
Abstract
Time series forecasting (TSF) is significant for many applications, therefore the exploration and study for this problem has been proceeding. With the advances of computing power, deep neural networks (DNNs) have shown powerful performance on many machine learning tasks when considerable amounts of data can be used. However, sufficient data may be unavailable in some scenarios, which leads to performance degradation or even not working of DNN-based models. In this paper, we focus on few-shot time series forecasting task and propose to employ meta-learning to alleviate the problems caused by insufficient training data. Therefore, we propose a meta-learning-based prediction mechanism for few-shot time series forecasting task, which mainly consists of meta-training and meta-testing. The meta-training phase uses first-order model-agnostic meta-learning algorithm (MAML) as a core component to conduct cross-task training, and thus our method also inherits the advantages of the MAML, i.e., model-agnostic, in the sense that our method is compatible with any model trained with gradient descent. In the meta-testing phase, the DNN-based models are fine-tuned by the small number of time series data from an unseen task in the meta-training phase. We design two groups of comparison models to validate the effectiveness of our method. The first group, as the baseline models, is trained directly on specific time series dataset from target task. The second group, as comparison models, is trained by our proposed method. Also, we conduct data sensitivity study to validate the robustness of our method. The experimental results indicate the second group models outperform the first in different degrees in terms of prediction accuracy and convergence speed, and our method has strong robustness for forecast horizons and data scales.
Introduction
Time series forecasting (TSF) is one of the fundamental scientific problems and also has general applications, such as traffic system [1, 2], power management [3, 4], health care [5], financial markets [6], etc. Unsurprisingly, there is a long history of forecasting methods that can be traced back to the 1990s. Box and Jenkins (1990) proposed the “Box-Jenkins” method [7] that is a widely used in classical time-series model. In addition, time-series forecasting methods based on SVM [8], Matrix Factorization [9] and other theories have been gradually proposed later. With the advance of deep learning techniques and the increase of computing power, deep neural networks (DNNs) have achieved great success on some challenging tasks [10–12]. DNNs gradually start to be applicable to TSF problem [13–15]. Conventionally, DNN-based forecasting models are trained using sufficient time-series data in a fixed target domain, and then the model is used to conduct corresponding forecasting task.
However, sufficient training data may be unavailable in some scenarios. On the practical side, some application scenarios only have quite a few historical time-series data, such as medical records of rare diseases, consumption records of new customers, etc., which leads to performance degradation or even not working of DNN-based models for the situations. The deployment of DNN-based models is challenged by these few-shot scenarios. To cope with the above situations, we propose a meta-learning-based prediction mechanism to train DNN-based models for few-shot time series forecasting task, which handles the above problems mainly from two aspects: (1) to supplement valid information from other tasks through meta-learning (2) to alleviate overfitting problem of DNN-based models with confronting few-shot scenarios through fast adaptation.
The overall prediction mechanism consists of two phases: meta-training and meta-testing. The idea of meta-training is to train DNN-based models on a large quantity of different tasks to learn and generalize some meta-knowledge that facilitates the model to adapt to a new task quickly. The meta training phase employs first-order model-agnostic meta learning algorithm (MAML) as a core component, and its essence is to find a set of optimal initial parameters for the training model, such that the model has maximal performance on a new task through only a few gradient steps computed on a small number of data. To conduct cross-task learning, we use a Bidirectional Gated Recurrent Units (BiGRU) to obtain consistent input dimension. In the meta-testing phase, a few data from the target task is used to fine-tune the model parameters through just a few gradient steps so that the model can perform well without overfitting.
To validate the effectiveness of the proposed prediction mechanism, we design two groups of comparison models. The first group called the Base model is directly trained on single task’s training dataset for each specific task, and the second group called the Meta model is trained using the method proposed in this paper.
The main contributions of this work are summarized as follow.
•We propose a meta-learning-based prediction mechanism for few-shot time series forecasting problem, which generalizes meta-knowledge by cross-task learning and alleviate overfitting problem of DNN-based models in few-shot scenarios through fast adaptation of first-order MAML algorithm.
•We introduce a new hyper-parameter γ in the meta-testing phase, which can be found in Eq. (12). Compared with the first-order MAML algorithm, the hyper-parameter α in Eq. (6) doesn’t directly use, but utilizing γ to achieve more fine-grained training control.
•We design two group comparison models, called Base model and Meta model respectively, and perform extensive experiments on multiple different domain’s time-series datasets, in which Meta model demonstrates superior performance compared with Base model . We also proceed with statistical tests for all models used in experiments, which indicate that the models in Meta model have consistent superior rank compared with counterparts in Base model .
•Furthermore, we conduct data sensitivity study, which indicates our prediction mechanism is robust for data scales and forecast horizons.
The remainder of this paper is organized as follows. Section 2 briefly reviews related work. Problem statement and evaluation metrics used in this work are provided in Section 3. Section 4 clearly introduces the proposed method. Comprehensive experiments are performed to evaluate the effectiveness of proposed method in Section 5 in which the experiment setups, datasets, results and analysis are all provided. Finally, Section 6 concludes the paper.
Related work
Time series forecasting (TSF)
Many classical statistical approaches have been applied to TSF task in the past decades, like Autoregressive Model (AR) [16], Autoregressive Moving Average model (ARMA) [17, 18], and Autoregressive Integrated Moving Average model (ARIMA) [19–21], in which ARIMA was most widely used in time series forecasting. With the development of deep learning techniques, Multi-layer Perceptron (MLP) [22], RNN-based model [13], and CNN-based model [14] were used to tackle time series forecasting problems. In recent years, the hybrid approaches that connect statistical model with deep learning model have become a new trend. A typical example is that the best approach of M4 Competition [23] was based on a hybrid between LSTM-based model with a classical Holt-Winters statistical model. In addition, some researchers have also explored pure neural network architecture for time series forecasting from the perspective of interpretability [24]. However, the works mentioned above often focus on scenarios with large amounts of time series data, and there are few studies on few-shot time series forecasting.
Meta-learning
Meta-learning is commonly described as learning to learn [28–30]. Meta-leaning represents a general methodology, which provides a direction to tackle many tough problems for conventional deep neural network architecture such as few-shot learning. Model-Agnostic Meta-Learning (MAML) [29], a well-known algorithm in meta-learning field, is compatible with any model trained using gradient descent, which can easily apply to solve a variety of different machine learning problems, including classification, regression and reinforcement learning. In addition to meta-learning, transfer learning is also a popular strategy to cope with the few-shot scenarios, which generally requires a strong relationship between the data from source domain and the data from target domain. However, in this work, we do not pay attention to the relationship of different tasks. Therefore, transfer learning is not applicable to this work. In this paper, we focus on studying the information gain of meta-learning for time series forecasting. A recent work [27] proposed a meta-learning framework for zero-shot time series forecasting problem. Unlike the work in this paper, reference [27] suggested to train a neural network on a large number of time-series datasets and then deploy it on a different target time-series dataset without retraining.
Few-shot learning (FSL)
Few-shot learning is proposed to tackle the performance degradation of DNN-based models when the dataset is quite small. The goal of FSL is that the model can rapidly generalize to new tasks with only a few samples through learning some transferable features or patterns from other tasks. Few-shot classification tasks have been paid considerable attention [31, 32]. As for few-shot time series forecasting, there are relatively few relevant studies. More recently, a RNN-based model [25] has been proposed to address few-shot and zero-shot time series forecasting and it expects directly addressing few-shot time series forecasting problem by learning a shared feature embedding over the space of quantities of time series. Iwata and Kumagai (2020) [26] propose a method that utilizes bidirectional LSTM with attention mechanisms to tackle few-shot time series forecasting, and the method aims to minimize the expected loss of query set through using LSTM Encoder and attention mechanism on support set. However, reference [26] does not consider overfitting problem of DNN-based models in few-shot scenarios, which can be found by experimental settings. Moreover, Oreshkin et al. (2020) [27] propose a meta-learning framework for zero-shot time series forecasting, and the method expects that model has good performance on new datasets through training the model on large-scale and diverse datasets. Compared with these methods, our method is to expect that model can adapt quickly to a new few-shot tasks through learning on a large number of different few-shot tasks, and all the tasks used on training phase and testing phase are both from few-shot scenarios.
Problem statement
We focus on the univariate interval forecasting problem in discrete time. Given a length-T historical data [y1, y2, . . . , y
T
] of a time series and a length-H forecast horizon, the task is to predict the next values of the series y = [yT+1, yT+2, . . . , yT+H]. we denote
RMSE(Root Mean Square Error) and sMAPE(symmetric Mean Absolute Percentage Error) are used to measure forecast accuracy.
Overview
Our method aims to train DNN-based models on lots of different few-shot time series forecasting tasks such that the models can achieve a fast adaptation on a new few-shot time series forecasting task and without overfitting. In this section, we will define and introduce three main components of our method orderly. The procedure of meta-training and meta-testing is outlined in Algorithm 1.
1. Randomly initialize
2.
3.
4. Sample batch of tasks
5.
6. Calculate loss
7. Update parameters
8. Add query set Q i to Q = {Q1, Q2, …}
9.
10. Calculate sum loss L Q on Q by Eq. (7)
11. Update parameters
12.
13.
14. Sample a few data S from Target task
15. Calculate loss
Shared encoder
To solve the problem of inconsistent length of time series from different tasks, a shared encoder (Bidirectional GRU networks) is structured to encode time-series data to a unified dimension, which is depicted in Fig. 1.
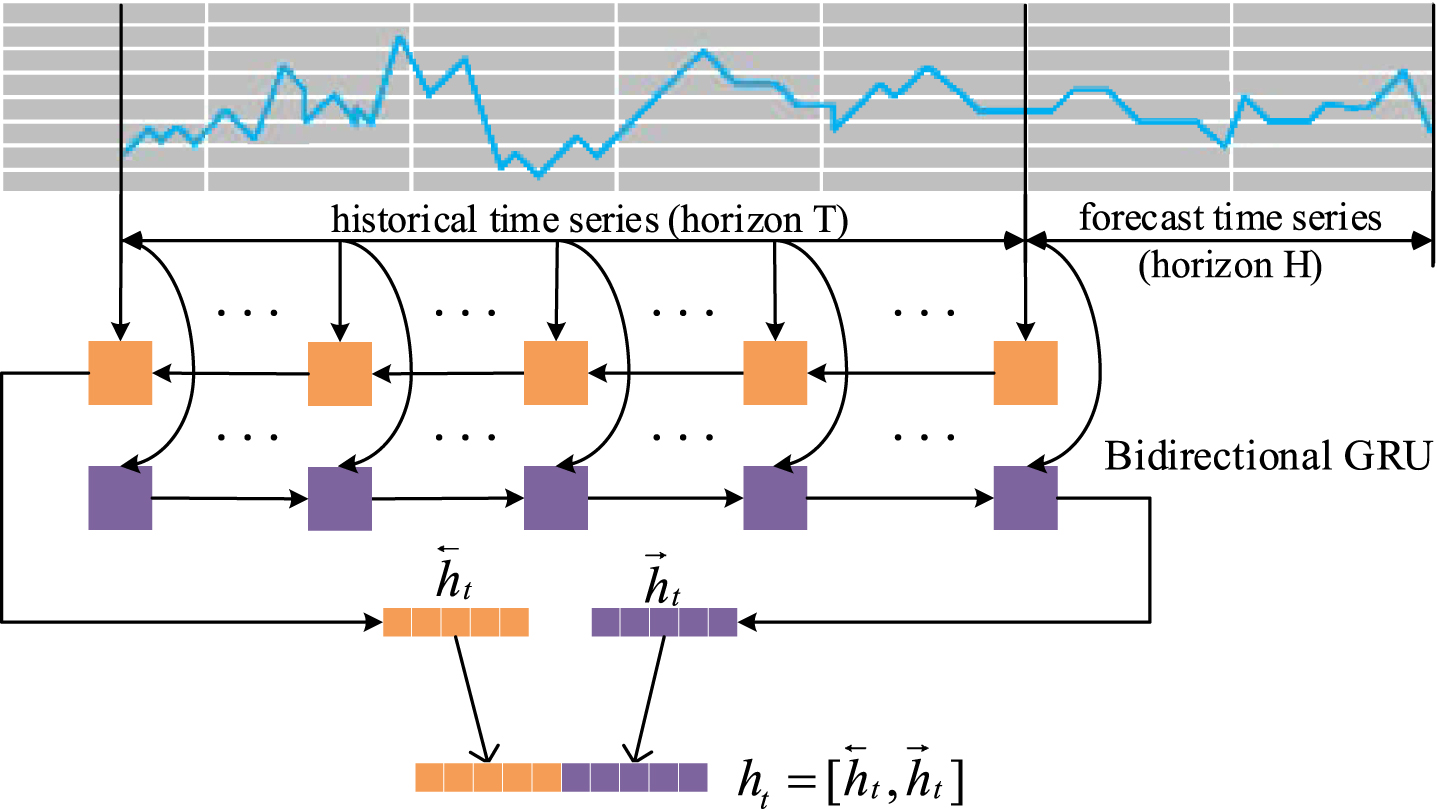
The bidirectional GRU encoder.
Meta-training is our model training mechanism for few-shot time series tasks. The overall procedure of meta-training is shown in Fig. 2, where steps 0-7 train model on training task-sets D T to learn and generalize the meta-knowledge that can help model quickly adapt to new tasks. The first-order MAML algorithm is the core component in meta-training phase. The support set and query set mentioned below refer to training set and testing set of the task respectively, and more details with training datasets can be found in Section 5.1.

Meta-training and Meta-testing learning mechanism.
Formally, we define Meta
model
= {Meta1, Meta2, …} where each model has corresponding parameter vector
Since there may be more than one sampling task in step 2, Eq. (6) could be performed several times to update the parameter vector
The cycle in step 6 proceeds to the next episode until the termination condition is met. Eq. (10) shows the general learning objective of meta-training. Step 7 obtains meta-knowledge ω* from MetaNet. In our method, the ω* is parameter vector
The goal of meta-testing is to rapidly generalize the Meta
model
to target task, where a small number of samples from the target task is used to update parameters of the Meta
model
through only a few iterations to prevent overfitting. Steps 8 and 9 utilize meta-knowledge ω* and the small number of samples S from the target task to fine-tune the M-CNN. The general learning objective of meta-testing is formalized in Eq. (11), where
Datasets
In this work, we have selected 13 publicly available datasets of different domains and one Electricity Power dataset to evaluate the proposed method. Table 1 shows the attributes of each dataset in detail.
Datasets from UCR Time Series Archive used for the experimental study, Columns N, length refer to the number of time series, time series length respectively
Datasets from UCR Time Series Archive used for the experimental study, Columns N, length refer to the number of time series, time series length respectively
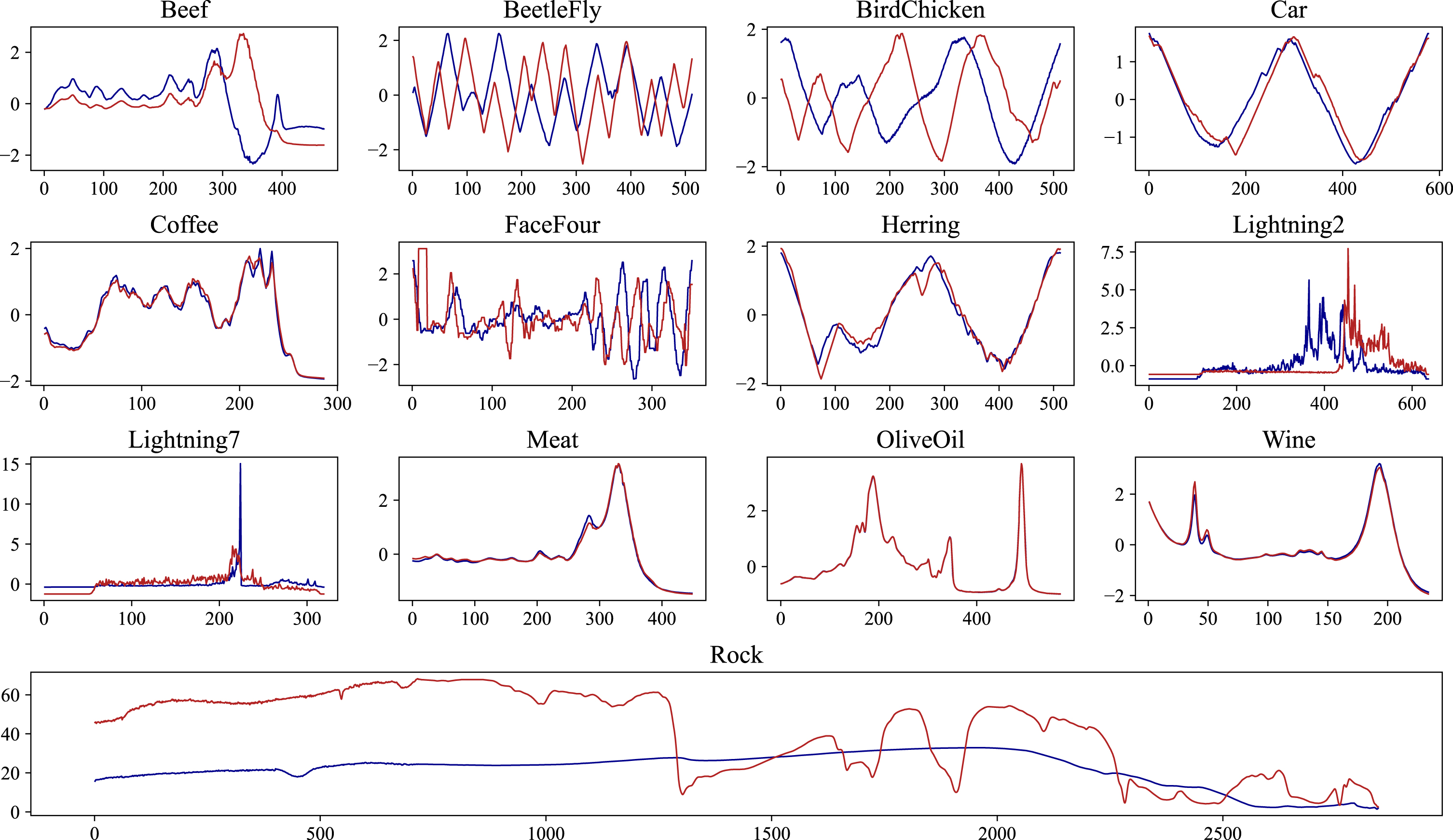
Time series instances for each dataset from UCR Time Series Archive.
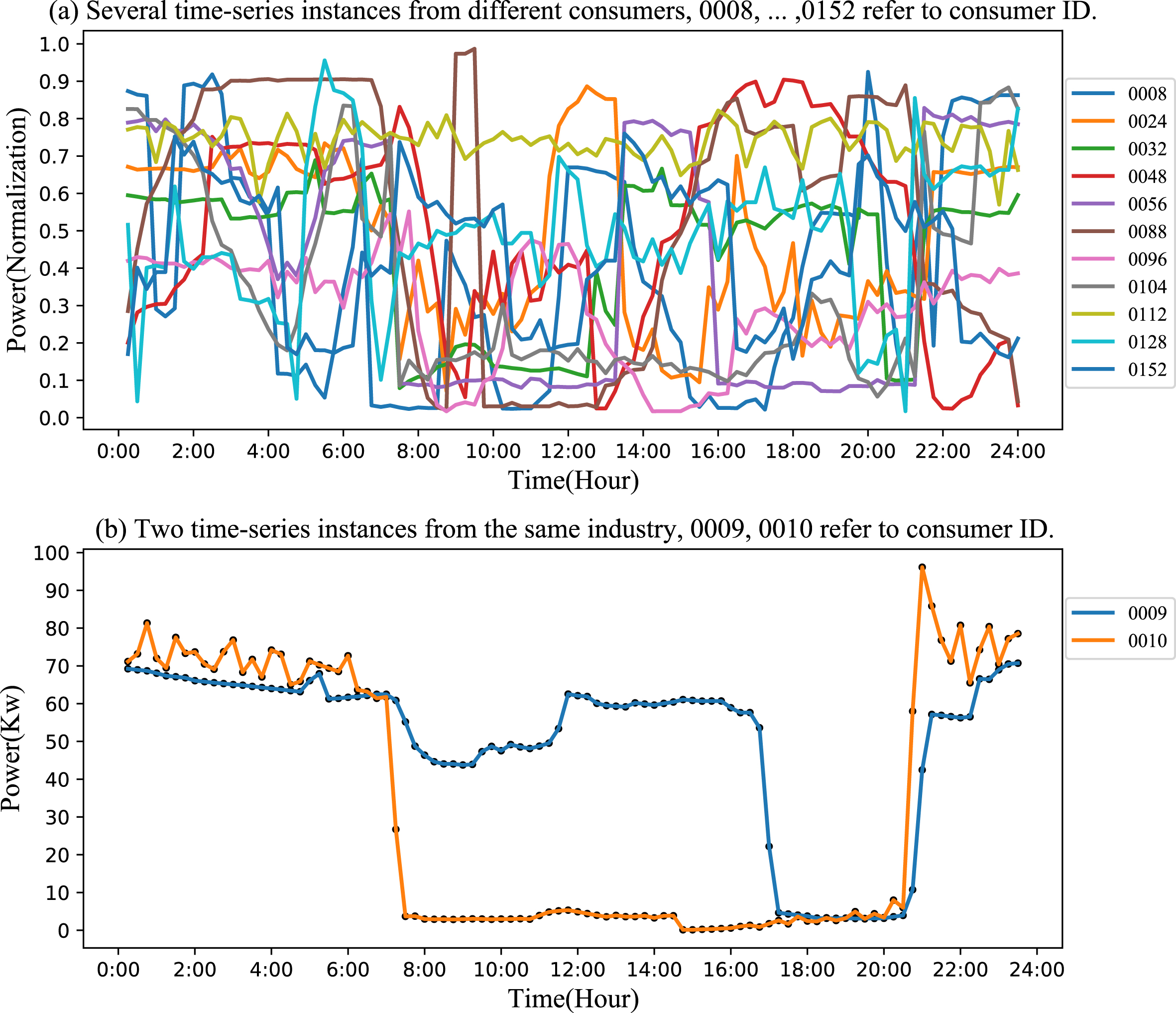
Time series instances from Electricity Power dataset.
Electricity Power dataset used for the experimental study, Columns Min-N, Max-N respectively refer to maximum and minimum number of time series records among all consumers
A recent comprehensive review [33] about using deep learning techniques for time series forecasting refers to that long short-term memory (LSTM) and convolutional neural networks (CNN) are the best alternatives among all studied models, including multi-layer perceptron (MLP), Elman recurrent neural network, LSTM, echo state network, GRU, CNN and temporal convolutional network (TCN). Therefore, the LSTM, CNN, are selected as baseline models in our experiments. In addition, a hybrid model of CNN concatenating LSTM (CCL) is also selected as one of baseline model in our experiments. Additionally, complex models are likely to suffer from overfitting problem, therefore a simple multi-layer perceptron (MLP) also is selected as baseline model in our experiments.
In this paper, two groups of comparison models are designed to validate the effectiveness of the proposed method. The first group is called Base
model
, including B-CNN, B-LSTM, B-CCL, which is trained directly on time-series dataset from target task, and the second is called Meta
model
, including M-CNN, M-LSTM, and M-CCL, which is trained using our proposed method. Also, we supplement a group of contrast experiment between Meta
model
and MLP to compare the performance difference between Meta
model
and simple model on few-shot scenario.
Training setups
The datasets from UCR Time Series Archive have split standard train set and test set, therefore, we split Electricity Power dataset according to tasks into train and test subsets with approximate scale. Table 3 shows detailed training and testing scales used time-series data in experiments.
Details of the time series data used in training and testing phase, Column Task N refer to the number of tasks, Column Min-N, Max-N refer to the minimum and maximum number of time-series records among all tasks in the training phase respectively, and Column Train ST, Test ST refer to the number of all time-series records used in training and testing phases respectively
Details of the time series data used in training and testing phase, Column Task N refer to the number of tasks, Column Min-N, Max-N refer to the minimum and maximum number of time-series records among all tasks in the training phase respectively, and Column Train ST, Test ST refer to the number of all time-series records used in training and testing phases respectively
For each task, we set four different forecast horizons (H = 10, 20, 30, 40) to check the robustness of the proposed method. Since time series forecasting is a typical regression task, the model parameters are updated by minimizing the MSE (Mean Square Error) loss:
For Meta model , we split training tasks-set and target task for cross-task learning, which is expected to be able to generalize some transferable knowledge to achieve rapid adaptation on target task. The specific splitting way is that one task is selected as target task and the rest as training tasks-set. Therefore, the size of training tasks-set is 118. For each task, the training set and testing set are treated as support set and query set respectively in this phase. The learning rate of meta-training phase is fine-tuned by support and query set, and the learning rate γ of meta-testing phase is the same with training process of Base model . Other model hyper-parameters are the same with Base model . Please refer to supplement for detailed hyper-parameter settings.
Figure 5 studies the difference of sMAPE between Meta model and Base model on four different forecast horizons for all tasks. X-axis represents different tasks, and Δ-sMAPE means sMAPE(Base model ) minus sMAPE(Meta model ). Δ-sMAPE is greater than zero, which means that the performance of Meta model has been improved compared with Base model . Figure 5 illustrates that compared with Base model , Meta model has a significant performance improvement on most tasks, with only a few tasks showing performance drop. Figure 6 studies the difference of RMSE between Meta model and Base model on four different forecast horizons for all tasks. Figure 6 shows that M-CNN in all configurations achieves significant RMSE’s decrease on some tasks and the increase of RMSE is occurred only on a small number of tasks, however, for M-LSTM and M-CCL, the task proportion with increased and decreased RMSE is very close on some configurations. For the phenomenon, a reasonable explanation is that M-LSTM and M-CCL have a more complex neural network architecture compared with M-CNN, thus they suffer relatively stronger overfitting in the meta-testing phase. Table 4, 5 clearly confirms the above conclusion with statistics. However, a reasonable question for the comparison results obtained above is whether the Base model suffer from overfitting problem in the training phase such that the Meta model look like achieving a better performance compared with Base model . With this question, we supplement a group of contrast experiment on a simple MLP model, and the model has only one hidden layer with 100 neurons. Table 6, 7 show the proportion of tasks with performance improvement and degradation among all tasks for Meta model compared with MLP in terms of sMAPE and RMSE, respectively. Experimental results indicate that Meta model have better performance than the MLP model on majority of tasks under four different forecast horizons, which not only solves the aforementioned question but demonstrates the effectiveness of Meta model again. Note that the percentages beside the up and the down arrows in Table 4, 5, 6, 7 represent the proportion of tasks with performance improvement and degradation, respectively, and the task will be counted when the absolute difference between Meta model and Base model is greater than 0.1. Therefore, the sum of the up and the down percentages may not equal 1 in Table 4, 5, and the remaining percentages represent that the differences between Meta model and Base model are not significant. A more detailed analysis and experimental result of RMSE are provided in supplement.
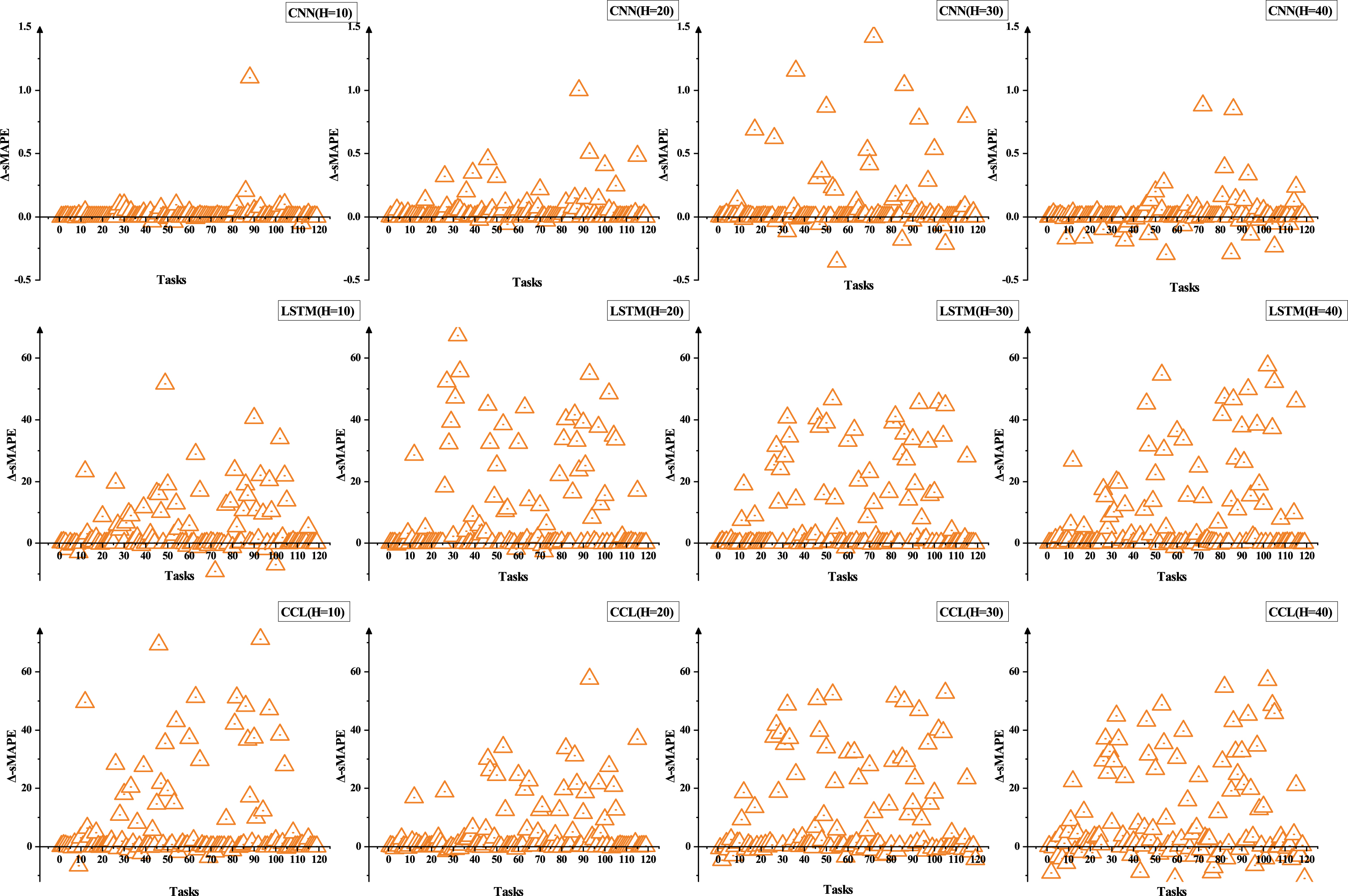
The comparison of sMAPE between Base model and Meta model , Δ-sMAPE means sMAPE(Base model ) minus sMAPE(Meta model ).
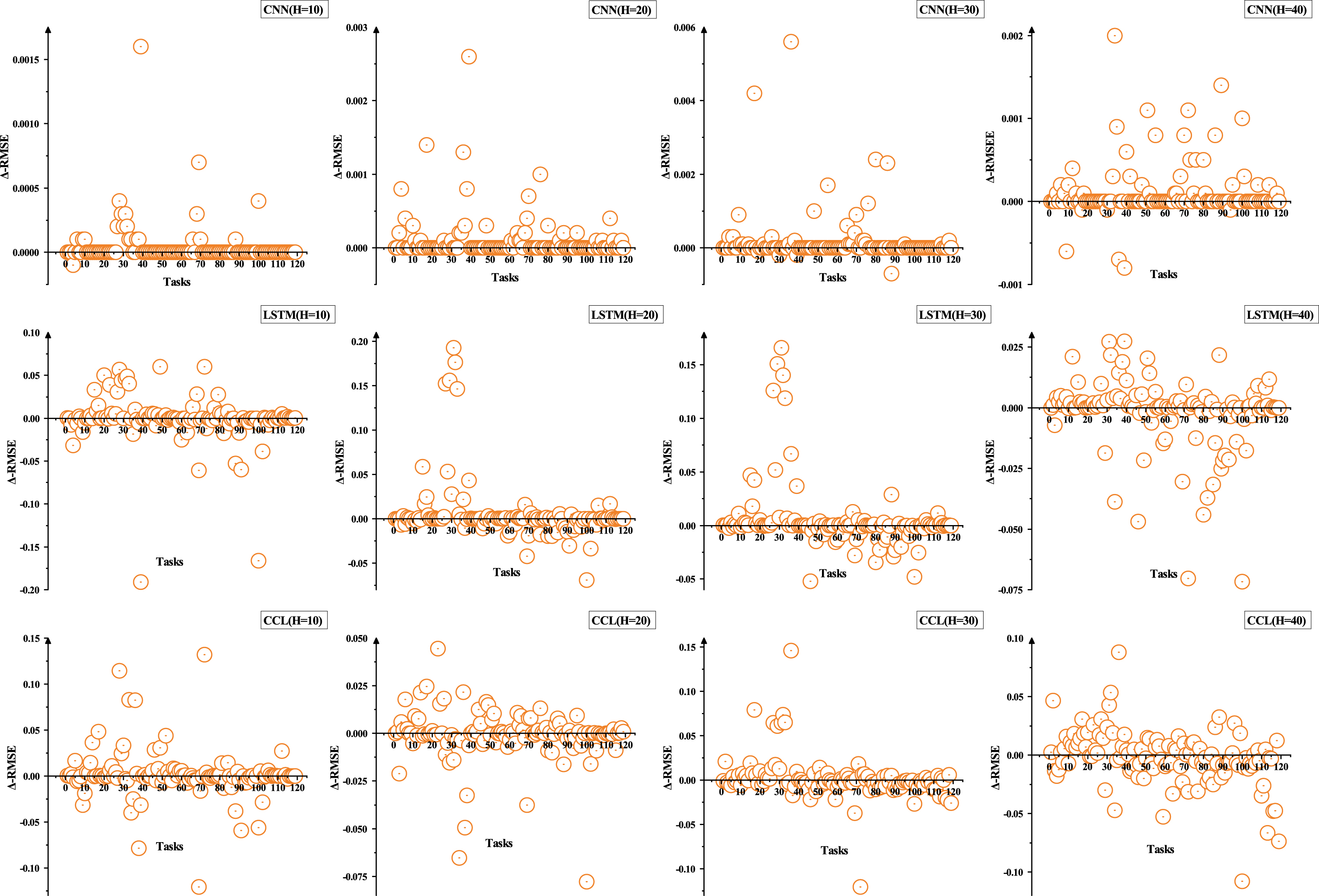
The comparison of RMSE between Base model and Meta model , Δ-RMSE means RMSE(Base model ) minus RMSE(Meta model ).
The proportion of tasks with performance improvement and degradation among all tasks on sMAPE for Meta model
The proportion of tasks with performance improvement and degradation among all tasks on RMSE for Meta model
The proportion of tasks with performance improvement and degradation among all tasks on sMAPE for Meta model compared with MLP
The proportion of tasks with performance improvement and degradation among all tasks on RMSE for Meta model compared with MLP
Figure 7 compares convergence epochs between Meta model and Base model on four different forecast horizons for all tasks. Δ-Epoch means that Epoch(Base model ) minus Epoch(Meta model ). It can be found that Meta model converges faster than Base model for most tasks, which means that Meta model can adapt to target task more quickly than Base model . Therefore, our method alleviates the overfitting problem of DNN-based models in few-shot scenarios. Note that in meta-testing phase, Meta model have exactly the same experimental settings with Base model , including model architecture, optimizer, learning rate, etc. In Table 8, the percentages beside the up arrow represent the proportion of tasks with faster convergence speed and no degradation of sMAPE, and beside the down arrow represent the proportion of tasks with degradation in both sMAPE and converge speed. Table 8 clearly confirms that the proposed method converges faster while no negative impact for model performance on most tasks, which effectively alleviates the overfitting problem that tends to occur in few-shot scenarios.
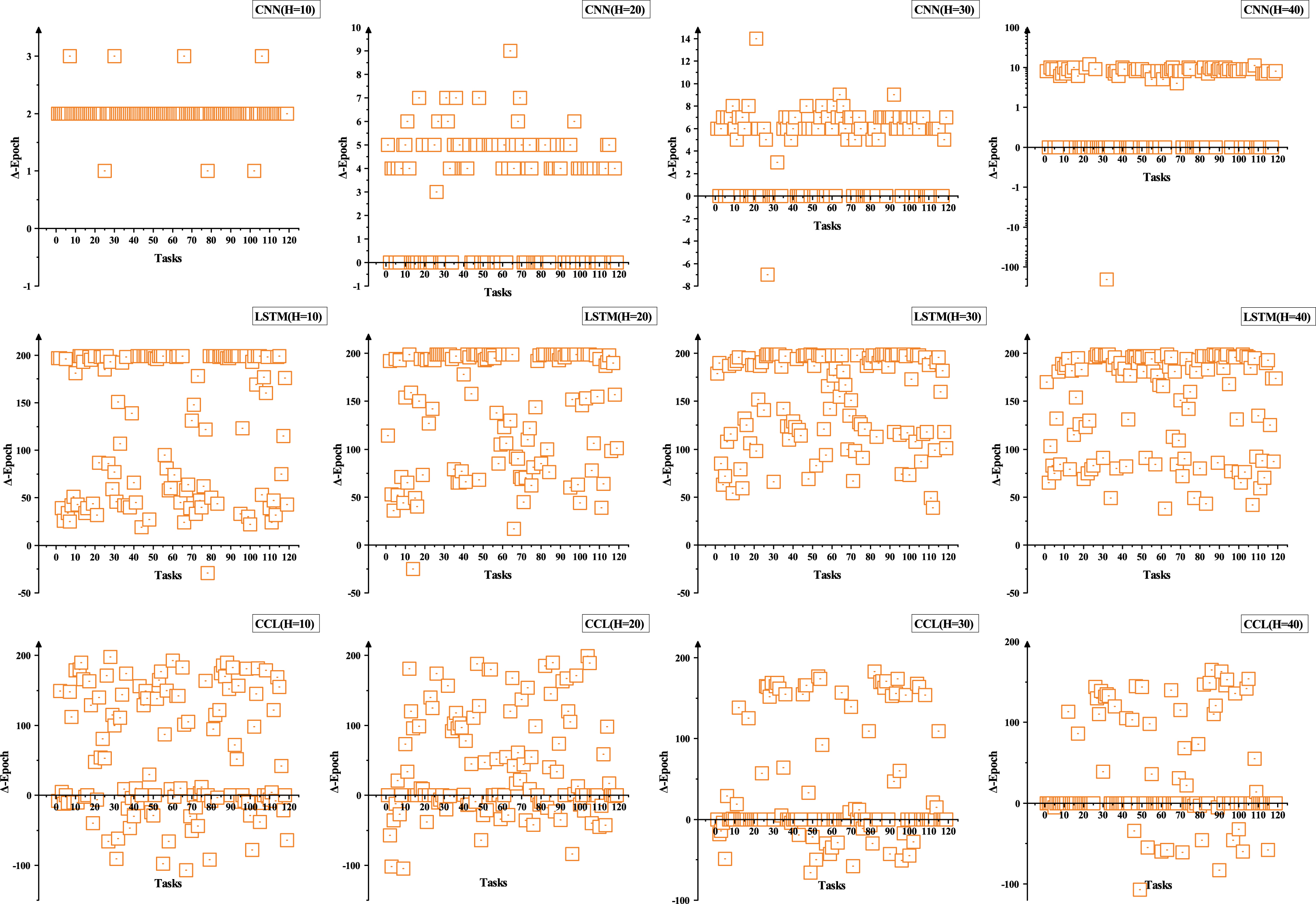
The comparison of Convergence Epochs between Base model and Meta model , Δ-Epoch refers to Epoch(Base model ) minus Epoch(Meta model ).
The proportion of tasks with convergence speed up and down among all tasks for Meta model
Figure 8 depicts the change in performance of the different Meta model on all tasks with the increase of forecast horizon, in which the performance of Meta model does not obviously fluctuate as the forecast horizon changes, and tends to improve in terms of the overall trend. It demonstrates the proposed method is strongly robust for the growth of forecast horizon.
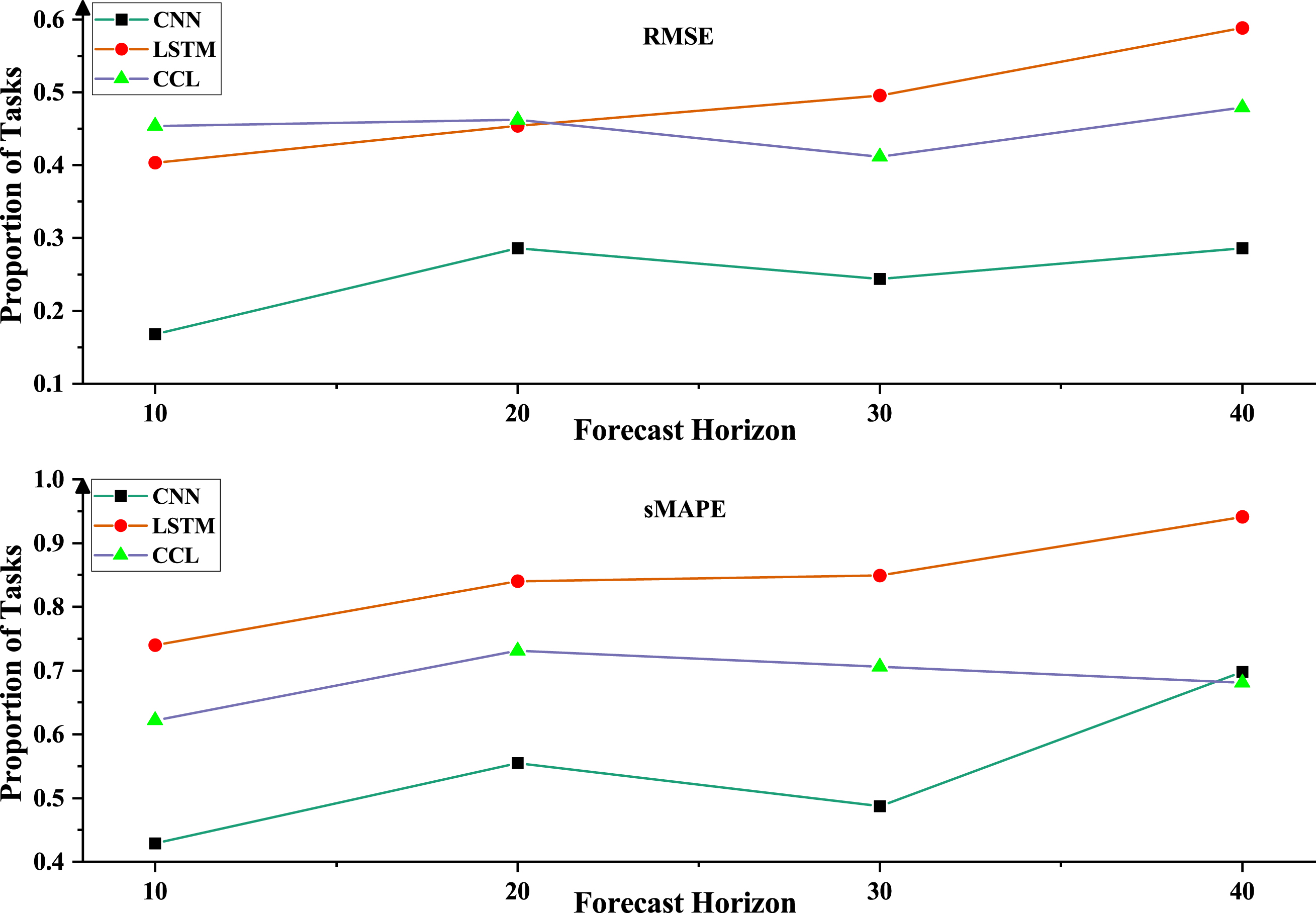
The proportion of tasks with improved performance among all tasks on four different forecast horizons.
We perform the statistical tests for all models used in experiments, grouping the results according to different forecast horizons with respect to ranking of sMAPE. In all cases, the p-value obtained in the Friedman test denotes that null hypothesis is rejected, which indicates that the performance differences in ranking among all models is significant. Therefore, we proceed with a post-hoc analysis based on the Wilcoxon-Holm method to perform a pairwise comparison between the models. Figure 9 displays the ranking of models from left to right on sMAPE for four different forecast horizons, and the horizontal lines linking the models indicate that it is hard to detect differences between models with similar performance in this scenario. In this critical differences diagram, Meta model show a consistent superior rank compared with counterparts in Base model . Furthermore, we can find the M-LSTM and M-CNN displays superior performance in all forecast horizons, and B-CNN also has a better rank compared with other Base model even surpasses M-CCL when forecast horizon is 30 and 40. A reasonable explanation is that B-CNN has a simpler architecture compared with other Base model , thus B-CNN suffers relatively weak overfitting when the training data is quite small.
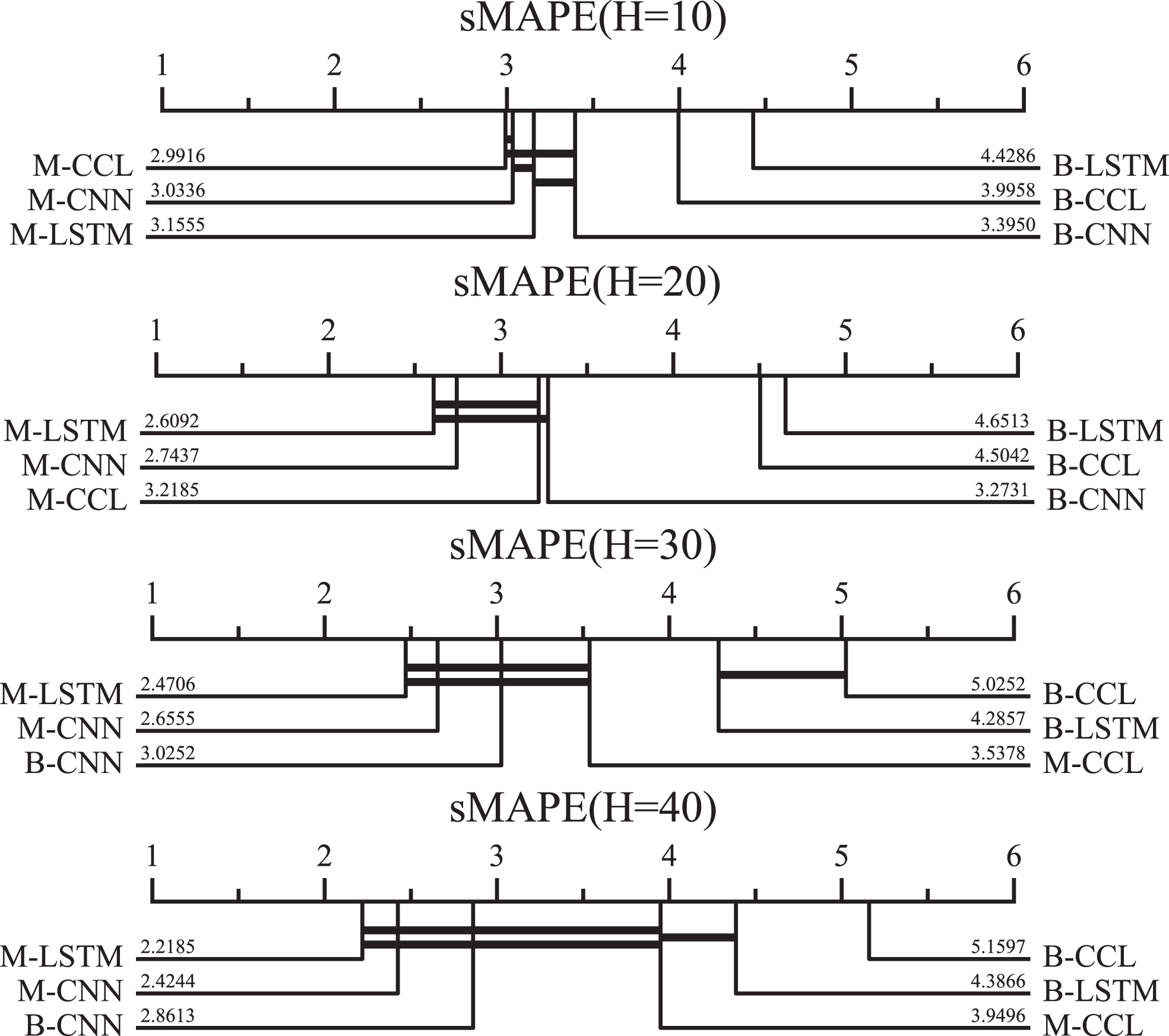
Ranking and critical differences diagram (using the Wilcoxon-Holm method) of the performance metric sMAPE on all tasks, significant level for Friedman test is set 0.05.
Although Section 5 mentions that the tasks from Electricity Power dataset are quite different, it is a fact that cannot be ignored that nearly 90% of the tasks used in experiments are from the Electricity Power dataset. An obvious question is that whether the experimental results obtained are affected by skewed data. With this question, we proceed with data sensitivity study. Table 9 shows the detailed data information used for the study. The training tasks-set consists of all tasks in UCR Archive and three randomly selected tasks from Electricity Power dataset.
Details of the time series data used in data sensitivity study, Column Train Min-N, Train Max-N refer to the minimum and maximum number of time-series records among all tasks respectively, and Column Train ST, Test ST refer to the number of all time-series records used in training and testing phases respectively
Details of the time series data used in data sensitivity study, Column Train Min-N, Train Max-N refer to the minimum and maximum number of time-series records among all tasks respectively, and Column Train ST, Test ST refer to the number of all time-series records used in training and testing phases respectively
arefers to Electricity Power dataset.
Table 10 displays that Meta model achieves performance improvement on four different forecast horizons compared with Base model , and there is no significant performance degradation on any of the tasks used in data sensitivity study. Note that the arrows in Table 10 have the same meaning as those in Table 4. Experimental results on convergence speed of models for data sensitivity study can be found in supplement. Furthermore, the statistical tests also are performed. Figure 10 depicts the ranking of models from left to right on sMAPE for four different forecast horizons. In Fig. 10, a similar conclusion can be found with Fig. 9, i.e. Meta model show a consistent superior rank compared with counterparts in Base model and B-CNN has a better rank compared with other Base model . The above results at least demonstrate two properties: (1) probable data skewing does not significantly affect the experimental conclusions obtained, and (2) the performance of Meta model does not obviously fluctuate when the scale of the dataset used changes significantly.
The proportion of tasks with performance improvement and degradation on sMAPE for Meta model
The proportion of tasks with convergence speed up and down for Meta model
Hyper-parameter configurations for training of Base model on all tasks
Hyper-parameter configurations on Meta-training phase for all tasks

Ranking and critical differences diagram (using the Wilcoxon-Holm method) of the performance metric sMAPE for data sensitivity study, significant level for Friedman test is set 0.05.

The comparison of RMSE among B-CNN, B-LSTM and B-CCL for four different forecast horizons.
In this paper, we focus on few-shot time series forecasting problems and propose employing meta-learning techniques to obtain valid and transferrable knowledge by cross-task training. Due to inconsistent time series length of cross-domain data, a shared encoder (BiGRU) is used to encode time-series records to a unified dimension. We select three DNNs architectures with superior performance on time series forecasting tasks as baseline models and design two groups of comparison models, including Meta model and Base model . Base model is trained on specific time-series dataset for each target task. For Meta model , we propose employing meta-training to learn transferable meta-knowledge from different time series tasks and meta-testing to perform fine-tuning on specific target task.
Extensive experimental results and analysis allow us to draw the following conclusions: (1) the performance of Meta model outperforms the Base model on most tasks, which indicate that Meta model successfully generalize transferable features that are conducive to cope with few-shot scenarios by cross-task learning on meta-training phase, (2) benefitting from the training mechanism of first-order MAML algorithm, Meta model has a faster convergence speed on meta-testing phase and without occurring performance degradation on most tasks, which largely alleviates the overfitting problems of DNN-based model in few-shot scenarios, (3) the proposed method has strong robustness for forecast horizons and data scales.
We also noticed that Meta model occurred performance degradation of different degree in our experiments. Specifically, with the increase of model’s complexity, the task ratio of performance degradation also tends to rise. For the phenomenon, we speculate that overfitting problem in some tasks dominates the model’s performance with the increase of model’s complexity. As for the Meta model used in this work, like M-LSTM and M-CCL, introducing regularization term to loss function is a promising solution to alleviate the overfitting problem. In addition, we expect to solve the problem in the future work via designing new neural network architecture as low-complexity as possible according to the inner features of time-series data and enlarging the task scale of cross-task training.
In the interest of reproducibility, the detailed hyper-parameters settings can be found in supplement, and integral experimental code is publicly available at https://github.com/2154022466/Meta-Learning4FSTSF.
Footnotes
Acknowledgment
This work is supported by the National Natural Science Foundation of China under grant No.61872163 and 61806084, Jilin Provincial Education Department project under grant No. JJKH20190160KJ, Jilin Province Key Scientific and Technological Research and Development Project under grant No. 20210201131GX, and the State Grid Corporation of China Technology Project under grant No. 522300190009.
Supplement
Figure 11 depicts the comparison of RMSE among B-CNN, B-LSTM and B-CCL for four different forecast horizon configurations. In Fig. 11, We can see that the RMSE of B-CNN is very close to that of B-LSTM and B-CCL on all tasks, which indicates that B-CNN has comparable performance with B-LSTM and B-CCL. This demonstrates M-CNN in ![]() gets a performance improvement not because B-CNN is a weak model.
gets a performance improvement not because B-CNN is a weak model.
Hyper-parameter settings
All models used in experiments are trained on one machine with 1 NVIDIA RTX 2080Ti GPU.