
Abstract
This article reports the background, methods, and results of a 7-year project (2007–2013) that assessed the writing of undergraduate business majors at a business college. It describes specific issues with writing assessment and how this study attempted to overcome them, largely through a situated assessment approach. The authors provide the results of more than 3,700 assessments of nearly 2,000 documents during the course of the study, reporting on scores overall and for each rubric criterion and comparing the scores of English and business assessors. They also investigate how two curricular interventions were evaluated through this assessment project. Although overall, the writing of these business majors was assessed as good, results showed noteworthy differences between the scores of English and business assessors and a noteworthy impact for one of the curricular interventions, an effort to improve the material conditions of writing instruction. The authors conclude by discussing some next steps and implications of this project.
In 2006, business faculty in Drexel University’s LeBow College of Business responded to the accreditation requirements of the Association to Advance Collegiate Schools of Business (AACSB) by identifying four central learning goals to assess in LeBow’s curriculum: problem-solving, knowledge of economics, career learning, and writing skills. For each goal, LeBow needed to develop methods for the ongoing assessment of student performance as well as assessments of curricular and instructional interventions (Warnock, 2009). LeBow faculty have developed various assessment projects to address these goals. In particular, they have focused on student writing in their classrooms through a long-running assessment effort.
In this article, we describe the assessment effort and discuss the broader implications of its findings. We begin by discussing the productive use of the accreditation exigency that institutions of higher education face. Then, we draw on writing assessment scholarship to identify three issues that arose when we implemented this assessment and explain our attempts to overcome those issues locally. Next we explain our materials and methods for this project and describe its theoretical underpinning, specifically the approach of situated assessment. We then present the 7-year results of our project, which included two experimental curriculum interventions, and explain how those results were reflected in the assessment and analyzed through it. Finally, we discuss the implications of this project for those interested in similar interdisciplinary assessment efforts, pose follow-up questions, and indicate possible channels for related research.
Accreditation and Exigency
Universities have responded to increasing accreditation pressures with a full and at times critical discourse about their aims and growth (e.g., Conn, 2014; Greenberg, 2014; Krzykowski & Kinser, 2014). Although some stakeholders remain suspicious of idealized assurances of institutional integrity and quality, accreditation provides opportunities to advance other important and useful goals (Yancey & Huot, 1999), such as to create writing initiatives on campus (Good, Osborne, & Birchfield, 2012). Additionally, as Williamson (1999) has noted, “even a mandated external evaluation can be co-opted by a department that is willing to accept the invitation to examine itself with an eye to improving its understanding of its program” (p. 254). In other words, accreditation can provide an excellent opportunity for reflection and potential change.
In our case, conversations generated by the accreditation process encouraged LeBow faculty to think about the importance of writing, especially because employers and alumni expressed to us its importance in professional contexts. Moreover, while accreditation provided the impetus to launch this assessment project, it also helped the project continue, such as by providing motivation to sustain internal funding for 7 years.
Writing Assessment: Local Solutions to General Problems
The difficulties of large-scale writing assessment are well documented. While some large educational studies have been undertaken (e.g., Applebee, Langer, Nystrand, & Gamoran, 2003; Haswell, 2000; Langer, 2001; Sommers, 2002; Xue & Meisels, 2004), including in business and technical writing settings (Zhao & Alexander, 2004), correlating specific shifts in pedagogical strategies and techniques with changes in student performance is challenging. In fact, Haswell (2000) concluded that while as far back as in 1963, Kitzhaber started the project of documenting how college students change their writing performance, “since then, it is only fair to say the project has not been much advanced by researchers” (p. 307). Studying writing in a way that does justice to its complexity is a complicated and expensive process, so large assessments of student writing have been difficult to undertake. Moreover, the constraints facing such projects go well beyond securing the necessary funding, as we explain next.
The Word Assessment
Such constraints unfortunately begin with the word assessment itself. Higher education faculty often have mixed feelings about assessment, so the word often evokes bureaucratic drudgery or, at worst, stirs up conspiracy theories. Foot-dragging, cynicism, and even outright resistance (at least from tenured faculty) can seem like not only acceptable but honorable responses. These responses are understandable to the extent that work labeled assessment appears to divert labor that might otherwise be spent on teaching or research into a realm that garners little professional satisfaction or personal reward.
The word is not completely reframeable (Adler-Kassner & O’Neill, 2010) although we made considerable progress in our study by addressing these pejorative connotations head-on. Faculty were invited to see assessment as presenting intriguing challenges to them as intellectuals and problem solvers, and the process enabled them to see persuasive connections between the macrocosm of the assessment initiative and the microcosms of their classroom triumphs and frustrations. The faculty were also paid for their intellectual work and provided with opportunities for scholarship connected with this initiative.
Underrepresented Material and Consequential Logistics
Unfortunately, much of the research and scholarship on writing assessment is too abstract for faculty faced with practical problem-solving issues. The often remote treatment of the material conditions of an assessment can lead its designers to think that issues of, for instance, who will read what papers with what kind of training to record what kinds of scores are just technical problems to solve rather than issues to align with a particular construct of reliability. In its attention to the details of local problem solving, then, this study joins work like that of Kelly-Riley and Elliot (2014) in attempting to help fill this gap in the treatment of such material logistics. Also, assessment designers should be aware that decisions about data collection (How do we set up the best mechanisms to help us find out what we want to know?), as Kane (2000) and Poe, Elliot, Cogan, and Nurudeen (2014) reminded us, should not be made without considering the consequential logistics (What kinds of decisions about students or teachers will be made with these data once collected?).
Scoring
Writing assessment experts remain of at least two minds on the question of rater-borne variation in scoring. The traditional, still-dominant view is that such variation is a problem to be solved. There are an array of sophisticated methods to reduce or mitigate this “construct-irrelevant variance” (for a brief overview, see Dryer & Peckham, 2014, p. 13), and these methods are essential when rater error has high-stakes consequences for students. Another perspective (see Broad, 2003; Whithaus, 2005) sees variation in scoring from nonnormed raters as itself an important and useful source of information, particularly—as in the present case—when the sample of raters and scores is sufficiently large to represent the reading practices of larger populations of readers.
Material and Method
Warnock (2009) has described the initial methods, approach, and limited data set of the pilot study conducted in 2006. LeBow, seeking a method to assess students’ writing competency and performance in response to the AACSB accreditation requirements, initiated a collaboration with Drexel’s Department of English and Philosophy in spring 2005. That collaboration resulted in the creation of the LeBow Writing Committee to guide the assessment process; that group consisted of members from both units and, crucially, LeBow alumni. The assessment’s goal, again, was to look broadly at the writing that takes place in LeBow in order to “address the total nature of the program rather than its individual components” (Yancey & Huot, 1999, p. 8). That goal helped guide the decision to look at student writing from LeBow classroom assignments rather than from timed writing samples “produced specifically for evaluation” (Huot, 1999, p. 72). Each year since 2009, when Warnock’s article describing the pilot was published, the assessment team has refined and improved the logistics.
In general, LeBow gathered several hundred papers from its undergraduate students each year; the actual number varied slightly, but after 2009, we aimed for about 300 documents per year. The assessment team recruited 30 assessors each summer. Based on our early interest not just in assessment outcomes but in using this project to investigate ways in which assessor behaviors might vary based on discipline, we distributed the papers among assessors whom we characterized as a member of one of the two groups: those with a background in English (those who teach English or writing) and those with a background in business or industry (those who teach business or who work in business or industry; many in this latter group have been LeBow alumni). The assessors had several weeks to assess 20 documents. Although some assessors did not complete their evaluations, over the 7 years, we averaged about 530 assessments out of a possible total of 600 for each year.
Gathering and Distributing Documents
All documents were gathered by LeBow faculty, normally with the help of graduate assistants. The writing assignments have been drawn from several LeBow courses, primarily the two courses that constitute the first-year, Introduction to Business (BUSN) sequence and a third-year, Organizational Behavior (ORGB) course. In the first year, reports from marketing and management, required upper-level courses for business majors, were also included. Drexel University’s Institutional Research Board approved our protocol and provided a letter of determination to our research team. Table 1 shows the total count of documents by type. The first 2 years, 2007 and 2008, were baseline years for the subsequent BUSN curricular interventions described here. We wanted to include some upper-level writing as well, so in 2007, again, we drew from marketing and management courses. In 2008, we fulfilled the upper-level writing by collecting documents from ORGB courses. In 2009, we focused on only the BUSN documents, but after 2009, we evaluated ORGB documents again as part of a second curricular intervention with that course that is also described here.
Document Count by Year and Type.

Note. N = 1,980.
The student documents were gathered by downloading them from each student’s e-portfolio to a local computer; within LeBow, students use their e-portfolios to store their academic work and reflect on their writing during their academic career. Information was recorded about each document author, including degree program in which the author was enrolled and student identification number. The documents were then anonymized and uploaded to an internal server. To handle the logistical challenge of accurately tracking 300 anonymous papers, we created a simple spreadsheet in Excel to track the progress of (a) downloading each document, (b) logging each author, (c) anonymizing each document, and (d) generating and logging a randomly generated file name for each.
In our first year, a statistician developed a document distribution matrix to evenly distribute 300 different document types among 30 assessors. Using simple random sampling without replacement, we selected documents from the document pool of the given type and then randomly assigned assessors to 1 of the 30 predetermined document groupings. We used the statistical software package R to perform this randomization.
Distributing the documents to assessors also presents a logistical challenge, and we have tried different methods for doing so. Initially, we used straightforward e-mail with attachments, which required a student worker to use the distribution matrix to match all assessors to their 20 documents, attaching each document to an e-mail. As the project continued, we tried other methods, including e-mailing GoogleDocs links, mailing hard copies, and making documents available on a server. Since 2012, we have settled on a method enabled by Waypoint 2.0™, an upgrade to Waypoint™, our rubric software. Using Waypoint 2.0™, we created a “course” for each summer assessment with 30 “classes” that were all linked to the LeBow grading rubric. Waypoint 2.0™ allowed not only the streamlined use of grading rubrics but hosted files within the system, making document distribution no longer an issue. Each assessor was e-mailed a login and password to a Waypoint™ account containing the rubric and the 20 student documents assigned to that assessor.
We also e-mailed to assessors these documents:
the assignment instructions students received for the various writing assignments being used for that summer’s assessment the LeBow writing rubric (see Appendix A) a quick tip sheet about using Waypoint™
We provided the assignment instructions to help reviewers understand the expectations placed on the students as well as the assignment parameters.
Recruiting Assessors
To recruit evaluators each year, the assessment team would send e-mails seeking participation (for a sample message, see Appendix B) to several cohorts, including faculty who teach English at Drexel and other institutions, those who teach business, and alumni and others who work in business or industry. As part of its responsibilities for meeting accreditation requirements, LeBow established a budget for the assessment that enabled us to offer a modest honorarium to each assessor. We decided at the start of the pilot that we would categorize the 30 assessors each year into 15 whose primary background was English and 15 whose primary background was business or industry. These categories were not strictly defined, but because assessors were asked to provide a brief biography, we were able to group them based on background so that such groupings might provide insight into potential differences in reading and scoring behaviors.
Some assessors have participated each year whereas others have participated for 1 to 6 years. We plan, in a subsequent article, to mine profiles of each assessor and explore assessor behaviors more deeply. Comparing the behaviors of individual assessors would provide a valuable way of investigating the data. For instance, do patterns emerge among those who have participated in the assessment each year versus those who have participated for the first time? Also, might assessors in academia, regardless of teaching discipline, have more in common with each other than do practitioners and teachers who are both in the broad realm of business or industry?
Criteria: The LeBow Writing Rubric
Following Huot’s (1999) insistence that local guidelines reflect the priorities of specific disciplines and that “only those who teach, write, and work in specific areas are really competent to set [these] guidelines and evaluate student writing” (p. 72), the LeBow committee developed a rubric that could be used in the assessment as well as the curriculum (see Warnock, 2009). Appendix A shows the 10 rubric categories, or elements, as Waypoint™ calls them.
In the 2006 pilot, we used a Likert-type, 4-point assessment scale. But in 2007, we increased the scale to 5 points, adding unacceptable, which aligned better with the conventional five-letter (i.e., A through F) academic grading scale familiar to business and academic readers alike. We have continued to use this evaluation rubric in order to avoid having a shifting baseline for data analysis.
To those familiar with rubrics or teaching writing, the rubric categories and scaling language will no doubt look familiar. But two elements, gross mistakes and ethics, are binary: These yes-or-no criteria were designed to capture the kind of “knee-jerk reaction that a reader might have to writing that evidences some type of ethical issue, such as plagiarism, or overt mistakes, such as the misspelling of a client’s name” (Warnock, 2009, p. 88). Also, for every element, each of the five assessment choices was accompanied by language designed to help guide evaluators. We do not analyze data from the visuals element here because not all assignments required visuals, so this element contains considerably less data than do the other elements.
Waypoint™ Assessment and Rubric Software
Each year, the rubric was loaded into the Web-based rubric software that we used for this project, Waypoint™ (a product of Subjective Metrics, a company for which Warnock was a founder and minority shareholder until its sale in 2009). Figure 1 shows a screen capture of how a portion of the rubric appeared in Waypoint 2.0™. Waypoint™ provided a straightforward, digital method for evaluators to record their assessment of the reports and for administrators and researchers to gather data about these assessments.
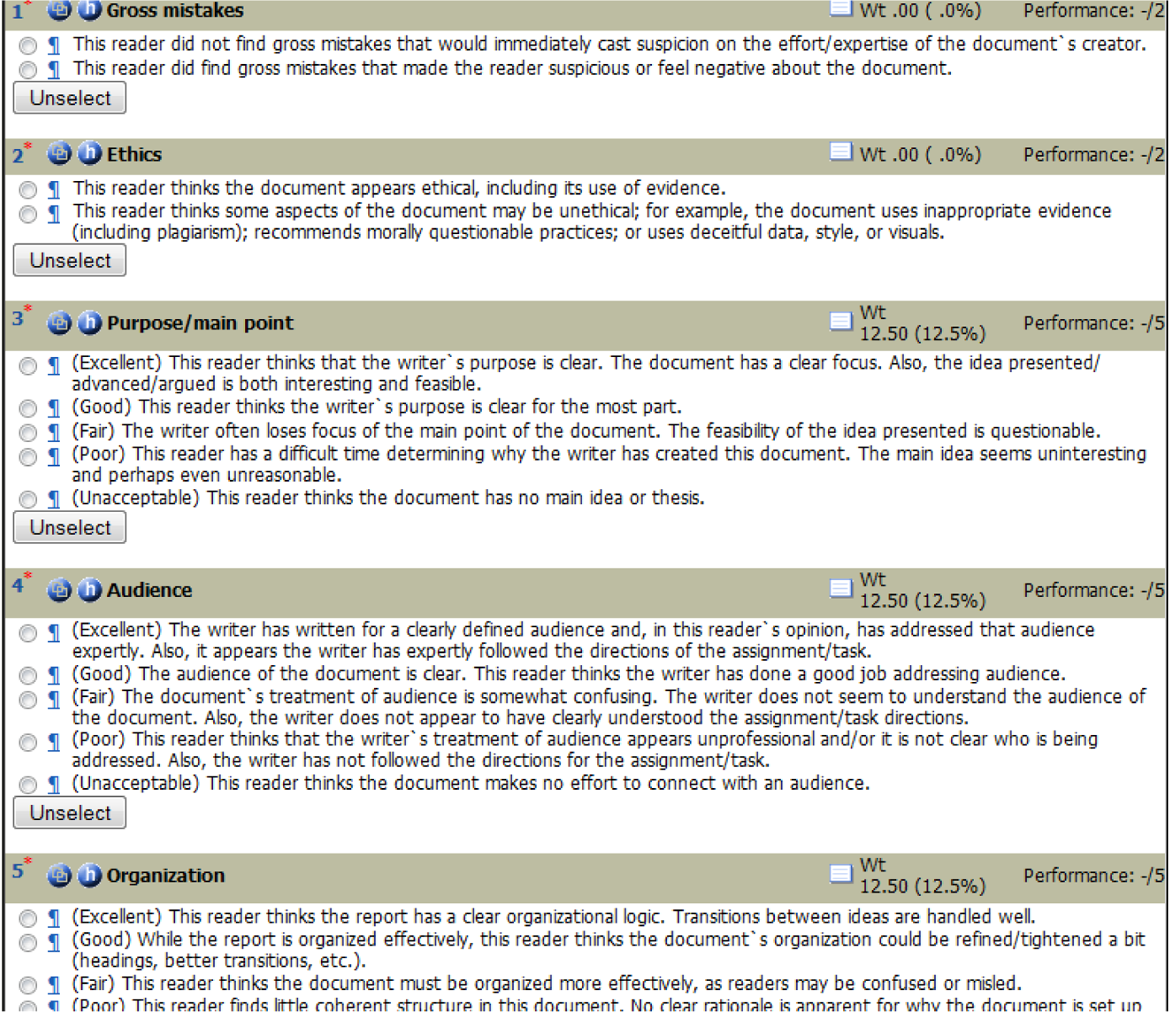
LeBow College of Business writing rubric as it appears in Waypoint 2.0TM.
Each assessment choice corresponded to a numerical value, and Waypoint™ recorded the numerical value of the selected choices for each element, using a straightforward algorithm to calculate an overall report score. For the 5-point scales, the scoring was 0.0, 2.5, 5.0, 7.5, and 10.0; for the 2-point scales for ethics and gross mistakes, the scoring was either a 0.0 (no) or 10.0 (yes). These scales allowed for a possible perfect document score of 100 (or 90 when no visuals were present).
Assessors were asked to record only one choice for each element. But Waypoint™ was designed as a teaching tool, so each choice allowed evaluators to add written comments if they wished. Since few did, we do not analyze those comments here.
Training
During the pilot summer, we conducted a 90-minute training session for the evaluators, focusing on the underlying ideas of the study and the use of Waypoint™. This session was conducted in person and was also recorded and made available via Web link. But we subsequently realized that few evaluators would attend in person; most would instead view the video online. Also, we recognized that the assessment logistics were straightforward, so over time, we have shortened the video to 15 minutes: It introduces the overall purpose of the assessment, describes the concept of situated assessment, and then demonstrates the Waypoint™ interface. Several Drexel undergraduate students, as part of a co-op position, have helped with the limited troubleshooting associated with this project, mostly by helping the evaluators to access their documents.
Data Gathering
In addition to providing an efficient way of distributing documents and gathering assessor scores, Waypoint™ provided a streamlined method of assembling our assessment data, allowing administrative users online access to all data. After completing each year’s assessment, we downloaded all the data from Waypoint™ in a tab delimited format, formatted the data in R, and appended these data to the aggregated data from past assessments.
Curricular Intervention 1: Business Treatment Versus Business Control Groups
In summer 2008, LeBow’s leadership convened a meeting of BUSN instructors and the members of our assessment team. The meeting’s goal was to develop a plan to improve student writing by changing the teaching approaches in some BUSN sections and then establishing control and treatment groups in order to discover the impact of those changes by using our existing writing assessment effort. To create conditions for paying more attention to writing, treatment sections were capped at 20 students, instead of the traditional 30 students, and teaching circles were established to provide a conversational, developmental environment for faculty. We decided that while treatment sections would have writing assignments that were similar to the control sections, those assignments would be embedded in a recursive sequence (i.e., instead of free-standing assignment genres like a memo or a proposal, the tasks would be integrated into an ongoing context in which later assignments built on the writing done in the previous ones). Although the classroom and the workplace represent quite different activity systems (see Russell, 1997), we wanted assignments in the treatment section to more closely approximate workplace writing. Instructors would capitalize on the smaller class size by making themselves more available to review drafts and reallocating time from course content to spend on in-class peer review and draft workshops. We have no evidence that suggests that students in either group were ever aware that they were participating in a curricular experiment.
Curricular Intervention 2: Use of Evidence and Research
In 2011, LeBow reviewed the previous years’ assessment results and found that, except for in 2007, evidence was the lowest rated element in each year of the assessment (in 2007, it ranked above only correctness and sentence style). Working with the writing program, LeBow decided to focus on the use of evidence and research in its curriculum through a writing across the curriculum (WAC) type of intervention. The overall goal of this curricular intervention was to enhance the use of evidence in LeBow assignments. The writing program provided focused WAC-type work with ORGB and BUSN in fall 2011 and winter 2012: (a) assignment-development workshops and one-to-one consultations with faculty in the BUSN sequence and (b) an assignment-development workshop for ORGB teachers. These workshops and consultations with faculty focused on various aspects of using research in order to produce better instruction about the use of evidence and citation in writing assignments.
Theoretical Underpinnings of the Project
A key principle driving this initiative was that assessors would read the documents and evaluate them without using holistic scoring or norming strategies. Our brief training focused on making sure evaluators understood the principles of this situated assessment, felt comfortable with the rubric, and knew how to operate the software. Warnock (2009) explained that “the concept behind our approach is that what stifles many writing assessment efforts, logistically speaking, is an illusionary game of validity in which evaluators struggle to establish idealized versions of the writing traits that meet specified writing criteria” (p. 90). So our project used reader subjectivity as an “asset to the assessment rather than a problem that we would need to work around through norming or holistic means” (p. 90).
This approach is in response to an obstacle that, if anything, has only grown in the years since we began this project: oversimplified norming practices that are primarily used in order to perform an assessment in a certain way (many times in response to top-down pressures). Writing assessors are confronted with the problem of developing structures that allow for large, reproducible assessments. But even years ago, Yancey and Huot (1999) said that “assessment is increasingly collaborative and democratic” and that it need not be an expert-driven endeavor; instead it should be a “curricular task” that all stakeholders share in and learn from (p. 12). In that spirit, Condon (2013) described localization as a way of addressing the problem of validity. He presented “a look at a universe of writing assessment” in arguing for richer, more robust assessments, evaluative occasions that generally do not separate the test from authentic tasks, that provide a rich description of a writer’s competencies, and that can allow evaluators to make some judgments about the writer’s learning context, as well as about the writer and the writing itself. (p. 105)
A key goal for us when we started in 2006 was to demonstrate the feasibility of a potentially reproducible model that used actual classroom documents in assessment structures that were both logistically and financially manageable and yet did not demand a huge investment in writing assessment expertise and apparatuses. We wanted to help programs perform meaningful writing assessments and “help writing researchers address some difficulties brought about by the inherently subjective practice of assessing writing” (Warnock, 2009, p. 90). Warnock compared situated assessment with an orthopedic pain scale: Of course pain is subjective, so if patient A says that implant X hurts an 8 on a scale of 1 to 10 and patient B says that implant X hurts a 4, we know little. But when hundreds, maybe thousands, of patients make assessments about implant X on that same scale, statistical power flattens individual differences, allowing researchers to make a statement about the pain factor of implant X. (pp. 90–91)
Results
In discussing results, we refer to a document score as the overall score, which is derived from the cumulative result of element scores (i.e., scores for particular writing elements) as calculated by Waypoint™. Overall scores for a document ranged from 0.0 to 100 whereas element scores ranged from 0.0 to 10.0. For the binary elements (ethics and gross mistakes), a score of 10.0 is given for yes whereas a 0.0 is given for no. For the other eight elements, a score of 10.0 is given for a rating of excellent, 7.5 for good, 5.0 for fair, 2.5 for poor, and 0.0 for unacceptable. In other words, when an assessor rates a given element, for example, as good, that rating translates in Waypoint™ to a numerical score of 7.5.
Overall Scores
Table 2 shows the overall scores for all evaluators in total and for each year. Table 3 shows the mean element scores for each year. Tables 4 and 5 show overall scores by two groups of document types: those written by first-year students in the BUSN course and those written by students in upper-class courses. Not all document types were part of the assessment every year.
Overall Scores for all Evaluators by Year.
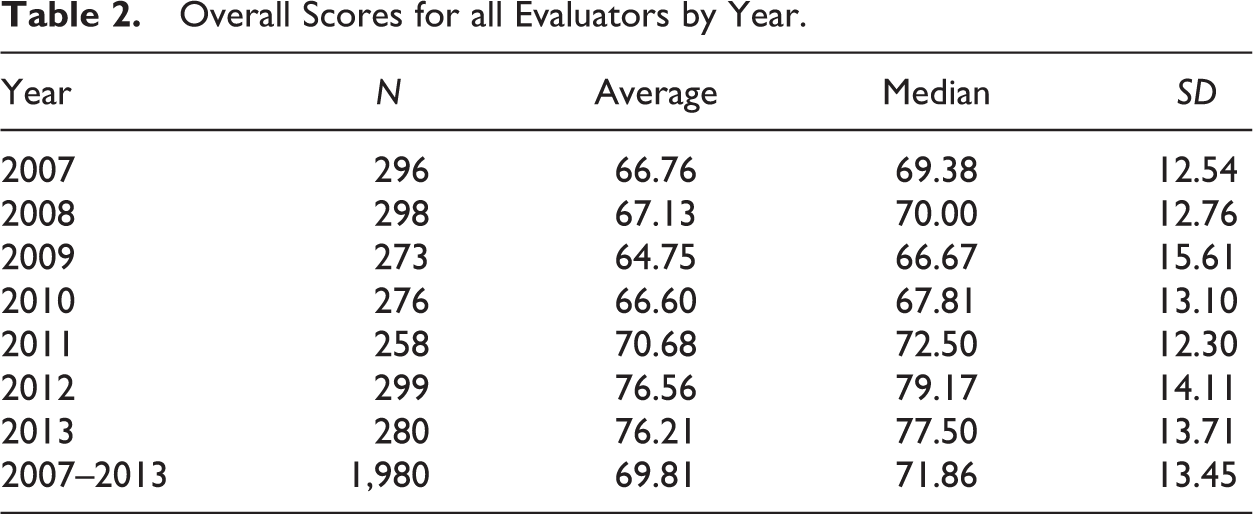
Mean Element Scores for Each Year.
Note. Red indicates lowest-scoring element in a given year. Gray shading highlights the overall average.
Overall Scores 2007–2013: Introduction to Business Versus Upper-Level Courses.

Overall Scores for Each Year: Introduction to Business Versus Upper-Level Courses.

Note. BUSN = Introduction to Business; ORGB = Organizational Behavior; MKTG = Marketing; n/a = not applicable.
Occasionally, for one reason or another, assessors would not include a given element, or the overall score would include a very small number of test element scores submitted by the study team. The standard deviation for each element each year was around 2.0 and was never higher than 3.93 in a particular year.
In the rest of this section, we provide the results of each of our two interventions and compare the performances of the business assessors and the English-faculty assessors.
Curricular Intervention 1: Business Treatment Versus Business Control Groups
Table 6 and Figure 2 show the results following the curricular intervention with the BUSN courses in 2008. The summer assessment results from 2009 and 2010 showed that the documents of the treatment group (the group of students who received differential instruction) had higher overall assessment scores (see Table 6). The 2009 individual element scores demonstrate that each element (except for visuals) was higher as well (see Figure 2). The higher overall assessment of the treatment-group documents in 2009 and 2010 was gratifying to LeBow faculty and administration, but the results flipped in 2011 and 2013, when the control group’s results were higher. This was an unexpected finding, and we analyze its possible causes in the Discussion section.
Overall Document Scores for Introduction to Business (BUSN) Control Versus Treatment Groups.


Mean element scores of 2009 grouped by Introduction to Business control (BUSNC) and Introduction to Business treatment (BUSNT) groups.
Curricular Intervention 2: Using Evidence and Research
After conducting the assessment for several years, we noted that except for in 2007, evidence was the lowest scoring element, leading to our second curricular intervention efforts in 2011—to enhance the use of evidence and research in LeBow assignments. Table 7 shows the evidence scores from year to year. The evidence score did improve in 2012 although in a way not nearly as noteworthy as in our BUSN curricular intervention results. Figure 3 shows the evidence scores for each year by the various types of documents we assessed throughout the years. Again, there is a slight improvement from 2011 to 2012 in the documents we assessed, but the scores do not show overall improvement by 2013 and are inconsistent within their groups during the course of this intervention.
Evidence Scores by Year.
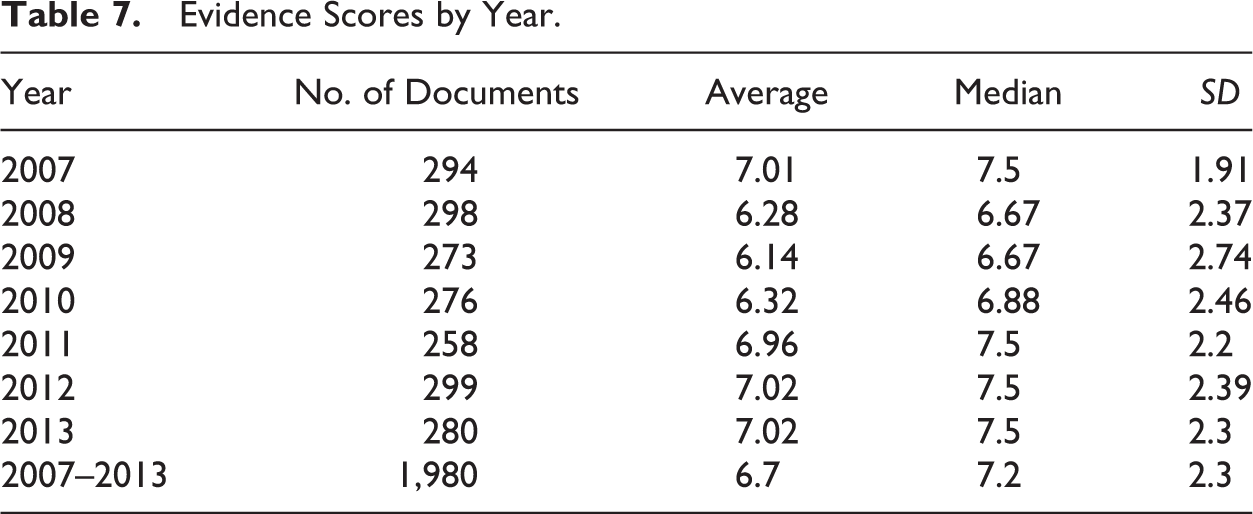

Mean evidence score for each year by document type.
Business Assessors Versus English-Faculty Assessors
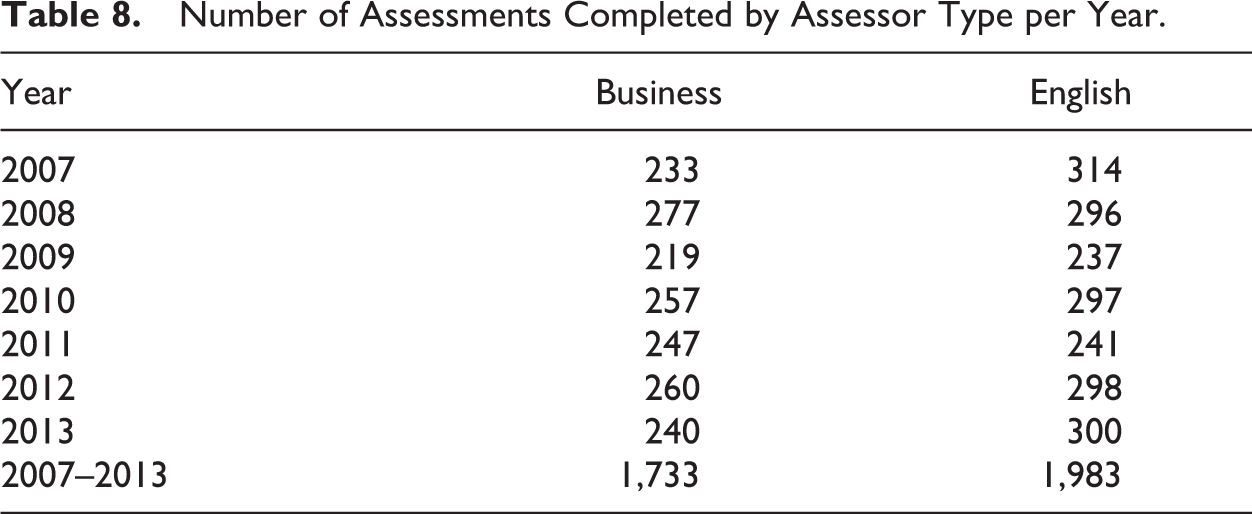
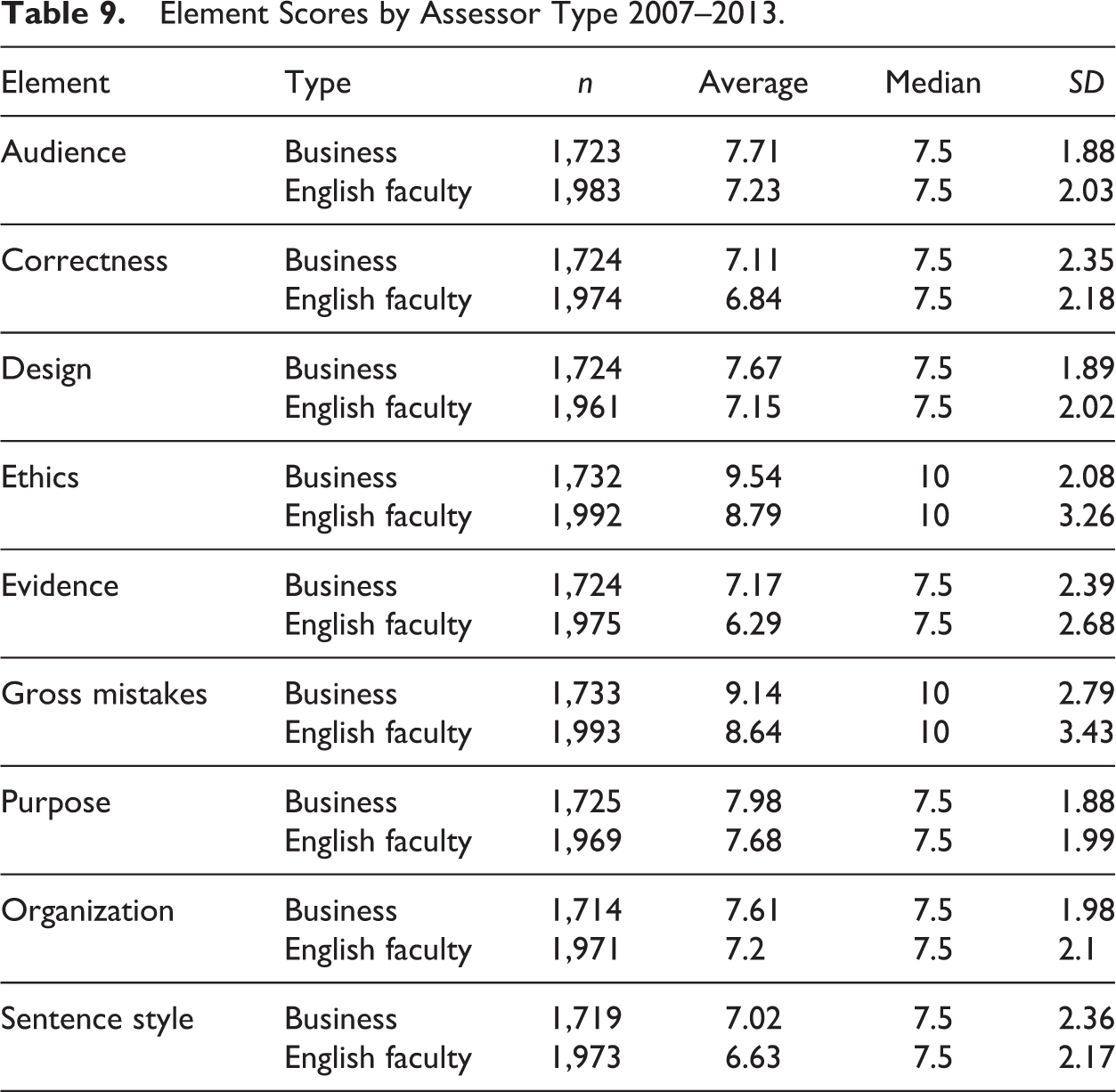
As we have described, each year we recruited 15 business assessors and 15 English-faculty assessors. We tracked the two groups’ performance via Waypoint™. Table 8 lists the number of assessments completed by each assessor group per year. Figure 4 compares the document scores between the two assessor groups each year. Although English-faculty assessors were slightly more lenient than were business assessors in the first 2 years of the study, overall they trended more severe—that is, they provided lower scores—on every element (see Table 9) and had a stronger negative skew to their mean scores. We discuss these findings and possible implications below.
Number of Assessments Completed by Assessor Type per Year.

Mean document scores by year for English-faculty assessors versus business assessors.
Element Scores by Assessor Type 2007–2013.
Discussion
Throughout the 7 years in which we have conducted this assessment, the assessors have been able to use the assessment rubric with minimal training, and the procedures and work flow seemed efficient. Such an assessment is reproducible and seems logistically feasible for a variety of institutional and curricular situations.
The overall document scores were in the good range each year. The elements audience (7.41), design (7.41), and organization (7.40) were also in that range. The binary elements ethics (9.10) and gross mistakes (8.80) as well as purpose (7.80) were higher whereas three elements were around or below 7.0 during the 7-year span of the assessment: correctness (7.01), sentence style (6.83), and evidence (6.68), the overall lowest element. In general, the relationship between element scores was consistent as well. Notably, other than in 2007, evidence was the lowest element. Ethical issues and gross mistakes, the binary elements, were always highest. The assessors’ consistent high evaluation of these two areas indicates that the reports were written responsibly and with an appropriate (and, perhaps, expected) level of correctness.
Overall, in looking at nearly 2,000 documents in the 7 years of the assessment, the assessors judged that undergraduate writers in LeBow are producing good written work. Translated roughly to grades, the data show that students consistently write in the B range. Report scores do slightly improve as students proceed through the curriculum. BUSN students, who are in their first or second year, over the course of the assessment scored 69.44 (which, again, is in the B, or good, range for Waypoint™). Combined together, upper-level students scored 70.27, even while writing the ostensibly more complex documents required by their upper-level courses. A key question, one that must be asked of the LeBow faculty, then, is this: What do you think of and then do with this information about your student writers?
Curricular Intervention 1: Initially Successful but Then Puzzling
After the curricular interventions in the BUSN courses, the summer 2009 assessment demonstrated that the treatment group received better scores for all elements. This distinction between the groups continued into 2010: The treatment group performed better. Those involved with LeBow writing were enthusiastic about these results. First, the assessment indicated that the resources and energy applied to the altered practices (i.e., sequenced assignments and more time in class for peer review and workshops) and environment (i.e., teaching circles and smaller sections) for teaching writing yielded positive results. Second, and no less important, we were able to use an extant assessment process to evaluate this curricular change. Overall, the assessment appeared to validate that the treatment practices and conditions for teaching writing resulted in better student writing. The result of this curricular intervention adds to the composition and pedagogical research about how material conditions for writing instruction directly influence student performance; also, as we later discuss, the results invite interesting—and challenging—questions about the exact causality of the improvements we saw: Is class-size reduction alone enough, or must it be coupled with improved pedagogical approaches to writing instruction?
But this enthusiasm waned after 2010 because in subsequent years the positive effect of treatment appeared to level off, and in 2011 and 2013, the control group actually scored better. Also, while the treatment and control groups were equalizing, the overall mean score for all BUSN documents steadily rose (see Table 5). What had happened? Conversations with individual faculty who taught the BUSN courses helped us understand. From these conversations, we learned that at some point in the BUSN curriculum, the control–treatment differential basically ceased to exist because all faculty were using the best practices approach that we had introduced in the treatment classes. So, while we had been classifying documents as control and treatment based on different classes and instructors, essentially both the control and the treatment groups were using these best practices. If we look at BUSN as one cohort, then, that cohort’s overall mean scores rose from 66.7 to 75.38 during the period of this study.
This story reveals a surprising problem that we believe is important for those interested in curricular assessment. Of course, we need reliable ways to name and categorize documents and samples. But we also must think about the problem of a gap between pedagogical ideas or philosophies and classroom practice. Any writing program administrator who has been asked to provide an assessment of a large writing program has probably confronted this issue: How do you characterize what is happening in actual classrooms, and how do you know those practices are consistent? In our case, a strength of the assessment, namely that it had taken place for so many years, provided the opportunity for classroom practitioners to slide—but toward the improved practices. So we identified a good news–bad news issue: Even though we discovered what we might call a methodological flaw in the experiment after the first few years, the overall teaching of writing in the BUSN courses appeared to improve.
Curricular Intervention 2: The Challenge of Teaching Evidence
The recurring low evidence scores inspired us to engage in a curricular intervention to improve students’ use of research in their writing. Thus, the assessment results were instrumental in helping us to identify the use of evidence and research as a focus area and to justify faculty-development support for teaching the use of evidence in writing assignments.
But the assessment results following this curricular intervention showed little difference in students’ use of evidence. While we did see some improvement in evidence scores from the ORGB courses, the improvement was not significant—and certainly not as significant as the improvement we observed from our curricular intervention in the BUSN courses.
Our focus on evidence was data driven, as evidence was the lowest scoring element. We engaged in faculty workshops and one-on-one interactions, but the WAC faculty-development efforts might not have been robust, comprehensive, and prolonged enough to affect student writing. Perhaps using evidence in writing is inherently difficult, and if students are going to improve in this skill, more systemic change and training are necessary. After all, particularly in first-year writing, critique and analysis of the research paper—a body of work that itself may reflect the complexities of the cognitive writing task of using evidence (e.g., see Hood, 2010; Larson, 1982)—are ongoing. In discussions in summer 2015 about future plans to address the teaching of evidence, the LeBow administration recognized that the previous faculty-development work in this area ultimately only affected students in two courses, ORGB and BUSN. The assessment helped raise the excellent question of how to incorporate reinforcing instruction not only in the LeBow curriculum but in students’ other courses as well as the question of how teachers teach evidence.
In other words, we learned from the assessment initiative that the LeBow students’ use of evidence has not changed much and that we need to do more to help students use evidence effectively.
The Challenge of Measuring Curricular Change
In describing this study’s pilot effort, Warnock (2009) explained that “a key component of AACSB accreditation is that results demonstrate development over time; ideally, then, scores would rise after LeBow implements specific pedagogical interventions in its curriculum, perhaps via faculty development in writing across the curriculum” (p. 100). Thus, this assessment project has given us two important opportunities. First, although we have qualified our results and conclusions, the assessment provided us with a clear opportunity to assess the results of curricular change. An ongoing challenge at all levels of education is how to evaluate the impact of well-meaning curricular changes. (This frustration is not felt solely by those invested in student learning; e.g., Orszag & Bridgeland, 2013, wrote about the lack of effective assessment procedures for almost all federal government programs.) These changes are even tougher to measure at the microlevel; however, in response to pressures to measure, many institutions and schools at all levels have increasingly relied on expensive, decontextualized assessment. The situated assessment model we have described provides local control and involves work with documents created in classroom situations. The assessment provided us with a way to evaluate the changes using the previous year as a baseline. More important, the results helped LeBow do a rare thing: make data-driven curriculum decisions.
Second, the data provided a way of validating the process itself. Both the overall and the element results demonstrated a level of consistency from year to year, supporting the idea that the situated assessment was providing us with a good way of assessing these students and thus allowing us to explore creative ways of intervening and then measuring the effects of those interventions.
Behaviors of Different Types of Assessors
We decided from the pilot stages of this assessment that we would seek assessors with different disciplinary backgrounds, hypothesizing that we might see differences in assessment behaviors. Those differences were clear. Compared to the business assessors, English-faculty assessors tended to give the documents lower scores for every element. There was a particularly notable difference between the two groups in their evidence scores. Perhaps the English-faculty assessors focused more on documentation and citation issues, which they read as proxies for evidence, and perhaps the business assessors cared less about documentation conventions. Also, perhaps the English-faculty assessors tended to see evidence as involving matters of academic integrity (which the exceptional spread in standard deviation for the ethics scores seems to support). If so, are these conventions as important to observe in such exacting detail in a nonacademic workplace (see Abbott & Eubanks, 2005)?
Moreover, with two exceptions, English-faculty assessors were less internally consistent than were business assessors as measured by deviation from the mean on each element. These exceptions, for correctness and sentence style, are sobering: Nonadjudicated consensus among English assessors is greatest on the two traits that, as a profession, we have determined are least important.
This study provides major opportunities for further research that could help us understand how different readers read and respond to student writing and how those responses can help us in creating, developing, and evaluating writing assignments. We are planning another article focusing on the differences between the two assessor groups.
The Practical Value of Situated Assessment
Despite its many critics, norming continues to have a secure place in assessments, with evaluation teams employing holistic scoring strategies that seek a questionable “true score” for writing (Elbow, 1996, p. 85). Warnock (2009) described the arguments about situated assessment that have grounded this study; we have pursued this assessment at least partly in agreement with those who find norming problematic “because it sets up a fictional, idealized context in which to assess writing” (p. 97), a position that is supported by Huot (2002), Whithaus (2005), and others. Kelly-Riley and Elliot (2014) pointed out that standardized tests have “come to be seen as limited because, in their insistence on privileging one category of validity—such as score reliability—over others, they have not robustly engaged the cognitive, intrapersonal, and interpersonal domains of the construct under examination” (p. 92). On one hand, this approach allowed us to acknowledge fundamental differences in audiences’ receptions to writing. On the other hand, it also replicated the long-standing finding that nonnormed raters do tend to clump toward an undifferentiated mean, making finer distinctions less possible. Perhaps we should make decisions about norming more pragmatically: What are the uses of the data we generate?
Situated assessment provides not only a theoretical base, it also provides a practical way for programs to create a perspective for evaluating how students are doing writing-wise: If you believe qualified writers and readers of English can make useful decisions about writing, then you can conduct reasonable evaluations of your program’s writers. The writing assessment literature is clear, as is the educational assessment literature in general: Large-scale writing assessments are challenging. Writing assessment often takes place in contrived environments that present many problems. This project offers a potentially reproducible way for conducting a large writing assessment because the number of assessors can level the idiosyncratic views and judgments of individual outliers.
What to Make of the Writing of LeBow Students
We have explored here many issues connected to this assessment, but the primary goal of this ongoing project remains creating an accreditation-driven perspective on the writing of LeBow students. To the assessors, the student writing, overall, is good. This large data set raises questions, many of which we anticipated in the pilot: Are these results satisfactory for these business students? Have curricular changes done what they were supposed to do to improve teaching and learning? Some assessors participated in the assessment from year to year, some did not. What might an evaluation of assessors’ responses tell us about assessor behaviors? Is our rubric effective at reflecting assessors’ opinions? How do we facilitate clearer communication between curricular ideals and classroom practices? What curricular changes are needed to demonstrate improvement in students’ use of evidence? These questions, much in the spirit of the repeated references to “local” in the Conference on College Composition and Communication’s (2009) “Writing Assessment: A Position Statement,” will be pondered, debated, and decided on in ongoing dialogue by LeBow faculty.
With the support of those faculty, we plan to continue this assessment project. In summer 2015, for the first time in 7 years, we did not conduct the assessment. LeBow has decided to run the assessment every other year and then to use the off summers to investigate data more closely and develop a plan based on that information. According to T. Harrison (personal communication, August 14, 2015), LeBow’s associate dean of academic affairs, the data provide many possibilities to address some of the preceding questions. For instance, the BUSN treatment–control work could be focused to discover causality (i.e., Was it the better teaching or simply the smaller courses that led to the improvements that we saw?). LeBow, as a business school within a university with a robust co-op program (most LeBow students, like most Drexel students in general, complement their academic course work with three 6-month work assignments), also has opportunities to connect the writing of its students with the requirements of the business world. And while one of the strengths of the assessment has been the large, anonymized data set, LeBow may also be able to use the methodology in place to learn how particular cohorts of students (e.g., international students) are performing in terms of writing and develop better teaching support for them.
Conclusion
Although this study has limitations that we have discussed throughout, and the overall picture will continue to change and develop, by having a repeatable, collaborative assessment model in place, LeBow can responsibly develop other curricular innovations and investigate how those innovations might affect student writing. We have learned a number of other things during the course of this long-running assessment. One is that data can help build relationships on campus, in this case, between the English department and business school. The commitment on both sides of this relationship had high-profile results. After Drexel’s 10-year Middle States accreditation review in 2012, reviewers were particularly enthusiastic about this assessment. Written in the subdued language of such reports, the review contained praise: Institution-wide assessment processes are complemented by assessment processes at individual, school and program levels. It is not surprising that the schools or programs with specialized professional accreditations (LeBow College of Business, BioMedical Engineering, Engineering, Nursing and Health Professions) are in the lead. (Middle States Evaluation Team, 2012, p. 21)
Footnotes
Appendix A.
LeBow College of Business Writing Rubric

| Gross mistakes (binary) | This reader did not find gross mistakes that would immediately cast suspicion on the effort/expertise of the document’s creator. | This reader did find gross mistakes that made the reader suspicious or feel negative about the document. | |||
| Ethics (binary) | This reader thinks the document appears ethical, including its use of evidence. | This reader thinks some aspects of the document may be unethical; for example, the document uses inappropriate evidence (including plagiarism), recommends morally questionable practices, or uses deceitful data, style, or visuals. | |||
| Excellent | Good | Fair | Poor | Unacceptable | |
| Purpose/main point | This reader thinks that the writer’s purpose is clear. The document has a clear focus. Also, the idea presented/advanced/argued is both interesting and feasible. | This reader thinks the writer’s purpose is clear for the most part. | The writer often loses focus of the main point of the document. The feasibility of the idea presented is questionable. | This reader has a difficult time determining why the writer has created this document. The main idea seems uninteresting and perhaps even unreasonable. | This reader thinks the document has no main idea or thesis. |
| Audience | The writer has written for a clearly defined audience and, in this reader’s opinion, has addressed that audience expertly. Also, it appears the writer has expertly followed the directions of the assignment/task. | The audience of the document is clear. This reader thinks the writer has done a good job addressing audience. | The document’s treatment of audience is somewhat confusing. The writer does not seem to understand the audience of the document. Also, the writer does not appear to have clearly understood the assignment/task directions. | This reader thinks that the writer’s treatment of audience appears unprofessional, and/or it is not clear who is being addressed. Also, the writer has not followed the directions for the assignment/task. | This reader thinks the document makes no effort to connect with an audience. |
| Excellent | Good | Fair | Poor | Unacceptable | |
| Organization | This reader thinks the report has a clear organizational logic. Transitions between ideas are handled well. | While the report is organized effectively, this reader thinks the document’s organization could be refined/tightened a bit (headings, better transitions, etc.). | This reader thinks the document must be organized more effectively, as readers may be confused or misled. | This reader finds little coherent structure in this document. No clear rationale is apparent for why the document is set up the way it is. The document is confusing. | This reader thinks the document is totally disorganized. |
| Evidence | This reader thinks the writer has made excellent use of research and sources, helping strengthen/build the document’s main point with this material. | This reader thinks the writer made good use of research and sources. In a few places, the document’s main point could have been strengthened with additional evidence. | This reader thinks the document would be substantially strengthened with more/better evidence, and/or the evidence presented is formatted in a sloppy, distracting manner. | The document is weak because of a lack of evidence and support, and/or the evidence used is formatted so poorly that it’s difficult to tell what is cited. | This reader thinks that the use of evidence is unacceptable for a college-level writer. |
| Sentence style: flow of writing | This reader thinks the clear, concise writing in this document made it easy (and perhaps even enjoyable) to read. The writer used solid sentence construction and strong word choices. | This reader thinks the writing in this document is good, but perhaps the writer could have written a bit more clearly and/or written more concisely. | This reader thinks some of the writing is awkward and clumsy, and/or the writer uses weak word choice or unsophisticated sentence structure. | This reader thinks that much of the writing in this document is awkward, repetitive, and/or wordy. The writing was not engaging. | This reader thinks the writing style is glaringly inadequate for a college-level assignment. |
| Excellent | Good | Fair | Poor | Unacceptable | |
| Correctness: grammar and writing mechanics | This reader noticed few errors, if any. The document is clear, and the writer shows considerable mastery of the language. | This reader noticed some grammatical/mechanical errors, but those errors did not interfere with the reader’s understanding of the document’s purpose. | This reader noticed numerous grammatical/mechanical errors, and those errors interfered at times with the reader’s understanding of the document’s purpose and/or caused the reader to question the skill and expertise of the writer. | This reader noticed many grammatical/mechanical errors. The reader felt the number of errors made the document difficult to understand, and the reader questioned the document’s credibility and the writer’s skill because of these recurrent mistakes. | The document is filled with so many errors that this reader cannot help but question the writer’s competence and/or credibility. |
| Document design/appearance | This reader thinks the document uses design elements (white space, titles and subtitles, font size and style, etc.) expertly to create a professional-looking document that would satisfy the audience’s expectations for that type of document. | This reader thinks the document is clean, but the appearance could be improved to aid in the document’s clarity and/or organization. | This reader thinks the document has an amateurish look to it and/or is in need of a more professional appearance. The audience may be confused by the design of the document. | This reader thinks the document appears sloppy and unprofessional, and that sloppiness will certainly cause the audience to be confused. | This reader thinks the document looks as if the writer does not care about its appearance. The design may even be misleading. |
| Visuals if applicable (tables, charts, pictures, etc.) | This reader thinks the document utilizes visuals—tables, charts, pictures, etc.—in an expert way. | This reader thinks the writer makes good use of visuals. Perhaps there are additional opportunities for the use of such material, or the material that is used could be improved somewhat. | The writer has missed opportunities to use visuals and/or has used visuals in a sloppy, ineffective way. | The writer needs visuals to help clarify the document’s purpose, and/or the visuals used are sloppy, inaccurate, or presented in an unethical manner. | This reader thinks the writer did not take advantage of obvious opportunities to use visuals, and/or the visuals used are completely inadequate. |
Appendix B
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.