
Abstract
The uninterrupted growth of transactions carried out over the Internet (e.g., adoption of digital payments) can lead to potential exposure to serious security problems. Regarding the implementation of innovative technological solutions, the scientific community strives to develop approaches which can effectively protect the entities from adversarial cyber-threats. This research focuses on improving network security, developing the Hybrid Ensemble Deep Learning Intrusion Detection System (
Introduction
Technological advancement during the last two decades has been exponential. Our post-modern societies are strongly dependent not only on the internet and its derivatives, but also on the smooth operation of information and communication systems. 1 Today, the number of applications for both personal and commercial use is growing rapidly, driven by the widespread adoption of the Internet of Things (IoT). 2 Cyber-space was once a domain of leisure, knowledge and international communication. However, as science progressed over the years, the internet–used daily around the world – was conceived. 3 Internet services, including cellular and information services, are provided either publicly or privately by organizations to enhance and stream-line their operations. 4 For example, trade, back office, financial, and material resources, and so on are controlled via cyberspace.
The rapid internet explosion, including the ingenuity to lead to more productive business processes, has come along with many risks that take advantage of potential weaknesses. 5 Nevertheless, the availability of computer networks and inter-linked systems might lead to the exploitation of their vulnerabilities. Hackers can exploit systems’ vulnerabilities, to breach privacy and steal or corrupt critical data, or they can cause serious problems in systems’ functionality. 6 More specifically, cyber-attacks can target personal identification information (PII) such as social security and credit card details, as well as unauthorized access to databases and Critical Infrastructure Facilities (CIF) such as hospitals, energy, water, and gas providers.7,8
Network security has improved dramatically, yet the state of computer networks remains risk-prone and existing solutions cannot provide totally fulfilling defense to the systems. 9 Although they are coping with mechanisms, firewalls, software, hardware, user identification, and data encryption cannot keep up with the quick development of security breaching techniques. 10 As a result, the use of more efficient strategies and methodologies is necessary.
Cyber and network security has made significant strides in countering the rapid evolution of attackers’ barrage of threats and technologies. However, the challenges posed by emerging trends in technology remain due to the lack of robust solutions against attacks, targeting computer networks and interconnected devices. 11
As for cyber risk management, Intrusion Detection Systems (IDS) can enhance people’s confidence in cyberspace. 12 IDS is expanding quickly in an effort to improve system security. IDS have the potential to distinguish between normal and malicious flow/behavior using respective patterns or specific rules. 13 There are two main types of cyber analytics in support of IDS: misuse-based (also called signature based) and anomaly-based. 14 Signature-based techniques detect anomalies by matching signatures of predefined attacks. 15 These methods are not only simple to implement, but they also have low False Positive rates. However, it is not feasible for them to detect new cyber threats. Anomaly-based (AB) detection techniques, rely on the assumption that the intruder’s behavior is different from the typical one. 16 They model the network’s normal patterns, and they identify anomalies as deviations from them. Anomaly-based Intrusion Detection Systems (ABIDSs) can detect zero-day attacks. However, they may often result in high False Alarm Rates (FARs) because several previously unseen (yet legitimate) system behaviors may be classified as anomalies. All in all, these systems allow a person or a group of people to monitor and analyze events on many computers connected to a given network.
The objective of this research is to pinpoint events that bear signals of potential intrusions, and to enable preservation of traces related to secrets’ mismanagement, even attacks on the systems. 17
Aim – Novelty of this research
This paper presents an innovative IDS, extending the hybrid ensemble approaches that have been already discussed in the literature.18,19 Specifically, it introduces the
Its architecture comprises an ensemble of three different types of eleven (11) Artificial Neural Networks as follows: 2 Deep Neural Networks (DNNs), 4 Convolutional Neural Networks (CNNs) and 5 Recurrent Neural Networks (RNNs) with Long-Short Term Memory (LSTM) layers. The above Machine Learning (ML) models function as ensembles during the weight update voting process, and they are incorporated into a specific classification system. The proposed approach was tested with the well-known and widely used UNSW-NB15 Dataset. 20 The UNSW-NB15 dataset was created by the IXIA PerfectStorm tool in the Cyber Range Lab of the University of New South Wales (UNSW) Canberra, for generating a hybrid of real modern normal activities and synthetic contemporary attack behaviors 20 (https://research.unsw.edu.au/projects/unsw-nb15-dataset).
The dataset includes network packets related to the following nine (9) different types of cyber-attacks namely: (Analysis, Backdoor, Denial of Service (DoS), Exploits, Fuzzers, Generic, Reconnaissance, Shellcode, Worms) and moreover packets that contain benign flow.
The
This ongoing research boosts the model’s architecture even further, offering more consistent results. The most significant difference in relation to the two previous approaches are the following:
The main contribution of this research is its dynamic architecture and adaptability. The determination of the number of networks of various predefined architectures, the number of layers and parameters to comprise the Specifically, this research paper introduces a new custom weighted vote of the 11 Neural Networks (NNs) that comprise the In the application process, the Custom Weighted Vote algorithm was implemented to minimize the complexity of the whole process. All data handling has been achieved by writing code from scratch in Matlab.
Several Machine Learning (ML) IDS approaches have been introduced during the last twenty years. Recently, more and more In order to identify malware, categorize network intrusions and phishing (online spam attacks), and examine website defacements, Deep Learning (DL) models have been presented in the literature.
In 2018, Potluri et al. 24 proposed an IDS based on CNN. In this research effort, they have used both the NSK-KDD and the UNSW-NB15 datasets. To exploit the full extent of the CNN they also converted the packets into images. Thereafter, they developed a CNN with three convolution layers. They achieved an overall accuracy of 91.14% on the NSL-KDD and 94.9% on the UNSW-NB15. Finally, they performed a comparison with the well-known deep networks ResNet 50 and GoogleNet, highlighting the superiority of their models. In 2018, Hajisalem and Babaie 25 proposed a hybrid approach combining the Artificial Bee Colony (ABC) algorithm with the Artificial Fish Swarm (AFS) algorithm. They also applied the Fuzzy C-Means Clustering (FCM) and the Correlation-based Feature Selection (CFS) techniques to divide the training dataset and to remove the irrelevant features, respectively. In addition, “If-Then” rules were generated through the Classification and Regression Tree (CART) technique, according to the selected features, in order to distinguish the normal and the anomaly class records. The authors of this research effort have achieved a mean accuracy of 97.5% for the testing set. In 2018, Malik and Khan, 26 introduced a hybrid model that combines the Binary Particle Swarm Optimization with the Decision Tree Pruning, for network intrusion detection. In 2018, Zhang et al., 27 employed a convolutional neural network, to model the B2C (Business to Consumer) online transaction dataset of a commercial bank. The model achieved a Precision as high as 91% and a Recall equal to 94%. Convolutional neural networks were also used by Basumallik et al. 28 for packet-data anomaly detection, in phasor measurement units-based state estimator (PHMUB). The IEEE-30 bus, and IEEE-118 bus systems were used as the PHMUB. This research uses a probability of 0.5 with 512 neurons on a fully connected layer. The accuracy reached the value of 98.67%.
In 2020, Zhang et al., 29 presented an innovative approach combining a Multiscale Convolutional Neural Network (MSCNN) with Long Short-Term Memory (LSTM). Their model was compared with Lenet-5, a simple MSCNN and the HAST-IDS achieving an overall accuracy of 95.6% in train data and 89.9% in test data. In 2020, Hassan et al., 30 presented a novel IDS consisting of a CNN network (to extract the features from the dataset) and a weight-dropped, long short-term memory (WDLSTM) network (to retain long-term dependencies among extracted features to prevent overfitting on recurrent connections), achieving an overall accuracy of 96.975% using the 10-fold cross validation technique. Thamilarasu and Chawla, 31 introduced a Deep Belief network to fabricate a feed-forward DNN for an Internet of Things (IoT)case. The proposed model was tested against five attacks, namely: The Sinkole, the Wormhole, the Blackhole, the Opportunistic service and the DDoS. The results show a Precision of 96% and a Recall of 98.6% for the case of the DDoS attacks. Khan et al., 32 proposed an intrusion detection system based on the two-stage deep learning model, named TSDL. The KDD99 and the UNSW-NB15 network intrusion public datasets were considered for TSDL training and testing, with an accuracy equal to 99.996% and 89.134% respectively. In 2020, Sarker et al., introduced the “IntruDTree” machine-learning security model, which is characterized by low computational complexity and high accuracy, due to the performed feature dimensionality reduction. 33 In 2020, Demertzis et al. suggested a Blockchain Security Architecture that aims to ensure network communication between traded Industrial IoT devices, following the industry 4.0 standard, based on Deep Learning Smart Contracts. The proposed smart contracts are implementing (via computer programming) a bilateral traffic control agreement to detect anomalies based on a trained Deep Auto-encoder Neural Network. 34 In 2022, Psathas et al., 18 presented a hybrid Intrusion Detecting System (IDS) comprised of a 2-Dimensional Convolutional Neural Network (2-D CNN), a RNN and a DNN for the detection of nine Cyber Attacks versus normal flow. The timely Kitsune Network attack dataset was used in this research. The proposed model achieved an overall accuracy of 92.66%, 90.64% and 90.56% in the train, validation and testing phases respectively. Extending their previous work, Psathas et al., 19 propose the second version of the Hybrid Ensemble Deep Learning Intrusion Detection System (HEDL-IDS2). The architecture of this hybrid approach is comprised by four CNNs, four RNNs with LSTM layers and four DNNs running in parallel. For each record, the output space is the majority vote from the nine models. The model was trained and evaluated using the UNSW-NB15 dataset and the overall accuracy for the training, validation and testing data was as high as 98.85%, 98.8% and 97.5% respectively. The values of the performance indices were above 0.96 for both benign and malicious traffic in all classes.
Moreover, the concept of combining multiple intelligent engines through adaptive weighting follows the principles of meta-algorithmics, as discussed by Simske. 35 Meta-algorithmics is related to the practice of employing meta-algorithms. It provides general patterns for creating robust, low-cost, and high-quality systems by balancing recall and precision, which is particularly relevant for intrusion detection systems. Meta-Algorithmic tools include (Confusion Matrices, Weighting schemes, Output space transformations (for output refinement) Sensitivity analysis and Feedback mechanisms that have the potential to refine the results).
Recent advances in deep learning and supervised machine learning (ML) have significantly enhanced classification performance across various domains, including biomedical signal processing, recommender systems, and cybersecurity. For instance, Hassanpour et al. 36 proposed an end-to-end deep learning scheme for classifying multiclass motor imagery Electroencephalography (EEG) signals, demonstrating the ability of deep networks to learn complex temporal and spatial features from neurophysiological data. Similarly, Martins et al. 37 explored deep learning techniques for recommender systems based on collaborative filtering, highlighting the capability of neural networks to model intricate user-item interactions for accurate prediction.
In the context of cybersecurity, recent studies have applied supervised and deep learning algorithms to classify cyber-attacks effectively. Be and Gokulraj 38 employed traditional supervised machine learning methods, including decision trees, support vector machines, and neural networks, to classify malware, phishing, and DDoS attacks, emphasizing feature extraction from network traffic and behavioral data. Becerra-Suarez et al. 39 evaluated deep learning models such as CNNs, RNNs, and LSTMs for cybersecurity attack detection in IoT networks, demonstrating their ability to capture complex patterns in large-scale traffic datasets. Additionally, Mehta et al. 40 proposed a hybrid Hidden Markov Model-Convolutional Neural Network (HMM-CNN) approach for malware classification, effectively combining sequential pattern recognition and hierarchical feature extraction to enhance detection performance. Collectively, these works underscore the growing potential of deep and supervised learning methods in handling diverse classification tasks across multiple domains.
It would be impossible to cover all of the numerous research projects taking place in the field of cyber security. However, a number of additional studies, such as Ganeshkumar and Pandeeswari, 41 Meidan et al., 42 Soe et al., 43 Zhang et al., 44 Dash, 45 Cordonsky et al., 46 Gibert Llauradó, 47 Loukas et al., 48 Zhang et al., 49 Al-Qatf et al., 50 Alsouda et al., 51 Dang et al., 52 also served as motivation for this study endeavor.
Description of the UNSW-NB15 dataset and pre-processing
The UNSW-NB15 dataset 20 is a powerful repository of data for research in network security, especially for those working on intrusion detection systems. It is free to use for academic research and it comprises raw network packets associated with nine distinct types of attacks. It was developed in 2015 at the University of New South Wales, within the Australian Defense Force Academy, Australian Centre for Cyber Security (ACCS), Canberra, Australia. 53 The dataset excels in the breadth and depth of its representation of attack types. It also does a commendable job of capturing normal network behavior. To create the dataset, the authors used a network simulation tool called IXIA PerfectStorm. 54 This tool enabled them to generate a sufficiently large and diverse collection of network packets that, when taken as a whole, do a reasonable job of mimicking real network traffic.
This method took not just normal traffic patterns but also many different attack patterns into account, capturing improved modeling of our cybersecurity threats. By using a Common Vulnerabilities and Exposures (CVE) repository
55
for real-time updates, the researchers ensured that the dataset was reflective of not just the time it was collected (The simulation covered a period of 16 hours of the
With a total data volume of 100 GB, the dataset presents a perfect testbed of information. This makes it a perfect testbed for our researchers to develop and assess not only the next generation of intrusion detection algorithms but also to gauge the ”real-world” performance of those algorithms. When those algorithms are assessed against both the simulated normal network traffic and the sophisticated simulated attacks that the dataset provides, it positions UNSW-NB15 as a widely recognized benchmark for network security research.
The overall number of packets in the dataset is 2,540,044. The malicious traffic comprises nine different Cyber Attacks (Fuzzers, Analysis, Backdoors, DoS, Exploits, Generic, Reconnaissance, Shellcode and Worms) and contains 321,283 packets. The rest of the traffic records consist of 2,218,761 instances of benign flow. Nevertheless, the initial dataset is rather unbalanced, something very well expected and typical for the specific case (Cyber Attacks are only 12.5% of the original dataset). Thus, the developers of the dataset provided a more balanced subset of the UNSW-NB15. The subset contains a total of 257,673 records, 164,673 of which correspond to malicious traffic (including nine cyber-attacks) and 93,000 correspond to benign flow (Table 1). Nevertheless, there is still an internal “minority-class” problem, in the Cyber-Attacks’ class (e.g., Worms and Shellcode are a small portion of the “minority” classes records). Thus, the authors had to cope with this challenge. The name and description of all 48 features of the UNSW-NB15 subset, has been listed in Table 2, according to The UNSW-NB15 Dataset. 20 There are 47 independent variables in the dataset, where the 48th variable contains the name of each class (if the packet is related to an attack, it states its name, else it is filled with the Normal string). The 42 features of the subset UNSW-NB15 are listed in in the following Table 2.
Type, description and number of subset packets, the number of dataset packets and label of the nine (9) cyber attacks and normal flow considered in this research.
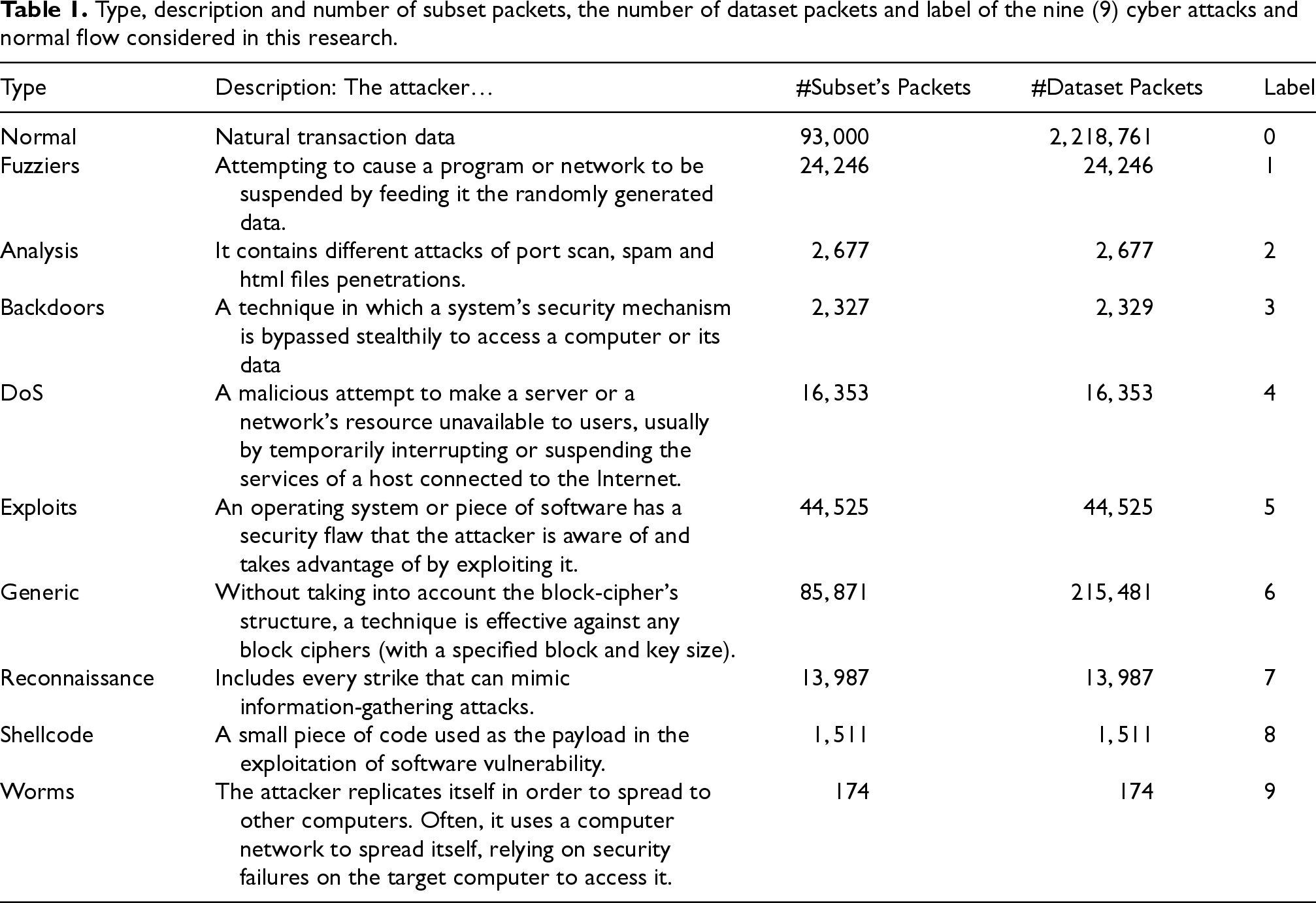
Type, description and number of subset packets, the number of dataset packets and label of the nine (9) cyber attacks and normal flow considered in this research.
Features’ abbreviation and respective description in the UNSW-NB15 subset.

The features proto, state, service, and attack_cat were stored as strings (sequences of characters). Thus, they were transformed by the authors from nominal to numeric. The transformations are presented in the following Tables 3 and 4.
Service with the corresponding label.

Service with the corresponding label.
State with the corresponding label.

Since the Proto feature has 133 different elements, the table with the correspondence to the labels has been omitted. For further information about the feature extraction process and the features, refer to Moustafa and Slay. 53 Furthermore, the features srcip, sport, dstip, and dsport have been transformed to integers using the ipaddress.py 56 library (e.g., 192.168.0.1 - 3232235521). The rest of the 40 features have numerical (either integer or float) values.
The rest of the data handling (except for the python code ipaddress.py that was used) has been achieved by writing code from scratch in Matlab. The dataset had the shape of a 257,673 x 48 Table (47 columns contain the independent variables and 1 contains the respective target label). The data was assigned to Training (75%) and Testing 25%. The dimensions of the training and testing tables were 193,254x48 and 64,419x43 respectively. All tables contain records of all classes. The optimal division emerged through a trial-and-error process.
As stated before,
DNNs represent a fundamental type of ANN that comprises multiple layers of interconnected neurons, each layer communicating with the next in a feedforward manner (Figure 1). Unlike simpler Perceptrons, DNNs possess hidden layers, which allow them to model complex relationships within data. Training a DNN involves adjusting the weights and biases of its connections following the principles of the backpropagation algorithm and employing the gradient descent protocol. This iterative process enables the network to learn from input-output pairs and to improve its performance over time. 57 Figure 1 presents schematic representation of a deep neural network (DNN). The architecture consists of an input layer that receives features, a hidden layer where weighted inputs are processed through activation functions, and an output layer that produces the final prediction. Each connection between neurons is associated with a weight, and the network learns by adjusting these weights during training.

The 3-layer DNN model architecture (1 input layer, 1 output layer and 1 hidden layers).
CNNs are characterized by their ability to extract features at a finer resolution and subsequently to transform them into more intricate features at a lower resolution, as depicted in Figure 2. Hence, CNNs consist of three primary types of layers: Convolutional, Pooling, and Fully Connected. The arrangement of these layers forms the architecture of a CNN.
60
The feature value at the position (x, y) within the 

The CNN model architecture with a Convolution Layer, a Pooling Layer, a Flatten, a Fully Connected Layer and a Softmax Layer.
Where 

The output generated by RNNs in each phase relies on the output computed in the preceding state, repeating the same task for every element of the sequence. Essentially, RNNs leverage their inherent memory to retain previously calculated information. 61 However, RNNs encounter difficulty in retaining information over extended periods, due to the issue of vanishing or exploding gradients during backpropagation. This leads to notable fluctuations in training weights. This challenge has been addressed by Long Short-Term Memory (LSTM) networks.
An LSTM unit typically consists of three gates: an input gate, an output gate, and a forget gate. These gates regulate the flow of information into and out of the memory cell. The input gate determines the proportion of input to influence the cell’s state value, while the forget gate manages the retention of information within the memory cell. Meanwhile, the output gate controls the accessibility of information from the memory cell to compute the output activation of the LSTM unit.
62
The architecture of an LSTM node is depicted in Figure 3, where

Architecture of an LSTM node.
The

Architecture of the
Layers and parameters set for the eleven HEDL-IDS models.

All experiments have been performed in Python, using a computer with an Intel Core i9-9900 CPU (3.10 GHz) processor, DDR4 memory (32 GBytes) and GPU NVIDIA GeForce RTX 2070 Super (8GBytes). The Keras 64 and Tensorflow 65 libraries have been employed to build the model’s architecture. Based on the literature, in all layers, Categorical Crossentropy, the Adam Optimizer and the ReLU functions were employed as the Loss Function, the Optimizer and the Activation Function respectively. The Softmax Activation Function has been used in the last dense layer of each model.
Before the initiation of the training process, the algorithm asks the user to enter the number of models of each NN architecture (DNN, RNN, CNN). to participate in the final hybrid network and the number of layers, following the deep learning architecture of each NN. For the purpose of this research effort, both the depth of the NNs and their number were set to 10. This means that potentially the final model could comprise ten NNs of each kind (30 in total) having 10 layers each. This is the reason the specific approach is called
DNNs and RNNs: number of nodes CNNs: number of filters
Assuming independent selection of DNN, CNN, and RNN networks, the total number of possible architecture combinations is:
550 (DNN)
For the purposes of this research effort, the authors proposed a new custom vote for the final prediction, combining the weighted vote and the majority vote of the ensemble models. Initially, all algorithms are trained and tested separately on the aforementioned dataset.
Traditional weighted voting strategies, as described in the meta-algorithmics framework of Simske,
35
typically assign weights based on classifier performance, such as overall accuracy or the inverse of error rate. These approaches improve over majority voting by leveraging the relative strengths of individual classifiers. However, they generally assume that performance is the only factor influencing ensemble utility. In contrast, the Custom Weighted Vote introduced in
Accuracy for each of the NNs in
.

Accuracy for each of the NNs in
Weights used for each of the NNs in

The following Table 6 presents the respective accuracies and Table 7 presents the weights employed for each of the NNs in the HEDL-IDS
In the proposed Custom Weighted Vote, classifiers are assigned weights proportional to their accuracy and computational efficiency. An alternative strategy, commonly used in ensemble d-sign, is to weight classifiers by the inverse of their error rate.
35
This approach strongly emphasizes the highest-performing models while down-weighting weaker ones. Although this was not implemented in the present work, it constitutes a promising direction for future extensions of
Accuracy is the overall evaluation index of the developed Machine Learning models. However, four additional evaluation indexes have been used to calculate the efficiency of the algorithms. Since we are dealing with a multiclass classification problem the One-versus-All Strategy has been used. Table 8 presents the name, abbreviation and the calculation method of each index.
confusion matrix for test data.

The training of the model was performed for 100 epochs for all models. The
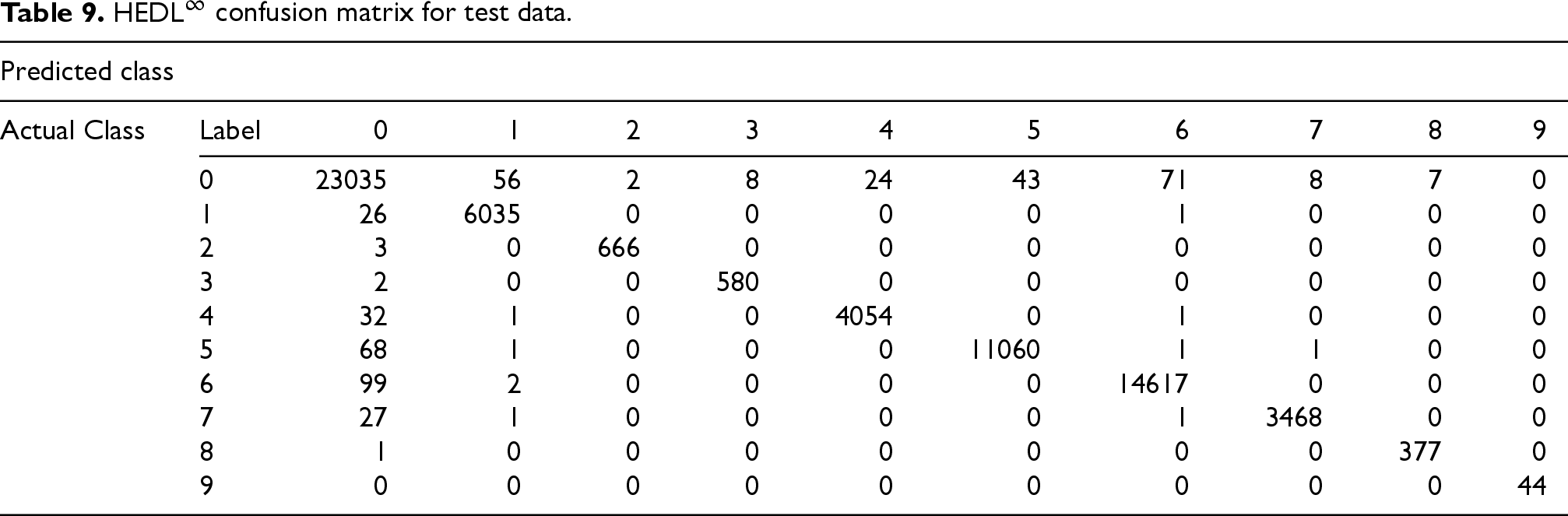

Although the tables are more than satisfactory to assume that the model works with great success, one can make the following observations. The model can generalize with high accuracy and performs exceptionally well with first time seen data. It seems that the model can overcome the minority classes problem, as it classifies with high accuracy all of the attacks. The algorithm seems to even distinguish even the normal flow in relation to malicious flow, which was the main problem in the previous two approaches. As it is indicated by Tables 9, and 10, the revised version of
It should be emphasized that intrusion detection systems can be optimized either toward high Precision or toward high Recall. Models characterized by High Precision values (e.g., Su et al.
15
) have low false positive indices, which results in the reduction of the operational burden. on analysts. However, sometimes ML fails to detect rare or novel attacks. High-recall approaches (e.g., Gao et al.
16
) aim to detect all possible attacks, but they often generate a large number of false positives, leading to alert fatigue and reduced usability. In designing
To demonstrate the statistical robustness and significance of the proposed
Below is a comparison with existing contemporary research efforts on the UNSW-NB15 dataset (Table 11). The comparison confirms the superiority of the model in relation to the existing literature, and reinforces the novelty and innovation presented in the manuscript so far.
To further test the robustness and the high performance of the proposed model, the authors tried to test it with another dataset, the Kitsune Network Attack dataset. Furthermore, the authors embedded the

The overall
Since Kitsune Attack Dataset and UNSW-NB15 Dataset have different features, the
Comparison of the proposed model with contemporary research efforts.

The Kitsune Network Attack dataset (KNAD) is accessible to the public, and it was created by Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai from the Department of Information Systems Engineering at Negev Ben-Gurion University.22,23 It contains a large volume of network packets that was recorded, totaling 21,017,588. Of these, 4,851,280 packets are associated with nine distinct cyber-attacks (refer to Table 12). The rest, amounting to 16,166,306 records, represent normal traffic. Each entry in the dataset corresponds to a 1x115-dimensional vector, meaning that every package is represented as a vector containing 115 features. Typically, each vector encapsulates temporal statistics that describe the packet’s channel, its sender, and the communication occurring between the sender and the receiver. More specifically, the statistics provide a summary of all the traffic attributes:
KNAD classes for malicious and benign flow.

KNAD classes for malicious and benign flow.
One can note from the description so far that the only thing that was changed in the
Building upon the foundational work on the
Confusion matrix for test data with updated values.

Confusion matrix for test data with updated values.
The integrated model was deployed, and its operational performance was benchmarked. The system achieved a high processing throughput, analyzing 10,000 packets every 9 seconds. Although this is slightly slower than the computational speed of the previous model deployed in
The hybrid ensemble architecture, introduces computational complexity. The measured processing speed of approximately 10,000 packets per 9 seconds (as noted in Section 6.3) translates to a throughput of over 1,100 packets per second. This performance was achieved on a high-end consumer-grade GPU (NVIDIA RTX 2070 Super). For real-world deployment, particularly in high-traffic enterprise or service provider networks, this latency must be contextualized. The model is likely best suited for deployment at strategic network aggregation points or within cloud-based security platforms where scalable GPU resources are available, rather than on resource-constrained edge devices. Future work will focus on model distillation and pruning techniques to create a lighter-weight version for broader deployment.
A significant practical challenge would be the integration of an AI-based IDS like
The static nature of a trained model poses a risk against evolving cyber threats. While
Conclusion and future work
This paper is an extended research attempt that introduces the third version of a Hybrid Ensemble Deep Learning Intrusion Detection System (
The model was also tested in the Kitsune Network Attack,22,23 achieving significant positive results. Furthermore, the authors used the proposed model as the basic one in the
Although the results were very good, there is always room for improvement. There are already plans for future expansion of this research. by extracting the same features, from the UNSW-NB15 dataset, in order to train again the
Future research would also explore recently developed supervised machine learning algorithms as alternative approaches to further enhance performance and efficiency. Techniques such as the Neural Dynamic Classification algorithm, 77 Dynamic Ensemble Learning algorithm, 78 and Finite Element Machine for fast learning 79 offer promising avenues for extending the current framework. The Neural Dynamic Classification algorithm adapts neural network parameters dynamically to improve generalization, the Dynamic Ensemble Learning approach combines multiple classifiers to exploit complementary strengths, and the Finite Element Machine accelerates learning by leveraging finite element-based model decomposition. Integrating these advanced methods into future extensions of this research could provide more robust, adaptive, and computationally efficient solutions, particularly in complex and evolving domains such as cybersecurity.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The authors declare no conflict of interest. There is no financial and personal relationships with other people or organizations that can inappropriately influence their work. There is no professional or other personal interest of any nature or kind in any product, service or company that could be constructed as influencing the position presented in, or the review of, the manuscript.