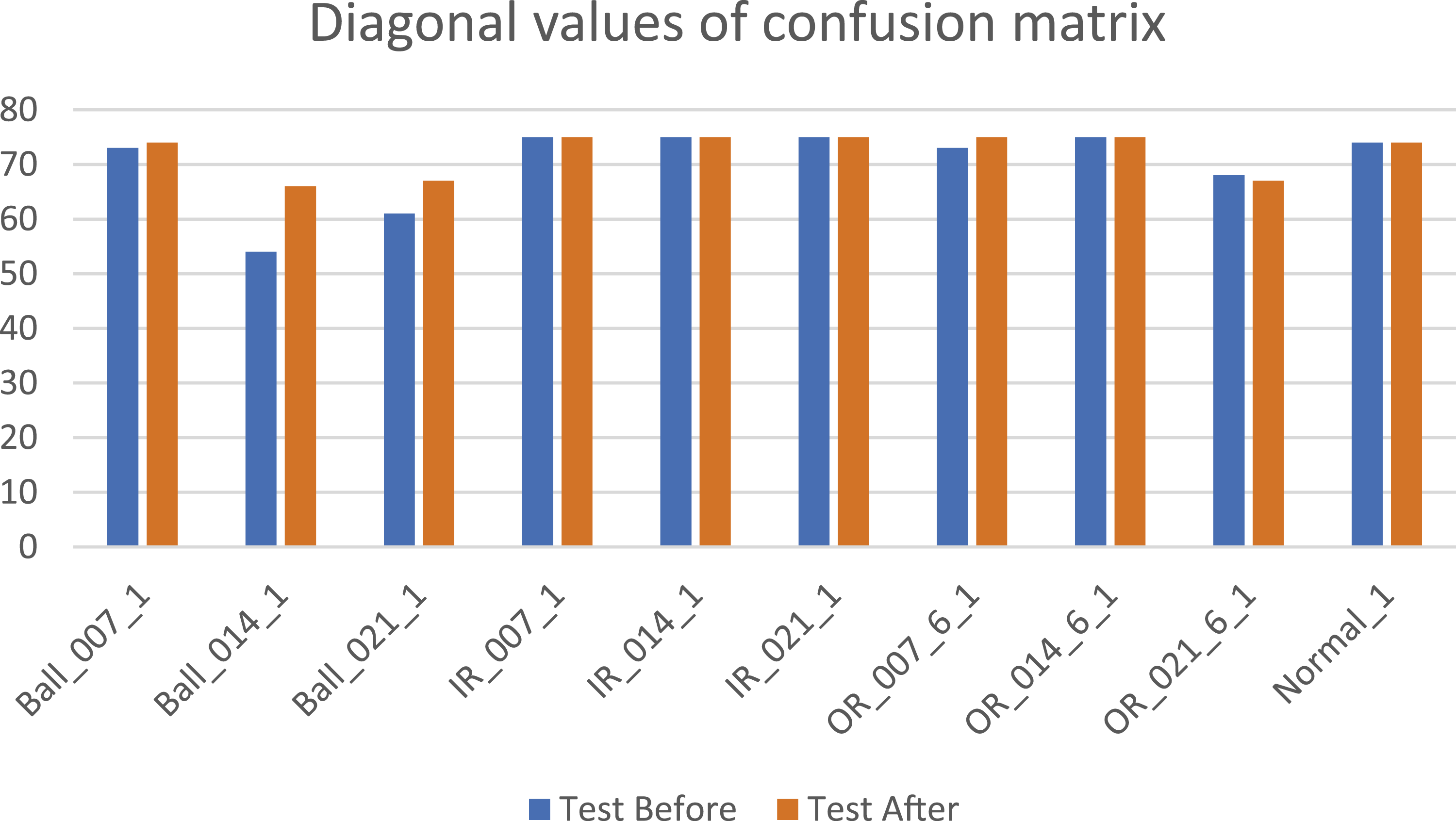
Diagonal values of the confusion matrix indicate the accuracy of the model hence they are compared to determine the increase in accuracy of the model after hypertuning. Figure 3 shows the comparison of diagonal values of train confusion matrices before and after hypertuning SVM models whereas Figure 4 shows comparison of diagonal values of test confusion matrices before and after hypertuning SVM models. Both the comparisons indicate that the accuracy of the SVM model has increased significantly. Comparison of diagonal values of train confusion matrices before and after hypertuning SVM models. Comparison of diagonal values of test confusion matrices before and after hypertuning SVM models.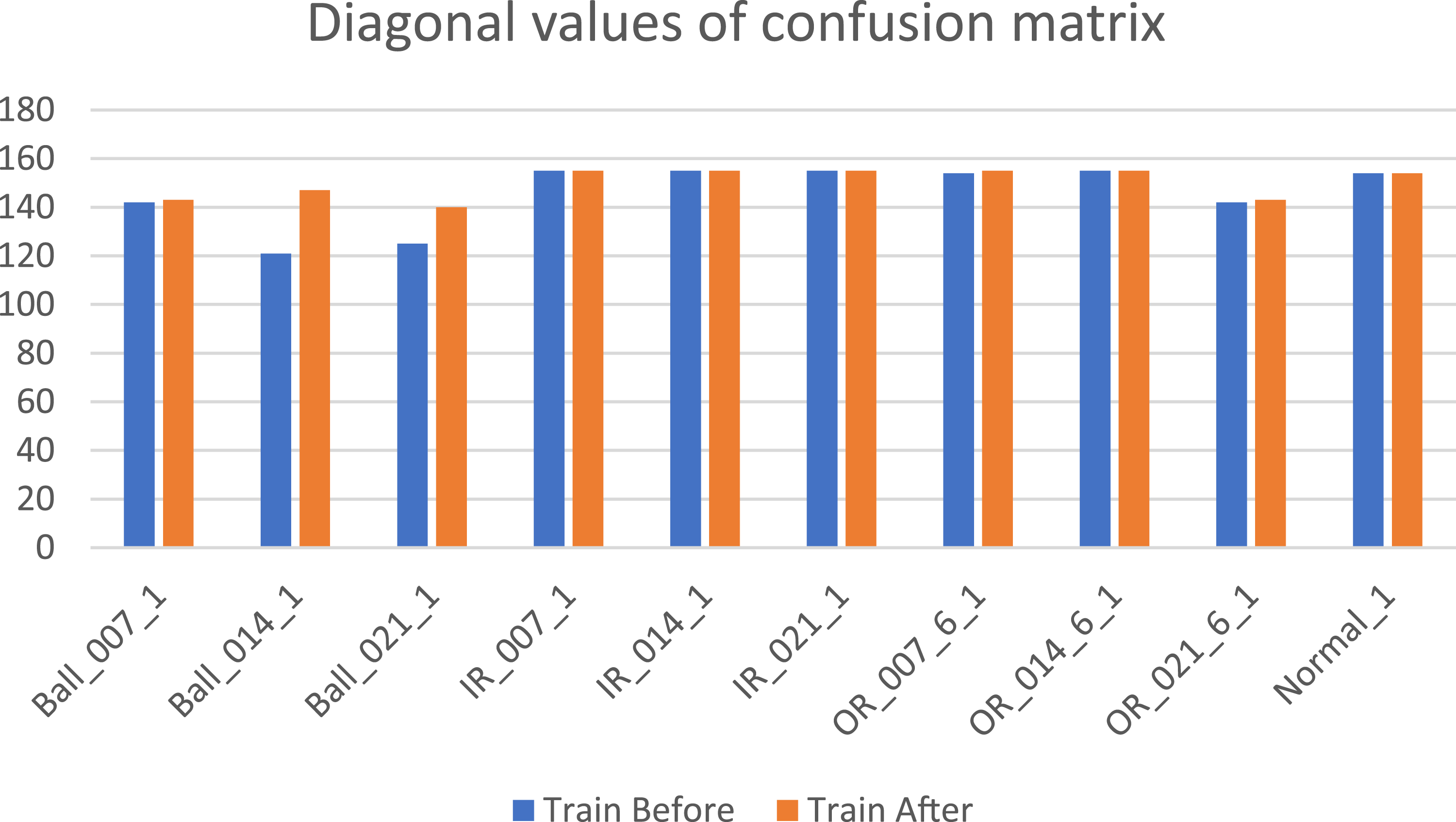
Comparison between SVM and multinomial logistic regression (MLR)
Different algorithms perform better on different datasets. Comparing two algorithms helps to determine which is more suitable based on the basis of Accuracy, Precision, Recall, F1-score, Training/Prediction time etc. So to get the confidence in model selection, comparing two models is a common and valuable practice in machine learning, especially for classification tasks. Here, SVM model is compared with a Multinomial Logistic Regression (MLR) model. MLR is a probabilistic linear classifier which assumes a linear relationship between input features and log-odds of class membership. So, if the dataset has complex class boundaries, SVM might outperform MLR. If the classes are more linearly separable, MLR might suffice and be faster.
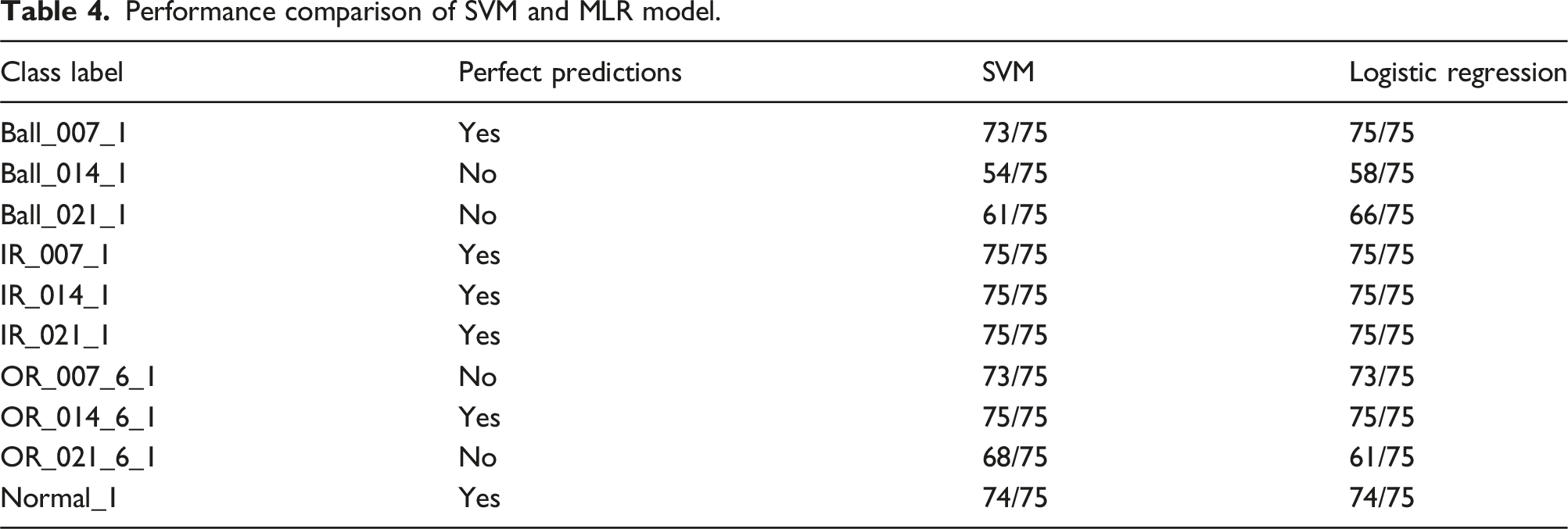
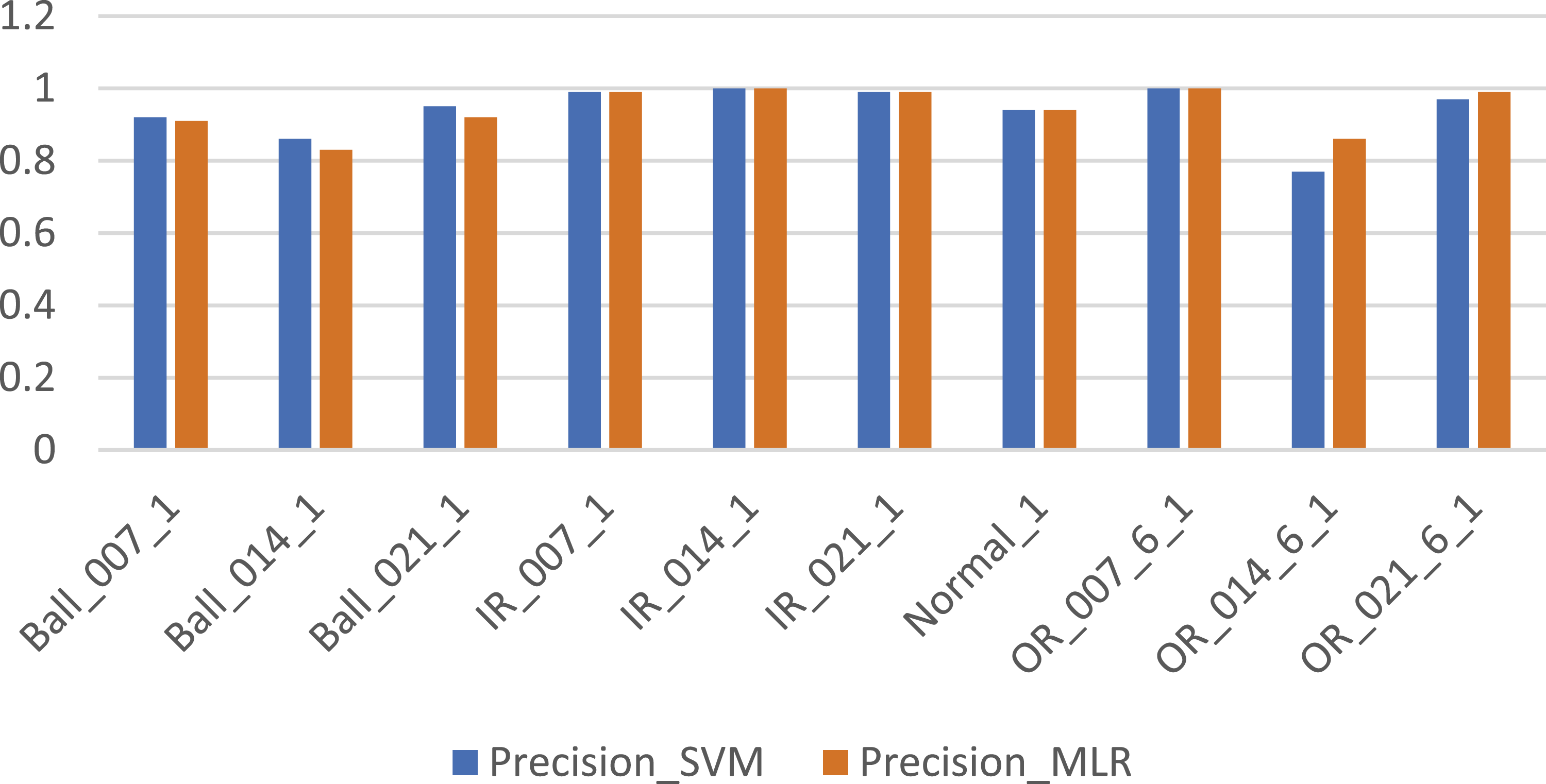
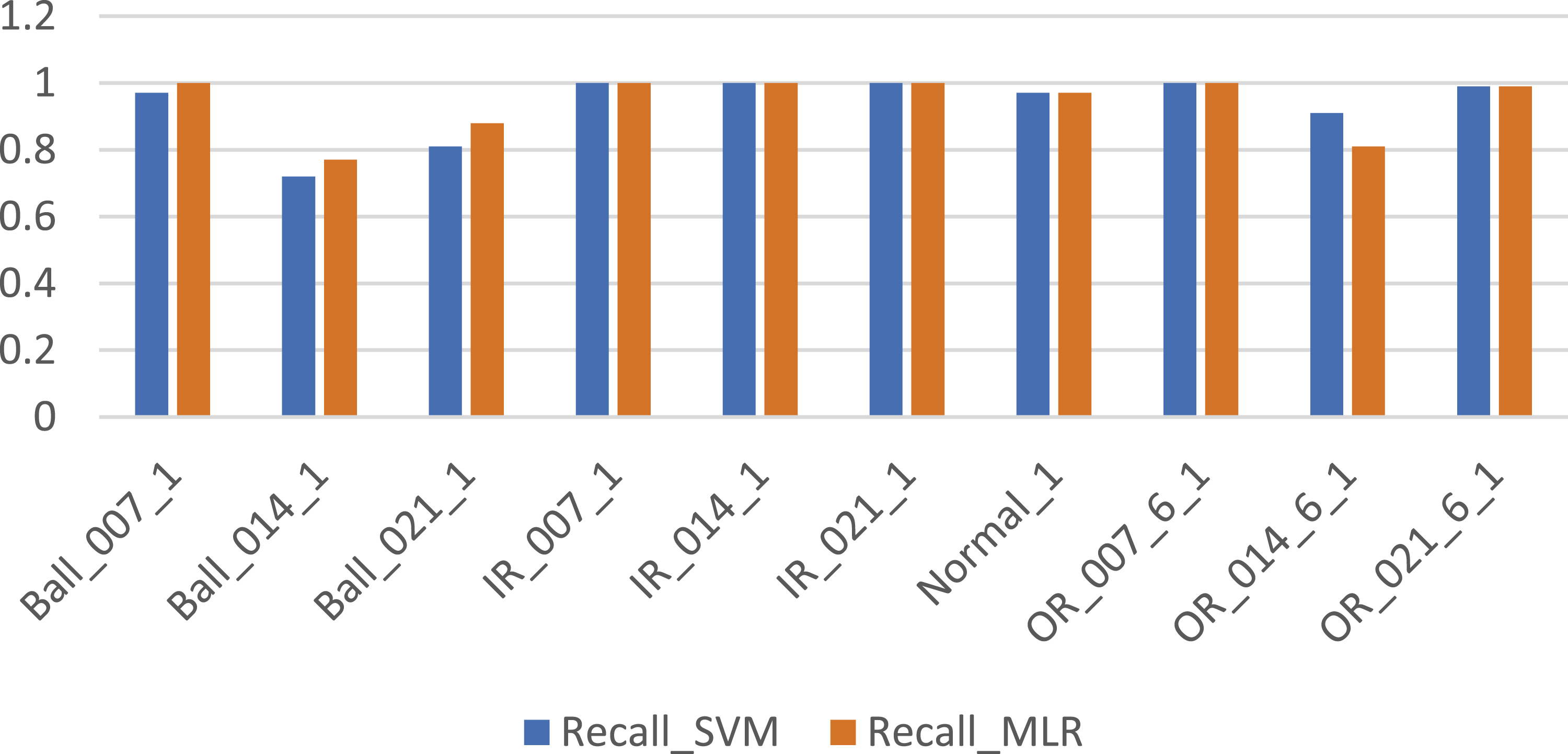
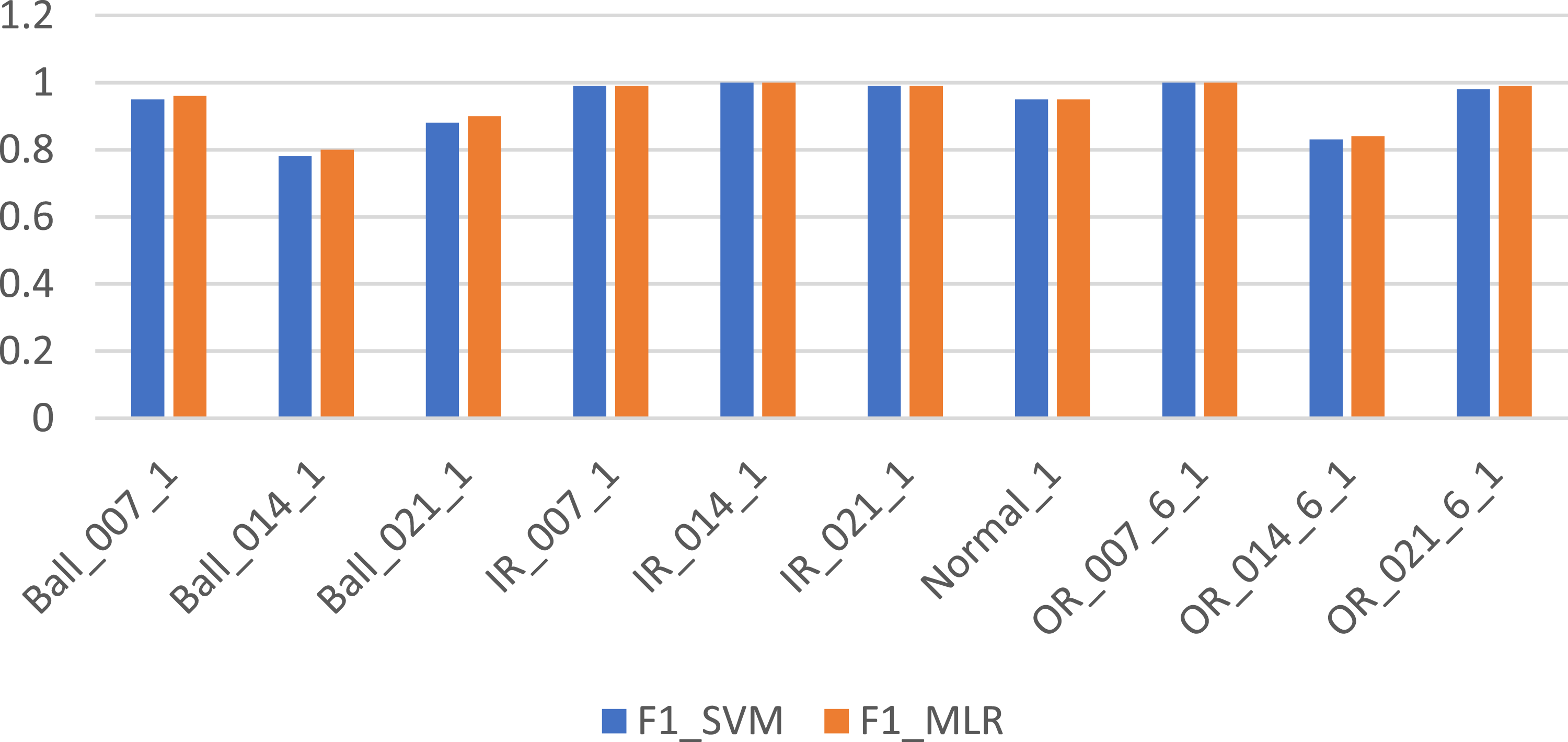
Figure 5 shows comparison of the Support Vector Machine (SVM) and Multinomial Logistic Regression (MLR) models based on their test Confusion Matrices. Both models are evaluated on 10 classes of bearing condition data, each having 75 samples, resulting in a 750-sample test set. In case of Ball_014_1 defect, SVM misclassified 21 times mainly as Ball_021_1 and OR_021_6_1whereas MLR misclassified 17 times as Ball_021_1 and OR_014_6_1. In case of Ball_021_1 defect, SVM misclassified 14 times whereas MLR misclassified 9 times. In case of OR_021_6_1 defect, SVM misclassified as Ball_021_1 and Ball_014_1 defect whereas MLR shows heavy confusion with misclassification for 14 times as Ball_014_1 and Ball_021_1 defect. Overall accuracy of SVM is about 95.3 % whereas that of Multinomial logistic regression is 93.3%. So Table 4 shows performance comparison of SVM and MLR model in fault classification. Both SVM and Logistic Regression performed perfectly (or nearly perfectly) on IR_007_1, IR_014_1, IR_021_1, OR_014_6_1, Normal_1 class which indicates that inner race faults (IR) and normal data are clearly separable for both models. However for Ball_014_1 and Ball_021_1, both models performed poorly, with logistic regression slightly outperforming SVM (but both still had high misclassifications). Ball_007_1 had slightly better performance with Logistic Regression (100%) than SVM (73/75). For OR_021_6_1, SVM did better (68/75) than Logistic Regression (61/75), showing that SVM handled this fault class slightly better. Logistic Regression gives slightly better results for some Ball fault classes. In most cases, both models agree in performance, either both predict well or both struggle. Slight differences in Ball_007_1 and OR_021_6_1 suggest that decision boundaries for these classes may benefit from the different classification strategies of each model. The Ball fault conditions (especially 014 & 021) are harder to classify. These may have features more similar to other classes, or less clear signal characteristics. Inner Race faults are easiest to detect, possibly because they have distinct vibration patterns. Figures 6–8 shows the comparison of SVM and MLR models in terms of precision, recall value and F1 score respectively. Confusion matrices for test data using MLR (left) and test data using untuned SVM models. Performance comparison of SVM and MLR model. Comparison of precision of SVM and MLR models. Comparison of recall value of SVM and MLR models. Comparison of F1 score of SVM and MLR models.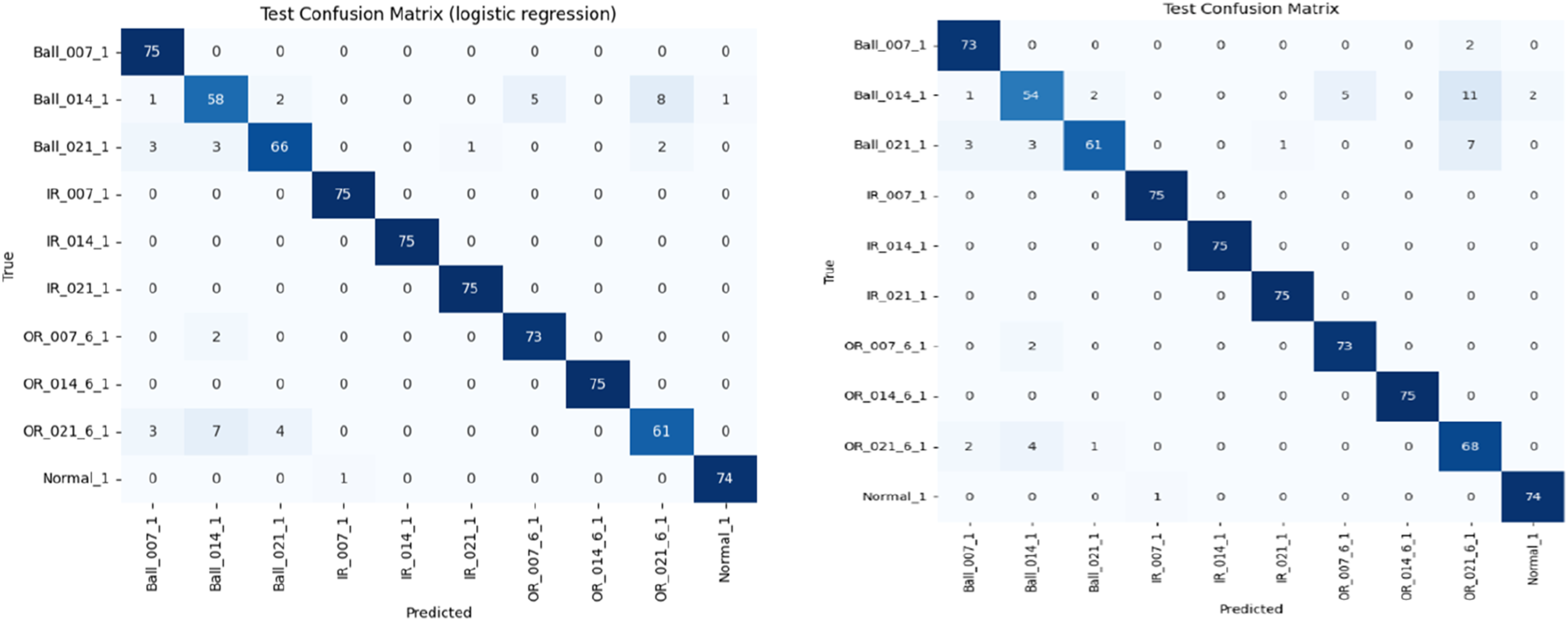
Conclusion
This study confirms that Support Vector Machine is an effective method for the detection and classification of bearing faults using vibration signal features. The proposed approach offers high accuracy and generalizability, making it suitable for real-time monitoring systems. The confusion matrices indicate that the SVM classifier is capable of accurately distinguishing between different bearing fault types. Although some misclassifications occur, the overall performance is strong, especially considering the balanced distribution and complex fault types.
Tuning hyperparameters is essential because it unlocks the full potential of a model, ensures robustness, and directly impacts the model’s success in real-world applications. Hyperparameter tuning using techniques like GridSearchCV significantly improves the model’s performance. It not only enhances the training accuracy but also greatly reduces the gap between training and test performance, indicating better generalization. The tuned model demonstrates increased reliability in identifying fault categories such as Ball_014_1 and OR_021_6_1, which previously showed high confusion with other classes. Therefore, hyperparameter optimization is a crucial step in deploying robust machine learning models for bearing fault diagnosis.
SVM outperforms Logistic Regression in accuracy and robustness, especially for complex class separations like Ball_021_1 vs OR_021_6_1. Logistic Regression performs decently but struggles with overlapping features across failure modes. Logistic Regression slightly outperforms SVM in overall perfect predictions (more 75/75 scores). However, SVM shows slightly better results in some difficult cases like OR_021_6_1. The choice of model may depend on which specific fault types are more critical in your application. Further improvements could be explored using feature selection, kernel methods (for SVM), or ensemble models. Machine learning provides an efficient, accurate, and automated way to detect bearing faults. By learning from data patterns, ML models outperform traditional rule-based methods in predictive maintenance applications.
The optimization approach adopted was data-driven and performance-oriented rather than physics-informed. This may be one of the limitations of the present study. Regarding scalability and real-world applicability, industrial environments exhibit significant variations in operating speed, load conditions, sensor noise, and structural uncertainties, which differ from controlled benchmark datasets. While the present results demonstrate strong robustness under balanced and standardized conditions, direct deployment in real-world systems would require: • Adaptive retraining under changing operating conditions, • Online learning strategies to accommodate non-stationary signals, and • Domain adaptation techniques to address data distribution shifts.
Future work can integrate deep learning for automated feature extraction and investigate online deployment for predictive maintenance.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
All vibration datasets used for fault diagnosis in this study are available in the CWRU Bearing Dataset repository.