
Abstract
Objective
Deep learning (DL) has shown promising results for improving mammographic breast cancer diagnosis. However, the impact of artificial intelligence (AI) on the breast cancer screening process has not yet been fully elucidated in terms of potential workload reduction. We aim to assess if AI-based triaging of breast cancer screening mammograms could reduce the radiologist's workload with non-inferior sensitivity.
Methods
PubMed, EMBASE, Cochrane Central, and Web of Science databases were systematically searched for studies that evaluated AI algorithms on computer-aided triage of breast cancer screening mammograms. We extracted data from homogenous studies and performed a proportion meta-analysis with a random-effects model to examine the radiologist's workload reduction (proportion of low-risk mammograms that could be theoretically ruled out from human's assessment) and the software's sensitivity to breast cancer detection.
Results
Thirteen studies were selected for full review, and three studies that used the same commercially available DL algorithm were included in the meta-analysis. In the 156,852 examinations included, the threshold of 7 was identified as optimal. With these parameters, radiologist workload decreased by 68.3% (95%CI 0.655–0.711, I² = 98.76%, p < 0.001), while achieving a sensitivity of 93.1% (95%CI 0.882–0.979, I² = 83.86%, p = 0.002) and a specificity of 68.7% (95% CI 0.684–0.723, I² = 97.5%, p < 0.01).
Conclusions
The deployment of DL computer-aided triage of breast cancer screening mammograms reduces the radiology workload while maintaining high sensitivity. Although the implementation of AI remains complex and heterogeneous, it is a promising tool to optimize healthcare resources.
Introduction
Breast cancer is the leading cause of cancer death among women worldwide. 1 In order to identify the disease at an early stage and reduce mortality, breast cancer screening programs have been established in many countries. Such programs result in a substantial volume of mammograms and workload associated with their interpretation. In 2022, about 39 million annual mammography procedures were reported in the USA, generating a high pressure on imaging related professionals. 2
Workforce shortage in healthcare is a global issue, with added impact in low resource settings. In addition, radiologists and technicians specialized in breast cancer screening are becoming increasingly scarce. For instance, a study revealed that Mexico had less than 300 breast radiologists to interpret mammograms for the 14 million eligible women. 3 Even in areas like Europe, 4 where double reading of mammograms is standard, and the USA, 5 personnel shortages have also been predicted. Alternative approaches, such as computer-aided screening, are being pursued to support breast cancer screening programs. However, no studies have proven that conventional computer-aided detection methods directly increase screening performance and cost effectiveness or impact workload. The lack of evidence has also made it impractical for computer systems to be used for stand-alone reading in mammography screening. 6
The development of techniques such as deep learning (DL) convolutional neural networks is revolutionizing the field of artificial intelligence (AI), and automation of some cognitively intense activities is becoming a reality. Well-known examples include self-driving vehicles and advanced speech recognition tools. In medical imaging, DL has shown promising results in several applications including image segmentation, cancer detection, characterization, classification, and monitoring. 7 There are currently more than 10 algorithms for mammographic interpretation authorized by the US Food and Drug Administration, particularly for use as clinical decision support systems. 8
Recent research has revealed that DL-based systems have the potential to identify breast cancer on mammography with diagnostic rates comparable to those of radiologists alone. 9 Compared to breast cancer detection rates, workload improvement has gotten significantly less attention, and how these systems should be used in real-time workflows remains unclear. In this context, the purpose of this systematic review and meta-analysis is to investigate whether AI-based triaging of breast cancer screening mammograms could effectively reduce radiologist workload without compromising sensitivity.
Methods
Protocol and search strategy
The systematic review and meta-analysis were performed in line with recommendations from the Cochrane Collaboration and the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) 2020 statement guidelines. 10 The meta-analysis protocol was registered on PROSPERO on 02 July 2022 (PROSPERO ID: CRD42022341374).
We systematically searched PubMed, EMBASE, Cochrane Central Register of Controlled Trials, and Web of Science databases for studies that met the eligibility criteria published from inception to June 2022. Search strategy consisted of (“artificial intelligence” OR “AI” OR “deep learning”) AND (“breast cancer” OR “breast neoplasm” OR “breast microcalcification” OR “breast”) AND (“screening” OR “triage” OR “CADt” OR “computer-aided triage” OR “computer aided triage”) AND (“mammography” OR “mammograms” OR “mammogram” OR “mammographic” OR “DM”) and was conducted by two different authors (D.X and C.A.C), which had no disagreements. The last search of all databases was conducted on 23 March 2023. No language restrictions were applied to the search.
Data extraction
Two authors (DX and CAC) independently extracted baseline characteristics and outcome data based on predefined search criteria. Information collected from studies included first author, year of publication, study design, country of patient recruitment, patient enrollment, technical specifications, reference standard, DL algorithm, and the number of true positives, true negatives, false positives, and false negatives. If more than one threshold was investigated, we extracted data from the approach with the most available information. In case of disagreements, a third author was consulted (IAM).
Inclusion and exclusion criteria
Inclusion in this meta-analysis was limited to studies that met all the following eligibility criteria: (1) retrospective, prospective, randomized, or non-randomized studies; (2) evaluating AI-based triaging of breast cancer screening mammograms; and (3) reporting any of the outcomes of interest. We excluded papers with overlapping populations, understood as derived from overlapping study locations and recruitment periods. The outcomes of interest were (1) workload reduction, (2) sensitivity, and (3) specificity.
Study quality assessment
The revised Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) tool 11 was used to assess the quality and potential bias of studies included in the meta-analysis by two independent reviewers (CAC and IAM). Conflicts were resolved with discussion and involvement of the third author (DX).
Statistical analysis
A proportion meta-analysis with a random-effects model from the DerSimonian method and 95% confidence interval (95% CI) was carried out to evaluate the radiologist's workload reduction. The meta-analysis was performed using OpenMeta-Analyst, an open-source, cross-platform software for advanced meta-analysis. 12
Meta-analysis was performed if a minimum of three papers used the same commercially available algorithm, with results from the same threshold available for data extraction, to estimate sensitivity and specificity. We contacted authors to obtain additional data, if necessary. Workload reduction was defined as the proportion of low-risk mammograms that could be theoretically ruled out from a human's assessment.
Pooled sensitivity and specificity for included studies with a 95% CI were obtained using a random-effects analysis and forest plots were constructed using MetaDTA. 13 Summary receiver-operating characteristic (SROC) curves using the bivariate method were constructed to display the summary point and the area under the curve (AUC) was calculated. The diagnostic odds ratio (DOR) was computed with the 95% CI. The inconsistency index (I²) was calculated to assess heterogeneity between studies.
Results
Study selection and description
The initial search yielded 1003 studies. After duplicate removal and exclusion through title and abstract reading, we reviewed 14 full articles and included 11 papers (Figure 1) in qualitative synthesis (Table 1),14,15–26 and three papers in quantitative synthesis (Figures 2 to 4).
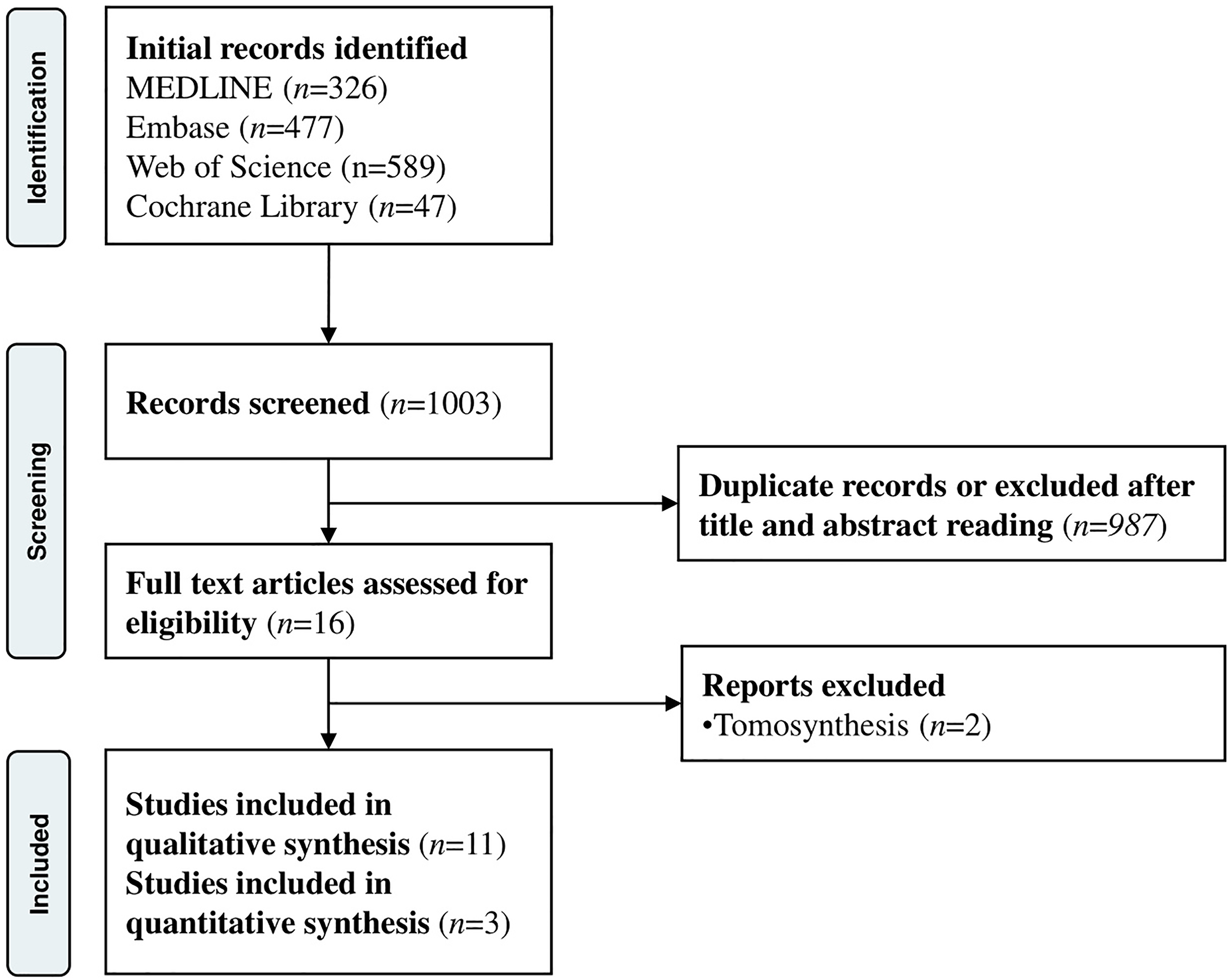
PRISMA 2020 flow diagram of literature search and selection.
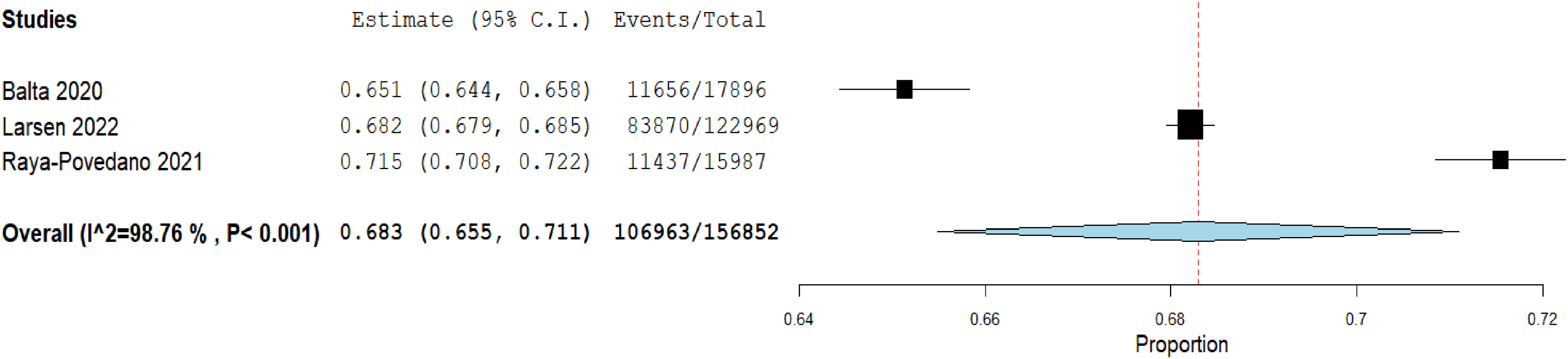
Workload reduction of 68.3% using a Transpara® score of 7 for triaging of breast cancer screening mammograms.

Sensitivity of 93.1% using a Transpara® score of 7 for triaging of breast cancer screening mammograms.

Specificity of 68.7% using a Transpara® score of 7 for triaging of breast cancer screening mammograms.
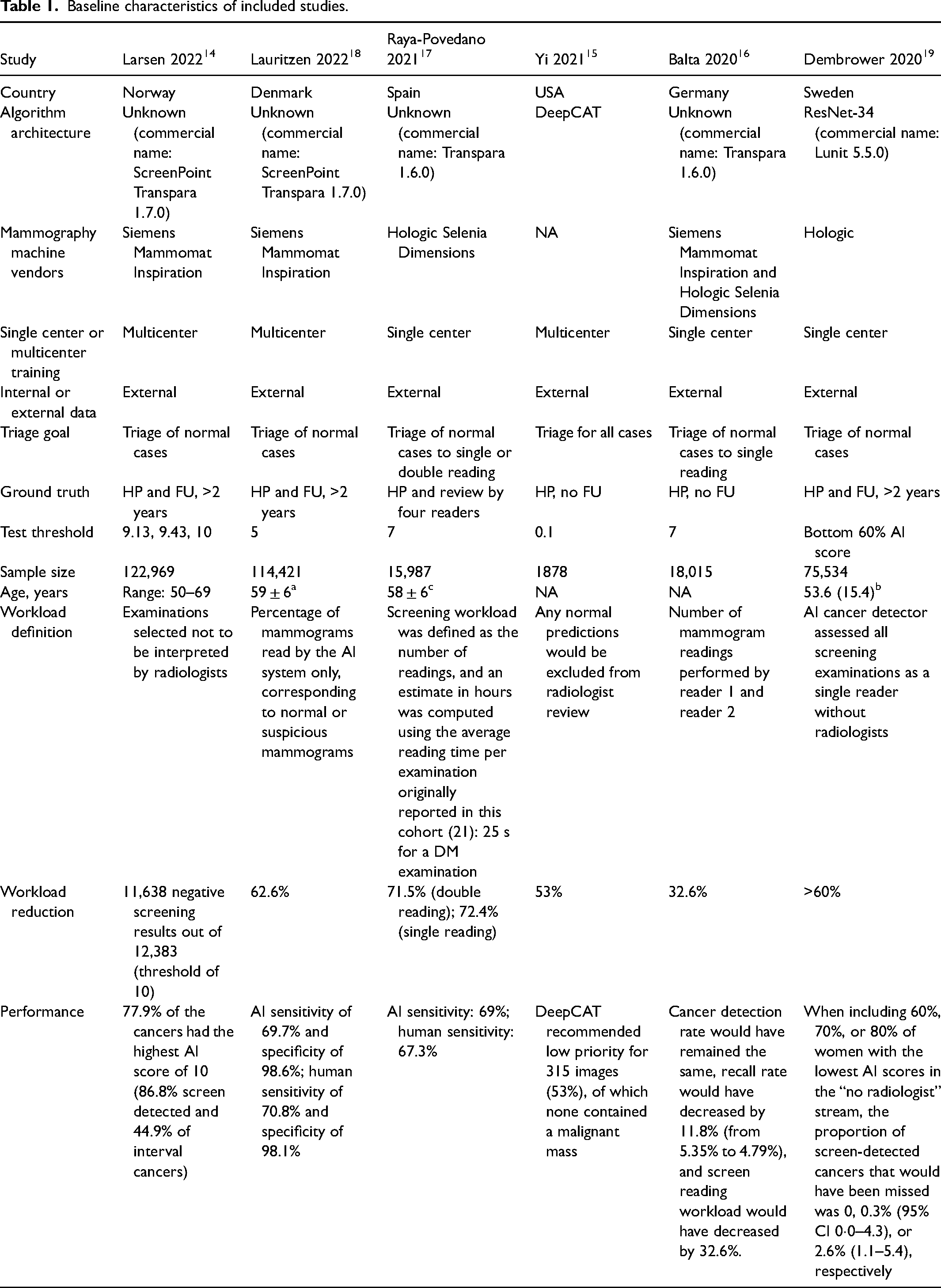
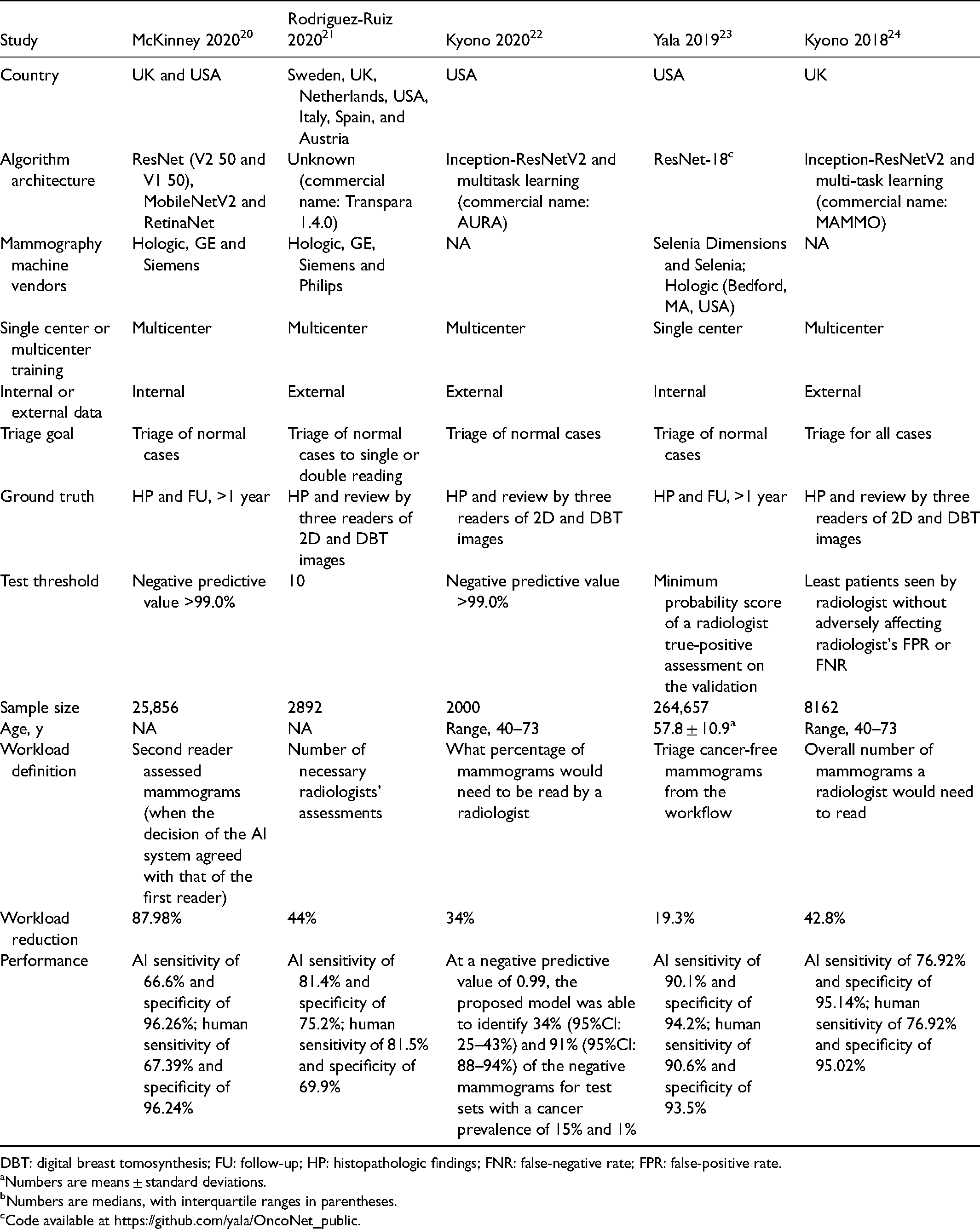
Baseline characteristics of included studies.
DBT: digital breast tomosynthesis; FU: follow-up; HP: histopathologic findings; FNR: false-negative rate; FPR: false-positive rate.
aNumbers are means ± standard deviations.
bNumbers are medians, with interquartile ranges in parentheses.
cCode available at https://github.com/yala/OncoNet_public.
All the included studies were retrospective in nature and conducted in the USA or Europe. Study designs and performance thresholds varied broadly, especially in the chosen threshold. A total of six algorithms were utilized; three out of the six computer codes are open-source, and one 15 of them was still being developed and tested. Five papers, out of 11, used the Transpara® system, a software that highlights and rates the suspicious findings with a score between 1 and 100. A proprietary conversion table generates an examination score from 1 to 10, with higher scores suggesting a higher likelihood of a visible cancer being present on the mammography, based on the maximum suspicious finding from the examination.
Algorithm performance was compared to reader performance for all included studies. All studies included histopathologic examination as ground truth.
Accuracy of AI for breast cancer screening and workload reduction
Three studies14,16,17 that used the same commercially available DL software (Transpara®) provided sufficient data to be included in the meta-analysis to assess workload reduction, sensitivity and specificity. To estimate sensitivity and specificity, the threshold of 7 was used (approximately 70% according to the device specifications), that is, images with a score of 7 or lower were likely normal and those with a score of 8 or higher were considered positive. The cut-off was chosen based on previous research indicating that replacing double reading with single reading for these very likely normal cases would not reduce screening sensitivity by more than 5%. 14 A total of 156,852 examinations were evaluated.
Workload reduction, diagnostic accuracy and heterogeneity
By using the AI algorithm with a score of 7, the radiologist workload significantly decreased by 68.3% (95% CI 0.655–0.711, p < 0.001, I² = 98.76%, Figure 2). The pooled sensitivity was 93.1% (95% CI 0.882–0.979) (Figure 3) and the pooled specificity was 68.7% (95% CI 0.659–0.715) (Figure 4). There was statistically significant heterogeneity for sensitivity (I² = 83.86%, p < 0.01) and specificity (I² = 98.75%, p < 0.01). The pooled SROC curve with the bivariate approach yielded an AUC of 1.0 and the DOR for the studies was 15.6 (95% CI 5.7–25.5, Figure 5).
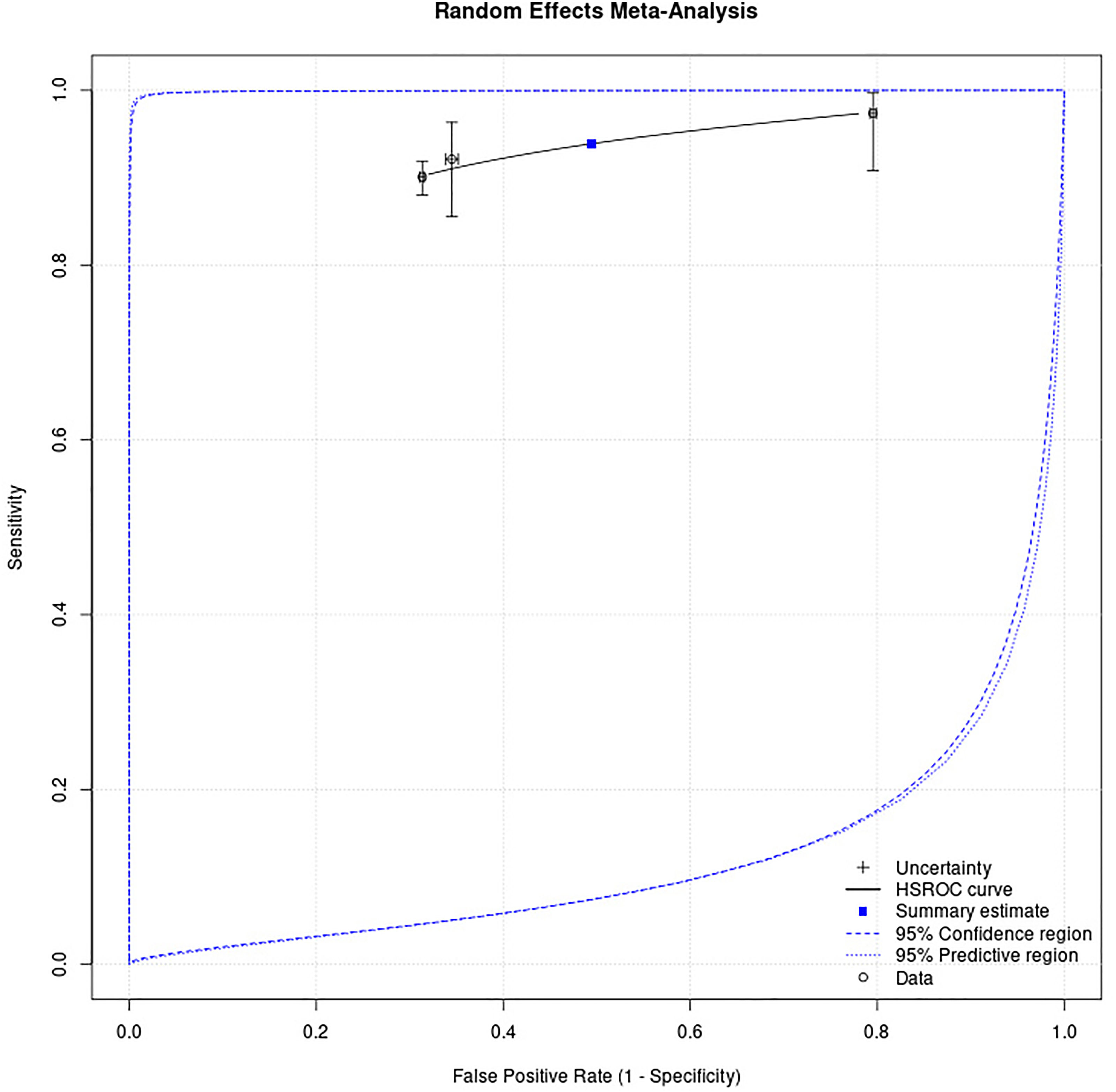
Hierarchical summarized receiver-operating curves (HSROC) using the bivariate approach yielded an area under the curve of 1.0 and the diagnostic odds ratio for the studies was 15.6.
Quality assessment
Concerning risk of bias, in the “patient selection” domain, all studies were at unclear risk of bias. In the “index test” domain, two studies were at low risk of bias, and one was unclear. In terms of “reference standard” and “flow and timing,” all studies were regarded as low risk of bias. Regarding applicability concerns, in the “patient selection” domain, all studies were at low risk of concerns. In the “index text” domain, two studies were at low risk of concerns, and one was unclear. Regarding reference standard, all studies show low risk of applicability concerns (Figure 6).

Summary of risk of bias and applicability concerns.
Discussion
Our comprehensive review of previous research suggests that the implementation of computer-aided screening algorithms into the workflow of screening breast mammograms may have a significant impact in terms of workload reduction. Evaluation of multiple studies showed that incorporating the Transpara® software with a test threshold of 7 resulted in a workload decrease by 68%. If applied to clinical practice, nearly 7 in 10 breast mammograms could potentially be assessed solely by the AI algorithm, whether as a second reader or a stand-alone interpreter. Importantly, the sensitivity and specificity of the screening programs are not compromised by these techniques. By using the AI algorithm with an optimized lesion detection threshold, the achieved sensitivity was 93.1%, indicating a false-negative rate of 6.9%. As a comparator, the false-negative rate of the current standard of care for screening mammograms is 12.5%. 25
Vulnerable populations disproportionally suffer from lack of resources, and AI could potentially be applied to decrease this gap. AI triage systems could expand screening programs, decrease turnaround time, and reduce cost of breast cancer screening in low resource settings, providing vulnerable populations with more equitable access. AI-enabled triaging is extremely scalable. In an adjusted screening workflow (i.e. using machine-only reading of cases assigned to be normal as an alternative to single or double reading), algorithms were performing a high volume of analysis and tasks without a negative impact on performance. A challenge in the field is that there is no agreement towards the acceptable “missed cases” rate for a machine-only mammogram triaging system, which has led to a high heterogeneity among study designs and chosen thresholds (above 80%). Additionally, there is a question of the ethics involved in how to manage a cancer diagnosis missed by a computer algorithm. Patients would need to be informed that their images were being read solely by a machine, which may also result in dissatisfaction. There is still much work to be done to address the appropriate implementation of AI-aided breast cancer screening across clinical practices.
Caution should be taken during the clinical implementation of AI products for breast image triage as it is possible that the relative improvement in performance of machine learning (ML) algorithms is overestimated. Even though the three studies included in the quantitative analysis presented with Low Risk regarding Applicability Concerns at QUADAS-2, the risk of bias in ML studies is underestimated. Underreporting of demographic information including resource setting and ethnic diversity used to train and test ML software could limit generalizability in diverse patient populations. Furthermore, since all studies are retrospective, non-randomized, risk of bias was deemed unclear in the “patient selection” domain. These and other common pitfalls in AI research have been extensively highlighted by a previous analysis by our group looking into study designs and bias of ML algorithms in breast oncology. 26
Limitations of the current study include the lack of access to raw data to reproduce or examine findings from the published articles, despite effort made to reach out to all corresponding authors. Even though half of the algorithms are available on open-source platforms, not all papers provided training weights, nor the criteria for the chosen cut-off point at which algorithm performance was determined, preventing the development of a deployable model and restricting reproducibility and transparency. The process of selection of studies for inclusion could be a limitation, since it is not always possible to identify if a study is suitable for inclusion solely by reading the abstract. The studies used to obtain the sensitivity, specificity, and AUC were all single center studies, and the sample was heavily influenced by Larsen 2022 15 due to its large sample size. Additional evaluations are needed to understand the broader impact of these AI tools in settings of variable resource availability and diverse populations. Our analysis was performed using data from three studies that all used Transpara® but in two different versions, and the scores differ slightly between versions. This could potentially affect the results. Our findings suggest a potential benefit from adopting Transpara® into a breast imaging workflow, but many other ML algorithms are commercially available for breast imaging triage (CMTriage, HealthMammo, Saige-Q, CogNet QmTriage). These AI products are not included in this analysis because there are no studies assessing their performance in the literature. It may be beneficial, both for providers and patients, to have performance data from these algorithms published and analyzed to ensure safe and practical adoption into health systems.
To our knowledge, this is the first meta-analysis of AI-based triaging of breast cancer screening mammograms applied to radiologists’ workload reduction. A previous systematic review 27 assessed seven studies evaluating computer-aided triage. Since then, there have been a high number of publications focused on triage. No prospective studies have yet been published. Our findings show the need to conduct well-planned prospective trials comparing different breast screening programs. To replicate the group imbalance in screening, these prospective studies should contain realistic case proportions, with readers of various expertise engaging with ML algorithm outputs inside the clinical workflow. This will make it possible to evaluate reader performance as well as technological viability, reading time, reader acceptance, and impact on performance. Prospective studies examining the use of ML for mammographic screening are now being conducted in the UK, Norway, Sweden, China, and Russia, and results are awaited.28–30
AI-enabled triaging of screening breast mammograms could reduce radiology workload and potentially be deployed to decrease healthcare disparities. ML can triage screening breast mammograms at a pace that is unattainable for human readers without compromising performance. Prospective data are necessary to evaluate the interaction between human readers and algorithms, their impact on reader performance and patient outcomes, and to validate algorithm thresholds.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.