
Abstract
Objective:
Scientometric studies of social work have stagnated due to problems with the organization and structure of the disciplinary literature. This study utilized data science to produce a set of research tools to overcome these methodological challenges.
Method:
We constructed a comprehensive list of social work journals for a 25-year time period and searched for all available article records using 35 different databases. Customized software was developed to restructure article records into a single analyzable database. We then computed the annual journal growth from the database.
Results:
A population of 90 disciplinary journals was established, and 33,330 article records were retrieved from 80 of these journals. Rapid and consistent growth in the number of social work journals was observed, particularly from 1997 up to 2005.
Conclusions:
The population list of social work journals, database of article records, and customized software builds the foundation for future scientometric studies in social work.
Scientometrics is the “quantitative study of science, communication in science, and science policy” (Hess, 1997, p. 75)—also commonly referred to as the science of science. Scientometrics is essential to helping academic disciplines understand various aspects of their research efforts, including (but not limited to) the productivity of their scholars (Abramo, D’Angelo, & Di Costa, 2011; Babu & Singh, 1998), emergence of specializations (Nicolaisen & Frandsen, 2013; Pianta & Archibugi, 1991;), collaborative networks (Hou, Kretschmer, & Liu, 2008), patterns of scientific communications (Braun, Glänzel, & Schubert, 2001), and quality of research products (Lawani, 1986). This knowledge can be leveraged to inform decisions related to resource allocation and science policy (Yazdani, Nejat, Rahimi-Movaghar, Ghalichee, & Khalili, 2015) as well as understanding the social impact of research (Bornmann & Leydesdorff, 2014). Scientometrics is also becoming increasingly important to guide the development of systems to effectively organize scientific knowledge and facilitate communications among scientists and across disciplines (Archambault, Vignola-Gagne, Côté, Larivière, & Gingrasb, 2006).
In 1963, de Solla Price published one of the most influential scientometric studies, conducting a count of journal abstracts published between 1907 and 1960 in the fields of chemistry, biology, physics, and mathematics. Based on the count of abstracts, de Solla Price estimated a doubling time for academic research of roughly 15 years, which corresponds to a cumulative annual growth rate of 4.7%. de Solla Price observed that, Science grows at a compound interest, multiplying by some fixed amount in equal periods of time.… Mathematically, the law of exponential growth follows from the simple condition that at any time the rate of growth is proportional to the size of the population or to the total magnitude already achieved—the bigger a thing is, the faster it grows. (1986, p. 4)
Scientometrics and Data Science
The tools and strategies of data science offer many unique opportunities to advance scientometric analyses. Data science is broadly defined as an area of study that draws on the fields of statistics, computer science, and information theory to manage and extract insights from massive collections of structured and unstructured data sources (Dhar, 2013). Data science methods provide alternatives to traditional ways of solving problems and produce innovative solutions through data mining, text mining, machine learning, and other analytic procedures. Besides offering descriptive and inferential analyses, data science can inform the development of practical solutions with respect to organizing, curating, and extracting information from the scientific literature.
Data science tools and techniques are already important to scientific disciplines and will become even more so as challenges arise due to the rapid expansion of the scientific literature. Gonzalez, Tahsin, Goodale, Greene, and Greene (2015), Fleuren and Alkema (2015), and Lu (2011) describe how data science tools like text mining and data mining are being used to advance the field of precision medicine through extraction, representation, and analysis of information from scholarly databases. One specific example is PubTator, an online tool designed to accelerate manual literature curation (e.g., annotating biological entities and their relationships) through the use of advanced text-mining techniques (Wei, Kao, & Lu, 2013). Furthermore, the National Center for Biotechnology Information recently released a variety of software technologies that allow researchers to conduct analyses with common data science tools on over 24 million article records in the PubMed database (National Center for Biotechnology Information, 2015). As the volume of science continues to grow, these kinds of tools will become increasingly useful for facilitating the retrieval and assimilation of research.
Scientometric Analyses of Social Work Research
Numerous scientometric analyses have been conducted in social work following the seminal work of Lindsey (1976, 1978) who set a standard for this line of research within the field. These have ranged from bibliometric studies focused on citation analysis (e.g., Hodge, Lacasse, & Benson, 2012), journal ranking (e.g., Holden, Rosenberg, Barker, & Onghena, 2006), and scholarly productivity (e.g., Lacasse, Hodge, & Bean, 2011) to examinations of the publishing and dissemination infrastructure in the field, such as editorial board composition (Pardeck, 1992) and the role of journals in social work (Baker, 1992). In particular, the release of the popular software Publish or Perish (Harzing, 2007) facilitated the production of many bibliometric studies in recent years, particularly in social work. This software extracts data from Google Scholar, which is widely used for bibliometric studies but can be problematic as a source of bibliometric data for empirical analysis. As demonstrated by Lopez-Cozar, Robinson-Garcia, and Salinas (2014), “data and bibliometric indicators offered by Google’s products can be easily manipulated” (p. 1).
The kinds of scientometric studies that can be performed on the field of social work’s body of research are necessarily limited by the availability of data sources. Unlike the fields of medicine and health sciences, which index the majority of their scholarly works in PubMed, a centralized database system open to the public, social work research is differentially indexed across many proprietary databases and accessible only through subscription-based mechanisms. These issues of differential indexing and access are serious challenges for the field that consequently make it extremely difficult to perform even rudimentary scientometric analyses of growth.
Three recent analyses reveal the challenges and limitations of conducting scientometric analyses on the growth and size of social work. Brekke (2012) used data from the ISI Web of Knowledge as the basis for commentary on social work’s contribution to the expanding social science knowledge base. This was done by comparing the number of social work journals and their impact factors with other social science disciplines. He reported a total of 39 social work journals in 2011, highlighting that only one journal had an impact factor over 2.0. The other fields being compared—that is, nursing, clinical psychology, and psychiatry—had much larger collections of journals, and those collections contained significantly more journals with higher impact factors. Ultimately, inferences made about the field of social work research based on data from this data source must be made cautiously. The ISI Web of Knowledge does not provide complete indexing for all the journals that comprise the field of social work, and a number of journals are erroneously labeled as disciplinary social work journals (e.g., American Journal of Community Psychology). Additionally, it isn’t clear how many journals in the field of social work research actually exist.
More recently, Howard and Garland (2015) conducted “free-text searches of three large databases—PsycINFO, Sociological Abstracts, and PubMed—using the phrase ‘social work’” (p. 180). Using a 30-year time frame (1984–2014), they observed a significant increase in the overall number of search results for each database: 699%, 891%, and 669%, respectively. These figures provide evidence of significant growth in social work research as well as serving as a point of departure for understanding the numerous complexities involved with estimating the growth of social work research. At the same time, it is unclear whether these figures reflect growth of the field of social work research or simply the usage of these terms. It is also unclear whether these three databases provide comprehensive coverage of all the journals in the field of social work.
Martinez, Cobo, Herrera, and Herrera-Viedma (2015) used the Science Mapping Analysis Software Tool to perform analyses on cowords and h-index values from research articles published in 25 social work journals indexed by the Web of Science over a period of 82 years (1930–2012). This study identified eight main thematic areas, providing both a conceptual and empirical understanding of how research themes have evolved in social work. Articles were categorized by thematic area and then an h-index score was calculated for each area using the associated articles. The inferences that can be drawn from this study are limited; however, given that, as noted earlier, the Web of Science does not index many social work journals.
A significant barrier to scientometric research in social work is the differential indexing of disciplinary journals across multiple proprietary databases. A comparative analysis of seven different databases revealed statistically significant differences when running the nearest equivalent search on each. The authors of this study emphasized that the social work professional would benefit from having a dedicated international database for social work research. More recently, McGinn, Taylor, McColgan and McQuilkan (2014) compared the performance of 14 databases relevant to social work. They attempted to retrieve 78 relevant articles but were successful in retrieving only 72 on just six of the databases.
In addition to the problem of social work journals being differentially indexed, numerous problems with the databases themselves have been observed. For example, Holden and colleagues (Holden, Barker, Covert-Vail, Rosenberg, & Cohen, 2009; Holden, Barker, Kuppens, Rosenberg, & LeBreton, 2015) have reported ongoing problems with indexing gaps in the Social Work Abstract databases. Larsen and von Ins (2010) also found that the coverage of the Social Sciences Citation Index has been declining over time. Taken together, these studies underscore the need for careful attention to the underlying organization and infrastructure for managing the research produced by the field.
Study Objectives
The purpose of this study is to develop a set of tools and strategies to serve as a foundation for future scientometric research in social work. Doing so necessarily requires practical solutions to numerous methodological challenges that have prevented growth in this area of research. Toward this end, we have adopted a data science framework and oriented our work around five specific objectives. These objectives are to: create a list of the entire population of social work journals; harvest all available articles records from these journals published within the past 25 years (1989–2103); create uniform article records to facilitate storage and analysis, both quantitative and text-based, and combine them into a Social Work Research Database (SWRD); demonstrate the utility of the data science approach by examining the overall coverage of the SWRD and analyzing trends in the growth of social work research; and make all aspects of the research available in an open and reproducible format to facilitate review of our methods and promote future research.
It should be noted that our fifth objective is particularly important for a number of reasons. Many methodological decisions were made that cannot be fully documented in the article. The open format that we used (described in the Method) allows the reader an opportunity to inspect our work and because it is fully reproducible, readers can make changes to our analyses to determine how methodological decisions may produce different results. Finally, the field of social sciences has recently come under serious scrutiny, given fraudulent and questionable research practices (see Bhattacharjee, 2013; McNutt, 2015). We use common tools of data science to make our work fully open and reproducible, which is regarded as an essential step in addressing quality concerns in the social sciences (see Dafoe, 2014; King, 1995; Yong, 2012). To our knowledge, this study is the first fully reproducible publication in a social work journal.
Method
This study was carried out in five stages to match the major research objectives. Although the study is described as a stage-based process, it is important to note that the process was highly iterative. This was due to a variety of data quality issues revealed in the process, which required additional searches for data and testing of computer code.
Defining the Population of Social Work Journals
No gold standard definition exists to clearly demarcate social work journals from other social science disciplines. For this study, we used the work of Hodge and Lacasse (2011) as our starting point. More specifically, Hodge and Lacasse created a comprehensive list of social work journals through an extensive review of multiple sources, including the book An Author’s Guide to Social Work Journals (National Association of Social Workers Press, 1997), Thyer’s (2005) more recent listing of social work periodicals, and the website Genamics JournalSeek (http://journalseek.net/). In creating their list, Hodge and Lacasse reviewed the mission and aims of each journal and eliminated those journals that were specific to another field or had an interdisciplinary focus.
All social work journals identified by Hodge and Lacasse (2011; n = 84) were included in our base list. We supplemented this list with historical titles of journals that changed names. The base list was then reviewed by the study team, and three journals were excluded from this list: The New Social Worker was excluded because it was regarded as a professional magazine rather than a social work journal with a peer review process, and the Journal of Rural Social Work & Social Development and the Electronic Journal of Social Work were excluded because we could not find any evidence of official journal activity.
We then performed supplemental searches in leading database aggregators EBSCOhost and ProQuest for journal titles that contained any of the following terms: “social work,” “social welfare,” “social casework,” “social service,” “human service,” “social development,” and “social environment.” In addition, web-based searches were conducted using these terms along with “journal” in an attempt to identify journals not indexed on either EBSCOhost or ProQuest, including open access journals. This process identified additional journal titles that the study team approved for inclusion. As the study team progressed through the subsequent stages of the study, additional journals were identified, reviewed by the study team, and added to the journal list upon approval of the study team. All decisions to exclude or include a journal title were based on the consensus of the study authors and consistent with the methodology of Hodge and Lacasse.
Harvesting All Available Article Records
Continuing to use EBSCOhost and ProQuest, we specified queries to retrieve all article records from the journals included on our updated journal list. We limited our search to “journal articles” as the type of publication. Doing so excluded other types of written material including editorials, comments on articles, letters to the editor, book reviews, and obituaries. EBSCOhost and ProQuest allowed us to extract article records from 35 different databases (summarized in Appendix A). Article records were exported as plain text files in a generic bibliographic format. Article records contained a set of metadata that described the attributes of the articles. These metadata included (but were not limited to) article title, journal title, publication year, author name(s), author affiliation(s), abstract, key words, methodological classification, funding source, location of study, subject groups, digital object identifier, number of references, and number of pages. Both EBSCOhost and ProQuest have strict limits on the number of records that can be exported at a time, requiring the export process to be performed in several batches.
The initial extraction of article records was performed from January 2015 to March 2015. A preliminary analysis of article records showed potential delays in indexing during 2014 and 2015 as well as potential gaps in indexing during the mid-1980s and earlier. We therefore restricted our study period to 1989–2013 in order to avoid these indexing gaps.
After the initial extraction of article records, we continued to perform searches throughout the rest of the study, as we identified other potential journals to be considered for review by the study team. If a journal was retained, we performed a separate article extraction for that journal exclusively.
Software Development to Create Uniform Article Records
Article records in raw text format were converted to a standard data file format using customized software entitled BibWrangleR (BWR; Victor, Perron, & Yochum, 2015). More specifically, BWR is comprised of a large set of functions authored and encapsulated as a software package using the R statistical language and programming environment (R Core Team, 2015). While BWR was developed with the needs of this project in mind, it is freely available in an open source format for use in other scientometric and bibliometric studies. The package reads raw text files from bibliographic databases. These files are restructured and combined into a single structured file for analysis.
After creating a standard analytic file, we conducted careful inspections of the data and developed a series of cleaning procedures to address data quality issues. For example, many journals had slightly different spellings (e.g., using “and” vs. “&”) or historical titles that needed to be merged and classified as a single journal. Another quality problem was the lack of reliable filtering of document types during the record extraction; a large number document types other than journal articles—for example, editorials, books reviews, obituaries, and other types of documents—were not properly filtered from our search results. We relied on the features of the original databases to remove duplicate article records during the extraction process. However, we found many instances of duplicate article records in the extracted records. It was also necessary to merge historical journal titles with their current names. These problems were addressed by creating a set of automated cleaning functions based on text matching procedures, referred to as regular expressions, that eliminated duplicate records and merged historical titles. These cleaning functions are specific to the current study and not formally part of the BWR package. However, these cleaning functions are publicly available on the GitHub repository and can be easily adapted to meet the needs of future studies.
Evaluating the Coverage of the Research Database
Next, we sought to establish the quality of article coverage in our finalized SWRD. This was done by making systematic comparisons of annual article counts by journal in the SWRD with annual article counts by journal available from Scopus, the largest academic database not included in our data collection process. These checks served as a rough indicator, as the Scopus data were available only in aggregate summary, meaning that specific checks against article titles were not possible.
The comparative analysis was facilitated by visual inspection using graphical outputs of publication data. These graphical outputs were used to evaluate how well the SWRD captured available article records and to identify potential gaps in our database. It should be noted that we expected the article counts of Scopus to be slightly higher than article counts contained in the SWRD, as Scopus includes editorials and book reviews, and these document types were specifically excluded from the SWRD.
Analyzing Trends in Growth of Social Work Research
Using the population list of social work journals and the SWRD to analyze trends in journal growth from 1989 to 2013, inclusive, we demonstrated the utility of the data science approach. Consistent with prior scientometric studies, we based our measurement of disciplinary research growth on annual journal counts over time (de Solla Price, 1986; Mabe & Amin, 2001). We estimated a compound annual growth rate (CAGR) using the number of journals in print in 1989 and 2013 as our beginning and ending values, respectively, using the following formula:

This calculation allowed us to then make a comparison with compound annual rates of journal growth reported in other academic disciplines (Mabe & Amin, 2001). Observed annual journal counts were plotted along with fitted linear estimates to contextualize journal growth during this time period. To further investigate trends in capacity and identify periods of differential growth, we plotted annual percentage change in journal counts.
Establishing Reproducibility of Research
To ensure full compliance with the best practices of reproducible research (King, 1995), the source code of the software, our data files, and code for all statistical analyses have been released in an open source format via the online services Zenodo and GitHub (see Victor et al., 2015) under a GNU General Public License (GPLv3). Zenodo is a service that allows researchers to share and preserve any scientific output, irrespective of size, format, or discipline (https://zenodo.ogr). GitHub is a versioning control system that is widely used to facilitate reproducible research (Gandrud, 2014).
The BWR software is available as an R package that can be installed using the devtools package freely available from the Comprehensive R Archive Network (https://cran.r-project.org/). The data files for replicating the original study, along with all the source code for the statistical analysis, are available on the GitHub repository. However, due to copyright restrictions, we are unable to provide a full release of all the data contained in the SWRD.
Results
Summary of Social Work Journals and Article Records
Based on a comprehensive search and expert consensus, we finalized a list of 90 disciplinary social work journals that were in print any time from 1989 through 2013. The full list of journal titles is presented in Table 1, along with the number of respective article records harvested from the database aggregators and the range of years of article records. This table is annotated to show journals that were added to the list of Hodge and Lacasse (2011) and those that have historical journal titles. The search of database aggregators yielded 33,330 article records from 88.9% (n = 80) of the journals on this list. We did not capture article records for 10 journals. Four of these journals are no longer in print, and the other six are currently in print but do not index with any database services.
Summary of Journals and Article Records Contained in the Social Work Research Database.
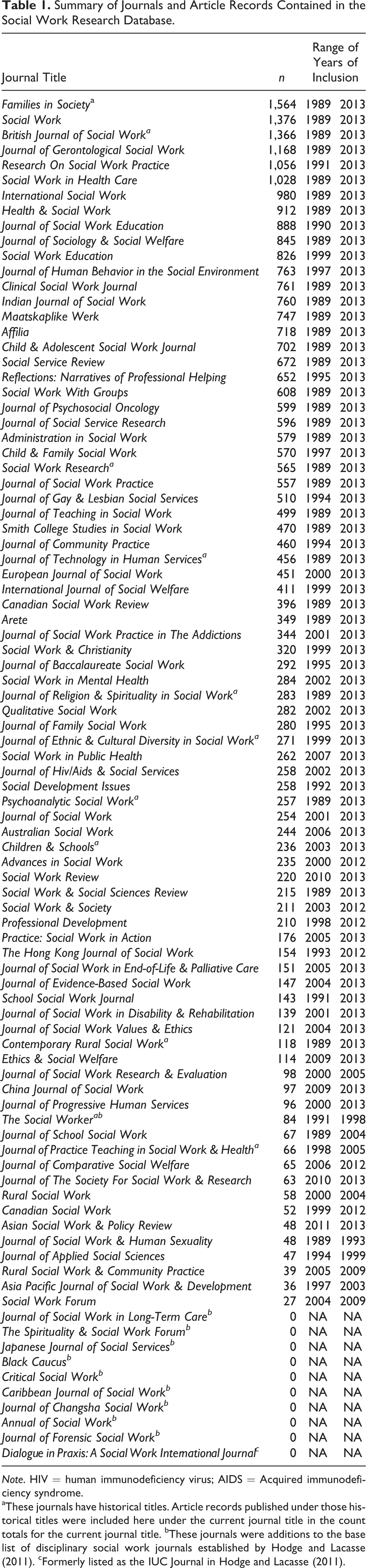
Note. HIV = human immunodeficiency virus; AIDS = Acquired immunodeficiency syndrome.
aThese journals have historical titles. Article records published under those historical titles were included here under the current journal title in the count totals for the current journal title. bThese journals were additions to the base list of disciplinary social work journals established by Hodge and Lacasse (2011). cFormerly listed as the IUC Journal in Hodge and Lacasse (2011).
Eleven journals in the research database have historical or former titles. For these journals, the count of article records also includes article records associated with their respective historical title. Sixty-four of the 90 journals have article records through 2013. Twenty-nine of the 90 have article records in every year throughout the 25-year study period. The journals with the largest number of article records were Families in Society (n = 1,564), Social Work (n = 1,376), and British Journal of Social Work (n = 1,366). Journals with the fewest article records were either newly established journals or had gaps or errors in indexing, which prevented us from capturing the article records. The issue of potential gaps or errors in indexing is given further consideration in the following section.
Evaluating the Coverage of the Research Database
As previously described, we encountered numerous data quality issues in the original article records extracted from the database aggregators, which required us to develop an extensive set of cleaning procedures to the data. To better understand the extent to which our search process captured the available article records, we made systematic comparisons with aggregate data from Scopus. Scopus is the single largest academic database not included in our search and provides indexing service for 55 journals (69%) that are contained in the SWRD. Scopus does not provide indexing for any social work journals that were not captured in the SWRD. The aggregate data provided by Scopus provide an annual count of publications for each journal starting from 1996.
When comparing these data sources, we expected to see high degrees of similarities in the article counts but not perfect correlations. Just as human error often results in incorrect citation (Mitchell-Williams, Skipper, Alexander, & Wilks, 2015; Spivey & Wilks, 2004), we recognized that some differences would be attributed to random error in the indexing process. We also expected some systematic differences, given that Scopus includes editorials and book reviews in the article counts, whereas these document types were specifically excluded from our search process and targeted for exclusion in subsequent data cleaning procedures.
To facilitate this comparison, we used a graphical strategy referred to as small multiples (Tufte, 2001). These are time-series plots that show number of article records for each journal over each year of the study period. This graphical presentation helped reveal correspondence and differences in the database contents. Figure 1 displays small multiples for nine journals with the largest number of article records.
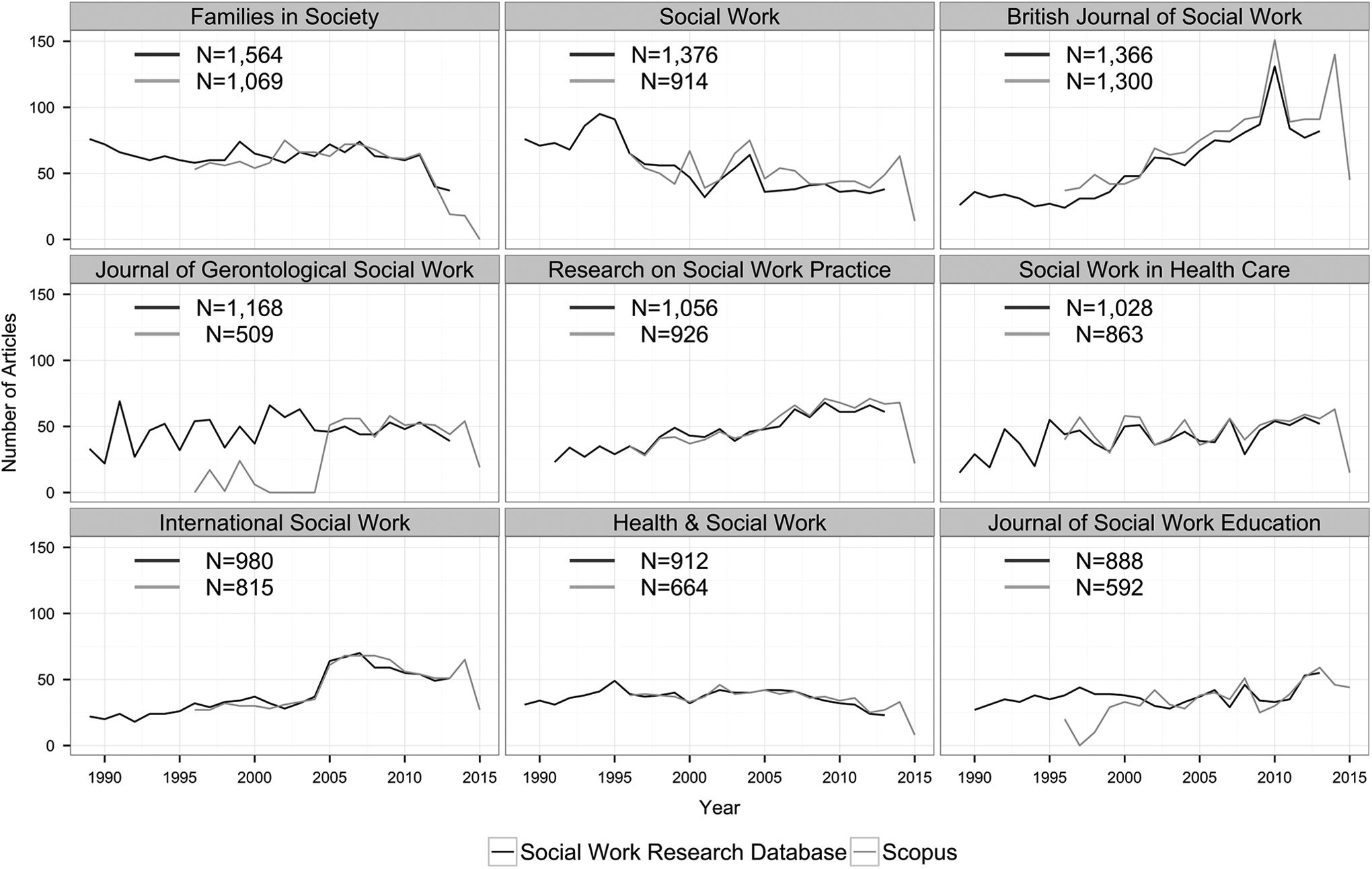
Comparison of research database with Scopus for journals with the most publications, 1989–2013.
As shown in Figure 1, a high degree of overlap is observed for all journals except The Journal of Gerontological Social Work and the Journal of Social Work Education. For these two journals, we can observe possible gaps in indexing in Scopus, as both journals show very few or no available article records for a subset of years. The small multiples for the remaining journals reveal small gaps and potential errors in indexing in both the SWRD and Scopus, which is consistent with prior research (e.g., see Holden et al., 2009, 2015). For the journals that are included in both the SWRD and Scopus, the SWRD provides more complete coverage—that is, more social work journals are represented, fewer gaps are observed, and the overall duration of indexing is longer.
Growth of Social Work Research
To demonstrate the utility of the data science approach, we conducted two sets of analyses related to the growth of social work research. Consistent with prior scientometric studies, we used an annual count of journals as a key indicator of scientific growth. These data are displayed graphically in Figure 2. The initial number of journals in 1989 was 30, and that number doubled by 2004. The final number of journals at the end of the study period was 64.
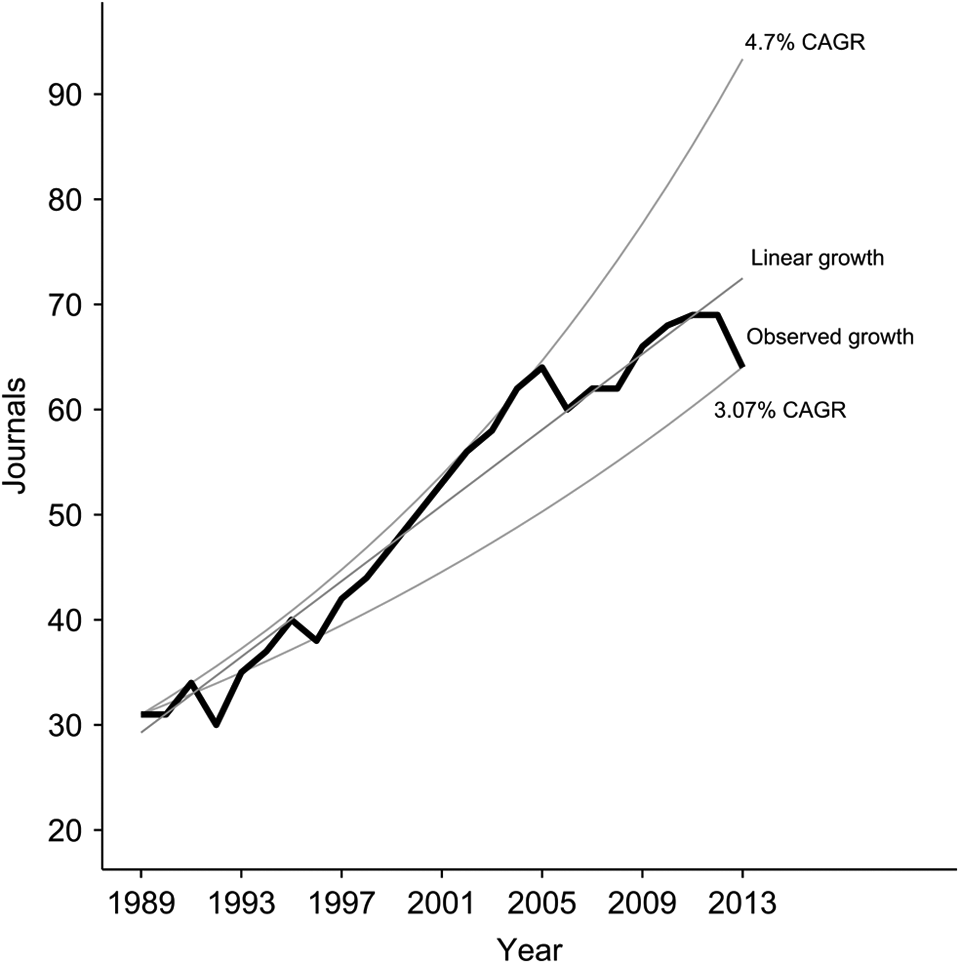
Compound annual growth (CAGR) and linear growth estimates of social work research, 1989–2013. 4.7 CAGR reflects historical estimate of overall scientific growth based on de Solla Price (1963). Linear growth (slope = 1.8) and 3.07% CAGR are based on data from the observed growth.
We summarized the growth of research using an unadjusted linear regression. This linear regression model, presented in Table 2, shows a near perfect fit with the data (adjusted R 2 = .95, p < .0001). The model shows that every year of the study period is associated with 1.8 new journals. We then computed a CAGR based on the number of journals in 1989 (n = 31) and 2013 (n = 64). The growth rate from 1989 to 2005 exceeded the 4.7% CAGR reported by de Solla Price (1986). The growth of science was more variable from 2005 to 2013, with a final CAGR for the 25-year study period of 3.07%. We also included both the linear trend and the CAGR with the observed values in Figure 2. Figure 3 presents the data slightly differently, to show the annual percentage change in the number of journals over the 25-year study period. From this figure, we can see that the most rapid and consistent growth occurred from 1997 up to 2005. The greatest amount of variability in growth occurred from 2005 through the end of the study period (2013). We can observe a reduction in positive growth from 2009 to 2011 and then negative growth in 2012 and 2013.
Linear Growth of the Number of Social Work Journals From 1989 to 2013.
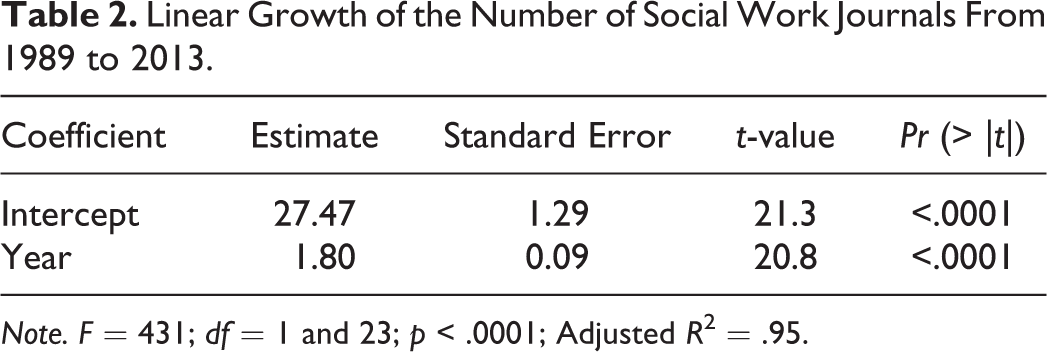
Note. F = 431; df = 1 and 23; p < .0001; Adjusted R 2 = .95.
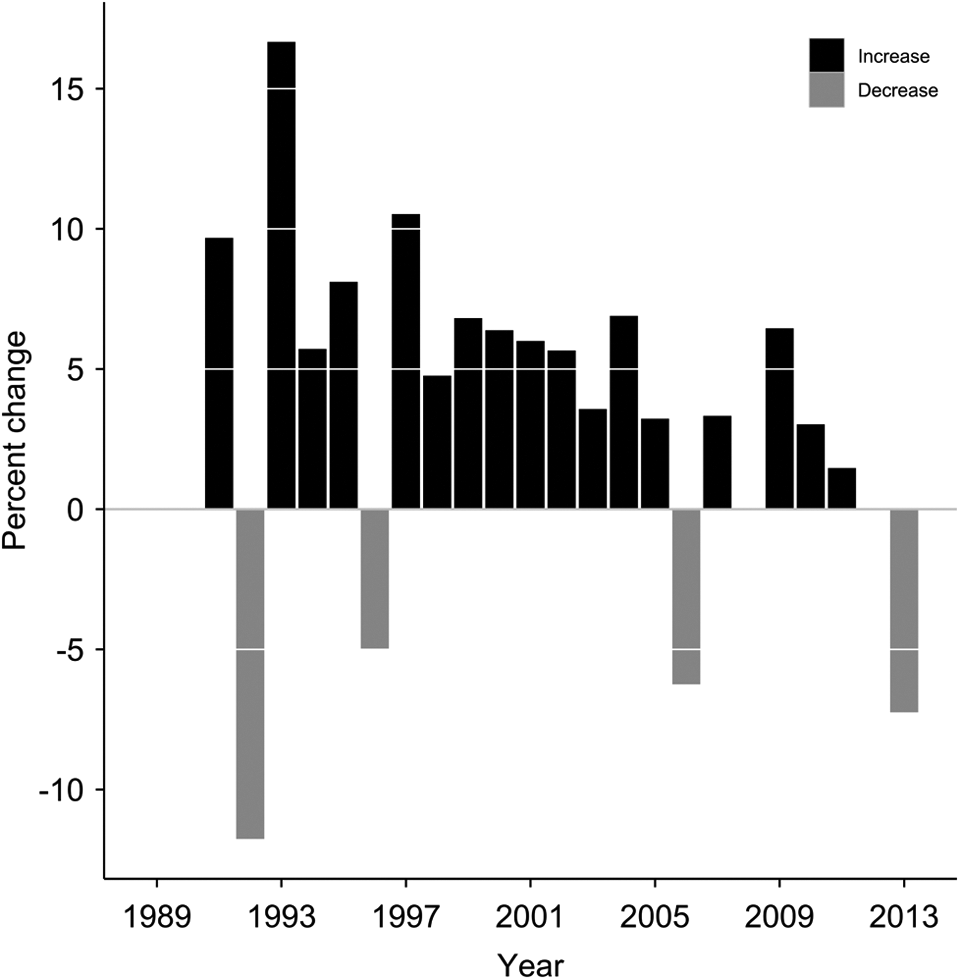
Annual percentage change in the number of journals, 1989–2013.
Discussion
The purpose of this study was to develop a set of tools and strategies to serve as a foundation for scientometric research in social work. We relied on methods from data science to achieve this and adhered to an open source philosophy in making these tools readily available to others.
Social Work Journals and Research Database
Our first contribution toward the building of this foundation was a comprehensive list of disciplinary social work journals. Our efforts built on the earlier work of Hodge and Lacasse (2011), whereby we excluded two journals from their original of 84 titles and added 8 more, producing a final list of 90 journals. Sixty-four of these journals were in print through the end of 2013. This list defines the population of social work journals, which has practical utility for planning and appraising bibliometric studies involving social work journals, in addition to serving as an indicator of the overall research infrastructure for the field.
In addition to creating this list, we attempted to harvest every available article record published in these journals over the past 25 years (1989–2013). The search process used two separate database aggregators that linked to 35 different academic databases and produced over 33,000 unique article records from 89% of the journals on our list. Our comparative analysis with Scopus suggests that our database is the largest stand-alone collection of article records from disciplinary social work journals over the past quarter century. It is important to note that we do have evidence of missing article records for journals that are included in the database, especially journals with relative lower levels of article output. The missing article records were not surprising given the prior work of Holden, who has identified persistent gaps in article indexing in Social Work Abstracts (Holden et al., 2015). Moreover, in the article records that were retrieved, we found many data quality problems including (but not limited to) character encoding problems encountered in processing raw data, missing data in key data fields (e.g., author names and article titles), different spellings of journal titles, reliability problems with certain pieces of metadata (e.g., study methodology), incomplete metadata, and variability in the indexing of journals with historical names.
While the data quality problems we observed in the harvesting and processing of article records give rise to limitations of the database, these limitations go well beyond this database and relate to any research initiative that involves a search for social work research. Any of the errors noted (as well as those that we haven’t noted) can negatively affect any search, especially studies like meta-analyses and systematic reviews that attempt to provide a comprehensive summary of research. Unfortunately, researchers performing searches can never detect and confirm these kinds of errors. Having access to the raw output data is essential to addressing quality issues. Our future research efforts will build on the work of Holden, Barker, Covert-Vail, Rosenberg, and Cohen (2009) and Holden, Barker, Kuppens, Rosenberg, and LeBreton, (2015) to help reveal other specific problems in the indexing of social work research.
Open Source Software and Reproducible Research
Developing software to restructure article records into a common format was an essential part of this research. We selected an open source solution for several reasons. Foremost, we wanted to ensure that our research was fully consistent with the tenets of reproducible research, a value that is widely expressed in data science and which allows the broader research community to inspect all aspects of our research, including all methodological decisions that were made in the restructuring of article records and the analysis. This is an important step in response to very serious concerns about the recent quality of social science research. Revealing the source code along with the data allows fully transparent research, which creates opportunities to detect and resolve errors and prevent the publication of fraudulent research. Furthermore, because the source code is fully open, researchers have the opportunity to make adaptations and test various assumptions that were made in the original research, to introduce or exclude data, and to build upon the work in order to address other research questions. To our knowledge, this is the first study in social work that meets the replication requirements of other journals (e.g., American Journal of Political Science and American Political Science Review).
In this study, we used the statistical programming language R for restructuring article records and performing analyses, R Markdown for documenting our source code, and the web-based service GitHub (www.github.com) for curating the research project. These tools are not commonly used in social work research, which is a challenge to making the software useful to researchers in the field. However, they are popular tools among the broader community of quantitative researchers, data analysts, and data scientists for making research reproducible.
Given the popularity and potential of the open philosophy (e.g., open source and open access) to advance the quality of science, it is important that doctoral programs introduce these freely available tools alongside closed source platforms (e.g., Stata, SPSS, and SAS). The data file we make available with this report contains the data available to rerun the analyses. Unfortunately, we are not permitted to make our full database of article records freely available due to copyright restrictions and the policies of the databases from which we harvested article records. In lieu of the full database of article records, we provide all the tools and instructions to reproduce the database.
Utility of the Data Science Approach
The ability to access a stand-alone database containing all available article records for a field opens many opportunities for scientometric studies. In this study, we used a data science framework to develop customized computer software to construct a population-level list of social work journals and build the SWRD. We then measured and analyzed the growth of social work journals over time in a manner consistent with other classic and current scientometric studies of scientific growth (e.g., Mabe & Amin, 2001). Based on our results, we found the growth of social work to be consistent with other studies. Specifically, the CAGR of social work research journals was approximately 3.07%, nearly the same as the 3.3% CAGR that has been observed in journal growth among other disciplines (Mabe & Amin, 2001).
The results of this study provide a more rigorous assessment of the growth of research within disciplinary social work journals compared to more general appraisals; however, we think it is important to interpret these results cautiously for two reasons. Foremost, estimates of growth should not be confused as an indicator of progress. That is, rapid growth can easily give rise to quality-related issues. In our analysis—and consistent with other scientometric studies—we do not have any existing data sources that would allow us to make adjustments or inferences related to research quality. It is clear that the field of social work is growing, but whether the quality has maintained or improved during rapid growth remains a very important question to address.
A second point of caution is that our analyses do not make any distinction between the type of article published, beyond the exclusion of book reviews, editorials, obituaries, and other forms of non-peer-reviewed communication. The article records harvested from the databases contain metadata on the type of study methodology; however, we found very serious problems in the reliability of these data. This is likely due to different database services using different coding conventions in the construction of their article records. It is also important to note that the SWRD contains only research published in social work journals, and many social work researchers publish in nonsocial work journals. Thus, estimates of growth derived from this database reflect growth of only research published in social work journals.
A next step in our research with the database is to continuing drawing upon the tools of data science by applying machine learning to classify studies according to the article type. Machine learning is a popular analytic strategy in data science that can be used to assign article records using a predefined set of categories. Establishing a reliable classification strategy can help determine whether social work journals are publishing more original research and, if so, the various types (e.g., experimental, survey, qualitative, etc.). Similar to the work of Martinez et al. (2015), analyses can be performed on the full-text abstracts that are available in a large proportion of the article records. For example, Latent Dirichlet Analysis can reveal the different subtopics within the field, the distance of the subtopics with each other, and the growth of these topic areas over time. Analysis of author names also opens up opportunities to examine networks of social work researchers as well as the emergence of team science. These kinds of analyses allow for a more accurate, data-driven understanding of the infrastructure and organization of the field of social work research, which is essential to setting sound scientific policy and a research agenda.
The data science framework was a critical component of the current study. As the amount of data available to social work researchers continues to grow, the tools of data science will become increasingly useful. However, the process of adoption and effective implementation of these tools will necessarily require important changes to the social work research infrastructure. Failing to do so can result in improper usage of tools and analyses that has been observed in other areas of social work and social science research (e.g., Guo, Perron, & Gillespie, 2008; Henson & Roberts, 2006). Minimally, doctoral programs expose students to new technologies and providing supports to seasoned researchers to acquire new knowledge and tools.
Footnotes
Appendix A
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.