
Abstract
Multi-arm multi-stage clinical trials in which more than two drugs are simultaneously investigated provide gains over separate single- or two-arm trials. In this paper we propose a generic Bayesian adaptive decision-theoretic design for multi-arm multi-stage clinical trials with K (
1. Introduction
Modern medicine has seen a rapid increase in the number of drugs on the market. The efficacy of a drug is traditionally evaluated in single-arm or two-arm trials. Trials with more than two arms are increasingly demanded and are particularly suited when multiple, competing drugs are being developed or combinations of drugs are being tested.1,2 Also, in the current COVID-19 pandemic there is an urgent need to investigate multiple treatments simultaneously. The RECOVERY trial, for example, compares efficacy of four candidate treatments for COVID-19 to a common control arm receiving usual care. 3 Trials with more than two arms typically require fewer overall resources than multiple two-arm trials and facilitate a direct comparison of drugs.4–7 In this paper, we study trials in which one or a few drugs are selected from a set of candidate drugs. The selected drugs may enter the next trial phase or may be proposed for approval. During the trial, it is desirable to select or deselect drugs as soon as possible. Timely decision making is facilitated by incorporating interim evaluations.8–10 We will refer to trials in which patients are randomized over multiple arms with multiple interim evaluations as multi-arm multi-stage (MAMS) trials. MAMS typically allow early termination of ineffective arms and early identification of effective arms.
Frequentist MAMS trials are characterized by repeated statistical tests of futility and efficacy null hypotheses. The critical boundaries are set such that the familywise error rate over the whole trial is controlled at a predefined nominal level.2,8,9,11–13 Experimental arms are compared to the control arm and each experimental arm may be declared effective or futile at each interim evaluation. Bayesian MAMS use a predefined stopping rule based on the posterior distribution of a function of the treatment efficacies. 14 Bayesian designs often involve response-adaptive randomization where randomization probabilities change throughout the trial based on newly collected treatment outcomes.14,15 A response-adaptive design will lead to a higher expected number of patients allocated to the best arm during the trial in comparison to trials with an equal randomization scheme and may therefore be attractive for ethical reasons. However, this may come at a price of lower statistical power for showing differences in efficacy between the arms. 16
Stopping rules in Bayesian MAMS trials may be based on direct, simple functions of the treatment efficacies, but more formal decision-theoretic approaches also exist.17–27 Decision-theoretic approaches quantify the value of all possible trial outcomes by means of a loss or utility function. The objective of the trial is to minimize the expected loss of the trial or to maximize the expected utility. A clever choice of the loss function may yield Bayesian trials with lower expected trial sizes than classical frequentist trials at the same nominal error rate.
17
Most Bayesian decision-theoretic designs have been proposed for trials with two arms. If the trial has a predefined maximum study size, then at each stage the optimal interim decision needs to be assessed by a computationally expensive dynamic programming approach.17–19,21–23,25,27 Several strategies have been proposed in the literature to limit the computational burden. Cheng and Shen
20
did not fix the maximum trial size before the start of the trial and propose a one-step backward induction algorithm. They showed that their study design will always result in a finite trial size. Jiang et al.
26
proposed a constrained backward induction algorithm on a reduced lower-dimensional state space to approximate the optimal stop or continue decision at each stage. Both Cheng and Shen
20
and Jiang et al.
26
studied two-arm trials only. Orawo and Christen
24
extended to the general situation of trials with K (
Willan and Kowgier 23 and Chen and Willan 25 considered multi-stage adaptive designs from a value of information perspective. 28 They did not fix the maximum total sample size, but fixed the maximum number of stages. They considered the expected net gain of the trial, which is defined as the difference between the expected value of sample information and the total costs of the trial. At each stage, they determine an optimal sample size for the remainder of the trial and the fraction of the sample size that needs to be recruited in the next stage through maximization of the expected net gain. Their method is computationally demanding and has only been developed for trials of two stages.
The one-step backward induction algorithm of Cheng and Shen 20 also has a link to value of information considerations. After each interim evaluation, Cheng and Shen compared the cost of continuing the trial for one more stage with the expected reduction in loss. If the extra costs exceed the expected loss reduction, the trial is stopped and the arm with the lowest expected loss is selected. Stated differently, if the expected marginal utility (or loss reduction) of continuing the trial does not exceed the marginal cost of continuing the trial, the trial is stopped. The approach is generic in the sense that any loss function can be defined and a different loss function can be defined for the experimental and control arm.
In the present study, we generalize the framework introduced by Cheng and Shen to the setting with K (
This paper is organized as follows. In the following section, we describe the Bayesian decision-theoretic framework and provide examples of loss functions. Next, we describe two simulation studies in which we evaluate the operating characteristics of our approach and make a comparison with nonadaptive single-stage and adaptive two-stage methods. In the simulations, we consider multi-arm trials with and without a control group. The results of the simulations are discussed in a later section. Finally, we show an illustration of a possible application of the methods in a future trial and we conclude with a discussion in the last section.
2. Methods
2.1. Notation
We consider the general setting of a MAMS trial with K (
2.2. Loss function and decision rules
Suppose we have a study design where all arms are active until a final decision is made. The predefined set of final decisions is denoted by D. The loss of each final decision depends on the unknown parameter vector
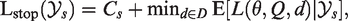
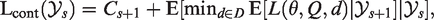
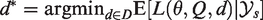
If
We now consider the possibility of early dropping of ineffective arms and, hence, in case of continuation an additional decision needs to be made on how to continue the trial. To describe a design with early dropping, we introduce
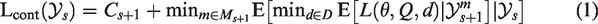
2.3. Examples
Select the best arm from K experimental arms. We define the set of final decisions as

If early dropping of ineffective arms is allowed in a setting with K > 2, options for continuing the trial also need to be defined. One may, for instance, adopt a strategy where at each interim analysis at most one arm is dropped from the trial. In case of K = 3 arms this is done by defining
Select the unique best arm from K experimental arms in the presence of an equivalence margin. If one wants to avoid that a best arm needs to be selected in case multiple arms show similar performance, then an equivalence margin can be incorporated in the loss function. We assume that one wants to select the best arm only if it outperforms the other arms by a prespecified margin
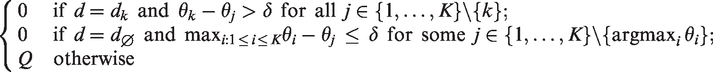
Select the T best arms from K experimental arms. Especially if K is large, the goal may be to select a predefined number of T (T < K) most promising experimental arms that warrant further investigation. If, for instance, one aims to select the two best arms, then the final decisions are
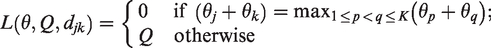
Compare K – 1 experimental arms to a control arm. We assume that θ1 refers to the parameter of interest in the control arm. In the presence of a control arm and multiple experimental arms the aim typically is to identify all the experimental arms that outperform the control arm. If, for instance, K = 3, then we define
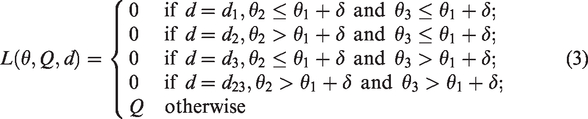
3. Simulation studies
We evaluate the frequentist operating characteristics of the Bayesian decision-theoretic designs in trials with multiple arms and a binary outcome. We consider the setting without and with a control arm. In simulation I, we consider selection of the best experimental arm from K (K = 3, 4, 5) experimental arms using loss function (2). In simulation II, we compare two experimental arms to a common control arm using loss function (3). In both simulation studies, we let each Yik (
Simulation I: Three to five experimental arms
In simulation I, we compare three Bayesian decision-theoretic designs B1, B2, and B3. In all three designs, the final decision is based on minimization of the posterior expected loss. Design B1 is a MAMS trial with adaptive stopping and the possibility of early dropping of ineffective arms from the trial. After each stage, it is decided whether the trial continues with the same arms, a single arm is dropped or the trial is stopped. The trial is stopped after stage s if

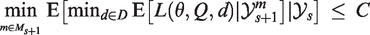
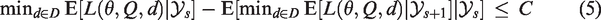
Design B3 is a single-stage, nonadaptive trial (with fixed trial size) in which patients are allocated to the K arms in equal numbers.
This simulation study consists of three substudies, which we denote by I.1–3. In simulation I.1, we compare B1 and B2 for settings with K = 3 to 5 arms and report the proportion of correct decisions and average trial sizes. We set the sizes for the initial batch and subsequent batches at 4 K, i.e.
In simulation I.2, we compare B1 and B2 to nonadaptive B3 in terms of the proportion of correct decisions after equalizing the average sample size of the three designs. More specifically, we start by setting C/Q for design B1 equal to 1/2500 and run simulations under B1. Then, for design B2 we determine separately for each setting of θ the value of C/Q for which the average trial size is equal to that observed under design B1. Similarly, for design B3, we use the trial sizes obtained under design B1. We confine ourselves to K = 3 and set batch size and
Finally, in simulation I.3, we study the frequentist operating characteristics of the relative costs C/Q. We set C/Q equal to
Simulation II: Two experimental arms and a control arm
In simulation II, we compare design B2 to three frequentist designs F1, F2, and F3. Design F1 is a single-stage, nonadaptive trial with fixed trial size and equal allocation of patients to arms. The final decision under F1 is based on the outcome of Dunnett’s multiple comparison hypothesis testing procedure for comparing multiple experimental arms to a control while controlling the familywise type I error rate. Design F2 and F3 are adaptive two-stage designs using the closed testing procedure of Urach and Posch
9
with equal allocation of patients to the active arms in both stages. Both F2 and F3 include an interim analysis after half of the maximum number of patients have been enrolled. We use arm-specific stopping rules where in the interim analysis each individual experimental arm can be declared futile or superior to the control after which accrual is stopped for that arm. Both designs F2 and F3 declare an arm futile when the interim Z test statistic is negative. For concluding superiority, design F2 uses O’Brien Fleming-type boundaries whereas F3 uses Pocock-type boundaries. We set the one-sided type I error rate at 5%. We assume that arm 1 is the control arm and that arms 2 and 3 are experimental arms. We set θ equal to: (0.5, 0.5, 0.7), (0.5, 0.7, 0.7), (0.5, 0.5, 0.8), (0.5, 0.7, 0.8), and (0.5, 0.8, 0.8). We set margin δ in loss function (3) equal to 0.15. For this margin, the decision that minimizes loss (3) is equal to d3 for
4. Simulation results
Results of simulation I.1 are presented in Figure 1 where each panel corresponds with a setting of θ and lines connect results for the same design under different relative costs C/Q. The proportion of correct decisions is at least 0.70 for most settings, except for the left panel in the middle row. Average trial sizes do not exceed 250 and are below 150 for the majority of settings. In the top row panels where the success probabilities differ at least 0.4 between the worst and other arms, average trial sizes are similar under B1 and B2, but proportions of correct decisions are higher under B1. An explanation for this is that design B1 adapts during the trial by allocating more patients to the best performing arms, thereby providing more information for identification of the best performing arm. In the middle row panels where all arms have the same success probability except for the best performing arm, we see that average trial sizes decrease and proportions of correct decisions increase when the success probability of the best performing arm increases. If the best arm is clearly superior to the other arms (middle row, right panel), then the average trial size remains below 100 for most of the settings. The proportion of correct decisions is slightly higher for B2 than for B1 at similar average trial sizes indicating that early dropping may negatively influence the performance of the trial when there is no clearly inferior treatment arm. In the bottom row panels where differences in success probability between the worst and other arms are smaller than in the upper row panels, we see that B1 and B2 perform similarly in terms of both average trial size and proportion of correct decisions.
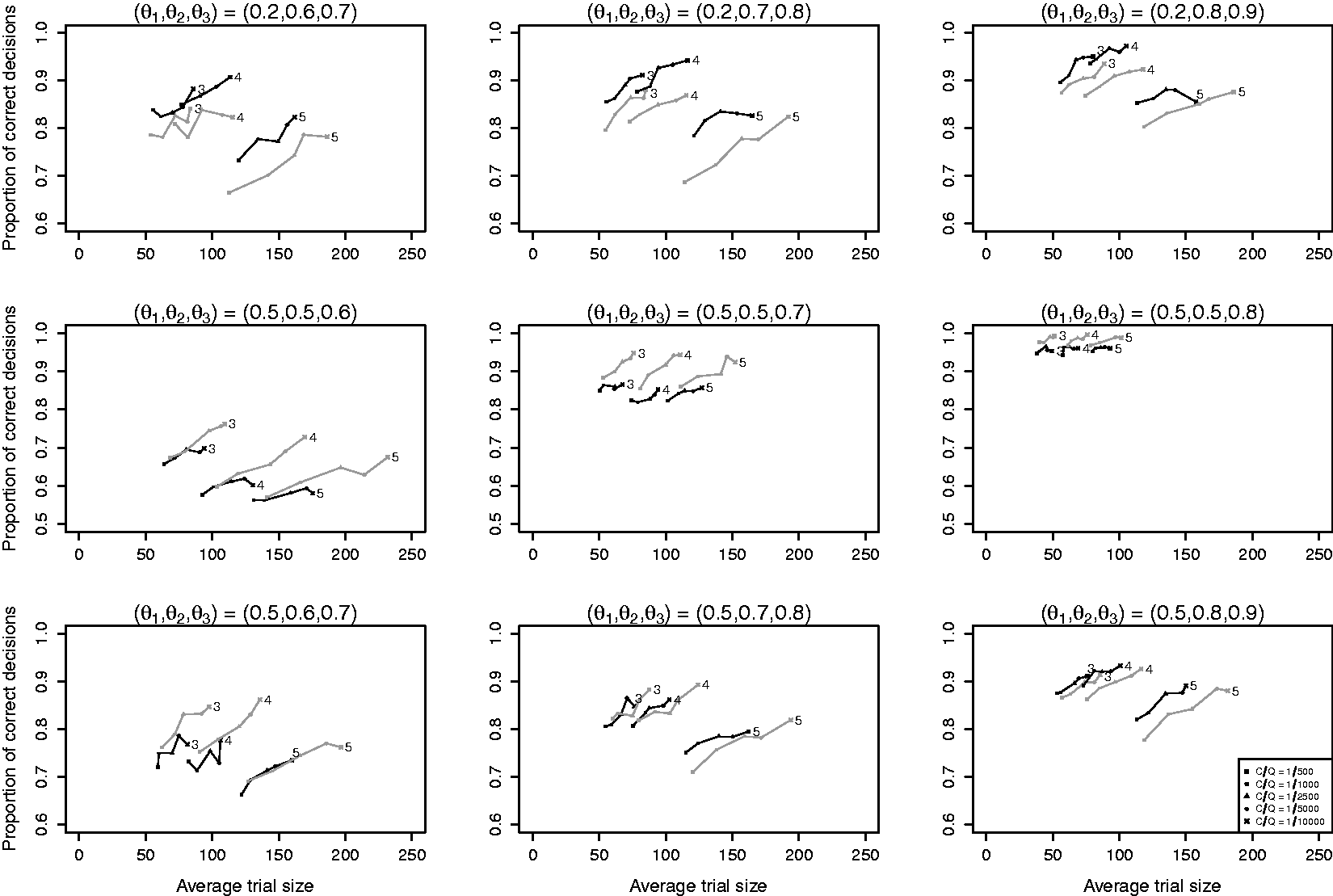
Results of simulation I.1 with K = 3, 4, 5 experimental arms. Line segments connect results for the same design and number of arms for different relative costs C/Q. Black lines are used for design B1 (Bayesian MAMS with dropping) and grey lines for design B2 (Bayesian MAMS without dropping). The numbers at the end of the lines denote the number of arms K.
When comparing the three rows, we see that the average trial size under both B1 and B2 depends strongly on the difference between the best and second-best arm (middle row), but only weakly on the difference between the worst and other arms (top versus bottom row). We also see that the effect of adding an extra arm on the average trial size depends on the success probability of the arm that is added. When the success probabilities of the added arms are equal to that of the worst arm (middle row), the average trial size increases approximately linearly with the number of arms. However, increases in average trials size were found to be larger when the success probability of the added arm was closer to that of the best arm as this made it more difficult to select the best arm (top and bottom row).
Figure 2 shows the results of simulation I.2 with the average trial size equalized across designs. Designs with adaptive stopping (designs B1 and B2) outperform the single-stage trial design B3 in terms of the proportion of correct decisions by 5% to 15%. The added value of early dropping depends on θ in accordance with what we observed in simulation I.1. Table 1 shows average trial sizes after equalizing the proportion of correct decisions. We see that average trial sizes of B2 are 26% to 33% higher than under B1 when
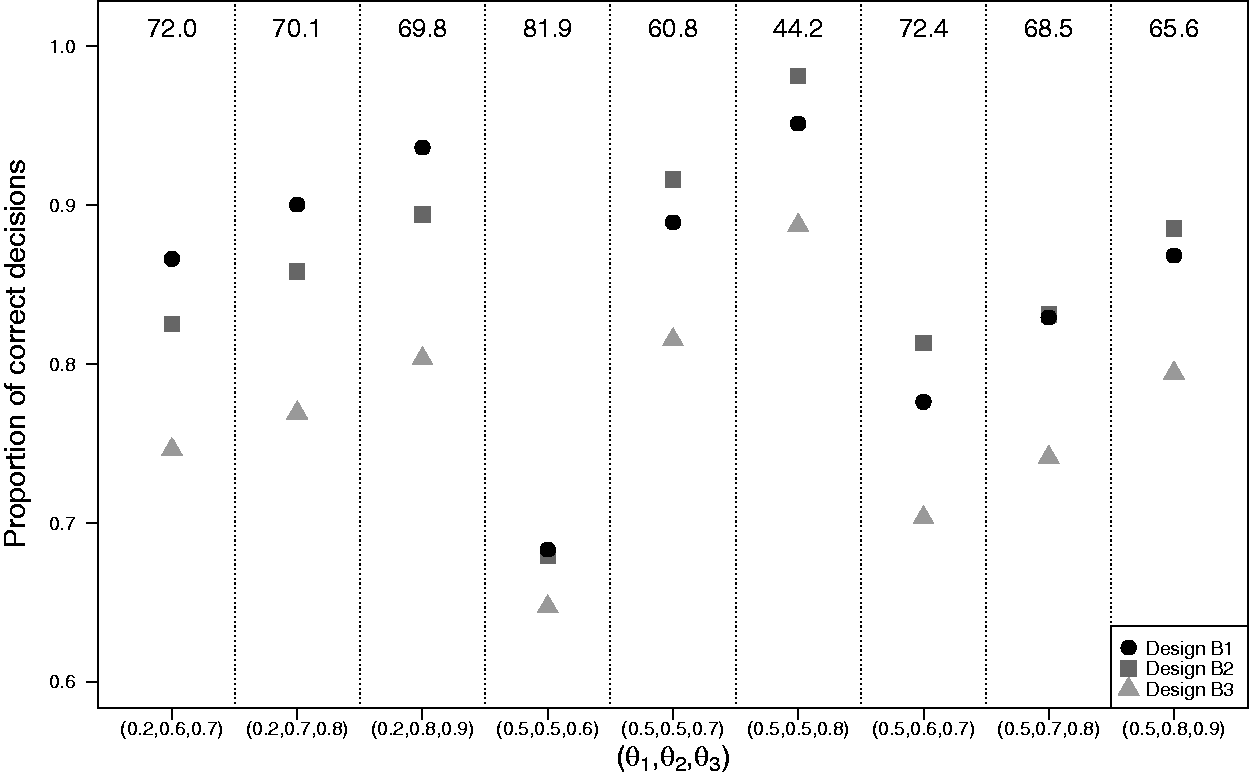
Results of simulation I.2 with K = 3 experimental arms with the average trial size equalized across designs. Matching of the designs in terms of the average trial size was done separately for each setting of
Results of simulation I.2 with K = 3 experimental arms with the proportion of correct decisions equalized across designs. Matching of the designs in terms of the proportion of correct decisions was done separately for each setting of
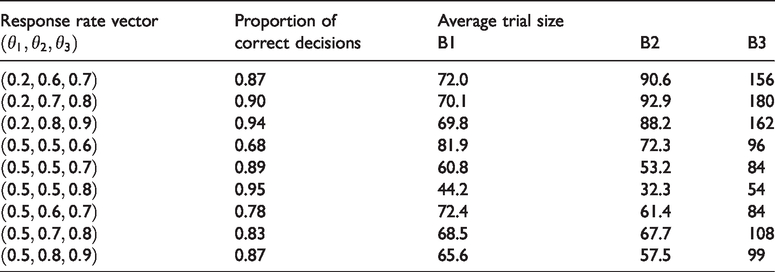
Figure 3 shows the results of simulation I.3. For all settings θ, the average change in the proportion of trials with a correct decision is slightly lower or approximately equal to the relative costs C/Q. Therefore, stopping based on (5) supports the frequentist interpretation of C/Q as a threshold for the average increase in the proportion of trials with a correct decision.

Results of simulation I.3 with K = 3 experimental arms. The change in proportion of trials with a correct decision when trials continue for a single additional stage after a decision to stop has been taken.
Figure 4 presents the results of simulation II with the average trial size equalized for the four designs. Design B2 performs best and design F1 (Dunnett’s frequentist procedure) performs worst under all scenarios. Designs F2 and F3 (both Urach and Posch’s frequentist procedure) generally perform better than F1, but worse than B2. The difference in performance between design B2 and designs F1, F2 and F3 depends on θ and is more pronounced when both experimental arms are superior to the control arm. Under those scenarios, the difference in the proportion of correct decisions can reach 50% for designs B2 and F1 and 25% for design B2 and designs F2 and F3. Under design B2, the proportion of correct decisions regarding superiority of experimental arm j (j = 2, 3) depends on the difference between θj and the threshold
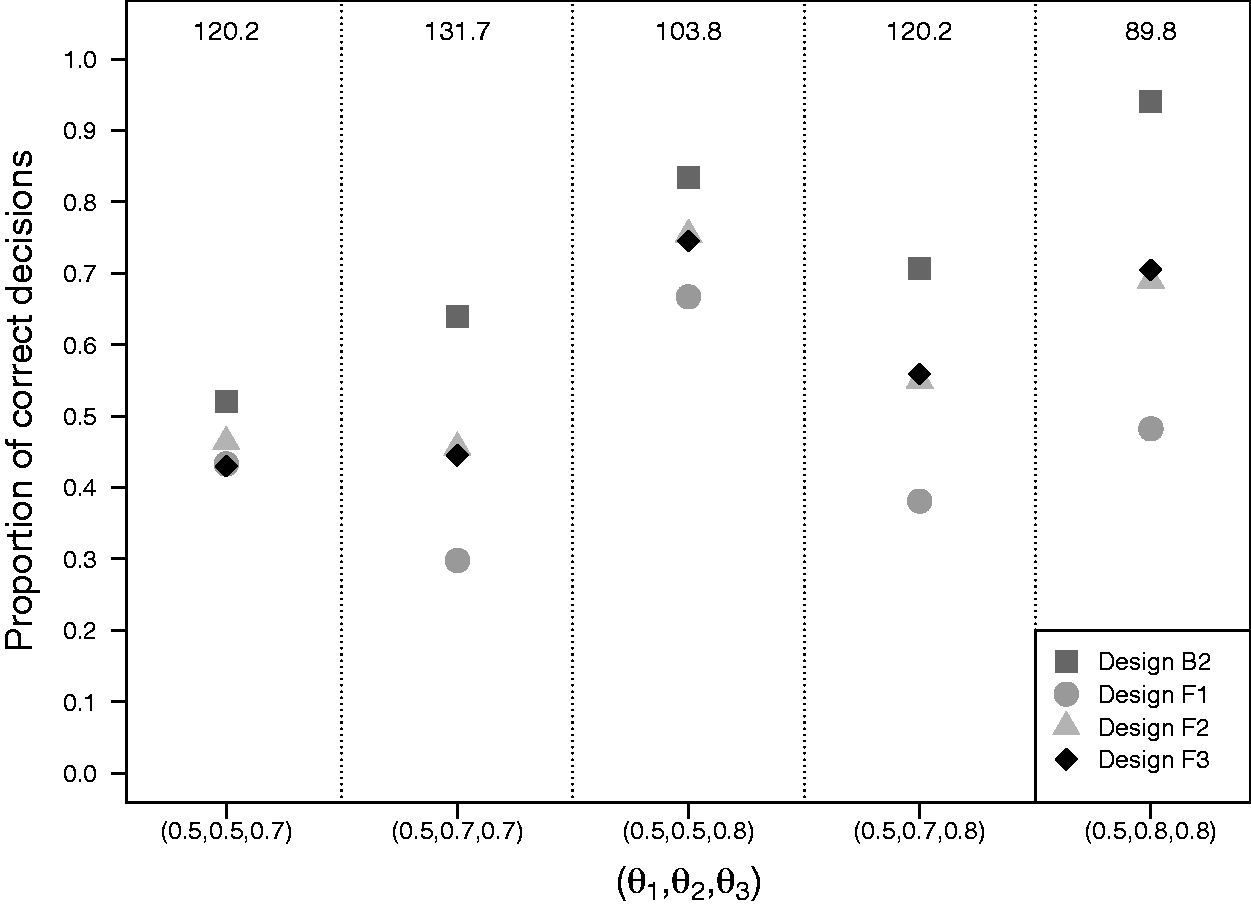
Results of simulation II with two experimental arms and a control arm with the average trial size equalized across designs. Matching of the designs in terms of the average trial size was done separately for each setting of
Results of simulation II with two experimental arms and a control arm with the proportion of correct decisions equalized across designs. Matching of the designs in terms of the proportion of correct decisions was done separately for each hypothesized response rate vector. Average trial sizes were determined when simulating new trial data under the hypothesized response rate vector

5. Practical example
Physical exercise programs have been shown to be effective in improving quality of life and physical functioning in patients with cancer. 30 Recently, it has been suggested that physical exercise programs during chemotherapy may also improve response to chemotherapy. 31 We designed a Bayesian decision-theoretic MAMS trial to compare two different physical exercise programs (resistance and aerobic exercise) to usual care in breast cancer patients receiving neoadjuvant chemotherapy. The primary outcome was tumor response defined as absence of invasive or noninvasive residual tumor after chemotherapy. The response rate under usual care was known to be around 0.20. A new exercise program for future patients and usual care were regarded equipoised when the exercise program improved tumor response rate by 0.10. An improvement of at least 0.15 was expected and was considered clinically relevant. In order to avoid exposing too many patients to ineffective exercise programs during the already burdensome chemotherapy, it was considered important that experimental arms could be dropped from the trial early if proven futile. A maximum number of 400 patients could be accrued to the trial.
We used loss function (3) with margin δ set at 0.10. Although the trial would be fully analyzed using Bayesian methods, adequate frequentist properties were desired. We defined the null scenario as
The procedure used for tuning the design parameters is described in Appendix 1. Parameter values selected for the Bayesian decision-theoretic MAMS design were
We compared the proportion of correct decisions for the selected Bayesian decision-theoretic MAMS design to frequentist single-stage trials using Dunnett’s procedure and the adaptive two-stage procedure of Urach and Posch. The average trial size was equalized across designs using the same procedure as in simulation II. After equalizing the average trial size, the two-stage procedure of Urach and Posch declared arm 3 superior to the control arm under
6. Discussion
We generalized the Bayesian adaptive decision-theoretic design for two-arm clinical trials proposed by Cheng and Shen
20
to the setting of MAMS trials with K (
We found that our Bayesian adaptive designs correctly identified the best arm more often than single-stage clinical trials with same total sample size, both in the setting with and without a control arm. In the setting with a control arm, we found our Bayesian adaptive designs to outperform frequentist single- and two-stage procedures, with largest differences in the proportion of correct decisions occurring when both experimental arms were superior to the control arm. In the setting with only experimental arms, we found that adaptive dropping of arms further increased the proportion of correct decisions only when at least one of the arms was clearly inferior. In those settings it is beneficial to drop the inferior arms early such that more data can be collected in the other arms. However, when arms were similarly effective, the proportion of correction decisions sometimes decreased when allowing for early dropping. This is related to the unfortunate decision early in the trial to drop the best arm and can be prevented by accruing a larger number of patients in the first stage.
An attractive feature of our decision-theoretic framework is that it uses the expected reduction in loss as the single quantity to inform stopping of the trial. This is in contrast to standard frequentist and Bayesian MAMS designs that generally require monitoring of two separate quantities. In those designs early stopping for efficacy is guided by a frequentist test statistic or a quantile of the posterior treatment efficacy, whereas early stopping for futility is based on conditional power or posterior predictive probability of success at the end of the trial. In our simulations, we observed that adaptive stopping in our designs occurred both for reasons of efficacy and futility. In our simulation studies, we considered symmetric loss functions where all incorrect decisions result in the same loss. Our framework, however, also permits incorporation of more elaborate loss functions where the losses are different for false-positive and false-negative findings and vary across the experimental arms.
In the simulation study, we found that even for trials with five arms an acceptable proportion of correct decisions could be achieved while average trial sizes remained below 200 patients. Although we did not put a cap on the sample size in our simulations, all simulated trials ended after a finite number of stages. This is in accordance with a theoretical result derived by Cheng and Shen 20 that states that for two-arm trials termination is achieved at finite study size with a probability of one. This means that even when the treatment efficacies are equal in the different arms, the study terminates at finite study size. In that situation, the proportion of correct decisions over replicated trials will be one over the number of arms when the different arms have equal priors. An additional simulation (not presented) showed that even when differences in efficacies tended to zero, expected total trial sizes for our designs remained quite stable. Nevertheless, one may consider putting a cap on the maximum number of stages in order to rule out very large studies and restrict total costs and duration of the trial. We illustrated the use of the cap in a practical example. Note also that both with and without specification of a cap, our procedures did not become computationally challenging, even not for settings with five arms. The computation time of our methods is determined by the number of times that an expected change in loss needs to be evaluated and therefore increases linearly with the number of stages, whereas the computation time of a backward induction procedure increases exponentially with the number of stages.19,24
Clinical trials involving human subjects are usually classified as phase I to IV trials. The four phases correspond to safety assessment, identification of effective drugs, confirmation of a drug’s efficacy and post-approval research. Our methods can improve efficiency of phase II trials by facilitating screening of multiple experimental drugs in a single trial. Another application is in phase IV trials in which multiple, approved drugs are compared and interest is in selecting a single drug that minimizes the expected loss in future patients. Bayesian approaches are not widely used in the setting of phase III trials because current guidelines for such trials require stringent control of the type I error. However, it has recently been recommended to shift the focus in phase III trials towards error rates that are more insightful than the familywise error rate, for instance, through use of decision-theoretic approaches that incorporate losses for incorrect decisions where the incurred losses depend on the seriousness of the incorrect decision. 32 Based on this, we think that our approach for comparing two experimental arms to a control arm, where parameters are tuned such that the type I error is controlled, is a sensible and feasible alternative to larger nonadaptive phase III trials.
Although the methods presented are very general, we made some specific decisions regarding the settings of our simulation studies. Firstly, we considered the primary outcome to be dichotomous. The framework can however also be applied to continuous outcomes. Secondly, we assumed that the outcomes of all included patients are available when the decision to continue or stop the trial is made. This is a common assumption in adaptive trials literature with early outcomes like disease progression or recurrent disease. It must be noted that our approach can still be applied when there is a delay between the time of inclusion of the patient and the time of outcome acquisition, but the benefit of using an adaptive design instead of a nonadaptive design becomes smaller when the delay increases. In such settings, the posterior predictive distributions are based on the data observed up to time of the interim analysis. Finally, we used uninformative, uniform priors for the success probabilities in all simulations. The Bayesian approach facilitates the incorporation of historical data by means of an informative prior distribution, such as for instance a power prior.33,34 Especially in settings where an already widely studied standard treatment serves as a control, efficiency may be increased by incorporation of information obtained in earlier studies.
Footnotes
Authors’ Note
Andrea Bassi is currently employed at Hypermynds S.r.l. (Milan, Italy). This work was conducted when he was employed at Amsterdam UMC.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Dutch Cancer Society (grant KWF 2012-5711).