
Abstract
For the past 140 years, numerous studies have been conducted to examine minimum durations of samples needed for the recognition of acoustic parameters such as pitch, timbre or vocal phonemes. Recent studies in this field are often based on short clips (plinks) of popular songs, using target variables such as titles and interpreters. These studies provide strong evidence that a wide range of intra- and extramusical information can be identified above chance level for stimuli lasting much shorter than a second. Nevertheless, a review of precedent studies revealed a heterogeneity in stimulus generation processes that could have influenced overall recognition rates. As a piece of music unfolds in time, its timbral structure is subject to a variety of changes. We assume that the position of stimulus extraction, therefore, could influence the outcomes of a subsequent recognition task, for instance. In this study, we offer a systematic and objective stimulus extraction procedure that might help to control for (a) a possible confounding of stimulus duration and timbre (caused by the extraction of stimulus sets of various length from different song positions), (b) possible confoundings of song section and timbre (caused by the comparison of stimulus sets from divergent song sections), and (c) the suspected influence of subjective criteria on extract selection (caused by the non-randomized selection of extract positions). As an alternative approach, the suggested Matryoshka principle produces randomized sets of nested stimuli controlled for song position and objective selection. Each set represents an individual section and consists of five short excerpts, cut from each other in decreasing duration. Correlation analyses confirmed that these sets prove to be stable in terms of their mel-frequency cepstrum coefficients, the so-called “psycho-acoustic fingerprint” of a sound. Based on the software Random Plink Generator, the suggested procedure can help to contribute to an objective selection of stimuli in future plink research.
Keywords
Attempts to determine the temporal borders of the acoustically perceivable have a long tradition in experimental designs within the field of music psychology. As high precision in time measurement emerged in the last quarter of the 19th century, experiments on reaction time became popular (e.g. Exner, 1876; Martius, 1891; von Kries & Auerbach, 1877). Participants in these studies were asked to identify the presence or absence of an acoustic stimulus and operate a mechanical measuring device as soon as they did. The central questions in all these studies remain quite up to date: Where are the temporal thresholds of auditory perception, and how do recognitions of auditory parameters unfold from very short to longer periods of time? Approaches towards determining minimum thresholds of sound qualities have been refined with the technological developments of the 20th century. For instance, Gray (1942) unknowingly built on Leimbach (1912) by suggesting a pendulum switch in order to segment exact sections of vocals transmitted via a microphone and a speaker box from one room to another. Gemelli and Pastori (1934) promoted the use of the cathode ray oscillograph to obtain reliable external criteria for linguistic analyses.
It was not until the turn of the millennium that new technologies gave additional impulses for the investigation of minimum durations needed for the perception of complex musical information. Referring to a conference contribution made in 1999, Gjerdingen and Perrott (2008) presented their paper “Scanning the Dial,” a study on the rapid assessment of 10 musical genres represented by very short excerpts of popular songs. Listeners (N = 52, “ordinary undergraduate fans of music”) were asked to name the genres of 400 excerpts in all (spanning a range of durations between 250, 325, 400, 475 ms, and 3 s), while the longest clips served for the observation of ceiling effects. Gjerdingen and Perrott found degrees of correct answers above chance level for all stimulus durations. Correct response rates increased with the length of the clips. For the genre of classical music, correct assignments reached the 70% mark for a sample length of 250 ms. In the same year as Gjerdingen and Perrott’s initial experiment, Schellenberg, Iverson, and McKinnon (1999) published a similar study in which they had asked for the exact titles and interpreters of the source materials as a new target variable, thus avoiding the blurriness of genre classifications. They found that recognition rates for 200 ms and 100 ms stimuli exceeded chance level.
The creation of the term plink for a short snippet of a song can be traced back to Krumhansl (2010). Following Gladwell’s popular scientific publication Blink: The Power of Thinking Without Thinking (Gladwell, 2007), Krumhansl defined her coinage as “thin slices” of musical information that allow for the anticipation of information exceeding their actual informational content. Referring to Gjerdingen and Perrott, Krumhansl pointed out that this type of stimuli holds potential for the investigation of acoustic cues that are crucial for the rapid and intuitive classification of musical information. In two experiments, Krumhansl asked participants for statements about the title and interpreter, emotional content, decade of production, and genre classification. In an analysis of the outcomes, the author stated that 25% of 400 ms clips were identified correctly as measured by identification titles and interpreters. Even when listeners did not know the exact origin of the stimulus, they agreed upon single characteristics (i.e. genre) to a high extent. Krumhansl added that recognition rates increased when sung words or word fragments were included. This interpretation contradicts the assumption presented by Gjerdingen and Perrott that voice fragments in stimulus materials would lead to masking effects and therefore decreasing recognition rates.
However, the crucial point is that previous plink research has been characterized by a great variety of target variables, different methods of stimulus extraction from a piece of music, and differences in the reported perceptual thresholds for the respective target category (for an overview on the methodological diversity of previous studies in the field, see Thiesen et al. (2016)). For example, while Mace, Wagoner, Teachout, and Hodges (2011) reported “impressive levels” for stimuli of 125 ms, Gjerdingen and Perrott (2008) determined the stabilization of results above chance level at 250 ms.
In an overview, Appendix A compares different extraction criteria and target variables used in five plink studies. For instance, while Schellenberg et al. (1999, p. 642) argued for “maximum excerpt representativeness of the recordings”, based on the experimenter’s judgments, Mace et al. (2011) used a manual randomization technique. Due to ambiguous results of many of the studies presented, we assumed that differences in the outcomes of previous studies might be based on differing criteria of stimulus selection from the musical sources. Appendix B shows different sets of stimulus durations used in the same publications. While the range of durational values roughly remained the same, the studies varied in terms of individual iterations, thus making results of the perceptual experiments hard to compare.
Rationale and aim of the study
In order to avoid this assumed confounding of variables, we followed a strict systematization of the stimulus extraction process. The so-called Matryoshka principle is based on a combination of different approaches in plink research: Krumhansl (2010) used different structural sections (verses and choruses of the original pieces) as stimulus sources, while Plazak and Huron (2011) introduced a pioneering iterative design of stimulus durations. In line with the randomization technique suggested by Mace et al. (2011), we propose a new approach for the construction of stimulus sets, the so-called Matryoshka principle of stimulus generation, to gain maximum control over the construction of stimulus sets with multiple durations. To control for the influence of song sections (e.g. chorus or verse) and plink durations on recognition rates, and to avoid the possible confounding between sample duration and timbral fluctuations, we suggest the use of a nested principle (“parent child” principle, inspired by Gjerdingen and Perrott (2008)) of stimulus extraction, which is controlled by mel-frequency cepstrum coefficients (MFCCs).
Method
The Matryoshka principle of stimulus generation is based on the idea that in pieces of popular music genres, arrangement-specific parameters are more likely to be stable within structural parts (i.e. chorus and verse) than between sections. Gjerdingen and Perrott (2008) and Schellenberg et al. (1999) used subjectively selected excerpts chosen because of their maximum representativeness of a song or genre. We believe that this could influence the outcome of perception studies by causing higher recognition rates than randomly selected excerpts, which was suggested by Plazak and Huron (2011). Thus, the suggested Matryoshka principle is preceded by an analysis of musical structures (e.g. chorus or verse) followed by a randomized extraction from individual structural parts: Plinks with the longest duration are selected from one section. In a next step, nested stimulus sets are created by extracting shorter plinks from the longer ones by shortening their durations in several steps. We assume that the informational stability of the stimuli produced is reflected in the stability of their timbral properties and can be controlled by using methods of music information retrieval. As a result, the Matryoshka principle is validated by analyses of low-level timbral texture features and calculations of overall correlations between nested stimuli of decreasing durations. When compared with randomly selected excerpts throughout the whole duration of the songs, these Matryoshka-type plinks reach high degrees of timbral stability. This finding was tested by an additional analysis of sequentially selected plink sets sliced from the same structural section.
Materials
For the creation of a new plink data set, we referred to the information provided in Krumhansl (2010). The author utilized a selection of 28 popular compositions covering different genres and release dates from the 1960s through 2010. To update the stimulus material, we added 10 No. 1 songs from the “Billboard Year End Charts,” 2006 to 2015 (Billboard, 2016). This resulted in a total of 33 source songs (see Table 1). In order to avoid possible confoundings that could be caused by recent remasterings and lossy audio formats, we purchased the original CD recordings of all songs and used them in a lossless format.
Songs used for the extraction of Matryoshka plinks analyzed in this study.
Note. Following an analysis of the musical structure, two sets of five nested stimuli were extracted from each song, representing the second chorus and verse, respectively.
The Matryoshka principle
A musical structure analysis of all pieces was initially undertaken to mark the borders of individual extraction periods. In a following step, the longest plink duration of interest was extracted from each section. In general, a stimulus generation from different structural sections of the sources is strongly recommended for obtaining maximum independence from subjective decisions. For a semi-automated extraction of plinks in a randomized manner, we developed a program for the audio programming language Csound. The Random Plink Generator can be accessed and operated easily by using the CsoundQt user interface (for a detailed description, see the Supplemental Material section). After loading a source sound file, different parameters can be adjusted: namely, the duration of the plink to be created, the time frame for extraction, and the duration of an optional fade-in and -out (see Figure 1). After the initial extraction of a plink, it can be manually reloaded into the script. It then serves as a source file for the next extraction of a sample with shorter duration, and so on (see the Acknowledgments section for the download of the program). Figure 1 depicts a flow chart of the extraction and documentation process.

The Matryoshka principle of stimuli extraction with decreasing duration size. All extraction points and stimulus durations are documented. The data set is completed by timbral texture features calculated for every individual file.
This process permitted sufficient control over the content of the stimuli created in this study, providing consistency over various stimulus durations. However, zero crossing while extracting clips from existing sound files is very likely, resulting in glitches, pops or click sounds when playing back the sound data (Ableton, 2017). Such irritating effects were avoided by the use of a 2 ms fade-in and fade-out (software option). For this study, we extracted five stimuli of 800, 400, 200, 100, and 50 ms from two structural parts (e.g. the second verse and chorus) of each source song. This wide range of durational values should allow future research to report both floor and ceiling effects in recognition tasks. Starting from our song database, this resulted in a total of 330 short clips.
Validation by MFCCs analysis
To control for the invariance of timbral features in stimuli of various length, an analysis of MFCCs was applied to the extracted sets of stimuli. In music information retrieval (MIR), MFCCs are used as so-called low-level features which represent properties of acoustic signals, such as loudness, amplitude, and overall energy (Mühlhans, 2017). These short-term psycho-acoustic features can be calculated in a windowed manner over the entire duration of a sound signal. Since their introduction by Davis and Mermelstein (1980), MFCCs have been used for a broad variety of applications. Originally developed for word recognition tasks in continuous speech, they have also been successfully used for purposes of sound classification tasks in various contexts (Logan, 2000).
MFCCs are generated by converting an audio signal into frames. After a discrete Fourier transformation (DFT), a log of the amplitude spectrum is taken. Subsequently, mel-scaling and smoothing are calculated. While the musical scale linearly divides the acoustically perceivable frequencies into octaves by doubling their ground frequency, the mel-scale is a non-linear psycho-acoustic model of pitch perception. In an experimental setup involving two beat-frequency oscillators, Stevens, Volkmann, and Newman (1937) presented n = 5 participants a row of reference tones (spanning 125, 200, 300, 400, 700, 1000, 2000, 5000, and 12,000 Hz). Participants were asked to adjust the frequency of a second oscillator (alternatingly presented with the reference signal by a relay switching between both tones) until it appeared to them as half of the pitch of the reference frequency. When the authors plotted the weighted geometric means of the ratings on a standard frequency scale, they found a non-linear function of pitch estimation. As a result, to date, the mel-scale has been used as a basis for the calculation of many psycho-acoustic features.
After the mel-scaling and smoothing of the initial signal are applied, a discrete cosine transformation (DCT) is used to generate the final coefficients. According to Lerch (2012), the advantages of MFCCs over the formerly used standard cepstrum analysis are the use of the non-linear mel-scale of pitch and the application of a DCT instead of a DFT.
Mel-frequency cepstrum coefficients have been applied to various music-related research questions, and differing sets of MFCCs have been referred to as the “individual fingerprints” of a sound. Tzanetakis and Cook (2002), McKinney and Breebaart (2003), and Baniya, Lee, and Li (2014) used MFCCs for automatic genre classification tasks. Tzanetakis and Cook (2002) reported a classification accuracy of 61% for a set of 30 psycho-acoustic features including (among others) 10 MFCCs, which they claimed was similar to human recognition rates (despite higher rates observed in some psychological experiments, e.g. Gjerdingen & Perrott (1999)). By including additional timbral texture features and using an improved classification algorithm, Baniya et al. found correct classification rates as high as 80.75%. Müller (2015) explained this by pointing to the potential of MFCCs to capture aspects like instrumentation and timbre. In line with this view, Müllensiefen and Siedenburg (2017) used MFCCs as external criteria for the validation of (dis)similarity ratings in music psychology.
Based on the MIR-Toolbox (Lartillot, Toiviainen, & Eerola, 2013), we calculated MFCCs for our set of 330 short Matryoshka-type stimuli (set I), resulting in a total of 4290 individual values (33 sources × 2 structural sections × 5 durations × 13 MFCCs). According to the authors, the DCT results in a strong “energy compaction.” In order to divergently validate the high amount of timbral stability provided by this principle, we created and analyzed another set of 165 stimuli (set II), each randomly picked throughout the entire durations of the source songs. Set III consists of an additional 330 excerpts, sequentially extracted from similar structural parts, beginning with a 50 ms plink, followed by a 100 ms plink beginning at the ending point of the first plink (juxtaposed plink sets). As most of the signal information is concentrated in a few low

In the original equation by Davis and Mermelstein (see equation 1), M is the number of cepstrum coefficients and X k , k = 1, 2,∙∙∙, 20, represents the log-energy output of the kth filter (Davis & Mermelstein, 1980).
Results
Data analysis
We aimed to investigate the consistency of MFCCs over the different durations of plinks, and therefore calculated bivariate Bravais-Pearson correlations between stimuli lengths of 50 and 100 ms, 100 and 200 ms, 200 and 400 ms, and 400 and 800 ms for identical source songs and structural parts. As averaging correlations can result in undesirable biases, a transformation should be applied before the averaging process (for details, see Alexander (1990); Donoghue & Collins (1990); Skidmore and Thompson (2011); and Eid, Gollwitzer, & Schmitt (2015), who suggest the G-transformation introduced by Olkin & Pratt (1958)). Thus, we transformed raw correlations into G values as suggested by Olkin and Pratt. These G-transformed correlations can then be averaged, resulting in non-biased Ḡ values. Equation 2 shows how a G-transformation following Olkin and Pratt is conducted. Being designed for averaging correlations of different studies (e.g. in the case of meta-analyses), it can imply different sample sizes: ni represents the sample size of the ith study in which the correlation ri is originated (Eid et al., 2015).

The greater ni, the more Gi approximates the original correlation. As our sample sizes (the subsets of stimuli of equal durations) were equally large, no further mathematical treatment had to be undertaken to calculate the mean correlations after the initial transformation. Table 2 gives an overview of the averaged correlations between the MFCCs of stimuli of adjacent durations.
Correlations between MFCCs of stimuli with adjacent stimulus durations extracted from identical extraction points (songs and structural parts), followed by transformed and averaged correlations (Ḡ) between all stimuli of identical source sections (n = 330, set I).

Note. Correlations were calculated between stimuli of 50 and 100 ms, 100 and 200 ms, 200 and 400 ms, and 400 and 800 ms. Decreasing raw correlations can be explained by an increase of spectral variability in stimuli of longer durations. High correlations point to high timbral stability within structural sections.
Table 2 shows very high correlations between stimuli of adjacent durations—even for the longest clips analyzed. As timbral variability increased with the size of the clips, individual correlations seemed to fall slightly with increasing durations. The averaged Ḡ values for all MFCCs over all five stimulus durations ranged from ḠMFCC10 ≈ .86 to ḠMFCC1 ≈ .93. On the basis of these very high overall correlations, we concluded that the Matryoshka principle provides a solid basis for high levels of timbral stability within stimulus sets of the same structural part.
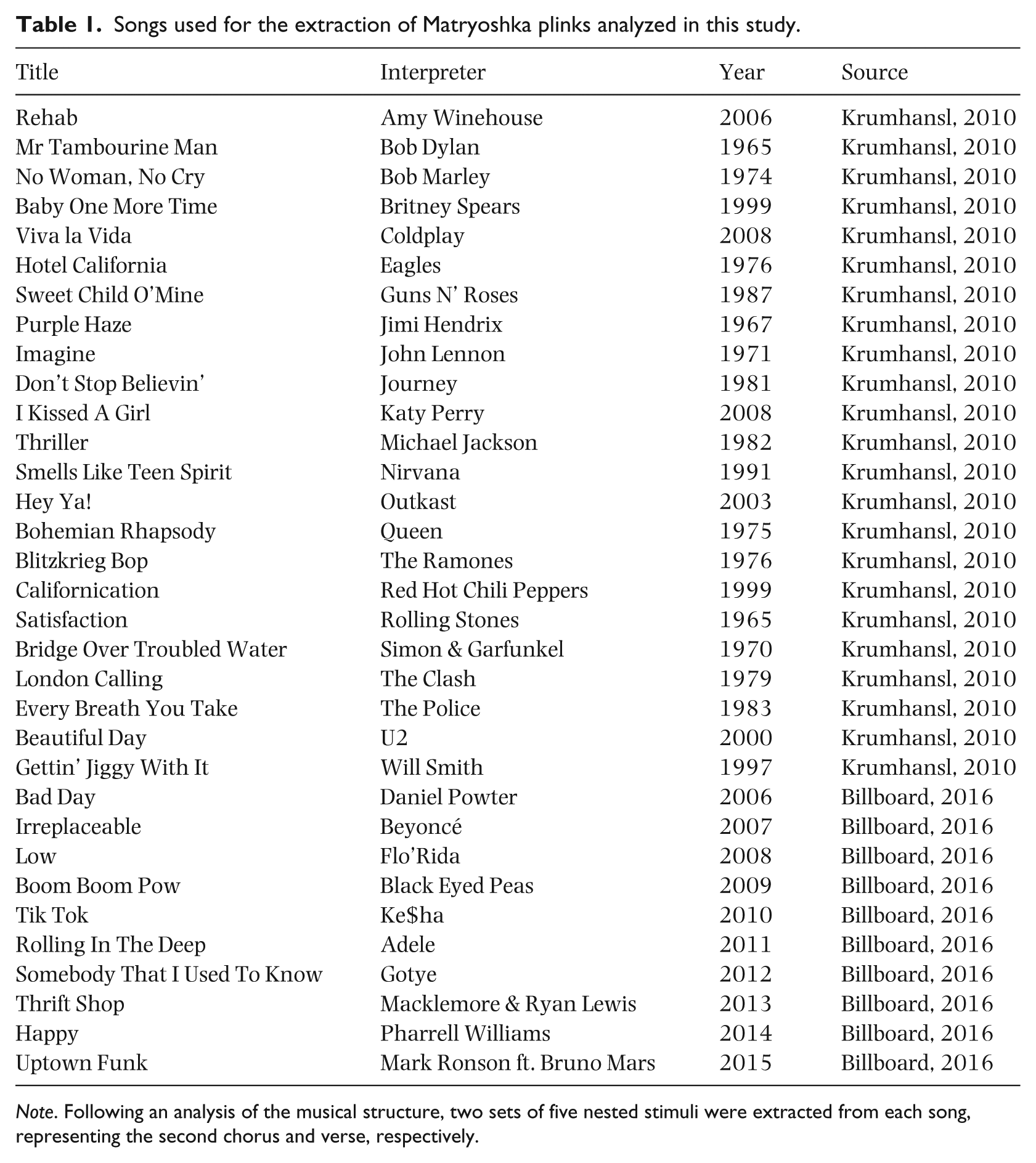
Following the assumption that plinks of different structural parts show much less arrangement-specific concordance, we expected the MFCCs of stimuli from identical sound sources and with identical lengths but from different structural parts to correlate on a much lower level. Therefore, we subsequently calculated correlations between the MFCCs of same-length, same-song but different section stimuli (see Table 3). Individual and averaged correlations remained mostly at very low to medium values (ḠMFCC5 ≈ −.18 to ḠMFCC6 ≈ .69).
Correlations between MFCCs of stimuli (n = 330, set I) with same durations from different sections (verse and chorus) of identical songs, followed by transformed and averaged correlations (Ḡ).
Note. All five stimulus durations are represented by n = 66 individual plinks each, derived from verses and choruses of the source materials. Correlations were calculated between the MFCCs of same-length stimuli derived from verses and choruses of identical source songs. Very low to moderate correlations point to high timbral variability between structural sections.
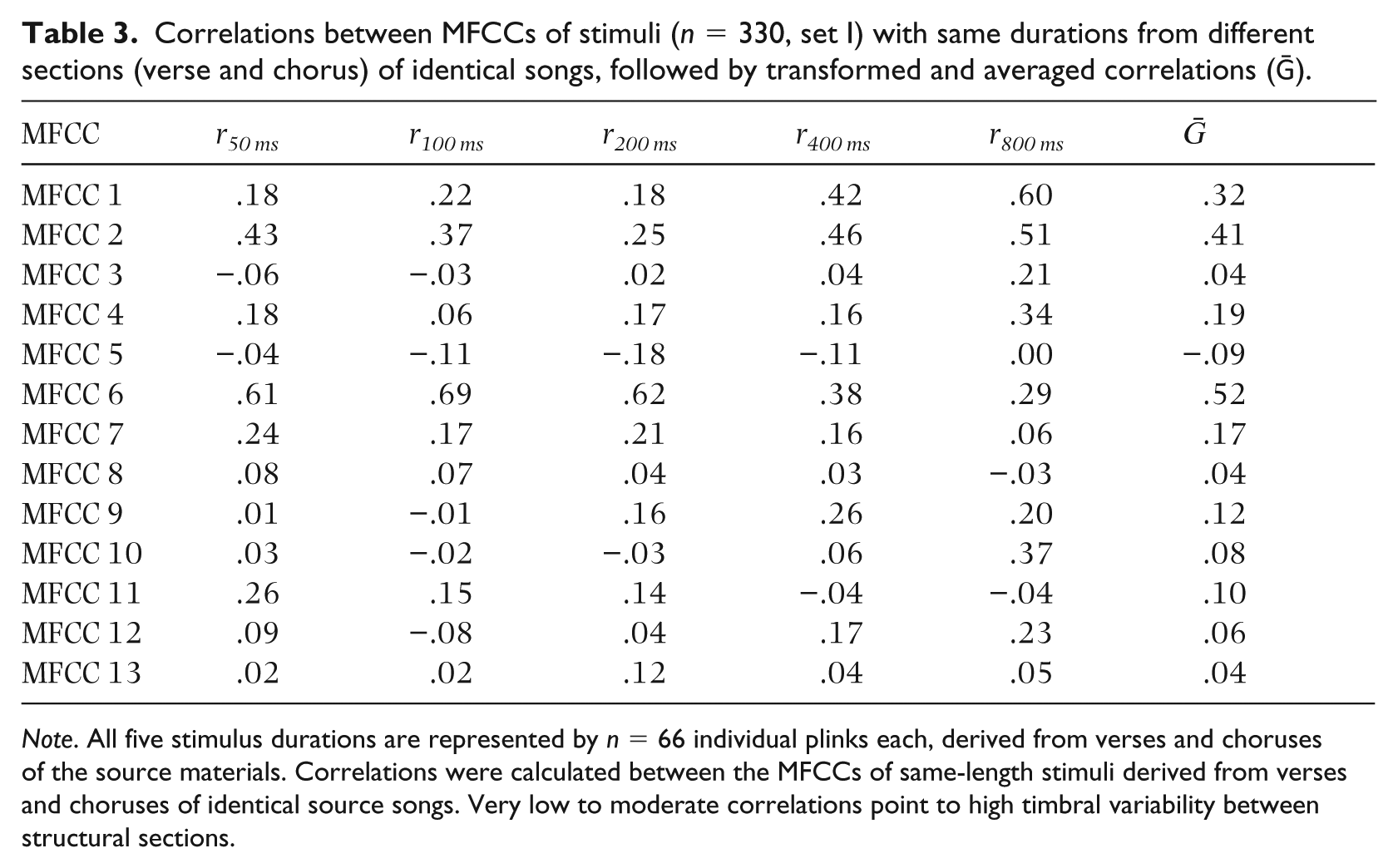
This broad range of data points illustrates that plinks extracted from different structural parts show high timbral variability. This assumption is underpinned by an additional analysis of n = 165 stimuli randomly selected from the entire duration of the source materials (stimulus set II, see Table 4). While we used the same songs for this analysis, the excerpts have been selected regardless of the structural parts of the underlying compositions. As a result, compared with the findings of the MFCCs for the Matryoshka-type stimuli, individual and averaged correlations of the randomly selected sections are surprisingly low (ḠMFCC8 ≈ −.18 to ḠMFCC4 ≈ .53). It is highly likely that mixing extracts from different formal sections of a song will result in an unstable basis for recognition tasks.
Correlations between MFCCs of stimuli with adjacent stimulus durations (n = 165, set II) randomly extracted over the entire duration of each song, followed by transformed and averaged correlations (Ḡ). The underlying audio data do not follow the Matryoshka principle of stimulus generation.
Note. All five stimulus durations are represented by n = 33 individual plinks each, derived from the entire sound signals of the source materials. Correlations were calculated between the MFCCs of 50 and 100 ms, 100 and 200 ms, 200 and 400 ms, and 400 and 800 ms. Negative to low correlations point to high timbral variability when picking stimuli from the full range of a source signal.
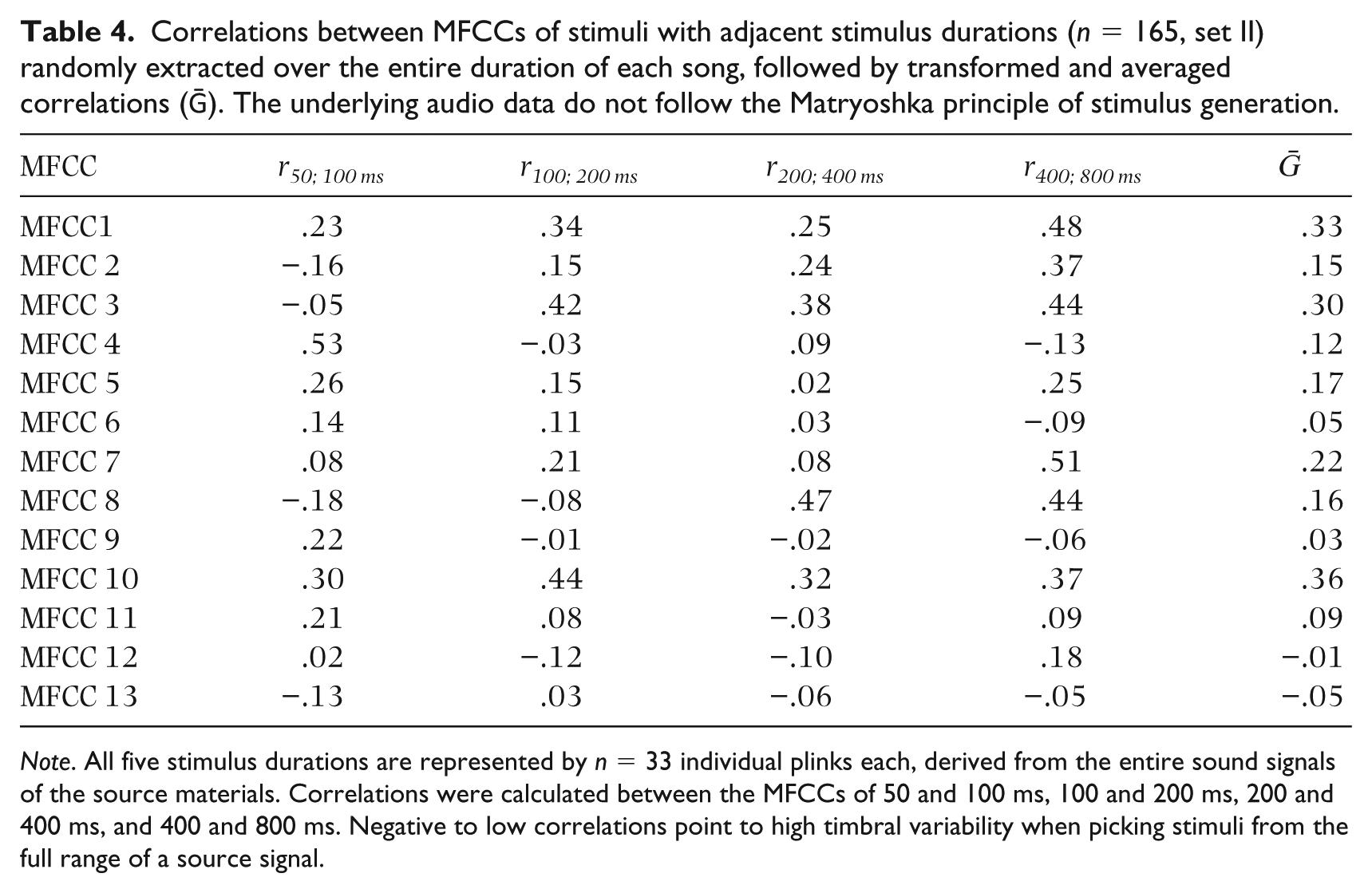
Set III, composed of 330 sequentially (juxtaposed) generated plinks from identical structural parts, was analyzed in the same manner (see Table 5). The timbral variability of these stimuli ranges between that of sets I and II, showing individual correlations between ḠMFCC13 ≈ .05 and ḠMFCC7 ≈ .78.
Correlations between MFCCs of sequentially generated stimuli with adjacent stimulus durations (n = 330, set III) extracted from two structural sections of each song, followed by transformed and averaged correlations (Ḡ). The underlying audio data do not follow the Matryoshka principle of stimulus generation.
Note: All five stimulus durations are represented by n = 66 individual plinks each, 33 derived from the choruses and 33 from the verses of the source songs. Correlations were calculated between the MFCCs of stimuli with 50 and 100 ms, 100 and 200 ms, 200 and 400 ms, and 400 and 800 ms stimulus duration. Mostly low to moderate correlations point to comparatively high timbral variability when sequentially picking stimuli from individual structural sections.
In line with our calculations, we concluded that (a) the coefficients remained very stable within the temporally nested stimulus sets but (b) differed between the structural parts of a song. This was the case for all the above-mentioned 330 Matryoshka-type short stimuli. The MFCC analyses of stimulus set II support this finding. Radar charts in Figure 2 show the MFCCs calculated for stimuli derived from two structural parts of three exemplary songs as well as a combined set of randomly selected stimuli spanning the same durational values (non-Matryoshka-type plinks). There was high consistency of all MFCCs for the stimuli of different lengths derived from individual sections. In comparison, the coefficients of stimuli derived from different structural parts showed far fewer similarities (as indicated by the degree of overlap of lines). In other words, when stimuli are chosen from individual sections in a sequential manner, correlations between stimulus lengths vary considerably, which gives support to our hypothesis that Matryoshka-type plinks are more stable in terms of their MFCCs.
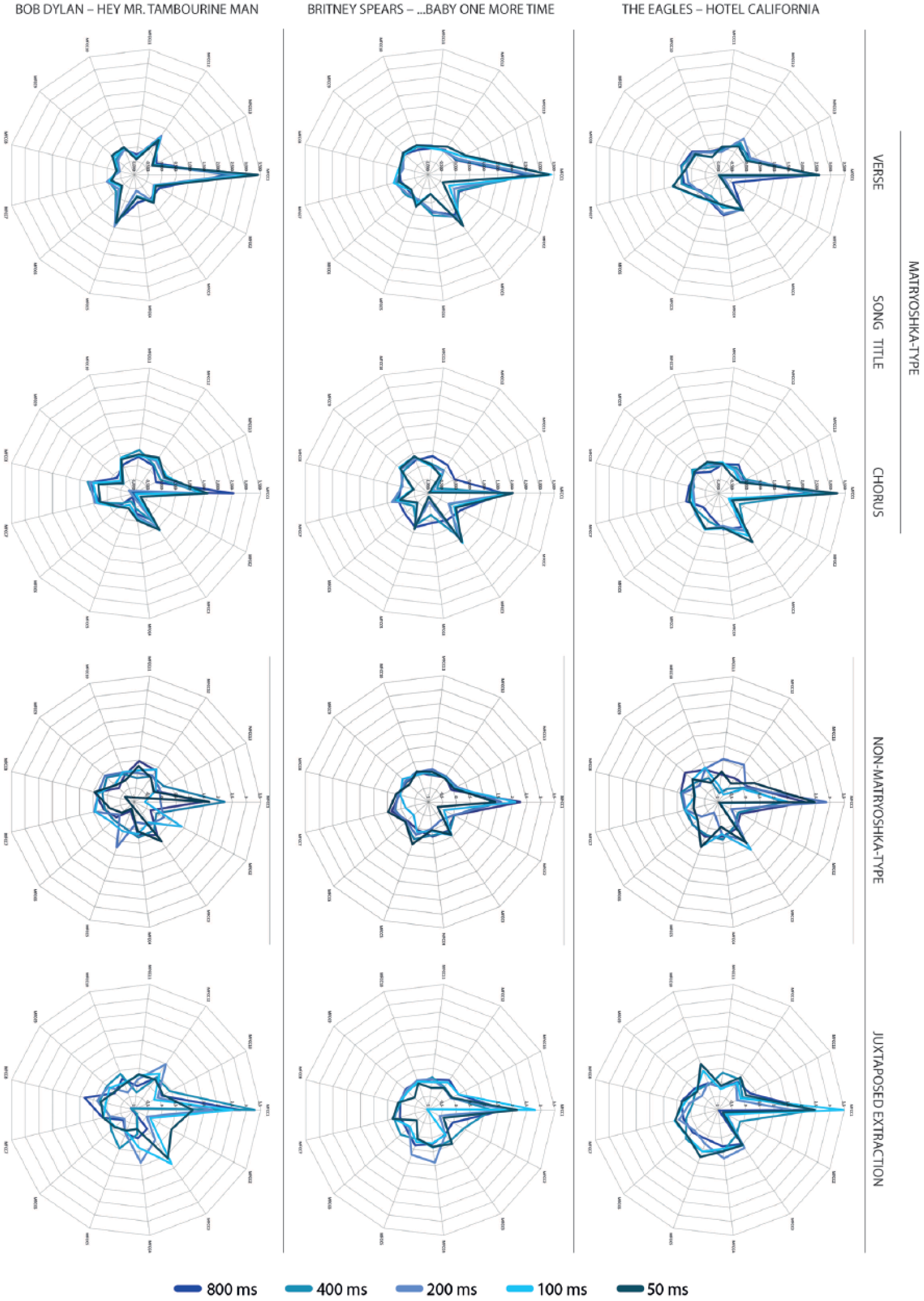
Exemplary radar charts of the 13 MFCCs calculated for selected Matryoshka-type stimulus sets of various length, extracted from three out of 33 specific songs (see Table 1) and sections (left: verse; right: chorus). For all differing songs and sections, the MFCCs of these stimuli showed high consistency over the five stimulus durations. Non-Matryoshka-type stimuli extracted over the entire duration of the source materials (right) show less overall timbral consistency. Timbral similarity of stimuli generated sequentially from the same structural parts of the same sources (juxtaposed extraction) ranges between the two extremes of Matryoshka-type and non-Matryoshka-type extraction.
Discussion
A review of precedent studies revealed a high degree of variability in partial and overall recognition of very short musical stimuli. The diversity of findings in precedent studies could be explained by divergent methods of stimulus generation. While some studies suggest maximum representativeness of stimulus materials achieved by expert selection, others follow an approach of randomization. Based on the Matryoshka principle, we offer an alternative paradigm for semi-randomized stimulus creation to avoid possible biases in results due to the use of subjective selection criteria. The publications reviewed (see Appendix A and B) show heterogeneous principles of stimulus construction. These divergent principles of extraction might have influenced the outcomes of these studies.
Another source of uncertainty is the test design itself: As long as stimuli with unspecified content are used, no conclusions about the unfolding of recognition rates for individual intra-musical parameters can be drawn. Hence, future work should encompass the creation of stimuli from multi-track recordings and a documentation of what kind of information is contained in every file that is rated. Only by knowing what is inside the black box can we break further ground in discovering the time span in which different partial recognition performances seem to develop. In line with our observations on precedent research and the MFCC-based validation of our stimulus data set, we are very optimistic about finding perceptual correspondences for the observations presented in this article. The results of an extensive online study are currently being analyzed.
The Matryoshka principle serves as a prerequisite for further development of the plink paradigm as it keeps the content of short musical stimuli as stable as possible over different durational values. By ruling out sources of timbral variance, this new paradigm for stimulus generation could help place research in the field on firmer ground.
Supplemental Material
MSX820212_supp_mat – Supplemental material for A snippet in a snippet: Development of the Matryoshka principle for the construction of very short musical stimuli (plinks)
Supplemental material, MSX820212_supp_mat for A snippet in a snippet: Development of the Matryoshka principle for the construction of very short musical stimuli (plinks) by Felix Christian Thiesen, Reinhard Kopiez, Christoph Reuter and Isabella Czedik-Eysenberg in Musicae Scientiae
Footnotes
Appendix
Overview of sample sizes and stimulus properties in plink literature.
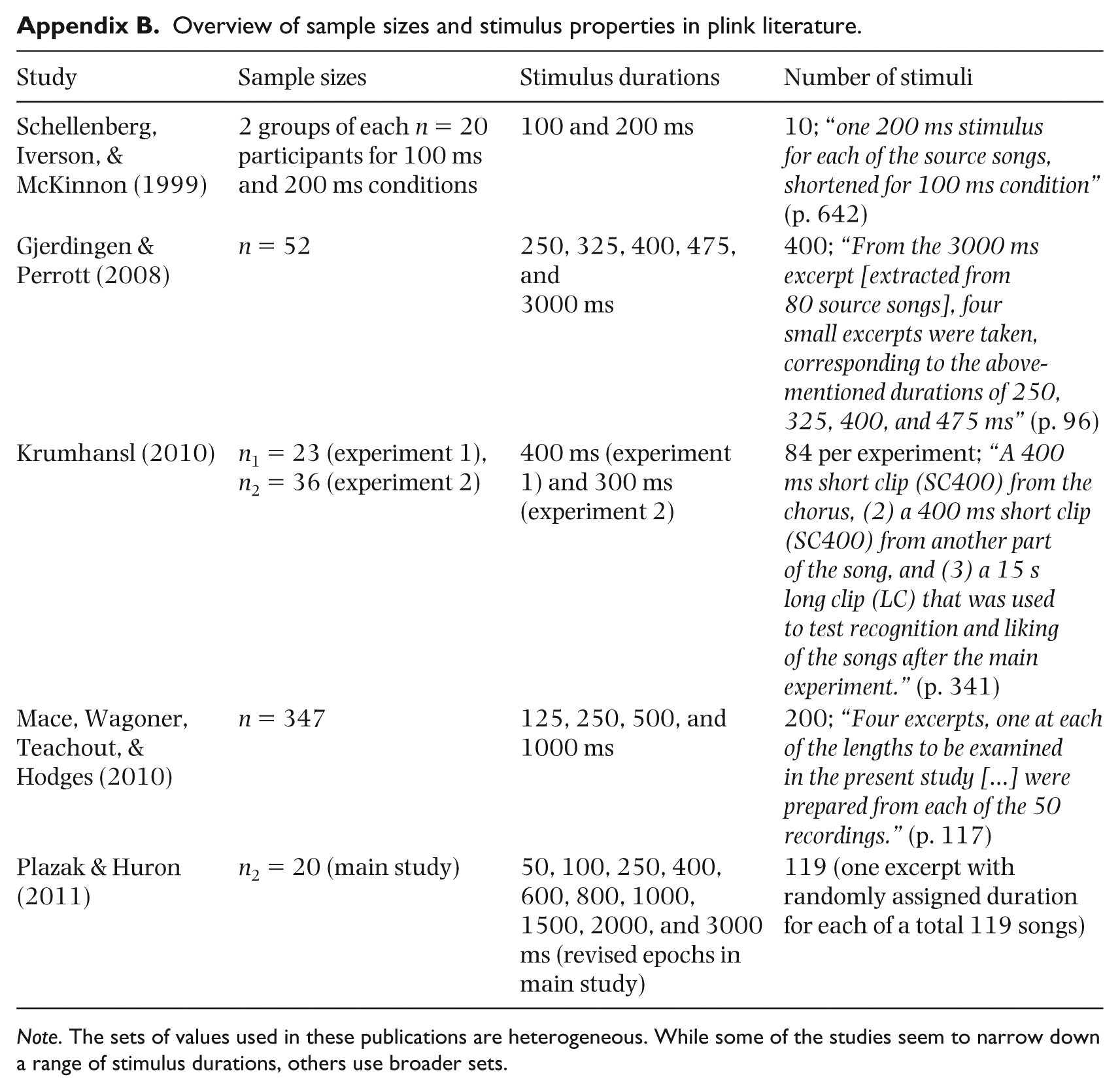
| Study | Sample sizes | Stimulus durations | Number of stimuli |
|---|---|---|---|
| Schellenberg, Iverson, & McKinnon (1999) | 2 groups of each n = 20 participants for 100 ms and 200 ms conditions | 100 and 200 ms | 10; “one 200 ms stimulus for each of the source songs, shortened for 100 ms condition” (p. 642) |
| Gjerdingen & Perrott (2008) | n = 52 | 250, 325, 400, 475, and 3000 ms |
400; “From the 3000 ms excerpt [extracted from 80 source songs], four small excerpts were taken, corresponding to the above-mentioned durations of 250, 325, 400, and 475 ms” (p. 96) |
| Krumhansl (2010) | n1 = 23 (experiment 1), n2 = 36 (experiment 2) |
400 ms (experiment 1) and 300 ms (experiment 2) | 84 per experiment; “A 400 ms short clip (SC400) from the chorus, (2) a 400 ms short clip
(SC400) from another part of the song, and (3) a 15 s long clip (LC) that was used to test recognition and liking of the songs after the main experiment.” (p. 341) |
| Mace, Wagoner, Teachout, & Hodges (2010) | n = 347 | 125, 250, 500, and 1000 ms | 200; “Four excerpts, one at each of the lengths to be examined in the present study […] were prepared from each of the 50 recordings.” (p. 117) |
| Plazak & Huron (2011) | n2 = 20 (main study) | 50, 100, 250, 400, 600, 800, 1000, 1500, 2000, and 3000 ms (revised epochs in main study) | 119 (one excerpt with randomly assigned duration for each of a total 119 songs) |
Note. The sets of values used in these publications are heterogeneous. While some of the studies seem to narrow down a range of stimulus durations, others use broader sets.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.