
Abstract
Organizations nowadays rely on intensive software systems to support their business operations but vulnerabilities within these systems can cause potential risks for major disruption. AI-based techniques are now widely considered for vulnera-bility identification; however effectiveness heavily relies on the dataset’s size and quality. These techniques often lack contextual information while processing data and pose challenges in resource-constrained environments. AI models are generally black box in nature which creates additional challenges to understand decision making processes. This work proposes a novel hybrid framework using LLM model based on CodeBERT with integration of fine-tuning and Model-Agnostic Meta-Learning for performing effective vulnerability detection. It includes few-shot learning technique for new vulnerability detection tasks while maintaining high performance on known cases. The approach adopts Explainable AI techniques from four dimensions including attention mechanisms, layer-wise analysis, feature contribution, and model confidence scores to explain model decision making. An experiment demonstrates the framework’s effectiveness, show-ing steady decrease in meta-loss from 0.45 to 0.14, accompanied by increase in support accuracy from 85.2% to 92.5%. These findings establish the proposed framework as a robust and interpretable solution for vulnerability detection and management.
Introduction
The frequency and sophistication of software vulnerabilities have increased consistently, posing significant threats to software-intensive systems. According to the report by the National Vulnerability Database, there were over 28,000 vulnera-bilities disclosed in the year 2023 alone, following their continued increase in the earlier years. 1 This increasing number highlights the necessity of detecting vulnerabilities promptly and accurately from the software system, as they frequently stay concealed within intricate codebases. AI-based traditional vulnerability detection techniques are promising yet suffer from limitations due to the inability to train effectively with limited and diverse data. These techniques also depend much on labelled data and contextual information about the application for the model outcome. 2 In this regard, Large Language Models (LLMs) have proven to be a revolutionary solution for detecting vul-nerabilities, as they utilize pre-training on diversified datasets composed of a wide variety of programming languages and styles, enabling them to obtain contextual information about the application. This enables LLMs to demonstrate a strong understanding of both syntactic and semantic nuances in source code and to identify intricate vulnerabilities. 3 This is possible in LLM by under-standing the dependencies among various parts of a codebase and, hence, finding vulnerabilities due to improper interactions between components, such as flawed function usage or variable handling across files. However, due to the parameters and multiple layers in LLMs, it is not possible to understand how these models arrive at their predictions, a concern in high-stakes applications like cybersecurity. 4 This opacity can result in a lack of trust by stakeholders, including developers, security analysts, and organizations that use these tools for the detection of vulnerabilities. The existing contribution focuses on various AI models for vulnerability detection; however, lack of focus on the interpretability and explainability of the model decision-making.5–7 Only a few works consider systemic architecture that combines distinct phases of the model implementation, overlooking the explainability of the model decision-making.
The novel contribution of this research is the LLM model based on CodeBERT hybrid frame-work that integrates fine-tuning with Model-Agnostic Meta-Learning (MAML) for effective vulnerability detection. The framework incorporates robust Explainable AI (XAI) techniques to provide insights into the model decision-making, thereby enhancing trust and interpretability in the vulnerability detection process. Hybrid-based approaches provide the capability to integrate dif-ferent AI models for fine-tuning, feature selection, and reduced resource consumption, enabling effective use in various application contexts under optimized resource constraints. The existing hybrid approaches, such as BERT-based representation with deep reinforcement learning, rule-based engines with LLMs and cloud-based LLMs with lightweight device-specific models, have already been proposed.8–10 The proposed hybrid approach in this paper integrates CodeBERT with MAML that supports deeper contextual understanding and adaptability with less data, which the other approaches have not taken into considera-tion. This research makes three unique contributions .
Firstly, the work introduces a CodeBERT-based hybrid framework that leverages both fine-tuning and MAML to develop context-specific adaptable models. By utilizing these techniques, the framework tackles the issue of limited labelled datasets, which are often encountered in vulnerability detection within source code. In our previous work, we fine-tuned CodeBERT successfully for specific tasks but were not able to use MAML because of its complexity.
11
This paper overcomes those challenges, successfully embedding MAML into the framework. With MAML’s few-shot learning ability, the model can quickly adapt itself to new vulnerability patterns using a small labelled dataset, making it effective, especially in scenarios with sparse annotation.
12
This ensures that the mod-el is not only well-trained but also effective in the task of vulnerability detection for large and complex codebases. This hybrid approach reduces the computational overhead yet retains high accuracy, suitable for resource-constrained environments. Finally, fine-tuning and MAML integration encourage robustness, ensuring that the model is resilient to noisy or incomplete data, which are common in real-world scenarios. The framework further enhances the de-tection capabilities through a number of architectural innovations, including a multi-head attention mechanism, bi-directional LSTM layers, and an uncertainty quantification module. This not only enables the model to capture complex patterns and long-range dependencies in source code but also provides robust support for decisions. The framework incorporates robust XAI practices to explain the model outcomes from a holistic aspect. XAI principles are integrated into the framework to ensure interpretability and reliability of the detection process by leveraging four dimensions: attention mechanisms, layer-wise analysis, feature contribution, and model confidence scores using techniques such as SHAP, LIME, and heatmap. Furthermore, the confidence scores will empower the developers to interpret and act upon the results with greater confidence. XAI enhances the ability of this framework to detect potential biases or anomalies in predictions for a fairer and more reliable system. Fur-ther, the explanations provided by XAI give con-fidence to stakeholders, since the decision process is now understandable and compliant with the organizational standards. Finally, the framework is validated through extensive experiments. The result shows that the system can detect and classify vulnerabilities efficiently under dynamic and fast-evolving threat landscapes. The result demonstrates a steady decrease in meta loss from 0.45 in the first epoch to 0.14 in the fifth, while the support accuracy increases from 85.2% to 92.5% and query accuracy from 88.1% to 95.7%. This showcases the model’s ability to adapt, reduce the error, and predict correctly with a higher probability. Moreover, advanced XAI techniques based on attention mechanisms, layer-by-layer analysis, and feature contribution evaluations are integrated into the framework to ensure trust and in-terpretability, further increasing its reliability and trustworthiness for the stakeholders. Key features identified with SHAP and LIME include tokens like “static,” “int,” “size_t,” and “struct,” which have a positive impact on predictions for certain classes, while terms like “header_len,” “sockaddr_x25,” and “skb” have a negative impact, which provides insight into the patterns the model associates with each class.
Related works
Vulnerability detection using fine-tuned and few-shot learning
In the fast-evolving domain of LLM, adapting models to diverse tasks with limited labelled data has become a critical challenge. Techniques like fine-tuning and Model-Agnostic Meta-Learning (MAML) have emerged as strong solutions that allow pretrained models to generalize across tasks and domains effectively. Recent research highlights the integration of fine-tuning and MAML to enhance information extraction (IE) tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), particularly in data-scarce scenarios. 13 Fine-tuning adapts pre-trained models to specific tasks, improving performance with minimal labelled data, while MAML optimizes model initialization for rapid adaptation through few-shot learning. This combination enables effective generalization across diverse datasets and domains, dealing with problems such as few labelled data and task diversity. The notable frameworks based on these techniques are MsFNER, MICRE, and MAML-en-LLM. MsFNER 5 uses MAML in training for the goal of optimization of initialization towards the entity span detection and classification models for fast adaptation to new tasks and fine-tuning for domain-specific refinement that has shown robust performance on complex datasets. Similarly, MICRE integrates meta in-context learning and fine-tuning into an approach to enhance relation extraction under zero-shot and few-shot learning scenarios. 6 MAML meta-trains LLMs for fast adaptation toward unseen tasks, while fine-tuning of the model during inference refines model performance and enhances the results in both relation classification and relational triple extraction. 7 In addition, the MAML-en-LLM framework fur-ther integrates MAML with fine-tuning to improve the in-context learning of LLMs. In particular, MAML-en-LLM employs a two-step optimization process involving inner-loop task adaptation and outer-loop meta-parameter updates, further complemented by fine-tuning on diverse task exemplars. This enables MAML-en-LLM to have the best adaptability, efficiency, and accuracy across domains compared to competing approaches such as MetaICL.
The paper by Islam et al. 13 considers ML models such as linear regression, decision tree, and random forest to predict the vulnerability exploitation using the base metrics of the CVSS for secure healthcare supply chain service delivery. The result from the experiment shows 63% accuracy considering the CVE dataset. Also, the paper by Silvestri et al. 14 adopts Natural Language Processing (NLP) to extract useful threat information specific to assets from text that contains security-related information. Besides, these frameworks identify that high-quality data plays a significant role in robust and reliable LLM performance, specifically for applications like vulnerability detection. 15 Pretraining on large, high-quality datasets allows LLMs to learn patterns, semantics, and contextual relationships effectively. This helps to ensure adaptability and generalization of LLMs in real-world applications, including those for critical domains such as disaster response and medical diagnostics. 16
Explainable AI in the context of LLM
The increasing presence of LLMs across diverse domains makes the integration of XAI imperative for reasons of transparency, trust, and usability. Recent studies focus on usable XAI, underlining that it is about improving LLMs with explainability and taking advantage of the human-like reasoning and synthesis of knowledge from LLMs to improve XAI’s usability. 17 Various techniques, including attribution-based explanations, knowledge-augmented prompting, and training data augmentation, have been proposed to bridge the gap between technical explainability and practical usability. Advanced methods include causal explainability with counterfactuals and feature extraction for decision explanation, which aim to provide semantic fidelity and deeper insights into model behavior, aligning AI systems with human expectations. 18 Complementing these developments, domain-specific applications, such as “x-[plAIn],” a domain-specific GPT-based LLM, make XAI accessible to wide classes of users by simplifying complex methods like LIME, SHAP, and Grad-CAM. 19 Specific domain applications, such as financial cybercrime detection using Graph Neural Networks (GNNs) and LLMs, further illustrate the practical value of XAI by integrating narrative generation, anomaly detection, and embedding-based insights to streamline investigative processes. 20 Similarly, for cybersecurity, embedding SHAP values with the LLMs in intrusion detection systems allows one to under-stand exactly where feature contribution is coming from and aids in trust problems with users. 21 A BERT-based model is proposed for source code vulnerabilities detection also emphasizes the need for explainability towards trustworthy AI. 11
In summary, fine-tuning and MAML have shown promising integration in solving the challenges of adapting LLMs to diverse tasks, especially for minimal data. With high quality data supporting such approaches, robust generalization and improved performance can be achieved in critical domains such as cybersecurity, disaster response, and medical diagnosis. Besides, the adoption of XAI techniques like SHAP, LIME, and counterfactuals allows the establishment of transparency, trust, and usability in AI systems to meet global regulatory standards. However, most of the XAI practices are still limited to a few available techniques, which require further innovation to bridge the gap between model performance and explainability.
Proposed framework
This section presents the proposed framework including the hybrid LLM framework, system architecture, and Explainable AI, for effective vul-nerability detection and explaining decision-making. In the hybrid approach, CodeBERT is integrated with fine-tuning and task-conditioned Model-Agnostic Meta-Learning (MAML) in a novel way, allowing the model to adapt dynamically to new vulnerability patterns while still showing impressive performance on the known cases. The methodology is thus embedded in the AI life cycle, from data preprocessing and model training to model evaluation. Each of these steps in the life cycle is towards better accuracy, adaptability, and efficiency consideration with challenges such as computation resource constraints and unavailability of diverse and high-quality data. Finally, XAI techniques are integrated into the approach to provide a detailed understanding of the decision-making process with insights on how vulnerabilities are identified.
Hybrid approach
The proposed hybrid approach aims to address the challenge of high quality diverse training data constraints to reach an optimal level of performance in the outcome model. We perform a hybrid-based approach applying the CodeBERT LLM model together with MAML. The reason for choosing CodeBERT is due to its ability to understand both the natural and programming language context. CodeBERT is pre-trained on large-scale paired data,
22
which enables support for various functionalities, including code search and summary, which bridges the gap between human-readable text and machine code.
23
Moreover, further selection of MAML within the hybrid approach supports the adaptability to train on new tasks. It is a meta-learning algorithm that augments a model’s parameters aimed at effi-ciently learning new tasks with very few labeled examples.
7
This collaboration allows for excellent performance even with a small amount of la-beled data while taking advantage of the specialized features of CodeBERT. This optimization in MAML is based on a two-step process, leading to an inner loop for task-specific updates and an outer loop for meta-learning, shown in Equation 1. Using the capabilities of meta-learning in MAML, the model rapidly adapts to new tasks with small-sized labeled data and significantly reduces the dependence on large, diversified datasets.
24
Hybrid integration maintains a strong balance between generalization and task-specific performance, which is effective in domains where code patterns show high variability. In addition, fine-tuned CodeBERT gives rise to improved accuracy and understanding of these complex code-related tasks for a more accurate and dependable result.
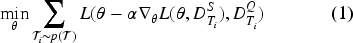
Figure 1 illustrates the hybrid approach of CodeBERT that integrates fine-tuning and MAML with few-shot learning. The process begins with CodeBERT, which captures the semantic relationship between natural language and code. This pre-trained model is then used as a basis to provide a good initialization of parameters
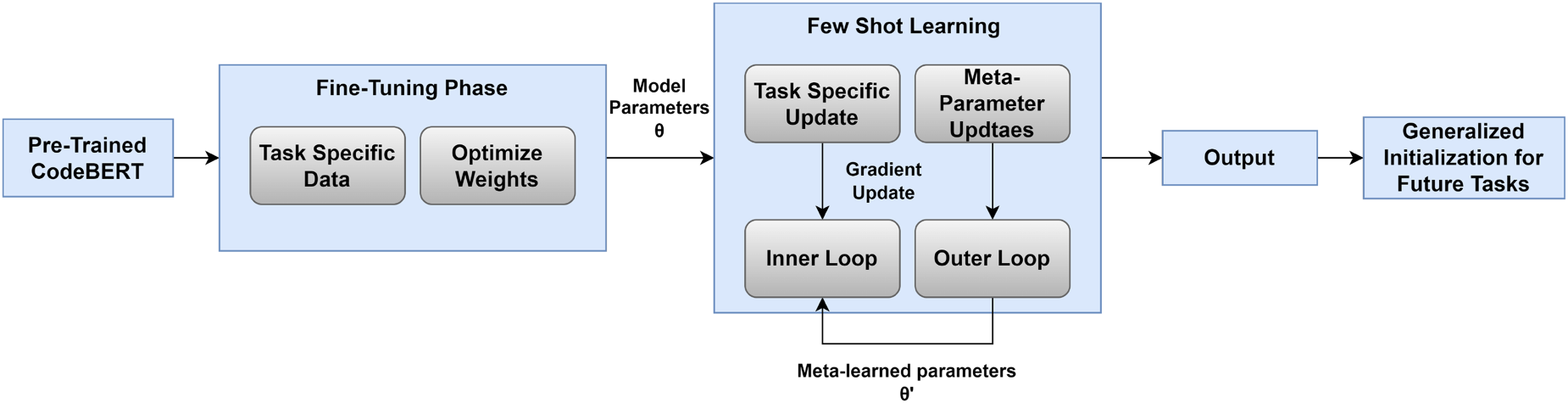
Integration of MAML with CodeBERT.
By combining these two loops, MAML optimizes the meta-parameters (
Large Language Models including BERT, and CodeBERT, are powerful tools capable of generating text, making predictions, and answering queries using vast amounts of training data. However, these models are black boxes in nature, making it difficult to understand how they generate their outputs. 25 Lack of transparency may cause problems regarding trust, especially in high-stakes domains such as healthcare, finance, or legal, where decisions supported by the output of LLM might have grave consequences. For example, an LLM-based system detects cybersecurity threats like phishing emails or malware. It could flag a legitimate financial email as phishing and block it, or it might fail to recognize a spear-phishing attempt and compromise the network. This implies that, within this framework, XAI is necessary in helping to make the inner mechanisms of LLMs transparent and interpretable. By offering insights into how the model arrives at its conclusion, XAI builds up the trust and confidence of its users. The application of XAI on LLMs differs from its application on more conventional models such as deci-sion trees or neural networks. 26
Unlike structured data models, LLMs operate on unstructured text, which makes their decision-making processes inherently more complex. The balanced approach is essential due to the wide deployment of LLM in sensitive domains, where the implications of where the implications of in-correct or biased outputs could be grave. 25 The uniqueness of XAI in LLMs is that it promotes a holistic view one where interpretability is valued just as much as the model’s capabilities to manage complex tasks. In this context, there are four distinct dimensions of XAI generally considered in LLM models to holistically explain the model outcome, as presented in Figure 2.
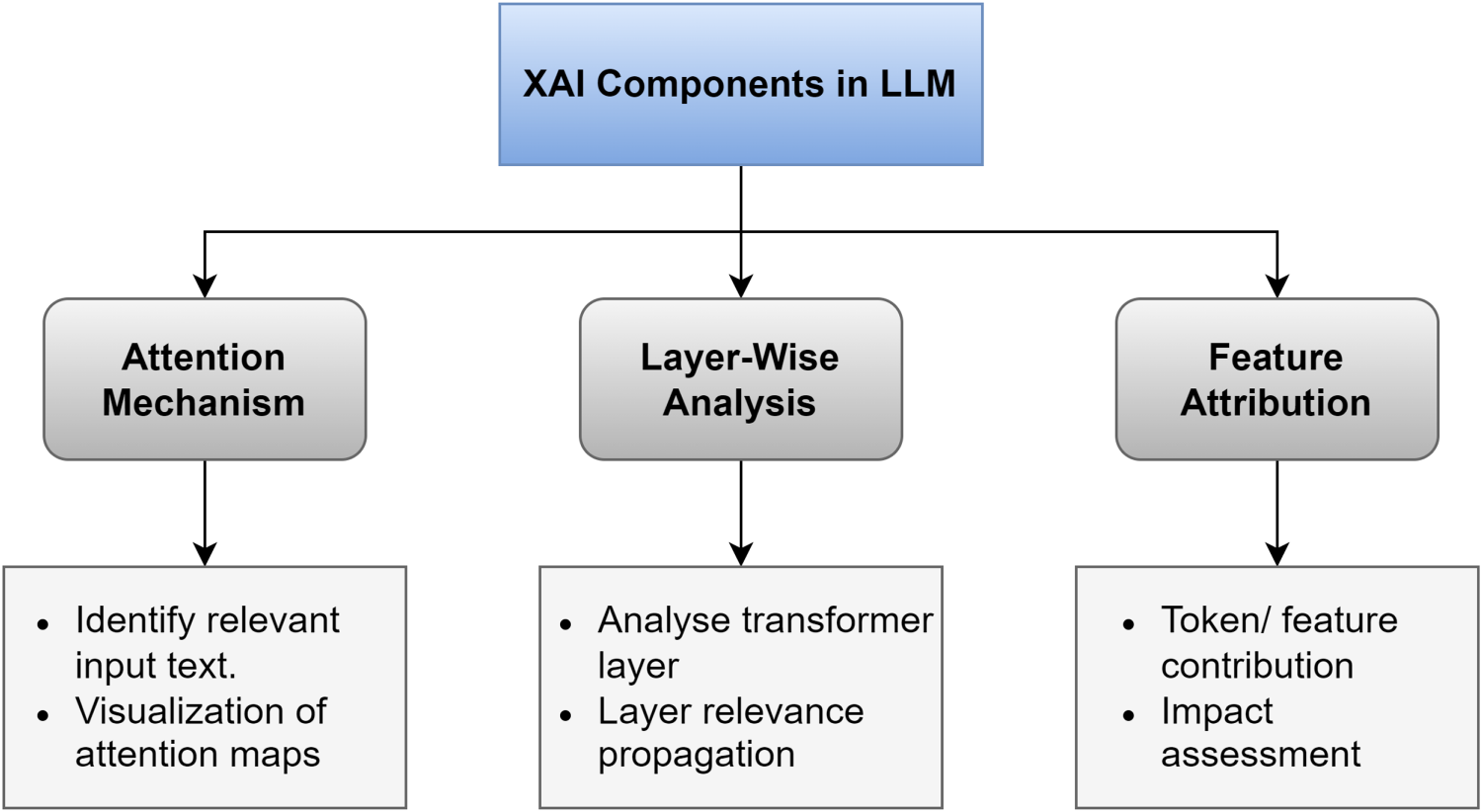
Components of XAI in LLM model.

The scaled scores are then passed through a SoftMax function to compute them as normalized attention weights (
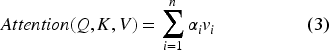
Afterward, this attention weight can be used to explain how the model has placed its focus during training on various parts of the input. We can rep-resent these attention weights as heatmaps that intuitively illustrate which part of the input the model is focusing on using varied color intensities to represent focus strength. 28 In the heatmap, one axis represents each of the input tokens, and the other axis represents the query tokens or sequence positions. The attention weights determine the intensity of the colors in the heatmap; higher weights are represented by brighter or more vivid colors.
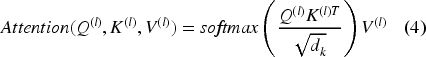
Where
Layer-wise analysis provides insights into how input data is processed across layers. The intensity of each cell reflects the importance of each token in each layer; a brighter color indicates higher weights of attention. Early layers usually show broader attention, capturing syntactic structures, while later layers focus on task-critical tokens, refining semantic understanding. By visualizing these shifts in focus, heatmaps help uncover hierarchical data representation, highlight key dependencies, and provide a transparent view of how layers contribute to the model’s decision-making, enhancing interpretability and trust.
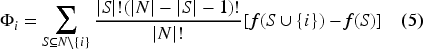
LIME follows a similar approach and locally approximates the model around an instance of interest by adding perturbations to the input and observing changes in the output.
11
LIME then fits a simple interpretable model to these generated perturbed samples and assigns weight to each feature based on its importance. The weight of a feature can be computed by the equation (6):
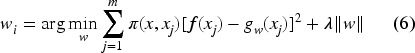
Where
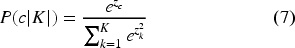
The architecture of the framework consists of three distinct phases in sequence, with Phase 2 and Phase 3 containing sub-phases, as depicted in Figure 3. In Phase 2, the hybrid model is developed by merging fine-tuning of the CodeBERT with MAML for robust and task-adaptive performance. Phase 3 ensures that the model is not only effective but also interpretable.
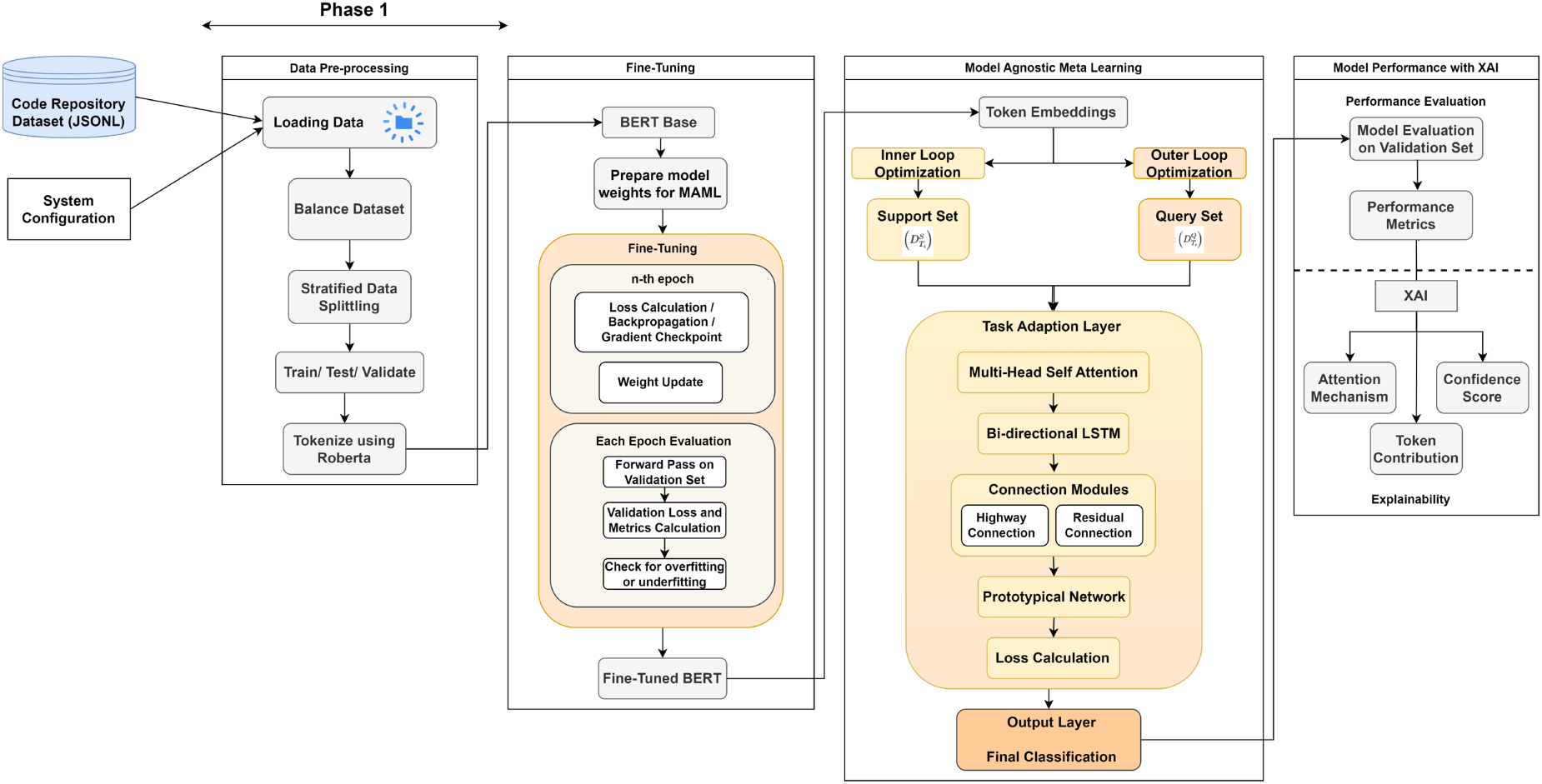
System architecture of the hybrid framework.
Phase 1: Data pre-processing
Data pre-processing is the first phase of the proposed architecture and consists of a number of activities. This step prepares the raw input data of the code repository for effective use in the successive stages of fine-tuning and meta-learning. It begins by loading the dataset and extracting the required information. Balancing is conducted after loading the data to take care of class imbalance. This step ensures that all categories or labels in the dataset are represented well to avoid any biases. Following this is the stratified splitting of data into training, validation, and test sets. Lastly, tokenization was performed as the final pre-processing activity using a RoBERTa-based tokenizer. Tokenization involves activities like truncation, padding, and the creation of attention masks to ensure that the input data aligns with the pre-trained architecture of CodeBERT. This structured pipeline lays a solid foundation for the fine-tuning and meta-learning phases, enabling CodeBERT to learn and adapt effectively to a variety of programming tasks.
Phase 2: Fine-Tuning and MAML Integration in CodeBERT
The next phase focuses on the adaptation of the novel hybrid approach of CodeBERT that integrates fine-tuning and MAML to enable it to effectively adapt to the task at hand. The preprocessed data from Phase 1 serves as the base for this phase. This integration further enhances the efficiency of the pre-trained model with MAML by quickly adapting to new tasks with minimal data. This phase is divided into two sub-phases to ensure a systematic and effective learning process.
Phase 2.1: Fine-Tuning CodeBERT
The goal of this sub-phase is to use pre-trained knowledge about source code of the CodeBERT and allow for task-specific adaptation using fine-tuning. The tokenized data from Phase 1 is used as input for CodeBERT to produce the rich embeddings, capturing syntactic and semantic relation-ships in the source code. These embeddings are then further refined using the multihead self-attention to capture the contextual dependencies.
In this hybrid approach, MAML aids in the task-adaptive learning mechanism using the loops. Specifically, the inner loop of MAML fine-tunes the parameters of CodeBERT using a support set (discussed in Section 3.1), allowing task adaptation with limited data. The contextual embeddings are fed to a bi-directional LSTM to model sequence-level dependencies, further enhanced by highway and residual connections to ensure robust gradient flow and effective representation learning. The task-specific adaptation is completed with a prototypical network that computes class prototypes in the embedding space and classifies new samples based on their distance to these prototypes. This fine-tuning on the task at hand enables the model to learn the nuances of the task quickly.
Phase 2.2: Model Agnostic Meta Learning
This sub-phase focuses on leveraging the outer loop of MAML, where the fine-tuned parameters from the inner loop are passed to perform few-shot learning, evaluating, and refining the CodeBERT model. In the outer loop of MAML, the adapted model from the inner loop is evaluated on a query set to compute a meta-loss. This meta-loss assesses how well the inner loop adaptation is performed and updates the global meta-parameters of CodeBERT. This dual-loop mechanism of task-specific adaptation and global optimization ensures the hybrid model generalizes effectively across diverse programming environments. The integration of MAML into CodeBERT also extends the model’s explainability. The task-specific adaptations performed during the inner loop highlight which features (tokens, embeddings, or sequences) are critical for the task, providing interpretability into the model’s decision-making process.
Phase 3: Model Performance and Explainability with XAI
This final phase focuses on evaluating the hybrid model developed in Phase 2 in terms of both performance and explainability. By leveraging both traditional performance metrics and innovative explainable AI (XAI) techniques, this phase provides a comprehensive analysis of the model’s effectiveness and trustworthiness. Performance metrics highlight how far the model can achieve objectives for which it has been fitted, and they give a normalized manner of examining the effectiveness of this model towards spotting areas that could be refined. Moreover, XAI helps understand the model’s decision process, uncovers hidden bias, and validates that the model predictions align with ethical considerations.
Sub-Phase 3.1 Model performance evaluation
It gives insight into the performance of the developed hybrid model by determining the performance based on different performance metrics: meta loss, support accuracy, query accuracy, and task diversity. The meta loss signifies the overall loss accrued through the entire meta-learning process, hence defining the model’s optimization efficiency over different tasks. 33 Support accuracy reflects the model’s ability to learn effectively from the few examples provided in the support set for each task. 34 Query accuracy reflects the performance of the model on unseen data for the same task after learning from the support set. 35 Finally, task diversity quantifies the variability and complexity of the tasks that the model is trained and evaluated on, providing insight into its generalizability to diverse scenarios. 36 These metrics together guarantee that one will have a complete understanding of the strengths and weaknesses of the model. The evaluation is necessary to ensure that the hybrid model meets the desired performance thresholds, robustness, reliability, and adaptability in practical applications.
Sub-Phase 3.2 Explainability of model
Finally, explainability in the AI model focuses on explaining the factors that influence the decision-making of the model. This sub-phase tries to fill the gap between model performance and interpretability using advanced explainability techniques, so the entire system becomes more dependable and trustworthy for any end user. The key techniques implemented in this sub-phase, as mentioned in Section 3.2, include: Attention mechanism helps a model to actively focus on selective parts of the input sequence when generating an output. By assigning every input element with a different importance level, the model learns complex dependencies and relationships between them.
37
Attention mechanisms calculate attention weights using components such as queries, keys, and values. The weights are displayed using heatmaps, an intuitive representation of the model’s areas of focus. Heatmaps make it easier to understand the model’s decision-making process, putting emphasis on which tokens or features were most impactful for a specific task or prediction.
38
Layer-wise analysis is instrumental in systematically studying how each layer of the model contributes to processing and transforming the input into meaningful output. In the transformer-based models, such as CodeBERT, information gets progressively refined by a number of layers. These are fitted with attention mechanisms inside that make the model concentrates on token interactions. Feature contribution is a way to determine the importance or influence of certain input features, such as words or tokens, on the model’s predictions. This technique assigns numerical scores to features that summarize their contribution to the output. SHAP and LIME are the two most common feature attribution methods. SHAP measures the contribution of each feature by considering all possible subsets of input features, yielding a more robust and global explanation of feature importance.
31
LIME works by locally perturbing the input and fitting a simple, interpretable model to approximate the predictions, providing local explanations around specific data instances.
31
Model confidence scores quantify the certainty or reliability of predictions by assigning probabilities to each possible outcome. These scores represent the model’s confidence in the correctness of its predictions, which is derived from the SoftMax function applied to the model’s raw outputs. High confidence scores reflect high certainty in the prediction, whereas lower scores indicate ambiguity or uncertainty.
39
Confidence scores improve the explainability of the model as they provide insight into the reliability of each decision and allow users to determine whether a prediction can be trusted. Further integration of the confidence scores with other techniques, such as attention visualization and feature attribution, will make the model even more interpretable and user-friendly.
This section outlines the experiment and results obtained from the experiment by implementing the proposed system architecture. The focus is on demonstrating the applicability of the proposed hybrid approach and robust XAI practice. The objective of this experiment is to: To assess the model’s performance for the proposed hybrid approach that integrates the CodeBERT model with fine-tuning and MAML. To demonstrate and explain the model’s decision-making process using robust XAI practice from a holistic aspect.
Dataset description
For this experiment, we have used the dataset, DiverseVul,
40
which is a diverse source code dataset meant for vulnerability detection with the support of machine learning models. This collection contains raw source code snippets (source code), labeled (annotated) as ’vulnerable’ or otherwise, and in representations necessary for machine learning, using representations such as Abstract Syntax Trees (ASTs) and Control Flow Graphs (CFGs). Sourced from real-world and simulated scenarios, DiverseVul allows the training and benchmarking of models aimed at detecting vulnerabilities and studying explainability, thus helping researchers evaluate performance and interpretability. Some of the key features of Diversevul are: 18,945 vulnerable functions and 330,492 non-vulnerable functions extracted from 7,514 commits. Coverage of 150 Common Weakness Enumerations (CWEs), making it the most diverse dataset compared to prior collections. Vulnerabilities focus on websites and extracts vulnerability-fixing commits from 797 projects, including 295 new projects not covered by previous datasets. The dataset emphasises on real-world applicability and solves several challenges such as label noise and generalization to unseen projects.
System implementation
Phase 1: Data pre-processing: We implemented a structured data pre-processing pipeline to prepare raw input data for fine-tuning and meta-learning with the CodeBERT model. Starting with loading the dataset, we extracted and organized relevant information. Biases in our models were further reduced by balancing the dataset for the right representation of all classes. Further preprocessing was performed to split data into training, validation, and test sets with stratified data division, hence maintaining the distribution across subsets. Finally, tokenization was done with the RoBERTa-based tokenizer. Preprocessing also includes truncation, padding, and attention mask creation to fit with CodeBERT’s architecture. In this pipeline, we achieved consistent and strong preparation for downstream tasks.
Phase 2: Fine-Tuning and MAML Integration in CodeBERT: In the second phase of our experiment, we implemented a hybrid approach by combining CodeBERT with fine-tuning and MAML, using an optimized configuration to enable efficient task-specific adaptations. The pre-processed data from the previous phase was used for fine-tuning CodeBERT to generate rich embeddings, refined with multi-head self-attention and a bi-directional LSTM for enhanced contextual understanding and sequence-level dependencies. CodeBERT is a pre-trained model with 6 transformer layers, including multi-head attention and feed-forward mechanisms. For configuration parameters, an inner learning rate was set to 0.01, while the outer one was 0.0001 and there were five task adaptation inner steps, while the number of outer steps was reduced to 100 to avoid overfitting. Enhanced settings, such as a task embedding dimension of 128, a dropout rate of 0.1, and prototype-based adaptation with three samples, ensured robust and adaptable task representations. These values allow us to balance generalization and effectively adapt the model to new vulnerability patterns. The outer loop of MAML optimized global meta-parameters, leveraging regularization weights like task diversity of 0.1 and prototype margin of 0.5, whereas early stopping further enhanced the stability of training. This architecture, combined with the transformer design in a layered manner, allowed the hybrid model to achieve impressive performance regarding few-shot learning, scalability, and interpretability on tasks related to programming.
Phase 3: Model performance and Explainability with XAI: In this last phase of the framework, the system is intended to assess hybrid model performance along with robust XAI practice. The data was split into 80% for training and 20% for testing in order to ensure an unbiased assessment on unseen data. Results of the experiments conducted during the two sub-phases are discussed below.
Sub-Phase 3.1 Model Performance Evaluation: In this sub-phase, we evaluate the performance of the fine-tuned CodeBERT model, which is integrated with MAML. The evaluation focuses on key metrics such as meta loss, support accuracy, query accuracy, and task diversity. Each of these metrics gives insight into the model’s learning efficiency, adaptation to a specific task, and generalization capability.
To show the model’s performance in the training phase, Table 1 presents these metrics across five epochs, while Figure 4 visualizes the result accordingly so that a comprehensive view of its progression and improvement is demonstrated. As the table shows, accuracy increases with the number of epochs, and it demonstrates the model is adopted with new tasks. The key insights from this table are: Meta loss decreases steadily, showing improved task generalization. This consistent drop in meta loss suggests that the model can better optimize its parameters for various tasks during meta-learning. Support accuracy grows from 85.2% to 92.5%, indicating better task-specific learning. Improvement reflects the model’s enhanced capability to adapt its fine-tuned weights to individual tasks within the support set. Query accuracy improves from 88.1% to 95.7%, showing better generalization to unseen data. This significant gain showcases the strength of the hybrid model in transferring learned knowledge to unseen query samples during meta-testing. Task diversity increases from 0.72 to 0.89, highlighting exposure to the varied tasks. This increase in task diversity shows that the model has been exposed to a wider range of tasks, ensuring robust learning across different programming contexts.
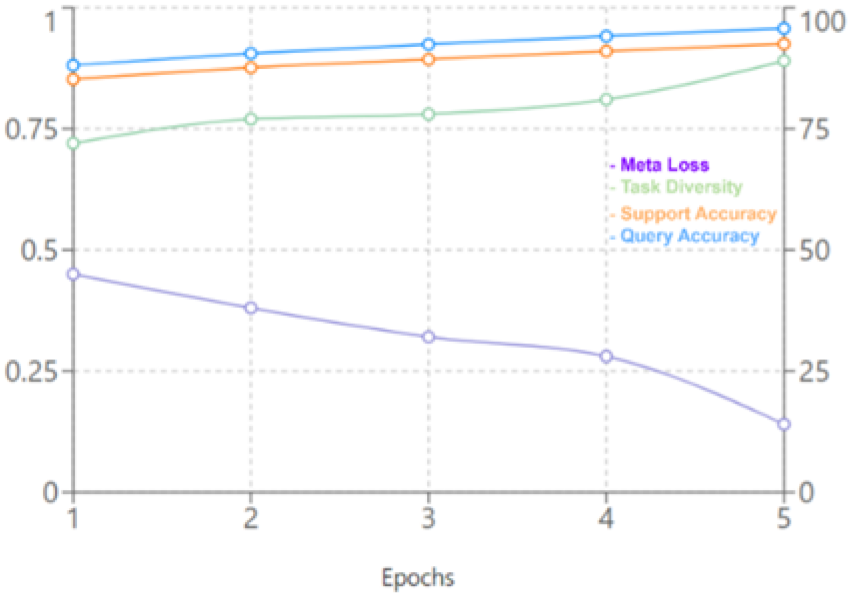
Model performance visualization.
Performance evaluation of the model.

Sub-Phase 3.2 Explainability of Model: This sub-phase explains the decision-making of the model to ensure that its predictions are interpretable and transparent. In other words, by providing insights into how the model processes information and arrives at conclusions, we enhance its interpretability. These explanations also help identify potential weaknesses in the model. We consider various techniques from the four dimensions of XAI as discussed in Section 3.2.
The results from each of these dimensions are discussed below. ensure that its predictions are interpretable and transparent. In other words, by providing insights into how the model processes information and arrives at conclusions, we enhance its interpretability. These explanations also help identify potential weaknesses in the model. We consider various techniques from the four dimensions of XAI as discussed in Section 3.2. The results from each of these dimensions are discussed below.
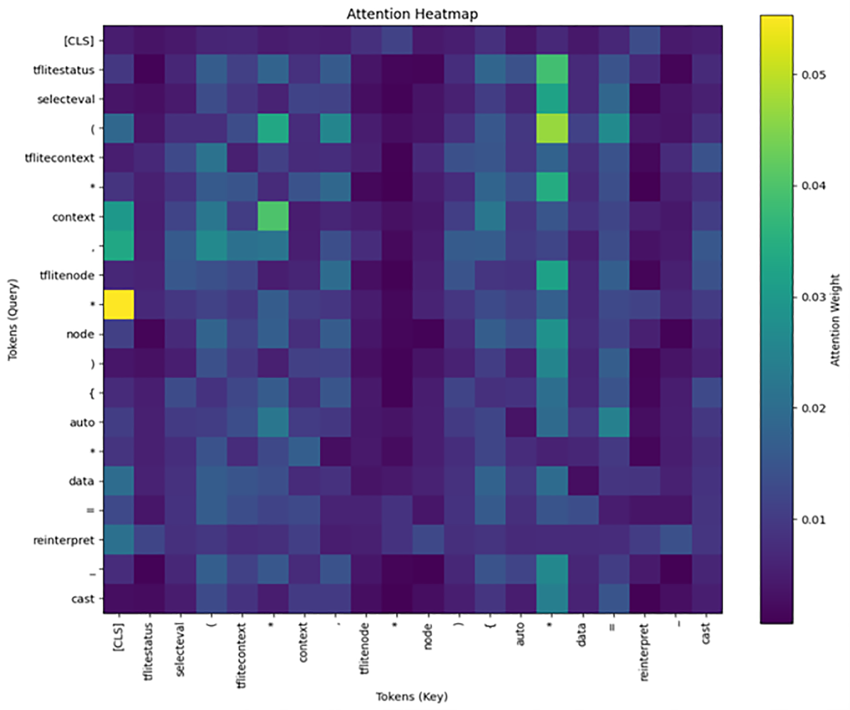
Attention weights heatmap for input token.
Figure 6 shows a seven-layer abstraction of the CodeBERT model. Each row here represents a layer, while columns represent tokens from the input sequence. The color intensity is determined by the magnitude of activation. Lighter areas (yellow) correspond to large activation values, while darker colors (blue or purple) correspond to smaller or negative activations. In Layer 0, the activations are far stronger for some tokens, like ’##eva’ and ’context.’ This indicates that the early layer is actively capturing lower-level token-specific features, such as syntax or word structure. In this layer, the activations are dominated by subword tokens like ’t,’ ’##fl,’ ’##ite,’ which the model processes collectively to arrive at meaningful word-level representations. As we go deeper into the intermediate layers, Layers 1 to 5, the activations become more uniform and subdued. This reflects the model’s development from low-level token representations towards more abstract contextual relations. These layers are not very token-focused but aim at building semantic understanding of the overall sequence. In the last layer, Layer 6, the activations are quite similar and consolidated, especially regarding special tokens like ’[CLS]’ and ’[SEP]’. First, the ’[CLS]’ token, representing the overall sequence embedding for classification, has a strong activation across layers, hence critical. Similarly, tokens like context, select, and node retain relatively higher activation to represent their importance in the semantic understanding of the input. Furthermore, layer-wise decision points are also summarized in Table 2, which highlights the key contributing tokens for each layer. Tokens such as ) and ( show high positive contribution in multiple layers, indicating their influence on the model’s decision. Conversely, tokens like ##text, and select appear as strong negative contributors, suggesting that the model associates them with reduced confidence in the predicted class.
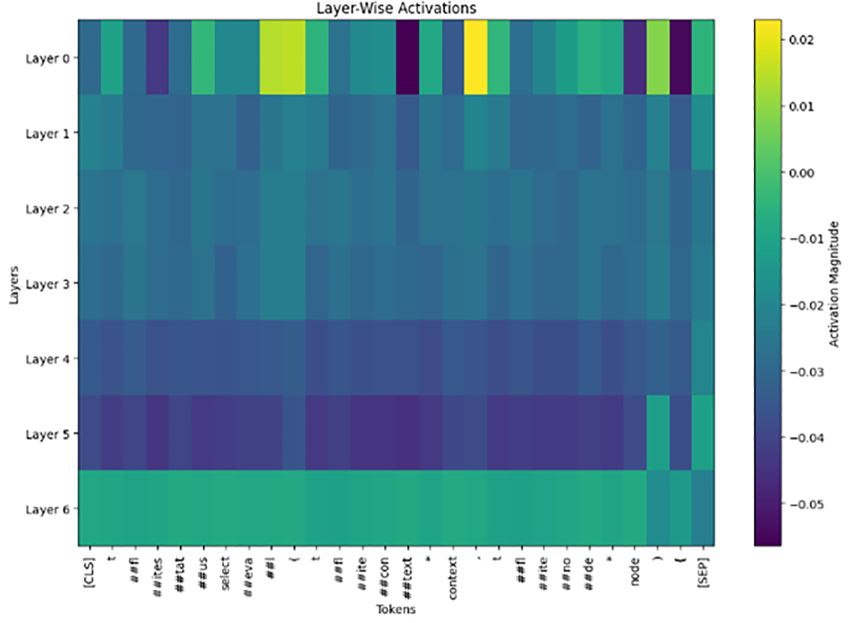
Layer-wise representation analysis of input tokens.
Token contribution for individual layers.


SHAP force plot for model prediction.
For Output 0, the predicted value f(inputs) is approximately 0.0114, which reflects the cumulative effect of all token contributions relative to the base value. Red-colored tokens, including those that contribute positively to Output 0, drive the prediction upwards from the base value. These are likely features that the model has learned for predicting this class. On the other hand, blue tokens contribute negatively, pulling the prediction downward, although their presence in this example is minimal. Neutral tokens are much closer to the base value and have little to no contribution. The sum of all these contributions is a shift from the base value to the final value of the model’s output and provides an interpretable view of the model’s decision-making process. This explanation helps developers understand why the model predicted a certain class by highlighting which features in the input text were influential and provides insights for debugging or improving the model.
Figure 8 represents the LIME visualization for the fine-tuned CodeBERT model that is integrated with MAML. The model predicted a 52% probability for the positive class and a 48% probability for the negative class. The close probabilities suggest that the model found the sample somewhat ambiguous, as it is near the decision boundary. The visualization highlights specific words in the input text that influenced the prediction. Orange-colored tokens contributed to the positive class prediction, including such keywords as ’static,’ ’int,’ ’size_t,’ and ’struct’. Their presence in the code seems to be related to the patterns the model learned to correlate with the positive label. On the other hand, tokens in blue contributed negatively, pushing the model toward the negative class. Examples include ’header_len,’ ’sockaddr_x25,’ and ’skb’. These terms may be associated with patterns the model found indicative of the negative class during training. By analyzing which tokens had the most influence, you can gain deeper insight into the model inner working mechanisms. This helps us to enhance our understanding of the decision-making process and allows us to refine query formulation, adjust preprocessing steps, and improve training strategies for better model performance and interpretability.

LIME analysis.
Model Confidence Score: Model confidence scope further enhances the explainability of the model outcome by providing insights into the certainty of predictions, allowing users to assess the reliability of the model’s decisions. Confidence scores help identify areas where the model may be uncertain, guiding efforts to improve robustness and ensuring informed trust in its outputs. In this regard, in Table 2, the model predicts Class 0 with a confidence score of 0.91, signifying high certainty that the input aligns with the features associated with this class. Conversely, the score for Class 1 is 0.09, suggesting minimal likelihood of the input belonging to this category. This significant difference between the two scores shows the high ability of the model in distinguishing between the classes because it clearly favors Class 0. These are the kinds of results that highlight the effectiveness of making confident and well-calibrated predictions from a model.
This paper aims to contribute to an effective source code-based vulnerability detection and comprehensively explains the model decision-making. Our approach balances computational efficiency and model interpretability, providing a practical solution to improve cybersecurity.
Adoption of hybrid LLM model in vulnerability detection
The proposed hybrid framework, based on a CodeBERT-powered LLM, integrates fine-tuning with Model-Agnostic Meta-Learning, providing an adaptable and efficient solution for software vulnerability detection. One of the key benefits of MAML is its potential for enabling quick adaptation, with very few data points, to diverse and evolving vulnerability patterns. Unlike in the case of traditional AI methods, which have a high dependency on extensive datasets for fine-tuning using huge computational resources, MAML trains models with only a small number of instances by leveraging few-shot learning capabilities. This makes the framework especially useful in dynamic environments, where new vulnerabilities emerge often, and labeled data is scarce. 42 MAML efficiently optimizes the initialization of model parameters to allow for faster and robust adaptation to complex tasks without further training of the model, reducing computational overhead and thus enabling quick deployment in real-world scenarios.
Another strength of this framework involves the higher detection of vulnerability with improved accuracy and robustness regarding complex vulnerabilities. It enables architectural innovations in state-of-the-art techniques of deep learning, including multi-head attention, bi-directional LSTMs, and residual connections, allowing for complex pattern capture with long-term source code dependencies. With such architecture, it has been shown that the model identifies inter-syntax and semantic knowledge besides picking out vulnerabilities emerging between various dependent components of code. 42 These are further validated by the experimental results, which turn out to be significantly improved on major metrics. The meta-loss decreased from 0.45 in the first epoch to 0.14 in the fifth epoch, showing that the framework has the ability to minimize the error in training. Likewise, query accuracy improved from 88.1% to 95.7%, and support accuracy increased from 85.2% to 92.5%, showing the model is able to adapt efficiently and achieve high performance with limited data. These results highlight the framework’s practical applicability and scalability. Moreover, maintaining a small number of epochs is in line with the practicality of our system’s deployment goals: quick adaptation, cheap computation, and feasibility for real-world, data-scarce settings. Although our emphasis was as much on high accuracy as proving that the framework was constraint-robust, this is especially crucial in software security contexts where quick update and sparse annotation are common. Additionally, to resolve the computational challenges of MAML, especially in the context of large-scale settings, we are considering lighter alternatives to MAML, such as First-Order MAML (FOMAML) 43 in our future work. This model seeks to streamline the training burden without compromising the model’s flexibility and effectiveness. This improvement makes the model more practical for use in resource-limited scenarios.
With regard to the generalization capability, the proposed model has only been evaluated on the DiverseVul dataset. However, as stated before, this dataset contains a wide range of vulnerability types from C/C++ code. Due to this diversity, the hybrid model can generalize effectively by identifying different types of vulnerability patterns. Further improvement in generalization can be attained through task diversity and regularization strategies. Apart from the diversity in datasets, generalization can be further enhanced by other approaches such as task diversity and regularization. Task diversity improves generalization since it enables the model to engage with a broad range of learning scenarios, reinforcing adaptability toward new and previously unencountered patterns of vulnerabilities. 44 Meanwhile, regularization techniques such as dropout and batch normalization mitigate overfitting, which boosts the model’s robustness and performance against previously unseen data. 45 Moreover, with CodeBERT as the underlying encoder having good generalization capability, when combined with MAML, our integrated framework can adapt rapidly to new data or novel domains with little fine-tuning. This makes the model extremely flexible and deployable for application on multiple repositories of code and programming languages, thus preventing dependence upon a particular dataset.
Integration of XAI to the hybrid framework
The integration of Explainable AI techniques into the proposed CodeBERT-based hybrid framework aims to enhance trust, interpretability, and usability for the model decision-making process. It also leverages advanced XAI techniques such as SHAP, LIME, and heatmaps to offer a comprehensive explanation of the model predictions for insights into the decision-making process. These techniques help in visualizing attention mechanisms, layer-wise analysis, and feature attribution to understand which parts of the input have contributed most from a holistic point of view to the model’s predictions. For instance, heatmaps provide a per-layer, in-depth look at token activations, thereby helping developers to identify crucial patterns the model used to detect vulnerabilities. The use of confidence scores adds another dimension to interpretability, enabling developers and security analysts to have an idea of the degree of certainty of the model’s predictions. The result from our experiment shows an almost 91% confidence score in predicting a non-vulnerable point in the code. A confidence score so high testifies to the strength of this framework and instills higher levels of trust in both the developer and security analysts. This also serves to underscore those areas that would still require further refinement or increased data for edge cases and complex vulnerabilities. With such identification of areas of high and low confidence, this framework enables the detection of biases or anomalies in predictions, making sure of fairness in a more reliable manner.
Furthermore, XAI practices not only build trust among stakeholders but also align the framework with organizational and regulatory standards that demand transparency in AI systems. The explanations provided by SHAP and LIME, along with visual insights from heatmaps, help bridge the gap between complex model architectures and user understanding. Overall, the seamless integration of XAI techniques into the framework ensures that it is not only effective in detecting vulnerabilities but also interpretable and reliable, fostering wider adoption and trust in the system. The proposed research has immense practical value in the field of software vulnerability detection, as it tries to solve some of the challenges faced by developers, security analysts, and organizations.
Practical implication
By incorporating CodeBERT with MAML, this framework provides an effective vulnerability identification method within dynamic and complex software system context. The capability to learn new vulnerability patterns with less labelled data makes sure organizations can quickly respond to emerging threats by reducing the time and resources required for model retraining. This is especially valuable in real-world scenarios where new vulnerabilities frequently arise, and annotated datasets are at a premium. It provides architecture with innovations such as multi-head attention and bi-directional LSTMs that enable it to detect vulnerabilities resulting from complex interactions within codebases, such as flawed uses of functions or variables across multiple files. This level of precision is critical for assuring security of software intensive systems and organization across different sectors such as finance, health care, and defense are heavily relied on such systems. Therefore, accurate and context specific vulnerability identification from the source code of the software system can certainly improve the security posture and mitigate the possible disruptions that can pose from the source code related vulnerabilities. This will also enhance the capabilities to timely update the patches as organization can identify possible patches in case of any vulnerability detected this can avoid the risk of remaining unpatched.
Moreover, the integration of Explainable AI techniques ensures that the model outcomes are well interpretable and trustworthy. The possibility of explaining predictions with methods such as SHAP, LIME, and heatmaps enhances stakeholder confidence and facilitates compliance with organizational and regulatory requirements for transparency in AI enabled systems. These explanations will help developers and analysts to understand, as well as refine the model’s predictions with the aim of enhancing security processes within an organization. The usage of few-shot learning can be applied in resource-constrained environments, such as startups with limited resource constraints. Furthermore, its capability to work across diverse programming languages and styles ensures wide applicability, making it a versatile tool for securing software-intensive systems across various domains.
However, our proposed approach can be extended to software-intensive system applications, as previously discussed. One main limitation relates to how tasks are defined. If task distributions are uneven and poorly specified, such as those that stem from inconsistent code structure or labeling, overfitting occurs, and the model’s adaptability suffers. In regard to explainability, CodeBERT unconditionally provides interpretable output at the token level using SHAP and LIME, which is supported by the integration of MAML. However, this reduces transparency, particularly in divergent task settings. Furthermore, the model presents additional constraints for real-word application. The integration of CI/CD pipelines and production environments raises issues concerning API integration and continuous learning flows. The hybrid architecture also has high computational costs, along with additional expenses to fine-tuning during inferencing that further complicates the integration into larger systems.
In order to mitigate such issues, we propose the following approaches. Firstly, MAML-based fine-tuning can be calculated offline beforehand to reduce runtime overhead. Secondly, pruning, quantization, or ONNX-based deployment can be employed for accelerating inference. 46 In addition, using lighter alternatives such as First-Order MAML (FOMAML) can reduce training complexity. 43 Lastly, using knowledge distillation can also aid in creating a faster, more compact student model without compromising too much accuracy.
Comparison with existing works
AI-based techniques are not yet widely adopted in cybersecurity, specifically in the context of vulnerability detection, despite their capabilities to handle large amounts of data. To position our contribution in the context of the related works in AI-driven vulnerability detection, it is necessary to provide a comparative analysis of other approaches.
In terms of model-based comparison, many existing works focus on either traditional machine learning or supervised fine-tuning LLM models. In comparison with the existing work, there are studies that focus on various LLM models for vulnerability detection. For instance, VulCoBERT is a vulnerability detection system that uses CodeBERT for representing the semantics of a of code and Bi-LSTM for modeling long-range dependencies in the source code. 47 The model pre-processes the C source code, encodes it using CodeBERT, and classifies the encoded representations for possible defects through a fully connected layer. Similar to this, other models such as sequence-based models like SVulD and LineVul 48 exhibit an over-reliance on supervised learning on large-scale-etched data. In contrast, our model leverages meta-learning to mitigate data scarcity issues and evolving patterns of vulnerabilities. In contrast, our model leverages meta-learning to mitigate data scarcity issues and evolving patterns of vulnerabilities. Additionally, DLAP is a framework that uses In-Context Learning (ICL) and Chain-of-Thought (COT) prompting techniques for implicit fine-tuning. 49 This helps enhance detection accuracy without expensive retraining. In comparison, our model achieves stronger vulnerability-specific fine-tuning by performing MAML-based inner and outer loop fine-tuning on CodeBERT embeddings. Not only does this approach go beyond the barriers of prompt-based enhancement, but it also guarantees deep generalization and high adaptability to a wide variety of vulnerabilities. Another research article focuses on the comprehensive assessment of the ChatGPT-based, graph-based, and sequence-based models of software vulnerability detection to find the best among learning-based models. 48 The results demonstrate that while ChatGPT is the most cost-effective and convenient, its performance when it comes to vulnerability detection is subpar. The model task-specific selection and its role provide meaningful instructions for realistic model implementation and operation for practical use. However, one limitation observed in recent LLM-based models, such as CodeGemma and CodeLlama, is their inconsistent output formatting and sensitivity to prompt variations, which can undermine reliability in real-world deployment scenarios. 50 Our hybrid offers more stability, interpretability, and fine-tunability for source code vulnerability detection than other frameworks.
Further comparison focuses on the evaluation metrics of the existing models. Our hybrid approach had a support accuracy of 92.5% and query accuracy of 95.7%, significantly outperforming several state-of-the-art models. For instance, the model Few-VulD is designed for software vulnerability detection using a few-shot learning framework. It achieves a classification accuracy of 82.5% and a recall of 94.9%. 51 This work aims to highlight the effectiveness of meta-learning on limited training data. On the other hand, VulCoBERT achieved 66.21% accuracy on the Devign dataset in full supervision setting, placing third in the CodeXGLUE benchmark. 47 In addition, another work assessed a RoBERTa-based model with the DiverseVul dataset achieving 91.68% accuracy but noted lower precision and F1-score of 46.02%, 28.22%, and 34.98%, indicating a lack of balance between accuracy and completeness in detection. 52 Moreover, another work used commit data from vulnerability-fixing and employed GPT-4 to identify vulnerabilities in code examples associated with common CWE concepts. Their results included 75.5% accuracy, 73.7% precision, 79.3% recall, and 76.4% F1-score, demonstrating a balanced capability in understanding and generalizing code-level logic by GPT-4. 53 Our hybrid model surpasses GPT-4 in few-shot query accuracy, highlighting favorable performance in realistic conditions where labeled data is scarce. Collectively, these comparisons shed light on the strength of our hybrid CodeBERT-MAML approach which maintains an elevated level of precision even under minimal supervision.
Conclusion
Exploitation of source code vulnerabilities may pose potential risk to organizations that heavily depend on software systems to support their operations. Despite the wider adoption of AI model in source code vulnerability detection, it often struggles to capture the intricate relationships and patterns in source code and lack of explainability can increase the difficulties to understand how the model makes the decision. This paper proposes a novel hybrid framework based on a CodeBERT-powered LLM for vulnerability detection in source code, which integrates fine-tuning with Model-Agnostic Meta-Learning to manage the key challenges in this domain. The framework effectively fuses the pre-trained capabilities of CodeBERT with MAML’s few-shot learning mechanism for rapid adaptation to new vulnerability patterns using a minimal amount of labelled data. This hybrid approach reduces computational overhead, thus making it especially suitable for resource-constrained environments while keeping the accuracy and robustness high, even for noisy or incomplete datasets. It also integrates four key dimensions of XAI, including attention mechanisms, layer-wise analysis, feature contribution, and model confidence scores. These XAI techniques present comprehensive explanations of model predictions to enhance transparency, interpretability, and trustworthiness. By making the decision-making process understandable, the framework aligns with organizational and regulatory standards while empowering developers and stakeholders to confidently act upon the model’s outputs. The experimental results show a continuously decreasing meta-loss while increasing the accuracy, which demonstrates that the proposed framework is more viable and applicable in real-world scenarios. However, we also plan to investigate hybrid frameworks such as CodeBERT with Reinforcement Learning for sequential decision-making for vulnerability prioritization and mitigation. We also plan to examine CodeBERT combined with Adapter Layers for efficient fine-tuning in resource-constrained environments and reducing computational overhead without degrading performance. We would also like to experiment with various vulnerability-based datasets to validate the robustness of the approach. The integration of sensitive analysis along with XAI techniques will also be one key area of exploration.
Footnotes
Funding
This work was partially supported by the European Union’s Horizon Europe Programme, CyberSecDome–An innovative Virtual Reality-based intrusion detection, incident investigation, and response approach for enhancing the resilience, security, privacy, and accountability of complex and heterogeneous digital systems and infrastructures, funded under grant agreement No. 101120779, European Union’s Digital Europe Programme, CONSOLE-Cybersecurity for Resilient Software Development, funded under Grant Agreement No 101128070 and the UK Research and Innovation (UKRI) with CHIST-ERA 2023, AI4MultiGIS- AI integrated framework for intelligent geospatial handling and robust operation in MultiGIS applications, funded under grant agreement no - EP/Z003490/1.
Declaration of conflicting interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.